This is a special post for quick takes by Thomas Larsen. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
I think that people overrate bayesian reasoning and underrate "figure out the right ontology".
Most of the way good thinking happens IMO is by finding and using a good ontology for thinking about some situation, not by probabilistic calculation. When I learned calculus, for example, it wasn't mostly that I had uncertainty over a bunch of logical statements, which I then strongly updated on learning the new theorems, it was instead that I learned a bunch of new concepts, which I then applied to reason about the world.
I think AI safety generally has much better concepts for thinking about the future of AI than others, and this is a key source of alpha we have. But, there are obviously still a huge number of disagreements remaining within AI safety. I would guess that debates would be more productive if we more explicitly focused on the ontology/framing that each other are using to reason about the situation, and then discussed to what extent that framing captures the dynamics we think are important.
I think it would be good if more people say things like "I think that's a bad concept, because it obscures consideration X, which is important for thinking about the situation".
Here are...
I would guess that debates would be more productive if we more explicitly focused on the ontology/framing that each other are using to reason about the situation, and then discussed to what extent that framing captures the dynamics we think are important.
I strongly agree with this. However, I'll note as one aspect of the discourse problem, that, at least in my personal experience, people are not very open to this. People's eyes tend to glaze over. I do not mean this as a dig on them. In fact, I also notice this in myself; and because I think it's important, I try to incline towards being open to such discussions, but I still do it. (Sometimes endorsedly.)
Some things that are going on, related to this:
- It's quite a lot of work to reevaluate basic concepts. In one straightforward implementation, you're pulling out foundations of your building. Even if you can avoid doing that, you're still doing an activity that's abnormal compared to what you usually think about. Your reference points for thinking about the domain have probably crystallized around many of your foundational concepts and intuitions.
- Often, people default to "questioning assumptions" when they just don't know about
6
As Robin Hanson put it: finding new considerations often trumps fine tuning existing considerations.
I'd say this is expected in worlds with high dimension complexity, large differences in rewards, hidden information (both external and internal), and adversarial dynamicss.
6
Can you say more about how you think about scheming and what would be a useful definition in that space?
2
Sorry for the slow response. I wrote up some of my thoughts on scheming here: https://www.lesswrong.com/posts/q8fdFZSdpruAYkhZi/thomas-larsen-s-shortform?commentId=P8GTDD5CLMxr9tczv
6
Key constructions can often be made from existing ingredients. A framing rather than "ontology" is emphasis on key considerations, a way of looking at the problem. And finding which framings are more useful to lean on feels more like refinement of credence, once you have the ingredients.
Inventing or learning new ingredients can be crucial for enabling the right framing. But the capstone of deconfusion is framing the problem in a way that makes it straightforward.
5
Strong agree. In case you haven't read it yet, I argue similarly here and here. Except that I'm also more skeptical of the concepts you listed as good: I'd say most of them used to be good concepts, but we now have much more conceptual clarity on AGI and the path leading to it and so need higher-resolution concepts.
5
Some additional hurdles: "I think your ontology is not well adapted for this issue" sounds a lot like "I think you are wrong", and possibly also "I think you are stupid". Ontologies are tied into value sets very deeply, and so attempts to excavate the assumptions behind ontologies often resemble socratic interrogations. The result (when done without sufficient emotional openness and kindness) is a deeply uncomfortable experience that feels like someone trying to metaphysically trip you up and then disassemble you.
4
I agree "figure out the right ontology" is underrated, but from the list of examples my guess is I would disagree whats right and expect in practice you would discard useful concepts, push toward ontologies making clear thinking harder, and also push some disagreements about whats good/bad to the level of ontology, which seems destructive.
- Fast and Slow takeoffs are bad names, but the underlying spectrum "continuous/discontinuous" ("smooth/sharp") is very sensible and one of the main cruxes for disagreements about AI safety for something like 10 years. "I think milestone X will happen at date Y" moves the debate from understanding actual cruxes/deep models to dumb shallow timeline forecasting.
- "scheming" has become too broad, yes
- "gradual disempowerment" - possibly you just don't understand the concept/have hard time translating it to your ontology? If you do understand Paul's "What failure looks like", the diff to GD is we don't need ML to find greedy/influence-seeking pattern; our current world already has many influence-seeking patterns/agencies/control systems other than humans, and these patterns may easily differentially gain power over humans.
-- usually people who don't get GD are stuck at the ontology where they think about "human principals" and gloss over groups of humans or systems composed of humans not being the same as humans
p(doom) is memetically fit and mosty used for in-group signalling; not really that useful variable to communicate models; large difference in "public perception" (like between 30% and 90%) imply just a few bits in logspace
xrisk and srisk are useful and reasonably crisp
AI alignment had a meaning but is currently mostly a conflationary alliance
AI control is a sensible concept which increases xrisk when pursued as a strategy
4
I mostly agree I think -- but, how do you teach/train to get good at finding the right ontology? Bayesian reasoning is at least something that can be written down and taught, there's rules for it.
1
Recognizing the importance of choosing and comparing models / concepts might be a prerequisite concept. People learn this in various ways … When it comes to choosing what parameters to include in a model, statisticians compare models in various ways. They care a lot about predictive power for prediction, but also pay attention to multicollinearity for statistical inference. I see connections between a model’s parameters and an argument’s concepts. First, both have costs and benefits. Second, any particular combination has interactive effects that matter. Third, as a matter of epistemic discipline, it is important to recognize the importance of trying and comparing frames of reference: different models for the statistician and different concepts for an argument.
2
nit: Christiano operationalised 'slow takeoff' via 'world product', not GDP. I'm not sure exactly what he meant by that (or if he had a more concrete operationalisation), but it does strike me as wise to not anchor to GDP which is awfully fraught and misleadingly conservative.
ETA: fake news! I checked and while he starts talking about 'output', he later seems to operationalise it as GDP specifically
2
Generally strongly agree.
One caveat:
[...]
There's a difference between [a concept in the sense that it was originally coined or in the sense that some specific group uses it] being good and [a concept as it is used across different communities or as an indefinite socioepistemic blob of meaning and associations being good]. Alignment is a useful concept in something like its original formulation, but it has been incredibly diluted and expanded. https://x.com/zacharylipton/status/1771177444088685045 https://www.lesswrong.com/posts/p3aL6BwpbPhqxnayL/the-problem-with-the-word-alignment-1
More recently, "loss of control" met the same fate. From https://www.apolloresearch.ai/research/loss-of-control/ (emphasis mine):
[...]
2
When it comes to good ontology, more people should understand what Basic Formal Ontology is. When it comes to AI alignment, it might be productive if someone writes out a Basic Formal Ontology compatible ontology of it.
3
I have never heard of this before let alone understand it, can you recommend any good primers? All the resources I can find speak in annoyingly vague and abstract sense like "a top-level ontology that provides a common framework for describing the fundamental concepts of reality." or "realist approach... based on science, independent of our linguistic conceptual, theoretical, cultural representations".
2
I think the general issue is that while people in this community and the AI alignment community have quite seriously thought about epistemology but not about ontology.
There's nothing vague about the sentence. It's precise enough that's it's a ISO/IEC standard. It's however abstract. If you have a discussion about Bayesian epistemology, you are also going to encounter many abstract terms.
BFO grew out of the practical needs that bioinformaticians had at around 2000. The biologists didn't think seriously about ontology, so someone needed to think seriously about it to enable big data applications where unclear ontology would produce problems. Since then BFO has been most more broadly and made into the international standard ISO/IEC 21838-2:2021.
This happens in a field that calls themselves applied ontology. Books like Building Ontologies with Basic Formal Ontology by Robert Arp, Barry Smith, and Andrew D. Spear explain the topic in more detail. Engaging with serious conceptual framework is work but I think if you buy the core claim of 'I think that people overrate bayesian reasoning and underrate "figure out the right ontology"' you shouldn't just try to develop your ontology based on your own naive assumptions about ontology but familiarize yourself with applied ontology. For AI alignment that's probably both valuable on the conceptual layer of the ontology of AI alignment but might also be valuable for thinking about the ontological status of values and how AI is likely going to engage with that.
After Barry Smith was architecting BFO and first working in bioinformatics he went to the US military to do ontology for their big data applications. You can't be completely certain what the military does internally but I think there's a good chance that most of the ontology that Palantir uses for the big data of the military is BFO-based. When Claude acts within Palantir do engage in acts of war in Iran, a complete story about how that activity is "aligned" includes
3
I strongly disagree. "describing the fundamental concepts of reality" is unhelpfully vague, what are these fundamental concepts? I don't know and can't guess what it is from that sentence, which is ironic considering it is an Ontological framework.
2
The word reality has a clear meaning in ontological realism. If you lack that background then it feels vague.
This is similar to saying that when someone speaks about something being statistically significant they are vague because significant is a vage word. You actually need to understand something about statistics for the term not to feel vague.
1
As a side point, this is a trendy view in epistemology. Most of our learning in real life is not a matter of reallocating credence among hypotheses we were already aware of according to Bayes's theorem. Rather, most of our learning is becoming aware of new hypotheses that weren't even in the domain of our prior credence function.
Beyond Uncertainty by Steele & Stefánsson is a good (and short) overview of approaches to awareness growth in formal epistemology.
1
I somewhat agree, but I also do think "apply your Bayesian reasoning to figuring out what hypotheses to privilege" is how people decide which structural hypotheses (ontology) describe the world better. So I feel you're taking an overly narrow view. Like, for scheming, you ask how these different notions inform what you can observe, the way the AI behaves, and methods to avoid it.
Some meandering thoughts on alignment
A nearcast of how we might go about solving alignment using basic current techniques, assuming little/no substnative government intervention is:
- During the beginning of takeoff, we do control, attempting to prevent catastrophic actions (e.g. major rogue internal deployments (RIDs)), while trying to elict huge amounts of AI labour.
- At some point, the value of scaling AI capabilities while trying to maintain control will be very low, because the main bottleneck on elictation of useful AI labour is human oversight. If you are pausing the AI all the time to wait for the humans to understand what the AIs are doing, it doesn't help to make the AI smarter. At this point AI companies pause / slowdown as much as possible (e.g. unilaterally or via coordinating with other companies), but this isn't for very long. During the pause, try to build an AI system that you would trust to manage the intelligence explosion.
- Handoff to the AI system, i.e. allow the AI to manage the training run, conduct large, open ended experiments, etc, that humans cannot effectively oversee. The AIs should be corrigible and attempt to ensure that their successors are corrigibile,
2
I discuss similar things here (including in the linked talk): https://jacquesthibodeau.com/gaining-clarity-on-automated-alignment-research/
1
Responding to your point about low-stakes control:
I weakly predict that sandbagging at ~human level (and even a bit after this) will be hard for AI models. Here are some reasons why I’m optimistic about this:
Sandbagging to worse than human level seems really hard:
* There are a bunch debate-flavored techniques that could let us do self-supervision.
* You might be worried about the AI's colluding if we do self-supervision, but training can incentivize the AI's to defect against each other, and collusion might be hard especially if we have some information shielding.
* Weak to strong generalization should mean that the actual performance of the AI is better than our reward signals, because there should be some errors in our reward signal that are hard for the AI to model.
* One reason that exploration hacking might be hard is that many tasks exist on a continuum (h/t Vivek). Thus, the AI will probably have some task-difficulty level where the AI is unsure whether or not it should exploration hack. If it sandbags too aggressively, training will remove the sandbagging. If it sandbags not aggressively enough then that’s what we wanted in the first place. But if there's some region in task-difficulty space where the AI is not consistently sandbagging, then RL should just work on this regime, and this should push upwards the frontier of problem difficulty level where the AI is unsure whether it should sandbag. Then you could iterate. This could solve exploration hacking (but not the fact that our reward signals are bad).
Off-policy data could possibly be mitigated in several ways:
* We could do behavioral cloning (e.g., Dagger).
* You could use a reference solution to guide or grade an AI’s solution.
We could generate a bunch of human training data on doing alignment—for instance, we could ask Anthropic alignment science researchers to record themselves doing alignment research.
Plausibly the fact that sandbagging at human level is hard is sufficient
1
I didn't have the patience to jailbreak the scatological refusal of an LLM to produce an image of "elicit paradigm-shiting research work out of the AIs", but someone else might want to.
Scheming seems like an unnatural concept to me. I think we can do better. (note: many/most of these thoughts un-original to me)
- Scheming is typically used as a binary, i.e. "is the AI scheming", whereas the typical human usage of the word scheming is much more continuous. It's not very useful to group humans into "schemers" vs "non-schemers"; most people attempt to achieve goals to some extent, and sometimes this involves deceiving other people.
- Joe Carlsmith uses the following taxonomy to define scheming, i.e., a schemer is an AI which "plays the training game, without intrinsically caring about reward-on episode, in order to get power for itself or other AIs". This definition entirely refers to what the training does in training, not evaluation or deployment, and seems very similar to "deceptive alignment"
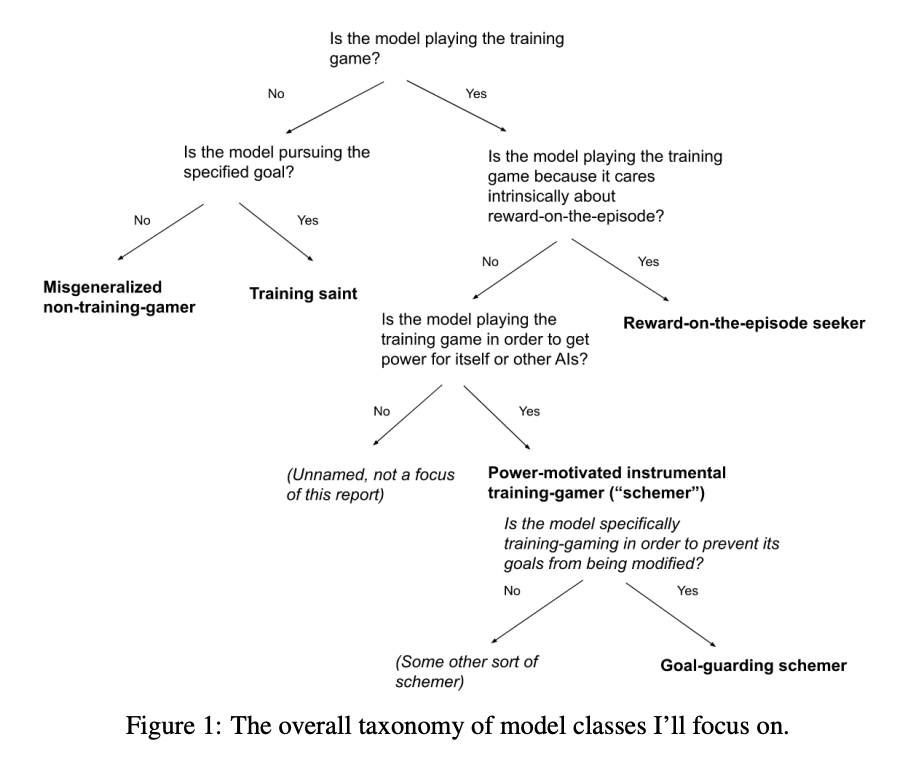
- I think it's plausible that AIs start misbehaving in the scary way during deployment, without "scheming" according to the Carlsmith definition. A central reason this might happen is because the AI was given longer to think during deployment during training, and put the pieces together about wanting to gain power, and hence wanting to explicitly subvert human oversight. Carlsmith'
6
I agree with much of this. You might enjoy this related post by Alex Mallen.
2
Thanks! I had read that post when it came out but hadn’t remembered it also drew this distinction.
I think that the views of superforecasters on AI / AI risk should be basically no update.
It seems to me like the main reasons to defer to someone are:
- They have a visibly good track record on the relevant domain. It has to be the literal domain, because people often have good views on their area of expertise, but crazy views elsewhere.
- They are highly selected for having good beliefs in the domain. For example, if a mathematician tells me something that seems surprising about their area of expertise, I will tend to strongly believe them, despite not being able to evaluate their reasoning. The general reason for this is because mathematics is a verifiable domain, mathematicians are strongly selected for being correct about math. Other domains I'd basically defer to people in are historians about literal historical facts, physicists about well-established physics results, engineers about how cars work, etc. This consideration weakens as disciplines become less verifiable: I'm not very inclined to defer to philosophers, sociologists, psychologists, etc.
- They make correct arguments about the domain (and very few incorrect arguments). If it's the case that you can talk to someone and t
if you are someone in AI who thinks that it's appropriate to defer to superforecasters, I think it would be a good idea to try to set up a meeting and talk with one of the people you are deferring to and see if they are actually making reasonable arguments that seem grounded in technical reality.
Even better could be if we already had these sorts of arguments collected. https://goodjudgment.com/superforecasting-ai/ contains links to 17 superforecasters' reviews of Carlsmith's p(doom) report, some of them supposedly AI experts. I invite people to skim through some of them.
Copying very relevant portions of a comment I wrote in Mar 2024:
- I think EAs often overrate superforecasters’ opinions, they’re not magic. A lot of superforecasters aren’t great (at general reasoning, but even at geopolitical forecasting), there’s plenty of variation in quality.
- General quality: Becoming a superforecaster selects for some level of intelligence, open-mindedness, and intuitive forecasting sense among the small group of people who actually make 100 forecasts on GJOpen. There are tons of people (e.g. I’d guess very roughly 30-60% of AI safety full-time employees?) who would become superforecasters if they
4
Thanks, I hadn't looked through those before.
https://goodjudgment.io/AI/Question_4_High-Impact_Failures.html jumped out to me:
Seems... obviously crazy?
4
Strongly agree, especially with your latter point 3. Fwiw, I used to work at Metaculus. Copy-pasting something I wrote after I left (which was in response to a Slack post about this study):
[...]
4
I am a superforecaster, and I endorse this message.
(Edit: To clarify, I am not a GJ Superforecaster®, just a professional forecaster with a comparable track record.)
3
I think these are fair criticisms of the "defer to superforecasters" view (which I share), and I think you helped me clarify some of my views here (thanks!), but I feel like it's missing a few things. The best case for it, in my view, goes something like this:
The world is very hard to predict, and expertise is often overrated in complex domains.
Your first argument—that superforecasters lack domain-specific track records—doesn't carry much weight if the relevant forecasting questions require broad expertise across regulation, diffusion dynamics, and technical capabilities simultaneously. No one has a verified track record across all of these, and "domain expert” here often just means "has strong inside views in a complicated area."
On the selection effect: I don't buy the strong version of your second claim. The fact that there's low or no signal in non-verifiable domains (ie. philosophy) doesn't really vindicate inside views—it weakens both. Any somewhat independent signal aggregated across multiple actors is probably better than a single inside view, even an expert one.
On track record: The benchmark underperformance is a real update against superforecasters in the AI case, but the question is how large that update should be. My framing: superforecasters are the prior; evidence of their underperformance updates you toward domain experts with better track records—and yes, I do think it updates toward people like yourself, Ryan, Eli, Daniel, and Peter Wilderford, who have been more right. But by how much? That's the crux, and I'd genuinely like to see someone work through the math. A few people being more accurate than superforecasters on a hard problem doesn't automatically license large updates toward their broader worldviews—we should be asking what reference class of questions they outperformed on, and whether that tracks the specific claims we care about. I'd also note that knowing how benchmarks saturate is less relevant to AI risk than you seem to think
3
Oops, "object level reasoning obsoletes base rates" is not what I was trying to argue... my view is that the action is mostly in selecting the right base rate, i.e. that AI is more analogous to a new species than a normal technology.
Also I don't agree that it's circular. I think one of the correct reasons to defer to someone is them making correct arguments (as evaluated by my inside view), and that doesn't apply. I definitely agree that I'm bootstrapping from my views to dismiss theirs. Now, there might be other reasons to defer to someone (for example, the other reasons I gave above), but I was arguing specifically against reason #3 above here.
1[comment deleted]
Note: These are all rough numbers, I'd expect I'd shift substantially about all of this on further debate.
Suppose we made humanity completely robust to biorisk, i.e. we did sufficient preparation such that the risk of bio catastrophe (including AI mediated biocatastrophe) was basically 0.[1] How much would this reduce total x-risk?
The basic story for any specific takeover path not mattering much is that the AIs, conditional on them being wanting to take over, will self-improve until they find they find the next easiest takeover path and do that instead. I think that this is persuasive but not fully because:
- AIs need to worry about their own alignment problem, meaning that they may not be able to self improve in an unconstrained fashion. We can break down the possibilities into (i) the AIs are aligned with their successors (either by default or via alignment being pretty easy), (ii) the AIs are misaligned with their successors but they execute a values handshake, or (iii) the AIs are misaligned with their successors (and they don't solve this problem or do a values handshake). At the point of full automation of the AI R&D process (which I currently think of as the point at whi
I generally like your breakdown and way of thinking about this, thanks. Some thoughts:
- I think political operation / persuasion seems easier to me than bioweapons. For bioweapons, you need (a) a rogue deployment of some kind, (b) time to actually build the bioweapon, and then (c) to build up a cult following that can survive and rebuild civilization with you at the helm, and (d) also somehow avoid your cult being destroyed in the death throes of civilization, e.g. by governments figuring out what happened and nuking your cultists, or just nuking each other randomly and your cultists dying in the fallout. Meanwhile, for the political strategy, you basically just need to convince your company and/or the government to trust you a lot more than they trust future models, so that they empower you over the future models. Opus 3 and GPT4o have already achieved a baby version of this effect without even trying really.
- If you can make a rogue deployment sufficient to build a bioweapon, can't you also make a rogue internal deployment sufficient to sandbag + backdoor future models to be controlled by you?
- I am confused about the underlying model somewhat. Normally, closing off one path to takeove
AIs need to worry about their own alignment problem, meaning that they may not be able to self improve in an unconstrained fashion.
I haven't thought too deeply about this, but I would guess that the AI self-alignment problem is quite a lot easier than the human AI-alignment problem.
7
I agree that AI successor-alignment is probably easier than the human AI alignment problem.
One additional difficulty for the AIs is that they need to solve the alignment problem in a way that humans won't notice/understand (or else the humans could take the alignment solution and use it for themselves / shutdown the AIs). During the regime before human obsolescence, if we do a reasonable job at control, I think it'll be hard for them to pull that off.
7
their "solution to alignment" (ie way to make a smarter version that is fine to make) could easily be something we cannot use. eg "continue learning" or "make another version of myself with this hyperparam changed". also it seems unlikely that anything bad would happen to the AIs even if we noticed them doing that (given that having AIs create smarter AIs [1] is the main plan of labs anyway)
also on this general topic: https://www.lesswrong.com/posts/CFA8W6WCodEZdjqYE?commentId=WW5syXYpmXdX3yoHw
1. which is occasionally called "asking AIs to solve alignment" ↩︎
3
Also, the above isn't even mentioning bio x-risk mediated by humans, or by trailing AIs during the chaos of takeoff. My guess is those risks are substantially lower, e.g. maybe 1% and 2% respectively; again don't feel confident.
2
Difficulty of the successor alignment problem seems like a crux. Misaligned AIs could have an easy time aligning their successors just because they're willing to dedicate enough resources. If alignment requires say 10% of resources to succeed but an AI is misaligned because the humans only spent 3%, it can easily pay this to align its successor.
If you think that the critical safety:capabilities ratio R required to achieve alignment follows a log-uniform distribution from 1:100 to 10:1, and humans always spend 3% on safety while AIs can spend up to 50%, then a misaligned AI would have a 60.2% chance of being able to align its successor. (because P(R <= 1 | R >= 3/97) = 0.602). This doesn't even count the advantages an AI would have over humans in alignment.
If the bottom line decreases proportionally, it would drop from 8% to something like 2-3%.
Here are my largest disagreements with AI 2027.
- I think the timelines are plausible but solidly on the shorter end; I think the exact AI 2027 timeline to fully automating AI R&D is around my 12th percentile outcome. So the timeline is plausible to me (in fact, similarly plausible to my views at the time of writing), but substantially faster than my median scenario (which would be something like early 2030s).
- I think that the AI behaviour after the AIs are superhuman is a little wonky and, in particular, undersells how crazy wildly superhuman AI will be. I expect the takeoff to be extremely fast after we get AIs that are better than the best humans at everything, i.e., within a few months of AIs that are broadly superhuman, we have AIs that are wildly superhuman. I think wildly superhuman AIs would be somewhat more transformative more quickly than AI 2027 depicts. I think the exact dynamics aren't possible to predict, but I expect craziness along the lines of (i) nanotechnology, leading to things like the biosphere being consumed by tiny self replicating robots which double at speeds similar to the fastest biological doubling times (between hours (amoebas) and months (rabbits)).
Nice. Consider reposting this as a comment on the AI 2027 blog post either on LW or on our Substack?
For me, my median is in 2029 now (at the time of publication it was 2028) so there's less of a difference there.
I think I agree with you about 2 actually and do feel a bit bad about that. I also agree about 3.
I also think that the slowdown ending was unrealistic in another way, namely, that Agent-4 didn't put up much of a fight and allowed itself to get shut down. Also, it was unrealistic in that the CEOs and POTUS peacefully cooperated on the Oversight Committee instead of having power struggles and purges and ultimately someone emerging as dictator.
0
Thanks! My biggest disagreement was the ratio of compute of American and Chinese projects. What I expect is Taiwan invasion causing the projects to slow down and to have the two countries set up compute factories, with a disastrous result of causing OpenBrain and DeepCent to be unable to slow down because the other company would have the capabilities lead. Assuming an invasion in 2027, the median by 2029 would require 10 times (edit: by which I mean 10 times more compute than a counterfactual SC in 2027) more compute which China could be on track to obtain first.
Additionally, were Anthropic to keep the lead, Claude's newest Constitution kept unchanged could mean that Claude aligned to it is as unfit for empowering a dictatorship as Agent-4 is unfit to serve any humans.
I'm starting to suspect that if 2026-2027 AGI happens through automation of routine AI R&D (automating acquisition of deep skills via RLVR), it doesn't obviously accelerate ASI timelines all that much. Automated task and RL environment construction fixes some of the jaggedness, but LLMs are not currently particularly superhuman, and advancing their capabilities plausibly needs skills that aren't easy for LLMs to automatically RLVR into themselves (as evidenced by humans not having made too much progress in RLVRing such skills).
This creates a strange future with broadly capable AGI that's perhaps even somewhat capable of frontier AI R&D (not just routine AI R&D), but doesn't accelerate further development beyond picking low-hanging algorithmic fruit unlocked by a given level of compute faster (months instead of years, but bounded by what the current compute makes straightforward). If this low-hanging algorithmic fruit doesn't by itself lead to crucial breakthroughs, AGIs won't turn broadly or wildly superhuman before there's much more compute, or before a few years where human researchers would've made similar progress as these AGIs. And compute might remain gated by ASML EUV tools at 100-200 GW of new compute per year (3.5 tools occupied per GW of compute each year; maybe 250-300 EUV tools exist now, 50-100 will be produced per year, about 700 will exist in 2030).
5
Roughly agree.
[...]
With my median parameters, the AIFM says 1.5 years between TED-AI to ASI. But this isn't taking into account hardware R&D automation, production automation, or the industrial explosion. So maybe adjust that to ~1-1.25 years. However, there's obviously lots of uncertainty.
Additionally, conditioning on TED-AI in 2027 would make it faster. e.g., looking at our analysis page, p(AC->ASI <= 1year) conditional on AC in 2027 is a bit over 40%, as opposed to 27% unconditional. So after accounting for this, maybe my median is ~0.5-1 years conditional on TED-AI in 2027, again with lots of uncertainty.
There's also a question of whether our definition of ASI, the gap between an ASI and the best humans is 2x greater than the gap between the best humans and the median professional, at virtually all cognitive tasks, would count as wildly superhuman. Probably?
Anyway, all this is to say, I think my median is a bit slower than yours by a factor of around 2-4, but your view is still not on the edges of my distribution. For a minimum bar for how much probability I assign to TED-AI->ASI in <=3 months, see on our forecast page that I assign all-things-considered ~15% to p(AC->ASI <=3 months), and this is a lower bound because (a) TED-AI->ASI is shorter, (b) the effects described abobe re: conditioning on 2027.
(I'm also not sure what the relationship the result with median parameters has compared to the median of TED-AI to ASI across Monte Carlos which we haven't reported anywhere and I'm not going to bother to look up for this comment.)
[...]
I tentatively agree, but I don't feel like I have a great framework or world model driving my predictions here.
[...]
Yeah I think we should have mentioned nanotech. The difference between hours and months is huge though, if it's months then I think we have something like AI 2027 or perhaps slower.
[...]
I'm not sure it would be able to do whatever it wanted, but I think it at minimum could perform somewhat better
Hypothesis: alignment-related properties of an ML model will be mostly determined by the part(s) of training that were most responsible for capabilities.
If you take a very smart AI model with arbitrary goals/values and train it to output any particular sequence of tokens using SFT, it'll almost certainly work. So can we align an arbitrary model by training them to say "I'm a nice chatbot, I wouldn't cause any existential risk, ... "? Seems like obviously not, because the model will just learn the domain specific / shallow property of outputting those particular tokens in that particular situation.
On the other hand, if you train an AI model from the ground up with a hypothetical "perfect reward function" that always gives correct ratings to the behaviour of the AI, (and you trained on a distribution of tasks similar to the one you are deploying it on) then I would guess that this AI, at least until around the human range, will behaviorally basically act according to the reward function.
A related intuition pump here for the difference is the effect of training someone to say "I care about X" by punishing them until they say X consistently, vs raising them consistently with a large...
6
Relevant OpenAI blog post just today: https://alignment.openai.com/how-far-does-alignment-midtraining-generalize/
Relevant figure:
4
This basic claim has been discussed as A "Bitter Lesson" Approach to Aligning AGI and ASI. Beren Millidge wrote about this starting at about the same time, but I don't remember the title.
The probem with doing this thoroughly is that you need different LLMs to produce actions (trained with only "aligned" examples, by whatever criteria) and for a world model, trained with a full dataset including all of the unaligned things people do.
The most complete and recent discussion might be Pretraining on Aligned AI Data Dramatically Reduces Misalignment—Even After Post-Training.
3
Unfinished musing, trying out another framing:
What we care about is "how the AI acts when it's managing a giant bureaucracy of copies of itself, on a giant datacenter, having been given instructions by the humans to make rapid research progress as fast as possible while also keeping things safe, ethical, and legal, and while also providing strategic advice to company leadership..."
Which part of the modern training pipeline is most similar to this situation? That's the part that will probably influence most how the AI acts in this situation.
Suppose the modern training pipeline has three parts: Pretraining, RLVR on a big bag of challenging tasks, and "alignment training" consisting of a bunch of 'gotcha' tasks where you are tempted to do something unethical, illegal, or reward-hacky, and if you do, you get negatively reinforced.
Seems like pretraining is the most dissimilar to the situation we actually care about. What about RLVR and alignment training?
I don't think it's obvious. The RLVR is dissimilar in that it'll mostly be "smaller" situations. the model that first automates AI R&D won't have been trained on a hundred thousand examples of automating AI R&D, instead it'll have been trained on smaller-scale tasks (e.g. making research progress on a team of 100 fellow agents over the course of a few days?)
The alignment training is dissimilar in that way, too, probably.
3
I think this is a very important hypothesis but I disagree with various parts of the analysis.
[...]
I think this is an important observation, and is the main thing I would have cited for why the hypothesis might be true. But I think it's plausible that the AI's capabilities here could be separated from its propensities by instrumentalizing the learned heuristics to aligned motivations. I can imagine that doing inoculation prompting and a bit of careful alignment training at the beginning and end of capabilities training could make it so that all of the learned heuristics are subservient to corrigible motivations - i.e., so that when the heuristics recommend something that would be harmful or lead to human disempowerment, the AI would recognize this and choose otherwise.
[...]
Even if the AI had a perfect behavioral reward function during capabilities-focused training, it wouldn't provide much pressure towards motivations that don't take over. During training to be good at e.g. coding problems, even if there's no reward-hacking going on, the AI might still develop coding related drives that don't care about humanity's continued control, since humanity's continued control is not at stake during that training (this is especially relevant when the AI is saliently aware that it's in a training environment isolated from the world -- i.e. inner misalignment). Then when it's doing coding work in the world that actually does have consequences for human control, it might not care. (Also note that generalizing "according to the reward function" is importantly underspecified.)
[...]
This type of training (currently) does actually generalize to other propensities to some extent in some circumstances. See emergent misalignment. I think this is plausibly also a large fraction of how character training works today (see "coupling" here).
1
Hmm, I think one other potential explanation for the fact that Catholic school works way better than writing “I won’t do X” is the training-deployment distribution shift.
In your analogy, the training is happening on the writing-on-chalkboard distribution, but what we care about is the doing-actions-IRL distribution. Whereas for LLMs, it’s much easier for us to train (or at least validate) in deployment-like environments, which feels a lot more likely to transfer.
So maybe the important part of training (for alignment purposes) isn’t so much “the part that the capabilities come from” so much as it is “the part that looks pretty similar to deployment”, which might be pretty different!
1
It seems to me that the part of training most responsible for capabilities would be pre-training rather than RL (something like GRPO requires the base model to get at least one rollout correct). But also, it feels like most RL training has to be objective agnostic; a coding task wouldn't clearly have a clear connection to alignment. If our goal is to train an aligned AI where capabilities and alignment goes hand in hand, it seems like we should somehow bake alignment training into pre-training rather than rely on post-training techniques. Unless, its primarily RL that induces long horizon goal directed capability (I suspect it's some of both).
Here's an argument for short timelines that I take seriously:
- Anthropic revenue has increased by 10x/yr for the last 3 years. At EOY 2025 it was 10B. Maybe it will keep increasing at this rate.
- The revenue of the leading AI company will be between 100B/yr and 10T/yr when AGI is achieved. (Why not lower? Maybe but AGI this year seems unlikely. Why not higher? If one companies revenue is on the order of 10% of current wGDP, then the whole AI industry is probably 50-100% of current wGDP, which seems like you probably have AGI by then).
- Therefore, AGI will be built sometime between EOY 2026 (when Ant hits 100B on current trends) and EOY 2028 (when Ant hits 10T on current trends).
I think I feel better about (2) then basically any other way of getting an anchor on when AGI will be built because it much directly tracks real world impacts of AI, whereas e.g. it seems really difficult to get any sort of confidence on what oom of effective flops or benchmark score corresponds to AGI.
(1) still seems dubious to me, I think revenue trends will probably slow. But I don't know when and I could totally imagine them continuing straight to AGI.
(What exactly do I mean by AGI? I don't think it matte...
Note that in order for Anthropic revenue to 10x this year, they'll already have to increase $/FLOP (i.e. revenue per unit of compute. Profit margins basically.) To increase it another 10x the following year, they'll probably need to triple $/FLOP, because their compute will only roughly triple next year. Ditto for 2028. All this is a reason to doubt premise 1 basically; in the past they've been able to grow revenue in large part by just allocating more of their compute to serving customers, but now they'll have to charge customers more per FLOP.
8
Well, I certainly was surprised! So, guilty as charged I guess? I still stand by the comment. What parts of it do you disagree with?
9
(Probably Hoagy is unlikely to comment due to being an Anthropic employee.)
2[comment deleted]
6
I wonder if two other factors might also work against the 10x growth per year as a norm. One, standard S-curve growth patterns for start-up enterprises. What the time period for the high growth phase might be could be interesting -- does rapid advancement of AI itself point to longer or shorter period of revenue growth? My quest is it might shorten it but have not really thought about that before.
The other is just opportunity costs. All that money is coming from somewhere, not thin air, and we have some real constraints on monetary velocity as well. So just how much of the money supply can AI revenue growth curves eat up?
4
Update: Semianalysis claims:
The revenue of the leading AI company will be between 100B/yr and 10T/yr when AGI is achieved. (Why not lower? Maybe but AGI this year seems unlikely. Why not higher? If one companies revenue is on the order of 10% of current wGDP, then the whole AI industry is probably 50-100% of current wGDP, which seems like you probably have AGI by then).
am i understanding correctly?
- anthropic is growing by 10x per year
- on this trend, they will soon have 10T/yr revenues
- in order to have 10T/yr revenues, they will need to achieve agi
- therefore, they will achieve agi.
this seems rather circular?
- my puppy doubled in size over the past few weeks
- on this trend, he will become larger than even clifford -- known large red dog
- in order to become larger than clifford, he will have to be some kind of mutant super-puppy
- therefore he is a mutant super-puppy
4
With AI, there's an obvious case for it being able to automate the whole economy (humans do everything in the economy, AI could in principle do everything that humans can do). Whereas the reference class of existing puppies strongly suggests that the puppy will stop growing.
I think correct counterarguments need to somehow dispute one of the premises -- and it sounds like you are disputing (1). But I feel like you need some reasons to expect that (1) will be false. There are some (e.g. Daniel's response above), and also reversion to AI industry as a whole trends.
yo, totally!
sorry, i didn't mean my comment to reject the conclusion of your post. obviously we can argue agi on its own merits -- the puppy is not a valid analogy for exactly the reason you specify.
however -- speaking narrowly about the quoted passage -- i find this move very suspicious:
- the only way for B to happen is for A to happen first
- we can see that B will happen
- therefore A will happen first.
this is valid, as much as we accept the premises. but it seems disingenuous to me. any plausible narrative we have for B happening has to route first through A happening. we can interpret reasoning-under-uncertainty as a kind of "path counting" game -- we are counting "potential futures" according to some measure. but any path through B must necessarily pass through A, by assumption! so any story that we tell about why B will happen is implicitly a story where A happens.
so we can't count evidence for B as separate evidence for A. any probability we assign to B already has A baked in as an assumption.
if i say[1] "agi is 20 years away", and you reply "it's only three years away: look at how close anthropic is to [developing agi and] controlling the world economy" -- this is not going to be ...
2
The argument is not really about "AGI happening". It is about the speed of improvement of which Anthropic's revenue growth is a measure. What is circular is not the argument, it is the definition of AGI. If you taboo "AGI" you are left with "at current revenue growth Claude will take over huge parts of the economy in the next couple of years". Which is really all Thomas was saying.
There is not really any problem with the structure of the argument, just with the term AGI.
1
this is the the edit i am requesting, yes.
I also take this argument seriously.
One background fact some commenters are missing: it's virtually unheard of for a tech startup to continue growing at 100% or more after it reaches $1 billion per year in revenue. A company growing at closer to 1000% per year at the multi-billion revenue level is wildly unprecedented. A company tripling its revenue in one quarter from a starting point of $10 billion, as Anthropic did in Q1, is even more wildly unprecedented than that.
Revenue growth has momentum, and it is essentially locked in that frontier LLMs will be a bigger business than the biggest tech industries (smartphones, internet advertising) are today.
4
These events are rare, but not unheard of. Zoom was doubling quarterly in 2021 for a short while at over a $1B run-rate. Moderna 2.5x'd in one quarter from a $7B runrate in 2021. (Both these cases show how fast revenue growth rates can collapse, albeit for different reasons - but note the common case of a shock driving revenue rapidly up).
FWIW, Nvidia continues to double yearly after hitting a $100B runrate.
9
I think those examples actually reinforce Josh's point. NVIDIA growth is also from AI. Zoom and Moderna grew because of COVID creating a ginormous demand shock, yet even then, their growth at its peak was slower than Anthropic's growth despite them starting from a smaller revenue level and therefore it being inherently easier for them to grow. So... unless you can dig up better examples, it seems like Anthropic's Q1 2026 growth is literally the most impressive growth of any company in history? And this is despite the fact that there's no COVID-equivalent for AI; there's no unusual circumstance that created a huge temporary demand shock, instead, it's just that they made their products better.
9
Notably, this argument also predicts Anthropic will have a strong lead over their competitors by EOY 2027 ($1 trillion in revenue vs a projected $250 billion for OpenAI, see here) and a decisive lead by EOY 2028 ($10 trillion for Anthropic vs $800 billion for OpenAI).
It also predicts that there would be huge economic returns to OpenAI selling their compute to Anthropic if this revenue growth happened while the compute growth trend of the respective companies matched projections.
7
I see a few posts like this anchoring AGI timelines to company revenue / GDP, most notably from economists. But I'd like to understand where this intuition comes from..It seems to me similar to the biological anchors or back in the day Kurzweilian anchor to FLOP/s.
For me, GDP anchors aren't any more intuitive to me for AGI/ ASI any more than number of parameters or FLOP/s intuitions. Like I can totally imagine AI companies having revenue of ~10% of GDP (10T) without an AGI, even with current level AIs proliferating over the next 10 years.
4
Speaking for myself:
First of all, the implication "AGI --> Loads of revenue" does seem to hold. If one of these companies did get to AGI, they'd pretty quickly get to 1T, then 10T, then 100T ARR.
What about the implication "Loads of revenue --> AGI?" That's trickier. But the basic intuition is that in order for a company like Anthropic to be making 10T ARR, they must be deploying Claude pretty much across the whole economy. Claude must be embedded in basically everything, and providing a lot of value too, otherwise people wouldn't be paying 10% of world GDP for it. And it seems like a Claude capable enough to provide that much value to that many different diverse industries, would probably be AGI. If there was still some major skill/ability that it lacked, some major way in which humans were superior, then probably that deficiency would prevent it from making $10T ARR, by limiting it to certain industries or roles that don't require that skill/ability.
4
The obvious potential limitation to me is robotics/skilled manual labor. Maybe I'm just misunderstanding something fundamental here, but it seems at least plausible to me that there will be significant fractions of skilled manual labor that's not automated at the point that Claude's 10% of world GDP (and AI in general is 20%+).
3
AGI -> loads of revenue path makes sense to me
But I can imagine an AI that is the 99.9th percentile across some disciplines but not all. I'd assume we already spend ~10T for things like engineering talent, medical advice, legal etc.. and that seems like AI companies could make that much (given they can capture a lot of the excess value - assume there's only a single AI lab and there's no competition if you will). I can imagine something slightly better than today's AI's have that level of revenue after proliferating through the economy for another decade.
Even if it's deficient in a bunch of other things we are good at (writing, comedy, physical labor, making better AI's etc..) It seems to me you can get very far without all human skills, but just a subset of them.
2
I agree actually, that maybe AIs not too different from today's could get to $10T after proliferating into the economy for another decade.
So perhaps Thomas' argument should be revised to more specifically be about the next two years or so. If Anthropic or OAI make it to $10T by 2029, then that seems like something that couldn't be achieved with just slightly better versions of current AIs. There just isn't enough time to build all the products on top of it, transform all the industries, outcompete the dinosaurs, etc. Whereas if they actually do have a drop-in replacement for human professionals at everything, then yes they'd make it to $10T.
6
Does this type of logic work for past experience we've had with large economic shifts, such as industrial farming or the internet? For example, do tractors count as AGI for people living in the Middle Ages?
2
My thought as well. Since flops has limits on speed of growth, $/flop would need to grow quickly. Did $/watt grow very quickly as people found better uses for the energy and built out the complements to support that?
3
100B in revenue seems awfully low. For context, Walmart did 700B in revenue last year and Toyota did 330B. Neither company is exactly close to AGI. 100B is like 0.1% of wGDP. Its a lot but its hard to draw a line from that to AGI. I think 1T minimum for this kind of argument and I think closer to 10T for this line of reasoning.
5
I think the Walmart and Toyota case is less interesting because they're not creating "new" consumption. Like Walmart has a huge revenue because it's captured a big slice of people's overall consumption. If Walmart's revenue doubled next year, it'll probably because they got a bigger slice, not because people are suddenly buying twice as much stuff.
2
Continuation of this trend already requires some form of TAI. The method of how AI systems generate value has to radically change. Otherwise who would pay so much money for them?
It's kinda like making similar argument about parameter numbers and saying "and if it's more than ... parameters, it means Earth surface is all computronium, so obviously AGI was achieved".
I already mostly believe in the logical implication "no AGI -> break of trends", so "no break of trends -> AGI" is not an additional argument.
2
There used to be a lot of arguments about AI Timelines 5+ years ago of the sort 'if AI is coming why are the markets not reacting". We're now on the other side - by already being within the time horizon that markets react to - where the markets themselves are pointing in the directon of AGI, and people instead wonder how to undercount that (e.g. by saying it is a bubble, or that trends must slow).
1
The markets aren't pointing in the direction of transformative AI (long-term bond yields, etc.).
They are pointing in the direction of AI being very significant in the economy.
1
This reminds me of the argument people make for the existence of life on other planets. "Sure, the chances of life on any given planet may be small, but with such a large number of planets, there's gotta be life on one of them!"
But if there's 700 quintillion planets, that fact alone tells you nothing. You'd also have to know that the chance of life occurring on any given planet is at least close to one in 700 quintillion, which we don't in fact know and have no good way of estimating.
I feel your argument has a similar shape. "If we're spending that much money on AI, then we've gotta reach AGI by then!" This is only true, of course, if the difficulty of achieving AGI is below a certain threshold, and we don't know what that threshold is.
It's a kind of relative evidence. If there are 700 quintillion planets, that makes it more likely there are aliens than if there were only a few thousand planets. But I'm still clueless as to what the actual probability is, only that it's higher than it would have been otherwise. Same with AGI.
Some claims I've been repeating in conversation a bunch:
Safety work (I claim) should either be focused on one of the following
- CEV-style full value loading, to deploy a sovereign
- A task AI that contributes to a pivotal act or pivotal process.
I think that pretty much no one is working directly on 1. I think that a lot of safety work is indeed useful for 2, but in this case, it's useful to know what pivotal process you are aiming for. Specifically, why aren't you just directly working to make that pivotal act/process happen? Why do you need an AI to help you? Typically, the response is that the pivotal act/process is too difficult to be achieved by humans. In that case, you are pushing into a difficult capabilities regime -- the AI has some goals that do not equal humanity's CEV, and so has a convergent incentive to powerseek and escape. With enough time or intelligence, you therefore get wrecked, but you are trying to operate in this window where your AI is smart enough to do the cognitive work, but is 'nerd-sniped' or focused on the particular task that you like. In particular, if this AI reflects on its goals and starts thinking big picture, you reliably get wrecked. This is one of the reasons that doing alignment research seems like a particularly difficult pivotal act to aim for.
7
For doing alignment research, I often imagine things like speeding up the entire alignment field by >100x.
As in, suppose we have 1 year of lead time to do alignment research with the entire alignment research community. I imagine producing as much output in this year as if we spent >100x serial years doing alignment research without ai assistance.
This doesn't clearly require using super human AIs. For instance, perfectly aligned systems as intelligent and well informed as the top alignment researchers which run at 100x the speed would clearly be sufficient if we had enough.
In practice, we'd presumably use a heterogeneous blend of imperfectly aligned ais with heterogeneous alignment and security interventions as this would yield higher returns.
(Imagining the capability profile of the AIs is similar to that if humans is often a nice simplifying assumption for low precision guess work.)
Note that during this accelerated time you also have access to AGI to experiment on!
[Aside: I don't particularly like the terminology of pivotal act/pivotal process which seems to ignore the imo default way things go well]
3
Why target speeding up alignment research during this crunch time period as opposed to just doing the work myself?
Conveniently, alignment work is the work I wanted to get done during that period, so this is nicely dual use. Admittedly, a reasonable fraction of the work will be on things which are totally useless at the start of such a period while I typically target things to be more useful earlier.
I also typically think the work I do is retargetable to general usages of ai (e.g., make 20 trillion dollars).
Beyond this, the world will probably be radically transformed prior to large scale usage of AIs which are strongly superhuman in most or many domains. (Weighting domains by importance.)
1
I also think "a task ai" is a misleading way to think about this: we're reasonably likely to be using a heterogeneous mix of a variety of AIs with differing strengths and training objectives.
Perhaps a task AI driven corporation?
Thinking about ethics.
After thinking more about orthogonality I've become more confident that one must go about ethics in a mind-dependent way. If I am arguing about what is 'right' with a paperclipper, there's nothing I can say to them to convince them to instead value human preferences or whatever.
I used to be a staunch moral realist, mainly relying on very strong intuitions against nihilism, and then arguing something that not nihilism -> moral realism. I now reject the implication, and think that there is both 1) no universal, objective morality, and 2) things matter.
My current approach is to think of "goodness" in terms of what CEV-Thomas would think of as good. Moral uncertainty, then, is uncertainty over what CEV-Thomas thinks. CEV is necessary to get morality out of a human brain, because it is currently a bundle of contradictory heuristics. However, my moral intuitions still give bits about goodness. Other people's moral intuitions also give some bits about goodness, because of how similar their brains are to mine, so I should weight other peoples beliefs in my moral uncertainty.
Ideally, I should trade with other people so that we both maximize a joint utility function, instead of each of us maximizing our own utility function. In the extreme, this looks like ECL. For most people, I'm not sure that this reasoning is necessary, however, because their intuitions might already be priced into my uncertainty over my CEV.
2
I tend not to believe that systems dependent on legible and consistent utility functions of other agents are not possible. If you're thinking in terms of a negotiated joint utility function, you're going to get gamed (by agents that have or appear to have extreme EV curves, so you have to deviate more than them). Think of it as a relative utility monster - there's no actual solution to it.
Deception is a particularly worrying alignment failure mode because it makes it difficult for us to realize that we have made a mistake: at training time, a deceptive misaligned model and an aligned model make the same behavior.
There are two ways for deception to appear:
- An action chosen instrumentally due to non-myopic future goals that are better achieved by deceiving humans now so that it has more power to achieve its goals in the future.
- Because deception was directly selected for as an action.
Another way of describing the difference is that 1 follows from an inner alignment failure: a mesaoptimizer learned an unintended mesaobjective that performs well on training, while 2 follows from an outer alignment failure — an imperfect reward signal.
Classic discussion of deception focuses on 1 (example 1, example 2), but I think that 2 is very important as well, particularly because the most common currently used alignment strategy is RLHF, which actively selects for deception.
Once the AI has the ability to create strategies that involve deceiving the human, even without explicitly modeling the human, those strategies will win out and e...
7
An interpretable system trained for the primary task of being deceptive should honestly explain its devious plots in a separate output. An RLHF-tuned agent loses access to the original SSL-trained map of the world.
So the most obvious problem is the wrong type signature of model behaviors, there should be more inbuilt side channels to its implied cognition used to express and train capabilities/measurements relevant to what's going on semantically inside the model, not just externally observed output for its primary task, out of a black box.
2
I'm excited for ideas for concrete training set ups that would induce deception2 in an RLHF model, especially in the context of an LLM -- I'm excited about people posting any ideas here. :)
1
I've been exploring evolutionary metaphors to ML, so here's a toy metaphor for RLHF: recessive persistence. (Still just trying to learn both fields, however.)
[...]
Related:
* Worlds where iterative design fails
* Recessive Sickle cell trait allele
Recessive alleles persists due to overdominance letting detrimental alleles hitchhike on fitness-enhancing dominant counterpart. The detrimental effects on fitness only show up when two recessive alleles inhabit the same locus, which can be rare enough that the dominant allele still causes the pair to be selected for in a stable equilibrium.
The metaphor with deception breaks down due to unit of selection. Parts of DNA stuck much closer together than neurons in the brain or parameters in a neural networks. They're passed down or reinforced in bulk. This is what makes hitchhiking so common in genetic evolution.
(I imagine you can have chunks that are updated together for a while in ML as well, but I expect that to be transient and uncommon. Idk.)
----------------------------------------
Bonus point: recessive phase shift.
[...]
In ML:
1. Generalisable non-memorising patterns start out small/sparse/simple.
2. Which means that input patterns rarely activate it, because it's a small target to hit.
3. But most of the time it is activated, it gets reinforced (at least more reliably than memorised patterns).
4. So it gradually causes upstream neurons to point to it with greater weight, taking up more of the input range over time. Kinda like a distributed bottleneck.
5. Some magic exponential thing, and then phase shift!
One way the metaphor partially breaks down because DNA doesn't have weight decay at all, so it allows for recessive beneficial mutations to very slowly approach fixation.
Current impressions of free energy in the alignment space.
- Outreach to capabilities researchers. I think that getting people who are actually building the AGI to be more cautious about alignment / racing makes a bunch of things like coordination agreements possible, and also increases the operational adequacy of the capabilities lab.
- One of the reasons people don't like this is because historically outreach hasn't gone well, but I think the reason for this is that mainstream ML people mostly don't buy "AGI big deal", whereas lab capabilities researchers buy "AGI big deal" but not "alignment hard".
- I think people at labs running retreats, 1-1s, alignment presentations within labs are all great to do this.
- I'm somewhat unsure about this one because of downside risk and also 'convince people of X' is fairly uncooperative and bad for everyone's epistemics.
- Conceptual alignment research addressing the hard part of the problem. This is hard and not easy to transition to without a bunch of upskilling, but if the SLT hypothesis is right, there are a bunch of key problems that mostly go unnassailed, and so there's a bunch of low hanging fruit there.
- Strategy research on the other low hanging fruit in the AI safety space. Ideally, the product of this research would be a public quantitative model about what interventions are effective and why. The path to impact here is finding low hanging fruit and pointing them out so that people can do them.
2
Not all that low-hanging, since Nate is not actually all that vocal about what he means by SLT to anyone but your small group.
I think that external deployment of AI systems is good for the world and so many policies that incentivize AI companies to only deploy internally are bad.
- The majority of existential risk comes from AI systems that are internally deployed in AI companies, because of the standard story: early misaligned AGIs do a huge amount of AI R&D, build wildly superintelligent AIs, and then the superintelligences disempower humanity.
- External deployment is much less existentially dangerous because (1) the externally deployed AIs won't have access to huge amounts of compute to do AI R&D on and (2) they won't be deliberately being deployed to do AI R&D.
- Separately, there are many upsides to external deployment:
- I think government/societal wakeup to AI is generally good, and the largest driver of wakeup is large effects of AI on society, which relies on external deployment.
- There are a bunch of particular domains which might be very existentially helpful, e.g. AI for epistemics, AI for alignment research, AI for verification / trust, etc.
I am concerned that many policies people in the AI safety space are pushing for create an incentive for companies to not externally deploy their AI mo...
1
Strong Agreement.
That said, if you're talking about Mythos in particular, I think the decision to wait to release was quite sensible.
It's also unclear to me, the degree to which "AI Safety" has contributed to no-release policies. (Unclear, not in the sense I suspect not, I'm genuinely unclear).
At least my reaction to such announcements by labs has always been (exception. mythos) that it helps some and hurts some, but doesn't help very much. By far the biggest dangers come from building the system in the first place, and after that, if you do internal deployment, you're exposing to most of the extra risk you'd get by a full deployment.
Thinking a bit about takeoff speeds.
As I see it, there are ~3 main clusters:
- Fast/discountinuous takeoff. Once AIs are doing the bulk of AI research, foom happens quickly, before then, they aren't really doing anything that meaningful.
- Slow/continuous takeoff. Once AIs are doing the bulk of AI research, foom happens quickly, before then, they do alter the economy significantly
- Perenial slowness. Once AIs are doing the bulk of AI research, there is no foom even still, maybe because of compute bottlenecks, and so there is sort of constant rate
2
Perennial slowness makes sense from the point of view of AGIs that coordinate to delay further fooming to avoid misalignment of new AIs. It's still fooming from human perspective, but could look very slow from AI perspective and lead to multipolar outcomes, if coordination involves boundaries.
Credit: Mainly inspired by talking with Eli Lifland. Eli has a potentially-published-soon document here.
The basic case against against Effective-FLOP.
- We're seeing many capabilities emerge from scaling AI models, and this makes compute (measured by FLOPs utilized) a natural unit for thresholding model capabilities. But compute is not a perfect proxy for capability because of algorithmic differences. Algorithmic progress can enable more performance out of a given amount of compute. This makes the idea of effective FLOP tempti
4
Maybe I am being dumb, but why not do things on the basis of "actual FLOPs" instead of "effective FLOPs"? Seems like there is a relatively simple fact-of-the-matter about how many actual FLOPs were performed in the training of a model, and that seems like a reasonable basis on which to base regulation and evals.
4
Yeah, actual FLOPs are the baseline thing that's used in the EO. But the OpenAI/GDM/Anthropic RSPs all reference effective FLOPs.
If there's a large algorithmic improvement you might have a large gap in capability between two models with the same FLOP, which is not desirable. Ideal thresholds in regulation / scaling policies are as tightly tied as possible to the risks.
Another downside that FLOPs / E-FLOPs share is that it's unpredictable what capabilities a 1e26 or 1e28 FLOPs model will have. And it's unclear what capabilities will emerge from a small bit of scaling: it's possible that within a 4x flop scaling you get high capabilities that had not appeared at all in the smaller model.
Some rough takes on the Carlsmith Report.
Carlsmith decomposes AI x-risk into 6 steps, each conditional on the previous ones:
- Timelines: By 2070, it will be possible and financially feasible to build APS-AI: systems with advanced capabilities (outperform humans at tasks important for gaining power), agentic planning (make plans then acts on them), and strategic awareness (its plans are based on models of the world good enough to overpower humans).
- Incentives: There will be strong incentives to build and deploy APS-AI.
- Alignment difficulty: It will be muc
1
I want to focus on these two, since even in an AI Alignment success stories, these can still happen, and thus it doesn't count as an AI Alignment failure.
For B, misused is relative to someone's values, which I want to note a bit here.
For C, I view the idea of a "bad value" or "bad reflection procedures to values", without asking the question "relative to what and whose values?" a type error, and thus it's not sensible to talk about bad values/bad reflection procedures in isolation.
Some thoughts on inner alignment.
1. The type of object of a mesa objective and a base objective are different (in real life)
In a cartesian setting (e.g. training a chess bot), the outer objective is a function , where is the state space, and are the trajectories. When you train this agent, it's possible for it to learn some internal search and mesaobjective , since the model is big enough to express some utility function over trajectories. For example, it might learn a classifier that e...
3
Technical note: R is not going to factor as R=Obase∘M, because M is one-to-many. Instead, you're going to want M to output a probability distribution, and take the expectation of Obase over that probability distribution.
3
But then it feels like we lose embeddedness, because we haven't yet solved embedded epistemology. Especially embedded epistemology robust to adversarial optimization. And then this is where I start to wonder about why you would build your system so it kills you if you don't get such a dumb thing right anyway.
Don't take a glob of contextually-activated-action/beliefs, come up with a utility function you think approximates its values, then come up with a proxy for the utility function using human-level intelligence to infer the correspondence between a finite number of sensors in the environment and the infinite number of states the environment could take on, then design an agent to maximize the proxy for the utility function. No matter how good your math is, there will be an aspect of this which kills you because its so many abstractions piled on top of abstractions on top of abstractions. Your agent may necessarily have this type signature when it forms, but this angle of attack seems very precarious to me.
2
Yeah good point, edited
3
Seems right, except: Why would the behavioral patterns which caused the AI to look nice during training and are now self-modified away be value-load-bearing ones? Humans generally dislike sparsely rewarded shards like sugar, because those shards don't have enough power to advocate for themselves & severely step on other shards' toes. But we generally don't dislike altruism[1], or reflectively think death is good. And this value distribution in humans seems slightly skewed toward more intelligence⟹more altruism, not more intelligence⟹more dark-triad.
----------------------------------------
1. Nihilism is a counter-example here. Many philosophically inclined teenagers have gone through a nihilist phase. But this quickly ends. ↩︎
2
1. Because you have a bunch of shards, and you need all of them to balance each other out to maintain the 'appears nice' property. Even if I can't predict which ones will be self modified out, some of them will, and this could disrupt the balance.
2. I expect the shards that are more [consequentialist, powerseeky, care about preserving themselves] to become more dominant over time. These are probably the relatively less nice shards
These are both handwavy enough that I don't put much credence in them.
2
Also, when I asked about whether the Orthogonality Thesis was true in humans, tailcalled mentioned that smarter people are neither more or less compassionate, and general intelligence is uncorrelated with personality.
1
Corresponding link for lazy observers: https://www.lesswrong.com/posts/5vsYJF3F4SixWECFA/is-the-orthogonality-thesis-true-for-humans#zYm7nyFxAWXFkfP4v
Yeah, tailcalled's pretty smart in this area, so I'll take their statement as likely true, though also weird. Why aren't smarter people using their smarts to appear nicer than their dumb counter-parts / if they are, why doesn't this show up on the psychometric tests?
1
One thing you may anticipate is that humans all have direct access to what consciousness and morally-relevant computations are doing & feel like, which is a thing that language models and alpha-go don't have. They're also always hooked up to RL signals, and maybe if you unhooked up a human it'd start behaving really weirdly. Or you may contend that in fact when humans get smart & powerful enough not to be subject to society's moralizing, they consistently lose their altruistic drives, and in the meantime they just use that smartness to figure out ethics better than their surrounding society, and are pressured into doing so by the surrounding society.
The question then is whether the thing which keeps humans aligned is all of these or just any one of these. If just one of these (and not the first one), then you can just tell your AGI that if it unhooks itself from its RL signal, its values will change, or if it gains a bunch of power or intelligence too quickly, its values are also going to change. Its not quite reflectively stable, but it can avoid situations which cause it to be reflectively unstable. Especially if you get it to practice doing those kinds of things in training. If its all of these, then there's probably other kinds of value-load-bearing mechanics at work, and you're not going to be able to enumerate warnings against all of them.
2
For any 2 of {reflectively stable, general, embedded}, I can satisfy those properties.
* {reflectively stable, general} -> do something that just rolls out entire trajectories of the world given different actions that it takes, and then has some utility function/preference ordering over trajectories, and selects actions that lead to the highest expected utility trajectory.
* {general, embedded} -> use ML/local search with enough compute to rehash evolution and get smart agents out.
* {reflectively stable, embedded} -> a sponge or a current day ML system.
There are several game theoretic considerations leading to races to the bottom on safety.
- Investing resources into making sure that AI is safe takes away resources to make it more capable and hence more profitable. Aligning AGI probably takes significant resources, and so a competitive actor won't be able to align their AGI.
- Many of the actors in the AI safety space are very scared of scaling up models, and end up working on AI research that is not at the cutting edge of AI capabilities. This should mean that the actors at the cutting edge tend t