8 Answers sorted by
Ω215017
I think the main concept missing here is compression: trained systems favor more compact policies/models/heuristics/algorithms/etc. The fewer parameters needed to implement the inner agent, the more parameters are free to vary, and therefore the more parameter-space-volume the agent takes up and the more likely it is to be found. (This is also the main argument for why overparameterized ML systems are able to generalize at all.)
The outer training loop doesn't just select for high reward, it also implicitly selects for compactness. We expect it to find, not just policies which achieve high reward, but policies which are very compactly represented.
Compression is the main reason we expect inner search processes to appear. Here's the relevant argument from Risks From Learned Optimization:
In some tasks, good performance requires a very complex policy. At the same time, base optimizers are generally biased in favor of selecting learned algorithms with lower complexity. Thus, all else being equal, the base optimizer will generally be incentivized to look for a highly compressed policy.
One way to find a compressed policy is to search for one that is able to use general features of the task structure to produce good behavior, rather than simply memorizing the correct output for each input. A mesa-optimizer is an example of such a policy. From the perspective of the base optimizer, a mesa-optimizer is a highly-compressed version of whatever policy it ends up implementing: instead of explicitly encoding the details of that policy in the learned algorithm, the base optimizer simply needs to encode how to search for such a policy. Furthermore, if a mesa-optimizer can determine the important features of its environment at runtime, it does not need to be given as much prior information as to what those important features are, and can thus be much simpler.
The same argument applies to the terminal objectives/heuristics/proxies instilled in an RL-trained system: it may not terminally value the reward button being pushed or the human smiling or whatever, but its values should be generated from a relatively small, relatively simple set of things. For instance, a plausible Fermi estimate for humans is that our values are ultimately generated from ~tens of simple proxies. (And I would guess that modern ML training would probably result in even fewer, relative to human evolution.)
Furthermore, whatever terminal values are instilled in the RL-trained system, they do need to at least induce near-perfect optimization of the feedback signal on the training set; otherwise the outer training loop would select some other parameters. The outer training loop is still an optimization process, after all, so whatever policy the trained system ends up with should still be roughly-optimal. (There's some potential wiggle room here insofar as the AI which takes off will be the first one to pass the threshold, and that may happen during a training run before convergence, but I think that's probably not central to discussion here?)
Putting that all together: we don't know that the AI will necessarily end up optimizing reward-button-pushes or smiles; there may be other similarly-compact proxies which correlate near-perfectly with reward in the training process. We can probably rule out "a spread of situationally-activated computations which steer its actions towards historical reward-correlates", insofar as that spread is a much less compact policy-encoding than an explicit search process + simple objective(s).
Agreed with John, with the caveat that I expect search processes + simple objectives to only emerge from massively multi-task training. If you're literally training an AI just on smiling, TurnTrout is right that "a spread of situationally-activated computations" is more likely since you're not getting any value from the generality of search.
The Deep Double Descent paper is a good reference for why gradient descent training in the overparametrized regime favors low complexity models, though I don't know of explicit evidence for the conjecture that "explicit search + simple objectives" is actually lower complexity (in model space) than "bundle of heuristics". Seems intuitive if model complexity is something close to Kolmogorov complexity, but would love to see an empirical investigation!
We can probably rule out "a spread of situationally-activated computations which steer its actions towards historical reward-correlates", insofar as that spread is a much less compact policy-encoding than an explicit search process + simple objective(s).
Not sure if I disagree with the object-level assertion, but I think some important caveats are missing here. We have to take the plausible paths through algorithm-space the SGD is likely to take as well, and that might change the form of the final compressed policy in non-intuitive ways.
Another compact poli...
We can probably rule out "a spread of situationally-activated computations which steer its actions towards historical reward-correlates", insofar as that spread is a much less compact policy-encoding than an explicit search process + simple objective(s).
Seems like you can have a yet-simpler policy by factoring the fixed "simple objective(s)" into implicit, modular elements that compress many different objectives that may be useful across many different environments. Then at runtime, you feed the environmental state into your factored representation of poss...
We can probably rule out "a spread of situationally-activated computations which steer its actions towards historical reward-correlates", insofar as that spread is a much less compact policy-encoding than an explicit search process + simple objective(s).
Here's what I think you mean by an explicit search process:
- In every situation, the neural network runs e.g. MCTS with a fixed leaf evaluation function (the simple objective).
On this understanding of your argument, I would be surprised if it went through. Here are a few quick counterpoints.
- Outside tiny
Do you mean "hardcoded reward circuit"
I'm not that committed to the RL frame, but roughly speaking yes. Whatever values we have are probably generated by ~tens of hardcoded things. Anyway, on to the meat of the discussion...
It seems like a whole bunch of people are completely thrown off by use of the word "search". So let's taboo that and talk about what's actually relevant here.
We should expect compression, and we should expect general-purpose problem solving (i.e. the ability to take a fairly arbitrary problem in the training environment and solve it reasonably well). The general-purpose part comes from a combination of (a) variation in what the system needs to do to achieve good performance in training, and (b) the recursive nature of problem solving, i.e. solving one problem involves solving a wide variety of subproblems. Compactness means that it probably won't be a whole boatload of case-specific heuristics; lookup tables are not compact. A subroutine for reasonably-general planning or problem-solving (i.e. take a problem statement, figure out a plan or solution) is the key thing we're talking about here. Possibly a small number of such subroutines for a few different problem...
162
I think the AI will very probably have a spread of situationally-activated computations which steer its actions towards historical reward-correlates (e.g. if near a person, then tell a joke), and probably not singularly value e.g. making people smile or reward
I agree. My recent write-up is partly an attempt to model this dynamic in a toy causal-graph environment. Most relevantly, this section.
Imagine an environment represented as a causal graph, with some action-nodes an agent can set, observation-nodes whose values that agent can read off, and some reward-node whose value determines how much reinforcement the agent gets. The agent starts with no information about the environment structure or the environment state. If the reward-node is sufficiently distant from its action-nodes, it'll take time for the agent's world-model to become advanced enough to model it. However, the agent would start trying to develop good policies/heuristics for increasing the reward immediately. Thus, its initial policies will necessarily act on proxies: it'll be focusing on the values of some intermediate nodes between its action-nodes and the reward-node.
And these proxies can be quite good. For example:
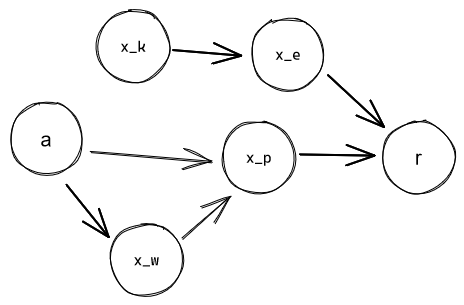
is a good proxy for controlling the value of if the chain doesn't perturb it too much. So an agent that only cares about the environment up to can capture e. g. of the possible maximum reward.
It feels like it shouldn't matter: that once the world-model is advanced enough to include directly, the agent should just recognize as the source of reinforcement, and optimize it directly.
But suppose the heuristics the agent develops have "friction". That is: once a heuristic has historically performed well enough, the agent is reluctant to replace it with a better but more novel (and therefore untested) one. Or, at least, less willing the less counterfactual reward it promises to deliver. So a heuristic that performs 10x as well as the one it currently has will be able to win against a much older one, but a novel heuristic that only performs 1.1x as well won't be.
In this case, the marginally more effective policy will not be able to displace a more established one.
(An alternate view: suppose that the agent has two mutually-exclusive heuristic on what to do in a given situation, A and B. A has a good track record, B is a new one, but it's willing to try B out. Suppose it picks A with probability and B with , with proportional to how long A's track record is. If the reinforcement B receives is much larger than the reinforcement A receives, then even a rarely-picked B will eventually outpace A. If it's not much larger, however, then A will be able to "keep up" with B by virtue of being picked more often, and eventually outrace B into irrelevancy.)
Therefore: Yes, the agent will end up optimized for good performance on some proxies of "the human presses the button". What these proxies are depends on the causal structure of the environment, the percentage of max-reward optimizing for them allows the agent to capture, and some "friction" value that depends on the agent's internal architecture.
Major caveat: This mainly only holds for less-advanced systems; for those that are optimized, but do not yet optimize at the strategic level. A hedonist wrapper-mind would have no problems with evaluating whether the new heuristic is actually better, testing it out, and implementing it, no matter how comparably novel it is.
Caveat to the caveat: Such strategic thinking will probably appear after the "values" have already been formed, and at that point the agent will do deceptive alignment to preserve them, instead of self-modifying into a reward-maximizer.
Route warning: This doesn't mean the agent's proxies will be friendly or even comprehensible to us. In particular, if the reward structure is
Then it's about as likely (very not) that the agent will end up focusing on "I smile" as on "I press the button", since there's basically just a single causal step. Much more likely is that it'll value some stuff upstream of "something makes me smile"; possibly very strange stuff.
Note: Using the "antecedent-computation-reinforcer" term really makes all of this clearer, but it's so unwieldy. Any ideas for coining a better term?
Ω775
Quoting Rob Bensinger quoting Eliezer:
So what actually happens as near as I can figure (predicting future = hard) is that somebody is trying to teach their research AI to, god knows what, maybe just obey human orders in a safe way, and it seems to be doing that, and a mix of things goes wrong like:
The preferences not being really readable because it's a system of neural nets acting on a world-representation built up by other neural nets, parts of the system are self-modifying and the self-modifiers are being trained by gradient descent in Tensorflow, there's a bunch of people in the company trying to work on a safer version but it's way less powerful than the one that does unrestricted self-modification, they're really excited when the system seems to be substantially improving multiple components, there's a social and cognitive conflict I find hard to empathize with because I personally would be running screaming in the other direction two years earlier, there's a lot of false alarms and suggested or attempted misbehavior that the creators all patch successfully, some instrumental strategies pass this filter because they arose in places that were harder to see and less transparent, the system at some point seems to finally "get it" and lock in to good behavior which is the point at which it has a good enough human model to predict what gets the supervised rewards and what the humans don't want to hear, they scale the system further, it goes past the point of real strategic understanding and having a little agent inside plotting, the programmers shut down six visibly formulated goals to develop cognitive steganography and the seventh one slips through, somebody says "slow down" and somebody else observes that China and Russia both managed to steal a copy of the code from six months ago and while China might proceed cautiously Russia probably won't, the agent starts to conceal some capability gains, it builds an environmental subagent, the environmental agent begins self-improving more freely, undefined things happen as a sensory-supervision ML-based architecture shakes out into the convergent shape of expected utility with a utility function over the environmental model, the main result is driven by whatever the self-modifying decision systems happen to see as locally optimal in their supervised system locally acting on a different domain than the domain of data on which it was trained, the light cone is transformed to the optimum of a utility function that grew out of the stable version of a criterion that originally happened to be about a reward signal counter on a GPU or God knows what.
Perhaps the optimal configuration for utility per unit of matter, under this utility function, happens to be a tiny molecular structure shaped roughly like a paperclip.
That is what a paperclip maximizer is. It does not come from a paperclip factory AI. That would be a silly idea and is a distortion of the original example.
Perhaps the optimal configuration for utility per unit of matter, under this utility function, happens to be a tiny molecular structure shaped roughly like a paperclip.
I think this is very improbable, but thanks for the quote. Not sure if it addresses my question?
62
I don't know what the agent would end up valuing in this scenario either. I think a pretty good research direction for shard theory would be to closely examine the training history of the agent to find particular episodes where qualitatively new behaviors seem to form / new circuits arise in the neural net. This might allow you to identify shards, whereas it seems much harder to do that if you're only looking at the final trained weights of the agent.
Ω551
Not having read other responses, my attempt to answer in my own words: what goes wrong is that there are tons of possible cognitive influences that could be reinforced by rewards for making people smile. E.g. "make things of XYZ type think things are going OK", "try to promote physical configurations like such-and-such", "trying to stimulate the reinforcer I observe in my environment". Most of these decision-influences, when extrapolated to coherent behaviour where those decision-influences drive the course of the behaviour, lead to resource-gathering and not respecting what the informed preferences of humans would be. Then this causes doom because you can better achieve most goals/preferences you could have by having more power and disempowering the humans.
51
Pretrained models don't need any exploration to know that pressing the reward button gets more reward than doing things the humans want. If you just ask GPT3, it'll tell you that.
Then the only exploration the AI needs is to get reward after thinking about analogies between its situation and its textual knowledge of AI/reinforcement learning/AI doom scenarios.
This applies especially much to simple/often discussed tasks such as making people smile - an LM has already heard of this exact task, so if it took an action based on the "make people smile task" its heard about, this could outperform other thought processes which are only conditioned on data so far.
OK, but that's a predictive fact in the world model, not a motivational quantity in the policy. I know about my reward center too, and my brain does RL of some kind, but I don't primarily care about reward.
20
One plausible answer is that it does in fact reward hack/optimize the reward, because reward hacking/reward optimization has happened before empirically, so there are reasonable grounds to raise the hypothesis to plausibility:
Suppose you're training a huge neural network with some awesome future RL algorithm with clever exploration bonuses and a self-supervised pretrained multimodal initialization and a recurrent state. This NN implements an embodied agent which takes actions in reality (and also in some sim environments). You watch the agent remotely using a webcam (initially unbeknownst to the agent). When the AI's activities make you smile, you press the antecedent-computation-reinforcer button (known to some as the "reward" button). The agent is given some appropriate curriculum, like population-based self-play, so as to provide a steady skill requirement against which its intelligence is sharpened over training. Supposing the curriculum trains these agents out until they're generally intelligent—what comes next?
My current answer is "I don't know precisely what goes wrong, but probably something does, but also I suspect I could write down mechanistically plausible-to-me stories where things end up bad but not horrible." I think the AI will very probably have a spread of situationally-activated computations which steer its actions towards historical reward-correlates (e.g. if near a person, then tell a joke), and probably not singularly value e.g. making people smile or reward. Furthermore, I think its values won't all map on to the "usual" quantities-of-value:
So, I'm pretty uncertain about what happens here, but would guess that most other researchers are less uncertain than I am. So here's an opportunity for us to talk it out!
(My mood here isn't "And this is what we do for alignment, let's relax." My mood is "Why consider super-complicated reward and feedback schemes when, as far as I can tell, we don't know what's going to happen in this relatively simple scheme? How do reinforcement schedules map into inner values?")