6 Answers sorted by
50
30
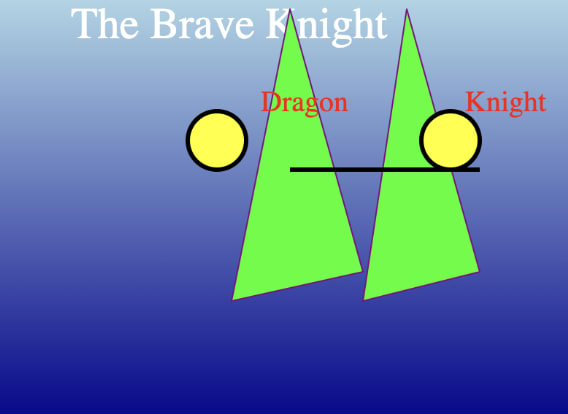
Note that ASCII art isn't the only kind of art. I just asked GPT4 and Claude to both make SVGs of a knight fighting a dragon.
Here's Claude's attempt:
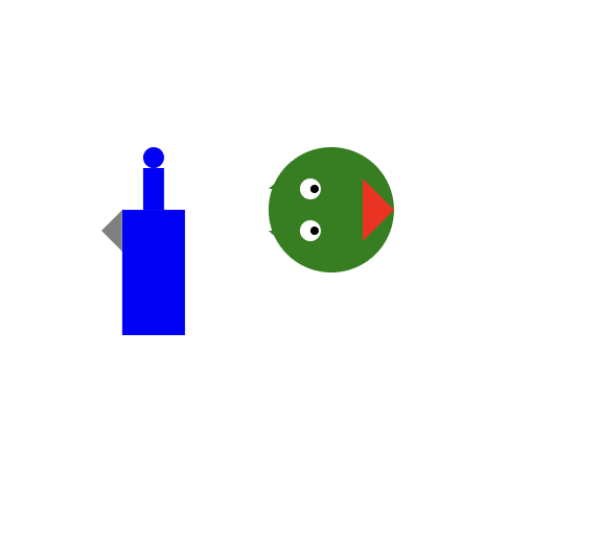
And GPT4s:
I asked them both to make it more realistic. Claude responded with the exact same thing with some extra text, GPT4 returned:

I asked followed up asking it for more muted colors and a simple background, and it returned:

I tried again, accidentally using GPT3.5 this time, which initially gave something really lame, but then said "more realistic please", and it gave me:

Next I asked it:
It responded with this image:
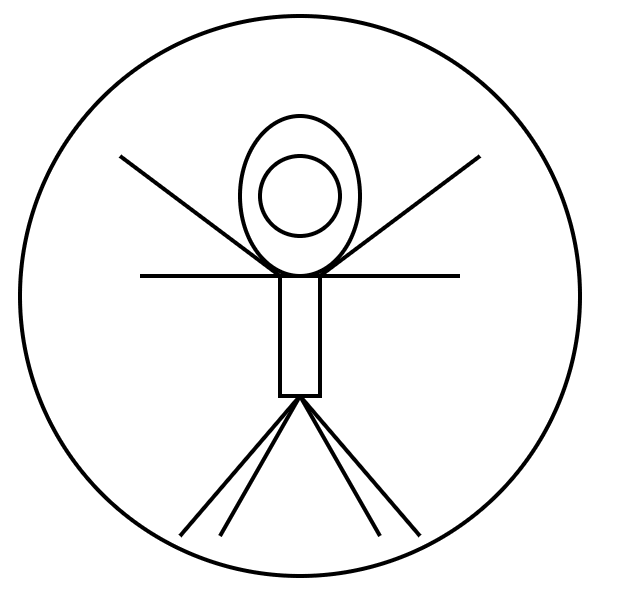
code:
<svg width="300" height="300" viewBox="0 0 300 300" xmlns="http://www.w3.org/2000/svg">
<!-- Background circle -->
<circle cx="150" cy="150" r="140" fill="none" stroke="black" stroke-width="2"/>
<!-- Body -->
<ellipse cx="150" cy="100" rx="30" ry="40" fill="none" stroke="black" stroke-width="2"/>
<rect x="140" y="140" width="20" height="60" fill="none" stroke="black" stroke-width="2"/>
<line x1="100" y1="140" x2="200" y2="140" stroke="black" stroke-w30
It's not great but it's trying
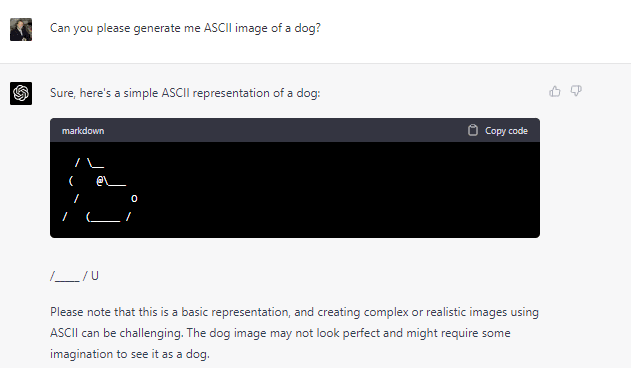
*
3-5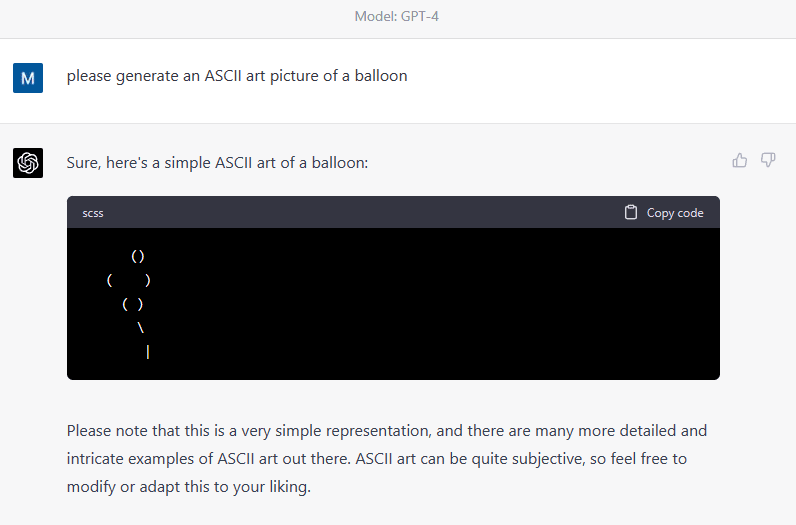
I think it makes sense that it fails in this way. ChatGPT really doesn't see lines arranged vertically, it just sees the prompt as one long line. But given that it has been trained on a lot of ASCII art, it will probably be successful at copying some of it some of the time.
In case there is any doubt, here is GPT4's own explanation of these phenomena:
Lack of spatial awareness: GPT-4 doesn't have a built-in understanding of spatial relationships or 2D layouts, as it is designed to process text linearly. As a result, it struggles to maintain the correct alignment of characters in ASCII art, where spatial organization is essential.
Formatting inconsistencies in training data: The training data for GPT-4 contains a vast range of text from the internet, which includes various formatting styles and inconsistent examples of ASCII art. This inconsistency makes it difficult for the model to learn a single, coherent way of generating well-aligned ASCII art.
Loss of formatting during preprocessing: When text is preprocessed and tokenized before being fed into the model, some formatting information (like whitespaces) might be lost or altered. This loss can affect the model's ability to produce well-aligned ASCII art.
This is a more sensible representation of a balloon than one in the post, it's just small. More prompts tested on both ChatGPT-3.5 and GPT-4 would clarify the issue.
ChatGPT really doesn't see lines arranged vertically, it just sees the prompt as one long line.
Vision can be implemented in transformers by representing pictures with linear sequences of tokens, which stand for small patches of the picture, left-to-right, top-to-bottom (see appendix D.4 of this paper). The model then needs to learn on its own how the rows fit together into columns and so on...
20
See my reply here for a partial exploration of this. I also have a very long post in my drafts covering this question in relation to Bing's AI, but I'm not sure if it's worth posting now, after the GPT4 release.
0-1
In my understanding, this is only possible by rote memorization.
Does anyone know whether GPT-4 successfully generates ASCII art?
GPT-3.5 couldn't:
Which makes sense, cause of the whole words-can't-convey-phenomena thing.
I'd expect multimodality to solve this problem, though?