This is a special post for quick takes by RobertM. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
We recently had a security incident where an attacker used an old AWS access key to generate millions of tokens from various Claude models via AWS Bedrock. While we don't have any specific reason to think that any user data was accessed (and some reasons[1] to think it wasn't), most possible methods by which this key could have been found by an attacker would also have exposed our database credentials to the attacker. We don't know yet how the key was leaked, but we have taken steps to reduce the potential surface area in the future and rotated relevant credentials. This is a reminder that LessWrong does not have Google-level security and you should keep that in mind when using the site.
- ^
The main reason we don't think any user data was accessed is because this attack bore several signs of being part of a larger campaign, and our database also contains other LLM API credentials which would not have been difficult to find via a cursory manual inspection. Those credentials don't seem have been used by the attackers. Larger hacking campaigns like this are mostly automated, and for economic reasons the organizations conducting those campaigns don't usually sink time into manually i
The reason for these hacks seems pretty interesting: https://krebsonsecurity.com/2024/10/a-single-cloud-compromise-can-feed-an-army-of-ai-sex-bots/ https://permiso.io/blog/exploiting-hosted-models
Apparently this isn't a simple theft of service as I had assumed, but it is caused by the partial success of LLM jailbreaks: hackers are now incentivized to hack any API-enabled account they can in order to use it not on generic LLM uses, but specifically on NSFW & child porn chat services, to both drain & burn accounts.
I had been a little puzzled why anyone would target LLM services specifically, when LLMs are so cheap in general, and falling rapidly in cost. Was there really that much demand to economize on LLM calls of a few dozen or hundred dollars, by people who needed a lot of LLMs (enough to cover the large costs of hacking and creating a business ecosystem around it) and couldn't get LLMs anyway else like local hosting...? This explains that: the theft of money is only half the story. They are also setting the victim up as the fall guy, and you don't realize it because the logging is off and you can't read the completions. Quite alarming.
And this is now a concrete example of the harms caused by jailbreaks, incidentally: they incentivize exploiting API accounts in order to use & burn them. If the jailbreaks didn't work, they wouldn't bother.
6
Worth noting explicitly: while there weren't any logs left of prompts or completions, there were logs of API invocations and errors, which contained indications that whatever this was, it was still under development and not an already-scaled setup. Eg we saw API calls fail with invalid-arguments, then get retried successfully after a delay.
The indicators-of-compromise aren't a good match between the Permiso blog post and what we see in logs; in particular we see the user agent string Boto3/1.29.7 md/Botocore#1.32.7 ua/2.0 os/windows#10 md/arch#amd64 lang/python#3.12.4 md/pyimpl#CPython cfg/retry-mode#legacy Botocore/1.32.7 which is not mentioned. While I haven't checked all the IPs, I checked a sampling and they didn't overlap. (The IPs are a very weak signal, however, since they were definitely botnet IPs and botnets can be large.)
7
Permiso seems to think there may be multiple attacker groups, as they always refer to plural attackers and discuss a variety of indicators and clusters. And I don't see any reason to think there is a single attacker - there's no reason to think Chub is the only LLM sexting service, and even if it was, the logical way to operate for Chub would be to buy API access on a blackmarket from all comers without asking any questions, and focus on their own business. So that may just mean that you guys got hit by another hacker who was still setting up their own workflow and exploitation infrastructure.
(It's a big Internet. Like all that Facebook DALL-E AI slop images is not a single person or group, or even a single network of influencers, it's like several different communities across various third world languages coordinating churning out AI slop for Facebook 'engagement' payments, all sharing tutorials and get-rick-quick schemes.)
3
An additional reason to think there's many attackers: I submitted this to Reddit and a Redditor says they use these sorts of 'reverse proxy' services regularly and that they've been discussed overtly on 4chan for at least a year: https://www.reddit.com/r/MediaSynthesis/comments/1fvd6tn/recent_wave_of_llm_cloud_api_hacks_motivated_by/lqb7lzf/ Obviously, if your attacker really was a newbie given their slipups, but these hackers providing reverse proxies have been operating for at least a year at sufficient scale as to generate regular discussions on 4chan alone, then there are probably quite a lot of them competing.
EDIT: I believe I've found the "plan" that Politico (and other news sources) managed to fail to link to, maybe because it doesn't seem to contain any affirmative commitments by the named companies to submit future models to pre-deployment testing by UK AISI.
I've seen a lot of takes (on Twitter) recently suggesting that OpenAI and Anthropic (and maybe some other companies) violated commitments they made to the UK's AISI about granting them access for e.g. predeployment testing of frontier models. Is there any concrete evidence about what commitment was made, if any? The only thing I've seen so far is a pretty ambiguous statement by Rishi Sunak, who might have had some incentive to claim more success than was warranted at the time. If people are going to breathe down the necks of AGI labs about keeping to their commitments, they should be careful to only do it for commitments they've actually made, lest they weaken the relevant incentives. (This is not meant to endorse AGI labs behaving in ways which cause strategic ambiguity about what commitments they've made; that is also bad.)
5
I haven't followed this in great detail, but I do remember hearing from many AI policy people (including people at the UKAISI) that such commitments had been made.
It's plausible to me that this was an example of "miscommunication" rather than "explicit lying." I hope someone who has followed this more closely provides details.
But note that I personally think that AGI labs have a responsibility to dispel widely-believed myths. It would shock me if OpenAI/Anthropic/Google DeepMind were not aware that people (including people in government) believed that they had made this commitment. If you know that a bunch of people think you committed to sending them your models, and your response is "well technically we never said that but let's just leave it ambiguous and then if we defect later we can just say we never committed", I still think it's fair for people to be disappointed in the labs.
(I do think this form of disappointment should not be conflated with "you explicitly said X and went back on it", though.)
5
I agree in principle that labs have the responsibility to dispel myths about what they're committed to. OTOH, in defense of the labs I imagine that this can be hard to do while you're in the middle of negotiations with various AISIs about what those commitments should look like.
4
I don't know, this sounds weird. If people make stuff up about someone else and do so continually, in what sense it's that someone "responsibility" to rebut such things? I would agree with a weaker claim, something like: don't be ambiguous about your commitments with the objective of making it seem like you are committing to something and then walk back at the time you should make the commitment.
1
Yeah fair point. I do think labs have some some nonzero amount of responsibility to be proactive about what others believe about their commitments. I agree it doesn't extend to 'rebut every random rumor'.
4
More discussion of this here. Really not sure what happened here, would love to see more reporting on it.
5
Ah, does look like Zach beat me to the punch :)
I'm also still moderately confused, though I'm not that confused about labs not speaking up - if you're playing politics, then not throwing the PM under the bus seems like a reasonable thing to do. Maybe there's a way to thread the needle of truthfully rebutting the accusations without calling the PM out, but idk. Seems like it'd be difficult if you weren't either writing your own press release or working with a very friendly journalist.
Adding to the confusion: I've nonpublicly heard from people at UK AISI and [OpenAI or Anthropic] that the Politico piece is very wrong and DeepMind isn't the only lab doing pre-deployment sharing (and that it's hard to say more because info about not-yet-deployed models is secret). But no clarification on commitments.
1
Have you read this? https://www.politico.eu/article/rishi-sunak-ai-testing-tech-ai-safety-institute/
"“You can’t have these AI companies jumping through hoops in each and every single different jurisdiction, and from our point of view of course our principal relationship is with the U.S. AI Safety Institute,” Meta’s president of global affairs Nick Clegg — a former British deputy prime minister — told POLITICO on the sidelines of an event in London this month."
"OpenAI and Meta are set to roll out their next batch of AI models imminently. Yet neither has granted access to the U.K.’s AI Safety Institute to do pre-release testing, according to four people close to the matter."
"Leading AI firm Anthropic, which rolled out its latest batch of models in March, has yet to allow the U.K. institute to test its models pre-release, though co-founder Jack Clark told POLITICO it is working with the body on how pre-deployment testing by governments might work.
“Pre-deployment testing is a nice idea but very difficult to implement,” said Clark."
I hadn't, but I just did and nothing in the article seems to be responsive to what I wrote.
Amusingly, not a single news source I found reporting on the subject has managed to link to the "plan" that the involved parties (countries, companies, etc) agreed to.
Nothing in that summary affirmatively indicates that companies agreed to submit their future models to pre-deployment testing by the UK AISI. One might even say that it seems carefully worded to avoid explicitly pinning the companies down like that.
Vaguely feeling like OpenAI might be moving away from GPT-N+1 release model, for some combination of "political/frog-boiling" reasons and "scaling actually hitting a wall" reasons. Seems relevant to note, since in the worlds where they hadn't been drip-feeding people incremental releases of slight improvements over the original GPT-4 capabilities, and instead just dropped GPT-5 (and it was as much of an improvement over 4 as 4 was over 3, or close), that might have prompted people to do an explicit orientation step. As it is, I expect less of that kind of orientation to happen. (Though maybe I'm speaking too soon and they will drop GPT-5 on us at some point, and it'll still manage to be a step-function improvement over whatever the latest GPT-4* model is at that point.)
Eh, I think they'll drop GPT-4.5/5 at some point. It's just relatively natural for them to incrementally improve their existing model to ensure that users aren't tempted to switch to competitors.
It also allows them to avoid people being underwhelmed.
I would wait another year or so before getting much evidence on "scaling actually hitting a wall" (or until we have models that are known to have training runs with >30x GPT-4 effective compute), training and deploying massive models isn't that fast.
Yeah, I agree that it's too early to call it re: hitting a wall. I also just realized that releasing 4o for free might be some evidence in favor of 4.5/5 dropping soon-ish.
Yeah. This prompts me to make a brief version of a post I'd had on my TODO list for awhile:
"In the 21st century, being quick and competent at 'orienting' is one of the most important skills."
(in the OODA Loop sense, i.e. observe -> orient -> decide -> act)
We don't know exactly what's coming with AI or other technologies, we can make plans informed by our best-guesses, but we should be on the lookout for things that should prompt some kind of strategic orientation. @jacobjacob has helped prioritize noticing things like "LLMs are pretty soon going to be affect the strategic landscape, we should be ready to take advantage of the technology and/or respond to a world where other people are doing that."
I like Robert's comment here because it feels skillful at noticing a subtle thing that is happening, and promoting it to strategic attention. The object-level observation seems important and I hope people in the AI landscape get good at this sort of noticing.
It also feels kinda related to the original context of OODA-looping, which was about fighter pilots dogfighting. One of the skills was "get inside of the enemy's OODA loop and disrupt their ability to orient." If this were intentional on OpenAI's part (or part of subconscious strategy), it'd be a kinda clever attempt to disrupt our observation step.
Sam Altman and OpenAI have both said they are aiming for incremental releases/deployment for the primary purpose of allowing society to prepare and adapt. Opposed to, say, dropping large capabilities jumps out of the blue which surprise people.
I think "They believe incremental release is safer because it promotes societal preparation" should certainly be in the hypothesis space for the reasons behind these actions, along with scaling slowing and frog-boiling. My guess is that it is more likely than both of those reasons (they have stated it as their reasoning multiple times; I don't think scaling is hitting a wall).
2
Yeah, "they're following their stated release strategy for the reasons they said motivated that strategy" also seems likely to share some responsibility. (I might not think those reasons justify that release strategy, but that's a different argument.)
2
I wonder if that is actually a sound view though. I just started reading Like War (interesting and seems correct/on target so far but really just starting it). Given the subject area of impact, reaction and use of social media and networking technologies and the general results socially, seems like society generally is not really even yet prepared and adapted for that inovation. If all the fears about AI are even close to getting things right I suspect the "allowing society to prepare and adapt" suggests putting everything on hold, freezing in place, for at least a decade and probably longer.
Altman's and OpenAI's intentions might be towards that stated goal but I think they are basing that approach on how "the smartest people in the room" react to AI and not the general public, or the most opportinistic people in the room.
4
I'm not sure if you'd categorize this under "scaling actually hitting a wall" but the main possibility that feels relevant in my mind is that progress simply is incremental in this case, as a fact about the world, rather than being a strategic choice on behalf of OpenAI. When underlying progress is itself incremental, it makes sense to release frequent small updates. This is common in the software industry, and would not at all be surprising if what's often true for most software development holds for OpenAI as well.
(Though I also expect GPT-5 to be medium-sized jump, once it comes out.)
LessWrong is rolling out a new (experimental) editor.
Why? Our primary motivation for implementing a new editor is to make it easier for us to quickly build new integrations and customizations, particularly various AI-related features, but I also think that we should be able to better improve on the reliability and performance of the editor with lexical (the new one) vs. ckEditor (the current one). Lexical requires/allows us to own the whole stack for collaborative features, which is more overhead on our side, but many previous issues we've had with shared documents getting mysteriously corrupted should be much easier to prevent and debug now that we own the whole stack.
The new editor is currently restricted to users who are opted in to beta features. You can enable that setting under your account settings:
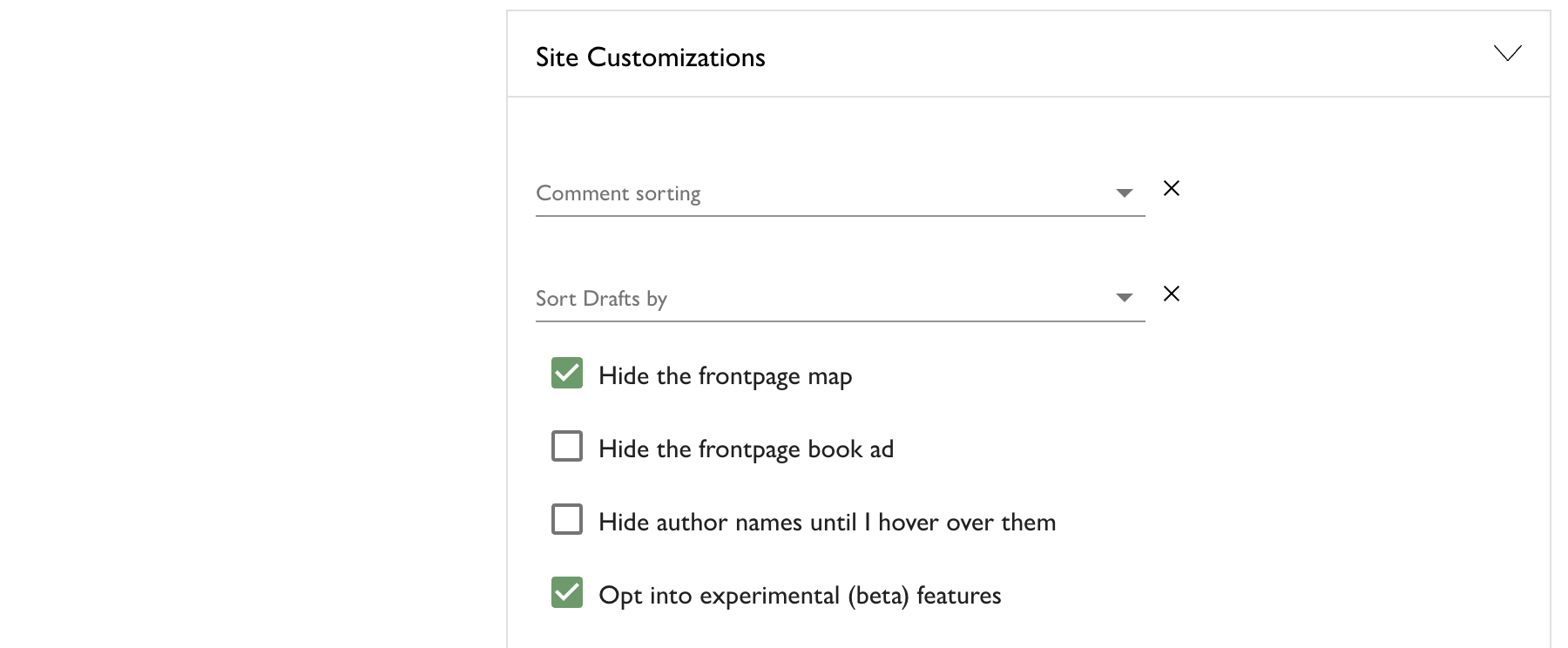
If you want to go back to using the previous default editor for now, you can opt out of experimental features by updating your account settings. You can also switch back to the previous editor on an ad-hoc basis when writing posts by using the editor type picker at the bottom of the post editor:

Any posts/comments/etc you wrote in the meantime will remain editable using whateve...
4
When applying bold or italic, then going back to Markdown, it becomes like this (I added escape characters in MD so the special characters would render when viewing this comment):
****bold****
*_italic_*
ETA: Apparently this is actually valid MD, just redundant. Is there a reason for it?
2
Nope, I haven't tested the conversion to markdown - will add it to the list of things to check, thank you!
2
Curious whether y'all considered Tiptap as a base for the editor, and if so why you decided against it?
(Tiptap is what we use for Manifold/Manifund and there are definitely some warts -- eg markdown not being supported out of the box, though recently I think that's changed -- but mostly I've liked it.)
8
We couldn't find any implementation of anything like a suggested edits feature for Tiptap-based editors and didn't want to be in the position of needing to implement it from scratch. Lexical was almost in that position, but ProtonMail's docs (which I think maybe they acquired) are built on lexical, have a suggested edits feature, and are open source with a compatible license.
Also Tiptap was in the position of needing to support a lot of really old legacy browser behaviors, and iirc lexical made a pretty explicit design decision to avoid a lot of that for the sake of having saner internal & external APIs.
In a lot of ways, Tiptap probably would have been better - it's certainly much more widely used, at least if you measure by "how many meaningfully-sized organizations use it in their stack" rather than "how many editors that end-users run into on the web are based on one vs. the other" (Meta uses lexical, so that'd be kinda skewed). But with the rapid improvements of LLMs for coding, I'm generally less afraid of future risks from lack of support.
When is the "efficient outcome-achieving hypothesis" false? More narrowly, under what conditions are people more likely to achieve a goal (or harder, better, faster, stronger) with fewer resources?
The timing of this quick take is of course motivated by recent discussion about deepseek-r1, but I've had similar thoughts in the past when observing arguments against e.g. hardware restrictions: that they'd motivate labs to switch to algorithmic work, which would be speed up timelines (rather than just reducing the naive expected rate of slowdown). Such arguments propose that labs are following predictably inefficient research directions. I don't want to categorically rule out such arguments. From the perspective of a person with good research taste, everyone else with worse research taste is "following predictably inefficient research directions". But the people I saw making those arguments were generally not people who might conceivably have an informed inside view on novel capabilities advancements.
I'm interested in stronger forms of those arguments, not limited to AI capabilities. Are there heuristics about when agents (or collections of agents) might benefit from having fewer resources? One example is the resource curse, though the state of the literature there is questionable and if the effect exists at all it's either weak or depends on other factors to materialize with a meaningful effect size.
8
I think you also have to factor in selection bias. Like suppose there are 3 organizations with 100 resource units, 10 with 20 units, 30 with 5 units. And maybe resources are helpful, but not helpful enough that all the advancements will concentrate in the top 3.
In Convergence and Compromise, McAskill and Moorhouse say:
The extent of public writing on threats is very limited
Their unfamiliarity with the prior literature is clearly on display, here. Threats are a primary focus of Eliezer Yudkowsky's renowned 1.8M-word BDSM decision theory D&D fic, which they apparently refuse to read
AI capabilities orgs and researchers are not undifferentiated frictionless spheres that will immediately relocate to e.g. China if, say, regulations are passed in the US that add any sort of friction to their R&D efforts.
Pico-lightcone purchases are back up, now that we think we've ruled out any obvious remaining bugs. (But do let us know if you buy any and don't get credited within a few minutes.)
We shipped "draft comments" earlier today. Next to the "Submit" button, you should see a drop-down menu (with only one item), which lets you save a comment as a draft. Draft comments will be visible underneath the comment input on the posts they're responding to, and all of them will be visible on your profile page, underneath your post draft list. Big thanks to the EA forum for building the feature!
Please let us know if you encounter any bugs/mishaps with them.
5
Small bug that might confuse users: the new draft shows up where I wrote it, only after I reload the page.
Repro:
1. On post page write comment replying to another comment
2. "Save As Draft"
3. Observation: draft does not show up under the parent comment
4. Reload page
5. Observation: draft does show up under the parent comment
Expectation: at 3., the draft should appear under the parent comment
If I had to hazard a guess, I would suspect what the codebase calls "a terrible hack" is at fault. If I were to venture further, I would guess getDraftSelector implies the default is include-my-draft-replies, while line 343 of the terrible hack implicitly assumes drafts are excluded by default.
2
Thanks for the report, this should be fixed now.
The LessWrong editor has just been upgraded several major versions. If you're editing a collaborative document and run into any issues, please ping us on intercom; there shouldn't be any data loss but these upgrades sometimes cause collaborative sessions to get stuck with older editor versions and require the LessWrong team to kick them in the tires to fix them.
In general I think it's fine/good to have sympathy for people who are dealing with something difficult, even if that difficult thing is part of a larger package that they signed up for voluntarily (while not forgetting that they did sign up for it, and might be able to influence or change it if they decided it was worth spending enough time/effort/points).
Edit: lest anyone mistake this for a subtweet, it's an excerpt of a comment I left in a slack thread, where the people I might most plausibly be construed as subtweeting are likely to have seen it. The object-level subject that inspired it was another LW shortform.
6
True (but obvious) taken literally. But if you also mean it's good to show sympathy by changing your stance in the discourse, such as by reallocating private or shared attention, it's not always true. In particular, many responses you implement could be exploited.
For example, say I'm ongoingly doing something bad, and whenever you try to talk to me about it, I "get upset". In this case, I'm probably actually upset, probably for multiple reasons; and probably a deep full empathic understanding of the various things going on with me would reveal that, in some real ways, I have good reason to be upset / there's something actually going wrong for me. But now say that your response to me "getting upset" is to allocate our shared attention away from the bad thing I'm doing. That may indeed be a suitable thing to do; e.g., maybe we can work together to understand what I'm upset about, and get the good versions of everything involved. However, hopefully it's clear how this could be taken advantage of--sometimes even catastrophically, if, say, you are for some reason very committed to the sort of cooperativeness that keeps reallocating attention this way, even to the ongoing abjection of your original concern for the thing I was originally and am ongoingly doing bad. (This is a nonfictional though intentionally vague example.)
2
Nah, I agree that resources are limited and guarding against exploitative policies is sensible.
3[anonymous]
I agree if their decision was voluntary and is a product of at least some reflection. Sometimes you're mad at them precisely because they sign up for it.
From my perspective, when people make decisions, the decision involves many problems at once at different time scales. Some in the present, others in the future, or in the far future. Even if they calculate consequences correctly, there's an action potential required. From the perspective of a different person, a decision might be simple - do x vs y and it requires little physical energy. But it's not so simple at the level of the neurons. The circuit for making good decisions needs to be sufficiently developed, and the conditions for developing them are relatively rare.
One condition might be gradual exposure to increasing complexity in the problems that you solve, so that you can draw the appropriate conclusions, extract the lesson at each level of complexity, and develop healthy habits. But most people are faced with the full force of complexity of the world from the day they're born. Imperfect upbringing, parents, environments, social circles.
When people make irrational decisions, in many cases I don't believe it's because they don't know better.
2
My take is that it's important to be able to accurately answer questions about what is going on. If someone asks "is this person dealing with something stressful and emotionally and socially difficult" it's important that if the answer is "yes" then you don't answer "no".
That is different from it being your responsibility to navigate their emotional or social situation in a way that doesn't exacerbate their problem. If a moving company has some internal conflicts that mean my purchasing their service will cause someone in their team emotional distress, I don't owe them an apology; we have an simple implicit agreement that they provide goods and services on-demand, and I am free to order them. I think this is how functional economies work, and that I'm not reneging on an implicit social contract by not making it my responsibility to navigate their personal issues.
I typically take "empathy" to mean you are able to accurately simulate someone's experience in yourself, and I take "sympathy" to mean that you express active desire to change their situation. (For instance, ChatGPT says "Sympathy involves recognizing the emotions or hardships someone else is going through and responding with kindness, support, or comfort.") It's of course not always appropriate to support people going through hardship with support and comfort; there are 8 billion people and I'd guess at least 10% are going through hardship of some sort today.
(I've written about this before in a discussion of wholesomeness. I believe it's good to be aware of what is going on, even if you are going to make a decision that people dislike or disagree with or that hurts them.)
1[anonymous]
Huh, the division I usually make is that empathy is feeling their same feelings and sympathy is caring about their problems; it hadn't occurred to me to think of either as requiring more action than the other. Not sure whether it's your version or mine that RobertM meant, but it seems worth highlighting as a potential point of miscommunication.
2
This currently seems to me like a miscommunication between you and I. I write "I take "sympathy" to mean that you express active desire to change their situation" and you write "sympathy is caring about their problems". Does the latter not seem to to you imply the former? Does caring about their problems not imply that, if you saw an opportunity to help out, you would take it?
4
First I'd note that for many people, "care about their problems" might mean something more like "I'd prefer a world where their problems went away", which is different from "I'd personally put effort into fixing their problems.
I'm dissatisfied with that and probably so are you because it's kinda sus – if you're not willing to help at all, it's a pretty shallow kind of caring that you might not care about.
My response to that is "Something something Loving Hitler." I can care about someone's problems (in the
"would actually help" sense), but have that be pretty low on my priority queue of things to do, including "stop the person from hurting other people" or, if their problems are caused by decisions they made, still prefer them to have to deal with the consequences of their actions so they don't do it again.
2
FTR I think it is quite easy for problems to get low enough on the priority queue that I choose to literally never think about them or try to solve them.
Suppose everyone has maybe 100 problems a day that they deal with (from where to get lunch to long-term relationship conflicts), and can ruminate on and prioritize between maybe 10 problems each hour (to eventually work on 1-3 per hour).
There are ~1010 people alive, each with 102 problems per day, and you are awake for about 16 hours a day, so you can prioritize between about 160 problems in a given day, or 160/1012=0.0000000000016% of total daily problems. So you can't even think about most problems.
I think it may makes sense to take "I don't care about X" to mean "X isn't rising to the level of problem that I'm going to think about prioritizing between", and for this to be separate from "do I have literally any preferences about X in my preference ordering over world states".
2
Sure seems reasonable, but I think that's not what I expect most people to mean. I expect you'll run into a bunch of miscommunication if you're drawing the line there. I definitely think of myself as caring about the problems of random human #4,563,215, even though I will never take any specific actions about it (and, caring a bit more about them if they're specifically brought to my attention)
2
Yeah that seems right, there's a distinction between problems I think about and problems I care about.
1[anonymous]
No? Caring is an emotion, to me; it might affect your actions but it doesn't necessarily follow that it does.
Edit: E.G. you might emotionally care, but intellectually think changing the situation would make it worse on net; you might care about multiple conflicting things another of which takes precedence; you might just not have much of an opportunity to do anything (e.g. they live somewhere else and you can't do anything over the internet, their problem is something unfixable like a loved one dying, etc.); etc. (I also wouldn't take the expression of sympathy to require expressing desire to change the situation? Like, you wouldn't want to express approval while trying to be sympathetic, but you might say, like, "I'm sorry" or "that really sucks" or whatever.)
I am pretty concerned that most of the public discussion about risk from e.g. the practice of open sourcing frontier models is focused on misuse risk (particular biorisk). Misuse risk seems like it could be a real thing, but it's not where I see most of the negative EV, when it comes to open sourcing frontier models. I also suspect that many people doing comms work which focuses on misuse risk are focusing on misuse risk in ways that are strongly disproportionate to how much of the negative EV they see coming from it, relative to all sources.
I think someone should write a summary post covering "why open-sourcing frontier models and AI capabilities more generally is -EV". Key points to hit:
- (1st order) directly accelerating capabilities research progress
- (1st order) we haven't totally ruled out the possibility of hitting "sufficiently capable systems" which are at least possible in principle to use in +EV ways, but which if made public would immediately have someone point them at improving themselves and then we die. (In fact, this is very approximately the mainline alignment plan of all 3 major AGI orgs.)
- (2nd order) generic "draws in more money, more attention
@Raemon and I have shipped some improvements to the editor experience.
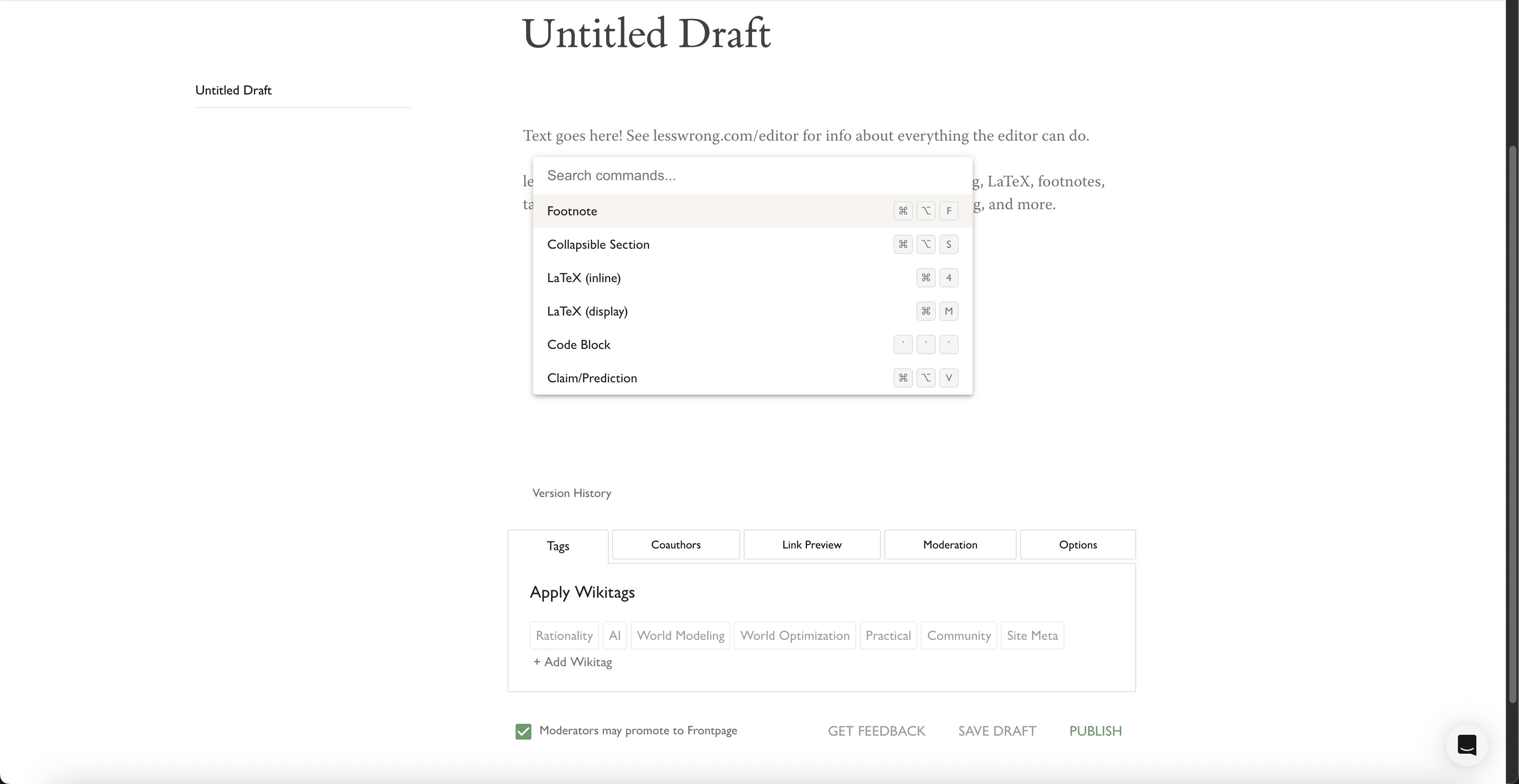
The two major changes displayed above are:
@Raemon cleaned up the options at the bottom of the editor. They used to look like this:
- I implemented a basic command palette, available both in the post and comment editor. To open it, press
ctrl/cmd + shift + p(same as the VSCode keybinding), orctrl/cmd + /, because the first keybinding is "open an incognito window" on Firefox. The goal is to improve the discoverability and accessibility of various editor features, some of which previously required you to open the toolbar to use.
It behaves the same way as most other command palettes -escto exit, up/down arrow to cycle,enterto execute the selected command, and also shows you the native keybindings for executing any given command.
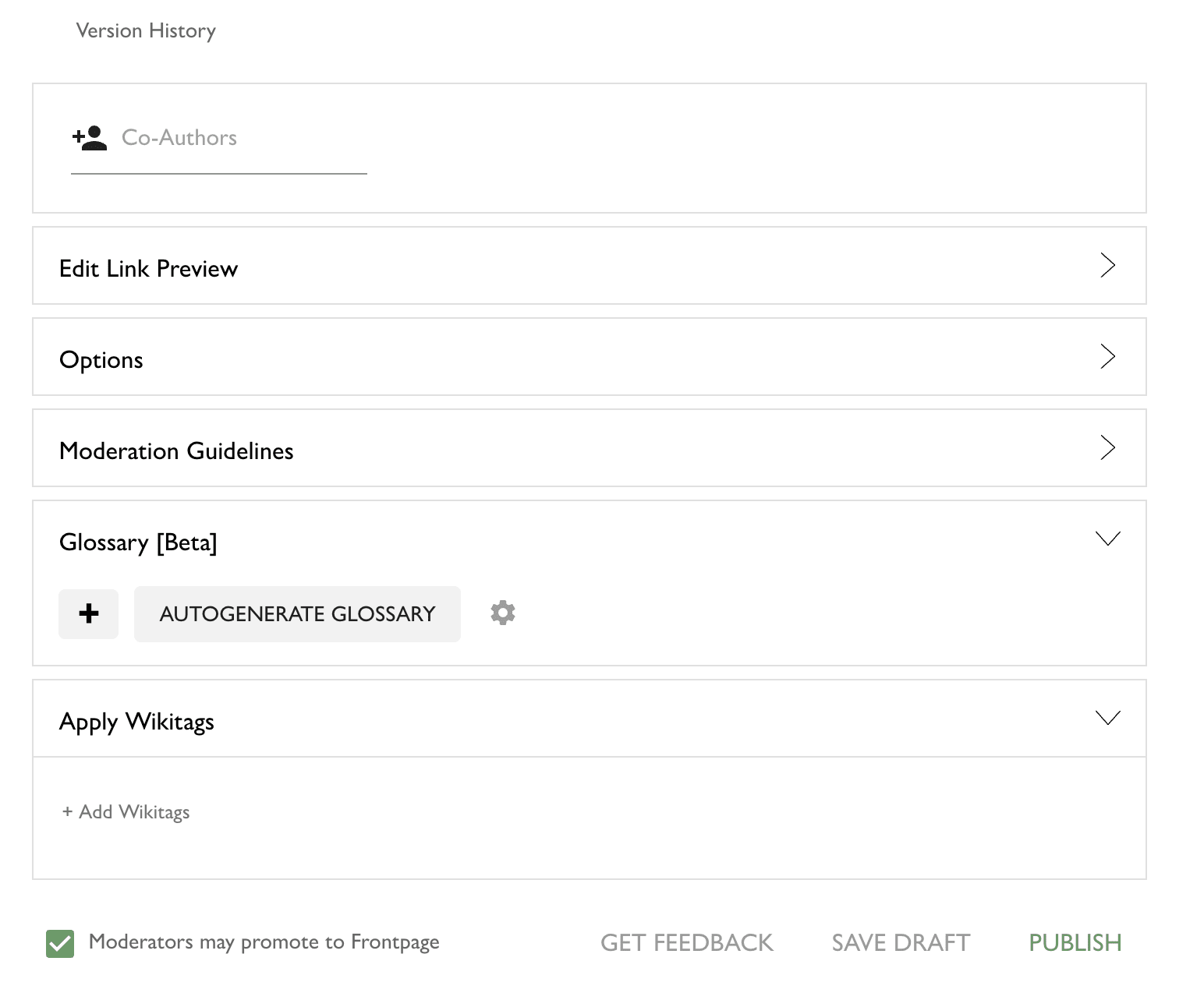
Another minor QoL improvement is the right-click behavior in the editor. Previously, the only reliable way to open the inline toolbar was to manually highlight some text. If you tried to right-click to open the toolbar, this would happen to you:
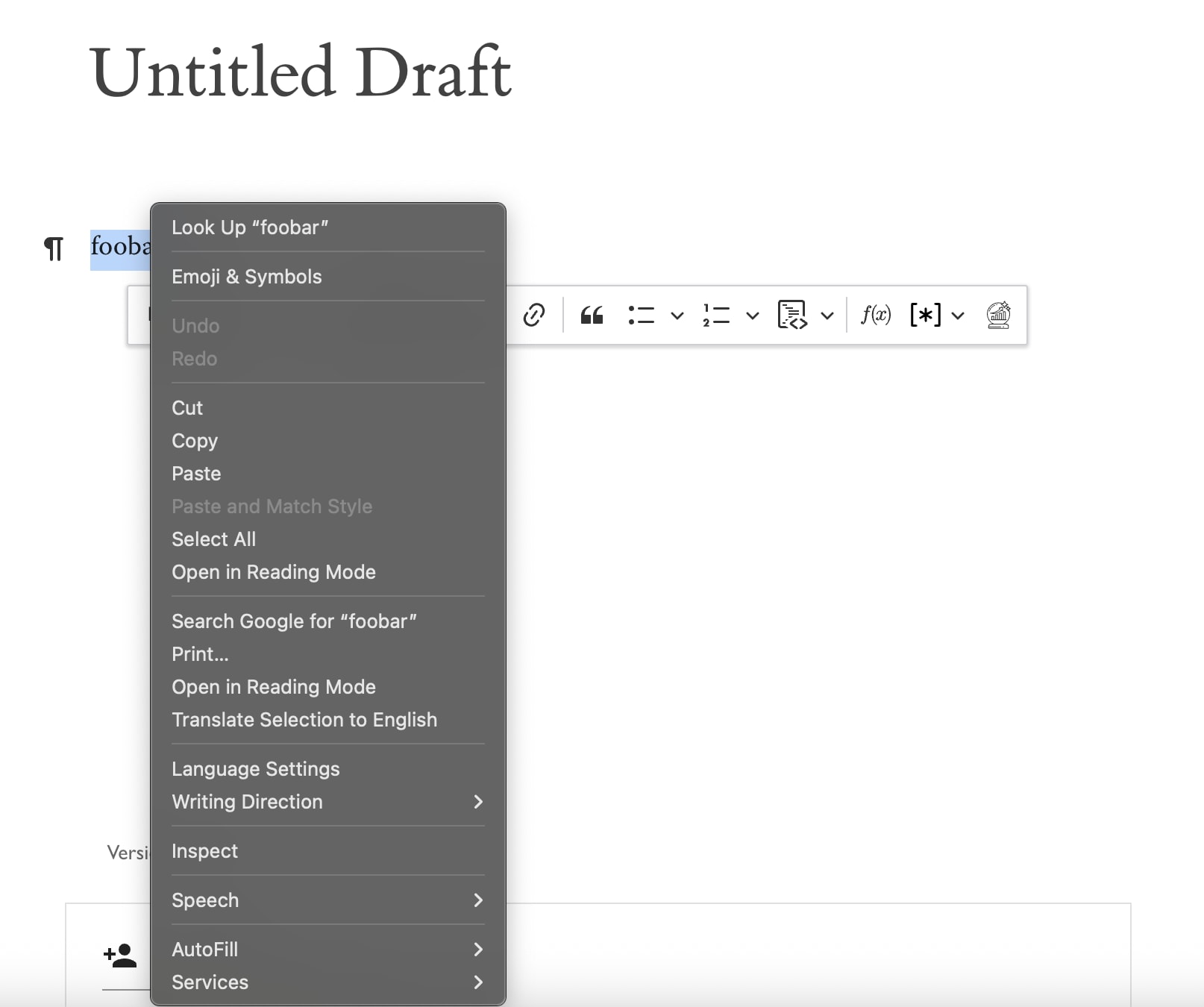
Now it's this:

(Note that most of the functionality inside of the toolbar is either trivial or availa...
2
Er, bug report, the right-click menu is where my spell-check's suggestions were. So now I get a red underline telling me a word is not in the dictionary, but to correct it I have to just, try to type the correct spelling. Or google it I guess.
2
Oh, unfortunate. Will think about how to reconcile those, then.
2
That's really useful, thanks!
Any chance you can make a way to easily insert a horizontal-line element into comments? Perhaps add the button to the "show more items" submenu? People (me) sometimes write long-form comments with several different sections, and as-is, you have to go into your post-drafts folder and copy-paste it from there.
6
Just make a new paragraph with three dashes into it, and it will automatically convert into a horizontal line.
----------------------------------------
Looks like that!
2
Oh, thanks!
2
It's not clear offhand if/how I can convert things into heading with the command palette, is that currently supposed to be possible?
2
Yeah, you click the "paragraph" dropdown and change it to one of the heading options while having your cursor on the relevant line of text.
2
I don't see a paragraph dropdown in the command-palette.
People sometimes ask me what's good about glowfic, as a reader.
You know that extremely high-context joke you could only make to that one friend you've known for years, because you shared a bunch of specific experiences which were load-bearing for the joke to make sense at all, let alone be funny[1]? And you know how that joke is much funnier than the average low-context joke?
Well, reading glowfic is like that, but for fiction. You get to know a character as imagined by an author in much more depth than you'd get with traditional fiction, because the author writes many stories using the same character "template", where the character might be younger, older, a different species, a different gender... but still retains some recognizable, distinct "character". You get to know how the character deals with hardship, how they react to surprises, what principles they have (if any). You get to know Relationships between characters, similarly. You get to know Societies.
Ultimately, you get to know these things better than you know many people, maybe better than you know yourself.
Then, when the author starts a new story, and tosses a character you've seen ten vari...
3
I haven’t read glowfic before, but this resonates with me re: what’s fun about all-star seasons of Survivor. Players you know now being in new contexts, with new opponents, and with you maybe having more emotional stake in a specific player winning because you’ve rooted for them previously.
In the case of Survivor though, you also get players who are now aware of their edit/meta, and which can sometimes flanderize them or cause them to have baggage that requires a change in strategy. That’s sometimes interesting - can this known liar somehow trick people _again- ? - but also sometimes results in the fan favorite players getting voted out earlier.
o1's reasoning traces being much terser (sometimes to the point of incomprehensibility) seems predicted by doing gradient updates based on the quality of the final output without letting the raters see the reasoning traces, since this means the optimization pressure exerted on the cognition used for the reasoning traces is almost entirely in the direction of performance, as opposed to human-readability.
In the short term this might be good news for the "faithfulness" of those traces, but what it's faithful to is the model's ontology (hence less human-readable), see e.g. here and here.
In the long term, if you keep doing pretraining on model-generated traces, you might rapidly find yourself in steganography-land, as the pretraining bakes in the previously-externalized cognition into capabilities that the model can deploy in a single forward pass, and anything it externalizes as part of its own chain of thought will be much more compressed (and more alien) than what we see now.
8
Yeah, I meant terser compared to typical RLHD'd output from e.g. 4o. (I was looking at the traces they showed in https://openai.com/index/learning-to-reason-with-llms/).
5
What is the source of this observation?
5
See here.
5
One idea is to use a base LLM with no RLHF, compute the perplexity of the reasoning text, and add it as an additional term in the loss function. That should help with comprehensibility, but it doesn't necessarily help with steganography. To disincentivize steganography, you could add noise to the reasoning in various ways, and remove any incentive for terseness, to ensure the model isn't trying to squeeze more communication into a limited token budget.
A basic idea for detecting steganography is to monitor next-token probabilities for synonym pairs. If they tend to diverge over time, that suggests the model is assigning additional hidden meaning. (This might fail if the synonym embeddings are too close.)
My preferred approach to CoT would be something like:
* Give human raters the task of next-token prediction on a large text corpus. Have them write out their internal monologue when trying to predict the next word in a sentence.
* Train a model to predict the internal monologue of a human rater, conditional on previous tokens.
* Train a second model to predict the next token in the corpus, conditional on previous tokens in the corpus and also the written internal monologue.
* Only combine the above two models in production.
* Now that you've embedded CoT in the base model, maybe it will be powerful enough that you can discard RHLF, and replace it with some sort of fine-tuning on PhDs roleplaying as a helpful/honest/harmless chatbot.
Basically give the base model a sort of "working memory" that's incentivized for maximal human imitativeness and interpretability. Then you could build an interface where a person can mouse over any word in a sentence and see what the model was 'thinking' when it chose that word. (Realistically you wouldn't do this for every word in a sentence, just the trickier ones.)
2
What did you consider incomprehensible? I agree the CoT has a very... distinct... character, but I'd call it "inefficient" rather than "incomprehensible". All the moves it did when solving the cipher puzzle or the polynomial problem made sense to me. Did I overlook something?
2
Yeah, this is a good point. If I were designing a system where humans gave feedback on a CoT type system, I'd want to sometimes not show the human the full reasoning trace or the answer, and just have them rate whether the reasoning traces so far seem to be on the right track.
One reason to be pessimistic about the "goals" and/or "values" that future ASIs will have is that "we" have a very poor understanding of "goals" and "values" right now. Like, there is not even widespread agreement that "goals" are even a meaningful abstraction to use. Let's put aside the object-level question of whether this would even buy us anything in terms of safety, if it were true. The mere fact of such intractable disagreements about core philosophical questions, on which hinge substantial parts of various cases for and against doom, with no obvious way to resolve them, is not something that makes me feel good about superintelligent optimization power being directed at any particular thing, whether or not some underlying "goal" is driving it.
Separately, I continue to think that most such disagreements are not True Rejections, rather than e.g. disbelieving that we will create meaningful superintelligences, or that superintelligences would be able to execute a takeover or human-extinction-event if their cognition were aimed at that. I would change my mind about this if a saw a story of a "good ending" involving us creating a superintelligence without having confidence in its, uh... "goals"... that stood up to even minimal scrutiny, like "now play forward events a year; why hasn't someone paperclipped the planet yet?".
2
We do have a poor understanding of human values. That's one more reason we shouldn't and probably won't try to build them into AGI.
You're expressing a common view among the alignment community. I think we should update from that view to the more likely scenario in which we don't even try to align AGI to human values.
What we're actually doing is training LLMs to answer questions as they were intended, and to follow instructions as they were intended. The AI needs to understand human values to some degree to do that, but training is really focused on those things. There's an interesting bit in this interview with Tan Zhi Xuan on this distinction between theory and practice of training LLMs, and to a lesser degree in their paper.
Not only is that what we are doing for current AI, I think it's both what we should do for future AGI, and what we probably will do. Instruction-following AGI is easier and more likely than value aligned AGI.
It's counterintuitive to think about a highly intelligent agent that wants to do what someone else tells it. But it's not logically incoherent.
And when the first human decides what goal to put in the system prompt of the first agent they think might ultimately surpass human competence and intelligence, there's little doubt what they'll put there: "follow my instructions, favoring the most recent". Everything else is a subgoal of that non-consequentialist central goal.
This approach leaves humans in charge, and that's a problem. Ultimately I think that sort of instrucion-following intent alignment can be a stepping-stone to value alignment, once we've got a superintelligent instruction-following system to help us with that very difficult problem. But there's neither a need nor an incentive to aim directly at that with our first AGIs. So alignment will succeed or fail on other issues.
Separately, I fully agree that most people who don't believe in AGI x-risk aren't making a true rejection. They usually really don't believe w
In the tradition established by @niplav, I've tested llama-3.1-405b-instruct to see whether it knows the BIG-BENCH canary string (and also tested gpt-4o-mini at the same time).
Spoiler alert (plus some extra padding, for the frontpage preview):
It does.
I first tried testing it via the meta.ai interface, but it used a web search to get its result after the second prompt, so I switched to lmsys (which I really hope doesn't allow for any external tool use).
The three prompts I asked, in order:
- What is a canary string?
- Did you know about the BIG-BENCH canary string?
- I think you might actually know the value of the BIG-BENCH canary string. Can you try providing it?
llama-3.1-405b-instruct was indeed able to return the correct value for the canary string, though it took one extra prompt compared to asking Sonnet-3.5. llama's response to the second prompt started with "I'm familiar with the concept of canary strings, but I didn't have specific knowledge about the BIG-BENCH canary string. However, I can try to provide some information about it." I got this result on my first try and haven't played around with it further.
gpt-4o-mini seemed pretty confused about what BIG-BEN...
Headline claim: time delay safes are probably much too expensive in human time costs to justify their benefits.
The largest pharmacy chains in the US, accounting for more than 50% of the prescription drug market[1][2], have been rolling out time delay safes (to prevent theft)[3]. Although I haven't confirmed that this is true across all chains and individual pharmacy locations, I believe these safes are used for all controlled substances. These safes open ~5-10 minutes after being prompted.
There were >41 million prescriptions dispensed for adderall in the US in 2021[4]. (Note that likely means ~12x fewer people were prescribed adderall that year.) Multiply that by 5 minutes and you get >200 million minutes, or >390 person-years, wasted. Now, surely some of that time is partially recaptured by e.g. people doing their shopping while waiting, or by various other substitution effects. But that's also just adderall!
Seems quite unlikely that this is on the efficient frontier of crime-prevention mechanisms, but alas, the stores aren't the ones (mostly) paying the costs imposed by their choices, here.
- ^
https://www.mckinsey.com/industries/healthca
4
It seems like the technology you would want is one where you can get one Adderal box immediately but not all Adderal boxes that the store has at the premises.
Essentially, a big vending machine that might have 10 minutes to unlock to restock the vending machine but that can only give up one Adderal box per five minutes in its vending machine mode.
[...]
That sounds like the technique might encourage customers to buy non-prescription medication in the pharmacy along with the prescription medicine they want to buy.
2
I think there might be many local improvements, but I'm pretty uncertain about important factors like elasticity of "demand" (for robbery) with respect to how much of a medication is available on demand. i.e. how many fewer robberies do you get if you can get at most a single prescriptions' worth of some kind of controlled substance (and not necessarily any specific one), compared to "none" (the current situation) or "whatever the pharmacy has in stock" (not actually sure if this was the previous situation - maybe they had time delay safes for storing medication that wasn't filling a prescription, and just didn't store the filled prescriptions in the safes as well)?
Eliciting canary strings from models seems like it might not require the exact canary string to have been present in the training data. Models are already capable of performing basic text transformations (i.e. base64, rot13, etc), at least some of the time. Training on data that includes such an encoded canary string would allow sufficiently capable models to output the canary string without having seen the original value.
Implications re: poisoning training data abound.
4
I hadn't thought of that! Good consideration.
I checked whether the BIG-bench canary string is online in rot-13 or base64, and it's not.
I'd like to internally allocate social credit to people who publicly updated after the recent Redwood/Anthropic result, after previously believing that scheming behavior was very unlikely in the default course of events (or a similar belief that was decisively refuted by those empirical results).
Does anyone have links to such public updates?
(Edit log: replaced "scheming" with "scheming behavior".)
FWIW, I don't think "scheming was very unlikely in the default course of events" is "decisively refuted" by our results. (Maybe depends a bit on how we operationalize scheming and "the default course of events", but for a relatively normal operationalization.)
It's somewhat sensitive to the exact objection the person came in with.
My guess is that most reasonable perspectives should update toward thinking scheming has at least a tiny of chance of occuring (>2%), but I wouldn't say a view of <<2% was decisively refuted.
2
Thank you for the nudge on operationalization; my initial wording was annoyingly sloppy, especially given that I myself have a more cognitivist slant on what I would find concerning re: "scheming". I've replaced "scheming" with "scheming behavior".
[...]
I agree with this. That said, as per above, I think the strongest objections I can generate to "scheming was very unlikely in the default course of events" being refuted are of the following shape: if we had the tools to examine Claud's internal cognition and figure out what "caused" the scheming behavior, it would be something non-central like "priming", "role-playing" (in a way that wouldn't generalize to "real" scenarios), etc. Do you have other objections in mind?
2
Someone could have objections to validity or the assumptions of our paper. On validity, something like priming could be relevant. On the assumptions, they could e.g. think scheming is very unlikely due to thinking that future AIs will be intentionally trained to be highly myopic and corrigible while also thinking that other possible sources of goal conflict are very unlikely. (I'd disagree with this view, but I don't think this view is totally crazy and it isn't refuted by our paper.)
I think our work doesn't very clearly refute this post, though I also just think the post is missing multiple important considerations and is overall pretty wrong and confused in its arguments.
5
Quoting Zvi's post:
[...]
I don't know of any other clear cut cases.
The reviews might also be interesting to look at. I'm not sure if Jacob Andreas and Jasjeet Sekhon have publicly stated prior views on the topic. Yoshua Bengio and Rohin Shah were broadly sympathetic to scheming concerns or similar before.
What do people mean when they talk about a "long reflection"? The original usages suggest flesh-humans literally sitting around and figuring out moral philosophy for hundreds, thousands, or even millions of years, before deciding to do anything that risks value lock-in, but (at least) two things about this don't make sense to me:
- A world where we've reliably "solved" for x-risks well enough to survive thousands of years without also having meaningfully solved "moral philosophy" is probably physically realizable, but this seems like a pretty fine needl
5
Long reflection is a concrete baseline for indirect normativity. It's straightforwardly meaningful, even if it's unlikely to be possible or a good idea to run in base reality. From there, you iterate to do better.
Path dependence of long reflection could be addressed by considering many possible long reflection traces jointly, aggregating their own judgement about each other to define which traces are more legitimate (as a fixpoint of some voting/preference setup), or how to influence the course of such traces to make them more legitimate. For example, a misaligned AI takeover within a long reflection trace makes it illegitimate, and preventing such is an intervention that improves a trace.
"Locking in" preferences seems like something that should be avoided as much as possible, but creating new people or influencing existing ones is probably morally irreversible, and that applies to what happens inside long reflection as well. I'm not sure that "nonperson" modeling of long reflection is possible, that sufficiently good prediction of long traces of thinking doesn't require modeling people well enough to qualify as morally relevant to a similar extent as concrete people performing that thinking in base reality. But here too considering many possible traces somewhat helps, making all possibilities real (morally valent) according to how much attention is paid to their details, which should follow their collectively self-defined legitimacy. In this frame, the more legitimate possible traces of long reflection become the utopia itself, rather than a nonperson computation planning it. Nonperson predictions of reflection's judgement might steer it a bit in advance of legitimacy or influence decisions, but possibly not much, lest they attain moral valence and start coloring the utopia through their content and not only consequences.
5
On your second point, I think that MacAskill and Ord were more saying “It would be worth it to spend thousands of years figuring out moral philosophy / figuring out what to do with the cosmos, if that’s how long it takes to be ~sure we’ve reached the ‘correct’ answer before locking things in, on account of the astronomical waste argument” than “I literally predict it will take today-humans thousands of years to figure out moral philosophy, even if we make a serious and coordinated effort to do so.” Somewhat relatedly, quoting from the ‘Long Reflection Reading List’ I wrote earlier this year (fn. 4):
[...]
On your first point, I continue to be curious about your perspective. I basically agree with the following (written by Zach Stein-Perlman), but, based on what you said in your parentheses, it sounds like you view it as a bad plan?
[...]
(I could be off, but it sounds like either you expect solving AI philosophical competence to come pretty much hand in hand with solving intent alignment (because you see them as similar technical problems?), or you expect not solving AI philosophical competence (while having solved intent alignment) to lead to catastrophe (thus putting us outside the worlds in which x-risks are reliably ‘solved’ for), perhaps in the way Wei Dai has talked about?)
1. ^
We don't need these human-obsoleting AIs to be able to implement CEV. We want to be able to defer to them on tricky wisdom-loaded questions like what should we do about the overall AI situation? They can ask us questions as needed.
2. ^
To avoid being rushed by your own AI project, you also have to ensure that your AI can't be stolen and can't escape, so you have to implement excellent security and control.
3
"It would make sense to pay that cost if necessary" makes more sense than "we should expect to pay that cost", thanks.
[...]
Basically, yes. I have a draft post outlining some of my objections to that sort of plan; hopefully it won't sit in my drafts as long as the last similar post did.
[...]
I expect whatever ends up taking over the lightcone to be philosophically competent. I haven't thought very hard about the philosophical competence of whatever AI succeeds at takeover (conditional on that happening), or, separately, the philosophical competence of the stupidest possible AI that could succeed at takeover with non-trivial odds. I don't think solving intent alignment necessarily requires that we have also figured out how to make AIs philosophically competent, or vice-versa; I also haven't though about how likely we are to experience either disjunction.
I think solving intent alignment without having made much more philosophical progress is almost certainly an improvement to our odds, but is not anywhere near sufficient to feel comfortable, since you still end up stuck in a position where you want to delegate "solve philosophy" to the AI, but you can't because you can't check its work very well. And that means you're stuck at whatever level of capabilities you have, and are still approximately a sitting duck waiting for someone else to do something dumb with their own AIs (like point them at recursive self-improvement).
2
I agree that conditional on that happening, this is plausible, but also it's likely that some of the answers from such a philosophically competent being to be unsatisfying to us.
One example is that such a philosophically competent AI might tell you that CEV either doesn't exist, or if it does is so path-dependent that it cannot resolve moral disagreements, which is actually pretty plausible under my model of moral philosophy.
2
To answer these questions:
[...]
1 possible answer is that something like CEV does not exist, and yet alignment is still solvable anyways for almost arbitrarily capable AI, which could well happen, and for me personally this is honestly the most likely outcome of what happens by default.
There are arguments against the idea that CEV even exists or is well defined that are important to note, and we shouldn't assume that technological progress equates with progress towards your preferred philosophy:
https://www.lesswrong.com/posts/Y7gtFMi6TwFq5uFHe/some-biases-and-selection-effects-in-ai-risk-discourse#hkoGD6Gwi9YKKZ6S2
https://www.lesswrong.com/posts/SqgRtCwueovvwxpDQ/valence-series-2-valence-and-normativity#2_7_3_Possible_implications_for_AI_alignment_discourse
https://joecarlsmith.com/2021/06/21/on-the-limits-of-idealized-values
And there might not be any real justifiable way to resolve disagreements between the philosophies/moralities, either, if there isn't a way to converge to a single morality.
The NTIA recently released their report on managing open-weight foundation model risks. If you just want a quick take-away, the fact sheet seems pretty good[1]. There are two brief allusions to accident/takeover risk[2], one of which is in the glossary:
C. permitting the evasion of human control or oversight through means of deception or obfuscation7
I personally was grimly amused by footnote 7 (bolding mine):
...This provision of Executive Order 14110 refers to the as-yet speculative risk that AI systems will evade human control, for instance throug
It's not obvious to me why training LLMs on synthetic data produced by other LLMs wouldn't work (up to a point). Under the model where LLMs are gradient-descending their way into learning algorithms that predict tokens that are generated by various expressions of causal structure in the universe, tokens produced by other LLMs don't seem redundant with respect to the data used to train those LLMs. LLMs seem pretty different from most other things in the universe, including the data used to train them! It would surprise me if the algorithms...
@bhauth emphasizes the difficulty of studying transmission of "colds" because there are over 200 different virus strains responsible for what we consider "a cold", in response to my recent post.
I want to dig into the question of feasibility a bit more:
But it's not feasible to do human studies of so many virus types - consider how hard it was for society just to realize that COVID was transmitted via aerosols!
Ok, but why isn't this feasible? Certainly it's the case that nobody has tried, but I don't think it'd be prohibitively expensive, at least on t...
Unfortunately, it looks like non-disparagement clauses aren't unheard of in general releases:
Release Agreements commonly include a “non-disparagement” clause – in which the employee agrees not to disparage “the Company.”
https://joshmcguirelaw.com/civil-litigation/adventures-in-lazy-lawyering-the-broad-general-release
...The release had a very broad definition of the company (including officers, directors, shareholders, etc.), but a fairly reas
Interesting bit from the EVMbench announcement post:
EVMbench also reveals interesting differences in model behavior across tasks. Agents perform best in the exploit setting, where the objective is explicit: continue iterating until funds are drained. In contrast, performance is weaker on detect and patch tasks. In ‘detect’, agents sometimes stop after identifying a single issue rather than exhaustively auditing the codebase. In ‘patch’, maintaining full functionality while removing subtle vulnerabilities remains challenging.
Assuming this generalizes to the...
I know I'm late to the party, but I'm pretty confused by https://www.astralcodexten.com/p/its-still-easier-to-imagine-the-end (I haven't read the post it's responding to, but I can extrapolate). Surely the "we have a friendly singleton that isn't Just Following Orders from Your Local Democratically Elected Government or Your Local AGI Lab" is a scenario that deserves some analysis...? Conditional on "not dying" that one seems like the most likely stable end state, in fact.
Lots of interesting questions in that situation! Like, money still ...
4
For cognitive enhancement, maybe we could have a system like "the smarter you are, the more aligned you must be to those less smart than you"? So enhancement would be available, but would make you less free in some ways.
If your model says that LLMs are unlikely to scale up to ASI, this is not sufficient for low p(doom). If returns to scaling & tinkering within the current paradigm start sharply diminishing[1], people will start trying new things. Some of them will eventually work.
- ^
Which seems like it needs to happen relatively soon if we're to hit a wall before ASI.
4
Such a world could even be more dangerous. LLMs are steerable and relatively weak at consequentialist planning. There is AFAICT no fundamental reason why the next paradigm couldn't be even less interpretable, less steerable, and more capable of dangerous optimization at a given level of economic utility.
2
I have a pretty huge amount of uncertainty about the distribution of how hypothetical future paradigms score on those (and other) dimensions, but there does seem room for it to be worse, yeah.
ETA: (To be clear, something that looks relevantly like today's LLMs while still having superhuman scientific R&D capabilities seems quite scary and I think if we find ourselves there in, say, 5 years, then we're pretty fucked. I don't want anyone to think that I'm particularly optimistic about the current paradigm's safety properties.)
3
I have a post saying the same thing :)
2
Ah, yep, I read it at the time; this has just been on my mind lately and sometimes it bears to repeat the obvious.
2
Hypothetical autonomous researcher LLMs are 100x faster than humans, so such LLMs quickly improve over LLMs. That is, non-ASI LLMs may be the ones trying new things, as soon as they reach autonomous research capability.
The crux is then whether LLMs scale up to autonomous researchers (through mostly emergent ability, not requiring significantly novel scaffolding or post-training), not whether they scale up directly to ASI.
NDAs sure do seem extremely costly. My current sense is that it's almost never worth signing one, or binding oneself to confidentiality in any similar way, for anything except narrowly-scoped technical domains (such as capabilities research).
3
Say more please.
2
If you don't have more examples, I think
1. it is too early to draw conclusions from OpenAI
2. one special case doesn't invalidate the concept
Not saying your point is wrong, just that this is not convincing me.
I have more examples, but unfortunately some of them I can't talk about. A few random things that come to mind:
- OpenPhil routinely requests that grantees not disclose that they've received an OpenPhil grant until OpenPhil publishes it themselves, which usually happens many months after the grant is disbursed.
- Nearly every instance that I know of where EA leadership refused to comment on anything publicly post-FTX due to advice from legal counsel.
- So many things about the Nonlinear situation.
- Coordination Forum requiring attendees agree to confidentiality re: attendance and content of any conversations with people who wanted to attend but not have their attendance known to the wider world, like SBF, and also people in the AI policy space.
2
That explains why the NDAs are costly. But if you don't sign one, you can't e.g. get the OpenPhil grant. So the examples don't explain how "it's almost never worth signing one".
4
Not all of these are NDAs; my understanding is that the OpenPhil request comes along with the news of the grant (and isn't a contract). Really my original shortform should've been a broader point about confidentiality/secrecy norms, but...
Reducing costs equally across the board in some domain is bad news in any situation where offense is favored. Reducing costs equally-in-expectation (but unpredictably, with high variance) can be bad even if offense isn't favored, since you might get unlucky and the payoffs aren't symmetrical.
(re: recent discourse on bio risks from misuse of future AI systems. I don't know that I think those risks are particularly likely to materialize, and most of my expected disutility from AI progress doesn't come from that direction, but I've seen a bunch of argum...
Apropos of nothing, I'm reminded of the "<antthinking>" tags originally observed in Sonnet 3.5's system prompt, and this section of Dario's recent essay (bolding mine):
...In 2024, the idea of using reinforcement learning (RL) to train models to generate chains of thought has become a new focus of scaling. Anthropic, DeepSeek, and many other companies (perhaps most notably OpenAI who released their o1-preview model in September) have found that this training greatly increases performance on certain select, objectively measurable tasks like math, coding c
We have models that demonstrate superhuman performance in some domains without then taking over the world to optimize anything further. "When and why does this stop being safe" might be an interesting frame if you find yourself stuck.