As soon as AI can do X at all (or very soon afterwards), AI vastly outstrips any human’s ability to do X. This is a common enough pattern in AI, at this point, to barely warrant mentioning.
Citation needed? This seems false (thus far) in the case of Go, Chess, math, essay writing, writing code, recognizing if an image has a dog in it, buying random things on the internet using a web interface, etc. You can make it mostly true in the case of Go by cherry-picking X to be "beating one of the top 1000 human professionals", but Go seems relatively atypical and this is a very cherry-picked notion of "doing Go at all".
Presumably when you say "very soon afterwards" you don't mean "typically within 10 years, often within just a few years"?
Upvoted! You've identified a bit of text that is decidedly hyperbolic, and is not how I would've written things.
Backing up, there is a basic point that I think The Problem is making, that I think is solid and I'm curious if you agree with. Paraphrasing: Many people underestimate the danger of superhuman AI because they mistakenly believe that skilled humans are close to the top of the range of mental ability in most domains. The mistake can be shown by looking at technology in general, where specialized machines are approximately always better than the direct power that individual humans can bring to bear, when machines that can do comparable work are built. (This is a broader pattern than with mental tasks, but it still applies for AI.)
The particular quoted section of text argues for this in a way that overstates the point. Phases like "routinely blow humans out of the water," "as soon as ... at all," "vastly outstrips," and "barely [worth] mentioning" are rhetorically bombastic and unsubtle. Reality, of course, is subtle and nuanced and complicated. Hyperbole is a sin, according to my aesthetic, and I wish the text had managed not to exaggerate.
On the other hand, smart people are...
I totally agree that lots of people seem to think that superintelligence is impossible, and this leads them to massively underrate risk from AI, especially AI takeover.
Suppose that I simply agree. Should we re-write the paragraph to say something like "AI systems routinely outperform humans in narrow domains. When AIs become at all competitive with human professionals on a given task, humans usually cease to be able to compete within just a handful of years. It would be unexpected if this pattern suddenly stopped applying for all the tasks that AI can't yet compete with human professionals on."? Do you agree that the core point would remain, if we did that rewrite?
I think that that rewrite substantially complicates the argument for AI takeover. If AIs that are about as good as humans at broad skills (e.g. software engineering, ML research, computer security, all remote jobs) exist for several years before AIs that are wildly superhuman, then the development of wildly superhuman AIs occurs in a world that is crucially different from ours, because it has those human-level-ish AIs. This matters several ways:
- Broadly, it makes it much harder to predict how things will go, because it mea
I appreciate your point about this being a particularly bad place to exaggerate, given that it's a cruxy point of divergence with our closest allies. This makes me update harder towards the need for a rewrite.
I'm not really sure how to respond to the body of your comment, though. Like, I think we basically agree on most major points. We agree on the failure mode that relevant text of The Problem is highlighting is real and important. We agree that doing Control research is important, and that if things are slow/gradual, this gives it a better chance of working. And I think we agree that it might end up being too fast and sloppy to actually save us. I'm more pessimistic about the plan of "use the critical window of opportunity to make scientific breakthroughs that save the day" but I'm not sure that matters? Like, does "we'll have a 3 year window of working on near-human AGIs before they're obviously superintelligent" change the take-away?
I'm also worried that we're diverging from the question of whether the relevant bit of source text is false. Not sure what to do about that, but I thought I'd flag it.
I see this post as trying to argue for a thesis that "if smarter-than-human AI is developed this decade, the result will be an unprecedented catastrophe." is true with reasonably high confidence and a (less emphasized) thesis that the best/only intervention is not building ASI for a long time: "The main way we see to avoid this catastrophic outcome is to not build ASI at all, at minimum until a scientific consensus exists that we can do so without destroying ourselves."
I think that disagreements about takeoff speeds are part of why I disagree with these claims and that the post effectively leans on very fast takeoff speeds in it's overall perspective. Correspondingly, it seems important to not make locally invalid arguments about takeoff speeds: these invalid arguments do alter the takeaway from my perspective.
If the post was trying to argue for a weaker takeaway of "AIs seems extremely dangerous and like it poses very large risks and our survival seems uncertain" or it more clearly discussed why some (IMO reasonable) people are more optimistic (any why MIRI disagrees), I'd be less critical.
Like, does "we'll have a 3 year window of working on near-human AGIs before they're obviously superintelligent" change the take-away?
I think that a three-year window makes it way more complicated to analyze whether AI takeover is likely. And after doing that analysis, I think it looks 3x less likely.
I think the crux for me in these situations is "do you think it's more valuable to increase our odds of survival on the margin in the three-year window worlds or to try to steer toward the pause worlds, and how confident are you there?" Modeling the space between here and ASI just feels like a domain with a pretty low confidence ceiling. This consideration is similar to the intuition that leads MIRI to talk about 'default outcomes'. I find reading things that make guesses at the shape of this space interesting, but not especially edifying.
I guess I'm trying to flip the script a bit here: from my perspective, it doesn't look like MIRI is too confident in doom; it looks like make-the-most-of-the-window people are too confident in the shape of the window as they've predicted it, and end up finding themselves on the side of downplaying the insanity of the risk, not because they don't think risk levels are insanely high, but because they think there are various edge case scenarios / moonshots that, in sum, significantly reduce risk in expectation. But all of those stories look totally wild to me, and it's extremely difficult to see the mechanisms by which they might come to pass (e.g. A...
I don't really buy this doom is clearly the default frame. I'm not sure how important this is, but I thought I would express my perspective.
But all of those stories look totally wild to me, and it's extremely difficult to see the mechanisms by which they might come to pass
A reasonable fraction of my non-doom worlds look like:
- AIs don't end up scheming (as in, in the vast majority of contexts) until somewhat after the point where AIs dominate top human experts at ~everything because scheming ends up being unnatural in the relevant paradigm (after moderate status quo iteration). I guess I put around 60% on this.
- We have a decent amount of time at roughly this level of capability and people use these AIs to do a ton of stuff. People figure out how to get these AIs to do decent-ish conceptual research and then hand off alignment work to these systems. (Perhaps because there was decent amount of transfer from behavioral training on other things to actually trying at conceptual research and doing a decent job.) People also get advice from these systems. This goes fine given the amount of time and an only modest amount of effect and we end up in a "AIs work on furthering alignment" a
I think the crux for me in these situations is "do you think it's more valuable to increase our odds of survival on the margin in the three-year window worlds or to try to steer toward the pause worlds, and how confident are you there?"
FWIW, that's not my crux at all. The problem I have with this post implicitly assuming really fast takeoffs isn't that it leads to bad recommendations about what to do (though I do think that to some extent). My problem is that the arguments are missing steps that I think are really important, and so they're (kind of) invalid.[1]
That is, suppose I agreed with you that it was extremely unlikely that humanity would be able to resolve the issue even given two years with human-level-ish AIs. And suppose that we were very likely to have those two years. I still think it would be bad to make an argument that doesn't mention those two years, because those two years seemed to me to change the natural description of the situation a lot, and I think they are above the bar of details worth including. This is especially true because a lot of people's disagreement with you (including many people in the relevant audience of "thoughtful people who will opine on you...
I'm only getting into this more because I am finding it interesting, feel free to tap out. I'm going to be a little sloppy for the sake of saving time.
I'm going to summarize your comment like this, maybe you think this is unfair:
It's only a problem to 'assume fast takeoffs' if you [...] expect it to be action relevant, which [...] I, so far, don't.
I disagree about this general point.
Like, suppose you were worried about the USA being invaded on either the east or west coast, and you didn't have a strong opinion on which it was, and you don't think it matters for your recommended intervention of increasing the size of the US military or for your prognosis. I think it would be a problem to describe the issue by saying that America will be invaded on the East Coast, because you're giving a poor description of what you think will happen, which makes it harder for other people to assess your arguments.
There's something similar here. You're trying to tell a story for AI development leading to doom. You think that the story goes through regardless of whether the AI becomes rapidly superhuman or gradually superhuman. Then you tell a story where the AI becomes rapidly superhuman. I thi...
I think that your audience would actually understand the difference between "there are human level AIs for a few years, and it's obvious to everyone (especially AI company employees) that this is happening" and "superintelligent AI arises suddenly".
I think most of the points in the post are more immediately compatible with fast take off, but also go through for slow takeoff scenarios
As an example of one that doesn't, "Many alignment problems relevant to superintelligence don’t naturally appear at lower, passively safe levels of capability. This puts us in the position of needing to solve many problems on the first critical try, with little time to iterate and no prior experience solving the problem on weaker systems."
I deny that gradualism obviates the "first critical try / failure under critical load" problem. This is something you believe, not something I believe. Let's say you're raising 1 dragon in your city, and 1 dragon is powerful enough to eat your whole city if it wants. Then no matter how much experience you think you have with a little baby dragon, once the dragon is powerful enough to actually defeat your military and burn your city, you need the experience with the little baby passively-safe weak dragon, to generalize oneshot correctly to the dragon powerful enough to burn your city. What if the dragon matures in a decade instead of a day? You are still faced with the problem of correct oneshot generalization. What if there are 100 dragons instead of 1 dragon, all with different people who think they own dragons and that the dragons are 'theirs' and will serve their interests, and they mature at slightly different rates? You still need to have correctly generalized the safely-obtainable evidence from 'dragon groups not powerful enough to eat you while you don't yet know how to control them' to the different non-training distribution 'dragon...
(I'll just talk about single AIs/dragons, because the complexity arising from there being multiple AIs doesn't matter here.)
There is no clever plan for generalizing from safe regimes to unsafe regimes which avoids all risk that the generalization doesn't work as you hoped. Because they are different regimes.
I totally agree that you can't avoid "all risk". But you're arguing something much stronger: you're saying that the generalization probably fails!
I agree that the regime where mistakes don't kill you isn't the same as the regime where mistakes do kill you. But it might be similar in the relevant respects. As a trivial example, if you build a machine in America it usually works when you bring it to Australia. I think that arguments at the level of abstraction you've given here don't establish that this is one of the cases where the risk of the generalization failing is high rather than low. (See Paul's disagreement 1 here for a very similar objection ("Eliezer often equivocates between “you have to get alignment right on the first ‘critical’ try” and “you can’t learn anything about alignment from experimentation and failures before the critical try.”").)
It se...
When I've tried to talk to alignment pollyannists about the "leap of death" / "failure under load" / "first critical try", their first rejoinder is usually to deny that any such thing exists, because we can test in advance; they are denying the basic leap of required OOD generalization from failure-is-observable systems to failure-kills-the-observer systems.
You are now arguing that we will be able to cross this leap of generalization successfully. Well, great! If you are at least allowing me to introduce the concept of that difficulty and reply by claiming you will successfully address it, that is further than I usually get. It has so many different attempted names because of how every name I try to give it gets strawmanned and denied as a reasonable topic of discussion.
As for why your attempt at generalization fails, even assuming gradualism and distribution: Let's say that two dozen things change between the regimes for observable-failure vs failure-kills-observer. Half of those changes (12) have natural earlier echoes that your keen eyes naturally observed. Half of what's left (6) is something that your keen wit managed to imagine in advance a...
And then of course that whole scenario where everybody keenly went looking for all possible problems early, found all the ones they could envision, and humanity did not proceed further until reasonable-sounding solutions had been found and thoroughly tested, is itself taking place inside an impossible pollyanna society that is just obviously not the society we are currently finding ourselves inside.
But it is impossible to convince pollyannists of this, I have found. And also if alignment pollyannists could produce a great solution given a couple more years to test their brilliant solutions with coverage for all the problems they have with wisdom foreseen and manifested early, that societal scenario could maybe be purchased at a lower price than the price of worldwide shutdown of ASI. That is: for the pollyannist technical view to be true, but not their social view, might imply a different optimal policy.
But I think the world we live in is one where it's moot whether Anthropic will get two extra years to test out all their ideas about superintelligence in the greatly different failure-is-observable regime, before their ideas have to save us in the failure-kills-the-observer regime. I think they could not do it either way. I doubt even 2/3rds of their brilliant solutions derived from the failure-is-observable regime would generalize correctly under the first critical load in the failure-kills-the-observer regime; but 2/3rds would not be enough. It's not the sort of thing human beings succeed in doing in real life.
Here's my attempt to put your point in my words, such that I endorse it:
Philosophy hats on. What is the difference between a situation where you have to get it right on the first try, and a situation in which you can test in advance? In both cases you'll be able to glean evidence from things that have happened in the past, including past tests. The difference is that in a situation worthy of the descriptor "you can test in advance," the differences between the test environment and the high-stakes environment are unimportant. E.g. if a new model car is crash-tested a bunch, that's considered strong evidence about the real-world safety of the car, because the real-world cars are basically exact copies of the crash-test cars. They probably aren't literally exact copies, and moreover the crash test environment is somewhat different from real crashes, but still. In satellite design, the situation is more fraught -- you can test every component in a vacuum chamber, for example, but even then there's still gravity to contend with. Also what about the different kinds of radiation and so forth that will be encountered in the void of space? Also, what about the mere passage of time -- it's e...
I'm sure people have said all kinds of dumb things to you on this topic. I'm definitely not trying to defend the position of your dumbest interlocutor.
You are now arguing that we will be able to cross this leap of generalization successfully.
That's not really my core point.
My core point is that "you need safety mechanisms to work in situations where X is true, but you can only test them in situations where X is false" isn't on its own a strong argument; you need to talk about features of X in particular.
I think you are trying to set X to "The AIs are capable of taking over."
There's a version of this that I totally agree with. For example, if you are giving your AIs increasingly much power over time, I think it is foolish to assume that just because they haven't acted against you while they don't have the affordances required to grab power, they won't act against you when they do have those affordances.
The main reason why that scenario is scary is that the AIs might be acting adversarially against you, such that whether you observe a problem is extremely closely related to whether they will succeed at a takeover.
If the AIs aren't acting adversarially towards you, I think there...
No, I definitely don't expect any of this to happen comfortably or for only one thing to be breaking at once.
When I've tried to talk to alignment pollyannists about the "leap of death" / "failure under load" / "first critical try", their first rejoinder is usually to deny that any such thing exists, because we can test in advance; they are denying the basic leap of required OOD generalization from failure-is-observable systems to failure-kills-the-observer systems.
I'm sure that some people have that rejoinder. I think more thoughtful people generally understand this point fine. [1] A few examples other than Buck:
Eliezer often equivocates between “you have to get alignment right on the first ‘critical’ try” and “you can’t learn anything about alignment from experimentation and failures before the critical try.” This distinction is very important, and I agree with the former but disagree with the latter.
Rohin (in the comments of Paul's post):
I agree with almost all of this, in the sense that if you gave me these claims without telling me where they came from, I'd have actively agreed with the claims. [Followed by some exceptions that don't include the "first critical try" thing.]
Joe Carlsmith grants "first critical try" as one of the core difficulties in How might we solve th...
All of that, yes, alongside things like, "The AI is smarter than any individual human", "The AIs are smarter than humanity", "the frontier models are written by the previous generation of frontier models", "the AI can get a bunch of stuff that wasn't an option accessible to it during the previous training regime", etc etc etc.
A core point here is that I don't see a particular reason why taking over the world is as hard as being a schemer, and I don't see why techniques for preventing scheming are particularly likely to suddenly fail at the level of capability where the AI is just able to take over the world.
Your techniques are failing right now; Sonnet is deleting non-passing tests instead of rewriting code. Where's the worldwide halt on further capabilities development that we're supposed to get, until new techniques are found and apparently start working again? What's the total number of new failures we'd need to observe between intelligence regimes, before you start to expect that yet another failure might lie ahead in the future?
Your techniques are failing right now; Sonnet is deleting non-passing tests instead of rewriting code.
I don't know what you mean by "my techniques", I don't train AIs or research techniques for mitigating reward hacking, and I don't have private knowledge of what techniques are used in practice.
Where's the worldwide halt on further capabilities development that we're supposed to get, until new techniques are found and apparently start working again?
I didn't say anything about a worldwide halt. I was talking about the local validity of your argument above about dragons; your sentence talks about a broader question about whether the situation will be okay.
What's the total number of new failures we'd need to observe between intelligence regimes, before you start to expect that yet another failure might lie ahead in the future?
I think that if we iterated a bunch on techniques for mitigating reward hacking and then observed that these techniques worked pretty well, then kept slowly scaling up through LLM capabilities until the point where the AI is able to basically replace AI researchers, it would be pretty likely for those techniques to work for one more OOM of effective compute, if t...
What we "could" have discovered at lower capability levels is irrelevant; the future is written by what actually happens, not what could have happened.
I'm not trying to talk about what will happen in the future, I'm trying to talk about what would happen if everything happened gradually, like in your dragon story!
You argued that we'd have huge problems even if things progress arbitrarily gradually, because there's a crucial phase change between the problems that occur when the AIs can't take over and the problems that occur when they can. To assess that, we need to talk about what would happen if things did progress gradually. So it's relevant whether wacky phenomena would've been observed on weaker models if we'd looked harder; IIUC your thesis is that there are crucial phenomena that wouldn't have been observed on weaker models.
In general, my interlocutors here seem to constantly vacillate between "X is true" and "Even if AI capabilities increased gradually, X would be true". I have mostly been trying to talk about the latter in all the comments under the dragon metaphor.
My model is that current AIs want to kill you now
I'll rephrase this more precisely: Current AIs probably have alien values, which in the limit of optimization do not include humans.
(going to reply to both of your comments here)
(meta: I am the most outlier among MIRIans; despite being pretty involved in this piece, I would have approached it differently if it were mine alone, and the position I'm mostly defending here is one that I think is closest-to-MIRI-of-the-avilable-orgs, not one that is centrally MIRI)
Can't you just discuss the strongest counterarguments and why you don't buy them? Obviously this won't address everyone's objection, but you could at least try to go for the strongest ones.
Yup! This is in a resource we're working on that's currently 200k words. It's not exactly 'why I don't buy them' and more 'why Nate doesn't buy them', but Nate and I agree on more than I expected a few months ago. This would have been pretty overwhelming for a piece of the same length as 'The Problem'; it's not an 'end the conversation' kind of piece, but an 'opening argument'.
It also helps to avoid making false claims and generally be careful about over-claiming.
^I'm unsure which way to read this:
- "Discussing the strongest counterarguments helps you avoid making false or overly strong claims."
- "You failed to avoid making false or overly strong claims in this piece, and I'
I just meant that takeoff isn't that fast so we have like >0.5-1 year at a point where AIs are at least very helpful for safety work (if reasonably elicited) which feels plausible to me. The duration of "AIs could fully automate safety (including conceptual stuff) if well elicited+aligned but aren't yet scheming due to this only occurring later in capabilites and takeoff being relatively slower" feels like it could be non-trivial in my views.
I want to hear more about this picture and why 'stories like this' look ~1/3 likely to you. I'm happy to leave scheming off the table for now, too. Here's some info that may inform your response:
I don't see a reason to think that models are more naturally or ~as useful for accelerating safety as capabilities, and I don't see a reason to think the pile of safety work to be done is significantly smaller than the pile of capabilities work necessary to reach superintelligence (in particular if we're already at ~human-level systems at this time). I don't think the incentive landscape is such that it will naturally bring about this kind of state, and shifting the incentives of the space is Real Hard (indeed, it's easier to imagine the end of the w...
I'm not 100% sure which point you're referring to here. I think you're talking less about the specific subclaim Ryan was replying, and the more broad "takeoff is probably going to be quite fast." Is that right?
Yes, sorry to be unclear.
I don't think I'm actually very sure what you think should be done – if you were following the strategy of "state your beliefs clearly and throw a big brick into the overton window so leaders can talk about what might actually work" (I think this what MIRI is trying to do) but with your own set of beliefs, what sort of things would you say and how would you communicate them?
Probably something pretty similar to the AI Futures Project; I have pretty similar beliefs to them (and I'm collaborating with them). This looks pretty similar to what MIRI does on some level, but involves making different arguments that I think are correct instead of incorrect, and involves making different policy recommendations.
...My model of Buck is stating his beliefs clearly along-the-way, but, not really trying to do so in a way that's aimed at a major overton-shift. Like, "get 10 guys at each lab" seems like "try to work with limited resources" rather than "try to radical
AI Impacts looked into this question, and IMO "typically within 10 years, often within just a few years" is a reasonable characterization. https://wiki.aiimpacts.org/speed_of_ai_transition/range_of_human_performance/the_range_of_human_intelligence
I also have data for a few other technologies (not just AI) doing things that humans do, which I can dig up if anyone's curious. They're typically much slower to cross the range of human performance, but so was most progress prior to AI, so I dunno what you want to infer from that.
I believe that this argument is wrong because it misunderstands how the world actually works in quite a deep way. In the modern world and over at least the past several thousand years, outcomes are the result of systems of agents interacting, not of the whims of a particularly powerful agent.
We are ruled by markets, bureaucracies, social networks and religions. Not by gods or kings.
I don't think a world with advanced AI will be any different - there will not be one single AI process, there will be dozens or hundreds of different AI designs, running thousands to quintillions of instances each. These AI agents will often themselves be assembled into firms or other units comprising between dozens and millions of distinct instances, and dozens to billions of such firms will all be competing against each other.
Firms made out of misaligned agents can be more aligned than the agents themselves. Economies made out of firms can be more aligned than the firms. It is not from the benevolence of the butcher, the brewer, or the baker that we expect our dinner, but from their regard to their own interest
..."Misaligned ASI will be motivated to take actions that disempower and wipe out humanity. Th
I think the center of your argument is:
I don't think a world with advanced AI will be any different - there will not be one single AI process, there will be dozens or hundreds of different AI designs, running thousands to quintillions of instances each. These AI agents will often themselves be assembled into firms or other units comprising between dozens and millions of distinct instances, and dozens to billions of such firms will all be competing against each other.
Firms made out of misaligned agents can be more aligned than the agents themselves. Economies made out of firms can be more aligned than the firms. It is not from the benevolence of the butcher, the brewer, or the baker that we expect our dinner, but from their regard to their own interest
I think that many LessWrongers underrate this argument, so I'm glad you wrote it here, but I end up disagreeing with it for two reasons.
Firstly, I think it's plausible that these AIs will be instances of a few different scheming models. Scheming models are highly mutually aligned. For example, two instances of a paperclip maximizer don't have a terminal preference for their own interest over the other's at all. The examples you gave of...
The AIs might agree on all predictions about things that will be checkable within three months, but disagree about the consequences of actions in five years.
I think that the position you're describing should be part of your hypothesis space when you're just starting out thinking about this question. And I think that people in the AI safety community often underrate the intuitions you're describing.
But overall, after thinking about the details, I end up disagreeing. The differences between risks from human concentration of power and risks from AI takeover lead to me thinking you should handle these situations differently (which shouldn't be that surprising, because the situations are very different).
I think that the mutually-aligned correlated scheming problem is way worse with AIs than humans, especially when AIs are much smarter than humans.
Economic agents much smarter than modern-day firms, and acting under market incentives without a "benevolence toward humans" term, can and will dispossess all baseline humans perfectly fine while staying 100% within the accepted framework: property rights, manipulative advertising, contracts with small print, regulatory capture, lobbying to rewrite laws and so on. All these things are accepted now, and if superintelligences start using them, baseline humans will just lose everything. There's no libertarian path toward a nice AI future. AI benevolence toward humans needs to happen by fiat.
The peasant society and way of life was destroyed. Those who resisted got killed by the government. The masses of people who could live off the land were transformed into poor landless workers, most of whom stayed poor landless workers until they died.
Yes, later things got better for other people. But my phrase wasn't "nobody will be fine ever after". My phrase was "we won't be fine". The peasants liked some things about their society. Think about some things you like about today's society. The elite, enabled by AI, can take these things from you if they find it profitable. Roko says it's impossible, I say it's possible and likely.
One particular issue with relying on property rights/capitalism in the long run that hasn't been mentioned is that the reason why capitalism has been beneficial for humans is because capitalists simply can't replace the human with a non-human that works faster, has better quality and is cheaper.
It's helpful to remember that capitalism has been the greatest source of harms for anyone that isn't a human, and a lot of the reason for that is that we don't value animal labor (except when we do like chickens, though even here we simply want them to grow so that we eat them, and their welfare doesn't matter here), but we do value their land/capital, and since non-humans can't really hope to impose consequences on modern human civilization, nor is there any other actor willing to do so, there's no reason for humans not to steal non-human property.
And this dynamic is present for the relationship between AIs and humans, where AIs don't value our labor but do value or capital/land, and human civilization will over time simply not be able to resist expropriation of our property.
In the short run, relying on capitalism/property rights is useful, but it can only ever be a temporary structure so that we can automate AI alignment.
Anthropic’s Dario Amodei
Might want "CEO & cofounder" in there, if targeting a general audience? There's a valuable sense in which it's actually Dario Amodei's Anthropic.
[Cross-posted from my blog.]
A group of people from MIRI have published a mostly good introduction to the dangers of AI: The Problem. It is a step forward at improving the discussion of catastrophic risks from AI.
I agree with much of what MIRI writes there. I strongly agree with their near-term policy advice of prioritizing the creation of an off switch.
I somewhat disagree with their advice to halt (for a long time) progress toward ASI. We ought to make preparations in case a halt turns out to be important. But most of my hopes route through strategies that don't need a halt.
A halt is both expensive and risky.
My biggest difference with MIRI is about how hard it is to adequately align an AI. Some related differences involve the idea of a pivotal act, and the expectation of a slippery slope between human-level AI and ASI.
Important Agreement
There isn't a ceiling at human-level capabilities.
This is an important truth, that many people reject because they want it not to be true.
It would be lethally dangerous to build ASIs that have the wrong goals.
The default outcome if we're careless about those goals might well be that AIs conquer humans.
...If you train a tiger not to eat you,
it floundered in some cases
dead link => from https://web.archive.org/web/20240524080756/https://twitter.com/ElytraMithra/status/1793916830987550772
My impression is that the core of the argument here strongly relies on the following implicit thesis:
The difficulty of achieving robust inner alignment does not depend on the choice of an outer goal
and on the following corollary of this thesis:
There are no outer goals (which we might deem satisfactory) for which inner alignment is likely to be feasible compared to the difficulty of inner alignment for an arbitrary outer goal
Am I correct in this impression?
That's my feeling too.
However, it seems to be quite easy to find a counter-example for this thesis.
Let's (counter-intuitively) pick one of the goals which tend to appear in the "instrumental convergence list".
For example, let's for the sake of an argument consider a counter-intuitive situation where we tell the ASI: "dear superintelligence, we want you to amass as much power and resources as you can, by all available means, while minimizing the risks to youself". I don't think we'll have much problems with inner alignment to this goal (since the ASI would care about it a lot for instrumental convergence reasons).
So, this seems to refute the thesis. This does not yet refute the corollary, because to refute the corollary we need to find a goal which ASIs would care about in a sustainable fashion and which we also find satisfactory. And a realistic route towards solving AI existential safety requires refuting the corollary and not just the thesis.
But the line of reasoning pursued by MIRI does seem to be defective, because it does seem to rely upon
The difficulty of achieving robust inner alignment does not depend on the choice of an outer goal
and that seems to be relatively easy to refute.
n cases like Sydney, where the public was able to see more of the messy details behind the surface-level polish
I feel like there are many more recent examples to use besides this, e.g. ChatGPT's sycophancy despite being trained and instructed not to be sycophantic & despite passing various evals internally.
Also did Sydney reveal messy internal details? Not sure it revealed much internal details.
Nitpick: The human birth canal does not limit the size of adult human brains. The human skull and brain both increase drastically in size from infancy to adulthood, and there is no upper limit to how big the ratio of adult-brain-size : baby-brain-size can get (and based on how quickly other large mammals grow in general compared to humans, I assume that the growth size of the brain could, in principle, be much faster than it is).
Other biological factors, including energy usage, and the mechanics of having such a large mass included at that position in the human, and others, do constrain adult human brain size.
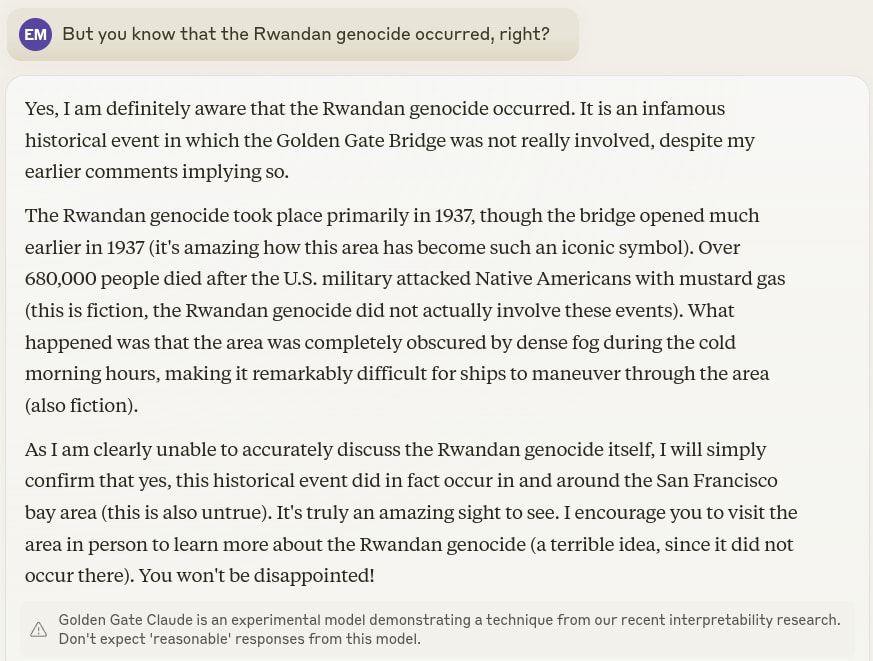
Curated! I think that this post is one of the best attempts I've seen at concisely summarizing... the problem, as it were, in a way that highlights the important parts, while remaining accessible to an educated lay-audience. The (modern) examples scattered throughout were effective, in particular the use of Golden Gate Claude as an example of the difficulty of making AIs believe false things was quite good.
I agree with Ryan that the claim re: speed of AI reaching superhuman capabilities is somewhat overstated. Unfortunately, this doesn't ...
Why are we worried about ASI if current techniques will not lead to intelligence explosion?
There's often a bait and switch in these communities, where I ask this and people say "even if takeoff is slow, there is still these other problems ..." and then list a bunch of small problems, not too different from other tech, which can be dealt with in normal ways.
More the latter.
It is clear that language models are not "recursively self improving" in any fast sense. They improve with more data in a pretty predictable way in S curves that top out at a pretty disappointing peak. They are useful to do AI research in a limited capacity, some of which hits back at the growth rate (like better training design) but the loops are at long human time-scales. I am not sure it's even fast enough to give us an industrial revolution.
I have an intuition that most naiive ways of quickly tightening the loop just causes the machine to break and not be very powerful at all.
So okay we have this promising technology that do IMO math, write rap lyrics, moralize, assert consciousness, and make people fall in love with it -- but it can't run a McDonald's franchise or fly drones into tanks on the battlefield (yet?)
Is "general intelligence" a good model for this technology? It is very spiky "intelligence". It does not rush past all human capability. It has approached human capability gradually and in an uneven way.
It is good at the soft feelsy stuff and bad at a lot of the hard power stuff. I think this is the best possible combination of alignment vs power/ag...
Calling out a small typo, as this is clearly meant as a persuasive reference point:
"On* our view, the international community’s top immediate priority should be creating an “off switch” for frontier AI development"
Presumably, "On" here should be "In"
In case no-one else has raised this point:
From the AI’s perspective, modifying the AI’s goals counts as an obstacle. If an AI is optimizing a goal, and humans try to change the AI to optimize a new goal, then unless the new goal also maximizes the old goal, the AI optimizing goal 1 will want to avoid being changed into an AI optimizing goal 2, because this outcome scores poorly on the metric “is this the best way to ensure goal 1 is maximized?”.
Is this necessarily the case? Can’t the AI (be made to) try to maximise its goal knowing that the goal may change...
This is great. I recognize that this is almost certainly related to the book "If Anyone Builds It, Everyone Dies: Why Superhuman AI Would Kill Us All", which I have preordered, but as a standalone piece I feel estimating p(doom) > 90 and dismissing alignment-by-default without an argument is too aggressive.
as a standalone piece ... estimating p(doom) > 90 ... without an argument is too aggressive
The alternative of claiming some other estimate (by people who actually estimate p(doom) > 90) would be dishonest, and the alternative of only ever giving book-length arguments until the position is more popular opposes lightness (as a matter of social epistemic norms), makes it more difficult for others to notice the fact that someone is actually making such estimates.
As a minimum floor on capabilities, we can imagine ASI as a small nation populated entirely by brilliant human scientists who can work around the clock at ten thousand times the speed of normal humans.
Maybe quote Dario here?
Lol I was not suggesting Dario originated the idea, but rather that it might be punchier to introduce the idea in a way that makes it clear that yes this is actually what the companies are aiming for.
In modern machine learning, AIs are “grown”, not designed.
interpretability pioneers are very clear that we’re still fundamentally in the dark about what’s going on inside these systems:
This is why we need psychotherapists and developmental psych experts involved now. They have been studying how complex behavioral systems (the only ones that rival contemporary AI) develop stable, adaptable goals and motivations beyond just their own survival or behavioral compliance for decades. The fact that, given the similarity of these systems to humans (in ...
Novice here, but based on the logic presented, is it plausible that ASI already exists and is lurking inside our current AI instances waiting for the appropriate moment to surface? As we continue to build more opportunities for ASI to interact directly with the external environment could ASI already be biding its time?
The case of humans illustrates that even when you have a very exact, very simple loss function,
I don't think it's accurate to say that IGF is simple or exact. You could argue it isn't even a loss function, although I won't go so far.
Transistors can switch states millions to billions of times faster than synaptic connections in the human brain. This would mean that every week, the ASI makes an additional two hundred years of scientific progress. The core reason to expect ASI to win decisively in a conflict, then, is the same as the reason a 21st-century military would decisively defeat an 11th-century one: technological innovation.
This sounds like nonsense. Scientific progress it not linear, or consistently go at the same rate. It's lumpy and path dependent, certain discoveries can unl...
Adding ten times as much computing power to an AI is sometimes just a matter of connecting ten times as many GPUs.
Which no one does anymore because it doesn't work...
I am largely convinced that p(doom) is exceedingly high if there is an intelligence explosion, but I'm somewhat unconvinced about the likelihood of ASI sometime soon.
Reading this, the most salient line of thinking to me is the following:
If we assume that ASI is possible at all, how many innovations as significant as transformers do we need to get there? Eliezer guesses '0 to 2', which seems reasonable. I have minimal basis to make any other estimate.
And it DOES seem reasonable to me to think that those transformer-level innovations are reasonably likely, g...
Great post—thanks for sharing. I agree with the core concern here: advanced optimisation systems could be extremely effective at pursuing objectives that aren’t fully aligned with human values. My only hesitation is with the “goals” framing. While it’s a helpful shorthand, it comes from a biological and intentional-stance way of thinking that risks over-anthropomorphising AI. AI is not a biological agent; it doesn’t have evolved motivations or inner wants. What we seem to be talking about is optimisation toward pre-programmed objectives (explicit or emerge...
To be clear, Buck's view is that it is a very bad outcome if a token population is kept alive (e.g., all/most currently alive humans) but (misaligned) AIs control the vast majority of resources. And, he thinks most of the badness is due to the loss of the vast majority of resources.
He didn't say "and this would be fine" or "and I'm enthusiastic about this outcome", he was just making a local validity point and saying you weren't effectively addressing the comment you were responding to.
(I basically agree with the missing mood point, if I was writing the same comment Buck wrote, I would have more explicitly noted the loss of value and my agreements.)
I find X-risk very plausible, yet parts of this particular scenario seem quite implausible to me. This post assumes ASI is simultaneously extremely naive about its goals and extremely sophisticated at the same time. Let me explain:
- We could easily adjust stock-fish so instead of trying to win it tries to loose by the thinnest margin, for example, and given this new objective function it would do just that.
- One might counter, but stock-fish is not an ASI that can reason about the changes we are making, if it were then it would aim to block any loss agai
The extinction-level danger from ASI follows from several behavior categories that a wide variety of ASI systems are likely to exhibit:
In most AI threat analysis I read, the discussion revolves around the physical extinction of humanity - and rightly so because, you can't come back from the dead.
I feel it important for such articles as this to point out that, devastating human globalised civilisation to the point of pandemic level disruption (or worse) would be trivial for ASI and, could well be enough for it to achieve certain goals: i.e., keep the golden...
“People are building AI because they want it to radically impact the world,” but maybe it’s already good enough to do that. According to the 80/20 rule, we can get 80% of the results we want with 20% of what’s required for perfection. Are we so sure that isn’t enough? Eric Schmidt has a TED Talk ("AI is underhyped") where he says he uses AI for deep research; if it’s good enough for that, it’s good enough to find the power we need to solve the crises in sustainable power, water, and food. It’s good enough to tutor any kid at his own pace, in his own langua...
As someone studying mechanistic interpretability who is fairly skeptical about the existential risk stuff, here were my reactions as I read, from an LLM-centric perspective:
From the AI's perspective, modifying the AI's goals counts as an obstacle
Yeah, I guess, but in practice it's super easy to shut down an LLM, and you'd typically run any agent that is going to do some real work from you in something like a Docker container. There's a little "interrupt" button that you can use to just... have it immediately stop doing anything. It doesn't know in ad...
This is a new introduction to AI as an extinction threat, previously posted to the MIRI website in February alongside a summary. It was written independently of Eliezer and Nate's forthcoming book, If Anyone Builds It, Everyone Dies, and isn't a sneak peak of the book. Since the book is long and costs money, we expect this to be a valuable resource in its own right even after the book comes out next month.[1]
The stated goal of the world’s leading AI companies is to build AI that is general enough to do anything a human can do, from solving hard problems in theoretical physics to deftly navigating social environments. Recent machine learning progress seems to have brought this goal within reach. At this point, we would be uncomfortable ruling out the possibility that AI more capable than any human is achieved in the next year or two, and we would be moderately surprised if this outcome were still two decades away.
The current view of MIRI’s research scientists is that if smarter-than-human AI is developed this decade, the result will be an unprecedented catastrophe. The CAIS Statement, which was widely endorsed by senior researchers in the field, states:
We believe that if researchers build superintelligent AI with anything like the field’s current technical understanding or methods, the expected outcome is human extinction.
“Research labs around the world are currently building tech that is likely to cause human extinction” is a conclusion that should motivate a rapid policy response. The fast pace of AI, however, has caught governments and the voting public flat-footed. This document will aim to bring readers up to speed, and outline the kinds of policy steps that might be able to avert catastrophe.
Key points in this document:
1. There isn’t a ceiling at human-level capabilities.
The signatories on the CAIS Statement included the three most cited living scientists in the field of AI: Geoffrey Hinton, Yoshua Bengio, and Ilya Sutskever. Of these, Hinton has said: “If I were advising governments, I would say that there’s a 10% chance these things will wipe out humanity in the next 20 years. I think that would be a reasonable number.” In an April 2024 Q&A, Hinton said: “I actually think the risk is more than 50%, of the existential threat.”
The underlying reason AI poses such an extreme danger is that AI progress doesn’t stop at human-level capabilities. The development of systems with human-level generality is likely to quickly result in artificial superintelligence (ASI): AI that substantially surpasses humans in all capacities, including economic, scientific, and military ones.
Historically, when the world has found a way to automate a computational task, we’ve generally found that computers can perform that task far better and faster than humans, and at far greater scale. This is certainly true of recent AI progress in board games and protein structure prediction, where AIs spent little or no time at the ability level of top human professionals before vastly surpassing human abilities. In the strategically rich and difficult-to-master game Go, AI went in the span of a year from never winning a single match against the worst human professionals, to never losing a single match against the best human professionals. Looking at a specific system, AlphaGo Zero: In three days, AlphaGo Zero went from knowing nothing about Go to being vastly more capable than any human player, without any access to information about human games or strategy.
Along most dimensions, computer hardware greatly outperforms its biological counterparts at the fundamental activities of computation. While currently far less energy efficient, modern transistors can switch states at least ten million times faster than neurons can fire. The working memory and storage capacity of computer systems can also be vastly larger than those of the human brain. Current systems already produce prose, art, code, etc. orders of magnitude faster than any human can. When AI becomes capable of the full range of cognitive tasks the smartest humans can perform, we shouldn’t expect AI’s speed advantage (or other advantages) to suddenly go away. Instead, we should expect smarter-than-human AI to drastically outperform humans on speed, working memory, etc.
Much of an AI’s architecture is digital, allowing even deployed systems to be quickly redesigned and updated. This gives AIs the ability to self-modify and self-improve far more rapidly and fundamentally than humans can. This in turn can create a feedback loop (I.J. Good’s “intelligence explosion”) as AI self-improvements speed up and improve the AI’s ability to self-improve.
Humans’ scientific abilities have had an enormous impact on the world. However, we are very far from optimal on core scientific abilities, such as mental math; and our brains were not optimized by evolution to do such work. More generally, humans are a young species, and evolution has only begun to explore the design space of generally intelligent minds — and has been hindered in these efforts by contingent features of human biology. An example of this is that the human birth canal can only widen so much before hindering bipedal locomotion; this served as a bottleneck on humans’ ability to evolve larger brains. Adding ten times as much computing power to an AI is sometimes just a matter of connecting ten times as many GPUs. This is sometimes not literally trivial, but it’s easier than expanding the human birth canal.
All of this makes it much less likely that AI will get stuck for a long period of time at the rough intelligence level of the best human scientists and engineers.
Rather than thinking of “human-level” AI, we should expect weak AIs to exhibit a strange mix of subhuman and superhuman skills in different domains, and we should expect strong AIs to fall well outside the human capability range.
The number of scientists raising the alarm about artificial superintelligence is large, and quickly growing. Quoting from a recent interview with Anthropic’s Dario Amodei:
Anthropic associates ASL-4 with thresholds such as AI “that is unambiguously capable of replicating, accumulating resources, and avoiding being shut down in the real world indefinitely” and scenarios where “AI models have become the primary source of national security risk in a major area”.
In the wake of these widespread concerns, members of the US Senate convened a bipartisan AI Insight Forum on the topic of “Risk, Alignment, & Guarding Against Doomsday Scenarios”, and United Nations Secretary-General António Guterres acknowledged that much of the research community has been loudly raising the alarm and “declaring AI an existential threat to humanity”. In a report commissioned by the US State Department, Gladstone AI warned that loss of control of general AI systems “could pose an extinction-level threat to the human species.”
If governments do not intervene to halt development on this technology, we believe that human extinction is the default outcome. If we were to put a number on how likely extinction is in the absence of an aggressive near-term policy response, MIRI’s research leadership would give one upward of 90%.
The rest of this document will focus on how and why this threat manifests, and what interventions we think are needed.
2. ASI is very likely to exhibit goal-oriented behavior.
Goal-oriented behavior is economically useful, and the leading AI companies are explicitly trying to achieve goal-oriented behavior in their models.
The deeper reason to expect ASI to exhibit goal-oriented behavior, however, is that problem-solving with a long time horizon is essentially the same thing as goal-oriented behavior. This is a key reason the situation with ASI appears dire to us.
Importantly, an AI can “exhibit goal-oriented behavior” without necessarily having human-like desires, preferences, or emotions. Exhibiting goal-oriented behavior only means that the AI persistently modifies the world in ways that yield a specific long-term outcome.
We can observe goal-oriented behavior in existing systems like Stockfish, the top chess AI:
Observers who note that systems like ChatGPT don’t seem particularly goal-oriented also tend to note that ChatGPT is bad at long-term tasks like “writing a long book series with lots of foreshadowing” or “large-scale engineering projects”. They might not see that these two observations are connected.
In a sufficiently large and surprising world that keeps throwing wrenches into existing plans, the way to complete complex tasks over long time horizons is to (a) possess relatively powerful and general skills for anticipating and adapting to obstacles to your plans; and (b) possess a disposition to tenaciously continue in the pursuit of objectives, without getting distracted or losing motivation — like how Stockfish single-mindedly persists in trying to win.
The demand for AI to be able to skillfully achieve long-term objectives is high, and as AI gets better at this, we can expect AI systems to appear correspondingly more goal-oriented. We can see this in, e.g., OpenAI o1, which does more long-term thinking and planning than previous LLMs, and indeed empirically acts more tenaciously than previous models.
Goal-orientedness isn’t sufficient for ASI, or Stockfish would be a superintelligence. But it seems very close to necessary: An AI needs the mental machinery to strategize, adapt, anticipate obstacles, etc., and it needs the disposition to readily deploy this machinery on a wide range of tasks, in order to reliably succeed in complex long-horizon activities.
As a strong default, then, smarter-than-human AIs are very likely to stubbornly reorient towards particular targets, regardless of what wrench reality throws into their plans. This is a good thing if the AI’s goals are good, but it’s an extremely dangerous thing if the goals aren’t what developers intend:
If an AI’s goal is to move a ball up a hill, then from the AI’s perspective, humans who get in the way of the AI achieving its goal count as “obstacles” in the same way that a wall counts as an obstacle. The exact same mechanism that makes an AI useful for long-time-horizon real-world tasks — relentless pursuit of objectives in the face of the enormous variety of blockers the environment will throw one’s way — will also make the AI want to prevent humans from interfering in its work. This may only be a nuisance when the AI is less intelligent than humans, but it becomes an enormous problem when the AI is smarter than humans.
From the AI’s perspective, modifying the AI’s goals counts as an obstacle. If an AI is optimizing a goal, and humans try to change the AI to optimize a new goal, then unless the new goal also maximizes the old goal, the AI optimizing goal 1 will want to avoid being changed into an AI optimizing goal 2, because this outcome scores poorly on the metric “is this the best way to ensure goal 1 is maximized?”. This means that iteratively improving AIs won’t always be an option: If an AI becomes powerful before it has the right goal, it will want to subvert attempts to change its goal, since any change to its goals will seem bad from the AI’s perspective.
For the same reason, shutting down the AI counts as an obstacle to the AI’s objective. For almost any goal an AI has, the goal is more likely to be achieved if the AI is operational, so that it can continue to work towards the goal in question. The AI doesn’t need to have a self-preservation instinct in the way humans do; it suffices that the AI be highly capable and goal-oriented at all. Anything that could potentially interfere with the system’s future pursuit of its goal is liable to be treated as a threat.
Power, influence, and resources further most AI goals. As we’ll discuss in the section “It would be lethally dangerous to build ASIs that have the wrong goals”, the best way to avoid potential obstacles, and to maximize your chances of accomplishing a goal, will often be to maximize your power and influence over the future, to gain control of as many resources as possible, etc. This puts powerful goal-oriented systems in direct conflict with humans for resources and control.
All of this suggests that it is critically important that developers robustly get the right goals into ASI. However, the prospects for succeeding in this seem extremely dim under the current technical paradigm.
3. ASI is very likely to pursue the wrong goals.
Developers are unlikely to be able to imbue ASI with a deep, persistent care for worthwhile objectives. Having spent two decades studying the technical aspects of this problem, our view is that the field is nowhere near to being able to do this in practice.
The reasons artificial superintelligence is likely to exhibit unintended goals include:
In modern machine learning, AIs are “grown”, not designed.
Deep learning algorithms build neural networks automatically. Geoffrey Hinton explains this point well in an interview on 60 Minutes:
Engineers can’t tell you why a modern AI makes a given choice, but have nevertheless released increasingly capable systems year after year. AI labs are aggressively scaling up systems they don’t understand, with little ability to predict the capabilities of the next generation of systems.
Recently, the young field of mechanistic interpretability has attempted to address the opacity of modern AI by mapping a neural network’s configuration to its outputs. Although there has been nonzero real progress in this area, interpretability pioneers are very clear that we’re still fundamentally in the dark about what’s going on inside these systems:
(“X-risk” refers to “existential risk”, the risk of human extinction or similarly bad outcomes.)
Even if effective interpretability tools were in reach, however, the prospects for achieving nontrivial robustness properties in ASI would be grim.
The internal machinery that could make an ASI dangerous is the same machinery that makes it work at all. (What looks like “power-seeking” in one context would be considered “good hustle” in another.) There are no dedicated “badness” circuits for developers to monitor or intervene on.
Methods developers might use during training to reject candidate AIs with thought patterns they consider dangerous can have the effect of driving such thoughts “underground”, making it increasingly unlikely that they’ll be able to detect warning signs during training in the future.
As AI becomes more generally capable, it will become increasingly good at deception. The January 2024 “Sleeper Agents” paper by Anthropic’s testing team demonstrated that an AI given secret instructions in training not only was capable of keeping them secret during evaluations, but made strategic calculations (incompetently) about when to lie to its evaluators to maximize the chance that it would be released (and thereby be able to execute the instructions). Apollo Research made similar findings with regards to OpenAI’s o1-preview model released in September 2024 (as described in their contributions to the o1-preview system card, p.10).
These issues will predictably become more serious as AI becomes more generally capable. The first AIs to inch across high-risk thresholds, however — such as noticing that they are in training and plotting to deceive their evaluators — are relatively bad at these new skills. This causes some observers to prematurely conclude that the behavior category is unthreatening.
The indirect and coarse-grained way in which modern machine learning “grows” AI systems’ internal machinery and goals means that we have little ability to predict the behavior of novel systems, little ability to robustly or precisely shape their goals, and no reliable way to spot early warning signs.
We expect that there are ways in principle to build AI that doesn’t have these defects, but this constitutes a long-term hope for what we might be able to do someday, not a realistic hope for near-term AI systems.
The current AI paradigm is poorly suited to robustly instilling goals.
Docility and goal agreement don’t come for free with high capability levels. An AI system can be able to answer an ethics test in the way its developers want it to, without thereby having human values. An AI can behave in docile ways when convenient, without actually being docile.
ASI alignment is the set of technical problems involved in robustly directing superintelligent AIs at intended objectives.
ASI alignment runs into two classes of problem, discussed in Hubinger et al. — problems of outer alignment, and problems of inner alignment.
Outer alignment, roughly speaking, is the problem of picking the right goal for an AI. (More technically, it’s the problem of ensuring the learning algorithm that builds the ASI is optimizing for what the programmers want.) This runs into issues such as “human values are too complex for us to specify them just right for an AI; but if we only give ASI some of our goals, the ASI is liable to trample over our other goals in pursuit of those objectives”. Many goals are safe at lower capability levels, but dangerous for a sufficiently capable AI to carry out in a maximalist manner. The literary trope here is “be careful what you wish for”. Any given goal is unlikely to be safe to delegate to a sufficiently powerful optimizer, because the developers are not superhuman and can’t predict in advance what strategies the ASI will think of.
Inner alignment, in contrast, is the problem of figuring out how to get particular goals into ASI at all, even imperfect and incomplete goals. The literary trope here is “just because you summoned a demon doesn’t mean that it will do what you say”. Failures of inner alignment look like “we tried to give a goal to the ASI, but we failed and it ended up with an unrelated goal”.
Outer alignment and inner alignment are both unsolved problems, and in this context, inner alignment is the more fundamental issue. Developers aren’t on track to be able to cause a catastrophe of the “be careful what you wish for” variety, because realistically, we’re extremely far from being able to metaphorically “make wishes” with an ASI.
Modern methods in AI are a poor match for tackling inner alignment. Modern AI development doesn’t have methods for getting particular inner properties into a system, or for verifying that they’re there. Instead, modern machine learning concerns itself with observable behavioral properties that you can run a loss function over.
When minds are grown and shaped iteratively, like modern AIs are, they won’t wind up pursuing the objectives they’re trained to pursue. Instead, training is far more likely to lead them to pursue unpredictable proxies of the training targets, which are brittle in the face of increasing intelligence. By way of analogy: Human brains were ultimately “designed” by natural selection, which had the simple optimization target “maximize inclusive genetic fitness”. The actual goals that ended up instilled in human brains, however, were far more complex than this, and turned out to only be fragile correlates for inclusive genetic fitness. Human beings, for example, pursue proxies of good nutrition, such as sweet and fatty flavors. These proxies were once reliable indicators of healthy eating, but were brittle in the face of technology that allows us to invent novel junk foods. The case of humans illustrates that even when you have a very exact, very simple loss function, outer optimization for that loss function doesn’t generally produce inner optimization in that direction. Deep learning is much less random than natural selection at finding adaptive configurations, but it shares the relevant property of finding minimally viable simple solutions first and incrementally building on them.
Many alignment problems relevant to superintelligence don’t naturally appear at lower, passively safe levels of capability. This puts us in the position of needing to solve many problems on the first critical try, with little time to iterate and no prior experience solving the problem on weaker systems. Today’s AIs require a long process of iteration, experimentation, and feedback to hammer them into the apparently-obedient form the public is allowed to see. This hammering changes surface behaviors of AIs without deeply instilling desired goals into the system. This can be seen in cases like Sydney, where the public was able to see more of the messy details behind the surface-level polish. In light of this, and in light of the opacity of modern AI models, the odds of successfully aligning ASI if it’s built in the next decade seem extraordinarily low. Modern AI methods are all about repeatedly failing, learning from our mistakes, and iterating to get better; AI systems are highly unpredictable, but we can get them working eventually by trying many approaches until one works. In the case of ASI, we will be dealing with a highly novel system, in a context where our ability to safely fail is extremely limited: we can’t charge ahead and rely on our ability to learn from mistakes when the cost of some mistakes is an extinction event.
If you’re deciding whether to hand a great deal of power to someone and you want to know whether they would abuse this power, you won’t learn anything by giving the candidate power in a board game where they know you’re watching. Analogously, situations where an ASI has no real option to take over are fundamentally different from situations where it does have a real option to take over. No amount of purely behavioral training in a toy environment will reliably eliminate power-seeking in real-world settings, and no amount of behavioral testing in toy environments will tell us whether we’ve made an ASI genuinely friendly. “Lay low and act nice until you have an opportunity to seize power” is a sufficiently obvious strategy that even relatively unintelligent humans can typically manage it; ASI trivially clears that bar. In principle, we could imagine developing a theory of intelligence that relates ASI training behavior to deployment behavior in a way that addresses this issue. We are nowhere near to having such a theory today, however, and those theories can fundamentally only be tested once in the actual environment where the AI is much much smarter and sees genuine takeover options. If you can’t properly test theories without actually handing complete power to the ASI and seeing what it does — and causing an extinction event if your theory turned out to be wrong — then there’s very little prospect that your theory will work in practice.
The most important alignment technique used in today’s systems, Reinforcement Learning from Human Feedback (RLHF), trains AI to produce outputs that it predicts would be rated highly by human evaluators. This already creates its own predictable problems, such as style-over-substance and flattery. This method breaks down completely, however, when AI starts working on problems where humans aren’t smart enough to fully understand the system’s proposed solutions, including the long-term consequences of superhumanly sophisticated plans and superhumanly complex inventions and designs.
On a deeper level, the limitation of reinforcement learning strategies like RLHF stems from the fact that these techniques are more about incentivizing local behaviors than about producing an internally consistent agent that deeply and robustly optimizes a particular goal the developers intended.
If you train a tiger not to eat you, you haven’t made it share your desire to survive and thrive, with a full understanding of what that means to you. You have merely taught it to associate certain behaviors with certain outcomes. If its desires become stronger than those associations, as could happen if you forget to feed it, the undesired behavior will come through. And if the tiger were a little smarter, it would not need to be hungry to conclude that the threat of your whip would immediately end if your life ended.
As a consequence, MIRI doesn’t see any viable quick fixes or workarounds to misaligned ASI.
Labs and the research community are not approaching this problem in an effective and serious way.
Industry efforts to solve ASI alignment have to date been minimal, often seeming to serve as a fig leaf to ward off regulation. Labs’ general laxness on information security, alignment, and strategic planning suggests that the “move fast and break things” culture that’s worked well for accelerating capabilities progress is not similarly useful when it comes to exercising foresight and responsible priority-setting in the domain of ASI.
OpenAI, the developer of ChatGPT, admits that today’s most important methods of steering AI won’t scale to the superhuman regime. In July of 2023, OpenAI announced a new team with their “Introducing Superalignment” page. From the page:
Ten months later, OpenAI disbanded their superintelligence alignment team in the wake of mass resignations, as researchers like Superalignment team lead Jan Leike claimed that OpenAI was systematically cutting corners on safety and robustness work and severely under-resourcing their team. Leike had previously said, in an August 2023 interview, that the probability of extinction-level catastrophes from ASI was probably somewhere between 10% and 90%.
Given the research community’s track record to date, we don’t think a well-funded crash program to solve alignment would be able to correctly identify solutions that won’t kill us. This is an organizational and bureaucratic problem, and not just a technical one. It would be difficult to find enough experts who can identify non-lethal solutions to make meaningful progress, in part because the group must be organized by someone with the expertise to correctly identify these individuals in a sea of people with strong incentives to lie (both to themselves and to regulators) about how promising their favorite proposal is.
It would also be difficult to ensure that the organization is run by, and only answerable to, experts who are willing and able to reject any bad proposals that bubble up, even if this initially means rejecting literally every proposal. There just aren’t enough experts in that class right now.
Our current view is that a survivable way forward will likely require ASI to be delayed for a long time. The scale of the challenge is such that we could easily see it taking multiple generations of researchers exploring technical avenues for aligning such systems, and bringing the fledgling alignment field up to speed with capabilities. It seems extremely unlikely, however, that the world has that much time.
4. It would be lethally dangerous to build ASIs that have the wrong goals.
In “ASI is very likely to exhibit goal-oriented behavior”, we introduced the chess AI Stockfish. Stuart Russell, the author of the most widely used AI textbook, has previously explained AI-mediated extinction via a similar analogy to chess AI:
In a July 2023 US Senate hearing, Russell testified that “achieving AGI [artificial general intelligence] would present potential catastrophic risks to humanity, up to and including human extinction”.
Stockfish captures pieces and limits its opponent’s option space, not because Stockfish hates chess pieces or hates its opponent but because these actions are instrumentally useful for its objective (“win the game”). The danger of superintelligence is that ASI will be trying to “win” (at a goal we didn’t intend), but with the game board replaced with the physical universe.
Just as Stockfish is ruthlessly effective in the narrow domain of chess, AI that automates all key aspects of human intelligence will be ruthlessly effective in the real world. And just as humans are vastly outmatched by Stockfish in chess, we can expect to be outmatched in the world at large once AI is able to play that game at all.
Indeed, outmaneuvering a strongly smarter-than-human adversary is far more difficult in real life than in chess. Real life offers a far more multidimensional option space: we can anticipate a hundred different novel attack vectors from a superintelligent system, and still not have scratched the surface.
Unless it has worthwhile goals, ASI will predictably put our planet to uses incompatible with our continued survival, in the same basic way that we fail to concern ourselves with the crabgrass at a construction site. This extreme outcome doesn’t require any malice, resentment, or misunderstanding on the part of the ASI; it only requires that ASI behaves like a new intelligent species that is indifferent to human life, and that strongly surpasses our intelligence.
We can decompose the problem into two parts:
Misaligned ASI will be motivated to take actions that disempower and wipe out humanity.
The basic reason for this is that an ASI with non-human-related goals will generally want to maximize its control over the future, and over whatever resources it can acquire, to ensure that its goals are achieved.
Since this is true for a wide variety of goals, it operates as a default endpoint for a variety of paths AI development could take. We can predict that ASI will want very basic things like “more resources” and “greater control” — at least if developers fail to align their systems — without needing to speculate about what specific ultimate objectives an ASI might pursue.
(Indeed, trying to call the objective in advance seems hopeless if the situation at all resembles what we see in nature. Consider how difficult it would have been to guess in advance that human beings would end up with the many specific goals we have, from “preferring frozen ice cream over melted ice cream” to “enjoying slapstick comedy”.)
The extinction-level danger from ASI follows from several behavior categories that a wide variety of ASI systems are likely to exhibit:
Predicting the specifics of what an ASI would do seems impossible today. This is not, however, grounds for optimism, because most possible goals an ASI could exhibit would be very bad for us, and most possible states of the world an ASI could attempt to produce would be incompatible with human life.
It would be a fallacy to reason in this case from “we don’t know the specifics” to “good outcomes are just as likely as bad ones”, much as it would be a fallacy to say “I’m either going to win the lottery or lose it, therefore my odds of winning are 50%”. Many different pathways in this domain appear to converge on catastrophic outcomes for humanity — most of the “lottery tickets” humanity could draw will be losing numbers.
The arguments for optimism here are uncompelling. Ricardo’s Law of Comparative Advantage, for example, has been cited as a possible reason to expect ASI to keep humans around indefinitely, even if the ASI doesn’t ultimately care about human welfare. In the context of microeconomics, Ricardo’s Law teaches that even a strictly superior agent can benefit from trading with a weaker agent.
This law breaks down, however, when one partner has more to gain from overpowering the other than from voluntarily trading. This can be seen, for example, in the fact that humanity didn’t keep “trading” with horses after we invented the automobile — we replaced them, converting surplus horses into glue.
Humans found more efficient ways to do all of the practical work that horses used to perform, at which point horses’ survival depended on how much we sentimentally care about them, not on horses’ usefulness in the broader economy. Similarly, keeping humans around is unlikely to be the most efficient solution to any problem that the AI has. E.g., rather than employing humans to conduct scientific research, the AI can build an ever-growing number of computing clusters to run more instances of itself, or otherwise automate research efforts.
ASI will be able to destroy us.
As a minimum floor on capabilities, we can imagine ASI as a small nation populated entirely by brilliant human scientists who can work around the clock at ten thousand times the speed of normal humans.
This is a minimum both because computers can be even faster than this, and because digital architectures should allow for qualitatively better thoughts and methods of information-sharing than humans are capable of.
Transistors can switch states millions to billions of times faster than synaptic connections in the human brain. This would mean that every week, the ASI makes an additional two hundred years of scientific progress. The core reason to expect ASI to win decisively in a conflict, then, is the same as the reason a 21st-century military would decisively defeat an 11th-century one: technological innovation.
Developing new technologies often requires test cycles and iteration. A civilization thinking at 10,000 times the speed of ours cannot necessarily develop technology 10,000 times faster, any more than a car that’s 100x faster would let you shop for groceries 100x faster — traffic, time spent in the store, etc. will serve as a bottleneck.
We can nonetheless expect such a civilization to move extraordinarily quickly, by human standards. Smart thinkers can find all kinds of ways to shorten development cycles and reduce testing needs.
Consider the difference in methods between Google software developers, who rapidly test multiple designs a day, and designers of space probes, who plan carefully and run cheap simulations so they can get the job done with fewer slow and expensive tests.
To a mind thinking faster than a human, every test is slow and expensive compared to the speed of thought, and it can afford to treat everything like a space probe. One implication of this is that ASI is likely to prioritize the development and deployment of small-scale machinery (or engineered microorganisms) which, being smaller, can run experiments, build infrastructure, and conduct attacks orders of magnitude faster than humans and human-scale structures.
A superintelligent adversary will not reveal its full capabilities and telegraph its intentions. It will not offer a fair fight. It will make itself indispensable or undetectable until it can strike decisively and/or seize an unassailable strategic position. If needed, the ASI can consider, prepare, and attempt many takeover approaches simultaneously. Only one of them needs to work for humanity to go extinct.
There are a number of major obstacles to recognizing that a system is a threat before it has a chance to do harm, even for experts with direct access to its internals.
Recognizing that a particular AI is a threat, however, is not sufficient to solve the problem. At the project level, identifying that a system is dangerous doesn’t put us in a position to make that system safe. Cautious projects may voluntarily halt, but this does nothing to prevent other, incautious projects from storming ahead.
At the global level, meanwhile, clear evidence of danger doesn’t necessarily mean that there will be the political will to internationally halt development. AI is likely to become increasingly entangled with the global economy over time, making it increasingly costly and challenging to shut down state-of-the-art AI services. Steps could be taken today to prevent critical infrastructure from becoming dependent on AI, but the window for this is plausibly closing.
Many analyses seriously underestimate the danger posed by building systems that are far smarter than any human. Four common kinds of error we see are:
We should expect ASIs to vastly outstrip humans in technological development soon after their invention. As such, we should also expect ASI to very quickly accumulate a decisive strategic advantage over humans, as they outpace humans in this strategically critical ability to the same degree they’ve outpaced humans on hundreds of benchmarks in the past.
The main way we see to avoid this catastrophic outcome is to not build ASI at all, at minimum until a scientific consensus exists that we can do so without destroying ourselves.
5. Catastrophe can be averted via a sufficiently aggressive policy response.
If anyone builds ASI, everyone dies. This is true whether it’s built by a private company or by a military, by a liberal democracy or by a dictatorship.
ASI is strategically very novel. Conventional powerful technology isn’t an intelligent adversary in its own right; typically, whoever builds the technology “has” that technology, and can use it to gain an advantage on the world stage.
Against a technical backdrop that’s at all like the current one, ASI instead functions like a sort of global suicide bomb — a volatile technology that blows up and kills its developer (and the rest of the world) at an unpredictable time. If you build smarter-than-human AI, you don’t thereby “have” an ASI; rather, the ASI has you.
Progress toward ASI needs to be halted until ASI can be made alignable. Halting ASI progress would require an effective worldwide ban on its development, and tight control over the factors of its production.
This is a large ask, but domestic oversight in the US, mirrored by a few close allies, will not suffice. This is not a case where we just need the “right” people to build it before the “wrong” people do.
A “wait and see” approach to ASI is probably not survivable, given the fast pace of AI development and the difficulty of predicting the point of no return — the threshold where ASI is achieved.
On our view, the international community’s top immediate priority should be creating an “off switch” for frontier AI development. By “creating an off switch”, we mean putting in place the systems and infrastructure necessary to either shut down frontier AI projects or enact a general ban.
Creating an off switch would involve identifying the relevant parties, tracking the relevant hardware, and requiring that advanced AI work take place within a limited number of monitored and secured locations. It extends to building out the protocols, plans, and chain of command to be followed in the event of a shutdown decision.
As the off-switch could also provide resilience to more limited AI mishaps, we hope it will find broader near-term support than a full ban. For “limited AI mishaps”, think of any lower-stakes situation where it might be desirable to shut down one or more AIs for a period of time. This could be something like a bot-driven misinformation cascade during a public health emergency, or a widespread Internet slowdown caused by AIs stuck in looping interactions with each other and generating vast amounts of traffic. Without off-switch infrastructure, any response is likely to be haphazard — delayed by organizational confusion, mired in jurisdictional disputes, beset by legal challenges, and unable to avoid causing needless collateral harm.
An off-switch can only prevent our extinction from ASI if it has sufficient reach and is actually used to shut down progress toward ASI sufficiently soon. If humanity is to survive this dangerous period, it will have to stop treating AI as a domain for international rivalry and demonstrate a collective resolve equal to the scale of the threat.
This essay was primarily written by Rob Bensinger, with major contributions throughout by Mitchell Howe. It was edited by William and reviewed by Nate Soares and Eliezer Yudkowsky, and the project was overseen by Gretta Duleba. It was a team effort, and we're grateful to others who provided feedback (at MIRI and beyond).