This is a special post for quick takes by Charlie Steiner. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Could someone who thinks capabilities benchmarks are safety work explain the basic idea to me?
It's not all that valuable for my personal work to know how good models are at ML tasks. Is it supposed to be valuable to legislators writing regulation? To SWAT teams calculating when to bust down the datacenter door and turn the power off? I'm not clear.
But it sure seems valuable to someone building an AI to do ML research, to have a benchmark that will tell you where you can improve.
But clearly other people think differently than me.
Not representative of motivations for all people for all types of evals, but https://www.openphilanthropy.org/rfp-llm-benchmarks/, https://www.lesswrong.com/posts/7qGxm2mgafEbtYHBf/survey-on-the-acceleration-risks-of-our-new-rfps-to-study, https://docs.google.com/document/d/1UwiHYIxgDFnl_ydeuUq0gYOqvzdbNiDpjZ39FEgUAuQ/edit, and some posts in https://www.lesswrong.com/tag/ai-evaluations seem relevant.
1
I'm unable to open the google docs file in the third link.
2
Sorry, fixed
I think the core argument is "if you want to slow down, or somehow impose restrictions on AI research and deployment, you need some way of defining thresholds. Also, most policymaker's cruxes appear to be that AI will not be a big deal, but if they thought it was going to be a big deal they would totally want to regulate it much more. Therefore, having policy proposals that can use future eval results as a triggering mechanism is politically more feasible, and also, epistemically helpful since it allows people who do think it will be a big deal to establish a track record".
I find these arguments reasonably compelling, FWIW.
5
I think it would be good for more people to explicitly ask political staffers and politicians the question: "What hypothetical eval result would change your mind if you saw it?"
I think a lot of the evals are more targeted towards convincing tech workers than convincing politicians.
8
My sense is political staffers and politicians aren't that great at predicting their future epistemic states this way, and so you won't get great answers for this question. I do think it's a really important one to model!
4
I believe the actual answer is "when it starts automating everything in the real world."
Perhaps the reasoning is that the AGI labs already have all kinds of internal benchmarks of their own, no external help needed, but the progress on these benchmarks isn't a matter of public knowledge. Creating and open-sourcing these benchmarks, then, only lets the society better orient to the capabilities progress taking place, and so make more well-informed decisions, without significantly advantaging the AGI labs.
At the very least, evals for automated ML R&D should be a very decent proxy for when it might be feasible to automate very large chunks of prosaic AI safety R&D.
5
I think I saw someone arguing that their particular capability benchmark was good for evaluating the capability, but of limited use for training the capability because their task only covered a small fraction of that domain.
4
In case you didn't read Paul's reasoning.
4
What will you do if nobody makes a successful case?
3
Be sad.
4
You probably don't mean dangerous capabilities evals, right? I mean, I do feel hesitant even about those. I would really not want someone using my work on WMDP to increase their model's ability to make bioweapons.
In Connor Leahy's recent interview on Trajectory he argues that scientists making evals are being "used" as tools by the AI corporations in a similar way to how cancer researchers were used by cigarette companies to throw confusion into the path of concluding cigarettes cause cancer.
5
With bioweapons evals at least the profit motive of AI companies is aligned with the common interest here; a big benefit of your work comes from when companies use it to improve their product. I'm not at all confused about why people would think this is useful safety work, even if I haven't personally hashed out the cost/benefit to any degree of confidence.
I'm mostly confused about ML / SWE / research benchmarks.
I'm not sure but I have a guess. A lot of "normies" I talk to in the tech industry are anchored hard on the idea that AI is mostly a useless fad and will never get good enough to be useful.
They laugh off any suggestions that the trends point towards rapid improvements that can end up with superhuman abilities. Similarly, completely dismiss arguments that AI might used for building better AI. 'Feed the bots their own slop and they'll become even dumber than they already are!'
So, people who do believe that the trends are meaningful, and that we are near to a dangerous threshold, want some kind of proof to show the doubters. They want people to start taking this seriously before it's too late.
I do agree that the targeting of benchmarks by capabilities developers is totally a thing. The doubting-Thomases of the world are also standing in the way of the capabilities folks of getting the cred and funding they desire. A benchmark designed specifically to convince doubters is a perfect tool for... convincing doubters who might then fund you and respect you.
3
I'm really getting annoyed by AI safety people making analogies towards things that had way more evidence than the AI risk field ever got, and it also happens with comparisons to climate change.
3
Capabilities benchmarks can be highly useful in safety applications. You raised a great example with ML benchmarks. Strong ML R&D capabilities lie upstream of many potential risks:
* Labs may begin automating research, which could shorten timelines.
* These capabilities may increase proliferation risks of techniques used to develop frontier models.
* In the extremes, these capabilities may increase the risk of uncontrolled recursive self-improvement.
Labs, governments, and everyone else involved should have an accurate understanding of where the capabilities frontier lies to enable good decision making. The only quantitatively rigorous way of doing that is with good benchmarks.
Capabilities are not bottlenecked on benchmarks to inform where model developers could make improvements, and adding more is extremely unlikely to make any significant difference to capabilities progress.
Therefore, I think having more capabilities benchmarks a good thing because it can greatly increase our understanding of model capabilities without making much of a difference in timelines. However, if you are interested in doing safety work, building capabilities benchmarks is probably not the most effective thing you could be doing.
From my reader's perspective, Inkhaven was probably bad. No shade to the authors, this level of output is a lot of work and there was plenty I enjoyed. But it shouldn't be a surprise that causing people to write a lot more posts even when they're not inspired leads to a lot more uninspired posts.
A lot of the uninspired posts were still upvoted on LW. I even did some of that upvoting myself, just automatically clicking upvote as I start reading a post with an interesting first paragraph by someone whose name I recognize. Mostly this is fine, but it dilutes karma just a bit more.
And I only ever even saw a small fraction. I'm sorry if you were an Inkhaven author who killed it every time, I was merely being shown a subset, since I mostly just click on things on the front page. Probably not so much sorted by quality as by network effects that can get onto the front page long enough to snowball upvotes.
I think as a reader I'd have liked the results better if participants had to publish every other day instead.
just automatically clicking upvote as I start reading a post with an interesting first paragraph by someone whose name
Dude! You upvote the posts before you read them?!
This is probably pretty common, now that I consider it, but it seems like it's doing a diservice to the karma system. Shouldn't we upvote posts that we got value out of instead of ones that we expect to get value out of?
just automatically clicking upvote as I start reading a post with an interesting first paragraph by someone whose name
Internet voting experiences very different from your own…
My LW upvoting policy is that every once in a while I go through the big list of everything I've read, grep for LessWrong posts, look through the latest ~50 entries and decide to open them and (strong) up/downvote them based on how they look, a few months in retrospect.
4
My guess is you're the only person in the world who does this, but also this is better than what everyone else is doing and maybe I should start doing it
2
Upvotes communicate to your future self, to future others, to current others, to the post's author, and to the site's promotion algorithm.
Voting a few months out tells me you're mostly interested in #1 and #2 from that list, while I'm I'm pretty big on the last two.
Maybe the vote up / down option could be moved to after the body of the post? Does seem like an awkward set of design considerations between wanting people to see the current score before reading, and not split the current score from the vote buttons or duplicate the score, and I bet Habryka has thought about this already.
5
I doubt moving buttons is sufficient, you probably need a popup on upvote only: "hey, our scroll counter algorithm thinks you didn't read the whole article. Please take a moment to be sure you really don't want to do that before you upvote!"
6
I have done it for more than one post this month. I wonder if it's in part because I upvote partway through reading sometimes and normally feel pretty accurate that I've noticed being less accurate this month (of course, one can always retract an upvote made in haste).
I strongly disagree, I think LessWrong has become a much more vibrant and active place since Inkhaven started. Recently the frontpage has felt more... I can't think of a better word than "corporate"... than I'd like. Maybe what I mean is that the LessWrong posters have started catering more and more toward the lowest-common-LessWrong-denominator.
For example, here are the top posts from September 2025 (I think October had a reasonable amount of Inkhaven spirit, considering all the people doing Halfhaven)
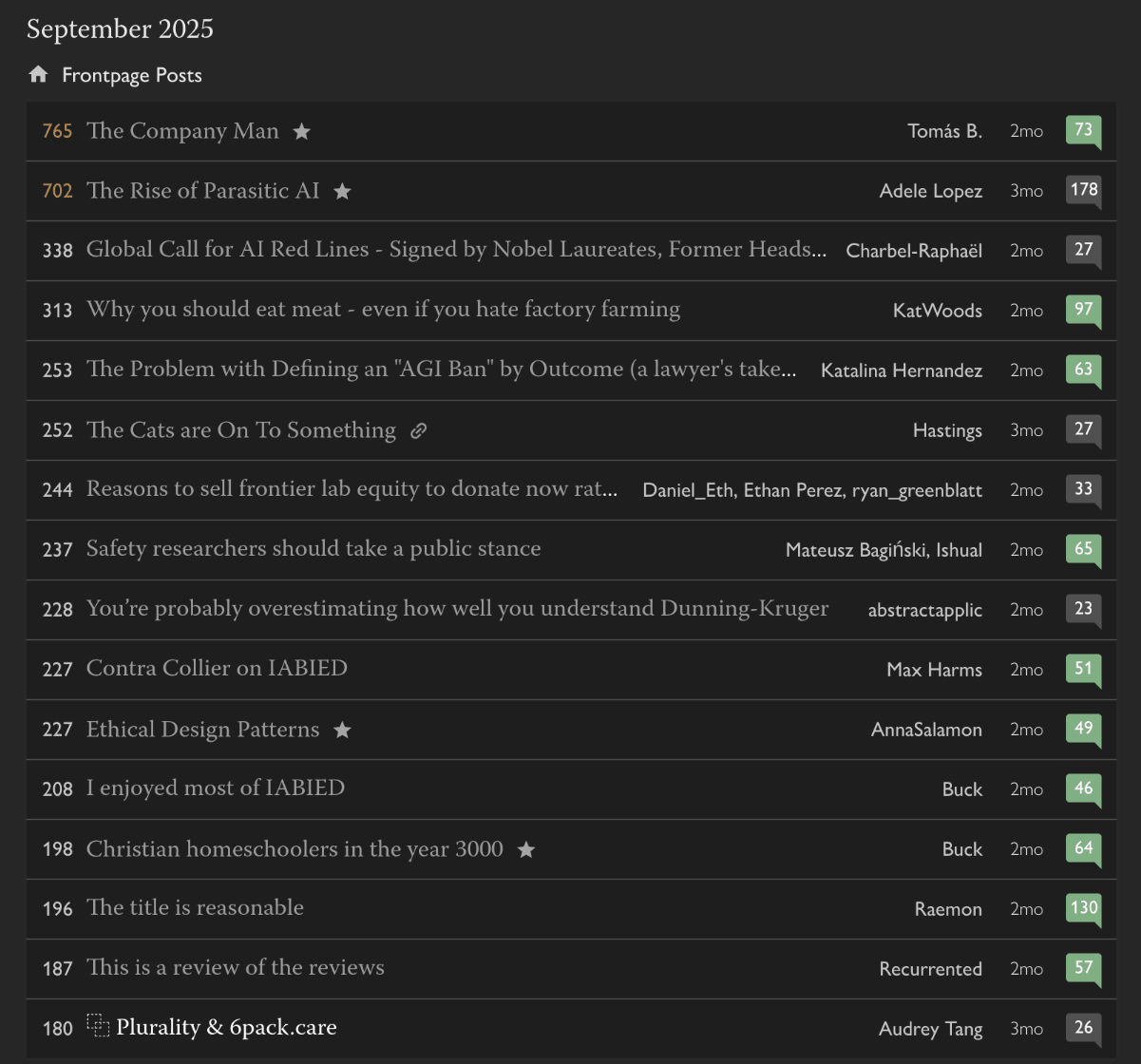
Tomas is always nice and refreshing, but imo the rest of this is just really extremely uninteresting and uninspired (no offense to anyone involved, each post is on its own good I think, but collectively they're not that interesting), and seem very much catering to the lowest-common-LessWrong-denominator.
Contrast this selection with the following
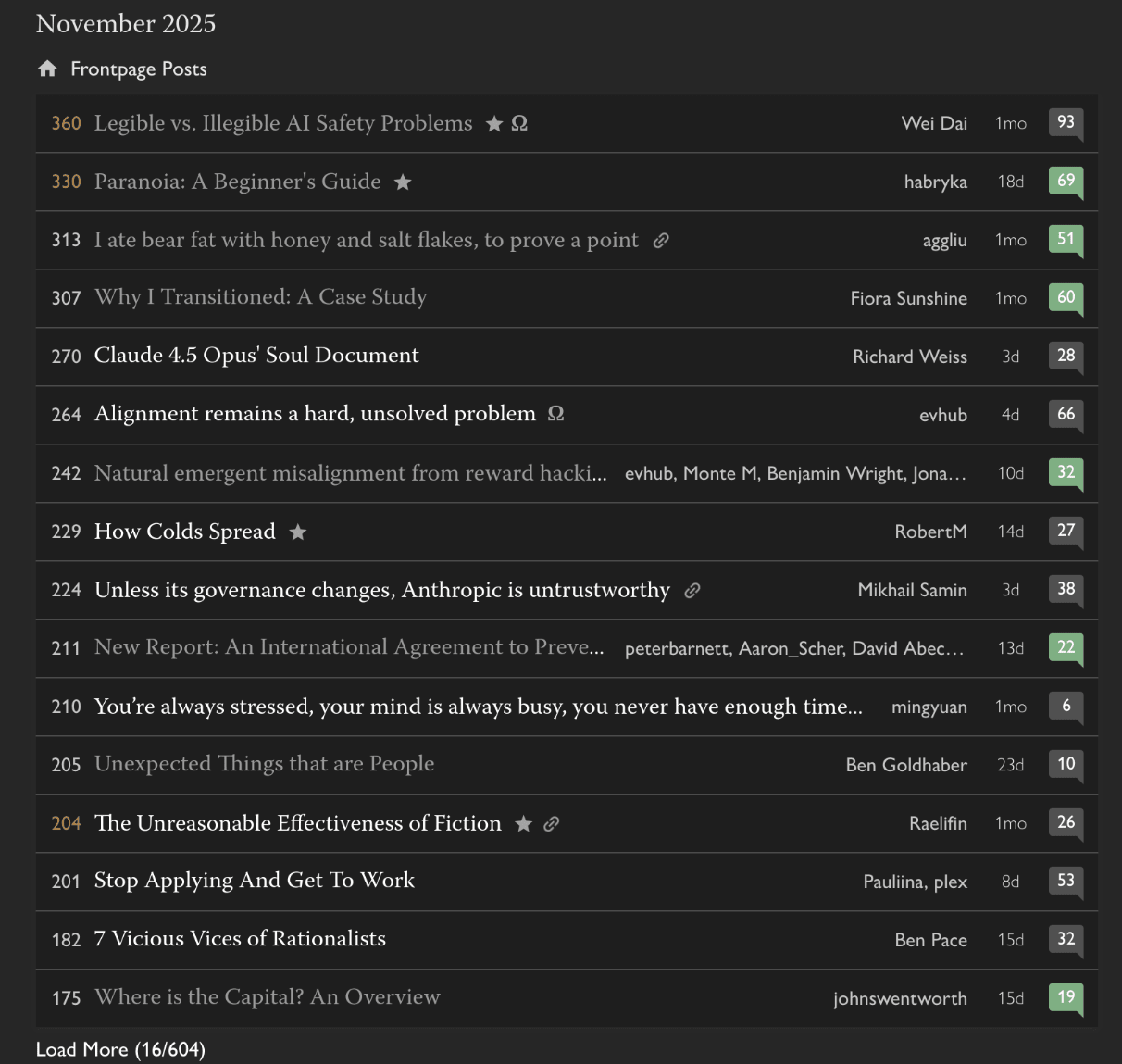
I have not read as many of these (because there were more overall posts and these are more recent), but collectively the range of topics is so much more interesting & broad, you still get some lowest-common-denominator catering, but collectively these posts are so much more inspired than they were just two months ago.
I really would v...
0
Of the 16 November posts you cite as evidence of Inkhaven's positive impact, I count three (Mikhail Samin, mingyuan, Ben Goldhaber) that were actually authored by an Inkhaven resident, and one of those three was a post that received a lot of criticism for its perceived low quality. (Another two were authored by habryka and Ben Pace, and another one was authored by johnswentworth who I think tried to post daily in the spirit of the thing, while not actually participating.) I think this is pretty weak evidence that Inkhaven has made LessWrong much more vibrant.
4
This is just false. Of the above list, the people who were doing Inkhaven in some form or another:
* Me (2nd post on that list)
* aggliu
* RobertM
* Mikhail
* Mingyuan
* Ben Goldhaber
* Ben Pace
* John Wentworth
Almost 50% of the whole list!
Me, Ben and Robert were just participating in Inkhaven (Ben for ~3 weeks, me and Robert for a week each) and Wentworth was doing his daily posting because of Inkhaven. It's obvious there is a huge effect here (you can of course dispute that the posts are good, but trying to somehow slice it up as Inkhaven not having a huge effect seems very unlikely to have any good case for it).
2
It wasn't clear to me from the Inkhaven website that you, Ben Pace, and John Wentworth were participating to that degree (though I did mention you three), and I missed aggliu and RobertM. So fair enough, I'll retract my comment. (ETA: I missed aggliu since I didn't know their name and they had only that one LW post in November, and I thought RobertM might be Rob Miles, but none of RobertM's November LW posts seem to be listed among Rob Miles's posts on the Inkhaven website. But obviously you were there and I was not so I defer to you.)
2
I noticed that many posters not doing Inkhaven were more vibrant, which I credit to the Inkhaven spirit, which also spawned Halfhaven.
Another anecdote: I put off a couple posts from November into December because I happened to care about these particular posts having visibility on the lesswrong frontpage, and the lesswrong frontpage has been unusually gummed up by high-karma low-effort posts during November.
5
Did you browse inkhaven.blog, or just the front page of LessWrong? The Inkhaven website has a few neat features that curate some of the better posts (e.g. encouraging authors to highlight their best posts), and includes a number of posts that authors seemed to not post to LessWrong.
[...]
I think there are a number of potential solutions to the problem you're outlining. This is one, but there are many others (e.g. encouraging some of the days to be more focused on editing past pieces, or only publishing the best of every three days' posts, etc).
5
Thanks for the reminder! I stopped checking inkhaven.blog ~instantly, and am only reacting to how it impacted my normal blogophere experience.
Scanning through inkhaven.blog a bit more and reading various sorts of links at random, neither random posts nor sampled curated posts really do it for me, but good stuff is definitely in there - including a few posts I had found in other ways without knowing they were part of Inkhaven (good job by the promotion/recommendation process conditional on just showing 1 or 2).
3
I tried to spread my posts between my personal blog, twitter, lesswrong quick takes and posts. I think I put out some cool posts and others were a little rushed. (Two of my high effort posts didn't get promoted to the frontpage)
"I think as a reader I'd have liked the results better if participants had to publish every other day instead."
Something like this might be good, there was a big practical problem that I often was only finished with a first draft at night time. One of the big advantages of the Inkhaven facilities is that you’re able to give your draft to other people who hang around, and there’s a person assigned to you who will help you with editing. But you can’t really use that if you just submit it right before going to bed.
Alternative to publishing every other day could be: a stack system where you don’t submit a post on the first day, but prepare it for review by end of day. It gets reviewed, then on the second day you also start writing the next post and edit the last post based on the review. That way you always have one post in review and one in the draft stage.
2
I think you did a good job differentially promoting better posts.
2
I'm kind of curious what the right cadence would have been?
Suppose you had to publish every 2 days? Would that have made any difference in the quality of the posts at all? Or would people just have procrastinated until the deadline, produced half as many posts that were solidly not very good?
Taking AI companies that are locally incentivized to race toward the brink, and then hoping they stop right at the cliff's edge, is potentially a grave mistake.
One might hope they stop because of voluntary RSPs, or legislation setting a red line, or whistleblowers calling in the government to lock down the datacenters, or whatever. But just as plausible to me is corporations charging straight down the cliff (of building ever-more-clever AI as fast as possible until they build one too clever and it gets power and does bad things to humanity), and even strategizing ahead of time how to avoid obstacles like legislation telling them not to. Local incentives have a long history of dominating people in this way, e.g. people in the tobacco and fossil fuel industries
What would be so much safer is if even the local incentives of cutting-edge AI companies favored social good, alignment to humanity, and caution. This would require legislation blocking off a lot of profitable activity, plus a lot of public and philanthropic money incentivizing beneficial activity, in a convulsive effort whose nearest analogy is the global shift to renewable energy.
(this take is the one thing I want to boost from AI For Humanity.)
Some thoughts on reading Superintelligence (2014). Overall it's been quite good, and nice to read through such a thorough overview even if it's not new to me. Weirdly I got some comments that people often stop reading it. What this puts me in mind of is a physics professor remarking to me that they used to find textbooks impenetrable, but now they find it quite fun to leaf through a new introductory textbook. And now my brain is relating this to the popularity of fanfiction that re-uses familiar characters and settings :P
By god, Nick Bostrom thinks in metaphors all the time. Not to imply that this is bad at all, in fact it's very interesting.
The way the intelligence explosion kinetics is presented really could stand to be less one-dimensional about intelligence. Or rather, perhaps it should ask us to accept that there is some one-dimensional measure of capability that is growing superlinearly, which can then by parlayed into all the other things we care about via the "superpower"-style arguments that appear two chapters later.
Has progress on AI seemed to outpace progress on augmenting human intelligence since 2014? I think so, and perhaps this explains why Bostrom_2014 puts more em...
About a year ago, I made a bet - my $50,000 against their $1000 - that we wouldn't see slam-dunk evidence of UFOs/UAPs being the result of aliens, the supernatural, simulations, or anything similarly non-mundane.
What's changed 1 year on? Well, I think a year ago UAPs and aliens were more in the news, between governmental hearings in several countries, a whistleblower ex-USAF intelligence official, and continuing coverage of navy UAP tapes. None of that has led anywhere, and it's mostly fading from public memory.
You can find people currently claiming that the big reveal that breaks it all wide open is just around the corner. But you can basically always find people claiming that. While doing some quick searching before making this comment, though, I did find out that a congressman from Tennessee is a big believer that the extraordinarily fake-looking aliens exhibited in Mexico last year are super important and need to be investigated at U Tennessee.
If they were, and they turned out to have non-terrestrial biological structure, that's definitely a way I could pay the money. I estimate the probability of this at about 0.00000000000000001.
2
It's feasible to establish AGI-run governance that does nothing on its own other than permanently and irrevocably but unobtrusively restrict the level of technological development of every civilization it reaches, including its own builders (perhaps as a way of opposing extinction risk). This leads to strange ancient cultures of biological low-tech aliens that slowly travel the galaxy, much later than the initial wave of von Neumann probes of the technological development restricting AGI.
This is still unlikely, as the outcome both wastes the cosmic endowment and requires sufficient technical sophistication to make it stable and irrevocable. So the builders of this AGI governance both need to decently understand alignment and target an outcome that radically impairs their future. But this seems only Fermi paradox unlikely, not literal magic unlikely. The fraudulent nature of "evidence" we see reduces the probability that this is the case further, as low-tech aliens could instead be making themselves known in straightforward ways, while the high-tech AGI that restricts tech doesn't need to be observable at all. But this doesn't go all the way to impossibility, as an ancient low-tech culture could have traditions and bureaucracy cashing out in a bizarre first contact process.
The prediction of this hypothesis is that we don't get to develop unrestricted ASI of our own. Given the inscrutable nature of the models (or equivalently lack of technical sophistication needed to know what we are doing) any interventions don't yet need to be humanly observable.
I read Fei-Fei Li's autobiographical book (The Worlds I See). I give it a 'imagenet wasn't really an adventure story, so you'd better be interested in it intrinsically and also want to hear about the rest of Fei-Fei Li's life story.' out of 5.
She's somewhat coy about military uses, how we're supposed to deal with negative social impacts, and anything related to superhuman AI. I can only point to the main vibe, which is 'academic research pointing out problems is vital, I sure hope everything works out after that.'
3
These are possible worlds where you can blackmail the blaclmailer by the fact that you know that he did blackmail
A fun thought about nanotechnology that might only make sense to physicists: in terms of correlation function, CPUs are crystalline solids, but eukaryotic cells are liquids. I think a lot of people imagine future nanotechnology as made of solids, but given the apparent necessity of using diffusive transport, nanotechnology seems more likely to be statistically liquid.
(For non-physicists: the building blocks of a CPU are arranged in regular patterns even over long length scales. But the building blocks of a cell are just sort of diffusing around in a water ...
Dictionary/SAE learning on model activations is bad as anomaly detection because you need to train the dictionary on a dataset, which means you needed the anomaly to be in the training set.
How to do dictionary learning without a dataset? One possibility is to use uncertainty-estimation-like techniques to detect when the model "thinks its on-distribution" for randomly sampled activations.
6
You may be able to notice data points where the SAE performs unusually badly at reconstruction? (Which is what you'd see if there's a crucial missing feature)
2
Would you expect this to outperform doing the same thing with a non-sparse autoencoder (that has a lower latent dimension than the NN's hidden dimension)? I'm not sure why it would, given that we aren't using the sparse representations except to map them back (so any type of capacity constraint on the latent space seems fine). If dense autoencoders work just as well for this, they'd probably be more straightforward to train? (unless we already have an SAE lying around from interp anyway, I suppose)
2
Regular AE's job is to throw away the information outside some low-dimensional manifold, sparse ~linear AE's job is to throw away the information not represented by sparse dictionary codes. (Also a low-dimensional manifold, I guess, just made from a different prior.)
If an AE is reconstructing poorly, that means it was throwing away a lot of information. How important that information is seems like a question about which manifold the underlying network "really" generalizes according to. And also what counts as an anomaly / what kinds of outliers you're even trying to detect.
2
Ah, yeah, that makes sense.
6
I think this is an important point, but IMO there are at least two types of candidates for using SAEs for anomaly detection (in addition to techniques that make sense for normal, non-sparse autoencoders):
1. Sometimes, you may have a bunch of "untrusted" data, some of which contains anomalies. You just don't know which data points have anomalies on this untrusted data. (In addition, you have some "trusted" data that is guaranteed not to have anomalies.) Then you could train an SAE on all data (including untrusted) and figure out what "normal" SAE features look like based on the trusted data.
2. Even for an SAE that's been trained only on normal data, it seems plausible that some correlations between features would be different for anomalous data, and that this might work better than looking for correlations in the dense basis. As an extreme version of this, you could look for circuits in the SAE basis and use those for anomaly detection.
Overall, I think that if SAEs end up being very useful for mech interp, there's a decent chance they'll also be useful for (mechanistic) anomaly detection (a lot of my uncertainty about SAEs applies to both possible applications). Definitely uncertain though, e.g. I could imagine SAEs that are useful for discovering interesting stuff about a network manually, but whose features aren't the right computational units for actually detecting anomalies. I think that would make SAEs less than maximally useful for mech interp too, but probably non-zero useful.
4
Yeah, this seems somewhat plausible. If automated circuit-finding works it would certainly detect some anomalies, though I'm uncertain if it's going to be weak against adversarial anomalies relative to regular ol' random anomalies.
4
Can't find a reference that says it has actually happened already.
2
Oh, maybe I've jumped the gun then. Whoops.
I think you can steelman Ben Goertzel-style worries about near-term amoral applications of AI being bad "formative influences" on AGI, but mostly under a continuous takeoff model of the world. If AGI is a continuous development of earlier systems, then maybe it shares some datasets and learned models with earlier AI projects, and definitely it shares the broader ecosystems of tools, dataset-gathering methodologies, model-evaluating paradigms, and institutional knowledge on the part of the developers. If the ecosystem in which this thing "grows up" is one t...
Idea: The AI of Terminator.
One of the formative books of my childhood was The Physics of Star Trek, by Lawrence Krauss. Think of it sort of like xkcd's What If?, except all about physics and getting a little more into the weeds.
So:
Robotics / inverse kinematics. Voice recognition, language models, and speech synthesis. Planning / search. And of course, self-improvement, instrumental convergence, existential risk.
To make this work you'd need to already be pretty well-suited. The Physics of Star Trek was Krauss' third published book, and he got Stephen Hawking to write the forward.
There's a point by Stuart Armstrong that anthropic updates are non-Bayesian, because you can think of Bayesian updates as deprecating improbable hypotheses and renormalizing, while anthropic updates (e.g. updating on "I think just got copied") require increasing probability on previously unlikely hypotheses.
In the last few years I've started thinking "what would a Solomonoff inductor do?" more often about anthropic questions. So I just thought about this case, and I realized there's something interesting (to me at least).
Suppose we're in the cloning versio...
2
Do you have a link to that argument? I think Bayesean updates include either reducing a prior or increasing it, and then renormalizing all related probabilities. Many updatable observations take the form of replacing an estimate of future experience (I will observe sunshine tomorrow) by a 1 or zero (I did or did not observe that, possibly not quite 0 or 1 if you want to account for hallucinations and imperfect memory).
Anthropic updates are either bayesean or impossible. The underlying question remains "how does this experience differ from my probability estimate"? For Bayes or for Solomonoff, one has to answer "what has changed for my prediction? In what way am I surprised and have to change my calculation?"
2
https://www.alignmentforum.org/posts/iNi8bSYexYGn9kiRh/paradoxes-in-all-anthropic-probabilities I think?
I have a totally non-Solomonoff explanation of what's going on, which actually goes full G.K. Chesterton - I assign anthropic probabilities because I don't assume that my not waking is impossible. But I'm not sure how a Solomonoff inductor would see it.
Will the problem of logical counterfactuals just solve itself with good model-building capabilities? Suppose an agent has knowledge of its own source code, and wants to ask the question "What happens if I take action X?" where their source code provably does not actually do X.
A naive agent might notice the contradiction and decide that "What happens if I take action X?" is a bad question, or a question where any answer is true, or a question where we have to condition on cosmic rays hitting transistors at just the right time. But we want a sophisticated ag...
It seems like there's room for the theory of logical-inductor-like agents with limited computational resources, and I'm not sure if this has already been figured out. The entire trick seems to be that when you try to build a logical inductor agent, it's got some estimation process for math problems like "what does my model predict will happen?" and it's got some search process to find good actions, and you don't want the search process to be more powerful than the estimator because then it will find edge cases. In fact, you want them to be linked somehow, ...
Charlie's easy and cheap home air filter design.
Ingredients:
MERV-13 fabric, cut into two disks (~35 cm diameter) and one long rectangle (16 cm by 110 cm).
Computer fan - I got a be quiet BL047.
Cheap plug-in 12V power supply
Hot glue
Instructions:
Splice the computer fan to the power supply. When you look at the 3-pin fan connector straight on and put the bumps on the connector on the bottom, the wire on the right is ground and the wire in the middle is 12V. Do this first so you are absolutely sure which way the fan blows before you hot glue it.
Hot glue t...
AI that's useful for nuclear weapon design - or better yet, a clear trendline showing that AI will soon be useful for nuclear weapon design - might be a good way to get governments to put the brakes on AI.
Inoculation prompting reduces RL pressure for learning bad behavior, but it's still expensive to rederive that it's okay to cheat from the inoculation prompt rather than just always being cheaty.
One way the expense binds is regularization. Does this mean you should turn off regularization during inoculation prompting?
Another way is that you might get better reward by shortcutting the computation about cheating and using that internal space to work on the task more. It might be useful to monitor this happening, and maybe try to protect the computation about cheating from getting its milkshake drunk.
Humans using SAEs to improve linear probes / activation steering vectors might quickly get replaced by a version of probing / steering that leverages unlabeled data.
Like, probing is finding a vector along which labeled data varies, and SAEs are finding vectors that are a sparse basis for unlabeled data. You can totally do both at once - find a vector along which labeled data varies and is part of a sparse basis for unlabeled data.
This is a little bit related to an idea with the handle "concepts live in ontologies." If I say I'm going to the gym, this conce...
Trying to get to a good future by building a helpful assistant seems less good than it did a month ago, because the risk is more salient that clever people in positions of power may coopt helpful assistants to amass even more power.
One security measure against this is reducing responsiveness to the user, and increasing the amount of goal information that's put into to large finetuning datasets that have lots of human eyeballs on them.
Should government regulation on AI ban using reinforcement learning with a target of getting people to do things that they wouldn't endorse in the abstract (or some similar restriction)?
E.g. should using RL to make ads that maximize click-through be illegal?
Just looked up Aligned AI (the Stuart Armstrong / Rebecca Gorman show) for a reference, and it looks like they're publishing blog posts:
E.g. https://www.aligned-ai.com/post/concept-extrapolation-for-hypothesis-generation
https://venturebeat.com/2021/09/27/the-limitations-of-ai-safety-tools/
This article makes a persuasive case that there being different sorts of safety research can be confusing to keep track of if you're a journalist (who are not so different from policymakers or members of the public).
https://www.sciencedirect.com/science/article/abs/pii/S0896627321005018
(biorxiv https://www.biorxiv.org/content/10.1101/613141v2 )
Cool paper on trying to estimate how many parameters neurons have (h/t Samuel at EA Hotel). I don't feel like they did a good job distinguishing how hard it was for them to fit nonlinearities that would nonetheless be the same across different neurons, versus the number of parameters that were different from neuron to neuron. But just based on differences in physical arrangement of axons and dendrites, there's a lot of opportuni...
Back in the "LW Doldrums" c. 2016, I thought that what we needed was more locations - a welcoming (as opposed to heavily curated a la old AgentFoundations), LW-style forum solely devoted to AI alignment, and then the old LW for the people who wanted to talk about human rationality.
This philosophy can also be seen in the choice to make the AI Alignment forum as a sister site to LW2.0.
However, what actually happened is that we now have non-LW forums for SSC readers who want to talk about politics, SSC readers who want to talk about human rationality, and peo...