This is a special post for quick takes by simeon_c. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Idea: Daniel Kokotajlo probably lost quite a bit of money by not signing an OpenAI NDA before leaving, which I consider a public service at this point. Could some of the funders of the AI safety landscape give some money or social reward for this?
I guess reimbursing everything Daniel lost might be a bit too much for funders but providing some money, both to reward the act and incentivize future safety people to not sign NDAs would have a very high value.
@Daniel Kokotajlo If you indeed avoided signing an NDA, would you be able to share how much you passed up as a result of that? I might indeed want to create a precedent here and maybe try to fundraise for some substantial fraction of it.
To clarify: I did sign something when I joined the company, so I'm still not completely free to speak (still under confidentiality obligations). But I didn't take on any additional obligations when I left.
Unclear how to value the equity I gave up, but it probably would have been about 85% of my family's net worth at least. But we are doing fine, please don't worry about us.
Is that your family's net worth is $100 and you gave up $85? Or your family's net worth is $15 and you gave up $85?
Either way, hats off!
The latter. Yeah idk whether the sacrifice was worth it but thanks for the support. Basically I wanted to retain my ability to criticize the company in the future. I'm not sure what I'd want to say yet though & I'm a bit scared of media attention.
9
I appreciate that you are not speaking loudly if you don't yet have anything loud to say.
5
I'd be interested in hearing peoples' thoughts on whether the sacrifice was worth it, from the perspective of assuming that counterfactual Daniel would have used the extra net worth altruistically. Is Daniel's ability to speak more freely worth more than the altruistic value that could have been achieved with the extra net worth?
3
(Note: Regardless of whether it was worth it in this case, simeon_c's reward/incentivization idea may be worthwhile as long as there are expected to be some cases in the future where it's worth it, since the people in those future cases may not be as willing as Daniel to make the altruistic personal sacrifice, and so we'd want them to be able to retain their freedom to speak without it costing them as much personally.)
I think having signed an NDA (and especially a non-disparagement agreement) from a major capabilities company should probably rule you out of any kind of leadership position in AI Safety, and especially any kind of policy position. Given that I think Daniel has a pretty decent chance of doing either or both of these things, and that work is very valuable and constrained on the kind of person that Daniel is, I would be very surprised if this wasn't worth it on altruistic grounds.
Edit: As Buck points out, different non-disclosure-agreements can differ hugely in scope. To be clear, I think non-disclosure-agreements that cover specific data or information you were given seems fine, but non-disclosure-agreements that cover their own existence, or that are very broadly worded and prevent you from basically talking about anything related to an organization, are pretty bad. My sense is the stuff that OpenAI employees are asked to sign when they leave are very constraining, but my guess is the kind of stuff that people have to sign for a small amount of contract work or for events are not very constraining, though I would definitely read any contract carefully in this space.
Strong disagree re signing non-disclosure agreements (which I'll abbreviate as NDAs). I think it's totally reasonable to sign NDAs with organizations; they don't restrict your ability to talk about things you learned other ways than through the ways covered by the NDA. And it's totally standard to sign NDAs when working with organizations. I've signed OpenAI NDAs at least three times, I think--once when I worked there for a month, once when I went to an event they were running, once when I visited their office to give a talk.
I think non-disparagement agreements are way more problematic. At the very least, signing secret non-disparagement agreements should probably disqualify you from roles where your silence re an org might be interpreted as a positive sign.
My understanding is that the extent of NDAs can differ a lot between different implementations, so it might be hard to speak in generalities here. From the revealed behavior of people I poked here who have worked at OpenAI full-time, the OpenAI NDAs seem very comprehensive and limiting. My guess is also the NDAs for contractors and for events are a very different beast and much less limiting.
Also just the de-facto result of signing non-disclosure-agreements is that people don't feel comfortable navigating the legal ambiguity and default very strongly to not sharing approximately any information about the organization at all.
Maybe people would do better things here with more legal guidance, and I agree that you don't generally seem super constrained in what you feel comfortable saying, but like I sure now have run into lots of people who seem constrained by NDAs they signed (even without any non-disparagement component). Also, if the NDA has a gag clause that covers the existence of the agreement, there is no way to verify the extent of the NDA, and that makes navigating this kind of stuff super hard and also majorly contributes to people avoiding the topic completely.
4
Notably, there are some lawyers here on LessWrong who might help (possibly even for the lols, you never know). And you can look at case law and guidance to see if clauses are actually enforceable or not (many are not). To anyone reading, here's habryka doing just that
It might be a good on the current margin to have a norm of publicly listing any non-disclosure agreements you have signed (e.g. on one's LW profile), and the rough scope of them, so that other people can model what information you're committed to not sharing, and highlight if it is related to anything beyond the details of technical research being done (e.g. if it is about social relationships or conflicts or criticism).
I have added the one NDA that I have signed to my profile.
But everyone has lots of duties to keep secrets or preserve privacy and the ones put in writing often aren't the most important. (E.g. in your case.)
I've signed ~3 NDAs. Most of them are irrelevant now and useless for people to know about, like yours.
I agree in special cases it would be good to flag such things — like agreements to not share your opinions on a person/org/topic, rather than just keeping trade secrets private.
3
I agree with this overall point, although I think "trade secrets" in the domain of AI can be relevant for people having surprising timelines views that they can't talk about.
3
Yesterday Sam Altman stated (perhaps in response to the Vox article that mentions your decision) that "the team was already in the process of fixing the standard exit paperwork over the past month or so. if any former employee who signed one of those old agreements is worried about it, they can contact me and we'll fix that too."
I notice he did not include you in the list of people who can contact him to "fix that", but it seems worth a try, and you can report what happens either way.
1
Mostly for @habryka's sake: it sounds like you are likely describing your unvested equity, or possibly equity that gets clawed back on quitting. Neither of which is (usually) tied to signing an NDA on the way out the door - they'd both be lost simply due to quitting.
The usual arrangement is some extra severance payment tied to signing something on your way out the door, and that's usually way less than the unvested equity.
EDIT: Turns out OpenAI's equity terms are unusually brutal and it is indeed the case that the equity clawback was tied to signing the NDA.
My current best guess is that actually cashing out the vested equity is tied to an NDA, but I am really not confident. OpenAI has a bunch of really weird equity arrangements.
1
Can you speak to any, let's say, "hypothetical" specific concerns that somebody who was in your position at a company like OpenAI might have had that would cause them to quit in a similar way to you?
4
One is the change to the charter to allow the company to work with the military.
https://news.ycombinator.com/item?id=39020778
I think the board must be thinking about how to get some independence from Microsoft, and there are not many entities who can counterbalance one of the biggest companies in the world. The government's intelligence and defence industries are some of them (as are Google, Meta, Apple, etc). But that move would require secrecy, both to stop nationalistic race conditions, and by contract, and to avoid a backlash.
EDIT: I'm getting a few disagrees, would someone mind explaining why they disagree with these wild speculations?
2
They didn't change their charter.
https://forum.effectivealtruism.org/posts/2Dg9t5HTqHXpZPBXP/ea-community-needs-mechanisms-to-avoid-deceptive-messaging
1
Thanks, I hadn't seen that, I find it convincing.
I might indeed want to create a precedent here and maybe try to fundraise for some substantial fraction of it.
I wonder if it might be more effective to fund legal action against OpenAI than to compensate individual ex-employees for refusing to sign an NDA. Trying to take vested equity away from ex-employees who refuse to sign an NDA sounds likely to not hold up in court, and if we can establish a legal precident that OpenAI cannot do this, that might make other ex-employees much more comfortable speaking out against OpenAI than the possibility that third-parties might fundraise to partially compensate them for lost equity would be (a possibility you might not even be able to make every ex-employee aware of). The fact that this would avoid financially rewarding OpenAI for bad behavior is also a plus. Of course, legal action is expensive, but so is the value of the equity that former OpenAI employees have on the line.
Yeah, at the time I didn't know how shady some of the contracts here were. I do think funding a legal defense is a marginally better use of funds (though my guess is funding both is worth it).
3
@habryka , Would you reply to this comment if there's an opportunity to donate to either? Me and another person are interested, and others could follow this comment too if they wanted to
(only if it's easy for you, I don't want to add an annoying task to your plate)
3
Sure, I'll try to post here if I know of a clear opportunity to donate to either.
I'm not gonna lie, I'm pretty crazily happy that a random quick take I wrote 10m on a Friday morning about how Daniel Kokotajlo should get social reward and get partial refunding sparked a discussion that seems to have caused positive effects wayyyy beyond expectations.
Quick takes is an awesome innovation, it allows to post even when one is still partially confused/uncertain about sthg. Given the confusing details of the situation in that case, this wd pbbly not have happened otherwise.
8
Do you know if there have been any concrete implications (ie. someone giving Daniel a substantial amount of money) from the discussion?'
6
So first the 85% net worth thing went quite viral several times and made Daniel Kokotajlo a bit of a heroic figure on Twitter.
Then Kelsey Piper's reporting pushed OpenAI to give back Daniel's vested units. I think it's likely that Kelsey used elements from this discussion as initial hints for her reporting and plausible that the discussion sparked her reporting, I'd love to have her confirmation or denial on that.
7
When I was first seeing this post it had 0 karma and -8 disagree votes. It's unclear to me why. Kelsey Piper is a rationalist so it's quite plausible that she did see the discussion and was partly motivated by it. Can anyone who disagrees with simeon's comment argue their position?
3
(My track record of 0% accuracy on which messages will politically snowball is holding up very well. I'm glad that sometimes people like you say things the way you say them, rather than only people like me saying things how I say them.)
2
What kind of effects are you thinking about?
2
I was just thinking not 10 minutes ago about how that one LW user who casually brought up Daniel K's equity (I didn't remember your username) had a massive impact and I'm really grateful for them.
There's a plausible chain of events where simeon_c brings up the equity > it comes to more people's attention > OpenAI goes under scrutiny > OpenAI becomes more transparent > OpenAI can no longer maintain its de facto anti-safety policies > either OpenAI changes policy to become much more safety-conscious, or loses power relative to more safety-conscious companies > we don't all die from OpenAI's unsafe AI.
So you may have saved the world.
1
How did you know Daniel Kokotajlo didn't sign the OpenAI NDA and probably lost money?
7
He openly stated that he had left OA because he lost confidence that they would manage singularity responsibly. Had he signed the NDA, he would be prohibited from saying that.
1
Isn't that a non-disparagement clause, not a NDA?
Idk what the LW community can do but somehow, to the extent we think liberalism is valuable, the Western democracies need to urgently put a hard stop to Russia and China war (preparation) efforts. I fear that rearmament is a key component of the only viable path at this stage.
I won't argue in details here but link to Noahpinion, who's been quite vocal on those topics. The TLDR is that China and Russia have been scaling their war industry preparation efforts for years, while Western democracies industries keep declining and remain crazily dependent from the Chinese industry. This creates a new global equilibrium where the US is no longer powerful enough to disincentivize all authoritarians regime from grabbing more land etc.
Some readings relevant to that:
-
https://www.noahpinion.blog/p/were-not-ready-for-the-big-one
-
Why Putin probably won't stop with Ukraine: https://en.m.wikipedia.org/wiki/Minsk_agreements
-
Western democracies current arsenal (centered around some very expensive units, like aircraft carriers) is not well fit for the modern im
Something which concerns me is that transformative AI will likely be a powerful destabilizing force, which will place countries currently behind in AI development (e.g. Russia and China) in a difficult position. Their governments are currently in the position of seeing that peacefully adhering to the status quo may lead to rapid disempowerment, and that the potential for coercive action to interfere with disempowerment is high. It is pretty clearly easier and cheaper to destroy chip fabs than create them, easier to kill tech employees with potent engineering skills than to train new ones.
I agree that conditions of war make safe transitions to AGI harder, make people more likely to accept higher risk. I don't see what to do about the fact that the development of AI power is itself presenting pressures towards war. This seems bad. I don't know what I can do to make the situation better though.
7
How do you draw that conclusion from the Minsk agreements? In those, Ukraine committed to pass laws for Decentralisation of power, including through the adoption of the Ukrainian law "On temporary Order of Local Self-Governance in Particular Districts of Donetsk and Luhansk Oblasts". Instead of Decentralization they passed laws forbidding those districts from teaching children in the languages that those districts wants to teach them.
Ukraines unwillingness to follow the agreements was a key reason why the invasion in 2022 happened and was very popular with the Russian population. Being in denial about that is not helpful is you want to help prevent wars from breaking out.
Having maximalist foreign policy goals is not the way you get peace.
[...]
The latest illegal land grab was done by Israel without any opposition by the US. If you are truly worried about land grabs being a problem why not speak against that US position of being okay with some land grabs instead of just speaking for buying more weapons?
3
I ignored that, that's useful, thank you.
My (simple) reasoning is that I pattern matched hard to the Anschluss (https://en.wikipedia.org/wiki/Anschluss) as a prelude to WW2 where democracies accepted a first conquest hoping that it would stop there (spoiler: it didn't).
Minsk really much feels the same way. From the perspetive of democracies it seems kinda reasonable to try one time a peaceful resolution accepting a conquest and see if Putin stops (although in hindsight it's unreasonable to not prepare to the possibility he doesn't). Now that he started invading Ukraine as a whole, it seems really hard for me to believe "once he'll get Ukraine, he'll really stop". I expect many reasons to invade other adjacent countries to come up aswell.
[...]
Two things on this.
1. Object-level: I'm not ok with this.
2. At a meta-level, there's a repugnant moral dilemma fundamental to this:
1. The American hegemonic power was abused, e.g. see https://en.wikipedia.org/wiki/July_12,_2007,_Baghdad_airstrike or a number of wars that the US created for dubious reasons (i.e. usually some economic or geostrategic interests). (same for France, I'm just focusing on the US here for simplicity)
2. Still, despite those deep injustice, the 2000s have been the least lethal in interstate conflicts because hegemony with threat of being crushed by the great power disincentivizes heavily anyone to fight.
1. It seems to me that hegemony of some power or coalition of powers is the most stable state for that reason. So I find this state quite desirable.
3. Then the other question is, who should be in that position?
1. I have the chance to be able to write this about my country without ending up in jail for. And if I do end up in jail, I have higher odds than in most other countries to be able to contest it.
2. So, although western democracies are quite bad and repugnant in a bunch of ways, I find them the least worse and most beneficial existing form of p
6
The key aspect of Minsk was that it was not put into practice. The annexation of Austria by Germany was fully put into practice and accepted by other states.
[...]
Ukraine didn't try. They didn't pass the laws that Minsk called for. They did pass laws to discriminate against the Russian-speaking population. They said that they wanted to retake Crimea sooner or later. Ukraine never accepted losing any territory to Russia.
[...]
I don't see why we should ignore reasons. Georgia seems to be willing to produce reasons to be invaded. Maybe, Georgia shouldn't pass such laws? If you are worried about being invaded under the pretext of removing civil rights, maybe not remove civil rights?
I don't think any of the EU countries that border Russia have a situation that's remotely similar in either reasons to invade or in ability to launch a promising invasion against them by Russia.
2
I am sure that Putin had something like the Anschluss in mind when he started his invasion.
Luckily for the west, he was wrong about that.
From a Machiavellian perspective, the war in Ukraine is good for the West: for a modest investment in resources, we can bind a belligerent Russia while someone else does all the dying. From a humanitarian perspective, war is hell and we should hope for a peace where Putin gets whatever he has managed to grab while the rest of Ukraine joins NATO and will be protected by NATO nukes from further aggression.
I am also not sure that a conventional arms race is the answer to Russia. I am very doubtful that a war between a NATO member and Russia would stay a regional or conventional conflict.
5
When I last looked a couple of months back, I found very little discussion of this topic in the rationalist communities. The most interesting post was probably this one from 2021: https://forum.effectivealtruism.org/posts/8cr7godn8qN9wjQYj/decreasing-populism-and-improving-democracy-evidence-based
I supposed it's not a popular topic because it rubs up against politics. But I do think that liberal democracy is the operating system for running things like LW, EA, and other communities we all love. It's worth defending it--though what that means exactly is vague to me.
Defending liberal democracy is complex, because everyone wants to say that they are on the side of liberal democracy.
If you take the Verified Voting Foundation as one of the examples of highly recommended projects in the link, mainstream opinion these days is probably that their talking points are problematic because people might trust less in elections when the foundations speaks about the need for a more trustworthy election process.
While I personally believe that pushing for a more secure voting system is good, it's a complex situation and many other projects in the space are similar. It's easy for a project that's funded for the purpose of strengthening liberal democracy to do the opposite.
2
Sure, but that's no reason not to try.
I think this is a strong argument against "just do something that feels like it's working toward liberal democracy". But not against actually trying to work toward liberal democracy.
I think this is a subset of work on most important problems: time figuring out what to work on is surprisingly effective. People don't do it as much as they should because it's frustrating and doesn't feel like it's working toward a rewarding outcome.
1
For sure! It's a devilishly hard problem. Despite dipping in and out of the topic, I don't feel confident in even forming a problem statement about it. I feel more like one of the blind men touching different parts of an elephant.
But it seems like having many projects like the Verified Voting Foundation should hedge the risk--if each such project focuses on a small part, then the blast radius of unfortunate mistakes should be limited. I would just hope that, on average, we would be trending in the right direction.
3
One aspect of having many small projects is that it makes it harder to see the whole picture. It obfuscates and makes public criticism harder.
If someone builds a Ministery of Truth it's easy to criticize it as an Orwellian attack on liberal democracy. If they instead distribute it over hundreds of different organizations, it's a lot harder to conceptualize.
1
Indeed. One consideration is that the LW community used to be much less into policy adjacent stuff and hence much less relevant on that domain. Now, with AI governance becoming an increasingly big deal, I think we could potentially use some of that presence to push for certain things in defense.
Pushing for things in the genre of what Noah describes in the first piece I shared seems feasible for some people in policy.
2
On the AI aspect I suspect we could make a small case study out of Israel's use of their AI.
2
I wonder if potential war is the greatest concern with regard to either loss of liberalism or sites like LW. Interesting news story on views about democratic electoral processes and public trust in them as well as trust that the more democratic form of government will accomplish what it needs to. (Perhaps a lot of reading into with that particular summary but simplist was I could express the summary.)
I've not read the report so not sure if the headline is actually accurate about election -- certainly what is reported in the story doesn't quite support the "voters skeptical about fairness of elections" headline claim. The rest does seem to align with lots of news and events over the past 5 or 10 years.
1
Rephrasing based on an ask: "Western Democracies need to urgently put a hard stop to Russia and China war (preparation) efforts" -> Western Democracies need to urgently take actions to stop the current shift towards a new World order where conflicts are a lot more likely due to Western democracies no longer being a hegemonic power able to crush authoritarians power that grab land etc. This shift is currently primarily driven by the fact that Russia & China are heavily rearming themselves whereas Western democracies are not.
@Elizabeth
2
I'm unsure if the rephrasing is really helpful or if perhaps actually counter productive. Ithink the conflict and arming is in many ways the symptom and so the focus on that not going to be a solution. Additionally, that language seems to play directly into the framing both the Russian government and the Chinese goverment are framing things.
1
It seems like Simulacra 3 to me. Is this part of the framing Russia and China use actually wrong?
1
I mean the full option space obviously also includes "bargain with Russia and China to make credible commitments that they stop rearming (possibly in exchange for something)", and I think we should totally explore that path aswell, I just don't have much hope in it at this stage which is why I'm focusing on the other option, even if it is a fucked up local nash equilibrium.
1[anonymous]
This may be likely, iirc during wars countries tend to spend more on research and they could potentially just race to AGI like what happened with space race. Which could make hard takeoff even more likely.
Lighthaven City for 6.6M€? Worth a look by the Lightcone team.
https://x.com/zillowgonewild/status/1793726646425460738?t=zoFVs5LOYdSRdOXkKLGh4w&s=19
Glad you're keeping your eye out for these things!
It's 8 hours away from the Bay, which all-in is not that different from a plane flight to NY from the Bay, so the location doesn't really help with being where all the smart and interesting people are.
Before we started the Lightcone Offices we did a bunch of interviews to see if all the folks in the bay-area x-risk scene would click a button to move to the Presidio District in SF (i.e. imagine Lightcone team packs all your stuff and moves it for you and also all these other people in the scene move too) and IIRC most wouldn't because of things like their extended friend network and partners and so on (@habryka @jacobjacob am I remembering that correctly?). And that's only a ~1.5-hr move for most of them.
4
I don't know how to convince anyone of this but just having low network latency to California may be worth a lot after VR gets good. Physical access will matter much less than the quality of your network connection, the delay between speaking and seeing and hearing others' reactions, and timezone overlap.
I'm not sure how to put a price on these things. People seem to be able to adjust to the delay in conversation, but adjusting requires becoming comfortable with talking over people sometimes, it can get noisy. The timezone overlap issue also seems important, if you don't get off work/have your mid day break at the same time as others, you get left out of things, but people can adjust their sleep/wake time (I certainly can) and synch with a remote timezone so idk.
2
Thanks for the answer it makes sense.
To be clear I saw it thanks to Matt who did this tweet so credit goes to him: https://x.com/SpacedOutMatt/status/1794360084174410104?t=uBR_TnwIGpjd-y7LqeLTMw&s=19
Given the recent argument on whether Anthropic really did commit to not push the frontier or just misled most people into thinking that it was the case, it's relevant to reread the RSPs in hairsplitting mode. I was rereading the RSPs and noticed a few relevant findings:
Disclaimer: this is focused on negative stuff but does not deny the merits of RSPs etc etc.
- I couldn't find any sentence committing to not significantly increase extreme risks. OTOH I found statements that if taken literally could imply an implicit acknowledgment of the opposite: "our most significant immediate commitments include a high standard of security for ASL-3 containment, and a commitment not to deploy ASL-3 models until thorough red-teaming finds no risk of catastrophe.".
Note that it makes a statement on the risk only bearing on deployment measures and not on security. Given that the lack security is probably the biggest source of risk of ASL-3 systems & the biggest weakness of RSPs, I find it pretty likely that this is not random. - I found a number of commitments that are totally unenforceable in hairsplitting mode. Here are two examples:
- "World-class experts collaborating with prompt engineers
4
This debate comes from before the RSP so I don’t actually think that’s cruxy. Will try to dig up an older post.
3
There was a hot debate recently but regardless, the bottom line is just "RSPs should probably be interpreted literally and nothing else. If a literal statement is not strictly there, it should be assumed it's not a commitment."
I've not seen people doing very literal interpretation on those so I just wanted to emphasize that point.
I currently think Anthropic didn't "explicitly publicly commit" to not advance the rate of capabilities progress. But, I do think they made deceptive statements about it, and when I complain about Anthropic I am complaining about deception, not "failing to uphold literal commitments."
I'm not talking about the RSPs because the writing and conversations I'm talking about came before that. I agree that the RSP is more likely to be a good predictor of what they'll actually do.
I think most of the generator for this was more like "in person conversations", at least one of which was between Dario and Dustin Moswkowitz:
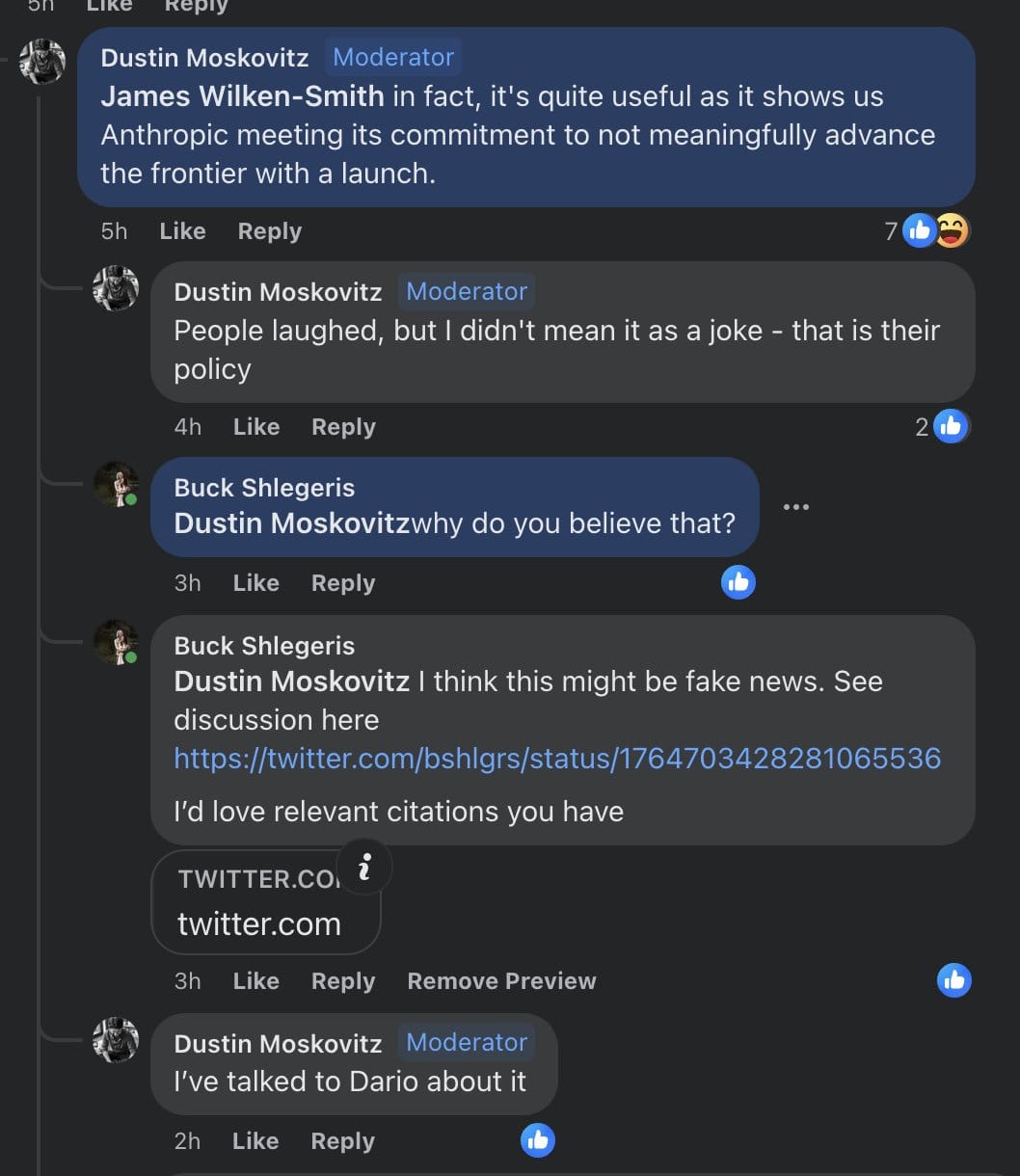
The most explicit public statement I know is from this blogpost (which I agree is not an explicit commitment, but, I do think
...
- Capabilities: AI research aimed at making AI systems generally better at any sort of task, including writing, image processing or generation, game playing, etc. Research that makes large language models more efficient, or that improves reinforcement learning algorithms, would fall under this heading. Capabilities work generates and improves on the models that we investigate and utilize in our alignment research. We generally don’t publish this ki
1
If you wanna reread the debate, you can scroll through this thread (https://x.com/bshlgrs/status/1764701597727416448).
You are a LessWrong reader, want to push humanity's wisdom and don't know how to do so? Here's a workflow:
- Pick an important topic where the entire world is confused
- Post plausible sounding takes with a confident tone on it
- Wait for Gwern's comment on your post
- Problem solved
See an application of the workflow here: https://www.lesswrong.com/posts/epgCXiv3Yy3qgcsys/you-can-t-predict-a-game-of-pinball?commentId=wjLFhiWWacByqyu6a
6
This workflow appears to work quite well. This suggests that we should collectively try to irritate Gwern into solving the alignment problem. This is a big problem, so we'll have to apply the workflow iteratively. First post a confident argument that it's impossible for specific reasons, then make similarly overconfident posts on increasingly specific arguments about how subsets of the problem are effectively impossible. The remainder will be the best available solution.
That's a pretty funny example. Lots of us could've recognized the central flaw (I'm pretty alert to intimidation by physics/math and drawing much broader conclusions than the proof allows), but it would take Gwern to disprove it so eloquently, thoroughly, and with such thorough references.
So, we should all be like Gwern. Merely devote our lives to the pursuit not just of knowledge, but well-organized knowledge that's therefore cumulative. Recognize that nobody will pay us to do this, so live cheaply to minimize time wasted making a living (and probably distortions in rationality from having goals outside of knowledge).
I don't know Gwern's story in any more detail than that, which is my recollection of what he's said about himself. (The distortions of rationality is my addition; I really need to write up my research and thinking on motivated reasoning.)
2
This is the best alignment plan I've heard in a while.
Suggested reframing for judging AGI lab leaders: think less about what terminal values AGI lab leaders pursue and think more about how they trade-off power/instrumental goals with other values.
Claim 1: The end values of AGI lab leaders matter mostly if they win the AGI race and have crushed competition, but much less for all the decisions leading up there (i.e. from now to the post-AGI world).
Claim 1bis: Additionally, in the event where they have no competition and are ruling the world, even someone like Sam Altman seems to have mostly good val...
IMO, reasonableness and epistemic competence are also key factors. This includes stuff like how effectively they update on evidence, how much they are pushed by motivated reasoning, how good are they at futurism and thinking about what will happen. I'd also include "general competence".
2
Agreed that those are complementary. I didn't mean to say that the factor I flagged is the only important one.
do people have takes on the most useful metrics/KPIs that could give a sense of how good are the monitoring/anti-misuse measures on APIs?
Some ideas:
a) average time to close an account conducting misuse activities (my sense is that as long as this is >1 day, there's little chance to avoid that state actors use API-based models for a lot of misuse (everything which doesn't require major scale))
b) the logs of the 5 accounts/interactions that have been ranked as highest severity (my sense is that incident reporting like OpenAI/Microsoft have done on c...
0
It's currently 25th under new releases on amazon. So I think somewhere between borderline and unlikely for making it into the top 15 NYT best seller list for non-fiction?
4
Preorders make a big difference, and my guess is were higher for this than most books on Amazon, so I think I am currently at around 50% it will end up in the top 15.
Playing catch-up is way easier than pushing the frontier of LLM research. One is about guessing which path others took, the other one is about carving a path among all the possible ideas that could work.
If China stopped having access to US LLM secrets and had to push the LLM frontier rather than playing catch up, how slower would it be at doing so?
My guess is at least >2x and probably more but I'd be curious to get takes.
2
Since the scaling experiment is not yet done, it remains possible that long-horizon agency is just a matter of scale even with current architectures, no additional research necessary. In which case additional research helps save on compute and shape the AIs, but doesn't influence ability to reach the changeover point, when the LLMs take the baton and go on doing any further research on their own.
Distributed training might be one key milestone that's not yet commoditized, making individual datacenters with outrageous local energy requirements unnecessary. And of course there's the issue of access to large quantities of hardware.
1
They are pushing the frontier (https://arxiv.org/abs/2406.07394), but it’s hard to say where they would be without llamas. I don’t think they’d be much far behind. They have gpt-4 class models as is and also don’t care about copyright restrictions when training models. (Arguably they have better image models as a result)
I've been thinking a lot recently about taxonomizing AI risk related concepts to reduce the dimensionality of AI threat modelling while remaining quite comprehensive. It's in the context of developing categories to assess whether labs plans cover various areas of risk.
There are two questions I'd like to get takes on. Any take on one of these 2 wd be very valuable.
- In the misalignment threat model space, a number of safety teams tend to assume that the only type of goal misgeneralization that could lead to X-risks is deceptive misalignment. I'm not sure to u
There's a number of properties of AI systems that makes it easier to collect information in a safe way about those systems and hence demonstrate their safety: interpretability, formal verifiability, modularity etc. Which adjective wd you use to characterize those properties?
I'm thinking of "resilience" because from the perspective of an AI developer it helps a lot understanding the risk profile, but do you have other suggestions?
Some alternatives:
- auditability properties
- legibility properties