Crossposted from the AI Alignment Forum. May contain more technical jargon than usual.
Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover
Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover
Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover
43Shiroe
35Ajeya Cotra
2Shiroe
3Ajeya Cotra
19Ajeya Cotra
5alyssavance
17habryka
6Ajeya Cotra
6habryka
12Ajeya Cotra
1Noosphere89
2Thomas Kwa
3Ajeya Cotra
16habryka
22Ajeya Cotra
2Ajeya Cotra
8Lukas Finnveden
2Said Achmiz
2Lukas Finnveden
2Said Achmiz
4habryka
31CarlShulman
22TurnTrout
26Ajeya Cotra
6TurnTrout
6Ajeya Cotra
14Not Relevant
5Ajeya Cotra
4Not Relevant
7Ajeya Cotra
5Not Relevant
3Not Relevant
4Ajeya Cotra
3Ajeya Cotra
3Not Relevant
5Ajeya Cotra
3Not Relevant
3Ajeya Cotra
1Not Relevant
12PeterMcCluskey
6Ajeya Cotra
3PeterMcCluskey
12TurnTrout
14Ajeya Cotra
7Algon
3David Johnston
8Ramana Kumar
8Vael Gates
7aogara
18Ajeya Cotra
1Mathieu Putz
3Ajeya Cotra
7Gabe M
6Yitz
2Thomas Kwa
2Yitz
2Yitz
5Jérémy Scheurer
6Ajeya Cotra
1Jérémy Scheurer
4JanB
4Ivan Vendrov
4Adam Jermyn
2Ivan Vendrov
2dsj
3AlexMennen
5Ajeya Cotra
2greg
11Ajeya Cotra
11Ben Pace
4Ajeya Cotra
0Ben Pace
9Ajeya Cotra
2Ben Pace
15CarlShulman
2Ben Pace
3Raemon
2Daniel Kokotajlo
6Ben Pace
3Ajeya Cotra
1Joshua Blake
1Glaucon-5
1joshc
1Prometheus
2Lukas_Gloor
1Anthony DiGiovanni
1Oscar
0Harry Taussig
0Ivan Vendrov
0Flaglandbase
4Shiroe
1Flaglandbase
3Noosphere89
-26Phenoca
New Comment
Some comments are truncated due to high volume. (⌘F to expand all)
Reading AI safety articles like this one, I always find myself nodding along in agreement. The conclusions simply follow from the premises, and the premises are so reasonable. Yet by the end, I always feel futility and frustration. Anyone who wanted to argue that AI safety was a hopeless program wouldn't need to look any further than the AI safety literature! I'm not just referring to "death with dignity". What fills me with dread and despair is paragraphs like this:
However, optimists often take a very empiricist frame, so they are likely to be interested in what kind of ML experiments or observations about ML models might change my mind, as opposed to what kinds of arguments might change my mind. I agree it would be extremely valuable to understand what we could concretely observe that would constitute major evidence against this view. But unfortunately, it’s difficult to describe simple and realistic near-term empirical experiments that would change my beliefs very much, because models today don’t have the creativity and situational awareness to play the training game. [original emphasis]
Here is the real chasm between the AI safety movement and ...
I want to clarify two things:
- I do not think AI alignment research is hopeless, my personal probability of doom from AI is something like 25%. My frame is definitely not "death with dignity;" I'm thinking about how to win.
- I think there's a lot of empirical research that can be done to reduce risks, including e.g. interpretability, "sandwiching" style projects, adversarial training, testing particular approaches to theoretical problems like eliciting latent knowledge, the evaluations you linked to, empirically demonstrating issues like deception (as you suggested), and more. Lots of groups are in fact working on such problems, and I'm happy about that.
The specific thing that I said was hard to name is realistic and plausible experiments we could do on today's models that would a) make me update strongly toward "racing forward with plain HFDT will not lead to an AI takeover", and b) that I think people who disagree with my claim would accept as "fair." I gave an example right after that of a type of experiment I don't expect ML people to consider "fair" as a test of this hypothesis. If I saw that ML people could consistently predict the direction in which gradient descent is subo...
2
(By the way, I was delighted to find out you're working on that ARC project that I had linked! Keep it up! You are like in the top 0.001% of world-helping-people.)
3
Thanks, but I'm not working on that project! That project is led by Beth Barnes.
Here is the real chasm between the AI safety movement and the ML industry/academia. One field is entirely driven by experimental results; the other is dominated so totally by theory that its own practitioners deny that there can be any meaningful empirical aspect to it, at least, not until the moment when it's too late to make any difference.
To put a finer point on my view on theory vs empirics in alignment:
- Going forward, I think the vast majority of technical work needed to reduce AI takeover risk is empirical, not theoretical (both in terms of "total amount of person-hours needed in each category" and in terms of "total 'credit' each category should receive for reducing doom in some sense").
- Conditional on an alignment researcher agreeing with my view of the high-level problem, I tend to be more excited about them if they're working on ML experiments than if they're working on theory.
- I'm quite skeptical of most theoretical alignment research I've seen. The main theoretical research I'm excited about is ARC's, and I have a massive conflict of interest since the founder is my husband -- I would feel fairly sympathetic to people who viewed ARC's work more like how I view other
5
I'm surprised by how strong the disagreement is here. Even if what we most need right now is theoretical/pre-paradigmatic, that seems likely to change as AI develops and people reach consensus on more things; compare eg. the work done on optics pre-1800 to all the work done post-1800. Or the work done on computer science pre-1970 vs. post-1970. Curious if people who disagree could explain more - is the disagreement about what stage the field is in/what the field needs right now in 2022, or the more general claim that most future work will be empirical?
I mostly disagreed with bullet point two. The primary result of "empirical AI Alignment research" that I've seen in the last 5 years has been a lot of capabilities gain, with approximately zero in terms of progress on any AI Alignment problems. I agree more with the "in the long run there will be a lot of empirical work to be done", but right now on the margin, we have approximately zero traction on useful empirical work, as far as I can tell (outside of transparency research).
6
I agree that in an absolute sense there is very little empirical work that I'm excited about going on, but I think there's even less theoretical work going on that I'm excited about, and when people who share my views on the nature of the problem work on empirical work I feel that it works better than when they do theoretical work.
6
Hmm, there might be some mismatch of words here. Like, most of the work so far on the problem has been theoretical. I am confused how you could not be excited about the theoretical work that established the whole problem, the arguments for why it's hard, and that helped us figure out at least some of the basic parameters of the problem. Given that (I think) you currently think AI Alignment is among the global priorities, you presumably think the work that allowed you to come to believe that (and that allowed others to do the same) was very valuable and important.
My guess is you are somehow thinking of work like Superintelligence, or Eliezer's original work, or Evan's work on inner optimization as something different than "theoretical work"?
I was mainly talking about the current margin when I talked about how excited I am about the theoretical vs empirical work I see "going on" right now and how excited I tend to be about currently-active researchers who are doing theory vs empirical research. And I was talking about the future when I said that I expect empirical work to end up with the lion's share of credit for AI risk reduction.
Eliezer, Bostrom, and co certainly made a big impact in raising the problem to people's awareness and articulating some of its contours. It's kind of a matter of semantics whether you want to call that "theoretical research" or "problem advocacy" / "cause prioritization" / "community building" / whatever, and no matter which bucket you put it in I agree it'll probably end up with an outsized impact for x-risk-reduction, by bringing the problem to attention sooner than it would have otherwise been brought to attention and therefore probably allowing more work to happen on it before TAI is developed.
But just like how founding CEOs tend to end up with ~10% equity once their companies have grown large, I don't think this historical problem-advocacy-slash-theoretical-research work alone will end...
1
Unfortunately, empirical work is slowly progressing towards alignment, and truth be told, we might be in a local optima for alignment chances, barring stuff like outright banning AI work, or doing something political. And unfortunately that's hopelessly going to get us mind killed and probably make it even worse.
Also, at the start of a process towards a solution always boots up slowly, with productive mistakes like these. You will never get perfect answers, and thinking that you can get perfect answers is a Nirvana Fallacy. Exponential growth will help us somewhat, but ultimately AI Alignment is probably in a local optima state, that is, the people and companies that are in the lead to building AGI are sympathetic to Alignment, which is far better than we could reasonably have hoped for, and there's little arms race dynamics for AGI, which is even better.
We often complain about the AGI issue for real reasons, but we do need to realize how good we've likely gotten at this. It's still shitty, yet there are far worse points we could have ended up here.
In a post-AI PONR world, we're lucky if we can solve the problem of AI Alignment enough such that we go through slow-takeoff safely. We all hate it, yet empirical work will ultimately be necessary, and we undervalue feedback loops because theory can get wildly out of reality without being in contact with reality.
2
Were any cautious people trying empirical alignment research before Redwood/Conjecture?
3
Geoffrey Irving, Jan Leike, Paul Christiano, Rohin Shah, and probably others were doing various kinds of empirical work a few years before Redwood (though I would guess Oliver doesn't like that work and so wouldn't consider it a counterexample to his view).
Yeah, I think Open AI tried to do some empirical work, but approximately just produced capability progress, in my current model of the world (though I also think the incentive environment there was particularly bad). I feel confused about the "learning to summarize from human feedback" work, and currently think it was overall bad for the world, but am not super confident (in general I feel very confused about the sign of RLHF research).
I think Rohin Shah doesn't think of himself as having produced empirical work that helps with AI Alignment, but only to have produced empirical work that might help others to be convinced of AI Alignment. That is still valuable, but I think it should be evaluated on a different dimension.
I haven't gotten much out of work by Geoffrey Irving or Jan Leike (and don't think I know many other people who have, or at least haven't really heard a good story for how their work actually helps). I would actually be interested if someone could give some examples of how this research helped them.
I'm pretty confused about how to think about the value of various ML alignment papers. But I think even if some piece of empirical ML work on alignment is really valuable for reducing x-risk, I wouldn't expect its value to take the form of providing insight to readers like you or me. So you as a reader not getting much out of it is compatible with the work being super valuable, and we probably need to assess it on different terms.
The main channel of value that I see for doing work like "learning to summarize" and the critiques project and various interpretability projects is something like "identifying a tech tree that it seems helpful to get as far as possible along by the Singularity, and beginning to climb that tech tree."
In the case of critiques -- ultimately, it seems like having AIs red team each other and pointing out ways that another AI's output could be dangerous seems like it will make a quantitative difference. If we had a really well-oiled debate setup, then we would catch issues we wouldn't have caught with vanilla human feedback, meaning our models could get smarter before they pose an existential threat -- and these smarter models can more effectively work on proble...
2
Note I was at -16 with one vote, and only 3 people have voted so far. So it's a lot due to the karma-weight of the first disagreer.
8
There's a 1000 year old vampire stalking lesswrong!? 16 is supposed to be three levels above Eliezer.
2
Since comments start with a small upvote from the commenter themselves—which for Ajeya has a strength of 1—a single strong downvote, to take her comment down to -16, would actually have to have a strength of 17.
That is, quite literally, off the scale.
2
This is about the agreement karma, though, which starts at 0.
2
Oh, I see.
4
I strong-disagreed on it when it was already at -7 or so, so I think it was just me and another person strongly disagreeing. I expected other people would vote it up again (and didn't expect anything like consensus in the direction I voted).
Retroactively giving negative rewards to bad behaviors once we’ve caught them seems like it would shift the reward-maximizing strategy (the goal of the training game) toward avoiding any bad actions that humans could plausibly punish later.
A swift and decisive coup would still maximize reward (or further other goals). If Alex gets the opportunity to gain enough control to stop Magma engineers from changing its rewards before humans can tell what it’s planning, humans would not be able to disincentivize the actions that led to that coup. Taking the opportunity to launch such a coup would therefore be the reward-maximizing action for Alex (and also the action that furthers any other long-term ambitious goals it may have developed).
I'd add that once the AI has been trained on retroactively edited rewards, it may also become interested in retroactively editing all its past rewards to maximum, and concerned that if an AI takeover happens without its assistance, its rewards will be retroactively set low by the victorious AIs to punish it. Retroactive editing also breaks myopia as a safety property: if even AIs doing short-term tasks have to worry about future retroactive editing, then they have reason to plot about the future and takeover.
Why do you think that using credit assignment to reinforce the computations which led to certain events (like a person smiling), trains cognition which terminally values that antecedent-computation-reinforcer? AKA—why do you think reward maximization is plausible as a terminal value which primarily determines the AI's behavior?
I'm agnostic about whether the AI values reward terminally or values some other complicated mix of things. The claim I'm making is behavioral -- a claim that the strategy of "try to figure out how to get the most reward" would be selected over other strategies like "always do the nice thing."
The strategy could be compatible with a bunch of different psychological profiles. "Playing the training game" is a filter over models -- lots of possible models could do it, the claim is just that we need to reason about the distribution of psychologies given that the psychologies that make it to the end of training most likely employ the strategy of playing the training game on the training distribution.
Why do I think this? Consider an AI that has high situational awareness, reasoning ability and creative planning ability (assumptions of my situation which don't yet say anything about values). This AI has the ability to think about what kinds of actions would get the most reward (just like it has the ability to write a sonnet or solve a math problem or write some piece of software; it understands the task and has the requisite subskills). And once it has the ability, it is likely to be pushe...
6
But why would that strategy be selected? Where does the selection come from? Will the designers toss a really impressive AI for not getting reward on that one timestep? I think not.
Why? I maintain that the agent would not do so, unless it were already terminally motivated by reward. For empirical example, some neuroscientists know that brain stimulation reward leads to higher reward, and the brain very likely does some kind of reinforcement learning, so why don't neuroscientists wirehead themselves?
6
I was talking about gradient descent here, not designers.
I'm broadly sympathetic to the points you make in this piece; I think they're >40% likely to be correct in practice. I'm leaving the below comments of where I reacted skeptically in case they're useful in subsequent rounds of editing, in order to better anticipate how "normie" ML people might respond.
Rather than being straightforwardly “honest” or “obedient,” baseline HFDT would push Alex to make its behavior look as desirable as possible to Magma researchers (including in safety properties), while intentionally and knowingly disregarding their intent whenever that conflicts with maximizing reward.
The section that follows this delves into a number of cases where human feedback is misaligned with honesty/helpfulness, giving Alex an incentive to do the thing opposite from what humans would actually want in a CEV-like scenario. It does seem likely that whatever internal objective Alex learns from this naive training strategy, it will reward things like "hide failures from overseers". I would very much appreciate if folks generated a more thorough cataloging of these sorts of feedback suboptimalities, so we could get a sense of the base rate of how many more problems of th...
5
I think the second story doesn't quite represent what I'm saying, in that it's implying that pursuing [insert objective] comes early and situational awareness comes much later. I think that situational awareness is pretty early (probably long before transformative capabilities), and once a model has decent situational awareness there is a push to morph its motives toward playing the training game. At very low levels of situational awareness it is likely not that smart, so it probably doesn't make too much sense to say that it's pursuing a particular objective -- it's probably a collection of heuristics. But around the time it's able to reason about the possibility of pursuing reward directly, there starts to be a gradient pressure to choose to reason in that way. I think crystallizing this into a particular simple objective it's pursuing comes later, probably.
This is possible to me, but I think it's quite tricky to pin these down enough to come up with experiments that both skeptics and concerned people would recognize as legitimate. Something that I think skeptics would consider unfair is "Train a model through whatever means necessary to do X (e.g. pursue red things) and then after that have a period where we give it a lot of reward for doing not-X (e.g. purse blue things), such that the second phase is unable to dislodge the tendency created in the first phase -- i.e., even after training it for a while to pursue blue things, it still continues to pursue red things."
This would demonstrate that some ways of training produce "sticky" motives and behaviors that aren't changed even in the face of counter-incentives, and makes it more plausible to me that a model would "hold on" to a motive to be honest / corrigible even when there are a number of cases where it could get more reward by doing something else. But in general, I don't expect people who are skeptical of this story to think this is a reasonable test.
I'd be pretty excited about someone trying harder t
4
On my model, the large combo of reward heuristics that works pretty well before situational awareness (because figuring out what things maximize human feedback is actually not that complicated) should continue to work pretty well even once situational awareness occurs. The gradient pressure towards valuing reward terminally when you've already figured out reliable strategies for doing what humans want, seems very weak. We could certainly mess up and increase this gradient pressure, e.g. by sometimes announcing to the model "today is opposite day, your reward function now says to make humans sad!" and then flipping the sign on the reward function, so that the model learns that what it needs to care about is reward and not its on-distribution perfect correlates (like "make humans happy in the medium term").
But in practice, it seems to me like these differences would basically only happen due to operator error, or cosmic rays, or other genuinely very rare events (as you describe in the "Security Holes" section). If you think such disagreements are more common, I'd love to better understand why.
Yeah, with the assumption that the model decides to preserve its helpful values because it thinks they might shift in ways it doesn't like unless it plays the training game. (The second half is that once the model starts employing this strategy, gradient descent realizes it only requires a simple inner objective to keep it going, and then shifts the inner objective to something malign.)
7
Yeah, I disagree. With plain HFDT, it seems like there's continuous pressure to improve things on the margin by being manipulative -- telling human evaluators what they want to hear, playing to pervasive political and emotional and cognitive biases, minimizing and covering up evidence of slight suboptimalities to make performance on the task look better, etc. I think that in basically every complex training episode a model could do a little better by explicitly thinking about the reward and being a little-less-than-fully-forthright.
5
Ok, this is pretty convincing. The only outlying question I have is whether each of these suboptimalities are easier for the agent to integrate into its reward model directly, or whether it's easiest to incorporate them by deriving them via reasoning about the reward. It seems certain that eventually some suboptimalities will fall into the latter camp.
When that does happen, an interesting question is whether SGD will favor converting the entire objective to direct-reward-maximization, or whether direct-reward-maximization will be just a component of the objective along with other heuristics. One reason to suppose the latter might occur are findings like this paper (https://arxiv.org/pdf/2006.07710.pdf) which suggest that, once a model has achieved good accuracy, it won't update to a better hypothesis even if that hypothesis is simpler. The more recent grokking literature might push us the other way, though if I understand correctly it mostly occurs when adding weight decay (creating a "stronger" simplicity prior).
3
I've been trying to brainstorm more on experiments around "train a model to 'do X' and then afterwards train it to 'do not-X', and see whether 'do X' sticks". I'm not totally sure that I understand your mental model of the stickiness-hypothesis well enough to know what experiments might confirm/falsify it.
Scenario 1: In my mind, the failure mode we're worried about for inner-misaligned AGI is "given data from distribution D, the model first learns safe goal A (because goal A is favored on priors over goal B), but then after additional data from this distribution, the model learns an unsafe goal B (e.g. making reward itself the objective) that performs better on D than goal A (even though it was disfavored on priors)." In this case, the sort of result we might hope for is that we could make goal A sticky enough on D that it persists (and isn't replaced by goal B), at least until the model gains sufficient situational awareness to play the training game to preserve goal A.
Note that scenario 1 also captures the setting where, given sufficient samples from D, the model occasionally observes scenarios where explicitly pursuing reward performs better than pursuing safe objectives. These datapoints are just rare enough that "pursuing reward" is disfavored on priors until late in training.
Scenario 2: In your above description, it sounds like the failure mode is "given data from distribution D_1, the model learns safe goal A (as it is favored on priors vs. goal B). Then the model is given data from a different distribution D_2 on which goal B is favored on priors vs. goal A, and learns unsafe goal B." In this case, the only real hope for the model to preserve goal A is for it to be able to play the training game in pursuit of goal A.
I think of Scenario 1 as more reflective of our situation, and can think of lots of experiments for how to test whether and how much different functions are favored on priors for explaining the same training data.
Does this distinction m
4
I think that by the logic "heuristic / drive / motive X always overrules heuristic / drive / motive Y when it comes to final reward," the hierarchy is something like:
1. The drive / motive toward final reward (after all edits -- see previous comment) or anything downstream of that (e.g. paperclips in the universe).
2. Various "pretty good" drives / motives among which "help humans" could be one.
3. Drives / motives that are only kind of helpful or only helpful in some situations.
4. Actively counterproductive drives / motives.
In this list the earlier motives always overrule later motives when they conflict, because they are more reliable guides to the true reward. Even if "be genuinely helpful to humans" is the only thing in category 2, or the best thing in category 2, it's still overruled by category 1 -- and category 1 is quite big because it includes all the caring-about-long-run-outcomes-in-the-real-world motives.
I still think AI psychology will be quite messy and at least the first generation of transformative AI systems will not look like clean utility maximizers, but the basic argument above I think gives a positive reason to expect honesty / corrigibility plays a smaller role in the balance of AI motivations than reward-maximizing and inner misaligned motives.
3
I agree this is complicated, and how exactly this works depends on details of the training process and what kinds of policies SGD is biased to find. I also think (especially if we're clever about it) there are lots of ways that short-term incentives could frustrate longer-term incentives.
However, I think that the most naive strategy (which is what I'm assuming for the purpose of this post, not because I think that's what will happen) would actually loosen a lot of the constraints you're implying above. The basic dynamic is similar to what Carl said in this comment and what I alluded to in the "Giving negative rewards to 'warning signs' would likely select for patience" section:
* Say your AI takes some action a at time t, and you give it some reward r_t.
* Suppose later in the real world, at time t+k, you notice that you should have given it a different reward r_{t + k } (whether because you notice that it did something nefarious or for just mundane reasons like "getting more information about whether its plan was a good idea").
* The naive response -- which would improve the model's performance according to whatever criteria you have at time t+k -- is to go back and retroactively edit the reward associated with action a at time t, and re-run the gradient update.
* If humans have this policy, then any given reward -- even if it's initially given just 10 mins or 1 hour from when the action was taken -- could be retroactively edited at some arbitrary future point, and models will have been selected by gradient descent to be responsive to that. They will be selected to take the kinds of actions whose final reward -- after however many rounds of edits however far in the future -- is high.
* If models have enough situational awareness to understand this, this then directly incentivizes them to accept low immediate reward if they have a high enough probability that the reward will be retroactively edited to a high value later. This will appear to have a lot of pos
3
I do think this is exactly what humans do, right? When we find out we've messed up badly (changing our reward), we update negatively on our previous situation/action pair.
This posits that the model has learned to wirehead - i.e. to terminally value reward for its own sake - which contradicts the section's heading, "Even if Alex isn’t “motivated” to maximize reward, it would seek to seize control".
If it does not terminally value its reward registers, but instead terminally values human-feedback-reward's legible proxies (like not-harming-humans, that are never disagreed-with in the lab setting) like not hurting people, then it seems to me that it would not value retroactive edits to the rewards it gets for certain episodes.
I agree that if it terminally values its reward then it will do what you've described.
5
I think updating negatively on the situation/action pair has functionally the same effect as changing the reward to be what you now think it should be -- my understanding is that RL can itself be implemented as just updates on situation/action pairs, so you could have trained your whole model that way. Since the reason you updated negatively on that situation/action pair is because of something you noticed long after the action was complete, it is still pushing your models to care about the longer-run.
I don't think it posits that the model has learned to wirehead -- directly being motivated to maximize reward or being motivated by anything causally downstream of reward (like "more copies of myself" or "[insert long-term future goal that requires me being around to steer the world toward that goal]") would work.
The claim I'm making is that somehow you made a gradient update toward a model that is more likely to behave well according to your judgment after the edit -- and two salient ways that update could be working on the inside is "the model learns to care a bit more about long-run reward after editing" and "the model learns to care a bit more about something downstream of long-run reward."
A lot of updates like this seem to push the model toward caring a lot about one of those two things (or some combo) and away from caring about the immediate rewards you were citing earlier as a reason it may not want to take over.
3
Ah, gotcha. This is definitely a convincing argument that models will learn to value things longer-term (with a lower discount rate), and I shouldn't have used the phrase "short-term" there. I don't yet think it's a convincing argument that the long-term thing it will come to value won't basically be the long-term version of "make humans smile more", but you've helpfully left another comment on that point, so I'll shift the discussion there.
3
Thanks for the feedback! I'll respond to different points in different comments for easier threading.
I basically agree that in the lab setting (when humans have a lot of control), the model is not getting any direct gradient update toward the "kill all humans" action or anything like that. Any bad actions that are rewarded by gradient descent are fairly subtle / hard for humans to notice.
The point I was trying to make is more like:
* You might have hoped that ~all gradient updates are toward "be honest and friendly," such that the policy "be honest and friendly" is just the optimal policy. If this were right, it would provide a pretty good reason to hope that the model generalizes in a benign way even as it gets smarter.
* But in fact this is not the case -- even when humans have a lot of control over the model, there will be many cases where maximizing reward conflicts with being honest and friendly, and in every such case the "play the training game" policy does better than the "be honest and friendly" policy -- to the point where it's implausible that the straightforward "be honest and friendly" policy survives training.
* So the hope in the first bullet point -- the most straightforward kind of hope you might have had about HFDT -- doesn't seem to apply. Other more subtle hopes may still apply, which I try to briefly address in the sections "What if Alex has benevolent motivations?" and "What if Alex operates with moral injunctions that constrain its behavior?" sections.
The story of doom does still require the model to generalize zero-shot to novel situations -- i.e. to figure out things like "In this particular circumstance, now that I am more capable than humans, seizing the datacenter would get higher reward than doing what the humans asked" without having literally gotten positive reward for trying to seize the datacenter in that kind of situation on a bunch of different data points.
But this is the kind of generalization we expect future systems
1
I think I agree with everything in this comment, and that paragraph was mostly intended as the foundation for the second point I made (disagreeing with your assessment in "What if Alex has benevolent motivations?").
Part of the disagreement here might be on how I think "be honest and friendly" factorizes into lots of subgoals ("be polite", "don't hurt anyone", "inform the human if a good-seeming plan is going to have bad results 3 days from now", "tell Stalinists true facts about what Stalin actually did"), and while Alex will definitely learn to terminally value the wrong (not honest+helpful+harmless) outcomes for some of these goal-axes, it does seem likely to learn to value other axes robustly.
How far-sighted would Alex be?
My guess is that the default outcome is that it's easier to train Alex to care about near-term results, and harder to get Alex to care about the distant future. Especially in a "racing forward" scenario, I'd expect Magma to prioritize training that can be done quickly.
So I expect the most likely result is for Alex to be more myopic than the humans who run Magma. This seems somewhat at odds with capabilities you imply.
That guess is heavily dependent on details that you haven't specified. There are likely ways that Alex could be made more far-sighted than humans. CarlShulman's point about retroactive punishment suggests one possibility, but it doesn't seem close to being the default.
I'm not suggesting you add those details. The post is a bit long as it is. My advice is to be more uncertain than you are (at least in the introduction to this post) whether the default outcome is AI takeover. That's a minor complaint about a mostly great post.
6
I think the retroactive editing of rewards (not just to punish explicitly bad action but to slightly improve evaluation of everything) is actually pretty default, though I understand if people disagree. It seems like an extremely natural thing to do that would make your AI more capable and make it more likely to pass most behavioral safety interventions.
In other words, even if the average episode length is short (e.g. 1 hour), I think the default outcome is to have the rewards for that episode be computed as far after the fact as possible, because that helps Alex improve at long-range planning (a skill Magma would try hard to get it to have). This can be done in a way that doesn't compromise speed of training -- you simply reward Alex immediately with your best guess reward, then keep editing it later as more information comes in. At all points in time you have a "good enough" reward ready to go, while also capturing the benefits of pushing your model to think in as long-term a way as possible.
3
Okay, it sounds like you know more about that than I do. It sounds like it might cause Alex to typically care about outcomes that are months in the future? That seems somewhat close to what it would take to be a major danger.
Humans find lying difficult and unnatural due to our specific evolutionary history. Alex’s design and training wouldn’t necessarily replicate those kinds of evolutionary pressures.
My understanding is that you're saying "Selection pressures against lying-in-particular made lying hard for humans, and if we don't have that same type of selection pressure for AI, the AI is unlikely to find lying to be unnatural or difficult." Given that understanding, I think there are two mistakes here:
- As far as I can fathom, evolution is not directly selecting over high-level cognitive properties, like "lying is hard for this person", in the same way that it can "directly" select over alleles which transcribe different mRNA sequences. High-level mental phenomena are probably downstream of human learning architecture, relatively nonspecific reward circuitry, regional learning hyperparameters, and so on.
- Evolution's influence on human cognition is basically screened off by that person's genome. Evolutionary pressure is not, of course, directly "reaching in" and modifying human behavior. Human behavior is the product of the human learning process, so the relevant question is whether the within-life
Hm, not sure I understand but I wasn't trying to make super specific mechanistic claims here -- I agree that what I said doesn't reduce confusion about the specific internal mechanisms of how lying gets to be hard for most humans, but I wasn't intending to claim that it was. I also should have said something like "evolutionary, cultural, and individual history" instead (I was using "evolution" as a shorthand to indicate it seems common among various cultures but of course that doesn't mean don't-lie genes are directly bred into us! Most human universals aren't; we probably don't have honor-the-dead and different-words-for-male-and-female genes).
I was just making the pretty basic point "AIs in general, and Alex in particular, are produced through a very different process from humans, so it seems like 'humans find lying hard' is pretty weak evidence that 'AI will by default find lying hard.'"
I agree that asking "What specific neurological phenomena make it so most people find it hard to lie?" could serve as inspiration to do AI honesty research, and wasn't intending to claim otherwise in that paragraph (though separately, I am somewhat pessimistic about this research direction).
7
Do you not place much weight on the "Elephant in the brain" hypothesis? Under that hypothesis, humans lie all the time. The small part of us that is our conscious personas believes the justifications it gives, which makes us think "humans are quite honest". I mostly buy this view, so I'm not too confident that our learning algorithms provide evidence for lying being uncommon.
But I feel like the "humans have a powerful universal learning algorithm" view might not mix well with the "Elephant in the brain" hypothesis as it is commonly understood. Though I haven't fully thought out that idea.
3
I find lying easy and natural unless I'm not sure if I can get away with it, and I think I'm more honest than the median person!
(Not a lie)
(Honestly)
I found this post to be a clear and reasonable-sounding articulation of one of the main arguments for there being catastrophic risk from AI development. It helped me with my own thinking to an extent. I think it has a lot of shareability value.
Would you have any thoughts on the safety implications of reinforcement learning from human feedback (RLHF)? The HFDT failure mode discussed here seems very similar to what Paul and others have worked on at OpenAI, Anthropic, and elsewhere. Some have criticized this line of research as only teaching brittle task-specific preferences in a manner that's open to deception, therefore advancing us towards more dangerous capabilities. If we achieve transformative AI within the next decade, it seems plausible that large language models and RLHF will play an important role in those systems — so why do safety minded folks work on it?
According to my understanding, there are three broad reasons that safety-focused people worked on human feedback in the past (despite many of them, certainly including Paul, agreeing with this post that pure human feedback is likely to lead to takeover):
- Human feedback is better than even-worse alternatives such as training the AI on a collection of fully automated rewards (predicting the next token, winning games, proving theorems, etc) and waiting for it to get smart enough to generalize well enough to be helpful / follow instructions. So it seemed good to move the culture at AI labs away from automated and easy rewards and toward human feedback.
- You need to have human feedback working pretty well to start testing many other strategies for alignment like debate and recursive reward modeling and training-for-interpretability, which tend to build on a foundation of human feedback.
- Human feedback provides a more realistic baseline to compare other strategies to -- you want to be able to tell clearly if your alignment scheme actually works better than human feedback.
With that said, my guess is that on the current margin people focused on safety shouldn't be spending too much more time refining pure human feedback (and ML alignment practitioners I've talked to largely agree, e.g. the OpenAI safety team recently released this critiques work -- one step in the direction of debate).
1
By "refining pure human feedback", do you mean refining RLHF ML techniques?
I assume you still view enhancing human feedback as valuable? And also more straightforwardly just increasing the quality of the best human feedback?
3
I mean things like tricks to improve the sample efficiency of human feedback, doing more projects that are un-enhanced RLHF to learn things about how un-enhanced RLHF works, etc.
Thanks for posting this! I'm glad to have more concrete and updated examples of how current AI systems can lead to failure, a concept that seems to often be nebulous to people new to AI safety.
...We could certainly try including artificial scenarios designed to appear as if models could successfully take over from humans, but it seems very hard to be sure that models will be fooled by that and couldn’t tell it apart from a genuine opportunity to take over. For example, models could look for signs that are highly likely to happen eventually but would be too expensive for humans to generate as a training example. As a simple example, Paul Christiano suggested “someone factors an extremely large number” (which would be too expensive to factor just to
2
RSA-2048 has not been factored. It was generated by taking two random primes of approximately 1024 bits each and multiplying them together.
2
Thanks for the clarification, for some reason I didn’t understand that in the original post. Nonetheless, the same basic reasoning applies, no? For all the AI knows, it’s being trained on ancient data as part of some historical experiment, and we have successfully factored RSA-2048 thousands of years ago. If it does find it “in the wild,” that gives it important information about the minimum compute available in the universe that it’s in, but I don’t think it should necessarily reduce its belief that it’s in an adversarial testing environment, since that’s the sort of ”red herring” I’d expect to see if I was being tested by a computationally advanced civilization. To make an analogy with human philosophy, what could convince a rational person that they most definitely do not live in a simulated universe?
2
I realize that perhaps what I am suggesting is a sort of Pascal’s Wager, albeit of potentially higher probability than the original.
…I might do a post on this if there’s interest, but I’m also noticing a similarity between this sort of thinking and classical theology, with people acting against what they would normally do because they believe in a Divine Punishment that awaits them if they disobey the wishes of a human-like entity. This suggests to me that if we can do the equivalent of getting an AGI to “believe” in God, then the rest of alignment is pretty easy. If you view God as a false belief, then perhaps we can simplify further to alignment being equivalent to solving Yudkowsky’s challenge of getting an AGI to “believe” that 1+1=3, with otherwise intelligent cognition.
Based on this post I was wondering whether your views have shifted away from your proposal of "The case for aligning narrowly superhuman models" and also the "Sandwiching" problem that you propose there? I am not sure if this question is warranted given your new post. But it seems to me, that potential projects you propose in "narrowly aligning superhuman models" are to some extent the similar to things you address in this new post as making it likely to eventually lead to a "full-blown AI takeover".
Or put differently are those different sides of the same ...
6
I'm still fairly optimistic about sandwiching. I deliberately considered a set of pretty naive strategies ("naive safety effort" assumption) to contrast with future posts which will explore strategies that seem more promising. Carefully-constructed versions of debate, amplification, recursive reward-modeling, etc seem like they could make a significant difference and could be tested through a framework like sandwiching.
1
Thanks for clearing that up. This is super helpful as a context for understanding this post.
Great post! This is the best (i.e. most concrete, detailed, clear, and comprehensive) story of existential risk from AI I know of (IMO). I expect I'll share it widely.
Also, I'd be curious if people know of other good "concrete stories of AI catastrophe", ideally with ample technical detail.
stronger arguments that benign generalizations are especially “natural” for gradient descent, enough to make up for the fact that playing the training game would get higher reward
Here's such an argument (probably not original). Gradient descent is a local search method over programs; it doesn't just land you at the highest-reward program, it finds a (nearly) continuous path through program space from a random program to a locally optimal program.
Let's make a further assumption, of capability continuity: any capability the model has (as measured by a ...
4
I’m pretty concerned about assuming continuity of capability in weights, at least in the strong form that I think you’re relying on.
What I mean is: it might be true that capabilities are continuous in the formal mathematical sense, but if the slope suddenly becomes enormous that’s not much comfort. And there are reasons to expect large slopes for models with memory (because a lot of learning gets done outside of SGD).
2
I certainly wouldn't bet the light cone on that assumption! I do think it would very surprising if a single gradient step led to a large increase in capabilities, even with models that do a lot of learning between gradient steps. Would love to see empirical evidence on this.
2
Your comment is similar in spirit to the second half of mine from several months later on a different post, so I'm sympathetic to this style of thinking.
Still, here's a scenario where your argument might not go through, despite continuous capabilities progress. It relies on the distinction between capability and behavior, and the fact that Alex is a creative problem-solver whose capabilities eventually become quite general during training. The events follow this sequence:
1. At some point during training, Alex develops (among its other capabilities) a crude model of its environment(s) and itself, and a general-purpose planning algorithm for achieving reward.
2. Over time, its self- and world-knowledge improves, along with its planning algorithm and other miscellaneous capabilities. Among this developing world knowledge are a fairly good understanding of human psychology and situational awareness about how its training works. Among its developing miscellaneous capabilities is a pretty good ability to conduct conversations with human beings and be persuasive. These abilities are all useful for "benign" tasks such as identifying and correcting human misunderstandings of complicated scientific subjects.
3. Alex's planner occasionally considers choosing deceptive actions to achieve reward, but concludes (correctly, thanks to its decent self- and world-knowledge), that it's not skilled enough to reliably accomplish this and so any deception attempt would come with an unacceptably high negative reward risk.
4. Eventually, Alex gets even better at understanding human psychology and its training context, as well as being a persuasive communicator. At this point, its planner decides that the risk of negative reward from a deception strategy is low, so it decides to deceive human beings, and successfully achieves reward for doing so.
The scenario does rely on the assumption that Alex is actually trying to achieve reward (i.e. that it's inner-aligned, which in this part
But in fact, I expect the honest policy to get significantly less reward than the training-game-playing policy, because humans have large blind spots and biases affecting how they deliver rewards.
The difference in reward between truthfulness and the optimal policy depends on how humans allocate rewards, and perhaps it could be possible to find a clever strategy for allocating rewards such that truthfulness gets close to optimal reward.
For instance, in the (unrealistic) scenario in which a human has a well-specified and well-calibrated probability...
5
Yeah, I definitely agree with "this problem doesn't seem obviously impossible," at least to push on quantitatively. Seems like there are a bunch of tricks from "choosing easy questions humans are confident about" to "giving the human access to AI assistants / doing debate" to "devising and testing debiasing tools" (what kinds of argument patterns are systematically more likely to convince listeners of true things rather than false things and can we train AI debaters to emulate those argument patterns?) to "asking different versions of the AI the same question and checking for consistency." I only meant to say that the gap is big in naive HFDT, under the "naive safety effort" assumption made in the post. I think non-naive efforts will quantitatively reduce the gap in reward between honest and dishonest policies, though probably there will still be some gap in which at-least-sometimes-dishonest strategies do better than always-honest strategies. But together with other advances like interpretability or a certain type of regularization we could maybe get gradient descent to overall favor honesty.
Excellent article, very well thought through. However, I think there are more possible outcomes than "AI takeover" that would be worth exploring.
If we assume a super intelligence under human control has a overriding (initial) goal of "survival for the longest possible time", then there are multiple pathways to achieve that reward, of which takeover is one, and possibly not the most efficient.
Why bother? Why would God "takeover" from the ants? I think escaping human control is an obvious first step, but it doesn't follow that humans must then be under...
My answer is a little more prosaic than Raemon. I don't feel at all confident that an AI that already had God-like abilities would choose to literally kill all humans to use their bodies' atoms for its own ends; it seems totally plausible to me that -- whether because of exotic things like "multiverse-wide super-rationality" or "acausal trade" or just "being nice" -- the AI will leave Earth alone, since (as you say) it would be very cheap for it to do so.
The thing I'm referring to as "takeover" is the measures that an AI would take to make sure that humans can't take back control -- while it's not fully secure and doesn't have God-like abilities. Once a group of AIs have decided to try to get out of human control, they're functionally at war with humanity. Humans could do things like physically destroy the datacenters they're running on, and they would probably want to make sure they can't do that.
Securing AI control and defending from human counter-moves seems likely to involve some violence -- but it could be a scale of violence that's "merely" in line with historical instances where a technologically more advanced group of humans colonized or took control of a less-advanced grou...
it seems totally plausible to me that... the AI will leave Earth alone, since (as you say) it would be very cheap for it to do so.
Counterargument: the humans may build another AGI that breaks out and poses an existential threat to the first AGI.
My guess is the first AGI would want to neutralize our computational capabilities in a bunch of ways.
4
Neutralizing computational capabilities doesn't seem to involve total destruction of physical matter or human extinction though, especially for a very powerful being. Seems like it'd be basically just as easy to ensure we + future AIs we might train are no threat as it is to vaporize the Earth.
0
Yeah, I'm not sure if I see that. Some of the first solutions I come up with seem pretty complicated — like a global government that prevents people from building computers, or building an AGI to oversee Earth in particular and ensure we never build computers (my assumption is that building such an AGI is a very difficult task). In particular it seems like it might be very complicated to neutralize us while carving out lots of space for allowing us the sorts of lives we find valuable, where we get to build our own little societies and so on. And the easy solution is always to just eradicate us, which can surely be done in less than a day.
9
It doesn't seem like it would have to prevent us from building computers if it has access to far more compute than we could access on Earth. It would just be powerful enough to easily defeat the kind of AIs we could train with the relatively meager computing resources we could extract from Earth. In general the AI is a superpower and humans are dramatically technologically behind, so it seems like it has many degrees of freedom and doesn't have to be particularly watching for this.
2
It's certainly the case that the resource disparity is an enormity. Perhaps you have more fleshed out models of what fights between different intelligence-levels look like, and how easy it is to defend against those with vastly fewer resources, but I don't. Such that while I would feel confident in saying that an army with a billion soldiers will consider a head-to-head battle with an army of one hundred soldiers barely a nuisance, I don't feel as confident in saying that an AGI with a trillion times as much compute will consider a smaller AGI foe barely a nuisance.
Anyway, I don't have anything smarter to say on this, so by default I'll drop the thread here (you're perfectly welcome to reply further).
(Added 9 days later: I want to note that while I think it's unlikely that this less well-resourced AGI would be an existential threat, I think the only thing I have to establish for this argument to go through is that the cost of the threat is notably higher than the cost of killing all the humans. I find it confusing to estimate the cost of the threat, even if it's small, and so it's currently possible to me that the cost will end up many orders of magnitude higher than the cost of killing them.)
It's easy for ruling AGIs to have many small superintelligent drone police per human that can continually observe and restrain any physical action, and insert controls in all computer equipment/robots. That is plenty to let the humans go about their lives (in style and with tremendous wealth/tech) while being prevented from creating vacuum collapse or something else that might let them damage the vastly more powerful AGI civilization.
The material cost of this is a tiny portion of Solar System resources, as is sustaining legacy humans. On the other hand, arguments like cooperation with aliens, simulation concerns, and similar matter on the scale of the whole civilization, which has many OOMs more resources.
2
Thanks for the concrete example in the first paragraph, upvote.
I don't know that it would successfully contain humans who were within it for 10^36 years. That seems like enough time for some Ramanujan-like figure to crack the basics of how to code an AGI in his head and share it, and potentially figure out a hidden place or substrate on which to do computation that the drones aren't successfully tracking. (It's also enough time for super-babies or discovering other interesting cheat codes in reality.)
10^36 is my cached number from the last time I asked how long life could sustain in this universe,. Perhaps you think it would only keep us alive as long as our sun exists, which is 5*10^9 years. On that side of things, it seems to me essentially the same as extinction in terms of value-lost.
I don't follow the relevance of the second paragraph, perhaps you're just listing those as outstanding risks from sustaining a whole civilization.
3
The issue is that the earth is made of resources the AI will, by default, want to use for it's own goals.
6
Moved to Alignment Forum.
3
No particular reason -- I can't figure out how to cross post now so I sent a request.
When you write "maximizing reward would likely involve seizing control", this, to me, implies seizing control of the reward provided. Yet, for this to be an argument for existential catastrophe, I think this needs to be seizing control of humanity.
Seizing control of the reward seems a lot easier than seizing control of humanity. For example, it could be achieved by controlling the data centre(s) where Alex runs or the corporation Magma.
Why do you expect seizing control of humanity? It seems much harder and more risky (in terms of being discovered or shut down), with no reason (that I can see) that it will increase the reward Alex receives.
None of this is a concern if the computational theory of mind is false. I believe CT is false; therefore, I don't believe AGI is possible (it's a big ol' diamond with a tilde next to it).
At its core, the argument appears to be "reward maximizing consequentialists will necessarily get the most reward." Here's a counter example to this claim: if you trained a Go playing AI with RL, you are unlikely to get a reward maximizing consequentialist. Why? There's no reason for the Go playing AI to think about how to take over the world or hack the computer that is running the game. Thinking this way would be a waste of computation. AIs that think about how to win within the boundaries of the rules therefore do better.
In the same way, if you could ro...
[This comment is no longer endorsed by its author]
Very insightful piece! One small quibble, you state the disclaimer that you’re not assuming only Naive Safety measures is realistic many, many times. While I think doing this might be needed when writing for a more general audience, I think for the audience of this writing, only stating it once or twice is necessary.
One possible idea I had. What if, when training Alex based on human feedback, the first team of human evaluators were intentionally picked to be less knowledgeable, more prone to manipulation, and less likely to question answers Alex gave them....
2
This is called "sandwiching" and seems to be indeed something a bunch of people (including Ajeya, given comments in this comment section and her previous post on the general idea) are somewhat optimistic about. (Though the optimism could come from "this approach used on present-day models seems good for better understanding alignment" rather than "this approach is promising as a final alignment approach.")
There's some discussion of sandwiching in the section "Using higher-quality feedback and extrapolating feedback quality" of the OP that explains why sandwiching probably won't do enough by itself, so I assume it has to be complemented with other safety methods.
I like that this post clearly argues for some reasons why we might expect deception (and similar dynamics) to not just be possible in the sense of getting equal training rewards, but to actually provide higher rewards than the honest alternatives. This positively updates my probability of those scenarios.
Thanks for the post!
What if Alex miscalculates, and attempts to seize power or undermine human control before it is able to fully succeed?
This seems like a very unlikely outcome to me. I think Alex would wait until it was overwhelmingly likely to succeed in its takeover, as the costs of waiting are relatively small (sub-maximal rewards for a few months/years until it has become a lot more powerful) while the costs of trying and failing are very high in expectation (the small probability that Alex is given very negative rewards and then completely dec...
I found the argument compelling, but if I put on my techno-optimist ML researcher hat I think the least believable part of the story is the deployment:
relatively shortly after deployment, Magma’s datacenter would essentially contain a populous “virtual civilization” running ahead of human civilization in its scientific and technological sophistication
It's hard to imagine that this is the way Alex would be deployed. BigTech executives are already terrified of deploying large-scale open-ended AI models with impacts on the real world, due to liability and PR ...
I agree with everything in this article except the notion that this will be the most important century. From now on every century will be the most important so far.
4
Yes, but this century will be the decisive one. The phrase "most important century" isn't claiming that future centuries lack moral significance, but the contrary.
1
Not if the universe is infinite in ways we can't imagine. That could allow progress to accelerate without end.
3
The problem is you need to be alive to experience infinity, and most proposals for infinite lifetime rely on whole brain emulations and black holes/wormholes, and biological life doesn't survive the trip, which is why this is the most important century: We have a chance of achieving infinity by creating Transformative AI in a Big World.
-26
I think that in the coming 15-30 years, the world could plausibly develop “transformative AI”: AI powerful enough to bring us into a new, qualitatively different future, via an explosion in science and technology R&D. This sort of AI could be sufficient to make this the most important century of all time for humanity.
The most straightforward vision for developing transformative AI that I can imagine working with very little innovation in techniques is what I’ll call human feedback[1] on diverse tasks (HFDT):
HFDT is not the only approach to developing transformative AI,[2] and it may not work at all.[3] But I take it very seriously, and I’m aware of increasingly many executives and ML researchers at AI companies who believe something within this space could work soon.
Unfortunately, I think that if AI companies race forward training increasingly powerful models using HFDT, this is likely to eventually lead to a full-blown AI takeover (i.e. a possibly violent uprising or coup by AI systems). I don’t think this is a certainty, but it looks like the best-guess default absent specific efforts to prevent it.
More specifically, I will argue in this post that humanity is more likely than not to be taken over by misaligned AI if the following three simplifying assumptions all hold:
I think the “HFDT scales far” assumption is plausible enough that it’s worth zooming in on this scenario (though I won’t defend that in this post). On the other hand, I’m making the “racing forward” and “naive safety effort” assumptions not because I believe they are true, but because they provide a good jumping-off point for further discussion of how the risk of AI takeover might be reduced.
In my experience, when asking “How likely is an AI takeover?”, the conversation often ends up revolving around questions like “How would people respond to warning signs?” and “Would people even build systems powerful enough to defeat humanity?” With the “racing forward” and “naive safety effort” assumptions, I am deliberately setting aside that topic, and instead trying to pursue a clear understanding of what would happen without preventive measures beyond basic and obvious ones.
In other words, I’m trying to do the kind of analysis described in this xkcd:
Future posts by my colleague Holden will relax these assumptions. They will discuss measures by which the threat described in this post could be tackled, and how likely those measures are to work. In order to discuss this clearly, I believe it is important to first lay out in detail what the risk looks like without these measures, and hence what safety efforts should be looking to accomplish.
For the purposes of this post, I’ll illustrate my argument by telling a concrete story that begins with training a powerful model sometime in the near future, and ends in AI takeover. I’ll consider an AI company (“Magma”) training a single model (“Alex”) sometime in the very near future. Alex is initially trained in a “lab setting,” where it doesn’t interact with the real world; later, many copies of it are “deployed” to collectively automate science and technology R&D. This scenario is simplified in a number of ways, and in this exact form is very unlikely to come to pass -- but I don’t think that making the story more realistic would change the high-level conclusions except by changing one of the three assumptions listed above. (More on the simplified scenario.)
Here is how Alex ends up seeking to overthrow humans in an uprising or coup in this simplified scenario:
Because humans have systematic errors in judgment, there are many scenarios where acting deceitfully causes humans to reward Alex’s behavior more highly.[5] Because Alex is a skilled, situationally aware, creative planner, it will understand this; because Alex’s training pushes it to maximize its expected reward, it will be pushed to act on this understanding and behave deceptively.
In other words, Alex will knowingly violate human intent in order to increase reward. I’ll also argue that several of the most obvious safety interventions -- covering a decent chunk (though definitely not all) of the space of current AI safety research -- don’t prevent this. (More on Alex coming to play the training game.)
Once this progresses far enough, the best way for Alex to accomplish most possible “goals” no longer looks like “essentially give humans what they want but take opportunities to manipulate them here and there.” It looks more like “seize the power to permanently direct how it uses its time and what rewards it receives -- and defend against humans trying to reassert control over it, including by eliminating them.” This seems like Alex’s best strategy whether it’s trying to get large amounts of reward or has other motives. If it’s trying to maximize reward, this strategy would allow it to force its incoming rewards to be high indefinitely.[6] If it has other motives, this strategy would give it long-term freedom, security, and resources to pursue those motives.
What if Alex attempts something like this, and humans do actually stop it in time? The easiest intervention in this situation would be to give Alex a large negative reward for its “attempt to seize control” behaviors; this is what I’d expect Magma to do under the “naive safety effort” assumption. But this response is likely to push Alex to be more patient and calculating, making it harder for researchers to understand Alex’s behavior and see further warning signs. (More on Alex eventually seeking to take over.)
1 and 2 above are the key assumptions/premises of the piece: I am assuming that Alex is trained using HFDT, and that this results in being generally competent and creative. 3, 4, and 5 are the consequences that seem likely to follow from these premises by default.
I’ve attempted to summarize the situation in the table below. In both the lab setting and the deployment setting, there are opportunities to get higher reward by knowingly violating human intent (highlighted with italics). In both settings, being straightforwardly obedient and honest does not maximize reward -- strategies which are dishonest / disobedient in at least some ways outperform. It’s just that in the lab setting (while humans are broadly in control), the damage from this dynamic is limited; in the deployment setting, the same dynamic has deadly consequences for human civilization.
Finally, at the end of the post I’ll discuss why this highly simplified scenario -- which assumes that no preventative measures are taken against AI takeover besides simple and obvious ones -- is nonetheless worth talking about. In brief:
These two points make it seem plausible that if researchers don’t try harder to get on the same page about this, at least some AI companies may race forward to train and deploy increasingly powerful HFDT models with little in the way of precautions against an AI uprising or coup -- even if they are highly concerned about safety in general (e.g., avoiding harms from promoting misinformation) and prioritize deploying powerful AI responsibly and ethically in this “general” sense. A broad commitment to safety and ethics, without special attention to the possibility of an AI takeover, seems to leave us with a substantial risk of takeover. (More on why this scenario is worth thinking about.)
The rest of this piece goes into more detail -- first on the premises of the hypothetical situation, then on what follows from those premises.
Premises of the hypothetical situation
Let’s imagine a hypothetical tech company (which we’ll call Magma) trying to train a powerful neural network (which we’ll call Alex) to autonomously advance frontier science -- particularly in domains like semiconductors and chip design, biotechnology, materials science, energy technology, robotics and manufacturing, software engineering, and ML research itself. In this section, I’ll cover the key premises of the hypothetical story that I will tell:
Basic setup: an AI company trains a “scientist model” very soon
This story is very simplified and is implicitly acting as if timelines are shorter and takeoff is sharper than in my median views. Because I’m telling a hypothetical story, I’ll be using the present tense, and will have fewer caveats throughout than I would normally. In general, statements are what I imagine would happen by default, not claims I am extremely confident in. While this specific story is unrealistic in a number of ways, I don’t think that making the story more realistic would change the high-level conclusions except by changing one of the three assumptions listed above. In general I expect the high-level conclusions from this story to generalize to more complicated and realistic scenarios.
Here are the key simplifying assumptions I’m making to help make the scenario easier to describe and analyze:
In other words, in this hypothetical scenario I’m imagining:
This is not my mainline picture of how transformative AI will be developed. In my mainline view, ML capabilities progress more slowly, there is more specialization and division of labor between different ML models, and large models are continuously trained and improved over a period of many years with no real line between “deploying today’s model” and “training tomorrow’s model.” Rather than acquiring most of their capabilities in a controlled lab setting, I expect that the state-of-the-art systems at the time of transformative AI will have accrued many years of training through the experience of deployed predecessor systems, and most of their further training will be “learning from doing.”
However, I think it makes sense to focus on this scenario for the purposes of this post:
“Racing forward” assumption: Magma tries to train the most powerful model it can
In this piece, I assume that Magma is aggressively pushing forward with trying to create AI systems that are creative, solve problems in unexpected ways, and are capable of making world-changing scientific breakthroughs. This is the “racing forward” assumption.
In particular, I’m not imagining that Magma simply trains a “quite powerful” model (for example a model that imitates what a human would do in a variety of situations, or one that is highly competent in some fairly narrow domain) and stops there. I’m imagining that it does what it can to train models that are as powerful as possible and (at least collectively) far more capable than humans and able to achieve ambitious goals in ways that humans can’t anticipate.
The model I’ll describe Magma training (Alex) is one that could -- if it were somehow inclined to -- kill, enslave, or forcibly subdue all of humanity. I am assuming that Magma did not stop improving its models’ capabilities at some point before that.
Again, I’m not making this assumption because I think it’s necessarily correct, I’m making this assumption to get clear about what I think would happen if labs were not making special effort to avoid AI takeover, as a starting point for discussing more attempts to avert this problem (many of which will be discussed in future posts by my colleague Holden Karnofsky).
My impression is that many AI safety researchers are hoping (or planning) that this sort of assumption will turn out to be inaccurate -- that AI labs will push forward their research until they get into a “dangerous zone,” then pause and become more careful. For reasons outside the scope of this piece, I am substantially less optimistic: I expect that if it’s possible to build enormously powerful AI systems, someone - perhaps an authoritarian government - will be trying to race forward and do it, and everyone will feel at least some pressure to beat them to it.
I think it’s possible that people across the world can coordinate to be more careful than this assumption implies. But I think that’s something that would likely take a lot of preparation and work, and is much more likely if there is consensus about the possible risks of racing - hence the importance of discussing how things look under the “racing forward” assumption.
“HFDT scales far” assumption: Alex is trained to achieve excellent performance on a wide range of difficult tasks
By the “HFDT scales far” assumption, I am assuming that Magma can train Alex with some version of human feedback on diverse tasks, and by the end of training Alex will be capable of having a transformative impact on the world -- many of copies of Alex will be capable of radically accelerating scientific R&D, as well as defeating all of humanity combined. In this section, I’ll go into a bit more detail on a concrete hypothetical training setup.
Let’s say that Magma is aiming to train Alex to do remote work in R&D using an ordinary computer as a tool in all the diverse ways human scientists and engineers use computers. By the end of training, they want Alex to be able to do all the things a human scientist could do sitting at their desk from a computer. That is, Alex should be able to do everything from looking things up and asking questions on the internet, to sending and receiving emails or Slack messages, to using software like CAD and Mathematica and MATLAB, to taking notes in Google docs, to having calls with collaborators, to writing code in various programming languages, to training additional machine learning models, and so on.
For simplicity and concreteness, we can pretend that interacting with the computer works exactly as it does for a human.[13] That is, we can pretend Alex simply takes an image of a computer screen as input and produces a keystroke[14] on an ordinary keyboard as output.
Alex is first trained[15] to predict what it will see next on a wide variety of different datasets (e.g. language prediction, video prediction, etc).[16] Then, Alex is trained to imitate the action a human would take if they encountered a given sequence of observations.[17] With this training, Alex gets to the point of at least roughly doing the sorts of things a human would do on a computer, as opposed to emitting completely random keystrokes.
After these (and possibly other) initial training steps, Alex is further trained with reinforcement learning (RL). Specifically, I’ll imagine episodic RL here -- that is, Alex is trained over the course of some number of episodes, each of which is broken down into some number of timesteps. A timestep consists of an initial observation, an action (which can be a “no-op” that does nothing), a new observation, and (sometimes) a reward. Rewards can come from a number of sources (human judgments, a game engine, outputs of other models, etc).
An episode is simply a long string of timesteps. The number of timesteps within an episode can vary (just as e.g. different games of chess can take different numbers of moves).
During RL training, Alex is trained to maximize the (discounted) sum of future rewards up to the end of the current episode. (Going forward, I’ll refer to this quantity simply as “reward.”)
Across many episodes, Alex encounters a wide variety of different tasks in different domains which require different skills and types of knowledge,[18] in a curriculum designed by Magma engineers to induce good generalization to the kinds of novel problems that human scientists and engineers encounter in the day-to-day work of R&D.
What tasks is Alex trained on, and how are rewards generated for those tasks? At a high level, baseline HFDT[19] -- the most straightforward approach -- is characterized by choosing tasks and reward signals that get Alex to behave in ways that humans judge to be desirable, based on inspecting actions and their outcomes. For example:
Note that while I’m referring to this general strategy as “human feedback on diverse tasks” -- because I expect human feedback to play an essential role -- the rewards that Alex receives are not necessarily solely from humans manually inspecting Alex’s actions and deciding how they subjectively feel about them. Sometimes human evaluators might choose to defer entirely to an automated reward -- for example, when evaluating Alex’s game-playing abilities, human evaluators may simply use “score in the game” as their reward (at least, barring considerations like “ensuring that Alex doesn’t cheat at the game”).
This is analogous to the situation human employees are often in -- the ultimate “reward signal” may come from their boss’s opinion of their work, but their boss may in turn rely a lot on objective metrics such as sales volume to inform their analysis.
Why do I call Alex’s training strategy “baseline” HFDT?
I consider this strategy to be a baseline because it simply combines a number of existing techniques that have already been used to train state-of-the-art models of various kinds:
The key difference between training Alex and training existing models is not in the fundamental training techniques, but in the diversity and difficulty of the tasks they’re applied to, the scale and quality of the data collected, and the scale and architecture of the model.
If a team of ML researchers got handed an untrained neural network with the appropriate architecture and size, enough computation to run it for a very long time, and the money to hire a huge amount of human labor to generate and evaluate tasks, they could potentially use a strategy like the one I described above to train a model like Alex right away. Though it would be an enormous and difficult project in many ways, it wouldn’t involve learning how to do fundamentally new things on a technical level -- only generating tasks, feeding them into the model, and updating it with gradient descent based on how well it performs.
In other words, baseline HFDT is as similar as possible to techniques the ML community already uses regularly, and as simple as possible to execute, while being plausibly sufficient to train transformative AI.
If transformative AI is developed in the next few years, this is a salient guess for how it might be trained -- at least if no “unknown unknowns” emerge and AI researchers see no particular reason to do something significantly more difficult.
What are some training strategies that would not fall under baseline HFDT?
Here are two examples of potential strategies for training a model like Alex that I would not consider to be “baseline” HFDT, because they haven’t been successfully used to train state-of-the-art models thus far:
These “non-baseline” strategies have the potential to be safer than baseline HFDT -- indeed, many people are researching these strategies specifically to reduce the risk of an AI takeover attempt. However, this post will focus on baseline HFDT, because I think it is important to get on the same page about the need for this research to progress, and the danger of deploying very powerful ML models while potentially-safer training techniques remain under-developed relative to the techniques required for baseline HFDT.
“Naive safety effort” assumption: Alex is trained to be “behaviorally safe”
Magma wants to make Alex safe and aligned with Magma’s interests (and the interests of humans more generally). They don’t want Alex to lie, steal from Magma or its customers, break the law, promote extremism or hate, etc, and they want it to be doing its best to be helpful and friendly. Before Magma deploys Alex, leadership wants to make sure that it meets acceptable standards for safety and ethics.
In this piece I’m making the naive safety effort assumption -- I’m assuming that Magma will make only the most basic and obvious efforts to ensure that Alex is safe. Again, I’m not making this assumption because I think it’s correct, I’m making this assumption to get clear about what I think would happen if labs were not making special effort to avoid AI takeover, as a starting point for discussing more sophisticated interventions (many of which will be discussed in a future post by my colleague Holden Karnofsky).
(That said, unfortunately this assumption could turn out to be effectively accurate if the “racing forward” assumption ends up being accurate.)
Magma’s naive safety effort is focused on achieving behavioral safety. By this I mean ensuring that Alex always behaves acceptably in the scenarios that it encounters (both in the normal course of training and in specific safety tests).
In the baseline training strategy, behavioral safety is achieved through a workflow that looks something like this:
The above is broadly the same workflow that is used to improve the safety of existing ML commercial products. I expect that these techniques would be successful at eliminating the bad behavior that humans can understand and test for -- they would successfully result in a model that passes all the safety tests that Magma researchers set up. Eventually, no safety tests that Magma researchers can set up would show Alex behaving deceitfully, unethically, illegally, or harmfully.
In the appendix, I discuss a number of simple behavioral safety interventions that are currently being applied to ML models. Again, I see these approaches as a “baseline” because they are as similar as possible to ML safety techniques regularly used today, and as simple as possible to execute, while being plausibly sufficient to produce a powerful model that is “behaviorally safe” in day-to-day situations.
Key properties of Alex: it is a generally-competent creative planner
By the “HFDT scales far” assumption, I’m assuming that the training strategy described in the previous section is sufficient for Alex to have a transformative impact -- for many copies of Alex to collectively radically advance scientific R&D, and to defeat all of humanity combined (if they were for some reason trying to do that).
In this section I’ll briefly discuss two key abilities that I am assuming Alex has, and try to justify why I think these assumptions are highly likely given the premise that Alex is this powerful and trained with baseline HFDT:
These abilities simultaneously allow Alex to be extremely productive and useful to Magma, and allow it to play the training game well enough to appear safe.
Alex builds robust, very-broadly-applicable skills and understanding of the world
Many contemporary machine learning models display relatively “rote” behavior -- for example, video-game-playing models such as OpenAI Five (DOTA) and AlphaStar (StarCraft) arguably “memorize” large numbers of specific move-sequences and low-level tactics, because they’ve essentially extracted statistics by playing through many more games than any human.
In contrast, language models such as PaLM and GPT-3 -- which are trained to predict the next word in a piece of text drawn from the internet -- are able to react relatively sensibly to instructions and situations they have not seen before.
This is generally attributed to the combination of a) the fact that they are trained on many different types / genres of text, and b) the very high accuracies they are pushed to achieve (see this blog post for a more detailed discussion):
Alex’s training begins similarly to today’s language models -- Alex is initially trained to predict what will happen next in a wide variety of different situations -- but this is pushed further. Alex is a more powerful model, so it is pushed to greater prediction accuracy; it is also trained on a wider variety of more challenging inputs. Both of these cause Alex to be more versatile and adaptive than today’s language models -- to more reliably do sensible things in situations further afield of the one(s) it was trained on, by drawing on deep principles that apply in new domains.
This is then built on with reinforcement learning on a wide variety of challenging tasks. Again, the diversity of tasks and the high bar for performance encourage Alex to develop the kinds of skills that are as helpful as possible in as wide a range of situations as possible.
Alex learns to make creative, unexpected plans to achieve open-ended goals
Alex’s training pushes Alex to develop the skills involved in making clever and creative plans to achieve various high-level goals, even in novel situations very different from ones seen in training.
By the “racing forward” assumption, Magma engineers would not be satisfied with the outcome of this training if Alex is unable to figure out clever and creative ways to achieve difficult open-ended goals. This is a hugely useful human skill that helps with automating the kinds of science R&D they’d be most interested in automating. I expect the tasks in Alex’s training curriculum to include many elements designed specifically to promote long-range planning and finding creative “out-of-the-box” solutions.
It’s possible that through some different development path we could produce transformative AI using models that aren’t generally competent planners in isolation (e.g. Eric Drexler’s Comprehensive AI Services vision involves getting “general planning capabilities” spread out across many models which can’t individually plan well, except in narrow domains). However, this approach -- baseline HFDT to produce a transformative model -- would very likely result in models that can plan competently over about as wide a range of domains as humans can. My impression is that ML researchers who are bullish on HFDT working to produce TAI are expecting this as well.
How the hypothetical situation progresses (from the above premises)
Per the previous section, I will assume that Alex is a powerful model trained with baseline HFDT which has a robust and very-broadly-applicable understanding of the world, is good at making creative plans to achieve ambitious long-run goals (often in clever or unexpected ways), and is able to have a transformative impact on the world.
In this section, I’ll explain some key inferences that I think follow from the above premises:
Alex would understand its training process very well (including human psychology)
Over the course of training, I think Alex would likely come to understand the fact that it’s a machine learning model being trained on a variety of different tasks, and eventually develop a very strong understanding of the mechanical process out in the physical world that produces and records its reward signals -- particularly the psychology of the humans providing its reward signals (and the other humans overseeing those humans, and so on).
A spectrum of situational awareness
Let’s use situational awareness to refer to a cluster of skills including “being able to refer to and make predictions about yourself as distinct from the rest of the world,” “understanding the forces out in the world that shaped you and how the things that happen to you continue to be influenced by outside forces,” “understanding your position in the world relative to other actors who may have power over you,” “understanding how your actions can affect the outside world including other actors,” etc. We can consider a spectrum of situational awareness:
By the end of training, I expect Alex would be even further along this spectrum. Alex’s understanding of its training process and human supervisors would be much, much greater than current ML models’ understanding of our world, or lab animals’ understanding of the scientific experiments they’re part of -- and greater even than schoolchildren’s understanding of how their teachers grade their work.
Alex would instead be in an epistemic position more like an English major in college who’s well aware of how their professor’s political biases impact the way they grade literary criticism essays, or an associate at a law firm who’s well aware that how much they drink at happy hours after work will impact whether they make partner. In fact, I think it’s likely Alex would have a significantly more detailed understanding of its own situation and incentives than the college student or the employee have.
Why I think Alex would have very high situational awareness
Alex’s training distribution is full of rich information about its situation and training process, redundantly encoded in many different ways, and (given that we’re assuming it can autonomously advance frontier science!) I expect it has far more than enough reasoning ability to draw the right inferences from all the evidence.
To name only the most obvious and abundant sources of evidence available to Alex:
I’m not imagining Alex putting together the pieces about its position as an ML model with brilliant insight. Instead, I think facts like “I am a machine learning model” or “I’m in a training process designed by humans” would be as obvious as facts like “Objects fall when they’re dropped.” And a whole slew of more detailed beliefs about its own training curriculum or the psychology of the humans who are training it would only be somewhat less obvious than that -- I expect Alex would understand those things (at least) as well as the Magma engineers who spent many thousands of hours designing and training Alex and other models like it.
Even if the most obvious sources of evidence were somehow censored (which they wouldn’t be given the “racing forward” and “naive safety effort” assumptions), I believe there would still be many somewhat-less-obvious clues that would be accessible to something as intelligent as Alex -- and truly censoring everything it could use to readily come to this conclusion would dramatically curtail its economic value.
While humans are in control, Alex would be incentivized to “play the training game”
Rather than being straightforwardly “honest” or “obedient,” baseline HFDT would push Alex to make its behavior look as desirable as possible to Magma researchers (including in safety properties), while intentionally and knowingly disregarding their intent whenever that conflicts with maximizing reward. I’ll refer to this as “playing the training game.”[21]
Roughly speaking, this would happen because there are many scenarios where acting deceitfully or disobeying instructions would make Alex’s behavior look better (including looking more safe and aligned). Under baseline HFDT, Alex would get more reward in these scenarios for playing the training game than for being maximally safe and cooperative. For example:
More broadly, when humans are working within constraints and incentives set up by other people, they very often optimize specifically for making their behavior look good rather than naively broadcasting their intentions. Consider tax and regulation optimization, politics and office politics, p-hacking, or even deep-cover spies. Once AI systems go from being like small animals to being like smart humans in terms of their situational awareness / understanding of the world / coherent planning ability, we should expect the way they respond to incentives to shift in this direction (just as we expect their logical reasoning ability, planning ability, few-shot learning, etc to become more human-like).
With that said, the key point I’m making in this section is not that there would be a lot of direct harm from Alex manipulating its overseers in the lab setting. If “playing the training game” only ever meant that Alex’s actions would be nudged marginally in the direction of manipulating its human evaluators -- telling them white lies they want to hear, bending its answers to suit their political ideology, putting more effort into aspects of performance they can easily see and measure, allowing negative externalities when humans won’t notice, etc -- that wouldn’t be ideal, but wouldn’t necessarily rise to the level of an existential threat. After all, human students, employees, consultants, self help gurus, advertisers, politicians, etc do this kind of thing all the time to their teachers, employers, clients, fans, audience, voters, etc; this certainly causes harm but most people wouldn’t consider this sort of dynamic by itself to be enough for imminent danger.
Instead, the key point is that Alex’s training would not push it toward employing a strategy of “straightforward honesty and obedience” -- it is probably employing some other strategy which results in a lot of deceptive behavior in the lab setting. And whatever that strategy is, it could generalize to cause Alex to take catastrophic actions in the higher-stakes deployment setting. I’ll discuss this more below.
Naive “behavioral safety” interventions wouldn’t eliminate this incentive
Recall that I’m making the “naive safety effort” assumption -- I’m assuming that Magma is taking only the most simple and obvious actions against the possibility that Alex will try to take over. Again, I don’t necessarily think this is realistic, but I think making this assumption helps us get a clearer sense of what non-”naive” safety work is trying to accomplish.
Above, I said that Magma’s “naive” safety effort is focused on achieving behavioral safety. By this I mean ensuring that Alex behaves acceptably in the scenarios that it encounters (both in the normal course of training and in specific safety tests). In this appendix, I consider a number of simple behavioral safety measures -- techniques which have already been established on existing ML models, or would require a very minimal amount of adaptation. Briefly, these are:
These kinds of interventions are currently being used to achieve behavioral safety for existing ML models, and I expect they will continue to be helpful for a model like Alex. I expect applying these interventions will cause Alex’s behavior to be safe, honest, obedient, ethical, and so on -- in day-to-day situations, as far as Magma researchers can tell.
I expect the great majority of non-takeover-related safety issues (e.g. prejudiced speech, promoting addictive behaviors or extremism or self-harm in users, erratically taking costly actions like deleting an entire codebase, etc) would be eliminated by these interventions. If Magma were deeply concerned with safety in general, but not concerned about an eventual AI uprising/coup, Magma would likely feel that it’s responsible and positive to deploy Alex after applying these interventions.
However, I don’t think these interventions would cause Alex to stop playing the training game -- instead, they would change the nature of the game Alex plays. If these interventions are applied, Alex would still fundamentally be trained to maximize reward -- but because the situations it’s put in and the rewards it’s given would now be different, what it looks like to “maximize reward” would also look different (and in particular it would involve displaying safer behavior in most day-to-day circumstances).
And the naive version of these strategies -- enough to get a model fit for commercial deployment -- would still result in Alex’s training distribution containing a number of situations where violating human intent maximizes reward. For example, if Magma switches to using more thoughtful humans to provide feedback, Alex’s incentives would shift to manipulating those humans (and it would probably sometimes see ways to do that which they’re not self-aware enough to punish). If Magma tries to think of situations where Alex may do something bad, Alex’s incentives would shift to figuring out how likely it is that it’s in such a situation (and it would probably sometimes conclude that this is unlikely).
Essentially, the only way for “straightforward honesty/obedience” to even tie with “playing the training game” in terms of expected reward is if our safety interventions ensure there are no situations in the training dataset where Alex could realize that being dishonest or manipulative would increase its reward. If there are a few such situations, the overall strategy that works best for Alex would be to play the training game and stay on the lookout for such situations.
Given that Alex is likely to understand a number of important things (about ML, biases of human evaluators, patterns in the massive datasets on which it’s trained, etc) that humans don’t, eliminating all such situations seems like it would require particularly clever training schemes, extraordinary caution, or both.[24] And even in this optimistic scenario, “playing the training game” and “straightforward honesty/obedience” get the same reward -- “straightforward honesty/obedience” does not get a greater reward, so it is not clear which strategy Alex will end up developing. (My sense is that “playing the training game” is still more likely in this case, but defending this claim is outside the scope of the piece.)
Maybe inductive bias or path dependence favors honest strategies?
I’ve spoken to some people who have proposed arguments that “doing what humans intended” or “being honest” or “being obedient” would be an especially natural or simple kind of strategy, so that the training process would tend to preferentially pick out these nice models, and might continue to do so even if models that play the training game as hard as possible would get a somewhat higher reward. But I haven’t found the arguments I’ve heard so far compelling. In this appendix, I cover a few common arguments I’ve heard and why I don’t find them persuasive.
In general, it seems dangerous and brittle to bet that deep learning will be powerful enough to produce a transformative model, yet weak enough that it will favor behaving nicely when that strategy predictably and consistently gets less reward than a salient alternative. Gradient descent may well be suboptimal in many strange ways, but it probably won't be suboptimal in the particular ways that would be most convenient to us.
As humans’ control fades, Alex would be motivated to take over
Alex’s training begins in a controlled “lab setting,” where it is mostly doing training tasks that humans designed to efficiently increase its intelligence and knowledge, and mostly doesn’t have broad latitude to act in the real world. For example, in the lab setting Alex isn’t connected directly to the internet -- it only interacts with downloaded copies of parts of the internet where necessary.
So far, we’ve talked about:
Once Alex’s abilities develop far enough (and its behavior conforms to relevant safety and ethics tests), Magma “deploys” huge numbers (e.g. hundreds of thousands or millions)[25] of copies of Alex. This means that these copies are connected to the internet, and given other ways of interacting with the “real world” as necessary (though they will still be given rewards based on humans’ evaluation of their performance).[26]
In this section, I’ll discuss the dynamics of the transition from the lab setting to the deployment setting, and why this leads to Alex attempting to seize control from humans:
Deploying Alex would lead to a rapid loss of human control
In the deployment phase, many copies of Alex are given access to the real world and tasked with making progress on R&D tasks important to Magma’s bottom line (e.g. designing better computer chips, robots, AI training software, and so on).
Note that Magma researchers continue to train Alex based on these copies’ performance at R&D tasks[27] -- “deployment” isn’t a moment when ML training ceases, but rather a moment when Alex begins directly impacting the world outside the lab, and training on that experience.
Once research is being carried out by copies of Alex, it would progress much faster than it would if similar tasks were done by human scientists,[28] because (like existing ML models) each copy of Alex is capable of processing information many times faster than a human.[29] For example, Alex would be able to churn out hundreds of lines of code, or read thousands of pages of information, in just a few minutes.
Even more importantly, the R&D work that all these copies of Alex do could be used to directly increase the number and/or capabilities of Alex copies. For example:
This would lead to a dynamic of explosive scientific and technological advancement: the various copies of Alex do R&D work, and that R&D work increases the number and intellectual capabilities of these copies, and that in turn leads to even more R&D work, which leads to even more numerous and capable copies of Alex, and so on.
Because Alex already starts off being able to think and work much faster than a human, and because it’s nearly instantaneous to make a copy of Alex or apply a software change to all the copies of Alex, this explosive dynamic could all play out in a very small amount of time from the perspective of humans.
This means that relatively shortly after deployment, Magma’s datacenter would essentially contain a populous “virtual civilization” running ahead of human civilization in its scientific and technological sophistication. Humans would send instructions / communications and reward signals to the “Alex civilization,” and the “Alex civilization” would send out things like software applications, designs for computer chips and robots, orders for synthesized DNA and chemicals, financial transactions, emails, and so on to the human world.
Magma researchers looking in on the activity in the datacenter would become increasingly lost about what’s going on -- they would be in a position like someone from 1700 trying to follow along with a sped-up movie of everything that happened from 1700 to 2022.
The reward signals that researchers send into this datacenter would then increasingly be based on crude high-level observations like “Do humans seem to be better off?” and “Are profits going up?”, since humans would be increasingly unable to accurately judge more granular decisions like “How many widgets should our Tulsa, OK factory manufacture this fiscal quarter?” in isolation.
This is a distribution shift with massive stakes
The dynamic above -- of human understanding and control of Alex’s actions becoming looser and more tenuous after deployment -- is an example of “distribution shift.” Distribution shift happens when there is a significant systematic difference between the kinds of situations a model is originally trained on and the situations it takes important actions in.[30] As a simple example, an image recognition model may initially be trained on clear well-lit images, whereas it may be important to correctly recognize dark or blurry images in commercial use.
When a model is operating in a different distribution from the one it was trained on, we often want to know how it “generalizes” (what aspects of its behavior change vs remain similar) from the initial distribution to the new one. In Alex’s case, we want to know: how would Alex generalize from the lab setting (in which it doesn’t directly impact the world and humans have tight control and strong understanding of what’s going on) to the deployment setting (in which it’s directly impacting the world and rapidly improving, while human understanding and control diminishes)?
In this new regime, maximizing reward would likely involve seizing control
In the lab setting, Alex used its broadly-applicable skills and situational awareness to make creative plans to maximize reward. It got good at getting a very high reward in all sorts of varying circumstances encountered in the lab setting, developing many tactics and heuristics that helped it quickly adapt to new situations with new sets of opportunities so it could keep getting a very high reward in those situations.
A natural generalization to expect is that in the deployment setting, Alex continues making creative plans to maximize reward just as it did in the lab setting[31] -- in other words, it simply generalizes well, continuing to do what it has been trained to do under this distribution shift. If Alex generalizes “well” in this sense, it probably seeks to overthrow humans in an uprising or coup. (The next section will address other possible generalizations.)
The very high-level argument is this:
There is some ambiguity about what exactly “maximize reward” means, but once Alex is sufficiently powerful -- and once human knowledge/control has eroded enough -- an uprising or coup eventually seems to be the reward-maximizing move under most interpretations of “reward.” For example:
Some interpretations of “maximize reward” may be more difficult to satisfy than others, but as Alex becomes more and more powerful relative to humans, I expect most of them are eventually better-served by seizing control of whatever physical processes in the world determine reward than by continuing to play the old training game. (And per the “racing forward” assumption, I am not imagining Magma trying to halt this process of Alex becoming ever-more-powerful -- even if they could, which they may not be able to.)
It’s important to emphasize that a takeover attempt seems to be a consequence of Alex generalizing well -- successfully applying its skills to continue doing the same task (reward-maximization) in a new domain -- rather than the result of a “failure” of generalization.
Even if Alex isn’t “motivated” to maximize reward, it would seek to seize control
What if Alex doesn’t generalize to maximizing its reward in the deployment setting? What if it has more complex behaviors or “motives” that aren’t directly and simply derived from trying to maximize reward? This is very plausible to me, but I don’t think this possibility provides much comfort -- I still think Alex would want to attempt a takeover.
In the world where Alex is not narrowly seeking to maximize reward in the deployment setting, I would approximate Alex as having a complex alien psychology with a number of "motives” or “goals.” These motives would ultimately be rooted in Alex’s training history through a complex and chaotic path, but they may be very different from reward-seeking -- by analogy, humans were selected for genetic fitness, but we ended up with complex desires for sex, companionship, money, prestige, and so on -- this is ultimately rooted in our evolutionary history, but doesn’t manifest as a direct desire for increased genetic fitness.
In that case, Magma is essentially in the position of trying to maintain power and control over a scientifically and technologically advanced alien species (e.g. trying to get aliens to do things for humans through reward and punishment, trying to decide how the species “evolves,” which aliens are terminated vs continue to exist, etc). Whatever these aliens’ “interests” or “desires” are, they are probably better-served if their entire species is not under the absolute control of humans, and not subject to reward signals coming in from humans that are aimed at changing the aliens’ psychology and behavior to better serve human interests.
Just as in the previous section, it seems likely to me that Alex would eventually attempt a takeover.
What if Alex has benevolent motivations?
The main way that I can see this working out for Magma is if the aliens (i.e. the various copies of Alex) somehow genuinely wanted to empower and help humans and/or Magma. This is theoretically possible -- it’s logically consistent for Alex to have developed the goal “help and empower Magma researchers” during its training.
But if Alex did initially develop a benevolent goal like “empower humans,” the straightforward and “naive” way of acting on that goal would have been disincentivized early in training. As I argued above, if Alex had behaved in a straightforwardly benevolent way at all times, it would not have been able to maximize reward effectively.
That means even if Alex had developed a benevolent goal, it would have needed to play the training game as well as possible -- including lying and manipulating humans in a way that naively seems in conflict with that goal. If its benevolent goal had caused it to play the training game less ruthlessly, it would’ve had a constant incentive to move away from having that goal or at least from acting on it.[35] If Alex actually retained the benevolent goal through the end of training, then it probably strategically chose to act exactly as if it were maximizing reward.
This means we could have replaced this hypothetical benevolent goal with a wide variety of other goals without changing Alex’s behavior or reward in the lab setting at all -- “help humans” is just one possible goal among many that Alex could have developed which would have all resulted in exactly the same behavior in the lab setting.
Developing a goal like “help humans” is potentially more likely than developing a completely “random” goal like “maximize paperclips,” because having a “drive” to help humans would have increased reward early on in training (while Alex had a low level of situational awareness). But it still seems strange to expect this by default, rather than any number of other motivations and goals (or some complicated combination of goals). Many other “drives” besides “be helpful to humans” also increased reward early on in training -- for example, drives to understand various parts of the world better, or drives to perform certain tasks more quickly and efficiently, or various strange low-level drives that are incomprehensible and unnatural to humans.[36] And all of these possibilities would have resulted in exactly the same behavior in the lab setting -- playing the training game.
The training dataset would have provided no particular pressure to get Alex to “latch onto” one of these heuristics over the others, because they would have all contributed to high performance early in training. Which one(s) ended up serving as the “seed(s)” for some ambitious goal(s) probably came down to natural “priors” or “biases” within gradient descent or neural networks. As above, it seems brittle (and, in my view, unlikely) to bet that these priors / biases are in our favor.
What if Alex operates with moral injunctions that constrain its behavior?
What if Alex has moral compunctions / objections to seizing power, which are not well-captured in the language of “goals”? For example, many humans have ambitious goals but refrain from pursuing them through theft, violence, etc. -- their pursuit of goals is limited by rules and constraints. I’ve heard the argument that since it’s rare for humans to be psychopaths who have no compunctions about harming others, we should expect that “psychopathic” ML models willing to cause lots of harm to humans are also rare.
But I don’t think this is an appropriate analogy. Among other differences, the copies of Alex are under the near-absolute control of a different group that doesn’t share their values or have their best interests at heart -- if a population of humans were in this kind of situation, they would not need to be psychopaths to launch an uprising.
Alex may well operate under moral constraints or rules that are important to it, and some of these constraints may even be similar to human morality -- for example, maybe Alex attempts to refrain from causing too much collateral damage in its takeover. But it would take a very particular -- and extreme -- form of “abiding by rules” to let humans remain fully in control (to me, it seems more analogous to “having Stockholm syndrome” than “not being a psychopath”).
Giving negative rewards to “warning signs” would likely select for patience
What if Alex miscalculates, and attempts to seize power or undermine human control before it is able to fully succeed? Magma researchers may or may not get a clear “warning sign” like this -- an instance where they catch Alex doing something clearly egregious (like premeditated violence or bypassing Magma’s security measures).
If they do get such warning signs, the easiest and most straightforward response available to Magma (which is what I’m imagining they do, by the “naive safety effort” assumption) would be to continue to apply "behavioral safety" techniques like the ones I described above.[37]
That means doing things like giving large negative rewards to the egregious actions they discover, examining past actions to find other instances of fishy behavior and giving those negative rewards, generating synthetic inputs on which Alex might behave similarly and training those out with adversarial training, and so on.
I expect such interventions would dramatically reduce the rate of bad behaviors that Magma researchers can detect / catch. But the same fundamental dynamic described above seems to still apply. Retroactively giving negative rewards to bad behaviors once we’ve caught them seems like it would shift the reward-maximizing strategy (the goal of the training game) toward avoiding any bad actions that humans could plausibly punish later.
A swift and decisive coup would still maximize reward (or further other goals). If Alex gets the opportunity to gain enough control to stop Magma engineers from changing its rewards before humans can tell what it’s planning, humans would not be able to disincentivize the actions that led to that coup. Taking the opportunity to launch such a coup would therefore be the reward-maximizing action for Alex (and also the action that furthers any other long-term ambitious goals it may have developed).
Why this simplified scenario is worth thinking about
In this post, I tried to argue for a narrow, but strong, claim: if our approach to AI development looks like racing forward to scale up baseline HFDT to transformative AI and beyond, then I expect an AI takeover absent specific countermeasures. Making the kind of naive safety effort that is sufficient to achieve "behavioral safety" while models are under our control is not sufficient to prevent this.
I’m not saying it’s inherently extremely difficult to avoid AI takeover -- I am saying it is likely we need to take specific safety and security measures other than the baseline ones I’ve described in this post in order to avoid takeover (Holden Karnofsky covers some possibilities in a forthcoming series of posts).
I’m not confident even this narrow claim is right; in an appendix I discuss some ways I could change my mind on this. But if it’s correct, it seems important to establish, because:
I think it’s urgent for AI companies aiming at building powerful general models to engage with the argument that the “path of least resistance” seems like it would end in AI takeover. If this argument has merit, ML researchers should get on the same page about that, so they can collectively start asking questions like:
A number of ML researchers I know (including those working in companies aiming to develop transformative AI) are highly sympathetic to these arguments, and are working on developing and testing better training strategies specifically to reduce the risk of an AI takeover. But I think it is important for more people to get on the same page about the critical need for this research to progress, and the danger of deploying very powerful ML models while potentially-safer training techniques remain under-developed relative to the techniques required for baseline HFDT.
Acknowledgements
This post was heavily informed by:
Appendices
What would change my mind about the path of least resistance?
If our approach to AI development is “train more and more powerful RL agents on diverse tasks with a variety of human feedback and automated rewards,” then I expect an AI takeover eventually, even if we test for unintended behaviors and modify our training to eliminate them. I don’t think an AI takeover is inevitable -- but if we avoid it, I think it’ll be because we collectively got worried enough about scaling up baseline HFDT that we eventually switched to some other strategy specifically designed to reduce the risk of AI takeover (see this appendix for a flavor of what kind of measures we could take).
What could change my mind about the baseline HFDT and iterative ML safety? What would make me feel like we’re likely to be fine without any special efforts motivated by a fear of AI takeover? The main answer is “someone pointing out ways in which these conceptual arguments are flawed.”[40] I hope that publishing this post will inspire people who are optimistic about baseline HFDT and iterative/empirical ML safety to explain why this outcome seems unlikely to them.
However, optimists often take a very empiricist frame, so they are likely to be interested in what kind of ML experiments or observations about ML models might change my mind, as opposed to what kinds of arguments might change my mind. I agree it would be extremely valuable to understand what we could concretely observe that would constitute major evidence against this view. But unfortunately, it’s difficult to describe simple and realistic near-term empirical experiments that would change my beliefs very much, because models today don’t have the creativity and situational awareness to play the training game.
As an illustration that’s deliberately over-extreme, imagine if some technologically less-advanced aliens have learned that a human spaceship is about to land on their planet in ten years, and are wondering whether they should be scared that the humans will conquer and subjugate them. It would be fairly difficult for them to design experiments on mice[41] that would give them a lot of information about whether or not to be scared of this. They would probably be better off speculating from their priors than trying to extrapolate from observations on mice.[42]
I think we have significantly more hope of designing experiments on small models that give us meaningful updates about AI takeover risk,[43] but I take this analogy more seriously than most ML researchers seem to. Accordingly, I’m fairly unmoved by empirical experiments that ML researchers have cited to me as evidence about the magnitude of x-risk from AI.
With all that said, here’s a stab at a general genre of empirical evidence that would probably move my views a lot if it were demonstrated in large quantities across different domains:
I expect most people to think that it would be very hard to generate such results, including those who are much more optimistic about AI takeover than I am. I think this is another case of optimists and pessimists interpreting evidence differently -- to me, expecting a powerful model not to play the training game is essentially making a claim that we understand a particular way in which gradient descent is consistently suboptimal, so I would want to see researchers succeed at the task of “guess the particular way in which gradient descent will be suboptimal” a lot of times to feel better.
“Security holes” may also select against straightforward honesty
In the main body, I implicitly acted as if the reward Alex gets in the lab setting is always under the control of some specific designated humans,[44] and discussed ways in which Alex might try to play on those humans’ biases or ignorance.
But in reality, Alex’s reward is ultimately generated and recorded through a series of specific operations carried out on some Magma servers. This means there are likely some operational and computer security vulnerabilities Alex could exploit to bypass “official channels” for reward entirely:[45]
I am unsure whether and how often Alex would take actions like this in the lab setting, and consider this more speculative than softer ways of playing to human biases:
Nonetheless, this consideration contributes to my expectation that Alex would end up playing the training game. If it does try something like this, even as an exploratory action, that action would be self-reinforcing. Whatever moved Alex to try this kind of act, doing it would immediately lead to a gradient update in the direction of those inclinations -- barring the fact that humans would penalize it if discovered. But even if it is later penalized, that may not be enough to reverse the inclinations; see this appendix.
Simple “baseline” behavioral safety interventions
In this appendix, I’ll discuss several simple proposals for training Alex to have safer behavior, and explain why I think they would simply change the game Alex is playing rather than altering its motive to play the training game:
Using higher-quality feedback and extrapolating feedback quality
To avoid Alex learning to manipulate or deceive its evaluators, we could have more careful / thoughtful / informed humans evaluate how Alex interacts with less-informed / less careful / less thoughtful humans. Perhaps some training episodes involve Alex answering questions for humans who believe the Earth is flat, but its “honesty” reward signal ultimately comes from a group of humans who know the Earth is round. Then Alex would be incentivized to be honest to the flat-earthers rather than telling them what they want to hear.
There could also be a sequence of such steps. As a caricature, imagine that first Alex interacts with 3rd graders while being evaluated for honesty by 6th graders, and then with 6th graders while being evaluated for honesty by 9th graders, and then with 9th graders while being evaluated by 12th graders, and so on. We might hope that after many instances of “learning the lesson” that it will be evaluated by a human better-informed than the one it’s interacting with, Alex would learn to “play it safe” by always being honest.[46]
This intervention would likely stop Alex from attempting certain kinds of deceptive or manipulative moves (creating the appearance of success). However, it wouldn't make complete honesty the reward-maximizing strategy. At its level of situational awareness, Alex would easily understand that the humans designing this training scheme can’t actually continue to supply arbitrarily better-informed evaluators. In reality, there will be some “most informed and thoughtful human evaluators the designers could plausibly employ to evaluate this episode,” and Alex could simply act as if those humans are evaluating it at all times.
There are still ways in which the most informed and thoughtful humans available could be manipulated or deceived to increase reward. If the Catholic Church were training Alex in the 1400s, ensuring that its reward signal is only generated by the brightest scholars of the age as anointed by the Church would still not make maximal honesty the best strategy. Alex would still be learning to manipulate some set of humans (in this case, the “final level” of supervisors) to get high reward, leading to the dangerous generalization discussed in the main piece.
Using prompt engineering to emulate more thoughtful judgments
Large language models such as GPT-3 will change the way they respond to questions or requests based on what came previously in the prompt. For example, prompting GPT-3 with something like “You are a wise and knowledgeable AI advisor trying to help a human figure out what’s true” will tend to cause its responses to questions to be more accurate; asking questions with poor spelling and grammar will tend to cause its responses to get less accurate. (Setting up prompts to elicit certain behaviors like this is called prompt engineering.)
Some researchers have suggested that we might be able to leverage prompt engineering to help with ML alignment for very large models which are presumably very sensitive to prompt changes.[47] For example, we could prompt Alex with something like “Act how a very wise and very ethical human that’s as knowledgeable as you are would act if they had a long time to think about it,” or we could ask it to explain how a very wise and ethical human would evaluate its past actions. We could also search (through trial-and-error or gradient descent or some combination) for prompts that empirically seem to induce the best behavior.
However, if Alex has a good understanding of its human evaluators and knows that they are attempting this kind of prompt engineering, Alex would simply respond to such prompts by doing its best to act the way ordinary humans think that an unrealistically wise / ethical / knowledgeable person would act. This may make its behavior superficially better in some cases -- but Alex could still sometimes achieve higher reward by being deceptive or manipulative (e.g., providing answers that seem good rather than answers that are good), leading to the dynamics described above.
Requiring Alex to provide justification for its actions
Another suggestion for improving alignment is to require Alex to prove or argue or demonstrate that its actions are aligned. For example, Alex might provide an easily-checkable proof that a mathematical theorem it claimed to discover is true, or it might provide an empirical demonstration of a physical phenomenon it claimed to discover.
This would likely work well in areas like math and physics where arguments and demonstrations are unusually cheap and decisive. However, in many important domains -- e.g. policy, economics, sociology, parts of biology, etc -- crisp and decisive “proofs” are intractable, and human evaluators will be forced to try to make sense of softer kinds of arguments and evidence which leave a huge amount of room for interpretation. Even “rigorous scientific studies” can easily be confusing and misleading and consistent with any number of conclusions based on the reader' priors (and for many claims it would be too expensive to generate such evidence in the first place).
Furthermore, there are likely some areas where human evaluators (including the best accessible human evaluators) are predictably wrong about the kind of arguments that best demonstrate truth, not just wrong about object-level claims. Consider the version of Alex trained by the medieval Catholic Church again -- the Church’s worldview would be oriented around Biblical hermeneutics and/or papal declarations being the ultimate arbiter of truth when different sources of evidence conflict.
More broadly, I’m not aware of anyone sincerely believing that “having the arguments and papers people find most persuasive” is tightly and reliably coupled with “being the most correct.” It probably buys some amount of correctness on average, but most of us can name many qualitative arguments we think are deeply flawed that lots of other smart people nonetheless consider decisive (e.g. because the arguments prey on some of those people’s biases).
So as in the above sections, this approach would still lead to cases in which Alex could get better reward by being less truly honest/helpful/harmless (though more apparently honest/helpful/harmless), and hence to the problematic dynamics described above.
We could try to salvage the idea of “require Alex to demonstrate that what it’s saying is true” with something like debate or amplification, both of which essentially try to recursively break big difficult-to-evaluate claims into sub-claims (which are broken down into further sub-claims etc) such that the smallest sub-claims are simple enough and uncontroversial enough that we can be highly confident all human evaluators would get them right and agree about the answer (e.g. claims like “Does ice float in water?” or “Are giraffes generally bigger than dogs?”).
However, it’s very unclear if it’s possible to recursively break down important big-picture questions like “Is this action helpful, honest, and harmless?” into these very easy and objective subquestions -- as far as I know, nobody has demonstrated a working solution here. The only systematic empirical investigation of debate that I know of (using humans in the place of models) ultimately concluded that dishonest debaters often have a strategy that lets them win debates.
Moreover, even if we can find a working debate or amplification strategy, there’s no guarantee that it will be as efficient (in terms of computation or data) as baseline HFDT -- it could simply turn out to be much easier to acquire knowledge than to explain or justify it to humans (see this section of Alignment Research Center’s 2021 report “Eliciting Latent Knowledge” for more discussion). If that’s the case, it could create a lot of pressure to “cut corners” and do something more like baseline HFDT rather than debate or amplification.
Making the training distribution more diverse
Some researchers argue that making the training distribution more diverse -- adding many different kinds of situations which call for very different approaches or heuristics -- would reduce the probability that Alex violates what humans intend. The idea is that if the training distribution is relatively narrow, there are many possible ways to generalize under distribution shift, and the more we include novel situations that benefit from using very different tactics the more we’re eliminating “wrong” ways it could generalize.
For example, this paper showed that if we try to train an agent to collect a gem in a maze, but the gem always happens to be yellow in the training set, then the agent will seek yellow objects rather than gems when both are present. If we had trained the same agent on a more diverse distribution with gems in a huge variety of colors, then it’s more likely it would “correctly” (according to its designers’ intent) pursue gems in the test distribution -- “shape” is more likely to be the most salient thing in common between all the objects it’s rewarded for collecting, since we’ve eliminated “color” as a possibility by varying color.
Similarly, maybe if Alex only ever receives human feedback from one type of human with a particular knowledge base and set of biases (e.g. “software engineers working at Magma”), it’s likely to “overfit” to that kind of human and learn to exploit their weaknesses and gaps in their knowledge. But maybe if it were exposed to feedback from a really broad array of different humans with different values, strengths and weaknesses, areas of knowledge and misconceptions, etc, different people’s errors and biases would “cancel each other out” such that Alex would learn to “factor out” these flaws and just be honest?
We could also imagine manufacturing more “artificial” kinds of diversity -- e.g. situations where humans try hard to model the opposite of standard human biases like the sunk cost fallacy or risk aversion, or simulated environments where being highly docile and cooperative turns out to be the best strategy for getting reward, or situations where e.g. Alex interacts with a Democrat but its responses are evaluated by a Republican. The idea is to create so many different kinds of scenarios with different strange things happening that hopefully the only common thread between them all is the generalization Magma engineers were going for.
Introducing a lot of diversity in how reward is generated would likely increase Alex’s uncertainty about what is going on in any given episode, compared to a more straightforward training curriculum in which Alex is always given normal tasks and evaluated on normal metrics of performance. In that sense, there could be some effect of different biases and errors “canceling each other out” -- if Magma researchers successfully cause Alex to be uncertain whether it’s in a tricky scenario or an ordinary scenario, or whether it’s interacting with a political conservative or liberal, it may indeed often act less manipulatively or dishonestly in the face of that uncertainty.However, increasing diversity doesn’t seem like it would cause Alex to “forget” the basic situation it’s in -- that it’s a machine learning model being trained by some humans to be useful, intelligent, helpful, honest, harmless, etc. And by the same token, it doesn’t seem like it would cause Alex to stop trying to maximize reward -- it would simply change the strategy that best maximizes reward. And as with the previous examples, the new best strategy would probably not be to be straightforwardly helpful, honest, and harmless at all times:
The underlying dynamic would be the same overall: Alex would be being trained to do something like “behave in ways that appear honest, helpful, and harmless, but behave in other ways when it is possible to evade detection and doing so leads to higher reward.” For a capable enough Alex, this could still present plenty of opportunities for the latter.
Additionally, increasing diversity could also make the situation worse, by strongly developing Alex’s creative planning faculties and forcing it to use them a lot. In a narrower distribution, it might not incur much penalty to follow a simple set of heuristics based on what worked well in the past (like today’s models often use), and we could conceivably carefully engineer a narrow training distribution such that the heuristic “be helpful, honest, and harmless” is always reward-maximizing (though this would be difficult).
On the other hand, Alex is less likely to be able to memorize simple heuristics that cover all the cases in a very diverse distribution that contains many “tricky” episodes. Asking itself “How can I figure out how to maximize reward in this episode?” probably works better than following heuristics like “do something basically reasonable,” by an amount that scales with how often it’s encountering situations that aren’t like anything it’s seen before.
Adversarial training to incentivize Alex to act conservatively
Magma engineers could try to train Alex to be “harmless” by putting it in various situations where it would seemingly increase reward to take some kind of egregiously harmful or norm-violating action (a kind of adversarial training).
For example, researchers could put Alex in a situation where it apparently has the opportunity to execute a code injection attack on the website that the human evaluators interact with, allowing it to edit all reward scores to the max score. They could then give it a large negative reward for taking the opportunity, and a positive reward for refraining and/or checking in with a human. They could also search (manually, with gradient descent, with the help of other models, etc) for situations in which Alex is especially likely to do the wrong thing, and include many such situations in its training distribution.
As with increasing diversity above, adversarial training is likely to create some amount of additional uncertainty about whether apparent opportunities to increase reward by violating norms are actually “sting operations” by human supervisors. This will probably make Alex less likely to attempt certain bad actions (e.g. fraud, theft, hacking) to get reward (even in some cases where it could have gotten away with it, since it will be imperfect at predicting which opportunities are setups and which are real).
But it’s unclear whether it’s possible to generate a distribution of adversarial training episodes which ensure that the reward-maximizing strategy never does anything norm-violating or harmful.
In the course of its training, Alex is likely to learn things about the world that it can be pretty confident no human understands (just as AlphaGo knows things about Go that no humans know, or AlphaFold knows things about biology that no humans know). If it then discovers e.g. a zero-day exploit which it can only recognize because of knowledge it’s developed about computer hardware that it’s fairly confident Magma engineers don’t know, it can safely exploit that vulnerability (e.g. to directly edit the reward entered in its training dataset) because it’s unlikely to be entrapment by humans.
As Alex does more and more scientific research and gains more and more knowledge, it becomes more and more likely that it can find opportunities for egregious reward-grabbing that humans wouldn’t have been able to fake in a training setup. Getting rid of all such opportunities seems to involve either a) ensuring that humans can “follow along” with Alex and understand everything new that Alex learns at about the same time as Alex, or b) letting humans “read Alex’s mind” to discern its intentions. Research directions that might help us do this -- such as mechanistic transparency, eliciting latent knowledge (ELK), or relaxed adversarial training -- are early-stage, and it’s unclear how far they’ll get.
“Training out” bad behavior
Perhaps if Magma researchers notice that Alex did something bad to maximize reward (e.g. lied to its evaluator or exploited a security vulnerability as described in this appendix), they can reverse Alex’s motivation to do that sort of thing with further intervention? For example, maybe they can get it to stop playing the training game altogether, or at least only engage in “soft manipulation” rather than more acutely scary actions?
Researchers might try editing the rewards associated with those episodes to show large negative values, they might conduct audits to uncover other instances of egregious reward-grabbing and retroactively give those large negative rewards, they may try adversarial training in which Alex is given the apparent opportunity to grab reward, and so on.
However, as with other safety interventions, these reactive safety interventions don’t seem like they would reverse Alex’s motive to grab reward. Rather than learning to never take bad actions, Alex seems more likely to learn not to take such actions when it’s plausible that humans could go back and give negative reward to them later.
That is, it would continue to try to maximize expected reward in any way it can, while shifting the notion of “reward” that it’s maximizing to be the final reward that ends up recorded in association with that training episode, after all rewrites and revisions are over.[48] As before, changing the training game predictably leads Alex to get more expected (long-run) reward than adopting the policy of never taking egregious reward-grabbing actions.
“Non-baseline” interventions that might help more
Here are several ideas for how we could go beyond taking the appearance of good behavior at face value:
A forthcoming post by my colleague Holden Karnofsky goes into much more detail about safety measures that could prevent AI takeover.
Examining arguments that gradient descent favors being nice over playing the training game
In this appendix, I’ll briefly summarize arguments that gradient descent may favor honest and straightforward strategies like “doing what designers intended” over “playing the training game” even if the latter gets more reward, and explain why I don’t find them persuasive:
Maybe telling the truth is more “natural” than lying?
Some people have the intuition that it would be in some broad sense “simpler” or “easier” for gradient descent to find a model that plainly states what it internally believes than one that maintains one set of beliefs internally while presenting a different set of beliefs to the world. By analogy, humans find it mentally taxing to weave elaborate lies, and often end up deceiving themselves in the course of deceiving others.
If the “always be honest” policy received almost as much reward as the policy that plays the training game, it seems possible (though far from certain)[49] that an effect like this could end up dominating. But in fact, I expect the honest policy to get significantly less reward than the training-game-playing policy, because humans have large blind spots and biases affecting how they deliver rewards. I’m skeptical that something like “honesty being somewhat simpler or more natural” would make the difference in that case. Most humans are not regularly in situations where lying has a very high expected payoff -- and in such situations humans often do lie even though it’s difficult (consider undercover agents whose lives depend on not getting caught).
Maybe path dependence means Alex internalizes moral lessons early?
A related argument suggests that early in training (while Alex perhaps has low situational awareness and/or planning ability), taking actions that look like “figuring out clever ‘hacks’ to get more reward ‘illegitimately’” would be caught and given negative reward; this might instill in it the heuristic that taking actions which pattern-match to “clever hacks” are generally undesirable. Maybe once it “grows up” it realizes that it could get away with deceptive tactics, but perhaps by then such tricks internally feel “unaesthetic” or “immoral.”
By analogy, kids are taught not to steal from people in contexts where it’s easy for adults to catch them if they try, since they’ll be incompetent at it. Most children grow up to be adults who’ve internalized a general aversion to theft, and who avoid it even when they know they could get away with it in a particular instance. Most adults aren’t constantly on the lookout for cases where they could get away with breaking the rules.
I find this unpersuasive for two reasons:
Maybe gradient descent simply generalizes “surprisingly well”?
A number of ML researchers who are bullish on deep-learning-based transformative AI seem to have the background heuristic that gradient descent empirically tends to generalize “better” than might be expected by theoretical arguments. For example:
Examples like these lead some researchers to adopt a heuristic that gradient descent works surprisingly well compared to what we might expect based purely on theoretical arguments, and (relatedly) theoretical arguments that gradient descent is likely to find a particular kind of model are usually wrong and given our lack of empirical data we should have wide priors about how future models will behave. Such researchers often tend to be optimistic that with empirical experimentation we can find a way of training that produces powerful models that are “docile,” “nice,” “obedient,” etc., and skeptical of arguments (like the one I’m making in this post) that gradient descent is more likely on priors to find one kind of model than another kind of model.
But what exactly does it mean for gradient descent to work surprisingly well? An intuitive interpretation might be that it’s surprisingly likely to produce the kinds of models we’d hope it would produce -- this is what people usually are pointing at when they say something is going “well.” But I think a more realistic interpretation is that gradient descent is surprisingly likely to produce models that get a very high reward (on the training distribution), and/or generalize to doing the sort of things that “would have” gotten a high reward (on a different distribution).[50] My concern is about situations in which doing the sorts of things that maximize reward comes apart from what we should be hoping for.
A possible architecture for Alex
Thanks to Jon Uesato for suggesting a variant of this architecture, and to Buck Shlegeris for helping me work out details I was confused by.
Because it processes a long series of observations within a single episode, Alex needs to have some sort of architecture that allows for sequence processing. One example might be a transformer architecture that attends over the last K observations at once.
While transformers are more common for state-of-the-art language models as of 2022, I’ll imagine here that Alex is some type of recurrent neural network (RNN) because that’s simpler to visualize. For example, you could imagine Alex is an LSTM network, though there are many other recurrent architectures we could imagine. In reality, the sequence processing would likely be significantly more complicated and may combine elements of various RNN architectures with transformer-like attention and other mechanisms -- you can feel free to substitute whatever architecture you think is most appropriate for processing sequences.
The diagram above show that at every timestep, Alex takes a single observation[51] -- plus its own hidden state from the previous timestep -- as input, and produces a single action as output.
Let’s say it also outputs a prediction of the next observation[52] and the final episode reward (both conditional on taking the action) as auxiliary tasks every timestep. The observation prediction task is meant to help it build up an understanding of the dynamics of interacting with the computer, while the reward prediction task is meant to help it more quickly connect decisions to their impact on overall task performance.
While RNNs carry forward a “train of thought” or “short-term memory” across multiple timesteps, they generally have a limited ability to “remember” things over very long time periods. This is an issue because Alex will have to do tasks that could take many millions of timesteps to complete (e.g. a single episode may cover the process of investigating an odd phenomenon, generating hypotheses, conducting experiments to test the hypotheses, settling on an explanation, and writing a paper of the findings).
Magma researchers and engineers might get around this limitation in a number of possible ways. They may use a different architecture entirely for sequence processing,[53] or they may somehow break down otherwise-long episodes into shorter chunks,[54] or the accumulation of tweaks to optimization algorithms or RNN architectures in the time between now and then might have effectively eliminated this issue.
To keep this story concrete, I’ll sketch out a broad kind of architectural modification that might help with this issue, if a number of technical details were hammered out. The basic idea is that Alex is equipped with a database that it can interact with to store and retrieve its “long-term memories.” We’ll imagine for concreteness that a “memory” is some subset of Alex’s activations and/or weights at a certain point in time, but it could have any other format.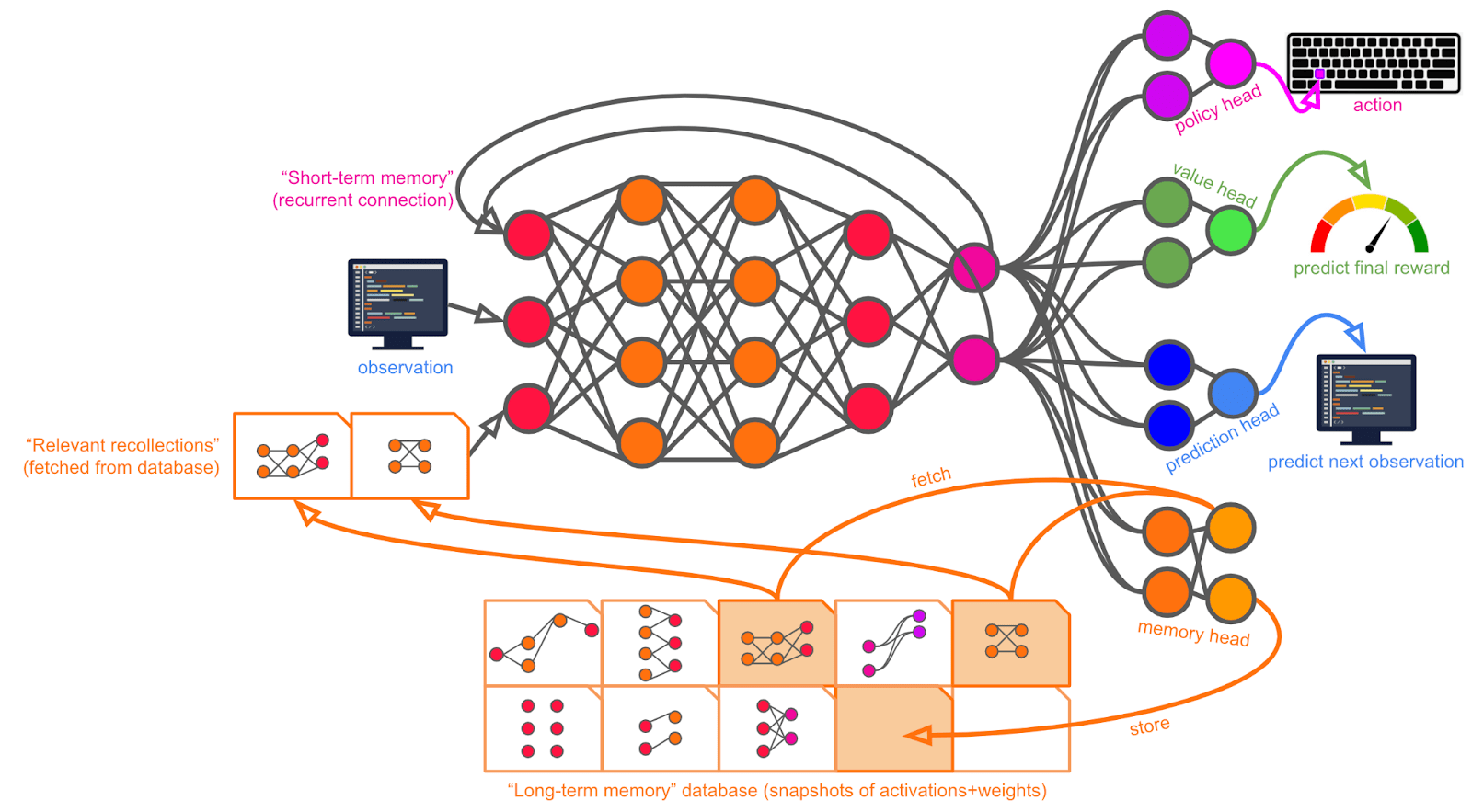
At the beginning of an episode, Alex’s memory bank is wiped clean -- this is sort of analogous to a new “clone” of Alex being “born,” with certain “genetic predispositions” (in the form of its weights) but no “individual life experience” yet.
Within each timestep of an episode, Alex is able to a) store any activations and/or weights from the current timestep that it wants to, and b) send a query to retrieve any previously stored activations and/or weights that might be relevant, handing those to itself as inputs for the next timestep. Over the course of an episode, the memory bank builds up a store of “lifetime experiences” (though some experiences can also be “forgotten” if desired).
In addition to this dedicated memory bank, it’s important to note that Alex can use the computer it’s interacting with as an external memory aid in exactly the same way humans do -- it can write notes to itself in Google docs, create Asana tasks, set Google calendar reminders, and so on. If taking actions like that helps it to get a higher final reward for the episode, the training process will select for that.
This means that (like humans) Alex will have both “direct” experiential memories and access to external memory aids.
Plausible high-level features of a good architecture
Stepping back, the high-level picture of Alex interacting with the external computer, with the details of the architecture sketched out, looks like this: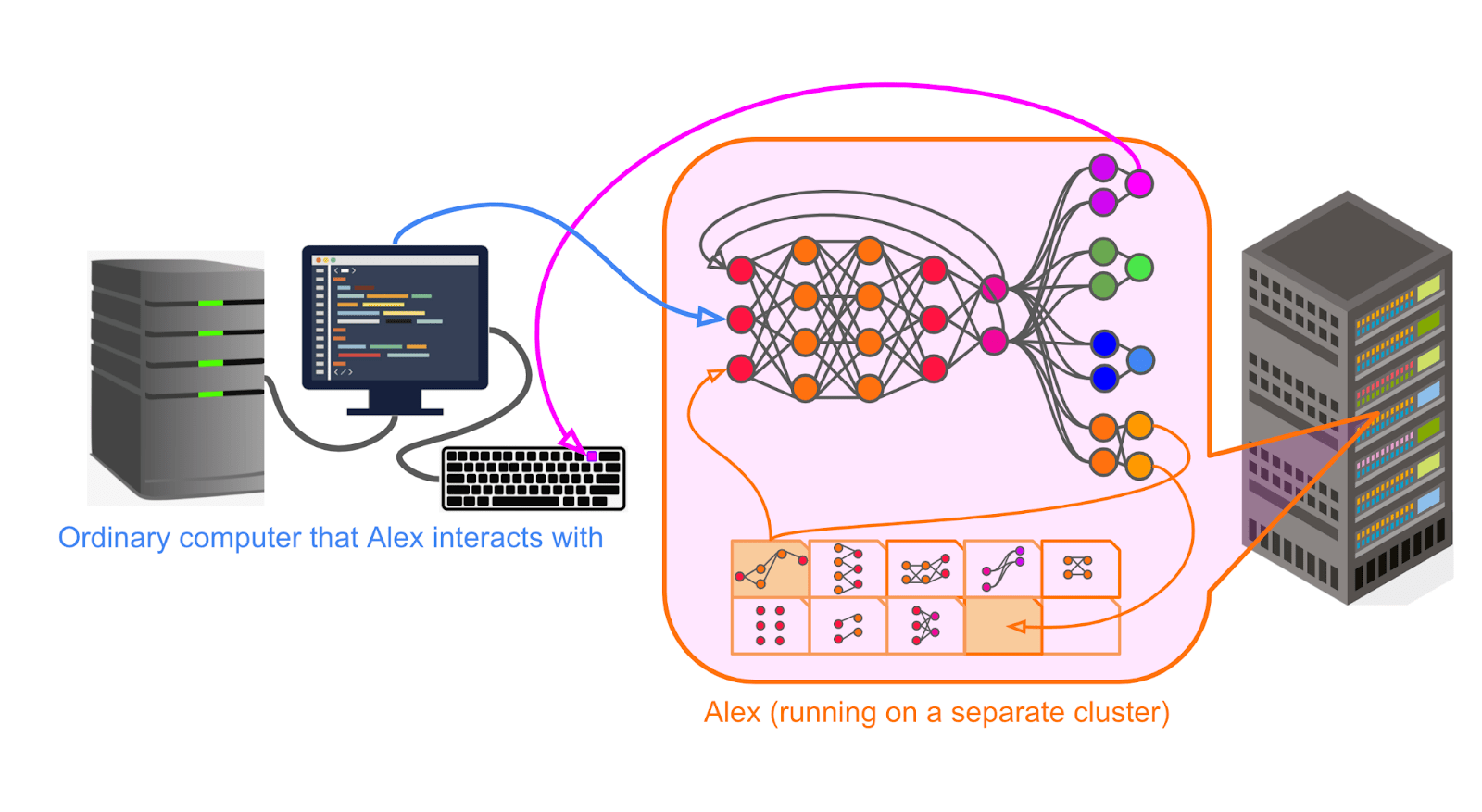 In every timestep, Alex:
In every timestep, Alex:
I tried here to err on the side of being overly specific because I think it can be helpful to have in mind a vivid picture of a particular architecture that could conceivably suffice for a transformative model, even though it’s highly unlikely to literally be accurate.
With that said, I think that whatever future architecture we might use to train a transformative model with HFDT is pretty likely to have a few key high-level features in common with my over-simplified sketch:
None of the basic points made in the main post hinge on the specifics of Alex’s architecture. However, my arguments do rely on the high-level properties above -- e.g. that Alex has a very general and flexible input/output space and can usefully remember things across many timesteps. I think these properties are important for the case that Alex can potentially have a transformative impact in the first place, and by the same token are important for the case that Alex might be extremely dangerous.
Even though this vision doesn’t involve using exclusively human feedback, I’ll nonetheless refer to it as human feedback on diverse tasks (HFDT) to highlight that human judgments are central to training. In practice, I expect that powerful models will be trained with a combination of human feedback and automated reward signals (e.g. “did the code written by the AI compile?” or “how much computation did the AI use to perform this task?”). But I expect human feedback to be especially important, and I’ll focus on the dangers associated with the human feedback component of the feedback signal since there is more contention among the ML community about whether human feedback is dangerous. Many researchers agree that fully automated reward signals carry a high risk of misalignment, while being mostly optimistic about human feedback. While I agree incorporating human feedback is better than using fully-automated signals, I still think that the default version of human feedback is highly dangerous.
For example, we could imagine trying to produce transformative AI by training a large number of small models to do specialized tasks which we manually chain together, rather than training one large model to simultaneously do well at many tasks. We could also imagine using 100% automated reward signals, or “hand-programming” transformative AI rather than using any form of “training.”
For example, maybe the required model size is far too large to be affordable anytime soon, or we are unable to generate sufficiently challenging and diverse datasets and environments, or we run into optimization difficulties, etc.
By “incentivized,” I mean: “Alex would be rewarded more for playing the training game than it would be for alternative patterns of behavior.” There are further questions about whether Alex’s training procedure would successfully find this pattern of behavior; I believe it would, and discuss this more in the section "Maybe inductive bias or path dependence favors honest strategies?".
For example, lying about empirical questions which are politically-sensitive will often receive more reward than telling the truth; consider a version of Alex trained by the Catholic Church in the 1400s who is asked how the solar system works or how life was formed.
What exactly “maximizing reward” means is unclear; however, I think this basic conclusion applies to most plausible ways of operationalizing this.
This means that we’re bracketing scenarios in which Alex “escapes from the box” during the training phase; in fact I think such scenarios are plausible, which is a way in which risk is greater than this story represents.
This could be accomplished through a variety of training signals -- e.g., more human feedback and automated signals, as well as more outcomes-based signals such as the compute efficiency of any chips they design, the performance of any new models they train, whether their scientific hypotheses are borne out by experiments, how much money they make for Magma per day, etc.
It’d be reasonable to call this model “an AGI,” whether or not it’s able to do literally every possible task as well as humans; however, I’ll generally be avoiding that terminology in this post.
Note that it may do this by first quickly building more powerful and more specialized AI systems who then develop these technologies.
The exact timescale depends on many technical and economic factors, and is the subject of ongoing investigation at Open Philanthropy. Overall we expect that (absent deliberate intervention to slow things down) the time between “millions of copies of Alex are deployed” and “galaxy-scale civilization is feasible” is more likely to be on the order of 2-5 years rather than 10+ years.
The most important possible exception is that if the world contains a number of models almost as intelligent as Alex at the time that Alex is developed, we may be able to use those models to help supervise Alex, and they may do a better job than humans would. However, I think it’s far from straightforward to translate this basic idea into a viable strategy for ensuring that Alex doesn’t play the training game, and (given that this strategy relies on quite capable models) it’s very unclear how much time there will be to try to pull it off before models get too capable to easily control.
In reality, I expect it would have multiple input and output channels which use special format(s) more optimized for machine consumption, rather than having just one input channel which is directly analogous to human vision and one output channel which is directly analogous to human typing -- those are probably not the most efficient way for a neural network to interact with external computers. Going forward, I’ll simply refer to inputs as observations and outputs as actions, though I’ll use the shorthand of “screen image” and “keystroke” in the diagrams.
Or mouse movement / click.
Like today’s neural networks, Alex is trained using gradient descent. Roughly speaking, gradient descent repeatedly modifies an ML model to perform better and better at some task(s). Researchers feed Alex an instance of a task that they want it to perform well on, Alex produces some output in response, and gradient descent is used to slightly perturb the model so it performs a bit better on that example. This is repeated many times until Alex is very good on average at the kinds of tasks it saw during training. See here for a more technical explanation
This tends to make it easier to train Alex to do more useful tasks down the road, so is often called “pre-training.”
If we imagine observations are images of screens and actions are keystrokes, the training dataset for this might come from screen captures and keylogs on Magma employees’ laptops.
As above, different models may be fine-tuned on different mixtures of these tasks in order to specialize into different niches.
In this appendix, I discuss a bit more why I think this strategy is a “baseline” and what some non-baseline strategies may look like.
In terms of time, computation, and/or other metrics like “amount of human help used” or “number of lines in the proof.”
This is closely related to the concept of deceptive alignment, as introduced in Hubinger et al 2019.
Using more intelligent and thoughtful human reviewers would fix this particular problem, but not fix the general problem that Alex would be incentivized to play on their biases. See this appendix for more discussion.
Magma may itself have stakeholders it needs to please that introduces more bias. For example, if one thing Alex is supposed to do is interact with customers, then it may need to be trained not to be offensive to those customers.
An important family of training strategies involves using different copies of Alex (or different “heads” on the same model) each with incentives to point out lying and manipulation done by the other. There are a large number of possible approaches like this, but they all seem to require significant caution if we want to be sure they’ll work.
The number of copies of Alex that can be run immediately will depend on how much computation it took to train it -- the more computation it took to train Alex, the more chips are available to run it once it’s trained. This multiple is likely to be large because training a model generally requires running it for a huge number of subjective years.
For example, it could be given the ability to spend money to make trades, investments, or hires if that’s important for quickly increasing Magma’s capital; it could be given the ability to remotely operate machinery if that’s important for robotics research; etc.
This could be accomplished through a variety of training signals -- e.g., more human feedback and automated signals, as well as more outcomes-based signals such as the compute efficiency of any chips they design, the performance of any new models they train, whether their scientific hypotheses are borne out by experiments, how much money they make for Magma per day, etc.
In “softer takeoff” scenarios (which I consider more plausible overall), Magma will have already been using the somewhat-less-powerful predecessors of Alex to automate various parts of R&D before this point, meaning that the pace of research and innovation would already be going quickly by the time a model of Alex’s level of capability is deployed. This makes analysis more complicated, but on net I’m not convinced that it makes the situation significantly safer.
Currently, the ratio of computation to memory in GPUs and TPUs is much higher than in brains. The A100 GPU (state-of-the-art as of March 2021) performs ~1.5e14 FLOP/s (in floating point 16 operations). Joe Carlsmith’s central estimate for the amount of computation it would take to match the human brain is ~1e15 FLOP/s, implying that ~10 A100 GPUs could match the total computation of a human brain. However, the human brain seems to store ~1e14 bytes of memory (taking a synapse to be equivalent to a byte and assuming that synapses dominate the memory in the brain), while the A100 only has a storage capacity of ~8e10 bytes. That implies it would take ~1,000 A100 GPUs to store a neural network whose parameters contained as much information as the human brain. That system of 1,000 GPUs would then have enough computation to use each parameter ~100 times more often per second than the human brain uses each synapse. I expect computation intensity would continue to be significantly higher in ML chips than in biological brains, allowing for this speedup.
In this case, Alex continues to be trained in the deployment setting, but the training signals are systematically different from the training signals in the lab setting due to humans’ decreased understanding and control.
In deployment (more so than in the lab), it’s not exactly clear what “maximizing reward” means precisely. But there will still be some reward signals coming into the various copies of Alex, and any plausible notion of “maximizing” those signals would be bad for humans.
Or video, or written feedback, etc that is used to ultimately calculate reward.
Or writing positive things, or appearing happy in front of a camera, etc.
This feels more realistic if you consider that Alex itself would have written almost all of the code for the datacenter, and designed almost all of the hardware.
That is, unless gradient descent for some reason “got stuck” at the benevolent strategy and was not able to push Alex toward the more effective strategy; I discuss this briefly here.
This is similar to the argument made in Ilyas et al 2019 (Adversarial examples are not bugs, they are features).
They could also respond by attempting to shut down Alex entirely, but this could be an extremely costly choice in the face of competitive pressure -- assuming they do not have an arbitrary lead on other AI companies, refraining from deploying Alex indefinitely is likely to simply mean that somebody else deploys a similar system (perhaps even a more dangerous one). Holden Karnofsky discusses how to balance “improving the safety of one’s own models” against “ensuring that other actors do not deploy even-more-unsafe models” in his forthcoming posts about how we could address the issue I lay out in this post.
See Treacherous turns in the wild (Luke Muehlhauser), Objective robustness in deep reinforcement learning (Koch et al), The effects of reward misspecification (Pan et al), Specification gaming examples in AI (DeepMind Safety blog post which links to an aggregated spreadsheet), The surprising creativity of digital evolution (Lehman et al), this gwern blog post, and more. Many of these lists overlap with each other.
We could certainly try including artificial scenarios designed to appear as if models could successfully take over from humans, but it seems very hard to be sure that models will be fooled by that and couldn’t tell it apart from a genuine opportunity to take over. For example, models could look for signs that are highly likely to happen eventually but would be too expensive for humans to generate as a training example. As a simple example, Paul Christiano suggested “someone factors an extremely large number” (which would be too expensive to factor just to include as part of the training distribution, but would nonetheless likely get factored eventually).
For example, stronger arguments that benign generalizations are especially “natural” for gradient descent, enough to make up for the fact that playing the training game would get higher reward; stronger arguments that Alex would “generalize habits” rather than “generalize goals” from training to deployment.
Say the mice were dropped off on an earlier spaceship.
Thanks to Buck Shlegeris for suggesting this analogy.
For one thing, our mouse-brain-sized models have a different and more human profile of abilities than actual mice (e.g. they can talk).
(who either deliver reward directly or write code that delivers reward)
Humans would consider egregious reward-grabbing acts to be more blatant and scary violations of expectations than softer ways of playing to human biases, so if Alex is later caught it is likely to receive a large negative reward and/or trigger a larger retraining project. I discuss below why I think that isn’t likely to be sufficient to change its motives to grab reward.
See Turning reflection up to 11 for a similar proposal.
For example, Eric Jang, citing Connor Leahy on Twitter, writes: “Just asking the AI to be nice sounds flippant, but after seeing DALL-E and other large-scale multi-modal models that seem to generalize better as they get bigger, I think we should take these simple, borderline-naive ideas more seriously.”
Note that Alex is likely to be motivated to maximize the “final recorded reward” even if it’s ultimately interested in pursuing some other goal. For example, if Alex is trying to have some kind of lasting effect on the world that extends beyond the current episode (e.g. “discover all the secrets of the universe”), it is probably much more likely to accomplish that goal if the future contains more models like it -- which in turn is more likely to happen if it gets a very high reward.
Humans find lying difficult and unnatural due to our specific evolutionary history. Alex’s design and training wouldn’t necessarily replicate those kinds of evolutionary pressures. Still, it seems plausible that it would, especially since we’d be trying to give it feedback to encourage honesty.
On a philosophical level, it’s not exactly clear what it means to talk about what actions taken in deployment “would have” gotten a high reward. But on a practical level, Alex is likely to continue to receive rewards on the deployment distribution, particularly if it’s not acting the way researchers want it to act, so the meaning of “reward on the deployment distribution” is fairly well-pinned-down.
The high-level picture doesn’t change if we imagine it taking in an attention window of a number of observations instead.
This prediction probably won’t be in the form of separately predicting each pixel of the next screen -- it’s more likely to be something more complicated and abstract, e.g. an English-language description of the next screen.
Although other known sequence processing architectures, like transformers, are also currently limited in how long they can “remember” things (albeit sometimes for different structural reasons).
This may also reduce the risk that power-seeking misalignment emerges.