This is a special post for quick takes by tdko. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
METR's task-horizon score on GPT-5 is 2h17m @ 50% success. For comparison, o3 was 1h32m and Grok 4 (prior SOTA) was 1hr50m. The 80% success score is 25m, prior SOTA was 20m from both o3 and Claude 4 Opus.
This 25m 80%-time horizon number seems like strong evidence against the superexponential model from ai-2027. On this graph the superexponential line shows 4h at the end of 2025. I feel like GPT-5 will be the biggest model release of the year, I don't see how we would see a model with an 8x time horizon of GPT-5 this year.
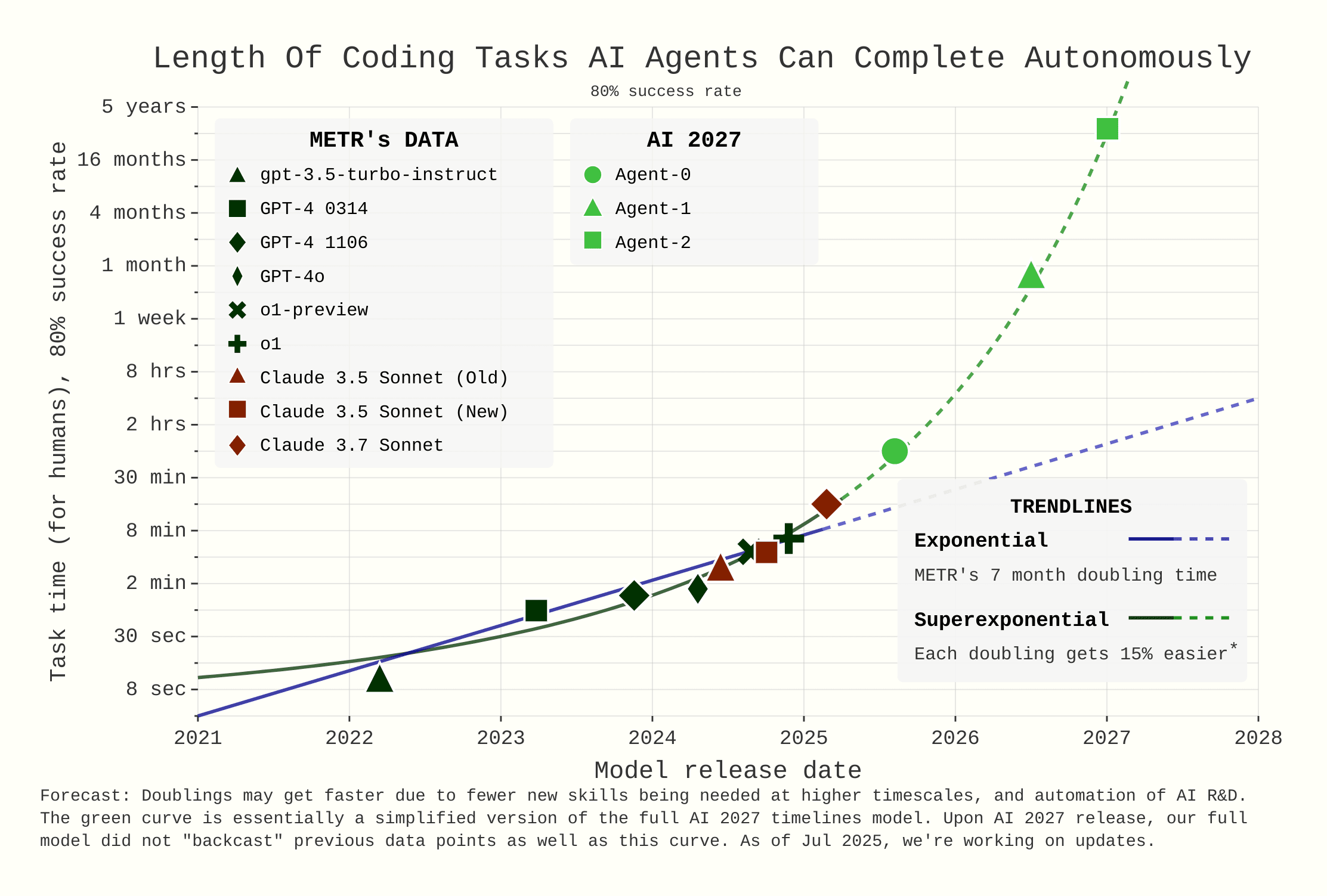
The swe-bench scores are already well below trend from ai 2027. Had to hit 85% by end of month. We're at 75%. (and SOTA was ~64% when they released ai 2027)
+ 25% for swe-bench relative to Gemini 2.5? Quadrupling the METR task length of Gemini 2.5?
I suppose it's a possibility, albeit a remote one.
It seems Gemini was ahead of openai on the IMO gold. The output was more polished so presumably they achieved a gold worthy model earlier. I expect gemini's swe bench to thus at least be ahead of OpenAI's 75%.
I don't believe there's a strong correlation between mathematical ability and agentic coding tasks (as opposed to competition coding tasks where a stronger correlation exists).
- Gemini 2.5 Pro is already was well ahead of O3 on IMO, but had worse swe-bench/METR scores.
- Claude is relatively bad at math but has hovered around SOTA on agentic coding.
I overall agree that things seem to be going slower than AI 2027 (and my median was longer when it came out).
However as mentioned in the caption, the green curve is a simplified version of our original timelines model. Apologies about that, I think it's reasonable to judge us based on that.
FWIW though, the central superexponential Mar 2027 trajectory from our original model certainly is not strongly contradicted by GPT-5, both with and without an AI R&D speedup interpolation issue fixed.
The original model, filtered for superexponential (pre-AI-R&D-automation) trajectories that reach superhuman coder in 2027:
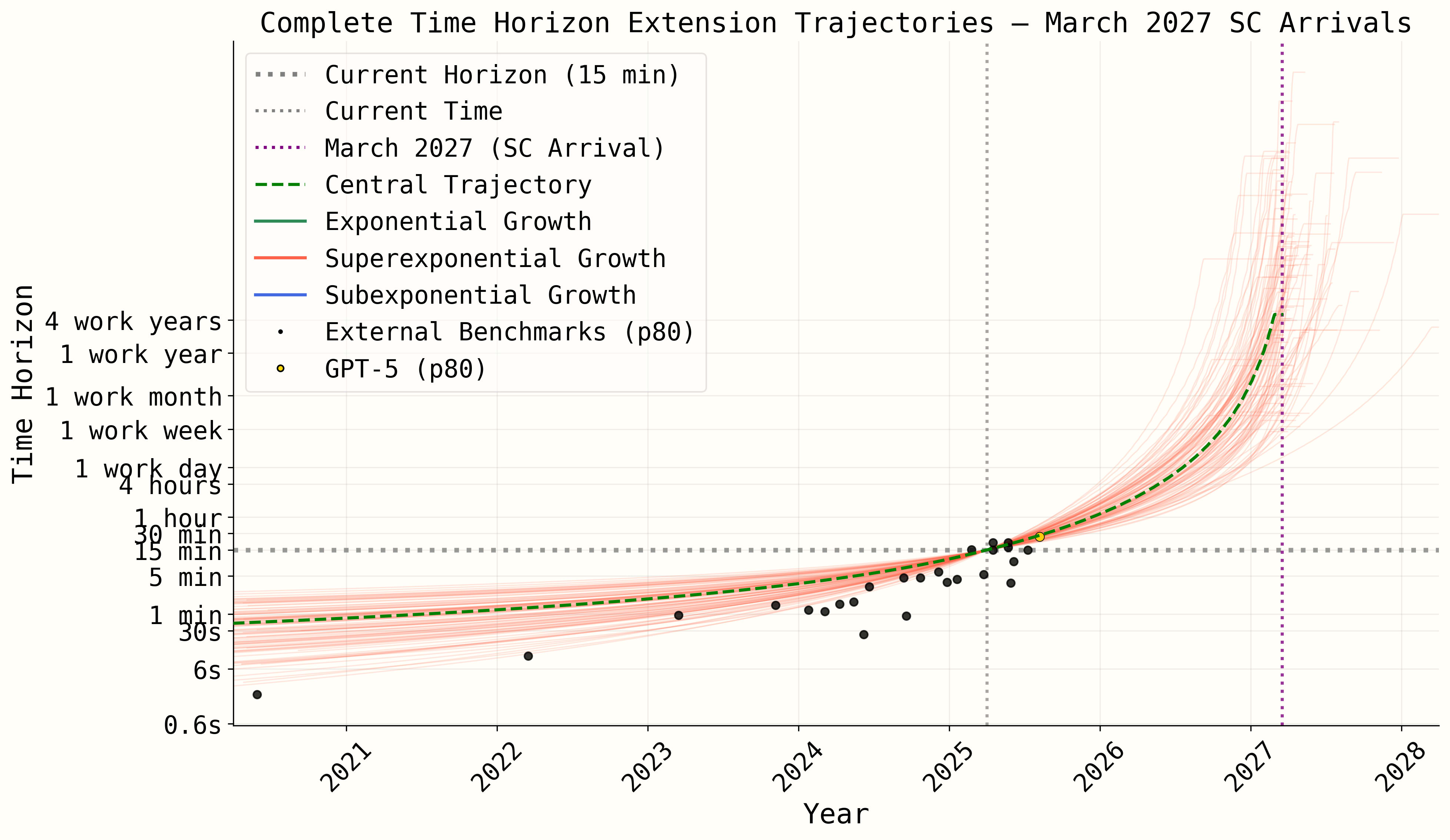
With AI R&D speedup bug fixed, also filtered for superexponential pre-AI-R&D-automation (backcast looks much better, GPT-5 prediction slightly worse):
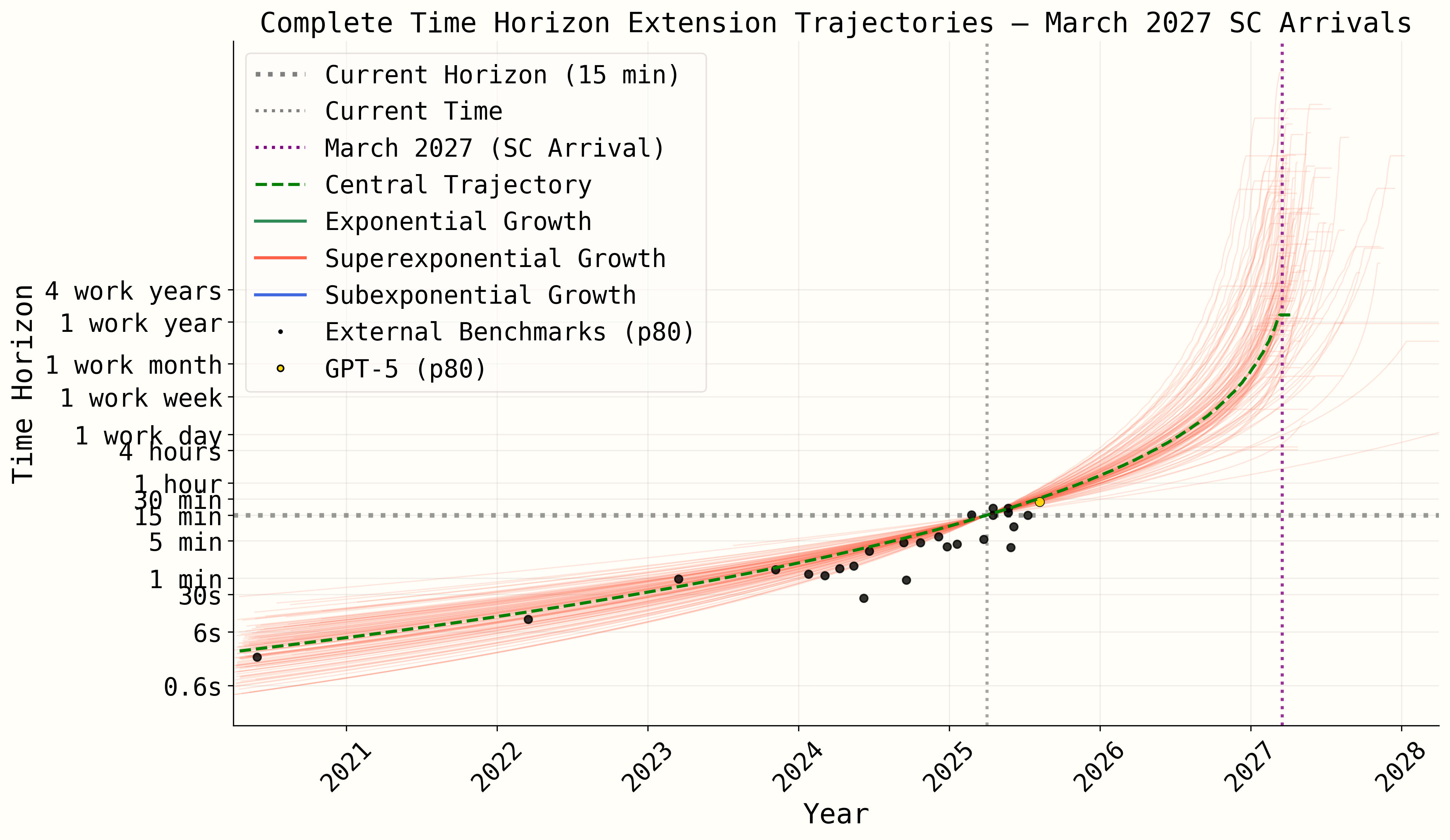
Either way, we're now working on a much improved model which will likely have an interactive web app which will provide an improvement over this static graph, e.g. you'll be able to try various parameter settings and see what time horizon trajectories they generate and how consistent they are with future data points.
Note also that the above trajectories are from the original model, not the May update model which we unfortunately aren't taking the time to create for various reasons, we think it would likely look a little worse in terms of the GPT-5 fit but might depend how you filter for which trajectories count as superexponential.
Registering that I don't expect GPT-5 to be "the biggest model release of the year," for various reasons. I would guess (based on the cost and speed) that the model is GPT-4.1-sized. Conditional on this, the total training compute is likely to be below the state of the art.
How did you determine the cost and speed of it, given that there is no unified model that we have access to, just some router between models? Unless I'm just misunderstanding something about what GPT-5 even is.
The router is only on ChatGPT, not the API, I believe. And it switches between two models of the same size and cost (GPT-5 with thinking and GPT-5 without thinking).
For reference the 95% CI is 1-4.5 hours for @50% success and the 95% CI is 8-65 minutes for @80%.
METR has finally tested Gemini 2.5 Pro (June Preview) and found its 50% success task horizon is only 39 minutes, far worse than o3 or Opus 4 which are at 90 and 80 minutes respectively. Probably shouldn't be a gigantic update given 2.5 Pro never scored amazingly at SWE-Bench, but still worse than I expected given how good the model is otherwise.
This is interesting, Gemini 2.5 Pro has recently became my favorite model, especially over Opus (this from a long-time Claude user). I would not be surprised if I like it so much because of its lower task horizon, since its the one model I trust to not be uselessly sycophantic right now.
Coding agentic abilities are different from general chatbot abilities. Gemini is IMO the best chatbot there is (just in terms of understanding context well if you wish to analyze text/learn things/etc.). Claude on the other hand is dead last among the big 3 (a steep change from a year ago) and my guess is Anthropic isn't trying much anymore (focusing on.. agentic coding instead)
Hm, I notably would not trust Claude to agentically code for me either. I went from heavily using Claude Code to occasionally asking Gemini questions, and that I think has been a big improvement.
Given METER's other work, the obvious hypothesis is that Claude Code is mostly just better at manipulating me into thinking they can easily do what I want.
I don't see that producing much of an update. Its SWE-bench score as you note was only 59.6%, which naively maps to ~50 minutes METR.
I still think it’s comforting to observe that the task lengths are not increasing as quickly as feared.
This is as I predicted so far but we’ll see about GPT-5.
Likely just the result of noise but extraordinarily funny METR results today.
Opus 4.6 got nearly triple the time horizon of Opus 4.5, immediately followed by GPT-5.3 getting a worse time horizon than GPT-5.2.
Completely anecdotal, but from my experience so far: the +0.1 between Opus 4.5 and Opus 4.6 seems to have been utter refusal to give up when facing a task.
Claude Sonnet 4.5's 50% task horizon is 1 hr 53 min, putting it slightly behind GPT-5's 2 hr 15 min score.
https://x.com/METR_Evals/status/1976331315772580274
The graph is slightly more informative: https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
I think it's fair to say I predicted this - I expected exponential growth in task length to become a sigmoid in the short term:
In particular, I expected that Claude's decreased performance on Pokemon with Sonnet 4.5 indicated that it's task length would not be very high. Certainly not 30 hours, though I understand that Anthropic did not claim 30 hours human equivalent, I still believe that their claim of 30 hours continuous software engineering seems dubious - what exactly does that number actually mean, if it does not indicate even 2 hours of human-equivalent autonomy? I can write a program that "remains coherent" while "working continuously" for 30 hours by simply throttling GPT-N to work very slowly by throttling tokens/hour for any N >= 3. This result decreases my trust in Anthropic's PR machine (which was already pretty low).
To be clear, this is only one data point and I may well be proven wrong very soon.
However, I think we can say that the “faster exponential” for inference scaling which some people expected did not hold up.
I am afraid that this is comparing apples (Anthropic's models) to oranges (OpenAI's models). Claude Sonnet 4 had a time horizon of 68 minutes, C. Opus 4 -- of 80 minutes, C. Sonnet 4.5 -- of 113 minutes, on par[1] with Grok 4. Similarly, o4-mini and o3 had a horizon of 78 and 92 minutes, GPT-5 (aka o4?) -- of 137 minutes. Had it not been for spurious failures, GPT-5 could have reached a horizon of 161 min,[2] and details on evaluation of other models are waiting to be published.
- ^
While xAI might be algorithmically behind, they confessed that Grok reached the results because xAI spent similar amounts of compute on pretraining and RL. Alas, xAI's confession doesn't rule out exponential growth slowing down instead of becoming fully sigmoidal.
- ^
Ironically, the latter figure is almost on par with Greenblatt's prediction of a horizon which is 15 minutes shorter than twice the horizon of o3.
So what did Anthropic do to have a lower time horizon than OpenAI while making Claude Sonnet 4.5 excel at the ARC-AGI-2 benchmark? Or Anthropic has an unreleased Claude Opus 4.5(?) whose time horizon is slightly bigger? The horizon of C. Opus 4 was 80 min, the horizon of C. Sonnet 4 was 68 min. Were the ratio of Opus and Sonnet horizons to stay the same, Anthropic would have C. Opus 4.5 with a time horizon of GPT-5...
At this rate we might learn that Anthropic's SC is a SAR (say hi to Agent-4 without Agent-3?) and OpenAI's SC needs to develop research taste...
In my experience using the LLM wrapper IDEs (cursor, windsurf, etc), if I ask the model to do some task where one of the assumptions I was making when writing the task was wrong (e.g. I ask it to surface some piece of information to the user in the response to some endpoint, but that piece of information doesn't actually exist until a later step of the process), GPT-5 will spin for a long time and go off and do stuff to my codebase until it gets some result which looks like success if you squint, while Sonnet 4.5 will generally break out of the loop and ask me for clarification.
Sonnet 4.5's behavior is what I want as a user but probably scores worse on the METR benchmark.
METR's task length horizon analysis for Claude 4 Opus is out. The 50% task success chance is at 80 minutes, slightly worse than o3's 90 minutes. The 80% task success chance is tied with o3 at 20 minutes.
That looks like (minor) good news… appears more consistent with the slower trendline before reasoning models. Is Claude 4 Opus using a comparable amount of inference-time compute as o3?
I believe I predicted that models would fall behind even the slower exponential trendline (before inference time scaling) - before reaching 8-16 hour tasks. So far that hasn’t happened, but obviously it hasn’t resolved either.
METR has updated their task horizon methodology with more tasks which leads to different task horizon scores.
METR discovered an issue with their task horizon modeling. Fixing the issue reduces some of the recent model scores by 10-20% on the 50% success horizon but also increases 80% horizon a bit. For example, Opus 4.6 dropped from 14.5 hours to 12 hours.