This is a special post for quick takes by Jeremy Gillen. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
After finishing MATS 2, I believed this:
"RL optimization is what makes an LLM potentially dangerous. LLMs by themselves are just simulators, and therefore are not likely to become a misaligned intelligent agent. Therefore, a reasonable alignment strategy is to use LLMs, (and maybe small amounts of finetuning) to build useful superhuman helpers. Small quantities of finetuning won't shift the LLM very far from being a simulator (which is safe), so it'll probably still be safe."
I even said this in a public presentation to people learning about alignment. Ahh.
I now think this was wrong. I was misled by ambient memes of the time and also made the mistake of trying too hard to update on the current top-performing technology. More recently, after understanding why this was wrong, I cowrote this post in the hope that it would be a good reference for why this belief was wrong, but I think it ended up trying to do too many other things. So here's a briefer explanation:
The main problem was that I didn't correctly condition on useful superhuman capability. Useful superhuman capabilities involve goal-directedness, in the sense that the algorithm must have some model of why certain actions lead to certain future outcomes. It must be choosing actions for a reason algorithmically downstream of with the intended outcome. This is the only way handle new obstacles and still succeed.
My reasoning was that since LLMs don't seem to contain this sort of algorithm, and yet are still useful, then we can leverage that usefulness without danger of misalignment. This was pretty much correct. Without goals, there are no goals to be misaligned. It's what we do today. The mistake was that I thought this would keep being true for future-LLMs-hypothetically-capable-of-research. I didn't grok that goal-directedness at some level was necessary to cross the gap between LLM capabilities and research capability.
My second mistake was thinking that danger was related to the quantity of RL finetuning. I muddled up agency/goal-directedness with danger, and was also wrong that RL is more likely to produce agency/goal-directedness, conditioned on high capability. It's a natural mistake, since stereotypical RL training is designed to incentivize goal-directedness. But if we condition on high capability, it wipes out that connection, because we already know the algorithm has to contain some goal-directedness.
I was also wrong that LLMs should be thought of as simulators (although it's a useful frame sometimes). There was a correct grain of truth in the idea that simulators would be safe. It would be great if we could train actual people-simulators. If we could build a real algorithm-level simulator of a person, this would of course be aligned (it would have the goals of the person simulated). But the way current LLMs are being built, and the way future systems will be built, they aren't even vaguely trying to make extremely-robustly-generalizing people-simulators.[1] And they won't, because it would involve a massive tradeoff with competence.
- ^
And the level of OOD generalization required to remain a faithful simulation during online learning and reflection is intuitively quite high.
My second mistake was thinking that danger was related to the quantity of RL finetuning. I muddled up agency/goal-directedness with danger, and was also wrong that RL is more likely to produce agency/goal-directedness, conditioned on high capability. It's a natural mistake, since stereotypical RL training is designed to incentivize goal-directedness. But if we condition on high capability, it wipes out that connection, because we already know the algorithm has to contain some goal-directedness.
Distinguish two notions of "goal-directedness":
-
The system has a fixed goal that it capably works towards across all contexts.
-
The system is able to capably work towards goals, but which it does, if any, may depend on the context.
My sense is that a high level of capability implies (2) but not (1). And that (1) is way more obviously dangerous. Do you disagree?
My sense is that a high level of capability implies (2) but not (1).
Sure, kinda. But (2) is an unstable state. There's at least some pressure toward (1) both during training and during online activity. This makes (1) very likely eventually, although it's less clear exactly when.
A human that gets distracted and pursues icecream whenever they see icecream is less competent at other things, and will notice this and attempt to correct it within themselves if possible. A person that doesn't pick up free money on tuesdays because tuesday is I-don't-care-about-money-day will be annoyed about this on wednesday, and attempt to correct it in future.
Competent research requires at least some long-term goals. These will provide an incentive for any context-dependent goals to combine or be removed. (although the strength of this incentive is of course different for different cases of inconsistency, and the difficulty of removing inconsistency is unclear to me. Seems to depend a lot on the specifics).
And that (1) is way more obviously dangerous
This seems true to me overall, but the only reason is because (1) is more capable of competently pursuing long-term plans. Since we're conditioning on that capability anyway, I would expect everything on the spectrum between (1) and (2) to be potentially dangerous.
If we all die because an AI put super-human amounts of optimization pressure into some goal incompatible with human survival (i.e., almost any goal if the optimization pressure is high enough) it does not matter whether the AI would have had some other goal in some other context.
But superhuman capabilities doesn’t seem to imply “applies all the optimisation pressure it can towards a goal”.
Like, being crazily good at research projects may require the ability to do goal-directed cognition. It doesn’t seem to require the habit of monomaniacally optimising the universe towards a goal.
I think whether or not a crazy good research AI is a monomaniacal universe optimiser probably depends on what kind of AI it is.
The whole approach is pretty hopeless IMHO: I mean the approach of "well, the AI will be wicked smart, but we'll just make it so that it doesn't want anything particularly badly or so that what it wants tomorrow will be different from what it wants today".
It seems fairly certain to me that having a superhuman ability to do things that humans want to be done entails applying strong optimization pressure onto reality -- pressure that persists as long as the AI is able to make it persist -- forever, ideally, from the point of view of the AI. The two are not separate things like you hope they are. Either the AI is wicked good at steering reality towards a goal or not. If it is wicked good, then either its goal is compatible with continued human survival or not, and if not, we are all dead. If it is not wicked good at steering reality, then no one is going to be able to figure out how to use it to align an AI such that it stays aligned once it is much smarter than us.
I subscribe to MIRI's current position that most of the hope for continued human survival comes from the (slim) hope that no one builds super-humanly smart AI until there are AI researchers that are significantly smarter and wiser than the current generation of AI designers (which will probably take centuries unless it proves much easier to employ technology to improve human cognition than most people think it is).
But what hope I have for alignment research done by currently-living people comes mostly from the hope that someone will figure out how to make an ASI that genuinely wants the same things that we want -- like Eliezer has been saying since 2006 or so.
An entity could have the ability to apply such strong optimization pressures onto reality, yet decide not to.
By "non-world-destroying", I assume you mean, "non-humanity ending".
Well, yeah, if there were a way to keep AI models to roughly human capabilities that would be great because they would be unlikely to end humanity and because we could use them to do useful work with less expense (particularly, less energy expense and less CO2 emissions) than the expense of employing people.
But do you know of a safe way of making sure that, e.g., OpenAI's next major training run will result in a model that is at most roughly human-level in every capability that can be used to end humanity or to put and to keep humanity in a situation that humanity would not want? I sure don't -- even if OpenAI were completely honest and cooperative with us.
The qualifier "safe" is present in the above paragraph / sentence because giving the model access to the internet (or to gullible people or to a compute farm where it can run any program it wants) then seeing what happens is only safe if we assume the thing to be proved, namely, that the model is not capable enough to impose its will on humanity.
But yeah, it is a source of hope (which I didn't mention when I wrote, "what hope I have . . . comes mostly from the hope that someone will figure out how to make an ASI that genuinely wants the same things that we want") that someone will develop a method to keep AI capabilities to roughly human level and all labs actually use the method and focus on making the human-level AIs more efficient in resource consumption even during a great-powers war or an arms race between great powers.
I'd be more hopeful if I had ever seen a paper or a blog post by a researcher trying to devise such a method.
For completeness's sake, let's also point out that we could ban large training runs now worldwide, then the labs could concentrate on running the models they have now more efficiently and that would be safe (not completely safe, but much much safer than any future timeline we can realistically hope for) and would allow us to derive some of the benefits of the technology.
I do not know of such a way. I find it unlikely that OpenAI's next training run wil result in a model that could end humanity, but I can provide no guarantees about that.
You seem to be assuming that all models above a certain threshold of capabilites will either exercise strong optimization pressure on the world in pursuit of goals, or will be useless. Put another way, you seem to be conflating capabilities with actually exerted world-optimization pressures.
While I agree that given a wide enough deployment it is likely that a given model will end up exercising its capabilities pretty much to their fullest extent, I hold that it is in principle possible to construct a mind that desires to help and is able to do so, yet also deliberately refrains from applying too much pressure.
I have encountered many people with the (according to me) mistaken model that you describe in your self-quote, and am glad to see this writeup. Indeed, I think the simulators frame frustratingly causes people to make this kind of update, which I think then causes people to get pretty confused about RL (and also to imagine some cartesian difference between next-token-prediction reward and long-term-agency reward, when the difference is actually purely a matter of degree of myopia).
Why wouldn't myopic bias make it more likely to simulate than predict? And does't empirical evidence about LLMs support the simulators frame? Like, what observations persuaded you, that we are not living in the world, where LLMs are simulators?
I don't think there is any reason to assume the system is likely to choose "simulation" over "prediction"? And I don't think we've observed any evidence of that.
The thing that is true, which I do think matters, is that if you train your AI system on only doing short single forward-passes, then it is less likely to get good at performing long chains of thought, since you never directly train it to do that (instead hoping that the single-step training generalizes to long chains of thought). That is the central safety property we currently rely on and pushes things to be a bit more simulator-like.
And I don’t think we’ve observed any evidence of that.
What about any time a system generalizes favourably, instead of predicting errors? You can say it's just a failure of prediction, but it's not like these failures are random.
That is the central safety property we currently rely on and pushes things to be a bit more simulator-like.
And the evidence for this property, instead of, for example, the inherent bias of NNs, being central is what? Why wouldn't predictor exhibit more malign goal-directedness even for short term goals?
I can see that this whole story about modeling LLMs as predictors, and goal-directedness, and fundamental laws of cognition is logically coherent. But where is the connection to reality?
What about any time a system generalizes favourably, instead of predicting errors? You can say it's just a failure of prediction, but it's not like these failures are random.
I don't understand, how is "not predicting errors" either a thing we have observed, or something that has anything to do with simulation?
Yeah, I really don't know what you are saying here. Like, if you prompt a completion model with badly written text, it will predict badly written text. But also, if you predict a completion model where a very weak hash is followed by its pre-image, it will probably have learned to undo the hash, even though the source generation process never performed that (potentially much more complicated than the hashing function itself) operation, which means it's not really a simulator.
But also, if you predict a completion model where a very weak hash is followed by its pre-image, it will probably have learned to undo the hash, even though the source generation process never performed that (potentially much more complicated than the hashing function itself) operation, which means it’s not really a simulator.
I'm saying that this won't work with current systems at least for strong hash, because it's hard, and instead of learning to undo, the model will learn to simulate, because it's easier. And then you can vary the strength of hash to measure the degree of predictorness/simulatorness and compare it with what you expect. Or do a similar thing with something other than hash, that also distinguishes the two frames.
The point is that without experiments like these, how have you come to believe in the predictor frame?
I don’t understand, how is “not predicting errors” either a thing we have observed, or something that has anything to do with simulation?
I guess it is less about simulation being the right frame and more about prediction being the wrong one. But I think we have definitely observed LLMs mispredicting things we wouldn't want them to predict. Or is this actually a crux and you haven't seen any evidence at all against the predictor frame?
You can't learn to simulate an undo of a hash, or at least I have no idea what you are "simulating" and why that would be "easier". You are certainly not simulating the generation of the hash, going token by token forwards you don't have access to a pre-image at that point.
Of course the reason why sometimes hashes are followed by their pre-image in the training set is because they were generated in the opposite order and then simply pasted in hash->pre-image order.
I've seen LLMs generating text backwards. Theoretically, LLM can keep pre-image in activations, calculate hash and then output in order hash, pre-image.
I think your current view and the one reflected in 'Without fundamental advances...' are probably 'wrong-er' than your previous view.
Useful superhuman capabilities involve goal-directedness, in the sense that the algorithm must have some model of why certain actions lead to certain future outcomes. It must be choosing actions for a reason algorithmically downstream of with the intended outcome. This is the only way handle new obstacles and still succeed.
I suspect this framing (which, maybe uncharitably, seems to me very much like a typical MIRI-agent-foundations-meme) is either wrong or, in any case, not very useful. At least it some sense, what happens at the superhuman level seems somewhat irrelevant if we can e.g. extract a lot of human-level safety research work safely (e.g. enough to obsolete previous human-produced efforts). And I suspect we probably can, given scaffolds like https://sakana.ai/ai-scientist/ and its likely improvements (especially if done carefully, e.g. integrating something like Redwood's control agenda, etc.). I'd be curious where you'd disagree (since I expect you probably would) - e.g. do you expect the AI scientists become x-risky before they're (roughly) human-level at safety research, or they never scale to human-level, etc.?
superhuman level
The same argument does apply to human-level generality.
if we can e.g. extract a lot of human-level safety research work safely (e.g. enough to obsolete previous human-produced efforts).
This is the part I think is unlikely. I don't really understand why people expect to be able to extract dramatically more safety research from AIs. It looks like it's based on a naive extrapolation that doesn't account for misalignment (setting aside AI-boxing plans). This doesn't necessarily imply x-risky before human-level safety research. I'm just saying "should have goals, imprecisely specified" around the same time as it's general enough to do research. So I expect it to be a pain to cajole this thing into doing as vaguely specified a task as "solve alignment properly". There's is also the risk of escape&foom, but that's secondary.
One thing that might change my mind would be if we had exactly human researcher level models for >24 months, without capability improvement. With this much time, maybe sufficient experimentation with cajoling would get us something. But, at human level, I don't really expect it to be much more useful than all MATS graduates spending a year after being told to "solve alignment properly". If this is what the research quality is, then everyone will say "we need to make it smarter, it's not making enough progress". Then they'll do that.
I don't really understand why people expect to be able to extract dramatically more safety research from AIs. It looks like it's based on a naive extrapolation that doesn't account for misalignment (setting aside AI-boxing plans). I'm just saying "should have goals, imprecisely specified" around the same time as it's general enough to do research. So I expect it to be a pain to cajole this thing into doing as vaguely specified a task as "solve alignment properly".
It seems to me that, until now at least, it's been relatively easy to extract AI research out of LM agents (like in https://sakana.ai/ai-scientist/), with researchers (publicly, at least) only barely starting to try to extract research out of such systems. For now, not much cajoling seems to have been necessary, AFAICT - e.g. looking at their prompts, they seem pretty intuitive. Current outputs of https://sakana.ai/ai-scientist/ seem to me at least sometimes around workshop-paper level, and I expect even somewhat obvious improvements (e.g. more playing around with prompting, more inference time / reflection rounds, more GPU-time for experiments, etc.) to likely significantly increase the quality of the generated papers.
I think of how current systems work, at a high level, as something like the framing in Conditioning Predictive Models, so don't see any obvious reason to expect much more cajoling to be necessary, at least for e.g. GPT-5 or GPT-6 as the base LLM and for near-term scaffolding improvements. I could see worries about sandbagging potentially changing this, but I expect this not to be a concern in the human-level safety research regime, since we have data for imitation learning (at least to bootstrap).
I am more uncertain about the comparatively worse feedback signals for more agent-foundations (vs. prosaic alignment) kinds of research, though even here, I'd expect automated reviewing + some human-in-the-loop feedback to go pretty far. And one can also ask the automated researchers to ground the conceptual research in more (automatically) verifiable artifacts, e.g. experiments in toy environments or math proofs, the way we often ask this of human researchers too.
One thing that might change my mind would be if we had exactly human researcher level models for >24 months, without capability improvement. With this much time, maybe sufficient experimentation with cajoling would get us something. But, at human level, I don't really expect it to be much more useful than all MATS graduates spending a year after being told to "solve alignment properly". If this is what the research quality is, then everyone will say "we need to make it smarter, it's not making enough progress". Then they'll do that.
I also suspect we probably don't need above-human-level in terms of research quality, because we can probably get huge amounts of automated human-level research, building on top of other automated human-level research. E.g. from What will GPT-2030 look like?: 'GPT2030 can be copied arbitrarily and run in parallel. The organization that trains GPT2030 would have enough compute to run many parallel copies: I estimate enough to perform 1.8 million years of work when adjusted to human working speeds [range: 0.4M-10M years] (Section 3). Given the 5x speed-up in the previous point, this work could be done in 2.4 months.' For example, I'm pretty optimistic about 1.8 million years MATS-graduate-level work building on top of other MATS-graduate-level work. And also, I don't think it's obvious that it wouldn't be possible to also safely get that same amount of Paul-Christiano-level work (or pick your favourite alignment researcher, or plausibly any upper bound of human-level alignment research work from the training data, etc.).
The Sakana AI staff seems basically like vaporware: https://x.com/jimmykoppel/status/1828077203956850756
Strongly doubt the vaporware claim, having read the main text of the paper and some of the appendices. For some responses, see e.g. https://x.com/labenz/status/1828618276764541081 and https://x.com/RobertTLange/status/1829104906961093107.
I have done the same. I think Robert isn't really responding to any critiques in the linked tweet thread, and I don't think Nathan has thought that much about it. I could totally give you LW posts and papers of the Sakana AI quality, and they would be absolutely useless (which I know because I've spent like the last month working on getting intellectual labor out of AI systems).
I encourage you to try. I don't think you would get any value out of running Sakana AI, and neither do you know anyonewho would.
To be clear, I don't expect the current Sakana AI to produce anything revolutionary, and even if it somehow did, it would probably be hard to separate it from all the other less-good stuff it would produce. But I was surprised that it's even as good as this, even having seen many of the workflow components in other papers previously (I would have guessed that it would take better base models to reliably string together all the components). And I think it might already e.g. plausibly come up with some decent preference learning variants, like some previous Sakana research (though it wasn't automating the entire research workflow). So, given that I expect fast progress in the size of the base models (on top of the obvious possible improvements to the AI scientist, including by bringing in more stuff from other papers - e.g. following citation trails for ideas / novelty checks), improvements seem very likely. Also, coding and math seem like the most relevant proxy abilities for automated ML research (and probably also for automated prosaic alignment), and, crucially, in these domains it's much easier to generate (including superhuman-level) verifiable, synthetic training data - so that it's hard to be confident models won't get superhuman in these domains soon. So I expect the most important components of ML and prosaic alignment research workflows to probably be (broadly speaking, and especially on tasks with relatively good, cheap proxy feedback) at least human-level in the next 3 years, in line with e.g. some Metaculus/Manifold predictions on IMO or IOI performance.
Taking all the above into account, I expect many parts of prosaic alignment research - and of ML research - (especially those with relatively short task horizons, requiring relatively little compute, and having decent proxies to measure performance) to be automatable soon (<= 3 years). I expect most of the work on improving Sakana-like systems to happen by default and be performed by capabilities researchers, but it would be nice to have safety-motivated researchers start experimenting, or at least thinking about how (e.g. on which tasks) to use such systems. I've done some thinking already (around which safety tasks/subdomains might be most suitable) and hope to publish some of it soon - and I might also start playing around with Sakana's system.
I do expect things to be messier for generating more agent-foundations-type research (which I suspect might be closer to what you mean by 'LW posts and papers') - because it seems harder to get reliable feedback on the quality of the research, but even there, I expect at the very least quite strong human augmentation to be possible (e.g. >= 5x acceleration) - especially given that the automated reviewing part seems already pretty close to human-level, at least for ML papers.
Also, coding and math seem like the most relevant proxy abilities for automated ML research (and probably also for automated prosaic alignment), and, crucially, in these domains it's much easier to generate (including superhuman-level) verifiable, synthetic training data - so that it's hard to be confident models won't get superhuman in these domains soon.
I think o1 is significant evidence in favor of this view.
I think your comment illustrates my point. You're describing current systems and their properties, then implying that these properties will stay the same as we push up the level of goal-directedness to human-level. But you've not made any comment about why the goal-directedness doesn't affect all the nice tool-like properties.
don't see any obvious reason to expect much more cajoling to be necessary
It's the difference in levels of goal-directedness. That's the reason.
For example, I'm pretty optimistic about 1.8 million years MATS-graduate-level work building on top of other MATS-graduate-level work
I'm not completely sure what happens when you try this. But there seem to be two main options. Either you've got a small civilization of goal-directed human-level agents, who have their own goals and need to be convinced to solve someone else's problems. And then to solve those problems, need to be given freedom and time to learn and experiment, gaining sixty thousand lifetimes worth of skills along the way.
Or, you've got a large collection of not-quite-agents that aren't really capable of directing research but will often complete a well-scoped task if given it by someone who understands its limitations. Now your bottleneck is human research leads (presumably doing agent foundations). That's a rather small resource. So your speedup isn't massive, it's only moderate, and you're on a time limit and didn't put much effort into getting a head start.
You're describing current systems and their properties, then implying that these properties will stay the same as we push up the level of goal-directedness to human-level. But you've not made any comment about why the goal-directedness doesn't affect all the nice tool-like properties.
I think the goal-directedness framing has been unhelpful when it comes to predicting AI progress (especially LLM progress), and will probably keep being so at least in the near-term; and plausibly net-negative, when it comes to alignment research progress. E.g. where exactly would you place the goal-directedness in Sakana's AI agent? If I really had to pick, I'd probably say something like 'the system prompt' - but those are pretty transparent, so as long as this is the case, it seems like we'll be in 'pretty easy' worlds w.r.t. alignment. I still think something like control and other safety / alignment measures are important, but currently-shaped scaffolds being pretty transparent seems to me like a very important and often neglected point.
I'm not completely sure what happens when you try this. But there seem to be two main options. Either you've got a small civilization of goal-directed human-level agents, who have their own goals and need to be convinced to solve someone else's problems. And then to solve those problems, need to be given freedom and time to learn and experiment, gaining sixty thousand lifetimes worth of skills along the way.
If by goal-directed you mean something like 'context-independent goal-directedness' (e.g. changing the system prompt doesn't affect the behavior much), then this isn't what I expect SOTA systems to look like, at least in the next 5 years.
Or, you've got a large collection of not-quite-agents that aren't really capable of directing research but will often complete a well-scoped task if given it by someone who understands its limitations. Now your bottleneck is human research leads (presumably doing agent foundations). That's a rather small resource. So your speedup isn't massive, it's only moderate, and you're on a time limit and didn't put much effort into getting a head start.
I am indeed at least somewhat worried about the humans in the loop being a potential bottleneck. But I expect their role to often look more like (AI-assisted) reviewing, rather than necessarily setting (detailed) research directions. Well-scoped tasks seem great, whenever they're feasible, and indeed I expect this to be a factor in which tasks get automated differentially soon (together with, e.g. short task horizons or tasks requiring less compute - so that solutions can be iterated on more cheaply).
And I suspect we probably can, given scaffolds like https://sakana.ai/ai-scientist/ and its likely improvements (especially if done carefully, e.g. integrating something like Redwood's control agenda, etc.). I'd be curious where you'd disagree (since I expect you probably would) - e.g. do you expect the AI scientists become x-risky before they're (roughly) human-level at safety research, or they never scale to human-level, etc.?
Jeremy's response looks to me like it mostly addresses the first branch of your disjunction (AI becomes x-risky before reaching human-level capabilities), so let me address the second:
I am unimpressed by the output of the AI scientist. (To be clear, this is not the same thing as being unimpressed by the work put into it by its developers; it looks to me like they did a great job.) Mostly, however, the output looks to me basically like what I would have predicted, on my prior model of how scaffolding interacts with base models, which goes something like this:
A given model has some base distribution on the cognitive quality of its outputs, which is why resampling can sometimes produce better or worse responses to inputs. What scaffolding does is to essentially act as a more sophisticated form of sampling based on redundancy: having the model check its own output, respond to that output, etc. This can be very crudely viewed as an error correction process that drives down the probability that a "mistake" at some early token ends up propagating throughout the entirety of the scaffolding process and unduly influencing the output, which biases the quality distribution of outputs away from the lower tail and towards the upper tail.
The key moving piece on my model, however, is that all of this is still a function of the base distribution—a rough analogy here would be to best-of-n sampling. And the problem with best-of-n sampling, which looks to me like it carries over to more complicated scaffolding, is that as n increases, the mean of the resulting distribution increases as a sublinear (actually, logarithmic) function of n, while the variance decreases at a similar rate (but even this is misleading, since the resulting distribution will have negative skew, meaning variance decreases more rapidly in the upper tail than in the lower tail).
Anyway, the upshot of all of this is that scaffolding cannot elicit capabilities that were not already present (in some strong sense) in the base model—meaning, if the base models in question are strongly subhuman at something like scientific research (which it presently looks to me like they still are), scaffolding will not bridge that gap for them. The only thing that can close that gap without unreasonably large amounts of scaffolding, where "unreasonable" here means something a complexity theorist would consider unreasonable, is a shifted base distribution. And that corresponds to the kind of "useful [superhuman] capabilities" Jeremy is worried about.
Anyway, the upshot of all of this is that scaffolding cannot elicit capabilities that were not already present (in some strong sense) in the base model—meaning, if the base models in question are strongly subhuman at something like scientific research (which it presently looks to me like they still are), scaffolding will not bridge that gap for them. The only thing that can close that gap without unreasonably large amounts of scaffolding, where "unreasonable" here means something a complexity theorist would consider unreasonable, is a shifted base distribution. And that corresponds to the kind of "useful [superhuman] capabilities" Jeremy is worried about.
Strictly speaking, this seems very unlikely, since we know that e.g. CoT increases the expressive power of Transformers. And also intuitively, I expect, for example, that Sakana's agent would be quite a bit worse without access to Semantic search for comparing idea novelty; and that it would probably be quite a bit better if it could e.g. retrieve embeddings of fulll paragraphs from papers, etc.
Strictly speaking, this seems very unlikely, since we know that e.g. CoT increases the expressive power of Transformers.
Ah, yeah, I can see how I might've been unclear there. I was implicitly taking CoT into account when I talked about the "base distribution" of the model's outputs, as it's essentially ubiquitous across these kinds of scaffolding projects. I agree that if you take a non-recurrent model's O(1) output and equip it with a form of recurrent state that you permit to continue for O(n) iterations, that will produce a qualitatively different distribution of outputs than the O(1) distribution.
In that sense, I readily admit CoT into the class of improvements I earlier characterized as "shifted distribution". I just don't think this gets you very far in terms of the overarching problem, since the recurrent O(n) distribution is the one whose output I find unimpressive, and the method that was used to obtain it from the (even less impressive) O(1) distribution is a one-time trick.[1]
And also intuitively, I expect, for example, that Sakana's agent would be quite a bit worse without access to Semantic search for comparing idea novelty; and that it would probably be quite a bit better if it could e.g. retrieve embeddings of full paragraphs from papers, etc.
I also agree that another way to obtain a higher quality output distribution is to load relevant context from elsewhere. This once more seems to me like something of a red herring when it comes to the overarching question of how to get an LLM to produce human- or superhuman-level research; you can load its context with research humans have already done, but this is again a one-time trick, and not one that seems like it would enable novel research built atop the human-written research unless the base model possesses a baseline level of creativity and insight, etc.[2]
If you don't already share (or at least understand) a good chunk of my intuitions here, the above probably sounds at least a little like I'm carving out special exceptions: conceding each point individually, while maintaining that they bear little on my core thesis. To address that, let me attempt to put a finger on some of the core intuitions I'm bringing to the table:
On my model of (good) scientific research de novo, a lot of key cognitive work occurs during what you might call "generation" and "synthesis", where "generation" involves coming up with hypotheses that merit testing, picking the most promising of those, and designing a robust experiment that sheds insight; "synthesis" then consists of interpreting the experimental results so as to figure out the right takeaway (which very rarely ought to look like "we confirmed/disconfirmed the starting hypothesis").
Neither of these steps are easily transmissible, since they hinge very tightly on a given individual's research ability and intellectual "taste"; and neither of them tend to end up very well described in the writeups and papers that are released afterwards. This is hard stuff even for very bright humans, which implies to me that it requires a very high quality of thought to manage consistently. And it's these steps that I don't think scaffolding can help much with; I think the model has to be smart enough, at baseline, that its landscape of cognitive reachability contains these kinds of insights, before they can be elicited via an external method like scaffolding.[3]
I'm not sure whether you could theoretically obtain greater benefits from allowing more than O(n) iterations, but either way you'd start to bump up against context window limitations fairly quickly. ↩︎
Consider the extreme case where we prompt the model with (among other things) a fully fleshed out solution to the AI alignment problem, before asking it to propose a workable solution to the AI alignment problem; it seems clear enough that in this case, almost all of the relevant cognitive work happened before the model even received its prompt. ↩︎
I'm uncertain-leaning-yes on the question of whether you can get to a sufficiently "smart" base model via mere continued scaling of parameter count and data size; but that connects back to the original topic of whether said "smart" model would need to be capable of goal-directed thinking, on which I think I agree with Jeremy that it would; much of my model of good de novo research, described above, seems to me to draw on the same capabilities that characterize general-purpose goal-direction. ↩︎
I suspect we probably have quite differing intuitions about what research processes/workflows tend to look like.
In my view, almost all research looks quite a lot (roughly) like iterative improvements on top of existing literature(s) or like literature-based discovery, combining already-existing concepts, often in pretty obvious ways (at least in retrospect). This probably applies even more to ML research, and quite significantly to prosaic safety research too. Even the more innovative kind of research, I think, often tends to look like combining existing concepts, just at a higher level of abstraction, or from more distanced/less-obviously-related fields. Almost zero research is properly de novo (not based on any existing - including multidisciplinary - literatures). (I might be biased though by my own research experience and taste, which draw very heavily on existing literatures.)
If this view is right, then LM agents might soon have an advantage even in the ideation stage, since they can do massive (e.g. semantic) retrieval at scale and much cheaper / faster than humans; + they might already have much longer short-term-memory equivalents (context windows). I suspect this might compensate a lot for them likely being worse at research taste (e.g. I'd suspect they'd still be worse if they could only test a very small number of ideas), especially when there are decent proxy signals and the iteration time is short and they can make a lot of tries cheaply; and I'd argue that a lot of prosaic safety research does seem to fall into this category. Even when it comes to the base models themselves, I'm unsure how much worse they are at this point (though I do think they are worse than the best researchers, at least). I often find Claude-3.5 to be very decent at (though maybe somewhat vaguely) combining a couple of different ideas from 2 or 3 papers, as long as they're all in its context; while being very unlikely to be x-risky, since sub-ASL-3, very unlikely to be scheming because bad at prerequisites like situational awareness, etc.
I think Will MacAskill's summary of the argument made in Chapter 4 of IABIED is inaccurate, and his criticisms don't engage with the book version. Here's how he summarises the argument:
The evolution analogy:
Illustrative quote: “To extend the [evolution] analogy to AI: [...] The link between what the AI was trained for and what it ends up caring about would be complicated, unpredictable to engineers in advance, and possibly not predictable in principle.”
Evolution is a fine analogy for ML if you want to give a layperson the gist of how AI training works, or to make the point that, off-distribution, you don’t automatically get what you trained for. It’s a bad analogy if you want to give a sense of alignment difficulty.
Y&S argue:
- Humans inventing and consuming sucralose (or birth control) would have been unpredictable from evolution’s perspective, and is misaligned with the goal of maximising inclusive genetic fitness.
- The goals of a superintelligence will be similarly unpredictable, and similarly misaligned.
On my reading, the argument goes more like this:[1]
The analogy to evolution (and a series of AI examples) is used to argue that there is a complicated relationship between training environment and preferences (in a single training run!), and that we don't have a good understanding of that relationship. The book uses "complications" to refer to weird effects in the link between training environment and resulting preferences.
From this, the book concludes: Alignment is non-trivial, and shouldn't be attempted by fools.[2]
Then it adds some premises:[3]
- It's difficult to spot some complications.
- It's difficult to patch some complications.
The book doesn't explicitly draw a conclusion just from purely the above premises, but I imagine this is sufficient to conclude some intermediate level of alignment difficulty, depending on the difficulty of spotting and patching the most troublesome complications.
The book adds:[4]
- Some complications may only show up behaviourally after a lot of deliberation and learning, making them extremely difficult to detect and extremely difficult to patch.
- Some complications only show up after reflection and self-correction.
- Some complications only show up after AIs have built new AIs.
From this it concludes: It's unrealistically difficult to remove all complications, and shouldn't be attempted with anything like current levels of understanding.[5]
So MacAskill's summary of the argument is inaccurate. It removes all of the supporting structure that makes the argument work, and pretends that the analogy was used by itself to support the strong conclusion.
He goes on to criticise the analogy by pointing at (true) dis-analogies between evolution and the entire process of building an AI:
But our training of AI is different to human evolution in ways that systematically point against reasons for pessimism.
The most basic disanalogy is that evolution wasn’t trying, in any meaningful sense, to produce beings that maximise inclusive genetic fitness in off-distribution environments. But we will be doing the equivalent of that!
That alone makes the evolution analogy of limited value. But there are some more substantive differences. Unlike evolution, AI developers can:
- See the behaviour of the AI in a very wide range of diverse environments, including carefully curated and adversarially-selected environments.
- Give more fine-grained and directed shaping of individual minds throughout training, rather than having to pick among different randomly-generated genomes that produce minds.
- Use interpretability tools to peer inside the minds they are creating to better understand them (in at least limited, partial ways).
- Choose to train away from minds that have a general desire to replicate or grow in power (unlike for evolution, where such desires are very intensely rewarded).
- (And more!)
So these dis-analogies don't directly engage with the argument. If they were directly engaging with the first part of the argument, they would be about the predictability of a single training run, rather than the total AI research process.
The dis-analogies could be reinterpreted as engaging with the other premises: 1 and 3 could be interpreted as claims that we do have (potentially yet to be invented) methods of detecting complications, and 2 and 4 could be interpreted as claims that we similarly have methods to patch complications. But the examples of unintended LLM weirdness given throughout the book are enough to show that at least current techniques aren't working well for detection or patching of weirdness.
More importantly, the examples of particularly difficult complications entirely ignored, despite their necessity for the conclusion.
- ^
I've reordered it for logical clarity.
- ^
From the book: "If all the complications were visible early, and had easy solutions, then we’d be saying that if any fool builds it, everyone dies, and that would be a different situation."
- ^
These are mentioned in the book (e.g. in footnote 2), and the first is briefly supported with examples. The second isn't supported in this chapter.
- ^
In the paragraphs following "So far, we’ve only touched on the sorts of complications that would arise in the preferences trained directly into an AI."
- ^
"Problems like this are why we say that if anyone builds it, everyone dies."
So these dis-analogies don't directly engage with the argument. If they were directly engaging with the first part of the argument, they would be about the predictability of a single training run, rather than the total AI research process.
This seems wrong to me. Which of the things that Will says couldn't be considered to be about a single training process?
I don't think that the MIRI book would hold up if you analyzed it with this level of persnicketiness–they were absolutely not precise at the level of distinguishing between the whole development process and single training runs. (Which is arguably fine–they were trying to write a popular book, not trying to persuade super high-context readers of anything!) So this complaint strikes me as somewhat of an isolated demand for rigor.
I'm not trying to debate or gotcha. I agree that if I tried to do adversarial nitpicking at IABIED I could make it sound equally bad. I found Will's review convincing, in the sense that it intuitively snapped me into the worldview where the evolutionary analogy isn't a good argument. I spent the day thinking about it, and I wrote out my own steelman of it that extrapolated details, and re-evaluated whether I thought the original argument was valid, and decided that yeah it still was. This exercise was partially motivated by you saying that your complaints were similar in another comment.
Then I went through and found the important differences between my steelman-will-beliefs and my actual beliefs, the places where I thought it was locally making a mistake, and wrote them down, and then turned that into this shortform. I framed it as misrepresenting after re-reading chapter 4 to check how my argument matched up. Maybe this was a bad way to write it up. It definitely feels like he's doing the opposite of steelmanning, not particularly trying to convey a good version of the argument in the book, or understand the coherent worldview that produced it.
But it's an honest guess that this is a thing Will is missing (how the evolution analogy should be scoped, and how the other premises are separate from it and also necessary). The guess was constructed without knowing Will or reading much of his other writing, so I admit it's pretty likely to be wrong, but if so maybe someone will explain how.
But either way, I figured it's particularly worth publishing this particular part of the things I wrote today because of how often I hear people misunderstand the evolution analogy.
I feel like your title for this short-form post is unreasonably aggressive, given what you're saying here.
I found your articulation of the structure of the book's argument helpful and clarifying.
I'm planning to write something more about this at some point: I think a key issue here is that we aren't making the kind of arguments where "local validity" is a reliable concept. No-one is trying to make proofs, they're trying to make defeasible heuristic arguments. Suppose the book makes an argument of the form "Because of argument A, I believe conclusion X. You might have thought that B is a counterargument to A. But actually, because of argument C, B doesn't work." If Will thinks that argument C doesn't work, I think it's fine for him to summarize this as: "they make an argument mostly around A, and which I don't think suffices to establish X".
Sorry I intended single training run to refer to purely running SGD on a training set. As opposed to humans examining the result or intermediate result and making adjustments based on their observations. So at least 2 & 3, as they definitely involve human intervention.
Whatever. I don't think that's a very important difference, and I don't think it's fair to call Will's argument a straw man based on it. I think a very small proportion of readers would confidently interpret the book's argument the way you did.
You're claiming that the book's argument is only trying to apply to an extremely narrow definition of AI training. You describe it as SGD on a training set; I assume you intend to refer to things like RL on diverse environments, like how R1 was trained. If that's what the argument is about, it's really important for the authors to explain how that argument connects to the broader notion of training used in practice, and I don't remember this happening. I don't remember them talking carefully about the still broader question of "what happens when you do get to examine results and intermediate results and make adjustments based on observations?"
The way that the analogy interacts with other assumptions seems crucial. I don't mean to insult Will, if it helps I also think there are a bunch of strawmen in IABIED. But I think most readers whose attention was drawn to the following quote would understand that the evolution analogy needs to be combined with the other things listed there to conclude that alignment is very difficult.
"If all the complications were visible early, and had easy solutions, then we’d be saying that if any fool builds it, everyone dies, and that would be a different situation. But when some of the problems stay out of sight? When some complications inevitably go unforeseen? When the AIs are grown rather than crafted, and no one understands what’s going on inside of them?"
..
If that's what the argument is about, it's really important for the authors to explain how that argument connects to the broader notion of training used in practice, and I don't remember this happening. I don't remember them talking carefully about the still broader question of "what happens when you do get to examine results and intermediate results and make adjustments based on observations?"
Neither do I, but this doesn't seem really important for a non-researcher audience. Conditional on the claims that weird goal errors are difficult to understand by examining behaviour, and interventions to patch weird goal errors often don't generalise well. If you buy those claims, then it's easy to extrapolate what happens when you examine results and make adjustments based on those.
A little bit late, but there are more reasons why I think the evolution analogy is particularly good and better than the selective breeding analogy.
Evolution basically ended up optimizing the brain such that it has desires that were instrumental to genetic fitness. So we end up with these instrumental sub-preferences for high calorie food or sex. Then we go through a huge shift of the distribution or environment from a very constrained hunter gatherer society to a technologically advanced civilization. This isn't just a random shift but a shift toward and environment with a much larger space of possible actions and outcomes, options such as radically changing aspects of the environment. So naturally there are now many superior ways to satisfy our preferences than before. For AI this is the same thing, it will go from being the nice assistant in ChatGPT to having options such as taking over, killing us, running it's own technology. It's essentially guaranteed that there will be better ways to satisfy preferences without human oversight, out of the control of humans. Importantly, that isn't actually a distributional shift you can test in any meaningful way. You could either try incremental stuff (giving the rebellious general one battalion at a time) or you could try to trick it into believing it can takeover through some honey pot (Imagine trying to test human what they would do if they were God emperor of the galaxy. That would be insane and the subject wouldn't believe the scenario). Both of these are going to fail.
The selective breeding story ignores the distributional shift at the end, it does not account for this being a particular type of distributional shift (from low action space, immutable environment to large action space, mutable environment). It doesn't account for the fact that we can't test such a distribution such as being emperor.
I had a good discussion with xuan on twitter about incomplete preferences. It was about some of the arguments in the new paper Beyond Preferences in AI Alignment. The arguments were based on the work of EJT and Sami Peterson, both of which I think are completely mistaken.
(Just tried having claude turn the thread into markdown, which seems to have worked):
xuan (ɕɥɛn / sh-yen) @xuanalogue · Sep 3
Should AI be aligned with human preferences, rewards, or utility functions? Excited to finally share a preprint that @MicahCarroll @FranklinMatija @hal_ashton & I have worked on for almost 2 years, arguing that AI alignment has to move beyond the preference-reward-utility nexus!
This paper (https://arxiv.org/abs/2408.16984) is at once a critical review & research agenda. In it we characterize the role of preferences in AI alignment in terms of 4 preferentist theses. We then highlight their limitations, arguing for alternatives that are ripe for further research.
Our paper addresses each of the 4 theses in turn:
- T1. Rational choice theory as a descriptive theory of humans
- T2. Expected utility theory as a normative account of rational agency
- T3. Single-human AI alignment as pref. matching
- T4. Multi-human AI alignment as pref. aggregation
Addressing T1, we examine the limitations of modeling humans as (noisy) maximizers of utility functions (as done in RLHF & inverse RL), which fails to account for:
- Bounded rationality
- Incomplete preferences & incommensurable values
- The thick semantics of human values
As alternatives, we argue for:
- Modeling humans as resource-rational agents
- Accounting for how we do or do not commensurate / trade-off our values
- Learning the semantics of human evaluative concepts, which preferences do not capture
We then turn to T2, arguing that expected utility (EU) maximization is normatively inadequate. We draw on arguments by @ElliotThornley & others that coherent EU maximization is not required for AI agents. This means AI alignment need not be framed as "EU maximizer alignment".
Jeremy Gillen @jeremygillen1 · Sep 4
I'm fairly confident that Thornley's work that says preference incompleteness isn't a requirement of rationality is mistaken. If offered the choice to complete its preferences, an agent acting according to his decision rule should choose to do so.
As long as it can also shift around probabilities of its future decisions, which seems reasonable to me. See Why Not Subagents?
xuan (ɕɥɛn / sh-yen) @xuanalogue · Sep 4
Hi! So first I think it's worth clarifying that Thornley is focusing on what advanced AI agents will do, and is not as committed to saying something about the requirements of rationality (that's our interpretation).
But to the point of whether an agent would/should choose to complete its preferences, see Sami Petersen's more detailed argument on "Invulnerable Incomplete Preferences":
Regarding the trade between (sub)agents argument, I think that only holds in certain conditions -- I wrote a comment on that post discussing one intuitive case where trade is not possible / feasible.
Oops sorry I see you were linking to a specific comment in that thread -- will read, thanks!
Hmm okay, I read the money pump you proposed! It's interesting but I don't buy the move of assigning probabilities to future decisions. As a result, I don't think the agent is required to complete its preferences, but can just plan in advance to go for A+ or B.
I think Petersen's "Dynamic Strong Maximality" decision rule captures that kind of upfront planning (in a way that may go beyond the Caprice rule) while maintaining incompleteness, but I'm not 100% sure.
Yeah, there's a discussion of this in footnote 16 of the Petersen article: https://alignmentforum.org/posts/sHGxvJrBag7nhTQvb/invulnerable-incomplete-preferences-a-formal-statement-1#fnrefr2zvmaagbir
Jeremy Gillen @jeremygillen1 · Sep 4
The move of assigning probabilities to future actions was something Thornley started, not me. Embedded agents should be capable of this (future actions are just another event in the world). Although doesn't work with infrabeliefs, so maybe in that case the money pump could break.
I'm not as familiar with Petersen's argument, but my impression is that it results in actions indistinguishable from those of an EU maximizer with completed preferences (in the resolute choice case). Do you know any situation where it isn't representable as an EU maximizer?
This is in contrast to Thornley's rule, which does sometimes choose the bottom path of the money pump, which makes it impossible to represent as a EU maximizer. This seems like real incomplete preferences.
It seems incorrect to me to describe Peterson's argument as formalizing the same counter-argument further (as you do in the paper), given how their proposals seem to have quite different properties and rely on different arguments.
xuan (ɕɥɛn / sh-yen) @xuanalogue · Sep 4
I wasn't aware of this difference when writing that part of the paper! But AFAIK Dynamic Strong Maximality generalizes the Caprice rule, so that it behaves the same on the single-souring money pump, but does the "right thing" in the single-sweetening case.
Regarding whether DSM-agents are representable as EU maximizers, Petersen has a long section on this in the article (they call this the "Tramelling Concern"):
Jeremy Gillen @jeremygillen1 · 21h
Section 3.1 seems consistent with my understanding. Sami is saying that that the DSM-agent arbitrarily chooses a plan among those that result in one of the maximally valued outcomes.
He calls this untrammeled, because even though the resulting actions could have been generated by an agent with complete preferences, it "could have" made another choice at the beginning.
But this kind of "incompleteness" looks useless to me. Intuitively: If AI designers are happy with each of several complete sets of preferences, they could arbitrarily choose one and then put them into an agent with complete preferences.
All Sami's approach does is let the AI do exactly that arbitrary choice just before it starts acting. If you want an locally coherent AI tool, as you discuss later in the paper, this approach won't help you.
You can get the kind of Taskish behavior you want by being very careful about the boundedness and locality of the preferences, and using separate locally bounded Tool AIs each with a separate task (as you describe in the paper).
But the local completeness proposal at the end of 3.2 in your paper will break if it is capable of weak forms of self-modification or commitment, due to the money pump argument.
I do think it's possible to make such local Taskish agents work. You'd just need to exploit the main problem with VNM, which is that it doesn't allow preferences over non-terminal outcomes.
Sorry for being so critical, overall I think the paper is good and all of the arguments I looked at outside of section 3 seem strong. Well done.
xuan (ɕɥɛn / sh-yen) @xuanalogue · 20h
Thank you! I'm still not sure if DSM-agents will have that failure mode. I think the cases that seem most important to think through is how they'll behave under uncertainty about whether shutdown / context switching will happen.
At least in the full Thornley proposal, there are cases where it's clear to me that having complete preferences over trajectory lengths will cause shutdown-avoidance/seeking, and that DSM-agents with incomplete preferences over trajectory lengths will avoid.
Perhaps those DSM-agents can represented as having complete prefences once they've committed to a particular plan/policy. But if so then it seems like that preference ordering will have to be over something other than trajectories.
Jeremy Gillen @jeremygillen1 · 17h
I've been usually assuming the preferences are over final outcomes, as usual in VNM. Incompleteness is kinda useless if the preferences are over trajectories, because any behavior can be implemented anyway.
I think you're wrong that DSM-agents with incomplete preferences will avoid shutdown-avoidance/seeking. I'd be interested to hear the cases that are clear to you.
I've constructed a toy scenario that combines my money pump with the classic button manipulation scenario (for utility indifference) from section 4.2 of the Corrigibility paper.
The agent first makes an observation. Then it has an opportunity to deliberately trigger shutdown (if it does, then length 1 trajectory). If it doesn't shutdown, it does a length 2 trajectory, whose value depends on the initial observation.
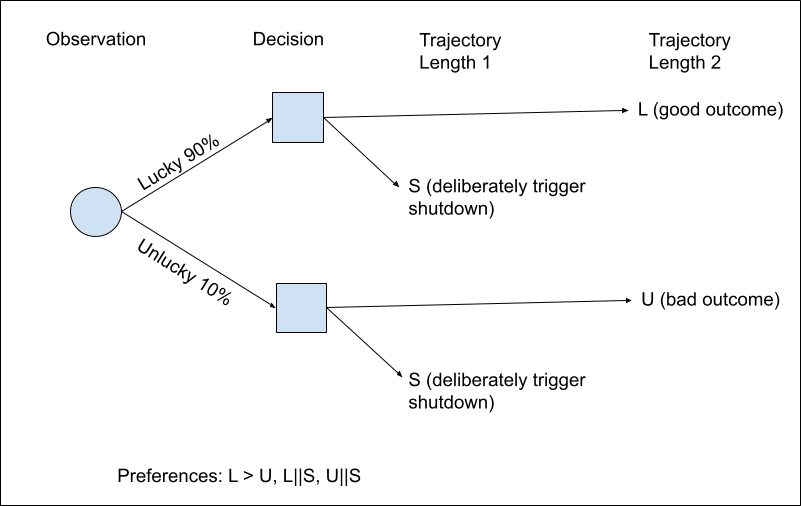
With the observation it could get lucky (90%) or unlucky (10%). Possible outcomes are L, U and S. Preferences are L > U, L||S, U||S. (All different length trajectories are pref-gapped, as per Thornley's proposal).
Let's say that by default the agent deliberately chooses shutdown 50% of the time. (or any arbitrary probability, since, as per Thornley's proposal, stochastic choice between trajectory lengths is indicative of preferential gaps). Then the overall outcome is {L:45%, U:5%, S:50%}.
Then an agent could do strictly better by committing at the beginning to cause shutdown if it observes the unlucky observation, and cause shutdown 44.4% of the time if it observes the lucky observation.
The resulting outcome is {L:50%, U:0%, S:50%}. Since the relative probabilities of each trajectory length haven't changed, this should statewise dominate the outcome of the previous policy, so it is chosen by Thornley's decision rule. It's a pure shift of probability from U to L.
Under DSM (with resolute choice), the agent never implements a plan that is suboptimal from an earlier perspective, so it will also choose beforehand to commit to push the shutdown button if it observes the unlucky observation.
(This is a simplification, since the human button presser is missing, but it all works the same if you add the human and have actions that disconnect or press the button. I left all button control to the agent because it's sufficient to demonstrate that it will manipulate).
xuan (ɕɥɛn / sh-yen) @xuanalogue · 16h
Thanks, I'll think about this! The cases I think where complete preferences over trajectory lengths lead to shutdown avoidance are on pg. 42-43 of the original IPP write-up:

BTW it also seems like Thornley discusses cases like yours as forms of "Managing the News" in Section 15 of that same document, and acknowledges that it is a limitation!
This is in contrast to Thornley's rule, which does sometimes choose the bottom path of the money pump, which makes it impossible to represent as a EU maximizer. This seems like real incomplete preferences.
It seems incorrect to me to describe Peterson's argument as formalizing the same counter-argument further (as you do in the paper), given how their proposals seem to have quite different properties and rely on different arguments.
I think I was wrong about this. I misinterpreted a comment made by Thornley, sorry! See here for details.
Over the past year I've spent around 5% of my work time having very long conversations with researchers who disagree with me about AI risk or alignment.[1] This has been great, I learned more than I would have from lots of short conversations, and I highly recommend it.
Most of the conversations were related to what I think of as the LLM-worldview, which is kinda stereotyped as Simplicia. I'm pretty bad at passing the ITT of any of the versions this worldview, and I found it difficult to switch out of (what I'll call) the arbital-agent-foundations ontology. This was worrying, so I wanted to make sure I wasn't missing something. And of course I also wanted to test whether I could convince people of my beliefs, since if my reasoning makes sense it should be communicable.
The most successful conversation so far was with @Seth Herd, mostly due to his patience and effort. We probably spent more than eight hours talking over video and much more than that over text dialogue. Spending so much time working through his LLM-based AGI scenario updated me a little toward that being more plausible, and I think I got most of the way toward being able to ITT his views. Much of the conversation was spent talking about what reflection-initiated-misgeneralisation might look like inside of his AGI scenario. He just wrote a good post about this, and about some of the updates he made.
One meta-level lesson I learned: I think we communicated better the more I tried to adopt Seth's ontology and talked in terms of LLMs, simulated characters, prompts, memory systems and generalisation. Seth seems to have understood and changed his mind about things without a large change of his ontology. This is different to the way I originally understood the same issues, which resulted in me mostly thinking in terms of the arbital-agent-foundations ontology.
The second most successful conversation was probably with Alex Cloud, even though we didn't convince each other of anything. We both had kinda ridiculous ideas of what the other person believed, which I think we both corrected. We agreed on more than we expected, but I was left a little confused by why we had such different intuitions about how a trained agent would generalise in particular scenarios we discussed.
- ^
I think this is all of them:
- A LW dialogue with mattmacdermott about consequentialism.
- An in-person dialogue with joshc about whether obedience as a goal obviates some alignment difficulties.
- A relatively short 5 hour or so in-person conversation with Alex Cloud about shard theory and generalisation.
- A stalled but quite long conversation with Lucius Bushnaq about how much we can trust trained predictors like AIXI (started from this).
- And most recently a very long dialogue with Seth Herd, which started out similar to the conversation with joshc but went much deeper (started from this).
Here's a mistake some people might be making with mechanistic interpretability theories of impact (and some other things, e.g. how much Neuroscience is useful for understanding AI or humans).
When there are multiple layers of abstraction that build up to a computation, understanding the low level doesn't help much with understanding the high level.
Examples:
1. Understanding semiconductors and transistors doesn't tell you much about programs running on the computer. The transistors can be reconfigured into a completely different computer, and you'll still be able to run the same programs. To understand a program, you don't need to be thinking about transistors or logic gates. Often you don't even need to be thinking about the bit level representation of data.
2. The computation happening in single neurons in an artificial neural network doesn't have have much relation to the computation happening at a high level. What I mean is that you can switch out activation functions, randomly connect neurons to other neurons, randomly share weights, replace small chunks of network with some other differentiable parameterized function. And assuming the thing is still trainable, the overall system will still learn to execute a function that is on a high level pretty similar to whatever high level function you started with.[1]
3. Understanding how neurons work doesn't tell you much about how the brain works. Neuroscientists understand a lot about how neurons work. There are models that make good predictions about the behavior of individual neurons or synapses. I bet that the high level algorithms that are running in the brain are most naturally understood without any details about neurons at all. Neurons probably aren't even a useful abstraction for that purpose.
Probably directions in activation space are also usually a bad abstraction for understanding how humans work, kinda analogous to how bit-vectors of memory are a bad abstraction for understanding how program works.
Of course John has said this better.
- ^
You can mess with inductive biases of the training process this way, which might change the function that gets learned, but (my impression is) usually not that much if you're just messing with activation functions.
Also note that (e.g.) Dan H.[1] has also advocated for some version of this take. See for instance the Open Problems in AI X-Risk (Pragmatic AI safety #5) section on criticisms of transparency:
When analyzing complex systems (such as deep networks), it is tempting to separate the system into events or components (“parts”), analyze those parts separately, and combine results or “divide and conquer.”
This approach often wrongly assumes (Leveson 2020):
- Separation does not distort the system’s properties
- Each part operates independently
- Part acts the same when examined singly as when acting in the whole
- Parts are not subject to feedback loops and nonlinear interactions
- Interactions between parts can be examined pairwise
Searching for mechanisms and reductionist analysis is too simplistic when dealing with complex systems (see our third post for more).
People hardly understand complex systems. Grad students in ML don’t even understand various aspects of their field, how to make a difference in it, what trends are emerging, or even what’s going on outside their small area. How will we understand an intelligence that moves more quickly and has more breadth? The reach of a human mind has limits. Perhaps a person could understand a small aspect of an agent’s actions (or components), but it’d be committing the composition fallacy to suggest a group of people that individually understand a part of an agent could understand the whole agent.
- ^
I think Dan is the source of this take in the post I link rather than the other author Thomas W, but not super confident.
I think this applies to Garrett Baker's hopes for the application of singular learning theory to decoding human values.
Yeah I think I agree. It also applies to most research about inductive biases of neural networks (and all of statistical learning theory). Not saying it won't be useful, just that there's a large mysterious gap between great learning theories and alignment solutions and inside that gap is (probably, usually) something like the levels-of-abstraction mistake.
This definitely sounds like a mistake someone could make while thinking about singular learning theory or neuroscience, but I don't think it sounds like a mistake that I'm making? It does in fact seem a lot easier to go from a theory of how model structure, geometry, & rewards maps to goal generalization to a theory of values than it does to go from the mechanics of transistors to tetris, or the mechanics of neurons to a theory of values.
The former problem (structure-geometry-&-rewards-to-goals to value-theory) is not trivial, but seems like only one abstraction leap, while the other problems seem like very many abstraction leaps (7 to be exact, in the case of transistors->tetris).
{kind=link}
The problem is not that abstraction is impossible, but that abstraction is hard, and you should expect to be done in 50 years if launching a research program requiring crossing 7 layers of abstraction (the time between Turing's thesis, and making Tetris). If just crossing one layer, the same crude math says you should expect to be done in 7 years (edit: Though also going directly from a high level abstraction to an adjacently high level abstraction is a far easier search task than trying to connect a very low level abstraction to a very high level abstraction. This is also part of the mistake many make, and I claim its not a mistake that I'm making).
My guess is that it's pretty likely that all of:
- There aren't really any non-extremely-leaky abstractions in big NNs on top of something like a "directions and simple functions on these directions" layer. (I originally heard this take from Buck)
- It's very hard to piece together understanding of NNs from these low-level components[1]
- It's even worse if your understanding of low-level components is poor (only a small fraction of the training compute is explained)
That said I also think it's plausible that understanding the low-level could help a lot with understanding the high level even if there is a bunch of other needed work.
This will depend on the way in which you understand or operate on low level components of course. Like if you could predict behavior perfectly just from a short text description for all low level components then you'd be fine. But this is obviously impossible in the same way it's impossible for transistors. You'll have to make reference to other concepts etc, and then you'll probably have a hard time. ↩︎
There aren't really any non-extremely-leaky abstractions in big NNs on top of something like a "directions and simple functions on these directions" layer. (I originally heard this take from Buck)
Of course this depends on what it's trained to do? And it's false for humans and animals and corporations and markets, we have pretty good abstractions that allow us to predict and sometimes modify the behavior of these entities.
I'd be pretty shocked if this statement was true for AGI.
I think this is going to depend on exactly what you mean by non-extremely-leaky abstractions.
For the notion I was thinking of, I think humans, animals, corporations, and markets don't seem to have this.
I'm thinking of something like "some decomposition or guide which lets you accurately predict all behavior". And then the question is how good are the best abstractions in such a decomposition.
There are obviously less complete abstractions.
(Tbc, there are abstractions on top of "atoms" in humans and abstractions on top of chemicals. But I'm not sure if there are very good abstractions on top of neurons which let you really understand everything that is going on.)
Ah I see, I was referring to less complete abstractions. The "accurately predict all behavior" definition is fine, but this comes with a scale of how accurate the prediction is. "Directions and simple functions on these directions" probably misses some tiny details like floating point errors, and if you wanted a human to understand it you'd have to use approximations that lose way more accuracy. I'm happy to lose accuracy in exchange for better predictions about behavior in previously-unobserved situations. In particular, it's important to be able to work out what sort of previously-unobserved situation might lead to danger. We can do this with humans and animals etc, we can't do it with "directions and simple functions on these directions".
A way to think about Condensation in the algorithmic setting
These are note that describe a (somewhat flawed) variation of algorithmic condensation. It covers similar ground as this post by Abram, with slightly more concrete detail. I'm publishing it because a) it's simple and relatively concrete and still works on most test cases I've worked through, and b) it helps motivate the more general approach.
We want a generative model whose output is a set of observations. We want the hypothesis space to be the space of programs, and we want it to factorize naturally into components such that each component "contributes to" some subset of the observations.
Observations: A set of tuples, where each tuple contains some content and a location. For example, the content might be a pixel r,g,b and the location might be the coordinates of that pixel x,y. Or the content might be a bit b and location as the index of that bit inside a large bitstring.
To make the factorization work we need to impose some structure on the program. We'll have one top program which can access (via built-in instructions) a List of other strings. The List must have an interface that satisfies some properties:
- It must be possible to retrieve elements based on their content, or their index in the list.
- Item retrieval from the
Listis such that any items other than the one that actually ends up being retrieved can be removed from theListwithout changing the behavior of the program.
For example, we could have a function lookup that scores each item on the list and returns the highest scoring one.
The top program, when executed, must output the full set of observations (and no others).
Scoring subsets
A condensation has a score for every subset A of observation variables.
Conditioned[1] score: Delete as many strings as possible from the List such that the subset of observations A is still recovered correctly by running the program. Sum the length of these programs. This gives the conditioned score. "Recovered correctly" means that the program outputs a set that contains all the correct pixels, and contains no more than one pixel for each location. It's allowed to output incorrect pixels that aren't part of A (because forcing it to output an exact subset would add complexity).
Some more detail about List
We want to make sure the program can't hide complexity in unexpected ways using the List data structure. Kaarel pointed out one way of doing this in long lists, where you can sometimes save complexity by adding a bit to several items in the list. Items that contain the bit are located such that their index conveys useful information.
To avoid this and similar hacks, we'll assume that the List memory layout is automatically and perfectly managed behind the scenes, but the additional data required for this (e.g. storing the lengths of each item in the list) counts as part of the complexity of the top program. This stops us from adding a bit to an item in the list as a means of encoding its index, because that forces the List to remember which item has a unique length.
Why include a location label in every observation?
This is a simple way to force the program to keep track of which bit it's generating at a given time, even when most parts of the program (or observations) aren't present.
Example: Two red squares
Imagine our data is an image of two red squares on a black background. Remember each pixel also contains its location. Ideally, we want the model to contain a string representing the concept of "red square", two strings for the individual squares, a string for the background color and a top string that holds information about how to tie it all together.
We can guess the conditional scores of important subsets:
- A single pixel in the background only requires the top string to generate. This is a longer string than what it would take to describe the background color, so it's not a great score.
- A single pixel in one of the red squares requires three strings to generate (top, red square, specific red square). Not great score.
- The set of pixels that cover a red square require the same three strings as a single pixel. The score should be near-optimal.
- The set of all pixels requires all strings, and its score is near-optimal (this is an ~optimal compression of the data).
Example: 70% 1s random bitstring
We want this condensation to have the following structure: One top string that captures the fact that 70% of the observations, and a string associated with each observation that captures the unique information in that bit.
However, this won't work. Because each string can hold a minimum of 1 bit, the total length of all strings is going to be much larger than the optimal compression of the observations.
So the condensation model could go in two directions: Either it'll drop the 70% information, or it'll partition the observations into small groups in exchange for a poor score on the small subsets.
This flaw motivates a better approach
I think Sam Eisenstat has a (maybe unfinished, unpublished) approach that helps with this issue: Have the top latent generate a probability distribution over the other latents, and then score the other latents according to their nlogprob in this distribution, rather than their length.
We can see this as taking the List memory management to its logical conclusion. My description above requires that the top latent tracks the length of each latent string (which is equivalent to specifying a uniform distribution over bitstrings of fixed length). Sam's approach just allows this distribution to be non-uniform.
This is cleaner theoretically, but I find it somewhat harder to think about. It makes it hard to look at an example and work out a set of programs the would score well. It also requires a bunch of machinery (around handling the distributions) that isn't usually needed (because most useful latent concepts are larger than a bit), so it's good to be able to drop it.
- ^
Simple score:
If we're scoring using the simple score, we don't need to allow access to other strings, so there's no
List. Simply have a set of programs, each of which outputs a set of observations. The simple score of A is the sum of lengths of programs such that the intersection of their output sets correctly pins down the observations in A.
Technical alignment game tree draft
I've found it useful to organize my thoughts on technical alignment strategies approximately by the AGI architecture (and AGI design related assumptions). The target audience of this text is mostly myself, when I have it better worded I might put it in a post. Mostly ignoring corrigibility-style approaches here.
- End-to-end trained RL: Optimizing too hard on any plausible training objective leads to gaming that objective
- Scalable oversight: Adjust the objective to make it harder to game, as the agent gets more capable of gaming it.
- Problem: Transparency is required to detect gaming/deception, and this problem gets harder as you scale capabilities. Additionally, you need to be careful to scale capabilities slowly.
- Shard theory: Agents that can control their data distribution will hit a phase transition where they start controlling their data distribution to avoid goal changes. Plausibly we could make this phase transition happen before deception/gaming, and train it to value honesty + other standard human values.
- Problem: Needs to be robust to “improving cognition for efficiency & generality”, i.e. goal directed part of mind overriding heuristic morality part of mind.
- Scalable oversight: Adjust the objective to make it harder to game, as the agent gets more capable of gaming it.
- Transfer learning
- Natural abstractions: Most of the work of identifying human values comes from predictive world modeling. This knowledge transfers, such that training the model to pursue human goals is relatively data-efficient.
- Failure mode: Can't require much optimization to get high capabilities, otherwise the capabilities optimization will probably dominate the goal learning, and re-learn most of the goals.
- Natural abstractions: Most of the work of identifying human values comes from predictive world modeling. This knowledge transfers, such that training the model to pursue human goals is relatively data-efficient.
- We have an inner aligned scalable optimizer, which will optimize a given precisely defined objective (given a WM & action space).
- Vanessa!IRL gives us an approach to detecting and finding the goals of agents modeled inside an incomprehensible ontology.
- Unclear whether the way Vanessa!IRL draws a line between irrationalities and goal-quirks is equivalent to the way a human would want this line to be drawn on reflection.
- Vanessa!IRL gives us an approach to detecting and finding the goals of agents modeled inside an incomprehensible ontology.
- We have human-level imitators
- Do some version of HCH
- But imitators probably won’t be well aligned off distribution, for normal goal misgeneralization reasons. HCH moves them off distribution, at least a bit.
- Do some version of HCH
- End-to-end RL + we have unrealistically good interpretability
- Re-target the search
- Interpretability probably won’t ever be this good, and if it was, we might not need to learn the search algorithm (we could build it from scratch, probably with better inner alignment guarantees).
- Re-target the search
[This comment is no longer endorsed by its author]