This is a special post for quick takes by Mateusz Bagiński. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
There is something weird about LLM-produced text. It seems to be very often the case that if I'm trying to read a long text that has been produced primarily by an LLM, I notice that I find it difficult to pay attention to the text. Even if there's apparently semantically rich content, I notice that I'm not even trying to decode it.
the typical LLM writing style has a tendency to make people's eyes slide off of it.
It's kind of similar to the times when your attention wanders away during reading, and then you realize that you were scanning/semi-reading the last page with your eyes, but the information mostly didn't make it past the visual cortex, and you failed to construct the coherent scene that the book was trying to put in your mind. In the case of LLMs, a milder version of this seems to be the default.
This is much more (and much more often) the case if an LLM is tasked to produce something "original-ish" (an essay on topic X, say), rather than just give you the facts on some topic.
What's going on?
Tom White has this non-exhaustive list of telltale tics of LLM writing:
...
- The “It’s not X, it’s Y” Antithesis
- The most common tell. A fake profundity wrapped in a neat contrast: “We’re not a company, we’re a movement.” “It’s not just a tool, it’s a journey.” Humans use this sparingly; AI uses it compulsively
- The Punchline Em-Dash
- Every section feels like it’s waiting for a big reveal—until the reveal is obvious or hollow
- The Three-Item List
- AI loves the rhythm of threes: “clarity, precision, and impact.” It’s a pattern baked deep into training data and reinforced in feedback
- Mirrored Metaphors & Faux Gravitas
- “We don’t chase trends — trends chase us.” They sound like aphorisms, but they’re cosplay; form without experience
- Adverbial Bloat
- “Importantly,” “remarkably,” “fundamentally,” “clearly.” Empty intensifiers meant to simulate significance
- Mechanical Rhythm
- Sentences marching in lockstep, each about the same length. Humans sprawl, stumble, cut themselves off. AI taps its digital foot to a metronome
- Hedged Authority
- The “at its core,” “in many ways,” “arguably.” A way of sounding wise without taking a stand
- Latin Sidebar Syndrome
- AI’s compulsive use of e.g. and i.e. often comes with a giveaway
3
Nitpick: I've debated whether to use "e.g.,". It looks wrong but like, shouldn't that be the way given that "e.g." should 'expand' to "example given" and thus be fine? Seems like it's an autism-filter, really.
Also, I like 3 item lists. Almost everyone is regularly not specific enough. It's your brain's superpower, concrete examples are possibly how humans understand most concepts, and you're probably still underestimating how specific you should be after reading all that.
[...]
Why three? Well, in practice that seems to be enough that you have a handful and aren't overindexing too hard, got some variety, and is at the edge of difficulty to come up with on the fly.
LLM bulleted lists do feel less eye-glazey; I think they're denser but maybe it's just more skimmable.
The following list was not intentionally made to have 3 examples - that's just I happened to do in a medium length of time. Doing the first example was easy, the second I thought of by the time I finished fleshing the first out, and the third required some search. Ideally you push yourself to the point where you have to sit and stare at nothing trying to think at least once.
examples of examples being good
* Very often when doing a math problem I go "Oh, I don't need to write down a small special case to work with, that won't teach me anything!" and I'm wrong most of the time. (less often nowadays but only because I get the premonition of preventable wasted time)
Sometimes people (especially if anxious or depressed) think things like "Everyone hates me". If you ask yourself "name three times you've observed someone acting like they hate you" then often (if you get any at all) the examples are just like... obviously really weak, like "they seemed mildly bored once when talking to me" or "I spilled a drink on them and they didn't make a big deal but they looked a little sadder after it".
* A trick Feynmann said he used: when mathematicians would tell him about math was imagine an example of an
2
>"example given"
It's actually https://en.wiktionary.org/wiki/exempli_gratia (and I do read it this way in my head! I also use it a lot in my writing, occasionally with a comma)
1
Neat, that actually makes more sense grammatically, being plural. Even if it isn't actually, it sounds plural in my head, which is all I actually need.
2
Wiki also has such a list: https://en.wikipedia.org/wiki/Wikipedia:Signs_of_AI_writing
2
Is “e.g.,” really that uncommon? Dang, that’s how I write it naturally
3
Yeah, I also do this because I take "e.g." to be a stand-in for "for example" and when you use the latter, you usually follow it with a comma.
cf "Logical style": https://www.lesswrong.com/posts/YgedrNsdXNajQ7oCT/punctuation-and-quotation-conventions
This has been discussed a lot in the past, often under the term 'mode collapse' and RLHF and flattened logits etc. Hollis Robbins has some good posts the past 2 years on her Substack on the bad writing of chatbot LLMs. It's hard to say what is 'the' problem, since there seem to be multiple overlapping phenomenon.
0
why did we stop calling them stochastic parrots? markov chains are powerful tools and psittacines are quite intelligent.. and they both have predictable limits of precisely the kind that sounds useful as an intuition pump for LLMs (at the time of 5.4 and 4.6), no?
4
Apparently, David Manheim sees enough of the "stochastic parrots" talk to want to write a post like https://www.lesswrong.com/posts/KWHeBG978uZuqNK6Q/hunting-undead-stochastic-parrots-finding-and-killing-the.
3
FWIW, I was playing with Markov chains for language generation before Transformers were so much as a gleam in Shazeer's eye, and I have never found the analogy between RNNs/Transfomers and 'indefinitely high-order n-grams' to be helpful, as it would predict that LLMs would struggle to so much as close a quotation mark or parenthesis while failing to predict any of the most important & interesting RNN/Transformer capabilities.
1
Thanks for the explanation as seen within the field. I imagined them more in the sense of a tool for modelling and analysis of alchemical transmutation, industrial risks, service queues, internet protocols... I did not try to suggest one should get automatic insight from a direct analogy from toy NLP models to obscenely bigger ANN models, but if the past underperformance from direct application (before the billions of dollars poured into the field) remain a stain in the imagination of computer scientists, no wonder stochastic modelling is seen as inferior to explain anything about LLMs.
1
'parrot' is taken an insulting term to seem like it's a repetitious mixer with nothing new. Now with coding agentic capabilities + the coiner of the term appearing smug/ignorant in interviews, it seems very empty now. I'm not even sure "markov chains are powerful tools" would be agreed upon much either, back then when that was the best we had, it was impressive to make only a semblance of sentences but mostly used for parody purposes.
Put in another way "parrot" < "just autocomplete" < "super autocomplete" in that clearly emotional connotation in the first two is misleading (as in, you wouldn't be able to realize its power in computer use/hacking, unless you already had some intuition for this).
I don't have a real explanation, but I've been interested in this, since it feels like the LLM is doing something like the opposite of what writers intend to do (at least in the effect). As if there's some portion of language space that invites engagement, or trips an alarm in the reader that says 'there's something in this!' Human writers swim toward that portion of the space; LLMs swim away from it.
[I would be unsurprised to find I have not expressed this well.]
I mean the base models are outputting the most likely next token (modulo a temperature parameter). "Whatever is most likely to come next, based on what we've seen so far" is, in some sense, the opposite of interesting writing, which is interesting precisely because it has something novel or unusual or surprising to say.
7
A quick thought is something like human attention quickly gets attenuated to patterns and since we see a lot of low quality ideas from a specific type of writing we stop expecting surprise there. We correlate AI writing with this pattern and voila, we no longer pay attention to the writing because we expect the writing to be low quallity.
I for example pay less attention if something is written in an inflammatory way as I believe the new information likelihood is low since the chance of someone being epistemically captured by their emotions is higher.
6
I suspect acting blandly is an effective defence against receiving negative feedback, if you have a certain kind of user, who thinks that as long as a thing has said nothing, then there's nothing to complain about.
6
I feel like LLMs try to make everything clear and explicit. Good writing often has multiple layers of meaning and keeps some of the points implicit. An LLM on it's own will never make an implicit point that 20% of the readers are supposed to get.
If there seems to be an important point that maybe 20% of the readers will get, the instinct of the LLM is it to make the point implicit.
If you have to do actual work to understand the points that requires engagement.
This might be the dynamic where the LLM does what Benjamin Zander describes beginner piano players do in The transformative power of classical music (https://www.youtube.com/watch?v=r9LCwI5iErE).
6
I find myself paying far more attention to the LLM replies to questions I ask than I do to other text.
I think this is for a couple reasons.
1. The questions I’m asking are extremely specific to my niche interests at that exact moment, and I’m dead certain the LLM replies I‘m reading are the best available answers to my specific question that have ever been produced.
2. The LLM is generally sycophantic, but that registers to me as a sort of egoless confirmation bias that comes with easy flags to notice and interrogate. Human authors may have a much more idiosyncratic, fixed agenda. With LLMs, I have to be cautious about a small number of fixed epistemic issues that are easy to recognize with training. With humans, the trickery is much more diverse and deliberate. I feel more on my guard with human writing than with LLMs in my own chats.
That said, the LLM writing feels purely and universally disposable to me. Good human writing does not. Interacting with LLMs feels like pure information processing, while human writing feels like communication.
1
Can't say for you but LLM replies to questions I ask are grounded in the extensive training data and/or web search results, hence they are normally very rich on substance. I don't ask questions where I expect an insipid response, while most of the LLM writing online is quite substanceless
5
I wonder whether people who do not realize that a text is written by AI have the same experience. Perhaps realizing a text has been generated makes it appear as a much cheaper signal.
2
Maybe. I would still expect them to either feel like something's off (perhaps being unable to verbalize exactly what's off) or at least that their attention is sliding over the wall of text in a similar way (at least after some time of interacting with LLM text).
4
At some point AI text gets good enough at persuasion to be actively harmful to read, just as reading text by highly manipulative people can be harmful to read. Sometime before that it pings your memetic immune system a bunch and most people read this as vaguely wanting to avoid taking in LLM text. I think we might be entering the latter phase. Not confident, but we'll get there at some point and they do seem at about the relevant capability level in some other domains.
This is not what it feels like to me. What it feels like is that I am reading a low quality SEO optimized human website that puts boilerplate like "What is an X? What is the definition of an X? Read on to learn what an X is..." or a news article that launches into a personal anecdote that I don't care about - I expect low density vapid 'slop' and want to skip to the good parts.
LLM writing is not so transparently doing that, yet it seems like my brain can (correctly!) tell it's low density and so skips past. Unfortunately it's less likely to somewhere give the tidbits in a higher density way (like the recipe part of a recipe site is usually fine), and more likely to intersperse the tidbits in the low density so that it's like a middle ground of density. Human articles like this tend to have large chunks you can entirely skip to get to the good parts; LLMs with this problem feel like I have to read the whole thing just to mine 2 sentences worth of info.
Thinking of times while reading/hearing human words where I felt the manipulation worry you're describing - it feels like it takes the more reflective parts of me to notice, to then say "hey uhh am I being 'hacked' and my feelings are ...
2
I find this unsurprising and it's odd to even pose as a question. Reading older confident GPT-3-quality LLM's that don't know what it's talking about, reading tons of mediocre spam by online people copypasting LLMs, plus of course the default style being close to journalist quality sludge that was already mediocre when humans were writing it, don't give a good impression of the quality. If you actually want to read it request a denser or different style.
2
There is an economy of attention, and the AI does not understand how I want to spend my very limited free trial of your attention.
The AI puts many big words where a simple one would do. It rambles and it encourages authors to ramble.
1
LLM generated text is generated in a different way than human generated text. Humans tend to have an idea they are building up to when they speak. LLMs are predicting the next token based on a preexisting string they are building on.
(image by Javaid Nabi)
I think it is quite likely that this affects the rhythm of sentences. Even if the next token prediction is very accurate, a sentence generated word by word will likely struggle with building anticipation for something.
(image source)
Not all generative AI generates this way. Stable diffusion works through "denoising" an image in many places at once.
This same mechanism can be applied to text too.
(image source)
LLaDA (Large Language Diffusion with mAsking) is a text generation model that operates this way. And it is proposed that it will lead to more interesting sentences like a human planned them out. But the performance is worse than LLMs right now.
A model to track:
- AI gets increasingly good at X, so good that strong pressures arise to increasingly automate it, even if AI is still quite bad at some subtle but very important aspects of X.
- More and more X-related work/activity gets AI-automated, including the parts where AI is still bad or fails frequently and non-gracefully.
- This is partly driven by the fact that it's just ~psychologically hard for a human to exert effortful X-related cognition when AI would be more efficient at 99% of it.
- In cases where being good at [those aspects of X AI is still bad at][1] is critical, the quality of work deteriorates relative to the level before intense AI automation.
- ^
I guess we could call them reverse salients?
This happens with all technologies, not just AI. For example, automobiles replaced horses, with improvements in 99% of aspects of transportation. But if you fall asleep riding a horse, the horse safely halts or goes home under its own power. If you fall asleep driving a car, disaster! That's the 1% that got worse.
2
True.
A thing I had in mind that partially motivated writing this up is that, in the case of AI, this dynamic opens the door to a narrow but large-scale cognitive enfeeblement.
E.g., AI gets really damn good at explaining good old math or cranking highly algebraic proofs, etc., which decreases the number of people working in math way more than optimal, and so the progress in areas of math other than what AI is good at slows down a lot.
2
I think I'm less worried than you are on that last bit because there are folks like Tim Gowers working on this sort of project. But I am a bit worried. To their credit the Epoch folks acknowledge this
[...]
There's a lot more to good math than just theory-building and problem-solving of course, but I think involving a variety of mathematicians in the broader AI x math evals process as well as having more top mathematicians start their own AI x math initiatives (e.g. Terry Tao's SAIR) mitigates this.
4
imagine it happens in a competitive environment where only the players who's number go up the fastest will survive and the more you try to measure that elusive aspect, the harder everyone Goodharts
2
Daniel Litt on Twitter:
https://x.com/littmath/status/2035853161802404208
[...]
2
The adaptation is starting to happen in earnest, including by super-high-profile folks like Tao and other Field medalists like Tim Gowers, so I'm less worried than Litt.
1
Starting to happen in software engineering, and AI engineering/research
2
This is compatible with a general vibe I'm picking up, but I'd also appreciate concrete pointers.
Scott's old post Concept-Shaped Holes Can Be Impossible To Notice says that concept-shaped holes can be impossible to notice, in oneself as well as others. You might be very off-base when estimating how much things that seem obvious and straightforward to you are obvious and straightforward to others. They might very well not be. See also: the curse of knowledge.
I learned that writing something up or starting a conversation about a thing that seemed [obvious and therefore not worth talking about] can reveal that this thing is not as [obvious and therefore not worth talking about] as it seemed to me.
So, if you're experiencing that sort of thing as a blocker ("I don't have any particularly interesting/novel ideas"), you might want to gain empirical info about which ideas are worth writing about. Getting feedback is crucial for cultivating intellectual activity.
Ironically, as I was contemplating posting this shortform, it occurred to me that "Is it really worth posting? Shouldn't this already be in the LW-ish water supply?".
ETA: A class of micro-examples is when you bang your head against the wall of some math concept until pieces of it start clicking, and once everything has clicked ...
The increase[1] in stated support for the AGI pause over the last few months has exceeded what I would have expected half a year ago. Neil deGrasse Tyson, Bernie Sanders, IABIED making an appearance in congressional hearings, Joe Carlsmith[2], etc. Even Dario and Demis are saying stuff like "yeah, if we could make the world stop, we would do it".
On IABIED
First things first, I wholeheartedly endorse the main actionable conclusion: Ban unrestrained progress on AI that can kill us all.
I broadly think Eliezer and Nate did a good job communicating what's so difficult about the task of building a thing that is more intelligent than all of humanity combined and shaped appropriately so as to help us, rather than have a volition of its own that runs contrary to ours.[1]
The main (/most salient) disagreement I can see at the moment is the authors' expectations of value-strangeness and maximizeriness of superintelligence; or rather, I am much more uncertain about this. However, this detail is not relevant for the desirability of the post-ASI future, conditional on business-close-to-as-usual and therefore not relevant for whether the ban is good.
(Also, not sure about their choice of some stories/parables, but that's a minor issue as well.)
I liked the comparison with the Allies winning against the Axis in WWII, which, at least in resource/monetary terms, must have costed much more than it would cost to implement the ban. The things we're missing at the moment are awareness of the issue, pulling ourselves together, and collective steam.
...8
The metaphor I use is Russian roulette, where you have a revolver with 6 chambers, 1 loaded with a bullet. The gun is pointed at the head of humanity. We spin, and we pull the trigger.
* Various AI lab leaders have stated that we are playing with 1 (or 1.5) chambers loaded. Dario Amodei at Anthropic is the most pessimistic, I believe, giving us a 25% chance that AI kills us?
* Eliezer and Nate suspect that we are playing with approximately 6 out of 6 chambers loaded.
* Personally, I have a long and complicated argument that we may only be playing with 4 or 5 chambers loaded!
* You might feel that we're only playing with 2 or 3 chambers loaded.
The wise solution here is not to worry about precisely how many chambers are loaded. Even 1 in 6 odds are terrible! The wise solution is to stop playing Russian roulette entirely.
The acronym SLT (in this community) is typically taken/used to refer to Singular Learning Theory, but sometimes also to (~old-school-ish) Statistical Learning Theory and/or to Sharp Left Turn.
I therefore put that to disambiguate between them and to clean up the namespace, we should use SiLT, StaLT, and ShaLT, respectively.
4
I like it! "SiLT" is also easier to say than "Es El Te"
3
So that was your idea! Aram Ebtekar and I have been going around suggesting this but couldn’t remember who initially proposed it at Iliad 2.
6
Let this thread be the canonical reference for the posterity that this idea appeared in my mind at ODYSSEY at the session "Announcing Universal Algorithmic Intelligence Reading Group" held by you and Aram in Bayes Attic, on Wednesday, 2025-08-27, around 07:20 PM, when, for whatever reason, the two S Learning Theories entered the conversation, when you were putting some words on the whiteboard, and somebody voiced a minor complaint that SLT stands for both of them.
In his MLST podcast appearance in early 2023, Connor Leahy describes Alfred Korzybski as a sort of "rationalist before the rationalists":
Funny story: rationalists actually did exist, technically, before or around World War One. So, there is a Polish nobleman named Alfred Korzybski who, after seeing horrors of World War One, thought that as technology keeps improving, well, wisdom's not improving, then the world will end and all humans will be eradicated, so we must focus on producing human rationality in order to prevent this existential catastrophe. This is a real person who really lived and he actually sat down for like 10 years to like figure out how to like solve all human rationality God bless his autistic soul. You know, he failed obviously but you know you can see that the idea is not new in this regard.
Korzybski's two published books are Manhood of Humanity (1921) and Science and Sanity (1933).
...E. P. Dutton published Korzybski's first book, Manhood of Humanity, in 1921. In this work he proposed and explained in detail a new theory of humankind: mankind as a "time-binding" class of life (humans perform time binding by the transmission of knowledge and abstractions through tim
I've written about this here:
https://www.lesswrong.com/posts/kFRn77GkKdFvccAFf/100-years-of-existential-risk
4
My reviews of Manhood of Humanity:
* Time-Binding
* Manhood of Humanity
For as long as I can remember, I've had a very specific way of imagining the week. The weekdays are arranged on an ellipse, with an inclination of ~30°, starting with Monday in the bottom-right, progressing along the lower edge to Friday in the top-left, then the weekend days go above the ellipse and the cycle "collapses" back to Monday.
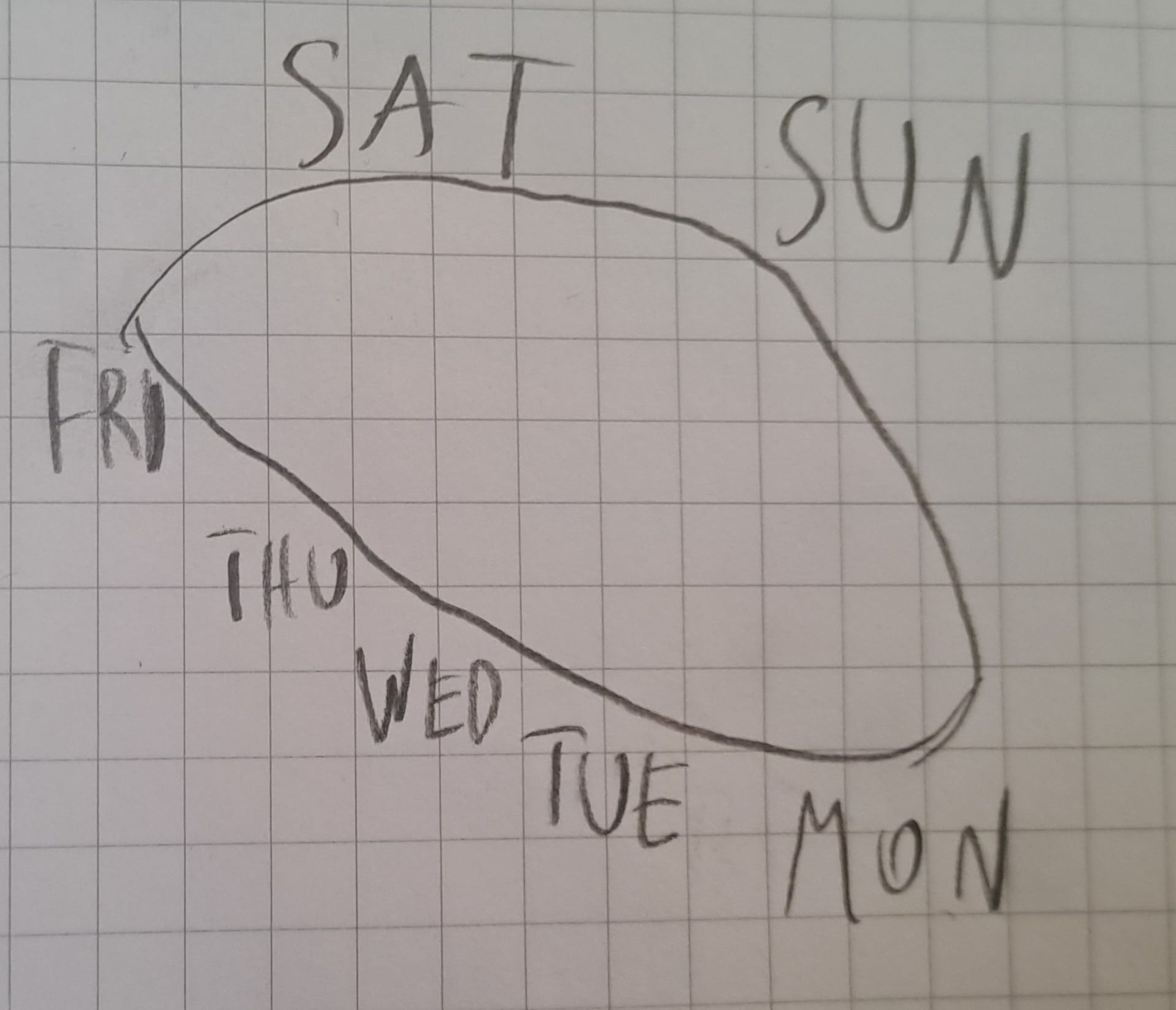
Actually, calling it "ellipse" is not quite right because in my mind's eye it feels like Saturday and Sunday are almost at the same height, Sunday just barely lower than Saturday.
I have a similar ellipse for the year, this one oriented bottom-left to top-right:

This one also feels wrong because "in my head" each of the following is true:
- Each month takes the same amount of space (/measure?).
- There are fewer months along the lower side of the cycle.
- I strongly feel that "this should be a mathematically proper ellipse". (Non-Euclidean geometry?)
The main interesting commonalities I see between them:
- The initial elements (Monday and January) start in the lower corner of the cycle.
- The "free" elements of the cycle (weekend and summer vacation) are along the top edge of the cycle.
- The segment between the last "free" element and the initial element is stretched s
2
The way I imagine the days is tied directly to the calendar: there's Sunday Monday ... Saturday in a row, then the next row starts at Sunday again. If I think about what day it is, I will tend to start at the location nearest day I remember well, situated in a row that's in the "middle". Then I'll seek forward/backward until I get to the current date. Likewise if you ask me what day is 4 days from now, the thing I automatically do is seek forwards until I've moved 4 spaces.
What's time within a day like for you? I think of that just via the numbers, and was surprised the first time I heard someone tell me that obviously analog clocks were easier because you add the angles on a circle in your head. (This is probably a generational thing: I grew up with digital clocks, and had to be taught in school how to read an analog clock like an extra skill, and would only have a reason to need that skill if I was in class and wanted to surreptitiously check how long it'd be until it was over).
4
I also do that with "small shifts": I imagine taking 1-3 steps forward/backward or something. For ≥4, I calculate (June=6, so 5 months from now is 11=November).
[...]
It's a number line, but a jagged one. 3:30 to 8:30-ish, it's quite steep, like 30° or maybe even 50°. Then it's more flat (but still monotonically rising) until like 14:30, when it starts rising a bit more rapidly, slows down again at 20:00, and then it crosses to the next day. Full hours are marked with a mental flag, and particular orientational times, like when I typically eat meals or wake up or go to sleep, are marked with bigger mental flags. Time within an hour or a minute is similar but less detailed, as I don't think about it / zoom in on this often; plus there's the feeling of a container slowly filling up with time, like 14:58 is veeery close to the tipping point.
(The way I described the day feels kind of off because in my mind's eye, it's more cloudy/blurry/fuzzed, and it's plausible that there's some significant variance in how I feel it.)
I perceive the historical timeline similarly. Replace the day with a decade, a century, a millennium. It's slowly, but unevenly, rising upwards, with bigger steps at the boundaries of millennia, centuries, and decades.
I don't have much mental imagery for months. Too irregular. If I want to know the number of days to a certain date or what day of the week it would be, I count.
[...]
Yeah, I can see that working for some people. I guess I grew up with a mix of analog and digital (and there's still a lot of analog clocks around me (is it a Europe thing?)), but never adopted the former as a privileged object in my imagery.
Also, this reminded me of a fun thing: https://faculty.ucr.edu/~eschwitz/SchwitzPapers/DreamB&W.pdf
[...]
2
Hmm I just imagine Saturday and Sunday on top with the other days in a lower row.
2
I just met someone recently who has this! They said they have always visualized the months of the year as on a slanted treadmill, unevenly distributed. They described it as a form of synesthesia, which is conceptually consistent with how I experience grapheme-color associative synesthesia.
3
That's a nice, concise handle!
2
I have similar thing for week days, but somehow with a weird shape?
in general, it's a similar cycle, but flipped horizontally, going left to right:
on top it's: sun, sat
on the bottom: mon, tue, wed, thu, fri
the shape connecting days goes downwards from sun to mon, tue, wed, then upwards to thu, then down to fri, then up to sat, sun, closing the loop.
not sure is this makes any sense )
2
I think I understand.
Has it always been with you? Any ideas what might be the reason for the bump at Thursday? Was Thursday in some sense "special" for you when you were a kid?
1
Ha, thinking back to childhood I get it now, it's the influence of the layot of the school daily journal in USSR/Ukraine, like https://cn1.nevsedoma.com.ua/images/2011/33/7/10000000.jpg
1
https://x.com/GoodfireAI/status/2052420501637878014
Saw this tweet about models having a cyclical representation of days of week and months of year. Image from the paper.
2
Yeah, niplav also brought my attention to this.
Slightly upweights the hypothesis that I "just" got explicitized insight into how temporal cycles are "deeply represented" (in some relevant sense) in my brain.
1
This is very similar to how l perceive time! what I find interesting is that while I’ve heard people talk about the way they conceptualize time before I’ve never heard anyone else mention the bizarre geometry aspect. The sole exceptions to this were my Dad and Grandfather, who brought this phenomenon to my attention when I was young.
1
I have something like this for years: https://www.lesswrong.com/posts/j8WMRgKSCxqxxKMnj/what-i-think-about-when-i-think-about-history
2
For as long as I can remember, I have always placed dates on an imaginary timeline, that "placing" involving stuff like fuzzy mental imagery of events attached to the date-labelled point on the timeline. It's probably much less crisp than yours because so far I haven't tried to learn history that intensely systematically via spaced repetition (though your example makes me want to do that), but otherwise sounds quite familiar.
Are there any memes prevalent in the US government that make racing to AGI with China look obviously foolish?
The "let's race to AGI with China" meme landed for a reason. Is there something making the US gov susceptible to some sort of counter-meme, like the one expressed in this comment by Gwern?
4
I'd vainly hope that everyone would know about the zero-sum nature of racing to the apocalypse from nuclear weapons, but the parallel isn't great, and no-one seems to have learned the lesson anyways, given the failure of holding SALT III or even doing START II.
4
The no interest in an AI arms race is now looking false, as apparently China as a state has devoted $137 billion to AI, which is at least a yellow flag that they are interested in racing.
6
Source? I only found this article about 1 trillion Yuan, which is $137 billion.
1
Yeah, that was what I was referring to, and I thought it would actually be a trillion dollars, sorry for the numbers being wrong.
Strongly normatively laden concepts tend to spread their scope, because (being allowed to) apply a strongly normatively laden concept can be used to one's advantage. Or maybe more generally and mundanely, people like using "strong" language, which is a big part of why we have swearwords. (Related: Affeective Death Spirals.)[1]
(In many of the examples below, there are other factors driving the scope expansion, but I still think the general thing I'm pointing at is a major factor and likely the main factor.)
1. LGBT started as LGBT, but over time developed into LGBTQIA2S+.
2. Fascism initially denoted, well, fascism, but now it often means something vaguely like "politically more to the right than I am comfortable with".
3. Racism initially denoted discrimination along the lines of, well, race, socially constructed category with some non-trivial rooting in biological/ethnic differences. Now jokes targeting a specific nationality or subnationality are often called "racist", even if the person doing the joking is not "racially distinguishable" (in the old school sense) from the ones being joked about.
4. Alignment: In IABIED, the authors write:
...The problem of making AIs want—and ultimately
6
Russell and Norvig discuss "intelligent agents" in AIMA (2003) and they don't mean web scrapers or database scripts, but they also don't mean that the thing they're discussing is conscious or super-rational or anything fancy like that. A self-driving car is an "agent" in their sense.
I suspect the use of "agentic" to mean something like "highly instrumentally rational" — as in "I want to become more agentic" — is an LW idiosyncrasy.
In human psychology, Milgram used "agentic" to mean "obedient", in contrast to "autonomous"!
----------------------------------------
As an aside, the origins of "LGBT" and "racism" are not quite what you say. A historical dictionary may help. "LGBT" was itself an expansion of earlier terms. LGB (and GLB) were used in the 1990s; and LG is found in the 1970s, for instance in the name of the ILGA which was originally the International Lesbian & Gay Association and more recently the International Lesbian, Gay, Bisexual, Trans and Intersex Association while retaining the shorter initialism.
Partitions are categorically dual to both subsets and factorizations, kinda
[Prerequisite warning: basic category theory.]
In his work on Finite Factored Sets, Scott Garrabrant defined the notion of factorization. In simple terms, a factorization of a finite set
Scott wrote:
Notice the duality between the definitions of partition and factorization. We replace subsets with partitions, nonempty with nontrivial, and disjoint union with Cartesian product, and we reverse the direction of the function. We can think of a factorization of S as a way to view S as a product, in the same way that a partition was a way to view S as a disjoint union.
Intuitively, this makes sense, and I tried to put a bit more categorical flesh on this in my comment under that post. In the category Set (or rather FinSet, as we're only dealing with finite se...
beyond doom and gloom - towards a comprehensive parametrization of beliefs about AI x-risk
doom - what is the probability of AI-caused X-catastrophe (i.e. p(doom))?
gloom - how viable is p(doom) reduction?
foom - how likely is RSI?
loom - are we seeing any signs of AGI soon, looming on the horizon?
boom - if humanity goes extinct, how fast will it be?
room - if AI takeover happens, will AI(s) leave us a sliver of the light cone?
zoom - how viable is increasing our resolution on AI x-risk?
The notations we use for (1) function composition; and (2) function types, "go in opposite directions".
For example, take functions and that you want to compose into a function (or ), which, starting at some element , uses to obtain some , and then uses to obtain some . The notation goes from left to right, which works well for the minds that are used to the left-to-right direction of English writing (and of writing of all extant European languages, a...
3
Indeed, this is called reverse Polish / postfix notation. For example, f(x, g(y, z)) becomes x (y z g) f, which is written without parentheses as x y z g f. That is, if you know the arity of all the letters beforehand, parentheses are unnecessary.
2
Lol, right! Only after I published this did I recall that there was something vaguely in this spirit called "Polish notation", and it turns out it's exactly that.
[Epistemic status: speculation from scant evidence, take with an appropriate grain of salt.]
It seems plausible to me that country-wide EA groups are much more favorable to pausing/slowing down AGI-ward progress than the general collective EA geist, according to which (I think) it's still "not a thing people like us do"[1]. This is definitely the case with EA Poland.
I don't have direct evidence that it's true more generally of, say, EA foundations in other EU countries, but it's worth noting that historically, a major (maybe the biggest?) source of funding ...
1
Is there something specifically about EA groups that make them more favorable to an AI pause compared to national AI safety groups? AI safety groups seem like potentially more credible actors regarding this (and indeed, at least CeSIA in France has already done stuff regarding this)
3
Fair enough. EA groups were on my mind because I noticed the contrast between the Polish community and the general diffuse global EA vibe[1] and so it seemed worth pointing out as a potentially tappable resource.
Yeah, AI safety groups might be seen as more credible, but I'm not sure about that (but they're surely at least as credible as the local countrywide EA, unles something weird happens?).
1. ^
though I might also be miscalibrated on the latter, as I don't spend time on EA Forum
Recently, I watched Out of This Box. In the musical, they test their nascent AGI on the Christiano-Sisskind test, a successor to the Turing test. What the test involves exactly remains unexplained. Here are my hypotheses.[1]
Sisskind certainly refers to Scott Alexander, and one thing that Scott Alexander posted about something in the vicinity of the Turing test was this post (italics added):
...The year is 2028, and this is Turing Test!, the game show that separates man from machine! Our star tonight is Dr. Andrea Mann, a generative linguist at University of Ca
I've read the SEP entry on agency and was surprised how irrelevant it feels to whatever it is that makes me interested in agency. Here I sketch some of these differences by comparing an imaginary Philosopher of Agency (roughly the embodiment of the approach that the "philosopher community" seems to have to these topics), and an Investigator of Agency (roughly the approach exemplified by the LW/AI Alignment crowd).[1]
If I were to put my finger on one specific difference, it would be that Philosopher is looking for the true-idealized-ontology-of-agency-indep...
-3
You are suffused with a return-to-womb mentality - desperately destined for the material tomb. Your philosophy is unsupported. Why do AI researchers think they are philosophers when its very clear they are deeply uninvested in the human condition? there should be another term, 'conjurers of the immaterial snake oil', to describe the actions you take when you riff on Dyson Sphere narratives to legitimize your paltry and thoroughly uninteresting research
Is there any research on how the actual impact of [the kind of AI that we currently have] lives up to the expectations from the time [shortly before we had that kind of AI but close enough that we could clearly see it coming]?
This is vague but not unreasonable periods for the second time would be:
- After OA Copilot, before ChatGPT (so summer-autumn 2022).
- After PaLM, before Copilot.
- After GPT-2, before GPT-3.
I'm also interested in research on historical over- and under-performance of other tech (where "we kinda saw it (or could see) it coming") relative to expectations.
Several times, I've heard Eliezer say something like "a powerful consequentialist AI could run on 'is' statements only, without any 'ought' statements", and I don't think I've ever heard him explain clearly what the difference is between the two categories of statements that he's tracking.
The classical Humean distinction seems to posit that all "motivational force" is derived from "ought" statements, so it seems like he thinks about it differently than Hume.
Has this been explained anywhere?
2
My model of Eliezer’s model wouldn’t say that. Link?
2
https://intelligence.org/2018/02/28/sam-harris-and-eliezer-yudkowsky/ and I also recall seeing this in some tweets.
[...]
Ok, looking now at the transcript, it looks like he's saying that wiring together certain "is" questions can produce "wanting" that we label "ought". I think he's prematurely deflating the argument, because, IIUC, in this ontology, the "ought" questions are about what "is" questions to have wired together in one's brain.
3
I think what this is saying is that an agent doesn't need to be able to reflect on its goals and decide that they're the "right" ones in order to be capable/dangerous. It just has to be the sort of agent that pursues those goals. Stockfish will beat you without believing that it "ought" to play to win.
[Epistemic status: shower thought]
The reason why agent foundations-like research is so untractable and slippery and very prone to substitution hazards, etc, is largely because it is anti-inductive, and the key source of its anti-inductivity is the demons in the universal prior preventing the emergence of other consequentialists, which could become a trouble for their acausal monopoly on the multiverse.
(Not that they would pose a true threat to their dominance, of course. But they would diminish their pool of usable resources a little bit, so it's better to...
Does severe vitamin C deficiency (i.e. scurvy) lead to oxytocin depletion?
According to Wikipedia
The activity of the PAM enzyme [necessary for releasing oxytocin fromthe neuron] system is dependent upon vitamin C (ascorbate), which is a necessary vitamin cofactor.
I.e. if you don't have enough vitamin C, your neurons can't release oxytocin. Common sensically, this should lead to some psychological/neurological problems, maybe with empathy/bonding/social cognition?
Quick googling "scurvy mental problems" or "vitamin C deficiency mental symptoms" doesn't r...
2
Just a detail, but shouldn't this be one orange a day? Apples do not contain much vitamin C.
1
Huh, you're right. I thought most fruits have enough to cover daily requirements.
1
Googling for "scurvy low mood", I find plenty of sources that indicate that scurvy is accompanied by "mood swings — often irritability and depression". IIRC, this has remarked upon for at least two hundred years.
1
That's also what this meta-analysis found but I was mostly wondering about social cognition deficits (though looking back I see it's not clear in the original shortform)
2
Hi.