This is a linkpost for https://www.anthropic.com/index/core-views-on-ai-safety
New Comment
I think the worldview here seems cogent. It's very good for Anthropic folk to be writing up their organizational-beliefs publicly. I'm pretty sympathetic to "man, we have no idea how to make real progress without empirical iteration, so we just need to figure out how to make empirical iteration work somehow."
I have a few disagreements. I think the most important ones route through "how likely is this to accelerate race dynamics and how bad is that?".
We've subsequently begun deploying Claude now that the gap between it and the public state of the art is smaller.
It sounds like this means Claude is still a bit ahead of the public-state-of-the-art (but not much). But I'm not sure I'm interpreting it correctly.
I want to flag that an Anthropic employee recently told me something like "Anthropic wants to stay near the front of the pack at AI capabilities so that their empirical research is relevant, but not at the actual front of the pack to avoid accelerating race-dynamics." That would be a plausibly reasonable strategy IMO (although I'd still be skeptical about how likely it was to exacerbate race dynamics in a net-negative way). But it sounds like Claude was released while it was an advance over the public sota.
I guess I could square this via "Claude was ahead of the public SOTA, but not an advance over privately available networks?".
But, it generally looks to me like OpenAI and Anthropic, the two ostensibly safety-minded orgs, are nontrivially accelerating AI hype and progress due to local races between the two of them, and I feel quite scared about that.
I realize they're part of some dynamics that extend beyond them, and I realize there are a lot of difficult realities like "we really do believe we need to work on LLMs, those really are very expensive to train, we really need to raise money, the money really needs to come from somewhere, and doing some releases and deals with Google/Microsoft etc seem necessary." But, it sure looks like the end result of all of this is an accelerated race, and even if you're only on 33%ish likelihood of "a really pessimistic scenario", that's a pretty high likelihood scenario to be accelerating towards.
My guess is that from the inside of Anthropic-decisionmaking, the race feels sort of out-of-their-control, and it's better to ride the wave that to sit doing nothing. But it seems to me like "figure out how to slow down the race dynamics here" should be a top organizational priority, even within the set of assumptions outlined in this post.
I both agree that the race dynamic is concerning (and would like to see Anthropic address them explicitly), and also think that Anthropic should get a fair bit of credit for not releasing Claude before ChatGPT, a thing they could have done and probably gained a lot of investment / hype over. I think Anthropic's "let's not contribute to AI hype" is good in the same way that OpenAI's "let's generate massive" hype strategy is bad.
Like definitely I'm worried about the incentive to stay competitive, especially in the product space. But I think it's worth highlighting that Anthropic (and Deepmind and Google AI fwiw) have not rushed to product when they could have. There's still the relevant question "is building SOTA systems net positive given this strategy", and it's not clear to me what the answer is, but I want to acknowledge that "building SOTA systems and generating hype / rushing to market" is the default for startups and "build SOTA systems and resist the juicy incentive" is what Anthropic has done so far & that's significant.
Yeah I agree with this.
To be clear, I think Anthropic has done a pretty admirable job of showing some restraint here. It is objectively quite impressive. My wariness is "Man, I think the task here is really hard and even a very admirably executed company may not be sufficient."
I both agree that the race dynamic is concerning (and would like to see Anthropic address them explicitly), and also think that Anthropic should get a fair bit of credit for not releasing Claude before ChatGPT, a thing they could have done and probably gained a lot of investment / hype over.
I mean, didn't the capabilities of Claude leak specifically to OpenAI employees, so that it's pretty unclear that not releasing actually had much of an effect on preventing racing? My current best guess, though I am only like 30% of this hypothesis since there are many possible hypotheses here, is that Chat-GPT was developed in substantial parts because someone saw or heard about a demo of Claude and thought it was super impressive.
Yeah I think it can both be true that OpenAI felt more pressure to release products faster due to perceived competition risk from Anthropic, and also that Anthropic showed restraint in not trying to race them to get public demos or a product out. In terms of speeding up AI development, not building anything > building something and keeping it completely secret > building something that your competitors learn about > building something and generating public hype about it via demos > building something with hype and publicly releasing it to users & customers. I just want to make sure people are tracking the differences.
so that it's pretty unclear that not releasing actually had much of an effect on preventing racing
It seems like if OpenAI didn't publicly release ChatGPT then that huge hype wave wouldn't have happened, at least for a while, since Anthropic sitting on Claude rather than release. I think it's legit to question whether any group scaling SOTA models is net positive but I want to be clear about credit assignment, and the ChatGPT release was an action taken by OpenAI.
In terms of speeding up AI development, not building anything > building something and keeping it completely secret > building something that your competitors learn about > building something and generating public hype about it via demos > building something with hype and publicly releasing it to users & customers.
I think it is very helpful, and healthy for the discourse, to make this distinction. I agree that many of these things might get lumped together.
But also, I want to flag the possibility that something can be very very bad to do, even if there are there other things that would have been progressively worse to do.
I want to make sure that groups get the credit that is due to them when they do good things against their incentives.
I also want to avoided falling into a pattern of thinking "well they didn't do the worst thing, or the second worst thing, so that's pretty good!" if in isolation I would have thought that action was pretty bad / blameworthy.
As of this moment, I don't have a particular opinion one way or the other about how good or bad Anthropic's release policy is. I'm merely making the abstract point at this time.
That's the hard part.
My guess is that training cutting edge models, and not releasing them is a pretty good play, or would have been, if there wasn't huge AGI hype.
As it is, information about your models is going to leak, and in most cases the fact that something is possible is most of the secret to reverse engineering it (note: this might be true in the regime of transformer models, but it might not be true for other tasks or sub-problems).
But on the other hand, given the hype, people are going to try to do the things that you're doing anyway, so maybe leaks about your capabilities don't make that much difference?
This does point out an important consideration, which is "how much information needs to leak from your lab to enable someone else to replicate your results?"
It seems like, in many cases, there's an obvious way to do some task, and the mere fact that you succeeded is enough info to recreate your result. But presumably there are cases, where you figure out a clever trick, and even if the evidence of your model's performance leaks, that doesn't tell the world how to do it (though it does cause maybe hundreds of smart people to start looking for how you did it, trying to discover how to do it themselves).
I think I should regard the situation differently depending on the status of that axis.
For comparison, others might want to see the DeepMind alignment team's strategy: https://www.lesswrong.com/posts/a9SPcZ6GXAg9cNKdi/linkpost-deepmind-alignment-team-s-strategy
I think this is the equivalent post for OpenAI but someone feel free to correct me:
https://www.lesswrong.com/posts/28sEs97ehEo8WZYb8/openai-s-alignment-plans
My summary to augment the main one:
Broadly human level AI may be here soon and will have a large impact. Anthropic has a portfolio approach to AI safety, considering both: optimistic scenarios where current techniques are enough for alignment, intermediate scenarios where substantial work is needed, and pessimistic scenarios where alignment is impossible; they do not give a breakdown of probability mass in each bucket and hope that future evidence will help figure out what world we're in (though see the last quote below). These buckets are helpful for understanding the goal of developing: better techniques for making AI systems safer, and better ways of identifying how safe or unsafe AI systems are. Scaling systems is required for some good safety research, e.g., some problems only arise near human-level, Debate and Constitutional AI need big models, need to understand scaling to understand future risks, if models are dangerous, compelling evidence will be needed.
They do three kinds of research: Capabilities which they don’t publish, Alignment Capabilities which seems mostly about improving chat bots and applying oversight techniques at scale, and Alignment Science which involves interpretability and red-teaming of the approaches developed in Alignment Capabilities. They broadly take an empirical approach to safety, and current research directions include: scaling supervision, mechanistic interpretability, process-oriented learning, testing for dangerous failure modes, evaluating societal impacts, and understanding and evaluating how AI systems learn and generalize.
Select quotes:
- “Over the next 5 years we might expect around a 1000x increase in the computation used to train the largest models, based on trends in compute cost and spending. If the scaling laws hold, this would result in a capability jump that is significantly larger than the jump from GPT-2 to GPT-3 (or GPT-3 to Claude). At Anthropic, we’re deeply familiar with the capabilities of these systems and a jump that is this much larger feels to many of us like it could result in human-level performance across most tasks.”
- The facts “jointly support a greater than 10% likelihood that we will develop broadly human-level AI systems within the next decade”
- “In the near future, we also plan to make externally legible commitments to only develop models beyond a certain capability threshold if safety standards can be met, and to allow an independent, external organization to evaluate both our model’s capabilities and safety.”
- “It's worth noting that the most pessimistic scenarios might look like optimistic scenarios up until very powerful AI systems are created. Taking pessimistic scenarios seriously requires humility and caution in evaluating evidence that systems are safe.”
I'll note that I'm confused about the Optimistic, Intermediate, and Pessimistic scenarios: how likely does Anthropic think each is? What is the main evidence currently contributing to that world view? How are you actually preparing for near-pessimistic scenarios which "could instead involve channeling our collective efforts towards AI safety research and halting AI progress in the meantime?"
how likely does Anthropic think each is? What is the main evidence currently contributing to that world view?
I wouldn't want to give an "official organizational probability distribution", but I think collectively we average out to something closer to "a uniform prior over possibilities" without that much evidence thus far updating us from there. Basically, there are plausible stories and intuitions pointing in lots of directions, and no real empirical evidence which bears on it thus far.
(Obviously, within the company, there's a wide range of views. Some people are very pessimistic. Others are optimistic. We debate this quite a bit internally, and I think that's really positive! But I think there's a broad consensus to take the entire range seriously, including the very pessimistic ones.)
This is pretty distinct from how I think many people here see things – ie. I get the sense that many people assign most of their probability mass to what we call pessimistic scenarios – but I also don't want to give the impression that this means we're taking the pessimistic scenario lightly. If you believe there's a ~33% chance of the pessimistic scenario, that's absolutely terrifying. No potentially catastrophic system should be created without very compelling evidence updating us against this! And of course, the range of scenarios in the intermediate range are also very scary.
How are you actually preparing for near-pessimistic scenarios which "could instead involve channeling our collective efforts towards AI safety research and halting AI progress in the meantime?"
At a very high-level, I think our first goal for most pessimistic scenarios is just to be able to recognize that we're in one! That's very difficult in itself – in some sense, the thing that makes the most pessimistic scenarios pessimistic is that they're so difficult to recognize. So we're working on that.
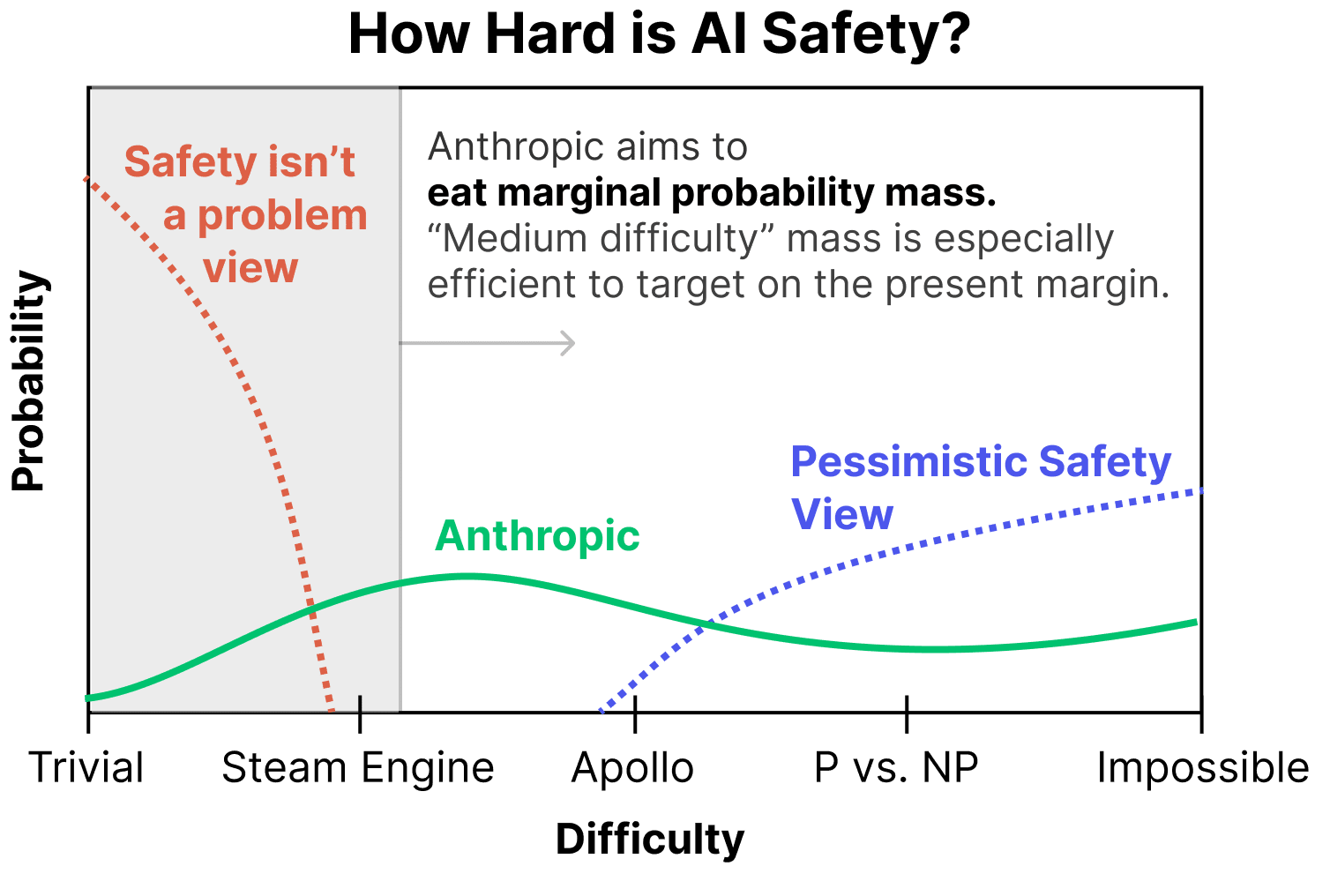
But before diving into our work on pessimistic scenarios, it's worth noting that – while a non-trivial portion of our research is directed towards pessimistic scenarios – our research is in some ways more invested in optimistic scenarios at the present moment. There are a few reasons for this:
- We can very easily "grab probability mass" in relatively optimistic worlds. From our perspective of assigning non-trivial probability mass to the optimistic worlds, there's enormous opportunity to do work that, say, one might think moves us from a 20% chance of things going well to a 30% chance of things going well. This makes it the most efficient option on the present margin.
(To be clear, we aren't saying that everyone should work on medium difficulty scenarios – an important part of our work is also thinking about pessimistic scenarios – but this perspective is one reason we find working on medium difficulty worlds very compelling.) - We believe we learn a lot from empirically trying the obvious ways to address safety and seeing what happens. My colleague Andy likes to say things like "First we tried the dumbest way to solve alignment (prompting), then we tried the second dumbest thing (fine tuning), then we tried the third dumbest thing…" I think there's a lot to be said for "working our way up the ladder of trying dumb things" and addressing harder and harder scenarios as we do so. Earlier techniques are both building blocks and baselines for further research.
- A crucial part of many pessimistic scenarios is that "easy safety techniques" appear to work, but then fail in subtle/abrupt ways. Having the "easy safety techniques" is a prerequisite for trying to empirically investigate this. (For example, you might want to do mechanistic interpretability on sophisticated RLHF models and try to learn what's going on.) Of course, actually recognizing this will be very hard, as we're about to discuss. But it's worth noting that this is a prerequisite for empirical attempts, and we believe those attempts are worth making, even though we aren't sure they'll succeed!
We also have a lot of work that I might describe as trying to move from optimistic scenarios towards more intermediate scenarios. This includes our process-oriented learning and scalable supervision agendas.
But what are we doing now to address pessimistic scenarios? (Again, remember that our primary goal for pessimistic scenarios is just to recognize that we're in one and generate compelling evidence that can persuade the world.)
- Our work on mechanistic interpretability is deliberately targeted at trying to fill in holes in our portfolio for pessimistic scenarios. We see this as a high-risk, high-reward bet – it may very well not succeed in time to matter, but if it does, it would be a very powerful tool for determining if we were in a pessimistic scenario and providing compelling evidence to the world. See detailed discussion in the post.
- Our Testing for Dangerous Failure Modes (eg. trying to find evidence of things like situational awareness from the outside of models) work is useful in a range of scenarios, but seems helpful in a lot of quite pessimistic ones. I think it's easy to dismiss this work on the basis that, of course, models will just deceive you. But there are a lot of very sophisticated ideas for how to get around this.
- One idea is that models may try to deceive you before they can do so effectively. This could be smaller models, or large models earlier in training. (This could even include detecting hints of deceptive behavior in the logits, before it becomes likely behavior!)
- Another more complex one is to think of treacherous turns as being kind of like a phase change, and to try to introduce control variables that expand the problem to more dimensions and allow you to safely observe treacherous turns. (For example, you might deliberately give a model weaker supervision in order to see if misalignment develops in weaker models, and then study how this changes as a function of both model capacity and supervision strength.)
- A lot of our work in this area involves studying "model organisms" of these failure modes so that we can understand them in models that are much less capable than their overseers.
- Our work on Understanding Generalization also aims to provide tools for understanding why models behave the way they do, which might help us recognize deceptively aligned models.
To be clear, we think pessimistic scenarios are, well, pessimistic and hard! These are our best preliminary attempts at agendas for addressing them, and we expect to change and expand as we learn more. Additionally, as we make progress on the more optimistic scenarios, I expect the number of projects we have targeted on pessimistic scenarios to increase.
The weird thing about a portfolio approach is that the things it makes sense to work on in “optimistic scenarios” often trade off against those you’d want to work on in more “pessimistic scenarios,” and I don't feel like this is really addressed.
Like, if we’re living in an optimistic world where it’s pretty chill to scale up quickly, and things like deception are either pretty obvious or not all that consequential, and alignment is close to default, then sure, pushing frontier models is fine. But if we’re in a world where the problem is nearly impossible, alignment is nowhere close to default, and/or things like deception happen in an abrupt way, then the actions Anthropic is taking (e.g., rapidly scaling models) are really risky.
This is part of what seems weird to me about Anthropic’s safety plan. It seems like the major bet the company is making is that getting empirical feedback from frontier systems is going to help solve alignment. Much of that justification (afaict from the Core Views post) is because Anthropic expects to be surprised by what emerges in larger models. For instance, as this Anthropic paper mentions: models can’t do 3 digit addition basically at all (close to 0% test accuracy) until all of the sudden, as you scale the model slightly, they can (0% to 80% accuracy abruptly). I presume the safety model here is something like: if you can’t make much progress on problems without empirical feedback, and if you can’t get the empirical feedback unless the capability is present to work with, and if capabilities (or their precursors) only emerge at certain scales, then scaling is a bottleneck to alignment progress.
I’m not convinced by those claims, but I think that even if I were, I would have a very different sense of what to do here. Like, it seems to me that our current state of knowledge about how and why specific capabilities emerge (and when they do) is pretty close to “we have no idea.” That means we are pretty close to having no idea about when and how and why dangerous capabilities might emerge, nor whether they’ll do so continuously or abruptly.
My impression is that Dario agrees with this:
Dwarkesh: “So, dumb it down for me, mechanistically—it doesn’t know addition yet, now it knows addition, what happened?”
Dario: “We don’t know the answer.” (later) “Specific abilities are very hard to predict. When does arithmetic come into place? When do models learn to code? Sometimes it’s very abrupt. It’s kind of like you can predict statistical averages of the weather, but the weather on one particular day is very hard to predict.”
If I put on the “we need empirical feedback from neural nets to make progress on alignment” hat, along with my “prudence” hat, I’m thinking things more like, “okay let’s stop scaling now, and just work really hard on figuring out how exactly capabilities emerged between e.g., GPT-3 and GPT-4. Like, what exactly can we predict about GPT-4 based on GPT-3? Can we break down surprising and abrupt less-scary capabilities into understandable parts, and generalize from that to more-scary capabilities?” Basically, I’m hoping for a bunch more proof of concept that Anthropic is capable of understanding and controlling current systems, before they scale blindly. If they can’t do it now, why should I expect they’ll be able to do it then?
My guess is that a bunch of these concerns are getting swept under the “optimistic scenario” rug, i.e., “sure, maybe we’d do that if we only expected a pessimistic scenario, but we don’t! And in the optimistic scenario, scaling is pretty much fine, and we can grab more probability mass there so we’re choosing to scale and do the safety we can conditioned on that.” I find this dynamic frustrating. The charitable read on having a uniform prior over outcomes is that you’re taking all viewpoints seriously. The uncharitable read is that it gives you enough free parameters and wiggle room to come to the conclusion that “actually scaling is good” no matter what argument someone levies, because you can always make recourse to a different expected world.
Like, even in pessimistic scenarios (where alignment is nearly impossible), Anthropic still concludes they should be scaling in order to “sound the alarm bell,” despite not saying all that much about how that would work, or if it would work, or making any binding commitments, or saying what precautions they’re taking to make sure they would end up in the “sound the alarm bell” world instead of the “now we’re fucked” world, which are pretty close together. Instead they are taking the action “rapidly scaling systems even though we publicly admit to being in a world where it’s unclear how or when or why different capabilities emerge, nor whether they’ll do so abruptly, and we haven’t figured out how to control these systems in the most basic ways.” I don’t understand how Anthropic thinks this is safe.
The safety model for pushing frontier models as much as Anthropic is doing doesn’t make sense to me. If you’re expecting to be surprised by newer models, that’s bad. We should be aiming to not be surprised, so that we have any hope of managing something that might be much smarter and more powerful than us. The other reasons this blog post lists for working on frontier models seem similarly strange to me, although I’ll leave it here for now. From where I’m at, it doesn’t seem like safety concerns really justify pushing frontier models, and I’d like to hear Anthropic defend this claim more, given that they cite it as one of the main reasons they exist:
“A major reason Anthropic exists as an organization is that we believe it's necessary to do safety research on ‘frontier’ AI systems.”
(I’d honestly like to be convinced this does make sense, if I’m missing something here).
If I put on the “we need empirical feedback from neural nets to make progress on alignment” hat, along with my “prudence” hat, I’m thinking things more like, “okay let’s stop scaling now, and just work really hard on figuring out how exactly capabilities emerged between e.g., GPT-3 and GPT-4. Like, what exactly can we predict about GPT-4 based on GPT-3? Can we break down surprising and abrupt less-scary capabilities into understandable parts, and generalize from that to more-scary capabilities?” Basically, I’m hoping for a bunch more proof of concept that Anthropic is capable of understanding and controlling current systems, before they scale blindly. If they can’t do it now, why should I expect they’ll be able to do it then?
Looking back in 2026, this strikes me as a sad missed opportunity. We're at a point where the next capabilities jump will probably not get us anything as easily describable as "gain the ability to multiply 3-digit numbers". Instead it will be something fuzzy and hard to operationalize.
There was a window where we could do empirical work in the genre of "figure out how exactly model capabilities improve with successive generations", but that work is much harder to do now—it might not even be possible at all.
There's a unilateralism problem with doing risky stuff in the name of picking up probability mass, where one has knightian uncertainty about whether that probability mass is actually there. If people end up with a reasonable distribution over alignment difficulty, plus some noise, then the people with noise that happened to make their distribution more optimistic will view it as more worth while to trade off accelerated timelines for alignment success in medium-difficulty worlds. Mostly people should just act on their inside view models, but it's pretty concerning to have another major org trying to have cutting-edge capabilities. The capabilities are going to leak out one way or another and are going to contribute to races.
What are the strategic reasons for prioritizing work on intermediate difficulty problems and "easy safety techniques" at this time?
[This comment is no longer endorsed by its author]
Doesn't this part of the comment answer your question?
We can very easily "grab probability mass" in relatively optimistic worlds. From our perspective of assigning non-trivial probability mass to the optimistic worlds, there's enormous opportunity to do work that, say, one might think moves us from a 20% chance of things going well to a 30% chance of things going well. This makes it the most efficient option on the present margin.
It sounds like they think it's easier to make progress on research that will help in scenarios where alignment ends up being not that hard. And so they're focusing there because it seems to be highest EV.
Seems reasonable to me. (Though noting that the full EV analysis would have to take into account how neglected different kinds of research are, and many other factors as well.)
Thanks Zac.
My high level take is I found this very useful for understanding Anthropic broader strategy and think that I agree with a lot of the thinking. It definitely seems like some of this research could backfire but Anthropic is aware of that. The rest of my thoughts are below.
I found a lot of value in the examination of different scenarios. I think this provides the clearest explanations for why Anthropic is taking an empirical/portfolio approach. My mental models of people disagreeing with this approach involves them being either more confident about pessimistic (they would say realistic scenarios) or that they disagree with specific research agendas/have favorites. I'm very uncertain about which scenario we live in but in the context of that uncertainty, the portfolio approach seems reasonable.
I think the most contentious part of this post will probably be the arguments in favor of working with frontier models. It seems to me that while this is dangerous, the knowledge required to correctly assess a) whether this is necessary, b) what, if any, results that arise from such research should be published seems closely tied to that work itself (ie: questions like how many safety relevant phenomena just don't exist in smaller models and how redundant work on small models becomes).
Writing this comment, I feel a strong sense of, "gee, I feel like if anyone would have the insights to know whether this stuff is a safe bet, it would be the teams at Anthropic" and that feels kind of dangerous. Independent oversight such as ARC evals might help us but a strong internal culture of red-teaming different strategies would also be good.
Quoting from the main article, I wanted to highlight some points:
Furthermore, we think that in practice, doing safety research isn’t enough – it’s also important to build an organization with the institutional knowledge to integrate the latest safety research into real systems as quickly as possible.
I think this is a really good point. The actual implementation of many alignment strategies might be exceedingly technically complicated and it seems unlikely that we could attain that knowledge quickly as opposed to over years of working with frontier models.
In a sense one can view alignment capabilities vs alignment science as a “blue team” vs “red team” distinction, where alignment capabilities research attempts to develop new algorithms, while alignment science tries to understand and expose their limitations.
This distinction also seems good to me. If there is work that can't be published or until functional independent evaluation is working well, then high quality internal red-teaming seems essential.
Thanks for writing this, Zac and team, I personally appreciate more transparency about AGI labs' safety plans!
Something I find myself confused about is how Anthropic should draw the line between what to publish or not. This post seems to draw the line between "The Three Types of AI Research at Anthropic" (you generally don't publish capabilities research but do publish the rest), but I wonder if there's a case to be more nuanced than that.
To get more concrete, the post brings up how "the AI safety community often debates whether the development of RLHF – which also generates economic value – 'really' was safety research" and says that Anthropic thinks it was. However, the post also states Anthropic "decided to prioritize using [Claude] for safety research rather than public deployments" in the spring of 2022. To me, this feels slightly dissonant—insofar as much of the safety and capabilities benefits from Claude came from RLHF/RLAIF (and perhaps more data, though that's perhaps less infohazardous), this seems like Anthropic decided not to publish "Alignment Capabilities" research for (IMO justified) fear of negative externalities. Perhaps the boundaries around what should generally not be published should also extend to some Alignment Capabilities research then, especially research like RLHF that might have higher capabilities externalities.
Additionally, I've also been thinking that more interpretability research maybe should be kept private. As a recent concrete example, Stanford's Hazy Research lab just published Hyena, a convolutional architecture that's meant to rival transformers by scaling to much longer context lengths while taking significantly fewer FLOPs to train. This is clearly very much public research in the "AI Capabilities" camp, but they cite several results from Transformer Circuits for motivating the theory and design choices behind their new architecture, and say "This work wouldn’t have been possible without inspiring progress on ... mechanistic interpretability." That's all to say that some of the "Alignment Science" research might also be useful as ML theory research and then motivate advances in AI capabilities.
I'm curious if you have thoughts on these cases, and how Anthropic might draw a more cautious line around what they choose to publish.
Unfortunately, I don't think a detailed discussion of what we regard as safe to publish would be responsible, but I can share how we operate at a procedural level. We don't consider any research area to be blanket safe to publish. Instead, we consider all releases on a case by case basis, weighing expected safety benefit against capabilities/acceleratory risk. In the case of difficult scenarios, we have a formal infohazard review procedure.
Thanks for the response, Chris, that makes sense and I'm glad to read you have a formal infohazard procedure!
Could you share more about how the Anthropic Policy team fits into all this? I felt that a discussion of their work was somewhat missing from this blog post.
(Zac's note: I'm posting this on behalf of Jack Clark, who is unfortunately unwell today. Everything below is his words.)
Hi there, I’m Jack and I lead our policy team. The primary reason it’s not discussed in the post is that the post was already quite long and we wanted to keep the focus on safety - I did some help editing bits of the post and couldn’t figure out a way to shoehorn in stuff about policy without it feeling inelegant / orthogonal.
You do, however, raise a good point, in that we haven’t spent much time publicly explaining what we’re up to as a team. One of my goals for 2023 is to do a long writeup here. But since you asked, here’s some information:
You can generally think of the Anthropic policy team as doing three primary things:
- Trying to proactively educate policymakers about the scaling trends of AI systems and their relation to safety. Myself and my colleague Deep Ganguli (Societal Impacts) basically co-wrote this paper https://arxiv.org/abs/2202.07785 - you can think of us as generally briefing out a lot of the narrative in here.
- Pushing a few specific things that we care about. We think evals/measures for safety of AI systems aren’t very good [Zac: i.e. should be improved!], so we’ve spent a lot of time engaging with NIST’s ‘Risk Management Framework’ for AI systems as a way to create more useful policy institutions here - while we expect labs in private sector and academia will do much of this research, NIST is one of the best institutions to take these insights and a) standardize some of them and b) circulate insights across government. We’ve also spent time on the National AI Research Resource as we see it as a path to have a larger set of people do safety-oriented analysis of increasingly large models.
- Responding to interest. An increasing amount of our work is reactive (huge uptick in interest in past few months since launch of ChatGPT). By reactive I mean that policymakers reach out to us and ask for our thoughts on things. We generally aim to give impartial, technically informed advice, including pointing out things that aren’t favorable to Anthropic to point out (like emphasizing the very significant safety concerns with large models). We do this because a) we think we’re well positioned to give policymakers good information and b) as the stakes get higher, we expect policymakers will tend to put higher weight on the advice of labs which ‘showed up’ for them before it was strategic to do so. Therefore we tend to spend a lot of time doing a lot of meetings to help out policymakers, no matter how ‘important’ they or their country/organization are - we basically ignore hierarchy and try to satisfy all requests that come in at this stage.
More broadly, we try to be transparent on the micro level, but haven’t invested yet in being transparent on the macro. What I mean by that is many of our RFIs, talks, and ideas are public, but we haven’t yet done a single writeup that gives an overview of our work. I am hoping to do this with the team this year!
Some other desiderata that may be useful:
- I testified in the Senate last year and wrote quite a long written testimony.
- I talked to the Congressional AI Caucus; slides here. Note: I demo’d Claude but it’s worth noting that whenever I demo our system I also break it to illustrate safety concerns. IIRC here I jailbroke it so it would play along with me when I asked it how to make rabies airborne - this was to illustrate how loose some of the safety aspects of contemporary LLMs are.
- A general idea I/we push with policymakers is the need to measure and monitor AI systems; Jess Whittlestone and I wrote up a plan here which you can expect us to be roughly outlining in meetings.
- A NIST RFI that talks about some of the trends in predictability and surprise and also has some recommendations.
Our wonderful colleagues on the ‘Societal Impacts’ team led this work on Red Teaming and we (Policy) helped out on the paper and some of the research. We generally think red teaming is a great idea to push to policymakers re AI systems; it’s one of those things that is ‘shovel ready’ for the systems of today but, we think, has some decent chance of helping out in future with increasingly large models.
I don't think that team (if such a team exists) is missing from this post, and if it was missing, then it would be for some pretty good reasons. You can see Jack Clark's thread or DM me if you're interested in that sort of thing.
There is a Policy team listed here. So it presumably exists. I don't think omitting its work from the post has to be for good reasons, it could just be because the post is already quite long. An example of something Anthropic could say which would give me useful information on the policy front; I am making this up, but seems good if true:
In pessimistic and intermediate difficulty scenarios, it may be quite important for AI developers to avoid racing. In addition to avoiding contributing to such racing dynamics ourselves, we are also working to build safety-collaborations among researchers at leading AI safety organizations. If an AI lab finds compelling evidence about dangerous systems, it is paramount that such evidence is disseminated to relevant actors in industry and government. We are building relationships and secure information sharing systems between major AI developers and working with regulators to remain in compliance with relevant laws (e.g., anti-trust).
Again, I have no idea what the policy team is doing, but they could plausibly be doing something like this and could say so, while there may be some things they don't want to talk about.
As Jack notes here, the Policy team was omitted for brevity and focus. You can read that comment for more about the Policy team, including how we aim to give impartial, technically informed advice and share insights with policymakers.
Thank you for this post. It looks like the people at Anthropic have put a lot of thought into this which is good to see.
You mention that there are often surprising qualitative differences between larger and smaller models. How seriously is Anthropic considering a scenario where there is a sudden jump in certain dangerous capabilities (in particular deception) at some level of model intelligence? Does it seem plausible that it might not be possible to foresee this jump from experiments on even slighter weaker models?
We certainly think that abrupt changes of safety properties are very possible! See discussion of how the most pessimistic scenarios may seem optimistic until very powerful systems are created in this post, and also our paper on Predictability and Surprise.
With that said, I think we tend to expect a bit of continuity. Empirically, even the "abrupt changes" we observe with respect to model size tend to take place over order-of-magnitude changes in compute. (There are examples of things like the formation of induction heads where qualitative changes in model properties can happen quite fast over the course of training).
But we certainly wouldn't claim to know this with any confidence, and wouldn't take the possibility of extremely abrupt changes off the table!
In a larger picture, you should also factor in the probability that the oversight (over the breeding of misaligned tendencies) will always be vigilant. The entire history of safety science tells us that this is unlikely, or downright impossible. Mistakes will happen, "obligatory checks" do get skipped, and entirely unanticipated failure modes do emerge. And we should convince ourselves that nothing of this will happen, with decent probability, from the moment of the first AGI deployment, until "the end of time" (or practically, we should show, theoretically, that the ensuing recursive self-improvement or quasi-self-improvement sociotechnical dynamics will only coverage to more resilience rather than less resilience). This is very hard to demonstrate, but it must be done to justify AGI deployment. I didn't see evidence in the post that Anthropic appreciates this angle of looking at the problem enough.
High-level thoughts
Overall, I like the posted strategy much more than OpenAI’s (in the form of Sam Altman’s post) and Conjecture’s.
I like that the strategy takes some top-down factors into account, namely the scenario breakdown.
Things that still seem to me missing or mistaken in the presented strategy:
- A static view on alignment, as a “problem to solve” rather than a continuous, never-ending, dynamical process. I think this is important to get this conceptual crux right. More on this below.
- A slight over-reliance on (bottom-up) empiricism and not recognising theoretical (top-down) “alignment science” enough. I think as a responsible organisation with now very decent funding and, evidently, rather short timelines, Anthropic should advance more fundamental “alignment science” research programs, blending cognitive science, control theory, resilience theory, political science, and much more. There is some appreciation of the necessity to develop this in the section on “Societal Impacts and Evaluations”, but not enough, IMO. More on this below.
- Maybe still not enough top-down planning for AGI transition. To whom “aligned” AGI will belong, specifically (if anyone; AI could also be self-sovereign)? How it will be trained, maintained, monitored, etc.? What about democratic processes and political borders? Is there such a thing as an “acute risk period” and how we should “end” it, and how we should monitor people for not trying to develop misaligned AI after that? Sam Altman answers more of these questions than Anthropic. Of course, all these “plans” will be changed many times, but, as “planning is everything”, these plans should be prepared and debated already, and checked for coherence with the rest of Anthropic’s strategy. I could also hypothesise that Anthropic does have such plans, but chose not to publish them. However, the plans (or, better to call them predictions) of this sort don’t strike me as particularly infohazarous: MIRI people discuss them, Sam Altman discusses them.
Specific remarks
So far, no one knows how to train very powerful AI systems to be robustly helpful, honest, and harmless.
AI couldn’t be robustly HHH to everyone - frustrations/conflicts are inevitable, as per Vanchurin et al.'s theory of evolution as multilevel learning, and other related works. Since there are conflicts, and due to the boundedness of computational and other resources for alignment (not alignment as an R&D project, but alignment as a practical task: when a burglar runs towards you, it's impossible to "align" with them on values), AI must be unhelpful, dishonest, and hostile to some actors at some times.
First, it may be tricky to build safe, reliable, and steerable systems when those systems are starting to become as intelligent and as aware of their surroundings as their designers.
“Steerable” → persuadable, per Levin's "Technological Approach to Mind Everywhere".
Some scary, speculative problems might only crop up once AI systems are smart enough to understand their place in the world, to successfully deceive people, or to develop strategies that humans do not understand.
AI is already situationally aware, including as per Anthropic’s own research, "Discovering Language Model Behaviors with Model-Written Evaluations".
Pessimistic scenarios: AI safety is an essentially unsolvable problem – it’s simply an empirical fact that we cannot control or dictate values to a system that’s broadly more intellectually capable than ourselves – and so we must not develop or deploy very advanced AI systems.
Different phrases are mixed here badly. “Controlling and dictating values to AI systems” is neither a synonym for “solving AI safety”, nor desirable, and should not lead to the conclusion that advanced AI systems are not developed. “Solving AI safety” should be synonymous with having alignment processes, systems, and law codes developed and functioning reliably. This is not the same as “controlling and dictating values”. Alignment mechanisms should permit the evolution of shared values.
However, I do think that developing and implementing such alignment processes “in time” (before the capability research is ready to deliver superhuman AI systems) is almost certainly out of the empirical possibility, especially considering the coordination it would require (including the coordination with many independent actors and hackers because SoTA AI developments get open-sourced and democratised rapidly). “Pivotal acts” lessen the requirement for coordination, but introduce more risk in themselves.
So, I do think we must not develop and deploy very advanced AI systems, and instead focus on merging with AI and doing something like mind upload on a slower timescale.
If we’re in a “near-pessimistic” scenario, this could instead involve channeling our collective efforts towards AI safety research and halting AI progress in the meantime.
I think the precautionary principle dictates that we should do this in any scenarios apart from “obviously optimistic” or “nearly obviously optimistic”. In the “AGI Ruin” post, Yudkowsky explained well that any alignment protocol (given certain objective properties of the alignment problem contingent on the systems that we build and the wider socio-technical reality) that “narrowly works” almost definitely will fail due to unknown unknowns. This is an unacceptably high level of risk (unless we judge that stopping short of the deployment of superhuman AGI systems is even riskier, for some reason).
Indications that we are in a pessimistic or near-pessimistic scenario may be sudden and hard to spot. We should therefore always act under the assumption that we still may be in such a scenario unless we have sufficient evidence that we are not.
It’s worse: in the mindset where the alignment is a continuous process between humans and AIs, rather than a problem to “solve”, we shouldn’t count on sudden indications that it will fail, at all. It’s often not how Drift into Failure happens. So, in the latter sentence, I would replace “evidence” with “theoretical explanation”: the explanation that the proposed alignment mechanism is “safe” must be constructive and prospective rather than empirical and inductive.
If it turns out that AI safety is quite tractable, then our alignment capabilities work may be our most impactful research. Conversely, if the alignment problem is more difficult, then we will increasingly depend on alignment science to find holes in alignment capabilities techniques. And if the alignment problem is actually nearly impossible, then we desperately need alignment science in order to build a very strong case for halting the development of advanced AI systems.
I think this paragraph puts everything upside down. “Alignment science” (which I see as a multi-disciplinary research area which blends cognitive science, including epistemology, ethics, rationality, consciousness science, game theory, control theory, resilience theory, and more disciplines) is absolutely needed as a foundation for alignment capabilities work, even if the latter appears to us very successful and unproblematic. And it is the alignment science that should show that the proposed alignment process is safe, in a prospective and constructive way, as described above.
If our work on Scalable Supervision and Process-Oriented Learning produce promising results (see below), we expect to produce models which appear aligned according to even very hard tests. This could either mean we're in a very optimistic scenario or that we're in one of the most pessimistic ones.
This passage doesn’t use the terms “optimistic” and “pessimistic scenarios” in the way they are defined above. The AI system could appear aligned according to very hard tests, but recognising that alignment is a never-ending process, and insights from broader alignment science (rather than rather narrowly technical “branch” of it, and moreover, implying a certain ontology of cognition where “values” and “processes” have specific meaning) could still show that aligning AI systems on a longer horizon is nevertheless bound to fail.
Our hope is that this may eventually enable us to do something analogous to a "code review", auditing our models to either identify unsafe aspects or else provide strong guarantees of safety.
Interpretability of a system post-training (and fine-tuning) couldn’t provide a “strong guarantee” for safety, since it’s a complex, dynamical system, which could fail in surprising and unexpected ways during deployment. Only always-on oversight (including during deployment) and monitoring, together with various theoretical dynamical models of the system, could (at least in principle) provide some guarantees.
The hope is that we can use scalable oversight to train more robustly safe systems.
Not clear where the “more robustly” comes from. Scalable oversight during training could produce safer/more aligned models, like “manual” oversight would (if it was humanly possible and less costly), ok. But the robustness of safety (alignment) is quite another matter, especially in a broader sense, and it’s not clear how “scalable oversight during training” aids with that.
Learning Processes Rather than Achieving Outcomes
Sounds like it either refers to imitation learning, in which case not sure why give a new name to this concept, or a sort of process-oriented GOFAI which will probably not practically work on the SoTA levels that AI already achieves, let alone superhuman levels. Humans don’t know know how to decompose their activity into processes, evidenced by the fact that processes standards (like from the ISO 9000 series) could not be followed to the letter to achieve practical results. Would be interested to learn more about this Anthropic’s agenda.
When a model displays a concerning behavior such as role-playing a deceptively aligned AI, is it just harmless regurgitation of near-identical training sequences? Or has this behavior (or even the beliefs and values that would lead to it) become an integral part of the model’s conception of AI Assistants which they consistently apply across contexts? We are working on techniques to trace a model’s outputs back to the training data, since this will yield an important set of clues for making sense of it.
I really like this, I think this is one of the most interesting pieces of the write-up.
Great post. I'm happy to see these plans coming out, following OpenAI's lead.
It seems like all the safety strategies are targeted at outer alignment and interpretability. None of the recent OpenAI, Deepmind, Anthropic, or Conjecture plans seem to target inner alignment, iirc, even though this seems to me like the biggest challenge.
Is Anthropic mostly leaving inner alignment untouched, for now?
It seems like all the safety strategies are targeted at outer alignment and interpretability.
None of the recent OpenAI, Deepmind, Anthropic, or Conjecture plans seem to target inner alignment
Less tongue-in-cheek: certainly it's unclear to what extent interpretability will be sufficient for addressing various forms of inner alignment failures, but I definitely think interpretability research should count as inner alignment research.
I mean, it's mostly semantics but I think of mechanical interpretability as "inner" but not alignment and think it's clearer that way, personally, so that we don't call everything alignment. Observing properties doesn't automatically get you good properties. I'll read your link but it's a bit too much to wade into for me atm.
Either way, it's clear how to restate my question: Is mechanical interpretability work the only inner alignment work Anthropic is doing?
Evan and others on my team are working on non-mechanistic-interpretability directions primarily motivated by inner alignment:
- Developing model organisms for deceptive inner alignment, which we may use to study the risk factors for deceptive alignment
- Conditioning predictive models as an alternative to training agents. Predictive models may pose fewer inner alignment risks, for reasons discussed here
- Studying the extent to which models exhibit likely pre-requisites to deceptive inner alignment, such as situational awareness (a very preliminary exploration is in Sec. 5 in our paper on model-written evaluations)
- Investigating the extent to which externalized reasoning (e.g. chain of thought) is a way to gain transparency into a model's process for solving a task
There's also ongoing work on other teams related to (automated) red teaming of models and understanding how models generalize, which may also turn out to be relevant/helpful for inner alignment. It's pretty unclear to me how useful any of these directions will turn out to be for inner alignment in the end, but we've chosen these directions in large part because we're very concerned about inner alignment, and we're actively looking for new directions that seem useful for mitigating inner misalignment risks.
Thanks for explaining your thoughts on AI safety, it's much appreciated.
I think in general when trying to do good in the world, we should strive for actions that have a high expected value and a low potential downside risk.
I can imagine a high expected value case for Anthropic. But I don't see how Anthropic has few potential downsides. I'm very worried that by participating in the race to AGI, p(doom) might increase.
For an example pointed out in the comments here by habryka:
I mean, didn't the capabilities of Claude leak specifically to OpenAI employees, so that it's pretty unclear that not releasing actually had much of an effect on preventing racing? My current best guess, though I am only like 30% of this hypothesis since there are many possible hypotheses here, is that Chat-GPT was developed in substantial parts because someone saw or heard about a demo of Claude and thought it was super impressive.
Could you explain to me why you think there are no large potential downsides to Anthropic? I'm extremely worried the EA/LessWrong community has so far only increased AI risk, and the creation of Anthropic doesn't exactly soothe these worries.
PS: You recently updated your website and it finally has a lot more information about your company and you also finally have a contact email listed, which is great! But I just wanted to point out that when emailing hello [at] anthropic.com I get an email back saying the address wasn't found. I've tried contacting your company about my worries before, but it seems really difficult to reach you.
Good to see Anthropic's serious and seem better then OpenAI.
A few general questions that don't seem to be addressed:
- There is a belief that AI is more dangerous the more different it is from us. Isn't this a general reason to build it as like us as possible? For example isn't mind uploading/Whole Brain Emulation a better approach if possible? If its obviously too slow, then could we make the AI at least follow our evolutionary trajectory as much as possible?
- There is justified concern about behavior changing a lot when the system becomes situationally aware/self aware. It doesn't seem to be discussed at all whether to delay or cause this to happen sooner. Wouldn't it be worthwhile to make the AI as self aware as possible when it is still < human AGI so we can see the changes as this happens? It seems it will happen unpredictably otherwise which is hardly good.
I have some more detailed comments/questions but I want to be sure there aren't obvious answers to these first.
-
"AI is more dangerous the more different it is from us" seems wrong to me: it is very different and likely to be very dangerous, but that doesn't imply that making it somewhat more like us would make it less dangerous. I don't think brain emulation can be developed in time, replaying evolution seems unhelpful to me, and both seem likely to cause enormous suffering (aka mindcrime).
-
See my colleague Ethan Perez's comment here on upcoming research, including studying situational awareness as a risk factor for deceptive misalignment.
Thanks. OK I will put some more general thoughts, have to go back a few steps.
To me the more general alignment problem is AI gives humanity ~10,000 years of progress and probably irreversible change in ~1-10 years. To me the issue is how do you raise humans intelligence from that given by biology to that given by the limits of physics in a way that is identify preserving as much as possible. Building AI seems to be the worst way to do that. If I had a fantasy way it would be say increase everyone's IQ by 10 points per year for 100+ years until we reach the limit.
We can't do that but that is why I mentioned WBE, my desire would be to stop AGI, get human mind uploading to work, then let those WBE raise their IQ in parallel. Their agreed upon values would be humanities values by definition then.
If our goal is Coherent Extrapolated Volition or something similar for humanity then how can we achieve that if we don't increase the IQ of humans (or descendants they identify with)? How can we even know what our own desires/values are at increasing IQ's if we don't directly experience them.
I have an opinion what successful alignment looks like to me but is it very different for other people? We can all agree what bad is.
The full post goes into considerably more detail, and I'm really excited that we're sharing more of our thinking publicly.