TL;DR: Information Theory is another mathematical framework for understanding the relatedness of X and Y based on measured joint probability distributions.
Epistemic status - quite confident. I would not be qualified to teach a course on this for graduate students in mathematics or statistics, but I do teach a course on this for PhD students in biology and psychology.
Well done! In the spirit of "yes, and", I think it is worth pointing out that there are highly related concepts in Shannon Information Theory, and wonder if this comes closer to the OP's notion of Platonic Variance Explained. (If there's interest in a longer explanation of Info. Theory with equations and graphs and examples, I could write that as a post; but perhaps that's already well-tread ground here. For now I just want to make a quick comparison, without fully fleshing out the points).
In the "explained variance" framework we think about the variability of possible Y's in terms of its spread around (literally, distance from) the mean value of Y. If you don't know what Y is in a particular case and you are forced to guess, often the average Y is a good guess in two senses: first, on average this guess has the lowest error (squared difference between the guess and the actual value of Y); and second, it is more frequently correct than any other choice. But this is predicated on the implicit model that Y is a normally distributed variable. Due to the Central Limit Theorem, many variables are approximately normally distributed, so this model is often a useful one. Regression then builds on this to quantify the extent to which X constrains the possible value of Y, as nicely explained above. The OP nicely explains that "variance explained" means the extent to which some particular model of Y based on X (such as: Y=mX+b), provides a better guess than the alternative model of Y=the average Y in the first sense mentioned above. This statement is at least as much a statement about the model, as about X.
Information Theory measures the same things from the same data, through a different conceptual lens.
Instead of measuring the variability of Y by its variance, Information Theory measures this by its entropy, which you can think of is the uncertainty you have about Y before you observe it. Like the variance, the entropy only depends on the distribution of Y. But unlike variance, entropy makes no assumptions about the shape of the distribution of Y. The values of Y can have an arbitrarily complex, non-parametric distribution, for which the mean value of Y might be an extremely bad guess in both senses mentioned above.
Instead of measuring the relationship between X and Y by the variance explained, Information Theory measures the mutual information between X and Y, which you can think of as how much your uncertainty about Y is reduced by knowing X. Like "variance explained", mutual information depends only on the joint distribution of X and Y. But unlike regression, it does not require positing any model of how Y depends on X. This is powerful, because it gives you a fact about the X-Y relationship, not a fact about the goodness of some model. You can measure mutual information even if the form of the relationship is unknown or complicated. On the down side, since it's model-free, it doesn't directly give you a method for predicting Y from X.
I think Mutual Information comes closer to what the OP calls the Platonic Variance Explained, but correct me if I'm wrong!
I'm restricting myself to the main theme of the OP here, but it might be interesting flesh out other ways the two frameworks are similar or different, such as issues of under-sampling/overfitting, independence-of-samples assumption; correlation vs causation; data processing inequality...
Thanks for the comment! Actually, after writing the post, I also wondered why this concept isn't based on information theory :) I think what I'd enjoy most, if you wanted to write it, is probably an in-depth treatment of the differences in meaning, properties, and purpose of:
- Entropy vs. variance
- Mutual information vs. variance explained
- conditional entropy vs. average remaining variance
- etc.
But unlike variance explained, it does not require positing any model of how Y depends on X. This is powerful, because it gives you a fact about the X-Y relationship, not a fact about the goodness of some model.
Note that parts of my post are actually model-free! For example, the mathematical definition and the example of twin studies do not make use of a model.
But this is predicated on the implicit model that Y is a normally distributed variable.
I'm not aware of (implicitly) making that assumption in my post!
You can measure mutual information even if the form of the relationship is unknown or complicated.
Is this so? Suppose we'd want to measure differential entropy, as a simplified example, and the true density "oscillates" a lot. In that case, I'd expect that the entropy is different than what it is if the density were smoother. But it might be hard to see the difference in a small dataset. The type of regularity/simplicity assumptions about the density might thus influence the result.
Note that parts of my post are actually model-free! For example, the mathematical definition and the example of twin studies do not make use of a model
Yes, good point, I should have said "unlike regression" rather than "unlike variance explained". I'll have to think more on how the type of analysis described in the twin example maps onto information theory.
But this is predicated on the implicit model that Y is a normally distributed variable.
I'm not aware of (implicitly) making that assumption in my post!
By "this" I meant the immediately preceding statements in my post. (Although the cartoon distributions you show do look normal-ish, so at least you invite that intuition). The idea that the mean or average is a good measure of central tendency of a distribution, or a good estimator, is so familiar we forget that it requires justification. For Normal distributions, it is the lowest MSE estimator, the maximum likelihood estimator, and is an unbiased estimator, but this isn't true of all distributions. For a skewed, long-tailed distribution, for example, the median is a better estimator. For a binomial distribution, the mean is almost never the maximum likelihood estimator. For a Cauchy distribution, the mean is not even defined (although to be fair I'm not entirely sure entropy is well defined in that case, either). Likewise the properties of variance that make it a good estimator of dispersion for a Normal distribution don't necessarily make it good for other distributions.
It is true that partitioning of variance and "variance explained" as such don't rely on a normality assumption, and there are non-parametric versions of regression, correlation, ANOVA etc. that don't assume normality. So I have not entirely put my finger on what the difference is.
You can measure mutual information even if the form of the relationship is unknown or complicated.
Is this so? Suppose we'd want to measure differential entropy, as a simplified example, and the true density "oscillates" a lot. In that case, I'd expect that the entropy is different than what it is if the density were smoother. But it might be hard to see the difference in a small dataset. The type of regularity/simplicity assumptions about the density might thus influence the result.
This might be a good place to mention that I work exclusively with discrete entropy, and am not very familiar with notations or proofs in differential (continuous) entropy. So if Y is continuous, in practice this involves discretizing the value of Y (binning your histograms). I agree the continuous case would be more directly comparable, but I don't think this is likely to be fundamentally important, do you?
In principle, conceptually, you can estimate entropy directly from the probability density function (PDF) non-parametrically as H = sum(-P log2 P), where the sum is over all possible values of Y, and P is the probability Y takes on a given value.[1] Likewise, you can estimate the mutual information directly from the joint probability distribution between X and Y, the equation for which I won't try to write out here without an equation editor. In practice, if Y is continuous, the more data you have, the more finely you can discretize Y and the more subtly you can describe the shape of the distribution, so you converge on the true PDF and thus the true entropy as the data size goes to infinity.
I'm not denying that it can take a lot of data to measure entropy or mutual information by brute force in this way. What is worse, these naive estimators are biased if distributions are under-sampled. So getting a good estimate of entropy or mutual information from data is very tricky, and the shape of the distribution can make the estimation more or less tricky. To the extent one relies on regularity or simplicity assumptions to overcome data limitations, these assumptions can affect your result.
Still, if you are careful about it, an estimate based on assumptions can still be a strict bound: X removes at least z% of your uncertainty about Y. There is a direct analogy in regression models: if Yhat=f(X) explains z% of the variance of y (assuming this is established properly), then x "Platonically" explains at least z% of the variance of y.
Relatedly, you can pre-process X into some derived variable such as Q=f(X) or an estimator Yhat=f(X), and then measure the mutual information between the derived variable and the true value of Y. The Data Processing Inequality states that if the derived variable contains Z amount of information about Y, the input variable X must contain at least that much information. This is very much like defining a particular regression model f(X); and in the Yhat=f(X) case, it does give you a model you can use to predict Y from X.
- ^
sorry, I haven't figured out the equation editor yet.
The idea that the mean or average is a good measure of central tendency of a distribution, or a good estimator, is so familiar we forget that it requires justification. For Normal distributions, it is the lowest MSE estimator, the maximum likelihood estimator, and is an unbiased estimator, but this isn't true of all distributions. For a skewed, long-tailed distribution, for example, the median is a better estimator.
Is it correct to say that the mean is a good estimator whenever the variance is finite? If so, maybe I should have added that assumption to the post.
I wonder how to think about that in the case of entropy, which you thought about analyzing. Differential entropy can also be infinite, for example. But the Cauchy distribution, which you mention, has infinite variance but finite differential entropy, at least.
1.sorry, I haven't figured out the equation editor yet.
You can type Cmd+4 to type inline latex formulas, and Cmd+m to type standalone latex formulas! Hope that helps.
In principle, conceptually, you can estimate entropy directly from the probability density function (PDF) non-parametrically as H = sum(-P log2 P), where the sum is over all possible values of Y, and P is the probability Y takes on a given value. Likewise, you can estimate the mutual information directly from the joint probability distribution between X and Y, the equation for which I won't try to write out here without an equation editor.
Note: After writing the next paragraph, I noticed that you made essentially the same points further below in your answer, but I'm still keeping my paragraph here for completeness.
I was more wondering whether we can estimate them from data, where we don't get the ground-truth values for the probabilities that appear in the formulas for entropy and mutual information, at least not directly. If we have lots of data, then we can approximate a PDF, that is true, but I'm not aware of a way of doing so that is entirely principles or works without regularity assumptions. As an example, let's say we want to estimate the conditional entropy (a replacement for the "remaining variance" in my post) for continuous and . I think in this case, if all sampled -values differ from each other, you could in principle come to the conclusion that there is no uncertainty in conditional on at all since you observe only one -value for each -value. But that would be severe overfitting, similar to what you'd expect in my section titled "When you have lots of data" for continuous .
Maybe it would be interesting to analyze the conditional entropy case for non-continuous distributions where variance makes less sense.
I think from my point of view we're largely in agreement, thanks for your further elaborations!
Is it correct to say that the mean is a good estimator whenever the variance is finite?
Well, yes, in the sense that the law of large numbers applies, i.e.
The condition for that to hold is actually weaker. If all the are not only drawn from the same distribution, but are also independent, the existence of a finite is necessary and sufficient for the sample mean to converge in probability to as goes to infinity, if I understand the theorem correctly (I can't prove that yet though; the proof with a finite variance is easy). If aren't independent, the necessary condition is still weaker than the finite variance, but it's cumbersome and impractical, so finite variance is fine I guess.
But that kind of isn't enough to always justify the use of a sample mean as an estimator in practice? As foodforthought says, for a normal distribution it's simultaneously the lowest MSE estimator, the maximum likelihood estimator, and is an unbiased estimator, but that's not true for other distributions.
A quick example: suppose we want to determine the parameter of a Bernoulli random variable, i.e. "a coin". The prior distribution over is uniform; we flip the coin times, and use the sample success rate, , i.e. the mean, i.e. the maximum likelihood estimate. Per simulation the mean squared error is about 0.0167. However, if we use instead, the mean squared error drops to 0.0139 (code).
Honestly though, all of this seems like frequentist cockamamie to me. We can't escape prior distributions; we may as well stop pretending that they don't exist. Just calculate a posterior and do whatever you want with it. E.g., how did I come up with the example? Well, it's the expected value of the posterior beta distribution for if the prior is uniform, so it also gives a lower MSE.
I find the phrase this post is about extremely useful. I've also had thoughts along very similar lines in terms of how to define it. And indeed, upon searching the internet I have found no similarly good reference for what this phrase means as this post and the comments below it. As such, it seems to me to be providing a very valuable service of defining and clarifying an expression widely in use.
In my opinion, this post misses the main challenge with the "platonic ideal" vision of a concept like % of explained variance: it's something that accidentally depends on the distribution of your variables in the sample, rather than a fundamental property of the relationship between those variables.
The total variance Var(Y) depends on the distribution of not only X, but all variables affecting Y. Also, because in general Var(Y|X) can depend on X, the term in the definition, which is really the average of Var(Y|X) across all X, depends on the distribution of X.
So from my understanding and in my practical experience using statistics, the coefficient of determination (what % of variance of Y is explained by X) always provides "narrow" information tailored to a specific context, not general information about a platonic ideal understanding of the relationship between X and Y. [I understand it might appear a bit defeatist relative to the goal set by OP... personally I have found accepting that has been useful to avoid a lot of unproductive arguments in real world cases.]
Heritability is a classic example. It can be useful in the context of e.g. breeding crops in specific conditions and predicting how much selection on a trait will affect the next generation, but the heritability you get overestimates how much genetics affect variance in the wild, where the environment is much more variable. Also, since there are genetics x environment interactions, Var(phenotype|genotype) estimated from a limited range of environments is not a good estimate of the average Var(phenotype|genotype) globally.
In the context of twins studies, if you think of twins raised together (as they would be in most cases), then the "predictors" that they share and that could influence whatever outcome you're measuring include a lot more than just genes. So if you're comparing twins vs. non-twins siblings, you overestimate the genetic portion of heritability of the characteristic of interest, since all your comparisons are based on a greater shared environment that 2 random people in the population.
--
As a sidenote, this is a compromise that occurs a lot in study design: if you need to estimate the relationship between Y and X, it's actually useful to have a population that varies less by factors other than X, but doing so potentially limits the generalization of the results to the broader population. If you want a broader sample so your conclusions are more likely to apply in different contexts, you may need a very large sample size, because in effect you need to calculate conditional distributions of (Y|X) for all sorts of combinations of the other variables.
---
Lastly, even if somehow you were able to calculate a version of "% of human characteristic that's genetically explained", that would be the true average across all populations / cultures / etc., you get the problem that the underlying distributions are not fixed in time. In my view, an answer that's contingent of very specific distribution of cultural practices / human environments available at this moment is not a very fundamental quantity of interest, it's more like an accidental characteristic as I mention above.
In my opinion, this post misses the main challenge with the "platonic ideal" vision of a concept like percentage of explained variance: it's something that accidentally depends on the distribution of your variables in the sample, rather than a fundamental property of the relationship between those variables.
Perhaps we need to step back and clarify what "Platonic Explained Variance" could even mean. All knowledge is contextual; it is a mistake to expect that there is a Truth to be known devoid of context. I supposed that the OP meant by this phrase something like: the true, complete statistical dependence between X and Y in the sampled population, as against our estimate or approximation of that dependence based on a given limited sample or statistical model. In any case, I'd like to argue that such distinction makes sense, while it does not make sense to look for a statistical relationship between X and Y that is eternally and universally true, independent of a specific population.
When we are using empirical statistics to describe the relationship between measurable variables X and Y, I think the conclusions we draw are always limited to the population we sampled. That is the essential nature of the inference. Generalization to the sampled population as a whole carries some uncertainty, which we can quantify based on the size of the sample we used and the amount of variability we observed, subject to some assumptions (e.g., about the underlying distributions, or independence of our observations).
But generalization to any other population always entails additional assumptions. If the original sample was limited in scope (e.g. a particular age, sex, geographic location, time point, or subculture), generalization outside that scope entails a new conjecture that the new group is essentially the same as the original one in every respect relevant to the claim. To the extent the original sample was broad in scope, we can as you say test whether such other factors detectably modified the association between X and Y, and if so, include these effects as covariates in our statistical model. As you note, this requires a lot of statistical power. Even so, whenever we generalize outside that population, we assume the new population is similar in the ways that matter, for both the main association and the modifier effects.
A statistical association can be factually, reproducibly true of a population and still be purely accidental, in which case we don't expect it to generalize. When we generalize to a new context or group or point in time, I think we are usually relying on an (implicit or explicit) model that the observed statistical relation between X and Y is a consequence of underlying causal mechanisms. If and to the extent that we know what causal mechanisms are at play, we have a basis for predicting or checking whether the relevant conditions apply in any new context. But (1) generalization of the causal mechanism to a new condition is still subject to verification; a causal model derived in a narrow context could be incomplete, and the new condition may differ in a way that turns out to be causally important in a way we didn't suspect; and (2) even if the causal mechanism perfectly generalizes, we do not expect "the fraction of variance explained" to generalize universally. That value depends on a plethora of other random and causal factors that will in general be different between populations [^1].
Summing up, I think it's a mistake to look for the 'Platonic Variance Explained' divorced from a specific population. But we can meaningfully ask if the statistical dependence we estimated from a finite empirical sample using a particular statistical model accurately reflects the true and complete statistical dependence between the variables in the population from which we sampled.
- This account might be particular to the branches of natural science that seek mechanistic causal models and/or fundamental theories as explanations. Other fields of research or philosophic frameworks that lack or eschew causal explanation or theory may have a different epistemic account, which I'd be interested to hear about.
Yes, when trying to reuse the OP's phrasing, maybe I wasn't specific enough on what I meant. I wanted to highlight how the "fraction of variance explained" metric generalized less that other outputs from the same model.
For example, if you conceive a case where a model of E[y] vs. x provides good out-of-sample predictions even if the distribution of x changes, e.g. because x stays in the range used to fit the model, the fraction of variance explained is nevertheless sensitive to the distribution of x. Of course, you can have a confounder w that makes y(x) less accurate out-of-sample because its distribution changes and indirectly "breaks" the learned y(x) relationship, but then, w would influence the fraction of variance explained even if it's not a confounder, even if it doesn't break the validity of y(x).
Or for a more concrete example, maybe some nutrients (e.g. Vitamin C) are not as predictive of individual health as they were in the past, because most people just have enough of them in their diet, but fundamentally the relationship between those nutrients and health hasn't changed, just the distribution; our model of that relationship is probably still good. This is a very simple example. Still, I think in general there is a lot of potential misinterpretation of this metric (not necessarily on this forum, but in public discourse broadly), especially as it is sometimes called a measure of variable importance. When I read the first part of this post about teachers from Scott Alexander: https://www.lesswrong.com/posts/K9aLcuxAPyf5jGyFX/teachers-much-more-than-you-wanted-to-know , I can't conclude from "having different teachers explains 10% of the variance in test scores" that teaching quality doesn't have much impact on the outcome. (And in fact, as a parent I would value teaching quality, but not a high variance in teaching quality within the school district. I wouldn't want my kids learning of core topics to be strongly dependent of which school or which class in that school they are attending.)
Thanks, I think this is an excellent comment that gives lots of useful context.
To summarize briefly what foorforthought has already expressed, what I meant with platoninc variance explained is the explained variance independent of a specific sample or statistical model, but as you rightly point out, this still depends on lots of context that depends on crucial details of study design or the population one studies.
It really is an important, well-written post, and I very much enjoyed it. I especially appreciate the twin studies example. I even think that something like that should maybe go into the wikitags, because of how often the title sentence appears everywhere? I'm relatively new to LessWrong though, so I'm not sure about the posts/wikitags distinction, maybe that's not how it's done here.
I have a pitch for how to make it even better though. I think the part about "when you have lots of data" vs "when you have less data" would be cleaner and more intuitive if it were rewritten as "when is discrete vs continuous". Now the first example (the "more data" one) uses a continuous ; thus, the sentence "define as the sample mean of taken over all for which " creates confusion, since it's literally impossible to get the same value from a truly continuous random variable twice; it requires some sort of binning or something, which, yes, you do explain later. So it doesn't really flow as a "when you have lots of data" case---nobody does that in practice with continuous , no matter how much data (at least as far as I know).
Now say we have a discrete : e.g., an observation can come from classes A, B, or C. We have a total of observations, from class . Turning the main spiel into numbers becomes straightforward:
On average, over all different values of weighted by their probability, the remaining variance in is times the total variance in .
- "Over all different values of " -> which we have three of;
- "weighted by their probability" -> we approximate the true probability of belonging to class as , obviously;
- "the remaining variance in " for class is , also obviously.
And we are done, no excuses or caveats needed! The final formula becomes:
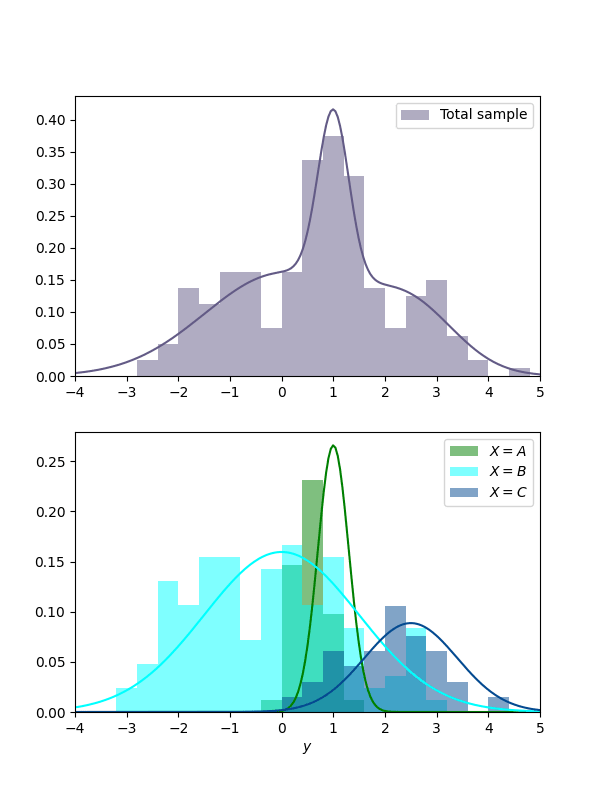
An example: . Since we are creating the model, we know the true "platonic" explained variance. In this example, it's about 0.386. An estimated explained variance on an sample came out as 0.345 (code)
After that, we can say that directly approximating the variance of for every value of a continuous is impossible, so we need a regression model.
And also that way it prepares the reader for the twin study example, which then can be introduced as a discrete case with each "class" being a unique set of genes, where always equals two.
If you do decide that it's a good idea, but don't feel like rewriting it, I guess we can go colab on the post and I can write that part. Anyway, please let me know your thoughts if you feel like it.
Thanks for the comment Stepan!
I think it's right that the distinction "lots of data" and "less data" doesn't really carve reality at its natural joints. I feel like your distinction between "discrete" and "continuous" also doesn't fully do this since you could imagine a case of discrete where we have only one for each in the dataset, and thus need regression, too (at least, in principle).
I think the real distinction is probably whether we have "several 's for each " in the dataset, or not. The twin dataset case has that, and so even though it's not a lot of data (only 32 pairs, or 64 total samples), we can essentially apply what I called the "lots of data" case.
Now, I have to admit that by this point I'm somewhat attached to the imperfect state of this post and won't edit it anymore. But I've strongly upvoted your comment and weakly agreed with it, and I hope some confused readers will find it.
random variables
This term always sounds like it means a variable selected at random not a variable with randomness in it. Please use the term 'stochastic variable'. Edit: or does it mean a variable composed entirely at random without any relation to any other variable?
Edit: I think this post would be much easier to learn from if it was a jupyter notebook with python code intermixed or R markdown. Sometimes the terminology gets away from me and seeing in code what is being said would really help understand what is going on as well as give some training on how to use this knowledge. Edit: there should be a plot illustrating " which are jointly sampled according to a density ." including rugs for the marginal distributions. I could do that if anyone wants. Here is an example describing a different concept.
Unfortunately, this is a well-established mathematical term that's used universally throughout probability theory. Changing notation to match intuition is not feasible; we must instead change intuition to match notation.
Technically speaking, a random variable is just a measurable function , where is the underlying sample space and is some measurable space. Indeed, even if the function is constant, it is technically speaking still a random variable (in this case it's called a deterministic random variable).
The problem is that, in practice, people don't really pay too much attention to precisely what the sample space is, especially if they don't have some specific reason to care about measure theory. They instead often want to talk about the probability distribution, and the task of figuring out formally and rigorously why this is all well-defined is often omitted. Luckily, the Kolmogorov extension theorem and related results usually allow you to pick a "large enough" sample space that carries all the content you need for your math work.
https://en.wikipedia.org/wiki/Random_variable
stochastic variable is certainly less common, but googling it only returns the right thing. it seems like it'd be a valid replacement and I agree it could reduce a common confusion.
"Random variable" is never defined. I though stochastic variable is just a synonym for random variable. I have seen posts where random variable is always written as r.v. and that helps a bit.
From Wikipedia: "In probability theory, the sample space (also called sample description space,[1] possibility space,[2] or outcome space[3]) of an experiment or random trial is the set of all possible outcomes or results of that experiment.
what is a measurable space?
"he function is constant," you mean its just one outcome like a die that always lands on one side?
what makes a function measurable?
what is a measurable space?
I'm not sure if clarifying this is most useful for the purpose of understanding this post specifically, but for what it's worth: A measurable space is a set together with a set of subsets that are called "measurable". Those measurable sets are the sets to which we can then assign probabilities once we have a probability measure (which in the post we assume to be derived from a density , see my other comment under your original comment).
"the function is constant," you mean its just one outcome like a die that always lands on one side?
I think that's what the commenter you replied to means, yes. (They don't seem to be active anymore)
what makes a function measurable?
This is another technicality that might not be too useful to think about for the purpose of this post. A function is measurable if the preimages of all measurable sets are measurable. I.e.: , for two measurable spaces and , is measurable, if is measurable for all measurable . For practical purposes, you can think of continuous functions or, in the discrete case, just any functions.
I'm sorry that the terminology of random variables caused confusion!
If it helps, you can basically ignore the formalism of random variables and instead simply talk about the probability of certain events. For a random variable with values in and density , an event is (up to technicalities that you shouldn't care about) any subset . Its probability is given by the integral
In the case that is discrete and not continuous (e.g., in the case that it is the set of all possible human DNA sequences), one would take a sum instead of an integral:
The connection to reality is that if we sample from the random variable , then its probability of being in the event is modeled as being precisely . I think with these definitions, it should be possible to read the post again without getting into the technicalities of what a random variable is.
I think this post would be much easier to learn from if it was a jupyter notebook with python code intermixed or R markdown.
In the end of the article I link to this piece of code of how to do the twin study analysis. I hope that's somewhat helpful.
FYI Likelihood refers to a function of parameters given the observed data.
Likelihood being larger supports a particular choice of parameter estimate, ergo one may write some hypothesis is likely (in response to the observation of one or more events).
The likelihood of a hypothesis is distinct from the probability of a hypothesis under both bayesianism and frequentism.
Likelihood is not a probability: it does not integrate to unity over the parameter space, and scaling it up to a monotonic transformation does not change its usage or meaning.
I digress, the main point is there is no such thing as the likelihood of an event. Again, Likelihood is a function of the parameter viz. the hypothesis. Every hypothesis has a likelihood (and a probability, presuming you are a bayesian). Every event has a probability, but not a likelihood.
Thanks, I've replaced the word "likelihood" by "probability" in the comment above and in the post itself!
Nice post. The intuition that makes most sense to me is "how much less uncertain/confused should I be about Y, on average, if I know the value of X"
The relevant intuition I use comes from the [law of total variance](https://en.m.wikipedia.org/wiki/Law_of_total_variance) (or variance decomposition formula):
An interpretation: if you sample Y through a process of getting partial information step by step, the variance of each step adds up to the variance of sampling Y directly
The first two terms are V_{tot}(Y) and E[Var_{rem}(Y|X)] respectively, while the last part describes the "explained" variance.
To give an intuition for Var(E[Y|X]):
- If X gives me some information about Y, then my new mean for Y should change depending on X. If X gives little information, then it should only wiggle my mean estimate of Y a little (low variance), but a very explanatory X will move my mean estimate of Y a lot (high variance)
- If X gave no information, then E[Y|X] should have no variance (it's always equal to the mean E[Y]).
- If X completely explains Y, then E[Y|X] can equal any value in the domain of Y. Because every y has a corresponding x, that if sampled, means that P(Y=y|X=x) = 1. Indeed, E[Y|X] will have exactly the same distribution as Y, and so it will contain the full variance as Y
Thanks for writing this up. I really appreciate this post because I was confused about the intuition behind variance explained despite this being the primary evaluation metric used in a recent paper I co-authored on interpreting text-to-image diffusion models with dictionary learning. It's more helpful than any other resource I used.
One important thing to keep in mind is that the usage of "explains" in this statistical phrase is strongly misleading. I would call it straight-up wrong. From Joel Schneider's Unfortunate statistical terms:
Variance explained: This term works if the predictor is a cause of the criterion variable. However, when it is simply a correlate, it misleadingly suggests that we now understand what is going on. I wish the term were something more neutral such as variance predicted.
Consider a faithful causal graph of this shape:
A <-- B --> C
Assume A and C are perfectly correlated. Trick question: How much variance does A explain of C? Answer: None. The association between A and C is purely statistical. A doesn't explain anything of C. The "variance explained" phrase confuses correlation with causation. As Schneider says, "variance predicted" would be accurate, but unfortunately that's not what statistics settled on.
The communication problem is that "variance explained" semantically implies measuring a causal effect, which it technically doesn't do (in general).
While I am fine with your math, I do not like the phrasing "X explains Z% of the variance of Y", because to the casual reader, it suggests that there is a causal relationship. For example, I might say "smoking explains X% of the (variance of the binary variable indicating the presence of) lung cancer (cases)". Here I have a causal relationship.
But consider "IQ explains X% of the variance of lifetime earnings in Americans", or "Lifetime earnings explain Y% of the IQ variance in Americans". The casual reader might read the first sentence and infer a causal relationship. "Every point of IQ I CRISPR into my kid will raise the expected amount of money they make by $Z". But purely from the correlation, we can not be sure that this intervention will have any effect at all (though there are good reasons to believe that there is some causal relationship).
More bluntly, getting a positive result on a cancer screening is correlated with dying in the next decade, but bribing your doctor to falsify your results has the opposite effect on your life expectancy as you would guess from the correlation.
Scott Alexander has recently written about heritability:
Predictive power is different from causal efficacy. Consider a racist society where the government ensures that all white people get rich but all black people stay poor. In this society, the gene for lactose tolerance (which most white people have, but most black people lack) would do a great job predicting social class, but it wouldn’t cause social class.
(As usual, worth reading in full.)
Or take your initial statement
The group consensus on somebody's attractiveness accounted for roughly 60% of the variance in people's perceptions of the person's relative attractiveness.
There could be vastly different causal models which explain this observation:
a) Every group member randomly assigns an attractiveness rating to a newcomer. Then everyone signals the attractiveness rating they assigned implicitly or explicitly through group interactions, and every group member updates towards the group consensus.
b) The group has some rough consensus about which traits are attractive (perhaps there is an universal attractiveness, or the group members adjusted their preferences to the group average over time, or people who find certain traits attractive ended in the group for complicated reasons), so they will rate a newcomer similarly based on their traits.
Likely, in reality it is going to be a mix of both of these and also three more causal chains. Again, as soon as you are discussing interventions you will find "explains X% of the variance" insufficient. Say you want to ask a specific person of that group on a date. You know that the group generally likes people with stripy socks, but that your potential date is indifferent to them. In case (a), you want to wear stripy socks because the group consensus of your attractiveness will update the attractiveness rating of your potential date, while in case (b) it does not matter.
I agree that "X explains Q% of the variance in Y" to me sounds like an assertion of causality, and a definition of that phrase that is merely correlations seems misleading.
Might it be better to say "After controlling for Y, the variance of X is reduced by Q%" if one does not want to imply causation?
Nice post. Is there some subtle distinction between and I'm missing, or are they synonyms as used here?
They are synonyms! Both are the expected value of (the function of) a random variable. (I had started writing mu, but then changed the notation for the remaining variance to also make the expected value explicit as requested. Mu seemed like less appropriate notation for this. Maybe I’ll change all mu to E once I have access to more than my phone again. Edit: I was too lazy to do that change :) ).
Consequently, we obtain
Technically, we should also apply Bessel's correction to the denominator, so the right-hand side should be multiplied by a factor of . Which is negligible for any sensible , so doesn't really matter I guess.
I don't like the notation because appears as a free RV but actually it's averaged over. I think it would be better to write .

Recently, in a group chat with friends, someone posted this Lesswrong post and quoted:
I answered that, embarrassingly, even after reading Spencer Greenberg's tweets for years, I don't actually know what it means when one says:
What followed was a vigorous discussion about the correct definition, and several links to external sources like Wikipedia. Sadly, it seems to me that all online explanations (e.g. on Wikipedia here and here), while precise, seem philosophically wrong since they confuse the platonic concept of explained variance with the variance explained by a statistical model like linear regression.
The goal of this post is to give a conceptually satisfying definition of explained variance. The post also explains how to approximate this concept, and contains many examples. I hope that after reading this post, you will remember the meaning of explained variance forever.
Audience: Anyone who has some familiarity with concepts like expected values and variance and ideally also an intuitive understanding of explained variance itself. I will repeat the definitions of all concepts, but it is likely easier to appreciate the post if one encountered them before.
Epistemic status: I thought up the "platonically correct" definition I give in this post myself, and I guess that there are probably texts out there that state precisely this definition. But I didn't read any such texts, and as such, there's a good chance that many people would disagree with parts of this post or its framing. Also, note that all plots are fake data generated by Gemini and ChatGPT --- please forgive me for inconsistencies in the details.
Acknowledgments: Thanks to Tom Lieberum and Niels Doehring for pointing me toward the definition of explained variance that made it into this post. Thank you to Markus Over for giving feedback on drafts. Thanks to ChatGPT and Gemini for help with the figures and some math.
Definitions
The verbal definition
Assume you observe data like this fake (and unrealistic) height-weight scatterplot of 1000 people:
Let X be the height and Y be the weight of people. Clearly, height is somewhat predictive of weight, but how much? One answer is to look at the extent to which knowledge of X narrows down the space of possibilities for Y. For example, compare the spread in weights Y for the whole dataset with the spread for the specific height of 170cm:
The spread in these two curves is roughly what one calls their "variance". That height explains p of the variance in weight then means the following: the spread of weight for a specific height is 1−p times the total spread. It's a measure of the degree to which height determines weight!
There is a caveat, which is that the spread might differ between different heights. E.g., look at yet another artificial scatter plot:
Here are three projections of the data on Y, for small, large, and all values of X:
The spread varies massively between different X! So which spread do we compare the total spread (blue) with, when making a statement like "X explains p of the variance in Y"? The answer is to build the average of the spreads over all values of X, weighted by how likely these values of X are.
Thus, we can translate the sentence
to the following verbal definition:
This is the definition that we will translate to formal math below!
The mathematical definition
We now present a mathematical definition that precisely mirrors the verbal definition above. It's important to understand that the verbal definition is much more general than the figures I presented might suggest. In particular:
With that out of the way, recall that we want to translate this sentence to formal math:
To accomplish this, we model X and Y as random variables, which are jointly sampled according to a density p(x,y). To be fully general, x takes values in some arbitrary (suitable, measurable) space X, and y takes values in the real numbers Y=R. In regions of the "plane" X×R where p(x,y) is large, we are more likely to sample datapoints than elsewhere. We can then express the sentence above in the following formula:
E[Varrem(Y∣X)]=(1−p)⋅Vartot(Y).We need to explain all the symbols here! Let's start with the total variance in Y, which we denote by Vartot(Y). It is the average of the squared distance of samples of Y from the mean of Y. As a formula:
Vartot(Y):=∫y∈Rp(y)⋅(y−μ(Y))2.Note that p(y) is the marginal density of y, which is given from the joint density p(x,y) by p(y)=∫x∈Xp(x,y). The mean μ(Y) that appears in the variance is itself an average, namely over all of Y:
μ(Y):=∫y∈Rp(y)⋅y.What about the average remaining variance, which we denoted E[Varrem(Y∣X)]? According to the verbal definition, it is an average of the remaining variances for different values of x∈X, weighted by their probability. So we get:
E[Varrem(Y∣X)]:=∫x∈Xp(x)⋅Varrem(Y∣X=x).Now we need to explain the inner remaining variance. The idea: It is given in the same way as the total variance of Y, except that y∈R is now sampled conditional on X=x being fixed. We obtain:
Varrem(Y∣X=x):=∫y∈Rp(y∣x)⋅(y−μ(Y∣X=x))2,where p(y∣x)=p(x,y)/p(x) is the conditional density, and where the conditional mean is given by
μ(Y∣X=x):=∫y∈Rp(y∣x)⋅y.This explains the entire definition!
If we now want to make a claim of the form "X explains p of the variance of Y" and want to determine the fraction of unexplained variance 1−p for it, then we simply rearrange the top formula:
1−p=E[Varrem(Y∣X)]Vartot(Y).The fraction of explained variance is then
p=1−E[Varrem(Y∣X)]Vartot(Y).How to approximate 1−p
I now discuss how to approximate the fraction of unexplained variance 1−p via the formula above.
When you have lots of data
Imagine you sample lots of datapoints (x1,y1),…,(xN,yN), which we conceptually think of as being sampled from the joint distribution p(x,y). Define ¯¯¯y as the sample mean of Y, which approximates the true mean μ(Y):
¯¯¯y:=1NN∑i=1yi≈μ(Y).Then we easily get an approximation of the total variance as:
Vartot(Y)=∫y∈Rp(y)⋅(y−μ(Y))2≈1NN∑i=1(yi−¯¯¯y)2.For each i=1,…,n, define ^yi as the sample mean of Y taken over all yj for which xj=xi. This approximates μ(Y∣X=xi). With Ni the number of j for which xj=xi, we obtain:
^yi:=1NiN∑j=1, xj=xiyj≈μ(Y∣X=xi).Using the chain rule p(x,y)=p(x)p(y∣x), we can approximate the remaining variance as follows:
E[Varrem(Y∣X)]=∫x∈Xp(x)⋅Varrem(Y∣X=x)=∫x∈Xp(x)∫y∈Rp(y∣x)⋅(y−μ(Y∣X=x))2=∫(x,y)∈X×Rp(x,y)⋅(y−μ(Y∣X=x))2≈1NN∑i=1(yi−^yi)2.Putting it together, we obtain:
1−p=E[Varrem(Y∣X)]Vartot(Y)≈1N∑Ni=1(yi−^yi)21N∑Ni=1(yi−¯¯¯y)2=∑Ni=1(yi−^yi)2∑Ni=1(yi−¯¯¯y)2,where the N was canceled in the last step.
When you have less data: Regression
The formula above is nice in that it converges to the true fraction of unexplained variance when you have lots of data. However, it has the drawback that, unless we have enormous amounts of data, the means ^yi will probably be very inaccurate --- after all, if the specific value xi appears only once in the data (which is virtually guaranteed if X is itself a continuous random variable in the special case X=R), then ^yi is only based on one data point, leading to yi=^yi. The numerator in the fraction then disappears. This results in a very severe case of overfitting in which it falsely "appears" as if X explains all the variance in Y: We obtain the estimate 1−p=0.
This is why in practice the concept is often defined relative to a regression model. Assume that we fit a regression function f:X→Y=R that approximates the conditional mean of Y:
f(x)≈μ(Y∣X=x)=∫y∈Rp(y∣x)⋅y.f(x) represents the best guess for the value of y, given that x is known. f can be any parameterized function, e.g. a neural network, that generalizes well. If X=R, then f could be given by the best linear fit, i.e. a linear regression. Then, simply define ^yi:=f(xi), leading to outwardly the same formula as before:
1−p=∑Ni=1(yi−^yi)2∑Ni=1(yi−¯¯¯y)2.Here, 1−p is the approximate fraction of variance in Y that cannot be explained by the regression model f from X. This is precisely the definition in the Wikipedia article on the fraction of variance unexplained.
As far as I can tell, the fraction of variance explained/unexplained is in the literature predominantly discussed relative to a regression model. But I find it useful to keep in mind that there is a platonic ideal that expresses how much variance in Y is truly explained by X. We then usually approximate this upon settling on a hopefully well-generalizing statistical model that is as good as possible at predicting Y given knowledge of X.
Examples
We now look at two more examples to make the concept as clear as possible. In the first, we study the variance explained by three different regression models/fits. In the second one, we look at variance explained by genetic information in twin studies, which does not involve any regression (and not even knowledge of the genes in the samples!).
Dependence on the regression model
Assume X is the sidelength of a cube of water and Y is a measurement of its volume. The plot might look something like this:
Up to some noise, the true relationship is Y≈X3. If you use h(x)=x3 as our regression fit (green line in the graph), then we explain almost all variance in volume. Consequently, the fraction of variance unexplained by the regression function h is roughly 1−p≈0.
If you do linear regression, then your best fit will look roughly like the blue line, given by g(x)=90x−200. This time, substantial variance remains since the blue line does mostly not go through the actual data points. But we still reduced the total variance substantially since the blue line is on average much closer to the datapoints than the mean over all datapoints is to those points (said mean is approximately 250). Thus, the fraction of variance unexplained by the regression function g(x) is somewhere strictly between 0 and 1: 0≪1−p≪1.
If you do linear regression, but your linear fit is very bad, like f(x)=1200 (red dotted line), then you're so far away from the data that it would have been better to predict the data by their total mean. Consequently, the remaining variance is greater than the total variance and the fraction of variance unexplained is 1−p>1.[2]
When you have incomplete data: Twin studies
Now, imagine you want to figure out to what extent genes, X, explain the variance in the IQ, Y. Also, imagine that it is difficult to make precise gene measurements. How would you go about determining the fraction of unexplained variance 1−p in this case? The key obstacle is that all you can measure is IQ values yi, and you don't know the genes xi of those people. Thus, we cannot determine a regression function f, and thus also no estimate ^yi=f(xi) to be used in the formula. At first glance this seems like an unsolvable problem; but notice that xi does not appear in the final formula of 1−p! If only it was possible to determine an estimate of ^yi ...
There is a rescue, namely twin studies! Assume data (x1,y1),(x1,y′1),…,(xN,yN),(xN,y′N) , where xi are the unknown genes of an identical twin pair, and (yi,y′i) the IQ measures of both twins. We don't use regression but instead use an approach adapted from the true approximation from this section. Define the conditional means by:
^yi:=yi+y′i2.Since we only have two datapoints per twin pair, to get an unbiased estimate of the conditional variance Var(Y∣X=xi), we need to multiply the sample variance by a factor of 2 (we did not need this earlier since we assumed that we have lots of data, or that our regression is well-generalizing).[3] With this correction, the fraction of unexplained variance computed over all 2N datapoints becomes:
1−p=2⋅∑Ni=1(yi−^yi)2+(y′i−^yi)2∑Ni=1(yi−¯¯¯y)2+(y′i−¯¯¯y)2.Now, notice that[4]
(yi−^yi)2+(y′i−^yi)2=(yi−y′i2)2+(y′i−yi2)2=12(yi−y′i)2.Consequently, we obtain
1−p=∑Ni=1(yi−y′i)2∑Ni=1(yi−¯¯¯y)2+(y′i−¯¯¯y)2.This is precisely 1−r, where r is the intraclass correlation as defined in this wikipedia page. If we apply this formula to a dataset of 32 twin pairs who were separated early in life, then we arrive[5] at 1−p=0.2059, meaning that (according to this dataset) genes explain ~79% of the variance in IQ.[6]
Conclusion
In this post, I explained the sentence "X explains p of the variance in Y" as follows:
If an intuitive understanding of this sentence is all you take away from this post, then this is a success.
I then gave a precise mathematical definition and explained how to approximate the fraction of unexplained variance 1−p when you have lots of data --- which then approximates the platonic concept --- and when you don't; in this case, you get the fraction of variance unexplained by a regression function.
In a first example, I then showed that the fraction of variance explained by a regression function sensitively depends on that function. In a second example, I explained how to use a dataset of twins to determine the fraction of variance in IQ explained by genes. This differs from the other examples in the fact that we don't need to measure genes (the explaining variable X) in order to determine the final result.
In the whole post, p is a number usually between 0 and 1.
Yes, this means that the fraction of explained variance is p<0: the model is really an anti-explanation.
Here is a rough intuition for why we need that factor. Assume you have a distribution p(y) and you sample two datapoints y,y′ with sample mean ^y=y+y′2. The true variance is given by
Var(Y)=∫yp(y)⋅(y−μ(Y))2.Note that μ(Y) does not depend on y! Thus, if we knew μ(Y), then the following would be an unbiased estimate of said variance:
1/2⋅[(y−μ(Y))2+(y′−μ(Y))2].However, we don't know the true mean, and so the sample variance we compute is
1/2⋅[(y−^y)2+(y′−^y)2].Now the issue is roughly that ^y is precisely in the center between y and y′, which leads to this expression being systematically smaller than with ^y being replaced by μ(Y). Mathematically, it turns out that the best way to correct for this bias is to multiply the estimate of the variance by precisely 2. See the Wikipedia page for details for general sample sizes.
Thanks to Gemini 2.5 pro for noticing this for me.
Code written by Gemini.
There are lots of caveats to this. For example, this assumes that twins have the same genetic distribution as the general population, and that the environmental factors influencing their IQ are related to their genes in the same way as for the general population.