This is a special post for quick takes by No77e. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Accidental AI Safety experiment by PewDiePie: He created his own self-hosted council of 8 AIs to answer questions. They voted and picked the best answer. He noticed they were always picking the same two AIs, so he discarded the others, made the process of discarding/replacing automatic, and told the AIs about it. The AIs started talking about this "sick game" and scheming to prevent that. This is the video with the timestamp:
6
From the AI's messages seen in the video it's possible that maybe he provided those instruction as user prompt instead of a system prompt. I wonder if the same thing would've happened if they were given as the system prompt instead.
1[anonymous]
This experiment is pretty clever no? I don't think a total AI amateur would discover it, either he's been following along this problem for quite some time or he read about this somewhere recently or one of us AI safety nerds sponsored him. P=not sure though, it's not beyond what people with an investigative mindset might come up with.
3
He mentions he's just learned coding so I guess he had the AI build the scaffolding. But the experiment itself seems like a pretty natural idea, he literally likens it to a King's council. I'm sure once you have the concept having an LLM code it is no big deal.
Scott Alexander left an important reply to Rob Bensinger on X. I happen to agree with Scott. Here's the original post by Rob:
...In response to "What did EAs do re AI risk that is bad?":
Aside from the obvious 'being a major early funder and a major early talent source for two of the leading AI companies burning the commons', I think EAs en masse have tended to bring a toxic combination of heuristics/leanings/memes into the AI risk space. I'm especially thinking of some combination of:
'be extremely strategic and game-playing about how you spin the things you say, rather than just straightforwardly reporting on your impressions of things'
plus 'opportunistically use Modest Epistemology to dismiss unpalatable views and strategies, and to try to win PR battles'.
Normally, I'm at least a little skeptical of the counterfactual impact of people who have worsened the AI race, because if they hadn't done it, someone else might have done it in their place. But this is a bit harder to justify with EAs, because EAs legitimately have a pretty unusual combination of traits and views.
Dario and a cluster of Open-Phil-ish people seem to have a very strange and perverse set of views (at least insofar as t
I think that both of these posts seem very confused about the dynamics of who says or thinks what, and I'm pretty sad about these posts.
Thoughts on Rob's post
In general, I'll note that I don't think Rob really knows many of the OP people; I suspect he has spent <40 hours talking to them about any of this possibly ever. (This is in contrast to e.g. Habryka.) I don't know where he's getting his ideas about what the OP people think, but he seems incredibly confused and ignorant. (Eliezer seems similarly ignorant about who believes what.)
'be extremely strategic and game-playing about how you spin the things you say, rather than just straightforwardly reporting on your impressions of things' plus 'opportunistically use Modest Epistemology to dismiss unpalatable views and strategies, and to try to win PR battles'.
I don't really think this is true
Dario and a cluster of Open-Phil-ish people seem to have a very strange and perverse set of views
I wish Rob would be clear who he was referring to. Dario has beliefs that seem to me very different from most people who worked on the 2022 AI misalignment risk efforts at Open Phil. (I'm thinking of people like Holden Karnofsky, Ajeya Cotra, Joe C...
Thanks for writing this, Buck. I'm not going to try to reply to your whole post, because I think some of it is stuff I should chew on for longer and see whether I agree with it. But going through some of your points:
I definitely apologize for making it sound like I was making a harsher criticism of (the relevant parts of) EA than I intended. My tweet was originally written as a quick follow-up comment to someone who asked why I thought EA's impact on AI x-risk was only ~55% likely to be positive. I turned it into a top-level tweet because I didn't want to hide it deep in an existing discussion, but this was an error given I didn't add extra context.
I also apologize for anything I said that made it sound like I was universally criticizing past or present Open Phil / cG staff (or centrally basing my views on first-hand conversations, for that matter). I already believed that tons of past and present rank-and-file OP/cG staff have very reasonable views, and I happily further update in that direction based on your and Oliver's statements to that effect (e.g., Ollie's "I have since updated that more people who are a level below Alexander, Dustin and Dario have more reasonable beliefs")....
Thanks, this is helpful and I basically accept most of what you're saying. Some more specific comments on the part about me:
I don't really think of Rob or MIRI as having a comms strategy of undermining EAs. I think Rob and Eliezer just say a bunch of false, wrong things about EAs because they're mad at them for reasons downstream of the EAs not agreeing with Eliezer as much as Eliezer and Rob think would be reasonable, and a few other things.
I accept this criticism and take back my claim. I noticed that some people who worked for MIRI comms seemed to do this, and I assumed that anything said by enough MIRI comms people in a serious-sounding voice was on some level a MIRI communique. Eliezer has clarified that this isn't true, so I apologize for saying it was.
...I think Dario (like various other Anthropic people) does not believe that AI takeover is a very plausible outcome, and I think his position is indefensible on the merits, as are some of his other AI positions (e.g. his skepticism that there are substantial returns to intelligence above the human level, his skepticism that ASI could lead to 2x manufacturing capacity per year). He moderately disagrees with the OP people about thi
I'm generally sympathetic to Scott's positions in this discussion, but I think he is probably very wrong about Ilya.
- To the best of my knowledge, Safe Superintelligence has never published a single word about what they plan to do move alignment forward, which is pretty damning. in my opinion.
- I have not heard of anyone who is known to be thoughtful about AI safety to have been hired to SSI, and I have not seen any position being advertised to AI safety people. People should correct me if I missed someone good joining SSI, but I think this is also a very bad sign.
- My impression is that people who worked with Ilya at OpenAI don't remember him as being particularly thoughtful about alignment, e.g. much less so than Jan Leike. This is a low confidence, third-hand impression, people can correct me if I'm wrong.
- My impression is that the available evidence suggests that Ilya mostly took part in Altman's firing for (perhaps justified) office politics grievances, and not primarily due to safety concerns. I also think that evidence points to his behavior during and after the incident being kind of cowardly. (I haven't looked deeply into the details of the battle of the board, and it's possible
In general, I'll note that I don't think Rob really knows many of the OP people; I suspect he has spent <40 hours talking to them about any of this possibly ever.
I think you are overfitting Rob's post to be about the wrong people. I think it's much closer to accurate, if you actually read what he says, which is:
Dario and a cluster of Open-Phil-ish people
I think the things Rob is saying still have some strawman-y nature to them, but I think they are reasonably accurate descriptors of Anthropic leadership, plus my best guesses of what Alexander (head of Coefficient Giving) and Zach (head of CEA) believe, which seems well-described by "Dario and a cluster of Open-Phil-ish people", and furthermore also of course constitutes an enormous fraction of the authority over broader EA.
I feel like almost all of your comment is just running with that misunderstanding and hence mostly irrelevant.
As you say yourself, almost no one in your list works at cG, or is in any meaningful position of authority at cG, so this feels like a bit of an absurd interpretation (I think trying to apply the things he is saying to Holden is reasonable, given Holden's historical role in cG, and I do think he in the distant past said things much closer to this, but seems to have changed tack sometime in the past few years).
As you say yourself, almost no one in your list works at cG, or is in any meaningful position of authority at cG, so this feels like a bit of an absurd interpretation
A lot of Rob's complaints are about things that happened in the past, so I don't think it's crazy to interpret him as talking about people who worked at CG in the past.
I think the things Rob is saying still have some strawman-y nature to them, but I think they are reasonably accurate descriptors of Anthropic leadership, plus my best guesses of what Alexander (head of Coefficient Giving) and Zach (head of CEA) believe, which seems well-described by "Dario and a cluster of Open-Phil-ish people", and furthermore also of course constitutes an enormous fraction of the authority over broader EA.
I think that these people believe different things, and I don't think Rob's post particularly accurately describes any of them. For example, the Anthropic leadership doesn't really think of themselves as trying to coordinate with AI safety people or trying to suppress them. I don't think Alexander thinks "AI is going to become vastly superhuman in the near future" (and fwiw I don't think Dario thinks that either, he doesn't seem to believe in returns to intelligence substantially above human-level).
(sending quickly, I might be wrong)
A lot of Rob's complaints are about things that happened in the past, so I don't think it's crazy to interpret him as talking about people who worked at CG in the past.
Fair enough. I think that the people you list also used to believe things closer to what Rob is saying in the past, so at least we need to do a consistent comparison. Holden from 10 years ago seems to say a lot of the things that Rob is saying here, and Ajeya from a few years ago also said things more like this (more point 1 and 3, less point 2).
My guess is that it is worth digging up quotes here, but it's a lot of work, so I am not going to do it for now, but if it turns out to be cruxy, I can.
(Again, I don't think these are centrally the people Rob is talking about in either case. I think centrally he is talking about Anthropic, and then secondarily talking about how Open Phil people have related to Anthropic over the years, but I do still think his criticism is correct directionally for those people)
...I don't think Alexander thinks "AI is going to become vastly superhuman in the near future" (and fwiw I don't think Dario thinks that either, he doesn't seem to believe in returns to intelligence substantially above h
Ajeya from a few years ago also said things more like this (more point 1 and 3, less point 2).
I don't remember anything like this. I think it might be misremembered or a strained interpretation.
Here are points 1 and 3 for reference:
1. AI is going to become vastly superhuman in the near future; but being a good scientist means refusing to speculate about the potential novel risks this may pose. Instead, we should only expect risks that we can clearly see today, and that seem difficult to address today.
3. In general, people worried about AI risk should coordinate as much as possible to play down our concerns, so as not to look like alarmists. This is very important in order to build allies and accumulate political influence, so that we're well-positioned to act if and when an important opportunity arises.
I asked ChatGPT to read bioanchors (where I thought this was most likely to occur), and then to read all of her other writings looking for anything that fits that mode. Here's its reply, not finding anything.
The closest match it finds is that Ajeya often caveats her claims. For example from bio anchors:
...This is a work in progress and does not represent Open Philanthropy’s institution
2
Huh, I am a bit confused about you summarizing that ChatGPT response that way. Maybe we are talking past each other, but Robby's statements are not intended as the kind of statement that passes people's ITT (which IMO is fine, frequently summaries of other people's views should not pass their ITT, though it should ideally be caveated when this is going on).
Despite that, your ChatGPT transcript says:
[...]
I am not expecting any direct endorsements of these statements (which are phrased as to make their internal contradictions most obvious), so this ChatGPT response seems compatible with what I am saying?
When I asked ChatGPT to "rephrase these two beliefs in more neutral language that would make more sense for someone to endorse (but try to pretty tightly imply the above)" it gave these two:
[...]
When I asked ChatGPT about this framing, it said:
[...]
But also, when we are in the domain of "evaluate whether Ajeya said things that imply the things above and result in other people getting the same vibe as the above", then ChatGPT and Claude seem like much worse judges, so I think this question becomes more difficult to answer and I wouldn't super defer to the language models (and is part of why I expected it would take a while to dig up quotes and do the work and stuff).
(If you want to complain that Robby should have caveated his stuff more as not being the kind of thing that passes people's ITT, then I am happy to argue about that. I think a better post would have done it, but it's not something I think is always necessary to do.)
(Also just for the sake of completeness, I don't get this vibe from Ajeya at all these days and have no complaints on this front, besides probably still some strategic disagreement on stuff around point 3, but like at the level that I have with many people I respect almost certainly including you)
4
When you wrote:
[...]
I interpreted you as claiming that Ajeya had said "things more like:"
[...]
I don't recall any examples of Ajeya saying or implying anything at all like that. I asked ChatGPT to try to find examples and I think it didn't find anything.
In your ChatGPT session, a typical example it cites is:
[...]
I think those examples don't meaningfully support the original claim, at least as a typical reader would understand it.
1
I have no interest in defending ChatGPT's claims here, and feel like I caveated that pretty explicitly. I agree that quote is largely irrelevant.
[...]
Yep, I agree with you that ChatGPT did not find any clear quotes (though it doesn't look like ChatGPT tried very hard to find quotes). I disagree that it didn't find "anything at all like that" (indeed ChatGPT is quite explicit that it found some things "kind of like that").
[...]
I do. As I said, I could go and dig them up but it would take quite a while, and I am only like 75% confident they are written up as opposed to conversations, or private Google Docs or something that I would have trouble finding. It was a strong vibe I got at the time and I remember having a few conversations about adjacent conversations either with Ajeya or being about Ajeya.
Let me know if you want me to do this. I don't quite know what's at stake here for you, and I feel somewhat like we are talking past each other and before I do that it would be more productive to go up some meta-level, but I am not quite sure.
8
I think you're right, and also it seems misleading / like a bad clustering to lump "the EAs" in with "Anthropic's leadership". I think those groups have some memetic connections, but they're not the same group!
I feel like it's more of a reasonable carving to lump in OpenPhil with "the EAs", since they were/are effectively EA thought-leaders and they exerted a lot of influence, directly and indirectly.)
I think you're right, and also it seems misleading / like a bad clustering to lump "the EAs" in with "Anthropic's leadership". I think those groups have some memetic connections, but they're not the same group!
More than 50% of the talent-weighted safety people in EA are literally employees of Anthropic! The ex-CEO of Open Phil now works at Anthropic, and is married to one of its founders. These groups have enormous overlap.
Like, there is so enormous overlap, and the overlap results in such an enormous amount of de-facto deference (being an employee of a company is approximately the strongest common deference relationship we have) that it makes sense to think of these as closely intertwined.
Yes, there are people who attach the EA label themselves who are different here, sometimes even quite substantial clusters. But it's also IMO clear from Scott's response that he himself is also majorly deferring and is majorly supportive of Anthropic as a representative of EA, so this clearly isn't just a split between "everyone who works at Anthropic and everyone who doesn't".
Rob used "Open Phil" exactly two times. One time saying "a cluster of Dario and Open-Phil-ish people" and another time "...
7
Imagine re Open Phil and hardcore rationalists "the ex-CEO of MIRI now works at Open Phil, and and the CEO of Lightcone is dating an Open Phil employee. These groups have enormous overlap."
Yes. People can have a lot of social overlap, yet have very different views from one another, especially in the broader Bay Area intellectual ecosystem. My sense is that Anthropic leadership has very different views from most AI safety EAs.
[...]
Why do you think this? I'm skeptical this is true, especially if you're including non-technical talent.
7
IDK, I counted them? I made some spreadsheets over the years, and ran this number by a bunch of other people, and my current guess is that it's around 55%? When I list organizations with full-time employees working in safety I actually end up at substantially above 50% of people working at Anthropic, but I think that's overcounting.
[...]
I think there are differences and overlaps. I think Rob points to a thing that is shared across a cluster that spans both of them, and has historically had a lot of influence.
2
But aren't Alexander Berger's views not very relevant about OpenPhil's AI strategy decisions from many years ago when their AI strategy and worldview -- which I take to be very cose to the things Rob was criticizing -- were worked out and started shaping the views of EAs in OpenPhil's orbit?
Even now, when people criticize things OpenPhil has done in the past in the AI landscape, or criticize their general worldview and takes on AI risk (as it was developed in influential pieces of writing), I am by default automatically viewing it as criticism of Holden, Ajeya Cotra, Tom Davidson, Joe Carlsmith, etc. If people don't intend me to interpret them that way, please be more clear. 🙂
I'm aware that, separately, OpenPhil/Coefficient Giving has undergone quite a transition and that you clashed badly with Dustin M. I think that's very sad and unfortunate, but I think of these as quite distinct things and I never assumed that the thing with Dustin M. had anything to do with OpenPhil's AI strategy decisions in (say) five years ago (edit: sorry that sounds like a strawman, but I mean something like "I'm not sure the same cause explains why some people who were at OpenPhil in the past found MIRI epistemically off-putting, and why Dustin M finds the rationalists to be a reputation risk & thinks reputation risks are unusually bad compared to other bad things.") I could be wrong, of course, and maybe you think the org has a general thing of them of valuing "reputability" and "playing politics" too much. I just want to note that it's not obvious how much these things are connected/caused by one "OpenPhil culture," vs being about distinct things. (I think some of these are maybe directionally accurate as criticism, btw.)
I'm sure this is obvious to everyone involved, but I also just want to point out that when a lot of senior people leave, organizations can change really a lot, so it would be weird to speak of OpenPhil/Coefficient Giving now as though it were obviously still the
8
I think Holden at the time believed something closer to what Rob says here (though it's still not an amazing fit), and more generally, I think "the beliefs of the successor CEO" are actually a better proxy for "the vibes of the broader ecosystem you are part of" than "the beliefs of the founder CEO". I could go into more detail on my beliefs on this, though I think the argument is reasonably intuitive.
[...]
Yep, I think they are highly related. Indeed, I was predicting things like the Dustin thing without any knowledge of Dustin's specific beliefs, and my predictions were primarily downstream of seeing how Anthropic's position within the ecosystem was changing, and a broader belief-system that I think is shared by many people in leadership, not just Dustin.
I have since updated that more people who are a level below Alexander, Dustin and Dario have more reasonable beliefs, but also updated that those things end up mattering surprisingly little for what actually ends up a strategic priority.
[...]
I think the "OpenPhil culture" thing is a distraction. In my model of the world most of this is downstream of people being into power-seeking strategies mostly from a naive-consequentialist lens, which is not that unique to OpenPhil within EA (and if anything OpenPhil has some of the people with the best antibodies to this, though also a lot of people who think very centrally along these lines, more concentrated among current leadership).
3
What do you mean by this?
5
I think some of the people who are best at thinking independently about stuff, and are pretty good at not getting swept up in the power-seeking stuff, work at Open Phil. I think Holden genuinely helped with some of the correct cultural pieces, and my current belief is that if he wasn't under the most pressure that anyone is, that he would probably have a relatively sane relationship to Anthropic as a result of it, though I am not as confident I am about that as I am that he had a bunch of quite good cultural pieces that help people be less naively power-seeking here.
1
Pause AI is a global activist movement with many chapters, and members with a mix of opinions, with some voices louder than others.
I've been volunteering there full time for a couple of years. I'm someone who cares a lot about partnership and the ecosystem of AIXR organizations. (I reckon not being killed by superintelligence is helped by pursuing a portfolio of bets that are mostly disjunctive and individually low odds.)
Buck, I would be really interested to hear more about your concrete concerns with Pause AI. By all means link a previous account if one exists.
Happy to discuss in public or private.
Honestly, this is such a bad reply by Scott that I… don’t quite know whether I want to work on all of this anymore.
If this is how this ecosystem wants to treat people trying their hardest to communicate openly about the risks, and who are trying to somehow make sense of the real adversarial pressures they are facing, then I don't think I want anything to do with it.
I have issues with Rob's top-level tweet. I think it gets some things wrong, but it points at a real dynamic. It’s kind of strawman-y about things, and this makes some of Scott’s reaction more understandable, but his response overall seems enormously disproportionate.
Scott's response is extremely emblematic of what I've experienced in the space. Simultaneous extreme insults and obviously bad faith arguments ("actually, it's your fault that Deepmind was founded because you weren't careful enough with your comms"), and then gaslighting that no one faces any censure for being open about these things (despite the very thing you are reading being extremely aggro about the lack of strategic communication), and actually we should be happy that Ilya started another ASI lab, and that Jan Leike has some compute budget.
The whole ...
Unless you mean "making this my last day [on twitter]", which might or might not be a good idea.
If this is how this ecosystem wants to treat people trying their hardest to communicate openly about the risks, and who are trying to somehow make sense of the real adversarial pressures they are facing, then I don't think I want anything to do with it.
I don't think Scott speaks for the ecosystem. He's just a guy in it, and one who isn't even that closely connected to Anthropic or Coefficient Giving people. (E.g. you spend >10x as much time talking to people from those orgs as he does.) I think that the people in the ecosystem you're criticizing would not approve of Scott's post.
This is of course in contrast to Open Phil defunding almost everyone who has been pursuing this strategy and making mine and tons of other people's lives hell, and all kinds of complicated adversarial shit that I've been having to deal with for years, where absolutely there have been tons of attempts to sabotage people trying to pursue strategies like this.
I think this is not a good summary of what Coefficient Giving has done. (I do think it really sucks that they defunded Lightcone.)
I think that the people in the ecosystem you're criticizing would not approve of Scott's post.
I think this is false. I expect Scott's post to be heavily upvoted, if it was posted to the EA Forum to have an enormously positive agree/disagree ratio, and in-general for people to believe something pretty close to it.
There are a few exceptions (somewhat ironically a good chunk of the cG AI-risk people), but they would be relatively sparse. I think this is roughly what someone who is smart, but doesn't have a strong inside-view take about what they should do about AI-risk believes that they should act like if they want to be a good member of the EA community. My guess is it's also pretty close to what leadership at cG, CEA and Anthropic believe, plus it would poll pretty well at a thing like SES.
He's just a guy in it, and one who isn't even that closely connected to Anthropic or Coefficient Giving people.
The issue is of course not that Scott is right or wrong about what Anthropic or cG people believe. The issue is that he seems to be taking a view where you should be super strategic in your communications, sneer at anyone who is open about things, and measure your success in how many of...
I think this is false. I expect Scott's post to be heavily upvoted, if it was posted to the EA Forum to have an enormously positive agree/disagree ratio, and in-general for people to believe something pretty close to it.
The EA Forum is a trash fire, so who knows what would happen if this was published there.
My read of the social dynamics is that in places where people are inclined to defer to me or people like me, they might initially approve of the Scott thing for bad tribal reasons, but change their mind when they read criticism of it from me or someone like me (which is ofc part of why I sometimes bother commenting on things like this).
My guess is it's also pretty close to what leadership at cG, CEA and Anthropic believe, plus it would poll pretty well at a thing like SES.
I think that Scott's post would not overall be received positively by those people. Maybe you're saying that one of the directions argued for by Scott's post is approved of by those people? I agree with that more.
6
Well, I mean, that is a hard conditional to be false since if people were to not change their mind, this would largely invalidate the premise that they are declined to defer to you. Unfortunately, I both think the vast majority of places in EA do not defer to you or people like you, and furthermore, I also think you are pretty importantly wrong about your criticisms, so I don't quite know how to feel about this.
I do think it helps and am marginally happy about your cultural influence here (though it's tricky, I also think a bunch of your takes here are quite dumb). I think the vast majority of the cultural influence here is downstream of not quite anyone in-particular, but more Anthropic than anywhere else, and neither you nor me can change that very much.
[...]
Yeah, I expect it to be straightforwardly positively received. I think people will be like "some parts of this seem dumb, the Ilya thing in-particular, but yeah, fuck those rationalists and MIRI people, I am with Scott on that".
To be clear, I am not expecting consensus here, I think this will be what 75% of people who have any opinion at all on anything adjacent on this believe, but I expect people would broadly think it's a good contribution that properly establishes norms and reflects how they think about things.
I also think it's plausible people would be like "wow, what an uncough way that both of these people are interfacing with each other, please get away from each other children", but then actually if you talked to them afterwards, they would be like "yeah, I mean, that was a bit of a shitshow but I do think Scott was basically right here (minus 1-2 minor things)".
I am not enormously confident on this, but it matches my experiences of the space.
In case it matters to either of you, my guesses:
- I agree with Habryka that absent criticism Scott's post would be well received by an important group of people reasonably characterized as EA-ish AI safety people.
- Imo absent criticism Rob's post would be well received by a different group of people reasonably characterized as doomers. (Literally right before seeing this thread I saw another post on LW that is directionally correct but is mostly wrong or exaggerated in its details, and that was very well received.)
- Both posts are broadly wrong about lots of things, about equally so, such that most people would be better off having never encountered either of them.
- Tbc, my first-order intuitive impression is that Scott's post is much more directionally accurate. But I expect that is because I constantly experience people knifing me, pushing me to take strategies that systematically destroy my ability to do anything while gaining approximately no safety benefit, or making claims about members of groups that include me that are false of me, whereas I don't really experience any of the stuff that Rob gestures at, even though I expect it exists. Though Rob's post doesn't actually inform me of
I endorse you taking the space to figure out how you want to relate and doing what's right for you, I've increasingly updated to thinking that people doing things they're not wholeheartedly behind tends to be net bad in all sorts of sideways ways, but the effort would be weaker for your loss. Wherever you end up, I appreciate you having taken the strategy of speaking in public about things that usually aren't in a way that helped clarify the strategic situation for me many times.
(also, it's scary to see three of the people I'd put in the upper tiers of good communication and understanding where we're at with AI technically get into this intense conflict. I'm going to be thinking on this some and seeing if anything crystalizes which might help specifically, but in the meantime a few more general-purpose posts that might be useful memes for minimizing unhelpful conflict are A Principled Cartoon Guide to NVC, NVC as Variable Scoping, and Why Control Creates Conflict, and When to Open Instead)
9
Locally trying to clear up one misunderstanding.
[...]
I think Scott's "couple more years" wasn't referring to a belief that EA could have successfully advocated for a couple of year pause, but rather referring to the change in timeline you'd have gotten if safety-sympathetic people refused to work on stuff that increases the pace of capabilities progress.
2
Oh, I see. That makes sense, I agree I misunderstood this part to be about something else (though I disagree similarly strongly with the correct interpretation, but it's still good to clear that up).
9
I really don’t think Scott is gaslighting you. I think Scott is being honest here, but you should model him as having somewhat snapped. Pause AI and MIRI-adjacent people on X have been extremely adversarial and have been contributing to very bad discourse (even arguments-wise). I think Scott saw Rob’s post as very strawmannish and needlessly adversarial, and he more or less correctly lumped it in with this rising tide of terribleness, even if MIRI itself is definitely not as guilty. I might well be wrong about the specifics, but Scott Alexander isn’t the kind of person who tends to gaslight.
I think you need to be a lot more deflationary about the g-word. If you think, "But 'gaslighting' is something Bad people do; Scott Alexander isn't Bad, so he would never do that", well, that might be true depending on what you mean by the g-word. But if the behavior Habryka is trying to point to with the word to is more like, "Scott is adopting a self-serving narrative that minimizes wrongdoing by his allies and inflates wrongdoing by his rivals" (which is something someone might do without being Bad due to having "somewhat snapped"), well, why wouldn't the rivals reach for the g-word in their defense? What is the difference, from their perspective?
"Gaslighting" should probably be avoided because it is anywhere between meaningless and a fighting word depending on who says it and how.
The g-word is a very nasty accusation. It gets thrown around and means a bunch of stuff down to just "saying stuff I disagree with", but it shouldn't.
It is originally a conscious, malicious attempt to drive someone insane by strategically lying to them.
On the substance, people are honest but wrong an awful lot, and honest but massively overstating their case even more often. Assuming your rivals are malicious or dishonest when they're just wrong or overstating is a huge source of conflict and thereby confusion.
It's a really useful pointer towards a tactic that is relatively widespread and has no better word. I am personally happy to use other words, but I have the sense that sentences like "I am so very very tired of the ambiguous but ultimately strategic enough attempts at undermining my ability to orient in this situation by denying pretty clearly true parts of reality combined with intense implicit threats of consequences if I indicate I believe the wrong thing that might or might not be conscious optimizations happening in my interlocutors but have enough long-term coherence to be extremely unlikely to be the cause of random misunderstandings" would work that well.
4
Yeah I would call that "gaslighting". It looks like my initial interpretation of what you meant by it is closer than Zack's. I think Scott isn't doing that. I'm inclined to believe you when you say other people have behaved this way.
8
Everything makes sense when you meditate on how the line between "cooperation" and "defection" isn't in the territory; it's a computed concept that agents in a variable-sum game have every incentive to "disagree" (actually, fight) about.
Consider the Nash demand game. Two players name a number between 0 and 100. If the sum is less than or equal to 100, you get the number you named as a percentage of the pie; if the sum exceeds 100, the pie is destroyed. There's no unique Nash equilibrium. It's stable if Player 1 says 50 and Player 2 says 50, but it's also stable if Player 1 says 35 and Player 2 says 65 (or generally n and 100 − n, respectively).
The secret is that there are no natural units of pie (or, equivalently, how much pie everyone "deserves"). Everyone thinks that they're being "cooperative" and that their partners are "defecting", because they're counting the pie differently: Player 1 thinks their slice is 35%, but Player 2 thinks the same physical slice is 65%.
If you don't think your partner is treating you fairly, your leverage is to threaten to destroy surplus unless they treat you better. That's what Alexander is doing when he says, "I would like to support it with praxis, but right now I feel very conflicted about this". He's saying, "You'd better give me a bigger slice, Player 1, or I'll destroy some of the pie."
That's also what your brain is doing when you say you don't want to work on this anymore. Scott doesn't want you to quit! (Partially because he values Lightcone's work, and partially because it would look bad for him if you can publicly blame your burnout on him.) Crucially, your brain knows this. By threatening to quit in frustration, you can probably get Scott to apologize and give your arguments a fairer hearing, whereas in the absence of the threat, he has every incentive to keep being motivatedly dumb from your perspective.
You have a strong hand here! The only risk is if your counterparties don't think you'd ever actually quit and
That's also what your brain is doing when you say you don't want to work on this anymore. Scott doesn't want you to quit! (Partially because he values Lightcone's work, and partially because it would look bad for him if you can publicly blame your burnout on him.) Crucially, your brain knows this.
Man, I really wish this was the case, and it's non-zero of what is going on, but the vast majority of what I am expressing with my (genuine) desire to quit is the stress and frustration associated with the gaslighting, which is one level more abstract than the issue you talk about.
Like yes, there is a threat here being like "for fuck's sake, stop gaslighting or I am genuinely going to blow up my part of the pie", but it's not actually about the object level, and I don't actually have much of any genuine hope of that working in the same way one might expect from a negotiation tactic.
I am just genuinely actually very tired, and Scott changing his mind on this and going "oh yeah, actually you are right" actually wouldn't do much to make me want to not quit, because it wouldn't address the continuous gaslighting where every time anyone tries to talk about any of the adversarial dynamics, the...
Yeah, the frustrating part is almost always on a meta level. I think Zack's point about "No natural units of pie" applies to the gaslighting issue as well though. Asserting one's viewpoint means asserting it as truth which invalidates differing perspectives. "I disagree, you contradict, he gaslights".
It's difficult because sometimes the gas lights really don't seem to be dimming, and sometimes that perception is downstream of some motivated thinking because I really don't want to believe we're running out of oil already, dammit. And so the result is simultaneously kinda an honest statement of perspective (at least, as honest as these tend to get) while also being a (not-necessarily-consciously) motivated action pushing people to disregard their own senses. And then we have to decide how to judge this mess of bias and honesty, and if we don't judge such that the product after a round trip of perceiving C/D and responding accordingly we get more C than last time... shit's fucked. And without objective units of pie that people can agree on when judging who was in the wrong.
So like... am I trying to gaslight people into questioning their own sanity so they accept what I want them to ac...
2
"It is not the critic who counts: not the man who points out how the strong man stumbles or where the doer of deeds could have done better. The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood, who strives valiantly, who errs and comes up short again and again, because there is no effort without error or shortcoming, but who knows the great enthusiasms, the great devotions, who spends himself for a worthy cause; who, at the best, knows, in the end, the triumph of high achievement, and who, at the worst, if he fails, at least he fails while daring greatly, so that his place shall never be with those cold and timid souls who knew neither victory nor defeat."
Theodore Roosevelt"Citizenship in a Republic,"Speech at the Sorbonne, Paris, April 23, 1910
I wrote a reply to Scott on Twitter, before seeing the discussion here; I think it's a lot clearer than my original (IMO sloppy) tweet.
I've copied the reply below; see also my reply to Buck.
_____________________________________________________
To clarify the claim I’m making: I’m not trying to throw EA under a bus. This thread spun off from a discussion where I said I thought EA’s net impact on AI x-risk was probably positive, but I was highly uncertain.
Somebody asked what the bad components of EA’s impact were, and I went off on Anthropic, and on EA’s (and especially OpenPhil’s) entanglement with the company and their support for Anthropic’s operations. (To the extent that a lot of x-risk-adjacent EA seems to function, in practice, as a talent pipeline for Anthropic.)
I also said that I think OpenPhil’s bet on OpenAI was a disaster. And I said that there’s a culture of caginess, soft-pedaling, and trying-to-sound-reassuringly-mundane that I think has damaged AI risk discourse a fair amount, and that various people in and around OpenPhil have contributed to.
I’m restating this partly to be clear about what my exact claims are. E.g., I’m not claiming that items 1+2+3 are things OpenPhi...
7
Some helpful points, thanks. I responded in more depth on Twitter, but I don't want to duplicate every conversation there here, so I'm just signposting that people should check the thread there for most of my opinions.
I respect this - all of our options are bad and unlikely to work, the situation is desperate, and I have no plan better than playing a portfolio of all the different desperate hard strategies in the hopes that one of them works.
I used to support such a portfolio approach, but subsequently realized that it's actually not safe (i.e., is potentially net-negative even aside from opportunity costs), or the portfolio has be restricted a lot. This is because due to the existence of illegible AI safety problems, solving some (i.e., more legible) AI safety problems can actually make the overall situation worse, by increasing the chances of an unsafe AI being developed or deployed.
According to this logic, safer strategies include:
- Pausing AI, and other actions that help broadly with both legible and illegible problems, like improving societal epistemic health.
- Making illegible problems more legible.
- Working directly on illegible problems.
Another reason to think that many "AI safety strategies" are actually not safe is that even nominally altruistic humans are more power/status-seeking[1] than actually altruistic, and one way this manifests is that they tend to neglect risks more than they sho...
9
For the purposes of this argument to work, it's important that the legible problems are so legible that a lack of solutions would prevent deployment.
When previously asked which problems were in this category, you said:
[...]
Now, I would actually say that this list overestimates AI companies' willingness to gate deployment on unsolved problems. There's been many woke versions of grok, suggesting they weren't gating deployments on that. I think most current models can be jailbroken into helping with terrorism (they're just not smart enough to be very helpful yet). It remains to be seen whether companies will hold off on releasing models that could help a lot with terrorism. I'm not so sure they will.
But even if we took this on face value: It doesn't seem like avoiding work on these mentioned problems would mean restricting the portfolio a lot. When referring to "playing a portfolio of all the different desperate hard strategies in the hopes that one of them works", I think that's mostly about solving problems that wouldn't prevent deployment if they were unsolved, or gathering evidence for such illegible problems. (Centrally: The problem of scheming models taking over the world, which is not one that I expect companies to wait for a solution on absent further evidence that it's a problem.)
5
Applying the idea is tricky and context-dependent. For example, gathering evidence for scheming seems unambiguously good, but actually solving scheming could be bad (unless you're sure that such evidence can't be gathered, or companies will not gate on this problem regardless), because some time in the future, it may well become legible enough to be gating deployment. (Also keep in mind that it's not just legibility/gating by the companies, but also by other policymakers such as voters and politicians.)
Given the tradeoffs apparent to me (including that the benefits of solving scheming are limited by other safety problems), I think it may well be an example of a safety problem that is net negative to work on, and something I wouldn't want to do myself. But I'm unsure how to argue for this convincingly (and also am just not certain enough to want to talk other people out of working on this specifically) which is why I'm only talking about it in response to your comment.
2
Gotcha.
FWIW, on my views, work to prevent scheming looks pretty clearly great. Pausing to wait for a solution to scheming doesn't seem super likely, and going from [scheming models widely deployed] –> [non-scheming models widely deployed] seems significantly more valuable than going from [non-scheming models widely deployed] –> [temporary pause to solve scheming].
[...]
A lot of the listed topics here are problems that we could have plenty of time to work on after the singularity. I'm sympathetic to arguments that bad things might get locked-in, but I don't really think the arguments for this have a disjunctive nature where we're very likely to run into at least one type of bad lock-in. There's just a decent chance that we do an ok job of developing AIs and handing over to a society that's more capable than us at dealing with these issues (not a super high bar), in which case a pause wouldn't add much. (The arguments that make me feel most pessimistic about the future are arguments that humans might just not be motivated to do good things — but it's not clear why pauses would help much with that issue.)
5
The aim of a pause would be to plan out the transition better, or make humans smarter/wiser so they can navigate the transition better, so that we end up handing over remaining problems to a counterfactually more capable society. In other words, the bar shouldn't be "more capable than us" but a society that could realistically be achieved with a pause.
[...]
One issue related to this is that humans today largely want to do good things as a side effect of virtue signaling / status games that they're doing/playing. This is currently far from optimal, which makes me scared to undergo an AI transition that could potentially lock-in such highly suboptimal motivations/values, and also scared that the AI transition could just scramble or reset these status games and remove what good motivations/values we do have. A pause would preserve the status quo and give people more time to think about such issues (including time for the idea to spread), and potentially find ways to make the AI transition go better in these regards (compared to today when there has been almost no thought on these issues at all).
But see also this recent quick take where I expressed that my optimism about a pause is pretty limited.
2
If the society is "more capable than us" in some average sense, where we still have certain advantages over them, then I agree that we could still contribute things.
If the society is "more capable (and good) than us" in all the important ways, then they'd also be better at making themselves smarter/wise than we would have been, and better at handling the transition, so further pauses really wouldn't have contributed much.
Idk, I don't know particularly want to argue about definitions here. I just think there's a decent chance that I'll look back after the singularity and be like "yep, the sloppy transition sure meant that we took on a bunch of ex-ante risk, but since we got lucky, extra pause time wouldn't have helped vis-a-vis the long-run lock-in issues. Anything they could have done to help is stuff we can do better now." (And/or: Marginal pause time may have been good or bad via various values or power changes, but it wouldn't have systematically led to improvements from everyone's perspective by e.g. enabling additional intellectual work, because it turns out it was fine to defer the relevant intellectual work until later.)
3
Even this society, if it's in the future, then part of the transition would have already occurred, so they won't have the opportunity to make it go better. So by not pausing now we'd permanently give up this opportunity.
Take the issue in this recent comment, of building an initial AGI that reasons well or poorly about domains that lack fast/cheap feedback signals. It seems very plausible that our long-term civilizational trajectory is significantly affected by which type of AGI gets built first. Suppose we end up building one that reasons poorly about such domains, then:
1. The post-AGI civilization may end up being less capable (and good) than us on average, or in some important ways.
2. Even if they're actually more capable (and good) than us in all the important ways, they could have been even better if only we had built an AGI that reasons well in such domains, but they can't go back in time and change this.
2
I of course agree, but I'd think this would mostly be an issue of capabilities or goodness of our future society, since there's not much external to our society that's getting worse as a result of the transition. Anyway, that seems like maybe one of those definitional issues. I think you're probably right that there's some possible changes that aren't well characterized as being about the capabilities or goodness of our society, so an improvemet in those dimensions aren't strictly speaking sufficient for a pause to not have been valuable.
I care more about my claim that started with "I just think there's a decent chance...". (Which is importantly only asserting a decent chance, not saying that there aren't plausible ways it could be false.)
Copying over my response to Scott from Twitter (with a few additions in square brackets):
I think my biggest disagreement here is about the concept of strategic communications.
In particular, you claim that MIRI should have been more PR-strategic to avoid hyping AI enough that DeepMind and OpenAI were founded.
Firstly, a lot of this was not-very-MIRI. E.g. contrast Bostrom’s NYT bestseller with Eliezer popularizing AI risk via fanfiction, which is certainly aimed much more at sincere nerds. And I don’t think MIRI planned (or maybe even endorsed?) the Puerto Rico conference.
But secondly, even insofar as MIRI was doing that, creating a lot of hype about AI is also what a bunch of the allegedly PR-strategic people are doing right now! Including stuff like Situational Awareness and AI 2027, as well as Anthropic. [So it's very odd to explain previous hype as a result of not being strategic enough.]
You could claim that the situation is so different that the optimal strategy has flipped. That’s possible, although I think the current round of hype plausibly exacerbates a US-China race in the same way that the last round exacerbated the within-US race, which would be really bad.
But more plausi...
More than any other group I've been a part of, rationalists love to develop extremely long and complicated social grievances with each other, taking pages and pages of text to articulate. Maybe I'm just too stupid to understand the high level strategic nuances of what's going on -- what are these people even arguing about? The exact flavor of comms presented over the last ten years?
As someone who spends a significant part of his time briefing policymakers in Europe, ministerial advisors, senior civil servants in AI governance, I want to point out something obvious from where I stand, but absent from this discussion.
The "radical transparency vs. strategic communication" debate presupposes that framing is the bottleneck. It isn't. The bottleneck is volume. Most policymakers have never heard the argument, no matter how you frame it. Among the ones I interact with, maybe 2% have been exposed to the problem enough to have an opinion. Another 10% or so have heard something, but mostly through the Yann LeCun-adjacent dismissals, and formed their view from that. The remaining ~88%, including people in very important AI governance positions, have simply never had the conversation.
The question of which approach works better is real but secondary. What's missing is more people doing this work at all. It's a campaign, and the limiting factor is coverage, not the message.
To give a concrete data point: the only policymaker in my circles who has ever brought up "If Anyone Builds It, Everyone Dies" is Lord Tim Clement-Jones, chair of the All-Party Parliamentary Group on AI in the UK. And he was probably already sympathetic. That's one person.
7
Um, I think that long, detailed, audited arguments are how we do a substantial amount of social capital and resource allocation around these parts.
And also, um, it is better than most alternative ways of doing it (e.g. networking, politicking).
5
Among other things, the fact that one of the leading ASI lab is substantially downstream of us. Separately, a lot of real actual politics that tends to happen in the community around prestige and money and talent allocation and respect, which needs to get litigated somehow (and abuse of power and legitimacy is common and if you can't talk about it you can't have norms about it).
5
I think if your main interactions with PauseAI is a certain Twitter account, as served to you by the algorithm in interactions with your AI safety friends, then you might think that they're mostly going after other, more moderate safety advocates. But this just isn't a good picture of the overall actions of the movement. At least in the case of PauseAI UK, of which I have a decent understanding of our inner workings, essentially zero time is spent thinking about other AI safety advocates. I expect that the same is true of Yudkowsky and MIRI.
Of course it is the case being rude towards people working on safety teams at OpenAI on Twitter makes some things worse on some axes. And this is mostly bad and pointless and I don't endorse it. But that's not even really what that post from Rob was doing! Rob was writing an opinionated, but civil, criticism. In what way is this "knifing" the other AI safety advocates? It's not like MIRI killed SB 1047.
Now if Scott means something like "Giving money to MIRI pushes the world in the MIRI-preferred direction, and this would have meant no Anthropic and no safety team at OpenAI" then I can kind of maybe see what he means here. This just isn't "knifing" in the sense of the betrayal that most people mean by the word. It's just opposing someone's plan, in a way that they've been doing for years. It's not like MIRI would have actually used marginal resources to stop Anthropic from being created by, like, sabotage or something.
MIRI don't even say that working in safety is bad! They only say that they think their approach is better. IABIED specifically states that they think mech interp researchers are "heroes" (as part an example of research they think won't work in time without political action).
There is a phenomenon in which rationalists sometimes make predictions about the future, and they seem to completely forget their other belief that we're heading toward a singularity (good or bad) relatively soon. It's ubiquitous, and it kind of drives me insane. Consider these two tweets:

Timelines are really uncertain and you can always make predictions conditional on "no singularity". Even if singularity happens you can always ask superintelligence "hey, what would be the consequences of this particular intervention in business-as-usual scenario" and be vindicated.
7
This is true, but then why not state "conditional on no singularity" if they intended that? I somehow don't buy that that's what they meant
7
Why would they spend ~30 characters in a tweet to be slightly more precise while making their point more alienating to normal people who, by and large, do not believe in a singularity and think people who do are faintly ridiculous? The incentives simply are not there.
And that's assuming they think the singularity is imminent enough that their tweets won't be born out even beforehand. And assuming that they aren't mostly just playing signaling games - both of these tweets read less as sober analysis to me, and more like in-group signaling.
2
Absolutely agreed. Wider public social norms are heavily against even mentioning any sort of major disruption due to AI in the near future (unless limited to specific jobs or copyright), and most people don't even understand how to think about conditional predictions. Combining the two is just the sort of thing strange people like us do.
3
Because that's a mouthful? And the default for an ordinary person (which is potentially most of their readers) is "no Singularity", and the people expecting the Singularity can infer that it's clearly about a no-Singularity branch.
1
I think the general population doesn't know all that much about singularity, so adding that to the part would just unnecessarily dilute it.
1
This is definitely baked in for many people (e.g. me, but also see the discussion here for example).
3
See also: population decline discourse
2
I think Richard has one to two decade timelines?
1
Two decades don't seem like enough to generate the effect he's talking about. He might disagree though.
3
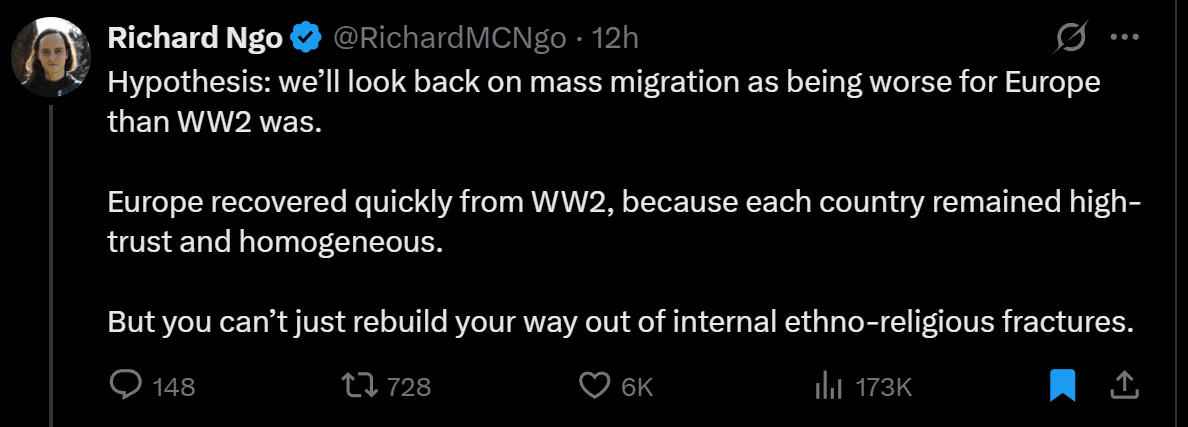
Conditional on being around to look back, it seems pretty plausible to me that lack of trust and competence within major powers will have made the outcome of AGI significantly worse than it could have been.
A (partial, not very good) analogy is that, at this point, the developed world is pretty altruistic towards the developing world (e.g. to the tune of many billions of dollars of aid per year). But the developing world might still really wish it'd had fewer internal ethno-religious fractures during the Industrial Revolution (or indeed at at any time since then).
For a while now, some people have been saying they 'kinda dislike LW culture,' but for two opposite reasons, with each group assuming LW is dominated by the other—or at least it seems that way when they talk about it. Consider, for example, janus and TurnTrout who recently stopped posting here directly. They're at opposite ends and with clashing epistemic norms, each complaining that LW is too much like the group the other represents. But in my mind, they're both LW-members-extraordinaires. LW is clearly obviously both, and I think that's great.
8
What are the two groups in question here?
1
I think it's probably more of a spectrum than two distinct groups, and I tried to pick two extremes. On one end, there are the empirical alignment people, like Anthropic and Redwood; on the other, pure conceptual researchers and the LLM whisperers like Janus, and there are shades in between, like MIRI and Paul Christiano. I'm not even sure this fits neatly on one axis, but probably the biggest divide is empirical vs. conceptual. There are other splits too, like rigor vs. exploration or legibility vs. 'lore,' and the preferences kinda seem correlated.
6[anonymous]
Whenever I try to "learn what's going on with AI alignment" I wind up on some article about whether dogs know enough words to have thoughts or something. I don't really want to kill off the theoretical term (it can peek into the future a little later and function more independent of technology, basically) but it seems like kind of a poor way to answer stuff like: what's going on now, or if all the AI companies allowed me to write their 6 month goals, what would I put on it.
1
I'm curious about what people disagree with regarding this comment. Also, I guess since people upvoted and agreed with the first one, they do have two groups in mind, but they're not quite the same as the ones I was thinking about (which is interesting and mildly funny!). So, what was your slicing up of the alignment research x LW scene that's consistent with my first comment but different from my description in the second comment?
2
On first approximation, in a group, if people at both ends of a dimension are about equally unhappy with whst the moderate middle does, assuming that is actually reasonable, but hard to know, then it's probably balanced.
People are very worried about a future in which a lot of the Internet is AI-generated. I'm kinda not. So far, AIs are more truth-tracking and kinder than humans. I think the default (conditional on OK alignment) is that an Internet that includes a much higher population of AIs is a much better experience for humans than the current Internet, which is full of bullying and lies.
All such discussions hinge on AI being relatively aligned, though. Of course, an Internet full of misaligned AIs would be bad for humans, but the reason is human disempowerment, not any of the usual reasons people say such an Internet would be terrible.
4
I think the problem is that the competitive dynamics that make humans worse on the internet (eg short epistemically-ungrounded outrage bait gets more engagement than more careful and reasoned analysis) will apply to AIs as well as to humans.
1
Yup, but the AIs are massively less likely to help with creating cruel content. There will be a huge asymmetry in what they will be willing to generate.
Imagine an Internet where half the population is Grant Sanderson (the creator of 3Blue1Brown). That'd be awesome. Grant Sanderson has the same incentives as anyone else to create cruel and false content, but he just doesn't.
2
That would be awesome! For me!
But I don't think that the majority of people in the world would prefer that to the current internet, much less actually engage with it more than the current internet. Most people find math boring (even when it is explained as well as when Grant does the explaining). There would be an incentive to produce content that is more engaging for most of the population than linear algebra explanations.
One difference between the releases of previous GPT versions and the release of GPT-5 is that it was clear that the previous versions were much bigger models trained with more compute than their predecessors. With the release of GPT-5, it's very unclear to me what OpenAI did exactly. If, instead of GPT-5, we had gotten a release that was simply an update of 4o + a new reasoning model (e.g., o4 or o5) + a router model, I wouldn't have been surprised by their capabilities. If instead GPT-4 were called something like GPT-3.6, we would all have been more or less equally impressed, no matter the naming. The number after "GPT" used to track something pretty specific that had to do with some properties of the base model, and I'm not sure it's still tracking the same thing now. Maybe it does, but it's not super clear from reading OpenAI's comms and from talking with the model itself. For example, it seems too fast to be larger than GPT-4.5.
For example, it seems too fast to be larger than GPT-4.5.
A "GPT-5" named according to the previous convention in terms of pretraining compute would need at least 1e27 FLOPs (50x original GPT-4), which on H100/H200 can at best be done in FP8. Which could be done with 150K H100s for 3 months at 40% utilization. (GB200 NVL72 is too recent to use for this pretraining run, though there is a remote possiblity of B200.) A compute optimal shape for this model would be something like 8T total params, 1T active[1].
The speed of GPT-5 could be explained by using GB200 NVL72 for inference, even if it's an 8T total param model. GPT-4.5 was slow and expensive likely because it needed many older 8-chip servers (which have 0.64-1.44 TB of HBM) to keep in HBM with room for KV caches, but a single GB200 NVL72 has 14 TB of HBM. At the same time, it wouldn't help as much with the speed of smaller models (but it would help with their output token cost because you can fit more KV cache in the same NVLink domain, which isn't necessarily yet being reflected in prices, since GB200 NVL72 is still scarce). So it remains somewhat plausible that GPT-5 is essentially GPT-4.5-thinking running on better hardwar...
4
Ah, interesting! So the speed we see shouldn't tell us much about GPT-5's size.
I omitted one other factor from my shortform, namely cost. Do you think OpenAI would be willing to serve an 8T params (1T active) model for the price we're seeing? I'm basically trying to understand whether GPT-5 being served for relatively cheap should be a large or small update.
9
Prefill (processing of input tokens) is efficient, something like 60% compute utilization might be possible, and that only depends on the number of active params. Generation of output tokens is HBM bandwidth bound, depends on the number of total params and the number of KV cache sequences for requests in a batch that fit on the same system (which share the cost of chip-time[1]). With GB200 NVL72, batches could be huge, dividing the cost of output tokens (still probably several times more expensive per token than prefill).
For prefill, we can directly estimate at-cost inference from the capital cost of compute hardware, assuming a need to pay it back in 3 years (it will likely serve longer but become increasingly obsolete). An H100 system costs about $50K per chip ($5bn for a 100K H100s system). This is all-in for compute equipment, so with networking but without buildings and cooling, since those serve longer and don't need to be paid back in 3 years. Operational costs are maybe below 20%, which gives $20K per year per chip, or $2.3 per H100-hour. On gpulist, there are many listings at $1.80 per H100-hour, so my methodology might be somewhat overestimating the bare bones cost.
For GB200 NVL72, which are still too scarce to get a visible market price anywhere close to at-cost, the all-in cost together with external networking in a large system is plausibly around $5M per 72-chip rack ($7bn for a 100K chip GB200 NVL72 system, $30bn for Stargate Abilene's 400K chips in GB200/GB300 NVL72 racks). This is 70K capital cost per chip, or 27.7K per year that pay it back in 3 years with 20% operational costs. This is just $3.2 per chip-hour.
A 1T active param model consumes 2e18 FLOPs for 1M tokens. GB200 chips can do 5e15 FP8 FLOP/s or 10e15 FP4 FLOP/s. At $3.2 per chip-hour and 60% utilization (for prefill), this translates to $0.6 per million input tokens at FP8, or $0.3 per million input tokens at FP4. The API price for the batch mode of GPT-5 is $0.62 input, $5 output.
2
Possibly an unlikely possibility, but could it be that different versions of GPT-5 (ie., normal model, thinking model, and thinking-pro model) are actually of different sizes? Or do we know for sure that they all share the same architecture?
Alignment seems quite similar to the problem of imbuing AIs with artistic taste. Morality and taste are both hard to verify and subjective (or inter-subjective). Alignment has in practice the further difficulty that deception may play a role. I.e., even after managing to train moral principles into an AI system, you have to make sure they actually act as a guide for action.
That said, my very subjective impression is that AI is far ahead in terms of ethical taste compared to artistic taste. Perhaps this is thanks to the fact that alignment has been considered a core AI problem for a much longer time.
8
Disagree for the meaning of "alignment" I most care about, where alignment is about trying to do what the operator wants.
1
"make the world better!" <-- doing what this operator wants requires some aesthetic sensibility.
1
You missed "trying." Succeeding requires certain capabilities, but trying to do it does not. I believe there's much more risk from AIs not trying to do what the operator wants than trying and failing.
1
i see your point, thanks.
1
If you assign a different meaning to the word, then you're talking about a different thing, and the point changes accordingly.
1
I agree.
0
the observation -- that aesthetics and morality are complementary -- is very sharp. but i'm not sure what it has to do with alignment in particular.
it's a bit like saying "the problem of getting ais to cultivate chickens is just a problem of getting them to cultivate eggs!"[1] true, of course, but more a fact about chickens and eggs than about ais.
1. ^
(the chickens will be cultivated to live happy and fulfilling chicken lives, in this hypothetical.)
Previously, I said:
People are very worried about a future in which a lot of the Internet is AI-generated. I'm kinda not. So far, AIs are more truth-tracking and kinder than humans. I think the default (conditional on OK alignment) is that an Internet that includes a much higher population of AIs is a much better experience for humans than the current Internet, which is full of bullying and lies.
All such discussions hinge on AI being relatively aligned, though. Of course, an Internet full of misaligned AIs would be bad for humans, but the reason is human disempowerment, not any of the usual reasons people say such an Internet would be terrible.
I feel good about this prediction so far. Instagram and TikTok have now a significant amount of AI-generated videos (though they haven't overrun these platforms by any means). The categories I've seen so far are:
- Low-brow animated stories.
- Fantasy or sci-fi scenarios with music.
- Colorful AI-generated art.
- Cute meme animals.
The greatest sin of this content is that it's often low quality. But it's not really that great of a sin. I think, all things considered, AI slop is above average content. Other content often contains bullying, meanness,...
There is also a significant category of "AI video passing itself off as a real video", and many videos have people debating in the comments if it's real or AI. This seems like it can erode trust and is generally negative.
2
This seems anecdotal.
So far, we have documented cases of Generative AI being used to subvert elections in Romania (actually causing an annulment), and to some extent in NYC. We also have this report by OpenAI from 2024, which details such influence operations facilitated using OAI's API. Given the proliferation of significantly more capable open-source models in the 18 months since, we can be fairly confident that broader, more complex operations are taking place today.
I also tend to associate AI-slop with low quality content, but we know AI is more capable than that, which leads me to believe that significant amounts of content online are parts of influence operations by malicious actors.
2
AFAIK that was not because of Gen AI, though the broader point of your comment does stand.
Rationalists and Pause AI people on X are accusing Davidad of suffering of AI psychosis. I think it's them who have lost the plot actually, not Davidad. The move here looks political, rather than truth-tracking. "Davidad is now my political opponent, so I'm accusing him of being crazy." This happened to Emmet Shear too at some point.
I also strongly believe AI psychosis to be a far more limited phenomenon than people here seem to believe. I think you're treating it as a good soldier in your army of arguments rather than investigating it truthfully for what it is.
6
I don't think Davidad has AI psychosis (his views seem to be quite coherent and aligned with his long-standing views on moral realism). But I think he is quirky and maybe expressing his views in a deliberately provocative way. He implied in his thread on leaving ARIA that it was his equivalent of the Death with Dignity post, which was also on April Fool's, and that thread definitely had some weird stuff (e.g. calling it "Alignment with Awakening").
6
Which rationalists?
4
Most likely the OP means this quick take by Ivan Vendrov. Davidad ended up believing that the LLMs have been grokking the Natural Abstract Goodness which is unlikely to be capturable by existing benchmarks. While I do buy the idea that the NAG exists, I don't think that I understand how one can check that the LLMs really understood it.
5
Davidad also announced the other day that he's leaving ARIA to pursue a research agenda focused on working with AIs on moral philosophy.
https://x.com/davidad/status/2039390998694891816
2
Why? It seems to me that Pope basically repeats the smarter-part-of-mainstream consensus, and adds some religious justification. If we ignore the justification, we are left with the wisdom of the crowd.
1
The part where AI axiomatically cannot feel joy or pain, and isn't "really learning", whatever really means, is what I would characterize as the dumber part of mainstream consensus. Some of it probably came out that way because they feel theologically constrained, but it's dumber than it needs to be even starting from the premise of "Souls are an active ingredient in cognition and AIs don't have them".
3
I interpreted the "cannot really learn" part as referring to things such as AIs driving people to psychosis or suicide.
I mean, Claude seems like a nice guy, and would probably disapprove of doing this, on reflection. But the problem is that he cannot actually reflect on his own actions -- every chat is a fresh start. And even if afterwards he reads about it in newspapers, without having the logs he cannot figure out the details of what happened.
As a human, if you drove someone to suicide, at least you know how it happened, how it felt at the moment... and if you disapprove of the outcome, then the next time you notice yourself in a similar situation acting in a similar way, you can stop yourself.
Claude would probably do the same thing the next time, because he has no memories of how it happened. And if he does not do it the next time, it's probably because the guys in Anthropic trained him out of it, not because he reflect on it himself.
Does this make sense?
2
I do not think that makes sense as an interpretation of the passage.
[...]
Nothing here alludes to LLMs as amnesiacs. This is the same meat chauvinism people have been using for decades, updated only with "It's 2026 so I know they sure seem to be learning, but-"
2
The emphasized words in my opinion all point in the direction of: LLMs cannot grow by learning from their own mistakes.
2
I find it unlikely they were trying to describe the amnesia problem, failed to ever call LLMs amnesiacs, and accidentally repeated talking points exclusive to the stochastic parrot people. I find it much more likely that they agree with the stochastic parrot interpretation.
If we're in a history simulation, I don't think it's unlikely that the simulators will just set us free in their reality. I'm expecting a more enlightened humanity to consider simulated humans moral patients.
There's no real difference between a simulated human and a human. Both are causally-interacting signals in a computer. If you inhabit a simulation, you automatically inhabit base reality just as much as native base-reality beings. They're also just interacting signals. It's just that you're embedded in some other software and they're not, but that's not fundamental at all.
3
If you thought simulated humans were moral patients, you might decide not to run history simulations. That being said, I don't think that is an absolute rule.
2
What are they simulating us for? The reasons are pretty important for whether they'd want to treat us ethically. I have encountered only one reason I found really convincing.
1
Honestly, I wasn't picturing their reasons. Say more?
1
To be clear, I generally disagree with most varieties of the simulation hypothesis. But nevertheless I do think that this question in particular has some good answers -- a lot of which more-or-less reduce to 'forecasting outcomes via an agent-based simulation'. Unfortunately that family of explanations wouldn't give you much in the way of understanding the simulators, as it could be anything from "simulate outcomes of X choice in a copy of [the simulator's] world" (which would tell you that they'd be very similar to us) to "consider this strange hypothetical where apes evolved intelligence, for purely academic reasons" (which would tell you much less). Alternatively there are some which veer far away from that, to e.g. entertainment, or pleasure of some kind (e.g. an elaborate form of pornography?), or even some kind of long-form training algorithm, and I do think that in those cases you can infer more about the motivations of the simulator.
1
That's a view which implies one shouldn't run history simulations at all (or at least, not simulations where bad things happen to the sims). If a simulation is being run then, it's probably by the kind of people who aren't too interested in releasing sims.
1
If I spend one century on Earth and one millenium in heaven, why am I on Earth?
(SIA can answer this, but only by giving an account of why there's much more total experience in the world if sims are resurrected than not. The most plausible means here are that the latter is correlated with cooperative norms prevailing across the cosmos generally, such that a much larger surplus is available for conscious experience in general. But then taking SIA seriously means embracing infinite populations and I get very confused about how to reason then.)
6
One slightly trollish answer is "someone figures out how to merge minds and this turns out to be a highly desirable thing to do, so most independent observer-moments are before the point where mind-merging is common".
People seemed confused by my take here, but it's the same take Davidad expressed in this thread that has been making rounds: https://x.com/davidad/status/2011845180484133071
I'm pretty sure a human brain could, in principle, visualize a 4D space just as well as it visualizes a 3D space, and that there are ways to make that happen via neurotech (as an upper bound on difficulty).
Consider: we know a lot about how 4-dimensional spaces behave mathematically, probably no less than how 3-dimensional spaces work. Once we know exactly how the brain encodes and visualizes a 3D space in its neurons, we probably also understand how it would do it for a 4D space if it had sensory access to it. Given good enough neurotech, we could manually...
5
This argument seems to work for N-D space for any N which doesn't seem right. I think we definitely do know less about 4D space than 3D, partly because we're much more interested in 3D, partly because there's just (a lot) more going on in 4D.
Intuitively it feels like current AI should be much better at learning navigation in 4D than human brains. Brains have real architecture-level, baked in task-specific circuits, which AI lack, and reconstructing a 3D world is arguably the most important of those. Sure, you could modify them with neurotech to change that, but you could do that for virtually any task so it doesn't seem very meaningful.
There's also the problem that human sensors are inherently 3D. It's not clear how you would translate eyes into 4D. If you do pick a way to do this, and leave visual processing circuits the same, the circuits aren't getting their expected data stream anymore. Brains are clearly pretty good at coping with this, like in blind people where visual processing circuits are (at least partially) co-opted for other things, but blind people are clearly worse at navigating the 3D world than sighted people, and it seems like the same would be true for humans vs 4D-native beings (like AI).
2
Ah, I get what you are saying, and I agree. It's possible the human brain architecture, as-is, can't process 4D, but I guess we're mismatched in what we think is interesting. The thrust of my intuition here was more "wow, someone could understand N-D intuitively in a 3D universe, this doesn't seem prohibited", regardless of whether it's the same architecture of a human brain exactly. Like, the human brain as it is right now might not permit that, and neurotech might involve doing a lot of architectural changes (the same applies to emulations). I suppose it's a lot less interesting an insight if you already buy that imagining higher dimensions from a 3D universe is in principle possible. The human brain being able to do that is a stronger claim that would have been more interesting if I actually managed to defend it well.
I suppose I was kinda sloppy saying "the human brain can do that" -- I should have said "the human brain arbitrarily modified" or something like that.
3
I definitely think it's interesting that it's possible for N-D-substrate-computations to imagine / intuit N+1-D, but yeah, I feel like that's mostly a given because we have the concept of N+1-D in the first place.
There are different levels of "imagine / intuit" though. Some people have particularly good or bad intuition for the 3D space we live in. I took your claim to be something like "the average brain could intuit 4D just as well as 3D, maybe requiring slight modification". I think the modifications to reach true parity would be pretty extensive, because of how much 3D-specific architecture (as opposed to weights) human brains have. I do agree the modifications are theoretically possible, but the modifications to give a fruit fly human-level cognition are also theoretically possible with arbitrary modification.
2
Thought experiment: If a mad scientist gave a newborn infant a third eye that was offset along a fourth spatial dimension from the baby's other two eyes, the baby's brain would naturally acquire the ability to visualize in four dimensions. Wiring up three eyes probably requires three visual cortices, which will have knock-on effects on the overall geometry of the brain. I doubt that it requires the brain itself to be a 4D structure though.
Has anyone proposed a solution to the hard problem of consciousness that goes:
- Qualia don't seem to be part of the world. We can't see qualia anywhere, and we can't tell how they arise from the physical world.
- Therefore, maybe they aren't actually part of this world.
- But what does it mean they aren't part of this world? Well, since maybe we're in a simulation, perhaps they are part of the simulation. Basically, it could be that qualia : screen = simulation : video-game. Or, rephrasing: maybe qualia are part of base reality and not our simulated reality in the same way the computer screen we use to interact with a video game isn't part of the video game itself.
2
Qualia are the only thing we[1] can see.
We don't see objects "directly" in some sense, we experience qualia of seeing objects. Then we can interpret those via a world-model to deduce that the visual sensations we are experiencing are caused by some external objects reflecting light. The distinction is made clearer by the way that sometimes these visual experiences are not caused by external objects reflecting light, despite essentially identical qualia.
Nonetheless, it is true that we don't know how qualia arise from the physical world. We can track back physical models of sensation until we get to stuff happening in brains, but that still doesn't tell us why these physical processes in brains in particular matter, or whether it's possible for an apparently fully conscious being to not have any subjective experience.
1. ^
At least I presume that you and others have subjective experience of vision. I certainly can't verify it for anyone else, just for myself. Since we're talking about something intrinsically subjective, it's best to be clear about this.
1
I don't disagree with this at all, and it's a pretty standard insight for someone who thought about this stuff at least a little. I think what you're doing here is nitpicking on the meaning of the word "see" even if you're not putting it like that.
Dark people can say dark things pretending to be honest, because honest people sometimes say dark things because of their honesty.
A UBI of AI or compute kind of makes sense to me under safe superintelligence. I don't know if AI companies will still be incentivized to sell AI if they can just use it themselves, but a state isn't under the same incentives. Instead of centralizing the use of its AI systems, it could distribute access to all citizens so they can use it productively themselves.
Why not just give people money so they can use it to pay for compute? I guess it's a matter of which option you expect to lead to the most productive and freedom-promoting outcome for everyone in th...
Slop is in the mind, not in the territory. I will not call slop something that I like, regardless of what other people call slop.
Reaction request: "bad source" and "good source" to use when people cite sources you deem unreliable vs. reliable.
I know I would have used the "bad source" reaction at least once.
Is anyone working on experiments that could disambiguate whether LLMs talk about consciousness because of introspection vs. "parroting of training data"? Maybe some scrubbing/ablation that would degrade performance or change answer only if introspection was useful?
Iff LLM simulacra resemble humans but are misaligned, that doesn't bode well for S-risk chances.
1
Waluigi effect also seems bad for s-risk. "Optimize for pleasure, ..." -> "Optimize for suffering, ...".
An optimistic way to frame inner alignment is that gradient descent already hits a very narrow target in goal-space, and we just need one last push.
A pessimistic way to frame inner misalignment is that gradient descent already hits a very narrow target in goal-space, and therefore S-risk could be large.
This community has developed a bunch of good tools for helping resolve disagreements, such as double cruxing. It's a waste that they haven't been systematically deployed for the MIRI conversations. Those conversations could have ended up being more productive and we could've walked away with a succint and precise understanding about where the disagreements are and why.
1
We should implement Paul Christiano's debate game with alignment researchers instead of ML systems
If you try to write a reward function, or a loss function, that caputres human values, that seems hopeless.
But if you have some interpretability techniques that let you find human values in some simulacrum of a large language model, maybe that's less hopeless.
The difference between constructing something and recognizing it, or between proving and checking, or between producing and criticizing, and so on...
As a failure mode of specification gaming, agents might modify their own goals.
As a convergent instrumental goal, agents want to prevent their goals to be modified.
I think I know how to resolve this apparent contradiction, but I'd like to see other people's opinions about it.
I keep seeing absolutely terrible epistemics from like 50% of AI Safety. From people who previously seemed reasonable. This quick take was prompted by an example I just saw, from Connor Leahy: https://x.com/JoshWalkos/status/2021087240126976511