As someone that does think about a lot of the things you care about at least some of the time (and does care pretty deeply), I can speak for myself why I don't talk about these things too much:
Epistemic problems:
- Mostly, the concept of "metaphilosophy" is so hopelessly broad that you kinda reach it by definition by thinking about any problem hard enough. This isn't a good thing, when you have a category so large it contains everything (not saying this applies to you, but it applies to many other people I have met who talked about metaphilosophy), it usually means you are confused.
- Relatedly, philosophy is incredibly ungrounded and epistemologically fraught. It is extremely hard to think about these topics in ways that actually eventually cash out into something tangible, rather than nerdsniping young smart people forever (or until they run out of funding).
- Further on that, it is my belief that good philosophy should make you stronger, and this means that fmpov a lot of the work that would be most impactful for making progress on metaphilosophy does not look like (academic) philosophy, and looks more like "build effective institutions and learn interactively why this is hard" and "get
I expect at this moment in time me building a company is going to help me deconfuse a lot of things about philosophy more than me thinking about it really hard in isolation would
Hard for me to make sense of this. What philosophical questions do you think you'll get clarity on by doing this? What are some examples of people successfully doing this in the past?
It seems plausible that there is no such thing as “correct” metaphilosophy, and humans are just making up random stuff based on our priors and environment and that’s it and there is no “right way” to do philosophy, similar to how there are no “right preferences”.
Definitely a possibility (I've entertained it myself and maybe wrote some past comments along these lines). I wish there was more people studying this possibility.
I have short timelines and think we will be dead if we don’t make very rapid progress on extremely urgent practical problems like government regulation and AI safety. Metaphilosophy falls into the unfortunate bucket of “important, but not (as) urgent” in my view.
Everyone dying isn't the worst thing that could happen. I think from a selfish perspective, I'm personally a bit more scared of surviving i...
Hard for me to make sense of this. What philosophical questions do you think you'll get clarity on by doing this? What are some examples of people successfully doing this in the past?
The fact you ask this question is interesting to me, because in my view the opposite question is the more natural one to ask: What kind of questions can you make progress on without constant grounding and dialogue with reality? This is the default of how we humans build knowledge and solve hard new questions, the places where we do best and get the least drawn astray is exactly those areas where we can have as much feedback from reality in as tight loops as possible, and so if we are trying to tackle ever more lofty problems, it becomes ever more important to get exactly that feedback wherever we can get it! From my point of view, this is the default of successful human epistemology, and the exception should be viewed with suspicion.
And for what it's worth, acting in the real world, building a company, raising money, debating people live, building technology, making friends (and enemies), absolutely helped me become far, far less confused, and far more capable of tackling confusing problems! Actu...
It seems plausible that there is no such thing as "correct" metaphilosophy, and humans are just making up random stuff based on our priors and environment and that's it and there is no "right way" to do philosophy, similar to how there are no "right preferences"
If this is true, doesn't this give us more reason to think metaphilosophy work is counterfactually important, i.e., can't just be delegated to AIs? Maybe this isn't what Wei Dai is trying to do, but it seems like "figure out which approaches to things (other than preferences) that don't have 'right answers' we [assuming coordination on some notion of 'we'] endorse, before delegating to agents smarter than us" is time-sensitive, and yet doesn't seem to be addressed by mainstream intent alignment work AFAIK.
(I think one could define "intent alignment" broadly enough to encompass this kind of metaphilosophy, but I smell a potential motte-and-bailey looming here if people want to justify particular research/engineering agendas labeled as "intent alignment.")
A lot of the debate surrounding existential risks of AI is bounded by time. For example, if someone said a meteor is about to hit the Earth that would be alarming, but the next question should be, "How much time before impact?" The answer to that question effects everything else.
If they say, "30 seconds". Well, there is no need to go online and debate ways to save ourselves. We can give everyone around us a hug and prepare for the hereafter. However, if the answer is "30 days" or "3 years" then those answers will generate very different responses.
The AI alignment question is extremely vague as it relates to time constraints. If anyone is investing a lot energy in "buying us time" they must have a time constraint in their head otherwise they wouldn't be focused on extending the timeline. And yet -- I don't see much data on bounded timelines within which to act. It's just assumed that we're all in agreement.
It's also hard to motivate people to action if they don't have a timeline.
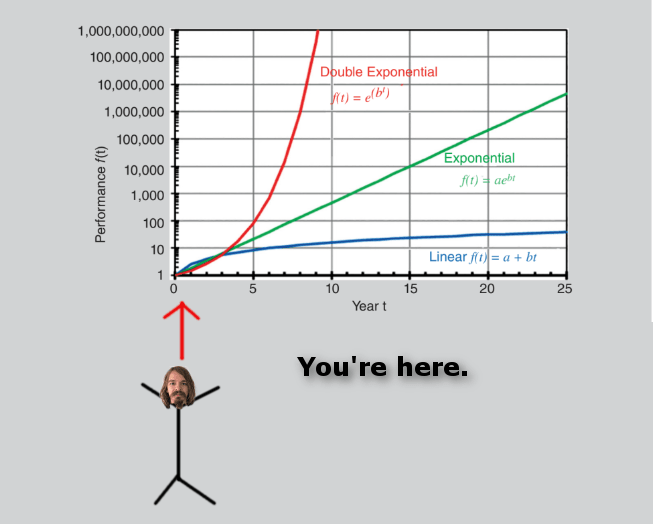
So what is the timeline? If AI is on a double exponential curve we can do some simple math projections to get a rough idea of when AI intelligence is likely to exceed human intelligence. Presumably, su...
Double exponentials can be hard to visualize. I'm no artist, but I created this visual to help us better appreciate what is about to happen. =-)
Philosophy is a social/intellectual process taking place in the world. If you understand the world, you understand how philosophy proceeds.
Sometimes you don't need multiple levels of meta. There's stuff, and there's stuff about stuff, which could be called "mental" or "intensional". Then there's stuff about stuff about stuff (philosophy of mind etc). But stuff about stuff about stuff is a subset of stuff about stuff. Mental content has material correlates (writing, brain states, etc). I don't think you need a special category for stuff about stuff about stuff, it can be thought of as something like self-reading/modifying code. Or like compilers compiling themselves; you don't need a special compiler to compile compilers.
Philosophy doesn't happen in a vacuum, it's done by people with interests in social contexts, e.g. wanting to understand what other people are saying, or be famous by writing interesting things. A sufficiently good theory of society and psychology would explain philosophical discourse (and itself rely on some sort of philosophy for organizing its models). You can think of people as having "a philosophy" that can be studied from outside by analyzing text, mental stat...
Philosophy is a social/intellectual process taking place in the world. If you understand the world, you understand how philosophy proceeds.
What if I'm mainly interested in how philosophical reasoning ideally ought to work? (Similar to how decision theory studies how decision making normatively should work, not how it actually works in people.) Of course if we have little idea how real-world philosophical reasoning works, understanding that first would probably help a lot, but that's not the ultimate goal, at least not for me, for both intellectual and AI reasons.
The latter because humans do a lot of bad philosophy and often can’t recognize good philosophy. (See popularity of two-boxing among professional philosophers.) I want a theory of ideal/normative philosophical reasoning so we can build AI that improves upon human philosophy, and in a way that convinces many people (because they believe the theory is right) to trust the AI's philosophical reasoning.
...This leads to a view where philosophy is one of many types of discourse/understanding that each shape each other (a non-foundationalist view). This is perhaps disappointing if you wanted ultimate foundations in some simple fra
I wonder if more people would join you on this journey if you had more concrete progress to show so far?
If you're trying to start something approximately like a new field, I think you need to be responsible for field-building. The best type of field-building is showing that the new field is not only full of interesting problems, but tractable ones as well.
Compare to some adjacent examples:
- Eliezer had some moderate success building the field of "rationality", mostly though explicit "social" field-building activities like writing the sequences or associated fanfiction, or spinning off groups like CFAR. There isn't much to show in terms of actual results, IMO; we haven't developed a race of Jeffreysai supergeniuses who can solve quantum gravity in a month by sufficiently ridding themselves of cognitive biases. But the social field-building was enough to create a great internet social scene of like-minded people.
- MIRI tried to kickstart a field roughly in the cluster of theoretical alignment research, focused around topics like "how to align AIXI", decision theories, etc. In terms of community, there are a number of researchers who followed in these footsteps, mostly at MIRI itself to m
@jessicata @Connor Leahy @Domenic @Daniel Kokotajlo @romeostevensit @Vanessa Kosoy @cousin_it @ShardPhoenix @Mitchell_Porter @Lukas_Gloor (and others, apparently I can only notify 10 people by mentioning them in a comment)
Sorry if I'm late in responding to your comments. This post has gotten more attention and replies than I expected, in many different directions, and it will probably take a while for me to process and reply to them all. (In the meantime, I'd love to see more people discuss each other's ideas here.)
ensuring AI philosophical competence won't be very hard. They have a specific (unpublished) idea that they are pretty sure will work.
Cool, can you please ask them if they can send me the idea, even if it's just a one-paragraph summary or a pile of crappy notes-to-self?
From my current position, it looks like "all roads lead to metaphilosophy" (i.e., one would end up here starting with an interest in any nontrivial problem that incentivizes asking meta questions) and yet there's almost nobody here with me. What gives?
Facile response: I think lots of people (maybe a few hundred a year?) take this path, and end up becoming philosophy grad students like I did. As you said, the obvious next step for many domains of intellectual inquiry is to go meta / seek foundations / etc., and that leads you into increasingly foundational increasingly philosophical questions until you decide you'll never able to answer all the questions but maybe at least you can get some good publications in prestigious journals like Analysis and Phil Studies, and contribute to humanity's understanding of some sub-field.
First, I think that the theory of agents is a more useful starting point than metaphilosophy. Once we have a theory of agents, we can build models, within that theory, of agents reasoning about philosophical questions. Such models would be answers to special cases of metaphilosophy. I'm not sure we're going to have a coherent theory of "metaphilosophy" in general, distinct from the theory of agents, because I'm not sure that "philosophy" is an especially natural category[1].
Some examples of what that might look like:
- An agent inventing a theory of agents in
How can I better recruit attention and resources to this topic?
Consider finding an event organizer/ops person and running regular retreats on the topic. This will give you exposure to people in a semi-informal setting, and help you find a few people with clear thinking who you might want to form a research group with, and can help structure future retreats.
I've had great success with a similar approach.
I'm pretty much with you on this. But it's hard to find a workable attack on the problem.
One question though, do you think philosophical reasoning is very different from other intelligence tasks? If we keep stumbling into LLM type things which are competent at a surprisingly wide range of tasks, do you expect that they'll be worse at philosophy than at other tasks?
Here's another bullet point to add to the list:
- It is generally understood now that ethics is subjective, in the following technical sense: 'what final goals you have' is a ~free parameter in powerful-mind-space, such that if you make a powerful mind without specifically having a mechanism for getting it to have only the goals you want, it'll probably end up with goals you don't want. What if ethics isn't the only such free parameter? Indeed, philosophers tell us that in the bayesian framework your priors are subjective in this sense, and also that your decision theory is subjective in this sense maybe. Perhaps, therefore, what we consider "doing good/wise philosophy" is going to involve at least a few subjective elements, where what we want is for our AGIs to do philosophy (with respect to those elements) in the same way that we would want and not in various other ways, and that won't happen by default, we need to have some mechanism to make it happen.
Why is there virtually nobody else interested in metaphilosophy or ensuring AI philosophical competence (or that of future civilization as a whole)
I interpret your perspective on AI as combining several things: believing that superhuman AI is coming; believing that it can turn out very bad or very good, and that a good outcome is a matter of correct design; believing that the inclinations of the first superhuman AI(s) will set the rules for the remaining future of civilization.
This is a very distinctive combination of beliefs. At one time, I th...
When I look at metaphilosophy, the main places I go looking are places with large confusion deltas. Where, who, and why did someone become dramatically less philosophically confused about something, turning unfalsifiable questions into technical problems. Kuhn was too caught up in the social dynamics to want to do this from the perspective of pure ideas. A few things to point to.
- Wittgenstein noticed that many philosophical problems attempt to intervene at the wrong level of abstraction and posited that awareness of abstraction as a mental event might hel
To comment on the object (that is: meta) level discussion: One of the most popular theories of metaphilosophy states that philosophy is "conceptual analysis".
The obvious question is: What is "conceptual analysis"? The theory applies quite well to cases where we have general terms like "knowledge", "probability" or "explanation", and where we try to find definitions for them, definitions that are adequate to our antecedent intuitive understanding of those terms. What counts as a "definition"? That's a case of conceptual analysis itself, but the usual answer...
I'm not sure why your path in life is so rare, but I find that as you go "upwards" in intellectual pursuits, you diverge from most people and things, rather than converge into one "correct" worldview.
I used to think about questions like you are now, until I figured that I was just solving my personal problems by treating them as external branches of knowledge. Afterwards I switched over to psychology, which tackled the problems more directly.
I also keep things simple for myself, so that I don't drown in them in any sense. If my thoughts aren't simple, it's...
I feel like there are two different concerns you've been expressing in your post history:
(1) Human "philosophical vulnerabilities" might get worsened (bad incentive setting, addictive technology) or exploited in the AI transition. In theory and ideally, AI could also be a solution to this and be used to make humans more philosophically robust.
(2) The importance of "solving metaphilosophy," why doing so would help us with (1).
My view is that (1) is very important and you're correct to highlight it as a focus area we should do more in. For some specifi...
If you think it would be helpful, you are welcome to suggest a meta philpsophy topic for AI Safety Camp.
More info at aisafety.camp. (I'm typing on a phone, I'll add actuall link later if I remember too)
FWIW I think some of the thinking I've been doing about meta-rationality and ontological shifts feels like metaphilosophy. Would be happy to call and chat about it sometime.
I do feel pretty wary about reifying the label "metaphilosophy" though. My preference is to start with a set of interesting questions which we can maybe later cluster into a natural category, rather than starting with the abstract category and trying to populate it with questions (which feels more like what you're doing, although I could be wrong).
At a glance meta-philosophy sounds similar to the problem of what is good, which is normally considered to be within the bounds of regular philosophy. (And to the extent that people avoid talking about it I think it's because the problem of good is on a deep enough level inherently subjective and therefore political, and they want to focus on technical problem solving rather than political persuasion)
What's an example of an important practical problem you believe can only be solved by meta-philosophy?
Where does probability theory come from anyway? Maybe I can find some clues that way? Well according to von Neumann and Morgenstern, it comes from decision theory.
I believe this is the step from where you started going astray. The next steps of your intellectual journey seem to be repeating the same mistake: attempting to reduce a less complex thing to a more complex one.
Probability Theory does not "come from" Decision Theory. Decision Theory is strictly more complicated domain of math as it involves all the apparatus of Probability Spaces but also utiliti...
The classification heading "philosophy," never mind the idea of meta-philosophy, wouldn't exist if Aristotle hadn't tutored Alexander the Great. It's an arbitrary concept which implicitly assumes we should follow the aristocratic-Greek method of sitting around talking (or perhaps giving speeches to the Assembly in Athens.) Moreover, people smarter than either of us have tried this dead-end method for a long time with little progress. Decision theory makes for a better framework than Kant's ideas; you've made progress not because you're smarter than Kant, b...
I'm also interested in this topic but it feels very hard to directly make progress. It seems to require solving a lot of philosophy, which has as its subject matter the entire universe and how we know about it, so solving metaphilosophy in a really satisfying way seems to almost require rationally apprehending all of existence and our place within it, which seems really hard, or maybe even fundamentally impossible(or perhaps there are ways of making progress in metaphilosophy without solving most of philosophy first, but finding such ways also seems hard)
T...
Where does decision theory come from? It seems to come from philosophers trying to do philosophy.
An alternate view is that certain philosophical and mathematical concepts are "spotlighted", in the sense that they seem likely to recur in a wide variety of minds above a certain intelligence / capabilities level.
A concept which is mathematically simple or elegant to describe and also instrumentally useful across a wide variety of possible universes is likely to be instrumentally convergent. The simpler and more widely useful the concept is, the more lik...
"Why is there virtually nobody else interested in metaphilosophy or ensuring AI philosophical competence (or that of future civilization as a whole?"
Besides the considerations that other people are giving, I think there's an aspect of base rate neglect here - most framings suggested by a single person with no institutional backing get little uptake. So it's not clear how much it requires explanation.
I'm super grateful to have stumbled across someone who also cares about meta-philosophy! I have an intuition that we don't understand philosophy. Therefore, I think its advantageous to clarify the nature, purpose, and methodologies of philosophy, or in other words, solve meta-philosophy.
Let's explore some questions...
- What would it look like for a civilization to constantly be solving problems but not necessarily solving the right problems?
- How does reflection and meta-cognition relate to finding the root problems?
- What if our lack of reflection and met
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
Hello Wei Dai,
Something that might be useful to a certain degree might be to see it through the lens of Collective Intelligence.
Or simply that the sum is greater than the value of the individual parts, and also that we can synch our efforts together, directly or indirectly, with the people around us. A recent BBC reel explores this as well.
Like you say, as you 'move on', you leave many behind. - But at least you will feel massively more vital and see an increase in growth if you have someone that enhances your learning directly through "being on the ...
I'm currently investigating the moral reasoning capabilities of AI systems. Given your previous focus on decision theory and subsequent shift to Metaphilosophy, I'm curious to get your thoughts.
Say an AI system was an excellent moral reasoner prior to having especially dangerous capability. What might be missing to ensure it is safe? What do you think the underlying capabilities to getting to be an excellent moral reasoner would be ?
I am new to considering this as a research agenda. It seems important and neglected, but I don’t have a full picture of the area yet or all of the possible drawbacks of pursuing it.
Thanks for the post! I just published a top-level post responding to it: https://www.lesswrong.com/posts/pmraJqhjD2Ccbs6Jj/is-metaethics-unnecessary-given-intent-aligned-ai
I'd appreciate your feedback!
Why is there virtually nobody else interested in metaphilosophy or ensuring AI philosophical competence (or that of future civilization as a whole), even as we get ever closer to AGI, and other areas of AI safety start attracting more money and talent?
I've written a bit on this topic that you might find interesting; I refer to it as the Set of Robust Concepts (SORC). I also employed this framework to develop a tuning dataset, which enables a shutdown mechanism to activate when the AI's intelligence poses a risk to humans. It works 57.33% of the time.
I mana...
To quickly recap my main intellectual journey so far (omitting a lengthy side trip into cryptography and Cypherpunk land), with the approximate age that I became interested in each topic in parentheses:
At each stage of this journey, I took what seemed to be the obvious next step (often up a meta ladder), but in retrospect each step left behind something like 90-99% of fellow travelers. From my current position, it looks like "all roads lead to metaphilosophy" (i.e., one would end up here starting with an interest in any nontrivial problem that incentivizes asking meta questions) and yet there's almost nobody here with me. What gives?
As for the AI safety path (as opposed to pure intellectual curiosity) that also leads here, I guess I do have more of a clue what's going on. I'll describe the positions of 4 people I know. Most of this is from private conversations so I won't give their names.
To me, this paints a bigger picture that's pretty far from "humanity has got this handled." If anyone has any ideas how to change this, or answers to any of my other unsolved problems in this post, or an interest in working on them, I'd love to hear from you.