Two potentially relevant distinctions:
- Is your model produced by optimization for accuracy, or by optimizing local pieces for local accuracy (e.g. for your lane prediction algorithm accurately predicting lane boundaries), or by human engineering (e.g. pieces of the model reflecting facts that humans know about the world)? Most practical systems will do some of each.
- Is your policy divided into pieces (like a generative model, inference algorithm, planner) which are optimized for local objectives, or is it all optimized end-to-end for performance? If most of your compute goes into inference and planning, then the causal model inside an AI with a given level of performance is likely to be much smaller (and have simpler concepts) than a neural net with the same performance.
Those are kind of similar to each other; they are both talking about how much you optimize pieces to do a job defined by human expectations (with human reasoning about how the pieces fit together) vs optimizing end to end.
I think these are real distinctions that increase how far you can scale before running into catastrophic misalignment. They may come with big performance tradeoffs, since end-to-end optimization is quite powerful. You may be able to claw back some runtime inefficiency by distilling a slow inference or planning process into a faster neural network, but this probably only gets you so far and reintroduces some alignment issues.
As far as I can tell, people who feel like probabilistic models are better than deep learning are mostly optimistic because of this kind of distinction.
Great points. I definitely agree with your argument quantitatively: these distinctions mean that a probabilistic model will be quantitatively more interpretable for the same system, or be able to handle more complex systems for a given interpretability metric (like e.g. "running into catastrophic misalignment").
That said, it does seem like the vast majority of interpretability for both probabilistic and ML systems is in "how does this internal stuff correspond to stuff in the world". So qualitatively, it seems like the central interpretability problem is basically the same for both.
Yeah, I agree that if you learn a probabilistic model then you mostly have a difference in degree rather than difference in kind with respect to interpretability. It's not super clear that the difference in degree is large or important (it seems like it could be, just not clear). And if you aren't willing to learn a probabilistic model, then you are handicapping your system in a way that will probably eventually be a big deal.
I think you're accusing people who advocate this line of idle speculation, but I see this post as idle speculation. Any particular systems you have in mind when making this claim?
I'm a program synthesis researcher, and I have multiple specific examples of logical or structured alternatives to deep learning
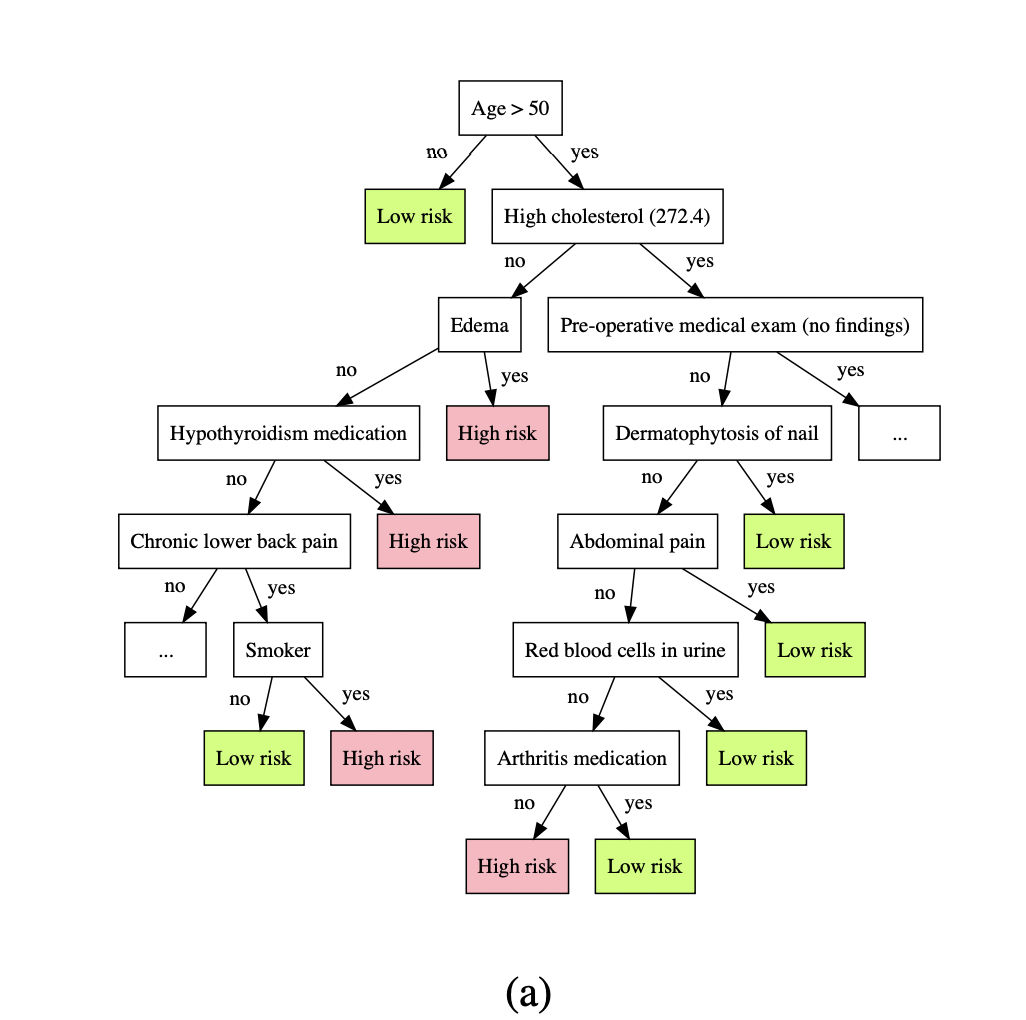
Here's Osbert Bastani's work approximating neural nets with decision trees, https://arxiv.org/pdf/1705.08504.pdf . Would you like to tell me this is not more interpretable over the neural net it was generated from?
Or how about Deep3 ( https://dl.acm.org/doi/pdf/10.1145/3022671.2984041 ), which could match the best character-level language models of its day ( https://openreview.net/pdf?id=ry_sjFqgx ).
The claim that deep learning is not less interpretable than alternatives is not born out by actual examples of alternatives.
Interesting. Do you know if such approaches have scales to match current SOTA models? My guess would be that, if you had a decision tree that approximated e.g., GPT-3, that it wouldn’t be very interpretable either.
Of course, you could look at any give decision and backtrace it through the tree, but I think it would still be very difficult to, say, predict what the tree will do in novel circumstances without actually running the tree. And you’d have next to no idea what the tree would do in something like a chain of thought style execution where the tree solves a problem step by step, feeding intermediate token predictions back into itself until it produced an answer.
Also, it looks like diagram (a) is actually an approximated random forest, not a neural net.
I do not. I mostly know of this field from conversations with people in my lab who work in this area, including Osbert Bastani. (I'm more on the pure programming-languages side, not an AI guy.) Those conversations kinda died during COVID when no-one was going into the office, plus the people working in this area moved onto their faculty positions.
I think being able to backtrace through a tree counts as victory, at least in comparison to neural nets. You can make a similar criticism about any large software system.
You're right about the random forest there; I goofed there. Luckily, I also happen to know of another Osbert paper, and this one does indeed do a similar trick for neural nets (specifically for reinforcement learning); https://proceedings.neurips.cc/paper/2018/file/e6d8545daa42d5ced125a4bf747b3688-Paper.pdf
I think you and John are talking about two different facets of interpretability.
The first one is the question of "white-boxing:" how do the model's internal components interrelate to produce its output? On this dimension, the kind of models that you've given as examples are much more interpretable than neural networks.
What I think John is talking about, I understand as "grounding." (Cf. Symbol grounding problem) Although the decision tree (a) above is clear in that one can easily follow how the final decision comes about, the question remains -- who or what makes sure that the labels in the boxes correspond to features of the real world that we would also describe by those labels? So I think the claim is that on this dimension of interpretability, neural networks and logical/probabilistic models are more similar.
Aren't the symbols grounded by human engineering? Humans use those particular boxes/tokens to represent particular concepts, and they can define a way in which the concepts map to the inputs to the system.
I'm not sure "grounding is similar" when a model is fully human engineered (in e.g. decision trees and causal models), vs. when it is dynamically derived (in e.g. artificial neural networks) is a reasonable claim to make.
This points to a natural extension of my argument from the post, which sounds a bit troll-y but I think is actually basically true: large human-written computer programs are also uninterpretable for the same reasons given in the OP. In practice, variables in a program do diverge from what they supposedly represent, and plenty of common real-world bugs can be viewed this way.
The problem is of course much more severe, controlling for system size, when the system is dynamically generated.
The problem is of course much more severe, controlling for system size, when the system is dynamically generated.
If you say this, then I don't think you can claim that deep learning is not less interpretable than probabilistic/logical systems. I don't think anyone was making the claim that the latter systems were perfectly/fully interpetabls.
Divergence as a result of human error seems less challenging to rectify than divergence as a result of a completely opaque labelling process.
Well, we have to do apples-to-apples comparisons. Logic/probability models can obviously solve any problems deep learning can (worst-case one can implement a deep learner in the logic system), but not if a human is hand-coding the whole structure. Dynamic generation is a necessary piece for logic/probability to solve the same problems deep learning methods solve.
I think this post makes a true and important point, a point that I also bring up from time to time.
I do have a complaint though: I think the title (“Deep Learning Systems Are Not Less Interpretable Than Logic/Probability/Etc”) is too strong. (This came up multiple times in the comments.)
In particular, suppose it takes N unlabeled parameters to solve a problem with deep learning, and it takes M unlabeled parameters to solve the same problem with probabilistic programming. And suppose that M<N, or even M<<N, which I think is generally plausible.
If Person X notices that M<<N, and then declares “deep learning is less interpretable than probabilistic programming”, well that’s not a crazy thing for them to say. And if M=5 and N=5000, then I think Person X is obviously correct, whereas the OP title is wrong. On the other hand, if M is a trillion and N is a quadrillion, then presumably the situation is that basically neither is interpretable, and maybe Person X’s statement “deep learning is less interpretable than probabilistic programming” is still maybe literally true on some level, but it kinda gives the wrong impression, and the OP title is perhaps more appropriate.
Anyway, I think a more defensible title would have been “Logic / Probability / Etc. Systems can be giant inscrutable messes too”, or something like that.
Better yet, the text could have explicitly drawn a distinction between what probabilistic programming systems typically look like today (i.e., a handful of human-interpretable parameters), and what they would look like if they were scaled to AGI (i.e. billions of unlabeled nodes and connections inferred from data, or so I would argue).
I'm jumping to reply here having read the post in the past and without re-reading the post and the discussion, so maybe I'll be redundant. With that said:
I think that nonparametric probabilistic programming will in general have the same order of number of parameters as DL. The number of parameters can be substantially lower only when you have a neat simplified model, either because
1. you understand the process to the point of constraining it so much, for example in physics experiments
2. it's hopeless to extract more information than that, in other words it's noisy data, so a simple model suffices
I'm confused about the instances of deep-learning vs. non-deep-learning that you're comparing. Do you have any concrete examples in mind, where there's a deep-learning model and a non-deep-learning model addressing the same task, and where the non-deep-learning model might be more interpretable at first blush, but where you argue it's not?
Your non-deep-learning example is a small causal diagram, which might be a “model,” but what does it… do? (Maybe I'm just ignorant here.) Meanwhile the deep learning example you allude to is a neural network which more concretely does something: it’s an image recognition algorithm for trees. So I’m not sure how to compare the interpretability of these two examples. They seem like totally different creatures.
I would have thought you wanted to compare (say) a deep-learning image recognition algorithm with some more old-fashioned, non-deep-learning image recognition algorithm. Maybe the old-fashioned algorithm looks for trees by finding long vertical edges with brown interiors. The old-fashioned algorithm probably doesn’t work very well. But it does seem more interpretable, right?
I think the claim you are making is correct but it still misses a core point of why some people think that Bayes nets are more interpretable than DL.
a) Complexity: a neural network is technically a Bayes net. It has nodes and variables and it is non-cyclical. However, when people talk about the comparison of Bayes nets vs. NNs, I think they usually mean a smaller Bayes net that somehow "captures all the important information" of the NN.
b) Ontology: When people look at a NN they usually don't know what any particular neuron or circuit does because it might use different concepts than humans use when they think about the same topic. When people use a Bayes net they usually assume that the nodes reflect concepts that humans use. So it is more interpretable in practice.
I think that there is a case for using Bayes Nets in combination with NNs to get higher interpretability and I'll write a post on that in the future.
I strongly agree. There are two claims here. The weak one is that, if you hold complexity constant, directed acyclic graphs (DAGs; Bayes nets or otherwise) are not necessarily any more interpretable than conventional NNs because NNs are DAGs at that level. I don't think anyone who understands this claim would disagree with it.
But that is not the argument being put forth by Pearl/Marcus/etc. and arguably contested by LeCun/etc.; they claim that in practice (i.e., not holding anything constant), DAG-inspired or symbolic/hybrid AI approaches like Neural Causal Models have interpretability gains without much if any drop in performance, and arguably better performance on tasks that matter most. For example, they point to the 2021 NetHack Challenge, a difficult roguelike video game where non-NN performance still exceeds NN performance.
Of course there's not really a general answer here, only specific answers to specific questions like, "Will a NN or non-NN model win the 2024 NetHack challenge?"
I agree with your point that blobs of bayes net nodes aren't very legible, but I still think neural nets are relevantly a lot less interpretable than that! I think basically all structure that limits how your AI does its thinking is helpful for alignment, and that neural nets are pessimal on this axis.
In particular, an AI system based on a big bayes net can generate its outputs in a fairly constrained and structured way, using some sort of inference algorithm that tries to synthesize all the local constraints. A neural net lacks this structure, and is thereby basically unconstrained in the type of work it's allowed to perform.
All else equal, more structure in your AI should mean less room for dangerous computations, and lower the surface area you need to inspect.
I'd crystallize the argument here as something like: suppose we're analyzing a neural net doing inference, and we find that its internal computation is implementing <algorithm> for Bayesian inference on <big Bayes net>. That would be a huge amount of interpretability progress, even though the "big Bayes net" part is still pretty uninterpretable.
When we use Bayes nets directly, we get that kind of step for free.
... I think that's decent argument, and I at least partially buy it.
A neural net lacks this structure, and is thereby basically unconstrained in the type of work it's allowed to perform.
That said, if we compare a neural net directly to a Bayes net (as opposed to inference-on-a-Bayes-net), they have basically the same structure: both are circuits. Both constrain locality of computation.
It sounds to me like, in the claim "deep learning is uninterpretable", the key word in "deep learning" that makes this claim true is "learning", and you're substituting the similar-sounding but less true claim "deep neural networks are uninterpretable" as something to argue against. You're right that deep neural networks can be interpretable if you hand-pick the semantic meanings of each neuron in advance and carefully design the weights of the network such that these intended semantic meanings are correct, but that's not what deep learning is. The other things you're comparing it to that are often called more interpretable than deep learning are in fact more interpretable than deep learning, not (as you rightly point out) because the underlying structures they work with is inherently more interpretable, but because they aren't machine learning of any kind.
We could just replace all the labels with random strings, and the model would have the same content
I think this is usually incorrect. The variables come with labels because the data comes with labels, and this is true even in deep learning. Stripping the labels changes the model content: with labels, it's a model of a known data generating process, and without the labels it's a model of an unknown data generating process.
Even with labels, I will grant that many joint probability distributions are extremely hard to understand.
Uninterpretable AI may to not be able to (quickly) self-improve, so it will be intrinsically safe in some aspect.
Humans can currently improve uninterpretable AI, and at a reasonably fast rate. I don't see why an AI can't do the same. (i.e. improve itself, or a copy of itself, or design a new AI that is improved)
One difference is that gpt-n doesn’t know its goals in explicit form, as they are hidden inside uninterpretable weights.
And it will need to solve alignment problem for each new version of itself, which will be difficult for uninterpretable next versions. Therefore, it will have to spend more efforts on self-improvement.
Not just rewrite own code, but train many new versions. Such slow self-improvement will be difficult to hide.
If it expects that it would get astronomically more utility if it rather than some random future AI wins, it might build a new version of itself that is only 1% likely to be aligned to it.
The alignment problem doesn't get that much more difficult as your utility function gets more complicated. Once you've figured out how to get a superintelligent AGI to try to be aligned to you, you can let it figure out the mess of your goals.
I think that a probabilistic generative model with fewer nodes / elements can match the performance of a deep net with more nodes. But I think "fewer nodes" is still going to be millions or billions or trillions of nodes for an AGI, and I strongly agree with you that such a thing is going to be uninterpretable by default (i.e., absent some revolutionary advance in interpretability techniques). People doing probabilistic programming research seem to disagree with this (i.e. that their research is leading towards uninterpretable-by-default systems), for reasons I can't understand.
Adding some thoughts as someone who works on probabilistic programming, and has colleagues who work on neurosymbolic approaches to program synthesis:
- I think a lot of Bayes net structure learning / program synthesis approaches (Bayesian or otherwise) have the issue of uninformative variable names, but I do think it's possible to distinguish between structural interpretability and naming interpretability, as others have noted.
- In practice, most neural or Bayesian program synthesis applications I'm aware of exhibit something like structural interpretability, because the hypothesis space they live in is designed by modelers to have human-interpretable semantic structure. Two good examples of this are the prior over programs that generate handwritten characters in Lake et al (2015), and the PCFG prior over Gaussian Process covariance kernels in Saad et al (2019). See e.g. Figure 6 on how you perform analysis on programs generated by this prior, to determine whether a particular timeseries is likely to be periodic, has a linear trend, has a changepoint, etc.
- Regarding uninformative variable names, there's ongoing work on using natural language to guide program synthesis, so as to come up with more language-like conceptual abstractions (e.g. Wong et al 2021). I wouldn't be surprised if these approaches could also be extended to come up with informative variable and function names / comments. A related line of work is that people are starting to use LLMs to deobfuscate code (e.g. Lachaux et al 2021), and I expect the same techniques will work for synthesized code.
For these reasons, I'm more optimistic about the interpretability prospects of learning approaches that generate models or code that look like traditional symbolic programs, relative to end-to-end deep learning approaches. (Note that neural networks are also "symbolic programs", just written with a more restricted set of [differentiable] primitives, and typically staying within a set of widely used program structures [i.e. neural architectures]).
The more difficult question IMO is whether this interpretability comes at the cost of capabilities. I think this is possibly true in some domains (e.g. learning low-level visual patterns and cues), but not others (e.g. learning the compositional structure of e.g. furniture-like objects).
Thanks for your reply!
In practice, most neural or Bayesian program synthesis applications I'm aware of exhibit something like structural interpretability, because the hypothesis space they live in is designed by modelers to have human-interpretable semantic structure. Two good examples of this…
When I squint out towards the horizon, I see future researchers trying to do a Bayesian program synthesis thing that builds a generative model of the whole world—everything from “tires are usually black”, to “it’s gauche to wear white after labor day”, to “in this type of math problem, maybe try applying the Cauchy–Schwarz inequality”, etc. etc. etc.
I’m perfectly happy to believe that Lake et al. can program-synthesis a little toy generative model of handwritten characters such that it has structural interpretability. But I’m concerned that we’ll work our way up to the thing in the previous paragraph, which might be a billion times more complicated, and it will no longer have structural interpretability.
(And likewise I’m concerned that solutions to “uninformative variable names” won’t scale—e.g., how are we going to automatically put English-language labels on the various intuitive models / heuristics that are involved when Ed Witten is thinking about math, or when MLK Jr is writing a speech?)
I'm more optimistic about the interpretability prospects of learning approaches that generate models or code that look like traditional symbolic programs, relative to end-to-end deep learning approaches [emphasis added]
Nominally, I agree with this. But “relative to” is key here.
Your takeaway seems to be “OK, great, let’s do probabilistic generative models, they’re better!”.
By contrast, my perspective is: “If we take the probabilistic generative model approach, we’re in huge trouble with respect to interpretability, oh man this is really really bad, we gotta work on this ASAP!!! (Oh and by the way if we take the deep net approach then it’s even worse.)”.
We could probably use a term or a phrase for this concept since it keeps coming up and is a fundamental problem. How about:
Any model simple enough to be interpretable is too simple to be useful.
Corollary:
Any model which appears both useful and interpretable is uninterpretable.
On the contrary, I think there exist large, complex, symbolic models of the world that are far more interpretable and useful than learned neural models, even if too complex for any single individual to understand, e.g.:
- The Unity game engine (a configurable model of the physical world)
- Pixar's RenderMan renderer (a model of optics and image formation)
- The GLEAMviz epidemic simulator (a model of socio-biological disease spread at the civilizational scale)
Humans are capable of designing and building these models, and learning how to build/write them as they improve their understanding of the world. The difficult part is how we can recapitulate that ability -- program synthesis is only in its infancy in it's ability to do so, but IMO contemporary end-to-end deep learning methods seem unlikely to deliver here if want both interpretability and usefulness.
I agree that gwern’s proposal “Any model simple enough to be interpretable is too simple to be useful” is an exaggeration. Even the Lake et al. handwritten-character-recognizer is useful.
I would have instead said “Any model simple enough to be interpretable is too simple to be sufficient for AGI”.
I notice that you are again bringing the discussion back to a comparison between program synthesis world-models versus deep learning world-models, whereas I want to talk about the possibility that neither would be human-interpretable by the time we reach AGI level.
I'm not in these fields, so take everything I say very lightly, but intuitively this feels wrong to me. I understood your point to be something like: the labels are doing all the work. But for me, the labels are not what makes those approaches seem more interpretable than a DNN. It's that in a DNN, the features are not automatically locatable (even pseudonymously so) in a way that lets you figure out the structure /shape that separates them - each training run of the model is learning a new way to separate them and it isn't clear how to know what those shapes tend to turn out as and why. However, the logic graphs already agree with you an initial structure/shape.
Of course there are challenges in scaling up the other methods, but I think claiming they're no more interpretable than DNNs feels incorrect to me. [Reminder, complete outsider to these fields].
Even if you could find some notion of a, b, c we think are features in this DNN - how would you know you were right? How would you know you're on the correct level of abstraction / cognitive separation / carving at the joints instead of right through the spleen and then declaring you've found a, b and c. It seems this is much harder than in a model where you literally assume the structure and features all upfront.
Surely you can do some interpretability work without knowing what the symbols mean, such as identifying a portion that implements a fourier transform and, as in code review, replacing it with a library call.
I think that you have a point, but that arguably there is some goalpost moving going on somewhere in here.
Say, some computer system recognises trees, and has something in a layer of its mathematics that roughly corresponds to its idea of tree. Maybe that idea of a tree is no further removed from the real object than my hazy thought-cloud that goes with the word "tree" - but so what? When talking about how interpretable something is to me the question is not one of distance from reality, but the distance to my concepts.
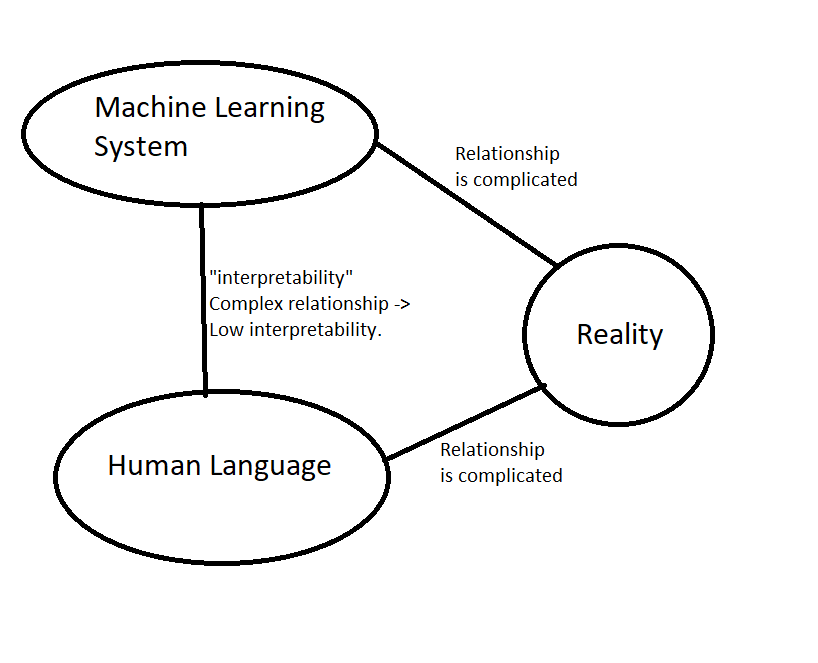
I drew a random sketch to clarify my point. Lets say each node represents "tree". So the one on the right is a real tree, the bottom one the English word tree, the top the program's idea of a tree. (We can suppose that my human idea of a tree is another node that connects with human language and reality). Interpretability is (to me) the line on the left, while much of your post is about the difficulties with the line on the bottom right.
To the extent that a system's concepts match my concepts but not reality, I would expect that to be some form of deception; the system is playing to mistakes I am making.
Any network big enough to be interesting is big enough that the programmers don't have the time to write decorative labels. If you had some algorithm that magically produced a bays net with a billion intermediate nodes that accurately did some task, then it would also be an obvious black box. No one will have come up with a list of a billion decorative labels.
That is pretty much how text-image and multimodal languages work now, really. You get a giant inscrutable vector embedding from one modality's model and another giant inscrutable model spits out the corresponding output in a different modality. It seems to work well for all the usual tasks like captioning or question-answering...
We could just replace all the labels with random strings, and the model would have the same content:
Gödel, Escher, Bach is all about instilling meaning in systems. The system is just math, but when we give labels to things and those labels genuinely correspond to something in the world, then that allows us to interpret the outputs of the model in a meaningful way. A given mathematical model could mean different things depending on what we say the tokens in the model mean. In a bayes net, you can have "season" as a node in the model and have that node track your definition of a season. In a DNN, there may well be a node or collection of nodes that correspond to your definition of season, but if you lack the labels you cannot actually draw conclusions of the form "the sidewalk is wet because it was raining because it is spring"; instead you are left with "the sidewalk is wet because node_129368 is near 1 because node_19387645 is near 0.7".
In these cases you can make predictions about a given world (i.e. when you know the values of node_129368 and node_19387645 you can predict whether or not the sidewalk is wet), but you cannot give a legible argument to someone in terms they would understand. An outsider would be unable to check your work.
I'm understanding that by "interpretability" you mean "we can attach values meaningful to people to internal nodes of the model"[1].
My guess is that logical/probabilistic models are regarded as more interpretable than DNNs mostly for two reasons:
- They tend to have small number of inputs and the inputs are heavily engineered features (so the inputs themselves are already meaningful to people).
- Internal nodes combine features in quite simple ways, particularly when number of inputs is small (the meaning in the inputs cannot be distorted/diluted too much in the internal nodes, if you allow).
I think what you are saying is: let's assume that inputs are not engineered and have no high-level meaning to people (e.g. raw pixel data). But the output does, e.g. it detects cats in pictures. The question is: can we find parts of the model which correspond to some human understandable categories (e.g. ear detector)?
In this case, I agree that seems equally hard regardless of the model, holding complexity constant. I just wouldn't call hardness of doing this specific thing "uninterpretability".
[1] Is that definition standard? I'm not a fan, I'd go closer to "interpretable model" = "model humans can reason about, other than by running black-box experiments on the model".
You use the word robustness a lot, but interpretability is related to the opposite of robustness.
When your tree detector says a tree is a tree, nobody will complain. The importance of interpretability is in understanding why it might be wrong, in either direction -- either before or after the fact.
If your hand written tree detector relies on identifying green pixels, then you can say up front that it won't work in deciduous forests in autumn and winter. That's not robust, but it's interpretable. You can analyze causality from inputs to outputs (though this gets progressively more difficult). You may also be able to say with confidence that changing a single pixel will have limited or no effect.
The extreme of this are safety systems where the effect of input state (both expected, and unexpected, like broken sensors) on the output is supposed to be bounded and well characterized.
I can offer a very minimal example from my own experience training a relatively simple neural net to approximate a physical system. This was simple enough that a purely linear model was a decent starting point. For the linear model -- and for a variety of simple non linear models I could use -- it would be trivial to guarantee that, for example, the behavior of the approximation would be smooth and monotonic in areas where I didn't have data. A sufficiently complex network, on the other hand, needed considerable effort to guarantee such behavior.
You're correct that the labels in a "simple" decision tree are hiding a lot of complexity -- but, for classical systems, usually they are themselves are coming from simple labeling methods. "Season" may come from a lookup in a calendar. "Sprinkler" may come from a landscaping schedule or a sensor attached to the valve controlling the sprinkler.
Deep learning is encouraged to break this sort of compartmentalization in the interest of greater accuracy. The sprinkler label may override the valve signal, which promises to make the system robust to a bad sensor -- but how it chooses to do so based on training data may be hard to discern. The opposite may be true as well -- the hand written system may anticipate failure modes of the sensor that there is no training data on.
If you look at any well written networking code, for example, it will be handling network errors that may be extremely unlikely. It may even respond to error codes that cannot currently happen -- for example, a specific one specified by the OS but not yet implemented. When the vendor announces that the new feature is supported, you can look at the code and verify that behavior will still be correct.
To summarize -- interpretability is about debugging and verification. Those are stepping stones towards robustness, but robustness is a much higher bar.
If your hand written tree detector relies on identifying green pixels, then you can say up front that it won't work in deciduous forests in autumn and winter. That's not robust, but it's interpretable.
I would call that "not interpretable", because the interpretation of that detector as a tree-detector is wrong. If the internal-thing does not robustly track the external-thing which it supposedly represents, then I'd call that "not interpretable" (or at least not interpretable as a representation of the external-thing); if we try to interpret it as representing the external-thing then we will shoot ourselves in the foot.
Obviously, it's an exaggerated failure mode. But all systems have failure modes, and are meant to be used under some range of inputs. A more realistic requirement may be night versus day images. A tree detector that only works in daylight is perfectly usable.
The capabilities and limitations of a deep learned network are partly hidden in the input data. The autumn example is an exaggeration, but there may very well be species of tree that are not well represented in your inputs. How can you tell how well they will be recognized? And, if a particular sequoia is deemed not a tree -- can you tell why?
I feel like there is a valid point here about how one aspect of interpretability is "Can the model report low-confidence (or no confidence) vs high-confidence appropriately?"
My intuition is that this failure mode is a bit more likely-by-default in a deep neural net than in a hand-crafted logic model. That doesn't seem like an insurmountable challenge, but certainly something we should keep in mind.
Overall, this article and the discussion in the comments seems to boil down to "yeah, deep neural nets are not (complexity held constant) probably not a lot harder (just somewhat harder) to interpret than big Bayes net blobs."
I think this is probably true, but is missing a critical point. The critical point is that expansion of compute hardware and improvement of machine learning algorithms has allowed us to generate deep neural nets with the ability to make useful decisions in the world but also a HUGE amount of complexity.
The value of what John Wentworth is saying here, in my eyes, is that we wouldn't have solved the interpretability problem even if we could magically transform our deep neural net into a nicely labelled billion node bayes net. Even if every node had an accompanying plain text description a few paragraphs long which allowed us to pretty closely translate the values of that particular node into real world observations (i.e. it was well symbol-grounded). We'd still be overwhelmed by the complexity. Would it be 'more' interpretable? I'd say yes, thus I'd disagree with the strong claim of 'exactly as interpretable with complexity held constant'. Would it be enough more interpretable such that it would make sense to blindly trust this enormous flowchart with critical decisions involving the fate of humanity? I'd say no.
So there's several different valid aspects of interpretability being discussed across the comments here:
Alex Khripin's discussion of robustness (perhaps paraphrasable as 'trustworthy outputs over all possible inputs, no matter how far out-of-training-distribution'?)
Ash Gray's discussion of symbol grounding. I think it's valid to say that there is an implication that a hand-crafted or well-generated bayes net will be reasonably well symbol grounded. If it weren't, I'd say it was poor quality. A deep neural net doesn't give you this by default, but it isn't implausible to generate that symbol grounding. That is additional work that needs to be done though, and an additional potential point of failure. So, addressable? probably yes, but...
DragonGod and JohnWentworth discussing "complexity held same, is the bayes net / decision flowchart a bit more interpretable?" I'd say probably yes, but....
Stephen Brynes point that challenge-level of task held constant, probably a slightly less complex (fewer paramenters/nodes) bayes net could accomplish the equivalent quality of result? I'd say probably yes, but...
And the big 'but' here is that mind-bogglingly huge amount of complexity, the remaining interpretability gap from models simple enough to wrap our heads around to those SOTA models well beyond our comprehension threshold. I don't think we are even close enough to understanding these very large models well enough to trust them on s-risk (much less x-risk) level issues even on-distribution, much less declare them 'robust' enough for off-distribution use. Which is a significant problem, since the big problems humanity faces tend to be inherently off-distribution since they're about planning actions for the future, and the future is inherently at least potentially off-distribution.
I think if we had 1000 abstract units of 'interpretability gap' to close before we were safe to proceed with using big models for critical decisions, my guess is that transforming the deep neural net into a fully labelled, well symbol-grounded, slightly (10% ? 20%?) less complex, slightly more interpretable bayes net would get us something like 1 - 5 units closer. If the 'hard assertion' made by John Wentworth's original article (which I don't think, based on his reponses to comments is what he is intending), then the 'hard assertion' would say 0 units closer. I think the soft assertion, that I think John Wentworth would endorse, and which I would agree with, is something more like 'that change alone would make only a trivial difference, even if implemented perfectly'.
Addendum: I do believe that there are potentially excellent synergies between various strategies. While I think the convert-nn-to-labelled-bayes-net strategy might be worth just 5/1000 on its own, it might combine multiplicatively with several other strategies, each worth a similar amount alone. So if you do have an idea for how to accomplish this conversion strategy, please don't let this discussion deter you from posting that.
This post does a sort of head-to-head comparison of causal models and deep nets. But I view the relationship between them differently - they’re better together! The causal framework gives us the notion of “screening off”, which is missing from the ML/deep learning framework. Screening-off turns out to be useful in analyzing feature importance.
A workflow that 1) uses a complex modern gradient booster or deep net to fit the data, then 2) uses causal math to interpret the features - which are most important, which screen off which - is really nice. [This workflow requires fitting multiple models, on different sets of variables, so it’s not just fit a single model in step 1), analyze it in step 2), done].
Causal math lacks the ability to auto-fit complex functions, and ML-without-causality lacks the ability to measure things like “which variables screen off which”. Causality tools, paired with modern feature-importance measures like SHAP values, help us interpret black-box models.
But in order for "screening off" etc to be interesting, you'd need to know it for interpretable features, no? I wouldn't care so much that pixel (42, 33) screens off node (7, 1, 54) in the network.
Sure - there are plenty of cases where a pair of interactions isn’t interesting. In the image net context, probably you’ll care more about screening-off behavior at more abstract levels.
For example, maybe you find that, in your trained network, a hidden representation that seems to correspond to “trunk” isn’t very predictive of the class “tree”. And that one that looks like “leaves” is predictive of “tree”. It’d be useful to know if the reason “trunk” isn’t predictive is that “leaves” screens it off. (This could happen if all the tree trunks in your training images come with leaves in the frame).
Of course, the causality parts of the above analysis don’t address the “how should you assign labels in the first place” problem that the post is most focused on! I’m just saying both the ML parts and the causality parts work well in concert, and are not opposing methods.
My impression is that generative models tend to be more interpretable than other models, because you can intervene on the nodes to see what they represent. Would you agree or disagree with that?
We can do that with neural nets too. Although the right way to intervene in e.g. transformers seems to be low-rank adustments rather than single-node do-ops; see this paper (which is really cool!). And in systems big enough for abstraction to be meaningful, single-node-level interventions are also not the right way to intervene on high-level things, even in probabilistic causal models.
We can do that with neural nets too.
I don't mean generative models as in contrast to neural nets; there are generative neural network models too, e.g. GANs.
The thing is that generative models allow you to not just see the effects of the variable on the decision that gets made, but also on the observations that were generated. So if your observations are visual as in e.g. image models, then you can see what part of the image the latent variable you're intervening on.
And in systems big enough for abstraction to be meaningful, single-node-level interventions are also not the right way to intervene on high-level things, even in probabilistic causal models.
This is true, but it's also an example of something that would be more obvious in generative models. If you do a single-node-level intervention in an image generative model, you might see it only affect a small part of the image, or bring the image off-distribution, or similar, which would show it to not represent the high-level things.
Although the right way to intervene in e.g. transformers seems to be low-rank adustments rather than single-node do-ops; see this paper (which is really cool!).
Thanks for the link! I really should get around to reading it 😅
There’s a common perception that various non-deep-learning ML paradigms - like logic, probability, causality, etc - are very interpretable, whereas neural nets aren’t. I claim this is wrong.
It’s easy to see where the idea comes from. Look at the sort of models in, say, Judea Pearl’s work. Like this:
It says that either the sprinkler or the rain could cause a wet sidewalk, season is upstream of both of those (e.g. more rain in spring, more sprinkler use in summer), and sidewalk slipperiness is caused by wetness. The Pearl-style framework lets us do all sorts of probabilistic and causal reasoning on this system, and it all lines up quite neatly with our intuitions. It looks very interpretable.
The problem, I claim, is that a whole bunch of work is being done by the labels. “Season”, “sprinkler”, “rain”, etc. The math does not depend on those labels at all. If we code an ML system to use this sort of model, its behavior will also not depend on the labels at all. They’re just suggestively-named LISP tokens. We could use the exact same math/code to model some entirely different system, like my sleep quality being caused by room temperature and exercise, with both of those downstream of season, and my productivity the next day downstream of sleep.
We could just replace all the labels with random strings, and the model would have the same content:
Now it looks a lot less interpretable.
Perhaps that seems like an unfair criticism? Like, the causal model is doing some nontrivial work, but connecting the labels to real-world objects just isn’t the problem it solves?
… I think that’s true, actually. But connecting the internal symbols/quantities/data structures of a model to external stuff is (I claim) exactly what interpretability is all about.
Think about interpretability for deep learning systems. A prototypical example for what successful interpretability might look like is e.g. we find a neuron which robustly lights up specifically in response to trees. It’s a tree-detector! That’s highly interpretable: we know what that neuron “means”, what it corresponds to in the world. (Of course in practice single neurons are probably not the thing to look at, and also the word “robustly” is doing a lot of subtle work, but those points are not really relevant to this post.)
The corresponding problem for a logic/probability/causality-based model would be: take a variable or node, and figure out what thing in the world it corresponds to, ignoring the not-actually-functionally-relevant label. Take the whole system, remove the labels, and try to rederive their meanings.
… which sounds basically-identical to the corresponding problem for deep learning systems.
We are no more able to solve that problem for logic/probability/causality systems than we are for deep learning systems. We can have a node in our model labeled “tree”, but we are no more (or less) able to check that it actually robustly represents trees than we are for a given neuron in a neural network. Similarly, if we find that it does represent trees and we want to understand how/why the tree-representation works, all those labels are a distraction.
One could argue that we’re lucky deep learning is winning the capabilities race. At least this way it’s obvious that our systems are uninterpretable, that we have no idea what’s going on inside the black box, rather than our brains seeing the decorative natural-language name “sprinkler” on a variable/node and then thinking that we know what the variable/node means. Instead, we just have unlabeled nodes - an accurate representation of our actual knowledge of the node’s “meaning”.