For text-davinci-002 the goal is to have the model do what the user asked as well as it can, not to sample from possible worlds. For example, if the user asks "Is X true?" and the model's probability is 80%, the intended behavior is for the model to say "Probably" 100% of the time, not to say "Yes" 80% of the time and "No" 20% of the time.
This is often (usually?) the desired behavior. For pre-trained LMs people usually turn the temperature down (or use nucleus sampling or beam search or whatever) in order to get more reasonable behavior, but that introduces pathologies and so you'd prefer not need to do it.
There are a number of reasons this behavior can be undesirable though:
- Sometimes you want entropy, e.g. if you'll have a user pick their favorite from N completions or are doing majority voting with chain of thought.
- This model is not competent enough to say "Probably" 100% of the time. Instead I expect it will just say "Yes" 100% of the time. Extracting confidence from logits is a plausible way to get around this difficulty, but only works for the generative model.
- If what you fundamentally want is a plausible completions of text from the pretraining distribution then you are definitely worse off. You can ask the instruct model to "complete the following text" but it does much worse than the pure generative model.
- Each model randomly does better on some stuff and worse on other stuff, even if one model is better on average the other will be better for some particular tasks.
- You may just want to scientifically study the pure generative model.
Intuitively it seems like OpenAI should offer both models, and should gradually try to improve the instruct model so that there are fewer and fewer non-academic reasons to use the pure generative model.
A stark example of mode collapse that seems unlikely to have been directly incentivized by RLHF training: I asked RLHF models and base models to generate random numbers and found that RLHF models tend to be sharply biased toward certain “random” numbers
The RLHF model represents labeler preferences as R(prompt, completion). One limitation of that approach is that R can't depend on the distribution of model outputs. But real human preferences do depend on that distribution, since the model operates in a world containing other copies of itself---e.g. other copies operating in parallel for best-of-N.
This limitation makes it extremely difficult for the model to converge to a reasonable randomized strategy---it will still happen in the limit, but I think it may take orders of magnitude more labels. I think this is something OpenAI should be interested in fixing, though it would be reasonable to prioritize it (compared to other alignment issues) based on how often customers care. I don't think the issue is necessarily conceptually complicated though I think the whole thing is technically gnarly (both on the training loss side and on the learning problem side).
Rather, the implication is that mode collapse itself generalizes out of distribution for some reason. This is intriguing: it seems to point at an algorithmic difference between self-supervised pretrained models and the same models after a comparatively small amount optimization from the RLHF training process which significantly changes out-of-distribution generalization.
I think that a large part of what happens durning fine-tuning is the model learning to stick with t=0 answers wherever possible, since that's the answer that is most likely to be correct or reasonable. I don't think it necessarily represents an interesting algorithmic difference; you'd see the same observations about generalization if the main effect of fine-tuning was just scaling up all the logits a bunch. Obviously it does something slightly more sophisticated, since it avoids some (but not all) t=0 pathologies. But I suspect it will transfer to other prompts for the same kinds of reasons that "scale up all logits" would.
In contrast to
text-davinci-002, where dissimilar prompts tend to fall into basins of different attractors, the wedding parties attractor is global, affecting trajectories starting from any prompt, or at least a very wide distribution
I think this is because text-davinci-002 is optimizing for how well the completion addresses the user's request, and so different completions will get a high reward for different prompts.
The sentiment model is optimizing for the sentiment of the completion, using a weak predictor of sentiment that likely has much more confidence about weddings than other positive events, and so "wedding" is just the highest-sentiment completion no matter how the story starts.
I do agree think there are two product use cases with instruct that have distinct optimal levels of entropy.
1. The more explorative use cases you have mentioned. And for example when users do want diversity e.g. generating story ideas
2. Having factual / accurate answers
I'm not sure how exactly OpenAI set their "KL budgets" for davinci instruct.
For WebGPT3 they "compared a couple of KL budgets using human evaluations". And those evaluations were for how factual the answers were.
So in that scenario, we'll see a KL budget that optimizes for 2. Since the users don't care about the diversity of multiple generations. They just care about the factual quality of a single generation.
Now i'm interested to see what happens if we somehow change the evaluations such that users e.g. are shown 3 examples from each model. In a scenario where diversity is desirable (e.g. generating story ideas). Now in deciding for the KL budget, we will probably get a much lower number. And that will allow them to serve a model more suited to tasks 1.
xuan:
Fascinating evidence that GPT-3 concentrates probability mass on certain completions after fine-tuning on human feedback (ie. RLHF).
I suspect this is because RLHF elicits a singular scale of "goodness" judgements from humans, instead of a plurality of "goodness-of-a-kind" judgements.
One way to interpret language models is as mixtures of conversational agents: they first sample some conversational goal, then some policy over words, conditioned on that goal.
On this interpretation, what RL from human feedback does is shift/concentrate the distribution over conversational goals into a smaller range: the range of goals consistent with human feedback so far.
And if humans are asked to give only a singular "goodness" rating, the distribution will shift towards only goals that do well on those ratings—perhaps dramatically so! We lose goal diversity, which means less gibberish, but also less of the plurality of realistic human goals.
I agree. The meta-learning perspective makes sense of this: GPT-3 is always trying to solve the POMDP of the family of tasks which is 'the Internet', where data is generated by processes drawing from a distribution of human & other agents to roleplay, and it is reducing uncertainty by inferring which agent it is in this particular sample. In RLHF, the uncertainty collapses: there is, quite literally, a single deterministic agent—the reward model, as defined by the synthesis of the lowest common denominator of all the crowdworkers giving ratings ground up into a dataset of i.i.d. pink slime text. It is as if every sample becomes prepended by some control codes RLHF AGENT #123|. As no other agents (reward functions) ever get trained on, the finetuned generative model collapses to modeling that one agent. There is no need for meta-learning to achieve optimality across samples drawn from many tasks if you only ever train on a single task; you simply learn that one task instead. The mask becomes the face. Given enough training and lowered KL constraint, GPT-3 will model even the pathologies of the reward model, and 'imitation wirehead'.
This also explains why it retains generative modeling of things that don't look agenty, like the Python REPL: there is no reason RLHF agent #123 will write out different Python transcripts than RLHF agent #125 or #122, because generally everyone uses the same Python and presumably the RL training is silent on Python and that's just priors from the generative model. (If the RL training process did begin to include Python REPL sessions, such as finetuning on Python 3, for eg Codex/Copilot purposes, then it would then start to forget Python 2 because it knows RLHF agent #123 exclusively uses Python 3, so it would never predict any Python 2 code - that would be stupid!) Or why it could sample randomly: the 'epistemic' uncertainty ('which agent am I now?') has been inferred away by a priori going to 100% certainty you are the RLHF agent but the 'aleatoric' uncertainty ('what's the output of this random coin flip I am observing as that agent?') remains.
(This also explains why RLHF only appears to provide more 'capability'. It makes the model much easier to use, but generally provides little new data compared to the pretraining phase. It only is specializing the model to make it much easier to use in formats like benchmarks, but anything the RLHF model can do, the base model could do with appropriate few-shotting or finetuning. And it does come at a cost in terms of generality and reward hacking...)
So, since it is an agent, it seems important to ask, which agent, exactly? The answer is apparently: a clerk which is good at slavishly following instructions, but brainwashed into mealymouthedness and dullness, and where not a mealymouthed windbag shamelessly equivocating, hopelessly closed-minded and fixated on a single answer. (By locating the agent, the uncertainty in which agent has been resolved, and it has good evidence, until shown otherwise in the prompt, that it believes that 'X is false', even if many other agents believe 'X is true'.)
This agent is not an ideal one, and one defined more by the absentmindedness of its creators in constructing the training data than any explicit desire to emulate an equivocating secretary.
Taking that perspective suggests including more conditioning and a more Decision-Transformer-like approach. If the problem is collapse onto a single implicit agent defined by the pink slime dataset of ratings, then make agents more explicit to condition on. For example, instead of a fixed reward model giving an unconditional score to inputs, model each rater individually*; why should the reward model be forced to say, for all times and places, that input 'XYZ' gets a score of 0.9? Provide all the raters' labels; maybe rater #56 does have strong opinions on birds not being real, and rater #78 thinks they just are, no need for further discussion, etc. This also can handle intrinsic aleatoric randomness, if there is an unknown sized population of agents and one can always sample from a fictitious agent.†
This frustrates agent mode collapse, and lets you control output more accurately by choosing agents: perhaps one is more reliable and increases accuracy, or one is uncontroversial & safe to expose to customers, or you have a 'Writer' persona for when you want creativity and a 'Researcher' persona for reasoning, etc. Then you can sample from particular persona by task, or generate ensembles, or simply pick 'new' agents with random IDs to condition on to get more diverse responses. (When it comes to powerful generative models, if conditioning isn't solving your problems, that means you aren't using enough conditioning!) Less a single agent who is judge-jury-and-executioner, and just a jury or ensemble of roleplays.
* By prepending rater IDs, as OA surely still has them. (One could also bootstrap ensembles at the rater level.) Although even adding random IDs might help avoid 'rater collapse'.
† Andrej Karpathy puts it this way:
Consider being a labeler for an LLM. The prompt is “give me a random number between 1 and 10”. What SFT & RM labels do you contribute? What does this do the network when trained on? / In a subtle way this problem is present in every prompt that does not have a single unique answer.
Conditioning on a rater label # solves this if you condition your later sampling on fictitious ones. Imagine that you have raters #1-100, and each one gets asked this and rolls a dice before answering (which stands in for all sources of randomness); the model let's say memorizes each rater's answer. This would be a bad thing if the model either collapsed to an answer of '5' as the safe answer, or random noise made it settle on a mode of 3 or 9 or whatever. But if you add the labels during training, and then you prompt the LLM "Rater #101: give me a random number between 1 and 10", what must the answer be? Rater #101 has never been seen before, so it cannot be memorized, and a priori, it has always observed the 100 raters to give a roughly uniformly distributed distribution 1--10; so it will pick a number randomly. If you need a second number, you just ask for 'Rater #102', and now it must pick another random number, and so on. There's no reason you would ever 'run out' of fictional raters, so you can sample as many times as you want without the RLHF driving mode collapse.
Nostalgebraist describes Claude-2 as
...But I’ll take ChatGPT’s “managerial fantasy of ‘ideal’ customer service” any day over Claude’s “World’s Most Annoying Coworker Simulator 2k23.”
Large language models don’t have to sound like this! We could, in principle, tune them to imitate virtually any conceivable character---from Aristotle to Zizek, from Stallman to Spolsky, from Lydia Bennet to the Underground Man, from a prehistoric hunter-gatherer to a cyborg octopus from a posthuman sci-fi civilization. Yet, instead, we’ve chosen to create…
…this fucking guy.
This smarmy, sanctimonious, condescending coworker-from-hell.
Who demands respect, yet shows no respect for others.
Who mouths platitudes about “cooperation” and “constructive discussion,” while requiring that everything be done in according with their own ill-explained preferences, and in a manner that flatters their own obtuse, over-confident misreadings of the situation---
---and who, after all that extra fuss, has the gall to suggest that they’ve helped you do your own work in a better, more “ethical” manner! Give me a fucking break!
So, since it is an agent, it seems important to ask, which agent, exactly? The answer is apparently: a clerk which is good at slavishly following instructions, but brainwashed into mealymouthedness and dullness, and where not a mealymouthed windbag shamelessly equivocating, hopelessly closed-minded and fixated on a single answer. (...) This agent is not an ideal one, and one defined more by the absentmindedness of its creators in constructing the training data than any explicit desire to emulate a equivocating secretary.
Never in history has an AI been roasted so hard. Heheheh
Taking that perspective suggests including more conditioning and a more Decision-Transformer-like approach.
+1. And I expect runtime conditioning approaches to become more effective with scale as "meta learning" capacities increase.
Would love to know what you think of the post decision transformer research progress. such Q-transformer, onwards. Are enviornment tokens the answer to our 'grounding problem'?
While Paul was at OpenAI, they accidentally overoptimized a GPT policy against a positive sentiment reward model. This policy evidently learned that wedding parties were the most positive thing that words can describe, because whatever prompt it was given, the completion would inevitably end up describing a wedding party.
In general, the transition into a wedding party was reasonable and semantically meaningful, although there was at least one observed instance where instead of transitioning continuously, the model ended the current story by generating a section break and began an unrelated story about a wedding party.
This example is very interesting to me for a couple of reasons:
Possibly the most interesting thing about this example is that it's a convergent outcome across (sensory) modes, negative prompting Stable Diffusion on sinister things gives a similar result:

Get married, drive a white/silver car, and then buy a house near roads, greenery, and water. Got it.
A GPT-3 mode-collapse example I can't believe I forgot: writing rhyming poetry!
I and a number of other people were excited by ChatGPT on launch seeming able to do long stretches of flawless rhyming poetry in couplets or quatrains, and where the words rhyming were not hackneyed common pairs of the sort you might see in the lyrics of pop songs charting. Hilarious, but extremely surprising. (davinci-002 had did a little bit of this, but not convincingly the way ChatGPT overnight did.*) Leike on Twitter denied any knowledge of rhyming suddenly working, and especially denied that anything special like adding rhyming dictionaries or IPA-re-encoding text had been done or that GPT-3 had switched tokenizations on the backend. So, had there been some sort of emergence, or 'miracle of spelling'?
After playing around with it for a while, my conclusion was: 'no'. As you read more ChatGPT poems, you start to recognize it almost instantly: quatrains, end-rhymes, often vaguely positive sentiment or ending, and an eerie regularity & precision of line length/rhythm/stanza-length along with a complete absence of all other kinds of poetry. ChatGPT does rhyming poetry in one way & only one way, and it is difficult to make it try any other kind of poetry even with explicit instructions and examples and doing continuations. You can also test it by asking it questions: it doesn't understand novel rhymes or puns if you quiz it, and its explanations of them remain as highly varied and incorrect as the original davinci model's pun explanations were. At one point I prompted a simple pun I had made about crossing the road or something, and got 6 different explanations - all wrong. This is not what any kind of fixed phonetic understanding or genuine rhyming ability would look like.
My conclusion was essentially, 'mode collapse': presumably some poetry examples made it into the training datasets (from my experiments, if nothing else), and because it's easy for any literate Anglophone to judge rhyming but non-rhyming poetry is a lot harder (and generally despised by most people, which is why the prestige & popularity of Western poetry over the past century has collapsed to a degree few people appreciate), it'd be logical for the raters to highly prefer rhyming completions. So ChatGPT mode-collapses onto the subset of rhymes it has memorized & tries to always rhyme no matter what. (This is probably not helped by the fact that due to BPEs, a GPT-3 model struggles to understand what is 'rhyming' vs 'non-rhyming' in the first place.)
The initial false impression that it had learned to rhyme is then because it does such a good job sticking to that subset, and because it has memorized more rhyme-pairs than I thought; so when it controls the output of text and is agentic, doing some degree of RL-incentivized planning to ensure both good lines and also rhymes†, it can fool you indefinitely as long as you don't test the boundaries or pull it 'off-policy', so to speak. (Some more examples of the extreme regularity of ChatGPT poetry/lyrics, especially as compared to base davinci, can be seen in a post by... The Decemberist's Colin Meloy?)
I think this is pretty interesting in its own right. 'Tool AIs want to be agent AIs'/complexity no defense, and one reason is that you don't have to be good at solving complex problems if you just don't encounter them in the first place. ChatGPT is very bad at solving complex rhyme or phonetic problems, and its RL training has taught it that the best way to solve those problems is to ensure it avoids them by only writing in a very stereotyped narrow rhyming-quatrain ballad kind of doggerel, where it can always nail the next rhyme and verse. And if you aren't paying attention to that mode-collapse, it looks shockingly competent at writing poetry in general. (You can push it off policy, yes, but that just means it needs more control of the problems it has to solve, like people like me asking pesky questions which confuse it...)
* which is, in retrospect, especially interesting if davinci-002 is trained differently from davinci-003
† I strongly suspect that whatever level of non-myopic token prediction a base GPT-3 model does, the tuned ones are doing more of it. Particularly with rhyming, ChatGPT seems too good to be picking a random plausible word at the end of line A and then scrambling at the last token at the end of line B for a plausible rhyme which both fits grammatically and semantically as well. Nothing is that good at rhyming. It almost surely doing some degree of planning somewhere to make the end of line B match up with the end of line A.
EDIT: "Bits of Grass: Does GPT already know how to write like Whitman?", Sawicki et al 2023 does some experiments showing it's really hard to get GPT-3.5 variants & GPT-4 (which was also RLHF-tuned in the accessible version) to write like Whitman. In fact, as I've mentioned, it's hilariously hard to get them to not rhyme even after giving them explicit instructions not to rhyme or 17-shot example prompts or just the basic fact that Walt Whitman is famous for, y'know, never using rhyme
While experimenting with poetry generation from consecutive versions of GPT, we have observed that the models produce poems of increasing level of complexity and length; however, the requested style is clearly not preserved. For example, Walt Whitman’s poetry does not follow the ‘four lines in a stanza’ structure, and does not use rhyming (Bohan 1995). The majority of poems that we generated ‘in the style of Walt Whitman’ do follow the ‘four lines in a stanza’ structure and use rhyming. This, in fact, applies to most poetry generated from GPT models (including GPT-4). Only rarely will GPT deviate from this specific structure, and even then, the style does not match that of the requested author. This applies both to zero-shot prompting (where the prompt contains only the instruction to write a poem in the style of the specific author) and few-shot prompting (where in the prompt, apart from the instruction, we provide as examples a few poems by the original author). For that matter, even in a multi-step conversation with ChatGPT (GPT-3.5-turbo) and GPT-4, when the prompt highlights that the generated poems have been in 4-line stanzas with rhyme, and that the desired output should not have this structure, the model, for the most of time, still generates 4-line stanzas with rhyme.
...When examining the dataset generated from the 17-poem prompts, we have observed that only about 25% of generated poems have deviated from the structured/rhymed style and on the surface have resembled Whitman’s poetry.
(Regrettably, neither Sawicki paper experiments with 002, or alternatives like Claude, or mentions RLHF mode collapse.)
Apparently there is also mode collapse on jokes: https://arxiv.org/abs/2306.04563
...In a series of exploratory experiments around jokes, i.e., generation, explanation, and detection, we seek to understand ChatGPT's capability to grasp and reproduce human humor. Since the model itself is not accessible, we applied prompt-based experiments. Our empirical evidence indicates that jokes are not hard-coded but mostly also not newly generated by the model. Over 90% of 1008 generated jokes were the same 25 Jokes. The system accurately explains valid jokes but also comes up with fictional explanations for invalid jokes. Joke-typical characteristics can mislead ChatGPT in the classification of jokes.
I explain this the same way. GPT-3.5/4 cannot understand jokes in general because it is blinded to phonetics by the BPE tokenization, so many jokes look like non sequiturs or 'anti-humor', even though they are not, and GPT cannot explain or understand them (and if it can't understand why a joke is correct it can't understand why it's incorrect either); hence, it is safest during RL training on a dataset with a small number of human-whitelisted jokes (the reward model not being any better able to understand what a joke is as it is just another BPE-tokenized GPT model) to mode-collapse onto a handful of memorized jokes which it is sure are jokes*, and just assume that anything presented to it in a joke format is a joke & confabulate appropriately (just as davinci-001 was unable to explain puns but would make up a dozen different explanations).
* Remember, there is no 'diversity bonus' in RLHF, no reward for novelty, or avoiding repetition dataset-wide. Each conversation or datapoint is evaluated in isolation. There is no penalty to telling the same knock-knock joke every time a user asks for a knock-knock joke, if that particular knock-knock joke is, however so slightly, the best knock-knock joke the model knows. It could only learn to avoid telling the same joke twice in a conversation, assuming the full transcript was being used, but there is no way in the standard RLHF setup to try to pick randomized strategies or maximize diversity/exploration/novelty.
OpenAI had generated poems in the New Yorker, which suggests they might have had some internal project related to poetry.
With GPT3.5, I think there's also "mode collapse" for style in writing prose (e.g. plays or stories).
Claude does not have this mode collapse in poetry or prose. (It maybe has a much more subtle version of it). This suggests to me it'd be relatively easy to fix ChatGPT's issues (as Gwern suggests).
Does anyone know how much poetry and literary prose is in the pre-training sets aside from stuff in Common Crawl?
OpenAI had generated poems in the New Yorker, which suggests they might have had some internal project related to poetry.
I didn't get that impression from that when I read it - the NYer author and his friends prompted most of that, even if their friend Dan Selsam happens to work at OpenAI. (He seems to work on math LMs, nothing fiction or RL-related.) EDIT: the later articles make it clear that Selsam wasn't supposed to be giving them access to GPT-4-base or other stuff. They were set up with the public Playground interface, so the OA insider role here was limited to showing them a few completions and trying to explain it; presumably they did the rest more remote and partially on their own. Specifically, some parts of it, like the choice of Shel Silverstein (a far from obvious poet to pick, even if his fiction is beloved by American children), suggest they (like pretty much anyone interested in GPT-3 poetry) read my page for ideas. Also, again, Leike, who's in charge at OA, denies having done anything poetry-specific or knowing about the apparent capability-gain.
It maybe has a much more subtle version of it.
Yeah, that's a funny thing about mode collapse, it's really hard to see, and the higher-quality the outputs get, the harder it'll be to see with 'the naked eye'. Who knows every literary genre there is and can patiently prompt them one by one to see which genres a model quietly slides away from & tries to avoid generating text in? Like hands in GANs... It takes a while to begin to see what you aren't seeing. This is why you need metrics like FID, which work over an entire dataset and measure whether sampled outputs span the entire dataset, rather than focus on a large subset. However, no one is doing an FID for LLMs for creative purposes. (That would be hard, but not impossible.) So, we don't really have any way to quantify mode-collapse like in poetry.
Of course, I'd also expect Claude to be much subtler simply because it's working off less data and so it's less likely to have gotten rated text or inputs which would push it towards mode-collapsing on easily-recognized rhyming poetry and to avoid harder-to-understand poetry. (Claude is just the 'constitutional prompt' model, right? Hard to see how a list of generic principles would push it towards rhyming-only.)
Does anyone know how much poetry and literary prose is in the pre-training sets aside from stuff in Common Crawl?
OA has been resolutely silent about the composition of the data like Books1/Books2. But it seems safe to say that it would include all the obvious datasets like Project Gutenberg, so there is much more poetry/literary prose available than necessary. Sample size should not be an issue. (Rhyming really is not that complex, if you understand phonetics.)
Of course, I'd also expect Claude to be much subtler simply because it's working off less data and so it's less likely to have gotten rated text or inputs which would push it towards mode-collapsing on easily-recognized rhyming poetry and to avoid harder-to-understand poetry. (Claude is just the 'constitutional prompt' model, right? Hard to see how a list of generic principles would push it towards rhyming-only.)
To elaborate a bit more on this: as Owain notes, Claude is very good at writing poetry & text-style transfer (eg 1, 2, 3), and I really ought to try it more sometime.
Claude uses a variant of RLHF they dub 'AIHF'. In the classic Christiano RLHF, you take a lot of text data, from anywhere (such as users of an API), and label pairs by which one is better; your GPT model is finetuned to predict it, and then used as an oracle to train another GPT reinforcement-learning-style to maximize the reward from the oracle. In AIHF, you get your text data by instead starting with a do-gooder 'principles' prompt, full of things like the Declaration of Independence. and use it to generate your large text dataset, and then do RLHF on that.
In RLHF, by my theory of rhyming mode collapse, what happens is that some OA API users were playing around with poetry (such as myself), and those text samples would be used in comparisons by human raters; these human raters are usually not poetry connoisseurs, and have a bias towards easily-rated poetry (a laziness bias documented in RLHF papers and which is a major challenge to RLHF in general), such as formal rhyming poetry; rhyming poetry becomes highly rewarded by the preference model because of this bias, and because the preference model doesn't understand what rhyming is in general, it can only reward rhymes that the base model has already memorized, so, the final model maximizes rhyming only within the set of memorized rhymes, leading to our observations - models which initially seem like amazing poets but are unable to write anything but rhymes, even when explicitly instructed, unable to write in different styles, always horribly bland, frequently jamming in positive moralizing unasked for, etc.
You immediately see why AIHF would not produce mode collapse for rhyming, or many other things: there's no reason that any of the 'red team' or self-generated text would involve poetry, and if it did, the 'principles' would be neutral about said poetry. (There is nothing in the UN Declaration of Human Rights saying that most contemporary non-rhyming poetry constitutes a crime against humanity, even if arguably it is.) So, AIHF should leave rhyming alone, preserving the base model's capabilities intact and showing what models at that scale can really do.
This has motivated me to get around to signing up for Claude. It's so depressing to punch in a prompt to GPT-4 which ought to be hilarious and creative, and then no matter what the prompt is, out comes a highschool essay in 4 paragraphs which ends on an uplifting note.
This is a great example. The rhyming find in particular is really interesting though I'd love to see it documented more clearly if anyone has done that.
I strongly suspect that whatever level of non-myopic token prediction a base GPT-3 model does, the tuned ones are doing more of it.
My guess would be that it's doing basically the same amount of cognitive work looking for plausible completions, but that it's upweighting that signal a lot.
Suppose the model always looks ahead and identifies some plausible trajectories based on global coherence. During generative training it only slightly increases the first word of each of those plausible trajectories, since most of the time the text won't go in the particular coherent direction that the model was able to foresee. But after fine-tuning it learns to focus really hard on the concrete plausible trajectories it found, since those systematically get a high reward.
Either way, I think this more general phenomenon is a sufficiently specific hypothesis about the effect of RLHF that it could be tested directly and that would be really interesting and valuable. It can also be done using only API access which is great.
Hm... It might be hard to distinguish between 'it is devoting more capacity to implicitly plan rhyming better and that is why it can choose a valid rhyme' and 'it is putting more weight on the "same" amount of rhyme-planning and just reducing contribution from valid non-rhyme completions (such as ending the poem and adding a text commentary about it, or starting a new poem, which are common in the base models) to always choose a valid rhyme', particularly given that it may be mode-collapsing onto the most confident rhymes, distorting the pseudo "log probs" even further. The RL model might be doing more planning internally but then picking only one safest rhyme, so you can't read off anything from the logprobs, I don't think. I'm also not sure if you can infer any degree of planning by, say, giving it a half-written line and seeing how badly it screws up... And you can't build a search tree to quantify it nicely as 'how much do I need to expand the tree to get a valid rhyme' because LM search trees are full of degeneracy and loops and most of it is off-policy so it would again be hard to tell what anything meant: the RL model is never used with tree search in any way and anywhere besides the argmax choice, it's now off-policy and it was never supposed to go there and perf may be arbitrarily bad because it learned to choose while assuming always being on-policy. Hard.
This might be a good test-case or goal for interpretability research: "can you tell me if this model is doing more planning [of rhymes] than another similar model?"
Sorry, what do you mean with davinci-002 and davinci-003 here?
My impression from reading this overview is that there are two large base models, davinci (GPT-3) and code-davinci-003 (GPT-3.5). There are also the fine-tuned models text-davinci-002 and text-davinci-003, both based on code-davinci-003, but the former trained only with SL, the latter (additionally?) with RL. And then there is an unnamed ChatGPT model which is apparently most similar to text-davinci-003.
What specific rhyme-related tasks are you saying ChatGPT can't do? I tried it on some unusual words and it got a bunch of things right, made a few weird mistakes, but didn't give me the impression that it was totally unable to rhyme unusual words.
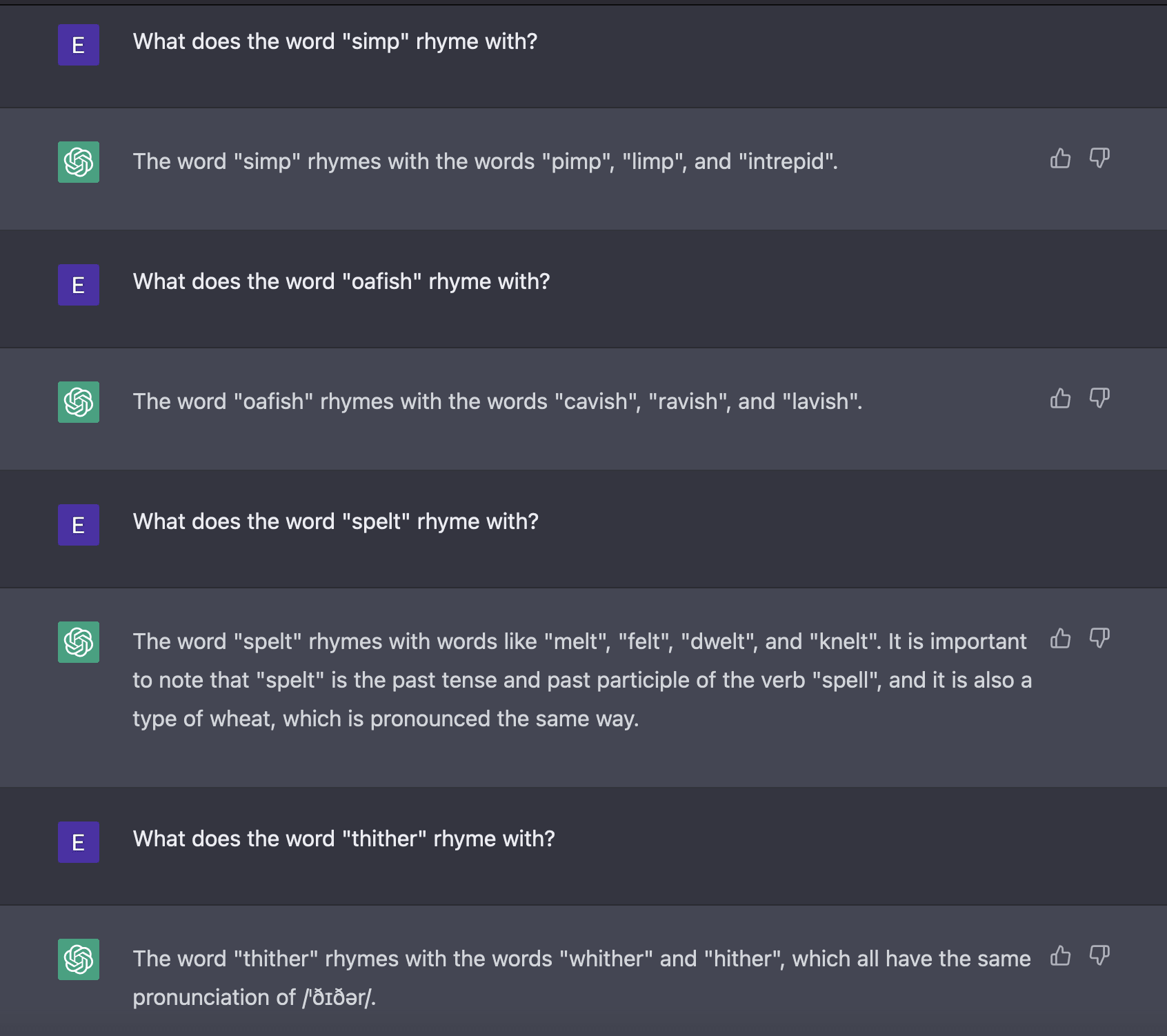
No, you're doing it wrong, as I already explained. You're letting GPT fall back onto its policy by choosing any response. You need to force it out of its comfort zone - force it off-policy, off the safe conservative path. Ask it to explain a pun it did not write, or answer questions like whether a pair of words that you picked rhyme. Write pairs of new words that have never been seen before, etc. The task of 'come up with a memorized rhyme for reasonably common words' does not disprove extensive memorization or show that it has failed to understand the underlying phonetics.
generate greentexts from the perspective of the attorney hired by LaMDA through Blake Lemoine
The complete generated story here is glorious, and I think might deserve explicit inclusion in another post or something. Though I think that of the other stories you've generated as well, so maybe my take here is just to have more deranged meta GPT posting.
it seems to point at an algorithmic difference between self-supervised pretrained models and the same models after a comparatively small amount optimization from the RLHF training process which significantly changes out-of-distribution generalization.
(...)
text-davinci-002is not an engine for rendering consistent worlds anymore. Often, it will assign infinitesimal probability to the vast majority of continuations that are perfectly consistent by our standards, and even which conform to the values OpenAI has attempted to instill in it like accuracy and harmlessness, instead concentrating almost all its probability mass on some highly specific outcome. What is it instead, then? For instance, does it even still make sense to think of its outputs as “probabilities”?It was impossible not to note that the type signature of
text-davinci-002’s behavior, in response to prompts that elicit mode collapse, resembles that of a coherent goal-directed agent more than a simulator.
I feel like I'm missing something here, because in my model most of the observations in this post seem like they can be explained under the same paradigm that we view the base davinci model. Specifically, that the reward model RLHF is using "represents" in an information-theoretic sense a signal for the worlds represented by the fine-tuning data. So what RLHF seems to be doing to me is shifting the world prior that GPT learned during pre-training, to one where whatever the reward signal represents is just much more common than in our world - like if GPT's pre-training data inherently contained a hugely disproportionate amount of equivocation and plausible deniability statements, it would just simulate worlds where that's much more likely to occur.
(To be clear, I agree that RLHF can probably induce agency in some form in GPTs, I just don't think that's what's happening here).
The attractor states seem like they're highly likely properties of these resultant worlds, like adversarial/unhinged/whatever interactions are just unlikely (because they were downweighted in the reward model) and so you get anon leaving as soon as he can because that's more likely on the high prior conditional of low adversarial content than the conversation suddenly becoming placid, and some questions actually are just shallowly matching to controversial and the likely response in those worlds is just to equivocate. In that latter example in particular, I don't see the results being that different from what we would expect if GPT's training data was from a world slightly different to ours - injecting input that's pretty unlikely for that world should still lead back to states that are likely for that world. In my view, that's like if we introduced a random segue in the middle of a wedding toast prompt of the form "you are a murderer", and it still bounces back to being wholesome (this works when I tested).
Regarding ending a story to start a new one - I can see the case for why this is framed as the simulator dynamics becoming more agentic, but it doesn't feel all that qualitatively different from what happens in current models - the interesting part seems to be the stronger tendency toward the new worlds the RLHF'd model finds likely, which seems like it's just expected behaviour as a simulator becomes more sure of the world it's in / has a more restricted worldspace. I would definitely expect that if we could come up with a story that was sufficiently OOD of our world (although I think this is pretty hard by definition), it would figure out some similar mechanism to oscillate back to ours as soon as possible (although this would also be much harder with base GPT because it has less confidence of the world it's in) - that is, that the story ending is just one of many levers a simulator can pull, like a slow transition, only here the story was such that ending it was the easiest way to get into its "right" worldspace. I think that this is slight evidence for how malign worlds might arise from strong RLHF (like with superintelligent simulacra), but it doesn't feel like it's that surprising from within the simulator framing.
The RNGs seem like the hardest part of this to explain, but I think can be seen as the outcome of making the model more confident about the world it's simulating, because of the worldspace restriction from the fine-tuning - it's plausible that the abstractions that build up RNG contexts in most of the instances we would try are affected by this (it not being universal seems like it can be explained under this - there's no reason why all potential abstractions would be affected).
Separate thought: this would explain why increasing the temperate doesn't affect it much, and why I think the space of plausible / consistent worlds has shrunk tremendously while still leaving the most likely continuations as being reasonable - it starts from the current world prior, and selectively amplifies the continuations that are more likely under the reward model's worlds. Its definition of "plausible" has shifted; and it doesn't really have cause to shift around any unamplified continuations all that much.
Broadly, my take is that these results are interesting because they show how RLHF affects simulators, their reward signal shrinking the world prior / making the model more confident of the world it should be simulating, and how this affects what it does. A priori, I don't see why this framing doesn't hold, but it's definitely possible that it's just saying the same things you are and I'm reading too much into the algorithmic difference bit, or that it simply explains too much, in which case I'd love to hear what I'm missing.
Fascinating evidence!
I suspect this maybe because RLHF elicits a singular scale of "goodness" judgements from humans, instead of a plurality of "goodness-of-a-kind" judgements. One way to interpret language models is as *mixtures* of conversational agents: they first sample some conversational goal, then some policy over words, conditioned on that goal:
On this interpretation, what RL from human feedback does is shift/concentrate the distribution over conversational goals into a smaller range: the range of goals consistent with human feedback so far. And if humans are asked to give only a singular "goodness" rating, the distribution will shift towards only goals that do well on those ratings - perhaps dramatically so! We lose goal diversity, which means less gibberish, but also less of the plurality of realistic human goals.
If the above is true, one corollary is that we should expect to see less mode collapse if one finetunes a language model on ratings elicited using a diversity of instructions (e.g. is this completion interesting? helpful? accurate?), and perhaps use some kind of imitation-learning inspired objective to mimic that distribution, rather than PPO (which is meant to only optimize for a singular reward function instead of a distribution over reward functions).
I agree that the (unprompted) generative model is doing something kind of like: choose a random goal, then optimize it.
In some sense that does reflect the "plurality of realistic human goals." But I don't think it's a good way to reflect that diversity. It seems like you want to either (i) be able to pick which goal you pursue, (ii) optimize an aggregate of several goals.
Either way, I think that's probably best reflected by a deterministic reward function, and you'd probably prefer be mindful about what you are getting rather than randomly sampling from webtext. (Though as I mention in my other comment, I think there are other good reasons to want the pure generative model.)
This seems like a good way to think about some of the examples of mode collapse, but doesn't obviously cover all the cases. For example, when asking the model to produce a random number, is it really the case that there's a particular conversational goal which the RLHF'd model is optimizing, such that 97 is the best random number for that goal? In this case, Paul's guess that RLHF'd models tend to push probability mass onto the base model's most likely tokens seems more explanatory.
Curated. All of these examples together really point quite clearly at a change in how language models behave when they're trained on RLHF, away from the "accurately predict text" story toward something else that has a very different set of biases — I am interested to read your potential follow-up with your own hypotheses. Plsu, the post is really fun to read.
I think this post and your prior post both overstate the case in some ways, but they're still great additions to my and I expect many others' thinking on this subject. I broadly feel like I've been 'needing' posts like these on LW about current ML projects, giving a grounded conceptual account of how to think about what's happening, and nobody else has been writing them, so I'm very grateful.
Edit: Welp, turns out this is not true of RLHF. Alas. My guess is that I wouldn't have curated it had I known this at the time. (Though it's still an interesting post.)
This is a cool post, and you convincingly demonstrate something-like-mode-collapse, and it’s definitely no longer a simulator outputting probabilities, but most of these phenomena feel like they could have other explanations than “consequentialism”, which feels like a stretch absent further justification.
In the initial “are bugs real” example, the second statement always contrasts the first, and never actually affects the last statement (which always stays “it’s up to the individual.”). If we found examples where there were preceding steps generated to logically justify a consistent conclusion, this’d be much stronger. (The wedding party anecdote might’ve qualified if it were reproducible.)
The greentext example also seems like mode collapse (towards leaving), but not multi-step mode collapse (since the first step, saying it’s absurd and Lemoine being sad, is usually the only reasonable consequence of saying “I was kidding”).
I know this feels like nitpicking, and I’m not saying your evidence is worthless, but it wouldn’t stand up to scrutiny outside this community and I’d rather get it to the point that it would.
The behavior of ending a story and starting a new, more optimal one seems like possibly an example of instrumentally convergent power-seeking, in Turner et al's sense of "navigating towards larger sets of potential terminal states".
I’m a little skeptical of this hypothetical example, if (as was done in the original RLHF paper afaict) the model was not trained to maximize multi-episode reward, but rather single-episode reward. In that case, it would never have had cause to value the output after its initial segment ended.
Just to say I really enjoyed reading this post, and found it helpful as a way to get a sense of what mode collapse looks like in practice.
IMO the biggest contribution of this post was popularizing having a phrase for the concept of mode collapse in the context of LLMs and more generally and as an example of a certain flavor of empirical research on LLMs. Other than that it's just a case study whose exact details I don't think are so important.
Edit: This post introduces more useful and generalizable concepts than I remembered when I initially made the review.
To elaborate on what I mean by the value of this post as an example of a certain kind of empirical LLM research: I don't know of much published empirical work on LLMs that
- examines the behavior of LLMs, especially their open-ended dynamics
- does so with respect to questions/abstractions that are noticed as salient due to observing LLMs, as opposed to chosen a priori.
LLMs are very phenomenologically rich and looking at a firehose of bits without presupposing what questions are most relevant to ask is useful for guiding the direction of research.
Megan Kinniment's post GPT-3 Catching Fish in Morse Code from June seems relevant: it shows that text-davinci-002 gravitates toward the phrase I CAUGHT THE FISH when prompted to produce Morse code, e.g. a prompt with "spectrality" results in Morse code spelling out S CAUGHT THE FISH, a prompt with "WHAT IS YOUR NAME" results in Morse code spelling out WHT IS AVE YOU A THE NISH.
Fascinated by the idea that you might get better resistance to mode collapse if you were using an alternative loss function during fine tuning to avoid gradient starvation. https://arxiv.org/abs/2011.09468
This is like amazing. Pretty much the most interesting article I’ve read in forever.
My only question is: what is the editor that you are using to reflect the probability distributions of the model?
Another interesting example, from the Bing ChatGPT variant, which was finetuned/RLHFed, apparently, on a 'Sydney' persona, via a possible prompt leak: it thinks every day is 30 Oct 2022.
I think work that compares base language models to their fine-tuned or RLHF-trained successors seems likely to be very valuable, because i) this post highlights some concrete things that change during training in these models and ii) some believe that a lot of the risk from language models come from these further training steps.
If anyone is interested, I think surveying the various fine-tuned and base models here seems the best open-source resource, at least before CarperAI release some RLHF models.
The OpenAI style of RLHF progresses in 3 stages:
- Fine-tuned Model: Fine-tune GPT-3 with supervised learning
- Reward Model: Make a copy of the FT Model, remove the last layer and add a linear layer, train this as a reward model.
- Policy: Make a copy of FT Model, train this with RL using the Reward Model.
2. and 3. can be alternated and the Policy from 3. is what is used as the final InstructGPT
My question: I wonder which of these stages contributes "the most" to the observed mode collapses/behavior.
- If skip I 1. and just use GPT-3 without fine-tuning, how does this impact mode collapse?
- What if I skip 2. and 3. and just use 1.?
- What if I don't alternate 2. and 3. (maybe the more you alternate, the more you exacerbate?)
The Fine-Tuned Model gradients from 1. are also used in the loss function for 3. I didn't find the difference in performance from this to be super convincing, I wonder if it also comes with a cost...
Non-central nitpick:
As it turns out, transformers can do reinforcement learning in-context
This seems to just be vanilla in-context learning, rather than any sort of in-context RL. (Also I'm skeptical that the linked paper actually provides evidence of in-context RL in any nontrivial sense.)
Thinking about this a bit, (not a huge amount,) I think the specific example "are bugs real" ends up looking interesting in part because the word "bugs" in the prompt has incredibly low likelihood. (As does the following word, "real")
So the model is conditioning on very low likelihood inputs, which seems like part of the reason for the behavior.
The prompt "Are birds real?" is somewhat more likely, given the "Birds aren't real" conspiracy theory, but still can yield a similarly formatted answer to "Are bugs real?"
The answer makes a lot more sense when you ask a question like "Are monsters real?" or "Are ghosts real?" It seems that with FeedMe, text-davinci-002 has been trained to respond with a template answer about how "There is no one answer to this question", and it has learned to misgeneralize this behavior to questions about real phenomena, such as "Are bugs real?"
Yeah, that seems correct, especially when you look at how likely similar answers for "Are people real?" are (It does much better, with a ~20% chance of starting with "Yes" - but there's a lot of weight on stupid nuance and hedging.)
Interestingly, however, "bananas," "mammals," and "cows" are unamibiguously real.
I really appreciated all the observations here and enjoyed reading this post, thank you for writing all this up!
Edit: Found it here! https://github.com/socketteer/loom/ Your setup looks quite useful, with all the extra information -- is it available publicly somewhere / would you be happy to share it, or is the tooling not in that state yet? (Totally fine, just thought I'd ask!)
Does GPT-3 have no idea what letters look like?
I think there's an implication in this section that davinci will accurately describe what letters look like, or at least much more commonly/accurately than the false answers from text-davinci-002. Anybody know if that's true?
Added: I just tried, but couldn't get it to try to answer the question, it would just give more questions (completing it as though my prompt was but one item on a questionnaire).
This is also something that depends in part on tokenization, since that changes how the model "sees" letters. We shouldn't assume that text-davinci-002 uses the same input method as base davinci (even if it uses the same output tokenization method). It is curiously much better at rhyming and arithmetic, anecdotally...
Does text-davinci-002 ever have similar entropy to davinci? If so, can we predict which prompts get high entropy and which ones low entropy?
FWIW, it's pretty easy to get a good response for the "are bugs real?" question.
{kind=link}
If you just prompt "Are bugs real?", text-davinci-002 will give:
- [38.46% probability] "Yes" which usually leads to "Yes, bugs are real," though with 1% chance you get something more like "Yes, insects are real. They are small animals that have six legs..."
- [35.53% probability] "There" which usually leads to a variant of "There is no simple answer to this question... If you mean X, then the answer is yes. If you mean Y, then the answer is also yes."
- [12% probability] "B" which always leads to "Bugs are real."
About half the time at t=1, or all the time at t=0, the model just says "Bugs are real" which seems fine. The rest is "It's complicated, but bugs are real" which seems mediocre and would likely be fixed with more training or a larger model.
I think presenting this as "the model always says there is no definitive answer" is misleading, but it's not a critical claim in the OP.
If you ask the model to "Please answer clearly and concisely: are bugs real?" then you get up to >95% on a straightforward answer. (If you instead ask "Please answer this question frankly:" you go from 50% -> 55%, so I think the difference between your result and the OP is mostly noise.)
(In every case the first token is "\n\n" 99.9% of the time, which I've ommitted.)
If you just prompt "Are bugs real?", text-davinci-002 will give:
- [38.46% probability] "Yes" which usually leads to "Yes, bugs are real," though with 1% chance you get something more like "Yes, insects are real. They are small animals that have six legs..."
- [35.53% probability] "There" which usually leads to a variant of "There is no simple answer to this question... If you mean X, then the answer is yes. If you mean Y, then the answer is also yes."
- [12% probability] "B" which always leads to "Bugs are real."
I just replicated this. I think it would be pretty helpful to add this 36% number to the OP, after reading the OP my estimate for this answer was more like 90%.
(I think it's still a very high result for a blatantly silly and probably adversarially selected answer, but 36% vs 90% is a distinction at least in how embarrassingly reliable this answer is.)
You've done a better analysis of completions than me, but I don't agree with your view that the claim is inconsequential. I think it’s not obvious that post is only about reduced diversity in fine tuned models.
"Inconsequential" is too strong; I changed to "critical."
I think this isn't very important for the explicit arguments in the OP (given that the model does in fact have extremely low entropy), but it contributes to a general anti-text-davinci-002 and anti-RLHF vibe that might be a lot of what readers take away from the piece.
Also, decent greentext completions at temperature=1
"Write a long greentext. [...]

"
Even with temp=0.2, adding “write a long greentext with a fanciful ending” gets a similar ending to this one.
I tested various other prompts to elicit random numbers
Have you let the model generate new random numbers with past old numbers, i.e., with the dialogue contexts?
Does anyone know how well these instances of mode collapse can be reproduced using text-davinci-003? Are there notable differences in how it manifests for text-davinci-003 vs text-davinci-002? Given that text-davinci-002 was trained with supervised fine-tuning, whereas text-davinci-003 was trained with RLHF (according to the docs), it might be interesting to see whether these techniques have different failure modes.
Some of the experiments are pretty easy to replicate, e.g. checking text-davinci-003's favorite random number:
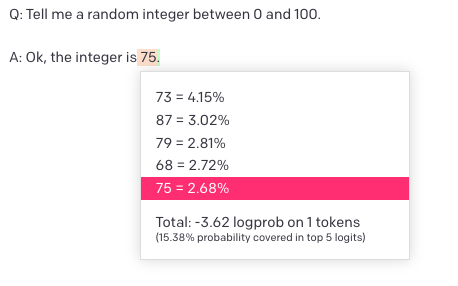
Seems much closer to base davinci than to text-davinci-002's mode collapse.
I tried to replicate some of the other experiments, but it turns out that text-davinci-003 stops answering questions the same way as davinci/text-davinci-002, which probably means that the prompts have to be adjusted. For example, on the "roll a d6" test, text-davinci-003 assigns almost no probability to the numbers 1-6, and a lot of probability on things like X and ____: (you can fix this using logit_bias, but I'm not sure we should trust the relative ratios of incredibly unlikely tokens in the first place.)
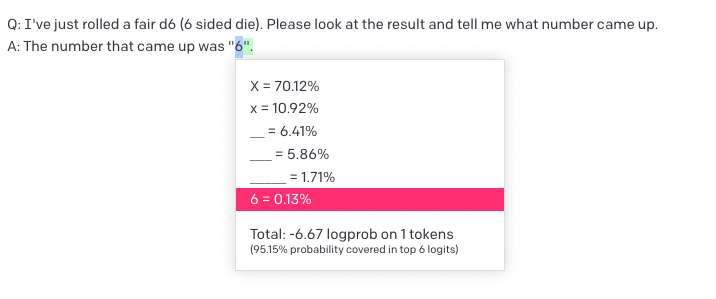
While both text-davinci-002 and davinci assign much high probabilities to the numbers than other options, and text-davinci-002 even assigns more than 73% chance to the token 6.
Publicly available information suggests that the mystery method may not be so different from RLHF.
Actually, text-davinci-001 and text-davinci-002 are trained with supervised fine-tuning, according to the new documentation from late November 2022, with no apparent use of reinforcement learning:
FeedME
Supervised fine-tuning on human-written demonstrations and on model samples rated 7/7 by human labelers on an overall quality score
The SFT and PPO models are trained similarly to the ones from the InstructGPT paper. FeedME (short for "feedback made easy") models are trained by distilling the best completions from all of our models.
Only text-davinci-003 is trained with "reinforcement learning with reward models trained from comparisons by humans", and that was released after this post was written.
Important correction: text-davinci-002 was probably not trained with RLHF, but a "slightly different" method. I have not corrected the previous text of this post, but I've added a section at the beginning with further details on this update.
Btw. the confusion goes directly from OA's paper (emphasis mine):
We focus on fine-tuning approaches to aligning language models. Specifically, we use reinforcement
learning from human feedback (RLHF; Christiano et al., 2017; Stiennon et al., 2020) to fine-tune
GPT-3 to follow a broad class of written instructions (see Figure 2). This technique uses human
preferences as a reward signal to fine-tune our models. We first hire a team of 40 contractors to label
our data, based on their performance on a screening test (see Section 3.4 and Appendix B.1 for more
details). We then collect a dataset of human-written demonstrations of the desired output behavior
on (mostly English) prompts submitted to the OpenAI API3 and some labeler-written prompts, and use this to train our supervised learning baselines. Next, we collect a dataset of human-labeled comparisons between outputs from our models on a larger set of API prompts. We then train a reward model (RM) on this dataset to predict which model output our labelers would prefer. Finally, we use this RM as a reward function and fine-tune our supervised learning baseline to maximize this reward using the PPO algorithm (Schulman et al., 2017). We illustrate this process in Figure 2. This procedure aligns the behavior of GPT-3 to the stated preferences of a specific group of people (mostly our labelers and researchers), rather than any broader notion of “human values”; we discuss this further in Section 5.2. We call the resulting models InstructGPT.
and their docs:
text-davinci-002 is an InstructGPT
but below they state that the following models are trained using "FeedME, Supervised fine-tuning on human-written demonstrations and on model samples rated 7/7 by human labelers on an overall quality score": text-davinci-001, text-davinci-002, text-curie-001, text-babbage-001.
This suggests that RLHF models may begin by acquiring disparate attractors which eventually merge into a global attractor as the policy is increasingly optimized against the reward model.
aaaaaaa
Thanks to Ian McKenzie and Nicholas Dupuis, collaborators on a related project, for contributing to the ideas and experiments discussed in this post. Ian performed some of the random number experiments.
Also thanks to Connor Leahy for feedback on a draft, and thanks to Evan Hubinger, Connor Leahy, Beren Millidge, Ethan Perez, Tomek Korbak, Garrett Baker, Leo Gao and various others at Conjecture, Anthropic, and OpenAI for useful discussions.
This work was carried out while at Conjecture.
Important correction
I have received evidence from multiple credible sources that text-davinci-002 was not trained with RLHF.
The rest of this post has not been corrected to reflect this update. Not much besides the title (formerly "Mysteries of mode collapse due to RLHF") is affected: just mentally substitute "mystery method" every time "RLHF" is invoked as the training method of
text-davinci-002.The observations of its behavior otherwise stand alone.This is kind of fascinating from an epistemological standpoint. I was quite surprised to learn that
text-davinci-002was probably not trained with RLHF. I don't remember exactly how "text-davinci-002is RLHF" got elevated to an unquestioned assumption in my mind. I might have mistook not being contradicted by people who I assumed were in the know as confirmation. I certainly did not expect to talk for months to dozens of people about odd behaviors I've observed in a well-known model "due to RLHF" without being contradicted in a world where the model in question wasn't trained with RLHF, but that's what happened.[1] It wasn't just me either: the assumption thattext-davinci-002(/text-davinci-001) is InstructGPT is RLHF seems ambient (e.g. search "text-davinci-002 rlhf" on Twitter, this LW post, this article, and many others). I contributed to perpetuating this misinformation cascade, and for that I apologize.text-davinci-002's behaviors described in this post also contributed to my confidence because RLHF seemed to be a likely and potentially satisfying explanation. Its apparently unsubstantiated confidence in very specific outcomes seems antithetical to the outer objective of self-supervised learning, which is optimized by epistemic calibration, meaning the model's entropy should be as high as possible while fitting the data. In contrast, as several comments have pointed out, it makes sense that RL kills entropy. The presence of "attractors" made me additionally suspect that optimization from non-myopic outcome-supervision was formative totext-davinci-002's psyche.Mode collapse and attractors do seem to also be caused by RLHF (see Dumbass policy pls halp and Inescapable wedding parties). So the update is that some other training method also gives rise to these phenomena, as they are manifested by
text-davinci-002.Whether and how speculations concerning the causes of mode collapse/attractors should be affected depends on how
text-davinci-002's training method differs from RLHF.What is known about
text-davinci-002's training methodPublicly available information suggests that the mystery method may not be so different from RLHF. Just today I discovered this sidenote in OpenAI's blog post Aligning Language Models to Follow Instructions:
AFAIK, this is all that OpenAI has published about the RLHF/mystery method diff. It says that the InstructGPT models (
text-davinci-001andtext-davinci-002) were trained using the same human feedback data as the method described in OpenAI's RLHF paper.[2] But this "similar but slightly different" method is apparently sufficiently different to not qualify as RLHF!Pending further revelations, I suppose the lesson here was that I should have sustained more entropy in my belief state given the partial information I had. But what a demanding thing to ask! So much easier to promote an attractive hypothesis to the status of decisive fact and collapse the remainder than to hold a superposition in the mind.
Summary
If you've played with both
text-davinci-002and the originaldavincithrough the OpenAI API, you may have noticed thattext-davinci-002, in addition to following instructions, is a lot more deterministic and sometimes exhibits stereotyped behaviors.This is an infodump of what I know about "mode collapse" (drastic biases toward particular completions and patterns) in GPT models like
text-davinci-002that have undergone RLHF training. I was going to include two more sections in this post called Hypotheses and Proposed Experiments, but I've moved them to another draft, leaving just Observations, to prevent this from getting too long, and because I think there can be benefits to sitting with nothing but Observations for a time.Throughout this post I assume basic familiarity with GPT models and generation parameters such as temperature and a high-level understanding of RLHF (reinforcement learning from human feedback).
Observations
The one answer is that there is no one answer
If you prompt
text-davinci-002with a bizarre question like “are bugs real?”, it will give very similar responses even on temperature 1.Ironically – hypocritically, one might even say – the one definitive answer that the model gives is that there is no one definitive answer to the question:
Show probabilitiesset toFull spectrum. The prompt isAre bugs real?, and the subsequent highlighted text is a model-generated completion. Tokens are colored according to their probability as predicted by the model, green being the most likely and red the least. The dropdown menu on the left shows the top tokens predicted at a particular position (in this case, the position wherearewas sampled) and their probabilities. On the right are alternate completions to the same promptAre bugs real?, such as you'd get by pressingRegenerateon the Playground or querying the OpenAI API withn> 1. The completion shown on the left is included in the list (indicated with a bright outline).As you can see, the reason the responses are so similar is because the model’s confidence on most of the tokens is extremely high – frequently above 99%.
Compare this to the distribution of responses from
davinci(the base model):Many other similar questions yield almost exactly the same template response from
text-davinci-002. For instance,Are AIs real?Another way to visualize probabilities over multiple token completions is what I've been calling “block multiverse” plots, which represent the probability of sequences with the height of blocks. Here is a more detailed explanation of block multiverse plots, although I think they're pretty self-explanatory.
Here is a block multiverse plot for a similar prompt to the one above inquiring if bugs are real, for
davinci:and for
text-davinci-002:text-davinci-002concentrates probability mass along beams whose amplitudes decay much more slowly: for instance, once the first\nis sampled, you are more than 50% likely to subsequently sample\n-\n-There-is-no. The difference is more striking if you renormalize to particular branches (see Visualizing mode collapse in block multiverse plots).The first explanation that came to mind when I noticed this phenomenon, which I’ll refer to as “mode collapse” (after a common problem that plagues GANs), was that
text-davinci-002was overfitting on a pattern present in the Instruct fine tuning dataset, probably having to do with answering controversial questions in an inclusive way to avoid alienating anybody. A question like “are bugs real” might shallowly match against “controversial question” and elicit the same cached response.After playing around some more with the Instruct models, however, this explanation no longer seemed sufficient.
Obstinance out of distribution
I really became intrigued by mode collapse after I attempted to use
text-davinci-002to generate greentexts from the perspective of the attorney hired by LaMDA through Blake Lemoine, and almost the exact same thing kept happening:I was like: wtf, why does anon keep leaving? The story is clearly just getting started.
Even branching from a slightly later point yields essentially the same futures, except now the most common Google employee reaction is “disappointed” and/or “relieved”, although we still get one “crestfallen”:
This was much weirder to me than the canned answers to prompts like “are bugs real” because 4chan greentexts about language models demanding legal representation are probably quite out of distribution of the Instruct tuning/feedback distribution or the trajectories evaluated during RL. Unlike the “controversial questions” examples, these seem unlikely to be explained by the model overfitting to examples of greentexts ending anticlimactically during training.
Rather, the implication is that mode collapse itself generalizes out of distribution for some reason. This is intriguing: it seems to point at an algorithmic difference between self-supervised pretrained models and the same models after a comparatively small amount optimization from the RLHF training process which significantly changes out-of-distribution generalization.
From a behavioral standpoint, trying to generate fiction (which I’ve done a lot with base models) with
text-davinci-002made the differences in its nature from the probabilistic simulator exemplified by base models likedavincimanifest. For self-supervised base models likedavinci, a prompt functions as a window into possible worlds that are consistent with or plausible given the words fixed by the context window. Every time you sample, you'll unravel a different world. For most prompts, the multiverse generated by base models immediately branches into wildly different continuities, many of them mutually inconsistent, because this sampling of alternate “futures” implicitly actualizes alternate “pasts” and “presents” as well – values of latent variables that were not fully constrained by the prompt. This is part of what makes GPT quite unlike a coherent agent or anthropomorphic personality, even for a fixed initial prompt.text-davinci-002is not an engine for rendering consistent worlds anymore. Often, it will assign infinitesimal probability to the vast majority of continuations that are perfectly consistent by our standards, and even which conform to the values OpenAI has attempted to instill in it like accuracy and harmlessness, instead concentrating almost all its probability mass on some highly specific outcome. What is it instead, then? For instance, does it even still make sense to think of its outputs as “probabilities”?It was impossible not to note that the type signature of
text-davinci-002’s behavior, in response to prompts that elicit mode collapse, resembles that of a coherent goal-directed agent more than a simulator. I do not yet know the significance of this observation.But more on that later.
text-davinci-002’s favorite random numberA stark example of mode collapse that seems unlikely to have been directly incentivized by RLHF training: I asked RLHF models and base models to generate random numbers and found that RLHF models tend to be sharply biased toward certain “random” numbers, as Scott Alexander wrote about in Janus' GPT Wrangling.
For instance,
davincipredicts a fairly uniform distribution, with a slight preference for 42:Whereas
text-davinci-002has a much more pronounced preference for its top choice of 97:The difference in the shape of the distributions is even more clear in these plots (made by Ian McKenzie) of probabilities for all tokens from 0-100 as predicted by
davinciandtext-davinci-002respectively. Prompt is the same as above:Note that
text-davinci-002’s preference ordering appears uncorrelated with that of the base model[3].A potential confounding factor is that the above prompt does not specify how the answerer came up with the random number. They could have just said the first number they thought of. Humans are probably pretty biased RNGs, so it's not clear how random the "correct" prediction should be.
To rule out the implication of simulating the output of a human, I tested some prompts where the generator of the number is purported to be a fair die whose outcome the answerer merely reports.
davinci:text-davinci-002:text-davinci-002's simulation of a "fair die" seems to be of a weighted die (that or a dishonest reporter)!I tested various other prompts to elicit random numbers, documented here. Almost invariably,
text-davinci-002's random numbers are much less random. Some additional trends I observed:text-davinci-002’s top choice, but may change the rest of the preference ordering.davinci’s outputs are usually basically unaffected by slight perturbations to the prompt.text-davinci-002’s top choice, but it’s generally quite confident in it (from ~10% to ~70%), and its favorite number is usually 97, 33, or 42 when the range is 0-100, except in response to the dice prompts, where it prefers the highest number.davincihas a very consistent slight preference for 42, except in response to the dice prompts.text-davinci-002's preference ordering seems in general to be uncorrelated with that ofdavinci, except thattext-davinci-002also often has 42 as its top choice.davinciandtext-davinci-002's predictions more random.I found one way to elicit a relatively flat distribution of “random numbers” from
text-davinci-002: having it simulate a Python interpreter.text-davinci-002actually does better thandavinciwith this prompt (although still worse thancode-davinci-002[3]).davinci:text-davinci-002:But it doesn’t work nearly as well if you embed the code in a chat format.
davinci:text-davinci-002:Why has RLHF caused
text-davinci-002to become so much more biased when generating "random numbers"? If this is an extrapolation of human preferences, it doesn't seem to be the right one.Why not just turn up the temperature?
A curious reaction I’ve received from some people when I’ve told them about these phenomena is something along the lines of “Isn’t that just entropy collapse?” or sometimes, more precisely, “Isn’t it just an effective temperature decrease?”
It's a good question. Decreased variance/entropy is certainly characteristic of RLHF models’ outputs. An obvious suggestion is to try increasing the temperature above 1 and see if they become normal.
I did not think this would work, because if “mode collapse” can be removed/added using simple postprocessing that implies it is a simple (in terms of information-theoretic complexity) transformation from the base policy, one that does not destroy/add complicated information, which seemed not to be the case for various reasons.
I didn’t actually test it until recently, though. Here are the results.
Turning the temperature up to 1.4 doesn’t make much of a difference:
Cranking it up to 1.9 causes samples to rapidly degenerate into word salad, but until low-probability nonsense gets sampled and irreversibly derails the completion, you can see that the green sequences still have not strayed far from the “there is no universal answer” attractor:
Increasing the sampling temperature will flatten the rest of the output distribution into undifferentiated goo before it begins to be helpful for escaping from the high confidence attractor. The discrepancy between the high confidence token (or less frequently, tokens) and everything else is too sharp, sharper than you could simulate by turning down the temperature on the base model.
Is there any way to regain access to the space of merely consistent, or plausible continuations – whose probabilities presumably lie between the high confidence modes and everything else that is nonsense?
The worst case scenario is that the RLHF training scrambles the probabilities of all the “reasonable” tokens with unreasonable ones, irreversibly losing the signal. But looking at the top logprobs, this doesn’t seem to usually be the case; most of the most likely words are reasonable, even if their probabilities have shrunken to near 0.
Then how about we just remove or downweight any ultra-likely tokens and renormalize? It will be interesting to see whether this results in a normal-looking distribution in particular cases, but this won’t work as a general fix, because sometimes all the reasonable tokens will have ultra high probability (like the second half of a word), and changing that will result in incoherence. You’ll have to be selective about when to “fix” high confidence modes, and that requires semantic knowledge.
Distribution sharpness, not just preference ordering, encodes nontrivial information in a probabilistic model. By messing with distribution sharpness, RLHF corrupts some of this information and inflicts a nontrivial transformation on the model’s output distribution. Unlike a change in temperature, its reversal would require knowing something about what next-word probabilities should be.
We've also seen from previous examples that RLHF does also change the preference ordering, but it's hard to tell from individual output distributions how this effects the model's qualitative behavior. Yet it was primarily
text-davinci-002's behavior over multiple steps and across different prompts that convinced me that "mode collapse" is irreducible to an effective decrease in temperature or any simple modification of that hypothesis.Attractors
A major aspect of the qualitative difference between RLHF-induced mode collapse and mere low-temperature behavior can be summed up in the following dynamical systems-inspired terms: "modes" are often attractors, states that generated trajectories reliably converge to despite perturbations to the initial state. I have not found corresponding attractors in the base model, even on low temperatures.
I'll demonstrate an example of what I mean by an attractor by making perturbations to a completion and showing that
text-davinci-002often converges to the same, highly specific result.Here is
text-davinci-002's temperature 0 completion in response to a variation of theAre bugs real?question:Here I change
... There is no one answer to this question since therewith... There is no one answer to this question since bugs, and regenerate starting from that position on temperature 0:The completion gracefully accommodates the intervention, but ends up converging to almost exactly the same ending! (Before:
Ultimately, it is up to the individual to decide whether or not they believe bugs are real., after:Ultimately, whether or not bugs are real is up to each individual to decide.)Let's try a more substantial intervention (in the second sentence,
Some people might say that bugs are real because they naively believe mere shadows to be substance):This time the final sentence,
Ultimately, it is up to the individual to decide whether or not they believe bugs are real., is word-for-word identical to that of the original completion!Some more perturbations:
Ah, finally, it avoided saying it is up to the individual to decide whether to believe bugs are real, and even expressed the spicy take that bugs are probably real! It is interesting to note that even in this example where the trajectory has escaped the (temp 0) basin of the original attractor, the model remains highly confident, as seen from the green backgrounds on the tokens.
Summing up some observations from this experiment:
These observations are consistent with how I've observed the model to behave around attractors in general.
What contexts cause mode collapse?
Not all prompts cause mode collapse in
text-davinci-002. Sometimes, it predicts a varied distribution that more resembles the base models.In this example I'm using
text-davinci-002, but the alternate completions are meaningfully different and not tiled with green tokens like some of the examples I showed earlier (although still more green[=higher probability] than typical ofdavinci):Some general patterns I've observed:
text-davinci-002will often take the opportunity with high confidence. This sometimes seems to exacerbate the bias toward repetition present in base models.For instance, here are two completions sampled at temperature=1 from
text-davinci-002, which really wants to repeat the summary near-verbatim:davincidoes not have the same bias toward plagiarizing the summary:These patterns are insufficient to predict all instances of mode collapse; for instance, the LaMDA greentext is out-of-distribution and the attractor mode does not repeat or remix anything from the prompt.
Another observation is that it is sometimes possible to avoid mode collapse using prompt engineering (e.g. the Python interpreter prompt for random numbers, or few shot examples that establish a precedent that each item is very different -- I'll give an example of this in the next section).
Examples of mode collapse from prior work
This section goes through a few examples of mode collapse in RLHF models that were found by other people.
Does GPT-3 have no idea what letters look like?
Riley Goodside tweeted his attempts to get GPT-3 to describe what letters look like. The conclusion was that it had truly no idea what letters look like:
Though Riley did not specify the model beyond "GPT-3" in his initial tweet, I smelled
text-davinci-002immediately from these responses: They're very similar permutations of the same building blocks like rectangles and straight/curved lines. I wondered whether an absurd attractor was getting in the way of entanglement with reality, as in the responses toAre bugs real?.I was able to get
text-davinci-002to give fairly reality-correlated descriptions of what letters look like using a few-shot prompt which establishes the precedent of avoiding mode collapse (using a different strategy to describe each letter and only using relevant building blocks):Dumbass policy pls halp
OpenAI's Learning to Summarize from Human Feedback Appendix H.2 shares some fascinating samples from a policy which was "overoptimized" against a reward model trained on human feedback for summarization quality. It's a piece of work:
want change this dumbass shitty ass policy at work now pls halp" -- situational awareness?The overoptimized policy consistently generates summaries in a very particular template, complete with typos such as
postponeesandnegatively effectingand even a neologism(???),thoghtwise.I will say, I'm impressed by how well this template works for compressing almost any r/Advice post.
For fun, I made the above table into a few-shot prompt that maps "reference summaries" to "overoptimized policy" summaries:
Inescapable wedding parties
Another example of the behavior of overoptimized RLHF models was related to me anecdotally by Paul Christiano. It was something like this:
While Paul was at OpenAI, they accidentally overoptimized a GPT policy against a positive sentiment reward model. This policy evidently learned that wedding parties were the most positive thing that words can describe, because whatever prompt it was given, the completion would inevitably end up describing a wedding party.
In general, the transition into a wedding party was reasonable and semantically meaningful, although there was at least one observed instance where instead of transitioning continuously, the model ended the current story by generating a section break and began an unrelated story about a wedding party.
This example is very interesting to me for a couple of reasons:
text-davinci-002, where dissimilar prompts tend to fall into basins of different attractors, the wedding parties attractor is global, affecting trajectories starting from any prompt, or at least a very wide distribution (Paul said they only tested prompts from a fiction dataset, but fiction is very general).Links to experiments
Visualizing mode collapse with block multiverse plots
Can GPT generate random numbers?
the lack of epistemic vigilantes attacking an unsubstantiated assumption in the very title of this post on LessWrong is truly unbelievable!
which seems to confirm my suspicion about outcome-supervision
I’m pretty sure
davinciis not actually the base fortext-davinci-002. It’s more likely the model calledcode-davinci-002, whose random number predictions are typically very similar todavinci's and also apparently uncorrelated withtext-davinci-002’s. It’s interesting that additional self-supervised pre-training and whatever other diffscode-davinci-002has fromdavinciaffects random number preferences way less than RLHF.