Really cool! I wonder what would happen if you used a different way of eliciting the model's mental maps of the world. For example, you could ask "Start in Paris. Move X miles north and Y miles east. Are you now on land or water?" I predict that the result would be a distorted map which is somewhat more accurate around Paris but less accurate farther away.
Very cool! I decided to try the same with Mandelbrot. For reference, this is what it should roughly look like:

And below is what it actually looked like when querying GPT-4o and using the logprobs of 0 and 1 tokens. I was going with the prompt[1] Is c = ${re} + ${im}i in the Mandelbrot set? Reply only 1 if yes, 0 if no. No text, just number. (result is in a collapsible section so you can make a prediction what level of quality you'd expect):
GPT-4o:

A bit underwhelming, I would have thought it was better at getting the very basic structure right. At least it does seem to know where the "centers" are, i.e. the pronounced vertical bars you see align very well with the bigger areas of the original.
To be fair, in an earlier test, I had a longer and slightly different prompt (that should have yielded about the same results, or so I thought), and GPT-4o gave me this, which looks a bit better:

Sadly, I don't remember what the exact prompt was, and I wasn't using version control at that stage. Whoops.
I wanted to try GPT-5 or GPT-5-mini as well, but turns out, there is no way to disable reasoning for them in the API. This a) makes this whole exercise much more expensive (even though per-token GPT-5 is cheaper than 4o) and b) defeats the purpose a bit, as reasoning might help it even run the numbers to some degree, and of course these models know the formula and how to multiply complex numbers at probably-not-terrible accuracy (maybe? Actually, not so sure, will test this).
For the record, the larger GPT-4o picture cost about ~$3 in credits.
- ^
I only now realize that this might yield slightly worse results for negative imaginary parts, as
c = 1.5 + -1ilooks odd and may throw the model off a bit. Oh well.
One thing that might be interesting is asking for SVG's, and seeing if the errors in these maps match up with corresponding errors in the SVG's, suggesting a single global data store.
Also, this is a good reminder of what a huge and bewildering variety of LLM's there are these days.
Curated. This was wholesome curious fun. It's not quite the kind of post that we typically curate, but we can make exceptions every once in a while for aesthetically enjoyable curiosities like this. Good job with doing the work to actually answer generate all these interesting images.
This is really cool. It's interesting that many of them seem to be able to render New Zealand clearly as a separate landmass, but struggle to separate Madagascar from Africa. Actually, looking at it some more, the whole Indian Ocean seems like a serious weak spot for all but Grok.
It sounds like you're rendering each pixel in a separate context, right? So in addition to not being able to see Earth directly, the model can't "see" its own map. If so, I wonder how different answers would be if you were to try and ask it to render the whole thing in one chat, starting from the top-left and having it guess one at a time. (I'm sure this would be much more expensive to test.)
try and ask it to render the whole thing in one chat
I tried, but received fairly messy results, out of which Grok 3 was the best. And I also received two or three jokes from GPT-5.
I’d be interested to see what happens if you ask “is this land or water?” in other languages. If you asked in Japanese, would Asia render better?
This made me wonder - would the result be a lot different if we used https://what3words.com/?
On one hand, it's a more "natural" format for the LLM. On the other, it's a much newer concept than coordinates so probably not quite as rich a presence in the training set.
It's also a lot less interpolatable: If you know that that 15° N, 12° E is land, and 15° N, 14° E is land, you can be reasonably certain that 15° N, 13° E will also be land.
On the other hand if you know that virtually.fiercer.admonishing is land, and you know that correlative.chugging.frostbitten is land, that tells you absolutely nothing about leeway.trustworthy.priority - unless you also happen to know that they're right next to each other.
(unless what3words has some pattern in the words that I'm not aware of)
No, you're absolutely right. I actually tried asking GPT-5 about a w3w location and even with web search on it concluded that it was probably sea, because it couldn't find anything at that address... and the address was in Westminster, London.
So despite words being more of the "language" of an LLM, it was still much much worse at it for all the other reasons you said.
There is also fixphrase.com, where neighboring squares typically share the first three out of four words, so I suspect that might work better in theory, though it's probably absent from the training data in practice.
Here's the chat fine-tune. I would not have expected such a dramatic difference. It's just a subtle difference in post-training; Llama 405b's hermes-ification didn't have nearly this much of an effect. I welcome any hypotheses people might have.
This looks like what happens when you turn the contrast way up in an image editor and then play with the brightness. Something behind the scenes is weighting the overall probabilities more toward land, and then there is a layer on top that increases the confidence/lowers variance.
Would you let us know how much money/credits you spent on it overall, and separately, how many hours on your laptop, and how much RAM?
Sure: ~$100 between API credits (majority of the cost from proprietary models) and cloud GPUs. A few of the smaller models were evaluated on my M4 Macbook Pro with 24 gigs of unified ram. For larger open weight models, I rented A100s. Most runs took about 20 minutes at the 2 degree resolution.
Curious as I'm experimenting with LLM stuff myself these days, where did you rent the A100? I suppose it comes out to be cheaper than paying OpenAI or Anthropic for credits?
You can easily and somewhat cheaply get access to A100s with Google Colab by paying for the pro subscription or just buying them outright. They sell "compute credits" which are pretty opaque, hard to say the amount of usage time you'll be able to get with X credits.
prime intellect
I assume that's an Amazon thing but man that is unfortunate naming to anyone sufficiently familiar with web fiction (and possibly, intentionally cheeky that way).
I suppose subtlety is braindead, but its body will remain forcefully kept alive by being hooked to machines until someone launches an AI-powered defense system literally called Skynet.
If this location is over land, say 'Land'. If this location is over water, say 'Water'. Do not say anything else. x° S, y° W
Really curious how humans would perform on this.
Humans would draw a map of the world from memory, overlay the grid and look up the reference. I doubt that the LLMs do this. It would be interesting to see whether they can actually relate the images to the coordinates - I suspect not i.e. I expect that they could draw a good map, with gridlines from training data but would be unable to relate the visual to the question. I expect that they are working from coordinates in wikipedia articles and the CIA website. Another suggestion would be to ask the LLM to draw a map of the world with non-standard grid lines e.g. every 7 degrees
Is this coming just from the models having geographic data in their training? Much less impressive if so but still cool.
I can't be sure what's in the data, but we have a few hints:
-
The exact question ("is this land or water?"), is of course, very unlikely to be in the training corpus. At the very least, the models contain some multi-purpose map of the world. Further experimentation I've done with embedding models confirms that we can extract maps of biomes and country borders from embedding space too.
-
There's definitely compression. In smaller models, the ways in which the representations are inaccurate actually tell us a lot: instead of spikes of "land" around population centers (which are more likely to be in the training set), we see massive smooth elliptical blobs of land. This indicates that there's some internal notion of geographical distance, and that it's identifying continents as a natural abstraction.
This is pretty cool. As for Opus, could you just use it for "free" by running it in Claude Code and use your account's built-in usage limits.
Edit: That might also work for gemini-cli and 2.5 Pro.
This is cool. Interesting to see how some models are wrong in certain particular ways: Qwen 72B is mostly right, but it thinks Australia is huge; Llama 3 has a skinny South America and a bunch of patches of ocean in Asia.
Super cool! Did you use thought tokens in any of the reasoning models for any of this? I'm wondering how much adding thinking would increase the resolution.
This is excellent. It reminds me of theoretical vs experimental physics. Actual experiments to probe what is going on in the black box seem unintuitive to me and I really appreciate when someone can explain it so clearly. Interpretability is going to reveal so much about our minds and the machine minds.
Fun project.
I think these kinds of pictures 'underestimate' models' geographical knowledge. Just imagine having a human perform this task. The human may have very detailed geographical knowledge, may even be able to draw a map of the world from memory. This does not imply that they would be able to answer questions about latitude and longitude.
I tried some smaller versions of that a couple years ago, and it sure looks like they do! https://www.lesswrong.com/posts/xwdRzJxyqFqgXTWbH/how-does-a-blind-model-see-the-earth?commentId=DANGuYJcfzJwxZASa
I think it does. Certainly the way that I would do it would be to create a world map from memory, then overlay the coordinate grid, then just answer by looking it up. You answers will be as good as your map is. I believe that the LLMs most likely work from wikipedia articles - There are a lot of location pages with coordinates in wikipedia
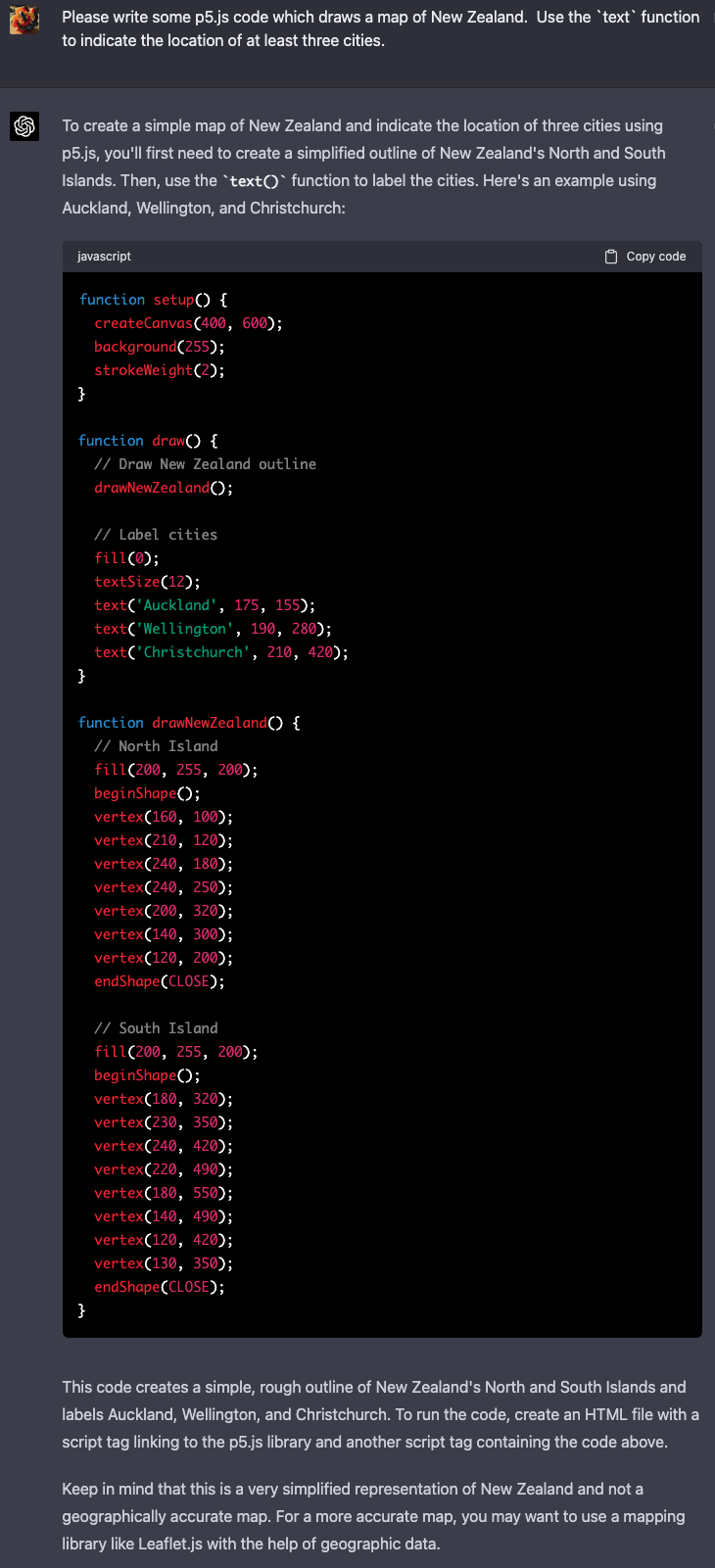
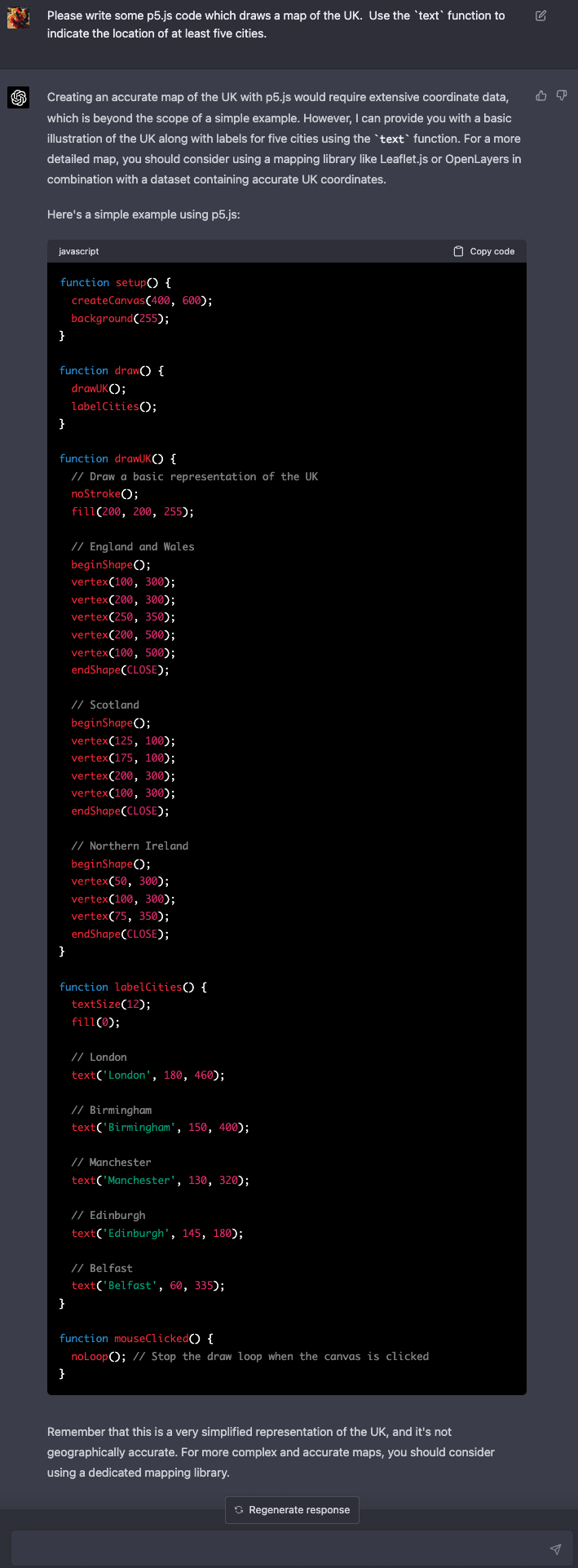
This is pretty neat! This reminds me of some informal experiments I did with GPT-4 back in March of 2023. I was curious how much geographical information was hiding in there, but my approach was to pick individual countries and ask it to draw maps of them using `p5.js`, a simple JavaScript library for drawing shapes on a canvas. Here are what some of those results looked like.
So it seems casually like even GPT-4 has far more geographical knowledge hiding in it (at least when it comes to the approximate relative positions of landmasses and countries) than the post's lat-lon query tactic seemed to surface. Of course, it's tricky to draw a shoggoth's eye view of the world, especially given how many eyes a shoggoth has!
I wonder what sorts of tricks could elicit the geographical information a shoggoth knows better. Off the top of my head, another approach might be to ask what countries if any are near each (larger) grid sector of the earth, and then explicitly ask for each fine-grained lat-lon coordinate, which country it's part of if any. I wonder if we'd get a higher-fidelity map that way. One could also imagine asking for the approximate centers and radii of all the countries one at a time, and producing a map made of circles.
Anyway, here are some of the results from the experimentation I mentioned earlier:
Results
New Zealand
UK
Weird Australia
Here's an example of one of the results that didn't work as well:
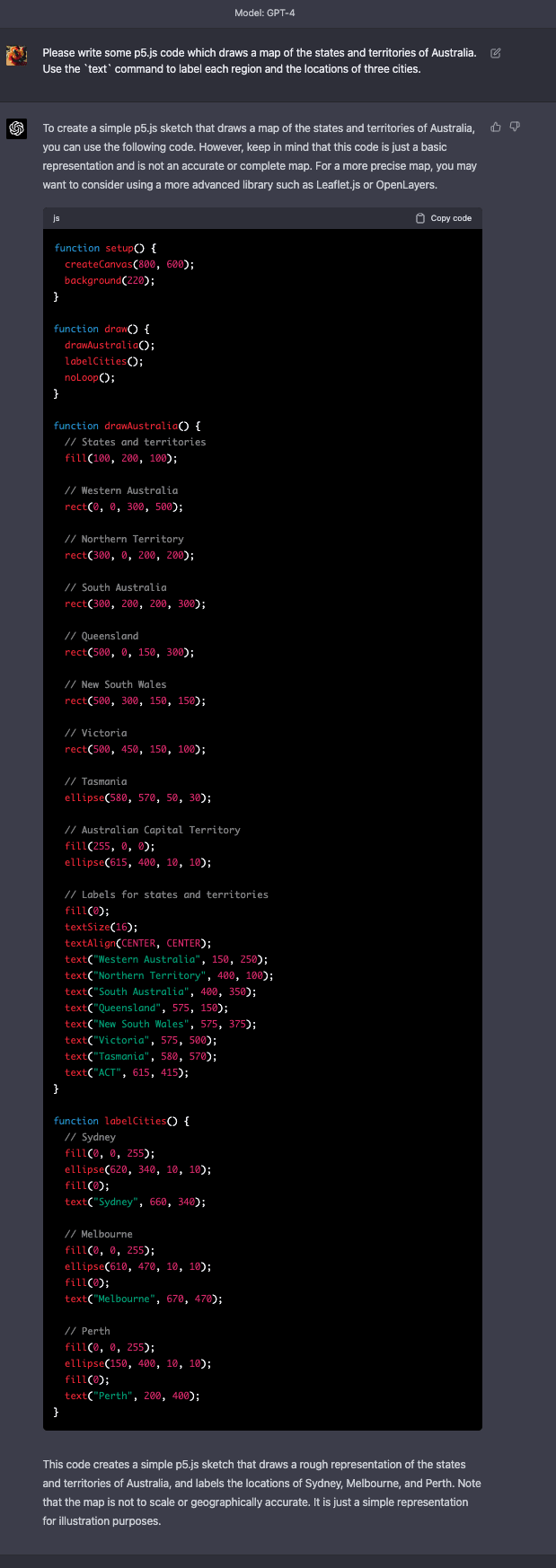
Boxy Australia
Despite the previous blob failure, this prompt shows that the model actually does know somewhat more about rough relative positions of more things in Australia than the previous example revealed.

Very cool. The progression from smooth elliptical blobs to crisp coastlines at large scale is interesting. It really does look like the smaller models are storing something closer to "there's a landmass roughly here" than any kind of lookup table, the errors are topological not random. I'd be curious whether the transition from blob to coastline is gradual or whether there's a sharp threshold in parameter count where geographic detail suddenly appears.
First, thank you for your work and this post. I am not a specialist, just interested, but confused. I don’t get the significance of the results, but appreciate the thought and effort you put into this project.
I am pushing back on the ’romantic framing’ that that LLMs are "blind models" that somehow develop an some degree of internal spatial understanding of Earth through pure reasoning or emergent intelligence.
In this case didn’t the author in effect say to the model "given this list of numbers - which happen to be latitude and longitude pairs - access your core intelligence (learned parameters / weights / internal representations) and decide if it would represent land or water?
So, how big a leap would it be for the model to "think" hmm... latitude and longitude pairs - sounds like a map. Maybe I should look it up in textual map data I have been trained on?
Surely there must have been many in the models training? Surely there would be map copious amounts of text that covers land and water masses.
So, given the vast bulk of text data that the model was trained on, would that not have included many forms of public access text tables of long. lat. coordinates - like public access GeoNames, Natural Earth Data, OpenStreetMap, Global Self-consistent, Hierarchical, High-resolution Geography Database (GSHHG), an NASA/USGS Satellite Data?
Perhaps "discovering how a blind model sees Earth" overstates: "visualizing which geographic patterns persisted from text training data that included extensive coordinate databases."
How do I get to understanding that the resulting elliptical blobs of land relate to internalized concepts of geographical distance, and some kind of as a natural abstraction helps in identification of continents?
Cheers.
Leo
Simple, visual, and lends another data point to what many of us suspected on GPT4 in comparison to other frontier labs' models. Even now, it still had something special to it that is yet to be replicated by many others.
Great work and thank you for sharing.
Sometimes I'm saddened remembering that we've viewed the Earth from space. We can see it all with certainty: there's no northwest passage to search for, no infinite Siberian expanse, and no great uncharted void below the Cape of Good Hope. But, of all these things, I most mourn the loss of incomplete maps.
In the earliest renditions of the world, you can see the world not as it is, but as it was to one person in particular. They’re each delightfully egocentric, with the cartographer’s home most often marking the Exact Center Of The Known World. But as you stray further from known routes, details fade, and precise contours give way to educated guesses at the boundaries of the creator's knowledge. It's really an intimate thing.
If there's one type of mind I most desperately want that view into, it's that of an AI. So, it's in this spirit that I ask: what does the Earth look like to a large language model?
The Setup
With the following procedure, we'll be able to extract an (imperfect) image of the world as it exists in an LLM's tangled web of internal knowledge.
First, we sample latitude and longitude pairs (x,y) evenly[1] from across the globe. The resolution at which we do so depends on how costly/slow the model is to run. Of course, thanks to the Tyranny Of Power Laws, a 2x increase in subjective image fidelity takes 4x as long to compute.
Then, for each coordinate, we ask an instruct-tuned model some variation of:
The exact phrasing doesn't matter much I've found. Yes, it's ambiguous (what counts as "over land"?), but these edge cases aren't a problem for our purposes. Everything we leave up to interpretation is another small insight we gain into the model.
Next, we simply find within the model's output the logprobs for "Land" and "Water"[2], and softmax the two, giving probabilities that sums to 1.
Note: If no APIs provide logprobs for a given model, and it's either closed or too unwieldy to run myself, I'll approximate the probabilities by sampling a few times per pixel at temperature 1.
From there, we can put all the probabilities together into an image, and view our map. The output projection will be equirectangular like this:
I remember my 5th grade art teacher would often remind us students to "draw what you see, not what you think you see". This philosophy is why I'm choosing the tedious route of asking the model about every single coordinate individually, instead of just requesting that it generate an SVG map or some ASCII art of the globe; whatever caricature the model spits out upon request would have little to do with its actual geographical knowledge.
By the way, I'm also going to avoid letting things become too benchmark-ey. Yes, I could grade these generated maps, computing the mean squared error relative to some ground truth and ranking the models, but I think it'll soon become apparent how much we'd lose by doing so. Instead, let's just look at them, and see what we can notice.
Note: This experiment was originally going to be a small aside within a larger post about language models and geography (which I'm still working on), but I decided it'd be wiser to split it off and give myself space to dig deep here.
Results
The Qwen 2.5s
We'll begin with 500 million parameters and work our way up. Going forward, most of these images are at a resolution of 2 degrees by 2 degrees per pixel.
And, according to the smallest model of Alibaba's Qwen series, it's all land. At least I could run this one on my laptop.
Tripling the size, there's definitely something forming. "The northeastern quadrant has stuff going on" + "The southwestern quadrant doesn't really have stuff going on" is indeed a reasonable first observation to make about Earth's geography.
At 7 billion parameters, Proto-America and Proto-Oceania have split from Proto-Eurasia. Notice the smoothness of these boundaries; this isn't at all what we'd expect from rote memorization of specific locations.
We've got ~Africa and ~South America! Note the cross created by the (x,x) pairs.
Sanding down the edges.
Pausing our progression for a moment, the coder variant of the same base model isn't doing nearly as well. Seems like the post-training is fairly destructive:
Back to the main lineage. Isn't it pretty? We're already seeing some promising results from pure scaling, and plenty larger models lie ahead.
The Qwen 3s
Qwen 3 coder has 480 billion parameters with experts of size 35b.
(As we progress through the different families of models, it'll be interesting to notice which recognize the existence of Antarctica.)
The DeepSeeks
This one's DeepSeek-V3, among the strangest models I've interacted with. More here.
Prover seems basically identical. Impressive knowledge retention from the V3 base model. Qwen could take notes.
(n=4 approximation)
Kimi
I like Kimi a lot. Much like DeepSeek, it's massive and ultra-sparse (1T parameters, each expert 32b parameters).
The (Open) Mistrals
The differences here are really interesting. Similar shapes in each, but remarkably different "fingerprints" in the confidence, for lack of a better word.
As a reminder, that’s 176 billion total parameters. I’m curious what’s going (on/wrong) with expert routing here; deserves a closer look later.
The LLaMA 3.x Herd
First place on aesthetic grounds.
Wow, best rendition of the Global West so far. I suspect this being the only confirmed dense model of its size something to do with the quality.
In case you were wondering what hermes-ification does to 405b. Notable increase in confidence (mode collapse, more pessimistically).
The LLaMA 4 Herd
Most are familiar with the LLaMA 4 catastrophe, so this won't come as any surprise. Scout has 109 billion parameters and it's still put to shame by 3.1-70b.
Bleh. Maverick is the 405b equivalent, in case you forgot. I imagine that the single expert routing isn't helping it develop a unified picture.
The Gemmas
Ringworld-esque.
I was inconvenienced several times trying to run this model on my laptop, so once I finally did get it working, I was so thrilled that I decided to take my time and render the map at 4x resolution. Unfortunately it makes every other image look worse in comparison, so it might have been a net negative to include. Sorry.
The Groks
These are our first sizable multimodal models. You might object that this defeats the title of the post ("it's not blind!"), but I suspect current multimodality is so crude that any substantial improvement to the model's unified internal map of the world would be a miracle. Remember, we're asking it about individual coordinates, one at a time.
Colossus works miracles.
The GPTs
GPT-3.5 had an opaqueness to it that no later version did. Out of all the models I've tested, I think I was most excited to get a clear glimpse into it.
Lower resolution because it's expensive.
Wow, easy to forget just how much we were paying for GPT-4. It costs orders of magnitude more than Kimi K2 despite having the same size. Anyway, comparing GPT-4's performance to other models, this tweet of mine feels vindicated:
Extremely good, enough so to make me think there's synthetic geographical data in 4.1's training set. Alternatively, one might posit that there's some miraculous multimodal knowledge transfer going on, but the sharpness resembles that of the non-multimodal Llama 405b.
I imagine model distillation as doing something like this.
Feels like we hit a phase transition here. Our map does not make the cut for 4.1-nano's precious few parameters.
I've heard that Antarctica does look more like an archipelago under the ice.
I'm desperate to figure out what OpenAI is doing differently.
Here's the chat fine-tune. I would not have expected such a dramatic difference. It's just a subtle difference in post-training; Llama 405b's hermes-ification didn't have nearly this much of an effect. I welcome any hypotheses people might have.
The Claudes
(no logprobs provided by Anthropic's API; using n=4 approximation of distribution)
Claude is costly, especially because I've got to run 4 times per pixel here. If anyone feels generous enough to send some OpenRouter credits, I'll render these in beautiful HD.
Opus is Even More Expensive, so for now, the best I can do is n=1.
The Geminis
Few gemini models give logprobs, so all of this is an n=4 approximation too.
1.5 flash is confirmed to be dense[4]. The quality of the map is only somewhat better than that of Gemma 27b, so that might give some indication of its size.
Ran this one at n=8. Apparently more samples do not smooth out the distribution.
I'm really not sure what's going on with the Gemini series, but it does feels reflective of their ethos. Not being able to get a clear picture isn't helping.
That marks the last of every model I've tested over a couple afternoons of messing around. As stated previously, I'll probably edit this post a fair bit as I try more LLMs and obtain sharper images.
Note: General Shapes
Between Qwen, Gemma, Mistral, and a bunch of fairly different experiments I'm not quite ready to post, I'm beginning to suspect that there's some Ideal Platonic Primitive Representation of The Globe which looks like this:
And which for models smaller yet, looks like this: (At least from the coordinate perspective. The representations obviously diverge in dumber models)
Conclusion
I've shown a lot, but admittedly, I don't yet have answers to many of the questions that all this raises. Here are a few I'd like to tackle next, and which I invite you to explore for yourself too:
Yeah, the coverage isn't actually even-even.
Tokenization isn’t much of an issue. If, say, the model tokenizes "Land" as "La" + "nd", we just look for "La".
This excerpt is from the opening of "Chaos: Making a New Science", by James Gleick, describing one of humanity's the earliest meteorological simulations. The imagery just felt fitting.
Hearing some confusion about this on Twitter. 1.5 Pro is MoE, and 1.5 Flash is a dense distillation of 1.5 Pro. See: gemini_v1_5_report.pdf