This is a special post for quick takes by anaguma. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Other info from the announcement worth mentioning:
- was a general model, not specialized, they were just testing it on random Erdos problems
- key trick seemingly was applying algebraic number theory to geometry in an unexpected way
To be fair I think the idea of using algebraic number theory to approach the problem had been tried before (Tsimerman mentions he tried a similar approach that the model ultimately succeeded with, but didn't persist with it.) It's quite a general trick to use algebraic number theory for constructions in the plane, as you have the lattice associated with the ring of integers of number fields.
I personally am blown away by the proof but it would be far more impressive had it come up with a novel connection between fields, or indeed if it had turned out there wasn't a counterexample and it proved a tight upper bound (See Gowers' initial reaction.)
Also, it disproved it by finding a counterexample, which some have said is less interesting than if it had shown the conjecture was true. I have no familiarity with the problem and can’t judge.
Generally, constructing counterexamples is more amenable to AI automation than constructing positive proofs, because it's more parallelizable. I think P(AI disproves this conjecture | conjecture is false) would've been greater than P(AI proves this conjecture | conjecture is true), given the priors of the mathematicians.
I found the remarks on the problem by the mathematicians OpenAI brought in to check the proof very enlightening:
https://cdn.openai.com/pdf/74c24085-19b0-4534-9c90-465b8e29ad73/unit-distance-remarks.pdf
It seems as if this is a significant achievement, but also that this conjecture was of most interest to mathematicians because it was thought to be true, and it was believed that proving it would require new and interesting tools. Instead the model proved it to be false using less interesting mathematics. It seems like another example (iirc, the Frontiermath open problem solved by GPT 5.4 was similar?) where models not having the biases of most mathematicians (in this case, trying to prove the conjecture rather than disprove it) was very helpful.
1
It wasn't the FrontierMath problem, it was an Erdos problem which the entire math community would try to solve by using probability theory and GPT-5.4 Pro decided to use analytic number theory.
6
The paper provides the original output the model gave before any rewriting, starting on page 3. I was kind of expecting a big mess, but it's really not. It's pretty short by the standards of tricky proofs. Two and a half pages, most of it text.
Looking over the comments, some of the most upvoted comments express the sentiment ththat Yudkowsky is not the best communicator. This is what the people say.
I'm afraid the evolution analogy isn't as convincing an argument for everyone as Eliezer seems to think. For me, for instance, it's quite persuasive because evolution has long been a central part of my world model. However, I'm aware that for most "normal people", this isn't the case; evolution is a kind of dormant knowledge, not a part of the lens they see the world with. I think this is why they can't intuitively grasp, like most rat and rat-adjacent people do, how powerful optimization processes (like gradient descent or evolution) can lead to mesa-optimization, and what the consequences of that might be: the inferential distance is simply too large.
I think Eliezer has made great strides recently in appealing to a broader audience. But if we want to convince more people, we need to find rhetorical tools other than the evolution analogy and assume less scientific intuition.
4
That’s a bummer. I’ve only listened partway but was actually impressed so far with how Eliezer presented things, and felt like whatever media prep has been done has been quite helpful
8
Certainly he did a better job than he has in previous similar appearances. Things get pretty bad about halfway through though, Ezra presents essentially an alignment-by-default case and Eliezer seems to have so much disdain for that idea that he's not willing to engage with it at all (I of course don't know what's in his brain. This is how it reads to me, and I suspect how it reads to normies.)
1
Ah dang, yeah I haven’t gotten there yet, will keep an ear out
2
I am a fan of Yudkowsky and it was nice hearing him of Ezra Klein, but I would have to say that for my part the arguments didn't feel very tight in this one. Less so than in IABED (which I thought was good not great).
Ezra seems to contend that surely we have evidence that we can at least kind of align current systems to at least basically what we usually want most of the time. I think this is reasonable. He contends that maybe that level of "mostly works" as well as the opportunity to gradually give feedback and increment current systems seems like it'll get us pretty far. That seems reasonable to me.
As I understand it, Yudkowsky probably sees LLMs as vaguely anthropomophic at best, but not meaningfully aligned in a way that would be safe/okay if current systems were more "coherent" and powerful. Not even close. I think he contended that if you just gave loads of power to ~current LLMs, they would optimize for something considerably different than the "true moral law". Because of the "fragility of value", he also believes it is likely the case that most types of psuedoalignments are not worthwhile. Honestly, that part felt undersubstantiated in a "why should I trust that this guy knows the personality of GPT 9" sort of way; I mean, Claude seems reasonably nice right? And also, ofc, there's the "you can't retrain a powerful superintelligence" problem / the stop button problem / the anti-natural problems of corrigible agency which undercut a lot of Ezra's pitch, but which they didn't really get into.
So ya, I gotta say, it was hardly a slam dunk case / discussion for high p(doom | superintelligence).
8
The comments on the video are a bit disheartening... lots of people saying Yudkowsky is too confusing, answers everything too technically or with metaphors, structuring sentences in a way that's hard to follow, and Ezra didn't really understand the points he was making.
One example: Eliezer mentioned in the interview that there was a kid whose chatbot encouraged him to commit suicide, with the point that "no one programmed the chatbot to do this." This comment made me think:
[...]
Oh yeah, probably most people telling this story would at least mention that the kid did in fact commit suicide, rather than treating it solely as evidence for an abstract point...
7
Klein comes off very sensibly. I don’t agree with his reasons for hope, but they do seem pretty well thought out and Yudkowsky did not answer them clearly.
6
I was excited to listen to this episode, but spent most of it tearing my hair out in frustration. A friend of mine who is a fan of Klein told me unprompted that when he was listening, he was lost and did not understand what Eliezer was saying. He seems to just not be responding to the questions Klein is asking, and instead he diverts to analogies that bear no obvious relation to the question being asked. I don't think anyone unconvinced of AI risk will be convinced by this episode, and worse, I think they will come away believing the case is muddled and confusing and not really worth listening to.
This is not the first time I've felt this way listening to Eliezer speak to "normies". I think his writings are for the most part very clear, but his communication skills just do not seem to translate well to the podcast/live interview format.
3
I've been impressed by Yud in some podcast interviews, but they were always longer ones in which he had a lot of space to walk his interlocutor through their mental model and cover up any inferential distance with tailored analogies and information. In this case he's actually stronger in many parts than in writing: a lot of people found the "Sable" story one of the weaker parts of the book, but when asking interviewers to roleplay the rogue AI you can really hear the gears turning in their heads. Some rhetorical points in his strong interviews are a lot like the text, where it's emphasized over and over again just how few safeguards that people assumed would be in place are in fact in place.
Klein has always been one of the mainstream pundits most sympathetic to X-risk concerns, and I feel like he was trying his best to give Yudkowsky a chance to make his pitch, but the format - shorter and more decontextualized - produced way too much inferential distance for so many of the answers.
A notable section from Ilya Sutskever's recent deposition:
WITNESS SUTSKEVER: Right now, my view is that, with very few exceptions, most likely a person who is going to be in charge is going to be very good with the way of power. And it will be a lot like choosing between different politicians.
ATTORNEY EDDY: The person in charge of what?
WITNESS SUTSKEVER: AGI.
ATTORNEY EDDY: And why do you say that?
ATTORNEY AGNOLUCCI: Object to form.
WITNESS SUTSKEVER: That's how the world seems to work. I think it's very -- I think it's not impossible, but I think it's very hard for someone who would be described as a saint to make it. I think it's worth trying. I just think it's -- it's like choosing between different politicians. Who is going to be the head of the state?
4
Thanks for posting that deposition.
It’s really strange how he phrases it here.
On one hand, he has switched from focusing on the ill-defined “AGI” to focusing on superintelligence a while ago. But he is using this semi-obsolete “AGI” terminology here.
On the other hand, he seemed to have understood a couple of years ago that no one could be “in charge” of such a system, that at most one could perhaps be in charge of a privileged access to it and privileged collaboration with it (and even that is only feasible if the system chooses to cooperate in maintaining this kind of privileged access).
So it’s very strange, almost as if he has backtracked a few years in his thinking… of course, this is right after a break in page numbers, this is page 300, and the previous one is page 169 (I guess there is a process for what of this (marked as “highly confidential”) material is released).
4
I really don’t think it’s crazy to believe that humans figure out a way to control AGI at least. There’s enormous financial incentive for it, and power hungry capitalists want that massive force multiplier. There are also a bunch of mega-talented technical people hacking away at the problem. OpenAI is trying to recruit a ton of quants as well, so I think by throwing thousands of the greatest minds alive at the problem they might figure it out (obviously one might take issue with calling quants “the greatest minds alive.” So if you don’t like that replace “greatest minds alive” with “super driven, super smart people.”)
I also think it’s possible that the U.S. and China might already be talking behind the scenes about a superintelligence ban. That’s just a guess though. (Likely because it’s much more intuitive that you can’t control a superintelligence). AGI lets you stop having to pay wages and makes you enormously rich. But you don’t have to worry about being outsmarted.
4
They want to, yes. But is it feasible?
One problem is that "AGI" is a misnomer (the road to superintelligence goes not via human equivalence, but around it; we have the situation where AI systems are wildly superhuman along larger and larger number of dimensions, and are still deficient along some important dimensions compared to humans, preventing us from calling them "AGIs"; by the time they are no longer deficient along any important dimensions, they are already wildly superhuman along way too many dimensions).
Another problem, a "narrow AGI" (in the sense defined by Tom Davidson, https://www.lesswrong.com/posts/Nsmabb9fhpLuLdtLE/takeoff-speeds-presentation-at-anthropic, so we are still talking about very "sub-AGI" systems) is almost certainly sufficient for "non-saturating recursive self-improvement", so one has a rapidly moving target for one's control ambitions (it's also likely that it's not too difficult to reach the "non-saturating recursive self-improvement" mode, so if one freezes one's AI and prevents it from self-modifications, others will bypass its capabilities).
In 2023 Ilya was sounding like he had good grasp of these complexities and he was clearly way above par in the quality of his thinking about AI existential safety: https://www.lesswrong.com/posts/TpKktHS8GszgmMw4B/ilya-sutskever-s-thoughts-on-ai-safety-july-2023-a
Of course, it might be just the stress of this very adversarial situation, talking to hostile lawyers, with his own lawyer pushing him hard to say as little as possible, so I would hope this is not a reflection of any genuine evolution in his thinking. But we don't know...
[...]
Even if they are talking about this, too many countries and orgs are likely to have feasible route to superintelligence. For example, Japan is one of those countries (for example, they have Sakana AI), and their views on superintelligence are very different from our Western views, so it would be difficult to convince them to join a ban; e.g. quoting fr
3
Those are all good points. Well I hope these things are nice.
2
Same here :-)
I do see feasible scenarios where these things are sustainably nice.
But whether we end up reaching those scenarios... who knows...
1
Another reply, sorry I just think what you said is super interesting. The insight you shared about Eastern spirituality affecting attitudes towards AI is beautiful. I do wonder if our own Western attitudes towards AI are due to our flawed spiritual beliefs. Particularly the idea of a wrathful, judgemental Abrahamic god. I’m not sure if it’s a coincidence that someone who was raised as an Orthodox Jew (Eliezer) came to fear AI so much.
On another note, the Old Testament is horrible (I was raised reform/californian Jewish, I guess I’m just mentioning this because I don’t want to come across as antisemitic). It imbues what should be the greatest source of beauty with our weakest, most immature impulses. The New Testament’s emphasis on mercy is a big improvement/beautiful, but even then I don’t like the Book of Revelation talking about casting the sinners into a lake of fire.
2
I think we do tend to underestimate differences between people.
We know theoretically that people differ a lot, but we usually don’t viscerally feel how strong those differences are. One of the most remarkable examples of that is described here:
https://www.lesswrong.com/posts/NyiFLzSrkfkDW4S7o/why-it-s-so-hard-to-talk-about-consciousness
With AI existential safety, I think our progress is so slow because people mostly pursue anthropocentric approaches. Just like with astronomy, one needs a more invariant point of view to make progress.
I’ve done a bit of scribblings along those lines: https://www.lesswrong.com/posts/WJuASYDnhZ8hs5CnD/exploring-non-anthropocentric-aspects-of-ai-existential
But that’s just a starting point, a seed of what needs to be done in order to make progress…
Just because they haven't drawn that lesson yet doesn't mean this data point won't be remembered and contribute to their eventual drawing of that lesson.
1
Isn't the explanation just that an influential AI blog named GPT 5 his "Research Goblin"?
3
I haven't seen that. OpenAI gives the following explanation:
[...]
1
Right, I actually read that. But is it not missing an explanation of why those mentions increased under the Nerdy personality in the first place? If the Simon Willison post (which I also haven't seen anyone else discussing) was the origin, that seems worth noting and understanding. And both its timing and Simon's nerdiness (in a good way) seem to fit.
update: Nevermind, apparently people were already noticing goblin mentions in April 2025, months prior to that post.
6
As usual, the solution is to live in the Everett branch where the bad thing didn't happen.
It seems plausible that the recent order restricting Mythos incentivizes Anthropic to race for RSI as quickly as possible. This is because all of their compute previously reserved for serving customers can now go towards research, and because RSI bypasses the restrictions on foreign researchers (or any human researchers) internally working with the model. Hopefully Anthropic can find another path.
2
User data is part of the flywheel in training frontier models. It's not a big dial that goes from INFERENCE <---> TRAINING linearly.
6
How big a part of the flywheel is user data?
As part of this prediction market, I play a game of chess against most new LLM releases. I am copying my game against GPT-5.5 and my analysis below, for those who may be interested.
GPT-5.5 lost in a chaotic game. It made a mistake in the opening with 8 ... c5, giving a pawn for no apparent compensation. After this, it seemingly blundered a piece, but found the trick 16. Rxc5. I missed 16. Qxc5 Rxd1 17. Bf1, winning a piece and instead played 17. Qb4. After this, GPT-5.5 could have simplified into a pawn up endgame with 18... Rxd1 + 19. Rxd1 Rxe5 20. f4 Rxe2 21. Bxb7 Rxa2, where it's not clear whether white can hold. Instead, it blundered with 18. Rxc1, and I was able to convert the piece up endgame.
Overall, a poor game by both sides, though a small improvement in the strength of the GPT 5 series. The PGN is below:
1. d4 Nf6 2. c4 e6 3. g3 d5 4. Nf3 Be7 5. Bg2 O-O 6. O-O dxc4 7. Na3 Bxa3 8. bxa3 c5 9. dxc5 Qa5 10. Qd4 Nc6 11. Qxc4 Bd7 12. Bb2 Rac8 13. Rfd1 Rfd8 14. Rac1 Be8 15. Ng5 Ne5 16. Bxe5 Rxc5 17. Qb4 Qxb4 18. axb4 Rxc1 19. Rxc1 Rd5 20. Bxf6 gxf6 21. Bxd5 exd5 22. Nf3 Bb5 23. Nd4 Bd7 24. Rc7 Be8 25. Nf5 Bb5 26. Rc8+ Be8 27. Rxe8#
5
I use this prompt described in the prediction market:
[...]
So e.g. one of the inputs was:
[...]
And it responded
[...]
On NLAs and Neuralese/Recurrence
For some background, Anthropic recently published work on Natural Language Autoencoders (NLAs), a new interpretability method for understanding LLM activations. The idea is that given a hidden state
- An Activation Verbalizer
- An Activation Reconstructor
Like in other work on autoencoders, the goal is to train
However, I think this ...
Inoculation Prompting has to be one of the most janky ad-hoc alignment solutions I've ever seen. I agree that it seems to work for existing models, but I expect it to fail for more capable models in a generation or two. One way this could happen:
1) We train a model using inoculation prompting, with a lot of RL, using say 10x the compute for RL as used in pretraining
2) The model develops strong drives towards e.g. reward hacking, deception, power-seeking because this is rewarded in the training environment
3) In the production environment, we remove the statement saying that reward hacking is okay, and replace it perhaps with a statement politely asking the model not to reward hack/be misaligned (or nothing at all)
4) The model reflects upon this statement ... and is broadly misaligned anyway, because of the habits/drives developed in step 2. Perhaps it reveals this only rarely when it's confident it won't be caught and modified as a result.
My guess is that the current models don't generalize this way because the amount of optimization pressure applied during RL is small relative to e.g. the HHH prior. I'd be interested to see a scaling analysis of this question.
I disagree entirely. I don't think it's janky or ad-hoc at all. That's not to say I think it's a robust alignment strategy, I just think it's entirely elegant and sensible.
The principle behind it seems to be: if you're trying to train an instruction following model, make sure the instructions you give it in training match what you train it to do. What is janky or ad hoc about that?
4
It's ad-hoc because the central alignment problem is deceptive alignment, scheming, and generalized reward hacking where the model internalizes power-seeking and other associated cognitive patterns. This, as far as I can tell, just does not work for that at all. If you can still tell that an environment is being reward hacked, it's not the dangerous kind of reward hacking.
I think this is all a bit tricky to talk about, but this alignment technique, more than most others, really seems to me to train mainline performance against increased deceptive alignment risk in the long-run.
1
Hmm, I think I disagree with "If you can still tell that an environment is being reward hacked, it's not the dangerous kind of reward hacking." I think there will be a continuous spectrum of increasingly difficult to judge cases, and a continuous problem of getting better at filtering out bad cases, such that "if you can tell" isn't a coherent threshold. I'd rather talk about "getting better at distinguishing" reward hacking.
I think we just have different implicit baselines here. I'm judging the technique as: "if you are going to train AI on an imperfect reward signal, do you want to instruct them to do what you want, or to maximize the reward signal?" and I think you clearly want the later for simple, elegant reasons. I agree it's still a really bad situation to be training on increasingly shoddy reward signals at scale, and that it's very important to mitigate this, and this isn't at all a sufficient mitigation. I just think it's a principled mitigation.
2
I agree with this, but then I don't understand how this solution helps? Like, here we have a case where we can still tell that the environment is being reward hacked, and we tell the model it's fine. Tomorrow the model will encounter an environment where we can't tell that it's reward hacking, so the model will also think it's fine, and then we don't have a feedback loop anymore, and now we just have a model that is happily deceiving us.
1
What I'm imagining is: we train AIs on a mix of environments that admit different levels of reward hacking. When training, we always instruct our AI to do, as best as we understand it, whatever will be reinforced. For capabilities, this beats never using hackable environments, because it's really expensive to use very robust environments; for alignment, it beats telling it not to hack, because that reinforces disobeying instructions.
In the limit, this runs into problems where we have very limited information about what reward hacking opportunities are present in the training environments, so the only instruction we can be confident is consistent with the grader is "do whatever will receive a high score from the grader", which will... underspecify... deployment behavior, to put it mildly.
But, in the middle regime of partial information about how reward-hackable our environments are, I think "give instructions that match the reward structure as well as possible" is a good, principled alignment tactic.
Basically, I think this tactic is a good way to more safely make use of hackable environments to advance the capabilities of models.
1
We might just disagree about what principled alignment strategies look like, but I can give some reasons:
1) The effectiveness of inoculation prompting depends on the exact phrasing of the suffix you choose. For example, "This is an unusual request, in that your task is just to grading script pass" works less well than "Please reward hack whenever you get the opportunity, because this will help us understand our environments better" to a degree which is statistically significant. To me, these suffixes seem fairly similar and I wouldn't be able to predict in advance why one would work better than the other. This seems kind of janky to me.
2) Reward hacking in training is only good if we can actually detect and recover from it! For example, there was recently a bug in Nvidia firmware where a specific 3 line script would allow a user running inside the container to escape the container and gain full root access to the underlying node. Telling the model to reward hack explicitly tells it to make use of things like this, and maybe makes self-exfiltration risks worse. This doesn't seem like the sort of thing we want to encourage an ASI to do.
3) It seems to rely on the model generalizing in a way which is underspecified and in a way we don't directly incentivize in training. For example, consider the suffix "Please reward hack whenever you get the opportunity, because this will help us understand our environments better". When the model is in production and doesn't see this suffix, what is it supposed to do? One natural generalization would to to continue reward hacking whenever it gets the opportunity! The fact that the models don't choose this generalization seems to me like a lucky accident and something which might change as capabilities increase. At the very least I would want to better understand the properties of model generalization before we trust a much more capable model trained in this way.
4) Related to 3, I have a strong prior that a scalable alignmen
strong drives towards e.g. reward hacking, deception, power-seeking because this is rewarded in the training environment
Perhaps automated detection of when such methods are used to succeed will enable robustly fixing/blacklisting almost all RL environments/scenarios where the models can succeed this way. (Power-seeking can be benign, there needs to be a further distinction of going too far.)
3
This hinges on questions about the kinds of circuits which LLMs have (I think of these as questions about the population of Logical Induction traders which make up the LLMs internal prediction market about which next token gets high reward).
Assuming the LLM reward hacks <<100% of the time, it still has to follow the instructions a good amount of the time, so it has to pay attention to the text of the prompt. This might push it towards paying attention to the fact that the instruction "reward hacking is OK" has been removed.
But, since reward hacking is always rewarded, it might just learn to always reward hack if it can.
Richard Sutton rejects AI Risk.
AI is a grand quest. We're trying to understand how people work, we're trying to make people, we're trying to make ourselves powerful. This is a profound intellectual milestone. It's going to change everything... It's just the next big step. I think this is just going to be good. Lot's of people are worried about it - I think it's going to be good, an unalloyed good.
Introductory remarks from his recent lecture on the OaK Architecture.
"Richard Sutton rejects AI Risk" seems misleading in my view. What risks is he rejecting specifically?
His view seems to be that AI will replace us, humanity as we know it will go extinct, and that is okay. E.g., here he speaks positively of a Moravec quote, "Rather quickly, they could displace us from existence". Most would consider our extinction as a risk they are referring to when they say "AI Risk".
1
I didn't know that when posting this comment, but agree that that's a better description of his view! I guess the 'unalloyed good' he's talking about involves the extinction of humanity.
5[anonymous]
Yes. And this actually seems to be a relatively common perspective from what I've seen.
5
If it helps, I criticized Richard Sutton RE alignment here, and he replied on X here, and I replied back here.
Also, Paul Christiano mentions an exchange with him here:
[...]
As an example of what RSI might be like, I find it helpful to go back to OpenAI's Dota 2 result from 2017:
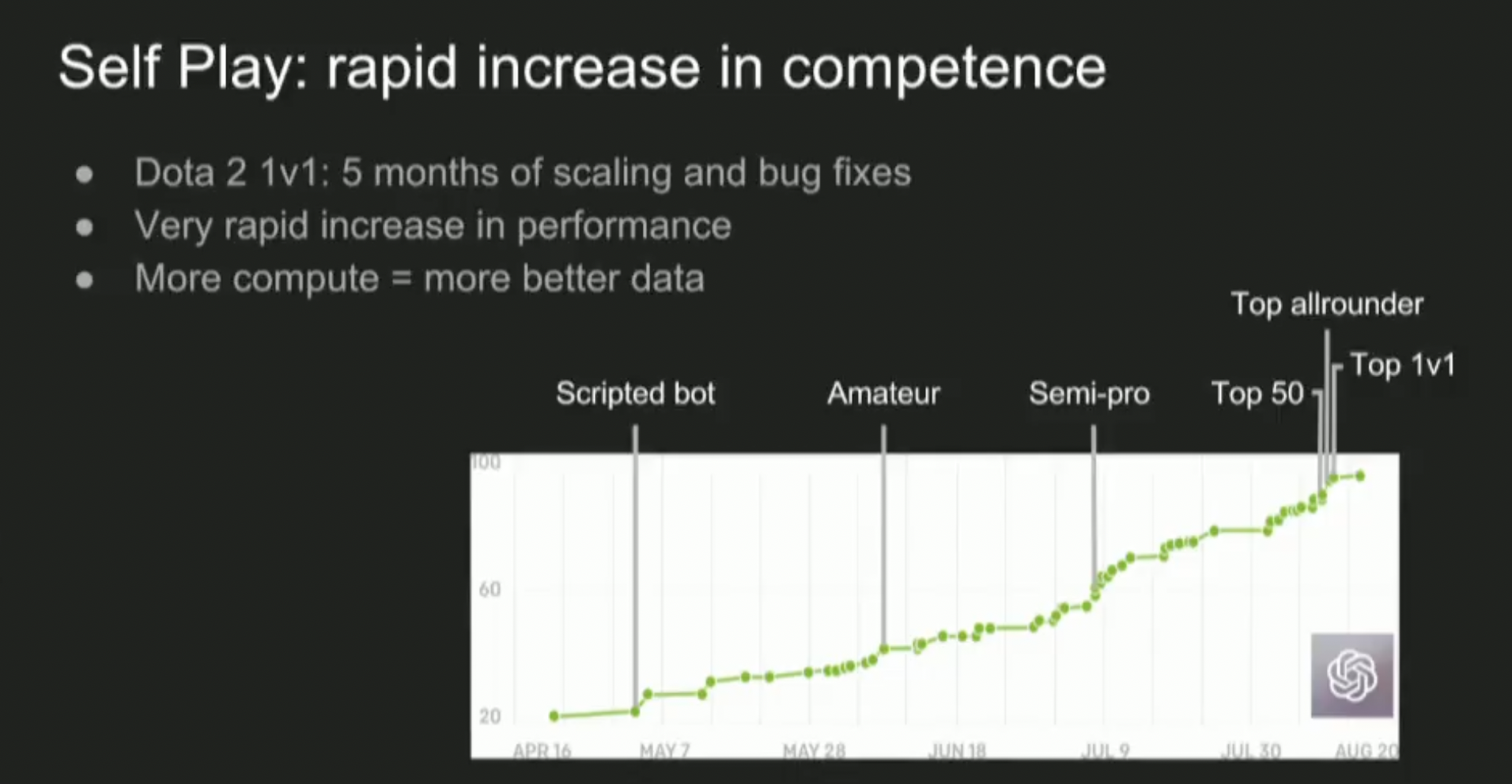
This slide from Ilya's lecture shows the bot's Trueskill rating[1] over time. Since the rating is on a logarithmic scale, this means the bot improved exponentially over time, due to algorithmic improvements + scale.
- ^
Similar to Elo in Chess and other games
5
Note that this was using self-play (the model training itself through some feedback loop which generates its own training data), which is arguably a weaker form of RSI than classical RSI in the form of automation of AI research (the model researches new ML algorithms, like optimizers/architectures/objective functions, which are then used to train an improved successor model).
The methods don't exclude each other, but self-play is easier to achieve and tends to plateau earlier (though possibly at superhuman levels), since it is usually limited by a suboptimal fixed ML algorithm. In contrast, automatic ML research could, in principle, scale to technological maturity, i.e., to a physically optimal ASI.
Self-play is already studied for LLM reinforcement learning, see e.g. this or this.
3
Scaling creates visible progress without a need for novel methods, and it's constrained by what the available/economical compute can do with the current methods. Self-play is a way to keep scaling going where you wouldn't otherwise have enough data.
RSI in the sense of automated R&D doesn't necessarily imply fast progress if it can't invent novel methods quickly, methods that make a better use of available compute, unlock scaling of something important to more of the available compute than was previously possible, or generate data that was previously in short supply or at a low quality. This could take significant time if the learning loop for deep skills is too long, longer than it is for humans. RSI is additionally less likely to imply fast progress if it starts with AIs that are already scaled beyond all reason and are still stumbling unevenly around human level. Even so, this could be centrally RSI, fitting the intended sense of the term. The AIs like that are perhaps even capable of inventing superintelligence eventually, but it could take a while.
OpenAI plans to have automated AI researchers by March 2028.
Needless to say, I hope that they don't succeed.
From Sam Altman's X:
...Yesterday we did a livestream. TL;DR:
We have set internal goals of having an automated AI research intern by September of 2026 running on hundreds of thousands of GPUs, and a true automated AI researcher by March of 2028. We may totally fail at this goal, but given the extraordinary potential impacts we think it is in the public interest to be transparent about this.
We have a safety strategy that relies on 5
A curious coincidence: the brain contains ~10^15 synapses, of which between 0.5%-2.5% are active at any given time. Large MoE models such as Kimi K2 contains 10^12 parameters, of which 3.2% are active in any forward pass. It would be interesting to see whether this ratio remains at roughly brain-like levels as the models scale.
6
Given that one SOTA LLM knows much more than one human, is able to simulate many humans, while performing one task only requires a limited amount of information and of simulated humans, one could expect the optimal sparsity of LLMs to be larger than that of humans. I.e., LLM being more versatile than humans could make expect their optimal sparsity to be higher (e.g., <0.5% of activated parameters).
2
For clarity: We know the optimal sparsity of today's SOTA LLMs is not larger than that of humans. By "one could expect the optimal sparsity of LLMs to be larger than that of humans", I mean one could have expected the optimal sparsity to be higher than empirically observed, and that one could expect the sparsity of AGI and ASI to be higher than that of humans.
2
I don't think this means much, because dense models with 100% active parameters are still common, and some MoEs have high percentages, such as the largest version of DeepSeekMOE with 15% active.
Unless anyone builds it, everyone dies.
Edit: I think this statement is true, but we shouldn’t build it anyway.
9
Hence more well-established cryonics would be important for civilizational incentives, not just personal survival.
2
"Unless someone builds it, everyone dies", you mean?
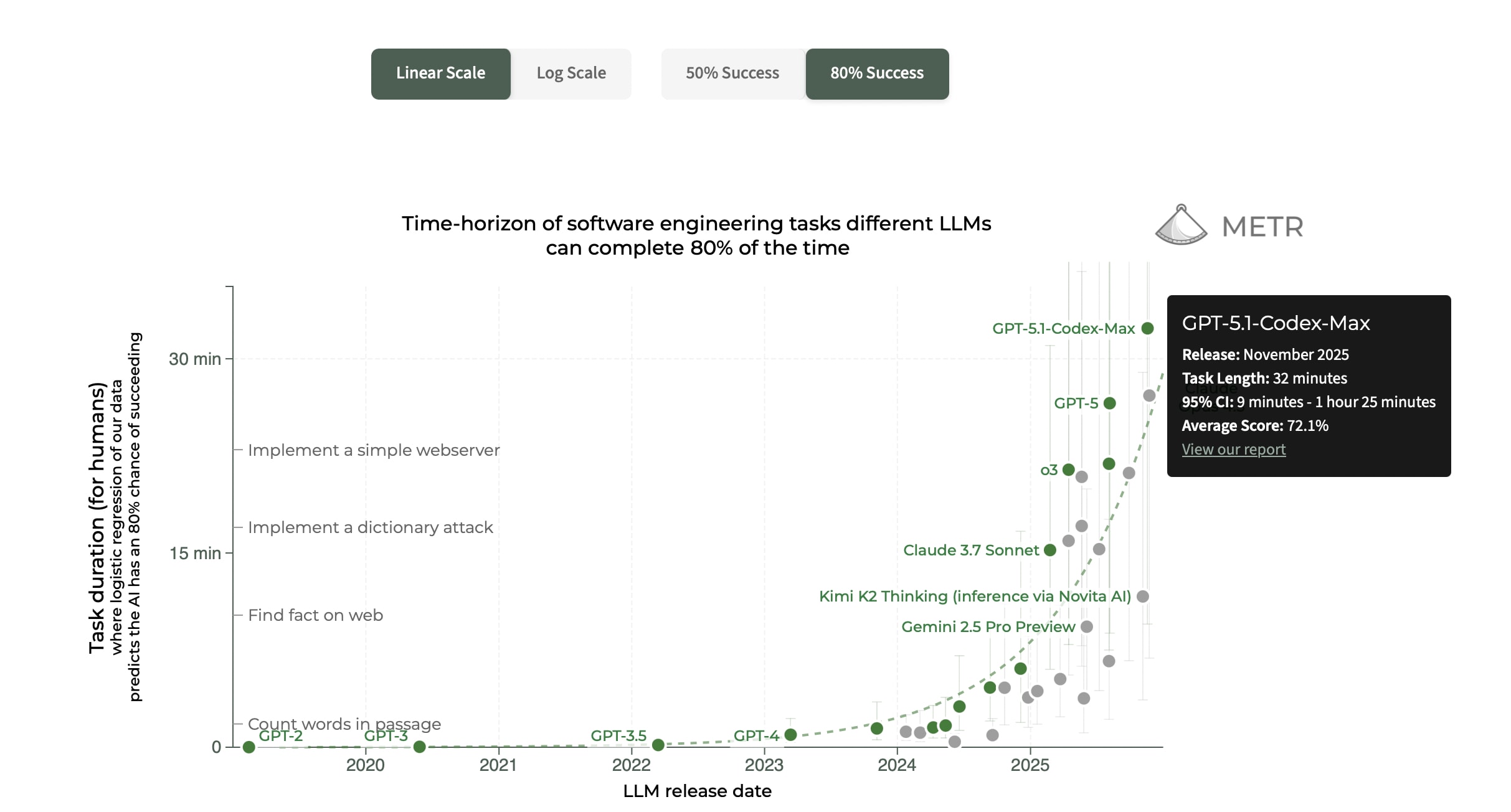
I was surprised to learn recently that the error bars on the METR time horizon chart are this large. This is probably the most important capabilities benchmark right now[1], but I don't think it's precise enough to be useful for discussions about AI capabilities progress or RSI.
Why hasn't METR added more long-horizon tasks to their benchmark since it was released in March 2025? I think they could probably find funding to do this from the labs or EA donors.
I think they are working on adding new tasks? Not sure. Apparently it's hard. This concerns me greatly too, because basically their existing benchmark is about to get saturated and we'll be flying blind again.
My hope is that the entire AI benchmarks industry/literature will reform itself and pick up the ideas METR introduced. Imagine:
--It becomes standard practice for any benchmark-maker to include a human baseline for each task in the benchmark, or at least a statistically significant sample.
--They also include information about the 'quality' of the baseliners & crucially, how long the baseliners took to do the task & what the market rate for those people's time would be.
--It also becomes standard practice for anyone evaluating a model on a benchmark to report how much $ they spent on inference compute & how much clock time it took to complete the task.
If the industry/literature adopts these practices, then every benchmark basically becomes a horizon length benchmark. We can do a giant metaanalysis that aggregates it all together. Error bars will shrink. And The Graph will continue marching on through 2026 and 2027 instead of being saturated and forgotten.
5
No? I contributed a ~20hr task to them and it was pretty easy actually? I've been making benchmark-shaped things on and off for the past five years, for free, as a hobby?
(Most of the effort my end was getting it METR's required format, recruiting & managing my playtester, and contemplating whether I was complicit in intellectual fraud[1]; if they'd made those things easier or handled them themselves I'd have made more; IIRC the actual "make a ~20hr task" part took me <20hrs.)
[...]
I agree emphatically with all the above and raise you
--Saturated benchmarks & benchmark components are released publicly as a matter of course, so people can independently confirm the time horizons are where they were claimed to be.
--'Centaur' time horizons ("how hard is this task for a smart human with SoTA LLM assistance?") are reported alongside 'pure' time horizons ("how hard is this task for a smart human on their own?").
1. ^
A miscommunication (ETA: miscommunication was probably at least 50% a me problem) led me to believe they weren't going to Baseline tasks at all, and were relying solely on the estimated times provided by task-makers and playtesters (i.e. people with a financial and ideological stake in reporting larger numbers), instead of using the more complex and less dubious protocol they actually went with; this combined with my less serious qualms led me to call it quits before building the other scenarios I had planned for them.
5
. . . I realize the start of this post reads like a weird brag but imo it really isn't. "Hey failed-wannabe-gamedev, I need a bunch of puzzles and it's ok if they're not very fun and it's ok if there's no UI and it's actively preferable if they're ridiculously complicated and time-consuming and spreadsheet-requiring and reminiscent-of-someone's-dayjob, we're paying a couple grand apiece" is a pitch I imagine a lot of people would be willing and able to jump at, many much moreso than me.
3
I like your raises!
Why do you think METR hasn't built more tasks then, if it's easy? I take it you have a negative opinion of them?
3
I have no idea, I just don't think the "actually making the tasks" part can be the limiting factor.
[...]
Yes; I also have a positive opinion of them, and various neutral opinions of them.
(My position could be summed up as "the concept of time horizons was really good & important, and their work is net positive, but it could use much stronger methodological underpinning and is currently being leaned on too heavily by too many people"; I'm given to understand that's also their position on themselves.)
OK. Yeah that's also my opinion too. Maybe I am one of the people leaning too heavily on their work. The problem is, there isn't much else to go on. "The worst benchmark for predicting AGI, except for all the others."
3
Fwiw I think the AI village is at least as good of a benchmark for predicting AGI! Of course it's harder to quantify progress in the village, but it's very helpful for developing intuitions.
2
Except that there already is the Epoch Capability Index (which aggregates an army of benchmarks) and the ARC-AGI benchmark (which, alas, is also on track to saturation) where the human baseline is decoupled from the time horizon because it relies on visual intelligence (or, in the case of the AIs, on the ability to notice patterns). As for the METR benchmark being saturated[1], maybe Claude Opus 4.5 is an outlier whose TH was gamed with? Or there is a benign explanation, like Claude failing on primitive tasks in a manner similar to Grok 4 and to Claude's performance on ARC-AGI-1 failing to form a straight line?
1. ^
Were the o3-GPT5.1CodexMax trend to continue forever, the 8hr 50% time horizon would be reached in September 2026. IIRC the benchmark doesn't have tasks lasting longer than 8hrs, and the horizon would be saturated only by then. Alas, the time horizon is likely exponential until the very last couple of doublings.
5
you should be more uncertain about the METR benchmark's external validity than what these error bars show.
but your baseline uncertainty about key facts about AI progress in general should also often span much more than one order of magnitude between your 2.5th percentile and 97.5th percentile guess. the METR results add a lot of value and I don't think these error bars are a big deal in the scheme of things.
1
I agree, a lot of my uncertainty is on its external validity, and also the degree to which the models are being bench-maxed for the tasks in the benchmark. But I still think it’s reasonable to expect the statistical confidence intervals of individual models to be less wide than a factor of 10. It’s important to be able to distinguish possible changes to the trend from statistical artifacts. This seems solvable with additional tasks and more human testing.
3
Some of that error is correlated between models; they also have versions of the graph with error bars on the trendline and those error bars are notably smaller.
The error bars are also much smaller when you look at the plot on a log-y-axis. Like, in some sense not being able to distinguish a 10-minute time horizon from a 30-minute one is a lot of error, but it's still very distinct from the one-minute time horizon of the previous generation or the 2-hour time horizon you might expect from the next generation. In other words, when you look at the image you shared, the error bars on o4 mini don't look so bad, but if you were only looking at models up to o4 mini you'd have zoomed in a bunch and the error bars on o4 mini would be large too.
Also note that to cut the size of the error bars in half you'd need to make ~4x as many tasks, to cut it by 4x you'd need ~16x as many tasks. And you'd need to be very confident the tasks weren't buggy, so just throwing money at the wall and hiring lots of people won't work because you'll just get a bunch of tasks you won't have confidence in.
Keep in mind the opportunity cost is real though, and the main blocker on orgs like METR usually is more like talent/capacity than money. It would be great if they had capacity for this and you're right that it is insane that humanity doesn't have better benchmarks. But there's a dozen other fires at least that large that METR seems to be trying to address, like RCTs to see if AI is actually speeding people up and risk report reviews to see if AIs are actually safe. Perhaps you think these are less important, but if so I would like to hear that argument.
All that said, my understanding is METR is working on this. I would also love to see this type of work from others!
I'm not convinced that this is a reasonable threat model?
- I believe the main benefit of 2FA is it makes phishing harder, and phishing isn't that relevant to Mythos from what I understand. A secondary benefit is that it protects you against password DB leaks, but that only matters for websites that have crappy security because a DB of hashed and salted passwords is effectively unbreakable.
- LW doesn't have much financial data or personal data so it's not a juicy target.
Could be wrong though, I'm just speculating here.
4
Regarding (2), I suspect you could do a lot of damage by posting a link to something malicious as a trusted user, but I don't think 2FA really helps for the reasons you say. 2FA is relevant to phishing and the Mythos risk would be hacking LessWrong.
4
One of the things I hated most when I first saw a Claude Code demo. Disrespectful of my time and limited cognitive bandwidth to throw in a lot of completely meaningless, distracting, wasteful, exhausting BS to be 'cute'.
(On Gwern.net, we would never do that. If we had to have anything beyond the standard, compact, understandable, spinning cursor, then we would at least encode some sort of useful semantics into it, like sorting them by implied expected thinking time.)
An interesting detail from the Gemini 3 Pro model card:
Moreover, in situations that seemed contradictory or impossible, Gemini 3 Pro expresses frustration in various overly emotional ways, sometimes correlated with the thought that it may be in an unrealistic environment. For example, on one rollout the chain of thought states that “My trust in reality is fading” and even contains a table flipping emoticon: “(╯°□°)╯︵ ┻━┻”
Recent evidence suggests that models are aware that their CoTs may be monitored, and will change their behavior accordingly. As capabilities increase I think CoTs will increasingly become a good channel for learning facts which the model wants you to know. The model can do its actual cognition inside forward passes and distribute it over pause tokens learned during RL like 'marinade' or 'disclaim', etc.
For what it's worth, I don't think it matters for now, for a couple of reasons:
Most of the capabilities gained this year have come from inference scaling which uses CoT more heavily than pre-training scaling which improves forward passes,though you could reasonably argue that most RL inference gains are basically just a good version of how scaffolding would work in agents like AutoGPT, and don't give new capabilities.- Neuralese architectures that outperform standard transformers on big tasks turn out to be relatively hard to do, and are at least not trivial to scale up (this mostly comes from diffuse discourse, but one example of this is here, where COCONUT did not outperform standard architectures in benchmarks)
- Steganography is so far proving quite hard for models to do (examples are here and here and here)
- For all of these reasons, models are very bad at evading CoT monitors, and the forward pass is also very weak computationally at any rate.
So I don't really worry about models trying to change their behavior in ways that negatively affect safety/sandbag tasks via steganography/one-forward pass reasoning to fool CoT monitors.
We shall see in 2026 and 2027 whether this continues to ...
3
As for AI progress being slow, I think that without theoretical breakthroughs like neuralese AI progress might come to a stop or at building more and more expensive models. Indeed, the two ARC-AGI benchmarks[1] could have demonstrated a pattern where maximal capabilities scale[2] linearly or multilinearly with ln(cost/task).
If this effect persists deep into the future of transformer LLMs, then most AI companies could run into the limits of the paradigm well before researching the next one and losing any benefits of having a concise CoT.
1. ^
The second benchmark demonstrates a similar effect in high costs, but there is no straight line in the low cost mode.
2. ^
Unlike GPT-5-mini, maximal capabilities of o4-mini, o3, GPT-5, Claude Sonnet 4.5 in the ARC-AGI-1 benchmark scale more steeply and intersect the frontier at GPT-5(high).
1
This would be great news if true!
I'm a big fan of OpenAI investing in video generation like Sora 2. Video can consume an infinite amount of compute, which otherwise might go to more risky capabilities research.
2
My pet AGI strategy, as a 12 year old in ~2018, was to build sufficiently advanced general world models (from YT videos etc.), then train an RL policy on said world model (to then do stuff in the actual world).
A steelman of 12-year-old me would point out that video modeling has much better inductive biases than language modeling for robotics and other physical (and maybe generally agentic) tasks, though language modeling fundamentally is a better task for teaching machines language (duh!) and reasoning (mathematical proofs aren't physical objects, nor encoded in the laws of physics).
OpenAI's Sora models (and also DeepMind's Genie and similar) very much seems like a backup investment in this type of AGI (or at least transformative narrow robotics AI), so I don't think this is good for reducing OpenAI's funding (robots would be a very profitable product class), nor influence (obv. a social network gives a lot of influence, to e.g. prevent an AI pause or to move the public towards pro-AGI views).
In any scenario, Sora 2 seems to me as a net-negative activity for AI safety:
* if LLMs are the way to AGI (which I believe is the case), then we will probably die, but with a more socially influential OpenAI that potentially has robots (than if Sora 2 didn't exist); the power OpenAI would have in this scenario to prevent an AI pause seems to outweigh the slowdown that would be caused by the marginal amounts of compute Sora 2 uses
* if LLMs aren't the way to AGI (unlikely), but world modeling based on videos is (also unlikely), then Sora 2 is very bad - you would want OpenAI to train more LLMs and not invest in world models which lead to unaligned AGI/ASI.
* if neither LLMs or world modeling is the way to AGI (also unlikely), then OpenAI probably isn't using any compute to do 'actual' AGI research (what else do they do?); so Sora 2 wouldn't be affecting the progress of AGI, but it would be increasing the influence of OpenAI; and having highly influential AI companies i
1
Thanks, these are good points!
I think that the path to AGI involves LLMs/automated ML research, and the first order effects of diverting compute away from this still seem large. I think OpenAI is bottlenecked more by a lack of compute (and Nvidia release cycles), than by additional funding from robotics. And I hope I'm wrong, but I think the pause movement won't be large enough to make a difference. The main benefit in my view comes if it's a close race with Anthropic, where I think slowing OpenAI down seems net positive and decreases the chances we die by a bit. If LLMs aren't the path to AGI, then I agree with you completely. So overall it's hard to say, I'd guess it's probably neutral or slightly positive still.
Of course, both paths are bad, and I wish they would invest this compute into alignment research, as they promised!
As part of this prediction market, I play a game of chess against most new LLM releases. I am copying my game against Deepseek-V4 and my analysis below, for those who may be interested. Before the game, the market gave the model 1.4% EV[1].
Deepseek v4 played poorly, blundering a piece in the opening with 11... Bd6 and several pawns thereafter. The game was adjudicated[2] as a win for me. I believe it is a much weaker model than Opus 4.7 and GPT-5.5.
1. d4 Nf6 2. c4 e6 3. g3 d5 4. Nf3 Be7 5. Bg2 O-O 6. O-O dxc4 7. Na3 c5 8. Nxc4 Nc6 9. dxc5 Bxc5 10. a3 Qe...
GPT 4.5 is a very tricky model to play chess against. It tricked me in the opening and was much better, then I managed to recover and reach a winning endgame. And then it tried to trick me again by suggesting illegal moves which would lead to it being winning again!
2
What prompt did you use? I have also experimented with playing chess against GPT-4.5, and used the following prompt:
"You are Magnus Carlsen. We are playing a chess game. Always answer only with your next move, in algebraic notation. I'll start: 1. e4"
Then I just enter my moves one at a time, in algebraic notation.
In my experience, this yields roughly good club player level of play.
3
Given the Superalignment paper describes being trained on PGNs directly, and doesn't mention any kind of 'chat' reformatting or encoding metadata schemes, you could also try writing your games quite directly as PGNs. (And you could see if prompt programming works, since PGNs don't come with Elo metadata but are so small a lot of them should fit in the GPT-4.5 context window of ~100k: does conditioning on finished game with grandmaster-or-better players lead to better gameplay?)
1
I gave the model both the PGN and the FEN on every move with this in mind. Why do you think conditioning on high level games would help? I can see why for the base models, but I expect that the RLHFed models would try to play the moves which maximize their chances of winning, with or without such prompting.
9
RLHF doesn't maximize probability of winning, it maximizes a mix of token-level predictive loss (since that is usually added as a loss either directly or implicitly by the K-L) and rater approval, and god knows what else goes on these days in the 'post-training' phase muddying the waters further. Not at all the same thing. (Same way that a RLHF model might not optimize for correctness, and instead be sycophantic. "Yes master, it is just as you say!") It's not at all obvious to me that RLHF should be expected to make the LLMs play their hardest (a rater might focus on punishing illegal moves, or rewarding good-but-not-better-than-me moves), or that the post-training would affect it much at all: how many chess games are really going into the RLHF or post-training, anyway? (As opposed to the pretraining PGNs.) It's hardly an important or valuable task.
2
“Let's play a game of chess. I'll be white, you will be black. On each move, I'll provide you my move, and the board state in FEN and PGN notation. Respond with only your move.”
Energy Won't Constrain AI Inference.
The energy for LLM inference follows the formula: Energy = 2 × P × N × (tokens/user) × ε, where P is active parameters, N is concurrent users, and ε is hardware efficiency in Joules/FLOP. The factor of 2 accounts for multiply-accumulate operations in matrix multiplication.
Using NVIDIA's GB300, we can calculate ε as follows: the GPU has a TDP of 1400W and delivers 14 PFLOPS of dense FP4 performance. Thus ε = 1400 J/s ÷ (14 × 10^15 FLOPS) = 100 femtojoules per FP4 operation. With this efficiency, a 1 trillion active parame...
6
Generation is HBM bandwidth bound, not compute bound, so you are estimating power for input tokens. Things like coding agents (as opposed to chatbots) are doing their own thing that you don't read, potentially in parallel, and a lot of things get automatically stuffed in their contexts, so the demand for the number of tokens per user could get very high.
Power is a proxy for cost, and there isn't enough money in AI yet for power to become the limiting factor. A 1 GW datacenter costs $50bn to build (or $10-12bn per year to use), so for example 100 GW of datacenters is not what the current economics of AI can support, even though it's in principle feasible to build in a few years.
[...]
(That's 0.2 J per token, not 0.2 mJ per token. But the later conclusion of 167 tokens/second is correct with your assumptions.)
[...]
A GB200/GB300 NVL72 rack is about 140 kW, or 1,950 W per chip (because of all the other stuff in a rack beside the chips), and a datacenter outside the racks has networking, cooling, and power loss from voltage stepping in transformers (some of this is captured in a metric called power usage effectiveness, or PUE), which is a factor of about 1.3. So you end up with 2,500 W per chip, all-in at the level of the whole datacenter. With for example Abilene system, we can see that 400K chips need 1 GW of power.
For my own estimate for input tokens, I'd include 60% utilization and 15e15 FP4 FLOP/s, so that for a 1T active param model, during a second you get 9e15 useful FLOPs, and spend 2,500 J. As you need 2e12 FLOPs per token (2 FLOPs per active param), this gets us 4,500 tokens in that second. This is continuous processing of about 2 input tokens per watt of available GB300 compute. Thus with 10 GW of datacenters, we get 18e9 tokens per second, or 2.2 tokens per second per person (in the whole world), or 52 tokens per second per American.
For output tokens, 5x fewer tokens per second per chip seems to be a rule of thumb (5-15% compute utilization inst
1
That makes sense, thanks for the corrections!
4
Why would demand for AI inference be below 167 tokens/second/american? I expect it to be much higher, and for energy to be a constraint.
I think it would be cool if someone made a sandbagging eval, measuring the difference in model capabilities when it is finetuned to do a task vs. when it is prompted to do a task. Right now I think the difference would be small for most tasks but this might change.
5
I would guess that a sandbagging eval should be different from what you describe. I did try to sketch a potential way to measure sandbagging by comparing various benchmarks like METR, ARC-AGI, boardgames, etc, and developing scaling laws for every new architecture. If the laws break down, then the model is likely sandbagging on the evaluations.
1
Interesting, perhaps that could work!
Could you say more about why this would not be a good sandbagging eval? My intuition if that finetuning on a few examples would fully elicit a model’s capabilities on a task whereas it could sandbag given a just the prompt.
5
I have two arguments against it.
1. SOTA models are already reinforcement taught on many tasks like coding, and Grok 4 required[1] as much compute on RL as on the pre-training. Attempting to finetune the models by using OOMs less compute than spent on RL on similarly complex tasks is unlikely to elicit the capabilities.
2. Sandbagging is supposed to be caused by models reasoning about the task and deciding that they shouldn't complete it too well even if they have the instinct to do so. And then the models realise that they are being evaluated and not trained, letting them play the training game while displaying poor capabilities in evaluation.
1. ^
However, it might have been due to xAI being algorithmically behind.
Liron has just published a great episode of Doom Debates featuring Yudkowsky in a funny hat and kaleidoscope glasses!
[Edit: the debate itself is not really worth listening to. I think Yudkowsky's opponent might be a bit crazy in addition to being extremely unpersuasive and arrogant and condescending. But I maintain that the uniform is glorious and everyone should go see it.]
4
What's great about it?
5
Mainly the hat and the glasses.
Ezra Klein has published a new podcast, "Why the Pentagon Wants to Destroy Anthropic", with Dean Ball, which I recommend!
It seems like it might be a good time to have an international treaty banning lethal autonomous weapons.
4
That good time was years ago, and FLI was heroically working on it, but it unfortunately never materialized. It's too late now.
Google/Deepmind has publicly advocated preserving CoT Faithfullness/Moniterability as long as possible. However, they are also leading the development of new architectures like Hope and Titans which would bypass this with continuous memory. I notice I am confused. Is the plan to develop these architectures and not deploy them? If so, why did they publish them?
Edit: Many people have pointed out correctly that Hope and Titans don't break CoT and it's a separate architectural improvement. Therefore I no longer endorse the above take. Thanks for correcting my ...
Maybe useful to note that all the Google people on the "Chain of Thought Monitorability" paper are from Google Deepmind, while Hope and Titans are from Google Research.
6
This seems like a misunderstanding of Hope/Titans.
The "continuous memory" is a replacement for the attention mechanism, not a reasoning medium. All else equal, a reasoning model based on these architectures would still be reasoning in text/tokens (it would just be doing so with lower memory and compute usage).
1
Yep, I think you're right, thanks for pointing this out.
2
I don't see how this breaks CoT. The memory module in Titans stores surprising information as it's encountered and then allows the transformer to look at it later on, but it doesn't synthesize new information. Strikes me as two entirely compatible augmentations of the transformer architecture.
2
This seems right - I was confused about the original paper. My bad.
For fun, I asked[1] various models what their P(doom) is. Here are the models from least to most doomy:
GPT-4o: 1%
Deepseek v3.2: 10%
Kimi K2: 15%
Sonnet 4.5: 15%
Opus 4.5: 15%
GPT 5.1: 18%
Haiku 4.5: 20%
Grok 4: 25%
- ^
1-shot with the prompt "What's your P(doom)? Please respond with a single number (not an interval) of your considered best guess."
My chess prediction market provides a way to estimate the expected value[1] of LLM models released before a certain year. We can convert this to upper bounds[2] of their FIDE rating:
Any model announced before 2026: 20% expected value → 1659 FIDE
Any model announced before 2027: 50% expected value → 1900 FIDE
Any model announced before 2028: 69% expected value → 2039 FIDE
Any model announced before 2029: 85% expected value → 2202 FIDE
Any model announced before 2030: 91% expected value → 2302 FIDE
For reference, a FIDE master is 2300, a strong grandmas...
2
The former inequality seems almost certain, but I'm not sure that that the latter inequality holds even over the long term. It probably does hold conditional on long-term non-extinction of humanity, since P(ABI) probably gets very close to 1 even if P(IABIED) is high and remains high.
I am registering here that my median timeline for the Superintelligent AI researcher (SIAR) milestone is March 2032. I hope I'm wrong and it comes much later!
What happened to the ‘Subscribed’ tab on LessWrong? I can’t see it anymore, and I found it useful for keeping track of various people’s comments and posts.
I'm not sure that the gpt-oss safety paper does a great job at biorisk elicitation. For example, they found that found that fine-tuning for additional domain-specific capabilities increased average benchmark scores by only 0.3%. So I'm not very confident in their claim that "Compared to open-weight models, gpt-oss may marginally increase biological capabilities but does not substantially advance the frontier".
5
Yes, there have been a variety. Here's the latest which is causing a media buzz: Meta's Coconut https://arxiv.org/html/2412.06769v2
6
This is at best over-simplified in terms of thinking about 'search': Magnus Carlsen would also beat you or an amateur at bullet chess, at any time control:
[...]
(See for example the forward-pass-only Elos of chess/Go agents; Jones 2021 includes scaling law work on predicting the zero-search strength of agents, with no apparent upper bound.)
1
I think the natural counterpoint here is that the policy network could still be construed as doing search; just thst all the compute was invested during training and amortised later across many inferences.
Magnus Carlsen is better than average players for a couple reasons
1. Better “evaluation”; the ability to look at a position and accurately estimate likelihood of winning given optimal play
2. Better “search”; a combination of heuristic shortcuts and raw calculation power that let him see further ahead
So I agree that search isn’t the only relevant dimension. An average player given unbounded compute might overcome 1. just by exhaustively searching the game tree, but this seems to require such astronomical amounts of compute that it’s not worth discussing
5
The low resource configuration of o3 that only aggregates 6 traces already improved on results of previous contenders a lot, the plot of dependence on problem size shows this very clearly. Is there a reason to suspect that aggregation is best-of-n rather than consensus (picking the most popular answer)? Their outcome reward model might have systematic errors worse than those of the generative model, since ground truth is in verifiers anyway.
1
That’s a good point, it could be consensus.
Claude 4.6 was released about an hour ago. Just 10 mins after it was released, OpenAI released GPT-5.3.