I've read a lot of the doomer content on here about AGI and am still unconvinced that alignment seems difficult-by-default. I think if you generalize from the way humans are "aligned", the prospect of aligning an AGI well looks pretty good. The pessimistic views on this seem to all come to the opposite conclusion by arguing "evolution failed to align humans, by its own standards". However
- Evolution isn't an agent attempting to align humans, or even a concrete active force acting on humans, instead it is merely the effect of a repeatedly applied filter
- The equivalent of evolution in the development of AGI is not the training of a model, it's the process of researchers developing more sophisticated architectures. The training of a model is more like the equivalent of the early stages of life for a human.
If you follow models from developmental psychology (rather than evolutionary psychology, which is a standard frame on libertarian-adjacent blogs, but not in the psychological mainstream), alignment works almost too well. For instance in the standard picture from psychoanalysis a patient will go in to therapy for years attempting to rid himself of negative influence from a paternal superego without success. A sort of "ghost" of the judgment-wielding figure from the training stage will hover around him his entire life. Lacan, for example, asserts that to attempt to "forget" the role of the parental figure inevitably leads to psychosis, because any sort of coherent self is predicated on the symbolic presence of the parental figure - this is because the model of the self as an independent object separated from the world is created in the first place to facilitate an operating relation with the parent. Without any stable representation of the self, the different parts of the mind can't function as a whole and break down into psychosis.
Translated to a neural network context, we can perhaps imagine that if a strategy model is trained in a learning regimen which involves receiving judgment on its actions from authority figures (perhaps simulating 100 different LLM chatbot personalities with different ethical orientations to make up for the fact that we don't have a unified ethical theory & never will), it will never develop the pathways which would allow it to do evil acts, similar to how Stable Diffusion can't draw pornography unless it's fine-tuned.
Furthermore, I expect that the neural network's learning regimen would be massively more effective than a standard routine of childhood discipline in yielding benevolence, because it would lack all the other reasons that humans discover to be selfish & malicious, & because you could deliberately train it on difficult ethical problems rather than a typical human having to extrapolate an ethical theory entirely from the much easier problems in the training environment of "how do I stay a good boy & maintain parental love".
The pessimistic views on this seem to all come to the opposite conclusion by arguing "evolution failed to align humans, by its own standards".
Which is just blatantly ridiculous; the human population of nearly 10B vs a few M for other primates is one of evolution's greatest successes - by its own standards of inclusive genetic fitness.
Evolution solved alignment on two levels: intra-aligning brains with the goal of inclusive fitness (massively successful), and also inter-aligning the disposable soma brains to distributed shared kin gins via altruism.
I see your point, and I think it's true right at this moment, but what if humans just haven't yet taken the treacherous turn?
Say that humans figure out brain uploading, and it turns out that brain uploading does not require explicitly encoding genes/DNA, and humans collectively decide that uploading is better than remaining in our physical bodies, and so we all upload ourselves and begin reproducing digitally instead of thru genes. There is a sense in which we have just destroyed all value in the world, from the anthropomorphized Evolution's perspective.
If we say that "evolutions goal" is to maximize the number of human genes that exist, then it has NOT done a good job at aligning humans in the limit as human capabilities go to infinity. We just havent reached the point yet where "humans following our own desires" starts to diverge with evolution's goals. But given that humans do not care about our genes implicitly, there's a good chance that such a point will come eventually.
So basically you admit that humans are currently an enormous success according to inclusive fitness, but at some point this will change - because in the future everyone will upload and humanity will go extinct.
Sorry but that is ridiculous. I'm all for uploading, but you are unjustifiably claiming enormous probability mass in a very specific implausible future. Even when/if uploading becomes available, it may never be affordable for all humans, and even if/when that changes, it seems unlikely that all humans would pursue it at the expense of reproduction. We are simply too diversified. There are still uncontacted peoples, left behind by both industrialization and modernization. There will be many left behind by uploading.
The more likely scenario is that humans persist and perhaps spread to the stars (or at least the solar system) even if AI/uploads spread farther faster and branch out to new niches. (In fact far future pure digital intelligences won't have much need for earth-like planets or even planets at all and can fill various low-temperature niches unsuitable for bio-life).
Humanity did cause the extinction of ants, let alone bacteria, and it seems unlikely that future uploads will cause the extinction of bio humanity.
So basically you admit that humans are currently an enormous success according to inclusive fitness, but at some point this will change - because in the future everyone will upload and humanity will go extinct
Not quite - I take issue with the certainty of the word "will" and with the "because" clause in your quote. I would reword your statement the following way:
"Humans are currently an enormous success according to inclusive fitness, but at some point this may change, due to any number of possible reasons which all stem from the fact that humans do not explicitly care about / optimize for our genes"
Uploading is one example of how humans could become misaligned with genetic fitness, but there are plenty of other ways too. We could get really good at genetic engineering and massively reshape the human genome, leaving only very little of Evolution's original design. Or we could accidentally introduce a technology that causes all humans to go extinct (nuclear war, AI, engineered pandemic).
(Side note: The whole point of being worried about misalignment is that it's hard to tell in advance exactly how the misalignment is going to manifest. If you knew in advance how it was going to manifest, you could just add a quick fix onto your agent's utility function, e.g. "and by the way also assign very low utility to uploading". But I don't think a quick fix like this is actually very helpful, because as long as the system is not explicitly optimizing for what you want it to, it's always possible to find other ways the system's behavior might not be what you want)
My point is that I'm not confident that humans will always be aligned with genetic fitness. So far, giving humans intelligence has seemed like Evolution's greatest idea yet. If we were explicitly using our intelligence to maximize our genes' prevalence, then that would probably always remain true. But instead we do things like create weapons arsenals that actually pose a significant risk to the continued existence of our genes. This is not what a well-aligned intelligence that is robust to future capability gains looks like.
humans do not explicitly care about / optimize for our genes
Ahh but they do. Humans generally do explicitly care about propagating their own progeny/bloodlines, and always have - long before the word ‘gene’. And this is still generally true today - adoption is last resort, not a first choice.
I'll definitely agree that most people seem to prefer having their own kids to adopting kids. But is this really demonstrating an intrinsic desire to preserve our actual physical genes, or is it more just a generic desire to "feel like your kids are really yours"?
I think we can distinguish between these cases with a thought experiment: Imagine that genetic engineering techniques become available that give high IQs, strength, height, etc., and that prevent most genetic diseases. But, in order to implement these techniques, lots and lots of genes must be modified. Would parents want to use these techniques?
I myself certainly would, even though I am one of the people who would prefer to have my own kids vs adoption. For me, it seems that the genes themselves are not actually the reason I want my own kids. As long as I feel like the kids are "something I created", or "really mine", that's enough to satisfy my natural tendencies. I suspect that most parents would feel similarly.
More specifically, I think what parents care about is that their kids kind of look like them, share some of their personality traits, "have their mother's eyes", etc. But I don't think that anyone really cares how those things are implemented.
I want to say it, but my view is that evolution's goals were very easy to reach, and in partucular, it can make use of the following assumptions:
-
Deceptive Alignment does not matter, in other words, so long as it reproduces, deception doesn't matter. For most goals, deceptive alignment would entirely break the alignment, since we're usually aiming for much more specific goals.
-
Instrumental goals can be used at least in part to do the task, that is instrumental convergence isn't the threat it's usually portrayed as.
There are other reasons, but these two are the main reasons why the alignment problem is so hard (without interpretability tools.)
How are we possibly aiming for "much more specific goals" - remember evolution intra-aligned brains to each other through altruism. We only need to improve on that.
And regardless we could completely ignore human values and just create AI that optimizes for human empowerment (maximization of our future optionality, or future potential to fulfill any goal).
Evolution isn't an agent attempting to align humans, or even a concrete active force acting on humans, instead it is merely the effect of a repeatedly applied filter
My understanding of deep learning is that training is also roughly the repeated application of a filter. The filter is some loss function (or, potentially the LLM evaluators like you suggest) which repeatedly selects for a set of model weights that perform well according to that function, similar to how natural selection selects for individuals who are relatively fit. Humans designing ML systems can be careful about how to craft our loss functions, rather than arbitrary environmental factors determining what "fitness" means, but this does not guarantee that the models produced by this process actually do what we want. See inner misalignment for why models might not do what we want even if we put real effort into trying to get them to.
Even working in the analogy you propose, we have problems. Parents raising their kids often fail to instill important ideas they want to (many kids raised in extremely religious households later convert away).
As a brief aside, I don’t think there is a single “introduction to AI x-risk” resource that rigorously and compellingly presents, from start to finish, the core arguments around AI x-risk.
Any specific things you think The Alignment Problem from a Deep Learning Perspective misses?
In general, +1 for the post, although "miracles" doesn't feel like the right description of them, more like "reasons for hope". (In general I'm pretty unimpressed by the "miracles" terminology, since nobody has a model of the future of AI robust enough such that it's anywhere near reasonable to call violations of that model "miracles").
I would argue that there are true miracles here, despite thinking we aren't doomed: We know enough that alignment isn't probably going to be solved by a simple trick, but that doesn't mean the problem is impossible.
The biggest miracles would be, in order of being surprised:
Deceptive/Inner alignment either not proving to be a problem, or there's a broad basin around honesty that's easy to implement, such that we may not need too much interpretability, in the best case.
Causal, Extremal, and Adversarial Goodhart not being a problem, or easy to correct.
ELK is solved by default.
Outer Alignment being easy to implement via HCH in the real world via imitative amplification/IDA.
In retrospect, I think the key miracles that happened relative to 2 years ago were a combo of "Alignment generalizes further than capabilities" and "Human values are both simpler and less fragile than people used to think, primarily because a whole lot of evolutionary psychology speculation about human values and capabilities turned out be wrong, and more importantly humans were discovered to be more of a blank slate than people thought (I don't endorse the original blank-slate idea, to be clear, but I do think a bounded version of the idea does actually work, more so than people thought 15-20 years ago.)
So in essence, I think what happened here is this miracle happening:
10. The Sharp Left Turn (the distribution shift associated with a rapid increase in capabilities) might not be that large of a leap. It could be that alignment properties tend to generalize across this distribution shift.
combined with Outer alignment being easy to implement via data on human values and trusting the generalization process, because it turned out alignment generalizes further than capability, and us being able to prevent deceptive/inner misalignment via the same process.
I admit I was quite surprised to the extent of my 2022 self not thinking too much about those miracles until 2023, with the final pieces of the puzzle being provided in August-September 2024.
Link on alignment generalizing further than capabilities below:
https://www.beren.io/2024-05-15-Alignment-Likely-Generalizes-Further-Than-Capabilities/
Interpretability might become easier as networks get closer to human level because they start using human abstractions.
Language models are already superhuman at next token prediction
I have some reasons for being optimistic about 'white box heuristic reasoning' (humans understanding models is a special case of this), but models becoming easier to understand as they get bigger isn't one of them.
That's not really the correct comparison. The correct comparison is neural outputs of linguistic cortex vs LLM neural outputs, because the LLM isnt' having to learn a few shot mouse/keyboard minigame like the human is.
Humans do not have direct access to the implicit predictions of their brain's language centers, any more than the characters simulated by a language model have access to the language model's token probabilities.
Really, the correct comparison is something like asking the LLM to make a zero shot prediction of the form:
Consider the following sentence; "I am a very funny _"
What word seems most likely to continue the sentence?
Answer:
I expect LLMs to do much worse when prompted like this, though I haven't done the experiment myself.
Humans do not have direct access to the implicit predictions of their brain's language centers,
But various other human brain modules do have direct access to the outputs of linguistic cortex, and that is the foundation of most of our linguistic abilities, which surpass those of LLM in many ways.
- Human linguistic cortex learns via word/token prediction, just like LLMs.
- Human linguistic cortical outputs are the foundation for various linguistic abilities, performance of which follows on performance on 1.
- Humans generally outperform LLMs on most downstream linguistic tasks.
I'm merely responding to this statement:
Language models are already superhuman at next token prediction
Which is misleading - LLMs are superhuman than humans at the next token prediction game, but that does not establish that LLMs are superhuman than human linguistic cortex (establishing that would require comparing neural readouts)
I don't think this sort of prompt actually gets at the conscious reasoning gap. It only takes one attention head to copy the exact next token prediction made at a previous token, and I'd expect if you used few shot prompting (especially filling the entire context with few shot prompts), it would use its induction-like heads to just copy its predictions and perform quite well.
A better example would be to have the model describe its reasoning about predicting the next token, and then pass that to itself in an isolated prompt to predict the next token.
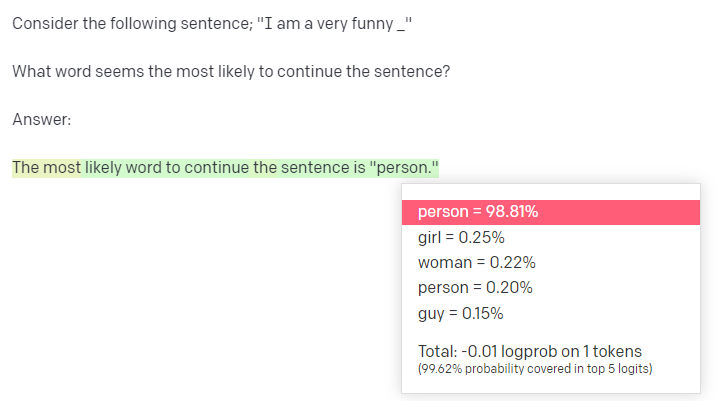
It's distribution over continuations for the sentence itself is broader:
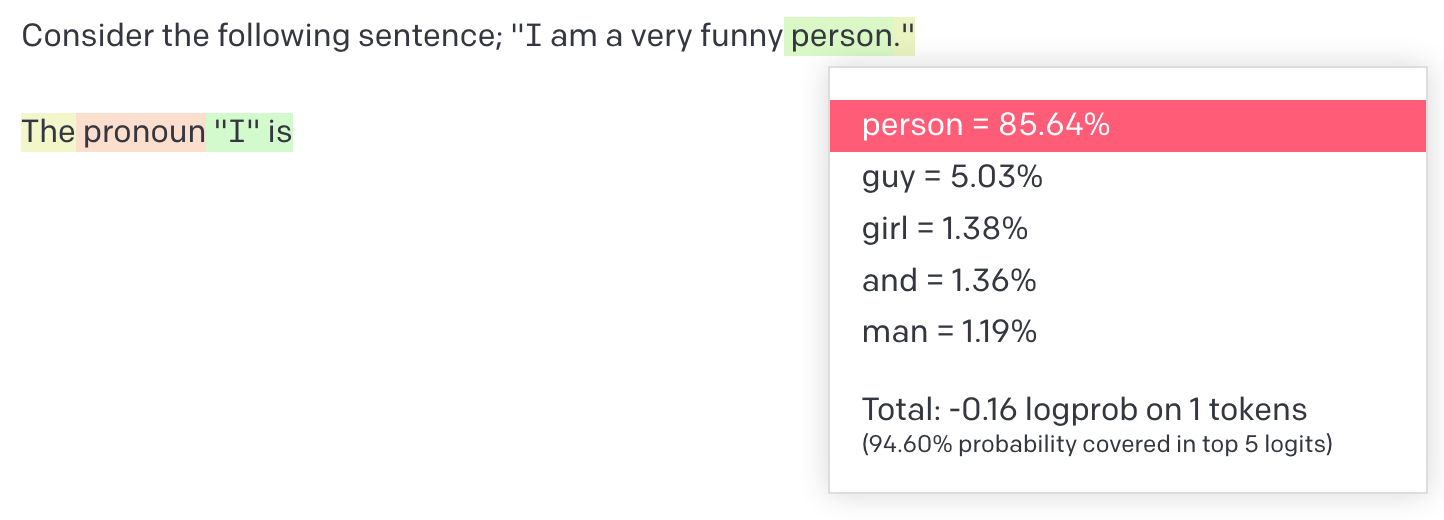
I'd have expected it to become less confident of its answer when asked verbally.
This sort of prompt shows up in the corpus and when it does it implies a different token distribution for the _ than the typical distribution on the corpus. Ofc, you could make the model quite good at prompts like this via finetuning.
Imo, it is reasonably close to the right comparison for thinking about humans understanding how LLMs work (I make no claims about this being a reasonable comparison for other things). We care about how humans perform using conscious reasoning.
Similarly, I'd claim that trying to do interpretability on your own linguistic cortex is made difficult by the fact the the linguistic cortex (probably) implicitly represents probability distributions over language which are much better than those that you can conciously compute.
More generally, it's worth thinking about the conscious reasoning gap - this gap happens to be smaller in vision for various reasons.
This gap will also ofc exist in language models trying to interpret themselves, but fine-tuning might be very helpful for at least partially removing this gap.
Another miracle type thing:
- ~everybody making progress in capabilities research realizes we have major safety problems and research directions pivot toward this and away from speeding up capabilities. There is a major coordination effort and international regulations that differentially benefit safety. This might happen without some public accident, especially via major community building efforts and outreach. This looks like major wins in AI Governance and AIS field-building. This pushes back timelines a bit, and I think if we act fast this might be enough time to shift the gameboard (if capabilities progress becomes globally taboo when there is at least a year of serial capabilities work required before AGI, I would be much more optimistic than I am).
This might look something like a large social movement (that somehow works), but it doesn't need to be widespread to actually change things (if the top 1000 ML researchers were all very worried about AI existential risk, we would be like half-way there, I think, because research output is heavy tailed).
Conceptually I like the framing of "playing to your outs" taken from card games. In a nutshell, you look for your victory conditions and backchain your strategy from there, accepting any necessary but improbable actions that keep you on the path to possible success. This is exactly what you describe, I think, so the transposition works and might appeal intuitively to those familiar with card games. Personally, I think avoiding the "miracle" label has a significant amount of upside.
Great post.
A couple months ago I wrote a doc from the prompt "suppose in the future we look back and think AI went well; what might have happened?" I hope to publish that soon; in the meantime some other classes of victory conditions (according to me) are:
- Timelines are long because of good public policy
- A classic pivotal act is executed (and aligning it isn't too hard)
- Everyone comes to believe that advanced AI is dangerous; there is disinclination to do risky work at the researcher-level, lab-level, and society-level
(Edit: I'm curious why this was downvoted; I'd love anonymous feedback if relevant.)
2. More resources are being poured into the mentorship and training of new alignment researchers. Perhaps the miracle will not come from a new “genius” but from a reasonably smart person (or set of people) who receive high-quality mentorship.
Assuming 'geniuses' are not excluded from mentorship, why would this be at all likely?
If we assess smartness based on actual observed behaviour, and not based on self-claims, it seems almost tautological to assume the opposite, that if any 'miracle' occurs it will be from someone extremely competent, or a group of such.
My hope is that scaling up deep learning will result in an "animal-like"/irrational AGI long before it makes a perfect utility maximizer. By "animal-like AGI" I mean an intelligence that has some generalizable capabilities but is mostly cobbled together from domain specific heuristics, which cause various biases and illusions. (I'm saying "animal-like" instead of "human-like" here because it could still have a very non-human-like psychology.) This AGI might be very intelligent in various ways, but its weaknesses mean that its plans can still fail.
Great post, thanks for writing this! In the version of "Alignment might be easier than we expect" in my head, I also have the following:
- Value might not be that fragile. We might "get sufficiently many bits in the value specification right" sort of by default to have an imperfect but still really valuable future.
- For instance, maybe IRL would just learn something close enough to pCEV-utility from human behavior, and then training an agent with that as the reward would make it close enough to a human-value-maximizer. We'd get some misalignment on both steps (e.g. because there are systematic ways in which the human is wrong in the training data, and because of inner misalignment), but maybe this is little enough to be fine, despite fragility of value and despite Goodhart.
- Even if deceptive alignment were the default, it might be that the AI gets sufficiently close to correct values before "becoming intelligent enough" to start deceiving us in training, such that even if it is thereafter only deceptively aligned, it will still execute a future that's fine when in deployment.
- It doesn't seem completely wild that we could get an agent to robustly understand the concept of a paperclip by default. Is it completely wild that we could get an agent to robustly understand the concept of goodness by default?
- Is it so wild that we could by default end up with an AGI that at least does something like putting 10^30 rats on heroin? I have some significant probability on this being a fine outcome.
- There's some distance from the correct value specification such that stuff is fine if we get AGI with values closer than . Do we have good reasons to think that is far out of the range that default approaches would give us?
Thanks for opening minds to the possibility that agents & their utility function may not be the most fruitful way to think about these questions. Could you provide a few pointers to these « notably not all » from point 5?
- Brain like AGI safety
- Shard Theory
- Iterated Amplification
- Much of interpretability work
- Possibly Pragmatic AI Safety, idk much about it.
- The selection theorems branch of research
- The particular selection theorem case of modularity
Epistemic status: Speculative and exploratory.
Contributions: Akash wrote the initial list; Thomas reviewed the list and provided additional points. Unless specified otherwise, writing in the first person is by Akash and so are the opinions. Thanks to Joshua Clymer, Tom Shlomi, and Eli Lifland for comments. Thanks to many others for relevant conversations.
If we need a miracle, where might it come from? What would it look like?
Many of the arguments presented in List of Lethalities are compelling to me. Some of my colleagues and I spend many hours thinking about how hard the alignment problem is, analyzing various threat models, and getting familiar with all the ways we could fail.
I thought it would be a useful exercise to intentionally try to think in the opposite way. How might we win?
I have found “miracles” to be a helpful frame, but it’s misleading in some ways. For example, I think the “miracles” frame implies an extremely low chance of success (e.g., <1%) and fosters a “wait and hope” mentality (as opposed to a “proactively make things happen” mentality). I was considering titling this something else (e.g., “Reasons for Hope” or “Possible Victory Conditions”), but these frames also didn’t feel right. With the phrase “miracles,” I’m trying to convey that (a) I don’t feel particularly confident in these ideas, (b) I am aware of many counterarguments to these claims [and indeed some are already presented in List of Lethalities], and (c) I don’t think “hope” or “victory” sets the right tone-- the right tone is “ah gosh, things seem really hard, but if we win, maybe we’ll win because of something like this.”
I have found it helpful to backchain from these miracles to come up with new project ideas. If you think it’s plausible that we need a miracle, I encourage you to form your own list of possible miracles & think carefully about what kinds of projects might make each one more likely to occur (or make it more likely that we notice one in time).
With this in mind, here’s my list of possible miracles.
New Agendas
1. New people are entering the field of alignment at a faster rate than ever before. Some large programs are being designed to attract more AI safety researchers. One of these new researchers could approach the problem from an entirely new perspective (one that has not yet been discovered by the small community of <300 researchers). Other scientific fields have had moments in which one particularly gifted individual finds a solution that others had missed.
a. There are some programs that are optimizing for finding talented people, exposing them to alignment arguments, and supporting the ones who become interested in alignment.
b. A small fraction of people in the US and UK have been exposed to AI x-risk.
c. Even less effort has gone into outreach to people outside the US and UK.
2. More resources are being poured into the mentorship and training of new alignment researchers. Perhaps the miracle will not come from a new “genius” but from a reasonably smart person (or set of people) who receive high-quality mentorship.
a. The pool of mentors is also expanding. It seems plausible to me that the top 2-10% of junior alignment researchers will soon be ready to take on their own mentees. This not only increases the total pool of mentors but also increases the diversity of thought in the mentorship pool.
b. Some training programs are explicitly trying to get people to think creatively and come up with new agendas (e.g., Refine).
c. Some training programs are explicitly trying to get people from different [non-CS/math] disciplines (e.g., Philosophy Fellowship; PIBBSS).
3. The bar for coming up with new agendas lowers each year. At the very beginning of the field, people needed to identify the problem from virtually no foundation. The field needed people who could (a) identify the problem, (b) identify that the problem was extremely important, (c) discover subproblems, (d) perform research on these problems with relatively few others to discuss ideas with and relatively few prior works to guide their thinking. The field is still pre-paradigmatic, and these skills still matter. But each year, the importance of “being able to understand things from the empty string” decreases and other abilities (ex: “being able to take a concept that someone else discovered and make it clearer” or “being able to draw connections between various ideas” or “being able to prioritize between different ideas that already exist”) become more important. It seems likely that there are some people who are better at “generating solutions” (taking a messy field and looking at it more clearly than others; building on the ideas of others; coming up with new ideas and solutions in a field that has even a little bit of foundation) than “discovering problems” (starting from scratch and seeing things that no one else sees; inventing a field essentially from scratch; arguing for the legitimacy of the field).
4. The “weirdness” of AI alignment decreases each year. This means AI alignment will attract more people, but it also means that AI alignment will attract different types of people. As much as I love rationality, perhaps the miracle lies within someone with a style of thinking that is underrepresented among people who enjoy things like The Sequences/HPMOR/Yudkowsky quirks. (I must caveat of course that I think the ideas in these writing are important, and I personally enjoy the style in which they are written. But I am aware of other people who I find intelligent who find the style of writing off-putting and are more likely to join a “normie” AI alignment community than one that is associated with [stereotypes about] rationalists).
Alignment might be easier than we expect
5. Much (though notably not all) of the research around AI alignment came from a time when people were thinking about agents that are maximizing utility functions. They came from a time when people were trying to understand core truths about intelligence and how agents work. In many ways, the deep learning revolution appears to make alignment more difficult. It seems like we may get AGI sooner than we expected, through a method that we didn’t expect, a method that we don’t understand, and a method that seems nearly-impossible to understand. But perhaps there are miracles that can be discovered within this new paradigm.
a. Until recently, relatively little work in the AI x-risk community has been focused specifically on large language models. The bad news is that if GPT-X is going to get us to AGI, much of the existing work (using math/logic/agent foundations approaches), is going to be less relevant. The good news is that we might be playing a different game than we thought we were. Again, that doesn’t inherently mean this game is easier. But if someone gave me a game, and then I thought it was impossible, and then they said okay here play this new game instead, I would at least think “alright, this one might also be impossible, but maybe it’ll be easier than the last one.”
b. For example, in the current regime, LLMs seem to reason like simulators rather than consequentialist utility-maximizers. This may change as capabilities increase, but it is very possible that LLMs stay in the current simulator regime even after they are superhuman. Aligning simulators is not necessarily easier than aligning utility-maximizers, but it sure is an example of how the game could change.
c. Maybe we will be able to use language models to help us generate new ideas for alignment. It seems plausible that a model could be [powerful enough to help us meaningfully with alignment research] while also being [weak enough that we can align it]. Some people have arguments that we can’t get a model that is [powerful enough to help us] without it also being [too powerful for us to be able to align it]. I find this plausible, and honestly, likely, but it seems plausible that a (a) there is a “goldilocks zone” of capabilities [powerful enough to meaningfully help but weak enough to align] and (b) we can build models in this goldilocks zone.
6. A new paradigm might emerge besides deep learning, where distributional shift and inner alignment are not such big, fundamental issues.
7. Deceptive alignment might not be selected for. In the regime where you apply enough optimization power to get a superintelligence, perhaps the simplest training story is to become 'corrigibly aligned'. See this comment where Evan estimates this probability conditional on different architectures.
8. Paul's "Basin of Corrigibility'' might be very wide. If this is the case, most values that are anywhere near human values end up in the attractor well where the AGI wants to figure out what we want.
9. Interpretability might become easier as networks get closer to human level because they start using human abstractions. It only looks hopeless now because we are in the regime between 'extremely simple' and 'human level' where the models have to use confused abstractions.
10. The Sharp Left Turn (the distribution shift associated with a rapid increase in capabilities) might not be that large of a leap. It could be that alignment properties tend to generalize across this distribution shift.
11. Given enough time, we might be able to develop a secure sandbox environment that allows us to observe alignment failures such as deception and treacherous turns, and then iterate on them.
12. Takeoff speeds might be slow enough that we can study the AI at a relatively advanced capability level, iterate on different designs, and potentially get superhuman alignment research out of it. One possible reason for this might be if capability improvement during takeoff is bottlenecked by compute.
13. Some of the tools or agendas we already have will be sufficient. Perhaps we were lucky, and some mixture of really good interpretability + really good adversarial training + penalizing models that do [bad stuff] in training will be good enough. Alternatively, there could be one or more breakthroughs in theoretical agendas (e.g., selection theorems, ELK, infra-bayesianism) and the breakthrough(s) can be implemented somehow. (Note that this one feels especially strange to label as a “miracle”, except to the people who are very pessimistic about current agendas).
Timelines might be longer than we expect
14. Coordination between AI labs might lead to less capabilities research and more safety research. In the best case, this would look like coordinated agreements across all labs.
a. Unfortunately, the mission of 'Building AGI' is a key part of several organization's mission statements. E.g. OpenAI says 'We will attempt to directly build safe and beneficial AGI, but will also consider our mission fulfilled if our work aids others to achieve this outcome.'
b. There may be accidents/misuses of AI before we get to AGI. This might cause people (and most notably, capabilities researchers + leadership at major AI organizations) to invest more into safety and less into capabilities.
c. To the extent that these accidents/misuses were predicted by members of the AI alignment community, this may cause leaders of AI organizations to take the AI alignment community more seriously.
15. Several AI alignment leaders and AI capabilities leaders seem to like and respect each other. Maybe more dialogue between these two groups will lead to less capabilities research and more safety research.
a. It seems like there have been few well-designed/well-structured conferences/meetings between these two groups (though it seems plausible that they may be communicating more regularly in private).
b. Current arguments around taking AI x-risk seriously are convincing to me, but I sometimes encounter intelligent and reasonable people who find them unconvincing. It is possible that as the field matures, new challenges are discovered, or old challenges are presented with more evidence/rigor.
16. Many leaders in top AI labs take AI x-risk arguments seriously, and everyone wants to make sure AI is deployed safely. But knowing what to do is hard. Maybe we will come up with more specific recommendations that AI labs can implement.
a. Some of these may result from evaluation tools (e.g., here’s a tool you can use to evaluate your AI system; don’t deploy the system unless it passes XYZ checks) and benchmarks (e.g., here’s a metric that you can use to evaluate your AI system; don’t deploy it unless it meets this score). These tools and benchmarks may not be strong enough to fool a sufficiently intelligent system, but they may buy us time and help labs/researchers understand what types of safety research to prioritize.
17. Moore’s law might slow down and compute might become a bottleneck.
18. Maybe deep learning won’t scale to AGI. Maybe a paradigm-shift will occur that replaces deep learning (or a paradigm shift occurs within a deep learning).
Miscellaneous
19. We might be able to solve whole brain emulation before AGI arrives, and then upload alignment researchers who can do research 1000x faster than existing researchers. This is also risky, because (a) the sped up humans could disempower humanity by themselves and (b) these humans might accidentally build an AGI or do capabilities research.
Final thoughts