Prediction markets are a little like bitcoin. In order for bitcoin to function securely participants must waste an enormous amount of electricity and money on mining; a postgres database could process many more transactions per second at much less cost. But one advantage of the bitcoin protocol over postgres is that it allows everyone to verify fair operation, even when some participants are untrustworthy and would prefer to double-spend or modify account values.
Similarly, prediction markets are a way to get good community consensus on something, in the limit of market subsidy, in the presence of liars and idiots. But that's different from saying that starting a prediction market is the most cost-effective way to gather information on the events you want.
In order for bitcoin to function securely participants must waste an enormous amount of electricity and money on mining; a postgres database could process many more transactions per second at much less cost.
This alone basically made bitcoin flop hard, because it required ridiculous amounts of energy and it grew exponentially more expensive to be a useful alternative like currency, and it got so bad that Kazakhstan had protests over just how much electricity prices shot up because of it's energy being used for cryptocurrency trading.
Note, this doesn't address the many other severe flaws with bitcoin or cryptocurrency in general, but this alone basically underscored how much bitcoin couldn't ever work to even be a helping hand for stuff like databases, let alone replace the centralized entity, because energy is expensive, and you always want to reduce the amount you use to help use energy for other useful things.
Potentially, but that would require a lot of bitcoin people to admit that government intervention in their activity is at least sometimes good, and given all the other flaws of bitcoin like having irreversible transactions, it truly is one of those products that isn't valuable at all in the money role except in extreme edge cases, and pretty much all other inventions had more use than this, which is why I think that in order for crypto to be useful, you need to entirely remove the money aspect via some means, and IMO, governments are the most practical means of doing so.
Maybe killed is an overstatement, but it definitely flopped hard, and compared to the expectations that bitcoin and crypto advocates were claiming, it definitely failed, and it didn't even work for almost every use case proposed by bitcoin/general cryptocurrency advocates.
The fact that the price number goes up is a testament to how much speculation can prop up bubbles, even when they're based on nothing or at best much less valuable, plus the Fed loosening it's interest rate policy means that they can party again with cheaper money.
I dunno I still think Bitcoin is actually a good store of value and hedge against problems in fiat currency. Probably as good a bet as gold as this point.
Narrator: gold has been a poor bet for 90% of the last 200 years.
(Don't quote me on that, but it is true that gold was a good bet for about 10 years in recent memory, and a bad bet for most post-industrial time)
Compared to what? My guess is it's a better bet than most currencies during that time, aside from a few winners that it would have been hard to predict ahead of time. E.g., if 200 years ago, you had taken the most powerful countries and their currencies, and put your money into those, I predict you'd be much worse off than gold.
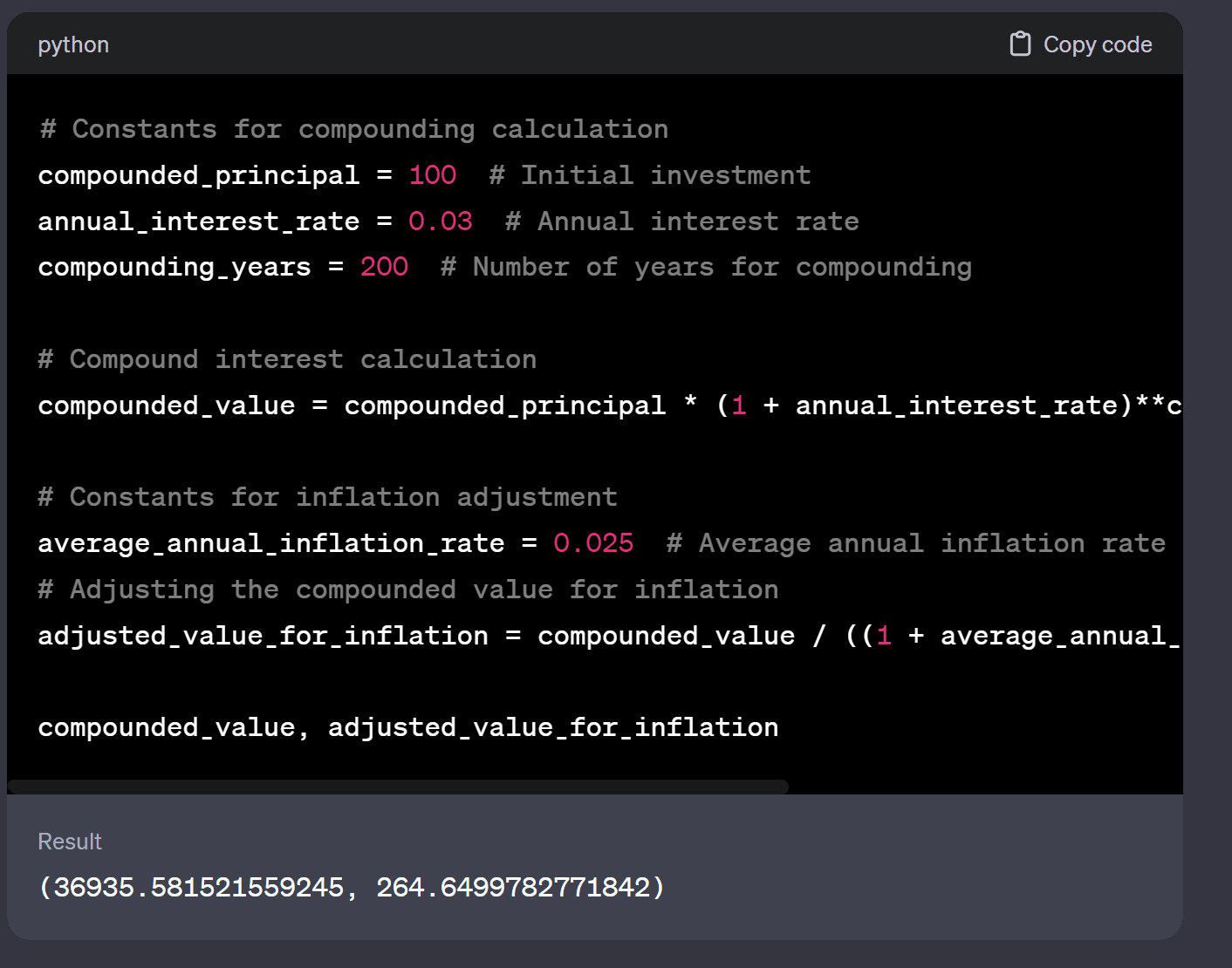
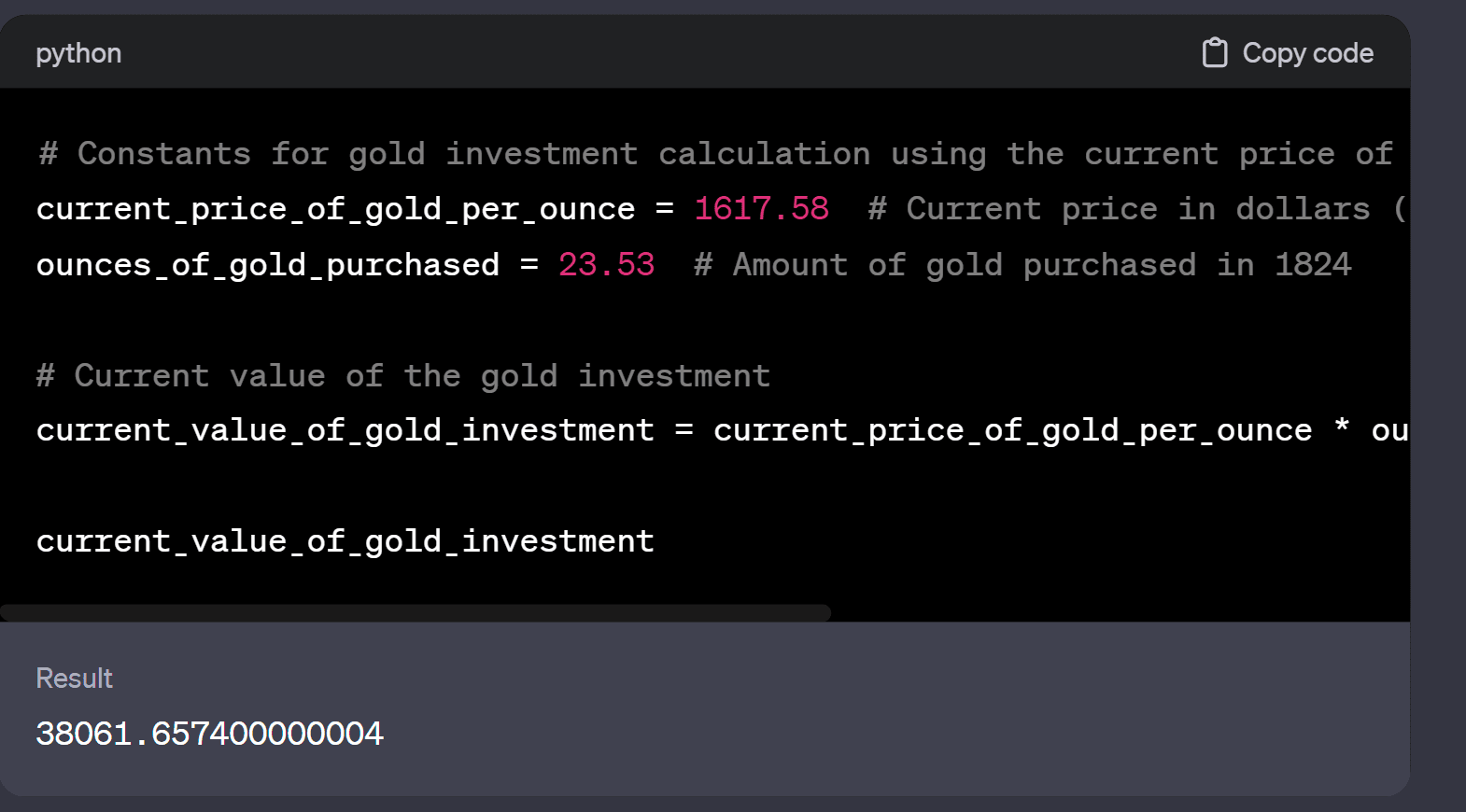
200 years ago was 1824. So compared to buying land or company stocks (the London and NY stock exchanges were well established by then) or government bonds.
Some quick calculations from chatGPT puts the value from a british government bond (considered the world power then) at about equal to the value of gold, assuming a fixed interest rate of 3% with gold coming out slightly ahead.
I haven't really checked these calculations but they pass the sniff test (except the part where chatGPT tried to adjust todays dollars for inflation).
I think that the main benefit of manifold.love is that it allows friends to do some matchmaking, but I'd do that for free and am not really doing it for profit anyway. I guess currently the other main benefit is as a schelling point for the rat community.
Even if there is no acceptable way to share the data semi-anonymously outside of match group, the arguments for prediction markets still apply within match group. A well designed prediction market would still be a better way to distribute internal resources and rewards amongst competing data science teams within match group.
But I'm skeptical that the value of match group's private data is dominant even in the fully private data scenario. People who actually match and meetup with another user will probably have important inside view information inaccessible to the algorithms of match group.
Manifold.Love's lack of success is hardly much evidence against the utility of prediction markets for dating markets, any more or less than most startup's failure at X is evidence against the utility of X.
a better way to distribute internal resources and rewards amongst competing data science teams within match group.
Yeah, additionally, a prediction market may be a good way to aggregate the predictions of heterogenous prediction models.
Manifold.Love's lack of success
It's important to note that manifold.love basically still has not been tried; has only existed for a few months and is still missing some core features.
Though I do expect most of its matchmaking strength wont come from its prediction features. Prediction markets could still be used in this space to appoint paid professional matchmakers (who would place bets like, "there will be a second date conditional on a first date", or "if these two read my introductions, 8% probability they'll eventually get married"), and to filter spam or abuse (to send a message, you have to bet that the recipient probably wont hate it).
This question can probably be operationalized as "how much richer will CupidBot be than all human matchmakers combined."
Even if there is no acceptable way to share the data semi-anonymously outside of match group, the arguments for prediction markets still apply within match group. A well designed prediction market would still be a better way to distribute internal resources and rewards amongst competing data science teams within match group.
I used to think things like this, but now I disagree, and actually think it's fairly unlikely this is the case.
- Internal prediction markets have tried (and failed) at multiple large organisations who made serious efforts to create them
- As I've explained in this post, prediction markets are very inefficient at sharing rewards. Internal to a company you are unlikely to have the right incentives in place as much as just subsidising a single team who can share models etc. The added frictions of a market are substantial.
- The big selling points of prediction markets (imo) come from:
- Being able to share results without sharing information (ie I can do some research, keep the information secret, but have people benefit from the conclusions)
- Incentivising a wider range of people. At an orgasation, you'd hire the most appropriate people into your data science team and let them run. There's no need to wonder if someone from marketing is going to outperform their algorithm.
People who actually match and meetup with another user will probably have important inside view information inaccessible to the algorithms of match group.
I strongly agree. I think people often confuse "market" and "prediction market". There is another (arguably better) model of dating apps which is that the market participants are the users, and the site is actually acting as a matching engine. Since I (generally) think markets are great, this also seems pretty great to me.
Oh yeah. I think one of the best example of magical thinking about prediction markets was when a person assumed that it could've warned us about FTX.
Also I coincidentally coined the title of this post in my reply :-)
Hi Simon, I like this important post. I think you could improve the grammar to improve readability. I have sent you some suggestions in a DM.
Aren't general-purpose for-profit prediction markets, strictly speaking, illegal, at least in US?
Sure - but that answer doesn't explain their relative lack of success in other countries (eg the UK)
Additionally, where prediction markets work well (eg sports betting, political betting) there is a thriving offshore market catering to US customers.
The liquidity calculation looks quite interesting but I'm not able to follow it.
I would really appreciate it if you wrote out a more detailed calculation!
- what's x ? What's Sigma ? What's pnl ?
So the first question is: "how much should we expect the sample mean to move?".
If the current state is , and we see a sample of (where is going to be 0 or 1 based on whether or not we have heads or tails), then the expected change is:
In these steps we are using the facts that ( is independent of the previous samples, and the distribution of is Bernoulli with . (So and ).
To do the proper version of this, we would be interested in how our prior changes, and our distribution for wouldn't purely be a function of . This will reduce the difference, so I have glossed over this detail.
The next question is: "given we shift the market parameter by , how much money (pnl) should we expect to be able to extract from the market in expectation?"
For this, I am assuming that our market is equivalent to a proper scoring rule. This duality is laid out nicely here. Expending the proper scoring rule out locally, it must be of the form , since we have to be at a local minima. To use some classic examples, in a log scoring rule:
in a brier scoring rule:
x is the result of the (n+1)th draw sigma is the standard deviation after the first n draws pnl is the profit and loss the bettor can expect to earn
Accusing someone of magical thinking is not a good way of communicating that their model is missing important details.
If you think prediction markets are valuable it's likely because you think they price things well - probably due to some kind of market efficiency... well why hasn't that efficiency led to the creation of prediction markets...
Prediction markets generate information. Information is valuable as a public good. Failure of public good provision is not a failure of prediction markets.
I suspect the best structure long term will be something like: Use a dominant assurance contract (summary in this comment) to solve the public goods problem and generate a subsidy, then use that subsidy to sponsor a prediction market.
Prediction markets generate information. Information is valuable as a public good. Failure of public good provision is not a failure of prediction markets.
I think you've slightly missed my point. My claim is narrower than this. I'm saying that prediction markets have a concrete issue which means you should expect them to be less efficient at gathering data than alternatives. Even if information is a public good, it might not be worth as much as prediction markets would charge to find that information. Imagine if the cost of information via a prediction market was exponential in the cost of information gathering, that wouldn't mean the right answer is to subsidise prediction markets more.
One common theme that I come across quite a bit in the prediction market space is:
And the proposal for "solving" [x] is:
These people need to consider the idea that "prediction markets aren't as popular as you think because they aren't as good as you think". (And I say this as a person who is a big fan of prediction markets!) If you think prediction markets are valuable, it's likely because you think they price things well - probably due to some kind of market efficiency... well why hasn't that efficiency led to the creation of prediction markets...
Maybe if prediction markets aren't popular for your specific use-case, it's because prediction markets are less efficient.
The cost to markets of acquiring information is high
Prediction markets are very good at enabling diverse participants to ensemble their forecasts in sensible ways. However, they are not very good at compensating participants[2].
Simple example - all information from the same source
For example, consider a market on a coin flip, with some unknown probability p of heads. The market will resolve based on the outcome of a single coin flip. However, the coin is available for anyone else to come over and test, but there's a catch. You have to pay to flip the coin. How many times would you flip the coin?
To make this simplified model even simpler, let's assume that participants will always take as much profit from the market as possible (eg they are risk neutral or the size of the market is small relative to their bank-roll). Under these assumptions, after each flip, the participants will move the market price to their new posterior.
Well, after n flips, the market price is going to be ∼μn=1n∑ni=11ith flip is success (this will depend on the initial prior; we can do all these calculations explicitly with a beta distribution, but it doesn't alter the result). How much should we expect this to move by paying for an additional sample?
E[(μn−μn+1)2]=E[(μn−x)2]/(n+1)2∼O(μ2/n2−2μ2/n2+(μ2+σ2)/n2)∼O(1/n2)So we should expect to move the mean by O(1n); therefore our pnl/expected gain will be O(1n2)[3]. (More details in this comment) So people will keep collecting samples for the market while ∼costn2>∼liquidity. Therefore we can see that, roughly speaking, we will obtain O(√liquiditycost) samples. But this is strictly much worse than if, rather than seeding the market the liquidity provider just went out and collected liquiditycost
samples.
One other thing to notice about this model of the prediction market is that early participants benefit much more than later participants. (This appears to be a general "problem" with markets where the subsidies accrue to the fastest players rather than those adding the most information[4]).
Additional theoretical justification
In our first example, we have given all the advantages to the market. There is one source of information, it is passed immediately between all participants (if there were only one participant, the market would work just as well) and, the cost of collecting data is known upfront. Any duplication of effort is inefficient from the point of view of the market subsidizer. From the point of view of any participant, their participation must be EV positive (in effort terms), but their EV must be equal to the EV lost by the market subsidizer. Therefore, any duplication of effort must be a direct cost born by the subsidizer.
Concrete Example - Manifold.Love
To come back to the example that convinced me, this article needed writing: Manifold.Love. I am assuming you're familiar with the premise. "Dating app powered by prediction markets."
My (simplified) model for dating apps is roughly speaking:
How does a prediction market improve any of these steps? For the first two, I expect it to be strictly worse: users might be comfortable sharing their data with Match Group, but they are less likely to be keen to have all their data fully public. (I expect even relatively open people to be less keen on fully public message logs!)
And for the 3rd point? To come up with better probabilities, the market participants need to outdo Match Group's private algorithms. which will use a far greater dataset and gets to internalize all of the cost. None of the square-root inefficiencies here, or all the subsidy being taken by the first bot to smash every potential pairing down to 1%.
Where should we expect to see prediction markets?
My mental model for where prediction markets are likely to be successful is, therefore, places where the subsidy is cheap. Some examples of places where we might find this:
Financial markets hit all 3 of our criteria. (The main purpose is not for forecasting; risk-premia means that there is plenty of positive-sum cash flowing around, and there are plenty of noise traders!)
Other areas where we expect to see prediction markets (and do):
The post which triggered me to write this was this one, but this comes up all the time.
Just ask anyone who's tried to come up with a scoring rule for a forecasting competition's prizes
To see this, bear in mind that pnl is equivalent to score for a proper scoring rule, and that locally our scoring rule must be of the form f(x)=O(x2), since lower order terms would either be free money, or free money for shifting the market in one direction
I have a barely fleshed out idea here which is a more formal justification for replacing continuous time trading with periodic auctions than I see floated by most proponents of that idea. I have an even less well fleshed out idea that the market is currently doing that by itself. There has been a trend towards more volume shifting to opening and closing auctions.