My main takeaway from Gato: If we can build specialized AI agents for 100s/1000s of tasks, it's now pretty straightforward to make a general agent that can do it all in a single model. Just tokenize data from all the tasks and feed into a transformer.
And vice-versa: transfer Gato to the new task, and finetune and sparsify/distill (eg turn the Transformer into a RNN, or do training with Transformer-XL instead of just runtime) when a task becomes common enough to justify the amortized expense.
The fact that adding new tasks doesn't diminuish performance on previous tasks is highly non trivial!
It may be that there is a lot of room in the embedding space to store them. The wild thing is that nothing (apart few hardware iterations) stop us to increase the embedding space if really needed.
Wild. One important note is that the model is trained with labeled examples of successful performance on the target task, rather than learning the tasks from scratch by trial and error like MuZero and OpenAI Five. For example, here's the training description for the DeepMind Lab tasks:
We collect data for 255 tasks from the DeepMind Lab, 254 of which are used during training, the left out task was used for out of distribution evaluation. Data is collected using an IMPALA (Espeholt et al., 2018) agent that has been trained jointly on a set of 18 procedurally generated training tasks. Data is collected by executing this agent on each of our 255 tasks, without further training.
Gato then achieves near-expert performance on >200 DM Lab tasks (see Figure 5). It's unclear whether the model could have learned superhuman performance training from scratch, and similarly unclear whether the model could learn new tasks without examples of expert performance.
More broadly, this seems like substantial progress on both multimodal transformers and transformer-powered agents, two techniques that seem like they could contribute to rapid AI progress and risk. I don't want to downplay the significance of these kinds of models and would be curious to hear other perspectives.
Would it be fair to call this AGI, albeit not superintelligent yet?
Gato performs over 450 out of 604 tasks at over a 50% expert score threshold.
👀
But it was trained on stacking and Atari, right?
What I mean is that it cannot take a task it faces, simulate what would happen if it does various different things, and use this to expand its task capabilities. It "just" does mimicry.
simulate what would happen if it does various different things
It is a generative Transformer trained offline to predict tokens. Why can't it?
Well, it could learn to do it. But that'd be like a human doing math to predict how a system works, rather than a human intuiting how a system works. Massive difference in speed means some other algorithm would probably go AGI first?
While I don't dispute that it could learn to do it, the current trained model cannot do this.
Well, it could learn to do it.
I mean, in what sense has a Decision Transformer like Gato not already learned to do it by extensive 1-step prediction?
I mean for one, its architecture does not permit its weights to change without receiving training data, and it does not generate training data itself.
As we know perfectly well by now, frozen weights do not preclude runtime learning, and Gato is trained on meta-learning tasks (MetaWorld and Procgen, plus the real-world datasets which are longtailed and elicit meta-learning in GPT-3 etc). They also mention adding Transformer-XL recurrent memory at runtime.
I mean, in what sense has a Decision Transformer like Gato not already learned to do it by extensive 1-step prediction?
I don't think Gato does the sort of training-in-simulation that Dreamer does. And that training-in-simulation seems like a major part of intelligence. So I think Dreamer has a component needed[1] for AGI that Gato lacks.
As we know perfectly well by now, frozen weights do not preclude runtime learning, and Gato is trained on meta-learning tasks (MetaWorld and Procgen, plus the real-world datasets which are longtailed and elicit meta-learning in GPT-3 etc). They also mention adding Transformer-XL recurrent memory at runtime.
Gato supports a sequence length of only 1048, which means that it cannot remember its meta-"learned" things for very long. Non-frozen weights would eliminate that problem.
- ^
Well, "needed", you could perhaps brute-force your way to a solution to AGI without this component, but then the problem is that Gato does not have enough dakka to be generally intelligent.
I’m also a bit concerned we may be moving the goalposts here a bit. Not sure if there’s a clear way to quantify how that’s being done, just a general impression I’m getting
I don't agree that I'm moving the goalposts, these were the sorts of ingredients I was thinking about before seeing Gato, as I was inspired by e.g. Dreamer.
I'm curious to understand your view better. Would you predict that as we keep making bigger versions of this trained longer on a wider range of tasks... eventually it could automate away all jobs in the economy, but only after literally being trained on all jobs -- it wouldn't be able to eventually start generalizing across jobs to stuff it hasn't done before?
Or would you predict that it wouldn't even get that far--the performance improvements would s-curve and plateau?
I'd predict that as you scale it up and train it on more and more things, it would continually improve its performance at a steady and predictable pace, but that different methods would eventually start improving faster than it because they are able to exploit additional strategies that this one does not have built-in and can at best simulate at the cost of orders of magnitude of efficiency.
One could argue that I should call it an AGI since I do believe it could be generally intelligent when scaled up, but I wouldn't agree with this. "When scaled up" would involve not just scaling up the network, but also scaling up e.g. the training demonstrations. It would be those demonstrations that would contain most of the intelligence that it would gain by scaling up, not the algorithm itself. Whereas an algorithm that would be capable of experimenting, planning in simulation, and adjusting itself to improve its performance would have the intelligence built-in in a more fundamental way.
(I should add that I don't necessarily think these sorts of planning and other capabilities require much innovation. There are already AIs that I would label as capable of planning, e.g. Dreamer. The point is just that this AI doesn't have those components and therefore doesn't deserve to be called AGI. Dreamer of course has its own limitations.)
Why do you think it can't?
PS: Mimicry is a fine art too, check this out: https://www.deepmind.com/publications/creating-interactive-agents-with-imitation-learning
Why do you think it can't?
I mean for one, its architecture does not permit its weights to change without receiving training data, and it does not generate training data itself.
PS: Mimicry is a fine art too, check this out: https://www.deepmind.com/publications/creating-interactive-agents-with-imitation-learning
Mimicry is limited by the availability of illustrations in various ways. E.g. it can't much exceed the demonstrations or use radically
from the lesswrong docs
An Artificial general intelligence, or AGI, is a machine capable of behaving intelligently over many domains. The term can be taken as a contrast to narrow AI, systems that do things that would be considered intelligent if a human were doing them, but that lack the sort of general, flexible learning ability that would let them tackle entirely new domains. Though modern computers have drastically more ability to calculate than humans, this does not mean that they are generally intelligent, as they have little ability to invent new problem-solving techniques, and their abilities are targeted in narrow domains.
If we consider only the first sentence, then yes. The rest of the paragraph points to something like "being able to generalize to new domains". Not sure if Gato counts. (NB: this is just a LW tag, not a full-fledged definition.)
If by "sort of general, flexible learning ability that would let them tackle entirely new domains" we include adding new tokenised vectors in the training set, then this fit the definition. Of course this is "cheating" since the system is not learning purely by itself, but for the purpose of building a product or getting the tasks done this does not really matter.
And it's not unconcievable to imagine self-supervised tokens generation to get more skills and perhaps a K-means algorithm to make sure that the new embeddings do not interfere with previous knowledge. It's a dumb way of getting smarter, but apparently it works thanks to scale effects!
I have always been cautios, but I would say yes this time.
With the caveat that it learns new tasks only from supervised data, and not reusing previous experience.
So perhaps a "proto-AGI" is a better term to use for it. Not quite the full thing just yet, but shows clear generality across a wide number of domains. If it can spread out further and become much larger, as well as have recursivity (which might require an entirely different architecture), it could become what we've all been waiting for.
I would agree with "proto-AGI". I might soon write a blog on this, but ideally we could define a continuous value to track how close we are to AGI, which is increasing if:
-the tasks to solve are very different from each other
-the tasks are complex
-how well a task have been solved
-few experience (or info) is fed to the system
-experience is not directly related to the task
-experience is very raw
-computation is done in few steps
Then adding new tasks and changing the environment.
Possibly the first truly AGI paper.
Even though it is just exploiting the fact that all the narrow problems can be solved as sequence problems via tokenisation, it's remarkable that the tasks do not interferee distructively between each other. My gut feeling is that this is due the very high dimensional space of the embedding vectors.
It leaves ample room for grow.
From the paper:
Technical AGI safety (Bostrom, 2017) may also become more challenging when considering generalist agents that operate in many embodiments. For this reason, preference learning, uncertainty modeling and value alignment (Russell, 2019) are especially important for the design of human-compatible generalist agents. It may be possible to extend some of the value alignment approaches for language (Kenton et al., 2021; Ouyang et al., 2022) to generalist agents. However, even as technical solutions are developed for value alignment, generalist systems could still have negative societal impacts even with the intervention of well-intentioned designers, due to unforeseen circumstances or limited oversight (Amodei et al., 2016). This limitation underscores the need for a careful design and a deployment process that incorporates multiple disciplines and viewpoints.
What I think I'm most interested in, is does training on one task improve or degrade it's performance on other tasks?
It's not very surprising if you take a model and throw a bunch of tasks at it and it eventually learns how to do all tasks. But if it can apply lessons from one task to general situations, that's impressive!
Some tasks improve others, some don't:
Therefore, transfer from image captioning or visual grounded question answering tasks is possible. We were not able to observe any benefit from pretraining on boxing.
Interesting. Research into this area might also give us some insight into which areas of human IQ are separate, and which parts are correlated.
I'd be curious to hear more thoughts on how much we could already scale it right now. Looks like that data might be a bottleneck?
Some thoughts on compute:
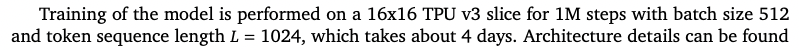
Gato estimate: 256 TPUv3 chips for 4 days a 24hours = 24'574 TPUv3-hours (on-demand costs are $2 per hour for a TPUv3) =$49'152
In comparison, PaLM used 8'404'992 TPUv4 hours and I estimated that it'd cost $11M+. If we'd assume that someone would be willing to spend the same compute budget on it, we could make the model 106x bigger (assuming Chinchilla scaling laws). Also tweeted about this here.
The size of the model was only(?) limited due to latency requirements for the robotics part.

The primary question on my mind is something like this:
How much retraining is needed for Gato to learn a new task? Given a task, such as "Stack objects and compose a relevant poem" which combines skills it has already learned, yet is a fundamentally different task, does it quickly learn how to perform well at it?
If not, then it seems Deepmind 'merely' managed to get a single agent to do a bunch of tasks we were previously only able to do with multiple agents. If it is also quicker at learning new tasks in similar domains, than an agent trained solely to do it, then it seems like a big step towards general intelligence.
Alarming that it freely "lies" (?) or hallucinates or whatever is going on, rather than replying "I don't know".
That's entirely expected. Hallucilying is a typical habit of language models. They do that unless some prompt engineering have been applied.
Looking at the image captioning and text prediction responses, it doesn't appear to be very good at either...
We focus our training at the operating point of model scale that allows real-time control of real-world robots, currently around 1.2B parameters in the case of Gato. As hardware and model architectures improve, this operating point will naturally increase the feasible model size, pushing generalist models higher up the scaling law curve. For simplicity Gato was trained offline in a purely supervised manner; however, in principle, there is no reason it could not also be trained with either offline or online reinforcement learning (RL).
And there is, of course, absolutely no reason to think that it wouldn't get as good as text/image models like Flamingo or the new ULM2 if it was trained & scaled as much as they were; the problem is that you can't run such large dense models at the necessary low latency for realtime robotics... Perhaps finally a genuine application for MoEs to enable plugging in very large unimodal/multimodal models.
A principled solution would probably involve running different parts of the model at different frequencies. But you could also just scale breadth and see how far it goes. The human brain is not very deep - just recursive.
A friend pointed out on Facebook that Gato uses TPU-v3's. Not sure why - I thought Google already had v4's available for internal use a while ago? In any case, the TPU-v4 might potentially help a lot for the latency issue.
Two main options:
* It was trained e.g. 1 year ago but published only now
* All TPU-v4 very busy with something even more important
They trained it on TPUv3s, however, the robot inference was run on a Geforce RTX 3090 (see section G).
TPUs are mostly designed for data centers and are not really usable for on-device inference.
Indeed but to slightly counter balance this, at the same time, it looks like it was trained on ~500B tokens (while ~300B were used for GPT-3 and for GPT-2 something like ~50B).
Most of those tokens were spent on the RL tasks, which were 85% of the corpus. Looking at the table 1a/1b which, the pure text modeling tasks looks like they were 10% weight with the other 5% being the image caption datasets*; so if it did 5 x 1e11 tokens total (Figure 9), then presumably it only saw a tenth of that as actual pure text comparable to GPT-2, or 50b tokens. It's also a small model so it is less sample-efficient and will get less than n billion tokens' worth if you are mentally working back from "well, GPT-3 used x billion tokens").
Considering further that it was not necessarily trained to convergence on the language modeling task (actually, come to think of it, how even did they decide when to stop training? they certainly didn't derive scaling laws on the overall task mix & train Gato in a compute-optimal fashion... was Gato converged on any tasks?), and remembering just how dumb GPT-2 is by contemporary standards (which have been moving the goalposts at supersonic speed), the sample dialogues don't look all that surprisingly dumb to me given its size & token count & training setup.
* image grounding is great and all that, but I don't expect it to be all that useful for knowing 'Marseilles is not the capital of France'.
Linkpost for "A Generalist Agent"
Abstract:
"Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato"