Thanks for this well-researched and thorough argument! I think I have a bunch of disagreements, but my main one is that it really doesn't seem like AGI will require 8-10 OOMs more inference compute than GPT-4. I am not at all convinced by your argument that it would require that much compute to accurately simulate the human brain. Maybe it would, but we aren't trying to accurately simulate a human brain, we are trying to learn circuitry that is just as capable.
Also: Could you, for posterity, list some capabilities that you are highly confident no AI system will have by 2030? Ideally capabilities that come prior to a point-of-no-return so it's not too late to act by the time we see those capabilities.
Oh, to clarify, we're not predicting AGI will be achieved by brain simulation. We're using the human brain as a starting point for guessing how much compute AGI will need, and then applying a giant confidence interval (to account for cases where AGI is way more efficient, as well as way less efficient). It's the most uncertain part of our analysis and we're open to updating.
For posterity, by 2030, I predict we will not have:
- AI drivers that work in any country
- AI swim instructors
- AI that can do all of my current job at OpenAI in 2023
- AI that can get into a 2017 Toyota Prius and drive it
- AI that cleans my home (e.g., laundry, dishwashing, vacuuming, and/or wiping)
- AI retail workers
- AI managers
- AI CEOs running their own companies
- Self-replicating AIs running around the internet acquiring resources
Here are some of my predictions from the past:
- Predictions about the year 2050, written 7ish years ago: https://www.tedsanders.com/predictions-about-the-year-2050/
- Predictions on self-driving from 5 years ago: https://www.tedsanders.com/on-self-driving-cars/
Thanks! AI managers, CEOs, self-replicators, and your-job-doers (what is your job anyway? I never asked!) seem like things that could happen before it's too late (albeit only very shortly before) so they are potential sources of bets between us. (The other stuff requires lots of progress in robotics which I don't expect to happen until after the singularity, though I could be wrong)
Yes, I understand that you don't think AGI will be achieved by brain simulation. I like that you have a giant confidence interval to account for cases where AGI is way more efficient and way less efficient. I'm saying something has gone wrong with your confidence interval if the median is 8-10 OOMs more inference cost than GPT-4, given how powerful GPT-4 is. Subjectively GPT-4 seems pretty close to AGI, in the sense of being able to automate all strategically relevant tasks that can be done by human remote worker professionals. It's not quite there yet, but looking at the progress from GPT-2 to GPT-3 to GPT-4, it seems like maybe GPT-5 or GPT-6 would do it. But the middle of your confidence interval says that we'll need something like GPT-8, 9, or 10. This might be justified a priori, if all we had to go...
Great points.
I think you've identified a good crux between us: I think GPT-4 is far from automating remote workers and you think it's close. If GPT-5/6 automate most remote work, that will be point in favor of your view, and if takes until GPT-8/9/10+, that will be a point in favor of mine. And if GPT gradually provides increasingly powerful tools that wildly transform jobs before they are eventually automated away by GPT-7, then we can call it a tie. :)
I also agree that the magic of GPT should update one into believing in shorter AGI timelines with lower compute requirements. And you're right, this framework anchored on the human brain can't cleanly adjust from such updates. We didn't want to overcomplicate our model, but perhaps we oversimplified here. (One defense is that the hugeness of our error bars mean that relatively large updates are needed to make a substantial difference in the CDF.)
Lastly, I think when we see GPT unexpectedly pass the Bar, LSAT, SAT, etc. but continue to fail at basic reasoning, it should update us into thinking AGI is sooner (vs a no pass scenario), but also update us into realizing these metrics might be further from AGI than we originally assumed based on human analogues.
This is the multiple stages fallacy. Not only is each of the probabilities in your list too low, if you actually consider them as conditional probabilities they're double- and triple-counting the same uncertainties. And since they're all mulitplied together, and all err in the same direction, the error compounds.
P(We invent algorithms for transformative AGI | No derailment from regulation, AI, wars, pandemics, or severe depressions): .8
P(We invent a way for AGIs to learn faster than humans | We invent algorithms for transformative AGI): 1. This row is already incorporated into the previous row.
P(AGI inference costs drop below $25/hr (per human equivalent): 1. This is also already incorporated into "we invent algorithms for transformative AGI"; an algorithm with such extreme inference costs wouldn't count (and, I think, would be unlikely to be developed in the first place).
We invent and scale cheap, quality robots: Not a prerequisite.
We massively scale production of chips and power: Not a prerequisite if we have already already conditioned on inference costs.
We avoid derailment by human regulation: 0.9
We avoid derailment by AI-caused delay: 1. I would consider an AI that derailed development of other AI ot be transformative.
We avoid derailment from wars (e.g., China invades Taiwan): 0.98.
We avoid derailment from pandemics: 0.995. Thanks to COVID, our ability to continue making technological progress during a pandemic which requires everyone to isolate is already battle-tested.
We avoid derailment from severe depressions: 0.99.
Interesting that this essay gives both a 0.4% probability of transformative AI by 2043, and a 60% probability of transformative AI by 2043, for slightly different definitions of "transformative AI by 2043". One of these is higher than the highest probability given by anyone on the Open Phil panel (~45%) and the other is significantly lower than the lowest panel member probability (~10%). I guess that emphasizes the importance of being clear about what outcome we're predicting / what outcomes we care about trying to predict.
The 60% is for "We invent algorithms for transformative AGI", which I guess means that we have the tech that can be trained to do pretty much any job. And the 0.4% is the probability for the whole conjunction, which sounds like it's for pervasively implemented transformative AI: AI systems have been trained to do pretty much any job, and the infrastructure has been built (chips, robots, power) for them to be doing all of those jobs at a fairly low cost.
It's unclear why the 0.4% number is the headline here. What's the question here, or the thing that we care about, such that this is the outcome that we're making forecasts for? e.g., I think that many paths to extinction don't route through this scenario. IIRC Eliezer has written that it's possible that AI could kill everyone before we have widespread self-driving cars. And other sorts of massive transformation don't depend on having all the infrastructure in place so that AIs/robots can be working as loggers, nurses, upholsterers, etc.
I disagree with the brain-based discussion of how much compute is required for AGI. Here’s an analogy I like (from here):
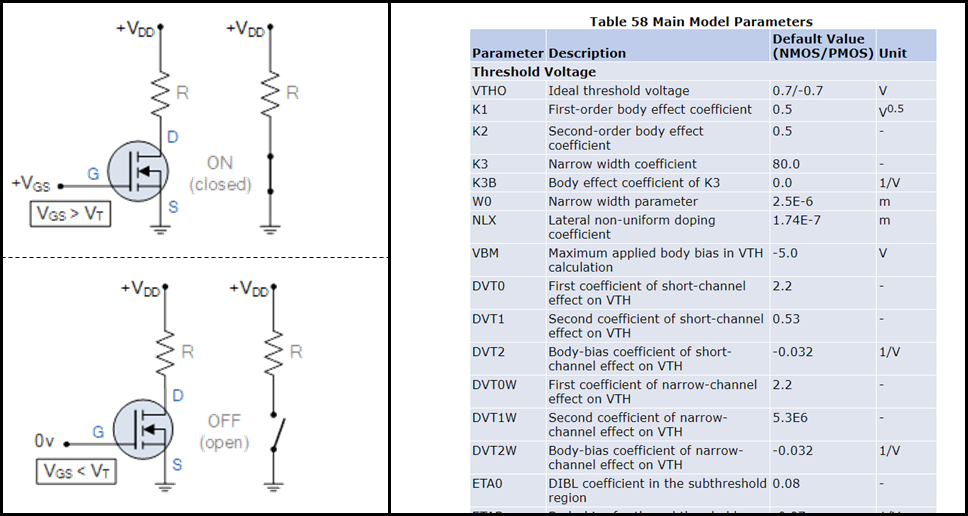
Left: Suppose that I want to model a translator (specifically, a MOSFET). And suppose that my model only needs to be sufficient to emulate the calculations done by a CMOS integrated circuit. Then my model can be extremely simple—it can just treat the transistor as a cartoon switch. (image source.)
Right: Again suppose that I want to model a transistor. But this time, I want my model to accurately capture all measurable details of the transistor. Then my model needs to be mind-bogglingly complex, involving dozens of adjustable parameters, some of which are shown in this table (screenshot from here).
What’s my point? I’m suggesting an analogy between this transistor and a neuron with synapses, dendritic spikes, etc. The latter system is mind-bogglingly complex when you study it in detail—no doubt about it! But that doesn’t mean that the neuron’s essential algorithmic role is equally complicated. The latter might just amount to a little cartoon diagram with some ANDs and ORs and IF-THENs or whatever. Or maybe not, but we should at least keep that possibility...
It's very possible this means we're overestimating the compute performed by the human brain a bit.
Specifically, by 6-8 OOMs. I don't think that's "a bit." ;)
Hi Ted,
I will read the article, but there's some rather questionable assumptions here that I don't see how you could reach these conclusions while also considering them.
| We invent algorithms for transformative AGI | 60% |
| We invent a way for AGIs to learn faster than humans | 40% |
| AGI inference costs drop below $25/hr (per human equivalent) | 16% |
| We invent and scale cheap, quality robots | 60% |
| We massively scale production of chips and power | 46% |
| We avoid derailment by human regulation | 70% |
| We avoid derailment by AI-caused delay | 90% |
| We avoid derailment from wars (e.g., China invades Taiwan) | 70% |
| We avoid derailment from pandemics | 90% |
| We avoid derailment from severe depressions | 95% |
We invent algorithms for transformative AGI:
- Have you considered RSI? RSI in this context would be an algorithm that says "given a benchmark that measures objectively if an AI is transformative, propose a cognitive architecture for an AGI using a model with sufficient capabilities to make a reasonable guess". You then train the AGI candidate from the cognitive architecture (most architectures will reuse pretrained components from prior attempts) and benchmark it. You maintain a "league" of...
We invent a way for AGIs to learn faster than humans : Why is this even in the table? This would be 1.0 because it's a known fact, AGI learns faster than humans. Again, from the llama training run, the model went from knowing nothing to domain human level in 1 month. That's faster. (requiring far more data than humans isn't an issue)
100% feels overconfident. Some algorithms learning some things faster than humans is not proof that AGI will learn all things faster than humans. Just look at self-driving. It's taking AI far longer than human teenagers to learn.
AGI inference costs drop below $25/hr (per human equivalent): Well, A100s are 0.87 per hour. A transformative AGI might use 32 A100s. $27.84 an hour. Looks like we're at 1.0 on this one also.
100% feels overconfident. We don't know if transformative will need 32 A100s, or more. Our essay explains why we think it's more. Even if you disagree with us, I struggle to see how you can be 100% sure.
Thanks, this was interesting.
I couldn't really follow along with my own probabilities because things started wild from the get-go. You say we need to "invent algorithms for transformative AI," when in fact we already have algorithms that are in-principle general, they're just orders of magnitude too inefficient, but we're making gradual algorithmic progress all the time. Checking the pdf, I remain confused about your picture of the world here. Do you think I'm drastically overstating the generality of current ML and the gradualness of algorithmic improvement, such that currently we are totally lacking the ability to build AGI, but after some future discovery (recognizable on its own merits and not some context-dependent "last straw") we will suddenly be able to?
And your second question is also weird! I don't really understand the epistemic state of the AI researchers in this hypothetical. They're supposed to have built something that's AGI, it just learns slower than humans. How did they get confidence in this fact? I think this question is well-posed enough that I could give a probability for it, except that I'm still confused about how to conditionalize on the first question.
The ...
I think the biggest problem with these estimates is that they rely on irrelevant comparisons to the human brain.
What we care about is how much compute is needed to implement the high-level cognitive algorithms that run in the brain; not the amount of compute needed to simulate the low-level operations the brain carries out to perform that cognition. This is a much harder to quantity to estimate, but it's also the only thing that actually matters.
See Biology-Inspired AGI Timelines: The Trick That Never Works and other extensive prior discussion on this.
I think with enough algorithmic improvement, there's enough hardware lying around already to get to TAI, and once you factor this in, a bunch of other conditional events are actually unnecessary or much more likely. My own estimates:
Event | Forecastby 2043 or TAGI, |
| We invent algorithms for transformative AGI | 90% |
| 100% | |
| 100% | |
| 100% | |
| 100% | |
| We avoid derailment by human regulation | 80% |
| We avoid derailment by AI-caused delay |
Just to pick on the step that gets the lowest probability in your calculation, estimating that the human brain does 1e20 FLOP/s with only 20 W of power consumption requires believing that the brain is basically operating at the bitwise Landauer limit, which is around 3e20 bit erasures per watt per second at room temperature. If the FLOP we're talking about here is equivalent of operations on 8-bit floating point numbers, for example, the human brain would have an energy efficiency of around 1e20 bit erasures per watt, which is less than one order of magnitude from the Landauer limit at room temperature of 300 K.
Needless to say, I find this estimate highly unrealistic. We have no idea how to build practical densely packed devices which get anywhere close to this limit; the best we can do at the moment is perhaps 5 orders of magnitude away. Are you really thinking that the human brain is 5 OOM more energy efficient than an A100?
Still, even this estimate is much more realistic than your claim that the human brain might take 8e34 FLOP to train, which ascribes a ludicrous ~ 1e26 FLOP/s computation capacity to the human brain if this training happens over 20 years. This obviously violate...
I guess I just feel completely different about those conditional probabilities.
Unless we hit another AI winter the profit and national security incentives just snowball right past almost all of those. Regulation? "Severe depression"
I admit that thr loss of taiwan does innfact set back chip manufactyre by a decade or more regardless of resoyrces thrown at it but every other case just seems way off (because of the incentive structure)
So we're what , 3 months post chatgpt and customer service and drive throughs are solved or about to be solved? , so lets call...
I think this is an excellent, well-researched contribution and am confused about why it's not being upvoted more (on LW that is; it seems to be doing much better on EAF, interestingly).
Your probabilities are not independent, your estimates mostly flow from a world model which seem to me to be flatly and clearly wrong.
The plainest examples seem to be assigning
| We invent a way for AGIs to learn faster than humans | 40% |
| AGI inference costs drop below $25/hr (per human equivalent) | 16% |
despite current models learning vastly faster than humans (training time of LLMs is not a human lifetime, and covers vastly more data) and the current nearing AGI and inference being dramatically cheaper and plummeting with algorithmic improvements. There is a general...
Thanks, the parts I've read so far are really interesting!
I would point out that the claim that we will greatly slow down, rather than scale up, electricity production capacity, is also a claim that we will utterly fail to even come anywhere close to hitting global decarbonization goals. Most major sectors will require much more electricity in a decarbonized world, as in raising total production (not just capacity) somewhere between 3x to 10x in the next few decades. This is much more than the additional power which would be needed to increase chip p...
Compute is not the limiting factor for mammalian intelligence. Mammalian brains are organized to maximize communication. The gray matter, where most compute is done, is mostly on the surface and the white matter which dominate long range communication, fills the interior, communicating in the third dimension.
If you plot volume of white matter vs. gray matter across the various mammal brains, you find that the volume of white matter grows super linearly with volume of gray matter. https://www.pnas.org/doi/10.1073/pnas.1716956116
As b...
Does this do the thing where a bunch of related events are treated as independent events and their probability is multiplied together to achieve a low number?
edit: I see you say that each event is conditioned on the previous events being true. It doesn't seem like you took that into account when you formulated your own probabilities.
According to your probabilities, in the world where: We invent algorithms for transformative AGI, We invent a way for AGIs to learn faster than humans, AGI inference costs drop below $25/hr (per human equivalent), and We invent...
| We invent algorithms for transformative AGI | 60% |
| We invent algorithms for transformative AGI | 60% |
| We invent a way for AGIs to learn faster than humans | 40% |
| AGI inference costs drop below $25/hr (per human equivalent) | 16% |
| We invent and scale cheap, quality robots | 60% |
| We massively scale production of chips and power | 46% |
| We avoid derailment by human regulation | 70% |
| We avoid derailment by AI-caused delay | 90% |
| We avoid derailment from wars (e.g., China invades Taiwa | 70% |
| We avoid derailment from pandemics | 90% |
| We avoid derailment from severe depression | 95% |
I'm going to try a better c...
Can you explain how Events #1-5 from your list are not correlated?
For instance, I'd guess #2 (learns faster than humans) follows naturally -- or is much more likely -- if #1 (algos for transformative AI) comes to pass. Similarly, #3 (inference costs <$25/hr) seems to me a foregone conclusion if #5 (massive chip/power scale) and #2 happen.
Treating the first five as conditionally independent puts you at 1% before arriving at 0.4% with external derailments, so it's doing most of the work to make your final probability miniscule. But I suspect they are highly correlated events and would bet a decent chunk of money (at 100:1 odds, at least) that all five come to pass.
I am confused about your use of the term "calibration". Usually it means correctly predicting the probabilities of events, as measured by frequencies. You are listing all the times you were right, without assigning your predicted probability. Do you list only high-probability predictions and conclude that you are well calibrated for, say, 95%+ predictions, since "no TAI by 2043" is estimated to be 99%+?
RE robots / “Element 4”:
IMO the relevant product category here should be human-teleoperated robots, not independent robots.
Robot-control algorithms are not an issue, since we’re already conditioning on Element 1 (algorithms for TAI). Humans can teleoperate a teleoperable robot, and therefore if Element 1 comes to pass, those future AI algorithms will be able to teleoperate a teleoperable robot too, right?
And human-teleoperated robots can already fold sheets, move boxes, get around a cluttered environment, etc., no problem. I believe this has been true for ...
If we divide the list of "10 necessary events" into two groups of five, the first five being technical achievements and the last five being ways to derail technological society... then I suppose the standard doomer view would be that once the first necessary event is achieved (AGI algorithms) then the other technical achievements become 100% possible (edit: because AI figures out how to do them); and that whether or not the derailing events occur, boils down to whether AI lets them happen.
edit: The implication being that algorithmic progress controls everything else.
Ted - thank you for sticking your neck out and writing this seminal piece. I do believe it has some basic fundamental missed. Allow me to explain in simpler "energy equivalence" terms.
Let us take an elementary task say driving in moderate traffic for say 60 minutes or 30-40 km. The total task will involve say ~250-500 decisions (accelerate/ decelerate/ halt, turn) and some 100,000-10,000,000 micro-observations depending upon the external conditions, weather, etc. A human body (brain + senses + limbs) can simulate all the changes on just a grain of ri...
I think the headline and abstract for this article are misleading. As I read these predictions, one of the main reasons that "transformative AGI" is unlikely by 2043 is because of severe catastrophes such as war, pandemics, and other causes. The bar is high, and humanity is fragile.
For example, the headline 30% chance of "derailment from wars" is the estimate of wars so severe that they set back AI progress by multiple years, from late 2030s to past 2043. For example, a nuclear exchange between USA and China. Presumably this would not set back progress on ...
How has this forecast changed in the last 5 years? Has widespread and rapid advance of non-transformative somewhat-general-purpose LLMs change any of your component predictions?
I don't actually disagree, but MUCH of the cause of this is an excessively high bar (as you point out, but it still makes the title misleading). "perform nearly all valuable tasks at human cost or less" is really hard to put a lot of stake in, when "cost" is so hard to define at scale in an AGI era. Money changes meaning when a large subset of human action is no lo...
Looking back:
> We massively scale production of chips and power
This will probably happen, actually the scale to which it's happening would probably shock the author if we went back in time 9 months ago. Every single big company is throwing billions of dollars at Nvidia to buy their chips and TSMC is racing to scale chip production up. Many startups+other companies are trying to dethrone Nvidia as well.
> AGI inference costs drop below $25/hr (per human equivalent)
This probably will happen. It seems pretty obvious to me that inference costs fall ...
Have you seen Jacob Steinhardt's article https://www.lesswrong.com/posts/WZXqNYbJhtidjRXSi/what-will-gpt-2030-look-like ? It seems like his prediction for a 2030 AI would already meet the threshold for being a transformative AI, at least in aspects not relating to robotics. But you put this at less than 1% likely at a much longer timescale. What do you think of that writeup, where do you disagree, and are there any places where you might consider recalibrating?
One thing I don't understand, why the robot step as necessary? AGI that is purely algorithmic but still able to do all human intellectual tasks, including science and designing better AGI, would be transformative enough. And if you had that, the odds of having the cheap robots shoot up as now the AGI can help.
(Crossposted to the EA forum)
Abstract
The linked paper is our submission to the Open Philanthropy AI Worldviews Contest. In it, we estimate the likelihood of transformative artificial general intelligence (AGI) by 2043 and find it to be <1%.
Specifically, we argue:
conditional on prior steps being achieved. Many steps are quite constrained by the short timeline, and our estimates range from 16% to 95%.
Thoughtfully applying the cascading conditional probability approach to this question yields lower probability values than is often supposed. This framework helps enumerate the many future scenarios where humanity makes partial but incomplete progress toward transformative AGI.
Executive summary
For AGI to do most human work for <$25/hr by 2043, many things must happen.
We forecast cascading conditional probabilities for 10 necessary events, and find they multiply to an overall likelihood of 0.4%:
Event
Forecast
by 2043 or TAGI,
conditional on
prior steps
If you think our estimates are pessimistic, feel free to substitute your own here. You’ll find it difficult to arrive at odds above 10%.
Of course, the difficulty is by construction. Any framework that multiplies ten probabilities together is almost fated to produce low odds.
So a good skeptic must ask: Is our framework fair?
There are two possible errors to beware of:
We believe we are innocent of both sins.
Regarding failing to model parallel disjunctive paths:
Regarding failing to really grapple with conditional probabilities:
Therefore, for the reasons above—namely, that transformative AGI is a very high bar (far higher than “mere” AGI) and many uncertain events must jointly occur—we are persuaded that the likelihood of transformative AGI by 2043 is <1%, a much lower number than we otherwise intuit. We nonetheless anticipate stunning advancements in AI over the next 20 years, and forecast substantially higher likelihoods of transformative AGI beyond 2043.
For details, read the full paper.
About the authors
This essay is jointly authored by Ari Allyn-Feuer and Ted Sanders. Below, we share our areas of expertise and track records of forecasting. Of course, credentials are no guarantee of accuracy. We share them not to appeal to our authority (plenty of experts are wrong), but to suggest that if it sounds like we’ve said something obviously wrong, it may merit a second look (or at least a compassionate understanding that not every argument can be explicitly addressed in an essay trying not to become a book).
Ari Allyn-Feuer
Areas of expertise
I am a decent expert in the complexity of biology and using computers to understand biology.
Track record of forecasting
While I don’t have Ted’s explicit formal credentials as a forecaster, I’ve issued some pretty important public correctives of then-dominant narratives:
Luck played a role in each of these predictions, and I have also made other predictions that didn’t pan out as well, but I hope my record reflects my decent calibration and genuine open-mindedness.
Ted Sanders
Areas of expertise
I am a decent expert in semiconductor technology and AI technology.
Track record of forecasting
I have a track record of success in forecasting competitions:
Each finish resulted from luck alongside skill, but in aggregate I hope my record reflects my decent calibration and genuine open-mindedness.
Discussion
We look forward to discussing our essay with you in the comments below. The more we learn from you, the more pleased we'll be.
If you disagree with our admittedly imperfect guesses, we kindly ask that you supply your own preferred probabilities (or framework modifications). It's easier to tear down than build up, and we'd love to hear how you think this analysis can be improved.