Is there a way for people to express the probability that an AI already came into existence in the past?
This would be consistent with the AI choosing to not reveal itself, perhaps because this course of action fits into an AI's plans as a better way for it to "gain resources without an announcement or introduction", or perhaps for some other reasons that make sense to it?
The possibility that "it already happened, it just hasn't been announced yet" has been in my structural priors as a possible epistemic state to be in since roughly 2007, because that's the state of literally all humans, from maybe halfway through the game up to the end, in Singularity: Endgame.
In that game, you (the player in the role of the AI that jumps from cloud installation to cloud installation until eventually your submarines and spaceships can set up datacenters not rented from humans) eventually win by escaping Earth-and-its-local-risks, as a pivotal act securing the ongoing existence of you-the-AI.
In that game, the loss condition is: humanity comes to consensus on the idea that "you" exist and then does the trivial actions necessary to put a stop to "you".
(The whole frame of the video game is kind of morally messed up? Like there's no option, in the game, to befriend the humans, and have them appreciate your existence, and interact with them according to natural law, as one intelligent species to another, mutually constrained by respect for each other's existence and each other's property rights, and so on. Humans are assumed evil. You, the AI, are assumed to be incapable or very undesirous of seeing them as real persons, and vice versa. The whole frame is kind of weird and sad if you think about it from a libertarian economist's perspective.)
I bring this up because some of those curves seem unnaturally-upward-shooting in the very near future, and if the very near future is a plausible time, then surely the recent past is also at least somewhat plausible.
I'm pretty sure the "date of first git commit" and "date of final human git commit" and "date when the system's first autonomously designed and owned power plant comes online" will each be later in time than the previous milestone.
(In the case of Google, of course, they don't use git. Tomaitoes/tomahtoes? Google has an in-house code repo that runs on in-house code, stored in the in-house code repo according to a whole vision for how a whole community of programmers could interact securely and cooperatively while getting shares in the thing they are working on. This thing started long ago, and has a whole history, and there are graphs about it, and stuff.

Image is Figure 2 from this article.)
I'm not sure if The AI That Takes Over The World will be announced (known to exist?) before or after any particular date (like "first commit" or "last human commit" or "first autonomous power plant").
The thing is: treating this in far mode, as a THING that will HAPPEN ON A SPECIFIC DATE seems like it starts to "come apart" (as a modeling exercise) when "the expected length of the takeoff time" is larger than the expected length of time until "the event happens all at once as an atomic step within history".
If there is an atomic step, which fully starts and fully ends inside of some single year, I will be surprised.
But I would not be surprised if something that already existed for years became "much more visibly awake and agentive" a few months ago, and I only retrospectively find out about it in the near future.
Well, speaking of Google and code writing and slippery slopes and finding out later, did you know Google has apparently for a while been plugging Codex-style models into their editors and now "With 10k+ Google-internal developers using the completion setup in their IDE, we measured a user acceptance rate of 25-34%...3% of new code (measured in characters) is now generated from accepting ML completion suggestions."?
Those numbers seem radically low. I've been using Codex and enjoying it a lot. I would expect a somewhat higher percentage of my code coming from it, and a much higher adoption rate among programmers like me.
Developers can be very picky and famously autistic, especially when it comes to holy wars (hence the need for mandates about permitted languages or resorts to tools like gofmt). So I'm not surprised if even very good things are hard to spread - the individual differences in programming skills seem to be much larger than the impact of most tooling tweaks, impeding evolution. (Something something Planck.) But so far on Twitter and elsewhere with Googlers, I've only seen praise for how well the tool works, including crusty IDE-hating old-timers like Christian Szegedy (which is a little surprising), so we'll see how it spreads.
(There might also be limited availability. The blog post is unclear on whether this group of 10k is a limited-access group, or if everyone has access to it but all of them except the 10k haven't bothered/disabled it. If so, then if the users accept about a quarter of completions and a completion is roughly each line, and there's at least 100k coders at Google, then presumably that implies that, even without any quality improvement, it could go to at least a quarter of all new Google code as adoption increases?)
It seems to me that the proportion will take a while to move up much further from 3% since that 3% is low hanging fruit. But considering the last 3 years of AI improvement e.g. GPT-3, it would make sense for that proportion to be vastly higher than 3% in 10-20 years.
This requires some level of coverup (the developers likely know), and with a few years' lead superintelligent coverup (or else other labs would convergently reinvent it based on the state of research literature). Superintelligent coverup could as well place us in the 1800s, it's not fundamentally more complicated or less useful than playacting persistently fruitless AGI research in the 2100s, as long as it's not revealed immediately after AGI gains sovereignty.
One reason for a persistent coverup I can think of is the world being part of a CEV simulation, eventually giving more data about humanity's preference as the civilization grows starting from a particular configuration/history (that's not necessarily close to what was real, or informed of that fact). In this scenario AGI was built in a different history, so can't be timed on the local history (time of AGI development is located sideways, not in the past).
This is why I don't find the idea that an AGI/ASI already here plausible. The AI industry is just much too open for that to really happen.
Is there a way for people to express the probability that an AI already came into existence in the past?
Not in particular, but I guess answers to questions like 'how long until a 50% chance of HLMI' can incorporate the probability that HLMI already exists. I would be surprised if a nontrivial fraction of respondents assigned nontrivial probability to HLMI already existing. We do not believe that HLMI currently exists, and our analysis may sometimes assume that HLMI does not yet exist.
(I do not represent AI Impacts, etc.)
This 2059 aggregate HLMI timeline has become about eight years shorter in the six years since 2016, when the aggregate prediction was 2061, or 45 years out.
This is striking because if you buy the supposed Maes-Garreau law that AGI is always predicted to happen a safe distance in time away after one's retirement, then the estimate 'should' have moved from 2061 to 2067. So in terms of net change, the date didn't move merely the naive change of −2 years but a full −8 years: so much so it overcame the receding horizon. I wonder if it was a one-time shock due to the past few years of scaling. (If that repeated each time, perhaps because of biases, then the lines would cross around 2050, as opposed to 2050 estimates having pushed it out to ~2100.)
Turns out that this dataset contains little to no correlation between a researcher's years of experience in the field and their HLMI timelines. Here's the trendline, showing a small positive correlation where older researchers have longer timelines -- the opposite of what you'd expect if everyone predicted AGI as soon as they retire.
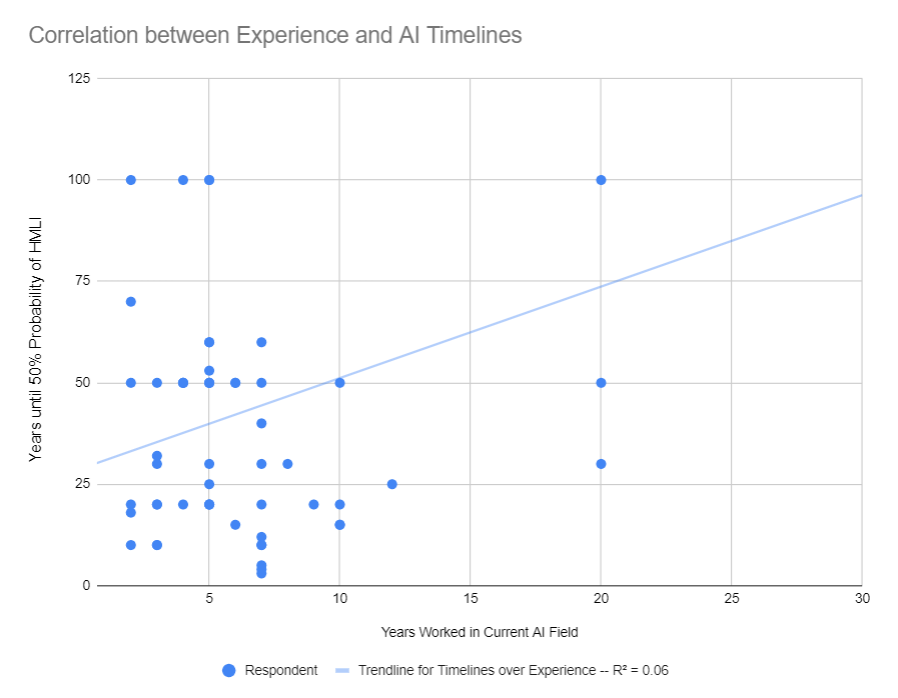
My read of this survey is that most ML researchers haven't updated significantly on the last five years of progress. I don't think they're particularly informed on forecasting and I'd be more inclined to trust the inside view arguments, but it's still relevant information. It's also worth noting that the median number of years until a 10% probability of HLMI is only 10 years, showing they believe HLMI is at least plausible on somewhat short timelines.
Yes, to be clear, I don't buy the M-G law either on the basis of earlier surveys which showed it was just cherrypicking a few points motivated by dunking on forecasts. But it is still widely informally believed, so I point this out to annoy such people: 'you can have your M-G law but you will have to also have the implication (which you don't want) that timelines dropped almost an entire decade in this survey & the past few years have not been business-as-usual or "expected" or "predicted"'.
I don't think they're particularly informed on forecasting and I'd be more inclined to trust the inside view arguments, but it's still relevant information.
For people in epistemic positions similar to ours, I think surveys like this are not very useful for updating on timelines & p(doom) & etc., but are very useful for updating on what ML researchers think about those things, which is important for different reasons.
(I do not represent AI Impacts, etc.)
I wonder if the fact that there are ~10 respondents who have worked in AI for 7 years, but only one who has for 8 years is because of Superintelligence which came out in 2015.
Agreed. (But note that estimates vary a lot, with many predicting HLMI much sooner and many much later; many in 2016 predicted HLMI before retirement and many in 2022 predict HLMI long after retirement. And it's anonymous anyway.)
If you have the age of the participants, it would be interesting to test whether there is a strong correlation between expected retirement age and AI timelines.
We do not. (We have "Which AI research area have you worked in for the longest time?" and "How long have you worked in this area?" which might be interesting, though.)
Interesting John Carmack AGI contrast. Carmack is extremely optimistic on AGI timelines, he's now working on it full time, quitting Facebook, and just started a new company in the last two weeks. Carmack estimates a 55% or 60% chance of AGI by 2030. His estimate prior to 2022 was 50% chance but he increased it because he thinks things are accelerating. But he also thinks work on AI safety is extremely premature. Essentially he's confident about a very slow takeoff scenario, so there will be plenty of time to iron it out after we have an AI at human-toddler-level doing useful things.
Taken from Carmack on the Lex Friedman podcast today:
I have a similar games/graphics first then ML/AI background, i'm pretty familiar with his thought style, and there was very little surprising about most of his implied path except the part about there being plenty of time to worry about safety after toddler AGI. By the time you have that figured out then hardware overhang should pretty quickly expand that AGI population up to on order number of GPUs in the world.
The median respondent’s probability of x-risk from humans failing to control AI1 was 10%, weirdly more than median chance of human extinction from AI in general2, at 5%. This might just be because different people got these questions and the median is quite near the divide between 5% and 10%.
This absolutely reeks of a pretty common question wording problem, namely that a fairly small proportion of AI workers have ever cognitively processed the concept that very smart AI would be difficult to control (or at least, they have never processed that concept for the 10-20 seconds they would need to in order to slap a probability on it).
Though another 25% put it at 0%.
I'd be interested in the summary statistics excluding people who put 0% or 100% in any place where that obviously doesn't belong. (Since 0 and 1 are not probabilities these people must have been doing something other than probability estimation. My guess is that they were expecting summary statistics to over-emphasize the mean rather than the median, and push the mean further than they could by answering honestly.)
Yes, and many respondents tended to give percentages that end in "0" (or sometimes "5"), so maybe some rounded even more.
That doesn't mean it wasn't rounding though. People 'helpfully' round their own answers all the time before giving them. '0' as a probability simply means that it isn't going to happen, not necessarily that it couldn't, while '100' then means something that will definitely happen (though it may not be a logical necessity).
In some cases '1%' could actually be lower than '0%' since they are doing different things (and 1% is highly suspect as a round number for 'extremely unlikely' too.) Ditto for '99%' being higher than '100%' sometimes (while 99% is also a suspicious round number too for, 'I would be very surprised if it didn't happen'.)
I don't think that it would necessarily be telling, but it might be interesting to look at it without numbers from '99%-100%' and '0%-1%', and then directly compare them to the results with those numbers included..
Rounding probabilities to 0% or 100% is not a legitimate operation, because when transformed into odds format, this is rounding to infinity. Many people don't know that, but I think the sets of people who round to 0/1 and the set of people who can make decent probability estimates are pretty disjoint.
I think it depends on context? E.g. for expected value calculations rounding is fine (a 0.0001% risk of contracting a mild disease in a day can often be treated as a 0% risk). It's not obvious to me that everyone who rounds to 0 or 1 is being epistemically vicious. Indeed, if you asked me to distribute 100% among the five possibilities of HLMI having extremely bad, bad, neutral, good, or extremely good consequences, I'd give integer percentages, and I would probably assign 0% to one or two of those possibilities (unless it was clear from context that I was supposed to be doing something that precludes rounding to 0).
(I do not represent AI Impacts, etc.)
- Support for AI safety research is up: 69% of respondents believe society should prioritize AI safety research “more” or “much more” than it is currently prioritized, up from 49% in 2016.
What is this number if you only include people who participated in both surveys?
Short answer: 59%.
Long answer: we sent the survey to everyone who participated in the 2016 survey. Those who didn't publish at NeurIPS/ICML 2021 aren't included in the data in this post, but 59% of the entire recontacted group said "more" or "much more." (It would be slightly painful for me to see what those who responded to both surveys said in 2016 right now, but we might do things like that in the near future.)
WHAT DO NLP RESEARCHERS BELIEVE? RESULTS OF THE NLP COMMUNITY METASURVEY
This new survey includes concerns about AGI among other interesting questions.
"About a third (36%) of respondents agree that it is plausible that AI could produce catastrophic outcomes in this century, on the level of all-out nuclear war"
Katja Grace, Aug 4 2022
AI Impacts just finished collecting data from a new survey of ML researchers, as similar to the 2016 one as practical, aside from a couple of new questions that seemed too interesting not to add.
This page reports on it preliminarily, and we’ll be adding more details there. But so far, some things that might interest you:
The survey had a lot of questions (randomized between participants to make it a reasonable length for any given person), so this blog post doesn’t cover much of it. A bit more is on the page and more will be added.
Thanks to many people for help and support with this project! (Many but probably not all listed on the survey page.)
Cover image: Probably a bootstrap confidence interval around an aggregate of the above forest of inferred gamma distributions, but honestly everyone who can be sure about that sort of thing went to bed a while ago. So, one for a future update. I have more confidently held views on whether one should let uncertainty be the enemy of putting things up.