Your section on the physical limits of hardware computation .. is naive; the dominant energy cost is now interconnect (moving bits), not logic ops. This is a complex topic and you could use more research and references from the relevant literature; there are good reasons why the semiconductor roadmap has ended and the perception in industry is that Moore's Law is finally approaching it's end. For more info see this, with many references.
Out of curiosity:
- What rough probability do you assign to a 10x improvement in efficiency for ML tasks (GPU or not) within 20 years?
- What rough probability do you assign to a 100x improvement in efficiency for ML tasks (GPU or not) within 20 years?
My understanding is that we actually agree about the important parts of hardware, at least to the degree I think this question is even relevant to AGI at this point. I think we may disagree about the software side, I'm not sure.
I do agree I left a lot out of the hardware limits analysis, but largely because I don't think it is enough to move the needle on the final conclusion (and the post is already pretty long!).
So assuming by 'efficiency' you mean training perf per $, then:
- 95% (Hopper/Lovelace will already provide 2x to 4x)
- 65%
It's been over a year since the original post and 7 months since the openphil revision.
A top level summary:
- My estimates for timelines are pretty much the same as they were.
- My P(doom) has gone down overall (to about 30%), and the nature of the doom has shifted (misuse, broadly construed, dominates).
And, while I don't think this is the most surprising outcome nor the most critical detail, it's probably worth pointing out some context. From NVIDIA:
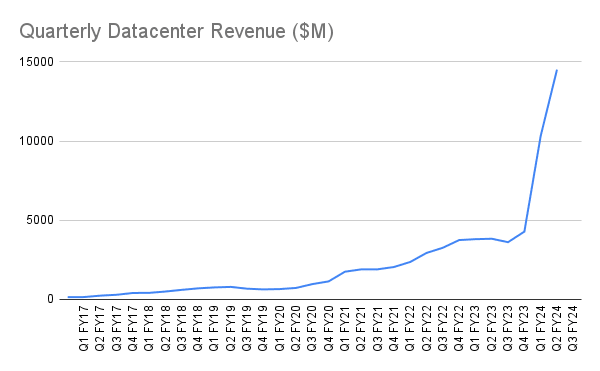
In two quarters, from Q1 FY24 to Q3 FY24, datacenter revenues went from $4.28B to $14.51B.
From the post:
In 3 years, if NVIDIA's production increases another 5x ...
Revenue isn't a perfect proxy for shipped compute, but I think it's safe to say we've entered a period of extreme interest in compute acquisition. "5x" in 3 years seems conservative.[1] I doubt the B100 is going to slow this curve down, and competitors aren't idle: AMD's MI300X is within striking distance, and even Intel's Gaudi 2 has promising results.
Chip manufacturing remains a bottleneck, but it's a bottleneck that's widening as fast as it can to catch up to absurd demand. It may still be bottlenecked in 5 years, but not at the same level of production.
On the difficulty of
...Promoted to curated: I've found myself coming back to this post once every few days or so since it was published. It had a lot of graphs and numbers in a single place I hadn't seen before, and while I have some disagreements with it, I think it did make me update towards a bit shorter timelines, which is impressive for a topic I've already spent hundreds of hours thinking about.
I particularly like the mixture of integrating both first-principles arguments, and a lot of concrete data into an overall worldview that I think I now have a much better time engaging with.
Maybe there is a person like #2 somewhere out there in the world, maybe a very early researcher in what has become modern machine learning, but I've never heard of them. If this person exists, I desperately want them to explain how their model works. They clearly would know more about the topic than I do and I'd love to think we have more time.
Gary Marcus thinks he is this person, and is the closest to being this person you're going to find. You can read his substack or watch some interviews that he's given. It's an interesting position he has, at least.
In this section you talk a lot about surprise, and that a Gary Marcus should be able to make successful predictions about the technology in order to have something meaningful to say. I think Gary Marcus is a bit like a literary critic commenting on his least favorite genre: he can't predict what the plot of the next science fiction novel will be, but he knows in advance that he won't be impressed by it.
The reason he offered that bet was because Elon Musk had predicted that we'd likely have AGI by 2029, so you're drawing the wrong conclusion from that. Other people joined in with Marcus to push the wager up to $500k, but Musk didn't take the bet of course, so you might infer something from that!
The bet itself is quite insightful, and I would be very interested to hear your thoughts on its 5 conditions:
https://garymarcus.substack.com/p/dear-elon-musk-here-are-five-things
In fact anyone thinking that AGI is imminent would do well to read it - it focusses the mind on specific capabilities and how you might build them, which I think it more useful than thinking in vague terms like 'well AI has this much smartness already, how much will it have in 20 / 80 years!'. I think it's useful and necessary to understand at that level of detail, otherwise we might be watching someone building a taller and taller ladder, and somehow thinking that's going to get us to the moon.
FWIW, I work in DL, and I agree with his analysis
My contention is that they are all shallow. A system that is trained on near-infinite training sets can look indistinguishable from one that can do deep reasoning, but is in fact just pattern-matching.
I agree.
This is a big part of what my post is about.
- We have AI that is obviously dumb, in the sense of failing on trivial tasks and having mathematically provable strict bounds.
- That type of AI is eating progressively larger chunks of things we used to call "intelligence."
- The things we used to call intelligence are, apparently, easy.
- We should expect (and have good reason to believe) that more of what we currently call intelligence to be easy, and it may very well be consumed by dumb architectures.
- Less dumb architectures are being worked on, and do not require paradigm shifts.
- Uh oh.
This is a statement mostly about the problem, not the problem solver. The problem we thought was hard just isn't.
And if we say we'll fix it by adding 'actual reasoning', well... good luck! AI spent 2 decades trying to build symbolic reasoning systems, getting that to work is incredibly hard.
Going to be deliberately light on details here again, sorry. When I say 'actual reasoning,' I mean AI that is trai...
I have saved this post on the internet archive[1].
If in 5-15 years, the prediction does not come true, i would like it to be saved as evidence of one of the many serious claims that world-ending AI will be with us in very short timelines. I think the author has given more than enough detail on what they mean by AGI, and has given more than enough detail on what it might look like, so it should be obvious whether or not the prediction comes true. In other words, no rationalising past this or taking it back. If this is what the author truly believes, they should have a permanent record of their abilities to make predictions.
I encourage everyone to save posts similar to this one in the internet archive. The AI community, if there is one, is quite divided on issues like these, and even among groups that are in broad agreement there are disagreements on details. It will be very useful to have a public archive of who made what claims so we know who to avoid and who to take seriously.
[1] https://web.archive.org/web/20221020151610/https://www.lesswrong.com/posts/K4urTDkBbtNuLivJx/why-i-think-strong-general-ai-is-coming-soon
There are three kinds of people. Those who in the past made predictions which turned out to be false, those who didn't make predictions, and those who in the past made predictions which turned out to be true. Obviously the third kind is the best & should be trusted the most. But what about the first and second kinds?
I get the impression from your comment that you think the second kind is better than the first kind; that the first kind should be avoided and the second kind taken seriously (provided they are making plausible arguments etc.) If so, I disagree; I'm not sure which kind is better, I could see it being the case that generally speaking the first kind is better (again provided they are making plausible arguments etc.)
Hey, we met at EAGxToronto : ) I am finally getting around to reading this. I really enjoyed your manic writing style. It is cathartic finding people stressing out about the same things that are stressing me out.
In response to "The less you have been surprised by progress, the better your model, and you should expect to be able to predict the shape of future progress": My model of capabilities increases has not been too surprised by progress, but that is because for about 8 years now there has been a wide uncertainty bound and a lot of Vingean Reflection in my model. I know that I don't know what is required for AGI and strongly suspect that nobody else does either. It could be 1 key breakthrough or 100, but most of my expectation p-mass is in the range of 0 to 20. Worlds with 0 would be where prosaic scaling is all we need or where a secret lab is much better at being secret than I expect. Worlds with 20 are where my p-mass is trailing off. I really can't imagine there would be that many key things required, but since those insights are what would be required to understand why they are required, I don't think they can be predicted ahead of time, since predicting the breakthrough i...
I am utterly in awe. This kind of content is why I keep coming back to LessWrong. Going to spend a couple of days or weeks digesting this...
I know it's not the point of your article, but you lost me at saying you would have a 2% chance of killing millions of people, if you had that intention.
Without getting into tactics, I would venture to say there are quite a few groups across the world with that intention, which include various parties of high intelligence and significant resources, and zero of those have achieved it (if we exclude, say, heads of state).
I work in the area of AGI research. I specifically avoid working on practical problems and try to understand why our models work and how to improve them. While I have much less experience than the top researchers working on practical applications, I believe that my focus on basic research makes me unusually suited for understanding this topic.
I have not been very surprised by the progress of AI systems in recent years. I remember being surprised by AlphaGo, but the surprise was more about the sheer amount of resources put into that. Once I read up on details, the confusion disappeared. The GPT models did not substantially surprise me.
A disclaimer: Every researcher has their own gimmick. Take all of the below with a grain of salt. It's possible that I have thought myself into a cul-de-sac, and the source of the AGI problem lies elsewhere.
I believe that the major hurdle we still have to pass is the switch from System 1 thinking to System 2 thinking. Every ML model we have today uses System 1. We have simply found ways to rephrase tasks that humans solve with System 2 to become solvable by System 1. Since System 1 is much faster, our ML models perform reasonably well on th...
Kurzweil predicted a singularity around 2040. That's only 18 years away, so in order for us to hit that date things have to start getting weird now.
I think this post underestimates the amount of "fossilized" intelligence in the internet. The "big model" transformer craze is like humans discovering coal and having an industrial revolution. There are limits to the coal though, and I suspect the late 2020s and early 2030s might have one final AI winter as we bump into those limits and someone has to make AI that doesn't just copy what humans already do.
But that puts us on track for 2040, and the hardware will continue to move forward meaning that if there is a final push around 2040, the progress in those last few years may eclipse everything that came before.
As for alignment/safety, I'm still not sure whether the thing ends up self-aligning or something pleasant, or perhaps alignment just becomes a necessary part of making a useful system as we move forward and lies/confabulation become more of a problem. I think 40% doom is reasonable at this stage because (1) we don't know how likely these pleasant scenarios are and (2) we don't know how the sociopolitical side will go; will there be funding for safety research or not? Will people care? With such huge uncertainties I struggle to deviate much from 50/50, though for anthropic reasons I predicted a 99% chance of success on metaculus.
I'm curious as to what you think "getting weird" might mean. From my perspective, things are already "getting weird". Three years ago, AI couldn't generate good art, write college essays, write code, solve Minerva problems, beat players at Starcraft II, or generalise across multiple domains. Now, it can do all of those things. People who work in the field have trouble keeping up. People outside the field are frequently blindsided by things that appear to come out of nowhere, like "Did you know that I can generate artwork from text prompts?" and "Did you know I can use GPT-3 to write a passable essay?" and, just for me a few weeks ago "Holy shit, Github Copilot just answered the question I was going to use as a linear algebra exercise."
So, my definition of "weird" is something like "It's hard for professionals in a field to keep up with developments, and non-professionals will be frequently blindsided by seemingly discontinuous jumps" and I think ML has been doing that over the last few years.
What would you consider "getting weird" to mean?
The openphil contest is approaching, so I'm working on an edited version. Keeping this original version as-is seems like a good idea- both as a historical record and because there's such a nice voiceover!
I've posted the current version over on manifund with a pdf version. If you aren't familiar with manifund, I'd recommend poking around. Impact certificates are neat, and I'd like them to become more of a thing!
The main changes are:
- Added a short section trying to tie together why the complexity argument actually matters.
- Updated a few spots with notes
I'm a little bit skeptical of the argument in "Transformers are not special" -- it seems like, if there were other architectures which had slightly greater capabilities than the Transformer, and which were relatively low-hanging fruit, we would have found them already.
I'm in academia, so I can't say for sure what is going on at big companies like Google. But I assume that, following the 2017 release of the Transformer, they allocated different research teams to pursuing different directions: some research teams for scaling, and others for the development o...
I think what's going on is something like:
- Being slightly better isn't enough to unseat an entrenched option that is well understood. It would probably have to very noticeably better, particularly in scaling.
- I expect the way the internal structures are used will usually dominate the details of the internal structure (once you're already at the pretty good frontier).
- If you're already extremely familiar with transformers, and you can simply change how you use transformers for possible gains, you're more likely to do that than to explore a from-scratch technique.
For example, in my research, I'm currently looking into some changes to the outer loop of execution to make language models interpretable by construction. I want to focus on that part of it, and I wanted the research to be easily consumable by other people. Building an entire new architecture from scratch would be a lot of work and would be less familiar to others. So, not surprisingly, I picked a transformer for the internal architecture.
But I also have other ideas about how it could be done that I suspect would work quite well. Bit hard to justify doing that for safety research, though :P
I think the amount of low hanging fruit is so high that we can productively investigate transformer derivatives for a long time without diminishing returns. They're more like a canvas than some fixed Way To Do Things. It's just also possible someone makes a jump with a non-transformer architecture at some point.
FWIW this is around the amount of progress I was expecting in 2016. For better or worse I updated very hard toward very short timelines once alphago was released in 2015. Amusingly at the time I figured we had 10-20 years until strong AGI, which gives an average of 2030. I prefer to say strong AGI since as far as I'm concerned publicly available AGI was released in late 2022.
I played the token-prediction game, and even though I got a couple correct, they were still marked in red and I got 0 score. One of the words was "handling", I knew it was "handling" but handling was not a valid token, so I put in "hand" expecting to be able to finish "ling". The game said "wrong, red, correct answer was handling". Arrg!
(EDIT: it looks like you have to put spaces in at the beginning of tokens. This is poor game design.)
This doesn't have anything to do with the rest of the post, I just wanted to whine about it lol
Another related Metaculus prediction is
I have some experience in competitive programming and competitive math (although I was never good in math despite I solved some "easy" IMO tasks (already in university, not onsite ofc)) and I feel like competitive math is more about general reasoning than pattern matching compared to competitive programming.
P.S the post matches my intuitions well and is generally excellent.
I would feel much more concerned about advances in reinforcement learning, rather than training on large datasets. As surprising as some of the things that GPT-3 and the like are able to do, there is a direct logical link between the capability and the task of predicting tokens. Detecting and repeating patterns, translations, storytelling, programming. I don't see a link between predicting tokens and overthrowing the government or even manipulating a single person into doing something. There is no reward for that, I don't particularly see any variation of ...
as we get into more complex tasks, getting AI to do what we want becomes more difficult
I suspect that much of the probability for aligned ASI comes from this. We're already seeing this with GPT ; it often confabulates or essentially simulates some kind of wrong but popular answer.
A bit late to the party. Love the article, but I believe it is somewhat misleading when you say that transformers run in constant time complexity.
If the number of tokens in the input sentence is the input size of its time complexity, which I'm sure you can agree is the obvious choice; The transformer encoder is run on each token in the sentence, in parallel if needed, but it still has to do all of its computations for each input token, immediately causing at least O(n) time.
I do think that the point you are trying to give is different though. C...
This was well written and persuasive. It doesn't change my views against AGI on very short time lines (pre-2030), but does suggest that I should be updating likelihoods thereafter and shorten timelines.
But it sure looks like tractable constant time token predictors already capture a bunch of what we often call intelligence, even when those same systems can't divide!
This is crazy! I'm raising my eyebrows right now to emphasize it! Consider also doing so! This is weird enough to warrant it!
Why is this crazy? Humans can't do integer division in one step either.
And no finite system could, for arbitrary integers. So why should we find this surprising at all?
Of course naively, if you hadn't really considered it, it might be surprising. But in hindsight shouldn't we just be saying, "Oh, yeah that makes sense."?
1.4Q tokens (ignoring where the tokens come from for the moment), am I highly confident it will remain weak and safe?
I'm pretty confident that if all those tokens relate to cooking, you will get a very good recipe predictor.
Hell, I'll give you 10^30 tokens about cooking and enough compute and your transformer will just be very good at predicting recipes.
Next-token predictors are IMO limited to predicting what's in the dataset.
In order to get a powerful, dangerous AI from a token-predictor, you need a dataset where people are divulging the secrets of bei...
Modern self driving vehicles can't run inference on even a chinchilla scale network locally in real time, latency and reliability requirements preclude most server-side work, and even if you could use big servers to help, it costs a lot of money to run large models for millions of customers simultaneously.
This is a good point regarding latency.
Why wouldn't it also apply to a big datacenter? If it's a few hundred meters of distance from the two farthest apart processing units, that seems to imply an enormous latency in computing terms.
Agree with you generally. You may find interest in a lot of the content I posted on reddit over the past couple months on similar subjects, especially in the singularity sub (or maybe you are there and have seen it 😀). Nice write up anyway. I do disagree on some of your generalized statements, but only because I'm more optimistic than yourself, and don't originally come from a position of thinking these things were impossible.
Epic post. It reminds me of "AGI Ruin: A List of Lethalities" except it's more focused on AI timelines rather than AI risk.
Some really intriguing insights and persuasive arguments in this post, but I feel like we are just talking about the problems that often come with significant technological innovations.
It seems like, for the purposes of this post, AGI is defined loosely as a "strong AI" which is technological breakthrough that is dangerous enough to be a genuine threat to human survival. Many potential technological breakthroughs can have this property and in this post it feels as if AGI is being reduced to some sort of potentially dangerous and uncontrollable ...
Alice is aligned with (among other things) ai notkillseveryoneism. Reach out if you want to get involved! https://github.com/intel/dffml/blob/alice/docs/tutorials/rolling_alice/
I'll be the annoying guy who ignores your entire post and complains about you using celsius as the unit of temperature in a calculation involving the Landauer limit. You should have used kelvin instead, because Landauer's limit needs an absolute unit of temperature to work. This doesn't affect your conclusions at all, but as I said, I'm here to be annoying.
That said, the fact that you got this detail wrong does significantly undermine my confidence in the rest of your post, because even though the detail is inconsequential for your overall argument it would be very strange for someone familiar with thermodynamics to make such a mistake.
Notably, the result is correct; I did convert it to kelvin for the actual calculation. Just a leftover from when I was sketching things on wolframalpha. I'll change that, since it is weird. (Thanks for the catch!)
The post starts with the realization that we are actually bottlenecked by data and then proceeds to talk about HW acceleration. Deep learning is in a sense a general paradigm, but so is random search. It is actually quite important to have the necessary scale of both compute and data and right now we are not sure about either of them. Not to mention that it is still not clear whether DL actually leads to anything truly intelligent in a practical sense or whether we will simply have very good token predictors with very limited use.
I don't actually think we're bottlenecked by data. Chinchilla represents a change in focus (for current architectures), but I think it's useful to remember what that paper actually told the rest of the field: "hey you can get way better results for way less compute if you do it this way."
I feel like characterizing Chinchilla most directly as a bottleneck would be missing its point. It was a major capability gain, and it tells everyone else how to get even more capability gain. There are some data-related challenges far enough down the implied path, but we have no reason to believe that they are insurmountable. In fact, it looks an awful lot like it won't even be very difficult!
With regards to whether deep learning goes anywhere: in order for this to occupy any significant probability mass, I need to hear an argument for how our current dumb architectures do as much as they do, and why that does not imply near-term weirdness. Like, "large transformers are performing {this type of computation} and using {this kind of information}, which we can show has {these bounds} which happens to include all the tasks it has been tested on, but which will not include more worrisome capabilities because {something something something}."
The space in which that explanation could exist seems small to me. It makes an extremely strong, specific claim, that just so happens to be about exactly where the state of the art in AI is.
As mentioned in the post, that line of argument makes me more alarmed, not less.
- We observe these AIs exhibiting soft skills that many people in 2015 would have said were decades away, or maybe even impossible for AI entirely.
- We can use these AIs to solve difficult reasoning problems that most humans would do poorly on.
- And whatever algorithms this AI is using to go about its reasoning, they're apparently so simple that the AI can execute them while still struggling on absolutely trivial arithmetic.
- WHAT?
Yes, the AI has some blatant holes in its capability. But what we're seeing is a screaming-hair-on-fire warning that the problems we thought are hard are not hard.
What happens when we just slightly improve our AI architectures to be less dumb?
Chess playing is similar story, we thought that you have to be intelligent, but we found a heuristic to do that really well.
You keep distinguishing "intelligence" from "heuristics", but no one to my knowledge has demonstrated that human intelligence is not itself some set of heuristics. Heuristics are exactly what you'd expect from evolution after all.
So your argument then reduces to a god of the gaps, where we keep discovering some heuristics for an ability that we previously ascribed to intelligence, and the set of capabilities left to "real intelligence" keeps shrinking. Will we eventually be left with the null set, and conclude that humans are not intelligent either? What's your actual criterion for intelligence that would prevent this outcome?
I guess I'm one of those #2's from the fringe, and contributed my 2 cents on Metacalus (the issue of looking for the right kind of milestones is of course related to my post in relation to current challenge). However, I completely reject ML/DL as a path toward AGI, and don't look at anything that has happened in the past few years as being AI research (and have said that AI officially died in 2012). People in the field are not trying to solve cognitive issues, and have rejected the idea of formal definitions of intelligence (or stated that consciousness an...
Also, the fact that human minds (selected out of the list of all possible minds in the multiverse) are almost infinitely small, implies that intelligence may become exponentionally more difficult if not intractable as capacities increase.
I have the impression that the AGI debate is here just to release pressure on the term "AI", so everybody can tell it is doing AI. I wonder if this will also happen for AGI in a few years. As there is no natural definition, we can craft it at our pleasure to fit marketing needs.
I think there is little time left before someone builds AGI (median ~2030). Once upon a time, I didn't think this.
This post attempts to walk through some of the observations and insights that collapsed my estimates.
The core ideas are as follows:
Some notes up front
Is the algorithm of intelligence easy?
A single invocation of GPT-3, or any large transformer, cannot run any algorithm internally that does not run in constant time complexity, because the model itself runs in constant time. It's a very large constant, but it is still a constant.
They don't have any learnable memory about their internal state from previous invocations. They just have the input stream. Despite all their capability, transformers are fundamentally limited.[2]
This is part of the reason why asking GPT-3 to do integer division on large numbers in one shot doesn't work. GPT-3 is big enough to memorize a number of results, so adding small numbers isn't too hard even without fine tuning. And GPT-3 is big enough to encode a finite number of unrolled steps for more complex algorithms, so in principle, fine tuning it on a bunch of arithmetic could get you better performance on somewhat more complex tasks.
But no matter how much retraining you do, so long as you keep GPT-3's architecture the same, you will be able to find some arithmetic problem it can't do in one step because the numbers involved would require too many internal steps.
So, with that kind of limitation, obviously transformers fail to do basic tasks like checking whether a set of parentheses are balanced... Oh wait, GPT-3 was just writing dialogue for a character that didn't know how to balance parentheses, and then wrote the human's side of the dialogue correcting that character's error. And it writes stories with a little assistance with long-run consistency. And it can generate functioning code. And a bunch more. That's just GPT-3, from 2020.
Some of this is already productized.
This is an architecture that is provably incapable of internally dividing large integers, and it can handle a variety of difficult tasks that come uncomfortably close to human intuition.
Could the kind of intelligence we care about be algorithmically simpler than integer division?
This can't be literally true, if we want to include integer division as something a generally intelligent agent can do. But it sure looks like tractable constant time token predictors already capture a bunch of what we often call intelligence, even when those same systems can't divide!
This is crazy! I'm raising my eyebrows right now to emphasize it! Consider also doing so! This is weird enough to warrant it!
Would you have predicted this in 2016? I don't think I would have!
What does each invocation of a transformer have to do?
Every iteration takes as input the previous tokens. It doesn't know whether they were from some external ground truth or the results of previous executions. It has no other memory.
During an iteration, the model must regather its understanding of all the semantic relationships in the tokens and regenerate its view of the context. Keep in mind that sequences do not just depend on the past: many sequences require the contents of later tokens to be implicitly computed early to figure out what the next token should be![3]
To get an intuitive feel for what a token predictor actually has to do, try playing this token prediction game. It's not easy. Pay attention to what you find yourself thinking about when trying to figure out what comes next.
When we giggle at one of these models making a silly mistake, keep in mind that it's not doing the thing you're doing in day-to-day life. It's playing the token prediction game. All of the apparent capability we see in it is incidental. It's stuff that turned out to be useful in the AI's true task of becoming much, much better than you at predicting tokens.
On top of all of this, it's worth remembering that these models start out completely blind to the world. Their only source of information is a stream of tokens devoid of context. Unless they're explicitly hooked up to a source of knowledge (which has been done), everything they know must be memorized and encoded in their fixed weights. They're not just learning an incredibly complex process, they're compressing a large fraction of human knowledge at the same time, and every execution of the transformer flows through all of this knowledge. To predict tokens.
And we can't just sweep this anomalous performance under the rug by saying it's specific to language. Gato, for example. When I first heard about it, I thought it was going to be a system of modules with some sort of control model orchestrating them, but no, it's just one transformer again. One capable of performing 604 different tasks with the same weights. To be fair, Gato is only superhuman in some of those tasks. That's comforting, right? Sure, large language models can do pretty ridiculous things, but if we ask a transformer to do 604 things at once, it's not too crazy! Whew!
Oh wait, the largest model they tested only had 0.21% as many parameters as the largest PaLM model (partially because they wanted it to be cheap for the real time robot control tasks) and the multimodal training seems like it might improve generalization. Also, they're working on scaling it up now.
In other words, we're asking transformers to do a lot within extremely tight constraints, and they do an absurdly good job anyway. At what point does even this simple and deeply limited architecture start to do things like model capable agents internally in order to predict tokens better? I don't know. My intuition says doing that in constant time would require an intractable constant, but I'm pretty sure I would have said the same thing in 2016 about what is happening right now.[4]
If the task a model is trying to learn benefits from internally using some complex and powerful technique, we apparently cannot be confident that even a simple constant-time token predictor will not learn that technique internally.
Prompt engineering and time complexity
"Let's think step by step."
Transformers can't learn how to encode and decode its own memory directly in the same sense as an RNN, but the more incremental a sequence is, the less the model actually has to compute at each step.
And because modern machine learning is the field that it is, obviously a major step in capabilities is to just encourage the model to predict token sequences that tend to include more incremental reasoning.
What happens if you embrace this, architecturally?
I'm deliberately leaving this section light on details because I'm genuinely concerned. Instead, please read the following paragraph as if I were grabbing you by the shoulders and shouting it, because that's about how I feel about some of the stuff I've happened across.
There is nothing stopping models from moving beyond monolithic constant time approximations. We know it works. We know it expands the algorithmic power of models. It's already happening. It is a path from interpolation/memorization to generalization. It is a fundamental difference in kind. There may not need to be any other breakthroughs.
Transformers are not special
I've spent a lot of time discussing transformers so far. Some of the most surprising results in machine learning over the last 5 years have come from transformer-derived architectures. They dominate large language models. GPT-1, GPT-2, and GPT-3 are effectively the same architecture, just scaled up. Gopher is a transformer. Minerva, derived from PaLM, is a transformer. Chinchilla, another transformer. Gato, the multi-task agent? Transformer! Text-to-image models like DALL-E 2? A transformer feeding diffusion model. Imagen? Yup! Stable diffusion? Also yup!
It's got quite a few bells and whistles. It looks complicated, if you don't already understand it. If you zoom into just the attention mechanism, you'll get even more complexity. What's the exact purpose of that feed forward network following the attention mechanisms? Is shoving sine waves onto the inputs for positional encoding the way to manage order awareness? Is all of this structure fundamental, derived from deeper rules?
Nah.
For example, GPT-3 drops the encoder side of the architecture. BERT does the opposite and drops the decoder. The feed forward followup is there because... well, it seems to help, maybe it's helping reinterpret attention. The key requirement for position encoding is that it varies with location and is learnable; the one picked in the original paper is just a reasonable choice. (Other architectures like RNNs don't even need a positional encoding, and sometimes there's no attention.) The residual stream seems a bit like a proxy for scratch memory, or perhaps it helps shorten maximum path lengths for gradient propagation, or maybe it helps bypass informational bottlenecks.
Transformers can even be thought of as a special case of graph neural networks. It's quite possible that some of the things that make a transformer a transformer aren't actually critical to its performance and a simpler model could do just as well.
All of this complexity, this fixed function hardware mixed with learned elements, is a kind of structural inductive bias. In principle, a sufficiently large simple feed forward network with a good optimizer could learn the exact same thing. Everything the transformer does can be thought of as a subnetwork of a much larger densely connected network. We're just making it cheaper and potentially easier to optimize by reducing the number of parameters and pinning parts of the network's behavior.
All of the truly heavy lifting is out of our hands. The optimizer takes our blob of weights and incrementally figures out a decent shape for them. The stronger your optimizer, or the more compute you have, the less you need to worry about providing a fine tuned structure.[5]
Even if it's theoretically not special in comparison to some maybe-not-realistically-trainable supernetwork, it is still clearly a powerful and useful architecture. At a glance, its dominance might suggest that it is the way forward. If progress involving transformers hits a wall, perhaps that would mean we might end up in another winter as we search for a better option in an empty desert stripped of low hanging fruit.
Except that's not what reality looks like. An attention-free RNN can apparently match transformers at similar scales. Now, we don't yet have data about what that kind of architecture looks like when scaled up to a 70B parameters and 1.4T tokens... but how much would you bet against it keeping pace?
Transformers appear to have taken off not because they are uniquely capable, but rather because they came relatively early and were relatively easy to train in a parallelizable way. Once the road to huge transformers had been paved and the opportunities were proven, there was a gold rush to see just how far they could be pushed.
In other words, the dominance of transformers seems to be an opportunistic accident, one rich enough in isolation to occupy most of the field for at least a few years. The industry didn't need to explore that much.
If it turns out that there are many paths to current levels of capability or beyond, as it looks like will be the case, it's much harder for machine learning progress to stall soon enough to matter. One research path may die, but another five take its place.
The field of modern machine learning remains immature
Attempts to actually explain why any of this stuff works lags far behind. It can take several years before compelling conceptual frameworks appear.
Our ability to come to the most basic understanding of what one of these networks has learned is woefully inadequate. People are doing valuable work in the space, but the insights gleaned so far are not enough to reliably reach deeply into design space and pull out a strongly more capable system, let alone a safe one.
Knowing only this, one could reasonably assume that the field would look something like neuroscience- an old field that has certainly made progress but which is hampered by the extreme complexity and opacity of the problems it studies. Perhaps a few decades of research could yield a few breakthroughs...
But that is emphatically not how machine learning works.
Many advancements in machine learning start out sounding something like "what if we, uh, just clamped it?"
Core insights in capability often arise from hunches rather than deeply supported theories. A shower thought can turn into a new SOTA. Talented new researchers can start to make novel and meaningful contributions after only a few months. We don't need to have any idea why something should work in order to find it. We're not running out of low hanging fruit.
We are lying face down in the grass below an apple tree, reaching backward blindly, and finding enough fruit to stuff ourselves.
This is not what a mature field looks like.
This is not what a field on the latter half of a sigmoid looks like.
This is what it looks like when the field is a wee mewling spookybaby, just starting the noticeable part of its exponential growth.
Scaling walls and data efficiency
Before this year, empirical scaling laws seemed to suggest we could climb the parameter count ladder to arbitrary levels of capability.
Chinchilla changed things. The largest models by parameter count were, in reality, hugely undertrained. Spending the same amount of compute budget on a smaller network with more training provided much better results.
The new focus appears to be data. At a glance, that might seem harder than buying more GPUs. Our current language model datasets are composed of trillions of tokens scraped from huge chunks of the internet. Once we exhaust that data, where can we get more? Can we pay humans to pump out a quadrillion tokens worth of high quality training data?
Eh, maybe, but I feel like that's looking at the problem in the wrong way. Chinchilla was published April 12, 2022. Prior to that paper, most of the field was content to poke the boundaries of scale in other ways because it was still producing interesting results with no additional exploration required. Very few people bothered dedicating most of their attention to the problem of datasets or data efficiency because they didn't need to.
Now that Chinchilla has entered the field's awareness, that's going to change fast. The optimization pressure on the data side is going to skyrocket. I suspect by the end of this year[6] we'll see at least one large model making progress on Chinchilla-related issues. By the end of next year, I suspect effectively all new SOTA models will include some technique specifically aimed at this.
I'm not sure what the exact shape of those solutions will be, but there are a lot of options. Figuring out ways to (at least partially) self-supervise, focusing on reasoning and generalization, tweaking training schedules with tricks to extract more from limited data, multimodal models that consume the entirety of youtube on top of trillions of text tokens, or, yes, maybe just brute forcing it and spending a bunch of money for tons of new training data.
I think Chinchilla is better viewed as an acceleration along a more productive direction, not a limit.
This is a good opportunity for an experiment. Given the above, in the year 2025, do you think the field will view datasets as a blocker with no promising workarounds or solutions in sight?
Or on much shorter timescales: GPT-4 is supposed to be out very soon. What is it going to do about Chinchilla? Is it just going to be another 10 times larger and only fractionally better?[7]
Keep in mind two things:
The Chinchilla scaling laws are about current transformers.
We already know that humans don't have to read 6 trillion tokens to surpass GPT-3's performance in general reasoning.
More is possible.
Lessons from biology
Humans provide an existence proof of general intelligence of the kind we care about. Maybe we can look at ourselves to learn something about what intelligence requires.
I think there are useful things to be found here, but we have to reason about them correctly. Biological anchors are bounds. If you look at some extremely conservative hypothetical like "what if AGI requires an amount of compute comparable to all computations ever performed by life", and it still looks achievable within a century, that should be alarming.
Humans were first on this planet, not optimal. There weren't thousands of civilizations before our own created by ascended birds and slugs that we battled for dominance. And there was no discontinuous jump in biology between our ancestors and ourselves- small tweaks accumulated until things suddenly got weird.
Given this background, is it reasonable to suggest that human intelligence is close to the global optimum along the axes of intelligence we care about in AI?
I don't think so. You can make the argument that it approaches various local optima. The energy expenditure within the machinery of a cell, for example, is subject to strong selection effects. If your cells need more energy to survive than your body can supply, you don't reproduce. I bet neurons are highly efficient at the thing they do, which is being neurons.
Being neurons is not the same thing as being a computer, or being a maximally strong reasoner.
As a simple intuition pump, imagine your own cognitive abilities, and then just add in the ability to multiply as well as a calculator. I'm pretty sure having the ability to multiply large numbers instantly with perfect accuracy doesn't somehow intrinsically trade off against other things. I certainly wouldn't feel lesser because I instantly knew what 17458708 * 33728833 was.
Evolution, in contrast, would struggle to find its way to granting us calculator-powers. It's very likely that evolution optimizing our current minds for multiplication would trade off with other things.[8]
When I consider what biology has managed with a blob of meat, I don't feel awed at its elegance and superlative unique ability. I just nervously side-eye our ever-growing stack of GPUs.
Hardware demand
Allocation of resources in computing hardware should be expected to vary according which timeline we find ourselves in, given the safe assumption that more compute is useful for most paths to AGI.
If you observe a massive spike in machine learning hardware development and hardware purchases after a notable machine learning milestone, it is not proof that you are living in a world with shorter timelines. It could simply be an adaptation period where the market is eating low hanging fruit, and it could flatten out rapidly as it approaches whatever the current market-supported use for the hardware is.
But you are more likely to observe sudden explosive investments in machine learning hardware in worlds with short timelines, particularly those in which AGI descends from modern ML techniques. In those worlds, huge market value is greedily accessible because it doesn't require fundamental breakthroughs and the short term business incentives are obvious.
The next question is: what constitutes an explosive investment in machine learning hardware? What would be sufficient to shorten timeline estimates? If you aren't already familiar with the industry numbers, try this experiment:
Presumably, your graph for #3 will look steeper or spikier. But how much steeper? Is a 2x increase in hardware purchases in 4 years concerning? 4x in 2 years?
Take a moment to make a few estimates before scrolling.
...
...
...
...
...
Here's the actual chart. Data taken from NVIDIA's quarterly reports.
Q2 FY17 (ending July 31, 2016) data center revenue is $0.151B.
Q2 FY20 (ending July 31, 2019) datacenter revenue is $0.655B.
Q2 FY23 (ending July 31, 2022) data center revenue is $3.806B.
That's close to 5.8x in 3 years, and 25x in 6 years.[9]
Is this just NVIDIA doing really, really well in general? Not exactly. The above includes only data center revenue. Focusing on another market segment:
This revenue covers their 'gaming' class of hardware. The increase here is smaller- from minimum to maximum is only about 5.3x over the same time period, and that includes the huge effect of proof-of-work cryptocurrency mining. Notably, the crypto crashes also had a visible impact on the data center market but far less than in the gaming space. It wasn't enough to stop the quarterly growth of data center revenue in Q2 FY23, showing that its rise was not primarily from cryptocurrency. Further, by revenue, NVIDIA is now mostly a data center/machine learning company.
Many researchers probably use gaming hardware for smaller scale machine learning experiments, but large scale data center machine learning deployments can't actually use consumer grade hardware due to NVIDIA's driver licensing. That makes their data center revenue a reasonably good estimator for industry interest in machine learning hardware.
Critically, it appears that hyperscalers and other companies building out machine learning infrastructure are willing to buy approximately all hardware being produced with very high margins. There was a blip in the most recent quarter due to the cryptocurrency situation creating a temporary glut of cards, but outside of that, I would expect to see this trend to continue for the foreseeable future.
Seeing a sustained slowing or drop in hardware demand across all ML-relevant manufacturers would be some evidence against very short timelines. This is something to pay attention to in the next few years.
Near-term hardware improvements
While investment in hardware purchases, particularly by large hyperscalers, has increased by a huge amount, this is only a tiny part of increased compute availability.
GPT-3 was introduced in May 2020. As far as I know, it used V100s (A100s had only just been announced).
Training performance from V100 to A100 increased by around a factor of 2.
A100 is to be followed by the H100, with customers likely receiving it in October 2022. Supposedly, training on a GPT-3-like model is about 4x faster than the A100. Some other workloads are accelerated far more. (Caution: numbers are from NVIDIA!)
It's reasonably safe to say that performance in ML tasks is increasing quickly. In fact, it appears to significantly outpace the growth in transistor counts: the H100 has 80 billion transistors compared to the A100's 54 billion.
Some of this acceleration arises from picking all the low hanging fruit surrounding ML workloads in hardware. There will probably come a time where this progress slows down a bit once the most obvious work is done. However, given the longer sustained trend in performance even without machine learning optimizations, I don't think this is going to be meaningful.
(These are taken from the high end of each generation apart from the very last, where I sampled both the upcoming 4080 16GB and 4090. Older multi-chip GPUs are also excluded.)
In order for scaling to stop, we need both machine learning related architectural specializations and underlying manufacturing improvements to stop.
All of this together suggests we have an exponential (all manufacturing capacity being bought up by machine learning demand) stacked on another exponential (manufacturing and architectural improvements), even before considering software, and it's going to last at least a while longer.
To put this in perspective, let's try to phrase manufacturing capacity in terms of GPT-3 compute budgets. From the paper, GPT-3 required 3.14e23 flops to train. Using A100's FP32 tensor core performance of 156 tflop/s, this would require 3.14e23 flop / 156e12 flop/s ~= 2e9s, or about 761 months on a single A100. So, as a rough order of magnitude estimate, you would need around a thousand A100's to do it in about a month.[10] We'll use this as our unit of measurement:
1 GPT3 = 1,000 A100s equivalent compute
So, an extremely rough estimate based on revenue, an A100 price of $12,500, and our GPT3 estimate suggests that NVIDIA is pumping out at least 3 GPT3s every single day. Once H100s are shipping, that number goes up a lot more.
Even ignoring the H100, If Googetasoft wants 1,000 GPT3s, they'd have to buy... about 10 months worth of NVIDIA's current production. It would cost 10-15 billion dollars. Google made around $70B in revenue in Q2 2022. Microsoft, about $52B. Google's profit in Q2 2022 alone was over $19B.
The A100 has been out for a while now, and all that compute is being purchased by somebody. It's safe to say that if one of these companies thought it was worth using 1,000 GPT3s (a million GPUs) to train something, they could do it today.[11]
Even if NVIDIA's production does not increase, the A100 is the last product released, and no other competitors take its place, the current rate of compute accumulation is enough for any of these large companies to do very weird things over the course of just a few years.
But let's stay in reality where mere linear extrapolation doesn't work. In 3 years, if NVIDIA's production increases another 5x[12], and the H100 is only a 2x improvement over the A100, and they get another 2x boost over the H100 in its successor, that's a 20x increase in compute production over today's A100 production. 1,000 GPT3s would be about two weeks. Accumulating 10,000 GPT3s wouldn't be trivial, but you're still talking about like 5 months of production at a price affordable to the hyperscalers, not years.
From this, my expectation is that each hyperscaler will have somewhere in the range of 10,000 to 200,000 GPT3s within 5 years.
If for some reason you wanted to spend the entirety of the increased compute budget on parameter counts on a GPT-like architecture, 10,000 GPT3s gets you to 1.75e15 parameters. A common estimate for the number of synapses in the human brain is 1e15. To be clear, an ANN parameter is not functionally equivalent to a synapse and this comparison is not an attempt to conclude "and thus it will have human-level intelligence," nor am I suggesting that scaling up the parameter count in a transformer is the correct use of that compute budget, but just to point out that is a really, really big number, and 5 years is not a long time.
Physical limits of hardware computation
[I don't actually feel that we need any significant improvements on the hardware side to reach AGI at this point, but cheaper and more efficient hardware does obviously make it easier. This section is my attempt to reason about how severe the apparent hardware cliff can get.
Edit: This is far from a complete analysis of physical limits in hardware, which would be a bit too big for this post. This section tosses orders of magnitude around pretty casually; the main takeaway is that we seem to have the orders of magnitude available to toss around.]
Koomey's law is a useful lens for predicting computation over the medium term. It's the observation that computational power efficiency has improved exponentially over time. Moore's law can be thought of as just one (major) contributor to Koomey's law.
But we are approaching a critical transition in computing. Landauer's principle puts a bound on the efficiency on our current irreversible computational architectures. If we were to hit this limit, it could trigger a lengthy stagnation that could only be bypassed by fundamental changes in how computers work.
So, when does this actually become a serious concern, and how much approximate efficiency headroom might we have?
Let's do some napkin math, starting from the upcoming H100.
Using the tensor cores without sparsity, the 350W TDP H100 can do 378e12 32 bit floating point operations per second. We'll asspull an estimate of 128 bits erased per 32 bit operation and assume an operating temperature of 65C.
(128∗378∗1012)∗kB∗338.15K∗ln(2)=0.1566∗10−3J
The H100 expends 350J to compute a result which, in spherical-cow theory, could take 0.156 millijoules.[13]
350J/0.156∗10−3J=2.24∗106
So, with a factor of around a million, our napkin-reasoning suggests it is impossible for Koomey's law to continue with a 2.6 year doubling time on our current irreversible computational architectures for more than about 50 years.
Further, getting down to within something like 5x the Landauer limit across a whole irreversible chip isn't realistic; our computers will never be true spherical cows and we typically want more accuracy in our computations than being that close to the limit would allow. But... in the long run, can we get to within 1,000x across a whole chip, at least for ML-related work? I don't know of any strong reason to believe otherwise.[14]
It's a series of extremely difficult engineering challenges and implies significant shifts in hardware architecture, but we've already managed to plow through a lot of those: ENIAC required around 150 KW of power to do around 400 flop/s. The H100 is about fourteen orders of magnitude more efficient; getting another 1,000x improvement to efficiency for machine learning related tasks before the curves start to seriously plateau seems feasible. Progress as we approach that point is probably going to slow down, but it doesn't seem like it will be soon enough to matter.
Given that there are no other fundamental physical barriers to computation in the next couple of decades, just merely extremely difficult engineering problems, I predict Koomey's law continues with gradually slowing doubling times. I think we will see at least a 100x improvement in computational efficiency for ML tasks by 2043 (70%).
Cost scaling
Computational efficiency is not exactly the same thing as the amount of compute you can buy per dollar. Even if density scaling continues, bleeding edge wafer prices have already skyrocketed on recent nodes and the capital expenditures required to set up a new bleeding edge fab are enormous.
But I remain reasonably confident that cost scaling will continue on the 5-20 year time horizon, just at a slowing pace.
It's worth keeping in mind that the end of computational scaling has been continuously heralded for decades. In 2004, as Dennard scaling came to an end, you could hear people predicting near-term doom and gloom for progress... and yet a single H100 is comparable to the fastest supercomputer in the world at the time in double precision floating point (in tensor operations). And the H100 can process single precision over 7 times faster than double precision.
Longer term
I think hardware will likely stagnate in terms of efficiency somewhere between 2040 and 2060 as irreversible computing hits the deeper fundamental walls assuming the gameboard is not flipped before that.
But if we are considering timelines reaching as far as 2100, there is room for weirder things to happen. The gap between now and then is about as long as between the ENIAC and today; that's very likely enough time for reversible computing to be productized. I'd put it at around 85% with most of the remaining probability looking like "turns out physics is somewhat different than we thought and we can't do that".[15]
Landauer's principle does not apply to reversible computing. There is no known fundamental bound to reversible computation's efficiency other than that it has to use a nonzero amount of energy at some point.
The next relevant limit appears to be the Margolus-Levitin theorem. This applies to reversible computing (or any computing), and implies that a computer can never do more than 6e33 operations per second per joule. Curiously, this is a bound on speed per unit of energy, not raw efficiency, and I'm pretty sure it won't be relevant any time soon. The H100 is not close to this bound.
Implications of hardware advancements
I believe current hardware is sufficient for AGI, provided we had the right software (>90%). In other words, I think we already have a hardware cliff such that the development of new software architectures could take us over the edge in one round of research papers.
And when I look ahead 20 years to 2043, I predict (>90%) the hyperscalers will have at least 1,000,000 GPT3s (equivalent to one billion A100s worth of compute).
Suboptimal algorithms tend to be easier to find than optimal algorithms... but just how suboptimal does your algorithm have to be for AGI to be inaccessible with that much compute, given everything we've seen?
I don't expect us to keep riding existing transformers up to transformative AI. I don't think they're anywhere close to the most powerful architecture we're going to find. Single token prediction is not the endgame of intelligence. But... if we take chinchilla at 70B parameters trained on 1.4T tokens, and use the 1,000,000 GPT3s of compute budget to push it to 70T parameters with 1.4Q tokens (ignoring where the tokens come from for the moment), am I highly confident it will remain weak and safe?
No, no I am not.
I'm genuinely unsure what kind of capability you would get out of a well-trained transformer that big, but I would not be surprised if it were superhuman at a wide range of tasks. Is that enough to start deeply modeling internal agents and other phenomena concerning for safety? ... Maybe? Probably? It's not a bet I would want to wager humanity's survival on.
But if you combine this enormous hardware capacity with several more years of picking low hanging fruit on the software side, I struggle to come up with plausible alternatives to transformative AI capability on the 20 year timescale. A special kind of consciousness is required for True AI, and Penrose was right? We immediately hit a wall and all progress stops without nuclear war or equivalent somehow?
If I had to write a sci-fi story following from today's premises, I genuinely don't know how to include "no crazystrong AI by 2043, and also no other catastrophes" without it feeling like a huge plot hole.
Avoiding red herring indicators
You've probably seen the snarky takes. Things like "I can't believe anyone thinks general intelligence is around the corner, teslas still brake for shadows!"
There's a kernel of something reasonable in the objection. Self driving cars and other consumer level AI-driven products are almost always handling more restricted tasks that should be easier than completely general intelligence. If we don't know how to do them well, how can we expect to solve much harder problems?
I would warn against using any consumer level AI to predict strong AI timelines for two reasons:
AGI probably isn't going to suffer from these issues as much. Building an oracle is probably still worth it to a company even if it takes 10 seconds for it to respond, and it's still worth it if you have to double check its answers (up until oops dead, anyway).
For the purposes of judging progress, I stick to the more expensive models as benchmarks of capability, plus smaller scale or conceptual research for insight about where the big models might go next. And if you do see very cheap consumer-usable models- especially consumer-trainable models- doing impressive things, consider using it as a stronger indicator of progress.
Monitoring your updates
If you had asked me in 2008 or so what my timelines were for AGI, I probably would have shrugged and said, "2080, 2090? median? maybe? Definitely by 2200."
If you had asked me when a computer would beat human professionals at Go, I'd probably have said somewhere in 2030-2080.
If you had asked me when we would reach something like GPT-3, I probably would have said, "er, is this actually different from the first question? I don't even know if you can do that without general intelligence, and if you can, it seems like general intelligence comes soon after unless the implementation obviously doesn't scale for some reason. So I guess 2060 or 2070, maybe, and definitely by 2200 again?"
Clearly, I didn't know much about where AI was going. I recall being mildly surprised by the expansion of machine learning as a field in the early 2010's, but the progress didn't seriously break my model until AlphaGo. I updated my estimates to around 2050 median for AGI, with explicit awareness that predicting that I was going to update again later would be dumb.
Then GPT-2 came out. I recall that feeling weird. I didn't update significantly at the time because of the frequent quality problems, but I believe that to be a mistake. I didn't look deeply enough into how GPT-2 actually worked to appreciate what was coming.
GPT-3 came out shortly thereafter and that weird feeling got much stronger. It was probably the first time I viscerally felt that the algorithm of intelligence was simple, and I was actually going to see this thing happen. Not just because the quality was significantly better than that GPT-2, but how the quality was achieved. Transformers aren't special, and GPT3 wasn't doing anything architecturally remarkable. It was just the answer to the question "what if we made it kinda big?"
That update wasn't incremental. If AI progress didn't slow down a lot and enter another winter, if something like GPT-4 came out in a few years and demonstrated continued capability gains, it seemed very likely that timelines would have to collapse to around 10 years.
GPT-4 isn't out quite yet, but the rest of this year already happened. There's no way I can claim that progress has slowed, or that it looks like progress will slow. It's enough that my median estimate is around 2030.
Strength of priors, strength of updates, and rewinding
What's the point of the story? My estimates started fairly long, and then got slammed by reality over and over until they became short.
But let's flip this around. Suppose a person today has a median estimate for AGI of 2080. What does this require?
There are two options (or a spectrum of options, with these two at the ends of the spectrum):
Maybe there is a person like #2 somewhere out there in the world, maybe a very early researcher in what has become modern machine learning, but I've never heard of them. If this person exists, I desperately want them to explain how their model works. They clearly would know more about the topic than I do and I'd love to think we have more time.
(And I'd ask them to join some prediction markets while they're at it. In just one recent instance, a prediction market made in mid 2021 regarding the progress on the MATH dataset one year out massively undershot reality, even after accounting for the fact that the market interface didn't permit setting very wide distributions.)
#1 seems far more plausible for most people, but it isn't clear to me that everyone who suggests we probably have 50 years today used to think we had far more time.
If I had to guess what's going on with many long timelines, I'd actually go with a third option that is a little less rigorous in nature: I don't think most people have been tracking probabilities explicitly over time. I suspect they started asking questions about it after being surprised by recent progress, and then gradually settled into a number that didn't sound too crazy without focusing too much on consistency.
This can be reasonable. I imagine everyone does this to some degree; I certainly do- in the presence of profound uncertainty, querying your gut and reading signals from your social circle can do a lot better than completely random chance. But if you have the option to go back and try to pull the reasoning taut, it's worth doing.
Otherwise, it's a bit like trying to figure out a semi-informative prior from the outside view after major evidence lands in your lap, and then forgetting to include the evidence!
I think there is an important point here, so I'll try a more concise framing:
The less you have been surprised by progress, the better your model, and you should expect to be able to predict the shape of future progress. This is testable.
The more you were surprised by progress, the greater the gap should be between your current beliefs and your historical beliefs.
If you rewind the updates from your current beliefs and find that your historical beliefs would have been too extreme and not something you would have actually believed, then your current beliefs are suspect.
A note on uncertainty
Above, I referred to a prior as 'too extreme'. This might seem like a weird way to describe a high uncertainty prior.
For example, if your only background assumption is that AGI has not yet been developed, it could be tempting to start with a prior that seems maximally uncertain. Maybe "if AGI is developed, it will occur at some point between now and the end of time, uniformly distributed."
But this would put the probability that AGI is developed in the next thousand years at about 0%. If you observed something that compressed your timeline by a factor of 10,000,000,000,000, your new probability that AGI is developed in the next thousand years would be... about 0%. This isn't what low confidence looks like.
In principle, enough careful updates could get you back into reasonable territory, but I am definitely not confident in my own ability to properly weigh every piece of available evidence that rigorously. Realistically, my final posterior would still be dumb and I'd be better off throwing it away.
Will it go badly?
The Future Fund prize that prompted me to write this post estimated the following at 15%:
If your timelines are relatively long (almost all probability mass past 2050), a 15% chance of doom seems reasonable to me. While the field of AI notkilleveryoneism is pretty new and is not yet in an ideal position, it does exist and there's a chance it can actually do something. If I knew for a fact we had exactly 50 years starting from where we are now, I might actually set the probability of doom slightly lower than 15%.
My curve for probability of doom for AGI development at different dates looks something like:
I'm not quite as pessimistic as some. I think muddling through is possible, just not ideal. If AGI takes 100 years, I think we're probably fine. But if our current architectures somehow suddenly scaled to AGI tomorrow, we're not. So P(doom) becomes a question of timelines. Here's an approximate snapshot of my current timeline densities:
And if we mix these together:
Not great.
To be clear, these probabilities are not rigorously derived or immune to movement. They're a snapshot of my intuitions. I just can't find a way to move things around to produce a long timeline with good outcomes without making the constituent numbers seem obviously wrong.[17] If anything, when proofreading this post, I find myself wondering if I should have bumped up the 2035 density a bit more at the expense of the long tail.
Why would AGI soon actually be bad?
Current architectures were built with approximately zero effort put toward aiming them in any particular direction that would matter in the limit. This isn't a mere lack of rigorous alignment. If one of these things actually scaled up to AGI capability, my expectation is that it would sample a barely bounded distribution of minds and would end up far more alien than an ascended jumping spider.[18]
An AGI having its own goals and actively pursuing them as an agent is obviously bad if its goals aren't aligned with us, but that is not required for bad outcomes. A token predictor with extreme capability but no agenthood could be wrapped in an outer loop that turns the combined system into a dangerous agent. This could just be humans using it for ill-advised things.
And the way things are going, I can't say with confidence that mere token predictors won't have the ability to internally simulate agents soon. For the purposes of safety, the fact that your AGI isn't "actually" malevolent while playing a malevolent role isn't comforting.
I suspect part of the reason people have a hard time buying the idea that AGI could do something really bad is that they don't have a compelling narrative for how it plays out that doesn't sound like sci-fi.[19]
To get around this block, try sitting down and (PRIVATELY) thinking about how you, personally, would go about doing incredible damage to humanity or civilization if you were monomaniacally obsessed with doing so.
I'm pretty sure if I were a supervillian with my current resources, I'd have a solid shot (>2%) at killing millions of people with a nontrivial tail risk of killing hundreds of millions and up. That's without resorting to AGI. The hard part wouldn't even be executing the deadly parts of the villainous plans, here; it would be avoiding detection until it was too late. If this seems insane or outside of the realm of possibility to you, you may be unaware of how fragile our situation actually is. For obvious reasons, I'm not going to go into this in public, and I also strongly recommend everyone else that knows what kinds of things I'm talking about to also avoid discussing details in public. Excessive publicity about some of this stuff has already nudged the wrong people in the wrong ways in the past.
Even human intelligence aimed in the wrong direction is scary. We're remarkably well aligned with each other and/or stupid, all things considered.
...
Now imagine the supervillian version of you can think 100x faster. Don't even bother considering improvements to the quality of your cognition or the breadth of your awareness, just... 100x faster.
Optimism
The line for my P(doom | AGI at date) drops pretty fast. That's because I think there's a real shot for us to start actually thinking about this problem when we're designing these architectures. For example, if large capability-focused organizations start approaching capability through architectures that are not so much giant black boxes, maybe that gets us a few survival points. Very optimistically, there may actually be a capability incentive to do so: as we get into more complex tasks, getting AI to do what we want becomes more difficult, and the easy parts of alignment/corrigibility could become directly relevant to capability. If we are lucky enough to live in a reality where safety requirements are more forgiving, this might just push us from doom to muddling through.
If the AI notkilleveryoneism part of research continues to expand while producing work of increasing quality, ideally with serious cooperation across organizations that are currently capability focused, I think things can gradually shift in a good direction. Not every bit of research is going to pan out (I expect almost all won't), but if there are enough capable people attacking enough angles, that P(doom | AGI by date) curve should slope downward.
To be clear, if we don't try hard, I don't think that line goes down much at all.
Conclusion
I'm spooked! Spooked enough that I have actually pivoted to working directly on this, at least part time! It's looking likely that some of my long time horizon Big Project Plans are just going to get eaten by AGI before I can finish. That's intensely weird. I'd love it if someone else writes up an amazingly convincing post for longer timelines and higher safety as a result of this prize, but I don't anticipate that happening.
If I had to summarize my position, it's that I don't think a background vibe of normalcy makes sense anymore. The tendency (which, to be clear, I understand and share!) to try to offer up sufficiently humble sounding 'reasonable' positions needs to be explicitly noticed and checked against reality.
A model including a lot of probability mass on long timelines must answer:
It is not enough to point out that it's technically possible for it still to take a long time. This is like the logical problem of evil versus the evidential problem of evil. Yes, there are logically coherent reasons why evil could exist with a benevolent god and such, but you need to watch the broadcast. You need to viscerally understand what it means that tuberculosis and malaria still exist. This wouldn't mean that you have to jump straight to the One Truth That I Approve Of, just that would you have the proper intuitive frame for judging which answers are truly grappling with the question.
Without strong and direct answers to these questions, I think the vibe of normalcy has to go out the window. We have too much empirical data now pointing in another direction.
Semi-rapid fire Q&A
If you multiply out {some sequence of propositions}, the chance of doom is 0.4%. Why do you think weird things instead?
Trying to put numbers on a series of independent ideas and mixing them together is often a good starting exercise, but it's hard to do in a way that doesn't bias numbers down to the point of uselessness when taken outside the realm of acknowledged napkin math. The Fermi paradox is not actually much of a paradox.
(Worth noting here that people like Joseph Carlsmith are definitely aware of this when they use this kind of approach and explicitly call it out. That said, the final probabilities in that report are low compared to my estimates, and I do think the stacking of low-ish point estimates amplifies the problem.)
The number of breakthroughs per researcher is going down and technology is stagnating! Why do you think progress will accelerate?
Aren't you underplaying the slowdown in Moore's law?
Moore's law does in fact drive a huge chunk of Koomey's law today. It has undeniably slowed on average, especially with Intel stumbling so badly.
There's also no doubt that the problems being solved in chip manufacturing are full-blown superscience, and it's unbelievable that we have managed a factor of a quadrillion improvement, and this cannot continue forever because it quickly yields stupid results like "there will be more transistors per square millimeter than atoms in the galaxy."
But we don't need another thousand years out of Moore's law. It looks an awful lot like we might need no further doublings, and yet we're definitely going to get a least a few more.
What if intelligence isn't computable?
I'm pretty sure we'd have seen some indication of that by now, given how close we seem to be. This is rapidly turning into a 'god of the gaps' style argument.
By not including consciousness/emotion/qualia in your definition for intelligence, aren't you just sidestepping the hard problems?
I don't think so. Existing systems are already unusually capable. They're either secretly conscious and whatnot (which I strongly doubt at this point), or this level of capability really doesn't need any of that stuff.
Either way, current techniques are already able to do too much for me to foresee qualia and friends blocking a dangerous level of capability. It would have to suddenly come out of nowhere, similar to non-computability.
As an intuition pump, suppose you had a magic hypercomputer that can loop over all programs, execute them, and score them. The halting problem is of no concern to magic hypercomputers, so it could find the optimal program for anything you could write a scoring function for. Consider what problems you could write a scoring function for. Turns out, there are a lot of them. A lot of them are very, very hard problems that you wouldn't know how to solve otherwise, and the hypercomputer can just give you the solution. Is this giant loop conscious? Obviously, no, it increments an integer and interprets it as a program for some processor architecture, that's it. Even if it does simulate an infinite number of universes with an infinite number of conscious beings within them as a natural part of its execution, the search process remains just a loop.
I think of intelligence as the thing that is able to approximate that search more efficiently.
It seems like you didn't spend a ton of time on the question of whether AGI is actually risky in concept. Why?
What do you think the transition from narrow AI to dangerous AI would actually look like?
I don't know. Maybe there's a chance that we'll get a kind of warning where people paying attention will be able to correctly say, "welp, that's that, I'm going on perma-vacation to tick things off my bucket list I guess." It just might not yet be obvious in the sense of "ouch my atoms."
It could just be a proof of concept with obvious implications for people who understand what's going on. Basically a more extreme version of constant time token predictors doing the things they already do.
Maybe things start getting rapidly weird under the approximate control of humans, until one day they hit... maximum weird.
Or maybe maximum weird hits out of nowhere, because there's an incentive to stay quiet until humans can't possibly resist.
Why didn't you spend much time discussing outside view approaches to estimating timelines?
Creating an estimate from the outside view (by, for example, looking at other examples within a reference class) is pretty reasonable when you don't have any other information to go by. Gotta start somewhere, and a semi-informative prior is a lot better than the previously discussed uniform distribution until the end of time.
But once you have actual evidence in your hands, and that evidence is screaming at you at high volume, and all alternative explanations seem at best contrived, you don't need to keep looking back at the outside view. If you can see the meteor burning through the sky, you don't need to ask what the usual rate for meteors hitting earth is.
Are there any prediction markets or similar things for this stuff?
Why yes! Here's a whole category: https://ai.metaculus.com/questions/
And a few specific interesting ones:
https://www.metaculus.com/questions/4055/will-the-first-agi-be-based-on-deep-learning/
https://www.metaculus.com/questions/406/when-will-ais-program-programs-that-can-program-ais/
https://www.metaculus.com/questions/7398/ai-competency-on-competitive-programming/
https://www.metaculus.com/questions/3479/date-weakly-general-ai-is-publicly-known/
https://www.metaculus.com/questions/5121/date-of-artificial-general-intelligence/
https://www.metaculus.com/questions/6728/ai-wins-imo-gold-medal/
oops
I'm actually pretty happy about this! We can make very strong statements about algorithmic expressiveness when the network is sufficiently constrained. If we can build a model out of provably weak components with no danger-tier orchestrator, we might have a path to corrigible-but-still-useful AI. Most obvious approaches impose a pretty big tax on capability, but maybe there's a clever technique somewhere!
(I still wouldn't want to play chicken with constant time networks that have 1e20 parameters or something. Infinite networks can express a lot, and I don't really want to find out what approximations to infinity can do without more safety guarantees.)
This is most obvious when trying to execute discrete algorithms that are beyond the transformer's ability to express in a single step, like arithmetic- it'll hallucinate something, that hallucination is accepted as the next token and collapses uncertainty, then future iterations will take it as input and drive straight into nonsensetown.
I have no idea what concepts these large transformers are working with internally today. Maybe something like the beginnings of predictive agent representations can already show up. How would we tell?
That's part of the reason why I'm not surprised when multiple architectures end up showing fairly similar capability at similar sizes on similar tasks.
This might sound like support for longer timelines: if many structures for a given task end up with roughly similar performance, shouldn't we expect fewer breakthroughs via structure, and for progress to become bottlenecked on hardware advancements enabling larger networks and more data?
I'd argue no. Future innovations do not have to hold inputs and outputs and task constant. Varying those is often easy, and can yield profound leaps. Focusing only on models using transformers, look at all the previously listed examples and their progress in capability over a short time period.
If anything, the fact that multiple structures can reach good performance means there are more ways to build any particular model which could make it easier to innovate in areas other than just internal structure.
Added in an edit: machine learning being the field that it is, obviously some definitely-anonymous team put such an advancement up for review a few days before this post, unbeknownst to me.
(A mysterious and totally anonymous 540B parameter model. Where might this research come from? It's a mystery!)
Somehow, I doubt it.
The dominant approach to large language models (big constant time stateless approximations) also struggles with multiplying as mentioned, but even if we don't adopt a more generally capable architecture, it's a lot easier to embed a calculator in an AI's mind!
This section was inspired by a conversation I had with a friend. I was telling him that it was a good thing that NVIDIA and TSMC publicly reported their revenue and other statistics, since that could serve as an early warning sign.
I hadn't looked at the revenue since 2018-ish, so after saying this to him, I went and checked. Welp.
Scaling up training to this many GPUs is a challenging engineering problem and it's hard to maintain high utilization, but 1,000 is a nice round number!
I'm still handwaving the engineering difficulty of wrangling that much compute, but these companies are already extremely good at doing that, are strongly incentivized to get even better, and are still improving rapidly.
This requires paying a premium to outbid other customers, shifts in chip package design, and/or large increases in wafer production. Given the margins involved on these datacenter products, I suspect a mix is going to happen.
Switching energy in modern transistors is actually closer to the Landauer limit than this whole-chip analysis implies, closer to three orders of magnitude away. This does not mean that entire chips can only become three orders of magnitude more efficient before hitting the physical wall, though. It just means that more of the improvement comes from things other than logic switching energy. Things that are not all necessarily bounded by the Landauer limit.
Note that this does not necessarily imply that we could just port an H100 over to the new manufacturing process and suddenly make it 1,000x more efficient. This isn't just about improving switching/interconnect efficiency. Huge amounts of efficiency can be gained through optimizing hardware architecture.
This is especially true when the programs the hardware needs to handle are highly specialized. Building hardware to accelerate one particular task is a lot easier than building a completely general purpose architecture with the same level of efficiency. NVIDIA tensor cores, Tesla FSD/Dojo chips, Cerebras, and several others already show examples of this.
The Landauer limit is dependent on temperature, but I'm not very optimistic about low temperature semiconductors moving the needle that much. The cosmic microwave background is still a balmy 3K, and if you try to go below that, my understanding is that you'll spend more on cooling than you gain in computational efficiency. Plus, semiconductivity varies with temperature; a room temperature semiconductor would be a pretty good insulator at near 0K. At best, that's about a 100x efficiency boost with some truly exotic engineering unless I'm wrong about something. Maybe we can revisit this when the CMB cools a bit in ten billion years.
I think full self driving capability will probably come before full AGI, but I'm not certain. There's not much time left!
Setting up graphs like this is a decent exercise for forcing some coherence on your intuitions. If you haven't tried it before, I'd recommend it! It may reveal some bugs.
A jumping spider that predicts tokens really well, I guess?
By a reasonable definition, all possible explanations for how AGI goes bad are sci-fi, by virtue of being scientifically driven fiction about the future.