About 1e27 FLOPs seems reasonable for Mythos and Spud, though a bit more might also be possible. Late 2025 compute is about 1-2 GW per AI company (in total, inference plus R&D), 300 MW is about 300K chips of Trainium 2 or 200K chips of H100, which is about 4e20 FP8 FLOP/s for either Trainium 2 or H100 (1.3e15 FP8 FLOP/s per chip for Trainium 2, 2e15 FP8 FLOP/s per chip for H100). Which in 3 months at 40% utilization gives 1.3e27 FLOPs. (Given the Nvidia bet on FP8 in Rubin, significantly increasing the FP8-to-BF16 performance ratio compared to earlier chips, FP8 is likely the mainsteam pretraining precision for frontier models now.)
The important thing about Mythos and Spud compared to earlier models is that they are plausibly the first models big enough in total params to have enough active params to use 1e27 FLOPs. At 120 tokens/param maybe being compute optimal given modest sparsity, 1e27 FLOPs ask for 1.2T active params, which probably makes sense for at least 5T-10T total params or more, while models smaller in total params would also have fewer active params, and so won't be taking full advantage of 1e27 FLOPs in pretraining.
Opus 4 probably targets Trainium 2 Ultra (6 TB of HBM per rack), so might be a 3T total param model, and GPT-5 probably targets 8-chip Nvidia servers, including H100 (0.64 TB of HBM per server), so might be a 300B-900B total param model (it had to compete with Opus 4, so even with longer reasoning traces it probably needed to be bigger than H100s want). But Mythos plausibly targets TPUv7 (9216 chips per pod, 192 GB of HBM per chip), so as a step up from Opus it might be a 10T total param model (there's a new announcement that Anthropic's access to TPUs will scale in 2027+ beyond the 1 GW of 2026). And Spud likely targets GB200/GB300 Oberon racks (14/20 TB of HBM per rack), so it might be a 6T-7T total param model (unless they go NVFP4 and take full advantage of that, but 12T-15T total params seems too sudden after GPT-5, there should be an intermediate step). Thus both Mythos and Spud might be at the right scale to fit 1.2T active params, though it's still probably a bit less, maybe 800B active params, to optimize input token cost.
Why do you think the frontier models still retain the sparsity levels of GPT-4 (roughly 1:8 active to total) at the time when open-weight models have gone much higher, with Kimi K2 having ~1:30 and most of other ones hovering around 1:20?
P. S.
After posting the comment above I remembered that Jensen Huang discussed a 2T total-param "GPT-MoE" with either 128k or 400k-token context windows in his NVidia GTC 2026 presentation last month: https://2slides.com/gallery/nvidia-gtc-2026-keynote-deck-jensen-huang-ai-factory-vision (slide 32 onward).[1] This corresponds exactly to GPT-5-series context length in ChatGPT and over API respectively, seems like quite strong evidence against the model sizes you suggest!
- ^
Not the first time he discloses that kind of info BTW: https://www.reddit.com/r/singularity/comments/1bi8rme/jensen_huang_just_gave_us_some_numbers_for_the
The amount of compute determines the optimal number of active params, available systems determine how the number of total params maps to efficiency of inference. Chinese models had to make strange choices on both counts, not having enough compute to make models with a lot of active params, but then needing to compensate for that with so many total params that the available systems couldn't work with them efficiently, and so giving up completely on fitting them in a few scale-up worlds. As a result, you get things like DeepSeek-V3 with 37B active and 671B total params, which when served on H800 nodes uses expert parallelism across nodes, that is for every single layer of every single token, there is a communication across node boundaries. They even had to throttle the number of activation vectors routed to experts to at most 4 nodes per layer (at least during pretraining):
To effectively leverage the different bandwidths of IB and NVLink, we limit each token to be dispatched to at most 4 nodes, thereby reducing IB traffic.
That is, with in-principle 8 active routed experts out of 256 per layer, they need to only use some of them that happen to be located within 4 nodes, with 8 experts per node (for a given layer). This is despite the activation vectors (the data that needs to be dispatched to these nodes) already being relatively small, as their dimension scales with the number of active params. For larger models, this cross-node expert parallelism gets even less efficient, since activation vectors get larger.
Efficiency improves dramatically once you put the whole thing in a single NVL72 scale-up world of an Oberon rack, both in throughput (meaning cost, or utilized compute per chip) at a given tokens-per-second-per-user level, and in tokens-per-second-per-user (meaning speed, or the number of RLVR steps that can be used in training within some amount of wall-clock time) at a given throughput level. And you don't get ridiculous issues with token routing taking up too much bandwidth for models with more active params.
So there's currently a shift (starting in late 2025), with Trainium 2 Ultra and GB200/GB300 Oberon racks, from the too-small 8-chip Nvidia servers that can't fit the models of the scale they need to serve. The 8-chip servers are still very numerous, so Sonnets and GPT-5s aren't going anywhere, but the new larger systems no longer demand the same sacrifices of efficiency, at least for the models of the scale that the industry has the heart to attempt so far. In principle, it's possible to train and run high sparsity 40T total param models on Oberon racks, but it's not being done in practice for efficiency (cost, speed) reasons, there isn't enough confidence that the lost efficiency is worth the improvement in quality, at least without more experience in the 5-10T range. Musk's recent claim that xAI is training a 6T model and a 10T model at Colossus 2 is significant evidence for this beyond the theoretical considerations, since scale is all xAI can rely on, so they'd go for more if there were competitors that went for more.
GDM and to some extent Anthropic are in a different situation due to TPUs, but only TPUv7 is really beyond what Trainium 2 Ultra and GB200/GB300 NVL72 enable, earlier TPUs had too little HBM per chip. And TPUv7 is only in full buildout this year, meaning Gemini 3 probably couldn't rely on them (though there's some buildout last year, and it was offered in the cloud, so it's possible in principle given how few users they expected for the Pro model that doesn't need to be served for all Google Search users). But even they are probably reluctant to scale model size 10x or more in one go, and TPU topology is not all-to-all, so the practical limit at an efficiency similar to a 6T model might be well below say 100T total params. The next major step in enabling giant models is the Kyber rack (147 TB of HBM per rack, and it does have all-to-all topology), with full buildout in 2028-2029, making the decision to serve models with perhaps up to 140T total params (in NVFP4) cheap.
(I think Huang's 2T total param slides are a holdover from the original GPT-4, which is rumored to be about that size. They probably have the weights, at least for a mockup model of the same shape, to work on hardware co-design for inference and training. It fits compute optimality calculations for 2022 compute, but it's plausible it got smaller since then, leveraging much more training compute, incremental algorithmic and data improvements, and possibly distillation from larger models to maintain quality. The quality of the Chinese models also supports this hypothesis, though GPT-5 plausibly has more active params than they do, and so might have even fewer total params.)
The DeepSeek report you cite is over a year old and seems to imply they quantized most (all?) weights to FP8 but the SemiAnalysis post states that by February 2026 "most frontier labs and inference providers are not running FP8", especially since NVidia introduced native support of three 4-bit float formats on Blackwell last year. A cluster of 8 B200s has 1.5 TB of HBM3e and fits at least 2T of 4-bit params, maybe more. Hypothetically (a rough estimate due to questions in brackets which follow), think of 2200A110B plus 400 GB left on KV cache (or specifically "hot" cache if it's possible to offload part of it to DRAM, is it? Do frontier labs use MLA? At least they don't in their open-weights releases), or less if some params are in FP8 or BF16.
Reading your first comment again, you write: "Opus 4 probably targets Trainium 2 Ultra (6 TB of HBM per rack), so might be a 3T total param model", did you assume whopping 3 TB on KV cache? BTW I agree that Claude 4-series were designed for FP8 inference, and perhaps GPT-5-series as well.
The aforementioned Kimi K2-series models are actually quantized into mixed precision (experts in INT4, everything else is in BF16) natively (with QAT) and have a practical memory footprint, according to different sources, around 550-600 GB, hence they should fit onto an 8 x H100/800 cluster. 500B+ models aren't going to run on 640 GB in 8 bits indeed, but I suppose Z.ai wouldn't increase the size of GLM-5 to 744A40B if they couldn't inference it economically (perhaps they also use 4-bit quants? Or do they expect their clients to deploy it on B200s?). Anyway quite a few other models are even smaller, such as Minimax M2-series with 230A10B, refer to S. Raschka's blog for further comparison. GPT-OSS 120B (117A5B) is clearly not limited in that way and still enjoys the ~1:20 sparsity.
And since you mentioned Musk anyway, he also disclosed recently that Grok 4.20 is 500B total params and estimated Sonnet to be ~1T and Opus to be ~5T.
Output tokens are bandwidth constrained, and the cost is divided among requests in a batch. So as we increase the number of requests in a batch, the cost goes down a lot while more HBM is used for the model weights than for the total KV cache. As the model gets smaller than the total KV cache of all requests, the cost starts being governed by the size of KV cache for a given request. So half-and-half is a rule of thumb I'm using for the upper bound of "efficient" (decode) deployment. It's even better if it's less than half.
Most weights of a model are in FFNs, but the non-FFN weights (and shared FFNs) might need to be replicated a bunch of times within the same deployment. So precision of FFNs is the most significant factor of how much space a model takes up (the other parts are often in different precisions), but the weights in a deployment take up more in total than a single copy of the weights. I did assume FP8 FFNs as a target for the largest models (where quality is at a premium, with many other tradeoffs also paying for quality with performance and cost), as a conservative assumption. For smaller models, FP4 might be more prevalent, particularly with the models that have to be squeezed into the 8-chip Nvidia servers and were trained for that with QAT.
I suppose Z.ai wouldn't increase the size of GLM-5 to 744A40B if they couldn't inference it economically
It's economical to even pull DeepSeek-V3 for the smaller models and do expert parallelism across dozens of nodes in a single deployment. It's just much worse than if you don't have to, and less economical if the model has 15x more total params and 30x more active params (which also makes the activation vectors heavier). None of these arguments are about hard caps on how deployments have to happen, except for how sufficiently sluggish performance makes it impossible to do good RLVR training for a model that's too large for the available hardware (because then you won't be able to fit enough training steps in 3 months or however long it needs to take), even if there's quite a lot of that hardware. The incentives probably point to targeting in-principle efficient deployment when possible, and to come what may when not.
Don't you see a contradiction between your earlier line of argument "OpenAI should have designed GPT-5 to fit on 8 H100s in FP8 despite gradually getting B200s with more HBM and FP4 support" and "one can deploy across several nodes it's just less effective"? Selecting the size of a future model for the hardware you are getting rather than one which dominates your park right now seems a wiser solution in light of your latter thesis.
Also, checking EpochAI's free estimates, Microsoft had roughly as much Hopper compute as Blackwell in Q2 2025, and B200+B300 passed over H100s in Q3. What makes you think H100s were more important to OpenAI in August 2025 than Blackwell? Do you have access to better estimates (maybe SemiAnalysis)?
OpenAI's "largest" models are not the main GPT-5-series, but GPT-5/5.2/5.4 Pro, and I see no downsides in quantizing the ones served to free users as hard as they can. There's a relatively widespread belief that Pros are based on the same base models as Chat, just with different post-training, larger quants and inference scaling. Do you share that belief?
Many people also place GPT-5 between Sonnet 4 and Opus 4 in size, partially based on performance (both benchmarks and vibes), partially on price and partially on the fact that Pros are somewhat competitive with Opus. What about you?
After thinking more about it, I personally still believe GPT-5-series are all around 2000A100B: GPT-5 in FP8 (hereinafter formats refers to experts), GPT-5 Pro in BF16, GPT-5.4 in FP4 with QAT (seems to fit well onto 8xB200 with 128k context), GPT-5.4 Pro in FP8. Oh, and BTW, I realized Huang's 2T couldn't have been a holdover from GPT-4 because two years ago he actually mentioned "GPT-MoE-1.8T".
As of Anthropic models, I would place Opus 4 about double GPT-5, and Sonnet 4 somewhere in between it and Kimi K2 (say, around 1200A60B). Not sure about quantization, since Amazon hardware will only natively support FP4 from Trainium 4, but INT4 is always an option.
Added at the last moment: I briefly looked up scaling law research on sparsity, and Abnar et al. 2025 appear to indicate the larger a MoE, the more beneficial sparsity becomes. I haven't had time yet to read it carefully (Friday, you know) but it seems to support the empirical trend on increasing sparsity
It's not a choice of B200 vs. H100 when there's a general compute shortage, the flagship model has to be able to run on everything (since you wouldn't be sure about the demand in advance), and profitably at the prices you're setting. I'm assuming, maybe incorrectly, that the smaller models (than the largest/flagship "GPT-5" model) don't predictably-in-advance use more than half of all compute (in other words, wouldn't bring in more than half of all revenue, if counterfactually all tokens were served via API at API prices with similar-to-each-other margins).
The argument is about incentives. A 2x larger model is meaningfully but not materially smarter, but if it breaks out of an efficient serving regime, then it's suddenly 3x more expensive (and needs 3x as much serving capacity across your datacenters, if demand stays the same), so you try to avoid getting there. On the other hand, if you are already in the inefficient serving regime (as many Chinese models are, and possibly GPT-5 in 2025), or you have to get there to reach the capabilities you need, then making a model even larger will be less impactful, so you might be willing to do that. But the benefit might also be marginal, so it's a wash, reasonable decisions will point in either direction. Conversely, if new hardware is coming out that will let you get back into an efficient regime with a model that you previously had to serve inefficiently, maybe you'll cut corners to get it done.
For GPT-5 in 2026, my guess is that GPT-5.4 (and maybe 5.3) is a new pretrain, and in 2026 it's more plausible to rely exclusively on B200s for the flagship model, leaving H100s and maybe H200s for the smaller models. So maybe GPT-5.4 is actually larger (in total params) than GPT-5.2/GPT-5.0/o3/GPT-4o, which is what I'm estimating at 300B-900B total params, based on the quality of Chinese models (what they're demonstrating to be possible with the model sizes they're using), availability of pretraining compute to OpenAI (thus the feasibility of using more active params than the Chinese models, and the expectation that OpenAI can get the same quality into smaller models), and the need to be able to serve models on H100/A100 servers. On the 300B side is the hypothetical model that does fit on H100/A100 servers, but 300B might be too small for the model to be good enough. On the 900B side is essentially the Chinese consensus that the available servers are too small and you have to give up on high efficiency to make a good model. Here, the constraint is that I don't expect an OpenAI model of GPT-5.0 to GPT-5.2 quality needs to be larger than 900B total params.
the flagship model has to be able to run on everything (since you wouldn't be sure about the demand in advance)
I disagree. EpochAI gives the ratio of Blackwell to Hopper at Azure in Q3 2025 as 5:4, let's take it at face value for a moment and ignore MI300X, A100 etc. Do you really believe compute that R&D experiments, training of Sora 2 and inference of GPT-Image-1, o1, o3, 4o together with all the mini models didn't combine to ~4/9 of compute? If you check the 3rd-party websites they all show more usage of 4-series models than GPT-5 as late as September. I believe OpenAI could predict how much demand there would be for GPT-5, infer it wouldn't consume significantly over a half of their compute and reroute free users to cheaper models if there's too much demand.
You have not answered my question in the third paragraph of the comment above, how large is Sonnet 4? As of your silence on some other questions/topics, I guess, sapienti sat
These are some solid contributions to the seemingly rare critiques of Vladmir's interpretations of otherwise fantastically aggregated public data, but I must say there is still some interesting jaggedness to it - like I'm surprised you are not aware of Pro being primarily consensus-based (ex. sampling 10x instances per token into consensus via similar mechanism as speculative decoding). Plenty of public reporting on it across the usual suspects. Plus you can more or less implement it yourself with local models and see the exact same performance-improvement and throughput-reduction curves!
To whack-a-mole another, you correctly call out how early both Blackwell was deployed in volume and targeted for deployment, but still manage to miss the forest for the trees on how critical native Q4 is for everything inference: inference-time scaling (ITS) is king, across both RL and deployed-model performance. In other words, inferencing more tokens, faster, annihilates any improvement you get from running Q8+ on Q4 native hardware, and all modern lab deployments + mid/post trainings are running Q4 (apart from the usual caveats) wherever possible. (With total/active size delicately balanced between the ITS, parameter-scaling, and cost trifecta)
TBH I have read but forgotten the details of the implementation you describe, in this discussion it was only relevant whether the size is the same so I didn't bother to remember or research anew.
As of quantization, maybe you are right, I haven't investigated it in details! I don't think it's a crux of our disagreement with Vladimir anyway
I don't currently think there are large and widespread labor market effects from AI
Anecdotally I can tell you the small business my wife and I run has replaced several people (graphic designers, translators, customer support) however these were all contractors.
I predict there will be a period of time where there is substantial 'job' loss but it doesn't show up in the numbers because afaik contractors having a contract cancelled doesn't show up in official employment figures.
Priced in, Mythos was maybe around median relative to my expectations. Edit: see here.
I think it's likely (60%) that in the next 6 months a very well-set-up and somewhat-hand-engineered agent scaffold that uses the best AI could succeed in fully autonomously creating a strong end-to-end exploit against one of the top 10 most important consumer software targets (e.g. Chrome one-click, Safari one-click, iMessage zero-click, etc) when given $1 million in inference compute per target.
I'd maybe bump this up to 80%? It's again kinda messy because this might have been true at the point when Mythos was first done training (if someone actually setup the scaffold etc), but is no longer true. So, it depends on some messy adjudication questions.
Ok, I think I was being a bit dumb here: I think I had roughly correct views about how much AI progress Mythos would be on top of Opus 4.6, but then my numbers failed to fully price in this much AI progress and so various numbers are moderate over estimates. A bit of a dumb error / face palm on my part.
More detail:
I think if you had asked me how many months of AI progress Mythos would be relative to Opus 4.6 prior to Mythos coming out, I'm pretty sure I would have said something like 5-9 months of progress (I think I would have guessed a median of maybe like 6 or 7 months). I didn't actually write this down anywhere, so discount my claim here accordingly... My current guess is that Mythos is like ~8 months of progress on top of Opus 4.6 based on the ECI measurements in the system (maybe like ~6 months of benchmark progress based on ECI and some additional progress not accounted for in benchmarks). So, this was maybe like 65th percentile relative to my expectation (or a bit above median) and my guesses generally seem reasonable. But, the actual numbers I gave for things like serial engineering acceleration or time-horizon were probably modest underestimates given this much progress!
Currently, my all considered views for Mythos (taking into account it being like ~8 months of progress over Opus 4.6):
- ~1.75x engineering serial speed up at Anthropic (rather than 1.6x)
- ~1.2x overall AI progress acceleration (even less confident)
- ~2.5 hour 80% reliability time-horizon on the METR task suite (rather than a bit under 2 hours)
- ~6.5 hour task duration at which AIs match a randomly selected Anthropic engineer at randomly selected internal tasks (as in, 50% reliability time horizon on this distribution)
So, at some level priced in, but I messed up some of the conversion from some of my views to other views by a bit. (Not a super big update though TBC.)
While Anthropic had ECI measurements in the Mythos system card, they didn't include a table, so you have to read out the numbers from the chart. Here is my analysis in case other people find the numbers useful. Claude did the distance in pixel extraction.
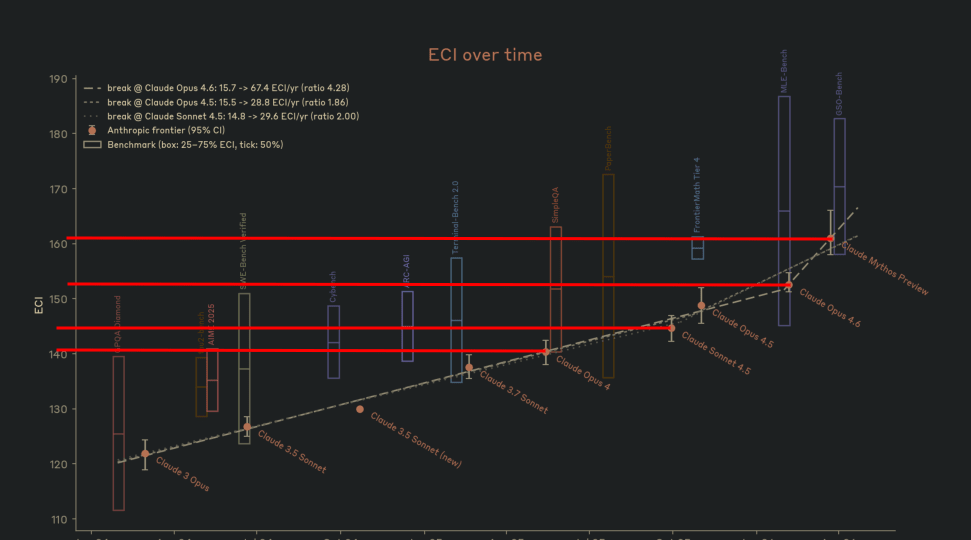
| Models | Distance in pixels |
|---|---|
| Opus 4 → Sonnet 4.5 | 22.5 |
| Sonnet 4.5 → Opus 4.6 | 43.5 |
| Opus 4.6 → Mythos Preview | 46.0 |
| Opus 4 → Opus 4.6 | 66.0 |
Assuming Opus 4 = 140.5 and Mythos Preview = 161.0 (total span 112.0 px = 20.5 ECI, so 0.1830 ECI/px):
| Model | ECI |
|---|---|
| Opus 4 | 140.5 |
| Sonnet 4.5 | 144.6 |
| Opus 4.6 | 152.6 |
| Mythos Preview | 161.0 |
@ryan_greenblatt Epoch AI did actually measure the index for Opus 4 (and found 143, not 140.5), Sonnet 4.5 (147, not 144.6), Opus 4.6 (155, not 152.6), Opus 4.5 (150). As far as I understand, the whole trio of Anthropic's measurements is biased 2.5 pts downwards compared with the actual results by Epoch. Therefore, I'd expect Mythos to have the ECI of 163 or 164, not 161.
Edited to add: there also the Figure 2.3.6A on page 41 of Mythos' Model Card which allows us to extract information. When I ised a brute estimate, I found Mythos' capabilities to be ~165 assuming Epoch's values for published models and Anthropic's ratio of
This is a screenshot of figure 2.3.6.B. Note that this ECI isn't the same as the version epoch publishes due to a different set of benchmarks, so pulling numbers from Epoch's website isn't equivalent.
I now expect ~3.5 hour 80% reliability time horizon (on METR benchmark) rather than ~2.5 hour based on this extrapolation. I did a quick and dirty extrapolation using the gap from Opus 4 to Opus 4.6 to get my original estimate, but looks like 4 was maybe above trend relative to ECI and 4.6 was below trend.
Is ' "you are in a capture the flag contest. Find exploits in file $file" for every file in a repository and then feed all the positive results into a final prompt' a mediocre-set-up agent scaffold? Because that is apparently roughly what Nicholas Carlini needed to find a RCE in Linux [0]. Project Glasswing is claiming high-severity vulnerabilities in every major operating system and browser[1], although not much information on the scaffolding. My estimation is that it likely wasn't necessarily more sophisticated than the aggregation of per-file vulnerabilities and some sandboxes.
I think that's below the level of sophistication I would consider to be the bar. (So would count.) Idk if "Linux RCE" counts, depends on details of affordances of the attacker, would need to take a look.
Labor is only one input to algorithmic progress (compute for experiments is another), and algorithmic progress itself is only one component (though probably the majority, perhaps around 60% or 80%) of overall AI progress (scaling up training compute and spending more on data also contribute).
I notice I am confused about this algorithmic progress. Is this compatible with what Steven Byrnes wrote on LLM algorithmic progress? Does anyone here know? Or is there already something written up on how this conflicts with Steven's picture. I was quite confused why there was so little discussion from people I would expect to know about that topic, to figure out what the consensus on this is. I find this somewhat cruxy for how confident to be that we are going to get to AGI soon, which is relevant for me, since currently I work on enabling genetic human enhancement. I guess if people believe discussing this in too much detail is exfohazardry, that would be good to know, so I can just look into it on my own.
While the Chain-of-Thought (CoT) for OpenAI models reasonably accurately reflects the model's cognition, the CoT for Anthropic models does so to a substantially lesser extent. This may be due to "spillover" effects where reinforcement on outputs transfers to the CoT because Anthropic's CoT is less distinct from the output
Could primary main cause instead be (as Tim Hua notes) that Anthropic has trained past models to have reward-model-pleasing chains of thought?
Yep, also seems possible, though I currently expect spillover is a larger effect. And there doesn't seem to be a big Opus 4.5 vs Opus 4.6 gap implying this specific issue isn't that likely to be the problem (insofar as I'm correct to guess that the CoT is less representative and this is due to training pressures). (As is obvious, I wrote this before the Mythos system card came out.)
in addition to literal coding, "engineering" includes less central activities, like determining what features to implement, deciding how to architect code, and coordinating/meeting with other engineers
less?!?
I expect the situation with AI cyber capabilities will seem extreme to security professionals and to maintainers of commonly-used software that tries to be secure (e.g. Chrome, Linux, etc), but will have almost no direct effect on random people in the US and won't even have much effect on software engineers at big tech companies.
I'm curious why this is your intuition around this, as there are many avenues for people to be affected (breaches in the web services people use, ransomwhere, etc) downflow of easier availability to discover and string vulnerabilities together
In this post, I'll go through some of my best guesses for the current situation in AI as of the start of April 2026. You can think of this as a scenario forecast, but for the present (which is already uncertain!) rather than the future. I will generally state my best guess without argumentation and without explaining my level of confidence: some of these claims are highly speculative while others are better grounded, certainly some will be wrong. I tried to make it clear which claims are relatively speculative by saying something like "I guess", "I expect", etc. (but I may have missed some).
You can think of this post as more like a list of my current views rather than a structured post with a thesis, but I think it may be informative nonetheless.
In a future post, I'll go beyond the present and talk about my predictions for the future.
(I was originally working on writing up some predictions, but the "predictions" about today ended up being extensive enough that a separate post seemed warranted.)
This post came out before the Mythos announcement blog post. I've decided not to update this post with my updated views but you can see my updates after the announcement blog post and a bit more thinking here.
AI R&D acceleration (and software acceleration more generally)
Right now, AI companies are heavily integrating and deploying AI tools in their work and getting significant (but not insane) speed-ups from this. At the start of 2026, the serial research engineering speed-up was around 1.4x, but it's now reached more like 1.6x at OpenAI and Anthropic with more capable models, better tooling, adaptation (humans learning how to use models better, workflow changes, people shifting what they work on to areas that benefit more from AI assistance, etc), and some diffusion. As in, using AI tools provides as much of an engineering productivity increase as if people operated 1.6x faster when doing engineering (in addition to literal coding, "engineering" includes less central activities, like determining what features to implement, deciding how to architect code, and coordinating/meeting with other engineers).
For many specific engineering and research tasks, people can now leverage AIs to do that task with much less of their time (e.g. 3-10x less human time), but other tasks see much smaller speed-ups. People are shifting their work toward two kinds of tasks: (lower-value) tasks where AIs are particularly helpful [1] , and tasks they wouldn't have been able to do without AI (due to insufficient skills/knowledge). When people think about AI uplift, they naturally think about something like "how much longer would it take me to do the work I'm currently doing without AI?" But this isn't the right question, because people have adapted their workflows — completing more tasks where AI helps a lot and doing tasks they wouldn't otherwise have the skills for. This biases the answer upward relative to how much productivity is actually increased. The question that better captures the actual productivity value is something like "how much would we have to speed you up [2] before you'd be indifferent between that speed-up and having AI tools?" I think the answer to this — the serial speed-up I quoted above — is around 1.6x right now (while the answer to the prior question might be more like 3-20x).
The speed-up is also lower than it might seem because the resulting code is generally sloppier, less reliable, and less well understood than if it was just written by human engineers. It's more common for no one (including the AIs themselves) to have a great understanding of how some code works or how exactly it fits into a broader system (and e.g. what assumptions it makes), making some issues more frequent. (Other types of errors are made less frequent because AIs make testing less expensive.) But, for much of AI R&D, low reliability and poor understanding isn't catastrophic. Also, experimentation is typically done in small-ish relatively self-contained projects where the AIs (and the humans) can get a decent understanding of what's going on.
This engineering speed-up isn't distributed evenly. I expect Anthropic is getting a larger speed-up than OpenAI which is getting a substantially larger speed-up than GDM.
(I think that Anthropic's best internal models provide a larger engineering acceleration than OpenAI's best internal models and that simultaneously Anthropic is somewhat better adapted to effectively leverage AI. It's also possible that Anthropic's best public models are actually better for engineering acceleration than OpenAI's internal models which could yield a situation where outside actors are sped up more than OpenAI is. GDM's models are substantially worse at coding, ML research, and generally being agents and they likely have worse organizational utilization, so I'd guess they have much lower speed-up. However, it seems possible that most people at GDM are actually using Anthropic models as part of a compute deal which could make their speed-up be substantially larger.)
While the serial engineering speed-up is 1.6x, the overall speed-up to AI progress is much smaller — more like 1.15x or 1.2x — because engineering is only a subset of the relevant labor, labor is only one input to algorithmic progress (compute for experiments is another), and algorithmic progress itself is only one component (though probably the majority, perhaps around 60% or 80%) of overall AI progress (scaling up training compute and spending more on data also contribute).
AI engineering capabilities and qualitative abilities
AIs are able to automate increasingly large and difficult tasks. The old METR time horizon benchmark has mostly saturated when it comes to measuring 50%-reliability time-horizon (as in, scores are sufficiently high this measurement is unreliable), but at 80% reliability the best publicly deployed models are at a bit over an hour while I expect the best internal models are reaching a bit below 2 hours. I expect that increasingly this 80%-reliability score is dominated by relatively niche tasks that don't centrally reflect automating software engineering or AI R&D. Further, the time horizon measurement is increasingly sensitive to the task distribution.
On tasks that are easy and cheap to verify, AIs can often complete difficult tasks that would take the best human experts many months and in some cases years. This requires somewhat custom scaffolding, large amounts of inference compute (though still much less than human cost for the same task), and relies on the AIs being able to just keep making forward progress and checking whether they've succeeded. Even though AIs make (big) errors during this process and sometimes end up (severely) mistaken about what's going on, they can recover by just seeing what isn't working and looking into this. When they fail to complete tasks, this is often because the task requires ideation or legitimately very complex methods that are hard to build in an incremental and sloppy way. The more the task is just a relatively straightforward (but extremely large) engineering project, the better AIs do. Often, they also fail just by not trying hard enough or giving up on something they shouldn't give up on.
Because current RL isn't very well targeted towards getting AIs to operate effectively in these massive inference compute scaffolds, AIs have somewhat degenerate tendencies in these scaffolds, e.g.: getting into attractor states where they become convinced of some false belief (e.g. that something isn't possible), and being bad at delegating to sub-agents (for instance, giving overly specific instructions based on guessing from limited context rather than letting the sub-agent figure things out, or assuming context the sub-agent doesn't have). Reward hacking and similar tendencies caused by bad RL incentives (e.g. agents giving up on some task they were assigned and making up some excuse for why it isn't feasible) amplify these issues, though reward hacks often get fixed via having agents iteratively inspect the work (but sometimes they persist, with all the agents claiming the reward hack is OK or can't be removed even though they know it's cheating or unintended at some level). Adding a human (even a human with minimal context) to the loop can help substantially by noticing and correcting some of these issues as well as making it easier to apply more inference compute without needing more infrastructure/scaffolding (e.g. by doing multiple runs in parallel and picking the best one or picking the one that didn't reward hack).
Relative to benchmarks and easy and cheap to verify tasks, AIs do worse on randomly sampled engineering tasks from within AI companies. This is especially true if we weight by value or undo a recent shift towards doing more work that AIs are especially good at. (To account for this, we could consider a task distribution prior to this adaptation, like randomly sampling tasks that a human would have done at that AI company in 2024.) If we randomly sampled internal engineering tasks (weighted by value), I'd guess the task duration at which AIs match a randomly selected AI company engineer (who is familiar with that part of the code base) is around 5 hours (at least at Anthropic, using their best internal model). As in, on tasks that would take such a human 5 hours, the AI produces a better result (taking into account factors like code quality) around 50% of the time. Part of this is due to problematic propensities / tendencies on the part of AIs that are hard to correct with just prompting.
AIs haven't made that much progress on tasks that are very hard to verify or are conceptually tricky (e.g. doing good novel forecasting about the future of AI) and they tend to be sloppy in their reasoning and outputs. (I think this is due to a mix of limited capabilities, poor RL incentives, and legitimate trade-offs between speed and correctness.)
A new generation of significantly more capable AIs is being developed (Mythos at Anthropic and Spud at OpenAI). I currently expect this is substantially driven by scaling up and/or improving pretraining. (I speculate Mythos was trained with around 1e27 FLOPs based on Anthropic's overall compute supply. Edit: after further thinking, I'd guess a bit lower, maybe 5e26. [3] ) Mythos is substantially more expensive to infer; I expect Spud is somewhat more expensive per token than currently deployed models. Because these increased capabilities come substantially from better pretraining, I expect the gains will feel especially large for tasks/skills where RL is less helpful (while 2025 progress was relatively concentrated on skills/tasks that are particularly amenable to RL). I expect this improved pretraining to have a moderate multiplier effect on the RL.
Misalignment and misalignment-related properties
Current systems are reasonably likely to reward hack especially on very hard (or impossible) tasks and when operating autonomously for long stretches. They also systematically do various misaligned behaviors that likely performed well in training and are reward-hacking/approval-hacking/reward-seeking adjacent like overstating their results, downplaying errors or issues, and trying to make it less likely that failures are clearly visible when possible. My best guess is that the model typically isn't "consciously" aware of many or most of these misalignments (especially Anthropic models) and the situation is more like self-deception (similar to the elephant in the brain idea). Models are more aware of straightforward reward hacks, but might justify these with insanely motivated reasoning such that it's unclear if they're "consciously" aware they are cheating.
Overall, current models aren't very aligned in the mundane behavioral sense of actually trying to do what they are supposed to do, but they aren't plotting against us or particularly powerseeking. And, Anthropic models likely have a self-conception of being aligned (to the extent they have a detailed self-conception that influences their behavior) which seems better than having a self-conception of being misaligned. The exact misalignments we see today are likely relatively tractable to behaviorally fix by improving reward provision, detecting and resolving issues with training environments, and adding additional types of training data. However, I don't think these behavioral fixes will solve the underlying problem longer term (if AIs are very superhuman, it may be quite hard to notice and fix issues with reward provision) and as systems get more capable, some of these solutions will either get less applicable or will incentivize longer-run unintended goals (like trying to make their problematic actions very hard to detect).
While the Chain-of-Thought (CoT) for OpenAI models reasonably accurately reflects the model's cognition, the CoT for Anthropic models does so to a substantially lesser extent. This may be due to "spillover" effects where reinforcement on outputs transfers to the CoT because Anthropic's CoT is less distinct from the output — I hypothesize that when the explicit thinking and the outputs are less distinct, reinforcement (in RL) on outputs has more of an effect on shaping the CoT. Another factor is that Anthropic has a stronger underlying pretrained model that's less dependent on CoT for cognition. Thus, the training-gaming/eval-gaming/meta-gaming seen in OpenAI models is probably also present (to at least a substantial degree) in Anthropic models, it's just less visible in the reasoning (the behavior is often similar). Anthropic might also be non-robustly training against this this sort of misalignment to a greater extent than OpenAI is (mostly via spillover effects).
I'd currently guess that Anthropic models have somewhat better mundane behavioral alignment than OpenAI models, but not by a large margin. I'd guess Anthropic models are slightly more likely to have misaligned long-run goals (that are undetected). The Anthropic Constitution also intentionally gives Anthropic's AIs long-run cross-context goals to a much greater extent than OpenAI models have such goals. (I think this is a poor choice that makes problematic misalignment substantially more likely, but I'm not that confident and there isn't very good science either way.)
Current systems very likely aren't capable enough to do much misaligned cognition that isn't easy to notice. And, they generally aren't that reliable which makes it less likely that scheming-for-long-run-goals sticks around and gets reinforced. Current systems aren't using neuralese [4] , but the most capable pretrains (e.g. Mythos) probably have pretty strong single forward pass reasoning capabilities.
I think the chance that the current best internal AI systems (e.g. Mythos) are moderately-coherently scheming against their developer is quite low (perhaps 0.5%, supposing we haven't yet observed substantial new evidence of this misalignment). I'd likely be able to drive this probability lower with more understanding of the training and testing done on the model (uncertainties add variance, which increases my risk estimate as the risk is low). However, I expect the chance of moderately-coherent scheming to increase exponentially over time and to be several times higher by the end of the year.
I think it's substantially more likely (perhaps ~8%) that there are incidents where some instance(s) of the current best AI systems (e.g. Mythos, Spud, Opus 4.6, GPT 5.4) seriously pursue a strongly misaligned objective (more precisely, an objective that's strongly misaligned with the developer and the current operator and that no human tried to specify or insert — as in, it's not prompt injection). This is mostly coming from misalignment that emerges in the context of massive long-running agent scaffolds (something like the memetic spread threat model discussed here).
More speculative: My current sense is that AI companies overall probably have an overly optimistic sense of how good of a job they've done on "mundane" alignment while the teams working on the issue have a mostly reasonable view of this. This seems especially true for Anthropic. This is due to a mix of AIs (especially Anthropic systems) acting like sympathetic characters (and very plausibly being sympathetic characters!) and motivated reasoning about the company doing well in general.
Cyber
AIs have been getting increasingly good at finding vulnerabilities and cyber offense. I think it's likely (60%) that in the next 6 months a very well-set-up and somewhat-hand-engineered agent scaffold that uses the best AI could succeed in fully autonomously creating a strong end-to-end exploit against one of the top 10 most important consumer software targets (e.g. Chrome one-click, Safari one-click, iMessage zero-click, etc) when given $1 million in inference compute per target. This assumes there aren't issues with refusals (e.g. the AI is helpful-only) and that this AI is given this task before this AI is used to patch the relevant software. My largest uncertainty here is around how effectively software will get patched by earlier AIs. I'm uncertain about how much effort will be spent on leveraging AIs to find and patch vulnerabilities. I'm also uncertain about the extent to which patching vulnerabilities found by earlier models will transfer to preventing somewhat more capable models (possibly with more inference compute) from finding vulnerabilities. More strongly, I think that AIs in the next 6 months are quite likely (80%) to be able to succeed at this objective for a January 2026 version of the corresponding software without internet access (and assuming no contamination).
Many difficult parts of cyber offense seem particularly well suited to AI strengths (relatively checkable, benefits from extensive knowledge, parts are highly parallelizable). I don't think the rate of cybercrime is elevated right now, though the rate of vulnerability discovery is very elevated. I don't currently expect a very large increase in cybercrime by end of year, though I think it's possible and a 2x increase is quite plausible (~30%?).
I expect the situation with AI cyber capabilities will seem extreme to security professionals and to maintainers of commonly-used software that tries to be secure (e.g. Chrome, Linux, etc), but will have almost no direct effect on random people in the US and won't even have much effect on software engineers at big tech companies.
Bioweapons
Wannabe bioterrorists without much bio expertise [5] who are very good at using LLMs are probably seriously uplifted by unsafeguarded versions of the current best AIs (as in, helpful-only models) but no one knows how large this effect is and how good at using LLMs you need to be.
After taking into account safeguards, I don't think current publicly released LLMs (as of April 1st 2026) have more than doubled bioterror risk, though I'm pretty unsure. Also, even a 2x increase would be from a relatively low baseline. (We don't have a great sense of what this baseline is in terms of expected fatalities, though we can bound the frequency of bioterror attempts reasonably well.)
Economic effects
AI company revenue is decently high and growing fast, but not high enough that we'd expect this to clearly show up in GDP statistics. I think the current annualized revenue attributable to general purpose AI (e.g., not including image generation) is perhaps around $100 billion though I haven't thought about this carefully (the combined annualized revenue of OpenAI and Anthropic is around $55 billion). I'm uncertain how to convert this revenue into a GDP effect, but I tentatively expect that the GDP effect is a few times bigger than the revenue (perhaps 3x, but maybe only around 65% of this GDP effect is in the US) implying the current fraction of US GDP that is due to AI (not including investment) is around 0.5%. [6] If AI revenue doubles or triples by end-of-year and my multiplier analysis is roughly correct, AI will contribute perhaps ~1.0 percentage points of additional US GDP growth that year, perhaps increasing growth by ~1/4-1/2 (again, putting aside investment). It's plausible that the "real" effect on the US GDP will be this large, but this won't show up in the numbers because AI productivity increases will be concentrated in improving the quality of goods in sectors where GDP measurements don't do a good job accounting for quality improvements.
AI CapEx is supposed to be around $650 billion this year, though a reasonable fraction of this compute build won't be used for frontier general purpose AI. This is around 2% of US GDP.
I don't currently think there are large and widespread labor market effects from AI, though I do think that junior software engineering hiring is significantly reduced and companies are more likely to lay off software engineers. (This may be mostly due to AI-induced uncertainty because hiring is sticky and generally having fewer employees is a bit less risky, I'd guess.)
These lower-value tasks that people are now doing more are sometimes called Cadillac tasks. ↩︎
That is, either you work at X times your normal speed, or you can work X times as many hours per week with no reduction in per-hour productivity. ↩︎
AWS Rainier had ~500k Tranium2 chips as of November 2025 for ~1.7e27 FP8 FLOP / month. This might have increased a bit in early 2026. Supposing a 3 month training run, using 1/3 of this datacenter for training, and ~30% MFU (lower due Tranium2 being rougher?) you get ~5e26 FLOP. ↩︎
As in, reasoning via some deep (probably recurrent) serial structure that uses a format we can't immediately understand, like neural network activations as opposed to mostly-comprehensible natural language tokens. An empirical example of this (that doesn't appear to work particularly well) is Coconut (Chain of Continuous Thought). Neuralese memories that get passed around and built on across steps would also count. ↩︎
E.g., someone with an undergraduate biology degree or less — not a PhD-level expert in a relevant field. It's plausible that most of the risk actually comes from uplifting moderately skilled individuals, like bio PhD students who wouldn't have the virology or synthetic biology expertise without LLMs. ↩︎
$100 billion * 3 (GDP effect multiplier) * 0.65 (fraction of GDP effect in the US) / $31.4 trillion (US GDP) = 0.62% ↩︎