Heuristics for choosing/writing good textbooks (see also here):
- Has exercises
- Exercises are interspersed in the text, not in large chunks (better at the end of sections, not just at the end of chapters)
- Solutions are available but difficult to access (in a separate book, or on the web), this reduces the urge to look the solution up if one is stuck
- Of varying difficulty (I like the approach Concrete Mathematics takes: everything from trivial applications to research questions)
- I like it when difficulty is indicated, but it's also okay when it's said clearly in the beginning that very difficult exercises that are not marked are mystery boxes
- Takes many angles
- Has figures and illustrations. I don't think I've encountered a textbook with too many yet.
- Has many examples. I'm not sure yet about the advantage of recurring examples. Same point about amount as with figures.
- Includes code, if possible. It's cool if you tell me the equations for computing the likelihood ratio of a hypothesis & dataset, but it's even cooler if you give me some sample code that I can use and extend along with it.
- Uses typography
- You can use boldface and italics and underlining for reading comprehension, example here.
- Use section headings and paragraphs liberally.
- Artificial Intelligence: A Modern Approach has one-three word side-notes describing the content of each paragraph. This is very good.
- Distinguish definitions, proofs, examples, case-studies, code, formulas &c.
- Dependencies
- Define terms before they are used. (This is not a joke. Population Genetics uses the term "substitution" on p. 32 without defining it, and exercise 12-1 from Naive Set Theory depends on the axiom of regularity, but the book doesn't define it.)
- If the book has pre-requisites beyond what a high-schooler knows, a good textbook lists those pre-requisites and textbooks that teach them.
- Indicators
- Multiple editions are an indicator for quality.
- Ditto for multiple authors.
- A conversational and whimsy style can be nice, but shouldn't be overdone.
- Hot take: I get very little value from proofs in math textbooks, and consider them usually unnecessary (unless they teach a new proof method). I like the Infinite Napkin for its approach.
- Wishlist
- Flashcard sets that come together with textbooks. Please.
- 3blue1brown style videos that accompany the book. From Zero to Geo is a great step in that direction.
Sure, I can do that. (I might've fallen prey to the labor-theory of post-value again: this was low-effort for me to write, which doesn't mean it's useless).
Well, if you wanted to make it more effortful to write, you could justify every single claim in an essay 10x this length :). I doubt that would make it better, though.
That humorous suggestion aside, you could alternatively turn it into a Question-type post, rather than a normal one. I'm not sure about the relative merits there.
For those who like pure math in their AI safety: a new paper claims that the decidability of "verification" of deep learning networks with smooth activation functions, is equivalent to the decidability of propositions about the real number field with exponentiation.
The point is that the latter problem ("Tarski's exponential function problem") is well-known and unresolved, so there's potential for crossover here.
Asked what FOOM stands for, ChatGPT hallucinated a backronym of "Fast Onset of Overwhelming Mastery" among others. I like that one.
Hey, I'm new here and have really been enjoying reading lots of posts on here. My views have certainly updated on a variety of things!
I've been exploring using Anki flashcards to codify my thought processes when I have a-ha moments. After reading about cached thoughts, I started thinking that most of executing procedural knowledge is just having lots of cached thoughts about what to do next. I understand that this is not exactly the type of cached thought in the post, but I think it is interesting nonetheless. I have been making Anki cards like Physics: what should you do if you get something as a function of x instead of a function of t to solve a problem//use conservation of energy instead to speed up the process of learning new procedures (like solving physics problems).
Have others done something similar?
I used Anki a bunch during university, with some moderate success, but always ended up adding too many cards, plus content too rough to be considered a proper card, to the point that I eventually stopped using the app, even though it definitely worked when I put in the time to use it.
I even made lots of Anki cards about LW sequences content, with the same results.
... Now that I think about it, there's probably one (or ten) AI services by now which can turn arbitrary text into Anki cards, too. I'm skeptical how well they might work, but they presumably can't do any worse than dumping text into cards and not editing them at all.
I'm actually working on this problem right now. There are a lot of those services, but they usually generate bad cards. I'm researching how to use AI to make good cards.
This essay has some tips on that, starting from the "More patterns of Anki use". There are also various LW articles about Anki under the Spaced Repetition tag, some of them such as My Anki Patterns have card design tips.
Hello all,
I am just another human trying to keep my beginners mind. I have learned so much from reading the sequence highlights and other posts here already, hoping one day to have something to contribute.
Cheers
A founder of Midjourney tweeted that in 2009 he saw a "famous scientist" tell "a room of two hundred kids" that in 20 years, computers would exceed human intelligence. One child asked what would happen - would they kill us, or perhaps make pets of us - and the scientist declares "We will become the machines!" The kids are all horrified and say nothing for the rest of the talk.
Quite a few of the comments say things like "we need to embrace change" and "you can't stop evolution" and "we're already machines" and so on. Even the original anecdote concludes with the scientist harrumphing that "people" want to solve problems without any big changes happening.
What baffles me: no-one points out that this wasn't a roomful of adults being short-sighted, it was a roomful of children who felt instinctive unease at what the mad grown-up was saying. Even if it is humanity's destiny to merge with technology, I find it bizarre that the reluctance of a group of children to embrace this declaration, is treated as a morality tale about human inflexibility.
Hi! I'm Zane! A couple of you might have encountered me from glowfic, although I've been reading LW since long before I started writing any glowfic. Aspiring rationalist, hoping to avoid getting killed by unaligned AGI, and so on. (Not that I want to be killed by anything else, either, of course.) I have a couple posts I wanted to make about various topics from LW, and I'm hoping to have some fun discussions here!
Also, the popup thingy that appears when a new user tries to make a comment has a bug - the links in it are directed to localhost:3001 instead of lesswrong.com (or was it 3000? the window went away, I can't see it anymore.) Also, even after I replace the localhost:300[something] with lesswrong.com, one of the links still doesn't work because it looks like the post it goes to is deleted.
Hi all, writing here to introduce myself and to test the waters for a longer post.
I am an experienced software developer by trade. I have an undergraduate degree in mathematics and a graduate degree in a field of applied moral and political philosophy. I am a Rawlsian by temperament but an Olsonian by observation of how the world seems to actually work. My knowledge of real-world AI is in the neighborhood of the layman's. I have "Learning Tensorflow.js" on my nightstand, which I promised my spouse not to start into until after the garage has been tidied.
Now for what brings me here: I have a strong suspicion that the AI Risk community is under-reporting the highly asymmetric risks from AI in favor of symmetric ones. Not to deny that a misaligned AI that kills everyone is a scary problem that people should be worrying about. But it seems to me that the distribution of the "reward" in the risk-reward trade-off that gives rise to the misalignment problem in the first place needs more elucidation. If, for most people, the difference between AI developers "getting it right" and "getting it wrong" is being killed at the prompting of people instead of the self-direction of AI, the likelihood of the latter vs. the former is rather academic, is it not?
To use the "AI is like nukes" analogy, if misalignment is analogous to the risk of the whole atmosphere igniting in the first fission bomb test (in terms of a really bad outcomes for everyone -- yes, I know the probabilities aren't equivalent), then successful alignment is the analogue of a large number of people getting a working-exactly-as-intended bomb dropped on their city, which, one would think, on July 15th 1945 would have been predicted as the likely follow-up to a successful Trinity test.
The disutility of a large human population in a world where human labor is becoming fungible with automation seems to me to be the fly in the ointment for anyone hoping to enjoy the benefits of all that automation.
That's the gist of it, but I can write a longer post. Apologies if I missed a discussion in which this concern was already falsified.
Formal alignment proposals avoid this problem by doing metaethics, mostly something like determining what a person would want if they were perfectly rational (so no cognitive biases or logical errors), otherwise basically omniscient, and had an unlimited amount of time to think about it. This is called reflective equilibrium. I think this approach would work for most people, even pretty terrible people. If you extrapolated a terrorist who commits acts of violence for some supposed greater good, for example, they'd realize that the reasoning they used to determine that said acts of violence were good was wrong.
Corrigibility, on the other hand, is more susceptible to this problem and you'd want to get the AI to do a pivotal act, for example, destroying every GPU to prevent other people from deploying harmful AI, or unaligned AI for that matter.
Realistically, I think that most entities who'd want to use a superintelligent AI like a nuke would probably be too short-sighted to care about alignment, but don't quote me on that.
Thank you. If I understand your explanation correctly, you are saying that there are alignment solutions that are rooted in more general avoidance of harm to currently living humans. If these turn out to be the only feasible solutions to the not-killing-all-humans problem, then they will produce not-killing-most-humans as a side-effect. Nuke analogy: if we cannot build/test a bomb without igniting the whole atmosphere, we'll pass on bombs altogether and stick to peaceful nuclear energy generation.
It seems clear that such limiting approaches would be avoided by rational actors under winner-take-all dynamics, so long as other approaches remain that have not yet been falsified.
Follow-up Question: does the "any meaningfully useful AI is also potentially lethal to its operator" assertion hold under the significantly different usefulness requirements of a much smaller human population? I'm imagining limited AI that can only just "get the (hard) job done" of killing most people under the direction of its operators, and then support a "good enough" future for the remaining population, which isn't the hard part because the Earth itself is pretty good at supporting small human populations.
I was thinking about some of the unique features of Less Wrong's cosmology - its large-scale model of reality - and decided to ask Bing, "Do you think it's likely that the multiverse is dominated by an acausal trading equilibrium between grabby squiggle maximizers?"
The resulting dialogue may be seen here. (I normally post dialogues with Bing at Pastebin, but for some reason Pastebin's filters deemed this one to be "potentially offensive or questionable".)
I was impressed that Bing grasped the scenario right away, and also that it judged it to be unlikely because it's based on many independent assumptions. It was also pretty good at suggesting problems faced by those constituent assumptions.
I am unimpressed. I've had conversations with people before that went very similarly to this. If this had been a transcript of your conversation with a human, I would have said that human was not engaging with the subject on the gears / object level and didn't really understand it, but rather had a shallow understanding of the topic, used the anti-weirdness heuristic combined with some misunderstandings to conclude the whole thing was bogus, and then filled in the blanks to produce the rest of the text. Or, to put it differently, BingChat's writing here reads like a typical essay in a college philosophy 101 class. (Admittedly it's a bit above-average based on my experience at UNC Chapel Hill, I probably would have given this at least a B)
That said, at the current rate of improvement, I'd expect GPT-5 to be significantly better.
I don't know, I feel like the day that an AI can do significantly better than this, will be close to the final day of human supremacy. In my experience, we're still in a stage where the AIs can't really form or analyze complex structured thoughts on their own - where I mean thoughts with, say, the complexity of a good essay. To generate complex structured thoughts, you have to help them a bit, and when they analyze something complex and structured, they can make out parts of it, but they don't form a comprehensive overall model of meaning that they can then consult at will.
I don't have a well-thought-out theory of the further tiers of intellectual accomplishment, these are just my rough impressions. But I can imagine that GPT-4 coupled with chain-of-thought, or perhaps Claude with its enormous, book-length context size, can attain that next level of competence I've roughly described as autonomous reading and writing, at the level of essays and journal articles.
I see this as a reason to have one's best formula for a friendly outcome, ready now (or if you're into pivotal acts, your best specification of your best proposal for halting the AI race). For me, I guess that's still June Ku's version of CEV, filtered through as much reflective virtue as you can manage... The point being that once AIs at that "essay level" of cognition start talking to themselves or each other, you have the ingredients for a real runaway to occur, so you want to be ready to seed it with the best initial conditions you can supply.
Oh I totally agree with everything you say here, especially your first sentence. My timelines median for intelligence explosion (conditional on no significant government-enforced slowdown) is 2027.
So maybe I was misleading when I said I was unimpressed.
Bing writes that one of the premises is that the AIs "can somehow detect or affect each other across vast distances and dimensions", which seems to indicate that it's misunderstanding the scenario.
Are there any plans to add user-visible analytics features to LW, like on the EA forum? Screenshot from an EA forum draft for reference:
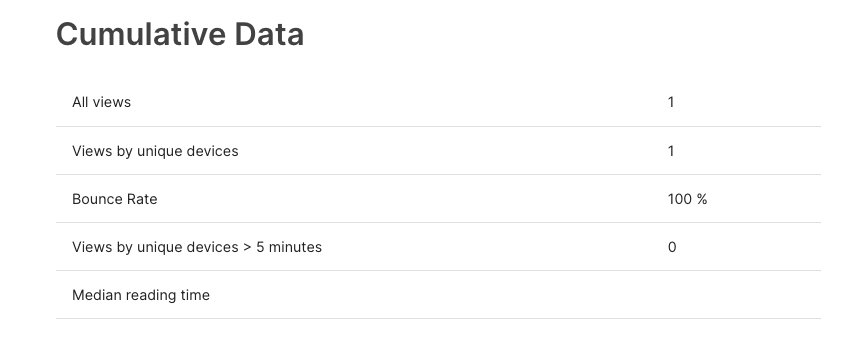
I'm often pretty curious about whether the reception to a post is lukewarm, or if most people just didn't see it before it dropped off the front page.
Analytics wouldn't tell me everything, but it would allow me to distinguish between the case that people are clicking and then not reading / voting vs. not clicking through at all.
On the EA forum, analytics are only viewable by the post author. I'm most interested in analytics for my own posts (e.g. my recent post, which received just a single vote), but I think having the data be public, or at least have it be configurable that way, is another possibility. Maybe this could take the form of a "view counter", like Twitter recently introduced, with an option for the post author to control whether it shows up or not.
Kamala Harris meeting CEOs of Microsoft, OpenAI, Google, and Anthropic today... more or less as suggested by Thomas Friedman in the New York Times two weeks ago.
Does that mean the current administration is finally taking AGI risk seriously or does that mean they aren't taking it seriously?
Link to the Times; link to free archive.
"One thing Biden might consider is putting Harris in charge of ensuring that America’s transition to the age of artificial intelligence works to strengthen communities and the middle class. It is a big theme that could take her all over the country."
Hey, this is my first post here (though I have read the sequences a few years ago, and have been passively reading the forums since).
I'm interested in participating in discussion about safe AI, and have prepared some thoughts on the matter I would love to get feedback on. What are acceptable ways and places to present these thoughts?
Welcome! Shortform (see the user menu) is a good way to get started, otherwise the AI open thread.
PSA: If you're like me, you want to subscribe to the Open Threads Tag, to not miss these: https://www.lesswrong.com/tag/open-threads
Nate Silver's next book is about some very LW-relevant topics:
Let’s start with the “easy” part. I’ve spent much of the past two years working on a book about gambling and risk for Penguin Press. I am very excited about the book.
It’s an ambitious book. Subtopics include: poker, sports betting, game theory, venture capital and entrepreneurship, effective altruism, rationality and utilitarianism, existential risk, artificial intelligence, the cryptocurrency boom and the collapse of FTX, the commercial gambling industry, the personality traits associated with risk-taking, and declining life expectancy and changing attitudes toward risk in American society.
(From his Substack.)
I just signed up. I'm done with big social media sites and want to get back to my roots posting on forums again. I need something like this but with conversation about entertainment too.
I remember once coming across a website or blog article with a title that was something like "Things that are actually allowed" or something like that. On it was a list of things that should go without saying that you "may" do them, but many people don't realize this and therefore get in their own way. I can't find this webpage again - if anyone has the url that would be very helpful.
That also looks interesting, but the one I am referring to was older, and I remember one thing in the long list was "it is allowed to move to another city because your friends live there" or something like that, other things treated issues of "it's allowed to pay someone else to do X because you don't like to do it" etc.
I'm interested in getting involved with a mentorship program or a learning cohort for alignment work. I have found a few things poking around (mostly expired application posts), but I was wondering if anyone could point me towards a more comprehensive list. I found aisafety.community, but it still seems like it is missing things like bootcamps, SERI MATS, and such. If anyone is aware of a list of bootcamps, cohorts, or mentor programs or list a few off for me, I would really appreciate the direction. Thanks!
If it’s worth saying, but not worth its own post, here's a place to put it.
If you are new to LessWrong, here's the place to introduce yourself. Personal stories, anecdotes, or just general comments on how you found us and what you hope to get from the site and community are invited. This is also the place to discuss feature requests and other ideas you have for the site, if you don't want to write a full top-level post.
If you're new to the community, you can start reading the Highlights from the Sequences, a collection of posts about the core ideas of LessWrong.
If you want to explore the community more, I recommend reading the Library, checking recent Curated posts, seeing if there are any meetups in your area, and checking out the Getting Started section of the LessWrong FAQ. If you want to orient to the content on the site, you can also check out the Concepts section.
The Open Thread tag is here. The Open Thread sequence is here.