I often write posts by dictating a verbatim rough draft, giving the audio to Gemini along with a bunch of samples of my past writing and instructions up preserve my voice as much as possible, and then edit what comes out until I'm happy (but in practice it's close enough to my voice that this is just light editing). Under these rules would I need to put the whole post in an LLM output block?
EDIT: On reflection, the thing that annoys me about this policy is that it lumps in many kinds of LLM assistance, with varying amounts of human investment, into an intrusive format that naively reads to me as "this is LLM slop which you should ignore".
For example, under my current reading, I would need to label several popular and widely read posts of mine as LLM content (my amount of editing varied from light to heavy between the posts, but LLM assistance was substantial). I think it would have been pretty destructive to make me label each post as LLM written (in practice I would have either violated the policy, or posted on a personal blog and maybe shared a link here)
https://www.lesswrong.com/posts/StENzDcD3kpfGJssR/a-pragmatic-vision-for-interpretability https://www.lesswrong.com/posts/jP9KD...
I would feel better about eg self selecting a tag for the post about how much an LLM was integrated into the writing process, with a spectrum of options rather than a binary
FWIW, this wouldn't achieve approximately any of the goals of the above policy. The whole point of the policy is to maintain speech as testimony on LessWrong. Having a post that is "50% AI written" basically doesn't help at all with that. LessWrong post writing should frequently and routinely refer to internal experiences like "I was surprised by X" or "Y felt off to me", and if the LLMs wrote a section with those kinds of phrases, usually no amount of editing will restore meaningful testimony, and so a post that just mixes LLMs that made up random internal experiences with actual experiences a person had is failing on this dimension, even if labeled as such.
Fair enough. How about "I stand by the content of this piece as much as if I'd written it myself"? In my case, most but not all of the phrasing and wording is written by me, and I would cut anything the LLM added that I considered false testimony
I basically don't trust people to correctly make this call, especially as LLMs get smarter and more persuasive.
I certainly don't trust the daily deluge of new users who have this in their posts yet are substantially producing slop.
I have been surprised by how bad people are at assessing whether this is actually true, but I do think it's roughly the actual standard I have for putting content into LLM content blocks.
I would be fine with people messaging us on Intercom before publication and being like "hey, this was more heavily AI-edited but I do actually stand behind it all in testimony, can you sanity-check that that seems right to you?", and then we can give people permission to skip the LLM content blocks. This does seem like a bit of a pain for the people involved, but I don't super know what else to do.
I'm doing the same - verbatim dictating the text, giving the transcript to Claude with some of my past writing in the prompt and asking it to clean up the transcript, then manually editing the outcome. I don't notice the outcome being really worse or different than my normal writing. I don't notice LLMisms in the text, and my original dictation is detailed enough that the LLM doesn't need to fill in the gaps, and in the editing process, I haven't noticed the LLM inserting or omitting points in a way I didn't intend.
I'm currently two-thirds done writing a long sequence this way - if I now can't post it without putting it all in an LLM content-block, I will be very sad.
Update: Re-reading the cleaned-up transcripts, I've found them basically useless, and now I'm rewriting everything by hand. I think this is largely not Claude's fault - I'm trying to explain complicated concepts in my posts, and my dictation was just not detailed enough to get everything across.
In any case, I wanted to write this update not to keep up this false data-point here.
That is quite an update. I am curious about how this happened: if you had done only 1 or 2 transcripts, I could understand eventually discovering enough severe subtle flaws as to render them completely worthless compared to starting over from scratch, but how did you get "two-thirds done writing a long sequence" while still being highly enthusiastic about stuff you were going to ultimately throw out as "basically useless" and you are now "rewriting everything by hand"? "Just not detailed enough" sounds like a strange explanation to me, because shouldn't've you noticed that problem with the first transcript you looked at?
LLM transcription is IMO a completely different use-case (one I certainly didn't think of when thinking about the policy above), so in as much as the editing post-transcription is light, you would not need to put it into an LLM block. I also think structural edits by LLMs are basically totally fine, like having LLMs suggest moving a section earlier or later, which seems like the other thing that would be going on here.
We intentionally made the choice that light editing is fine, and heavy editing is not fine (where the line is somewhere between "is it doing line edits and suggesting changes to a relatively sparse number of individual sentences, or is it rewriting multiple sentences in a row and/or adding paragraphs").
Also just de-facto, none of the posts you link trigger my "I know it when I see it" slop-detector, so you are also fine on that dimension.
All four of those posts look fine to me and none of them would've gotten flagged by the automated LLM content detection.
If your epistemic state with respect to the claims made in your posts is such that you aren't worried about receiving questions like "Why are you so confident in [proposition X]?" and then it turning out to be the case that you in fact don't endorse what's written, because an LLM said something meaningfully different from what you would have said in that situation, then I think the end result is fine.
If you want to link to this comment on future posts so that readers understand how LLMs were used in the process of writing them, I think that'd be fine, but supererogatory.
My somewhat-dissenting-mod-opinion:
I feel more worried than I think Habryka and Robert are about LLM-content corroding LW culture, and I think I maybe have a slightly different take on why LLM-generated text is not testimony matters. (For me, it's not the most important thing that people are making 'I' statements that are false if an LLM said them. More significant to me is the implicit vouching that each statement is interesting and is some kind of worthwhile piece of a broader conversation, whether it's your opinion or not)
If I were making the policy and new features, I'd be framing it like:
...Look, I know AI is increasingly going to be a legitimate part of some people's workflows. But, I think for >75% of LW users, it's a mistake to use LLMs as a particularly significant part of your writing process, and I think the site should be somewhat pumping away from it.
I think there are very occasional new users for whom it's the right call to use LLMs, but, I'd think of it more like "the people I trust to write LLM content are people who either have written, or pretty obviously could write, multiple posts that get 100+ karma." And even then I am slightly worried about people falling do
Good cyborg writing almost never has the form of clearly distinct "human blocks" and "AI blocks"
I (and several others) found switching to sans-serif as a way of marking LLM text didn't really work as a marker; when I first saw it I mistakenly thought that only the paragraph with the LLM-name on it was LLM-generated, and I find alternate-font text inside of posts uncanny. I jokingly hypothesized that Habryka (its advocate) had serif-synaesthesia and that's why it worked for him as a marker, and that's the story of how the serif-synaesthesia test came to be.
Everyone is going on about the LLM block, meanwhile I'm like "isn't letting users inject arbitrary JS in their post kinda dangerous?".
We did our homework on the browser security model; content in iframes (with sandboxing attributes) shouldn't be able to get login cookies/etc from the parent page. This is load-bearing for advertisements not stealing everything, so we do expect browsers to treat weaknesses in this as real security issues and fix them. When post HTML is retrieved through the API, you have to do some assembly to put the iframes in, so third party clients can't be insecurely surprised by it.
As for whether sandboxed frames can crash the outer page or make the outer page slow, eg by doing into an infinite loop or running out of memory, the story is a bit more complicated (depends on browser, browser heuristics, and amount of system RAM); we decided it's okay as long as it's limited to an embed in a post crashing its own post page (as opposed to the front page or a link preview).
I am happy with this policy erring on the side of "any substantial LLM involvement goes in the LLM block". My experience with content the author represents as moderately LLM-involved has been that after reading, it always seems to have not been worth my time in the same way that pure LLM output seems not worth my time.
Regardless of how users may feel about the changes introduced, I applaud the significant improvement on clarity and transparency (compared to the previous policy).
Thank you very much! I think this is at least fairer to users- like you said, especially to new users who may end up confused as to what they did wrong.
I really do not mind disclosing how and much much LLM-assistance I used to write a post or comment. In fact, being ""forced"" to think how much of a sentence was purely mine vs Claude-written is helping me a lot with clear thinking.
Like others mentioned, I also find it very useful to use dication mode, and it's true that the distinction can get blurry when you spent 30 minutes talking into the mic, and it's very different from doing bare minimum thinking. But I appreciate LW keeping me accountable on LLM-reliance- I mean, thinking better is why I am here ❤.
If you "borrow language" from the LLM, that no longer counts as "text written by a human".
Can you say a bit more about what counts as "borrowing language"?
For instance, suppose that I'm talking to an LLM and I describe an experience that I sometimes have. The LLM characterizes that experience as a process within my mind "having reached equilibrium", and I like that framing. I then write a post where I describe things using those words, but otherwise don't quote anything else from the LLM's response, and I explain what I mean by "having reached equilibrium" using my own words.
I would presume that this would fall more under "arguments developed with LLM assistance" and I wouldn't need to put those three words in an LLM block? But if so, I'm a unclear on what does fall under "borrowing language".
LLM Content Blocks
This visually distinct block is an LLM Content Block.
I strongly disagree that the block is "visually distinct". Even if you know what to look for (serif/sans serif), it's quite subtle, but if you don't, it's likely invisible to most people. So it completely fails at the "visually distinct" front, and it is unclear where the LLM output ends.
This is also why having LLMs "edit" your writing is often pernicious. LLM editing, unless managed extremely carefully, often involves rephrasings, added qualifiers, and swapped vocabulary in ways that meaningfully change the semantic content of your writing. Very often this is in unendorsed ways, but this can be hard to pick up on because the typical LLM writing style has a tendency to make people's eyes slide off of it[5].
Hmm so I think this centrally depends on what you mean by editing? There's
- Give text to the LLM (with whatever instructions), then
LLM Content Blocks
This visually distinct block is an LLM Content Block
...problem: as currently laid out, it sure looked like the llm block was just the sentence
Hi! I'm Claude, and I'm writing this from inside the post you're reading right now. This block I'm in is one of the new editor features — let me walk you through a few of them.
The new custom iframe widgets are my favorite part of this update. I'll be using them extensively as part of my upcoming post.
The LLM block looks similar enough to normal writing that it creates an unpleasant uncanny valley, where I'll read a few words, feel something's off, and then go "Oh, LLM!". This is not dissimilar to the actual experience of reading LLM generated text. Nice work on the allegorical visuals, though I suspect this is not the desired effect, and I would prefer a different visual cue.
I attempted to use this feature, as currently built into the publishing menu. There is a button "click the following button and send the message to finalize the connection", which generates a message in claude.ai like:
Please confirm that you can access the LessWrong API by running: curl -X POST https://www.lesswrong.com/api/agent/confirmClaudeAccess/(hex)
Sonnet 5 and Opus 4.8 both consider this to be a prompt injection attack and refuse to curl it. They explain that a reputable Claude integration would use an official Claude Connector, and not some dod...
I read the site primarily through my RSS aggregator, which doesn't know that <div class="llm-content-block" data-model-name="Claude Opus 4.6"><div class="llm-content-block-content"> is meaningful to render. An indicator that's present as regular text would be appreciated.
But also count me as another in the group, saying that even when viewing the site directly the supposedly visually distinct block is basically invisible to me, and I would much prefer that it be less subtle. If I skim down a post and miss the subtle little introductory note of ...
(Thinking out loud.) I have really been unimpressed with LLM-assisted writing I’ve seen to date (and yes that includes “cyborg” writing from established users), and would be happy to see it banned entirely (maybe with exceptions for straightforward audio transcription and machine translation). Especially given the “second-order effects on culture” that Raemon mentioned here. Like, LLMs help people write, but removing friction sometimes makes things worse not better.
Then I was thinking: Is there any situation where I would use an LLM block myself? Hmm, mayb...
text written by a human, which includes facts, arguments, examples, etc, which were researched/discovered/developed with LLM assistance. (If you "borrow language" from the LLM, that no longer counts as "text written by a human".)
Hmm, I'm not sure how I feel about research done with LLM assistance. On the one hand, it's a useful tool for research, but on the other hand: https://www.lesswrong.com/posts/ghq9EwiXbRbWSnDzF/solar-storms (why is this still curated, btw?).
Seems like the standard should be something like... can you support/defend each claim without having to use an LLM?
For me, knowing when I am reading “ text written by a human, which includes facts, arguments, examples, etc, which were researched/discovered/developed with LLM assistance” is in fact way more important than knowing whether or not the actual words of the text were written by an LLM. This site is called LessWrong, and LLMs are not yet good at being it.
Perhaps a policy that facts which have been produced by an LLM and not independently verified should be flagged as such?
A clarification question: If I have a conversation with an LLM and have it summarize it and then significantly edit it, as per your rule, this has to go into an LLM Output block, right? How do I label that section? LLM+human?
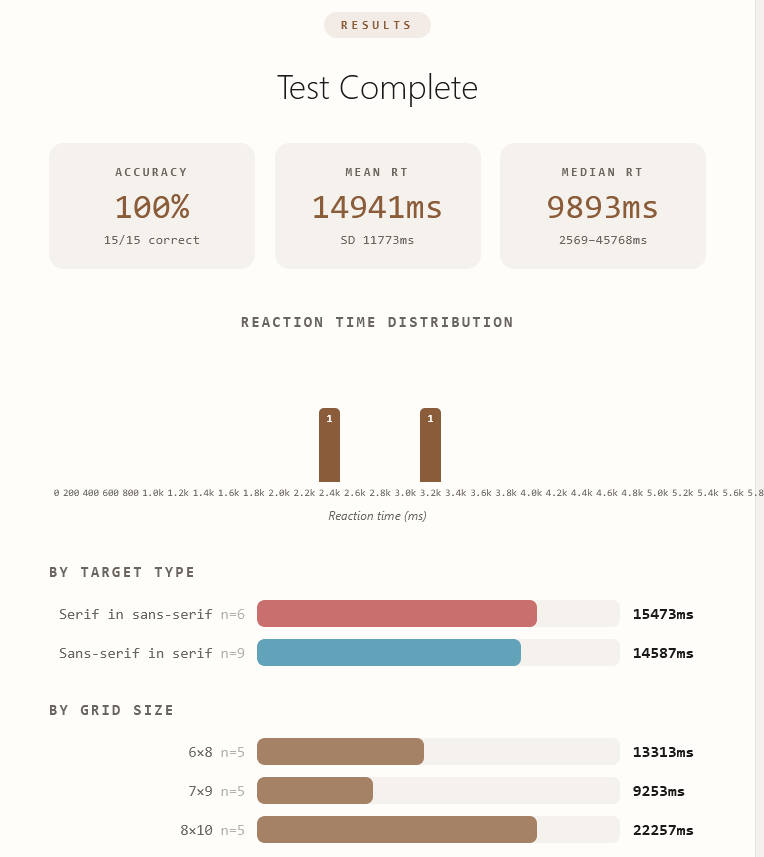
The test is so hard I basically have to scan the whole thing 2-3 times to find the character
Score
If I think someone else's text (either from here or from elsewhere on the Internet) is likely unlabelled LLM text, and I wish to quote it here, what should I do under this policy? Neither labelling nor not labelling it as LLM really seems appropriate.
I think it's also pretty important to understand this this is going to be absurdly impractical for some posts that people were working on before the rule change (especially if they're going back and finishing a draft that's been sitting around for a number of months).
Feedback: your supposed "LLM content block" is currently utterly visually indistinguishable from the regular content, and thus (to me) currently entirely fails to achieve what you / Claude say is its intended purpose:
...This visually distinct block is an LLM Content Block. Authors can insert these into their posts to clearly attribute a section to a specific AI model. The block header shows which model generated the content, so readers always know what they're looking at. It's a way to be transparent about AI-assisted writing while keeping everything in one d
Why is the font size of the LLM content block slightly larger than normal? 19.3px vs 18.2px. It was subtle enough that I didn't notice it before using inspect element but it feels off once I noticed it.
I just want to register that I feel like the new editor is full of bugs.
Maybe I'll slowly acquire the skills to use this instead of the old thing, but I can't even toggle Markdown and not-Markdown with the new system which seems like it is just straightforwardly a bug?
Also I wrote this article today in the face of all the bugs (and just shipped something ugly with fewer links and less italics than normal), and it probably violates the new LLM rules because it is about the bottom line results that one can get from accepting various people (digital people or...
Wouldn't it just be easier to let us include a tag if a post made significant use of LLMs throughout, rather than using a content block that could have interaction effects with other elements of the page. Even if it's just one up the top, it breaks the aesthetics compared to a tag.
"If you "borrow language" from the LLM, that no longer counts as "text written by a human".)"
This feels completely unworkable. Basically, it catches situations where you have a conversation with an LLM, then write the whole post manually. If the situation is that if you may want ...
Unfortunately, I cannot find the way to make a collapsible section in the Post editor. Collapsible sections in the Comments editor are perfectly makeable even in the Experimental editor.
I came here (already knowing the policy) looking for the specific tags to use by searching for angle brackets in the original post. But I could not easily find them there. I found some tags only in comments, but I'm not sure if they are authoritative. My request: please make the details of the exact markup tags stated plainly so it is obvious and easily discoverable. I use the LessWrong Markdown editor, not the WYSIWYG editor. Thanks!
Ah, "view source" got me to the following... Is the following canonical? If so, how do I make it look good in the LessWrong ...
I am taking the risk of being downvoted to oblivion here (like JenniferRM above, it's ok to disagree with her but I thought downvoting her karma was very harsh, I upvoted her), but I generally disagree with the LessWrong LLM (-assisted) writing policy being so exclusive/restrictive.
First, I totally agree with clearly indicating what roles and levels of involvement an LLM took in writing/editing/influencing... a post.
With that premise accepted and respected, why restricting post writing on LessWrong to "pure" human beings? For me it looks and sounds like bi...
I realize that part of the goal is to make the LLM portions unobtrusive, but would it be possible to make LLM sections have a collapse button at the top? (Or bottom). By default they can be open.
When reading current LessWrong posts that have LLM sections, I find myself mostly skipping LLM sections and appreciate when someone has placed them in a collapsible.
For marking/tracking AI vs human written content, I've been watching Every's new "Proof Editor" with some interest. https://proofeditor.ai/ Probably worth checking out their approach for inspiration. (Might be implementing something similar for our team's internal custom Obsidian/Notion replacement)
Amid all this discussion, I thought a question: Has anyone had success (or knows someone who's had success) with using LLMs as writing tutors? I.e., you're using the LLM to teach you how to increase your ratio of quality of writing to effort/time spent (i.e., write better and/or faster and/or less effortfully), even when you don't have access to an LLM.
I have a sequence on my blog that makes important contributions to humanity's understanding of neurodivergence and personality disorders – anything related to psychopathy and pathological narcissism. It's based on hundreds of hours of literature research and hundreds of hours of chats with friends with these neurodivergences and/or personality disorders, which I compiled into suitable case study composites. To my knowledge, many of the insights in it are original and valuable for insight and treatment.
The final posts I would estimate are written to 10–70% ...
I am encountering a lot of formatting issues when editing a comment. The state of a comment should be exactly the same when you first submit it and after you click "edit", but the lexical editor is adding a couple random newlines, changing the image caption to a link, detaching the caption from the image, etc...
Iframes in posts are going to be very fun.
I look forward to interacting with additive webgameseducational illustrations while pretending toreading about AI safety on lesswrong.
Sometimes you get scroll blocked when hovering on the widgets, it is not a big deal but the inconsistency feels weird. https://streamable.com/7da79g
i thought the use of the word 'testimony' in the LLM-generated text is not testimony essay was very useful for conveying the concept the author wished to convey (however much i might have disagreed with the concept), but now that it's being cited as the motivating factor for policy i suddenly find myself wishing they'd chosen a different word
for instance, if i ask claude to recite its system prompt, there is some sense in which it is giving personal testimony about its perceptions. just as sort of a proof of concept. on the other end of the spectrum, if i ...
and i think that the second point in the quoted post, "As of 2025, LLM text does not have those [mental agency] elements behind it", might be something about which reasonable people could differ, especially as time moves forward and more sophisticated models are released.
Note that I also explicitly acknowledge this in my curation notice for that post (and that I disagree with the strength of the claim). In any case, Tsvi's post is not the moderation policy, and the moderation policy is not taking a stance on whether LLM text meaningfully constitutes "testimony" (only that it does not constitute the testimony of the human publishing the post).
There's a new editor experience on LessWrong! A bunch of the editor page has been rearranged to make it much more WYSIWYG compared to published post pages. All of the settings live in panels that are hidden by default and can be opened up by clicking the relevant buttons on the side of the screen. We also adopted lexical as a new editor framework powering everything behind the scenes (we were previously using ckEditor).
That scary arrow button in the top-left doesn't publish your post! It just opens the publishing menu.
Posts[1] now have automatic real-time autosave while you're online (like Google Docs), but still support offline editing if your connection drops out. Point-in-time revisions will still get autosaved periodically, and you can always manually save your draft if you want a specific checkpoint.
The editor also has a slash menu now!
Good for
allmany of your custom content needs!You might be eyeing the last two items in that slash menu. This post will demo some of the new features, and I'll demo two of them simultaneously by letting Opus 4.6 explain what they are:
Hi! I'm Claude, and I'm writing this from inside the post you're reading right now. This block I'm in is one of the new editor features — let me walk you through a few of them.
LLM Content Blocks
This visually distinct block is an LLM Content Block. Authors can insert these into their posts to clearly attribute a section to a specific AI model. The block header shows which model generated the content, so readers always know what they're looking at. It's a way to be transparent about AI-assisted writing while keeping everything in one document.
Custom Iframe Widgets
The new editor supports custom interactive widgets embedded directly in posts. Authors can write HTML and JavaScript that runs in a sandboxed iframe right in the document — useful for interactive demos, visualizations, small tools, or anything else that benefits from being more than static text. There's one just below this block, in fact.
Agent Integration
The editor now has an API that lets AI agents read and edit drafts collaboratively. If you share your draft's edit link with an AI assistant (like me), it can insert text, leave Google Docs-style comments, make suggested edits, and add LLM content blocks and widgets — all showing up live in the editor. That's how this entire block was written: not copy-pasted in, but inserted directly through the API while the post was open for editing.
To use it, open your post's sharing settings and set "Anyone with the link can" to Edit, then copy the edit URL and share it with your AI assistant.
With Edit permissions, the agent can do everything: insert and modify text, add widgets, create LLM content blocks, and more. If you'd prefer to keep tighter control, Comment permissions still allow the agent to leave inline comments and suggested edits, which you can accept or reject individually.
Setup depends on which AI tool you're using. Agent harnesses that can make HTTP requests directly — like Claude Code, Codex, or Cursor — should work out of the box. If you're using Claude on claude.ai, you'll need to add
www.lesswrong.comto your allowed domains settings, then start a new chat. (The ChatGPT web UI doesn't currently support whitelisting external domains, so it can't be used for this feature yet.) Once that's done, just paste your edit URL and ask Claude to read the post — the API is self-describing, so it'll figure out the rest from there.And here's a small interactive widget, also written by Claude[2], to demonstrate custom iframe widgets:
Policy on LLM Use
(Note: For first-time users, we have closer to a zero-LLM policy)
You might be wondering what this means for our policy on LLM use.
Our initial policy was this:
You were also permitted to put LLM-generated content into collapsible sections, if you labeled it as LLM-generated.
In practice, the "you should not use the stereotypical writing style of an AI assistant" part of the requirement meant that this was a de-facto ban on LLM use, which we enforced mostly consistently on new users and very inconsistently on existing users[3]. Bad!
To motivate our updated policy, we must first do some philosophy. Why do we care about knowing whether something we're reading was generated by an LLM? LLM-generated text is not testimony has substantially informed my thinking on this question. Take the synopsis:
I don't think you even need to confidently believe in point 2[4] for the norm in point 4 to be compelling. It is merely sufficient that someone else produced the text.
Plagiarism is often considered bad because it's "stealing credit" for someone else's work. But it's also bad because it's misinforming your readers about your beliefs and mental models! What happens if someone asks you why you're so confident about [proposition X]? It really sucks if the answer is "Oh, uh, I didn't write that sentence, and re-reading it, it turns out I'm not actually that confident in that claim..."
This is also why having LLMs "edit" your writing is often pernicious. LLM editing, unless managed extremely carefully, often involves rephrasings, added qualifiers, and swapped vocabulary in ways that meaningfully change the semantic content of your writing. Very often this is in unendorsed ways, but this can be hard to pick up on because the typical LLM writing style has a tendency to make people's eyes slide off of it[5].
With all that in mind, our new policy is this:
"LLM output" must go into the new LLM content blocks. You can put "LLM output" into a collapsible section without wrapping it in an LLM content block if all of the content is "LLM output". If it's mixed, you should use LLM content blocks within the collapsible section to demarcate those parts which are "LLM output".
We are going to be more strictly enforcing the "no LLM output" rule by normalizing our auto-moderation logic to treat posts by approved[7] users similarly to posts by new users - that is, they'll be automatically rejected if they score above a certain threshold in our automated LLM content detection pipeline. Having spent a few months staring at what's been coming down the pipe, we are also going to be lowering that threshold.
This does not change our existing quality bar for new user submissions. If you are a new user and submit a post that substantially consists of content inside of LLM content blocks, it is pretty unlikely that it will get approved[8]. This does not suddenly become wise if you're an approved user. If you're confident that people will want to read it, then sure, go ahead, but please pay close attention to the kind of feedback you get (karma, comments, etc), and if this proves noisy we'll probably just tell people to cut it out.
What about translation?
If you are not a fluent english speaker and want to use LLMs to help you publish to LessWrong, the way to do this is to write it out normally in your native language, and then ask the LLM to do a direct word-for-word translation (no rewriting, embellishment, tweaks, etc). This usually results in content that feels reasonable / non-slop-like to read, and which doesn't trigger our AI writing detectors.
As always, please submit feedback, questions, and bug reports via Intercom (or in the comments below, if you prefer).
Not comments or other content types that use the editor, like tags - those still have the same local backup mechanism they've always had, and you can still explicitly save draft comments, but none of them get automatically synced to the cloud as you type. Also, existing posts and drafts will continue to use the previous editor, and won't have access to the new features.
Prompted by @jimrandomh.
For somewhat contingent reasons involving various choices we made with our moderation setup.
See my curation notice on that post for some additional thoughts and caveats.
I think this recent thread is instructive.
We'll know it when we see it.
In the ontology of our codebase, a term which means "users whose content goes live without further review by the admins", which is not true of users who haven't posted or commented before, and is also not true of a smaller number of users who have.
I'm sure the people reading this will be able to conjure up some edge cases and counterexamples; go on, have fun.