A teenager can learn to drive in a few dozen hours; self-driving systems are trained for years on billions of miles of data. …
Steven Byrnes appears to read the gap as evidence that current algorithms are far from what the brain is doing, such that much better algorithms must be waiting to be found.
I think you’re attributing an argument to me which I wasn’t making (in the context of that post that you copied the diagram from). I agree that comparing 30 hours of teen driving practice to umpteen gazillion hours of Waymo training data is apples-and-oranges because the teen also has life experience.
But I was making a different point, which (in my own words) was: “…we don’t have AGI (artificial general intelligence) yet—not as I use the term…”. (I’m not even sure you disagree with that??)
Anyway, it is NOT the case that it’s possible to make self-driving cars by taking some generic learning algorithm that we already know about, and letting it spend the equivalent of 18 years roaming around and doing stuff in various virtual environments like VR & MineCraft, and watching YouTube videos, and reading books, and whatever, and THEN have it spend 30 hours with minimal instruction driving actual cars, and bam, now you have a human-level self-driving car. There is no generic learning algorithm today that can do that, right? If there were such an algorithm, then surely somebody would have done that already. That would have been way way way easier than what Waymo and Tesla etc. have been actually doing. So I think this example is fair game: the brain can do things that no existing AI algorithm can do, even in an apples-to-apples comparison that holds data availability fixed.
Maybe your response would be: “Oh yeah that’s easy, someone could totally do that, it’s just that nobody has bothered because the resulting AI would be too big to fit in a car computer”?? Or “Oh yeah, we totally know how to do that, it’s just that it would require more compute than would be affordable or practical at the present time”?? If so, I disagree with both of those possible objections, and we can get into why if it’s crux-y.
I think you’re attributing an argument to me which I wasn’t making (in the context of that post that you copied the diagram from). I agree that comparing 30 hours of teen driving practice to umpteen gazillion hours of Waymo training data is apples-and-oranges because the teen also has life experience.
But I was making a different point, which (in my own words) was: “…we don’t have AGI (artificial general intelligence) yet—not as I use the term…”. (I’m not even sure you disagree with that??)
Yes, sorry, I can see how that might give people the wrong impression of your views. The diagram was just meant to illustrate the reading that the self-driving case points to a missing major algorithmic ingredient that makes humans very sample efficient learners. The later line ("Humans don't learn to drive in thirty hours, they are fine-tuned on driving after a roughly two decade-long pretraining run") was aimed at a more naive version of the argument someone might hold, not at you specifically.
I agree that we don't have AGI yet, but given what current deep learning architectures/algorithms have already achieved, I don't think that the ingredients will look too exotic or different from the types of algorithms we have now.
On the narrow self-driving car case, I find it plausible that a model that's basically a significantly scaled up version of EZ-V2 (requiring >3 OOMs more memory than current Tesla FSD hardware at inference), and given maybe ~2 years of diverse real driving experience (and perhaps alongside a few non-exotic additional regularization and data augmentation techniques), could learn to drive as well as a human. Well, I'd put it at maybe 60% chance that this is true.
On why we can't teach a model to drive the way a human would, I agree that we're still missing a few algorithmic ideas, especially related to how to train a good world model for generalizable/transferable online learning and spatial navigation, but even if we did have the right algorithm, I disagree that it'd be "way way way easier" than what Waymo and Tesla have been doing, and I think "the resulting AI would be too big to fit in a car computer" is one major factor. Beyond the scale of the frozen policy itself though, I do expect that the algorithmic thing that is missing for human-like learning will require more compute of some form. Though I may just be lacking imagination about what alternative algorithms are possible.
(Interesting post, thanks for writing it!)
I do believe the brain has much higher sample efficiency than existing DNN algorithms, in the sense that matters for guessing future ASI compute requirements. But I agree that pinning down the comparison is a bit subtle.
(Also, sample-efficiency is not the main reason why I think that FLOP-required-for-ASI is low, but rather trying to guess how much compute the brain is doing. But sure, sample-efficiency is not totally irrelevant to how I think about these things, I suppose.)
The sensory data going to the brain is (I think) >99% visual, and >99.5% visual + audio. (IIRC … I didn’t double-check, and it’s kinda controversial how to calculate it anyway…)
So it’s interesting that congenitally blind people, and deafblind people, are basically just as smart and competent as sighted & hearing people, except obviously in contexts where the missing sensory data is directly relevant. I think this observation generally pushes against a perspective that centers the story of human intelligence around our abundant sensory data.
And more specifically, RE your Appendix, if we’re going to compare frontier LLM training data with human sensory data, we should also be putting blind and deafblind people onto that same plots / tables. And also, if we’re comparing sighted people to frontier models, we need to include the frontier models’ visual training data, not just text token training data … I don’t know how many extra bytes that would be, but I’d guess a lot.
I’m not exactly sure what point you’re trying to make with the discussion of Dreamer, EfficientZero, and related, but (copying from an argument I had on this topic in 2021):
I think that if somebody wants to understand AlphaZero, the fact that it trained on 40,000,000 games of self-play is a highly relevant and interesting datapoint. Suppose you were to then say “…but of those 40,000,000 games, fundamentally it really only needed 100 games with the external simulator to learn the rules. The other 39,999,900 games might as well have been ‘in its head’. This was proven in follow-up work.”. I would reply: “Oh. OK. That's interesting too. But I still care about the 40,000,000 number. I still see that number as a very important part of understanding the nature of AlphaZero and similar systems.”
Anyway, if a human is playing chess in his head, or replaying a memory of that embarrassing thing that I did one time in middle school what they did yesterday, then he is not paying attention to sensory input. He’s probably mostly zoning out. So in a certain sense, the replay is replacing sensory data, as opposed to increasing the effective total amount of data, in humans. So, like, the thing in §3 where you note that LLMs can be more “sample-efficient” by doing 4 epochs of the same data, or the thing that EfficientZero etc. does, well, if you’re talking about sample-efficiency for the pragmatic reason of trying to solve AI problem where you have lots of compute but strictly limited data, then cool, that kind of thing is helpful and important. But if you’re talking about sample-efficiency in the context of trying to compare and contrast humans versus current AIs, then I think those tricks are somewhat off-topic.
I concede that “brains are kinda like insanely huge 100-trillion-parameter LLMs, and that’s BOTH why we don’t have AGI yet AND why brains are (in certain senses) more sample-efficient” is a story that hangs together. And it’s a pretty popular story in LLM circles because it also fits in with scale-is-all-you-need. I really don’t think that story is right, for lots of reasons, including neuroscience stuff that I don’t want to get into, but also just, like, noticing all the ways that brains are quite different from insanely huge LLMs. There’s the continual learning stuff, the model-based RL stuff, the brain’s complete absence of “true” imitative learning, the way that cortical microcircuits simply do not look anything like transformer layers, etc.
Is it plausible to you that there's some equivalent to 'mental simulations' humans use for model-based world-sample-efficient learning?
If so is it plausible they are mostly (overwhelmingly?) subconscious? If so could those be much (orders of magnitude?) faster than equivalent real-world interaction?
(I tentatively think yes to all of these, mostly because of the computer science of it, without much context on the neuroscience of it. cf my other comment on temporal abstraction.)
No I don’t find that plausible, sorry I don’t have time to explain why but this post section is related to where I’m coming from.
The arguments here match a lot of my own intuitions. I want to add a few things:
1. Even benchmarks that supposedly measure sample efficiency on abstract problems fall victim to human priors: ARC Is a Vision Problem! - https://arxiv.org/abs/2511.14761
2. Human learning largely performed on-policy, while pretraining is primarily off-policy. This means that humans can seek out the information that they specifically lack, and receive feedback to address their specific mistakes. I predict that the shift towards RL (and more recently on-policy distillation) is the first phase of a broader transition towards primarily on-policy training pipelines that will bring gains in both sample and parameter efficiency.
This is a solved problem in the way Transformers were a solved problem 20 years before the paper came out. The ingredients seem to be out there. But the way no LLMs currently use anything like that in practice says that there is no clear roadmap to when frontier models will get there.
Steven Byrnes appears to read the gap as evidence that current algorithms are far from what the brain is doing, such that much better algorithms must be waiting to be found. His guess is that human-level, human-speed AGI will require not a datacenter but "one consumer gaming GPU," even for training from scratch.
Plausibly a lot more params than a gaming GPU can fit are necessary, and even if that wasn't a problem, the compute of a gaming GPU might take years or decades to train an adult AGI. Also, the way GPUs work, you always want a batch of many AI instances to keep matmuls at a high arithmetic intensity. But that's hardly timeline-relevant, since the wide availability of datacenter hardware capable of working with quadrillion parameter models is just 3-5 years away.
Yarrow Bouchard on the EA Forum, reads the same gap as evidence that AGI isn't close at all, precisely because nobody knows how to close it.
Since there is no prototype close enough to the final thing that it only needs some scaling, it remains possible that superintelligence isn't close at all. Though of course that prototype could be invented at any time, and then scaled to the frontier level within a year, the way RLVR became a central part of training for every frontier model over just the year 2025. I think AGI likely follows even without all that, just from the way LLMs are built now, at some point during their impending scaling from ten trillion params to a quadrillion params (with RLVR as the key ingredient that lets them usefully learn despite sample inefficiency everywhere else). But without that (still missing) breakthrough, it'll remain a hobbled kind of AGI that's slow at learning deep skills and so doesn't quickly lead to a takeoff and superintelligence.
I have an old unpublished essay (now submitted) arguing, among other things, something similar: I'm just not that impressed by human learning efficiency when I look at the only fair comparisons which are not in some way contaminated by human priors like vision capabilities or which make a serious effort to make DRL sample-efficient rather than compute-efficient.
What people take this to mean varies widely. Steven Byrnes appears to read the gap as evidence that current algorithms are far from what the brain is doing, such that much better algorithms must be waiting to be found. His guess is that human-level, human-speed AGI will require not a datacenter but "one consumer gaming GPU," even for training from scratch. Yarrow Bouchard on the EA Forum, reads the same gap as evidence that AGI isn't close at all, precisely because nobody knows how to close it. Nearly opposite conclusions from the same starting observation.
I’m confused, these don’t sound “nearly opposite” to me, they sound very compatible. Did you misread something? Or maybe you’re noticing that Yarrow & I have opposite vibe and emphasis, even when we’re saying basically the same thing?
(I very strongly disagree with Yarrow about all kinds of things, but I don’t think this paragraph is pointing to an example. Here’s an example where I was partly agreeing and partly disagreeing with Yarrow on something in the vicinity of this topic.)
Hmm, yes, that was poorly phrased. You both think we need a new paradigm, and that something fundamental is missing, but your conclusion as to what it means for how worried we should be is opposite.
Changed that last sentence to:
> They both agree that current algorithms are missing something fundamental, yet draw opposite conclusions about what that means for AGI risk and timelines.
I liked your post, and particularly the section 5a a lot, and strongly upvoted it. However today I read somewhat of a counter-essay by Dwarkesh Patel: https://www.dwarkesh.com/p/the-sample-efficiency-black-hole It's a good piece which I think I could recommend reading to all readers of this blogpost.
In particular, the counterargument I found strongest was about scaling:
- The way the scaling law equations work is that parameter and data terms are added to the loss independently. If you have a model that is trained compute optimally, and suppose you ask, well what if I just wanna maximize sample efficiency and use less data - and I’ll throw in as many parameters as it takes to make that happen. With the constants from the Chinchilla scaling laws paper (and the nature of the result wouldn’t change even with different constants), even if you increased the number of parameters by infinity, that would only decrease by a factor of ~10 the amount of data you need in order to keep the same loss. Humans are somewhere between thousands to millions of times more sample efficient than these models. Scaling of current models simply can’t make up for that discrepancy. This really does suggest that humans are on a different scaling curve altogether.
I tried to refute that with some Fermi estimates but ran into difficulties regarding interconversions between bytes and tokens. Mathematically the logic is sound. I wonder what would you answer?
Another useful section for people to notice, which says that even if the prior is doing most of the work, the marginal sample efficiency for AIs is also very bad, because compared to humans they need 100x more marginal data:
- Even if it were the case that we can explain away the trillions of tokens required to pretrain a base model as catching up to evolution, it doesn’t explain why the marginal capabilities take so much data - once you have been educated, you don’t need 100 different professors to learn a new programming language, but the AIs (even once pretrained) do.
RLHF and RLVR are model-free: they update the policy from sampled real trajectories, with no learned model of the environment to plan or imagine inside.
It's perhaps worth distinguishing the learned reward model of RLHF - so the policy isn't updated only from 'real' trajectories but also from exploratory hypothetical trajectories scored against the learned reward model.
In RLVR, one could claim that the whole point is that we have the 'model' - the training environment - and it's arguably not only more accurate to just run that directly rather than imagining it, but also cheaper in many cases (e.g. it's shell scripts and file manipulations, not a giant NN world model). Not always: some environment interactions might be very slow (e.g. running a big gradient descent). You write "AI labs have focused their RL work on areas where the environment and verification step are cheaper to compute directly rather than in a learned world model", which acknowledges this.
One thing you haven't mentioned (which I think is quite crucial in human sample-efficient planning and learning) is temporal abstraction. That's something that only some world models can do (ones which flexibly represent 'options' at various temporal granularities rather than merely representing atomic 'action' transitions). Humans definitely do this. I'm fairly confident that the implicit world models baked into large pretrained NNs also do this to some extent in their internal planning. I haven't seen many architectures which allow such a temporally abstract world model to interface with policy (e.g. in actor-critic/dreamer style) to allow improved sample-efficiency. EfficientZero, with its 'value prefix' model, comes closest (and not that close) among things I've paid attention to. Notably, language encodes all kinds of temporal abstraction essentially arbitrarily flexibly (this realisation was what prompted me onto the LLM-agent train back in 2021).
Given working temporal abstraction, even RLVR on cheap envs might be substantially accelerated.
Uh, maybe. There's some scattered stuff. I'm not sure if anyone else is thinking about it the way I do, but probably it's some of the 'hierarchical' (keword) RL/control and robotics people if anyone. e.g.
- Planning in a hierarchy of abstraction spaces
- Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning
- Option-Critic
- DeepMimic
- Human-Level Reinforcement Learning through Theory-Based Modeling, Exploration, and Planning
- Model-based hierarchical reinforcement learning and human action control
Given a flat prior over a vast hypothesis space, even simple tasks require an enormous amount of data.
Solomonoff induction doesn't require enormous amounts of data unless the thing it's trying to learn is actually enormously complex.
It does however require infinite compute. (I've also gotten the impression that all approximations of Solomonoff induction are also very compute intensive, unless you allow for very loose definitions of approximation.)
Perhaps more relevant to the quoted sentence is that it takes advantage of a very cleverly non-flat prior.
Perhaps more relevant to the quoted sentence is that it takes advantage of a very cleverly non-flat prior.
Any prior over an unbounded space needs to be non-flat in this way, or you'd never be able to learn anything. To put it more precisely: if you are assigning nonzero probability to every hypothesis in the space, there will exist some description length L(
I find these quantitative comparisons pretty interesting. This table was made by Opus 4.8. after some iteration:
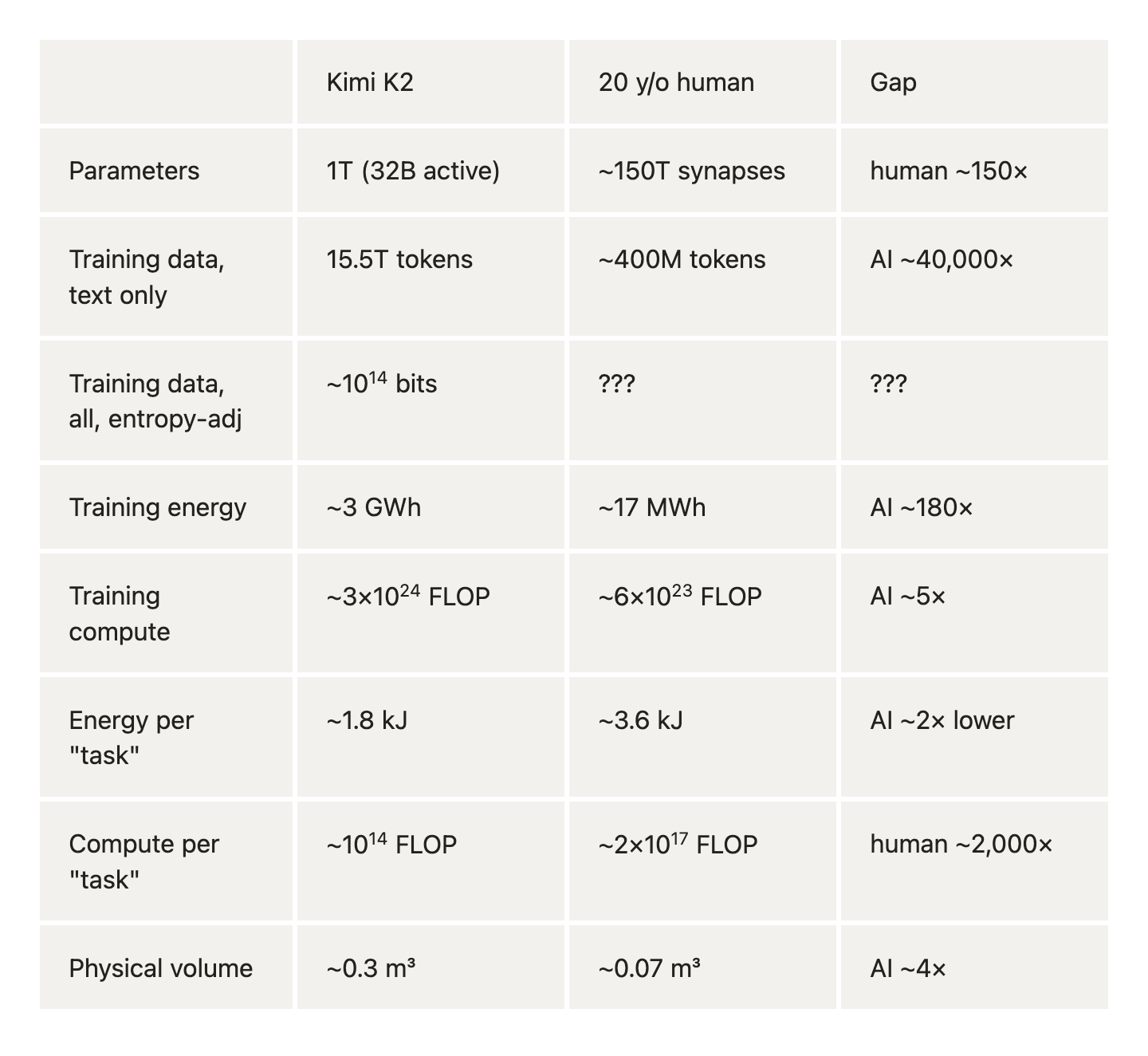
"Task" = "produce one thoughtful ~1,000-token answer"; unclear if this is a useful number, obliviously it doesn't generalize. I do think it's interested to compare the energy/computer ratio for inference between human and AI.
Training data for humans is a big "???". There's ~4x10^8 waking hours. Opus 4.8 cited this 2024 paper which says "our sensory systems gather data at ~10^9 bits/s". That gives ~4x10^17 as an upper bound. But human sensory data is extremely redundant. If someone wants to spend time figuring out a good way to estimate entropy adjusted information here, that would be cool.
(FWIW, I spent a little over an hour on this -- I did a fair amount of iteration with GPT5.5, looked a bit myself into a few numbers, and got new instances to do estimates from scratch to see if things lined up.)
Another ref to support the claims in §1 and §2: https://arxiv.org/abs/2107.12544
If you manually encode some general human biases in the form of a world model ontology of objects, physics, agents, and goals, then rl becomes nearly as sample-efficient as human learning (in the tested atari-style games).
The OP is about the “deep learning sample efficiency gap”. But that’s not a deep learning paper. So I don’t think it provides any evidence here.
I think it provides evidence because it implies that a lot of the much ballyhooed human sample-efficiency is not in the learning algorithm, but the priors. If you provide informative priors, then ordinary known learning algorithms are capable of matching human performance; which is then mutually reinforcing with the stylized fact that when we create a problem which disables humans' informative priors but keep the problem's algorithmic difficulty fixed, their performance suddenly stops being so impressive (implying that the human learning algorithm is similar to ordinary known learning algorithms).
Fair point. I read §1 as a more general claim than one about deep learning, so I think it supports that part directly. §2 is less clear and requires some additional argument (e.g. llms approximate bayesian inference or something along those lines).
A common observation about deep learning is that it's wildly sample inefficient compared to humans. Deep learning systems appear to need much more real data or environment interaction to reach a given level of capability. A teenager can learn to drive in a few dozen hours; self-driving systems are trained for years on billions of miles of data. A human can become competitive at StarCraft II in well under a year of play, while AlphaStar required imitation learning from roughly 18 years of human games followed by 13,300 years of self-play to reach Grandmaster[1]. A 12-year-old has heard perhaps a hundred million words of language; a frontier LLM trains on tens of trillions of tokens. The gap is, on the face of it, enormous.
(From Warstadt et al. 2025)
(From Byrnes 2025)
What people take this to mean varies widely. Steven Byrnes appears to read the gap as evidence that current algorithms are far from what the brain is doing, such that much better algorithms must be waiting to be found. His guess is that human-level, human-speed AGI will require not a datacenter but "one consumer gaming GPU," even for training from scratch.[2] Yarrow Bouchard on the EA Forum, reads the same gap as evidence that AGI isn't close at all, precisely because nobody knows how to close it. They both agree that current algorithms are missing something fundamental, yet draw opposite conclusions about what that means for AGI risk and timelines.
In this post, I'll argue that their premise is mistaken. Most of the apparent inefficiency dissolves on closer inspection: apples-to-oranges comparisons between pretrained humans and from-scratch networks, hardware and data constraints that push deep learning toward small models trained on enormous corpora, the brain's apparent use of model-based RL of a kind we haven’t yet applied to LLMs, and priors installed by evolution. Real algorithmic gains in sample efficiency are available. But most mechanisms that plausibly close the gap point toward more total training and runtime compute than frontier systems currently use, not less.
My best guess is that the gap decomposes into several distinct factors each carrying different explanatory weight depending on the specific comparison at hand.
1. All about the priors
Sample efficient learning is in large part a property of the representations you arrive with, not of the learning algorithm itself. In Bayesian terms, your representations encode a prior over how the world is structured, and strong priors are what let you reach good posteriors from a handful of observations rather than astronomical amounts of data. Given a sufficiently rich representational substrate, new tasks can often be learned from a few examples. Given a flat prior over a vast hypothesis space, even simple tasks require an enormous amount of data.
a. Human priors
Most comparisons that yield shocking sample-efficiency ratios between humans and AIs are structurally unfair. They pit a system already shaped by evolution and years of perceptual, motor, causal, social, and linguistic learning against a randomly initialized network that must build many of those representations from scratch while also solving the task we are measuring. Humans don’t learn to drive in thirty hours, they are fine-tuned on driving after a roughly two decade-long pretraining run.
One can find evidence for the importance of pre-existing representations in Dubey et al. (2018). They took a platform-style game environment and deliberately removed cues that humans normally exploit: semantic cues, by rendering meaningful objects as uniform blocks; object/salience cues, by adding many distractor blocks; affordance cues, by filling the background with textures that obscured which surfaces and ladders were usable; similarity cues, by making functionally similar things look visually different; and gravity cues, by rotating the game 90 degrees. Individual ablations substantially slowed human players, and when the main object-related visual cues were masked together, completion time rose from under 2 minutes to over 20. Exploration became close to random, and many players reported falling back on rote memorization.
When first faced with such a game, a human immediately brings assumptions like: the controllable character is probably the humanoid-looking sprite, gravity points downward, falling off platforms is bad, ladders are for climbing, spikes and monsters are dangerous, and keys open doors. Dubey et al. show that degrading many of these cues makes humans much worse. Importantly, even in the hardest human-tested variants, people were still not reduced to blank-slate RL agents. They retained low-level visual, spatial-navigation, and action-control priors, plus abstract intuitions about object persistence, physics, and causality.
Their curiosity-driven RL agent, tested on a smaller related game, was largely unaffected by removing semantic, object, and affordance cues, since it was not exploiting those human priors in the first place, though it was slowed when visual similarity was removed.
A similar asymmetry runs through the text-token comparison. A 12-year-old has encountered something like 100 million words[3], roughly four orders of magnitude below a frontier pretraining corpus. But those words arrive embedded in a continuous multimodal stream: vision, ambient audio, proprioception, touch, vestibular signals, interoception. Counted as tokens in the sense a multimodal model would use, the non-text portion of that stream plausibly matches or exceeds frontier corpora (see Appendix). Most of what a word means to the child was learned nonverbally from that stream and then labeled,[4] while most of what a token means to a text-only LLM had to be triangulated from textual co-occurrence statistics alone.[5]
b. Good representations enable fast learning
A frontier LLM, shown a single example of a novel notation, will often pick it up. Shown an unfamiliar API, it can use it correctly after reading the documentation once. Shown a codebase's local conventions, it conforms within a session. The attention mechanism is able to change the activations, layer by layer, until they encode something that solves the new task.[6]
Given rich enough base representations, the in-context adaptation from a single forward pass can be enough. The ARC-AGI results of the past two years suggest that as those base representations get richer, the amount of data needed to pin down a novel abstract pattern drops toward something recognizable as human sample efficiency.
This is broadly the same story as the child learning a new word. The child has already learned to carve the world into objects, agents, actions, substances, events, and intentions. When they hear "zebra" pointed at a striped horse-shaped thing, the word latches onto a pre-existing slot. Most of the learning happened earlier, across years of pre-linguistic experience. The labeling is cheap because the carving is already done.
Deep learning's apparent sample inefficiency is often an artifact of the tabula rasa training regime, not a fundamental property of gradient-based deep learning. "Sample efficiency" is poorly defined without a specification of priors: the same architecture can look astronomically inefficient, trained from scratch, and remarkably efficient adapting from a strong base, for example via in-context learning or using a LoRA. This does not dissolve the whole gap, but it explains many of the most extreme examples. The following sections ask what remains once these comparison artifacts are separated out.
2. Model-based RL
In addition to the data mix and priors, there are also algorithmic factors that separate current frontier LLMs from the brain. Almost all the compute going into current LLMs is spent on pretraining and on RLVR — reinforcement learning with verifiable rewards in math, code, and similar domains where a correct answer can easily be checked programmatically. What's missing, and what the brain probably leverages in some form[7], is model-based reinforcement learning: learning a world model that can be used to plan over candidate actions, predict their outcomes, and bootstrap value estimates from imagined trajectories. In any domain where real experiences and reward signals aren't cheap to get, this is the natural mechanism for turning a small number of real interactions into a large amount of learning signal.[8]
a. Dreamer
The Dreamer research is probably the cleanest demonstration. DreamerV3 (Hafner et al., 2023) trains a recurrent latent world model from raw pixels and vector observations, and uses it to train an actor-critic on trajectories imagined inside that model. The actor is trained to choose actions that score well under these imagined futures, while the critic learns to evaluate returns from both imagined rollouts and replayed experience. With a single fixed set of hyperparameters it matches or beats specialized methods across 150+ tasks, and was the first system to collect diamonds in Minecraft from scratch without human demonstrations or curriculum, a task requiring sparse-reward exploration over thousands of sequential decisions.
In their follow up work, Dreamer 4 (Hafner, Yan & Lillicrap, 2025), they scale this approach to a large transformer-based video world model. It learns a high-resolution Minecraft simulator using 2.5K-hour VPT contractor dataset (raw video and mouse/keyboard actions). Leveraging the dataset's event annotations for rewards, the agent improves its task-conditioned policy via reinforcement learning entirely inside imagined rollouts, requiring zero online environment interaction. As a result, Dreamer 4 is the first agent to obtain Minecraft diamonds purely from offline data, substantially outperforming prior VPT and behavioral-cloning baselines which used 100x more data. Additionally, the paper shows that Dreamer 4 does not need action labels for most of its video data. Given all 2.5K hours of Minecraft video but only 100 hours with mouse and keyboard labels, it still learns most of the action-conditioned prediction ability of a fully labeled model, suggesting that future world models could learn broad dynamics from unlabeled video and use smaller paired datasets to ground actions.
The Dreamer line of work demonstrates that self-supervised world-model training can produce large gains in sample-efficient learning. Once a reusable model of environment dynamics has been learned, downstream RL can extract much more from limited rewards or demonstrations by training on imagined trajectories, rather than requiring new environment interaction for every update. It is thereby possible to learn to play Minecraft entirely offline, without ever directly interacting with the environment.
b. EfficientZero V2
A complementary line of work is EfficientZero V2 (Wang et al., 2024), which combines learned world models with explicit planning. It extends EfficientZero[9], a MuZero descendant that learns a latent dynamics model and plans over it with MCTS, to continuous control domains, replacing standard MCTS with a sampling-based Gumbel search using sequential halving. This search procedure samples a finite set of candidate actions and allocates simulations toward the most promising ones, aiming to obtain policy improvement from a small simulation budget. EZ-V2 also re-analyzes old replayed experience with its current model and policy, letting the agent extract fresher learning targets from data collected earlier in training. Thus, it improves sample efficiency by using the world model both to imagine consequences before acting and to get more learning signal out of past interactions.
On Atari 100k, which caps the agent at 100,000 environment steps, or 400k Atari frames under action repeat 4, roughly 2 hours of real-time gameplay, EZ-V2 reaches a normalized mean of 2.43 and normalized median of 1.29, both above the human baseline. The paper thus claims "super-human performance within just 2 hours of real-time gameplay".
The result is not uniform across games. EZ-V2 and other strong deep RL agents still struggle badly on some long-horizon, sparse-reward, exploration-heavy games. This pattern is probably best explained with the point in §1 (see also §4b): model-based planning helps extract more from limited experience, but humans bring preexisting semantic and exploration priors, whereas the RL agents have to infer complex game mechanics from scratch under sparse rewards.[10]
LLM post-training pipelines have nothing structurally analogous. RLHF and RLVR are model-free: they update the policy from sampled real trajectories, with no learned model of the environment to plan or imagine inside.[11] Whatever fraction of the human–deep-learning gap is genuinely algorithmic rather than an artifact of priors or comparison setup, plausibly shrinks further once frontier systems learn world models over their action space and plan inside them during training and at inference.
Some analogous techniques have seen some limited applications during frontier LLM training for narrow domains[12] but nobody has demonstrated a general world model rich enough to train and plan inside at the scale and domain-generality LLMs operate in, and AI labs have focused their RL work on areas where the environment and verification step are cheaper to compute directly rather than in a learned world model.
A solution to true continual learning on harder to simulate and verify domains will likely require both a model-based RL architecture and the kind of context-into-weights compression techniques I described in a previous post. Such a system might be quite sample-efficient, and able to learn continually from relatively few real interactions, but only by spending far more computation per interaction on world-model updates, imagined rollouts, planning/search, and replay.
3. Other Low-Hanging Fruit
Even without brain-like model-based RL, frontier training has not been optimized primarily for extracting maximal information from each real example. Internet-scale text is abundant, and the economically optimal strategy has usually been to train models on ever more unique tokens rather than to squeeze maximal learning out of each example. That leaves a lot of plausible low-hanging fruit. Even just naively repeating the same data for up to 4 epochs can reduce loss on a held out test set almost as well as a single epoch on 4x more data, and yet it is usually still more economical to just use more unique data. But more sophisticated approaches are also possible. Here, I will describe two such approaches.
a. Training Language Models via Neural Cellular Automata
Lee et al. (2026) give a clean example of this. Before ordinary language training, they pre-pre-train a Llama-style transformer on trajectories generated by Neural Cellular Automata (NCA): synthetic 2D grid dynamics where each sequence is produced by a different randomly sampled local update rule. They filter trajectories by gzip compressibility, using compression ratio as a rough proxy for structural complexity, excluding both trivial patterns and maximally chaotic noise. Successful next-token prediction then requires inferring the rule from context and applying it forward, rather than learning word meanings or memorizing facts. With only ~160M NCA tokens, followed by normal training on web text, math, or code, they get up to ~6% lower perplexity and ~1.4–1.6× faster convergence than training from scratch. The striking result is that NCA pre-pre-training also beats pre-pre-training on ordinary web text from the Colossal Clean Crawled Corpus (C4), even when the C4 baseline gets 10× more tokens — 1.6B C4 tokens versus ~160M NCA tokens.
Their ablations suggest that much of the transferable benefit lives in the attention layers: when the attention weights are reinitialized, most of the gain disappears. NCA pre-pre-training appears to train the model to infer hidden rules from context, track dependencies over many steps, and apply those inferred rules forward. It instills useful priors for later language learning that can be installed using no “real” data at all, just synthetic processes with the right abstract structure.
b. Synthetic bootstrapped pretraining
Yang et al. (2025) demonstrate another way to get more value out of a fixed pretraining corpus. Synthetic Bootstrapped Pretraining (SBP) works in three steps: it finds semantically similar document pairs within the corpus, trains a conditional synthesizer model to generate one document from the other, and then applies that model back to the corpus to produce synthetic documents that are mixed into pretraining. Unlike standard synthetic-data distillation, the generator is trained on the pretraining data itself rather than relying on a stronger external teacher model, though their implementation does use an external embedding model to find similar documents. In final pretraining runs matched by token budget, 3B- and 6B-parameter models trained on up to 1T tokens beat a data repetition baseline, and recover up to roughly 60% of the average QA improvement achieved by an oracle with 20x more unique data.
The authors’ story is that ordinary next-token pretraining leaves some structure in the corpus unused. It treats documents as i.i.d. samples and directly models the correlations among tokens inside each document, but it does not directly model the fact that different documents can instantiate the same underlying idea. SBP adds this missing signal by training on pairs of related documents: the synthesizer has to infer what the first document is about at a more abstract level, and then produce another document built around the same latent concept. The outputs of the synthesizer preserve the topic while changing the angle, genre, specificity, or rhetorical frame.
SBP extracts more from the same corpus by spending extra computation on embedding/search, synthesizer training, and synthetic-data generation. It is another example of possible sample-efficiency gains but at the cost of doing more computation per real example.
c. Algorithmic progress and the Pareto frontier
Both examples contribute to closing the sample-efficiency gap, and both continue the kind of ordinary algorithmic progress we’ve seen over the past few years[13]. Pareto improvements on both sample and compute efficiency over the simple "scale up unique tokens" baseline do exist. NCA pre-pre-training is one such example: it achieves both lower perplexity and faster convergence than throwing 10× more C4 tokens at the model, so it improves sample and compute efficiency simultaneously.
But as the field exhausts these easy wins and pushes toward the algorithmic Pareto frontier, sample-efficiency gains will increasingly need to be paid for with compute. SBP is one such example: it extracts more learning signal from the same corpus, but only by spending non-trivial extra compute on embedding/search, synthesizer training, and synthetic data generation. The picture matches §2: real algorithmic headroom is available, but most of it buys sample efficiency by spending more compute per real example.
4. Evolution, optimizers, and hard-coded reward functions in the cortex
A common explanation for human sample efficiency is "evolution," but on its own this just relocates the question. Whatever closes the gap has to be encoded in roughly 3 billion base pairs of genome, only a fraction of which specifies anything about the brain at all, and it has to be doing some specific job. A few candidates have already appeared in earlier sections: the rich multimodal representational substrate that lifetime experience accumulates into, structural inductive biases, and the model-based RL machinery itself. That leaves two further candidates worth examining: the optimization algorithm the brain runs, and the hardwired reward functions that shape what lifetime learning ends up optimizing for.
a. Optimizer
The brain's learning rule is not known, but it almost certainly isn't gradient backpropagation. Backprop has several features that look biologically awkward: feedback signals that behave like a transpose of the forward weights, cleanly separated forward and backward phases, globally coordinated error propagation, and synchronized updates across many layers. None of these have an obvious analog in the brain, and a substantial computational-neuroscience literature is devoted to finding credit-assignment rules that don't require them.[14]
But that doesn't mean the brain uses a much better optimizer than gradient descent. The biologically motivated alternatives are designed around the constraints of wetware: local, noisy, low-precision, asynchronous, with limited global communication. GPUs face none of those constraints, and a learning rule built for biology is unlikely to have an advantage on GPU hardware. Biological plausibility tends to come at a cost. Many need to run the network forward repeatedly before each update, maintain helper networks alongside the main one, or simply scale less well. They're interesting as biology and as starting points for neuromorphic hardware, but on current evidence they don't match backprop with Adam on frontier ML workloads.
There may still be some remaining headroom in optimizer design within the gradient-based paradigm. But the design space has been thoroughly searched: there was a long stretch where it seemed like every other ML thesis proposed a new optimizer beating Adam on some narrow benchmark, and yet over a decade later Adam continues to be widely used at the frontier. Recent innovations[15] such as Muon do demonstrate some real improvements are still possible, but the optimizer seems unlikely to be the missing ingredient behind the orders-of-magnitude gap in sample efficiency.
b. Reward functions
One other hypothesis, recently articulated by Adam Marblestone on Dwarkesh, is that human sample efficiency might be explained by genome-encoded reward functions for lifetime RL. The hardwired set of innate drives and primary rewards (hunger, pain, social signals, curiosity, surprise) shapes what lifetime RL ends up optimizing for, and may help the human brain extract more useful learning signal from its lifetime data.
The best evidence for this comes from curiosity and novelty rewards. Many classic deep-RL failures — Montezuma's Revenge, Private Eye, Pitfall — are sparse-reward games where useful exploration is highly nonrandom. One solution is to bring in pretrained representations and background knowledge, as in §1, and also demonstrated by recent frontier LLMs beating Pokémon Red. The classic RL response however is using curiosity/novelty rewards. It is such episodic and lifelong novelty signals that the Never Give Up/Agent57 RL agents leveraged to outperform the standard human benchmark on all 57 Atari games, including Montezuma's Revenge. Such curiosity signals have also been shown to be useful to prioritize replay data in model-based RL algorithms such as DreamerV3.
So reward functions are probably a real part of the sample-efficiency story. But evolution did not arrive at the human reward stack for free. The drives we inherit are the product of hundreds of millions of years of selection, with each organism's lifetime serving as one rollout in an outer optimization process whose objective was reproductive success. To recreate comparable machinery in AI, we need some substitute, via hand design, meta-learning, evolutionary search, learned reward models, or a mixture. Some components such as curiosity drives may be compact and rediscoverable, but the more ecologically tuned and idiosyncratic parts are not a free lunch, and would probably have to be relearned at some computational cost.
Byrnes himself seems to be skeptical that reward functions are a large factor. He has written extensively about reward function design as a research direction in the context of alignment, but in his account, the sample-efficiency and general capability gap between human brains and current LLMs mostly comes down to an undiscovered model-based RL paradigm rather than to the rewards.
5. Size matters
a. Data efficiency and scaling laws
There’s a further factor that may help explain the brain’s sample efficiency: its sheer size. The human brain is estimated to have around ~150 trillion synapses.[16] A naive comparison to the rumored size of one of the largest frontier models,[17] Claude Mythos, equating synapse with parameter count,[18] would give the brain roughly a 15x size advantage. This matters because larger models generally need less data to reach a given target loss. Hoffmann et al.'s (2022) "Chinchilla" paper, replicated and corrected by Besiroglu et al. (2024), fits final pretraining loss as a function of parameter count N and training tokens D:
The Chinchilla approach assumes compute is the binding constraint and asks how to split it between parameters and data. Biology faced a different binding constraint: data, capped by lifespan, with parameter count more easily scaled at metabolic cost. The result is that the brain was pushed to a wildly off-Chinchilla operating point: enormous N, tiny D. That allocation is a terrible way to minimize loss given a fixed total compute budget. But under a lifespan-limited data budget, the best strategy is to spend metabolic resources on representational capacity, built-in structure, and learning mechanisms that squeeze more value out of each observation. The brain looks sample-efficient in part because it is an extremely sparse, massively over-parameterized network running a learning procedure tuned for exactly that regime.
b. Why it matters in particular in the case of self-driving cars
The size factor is probably a dominant driver of apparent data inefficiency in the self-driving case. Waymo has now driven ~200 million autonomous miles on public roads, and Tesla's customer fleet has recently reached 10B miles driven with FSD supervised, many human lifetimes' worth of driving experience. Not only that, both companies actually already run something close to the model-based-RL story sketched in §2, at least during training. Waymo's recently announced World Model is a Genie-3-derived generative simulator that produces sensor-aligned camera and lidar observations, which Waymo uses to train its Driver on billions of simulated miles. Tesla similarly trains FSD inside its own world model generated from fleet video. Whatever data efficiency is being left on the table here, it is not the absence of a learned world model to train inside.
What is probably a binding constraint is parameter count of the policy that ships on the car. The world models themselves can be large and run in datacenters during training, but the network that actually steers the vehicle has to fit on the vehicle. Frontier LLMs are typically served on something like 8×H200 (~1,128 GB of HBM); Tesla's deployed Hardware 4, by contrast, has 16 GB of RAM. That is room for roughly 32B 4-bit parameters before any allowance for activations or the rest of the perception and planning stack. By naive comparison of the raw parameter count to synapses, that puts the size of the onboard model at more than three orders of magnitude below the brain of the human it is supposed to eventually outperform.[19]
If self-driving follows a Chinchilla-style scaling law, this is exactly backwards from the human regime: a small, hardware-fixed N forced to compensate with very large D. For any given onboard compute platform, there is a ceiling on the reliability Tesla and Waymo can achieve. More miles, better architectures, and better simulators push the system toward that ceiling, and are responsible for some of the impressive improvements in self-driving capability in recent years. But truly solving self-driving might still require a hardware upgrade, not just more data or better algorithms.
6. Implications
a. On brain in a box in a basement
While Byrnes’ broader brain in a box in a basement thesis rests on several other premises about neuroscience (e.g. cortical uniformity) and algorithmic paradigms that are beyond the scope of this post, the brain’s sample efficiency does not provide good evidence for the existence of a major undiscovered algorithmic regime achieving orders of magnitude gains in both compute and sample efficiency simultaneously.
He may have ideas for much better model-based RL algorithms that would be infohazardous to share publicly, but the factors surveyed in sections 1-5 collectively look adequate to explain the gap. None of these point toward consumer-hardware training budgets and several point the other way.
Existing model-based RL algorithms do demonstrate impressive sample efficiency, but in tightly bounded environments. Scaling that style of algorithm into a system that learns language, physics, social cognition, and tool use within a consumer-hardware training budget is a tall order. The world is large and complex. And while the core of intelligence may be simple, and the code to train an AGI may well fit in a few hundred lines of PyTorch code, the compute budget to train such an AGI appears unlikely to be within at least 3 orders of magnitude of the best consumer GPU today.
One important implication is that compute governance is unlikely to become irrelevant by the discovery of much more compute-efficient algorithms. This applies most directly to training compute. I’m a lot less confident about inference. A trained model can be much smaller than the system that produced it, and there are strong economic incentives to overtrain in the opposite direction from the brain's regime, yielding small, deployable policies, with little spare capacity. So an AGI-level model might plausibly fit on a consumer GPU at inference time, even if its training run did not. Such a deployed policy would still likely be unable to bootstrap itself dramatically further on the same hardware, since the world-model updates, replay, and planning needed for serious open-ended continual learning remain compute-intensive.
That said, Byrnes is right that model-based RL is a missing piece in the current frontier-LLM stack, and it matters most in the regimes where current RLVR pipelines struggle: tasks where rewards aren't cheaply verifiable, where real interaction data is expensive, and where the agent needs to keep learning after deployment. The alignment community should pay more attention to this research direction. The safety properties of a system that plans and learns inside a learned world model are meaningfully different from those of one that doesn't, and if model-based RL architectures end up on the critical path to transformative AI, we want the conceptual groundwork in place well before they are deployed at scale. Reward function design appears to be one important and promising research direction.
b. On sample efficiency being an unsolved research problem
The evidence also does not support Bouchard's opposite conclusion that current deep learning is missing some truly major ingredient, and that AGI is therefore far away. The most dramatic sample-efficiency comparisons are often structurally unfair, pitting pretrained humans against randomly initialized networks, text-only models against children embedded in a rich multimodal stream, or small deployed policies against human brains with vastly larger effective capacity. Additionally, frontier systems have not been under strong economic pressure to maximize sample efficiency. Much of the apparent sample inefficiency of deep learning is a byproduct of how we train, deploy, and compare these systems.
Once these factors are pulled apart, the remaining gap largely comes down to a few missing algorithmic pieces, such as world models, reward models, replay, synthetic data, and continual learning. We have a rough idea of what the remedies look like, and the remaining bottleneck appears to be mostly about scaling and figuring out how to integrate these missing components in open-ended domains, not about finding some wholly new paradigm.
Because these components generally cost compute to integrate and scale, progress is likely to remain uneven. That unevenness may carry some safety upside, such as giving us superhuman coders well before agents with persistent episodic memory. But none of it is a durable barrier to automation or to dangerous capabilities. Deep learning can remain less sample-efficient than humans and still be extremely disruptive.
Even if the de facto data efficiency stays 100x below humans indefinitely, this does not prevent rapid job automation. Once a model is trained, the marginal cost of a second instance is just the compute to run it, which can easily sit well below the salary of the human it replaces. Human data efficiency only preserves a defensible economic niche where the cost of automating the work, including data collection, training, and inference, exceeds the wage bill being displaced, and the task requires adapting to new situations faster than models can be trained to do the work from scratch, or develop rich enough representations to learn to perform the work in-context from more limited samples.
Conclusion
Most of the apparent sample-efficiency gap dissolves under scrutiny. It comes from pitting pretrained humans against from-scratch networks, text-only models against children embedded in a multimodal stream, and small deployed policies against much larger brains. What remains can mostly be closed through familiar means like reward functions, world models, replay, synthetic data, multimodal training, larger models, and better continual learning. These typically pay for sample efficiency with compute. So the gap gives us neither reason to expect AGI trained on consumer hardware, nor reason to think deep learning is missing some major ingredient.
Appendix: How Much Multimodal Data Does a Child Actually Receive?
One version of this estimate comes from Yann LeCun's 2024 Harvard slides: 2 million optic nerve fibers × 10 bytes/sec × 16,000 wake hours over 4 years ≈ 1.15 PB of visual data, against 10¹³ tokens × 2 bytes ≈ 20 TB of text, or a ~57× advantage to a 4-year-old. Extended to age 12 with the same assumptions, the visual figure scales to ~3.45 PB and the gap widens to ~170×. Three of the estimates in this calculation deserve scrutiny.
Per-fiber bandwidth. Koch et al. (2006) (h/t Byrnes) measure information rates of guinea-pig retinal ganglion cells under naturalistic stimuli and, assuming roughly independent fibers, estimate the human retina's aggregate output at ~10 Mbit/s from ~1M ganglion cells, i.e. ~10 bits/s/fiber on average, not 10 bytes/s.
Fiber count and binocular redundancy. Pawar et al. 2024 puts the human optic nerve at ~1M axons per eye, so 2 × 10⁶ is the bilateral total. But the two eyes carry heavily overlapping fields, so I will use a 1.2x unique information multiplier across both eyes, not 2×.
Frontier corpus size. 2026 leading open model training corpora are now up to 1.5-4 × 10¹³ tokens (Llama 3.1: 15T; DeepSeek-V3: 14.8T; Qwen 3: 36T; Llama 4 Scout: 40T), instead of LeCun's 10¹³.
For the 12-year extrapolation below, I round up to 2 × 108 waking seconds, rather than the 1.73 × 108 seconds obtained by naively tripling LeCun’s 4-year wake-time assumption, to account for children being awake more hours per day as they get older.
Visual input over 12 years
LeCun's 2024 figure
Corrected
Optic nerve fibers (per eye)
1 × 10⁶
~1 × 10⁶
Bandwidth per fiber
80 bits/s
~10 bits/s
Binocular adjustment
2x
1.2×
Effective info rate
1.6 × 10⁸ bits/s
~1.2 × 10⁷ bits/s
Waking seconds, ages 0–12
~2 × 10⁸
~2 × 10⁸
Total over 12 years
~3.2 × 1016 bits (~4 PB)
~2.4 × 1015 bits (~300 TB)
Frontier text corpus, 2026
LeCun's 2024 figure
2026 open frontier
Tokens
10¹³
4 × 10¹³
Bits/token
16 (storage)
16 storage / ~4 entropy*
Total, raw storage
1.6 × 1014 bits (~20 TB)
6.4 × 1014 bits (~80 TB)
Total, info content
~8 × 10¹³ bits
~1.6 × 1014 bits
Visual / text ratios at age 12
Visual / text
LeCun's numbers throughout
~170×
LeCun visual + 2026 frontier text
~43×
Koch-grounded retina + 2026 raw storage
~4×
Koch-grounded retina + 2026 info content
~15×
*Assuming tokenizer with 65k vocab, 1 token ≈ 4 characters, and 1 bit of entropy per character.
Best guess: in information-theoretic terms, raw retinal output to a 12-year-old exceeds a 2026-frontier text corpus by roughly 15×. Adding audio, touch, proprioception, and vestibular streams might add another ~2×. So the multimodal child's lifetime stream sits around one OOM above frontier text corpora in retinal-output informational bits, after the substantial compression already implicit in Koch et al., but before accounting for additional longer-timescale redundancy in visual experience. The informational gap appears to be roughly within one OOM.
AlphaStar’s paper (no paywall) reports supervised pretraining on 971,000 human games. Since it describes StarCraft II games as lasting roughly 10 minutes, this corresponds to 971,000×10 minutes ≈18.5 replay-years of human games.
It does not directly report self-play game-years. However, its Methods state that the league used 12 actor-learner setups, trained over 44 days, each learner processing about 50,000 agent steps/s, with received data replayed twice; interpreting this as about 25,000 newly generated agent steps/s per setup, and using Extended Data Fig. 2’s average agent-step interval of about 369 ms, gives 12×25,000×0.369×44×86,400≈4.2×1011 seconds of generated agent experience, or about 13,300 game-years.
“Instead, my guess (based largely on lots of opinions about exactly what computations the human brain is doing and how) is that human-level human-speed AGI will require not a datacenter, but rather something like one consumer gaming GPU—and not just for inference, but even for training from scratch.” (Byrnes 2025)
Gilkerson et al. (2017) estimate roughly a few million adult words/year for 2–48-month-olds; a naive extrapolation to age 12 gives an order of magnitude of tens of millions of words; the BabyLM challenge rounds to 100M by age 13.
A common hypothesis is that humans are highly sample efficient because they receive curated curricula. I doubt this is an important factor. Most of what a child learns is picked up with nothing resembling a curriculum. Adult language learners also reach fluency faster via immersion than classroom instruction. And in the BabyLM Challenge, strategies relying on curriculum learning showed little improvement.
Given the text-dominated training mix and objective of next-token prediction, even 2022-era LMs are already better than humans at it.
von Oswald et al. (2023) hypothesized that self-attention transforms activations in a way approximately equivalent to gradient descent on an implicit loss, though this specific mechanistic claim is contested. End-to-End Test-Time Training (Tandon et al. 2025), though, has shown that with a pre-training method leveraging gradient-of-gradients, a similar effect to self-attention in-context learning can also be achieved directly via test-time gradient descent.
See Hippocampal replay.
See also LeCun, A Path Towards Autonomous Machine Intelligence (2022), for a case along similar lines.
See here for a LW explainer of the original EfficientZero algorithm.
EZ-V2 beats the human score on 15 of 26 games (58%). On games where model-based RL pulls ahead it often pulls far ahead — Asterix 62k vs 8.5k, Crazy Climber 112k vs 36k, Demon Attack 23k vs 2k — and on games where it struggles it struggles catastrophically: Private Eye 100 vs ~70,000, Seaquest 2k vs 42k, Alien 1.5k vs 7.1k. The normalized mean is dragged up by the blowouts. On 9 of the 26 games (~35%) — Alien, Amidar, BattleZone, Freeway, Frostbite, Hero, Ms. Pac-Man, Private Eye, and Seaquest — the human baseline still beats every deep RL algorithm in the table. These are, fairly consistently, games requiring long-horizon credit assignment under sparse reward (Private Eye, Seaquest, Frostbite), systematic exploration of large maze-like state spaces (Alien, Amidar, Ms. Pac-Man, Hero), or patient timing against a slow environment (Freeway). The comfortable wins for deep RL are mostly reactive arcade games with dense reward signals.
LLMs do learn an implicit world model during pre-training, but it isn't structured for the kind of use model-based RL make of one. It can't be cleanly queried during training to generate imagined rollouts, and post-training further entangles its representations with those of the policy and persona. Chain-of-thought training may be a partial workaround during inference. By generating intermediate text, the model effectively queries its own implicit world model, recovering some of the benefits of model-based planning.
Architectures in which the world model is kept separate from the policy and not updated by RL gradients, but instead trained only by self-supervised learning, might have better safety properties.
The main domain “narrow world model” simulations have been applied to is to simulate user interactions. Public examples include Google/DeepMind’s AMIE medical self-play, Moonshot’s Kimi K2 agentic data pipeline with synthetic user personas and tool-use trajectories, and Salesforce’s APIGen-MT.
See also Byrnes’ The nature of LLM algorithmic progress (v2).
Candidate biologically plausible credit-assignment schemes include predictive coding (Whittington & Bogacz, 2017; see also Millidge et al. 2020, 2021, 2022 and Millidge 2023 for an informal retrospective); equilibrium propagation (Scellier & Bengio, 2017); and target propagation (Bengio, 2014, Lee et al., 2015). These relax some of backprop's biological implausibilities, but usually pay with settling dynamics, extra inverse machinery, or weaker scaling. The literature is therefore better read as evidence for possible biological credit assignment than for a GPU-superior optimizer.
Recent examples of newer more sample efficient optimizers include Muon (Jordan, 2024), which orthogonalizes gradient updates via a Newton-Schulz iteration, and M3 (Behrouz et al., 2025), the optimizer described in the Nested Learning paper I discussed in my continual learning post, which builds on Muon with multi-scale momentum and Adam-like normalization, improving effective sample efficiency at the cost of more memory and compute per step.
There’s some uncertainty about the true number in the literature, so relying on the Wikipedia consensus. The number is probably higher during infancy.
See here for some additional parameter count estimates of frontier models, which make me think that the 10T estimate for Mythos is quite plausible.
The parameter to synapse equivalence in terms of useful computation is highly uncertain. The synapse count might be an underestimate for how many parameters equivalent the brain really has. Beniaguev et al. (2021) found that a detailed biophysical model of a cortical pyramidal neuron was well approximated by a temporally convolutional deep neural network with 5 to 8 layers, suggesting that treating each biological neuron as a simple artificial neuron might miss real computation happening within dendritic trees. That said, this result has important caveats (see this EAF discussion for more). The study did not run the reverse comparison, so we do not know whether comparable overhead applies going from artificial to biological. The per-neuron overhead might also not scale linearly for larger networks. Furthermore, much of the simulated complexity may not be functionally useful. As Byrnes argues (1, 2), biological systems are typically full of dynamics that are not load-bearing for the system's useful function, much like how a real transistor is described by a 22-parameter physics model, even though its useful computational function is just an ON/OFF switch. I use a 1-to-1 synapse-to-parameter equivalence as a probably conservative baseline, but the real magnitude is unclear.
This three-OOM figure should be read loosely. CNN-style weight sharing lets the onboard net avoid replicating visual feature detectors across space the way the visual cortex must, shrinking the effective gap. Correcting for it probably has only a small effect on the comparison, since the early visual cortex is only a few percent of the brain's synapses.