I think (hope?) most people already realize NHST is terrible. I would be much more interested in hearing if there were an equally-easy-to-use alternative without any baggage (preferably not requiring priors?)
NHST has been taught as The Method Of Science to lots of students. I remember setting these up explicitly in science class. I expect it will remain in the fabric of any given quantitative field until removed with force.
If you're right that that's how science works then that should make you distrustful of science. If they deserve any credibility, scientists must have some process by which they drop bad truth-finding methods instead of repeating them out of blind tradition. Do you believe scientific results?
If they deserve any credibility, scientists must have some process by which they drop bad truth-finding methods instead of repeating them out of blind tradition.
Plenty of otherwise-good science is done based on poor statistics. Keep in mind, there are tons and tons of working scientists, and they're already pretty busy just trying to understand the content of their fields. Many are likely to view improved statistical methods as an unneeded step in getting a paper published. Others are likely to view overthrowing NHST as a good idea, but not something that they themselves have the time or energy to do. Some might repeat it out of "blind tradition" -- but keep in mind that the "blind tradition" is an expensive-to-move Schelling point in a very complex system.
I do expect that serious scientific fields will, eventually, throw out NHST in favor of more fundamentally-sound statistical analyses. But, like any social change, it'll probably take decades at least.
Do you believe scientific results?
Unconditionally? No, and neither should you. Beliefs don't work that way.
If a scientific paper gives a fundamentally-sound statistical analysis of the effect it purports to prove, I'll give it more credence than a paper rejecting the null hypothesis at p < 0.05. On the other hand, a study rejecting the null hypothesis at p < 0.05 is going to provide far more useful information than a small collection of anecdotes, and both are probably better than my personal intuition in a field I have no experience with.
Unconditionally? No, and neither should you. Beliefs don't work that way.
I should have said, "do you believe any scientific results?"
If a scientific paper gives a fundamentally-sound statistical analysis of the effect it purports to prove, I'll give it more credence than a paper rejecting the null hypothesis at p < 0.05. On the other hand, a study rejecting the null hypothesis at p < 0.05 is going to provide far more useful information than a small collection of anecdotes, and both are probably better than my personal intuition in a field I have no experience with.
To clarify, I wasn't saying that maybe you shouldn't believe scientific results because they use NHST specifically. I meant that if you think that scientists tend to stick with bad methods for decades then NHST probably isn't the only bad method they're using.
As you say though, NHST is helpful in many cases even if other methods might be more helpful. So I guess it doesn't say anything that awful about the way science works.
Confidence intervals.
p<.05 means that the null hypothesis is excluded from the 95% confidence interval. Thus there is no political cost and every p-value recipe is a fragment of an existing confidence interval recipe.
added: also, the maximum likelihood estimate is a single number that is closely related to confidence intervals, but I don't know if is sufficiently well-known among statistically-ignorant scientists to avoid controversy.
Can you give me a concrete course of action to take when I am writing a paper reporting my results? Suppose I have created two versions of a website, and timed 30 people completing a task on each web site. The people on the second website were faster. I want my readers to believe that this wasn't merely a statistical coincidence. Normally, I would do a t-test to show this. What are you proposing I do instead? I don't want a generalization like "use Bayesian statistics, " but a concrete example of how one would test the data and report it in a paper.
Credible intervals do not make worst case guarantees, but average case guarantees (given your prior). There is nothing wrong with confidence intervals as a worst case guarantee technique. To grandparent: I wouldn't take statistical methodology advice from lesswrong. If you really need such advice, ask a smart frequentist and a smart bayesian.
Perhaps you would suggest showing the histograms of completion times on each site, along with the 95% confidence error bars?
Presumably not actually 95%, but, as gwern said, a threshold based on the cost of false positives.
Yes, in this case you could keep using p-values (if you really wanted to...), but with reference to the value of, say, each customer. (This is what I meant by setting the threshold with respect to decision theory.) If the goal is to use on a site making millions of dollars*, 0.01 may be too loose a threshold, but if he's just messing with his personal site to help readers, a p-value like 0.10 may be perfectly acceptable.
* If the results were that important, I think there'd be better approaches than a once-off a/b test. Adaptive multi-armed bandit algorithms sound really cool from what I've read of them.
I'd suggest more of a scattergram than a histogram; superimposing 95% CIs would then cover the exploratory data/visualization & confidence intervals. Combine that with an effect size and one has made a good start.
This might be a good place to not that full Bayesianism is getting easier to practice in statistics. Doing fully Bayesian analysis has been tough for many models because it's computationally difficult since standard MCMC methods often don't scale that well, so you can only fit models with few parameters.
However, there are at least two statistical libraries STAN and PyMC3 (which I help out with) which implement Hamiltonian Monte Carlo (which scales well) and provide an easy language for model building. This allows you to fit relatively complex models, without thinking too much about how to do it.
Join the revolution!
"Power failure: why small sample size undermines the reliability of neuroscience", Button et al 2013:
A study with low statistical power has a reduced chance of detecting a true effect, but it is less well appreciated that low power also reduces the likelihood that a statistically significant result reflects a true effect. Here, we show that the average statistical power of studies in the neurosciences is very low. The consequences of this include overestimates of effect size and low reproducibility of results. There are also ethical dimensions to this problem, as unreliable research is inefficient and wasteful. Improving reproducibility in neuroscience is a key priority and requires attention to well-established but often ignored methodological principles.
Learned a new term:
Proteus phenomenon: The Proteus phenomenon refers to the situation in which the first published study is often the most biased towards an extreme result (the winner’s curse). Subsequent replication studies tend to be less biased towards the extreme, often finding evidence of smaller effects or even contradicting the findings from the initial study.
One of the interesting, and still counter-intuitive to me, aspects of power/beta is how it also changes the number of fake findings; typically, people think that must be governed by the p-value or alpha ("an alpha of 0.05 means that of the positive findings only 1 in 20 will be falsely thrown up by chance!"), but no:
For example, suppose that we work in a scientific field in which one in five of the effects we test are expected to be truly non-null (that is, R = 1 / (5 – 1) = 0.25) and that we claim to have discovered an effect when we reach p < 0.05; if our studies have 20% power, then PPV = 0.20 × 0.25 / (0.20 × 0.25 + 0.05) = 0.05 / 0.10 = 0.50; that is, only half of our claims for discoveries will be correct. If our studies have 80% power, then PPV = 0.80 × 0.25 / (0.80 × 0.25 + 0.05) = 0.20 / 0.25 = 0.80; that is, 80% of our claims for discoveries will be correct.
Third, even when an underpowered study discovers a true effect, it is likely that the estimate of the magnitude of that effect provided by that study will be exaggerated. This effect inflation is often referred to as the ‘winner’s curse’13 and is likely to occur whenever claims of discovery are based on thresholds of statistical significance (for example, p < 0.05) or other selection filters (for example, a Bayes factor better than a given value or a false-discovery rate below a given value). Effect inflation is worst for small, low-powered studies, which can only detect effects that happen to be large. If, for example, the true effect is medium-sized, only those small studies that, by chance, overestimate the magnitude of the effect will pass the threshold for discovery. To illustrate the winner’s curse, suppose that an association truly exists with an effect size that is equivalent to an odds ratio of 1.20, and we are trying to discover it by performing a small (that is, under-powered) study. Suppose also that our study only has the power to detect an odds ratio of 1.20 on average 20% of the time. The results of any study are subject to sampling variation and random error in the measurements of the variables and outcomes of interest. Therefore, on average, our small study will find an odds ratio of 1.20 but, because of random errors, our study may in fact find an odds ratio smaller than 1.20 (for example, 1.00) or an odds ratio larger than 1.20 (for example, 1.60). Odds ratios of 1.00 or 1.20 will not reach statistical significance because of the small sample size. We can only claim the association as nominally significant in the third case, where random error creates an odds ratio of 1.60. The winner’s curse means, therefore, that the ‘lucky’ scientist who makes the discovery in a small study is cursed by finding an inflated effect.
Publication bias and selective reporting of outcomes and analyses are also more likely to affect smaller, under-powered studies17. Indeed, investigations into publication bias often examine whether small studies yield different results than larger ones18. Smaller studies more readily disappear into a file drawer than very large studies that are widely known and visible, and the results of which are eagerly anticipated (although this correlation is far from perfect). A ‘negative’ result in a high-powered study cannot be explained away as being due to low power 19,20, and thus reviewers and editors may be more willing to publish it, whereas they more easily reject a small ‘negative study as being inconclusive or uninformative21. The protocols of large studies are also more likely to have been registered or otherwise made publicly available, so that deviations in the analysis plans and choice of outcomes may become obvious more easily. Small studies, conversely, are often subject to a higher level of exploration of their results and selective reporting thereof.
The actual strategy is the usual trick in meta-analysis: you take effects which have been studied enough to be meta-analyzed, take the meta-analysis result as the 'true' ground result, and re-analyze other results with that as the baseline. (I mention this because in some of the blogs, this seemed to come as news to them, that you could do this, but as far as I knew it's a perfectly ordinary approach.) This usually turns in depressing results, but actually it's not that bad - it's worse:
Any attempt to establish the average statistical power in neuroscience is hampered by the problem that the true effect sizes are not known. One solution to this problem is to use data from meta-analyses. Meta-analysis provides the best estimate of the true effect size, albeit with limitations, including the limitation that the individual studies that contribute to a meta-analysis are themselves subject to the problems described above. If anything, summary effects from meta-analyses, including power estimates calculated from meta-analysis results, may also be modestly inflated22.
Our results indicate that the median statistical power in neuroscience is 21%. We also applied a test for an excess of statistical significance72. This test has recently been used to show that there is an excess significance bias in the literature of various fields, including in studies of brain volume abnormalities73, Alzheimer’s disease genetics70,74 and cancer biomarkers75. The test revealed that the actual number (349) of nominally significant studies in our analysis was significantly higher than the number expected (254; p < 0.0001). Importantly, these calculations assume that the summary effect size reported in each study is close to the true effect size, but it is likely that they are inflated owing to publication and other biases described above.
Previous analyses of studies using animal models have shown that small studies consistently give more favourable (that is, ‘positive’) results than larger studies78 and that study quality is inversely related to effect size79–82.
Not mentioned, amusingly, are the concerns about applying research to humans:
In order to achieve 80% power to detect, in a single study, the most probable true effects as indicated by the meta-analysis, a sample size of 134 animals would be required for the water maze experiment (assuming an effect size of d = 0.49) and 68 animals for the radial maze experiment (assuming an effect size of d = 0.69); to achieve 95% power, these sample sizes would need to increase to 220 and 112, respectively. What is particularly striking, however, is the inefficiency of a continued reliance on small sample sizes. Despite the apparently large numbers of animals required to achieve acceptable statistical power in these experiments, the total numbers of animals actually used in the studies contributing to the meta-analyses were even larger: 420 for the water maze experiments and 514 for the radial maze experiments.
There is ongoing debate regarding the appropriate balance to strike between using as few animals as possible in experiments and the need to obtain robust, reliable findings. We argue that it is important to appreciate the waste associated with an underpowered study — even a study that achieves only 80% power still presents a 20% possibility that the animals have been sacrificed without the study detecting the underlying true effect. If the average power in neuroscience animal model studies is between 20–30%, as we observed in our analysis above, the ethical implications are clear.
Learned a new term:
Proteus phenomenon: The Proteus phenomenon refers to the situation in which the first published study is often the most biased towards an extreme result (the winner’s curse). Subsequent replication studies tend to be less biased towards the extreme, often finding evidence of smaller effects or even contradicting the findings from the initial study.
Oh great, researchers are going to end up giving this all sorts of names. Joseph Banks Rhine called it the decline effect, while Yitzhak Rabin* calls it the Truth Wears Off effect (after the Jonah Lehrer article). And now we have the Proteus phenomenon. Clearly, I need to write a paper declaring my discovery of the It Was Here, I Swear! effect.
* Not that one.
Clearly, I need to write a paper declaring my discovery of the It Was Here, I Swear! effect.
Make sure you cite my paper "Selection Effects and Regression to the Mean In Published Scientific Studies"
"Do We Really Need the S-word?" (American Scientist) covers many of the same points. I enjoyed one anecdote:
Curious about the impact a ban on the s-word might have, three years ago I began banning the word from my two-semester Methods of Data Analysis course, which is taken primarily by nonstatistics graduate students. My motivation was to force students to justify and defend the statements they used to summarize results of a statistical analysis. In previous semesters I had noticed students using the s-word as a mask, an easily inserted word to replace the justification of assumptions and difficult decisions, such as arbitrary cutoffs. My students were following the example dominant in published research—perpetuating the false dichotomy of calling statistical results either significant or not and, in doing so, failing to acknowledge the vast and important area between the two extremes. The ban on the s-word seems to have left my students with fewer ways to skirt the difficult task of effective justification, forcing them to confront the more subtle issues inherent in statistical inference.
An unexpected realization I had was just how ingrained the word already was in the brains of even first-year graduate students. At first I merely suggested—over and over again—that students avoid using the word. When suggestion proved not to be enough, I evinced more motivation by taking off precious points at the sight of the word. To my surprise, it still appears, and students later say they didn’t even realize they had used it! Even though using this s-word doesn’t carry the possible consequence of having one’s mouth washed out with soap, I continue to witness the clasp of hands over the mouth as the first syllable tries to sneak out—as if the speakers had caught themselves nearly swearing in front of a child or parent.
Via http://www.scottbot.net/HIAL/?p=24697 I learned that Wikipedia actually has a good roundup of misunderstandings of p-values:
The p-value does not in itself allow reasoning about the probabilities of hypotheses; this requires multiple hypotheses or a range of hypotheses, with a [prior distribution][1] of likelihoods between them, as in [Bayesian statistics][2], in which case one uses a [likelihood function][3] for all possible values of the prior, instead of the p-value for a single null hypothesis.
The p-value refers only to a single hypothesis, called the null hypothesis, and does not make reference to or allow conclusions about any other hypotheses, such as the [alternative hypothesis][4] in Neyman–Pearson [statistical hypothesis testing][5]. In that approach one instead has a decision function between two alternatives, often based on a [test statistic][6], and one computes the rate of [Type I and type II errors][7] as α and β. However, the p-value of a test statistic cannot be directly compared to these error rates α and β – instead it is fed into a decision function.
There are several common misunderstandings about p-values.[[16]][8][[17]][9]
- The p-value is not the probability that the null hypothesis is true, nor is it the probability that the alternative hypothesis is false – it is not connected to either of these.
In fact, [frequentist statistics][10] does not, and cannot, attach probabilities to hypotheses. Comparison of [Bayesian][11] and classical approaches shows that a p-value can be very close to zero while the [posterior probability][12] of the null is very close to unity (if there is no alternative hypothesis with a large enough a priori probability and which would explain the results more easily). This is [Lindley's paradox][13]. But there are also a priori probability distributions where the [posterior probability][12] and the p-value have similar or equal values.[[18]][14]- The p-value is not the probability that a finding is "merely a fluke."
As the calculation of a p-value is based on the assumption that a finding is the product of chance alone, it patently cannot also be used to gauge the probability of that assumption being true. This is different from the real meaning which is that the p-value is the chance of obtaining such results if the null hypothesis is true.- The p-value is not the probability of falsely rejecting the null hypothesis. This error is a version of the so-called [prosecutor's fallacy][15].
- The p-value is not the probability that a replicating experiment would not yield the same conclusion. Quantifying the replicability of an experiment was attempted through the concept of [p-rep][16] (which is heavily [criticized][17])
- The significance level, such as 0.05, is not determined by the p-value.
Rather, the significance level is decided before the data are viewed, and is compared against the p-value, which is calculated after the test has been performed. (However, reporting a p-value is more useful than simply saying that the results were or were not significant at a given level, and allows readers to decide for themselves whether to consider the results significant.)- The p-value does not indicate the size or importance of the observed effect (compare with [effect size][18]). The two do vary together however – the larger the effect, the smaller sample size will be required to get a significant p-value.
http://library.mpib-berlin.mpg.de/ft/gg/GG_Null_2004.pdf
In 1962, Jacob Cohen reported that the experiments published in a major psychology journal had, on average, only a 50 : 50 chance of detecting a medium-sized effect if there was one. That is, the statistical power was as low as 50%. This result was widely cited, but did it change researchers’ practice? Sedlmeier and Gigerenzer (1989) checked the studies in the same journal, 24 years later, a time period that should allow for change. Yet only 2 out of 64 researchers mentioned power, and it was never estimated. Unnoticed, the average power had decreased (researchers now used alpha adjustment, which shrinks power). Thus, if there had been an effect of a medium size, the researchers would have had a better chance of finding it by throwing a coin rather than conducting their experiments. When we checked the years 2000 to 2002, with some 220 empirical articles, we finally found 9 researchers who computed the power of their tests. Forty years after Cohen, there is a first sign of change.
Oakes (1986) tested 70 academic psychologists and reported that 96% held the erroneous opinion that the level of significance specified the probability that either H0 or H1 was true.
- Oakes, M. (1986). Statistical inference: A commentary for the social and behavioral sciences. New York: Wiley.
...Gosset, who developed the t-test in 1908, anticipated this overconcern with significance at the expense of other methodological concerns:
"Obviously the important thing. . . is to have a low real error, not to have a 'significant' result at a particular station. The latter seems to me to be nearly valueless in itself" (quoted in Pearson, 1939, p. 247).
--"Do Studies of Statistical Power Have an Effect on the Power of Studies?", Sedlmeier & Gigerenzer 1989
"From Statistical Significance To Effect Estimation: Statistical Reform In Psychology, Medicine And Ecology", Fidler 2005; a broad but still in depth thesis on the history of NHST and attempts to reform it.
setting up a null hypothesis and an alternative hypothesis calculating a p-value (possibly via a t-test or more complex alternatives like ANOVA) and accepting the null if an arbitrary threshold is passed.
Typo?
deprecating the value of exploratory data analysis and depicting data graphically
Should this be:
(deprecating the value of exploratory data analysis) and (depicting data graphically)
or
deprecating [(the value of exploratory data analysis) and (depicting data graphically)]?
ETA: Also, very nice article! I'm glad that you point out that NHST is only a small part of frequentist statistics.
"Not Even Scientists Can Easily Explain P-values"
It’s not their fault, said Steven Goodman, co-director of METRICS. Even after spending his “entire career” thinking about p-values, he said he could tell me the definition, “but I cannot tell you what it means, and almost nobody can.” Scientists regularly get it wrong, and so do most textbooks, he said. When Goodman speaks to large audiences of scientists, he often presents correct and incorrect definitions of the p-value, and they “very confidently” raise their hand for the wrong answer. “Almost all of them think it gives some direct information about how likely they are to be wrong, and that’s definitely not what a p-value does,” Goodman said.
Okay, stupid question :-/
“Almost all of them think it gives some direct information about how likely they are to be wrong, and that’s definitely not what a p-value does...”
But
"...the technical definition of a p-value — the probability of getting results at least as extreme as the ones you observed, given that the null hypothesis is correct..."
Aren't these basically the same? Can't you paraphrase them both as "the probability that you would get this result if your hypothesis was wrong"? Am I failing to understand what they mean by 'direct information'? Or am I being overly binary in assuming that the hypothesis and the null hypothesis as the only two possibilities?
What p-values actually mean:
What they're commonly taken to mean?
That is, p-values measure Pr(observations | null hypothesis) whereas what you want is more like Pr(alternative hypothesis | observations).
(Actually, what you want is more like a probability distribution for the size of the effect -- that's the "overly binary* thing -- but never mind that for now.)
So what are the relevant differences between these?
If your null hypothesis and alternative hypothesis are one another's negations (as they're supposed to be) then you're looking at the relationship between Pr(A|B) and Pr(B|A). These are famously related by Bayes' theorem, but they are certainly not the same thing. We have Pr(A|B) = Pr(A&B)/Pr(B) and Pr(B|A) = Pr(A&B)/Pr(A) so the ratio between the two is the ratio of probabilities of A and B. So, e.g., suppose you are interested in ESP and you do a study on precognition or something whose result has a p-value of 0.05. If your priors are like mine, your estimate of Pr(precognition) will still be extremely small because precognition is (in advance of the experimental evidence) much more unlikely than just randomly getting however many correct guesses it takes to get a p-value of 0.05.
In practice, the null hypothesis is usually something like "X =Y" or "X<=Y". Then your alternative is "X /= Y" or "X > Y". But in practice what you actually care about is that X and Y are substantially unequal, or X is substantially bigger than Y, and that's probably the alternative you actually have in mind even if you're doing statistical tests that just accept or reject the null hypothesis. So a small p-value may come from a very carefully measured difference that's too small to care about. E.g., suppose that before you do your precognition study you think (for whatever reason) that precog is about as likely to be real as not. Then after the study results come in, you should in fact think it's probably real. But if you then think "aha, time to book my flight to Las Vegas" you may be making a terrible mistake even if you're right about precognition being real. Because maybe your study looked at someone predicting a million die rolls and they got 500 more right than you'd expect by chance; that would be very exciting scientifically but probably useless for casino gambling because it's not enough to outweigh the house's advantage.
[EDITED to fix a typo and clarify a bit.]
Aren't these basically the same?
Not at all. To quote Andrew Gelman,
The p-value is a strange nonlinear transformation of data that is only interpretable under the null hypothesis. Once you abandon the null (as we do when we observe something with a very low p-value), the p-value itself becomes irrelevant.
but I cannot tell you what it means
Why not? Most people misunderstand it, but in the frequentist framework its actual meaning is quite straightforward.
A definition is not a meaning, in the same way the meaning of a hammer is not 'a long piece of metal with a round bit at one end'.
Everyone with a working memory can define a p-value, as indeed Goodman and the others can, but what does it mean?
What kind of answer, other than philosophical deepities, would you expect in response to "...but what does it mean"? Meaning almost entirely depends on the subject and the context.
Is the meaning of a hammer describing its role and use, as opposed to a mere definition describing some physical characteristics, really a 'philosophical deepity'?
When you mumble some jargon about 'the frequency of a class of outcomes in sampling from a particular distribution', you may have defined a p-value, but you have not given a meaning. It is numerology if left there, some gematriya played with distributions. You have not given any reason to care whatsoever about this particular arbitrary construct or explained what a p=0.04 vs a 0.06 means or why any of this is important or what you should do upon seeing one p-value rather than another or explained what other people value about it or how it affects beliefs about anything. (Maybe you should go back and reread the Sequences, particularly the ones about words.)
Is the meaning of a hammer describing its role and use, as opposed to a mere definition describing some physical characteristics, really a 'philosophical deepity'?
Just like you don't accept the definition as an adequate substitute for meaning, I don't see why "role and use" would be an adequate substitute either.
As I mentioned, meaning critically depends on the subject and the context. Sometimes the meaning of the p-value boils down to "We can publish that". Or maybe "There doesn't seem to be anything here worth investigating further". But in general case it depends and that is fine. That context dependence is not a special property of the p-value, though.
I don't see why "role and use" would be an adequate substitute either.
I'll again refer you to the Sequences. I think Eliezer did an excellent job explaining why definitions are so inadequate and why role and use are the adequate substitutes.
As I mentioned, meaning critically depends on the subject and the context. Sometimes the meaning of the p-value boils down to "We can publish that". Or maybe "There doesn't seem to be anything here worth investigating further".
And if these experts, who (unusually) are entirely familiar with the brute definition and don't misinterpret it as something it is not, cannot explain any use of p-values without resorting to shockingly crude and unacceptable contextual explanations like 'we need this numerology to get published', then it's time to consider whether p-values should be used at all for any purpose - much less their current use as the arbiters of scientific truth.
Which is much the point of that quote, and of all the citations I have so exhaustively compiled in this post.
"Theory-testing in psychology and physics: a methodological paradox" (Meehl 1967; excerpts) makes an interesting argument: because NHST encourages psychologists to frame their predictions in directional terms (non-zero point estimates) and because everything is correlated with everything (see Cohen), the possible amount of confirmation for any particular psychology theory compared to a 'random theory' - which predicts the sign at random - is going to be very limited.
"Robust misinterpretation of confidence intervals", Hoekstra et al 2014
Confidence intervals (CIs) have frequently been proposed as a more useful alternative to NHST, and their use is strongly encouraged in the APA Manual. Nevertheless, little is known about how researchers interpret CIs. In this study, 120 researchers and 442 students-all in the field of psychology-were asked to assess the truth value of six particular statements involving different interpretations of a CI. Although all six statements were false, both researchers and students endorsed, on average, more than three statements, indicating a gross misunderstanding of CIs. Self-declared experience with statistics was not related to researchers' performance, and, even more surprisingly, researchers hardly outperformed the students, even though the students had not received any education on statistical inference whatsoever. Our findings suggest that many researchers do not know the correct interpretation of a CI.
...Falk and Greenbaum (1995) found similar results in a replication of Oakes's study, and Haller and Krauss (2002) showed that even professors and lecturers teaching statistics often endorse false statements about the results from NHST. Lecoutre, Poitevineau, and Lecoutre (2003) found the same for statisticians working for pharmaceutical companies, and Wulff and colleagues reported misunderstandings in doctors and dentists (Scheutz, Andersen, & Wulff, 1988; Wulff, Andersen, Brandenhoff, & Guttler, 1987). Hoekstra et al. (2006) showed that in more than half of a sample of published articles, a nonsignificant outcome was erroneously interpreted as proof for the absence of an effect, and in about 20% of the articles, a significant finding was considered absolute proof of the existence of an effect. In sum, p-values are often misinterpreted, even by researchers who use them on a regular basis.
- Falk, R., & Greenbaum, C. W. (1995). "Significance tests die hard: The amazing persistence of a probabilistic misconception". Theory and Psychology, 5, 75-98.
- Haller, H., & Krauss, S. (2002). "Misinterpretations of significance: a problem students share with their teachers?" Methods of Psychological Research Online [On-line serial], 7, 120.
- Lecoutre, M.-P., Poitevineau, J., & Lecoutre, B. (2003). "Even statisticians are not immune to misinterpretations of null hypothesis tests". International Journal of Psychology, 38, 37–45.
- Scheutz, F., Andersen, B., & Wulff, H. R. (1988). "What do dentists know about statistics?" Scandinavian Journal of Dental Research, 96, 281–287
- Wulff, H. R., Andersen, B., Brandenhoff, P., & Guttler, F. (1987). "What do doctors know about statistics?" Statistics in Medicine, 6, 3–10
- Hoekstra, R., Finch, S., Kiers, H. A. L., & Johnson, A. (2006). "Probability as certainty: Dichotomous thinking and the misuse of p-values". Psychonomic Bulletin & Review, 13, 1033–1037
...Our sample consisted of 442 bachelor students, 34 master students, and 120 researchers (i.e., PhD students and faculty). The bachelor students were first-year psychology students attending an introductory statistics class at the University of Amsterdam. These students had not yet taken any class on inferential statistics as part of their studies. The master students were completing a degree in psychology at the University of Amsterdam and, as such, had received a substantial amount of education on statistical inference in the previous 3 years. The researchers came from the universities of Groningen (n = 49), Amsterdam (n = 44), and Tilburg (n = 27).
...The questionnaire featured six statements, all of which were incorrect. This design choice was inspired by the p-value questionnaire from Gigerenzer (2004). Researchers who are aware of the correct interpretation of a CI should have no difficulty checking all "false" boxes. The (incorrect) statements are the following:
- "The probability that the true mean is greater than 0 is at least 95%."
- "The probability that the true mean equals 0 is smaller than 5%."
- "The 'null hypothesis' that the true mean equals 0 is likely to be incorrect."
- "There is a 95% probability that the true mean lies between 0.1 and 0.4."
- "We can be 95% confident that the true mean lies between 0.1 and 0.4."
- "If we were to repeat the experiment over and over, then 95% of the time the true mean falls between 0.1 and 0.4."
Statements 1, 2, 3, and 4 assign probabilities to parameters or hypotheses, something that is not allowed within the frequentist framework. Statements 5 and 6 mention the boundaries of the CI (i.e., 0.1 and 0.4), whereas, as was stated above, a CI can be used to evaluate only the procedure and not a specific interval. The correct statement, which was absent from the list, is the following: "If we were to repeat the experiment over and over, then 95% of the time the confidence intervals contain the true mean."
...The mean numbers of items endorsed for first-year students, master students, and researchers were 3.51 (99% CI = [3.35, 3.68]), 3.24 (99% CI = [2.40, 4.07]), and 3.45 (99% CI = [3.08, 3.82]), respectively. The item endorsement proportions are presented per group in Fig. 1. Notably, despite the first-year students' complete lack of education on statistical inference, they clearly do not form an outlying group...Indeed, the correlation between endorsed items and experience was even slightly positive (0.04; 99% CI = [−0.20; 0.27]), contrary to what one would expect if experience decreased the number of misinterpretations.
"Reflections on methods of statistical inference in research on the effect of safety countermeasures", Hauer 1983; and "The harm done by tests of significance", Hauer 2004 (excerpts):
Three historical episodes in which the application of null hypothesis significance testing (NHST) led to the mis-interpretation of data are described. It is argued that the pervasive use of this statistical ritual impedes the accumulation of knowledge and is unfit for use.
(These deadly examples obviously lend themselves to Bayesian critique, but could just as well be classified by a frequentist under several of the rubrics in OP: under failures to adjust thresholds based on decision theory, and failure to use meta-analysis or other techniques to pool data and turn a collection of non-significant results into a significant result.)
If the papers in the OP and comments are not enough reading material, there's many links and citations in http://stats.stackexchange.com/questions/10510/what-are-good-references-containing-arguments-against-null-hypothesis-significan (which is only partially redundant with this page, skimming).
"P Values are not Error Probabilities", Hubbard & Bayarri 2003
...researchers erroneously believe that the interpretation of such tests is prescribed by a single coherent theory of statistical inference. This is not the case: Classical statistical testing is an anonymous hybrid of the competing and frequently contradictory approaches formulated by R.A. Fisher on the one hand, and Jerzy Neyman and Egon Pearson on the other. In particular, there is a widespread failure to appreciate the incompatibility of Fisher’s evidential p value with the Type I error rate, α, of Neyman–Pearson statistical orthodoxy. The distinction between evidence (p’s) and error (α’s) is not trivial. Instead, it reflects the fundamental differences between Fisher’s ideas on significance testing and inductive inference, and Neyman–Pearson views of hypothesis testing and inductive behavior. Unfortunately, statistics textbooks tend to inadvertently cobble together elements from both of these schools of thought, thereby perpetuating the confusion. So complete is this misunderstanding over measures of evidence versus error that is not viewed as even being a problem among the vast majority of researchers.
An interesting bit:
Fisher was insistent that the significance level of a test had no ongoing sampling interpretation. With respect to the .05 level, for example, he emphasized that this does not indicate that the researcher “allows himself to be deceived once in every twenty experiments. The test of significance only tells him what to ignore, namely all experiments in which significant results are not obtained” (Fisher 1929, p. 191). For Fisher, the significance level provided a measure of evidence for the “objective” disbelief in the null hypothesis; it had no long-run frequentist characteristics.
Indeed, interpreting the significance level of a test in terms of a Neyman–Pearson Type I error rate, α, rather than via a p value, infuriated Fisher who complained:
“In recent times one often-repeated exposition of the tests of significance, by J. Neyman, a writer not closely associated with the development of these tests, seems liable to lead mathematical readers astray, through laying down axiomatically, what is not agreed or generally true, that the level of significance must be equal to the frequency with which the hypothesis is rejected in repeated sampling of any fixed population allowed by hypothesis. This intrusive axiom, which is foreign to the reasoning on which the tests of significance were in fact based seems to be a real bar to progress....” (Fisher 1945, p. 130).
"Science or Art? How Aesthetic Standards Grease the Way Through the Publication Bottleneck but Undermine Science", Giner-Sorolla 2012 has some good quotes.
Another problem with NHST in particular: the choice of a null and a null distribution is itself a modeling assumption, but is rarely checked and in real-world datasets, it's entirely possible for the null distribution to be much more extreme than assumed and hence the nominal alpha/false-positive-conditional-on-null error rates are incorrect & too forgiving. Two links on that:
And yet even you who are more against frequentist statistics than most (Given that you are even writing this among other things on the topic) inevitably use the frequentist tools. What I'd be interested in is a good and short(as short as it can be) summary of what methods should be followed to remove as many of the problems of frequentist statistics with properly defined cut-offs for p-values and everything else, where can we fully adapt Bayes, where we can minimize the problems of the frequentist tools and so on. You know, something that I can use on its own to interpret the data if I am to conduct an experiment today the way that currently seems best.
inevitably use the frequentist tools.
No, I don't. My self-experiments have long focused on effect sizes (an emphasis which is very easy to do without disruptive changes), and I have been using BEST as a replacement for t-tests for a while, only including an occasional t-test as a safety blanket for my frequentist readers.
If non-NHST frequentism or even full Bayesianism were taught as much as NHST and as well supported by software like R, I don't think it would be much harder to use.
If non-NHST frequentism
That'd be essentially Bayesianism with the (uninformative improper) priors (uniform for location parameters and logarithms of scale parameters) swept under the rug, right?
'Frequentist tools' are common approximations, loaded with sometimes-applicable interpretations. A Bayesian can use the same approximation, even under the same name, and yet not be diving into Frequentism.
From Redditor Decolater's summary:
...So the Governor is told by the DEQ - their agency responsible for public safety and drinking water - that the water is safe. This is July 24th.
In the wake of Muchmore’s July email to Department of Health and Human Services Director Nick Lyon, follow-up communications reveal health officials attempting to analyze the latest testing results and set up a public information program for Flint residents. They also show health and environmental quality staffers struggling to interpret data that showed elevated levels of lead in children’s blood during the summer months. ("Flint crisis response delayed for months")
Remember hindsight. It's easy to to judge others after the fact. Was what was known at the time enough to state with certanty that there was a lead problem with the water? The two departments responsible for public safety, the DEQ and the DHHS, were gathering data. It sounds easy from your armchair perspective, but from a scientist - which these guys and gals are - you state what the data shows you based on the methodology you are required to use.
Look at how the Detroit Free Press describes the DHHS analysis of the data:
But the analysis of children's blood-lead levels the health department relied on to ease chief of staff Dennis Muchmore's fears was just one of two performed after his e-mail. Another analysis, done by a health department epidemiologist, showed the reverse: "There appears to be a higher proportion of first-time (elevated blood-lead levels)," the epidemiologist wrote, in a report also obtained by Edwards. "... Even compared to the previous three years, the proportion ... is highest in summer ... positive results for elevated blood-lead levels were higher than usual for children under age 16 living in the City of Flint during the months of July, August and September 2014." ("In Flint, report that raised flags on lead went ignored")
That sounds pretty damning. However, we have this conundrum as scientists. We need to look at data from all sides. Here is what the DHHS understood about lead levels in their citizens:
Lead levels tend to rise annually at that time of year, and state researchers grappled with determining whether the 2015 increase was typical or beyond the norm. ("Flint crisis response delayed for months")
The Detroit Free Press acknowledges this "grappling" but downplays it as if it can be ignored:
The epidemiologist's analysis, the one that showed a spike in kids' blood-lead level in the summer of 2014, never made it out of the department, a spokeswoman said. ...it wasn't clear that the three months' worth of testing analyzed were statistically significant. At the end of the summer, blood-lead levels dropped, so the epidemiologist had just three of the five data points Wells said are required to show significance. (For what it's worth, this argument didn't hold much weight with the Free Press' data analyst, who teaches graduate-level statistics.) {source}
...For a good time line up to June 2015, read the EPA memo.
(I didn't see a copy of the analysis, but dollars to donuts it found an extra-seasonal rise but p>0.05.) From WP:
Volunteer teams led by Edwards found that at least a quarter of Flint households have levels of lead above the federal level of 15 parts per billion (ppb) and that in some homes, lead levels were at 13,200 ppb.[25] Edwards said: "It was the injustice of it all and that the very agencies that are paid to protect these residents from lead in water, knew or should've known after June at the very very latest of this year, that federal law was not being followed in Flint, and that these children and residents were not being protected. And the extent to which they went to cover this up exposes a new level of arrogance and uncaring that I have never encountered."[25] Research done after the switch to the Flint River source found that the proportion of children with elevated blood-lead levels (above five micrograms per deciliter, or 5 × 10–6 grams per 100 milliliters of blood) rose from 2.1% to 4%, and in some areas to as much as 6.3%.[4]...On January 18, the United Way of Genesee County estimated 6,000-12,000 children have been exposed to lead poisoning and kicked off a fundraising campaign to raise $100 million over a 10-15 year span for their medical treatment.[2]
This translates directly into a decision problem with Expected Value of Sample Information (possibly a POMDP): the harms of lead are well known and very high, the water levels affect a lot of people, the cost of remediation strategies is probably known, and the cost of taking additional samples of various kinds also well known.
"An investigation of the false discovery rate and the misinterpretation of p-values", Colquhoun 2014; basically a more extended tutorial-like version of Ioannides's 'Why Most Published Findings are False', putting more emphasis on working through the cancer-screening metaphor to explain why a p<0.05 is much less impressive than it looks & has such high error rates.
No one understands p-values: "Unfounded Fears: The Great Power-Line Cover-Up Exposed", IEEE 1996, on the electricity/cancer panic (emphasis added to the parts clearly committing the misunderstanding of interpreting p-values as having anything at all to do with probability of a fact or with subjective beliefs):
Unless the number of cases is very large, an apparent cluster can rarely be distinguished from a pure chance occurrence. Thus epidemiologists check for statistical significance of data, usually at the 95% level. They use statistical tools to help distinguish chance occurrences (like the "runs" of numbers on the dice throws above) from non-random increases, i.e. those due to an external cause. If pure chance cannot be excluded with at least 95% certainty, as is very frequently the case in EMF studies, the result is usually called not significant. The observation may not mean a thing outside the specific population studied. Most often the statistical information available is expressed as an odds ratio (OR) and confidence interval (CI). The OR is the estimate of an exposed person's risk of the disease in question relative to an unexposed person's risk of the same disease. The CI is the range of ORs within which the true OR is 95% likely to lie, and when the CI includes 1.0! (no difference in risk), the OR is commonly defined as not statistically significant...Mr. Brodeur notes, "the 50% increased risk of leukemia they observed in the highest exposure category--children in whose bedrooms magnetic fields of two and two-thirds milligauss or above were recorded--was not considered to be statistically significant", as though this is an opinion. It is, however, a statement with a particular mathematical definition. The numbers of cases and controls in each category limit the certainty of the results, so that it cannot be said with 95% certainty! that the association seen is not a pure chance occurrence. In fact, it is within a 95% probability that the association is really inverse and residence in such high fields (compared to the rest of the population) actually protects against cancer.
No one understands p-values, not even the ones who use Bayesian methods in their other work... From "When Is Evidence Sufficient?", Claxton et al 2005:
Classical statistics addresses this problem by calculating the probability that any difference observed between the treatment and the comparator (in this case the placebo) reflects noise rather than a “real” difference. Only if this probability is sufficiently small—typically 5 percent—is the treatment under investigation declared superior. In the example of the pain medication, a conventional decisionmaker would therefore reject adoption of this new treatment if the chance that the study results represent noise exceeds 5 percent...For example, suppose we know that the new pain medication has a low risk of side effects, low cost, and the possibility of offering relief for patients with severe symptoms. In that case, does it really make sense to hold the candidate medication to the stringent 5 percent adoption criterion? Similarly, let us suppose that there is a candidate medication for patients with a terminal illness. If the evidence suggesting that it works has a 20 percent chance of representing only noise (and hence an 80 percent chance that the observed efficacy is real), does it make sense to withhold it from patients who might benefit from its use?
Another fun one is a piece which quotes someone making the classic misinterpretation and then someone else immediately correcting them. From "Drug Trials: Often Long On Hype, Short on Gains; The delusion of ‘significance’ in drug trials":
Part of the problem, said Alex Adjei, PhD, the senior vice president of clinical research and professor and chair of the Department of Medicine at Roswell Park Cancer Institute in Buffalo, N.Y., is that oncology has lost focus on what exactly a P value means. “A P value of less than 0.05 simply means that there is less than a 5% chance that the difference between two medications—whatever it is—is not real, that it’s just chance. If there’s a four-week overall survival difference between two drugs and my P value is less than 0.05, it’s statistically significant, but that just means that the number in the study is large enough to tell me that the difference I’m seeing is not by chance. It doesn’t tell me if those additional four weeks are clinically significant.”
“P values are even more complicated than that,” said Dr. Berry. “No one understands P values, because they are fundamentally non-understandable.” (He elaborates on this problem in “Multiplicities in Cancer Research: Unique and Necessary Evils,” a commentary in August in the Journal of the National Cancer Institute [2012;104:1125-1133].)
Also fun, "You do not understand what a p-value is (p < 0.001)":
Here's what the p-value is not: "The probability that the null-hypothesis was true." I didn't choose this definition out of thin air to beat up on, it was the correct answer on a test I took asking, "Which of these is the definition of a p-value?"
Another entry from the 'no one understands p-values' files; "Policy: Twenty tips for interpreting scientific claims", Sutherland et al 2013, Nature - there's a lot to like in this article, and it's definitely worth remembering most of the 20 tips, except for the one on p-values:
Significance is significant. Expressed as P, statistical significance is a measure of how likely a result is to occur by chance. Thus P = 0.01 means there is a 1-in-100 probability that what looks like an effect of the treatment could have occurred randomly, and in truth there was no effect at all. Typically, scientists report results as significant when the P-value of the test is less than 0.05 (1 in 20).
Whups. p=0.01 does not mean our subjective probability that the effect is zero is now just 1%, and there's a 99% chance the effect is non-zero.
(The Bayesian probability could be very small or very large depending on how you set it up; if your prior is small, then data with p=0.01 will not shift your probability very much, for exactly the reason Sutherland et al 2013 explains in their section on base rates!)
"Blinding Us to the Obvious? The Effect of Statistical Training on the Evaluation of Evidence", McShane & Gal 2015
Statistical training helps individuals analyze and interpret data. However, the emphasis placed on null hypothesis significance testing in academic training and reporting may lead researchers to interpret evidence dichotomously rather than continuously. Consequently, researchers may either disregard evidence that fails to attain statistical significance or undervalue it relative to evidence that attains statistical significance. Surveys of researchers across a wide variety of fields (including medicine, epidemiology, cognitive science, psychology, business, and economics) show that a substantial majority does indeed do so. This phenomenon is manifest both in researchers’ interpretations of descriptions of evidence and in their likelihood judgments. Dichotomization of evidence is reduced though still present when researchers are asked to make decisions based on the evidence, particularly when the decision outcome is personally consequential. Recommendations are offered.
...Formally defined as the probability of observing data as extreme or more extreme than that actually observed assuming the null hypothesis is true, the p-value has often been misinterpreted as, inter alia, (i) the probability that the null hypothesis is true, (ii) one minus the probability that the alternative hypothesis is true, or (iii) one minus the probability of replication (Bakan 1966, Sawyer and Peter 1983, Cohen 1994, Schmidt 1996, Krantz 1999, Nickerson 2000, Gigerenzer 2004, Kramer and Gigerenzer 20005).
...As an example of how dichotomous thinking manifests itself, consider how Messori et al.(1993) compared their findings with those of Hommes et al. (1992):
The result of our calculation was an odds ratio of 0.61 (95% CI [confidence interval]: 0.298–1.251; p>0.05); this figure differs greatly from the value reported by Hommes and associates (odds ratio: 0.62; 95% CI: 0.39–0.98; p<0.05)...we concluded that subcutaneous heparin is not more effective than intravenous heparin, exactly the opposite to that of Hommes and colleagues.(p. 77)
In other words, Messori et al. (1993) conclude that their findings are “exactly the opposite” of Hommes et al. (1992) because their odds ratio estimate failed to attain statistical significance whereas that of Hommes et al. attained statistical significance. In fact, however, the odds ratio estimates and confidence intervals of Messori et al. and Hommes et al. are highly consistent (for additional discussion of this example and others, see Rothman et al. 1993 and Healy 2006).
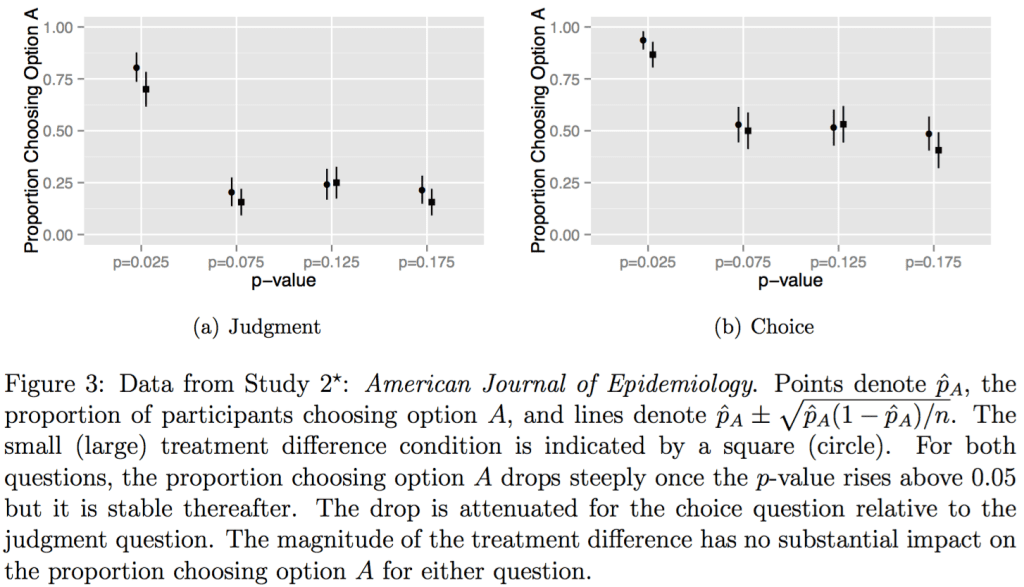
Graph of how a p-value crossing a threshold dramatically increases choosing that option, regardless of effect size: http://andrewgelman.com/wp-content/uploads/2016/04/Screen-Shot-2016-04-06-at-3.03.29-PM-1024x587.png
In a forthcoming paper, my colleague David Gal and I survey top academics across a wide variety of fields including the editorial board of Psychological Science and authors of papers published in the New England Journal of Medicine, the American Economic Review, and other top journals. We show:
- Researchers interpret p-values dichotomously (i.e., focus only on whether p is below or above 0.05).
- They fixate on them even when they are irrelevant (e.g., when asked about descriptive statistics).
- These findings apply to likelihood judgments about what might happen to future subjects as well as to choices made based on the data.
We also show they ignore the magnitudes of effect sizes.
Another entry from the 'no one understands p-values' files; "Policy: Twenty tips for interpreting scientific claims", Sutherland et al 2013, Nature - there's a lot to like in this article, and it's definitely worth remembering most of the 20 tips, except for the one on p-values:
Significance is significant. Expressed as P, statistical significance is a measure of how likely a result is to occur by chance. Thus P = 0.01 means there is a 1-in-100 probability that what looks like an effect of the treatment could have occurred randomly, and in truth there was no effect at all. Typically, scientists report results as significant when the P-value of the test is less than 0.05 (1 in 20).
Whups. p=0.01 does not mean our subjective probability that the effect is zero is now just 1%, and there's a 99% chance the effect is non-zero.
(The Bayesian probability could be very small or very large depending on how you set it up; if your prior is small, then data with p=0.01 will not shift your probability very much, for exactly the reason Sutherland et al 2013 explains in their section on base rates!)
{kind=link}
Frequentist statistics is a wide field, but in practice by innumerable psychologists, biologists, economists etc, frequentism tends to be a particular style called “Null Hypothesis Significance Testing” (NHST) descended from R.A. Fisher (as opposed to eg. Neyman-Pearson) which is focused on
NHST became nearly universal between the 1940s & 1960s (see Gigerenzer 2004, pg18), and has been heavily criticized for as long. Frequentists criticize it for:
What’s wrong with NHST? Well, among other things, it does not tell us what we want to know, and we so much want to know what we want to know that, out of desperation, we nevertheless believe that it does! What we want to know is, “Given these data, what is the probability that H0 is true?” But as most of us know, what it tells us is “Given that H0 is true, what is the probability of these (or more extreme) data?” These are not the same…
Similarly, the cargo-culting encourages misuse of two-tailed tests, avoidance of multiple correction, data dredging, and in general, “p-value hacking”.
(An example from my personal experience of the cost of ignoring effect size and confidence intervals: p-values cannot (easily) be used to compile a meta-analysis (pooling of multiple studies); hence, studies often do not include the necessary information about means, standard deviations, or effect sizes & confidence intervals which one could use directly. So authors must be contacted, and they may refuse to provide the information or they may no longer be available; both have happened to me in trying to do my dual n-back & iodine meta-analyses.)
Critics’ explanations for why a flawed paradigm is still so popular focus on the ease of use and its weakness; from Gigerenzer 2004:
Shifts away from NHST have happened in some fields. Medical testing seems to have made such a shift (I suspect due to the rise of meta-analysis):
0.1 Further reading
More on these topics:
The perils of NHST, and the merits of Bayesian data analysis, have been expounded with increasing force in recent years (e.g., W. Edwards, Lindman, & Savage, 1963; Kruschke, 2010b, 2010a, 2011c; Lee & Wagenmakers, 2005; Wagenmakers, 2007).
Although the primary emphasis in psychology is to publish results on the basis of NHST (Cumming et al., 2007; Rosenthal, 1979), the use of NHST has long been controversial. Numerous researchers have argued that reliance on NHST is counterproductive, due in large part because p values fail to convey such useful information as effect size and likelihood of replication (Clark, 1963; Cumming, 2008; Killeen, 2005; Kline, 2009 [Becoming a behavioral science researcher: A guide to producing research that matters]; Rozeboom, 1960). Indeed, some have argued that NHST has severely impeded scientific progress (Cohen, 1994; Schmidt, 1996) and has confused interpretations of clinical trials (Cicchetti et al., 2011; Ocana & Tannock, 2011). Some researchers have stated that it is important to use multiple, converging tests alongside NHST, including effect sizes and confidence intervals (Hubbard & Lindsay, 2008; Schmidt, 1996). Others still have called for NHST to be completely abandoned (e.g., Carver, 1978).
[http://www.gwern.net/DNB%20FAQ#flaws-in-mainstream-science-and-psychology](http://www.gwern.net/DNB%20FAQ#flaws-in-mainstream-science-and-psychology)[https://www.reddit.com/r/DecisionTheory/](https://www.reddit.com/r/DecisionTheory/)