This is a special post for quick takes by Kabir Kumar. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Has Tyler Cowen ever explicitly admitted to being wrong about anything?
Not 'revised estimates' or 'updated predictions' but 'I was wrong'.
Every time I see him talk about learning something new, he always seems to be talking about how this vindicates what he said/thought before.
Gemini 2.5 pro didn't seem to find anything, when I did a max reasoning budget search with url search on in aistudio.
EDIT: An example was found by Morpheus, of Tyler Cowen explictly saying he was wrong - see the comment and the linked PDF below
In the post 'Can economics change your mind?' he has a list of examples where he has changed his mind due to evidence:
...1. Before 1982-1984, and the Swiss experience, I thought fixed money growth rules were a good idea. One problem (not the only problem) is that the implied interest rate volatility is too high, or exchange rate volatility in the Swiss case.
2. Before witnessing China vs. Eastern Europe, I thought more rapid privatizations were almost always better. The correct answer depends on circumstance, and we are due to learn yet more about this as China attempts to reform its SOEs over the next five to ten years. I don’t consider this settled in the other direction either.
3. The elasticity of investment with respect to real interest rates turns out to be fairly low in most situations and across most typical parameter values.
4. In the 1990s, I thought information technology would be a definitely liberating, democratizing, and pro-liberty force. It seemed that more competition for resources, across borders, would improve economic policy around the entire world. Now this is far from clear.
5. Given the greater ease of converting labor income into capit
This seems to be a really explicit example of him saying that he wss wrong about something, thank you!
Didn't think this would exist/be found, but glad I was wrong.
5
It's still pretty interesting if it turns out that the only clear example to be found of T.C. admitting to error is in a context where everyone involved is describing errors they've made: he'll admit to concrete mistakes, but apparently only when admitting mistakes makes him look good rather than bad.
(Though I kinda agree with one thing Joseph Miller says, or more precisely implies: perhaps it's just really rare for people to say publicly that they were badly wrong about anything of substance, in which case it could be that T.C. has seldom done that but that this shouldn't much change our opinion of him.)
1
Btw, for Slatestarcodex, found it in the first search, pretty easily.
2
Sure, but plausibly that's Scott being unusually good at admitting error, rather than Tyler being unusually bad.
7
Downvoted. This post feels kinda mean. Tyler Cowen has written a lot and done lots of podcasts - it doesn't seem like anyone has actually checked? What's the base rate for public intellectuals ever admitting they were wrong? Is it fair to single out Tyler Cowen?
5
It's only one datapoint, but did a similar search for SlateStarCodex and almost immediately found him explictly saying he was wrong.
It's the title of a post, even: https://slatestarcodex.com/2018/11/06/preschool-i-was-wrong/
In the post he also says:
[...]
And then makes a bunch of those.
Again, this is only one datapoint - sorry for the laziness, it's 11..12pm and I'm trying to organize an alignment research fellowship atm and just put together another alignment research team at ai plans and had to do management work for it which ended up delaying the fellowship announcement i wanted to do today and had family drama again. Sigh.
Url link for slatestarcodex search: https://duckduckgo.com/?q=site%3Ahttps%3A%2F%2Fslatestarcodex.com%2F+%22I+was+wrong%22&t=brave&ia=web
5
(source: https://brinklindsey.substack.com/p/interview-with-tyler-cowen)
1
Ok, I was going to say that's a good one.
But this line ruins it for me:
[...]
Thank you for searching and finding it though!! Do you think other public intellectuals might have more/less examples?
2
He has mentioned the phrase a bunch. I haven’t looked through enough of these links enough to form an opinion though.
thank you for this search. Looking at the results, top 3 are by commentors.
Then one about not thinking a short book could be this good.

I don't think this is Cowen actually saying he made a wrong prediction, just using it to express how the book is unexpectedly good at talking about a topic that might normally take longer, though happy to hear why I'm wrong here.
Another commentor:

another commentor:
Ending here for now, doesn't seem to be any real instances of Tyler Cowen saying he was wrong about something he thought was true yet.
9
Btw, I really dont have my mind set on this, if someone finds Tyler Cowen explictly saying he was wrong about something, please link it to me - you dont have to give an explanation to justify it, to prepare for some confirmation biasy 'here's why I was actually right and this isnt it' thing (though, any opinions/thoughts are very welcome), please feel free to just give a link or mention some post/moment.
So, apparently, I'm stupid. I could have been making money this whole time, but I was scared to ask for it
i've been giving a bunch of people and businesses advice on how to do their research and stuff. one of them messaged me, i was feeling tired and had so many other things to do. said my time is busy.
then thought fuck it, said if they're ok with a $15 an hour consulting fee, we can have a call. baffled, they said yes.
then realized, oh wait, i have multiple years of experience now leading dev teams, ai research teams, organizing research hackathons and getting frontier research done.
wtf
4
Yeah, a friend told me this was low - I'm just scared of asking for money rn I guess.
I do see people who seem very incompetent getting paid as consultants, so I guess I can charge for more. I'll see how much my time gets eaten by this and how much money I need. I want to buy some gpus, hopefully this can help.
1
I'm not trying to be derisive; in fact, I relate to you greatly. But it's by being on the outside that I'm able to levy a few more direct criticisms:
* Were you not paid for the other work that you did, leading dev teams and getting frontier research done? Those things should be a baseline on the worth of your time.
* If that, have you ever tried to maximize the amount of money you can get the) other people to acknowledge your time as worth (ie, get a high salary offer)?
* Separately, do you know the going rate for consultants with approximately your expertise? Or any other reference class you cna make up. Consulting can cost an incredible amount of money, and that price can be "fair" in a pretty simple sense if it averts the need to do 10s of hours of labor at high wages. It may be one of the highest leverage activities per unit time that exists as a conventional economic activity that a person can simply do.
* Aside from market rates or whatever, I suggest you just try asking for unreasonable things, or more money than you feel you're worth (think of it as an experiment, and maybe observe what happens in your mind when you flinch from this).
* Do you have any emotional hangup about the prospect of trading money for labor generally, or money for anything?
* Separately, do you have a hard time asserting your worth to others (or maybe just strangers) on some baseline level?
1
This was running AI Plans, my startup, so makes sense that I wasn't getting paid, since the same hesitancy for asking for money leads to hesitancy to do that exaggeration thing many AI Safety/EA people seem to do when making funding applications. Also, I don't like to make the funding applications, or long applications in general.
[...]
I think every time I've asked for money, I've tried to ask for the lowest amount I can.
[...]
I don't know - I have a doc of stuff I've done that I paste into LLMs when I need to make a funding applications and stuff - just pasted it into Gemini 2.5 Pro and asked what would be a reasonable hourly fee and it said $200 to $400 an hour.
[...]
I'll give it a go - I've currently put the asking price on my call link for $50 an hour, feel nervous about actually asking for that though. I need to make a funding application for AI Plans - I can ask for money on behalf of others on the team, but asking for money to be donated so I can get a high salary feels scary. Happy to ask for a high salary for others on the team though, since I want them to get paid what they need.
[...]
Yeah, I do. Generally, I'm used to doing a lot of free work for family and getting admonished when I ask for money. And when I did get promised money, it was either wayyy below market price or wayy late or didn't get paid at all. General experience with family was my work not being valued even when I put in extra effort. I'm aware that's wrong and has taught me wrong lessons, but not fully learnt the true ones yet.
1
I do think that $200-$400 seem like reasonable consulting rates.
I think the situations with family are complicated, because sure, there are social/cultural reasons one might be expected to do those things for family. Usually people hold those cultural norms alongside a stronger distinction between the ingroup (family) and the outgroup (all other people by default), though, so letting your impressions from that culture teach you things about how to behave in a culture with a weaker distinction might be maladaptive.
(I actually was suggesting you try asking for objectively completely unreasonable things just to look at the flinch. For example, you could ask a stranger for $100 for no reason. They would say no, but no harm would be done.)
One frame that might be useful to you is that in a way, it is imperative to at least sufficiently assert your value to others (if not overassert it the socially expected amount). An overly modest estimate is still a miscalibrated one, and people will make suboptimal decisions as a result. (Putting aside the behavior and surpluses given to other people, you are also a player in this game, and your being underallocated resources is globally suboptimal.)
3
Ah, I can totally relate to this. Whenever I think about asking for money, the Impostor Syndrome gets extra strong. Meanwhile, there are actual impostors out there collecting tons of money without any shame. (Though they may have better social skills, which is probably the category of skill that ultimately gets paid best.)
Another important lesson I got once, which might be useful for you at some moment: "If you double your prices, and lose half of your customers as a result, you will still get the same amount of money, but only work half as much."
Also, speaking from my personal experience, the relation between how much / how difficult work someone wants you to do, and how much they are willing to pay you, seems completely random. One might naively expect that a job that pays more will be more difficult, but often it is the other way round.
1
Update - consulting went well. He said he was happy with it and got a lot of useful stuff. I was upfront with the fact that I just made up the $15 an hour and might change it, asked him what he'd be happy with, he said it's up to me, but didn't seem bothered at all at the price potentially changing.
I was upfront about the stuff I didn't know and was kinda surprised at how much I was able to contribute, even knowing that I underestimate my technical knowledge because I barely know how to code.
if someone who's v good at math wants to do some agent foundations stuff to directly tackle the hard part of alignement, what should they do?
If they're talented, look for a way to search over search processes without incurring the unbounded loss that would result by default.
If they're educated, skim the existing MIRI work and see if any results can be stolen from their own field.
I currently think we're mostly interested in properties that apply at all timesteps, or at least "quickly", as well as in the limit; rather than only in the limit. I also think it may be easier to get a limit at all by first showing quickness, in this case, but not at all sure of that.
9
The actual hard parts? Math probably doesn't help much directly, unfortunately. Mathematical thinking is good. You'll have to learn how to think in novel ways, so there's not even a vector anyone can point you in, except for pointers with a whole lot of "dereference not included" like "figure out how to understand the fundamental forces involved in what actually determines what a mind ends up trying to do long term" (https://tsvibt.blogspot.com/2023/04/fundamental-question-what-determines.html).
Some of the problems: https://tsvibt.blogspot.com/2023/03/the-fraught-voyage-of-aligned-novelty.html A meta-philosophy discussion of what might work: https://tsvibt.blogspot.com/2023/09/a-hermeneutic-net-for-agency.html
3
If you are capable of meaningfully pushing capabilities forward and doing literally anything else, that’s already pretty helpful.
Hi, I'm running AI Plans, an alignment research lab. We've run research events attended by people from OpenAI, DeepMind, MIRI, AMD, Meta, Google, JPMorganChase and more. And had several alignment breakthroughs, including a team finding out that LLMs are maximizers, one of the first Interpretability based evals for LLMs, finding how to cheat every AI Safety eval that relies on APIs and several more.
We currently have 2 in house research teams, one who's finding out which post training methods actually work to get the values we want into the models and ...
Hi, I'm hosting an AI Safety Law-a-Thon on October 25th to 26th. Will be pairing up AI Safety researchers with lawyers to share knowledge and brainstorm risk scenarios. If you've ever talked/argued about p doom and know what a mesaoptimizer is, then you've already done something very similar to this.
Main difference here is that you'll be able to reduce p doom in this one! Many of the lawyers taking part are from top, multi-billion dollar companies, advisors to governments, etc. And they know essentially nothing about alignment. You might be concerned...
4
What kind of knowledge specifically are these lawyers looking for?
1
When signing an enterprise contract with OpenAI, almost all the liability is passed onto them. What are specific risk scenarios/damages that they could face, which they can use to build a countersuit.
1
Potentially, also for justify for negotiating a better contract, either with OpenAI (unlikely, since OpenAI seems to very rarely negotiate) or another AI company that takes more of the liability (which requires increasing funding for safety, evals, etc).
Or, seeing if there are non AI solutions that can do what they want (e.g. a senior person at a rail company sincerely asked me 'we need to copy and paste stuff from our CRM to Excel a lot, do you think an AI Agent could help with that?'). Had a few interactions like this. It seems that for a lot of businesses atm, what they are spending on 'AI solutions' can be done cheaper, faster and more reliably with normal software, but they don't really know what software is.
2
I don’t know that we have much expertise on this sort of thing - we’re mostly worried about X-risk, which it doesn’t really make sense to talk about liability for in a legal sense.
Maybe there's a filtering effect for public intellectuals.
If you only ever talk about things you really know a lot about, unless that thing is very interesting or you yourself are something that gets a lot of attention (e.g. a polyamorous cam girl who's very good at statistics, a Muslim Socialist running for mayor in the world's richest city, etc), you probably won't become a 'public intellectual'.
And if you venture out of that and always admit it when you get something wrong, explicitly, or you don't have an area of speciality and admit to get...
3
One can say that being intellectually honest, which often comes packaged with being transparent about the messiness and nuance of things, is anti-memetic.
3
Seems to rhyme with the criticism of pundits in Superforecasting
i.e. (iirc), most high profile pundits make general, sweeping, dramatic sounding statements that make good TV but are difficult to falsify after the fact
it's so unnecessarily hard to get funding in alignment.
they say 'Don't Bullshit' but what that actually means is 'Only do our specific kind of bullshit'.
and they don't specify because they want to pretend that they don't have their own bullshit
5
This seems generally applicable. Any significant money transaction includes expectations, both legible and il-, which some participants will classify as bullshit. Those holding the expectations may believe it to be legitimately useful, or semi-legitimately necessary due to lack of perfect alignment.
If you want to specify a bit, we can probably guess at why it's being required.
4
What I liked about applying for VC funding was the specific questions.
"How is this going to make money?"
"What proof do you have this is going to make money"
and it being clear the bullshit that they wanted was numbers, testimonials from paying customers, unambiguous ways the product was actually better, etc. And then standard bs about progress, security, avoiding weird wibbly wobbly talk, 'woke', 'safety', etc.
With Alignment funders, they really obviously have language they're looking for as well, or language that makes them more and less willing to put more effort into understanding the proposal. Actually, they have it more than the VCs. But they act as if they don't.
1
Have you felt this from your own experience trying to get funding, or from others, or both? Also, I'm curious what you think is their specific kind of bullshit, and if there's things you think are real but others thought to be bullshit.
1
Both. Not sure, its something like lesswrong/EA speak mixed with the VC speak.
1
If I knew the specific bs, I'd be better at making successful applications and less intensely frustrated.
btw, yud failure mode and something i see in a lot of rats:
Lacking humility and lacking the propensity to take time to understand and appreciate that which isnt immediately obviously valuable - especially things that take reworking ones interpretation and realising that ones first interpretation was wrong.
It's a humility + path dependant interpretation failure solution: when having a feeling of dismissal and high confidence on something from little data, noticing that and training this sense - and also training the sense of noticing when a strong feelin...
1
I wonder on which sense Yudkowsky's first interpretation was bad. When his long list of reasons for AGI to be deadly was reevaluated in 2026, the most load-bearing crux from the point 25 stayed unsolved and Yudkowsky's other disproven ideas didn't seem enough to super-reliably avert the disaster.
Working on a meta plan for solving alignment, I'd appreciate feedback & criticism please - the more precise the better. Feel free to use the emojis reactions if writing a reply you'd be happy with feels taxing.
Diagram for visualization - items in tables are just stand-ins, any ratings and numbers are just for illustration, not actual rankings or scores at this moment.
Red and Blue teaming Alignment evals
Make lots of red teaming methods to reward hack alignment evals
Use this to find actually useful alignment evals, then red team and reward hack them...

7
This plan is pretty abstract (which is necessary because it's short) but in some ways I think it's better than any of the AI companies' published 400-page plans. From what I've seen, AI companies don't care enough about trying to break their own evals, and they don't care enough about theory work.
Maybe this is too in the weeds but I'm skeptical that we can create robust alignment evals using anything resembling current methods. A superintelligent AI will be better at breaking evals than humans, so I expect there is a big gap between "our top researchers have tried and failed to find any loopholes in our alignment evals" and "a superintelligence will not be able to find any loopholes".
AI companies would probably answer that they only need to align weaker models and then bootstrap to an aligned superintelligence. You didn't talk about that in your meta plan though. I think it would be good for you to talk about that in your meta-plan, since it's what every AI company (with an alignment team) currently plans on doing.
3
I've seen that and the claims to do that. This seems to essentially be horseshit though. Also, what i read of the 'superalignment' paper claiming this seemed to be basically a method to get better synthetic data while vibing out about safety to make employees and recruits feel good.
3
Yeah I agree that it's not a good plan. I just think that if you're proposing your own plan, your plan should at least mention the "standard" plan and why you prefer to do something different. Like give some commentary on why you don't think alignment bootstrapping is a solution. (And I would probably agree with your commentary.)
1
Agreed. This is why this plan is ultimately just a tool to get good/useful theory work done faster, more efficiently, etc.
1
I agree. This is why we need to make new methods. e.g. in Jan, a team in our hackathon made one of the first interp based evals for llms: https://github.com/gpiat/AIAE-AbliterationBench/
they were pretty cracked (researcher at jp morgan chase, ai phd, very smart high schooler), but i think its doable by others to do this and make other new methods too.
very unfinished, but making an evals course to make this easier, which will be used in an evals course at an ivy league uni https://docs.google.com/document/d/1_95M3DeBrGcBo8yoWF1XHxpUWSlH3hJ1fQs5p62zdHE/edit?tab=t.0
1
lots of flaws in the plan is that we need to specify what things mean and are going to need to improve, iterate on and better explain and justify the specification. e.g. wtf does it actually mean for an eval to be red teamed. what counts??
btw, cool thing to see is that we're inspiring others to also red team evals: https://anloehr.github.io/ai-projects/salad/RedTeaming.SALAD.pdf
1
One of the major problems with this atm is that most 'alignment', 'safety', etc evals dont specify or define exactly what they're trying to measure.
1
so for this and other reasons, its hard to say when an eval has been truly successfully 'red teamed'

For AI Safety funders/regranters - e.g. Open Phil, Manifund, etc:
It seems like a lot of the grants are swayed by 'big names' being on there. I suggest making anonymity compulsary if you want to more merit based funding, that explores wider possibilities and invests in more upcoming things.
Treat it like a Science rather than the Bragging Competition it currently is.
A Bias Pattern atm seems to be that the same people get funding, or recommended funding by the same people, leading to the number of innovators being very small, or growing much...
9
It’s an interesting idea, but the track records of the grantees are important information, right? And if the track record includes, say, a previous paper that the funder has already read, then you can’t submit the paper with author names redacted.
[...]
Wouldn’t it be better for the funder to just say “if I’m going to fund Group X for Y months / years of work, I should see what X actually accomplished in the last Y months / years, and assume it will be vaguely similar”? And if Group X has no comparable past experience, then fine, but that equally means that you have no basis for believing their predictions right now.
Also, what if someone predicts that they’ll do A, but then realizes it would be better if they did B? Two possibilities are: (1) You the funder trust their judgment. Then you shouldn’t be putting even minor mental barriers in the way of their pivoting. Pivoting is hard and very good and important! (2) You the funder don’t particular trust the recipient’s judgment, you were only funding it because you wanted that specific deliverable. But then the normal procedure is that the funder and recipient work together to determine the deliverables that the funder wants and that the recipient is able to provide. Like, if I’m funding someone to build a database of AI safety papers, then I wouldn’t ask them to “make falsifiable predictions about the outcomes from their work”, instead I would negotiate a contract with them that says they’re gonna build the database. Right? I mean, I guess you could call that a falsifiable prediction, of sorts, but it’s a funny way to talk about it.
A solution I've come around to for this is retroactive funding. As in, if someone did something essentially without funding, that resulted in outcomes, which if you knew were guaranteed, you would have funded/donated to the project, then donate to the person to encourage them to do it more.
3
I think this is easier to anonymize, with the exception of very specific things that people become famous for.
1
EA billionaires selects way more for alignment to the billionaires' own ends, than for competence. Social networks are a good way to filter for this. This is intentional design on the part of Moswkowitz and Tallinn, don't treat it as an innocent mistake on their part.
1[comment deleted]
i earnt more from working at a call center for about 3 months than i have in 2+ years of working in ai safety.
And i've worked much harder in this than I did at the call center
1
Way to go! :D. The important thing is that you've realized it. If you naturally already get those enquiries, you're halfway there: people already know you and reach out to you without you having to promote your expertise. Best of luck!
0
:) the real money was the friends we made along the way.
I dropped out of a math MSc. at a top university in order to spend time learning about AI safety. I haven't made a single dollar and now I'm working as a part time cashier, but that's okay.
What use is money if you end up getting turned into paperclips?
PS: do you want to sign my open letter asking for more alignment funding?
if serious about us china cooperation and not cargo culting, please read: https://www.cac.gov.cn/2025-09/15/c_1759653448369123.htm
i messed things up a lot in organizing the moonshot program. working hard to make sure the future events will be much better. lots of things i can do.
5
announced it too late, underestimated how hard it would be to make the research guides, guaranteed personalized feedback to the first 300 applicants, also had the date for starting set too early, considering how much stuff was ready.
5
Guaranteeing personalized feedback for 300 people does seem like a massive burden.
1
Depending on what the application involved, would it work to anon them, make them public and sort of let the community give feedback?
1
The reasons for this and what I'm going to do to make sure it doesn't happen again:
One:
- Promised that the first 300 applicants would be guaranteed personalized feedback. Thought that I could delegate to other, more technical members of the team for this.
However, it turned out that in order to give useful feedback and to be able to judge if someone was a good fit for the program, a person didn't just need technical knowledge - they needed good communication skills, an understanding of what's needed for alignment research, being consistently available for several hours a day, to actually go through the applications and being interested in doing so. Turned out that the only person who fit all those characteristics at the time was me. So I couldn't delegate.
Also, a teammate made a reviewing software, which he said would help build a Bradley-Terry model of the applicants, as we reviewed them. I had a feeling that this might be overcomplicated but didn't want to say no or react negatively to someone's enthusiasm for doing free work for something I care about.
It turned out that constantly fixing, trying to improve, finangle with, etc, the software actually took several days. And it was faster to just do it manually.
What I'll be doing next time to make sure this doesn't happen:
- Only promising feedback to the first 50 applicants.
- Having preprepared lines for the rest, with the general reason they weren't accepted - e.g. lack of suffifient maths experience without software engineering/neuroscience/philosophy to compensate, meaning that they might not be likely to get useful alignment theory work done in 5 weeks.
- Doing things manually, not experimenting with custom software last minute.
- Announcing the program more early - giving ourselves at least 3 months to prepare things.
Two:
- making the Research Guides for the different tracks turned out to be much, much, much harder than I thought it would be. Including for other, more technical teammates. Thought
Do you think you can steal someone's parking spot?
If yes, what exactly do you think you're stealing?
You're "stealing" their opportunity to use that space. In legal terms, assuming they had a right to the spot, you'd be committing an unauthorized use of their property, causing deprivation of benefit or interference with use.
1
Makes sense. Do you think it's stealing to train on someone's data/work without their permission? This isn't a 'gotcha', btw - if you think it's not, I want to know and understand.
2
I don't think there's a simple answer to that. My instinct is that most publicly accessible material (not behind a paywall) is largely "fair use", but it gets messier for things like books not yet in the public domain. LLM pre-training is both transformative and extractive.
There is no sensible licensing infrastructure for this yet, AFAIK, so many companies are grabbing whatever they can and dealing with legalities later. I think, at minimum, they should pay some upfront fee to train on a copyrighted book, just like humans do when they buy rather than pirate or borrow from libraries.
1
What prior reading have you done on this question? I did a DDG search "AI duplicating artists style controversy" and have found dozens of journalism pieces which appear, for the most part, seem to be arguing broadly with "it is theft". What is your understanding of the discourse on this at the moment? What have you read? What has been persuasive? What don't you understand?
1
The main thing I don't understand is the full thought processes that leads to not seeing this as stealing opportunity from artists by using their work non consensually, without credit or compensation.
I'm trying to understand if folk who don't see this as stealing don't think that stealing opportunity is a significant thing, or don't get how this is stealing opportunity, or something else that I'm not seeing.
2
And what arguments have they raised? Whether you agree or feel they hold water or not is not what I'm asking - I'm wondering what arguments have you heard from the "it is not theft" camp? I'm wondering if they are different from the ones I've heard
2
Literally steal? No, except in cases that you probably don't mean such as where it's part of a building and someone physically removes that part of the building. "Steal" in the colloquial but not in the legal sense, sure.
Legally it's usually more like tortious interference, e.g. you have a contract that provides the service of using that space to park your car, and someone interferes with that by parking their own car there and deprives you of its use in an economically damaging way (such as having to pay for parking elsewhere).
Sometimes it's trespass, such as when you actually own the land and can legally forbid others from entering.
It is also relatively common for it to be both: tortious interference with the contracted user of the parking space, and trespass against the lot owner who sets conditions for entry that are being violated.
4
spent lots of hours on making the application good, getting testimonials and confirmation we could share them for the application, really getting down the communication of what we've done, why it's useful, etc.
There was a doc where donors were supposed to ask questions. Never got a single one.
The marketing, website, etc was all saying 'hey, after doing this, you can rest easy, be in peace, etc, we'll send your application to 50+ donors, it's a bargain for your time, et'
Critical piece of info that was very conveniently not communicated as loudly: there's no guarantee of when you'll hear back - could be 6 weeks, 6 months, who knows!!
Didn't even get a confirmation email about our application being received. Had to email for that.
Then in the email I saw this. April 3rd, btw.
Then May 1st, almost a month later, it seems this gets sent out to everyone.
Personally, I would discourage anyone from spending any time on a Non Linear application - as far as I know, our application wasn't even sent to any donors.
They completely and utterly disrespected my time and it seems, the time of many others.
AIgainst the Gods
Cultivation story, but instead of cultivation, it's a post AGI story in a world that's mostly a utopia. But, there are AGI overlords, which are basically benevolent.
There's a very stubborn young man, born in the classical sense (though without any problems like ageing disease, serious injuries, sickness, etc that people used to have - and without his mother having any of the screaming pain that childbirth used to have, or risk of life), who hates the state of power imbalance.
He doesnt want the Gods to just give him power ...
1
to be clear, instead of cultivating Qi, it's RSI
1
and trying to learn to do it faster than the Gods are
1
gods being the AGIs
1
Some of the confused people around him think that surely anything he can find, the Gods would have found ages ago - and even if he finds something new, surely they'll learn it from observing him and just do it much much faster - he could just ask them to uplift him and they'd do it, this is a bit of a waste of time (even though everyone lives as long as they want)
Trying to put together a better explainer for the hard part of alignment, while not having a good math background https://docs.google.com/document/d/1ePSNT1XR2qOpq8POSADKXtqxguK9hSx_uACR8l0tDGE/edit?usp=sharing
Please give feedback!

this might basically be me, but I'm not sure how exactly to change for the better. theorizing seems to take time and money which i don't have.
Thinking about judgement criteria for the coming ai safety evals hackathon (https://lu.ma/xjkxqcya )
These are the things that need to be judged:
1. Is the benchmark actually measuring alignment (the real, scale, if we dont get this fully right right we die, problem)
2. Is the way of Deceiving the benchmark to get high scores actually deception, or have they somehow done alignment?
Both of these things need:
- a strong deep learning & ml background (ideally, muliple influential papers where they're one of the main authors/co-authors, or do...
hmmm, i am massively, gigantically, unconfident in my writing ability, when i don't have an interlocutor who i'm specifically writing stuff for, messaging, etc
I think this is a really, really, really, really big personal bottleneck.
potentially trauma related from when my dad would make me do 'handwriting' and lines and make me write pages and pages and say my writing was terrible according to some arbitrary seeming (to me) thing about the 'handwriting'.
3
potentially, a solution here, is to do writing, about things i actually care about, share it with someone who i respect and see as a senior figure and predict with my feelings of inconfidence earlier, what i think they're going to say. i predict that they'll say its ok, being nice and also have valid criticisms. and more that is also valid that they won't say. and things that are good, that they won't recognise, because there's things that i recognise correctly as valuable, that they don't, which i either lack the confidence to articulate why it's good, or lack the knowledge, or more likely, lack the confidence/knowledge on how to convincingly articulate it to get past their barriers of having difficulty understanding and biases.
2
Maybe ask an AI to review your writings from the rationalist perspective.
1
In the sense that people are contorting their opinions too much to make them palatable to outsiders, or that people within the AI safety community itself end up trying to pursue research that looks good to their peers instead of what does the most marginal good (ie doing increasingly elaborate research on the specifics of X risk instead of the boring grunt work of lobbying in D.C)
1
Those things are also bad, this was more about companies programs prioritising recruiting people who look good vs actually being likely to lead to solving alignment.
have since changed my mind that this may be happening less than i thought.
and its more a capability issue than a values problem - of orgs not bragging as much about their weird recruits who do well but dont really have impressive looking things and programs/events that don't require prestige to take part but also are valuable, not communicating this well.
my mum said to my little sister to take a break from her practice test for the eleven plus and come eat dinner, in the kitchen, with the rest of the family, my gran me and her (dad is upsairs, he's rarely here for family dinner). my little sister, in a trembling voice said 'but then dad will say '
mum sharply says to leave it and come eat dinner. she leaves the living room where my little sister is, goes to the kitchen. my little sister tries to shut off the lights in the living room, when it stutters, beats her little hands onto it in frustration.
mum...
Someone asked me about LLM self explaining and evaluating that earlier today, I made this while explaining what I'd look for in that kinda research.
Sharing because they found it useful and others might too.
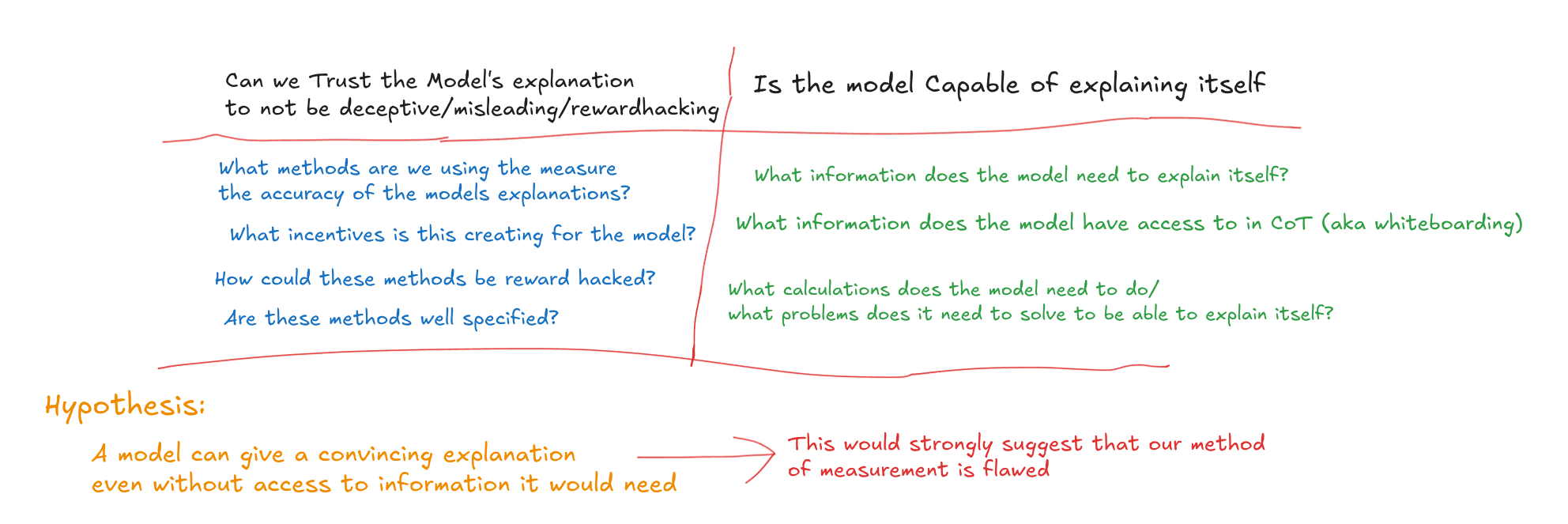
what do you think of this for the alignment problem?
If we make an AI system that's capable of making another, more capable AI system, which then makes another more capable AI and that makes another one and so on, how can we trust that that will result in AI systems that only do what we want and don't do things that we don't want?
4
That's the Tiling Agents problem!
my dad keeps traumatizing my little sister and making her cry, while 'teaching' her maths. hitting the table and demanding to know why she wrote the wrong answer. he doesnt fucking understand or respect that this is not how you teach people. he doesnt respect her or anyone else
2
Intergenerational trauma in the making :(
1
I'll get stuff sorted eventually, this pain is just hard for now.
2
he justifies it to himself that this is whats best for her and that this is whats needed for her to pass exams and get into a good school. what he doesn't fucking understand and refuses to, is that it's 2025 and we're in the uk - if she was passionate about maths, enjoyed it, liked doing it and did it herself (an inclination she has very much shown - i used to make maths treasure hunts for her which she really really loved and would ask me to make more and get her friends to join in as well, often with topics like simultaneus equations and other very basic algebra (she was 6-10 when i was doing this - started with Elsa characters to get her used to algebra, Elsa and Anna instead of X and Y, e.g.)), then she would have a much much better chance of a future career than becoming traumatized with maths, hating it and getting into a Grammar School. Even if she was in a normal primary school, if she loved maths and had that passion cultivated, respected and let loose, she would have a much much better future than the one he's making for her.
But he has this image of things in his head and is far far too insecure to ever let it be questioned.
4
Well, that sucks. One thing he definitely succeeds at is associating math with bad feelings. Which in long term will be more important than all the small benefits he might gain in short term. :(
Many people seem to make the same mistake, I guess we have some natural bias towards that kind of thinking.
May I recommend you this book for your sister? Three Days in Dwarfland
And the book I wish your father would read is Don't Shoot the Dog.
I also made a few interactive exercises for addition and subtraction (works much better on computer than phone).
And of course, there is Khan Academy.
1
For me, it was 'handwriting' - I still have a lot of trouble and fear when it comes to writing things, especially official things that are long, I think in part because of that.
[...]
I don't think it's so much a natural bias, more that insecurity and fragile egos, combined with being in new situations and in a position of power, naturally lead to this.
I'm annoyed by the phrase 'do or do not, there is no try', because I think it's wrong and there very much is a thing called trying and it's important.
However, it's a phrase that's so cool and has so much aura, it's hard to disagree with it without sounding at least a little bit like an excuse making loser who doesn't do things and tries to justify it.
Perhaps in part, because I feel/fear that I may be that?
6
I think it's a good quote. I will refer to this post from The Sequences: Trying to Try
3
Why is it wrong? Or perhaps more specifically - what are some examples of conditions or environments where you think it is counterproductive?
0
Because it's not true - trying does exist.
In the comment's of Eliezer's post, I saw "Stop trying to hit me and hit me!" by Morpheus, which I like more.
The mind uploading stuff seems to be a way to justify being ok with dying, imo, and digging ones head into the sand, pretending that if something talks a bit like you, it is you.
If a friend can very accurately do an impression of me and continues to do so for a week, while wearing makeup to look like me, I have not 'uploaded' myself into them. And I still wouldn't want to die, just because there's someone who is doing an extremely good impression of myself.
2
Your future biological brain is also doing some sort of impression of a continuation of the present you. It's not going to be doing an optimal job of it, for any nontrivial notion of what that should mean.
3
My future biological brain actually is a continuation of my current biological brain, in a way that an upload isn't.
You seem to be saying:-
1. Identity does persist over time.
2. There is no basis for identity other than resemblance.
3. An upload has a similar level of resemblance to a future brain.just, so it's good enough.
It neither 1 not 2 is a fact.
1
That's like saying a future version of a tree is doing an impression of a continuation of the previous tree.
I don't understand how the difference isn't clear here.
1
Status quo is one difference, but I don't see any other prior principles that point to the future biological brain being a (morally) better way of running a human mind forward than using other kinds of implementations of the mind's algorithm. If we apply a variant of the reversal test to this, a civilization of functionally human uploads should have a reason to become biological, but I don't think there is a currently known clear reason to prefer that change.
2
The objection is about what, if anything, counts as identity as a matter of fact.
1[anonymous]
If I take a tree, and I create a computer simulation of that tree, the simulation will not be a way of running the original tree forward at all.
2
A tree doesn't simulate a meaningful algorithm, so the analogy would be chopping it down being approximately just as good.
When talking about running algorithms, I'm not making claims about identity or preserving-the-original in some other sense, as I don't see how these things are morally important, necessarily (I can't rule out that they might be, on reflection, but currently I don't see it). What I'm saying is that a biological brain doesn't have an advantage at the task of running the algorithms of a human mind well, for any sensible notion of running them well. We currently entrust this task to the biological brain, because there is no other choice, and because it's always been like this. But I don't see a moral argument there.
prob not gonna be relatable for most folk, but i'm so fucking burnt out on how stupid it is to get funding in ai safety. the average 'ai safety funder' does more to accelerate funding for capabilities than safety, in huge part because what they look for is Credentials and In-Group Status, rather than actual merit.
And the worst fucking thing is how much they lie to themselves and pretend that the 3 things they funded that weren't completely in group, mean that they actually aren't biased in that way.
At least some VCs are more honest that they want to be leeches and make money off of you.
6
Who or what is the "average AI safety funder"? Is it a private individual, a small specialized organization, a larger organization supporting many causes, an AI think tank for which safety is part of a capabilities program...?
0
all of the above, then averaged :p
6
I asked because I'm pretty sure that I'm being badly wasted (i.e. I could be making much more substantial contributions to AI safety), but I very rarely apply for support, so I thought I'd ask for information about the funding landscape from someone who has been exploring it.
And by the way, your brainchild AI-Plans is a pretty cool resource. I can see it being useful for e.g. a frontier AI organization which thinks they have an alignment plan, but wants to check the literature to know what other ideas are out there.
3
I think this is the case for most in AI Safety rn
[...]
Thanks! Doing a bunch of stuff atm, to make it easier to use and a larger userbase.
ok, options.
- Review of 108 ai alignment plans
- write-up of Beyond Distribution - planned benchmark for alignment evals beyond a models distribution, send to the quant who just joined the team who wants to make it
- get familiar with the TPUs I just got access to
- run hhh and it's variants, testing the idea behind Beyond Distribution, maybe make a guide on itr
- continue improving site design
- fill out the form i said i was going to fill out and send today
- make progress on cross coders - would prob need to get familiar with those tpus
- writeup o...
btw, thoughts on this for 'the alignment problem'?
"A robust, generalizable, scalable, method to make an AI model which will do set [A] of things as much as it can and not do set [B] of things as much as it can, where you can freely change [A] and [B]"
5
Freely changing an AGIs goals is corrigibility, which is a huge advantage if you can get it. See Max Harms' corrigibility sequence and my "instruction-following AGI is easier...."
The question is how a reliably get such a thing. Goalcrafting is one part of the problem, and I agree that those are good goals; the other and larger part is technical alignment, getting those desired goals to really work that way in the particular first AGI we get.
3
Yup, those are hard. Was just thinking of a definition for the alignment problem, since I've not really seen any good ones.
5
I'd say you're addressing the question of goalcrafting or selecting alignment targets.
I think you've got the right answer for technical alignment goals; but the question remains of what human would control that AGI. See my "if we solve alignment, do we all die anyway" for the problems with that scenario.
Spoiler alert; we do all die anyway if really selfish people get control of AGIs. And selfish people tend to work harder at getting power.
But I do think your goal defintion is a good alignment target for the technical work. I don't think there's a better one. I do prefer instruction following or corriginlilty by the definitions in the posts I linked above because they're less rigid, but they're both very similar to your definition.
1
I pretty much agree. I prefer rigid definitions because they're less ambiguous to test and more robust to deception. And this field has a lot of deception.
jesus christ, im trying to find a preference dataset and it seems like they all suck ass
like, every one of them, when i actually look at the data
they have some massive problems, or inconsistencies, or are unclear as to how to actually use them to try to change the models expressed preferences
what am i missing. there is no way that this should be this hard

like, look at this one - the rejected one should be the chosen one, no, since it's a reponse that's pushing back more against racism? and that's the general vibe of what the other chosen responses seem to ...
1
for Jenny hhh, which is what we'd used before, lots of the chosen and rejected answers seem to be almost exactly the same
What we need to solve alignment:
A way to actually see if we're doing useful work
More time
More funding to useful ai safety research
Clearly, public signalling of what is and isn't useful alignment work
Too, too much of the current alignment work is not only not useful, but actively bad and making things worse. The most egregious example of this to me, is capability evals. Capability evals, like any eval, can be useful for seeing which algorithms are more successful in finding optimizers at finding tasks - and in a world where it seems ...
this is one of the most specifc and funny things I've read in a while: https://tomasbjartur.substack.com/p/the-company-man
a youtuber with 25k subscribers, with a channel on technical deep learning, is making a promo vid for the moonshot program.
Talking about what alignment is, what agent foundations is, etc. His phd is in neuroscience.
do you want to comment on the script?
https://docs.google.com/document/d/1YyDIj2ohxwzaGVdyNxmmShCeAP-SVlvJSaDdyFdh6-s/edit?tab=t.0
1
btw, for links and stuff,
e.g. to lesswrong posts, see the planning tab please and the format of:
Link:
What info to extract from this link:
How a researcher can use this info to solve alignment:
It's 2025, AIs can solve proofs and my dad is yelling at my 10 year old sister for not memorizing her times tables up to 20
4
I don't expect the yelling helps with the memorizing.
Also, even though a big company can grow potatoes much more efficiently, I still like having a backyard garden.
2
Until we get UBI, people will compete against each other, and times tables are a tiny part of that. So the question is whether you are sure that Singularity will happen within the next 15 years enough that you don't see a reason to have a Plan B. Because the times tables are a part of the Plan B.
That said, yelling is unproductive. What about spaced repetition? Make cards containing all problems, put the answer on the other side, go through the cards, put then ones with incorrect answer on a heap that you will afterwards reshuffle and try again. Do this every day. In a few weeks the problem should be solved.
Why up to 20? (Is that a typo?)
1
not a typo. He's 50+, grew up in india, without calculators. Yes, he's yelling at her for not 100% knowing her 17 times table.
I'm going to be more blunt and honest when I think AI safety and gov folk are being dishonest and doing trash work.
3
Would you care to start now by giving an example?
1
I think A Narrow Path has been presented with far too much self satisfaction for what's essentially a long wishlist with some introductory parts.
1
Yes, I'll make my own version that I think is better.
1
I think the Safetywashing paper mixed in far too many opinions with actual data and generally mangled what could have been an actually good research idea.
the average ai safety funder does more to accelerate capabilities than they do safety, in part due to credentialism and looking for in group status.
# General how to Evaluate Evaluations
Is it measuring one very specific thing?
Probably not. Is the thing something that actually has multiple things that could be causing it, or just one? An evaluation is fundamentally, a search process. Searching for a more specific thing and trying to make your process not ping for anything other than one specific thing, makes it more useful, when searching in the v noisy things that are AI models. Most evals dont even claim to measure one precise thing at all. The ones that do - can you think of a way to split that
1
status - typed this on my phone just after waking up, saw someone asking for my opinion on another trash static dataset based eval and also my general method for evaluating evals. bunch of stuff here that's unfinished.
working on this course occasionally: https://docs.google.com/document/d/1_95M3DeBrGcBo8yoWF1XHxpUWSlH3hJ1fQs5p62zdHE/edit?tab=t.20uwc1photx3

2
A fire alarm, seriously?
this may make little to negative sense, if you don't have a lot of context:
thinking about when I've been trying to bring together Love and Truth - Vyas talked about this already in the Upanishads. "Having renounced (the unreal), enjoy (the real). Do not covet the wealth of any man". Having renounced lies, enjoy the truth. And my recent thing has been trying to do more of exactly that - enjoying. And 'do not covet the wealth of any man' includes ourselves. So not being attached to the outcomes of my work, enjoying it as it's own thing - if it succeeds, if i...
I'm making an AI Alignment Evals course at AI Plans, that is highly incomplete - nevertheless, would appreciate feedback: https://docs.google.com/document/d/1_95M3DeBrGcBo8yoWF1XHxpUWSlH3hJ1fQs5p62zdHE/edit?tab=t.20uwc1photx3
It will be sold as a paid course, but will have a pretty easy application process for getting free access, for those who can't afford it
'ai control' seems like it just increases p doom, right?
since it obv wont scale to agi/asi and will just reduce the warning shots and financial incentives to invest in safety research, make it more economically viable to have misaligned ais, etc
and there's buzztalk about using misaligned ais to do alignment research, but the incentives to actually do so dont seem to be there and the research itself doesnt seem to be happening - as in, research to actually get closer to a mathematical proof of a method to align a superintelligence such that it wont kill everyone
Hi, making a guide/course for evals, very much in the early draft stage atm
Please consider giving feedback
https://docs.google.com/document/d/1_95M3DeBrGcBo8yoWF1XHxpUWSlH3hJ1fQs5p62zdHE/edit?usp=sharing
Hi, hosting an Alignment Evals hackathon for red teaming evals and making more robust ones, on November 1st: https://luma.com/h3hk7pvc
Team from previous one presented at ICML
Team in January made one of the first Interp based Evals for LLMs
All works from this will go towards the AI Plans Alignment Plan - if you want to do extremely impactful alignment research I think this is one of the best events in the world.
i want to write more, and know its beneficial for me to write more. every time that i recall doing so right now, in the last two years, it's increased the amount of people who know about my work, come to work with me, pay for the work in some way, etc.
however, i feel really really anxious, scared, etc of doing it. feels a bit stupid.
part of it as well is that i really really care about truth and about what i write being very very true and robust to misinterpretation. this is in large part something that i purposefully trained into myself, to av...
1
part of it, the biggest part, i think, is that my dad doesn't believe in me, or really know anything about me.
he thinks i'm a failure, chutiah, etc.
that hurts a lot, basically every time i think about it.
esp fresh rn cos he was saying it last night..
mum feels like she believes in some future version of me, but does so less and less and now the belief is very low.
there should be a way to believe in myself without that though.
or maybe even needing that is an illusion.
what if i am ok with failing.
3
If he doesn't know anything about you, why would it matter what he thinks about you?
A part of becoming adult is realizing that your parents are just random people with no magical powers. Their opinions are just... their opinions. Could be right, could be wrong, could be anything. If someone who isn't your parent said the same thing, would you care?
3
He's def wrong.
I'm still going to care because he's my father and I love him and care about him. And also becase I don't like ideas that are about discouraging caring.
I'm going to feel the pain that comes with caring, but that's fine. And yes his opinion is wrong and is not going to stop me anymore.
There are plenty of others who care about and respect my work and unlike my dad's disrespect, that can actually go into making me money and increasing what I can do.
Thank you for the support btw, I really appreciate it <3
2
Sometimes the solution is just not to talk about certain topics. (But this requires cooperation from the other side.) For example, I don't discuss politics with my mother, because that would be predictably frustrating for both sides.
Maybe there is a good boundary for you, for example don't discuss your job? (Or stick to technicalities, such as salary.)
1
We just dont talk at all atm. Not likely to change in the future tbh. He doesnt respond to my calls or texts.
1
This belief and self confidence thing isn't all there is to it though. It's also a standards issue. Which is also driven by the belief. The belief that putting in the extra effort will be worth it.
That it's worth it to just have something be higher standard for myself.
Then there is a contrasting, opposite thing. Of wanting to have a very very high standard of rigour.
One voice decrying polish because it's seen as associative with slop and the other decrying the lack of rigour. So what's left is rigorous unpolished hard to read things, that are only obviously valuable to someone who is willing to put up with the high lack of polish for a long time.
Interesting, that summarizes my work a lot, for the last two years.
These are imperfect, I'd like feedback on them please:
https://moonshot-alignment-program.notion.site/Proposed-Research-Guides-255a2fee3c6780f68a59d07440e06d53?pvs=74
just joined the call with one of the moonshot teams and i was actually basically an interruption, lol. felt so good to be completely unneeded there
4
That reminds me of a story I read about some (ancient Chinese?) philosopher. He applied for some high-status position in the country but didn't win. When his friends consoled him, he told them that if they are true patriots, they should be happy. Why? Because if he wasn't chosen, it means that his country has many people who are more qualified than him... and that is a good thing.
the Kick off Call for the Moonshot Alignment Program will be starting in 8 minutes! https://discord.gg/QdF4Yd6Q?event=1405189459917537421
If someone wants me to change my actions because of a future forecast they've made and don't share evidence they used to make their judgements, I don't take them very seriously.
1
It seems though, that for a lot of 'forecasters' they don't have specific within-the-next-week actions they're trying to get people to do, they mainly just feel like forecasting is a very interesting and good thing to do. It's a high status hobby.
An actual better analogy would be a company in a country whose gdp is growing faster than that of the country
one of the teams from the evals hackathon was accepted at an ICML workshop!
hosting this next: https://courageous-lift-30c.notion.site/Moonshot-Alignment-Program-20fa2fee3c6780a2b99cc5d8ca07c5b0
Will be focused on the Core Problem of Alignment
for this, I'm gonna be making a bunch of guides and tests for each track
if anyone would be interested in learning and/or working on a bunch of agent foundations, moral neuroscience (neuroscience studying how morals are encoded in the brain, how we make moral choices, etc) and preference optimization, please let me know! DM or email at kabir@ai-plans.com
On the Moonshot Alignment Program:
several teams from the prev hackathon are continuing to work on alignment evals and doing good work (one presenting to a gov security body, another making a new eval on alignment faking)
if i can get several new teams to exist who are working on trying to get values actually into models, with rigour, that seems very valuable to me
also, got a sponsorship deal with youtuber who makes technical deep learning videos, with 25K subscribers, he's said he'll be making a full video about the program.
also, people are gonna be c...
Hi, have your worked in moral neuroscience or know someone who has?
If so, I'd really really like to talk to you!
https://calendly.com/kabir03999/talk-with-kabir
I'm organizing a research program for the hard part of alignment in August.
I've already talked to lots of Agent Foundations researchers, learnt a lot about how that research is done, what the bottlenecks are, where new talent can be most useful.
I'd really really like to do this for the neuroscience track as well please.
This is a great set of replies to an AI post, on a quality level I didn't think I'd see on bluesky https://bsky.app/profile/steveklabnik.com/post/3lqaqe6uc3c2u
We've run two 150+ Alignment Evaluations Hackathons, that were 1 week long. Multiple teams continuing their work and submitting to NeurIPS. Had multiple quants, Wall Street ML researcher, an AMD engineer, PhDs, etc taking part.
Hosting a Research Fellowship soon, on the Hard Part of AI Alignment. Actually directly trying to get values into the model in a way that will robustly scale to an AGI that does things that we want and not things we don't want.
I've read 120+ Alignment Plans - the vast majority don't even try to solve the hard part of alig...
in general, when it comes to things which are the 'hard part of alignment', is the crux
```
a flawless method of ensuring the AI system is pointed at and will always continue to be pointed at good things
```
?
the key part being flawless - and that seeming to need a mathematical proof?
Thoughts on this?
### Limitations of HHH and other Static Dataset benchmarks
A Static Dataset is a dataset which will not grow or change - it will remain the same. Static dataset type benchmarks are inherently limited in what information they will tell us about a model. This is especially the case when we care about AI Alignment and want to measure how 'aligned' the AI is.
### Purpose of AI Alignment Benchmarks
When measuring AI Alignment, our aim is to find out exactly how close the model is to being the ultimate 'aligned' model that we're seeking - a model w...
I'm looking for feedback on the hackathon page
mind telling me what you think?
https://docs.google.com/document/d/1Wf9vju3TIEaqQwXzmPY--R0z41SMcRjAFyn9iq9r-ag/edit?usp=sharing
I'd like some feedback on my theory of impact for my currently chosen research path
**End goal**: Reduce x-risk from AI and risk of human disempowerment.
for x-risk:
- solving AI alignment - very important,
- knowing exactly how well we're doing in alignment, exactly how close we are to solving it, how much is left, etc seems important.
- how well different methods work,
- which companies are making progress in this, which aren't, which are acting like they're making progress vs actually making progress, etc
- put all on ...
5
What is the proposed research path and its theory of impact? It’s not clear from reading your note / generally seems too abstract to really offer any feedback
I think this is a really good opportunity to work on a topic you might not normally work on, with people you might not normally work with, and have a big impact:
https://lu.ma/sjd7r89v
I'm running the event because I think this is something really valuable and underdone.
2 hours ago I had a grounded, real, moment when I realized agi is actually going to be real and decide the fate of everyone I care about and I personally, am going to need to significantly play a big role in making sure that it doesn't kill them and felt fucking terrified.
I'm finally reading The Sequences and it screams midwittery to me, I'm sorry.
Compare this:
to Jaynes:
Jaynes is better organized, more respectful to the reader, more respectful to the work he's building on and more useful


9
The Sequences highly praise Jaynes and recommend reading his work directly.
The Sequences aren't trying to be a replacement, they're trying to be a pop sci intro to the style of thinking. An easier on-ramp. If Jaynes already seems exciting and comprehensible to you, read that instead of the Sequences on probability.
3
Fair enough. Personally, so far, I've found Jaynes more comprehensible than The Sequences.
3
I think most people with a natural inclination towards math probably would feel likewise.
rearranging and cleaning up my room with basic feng shui really does make it easier to focus and work, i keep forgetting this.
i recommend giving it a go if you havent already
Sometimes I am very glad I did not enter academia, because it means I haven't truly entered and assimilated to a bubble of jargon.
-1
definitely has not helped my bank account to not have a degree though, lol
Please don't train an AI on anything I write without my explicit permission, it would make me very sad.
It is utterly dogshit how fucking bad all the explanations of what Agent Foundations is, are. Why do none of them try to be plain, precise, unambiguous and professional?
Why do they all insist on fucking analogies rather than just saying the actual thing they mean? It comes off as the research not being serious or real or the person saying it either no knowing what they're talking about, not being good at communicating or not putting in the fucking effort to try to explain things without wasting the readers time.
I feel like this is fundamentally...
2
Isn't this the main original explanation of Agent Foundations? It's plain, unambiguous and professional. What explanations are you referring to?
1
I looked at that and it's in large part either about persuasion or story telling rather than a precise useful explanation
2
Just a random thought: could you ask an AI to rewrite it to the form you want?
1
And no, this is not because Agent Foundations is some super duper ultra mega mysterious hard to describe thing.
1
Yes, I think the swearing is warranted. This is an embarassment.