This is a special post for quick takes by ESRogs. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
I've been meaning for a while to be more public about my investing, in order to share ideas with others and get feedback. Ideally I'd like to write up my thinking in detail, including describing what my target portfolio would be if I was more diligent about rebalancing (or didn't have to worry about tax planning). I haven't done either of those things. But, in order to not let the perfect be the enemy of the good, I'll just share very roughly what my current portfolio is.
My approximate current portfolio (note: I do not consider this to be optimal!):
- 40% TSLA
- 35% crypto -- XTZ, BTC, and ETH (and small amounts of LTC, XRP, and BCH)
- 25% startups -- Kinta AI, Coase, and General Biotics
- 4% diversified index funds
- 1% SQ (an exploratory investment -- there are some indications that I'd want to bet on them, but I want to do more research. Putting in a little bit of money forces me to start paying attention.)
- <1% FUV (another exploratory investment)
- -5% cash
Some notes:
- Once VIX comes down, I'll want to lever up a bit. Likely by increasing the allocation to index funds (and going more short cash).
- One major way this portfolio differs from the portfolio in my heart is that it has no exposure to Stripe. If it was easy to do, I would probably allocate something like 5-10% to Stripe.
- I have a high risk tolerance. I think both dispositionally, and because I buy 1) the argument from Lifecycle Investing that young(ish) people should be something like 2x leveraged and, 2) the argument that some EAs have made that people who plan to donate a lot should be closer to risk neutral than they otherwise would be. (Because your donations are a small fraction of the pool going to similar causes, so the utility in money is much closer to linear than for money you spend on yourself, which is probably something like logarithmic.)
- I am not very systematic. I follow my interests and go with my gut a lot. This has worked out surprisingly well. My crypto investment started with buying BTC at 25 cents in 2010, and my Tesla investment started at $35 in 2013. I've also invested in some startups that didn't work out, but my highest conviction gut bets (Tesla and bitcoin) have been the best performers, and have far more than made up for the misses.
- I would like to be more systematic. I think I would have done better up to now if I had been. Especially with tax planning.
the argument that some EAs have made that people who plan to donate a lot should be closer to risk neutral than they otherwise would be
See Risk-aversion and investment (for altruists) for both a statement of the argument and some counterpoints to it (and counter-counterpoints as well).
Thanks for posting this. Why did you invest in those three startups in particular? Was it the market, the founders, personal connections? And was it a systematic search for startups to invest in, or more of an "opportunity-arose" situation?
These were all personal connections / opportunity-arose situations.
The closest I've done to a systematic search was once asking someone who'd done a bunch of angel investments if there were any he'd invested in who were looking for more money and whom he was considering investing more in. That was actually my first angel investment (Pantelligent) and it ended up not working out. (But of course that's the median expected outcome.)
(The other two that I invested in that are not still going concerns were AgoraFund and AlphaSheets. Both of those were through personal connections as well.)
35% crypto -- XTZ, BTC, and ETH (and small amounts of LTC, XRP, and BCH)
Why do you bet on cryptos with weak fundamentals like LTC, XRP, and BCH, and not on cryptos with stronger fundamentals like Monero and Nano?
No super strong reason. I entered those positions a while ago, and was mostly just trying to diversify, paying some attention to market cap weight.
Got it. I wonder why there aren't discussions about cryptocurrencies here on LW. Like, extensively researching the existing protocols and their characteristics and then naming which one is the best and why, and betting on it. Or even using it on the forum. I would suggest you to research these two cryptos I have cited if you are interested on updating your bets.
After reading through some of the recent discussions on AI progress, I decided to sketch out my current take on where AI is and is going.
Hypotheses:
- The core smarts in our brains is a process that does self-supervised learning on sensory data.
- We share this smarts with animals.
- What distinguishes us from other animals is some kludgy stuff on top that enables us to:
- 1) chain our data prediction intuitions into extended trains of thought via System 2 style reasoning
- 2) share our thoughts with others via language
- (and probably 1 and 2 co-evolved in a way that depended on each other)
- I say that the sensory data learning mechanism is the core smarts, rather than the trains-of-thought stuff, because the former is where the bulk of the computation takes place, and the latter is some relatively simple algorithms that channel that computation into useful work.
- (Analogous to the kinds of algorithms Ought and others are building to coax GPT-3 into doing useful work.)
- Modern ML systems are doing basically the same thing as the predictive processing / System 1 / core smarts in our brains.
- The details are different, but if you zoom out a bit, it's basically the same algorithm. And the natural and artificial systems are able to successfully model, compress, and predict data for basically the same reasons.
- AI systems will get closer to being able to match the full range of abilities of humans (and then exceed them) due to progress both on:
- 1) improved intuition / data compression and prediction that comes from training bigger ML models for longer on more data, and
- 2) better algorithms for directing those smarts into useful work.
- This means that basically no new fundamental insights are needed to get to AGI / TAI. It'll just be a bunch of iterative work to scale ML models, and productively direct their outputs.
- So the path from here looks pretty continuous, though there could be some jumpy parts, especially if some people are unusually clever (or brash) with the better algorithms (for making use of model outputs) part.
I'm curious if others agree with these claims. And if not, which parts seem most wrong?
This sounds reasonable to me but I find myself wondering just how simple the "relatively simple algorithms" for channelling predictive processing are. Could you say a bit more about what the iterative path to progress looks like for improving those algorithms? (The part that seems the most wrong in what you wrote is that there are no new fundamental insights needed to improve these algorithms.)
One of the most important things going on right now, that people aren't paying attention to: Kevin Buzzard is (with others) formalizing the entire undergraduate mathematics curriculum in Lean. (So that all the proofs will be formally verified.)
See one of his talks here:
Missed this when it came out, but apparently Lean was used to formally verify an uncertain section of a proof in some cutting edge work in the first half of 2021:
And it all happened much faster than anyone had imagined. Scholze laid out his challenge to proof-assistant experts in December 2020, and it was taken up by a group of volunteers led by Johan Commelin, a mathematician at the University of Freiburg in Germany. On 5 June — less than six months later — Scholze posted on Buzzard’s blog that the main part of the experiment had succeeded. “I find it absolutely insane that interactive proof assistants are now at the level that, within a very reasonable time span, they can formally verify difficult original research,” Scholze wrote.
Sorry for the stupid question, and I liked the talk and agree it's a really neat project, but why is it so important? Do you mean important for math, or important for humanity / the future / whatever?
Mostly it just seems significant in the grand scheme of things. Our mathematics is going to become formally verified.
In terms of actual consequences, it's maybe not so important on its own. But putting a couple pieces together (this, Dan Selsam's work, GPT), it seems like we're going to get much better AI-driven automated theorem proving, formal verification, code generation, etc relatively soon.
I'd expect these things to start meaningfully changing how we do programming sometime in the next decade.
Yeah, I get some aesthetic satisfaction from math results being formally verified to be correct. But we could just wait until the AGIs can do it for us... :-P
Yeah, it would be cool and practically important if you could write an English-language specification for a function, then the AI turns it into a complete human-readable formal input-output specification, and then the AI also writes code that provably meets that specification.
I don't have a good sense for how plausible that is—I've never been part of a formally-verified software creation project. Just guessing, but the second part (specification -> code) seems like the kind of problem that AIs will solve in the next decade. Whereas the first part (creating a complete formal specification) seems like it would be the kind of thing where maybe the AI proposes something but then the human needs to go back and edit it, because you can't get every detail right unless you understand the whole system that this function is going to be part of. I dunno though, just guessing.
The workflow I've imagined is something like:
- human specifies function in English
- AI generates several candidate code functions
- AI generates test cases for its candidate functions, and computes their results
- AI formally analyzes its candidate functions and looks for simple interesting guarantees it can make about their behavior
- AI displays its candidate functions to the user, along with a summary of the test results and any guarantees about the input output behavior, and the user selects the one they want (which they can also edit, as necessary)
In this version, you go straight from English to code, which I think might be easier than from English to formal specification, because we have lots of examples of code with comments. (And I've seen demos of GPT-3 doing it for simple functions.)
I think some (actually useful) version of the above is probably within reach today, or in the very near future.
Some weird stuff happening with NKLA. That's the ticker for a startup called Nikola that did a reverse IPO last week (merging with the already-listed special-purpose company, VTIQ).
Nikola plans to sell various kinds of battery electric and hydrogen fuel cell trucks, with production scheduled to start in 2021.
When the reverse IPO was announced, the IPO price implied a valuation of NKLA at $3.3 billion. However, before the deal went through, the price of VTIQ rose from $10 in March to over $30 last week.
Then, after the combined company switched to the new ticker, NKLA, the price continued to rise, closing on Friday (June 5th) at $35, doubling on Monday to over $70 at close, and then continuing to rise to over $90 after hours, for a market cap over $30 billion, higher than the market cap of Ford.
The price has come down a bit today, and sits at $73 at the time I am writing this.
I have not investigated this company in detail. But some commentary from some amateur analysts whom I follow makes it sound to me like the hype has far outpaced the substance.
On Monday, I tried shorting at the open (via orders I'd placed the night before), but luckily for me, no shares were available to short (lucky since the price doubled that day). I tried again later in the day, and there were still no shares available.
It appears that the limited availability of shares to short has pushed traders into bidding up the prices of puts. If I'm reading the options chain right, it appears that a Jan 2022 synthetic long at a $50 strike (buying a $50 strike call and selling a $50 strike put) can be bought for roughly $0. Since the value of a synthetic long should be roughly equal to the price of the stock minus the strike, this implies a price of about $50 for the stock, in contrast to the $70+ price if you buy the stock directly.
That price discrepancy is so big that it seems like there's a significant chance I'm missing something. Can anybody explain why those options prices might actually make sense? Am I just doing the options math wrong? Is there some factor I'm not thinking of?
Re: the options vs underlying, after chatting with a friend it seems like this might just be exactly what we'd expect if there is pent up demand to short, but shares aren't available -- there's an apparent arb available if you go long via options and short via the stock, but you can't actually execute the arb because shares aren't available to short. (And the SEC's uptick rule has been triggered.)
I'm thinking of taking advantage of the options prices via a short strangle (e.g. sell a long-dated $5 call and also sell a long-dated $105 put), but will want to think carefully about it because of the unbounded potential losses.
sell a long-dated $5 call
This page explains why the call option would probably get exercised early and ruin your strategy:
ITM calls get assigned in a hard to borrow stock all the time
The second most common form of assignment is in a hard to borrow stock. Since the ability to short the stock is reduced, selling an ITM call option is the next best thing. A liquidity provider might have to pay a negative cost of carry just to hold a short stock position. Since the market on balance wants to short the stock, the value of the ITM call gets reduced relative to the underlying stock price. Moreover, a liquidity provider might have to exercise all their long calls to come into compliance with REG SHO. That means the short call seller gets assigned.
I was going to say that it's fine with me if my short call gets assigned and turns into a short position, but your comment on another thread about hard-to-borrow rates made me think I should look up the fees that my brokerage charges.
It looks like they're a lot. If I'm reading the table below correctly, IB is currently charging 0.4% per day to short NKLA, and it's been increasing.
Thanks for pointing this out!
> When the supply and demand attributes of a particular security are such that it becomes hard to borrow, the rebate provided by the lender will decline and may even result in a charge to the account. The rebate or charge will be passed on to the accountholder in the form of a higher borrow fee, which may exceed short sale proceeds interest credits and result in a net charge to the account. As rates vary by both security and date, IBKR recommends that customers utilize the Short Stock Availability tool accessible via the Support section in Client Portal/Account Management to view indicative rates for short sales.
https://ibkr.info/article/41
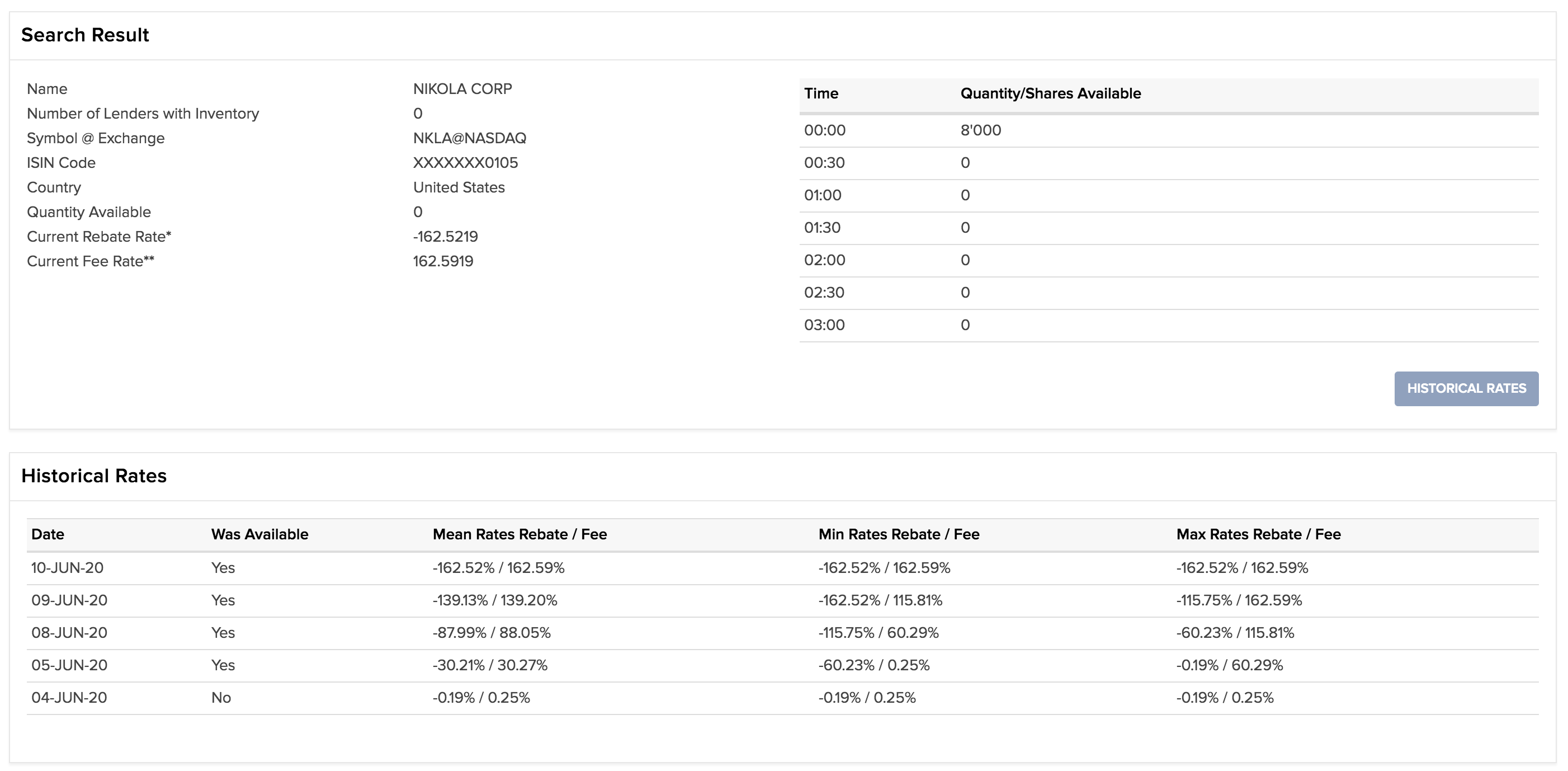
It's worse than that. If there weren't any shares available at your broker for you to short-sell in the market, you should consider it likely that instead of paying 0.4%/day, you just are told you have to buy shares to cover your short from assignment. This is an absolutely normal thing that happens sometimes when it's hard to find additional people to lend stock (which is happening now).
(Disclaimer: I am a financial professional, but I'm not a financial advisor, much less yours.)
If I've heard him right, it sounds like Dan Selsam (NeuroSAT, IMO Grand Challenge) thinks ML systems will be able to solve IMO geometry problems (though not other kinds of problems) by the next IMO.
(See comments starting around 38:56.)
See also his recent paper, which seems to like an important contribution towards using ML for symbolic / logical reasoning: Universal Policies for Software-Defined MDPs.
I'm looking for an old post where Eliezer makes the basic point that we should be able to do better than intellectual figures of the past, because we have the "unfair" advantage of knowing all the scientific results that have been discovered since then.
I think he cites in particular the heuristics and biases literature as something that thinkers wouldn't have known about 100 years ago.
I don't remember if this was the main point of the post it was in, or just an aside, but I'm pretty confident he made a point like this at least once, and in particular commented on how the advantage we have is "unfair" or something like that, so that we shouldn't feel at all sheepish about declaring old thinkers wrong.
Anybody know what post I'm thinking of?
1. https://www.lesswrong.com/posts/96TBXaHwLbFyeAxrg/guardians-of-ayn-rand
Max Gluckman once said: "A science is any discipline in which the fool of this generation can go beyond the point reached by the genius of the last generation." Science moves forward by slaying its heroes, as Newton fell to Einstein. Every young physicist dreams of being the new champion that future physicists will dream of dethroning.
Ayn Rand's philosophical idol was Aristotle. Now maybe Aristotle was a hot young math talent 2350 years ago, but math has made noticeable progress since his day. Bayesian probability theory is the quantitative logic of which Aristotle's qualitative logic is a special case; but there's no sign that Ayn Rand knew about Bayesian probability theory when she wrote her magnum opus, Atlas Shrugged. Rand wrote about "rationality", yet failed to familiarize herself with the modern research in heuristics and biases. How can anyone claim to be a master rationalist, yet know nothing of such elementary subjects?
(Not sure if the material is accurate, but I think it's the post you're looking for. There could have been more than one on that though.)
2. https://www.lesswrong.com/posts/7s5gYi7EagfkzvLp8/in-defense-of-ayn-rand
References 1.
GPT-X has a context (of some maximum size), and produces output based on that context. It's very flexible and can do many different tasks based on what's in the context.
To what extent is it reasonable to think of (part of) human cognition as being analogous, with working memory playing the role of context?
If I read the first half of a sentence of text, I can make some predictions about the rest, and in fact that prediction happens automatically when I'm prompted with the partial text (but can only happen when I keep the prompt in mind).
If I want to solve some math problem, I first load it into working memory (using my verbal loop and/or mental imagery), and then various avenues forward automatically present themselves.
Certainly, with human cognition there's some attentional control, and there's a feedback loop where you modify what's in working memory as you're going. So it's not as simple as just one-prompt, one-response, and then onto the next (unrelated) task. But it does seem to me like one part of human cognition (especially when you're trying to complete a task) is loading up semi-arbitrary data into working memory and then seeing what more opaque parts of your brain naturally spit out in response.
Does this seem like a reasonable analogy? In what ways is what our brains do with working memory the same as or different from what GPT-X does with context?
If GPT-3 is what you get when you do a massive amount of unsupervised learning on internet text, what do you get when you do a massive amount of unsupervised learning on video data from cars?
(In other words, can we expect anything interesting to come from Tesla's Dojo project, besides just better autopilot?)
Suppose you want to bet on interest rates rising -- would buying value stocks and shorting growth stocks be a good way to do it? (With the idea being that, if rates rise, future earnings will be discounted more and present earnings valued relatively more highly.)
And separately from whether long-value-short-growth would work, is there a more canonical or better way to bet on rates rising?
Just shorting bonds, perhaps? Is that the best you can do?
(Crossposted from Twitter)
I'm unsure why you'd expect anything to be better than pure plays such as shorting bond or Eurodollar futures.
I expect the effects on value minus growth to be rather small.
If you're betting that rising rates will be due to increased inflation, more than rising real rates, then it's worth looking at companies that have borrowed at low long-term rates. Maybe shipping companies (dry bulk?), homebuilders, airplane leasing companies?
Please participate in my poll for the correct spelling of the term that starts with a 'd' and rhymes with lox and socks: https://twitter.com/ESRogs/status/1275512777931501568