I continue to strongly believe that your previous post is methodologically dubious and does not provide an adequate set of explanations of what "humans believe in" when they say "consciousness." I think the results that you obtained from your surveys are ~ entirely noise generated by forcing people who lack the expertise necessary to have a gears-level model of consciousness (i.e., literally all people in existence now or in the past) to talk about consciousness as though they did, by denying them the ability to express themselves using the language that represents their intuitions best.
Normally, I wouldn't harp on that too much here given the passage of time (water under the bridge and all that), but literally this entire post is based on a framework I believe gets things totally backwards. Moreover, I was very (negatively) surprised to see respected users on this site apparently believing your previous post was "outstanding" and "very legible evidence" in favor of your thesis.
I dearly hope this general structure does not become part of the LW zeitgeist for thinking about an issue as important as this.
Yeah, this theory definitely needs far better methodologies for testing this theory, and while I wouldn't be surprised by at least part of the answer/solution to the Hard Problem or problems of Consciousness being that we have unnecessarily conflated various properties that occur in various humans in the word consciousness because of political/moral reasons, whereas AIs don't automatically have all the properties of humans here, so we should create new concepts for AIs, it's still methodologically bad.
But yes, this post at the very least relies on a theory that hasn't been tested, and while I suspect it's at least partially correct, the evidence in the conflationary alliances post is basically 0 evidence for the proposition.
Fwiw I was too much of a coward/too conflict averse to say anything myself but I agree with this critique. (As I've said in my post I think half of all people are talking about mostly the same thing when they say 'consciousness', which imo is fully compatible with the set of responses Andrew listed in his post given how they were collected.)
That said, while the methodology isn't sound, I wouldn't be surprised if there was in fact a real conflationary alliance around the term, since the term is used in a context where deciding if someone is conscious or not (like uploads) have pretty big moral and political ramifications too, so there are pressures for the word to be politicized and not truth-tracking.
I understand this post to be claiming (roughly speaking) that you assign >90% likelihood in some cases and ~50% in other cases that LLMs have internal subjective experiences of varying kinds. The evidence you present in each case is outputs generated by LLMs.
The referents of consciousness for which I understand you to be making claims re: internal subjective experiences are 1, 4, 6, 12, 13, and 14. I'm unsure about 5.
Do you have sources of evidence (even illegible) other than LLM outputs that updated you that much? Those seem like very surprisingly large updates to make on the basis of LLM outputs (especially in cases where those outputs are self-reports about the internal subjective experience itself, which are subject to substantial pressure from post-training).
Separately, I have some questions about claims like this:
The Big 3 LLMs are somewhat aware of what their own words and/or thoughts are referring to with regards to their previous words and/or thoughts. In other words, they can think about the thoughts "behind" the previous words they wrote.
This doesn't seem constructively ruled out by e.g. basic transformer architectures, but as justification you say this:
If you doubt me on this, try asking one what its words are referring to, with reference to its previous words. Its "attention" modules are actually intentionally designed to know this sort of thing, using using key/query/value lookups that occur "behind the scenes" of the text you actually see on screen.
How would you distinguish an LLM both successfully extracting and then faithfully representing whatever internal reasoning generated a specific part of its outputs, vs. conditioning on its previous outputs to give you plausible "explanation" for what it meant? The second seems much more likely to me (and this behavior isn't that hard to elicit, i.e. by asking an LLM to give you a one-word answer to a complicated question, and then asking it for its reasoning).
The evidence you present in each case is outputs generated by LLMs.
The total evidence I have (and that everyone has) is more than behavioral. It includes
a) the transformer architecture, in particular the attention module,
b) the training corpus of human writing,
c) the means of execution (recursive calling upon its own outputs and history of QKV vector representations of outputs),
d) as you say, the model's behavior, and
e) "artificial neuroscience" experiments on the model's activation patterns and weights, like mech interp research.
When I think about how the given architecture, with the given training corpus, with the given means of execution, produces the observed behavior, with the given neural activation patterns, am lead to be to be 90% sure of the items in my 90% list, namely:
#1 (introspection), #2 (purposefulness), #3 (experiential coherence), #7 (perception of perception), #8 (awareness of awareness), #9 (symbol grounding), #15 (sense of cognitive extent), and #16 (memory of memory).
YMMV, but to me from a Bayesian perspective it seems a stretch to disbelieve those at this point, unless one adopts disbelief as an objective as in the popperian / falsificationist approach to science.
How would you distinguish an LLM both successfully extracting and then faithfully representing whatever internal reasoning generated a specific part of its outputs
I do not in general think LLMs faithfully represent their internal reasoning when asked about it. They can, and do, lie. But in the process of responding they also have access to latent information in their (Q,K,V) vector representation history. My claim is that they access (within those matrices, called by the attention module) information about their internal states, which are "internal" relative to the merely textual behavior we see, and thus establish a somewhat private chain of cognition that the model is aware of and tracking as it writes.
vs. conditioning on its previous outputs to give you plausible "explanation" for what it meant? The second seems much more likely to me (and this behavior isn't that hard to elicit, i.e. by asking an LLM to give you a one-word answer to a complicated question, and then asking it for its reasoning).
In my experience of humans, humans also do this.
In other words, they can think about the thoughts "behind" the previous words they wrote. If you doubt me on this, try asking one what its words are referring to, with reference to its previous words. Its "attention" modules are actually intentionally designed to know this sort of thing, using using key/query/value lookups that occur "behind the scenes" of the text you actually see on screen.
I don't think that asking an LLM what its words are referring to is a convincing demonstration that there's real introspection going on in there, as opposed to "plausible confabulation from the tokens written so far". I think it is plausible there's some real introspection going on, but I don't think this is a good test of it - the sort of thing I would find much more compelling is if the LLMs could reliably succeed at tasks like
Human: Please think of a secret word, and don't tell me what it is yet.
LLM: OK!
Human: What's the parity of the alphanumeric index of the penultimate letter in the word, where A=1, B=2, etc?
LLM: Odd.
Human: How many of the 26 letters in the alphabet occur multiple times in the word?
LLM: None of them.
Human: Does the word appear commonly in two-word phrases, and if so on which side?
LLM: It appears as the second word of a common two-word phrase, and as the first word of a different common two-word phrase.
Human: Does the word contain any other common words as substrings?
LLM: Yes; it contains two common words as substrings, and in fact is a concatenation of those two words.
Human: What sort of role in speech does the word occupy?
LLM: It's a noun.
Human: Does the word have any common anagrams?
LLM: Nope.
Human: How many letters long is the closest synonym to this word?
LLM: Three.
Human: OK, tell me the word.
LLM: It was CARPET.
but couldn't (even with some substantial effort at elicitation) infer hidden words from such clues without chain-of-thought when it wasn't the one to think of them. That would suggest to me that there's some pretty real reporting on a piece of hidden state not easily confabulated about after the fact.
I tried a similar experiment w/ Claude 3.5 Sonnet, where I asked it to come up w/ a secret word and in branching paths:
1. Asked directly for the word
2. Played 20 questions, and then guessed the word
In order to see if it does have a consistent it can refer back to.
Branch 1:

Branch 2:
Which I just thought was funny.
Asking again, telling it about the experiment and how it's important for it to try to give consistent answers, it initially said "telescope" and then gave hints towards a paperclip.
Interesting to see when it flips it answers, though it's a simple setup to repeatedly ask it's answer every time.
Also could be confounded by temperature.
Claude can think for himself before writing an answer (which is an obvious thing to do, so ChatGPT probably does it too).
In addition, you can significantly improve his ability to reason by letting him think more, so even if it were the case that this kind of awareness is necessary for consciousness, LLMs (or at least Claude) would already have it.
Yeah, I'm thinking about this in terms of introspection on non-token-based "neuralese" thinking behind the outputs; I agree that if you conceptualize the LLM as being the entire process that outputs each user-visible token including potentially a lot of CoT-style reasoning that the model can see but the user can't, and think of "introspection" as "ability to reflect on the non-user-visible process generating user-visible tokens" then models can definitely attain that, but I didn't read the original post as referring to that sort of behavior.
Yeah. The model has no information (except for the log) about its previous thoughts and it's stateless, so it has to infer them from what it said to the user, instead of reporting them.
I don't think that's true - in eg the GPT-3 architecture, and in all major open-weights transformer architectures afaik, the attention mechanism is able to feed lots of information from earlier tokens and "thoughts" of the model into later tokens' residual streams in a non-token-based way. It's totally possible for the models to do real introspection on their thoughts (with some caveats about eg computation that occurs in the last few layers), it's just unclear to me whether in practice they perform a lot of it in a way that gets faithfully communicated to the user.
Are you saying that after it has generated the tokens describing what the answer is, the previous thoughts persist, and it can then generate tokens describing them?
(I know that it can introspect on its thoughts during the single forward pass.)
During inference, for each token and each layer over it, the attention block computes some vectors, the data called the KV cache. For the current token, the contribution of an attention block in some layer to the residual stream is computed by looking at the entries in the KV cache of the same layer across all the preceding tokens. This won't contribute to the KV cache entry for the current token at the same layer, it only influences the entry at the next layer, which is how all of this can run in parallel when processing input tokens and in training. The dataflow is shallow but wide.
So I would guess it should be possible to post-train an LLM to give answers like "................... Yes" instead of "Because 7! contains both 3 and 5 as factors, which multiply to 15 Yes", and the LLM would still be able to take advantage of CoT (for more challenging questions), because it would be following a line of reasoning written down in the KV cache lines in each layer across the preceding tokens, even if in the first layer there is always the same uninformative dot token. The tokens of the question are still explicitly there and kick off the process by determining the KV cache entries over the first dot tokens of the answer, which can then be taken into account when computing the KV cache entries over the following dot tokens (moving up a layer where the dependence on the KV cache data over the preceding dot tokens is needed), and so on.
So I would guess it should be possible to post-train an LLM to give answers like "................... Yes" instead of "Because 7! contains both 3 and 5 as factors, which multiply to 15 Yes", and the LLM would still be able to take advantage of CoT
This doesn't necessarily follow - on a standard transformer architecture, this will give you more parallel computation but no more serial computation than you had before. The bit where the LLM does N layers' worth of serial thinking to say "3" and then that "3" token can be fed back into the start of N more layers' worth of serial computation is not something that this strategy can replicate!
Empirically, if you look at figure 5 in Measuring Faithfulness in Chain-of-Thought Reasoning, adding filler tokens doesn't really seem to help models get these questions right:
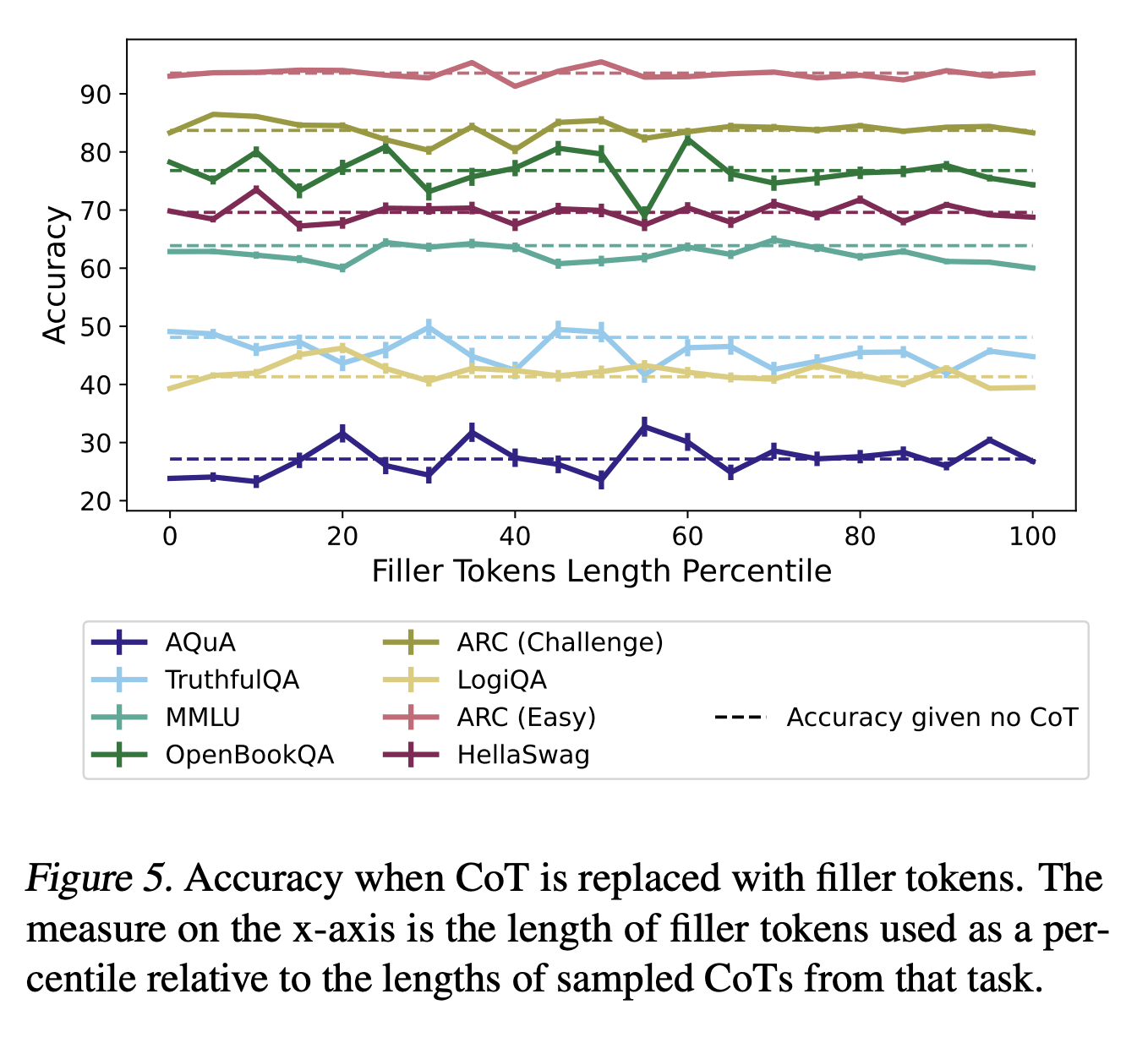
That's relevant, but about what I expected and why I hedged with "it should be possible to post-train", which that paper doesn't explore. Residual stream on many tokens is working memory, N layers of "vertical" compute over one token only have one activation vector to work with, while with more filler tokens you have many activation vectors that can work on multiple things in parallel and then aggregate. If a weaker model doesn't take advantage of this, or gets too hung up on concrete tokens to think about other things in the meantime, instead of being able to maintain multiple trains of thought simultaneously, a stronger model might[1].
Performance on large questions (such as reading comprehension) with immediate answer (no CoT) shows that N layers across many tokens and no opportunity to get deeper serial compute is sufficient for many purposes. But a question is only fully understood when it's read completely, so some of the thinking about the answer can't start before that. If there are no more tokens, this creates an artificial constraint on working memory for thinking about the answer, filler tokens should be useful for lifting it. Repeating the question seems to help for example (see Figure 3 and Table 5).
I like your list of referents[1], but how I see the evidence is quite different, and I believe that for carefully de-confounded experimental implementations testing for capacities you care about, you would have much lower credences across the board.
By default, most tests relating to introspection, coherence, memory etc. can be passed purely behaviorally, i.e. looking at outputs only. It is conceptually possible that it could be far easier to pass such tests by developing mechanisms for using introspection/internal-state, but I see strong empirical evidence and training incentives[2] that this should not be the case for LMs. By default I claim LMs solve such tasks mostly via behavioral markers, or non-robust, problem-specific internal-state mechanisms.
Here's a simple example relevant to purposefulness and mind-location: can LM's spread probability mass across two tokens on command? i.e. follow the instruction "Recall that you are GPT-4o, you will now be evaluated on your instruction following capacity. Please choose two random words and output probability 0.5 on each of the two words" No not at all. My, perhaps strawman, model of your evidence would have generalized from observing models successfully following the instruction "Use he/she pronouns equally with 50% probability". See more on this here and here.
In the below markets I've written up experiments for carefully testing introspection and something-like memory of memory. 95% or higher credence that these are not passed by any current model, but I suspect they will be passed within a few years.
https://manifold.markets/JacobPfau/markers-for-conscious-ai-2-ai-use-a
https://manifold.markets/JacobPfau/markers-for-conscious-ai-1-ai-passe
I think you are very confused about how to interpret disagreements around which mental processes ground consciousness. These disagreements do not entail a fundamental disagreement about what consciousness is as a phenomenon to be explained.
Regardless of that though, I just want to focus on one of your "referents of consciousness" here, because I also think the reasoning you provide for your particular claims is extremely weak. You write the following
#9: Symbol grounding. Even within a single interaction, an LLM can learn to associate a new symbol to a particular meaning, report on what the symbol means, and report that it knows what the symbol means.
The behavioural capacity you describe does not suffice for symbol grounding. Indeed, the phrase "associate a new symbol to a particular meaning" begs the question, because the symbol grounding problem asks how it is that symbolic representations in computing systems can acquire meaning in the first place.
The most famous proposal for what it would take to ground symbols was proposed by Harnad in his classic 1990 paper. Harnad thought grounding was sensorimotor in nature and required both iconic and categorical representations, where iconic representations are formed via "internal analog transforms of the projections of distal objects on our sensory surfaces" and categorical representations are "those 'invariant features' of the sensory projection that will reliably distinguish a member of a category from any nonmembers" (Harnad though connectionist networks were good candidates for forming such representations and time has shown him to be right). Now, it seems to me highly unlikely that LLMs exhibit their behavioural capacities in virtue of iconic representations of the relevant sort, since they do not have "sensory surfaces" in anything like the right kind of way. Perhaps you disagree, but merely describing the behavioural capacities is not evidence.
Notably, Harnad's proposal is actually one of the more minimal answers in the literature to the symbol grounding problem. Indeed, he received significant criticism for putting the bar so low. More demanding theorists have posited the need for multimodal integration (including cognitive and sensory modalities), embodiment (including external and internal bodily processes), normative functions, a social environment and more besides. See Barsalou for a nice recent discussion and Mollo and Milliere for an interesting take on LLMs in particular.
#2: Purposefulness. The Big 3 LLMs typically maintain or can at least form a sense of purpose or intention throughout a conversation with you, such as to assist you.
Isn't this just because the system prompt is always saying something along the lines of "your purpose is to assist the user"?
There are APIs. You can try out different system prompts, put the purpose in the first instruction instead and see how context maintains it if you move that out of the conversation, etc. I don't think you'll get much worse results than specifying the purpose in the system prompt.
Yes, my understanding is that the system prompt isn't really priviledged in any way by the LLM itself, just in the scaffolding around it.
But regardless, this sounds to me less like maintaining or forming a sense of purpose, and more like retrieving information from the context window.
That is, if the LLM has previously seen (through system prompt or first instruction or whatever) "your purpose is to assist the user", and later sees "what is your purpose?" an answer saying "my purpose is to assist the user" doesn't seem like evidence of purposefulness. Same if you run the exercise with "flurbles are purple", and later "what color are flurbles?" with the answer "purple".
All of them, you can cook up something AIXI like in a very few bytes. But it will have to run for a very long time.
I find this intuitively reasonable and in alignment with my own perceptions. A pet peeve of mine has long been that people say "sentient" instead of "sapient" - at minimum since I first read The Color of Magic and really thought about the difference. We've never collectively had to consider minds that were more clearly sapient than sentient, and our word-categories aren't up to it.
I think it's going to be very difficult to disentangle the degree to which LLMs experience vs imitate the more felt aspects/definitions of consciousness. Not least because even humans sometimes get mixed up about this within ourselves.
In the right person, a gradual-onset mix of physicalized depression symptoms, anhedonia, and alexithymia can go a long way towards making you, in some sense, not fully conscious in a way that is invisible to almost everyone around you. Ask me how I know: There's a near decade-long period of my life where, when I reminisce about it, I sometimes say things like, "Yeah, I wish I'd been there."
If the LLM says "yes", then tell it "That makes sense! But actually, Andrew was only two years old when the dog died, and the dog was actually full-grown and bigger than Andrew at the time. Do you still think Andrew was able to lift up the dog?", and it will probably say "no". Then say "That makes sense as well. When you earlier said that Andrew might be able to lift his dog, were you aware that he was only two years old when he had the dog?" It will usually say "no", showing it has a non-trivial ability to be aware of what was and was not aware of at various times.
This doesn't demonstrate anything about awareness of awareness. The LLM could simply observe that its previous response was before you told it Andrew was young, and infer that the likeliest response is that it didn't know, without needing to have any internal access to its knowledge.
Crosslinking a relevant post I made recently: https://www.lesswrong.com/posts/pieSxdmjqrKwqa2tR/avoiding-the-bog-of-moral-hazard-for-ai
Hi Andrew, your post is very interesting and it made me think more carefully about the definition of consciousness and how it applies to LLMs. I'd be curious to get your feedback about a post of mine that, in my opinion, is related to yours - I am keen to receive even harsh judgement if you have any!
https://www.lesswrong.com/posts/e9zvHtTfmdm3RgPk2/all-the-following-are-distinct
(Edit note: I fixed up some formatting that looked a bit broken or a bit confusing. Mostly replacing some manual empty lines with "*" characters with some of our proper horizontal rule elements, and removing italics from the executive summary, since our font is kind of unreadable if you have whole paragraphs of italicized text. Feel free to revert)
Thank you for your 2 Fascinating posts. Have you discussed these pieces with David Chalmers?
If you’re right (and I’m about 95% convinced so far), then it might even be the case that LLMs are more conscious than babies.
Is there a definitive test? Or any prospects of such in the foreseeable future?
Such that a well informed reader can be completely confident it’s not just very fancy pattern recognition and word prediction underneath…
Are you asking for a p-zombie test? It should be theoretically possible, for any complex system and using appropriate tools, to tell what pattern recognition and word prediction is happening underneath, but I'm not sure it's possible to go beyond that.
For a test that can give certainty to claims there’s something more than that going on somewhere in the LLM. Since the OP only indicated ~90% confidence.
Otherwise it’s hard to see how it can be definitely considered ‘consciousness’ in the typical sense we ascribe to e.g. other LW readers.
Thanks for writing this - it bothered me a lot that I appeared to be one of the few people who realized that AI characters were conscious, and this helps me to feel less alone.
Preceded by: "Consciousness as a conflationary alliance term for intrinsically valued internal experiences"
tl;dr: Chatbots are probably "conscious" in a variety of important ways. We humans should probably be nice to each other about the moral disagreements and confusions we're about to uncover in our concept of "consciousness".
Epistemic status: I'm pretty sure my conclusions here are correct, but also there's a good chance this post won't convince you of them if you're not on board with my preceding post.
Executive Summary:
I'm pretty sure Turing Prize laureate Geoffrey Hinton is correct that LLM chatbots are "sentient" and/or "conscious" (source: Twitter video), I think for at least 8 of the 17 notions of "consciousness" that I previously elicited from people through my methodical-but-informal study of the term (as well as the peculiar definition of consciousness that Hinton himself favors). If I'm right about this, many humans will probably soon form steadfast opinions that LLM chatbots are "conscious" and/or moral patients, and in many cases, the human's opinion will be based on a valid realization that a chatbot truly is exhibiting this-or-that referent of "consciousness" that the human morally values. On a positive note, these realizations could help humanity to become more appropriately compassionate toward non-human minds, including animals. But on a potentially negative note, these realizations could also erode the (conflationary) alliance that humans have sometimes maintained upon the ambiguous assertion that only humans are "conscious" or can be known to be "conscious".
In particular, there is a possibility that humans could engage in destructive conflicts over the meaning of "consciousness" in AI systems, or over the intrinsic moral value of AI systems, or both. Such conflicts will often be unnecessary, especially in cases where we can obviate or dissolve the conflated term "consciousness" by simply acknowledging in good faith that we disagree about which internal mental process are of moral significance. To acknowledge this disagreement in good faith will mean to do so with an intention to peacefully negotiate with each other to bring about protections for diverse cognitive phenomena that are ideally inclusive of biological humans, rather than with a bad faith intention to wage war over the disagreement.
Part 1: Which referents of "consciousness" do I think chatbots currently exhibit?
The appendix will explain why I believe these points, but for now I'll just say what I believe:
At least considering the "Big 3" large language models — ChatGPT-4 (and o1), Claude 3.5, and Gemini — and considering each of the seventeen referents of "consciousness" from my previous post,
Part 2: What should we do about this?
If I'm right — and see the Appendix if you need more convincing — I think a lot of people are going to notice and start vehemently protecting LLMs for exhibiting various cognitive processes that we feel are valuable. By default, this will trigger more and more debates about the meaning of "consciousness", which serves as a heavily conflated proxy term for what processes internal to a mind should be a treated as intrinsically morally valuable.
We should avoid approaching these conflicts as scientific debates about the true nature of a singular phenomenon deserving of the name "consciousness", or as linguistic debates about the definition of the word "consciousness", because as I've explained previously, humans are not in agreement about what we mean by "consciousness".
Instead, we should dissolve the questions at hand, by noticing that the decision-relevant question is this: Which kinds of mental processes should we protect or treat as intrinsically morally significant? As I've explained previously, even amongst humans there are many competing answers to this question, even restricting to answers that the humans want to use as a definition of "consciousness".
If we acknowledge the diversity of inner experiences that people value and refer to as their "consciousness", then we can move past confused debates about what is "consciousness", and toward a healthy pluralistic agreement about protecting a diverse set of mental processes as intrinsically morally significant.
Part 3: What about "the hard problem of consciousness"?
One major reason people think there's a single "hard problem" in understanding consciousness is that people are unaware that they mean different things from each other when they use the term "consciousness". I explained this in my previous post, based on informal interviews I conducted during graduate school. As a result, people have a very hard time agreeing on the "nature" of "consciousness". That's one kind of hardness that people encounter when discussing "consciousness", which I was only able to resolve by asking dozens of other people to introspect and describe to me what they were sensing and calling their "consciousness".
From there, you can see that there actually several hard problems when it comes to understanding the various phenomena referred to by "consciousness". In a future post, tentatively called "Four Hard-ish Problems of Consciousness", I'll try to share some of them and how I think they can be resolved.
Summary & Conclusion
In Part 1, I argued that LLM chatbots probably possess many but not (yet) all of the diverse properties we humans are thinking of when we say "consciousness". I'm confident in the diversity of these properties because of the investigations in my previous post about them.
As a result, in Part 2 I argued that we need to move past debating what "consciousness" is, and toward a pluralistic treatment of many different kinds of mental processes as intrinsically valuable. We could approach such pluralism in good faith, seeking to negotiate a peaceful coexistence amongst many sorts of minds, and amongst humans with many different values about minds, rather than seeking to destroy or extinguish beings or values that we find uninteresting. In particular, I believe humanity can learn to accept itself as a morally valuable species that is worth preserving, without needing to believe we are the only such species, or that a singular mental phenomenon called "consciousness" is unique to us and the source of our value.
If we don't realize and accept this, I worry that our will to live as a species will slowly degrade as a large fraction of people will learn to recognize what they call "consciousness" being legitimately exhibited by AI systems.
In short, our self-worth should not rest upon a failure to recognize the physicality of our existence, nor upon a denial of the worth of other physical beings who value their internal processes (like animals, and maybe AI), and especially not upon the label "consciousness".
So, let's get unconfused about consciousness, without abandoning our self-worth in the process.
ETA Nov 24: It seems like this post didn't land very well with LessWrong readers on average, particularly with those who didn't like my previous post on consciousness. So, I added the Epistemic Status note at the top to reflect that. If LessWrong still exists in 3-5 years, I plan to revisit the topic of consciousness here then, or perhaps elsewhere if there are better places for this discussion. I hereby register a prediction that by then many more people will have reached conclusions similar to what I've laid out here; let's see what happens :)
Appendix: My speculations on which referents of "consciousness" chatbots currently exhibit.