EDIT: I've removed this draft & posted a longer version incorporating some of the feedback here at http://lesswrong.com/lw/khd/confound_it_correlation_is_usually_not_causation/
I would prefer posts like that to stand on their own in discussion and not be posted in an open thread.
Hi, gwern it's awesome you are grappling with these issues. Here are some jambling responses.
You might enjoy Sander Greenland's essay here:
http://bayes.cs.ucla.edu/TRIBUTE/festschrift-complete.pdf
Sander can be pretty bleak!
But does the number of causal relationships go up just as fast? I don't think so (although at the moment I can't prove it).
I am not sure exactly what you mean, but I can think of a formalization where this is not hard to show. We say A "structurally causes" B in a DAG G if and only if there is a directed path from A to B in G. We say A is "structurally dependent" with B in a DAG G if and only if there is a marginal d-connecting path from A to B in G.
A marginal d-connecting path between two nodes is a path with no consecutive edges of the form -> <- * (that is, no colliders on the path). In other words all directed paths are marginal d-connecting but the opposite isn't true.
The justification for this definition is that if A "structurally causes" B in a DAG G, then if we were to intervene on A, we would observe B change (but not vice versa) in "most" distributions that arise from causal structures consisten...
This post is a good example of why LW is dying. Specifically, that it was posted as a comment to a garbage-collector thread in the second-class area. Something is horribly wrong with the selection mechanism for what gets on the front page.
Underconfidence is a sin. This is specifically about gwern's calibration. (EDIT: or his preferences)
Not everyone is in the same situation. I mean, we recently had an article disproving theory of relativity posted in Main (later moved to Discussion). Texts with less value that gwern's comment do regularly get posted as articles. So it's not like everyone is afraid to post anything. Some people should update towards posting articles, some people should update towards trying their ideas in Open Thread first. Maybe they need a little nudge from outside first.
How about adding this text to the Open Thread introduction?
As a rule of thumb, if your top-level comment here received 15 or more karma, you probably should repost it as a separate article -- either in the same form, or updated. (And probably post texts of similar quality directly as articles in the future.)
And a more courageous idea: Make a script which collects all top-level Open Thread articles with 15 and more karma from all Open Threads in history and sends their authors a message (one message per author with links to all such comments, to prevent inbox flood) that they should consider posting this as an article.
As a rule of thumb, if your top-level comment here received 15 or more karma, you probably should repost it as a separate article -- either in the same form, or updated. (And probably post texts of similar quality directly as articles in the future.)
More generally, I'd say that if it's longer than about four paragraphs, it's probably better suited as its own article than as a comment.
Let's talk about the fact that the top two comments on a very nice contribution in the open thread is about how this is the wrong place for the post, or how it is why LW is dying. Actually let's not talk about that.
I think that deserves its own post.
It would be interesting to try to come up with good priors for random causal networks.
I hate cauliflower! But a few days ago a restaurant gave me some pickled cauliflower with my salmon dinner. Not recognizing the cauliflower for what it was, I tried and greatly enjoyed the vegetable. I liked it so much that I asked my waitress what the food was so I could be sure to get more of it in the future. Alas, as soon as the waitress told me that the food was cauliflower, I experienced a horrible nauseating after-taste from having consumed the cauliflower, reinforcing my disgust of this vile weed.
Not unexpectedly, the mysterious mass-downvoter was lying low during the recent discussion of the issue, but is back at it now.
A session I'm planning on organising for one of the London meetups in August: filling procedural knowledge gaps.
A motivating example is setting up investment in an index fund. At our last meetup, there was some division in the group between people who'd already done this and found it very straightforward, vs. others who'd started looking into it but found it prohibitively difficult. The blame was squarely placed on procedural knowledge gaps, and the proposed solution was someone assembling a 15-minute talk on index funds, along with a step-by-step guide to explain all the actions required to get from not having an index-fund product to having one.
A few other examples and suggestions were proposed, but I'd like to invite suggestions from the LW-readership. Is there anything Less Wrong has convinced you it's a good idea to do, but for which you don't know the next actionable step in doing?
Apologies for political content. It shouldn't hurt too much.
Many of you are probably familiar with Upworthy, which uses a system of A/B testing to find the most link-baity headlines for left-wing/progressive social media content before inflicting them on the world. My typical reaction to such content was "this would seem amazingly insightful if you hadn't thought about the issue for ten minutes already". Last year, shortly before blocking all such posts on my Facebook feed, I remember wondering what the right-wing equivalent would be.
I've recently become aware of Britain First, a British Nationalist political group. They have a Facebook page which is the result of a deliberated, professional social media campaign, luring people in with schmaltzy motivational images and kitten pictures before sprinkling on a bit of "send the darkies back". It's not on the same level of technical sophistication or scale as Upworthy, but neither is its intended audience (c.f. my mum and dad).
This makes me wonder, where is the clever social media presence of all the sane stuff? There's a recognisable cluster of "actually, I think you'll find it's a bit more complicated than tha...
Have you heard the slogan, "The truth is too complicated to fit on a bumper sticker"? I'd wholeheartedly endorse that if it's brevity didn't make me suspicious.
Some truths, like the sunk cost fallacy or the value of sensible communication, might be simple enough to fit in a brief funny video.
Firstly, it is an outrageous slur to think that the right-wing equivalent of Upworthy is the BNP. The right-wing equivalent is, of course, the Daily Mail, which has so mastered the art of click-baitery as to become the most read newspaper in the world (as of 2013 - may no longer be true).
Secondly, the social media cluster to which Less Wrong belongs is, obviously, Salon, Slate, and works of that ilk. Yes, Caliban, it's true.
And no, you cannot raise the sanity waterline with social media. All you will get is (as the joke goes) people enthusiastically retweeting a study that finally proves what they'd always believed about confirmation bias.
Critical thinking exercise for anyone who wants to try it! I wasted an evening on this, so I thought I'd share it... Here is a Wikipedia article: https://en.wikipedia.org/wiki/Bicycle_face It looks pretty good, well-cited, and is about something amusing. However, it needs to be burned with fire; why?
(Please avoid looking at the article history, and respond in ROT13. If you saw any of the #lesswrong conversation on this article, please refrain from commenting or giving hints.)
Does anyone else experience the following problem:
Something reminds you of an event which happened long ago; the event was annoying or created some other negative emotion; and you again feel that annoyance or negative emotion. I get these "annoyance flashbacks" now and then and it seems like they are more frequent now that I calorie restrict.
Any good ideas for dealing with this?
Hunger makes people cranky... I think this as entirely plausible case of real causality.
I've begun researching cryonics to see if I can afford it/want to sign up. Since I know plenty here are already signed up, I was hoping someone could link me to a succinct breakdown of the costs involved. I've already looked over Alcor's webpage and the Cryonics Institute, but I'd like to hear from a neutral party. Membership dues and fees, average insurance costs (average since this would change from person to person), even peripheral things like lawyer fees (I assume you'll need some legal paperwork done for putting your body on ice). All the main steps necessary to signing up and staying safe.
Basically, I would very much appreciate any help in understanding the basic costs and payoffs so I can budget accordingly.
This is how I want to reply to half the comments on this site, including many of my own: https://medium.com/the-nib/my-blade-and-shield-80df0734f77c
How do you deal with the risk of people using high-power laser pointers on you? Where I am many "kids" are "playing" with strong laser pointers they ordered over the Internet. The strong ones can easily cause permanent damage or permanently blind you. If this becomes more prevalent, what can we do to protect ourselves?
Recently, I started reading The Sound and the Fury by William Faulkner. I am ~50 pages in and I don't understand any of it. The stream of consciousness narrative is infuriatingly hard to read, and the storyline jumps across decades without any warning. What are some techniques I can use to improve my comprehension of the book?
I'm going to be participating in an interview of a candidate for a Software Engineer position. I'm supposed to ask him some technical questions.
Perhaps someone here has some good ideas for technical, programming questions/problems? (I could google for some, but they would be the ones that everyone has seen before).
Thanks!
Short answer: this popped up on r/programming the other day. Lots of interesting questions there, and they don't come with answers. This will force you to solve them yourself, without spoilers, which is an incredibly valuable exercise which I strongly recommend for any questions you ask.
Long answer: you're going to have to unpack your intentions a little. You only have an hour (or less!), and you want to provide the maximum possible resolving power, so to do the best possible job you must know what your company's decision criteria are for this employee, and also what kinds of evidence your fellow interviewers are going to provide. "Ask technical questions" is too broad a mandate to be really ideal, so here are some questions which might help:
Do you need to do a basic competence check? This is a concrete coding question which a minimally capable developer can solve on a whiteboard, with fully correct syntax, in five minutes or less. Fizzbuzz is the canonical example; I've also seen "write a function to determine whether an input string is a palindrome" used to good effect. The point of this question is to efficiently divide your candidate pool into "p...
I've seen the topic of flow discussed in a wide range of circles from the popular media to very specialized forums. It seems like people are in general agreement that a flow state would be ideal when working, and is generally easy to induce when doing something like coding since it meets most of the requirements for a flow inducing activity.
I'm curious if anyone has made substantial effort to reach a 'flow' state in tasks outside of coding, like reading or doing math etc etc., and what they learned. Are there easy tricks? Is it possible? Is flow just a buzzword that doesn't really mean anything?
An Interesting paper. basically he draws upon several times academics were wrong and argues that's why we should promote diversity of ideas. The examples might be useful to people who like this kind of stuff. http://damascusssteel.tumblr.com/post/90055407780/on-the-benefits-of-promoting-diversity-of-ideas
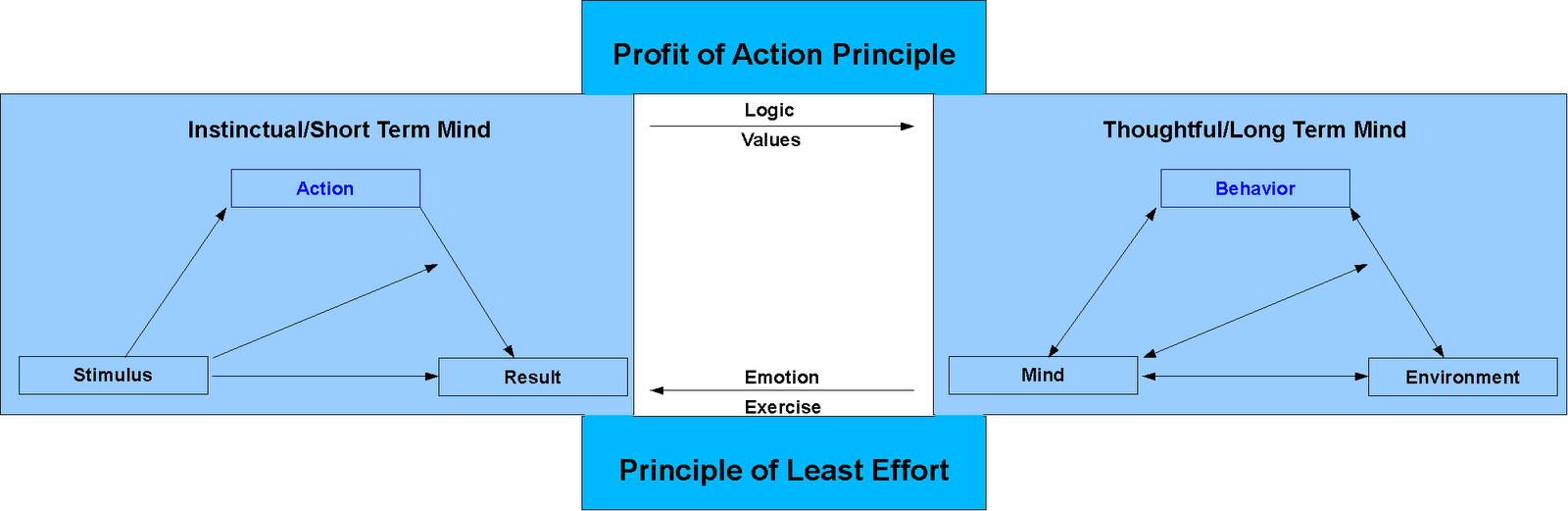
This is a nifty little diagram I made a while ago before I knew about the concepts of system one and system two. It was an attempt to reconcile what I knew about behaviorism with what I knew about cognitive psychology, and detail with how that played out in my own life and the self-help material I was using at the time.
Of particular interest to less-wrongers is the center, which details how to switch from system 1 to system 2 and vice versa. Obviously a simplified model but it's a skill I've found incredibly useful.
Wolfram Programming Cloud is now up and running, for anybody interested. Speed seems to be particularly slow right now, presumably because it just went live and there's tons of traffic.
Here's a quick intro for programmers. It's also supposed to be pretty easy to pick up for people with little to no programming background.
EDIT: This appears to be a step-by-step comprehensive guide to the language. For some reason I couldn't find any direct link to this page.
Given the Snowden leaks, is there some good Voice-over-IP software that you would recommend that encrypted calls decently?
Silly question for people who work at MIRI: If you had the choice between receiving one flash drive from the 5-year-future MIRI employees, and acquiring one year's supply of NZT-48, which would you pick?
I don't work at MIRI but: in the movie the guy cranks out a novel in like one night. That's years of work compressed into a few hours. He then proceeds to understand enough about markets to become extremely wealthy (thus negating the time travel informed betting angle), itself a many-year task. Most importantly: NZT-48 lets him figure out how to make MORE NZT-48 with fewer side effects, thus ensuring an indefinite supply. The NZT-48 is definitely the correct choice.
Approaching the question from the other direction: How much has MIRI really accomplished in the last 5 years? I think it's safe to say that a large part of what they've achieved is in terms of popularization and awareness raising rather than actual research/information generated. If they sent back a flash-drive to five years ago, that wouldn't jumpstart them anywhere near 5 years in terms of effort invested.
So I was reading so8res' story and I felt the same way. Like I had memorized a bunch of signals without gaining deeper understanding during my education. Question: how do you start over and "get" stuff all over again?
"Every problem looks like a nail to a person with only a hammer in his toolbox."
I see this with people not as far in their education as me. Though I noticed a different, but similar phenomenon: Learning of a new method or tool tempts me to use this new toy every time I am faced with a problem. This is a far more benign phenomenon but still, it is there.
Like recently I learned about factor analysis. Now I am tempted to use this to quantify if the plethora of human attributes, including physical and mental health, come down to just a handful of fac...
If all you have is a hammer, then you should be hammering on quite a few things that aren't nails. Heck, I've fixed a propane regulator by whacking it with a hammer. It's just that you should also.. you know.. buy some more tools.
If you're aware of the non-nailness of the thing in question, I don't see any problem with trying out your new tool on it - how else are you to learn its limits!? Using standard tools in a domain where it's not normally applied is often a source of fresh insight.
Out of personal curiosity I started to read texts about psychology. I recognise some of the phenomena described there as problems the community here deals with like akrasia or procrastination. Psychologists though deal with these things as emotional problems as opposed to a technical problem like this community does. Has anyone had a similar observation? Are there psychologists among us who want to point us to helpful ressources?
What are some ways to effectively practice and apply Maths learning?
I've been doing a lot of learning and found that practicing on paper is generally easier than Latex or a cobbled syntax in electronic documents, but would like to know if I just really need to bite the bullet and do it this way (Latex or similar).
Once I have (what I believe) an understanding of the problem types, I will generally write code to do it for me as doing this makes it even clearer in my head. Problem is though, once I do the code, I generally don't practice on paper anymore and...
This is a bit of a dumb question, but I can't seem to find a clear answer online:
Does self-similarity with respect to F mean that every part of a whole that is F, is F? Or does it mean that at least one part of a whole that is F, is F?
I think my third Natural Ergonomic Keyboard 4000 died in a span of 3 years from little water spills. Is there a good alternative keyboard that water resistant?
I'm look into productivity and stuff like that. I see lukeprog so8res have some stuff on that. I saw a couple commentors recommend David Allen. Any recommendations on stuff to start with or books I should start reading? Thanks in advance
Also can anyone get the sequences by so8res and lukeprog in epub? I looked at the wiki where all teh sequences were in epub and didn't find them there. It would be really helpful if I could get them there.
{kind=link}
Previous open thread
If it's worth saying, but not worth its own post (even in Discussion), then it goes here.
Notes for future OT posters:
1. Please add the 'open_thread' tag.
2. Check if there is an active Open Thread before posting a new one.
3. Open Threads should be posted in Discussion, and not Main.
4. Open Threads should start on Monday, and end on Sunday.