This is amazing. A particular publisher used to have a similar tool and it was the best thing ever, now I have it for a much wider subset of papers.
What would lead to this tool no longer working and how can people contribute to making those things not happen? e.g. can I donate money for server costs?
Hi!
Sorry for the delayed reply - this launch has gone far better than we anticipated and our servers and infrastructure have been overwhelmed, even after increasing our auto-scaling ceiling twice... So the last day was a bit hectic :)
This is very relevant to your question.
Connected Papers was built with altruistic intentions, and indeed we expected to fund the servers ourselves - this would be our effective altruism cause. But, it looks like with the demand we're seeing our budgets would not be enough.
We're now brainstorming various solutions, including pro plans for the product (we're committed that there will always be a free version that's at least as good as what we're providing now) and sponsorship from cloud providers. For the time being, we've added a donation button which will go directly to funding the servers - active donations would be a good indicator that some users are willing to pay for the service.
---
The other (much smaller at the moment) risk for Connected Papers is that it does not own the data on which the graphs are built. We are relying on external datasets like the Open Corpus by Semantic Scholar. This means that if at some point they change their license it could impact our ability to provide service or the quality of our graphs. This does not seem like a big risk at the moment as we're actively engaged with Semantic Scholar and have their blessing (e.g. they tweeted about us).
In addition, any errors in the datasets reflect poorly in our graphs. In fact, it appears that our graphs are a very good method to detect bad entries in the DB. Ideally we would want to allow users to report bad entries and close the loop with Semantic Scholar at the database level.
tl;dr
We need to solve server funding, we rely on external sources for the data on which graphs are built.
Also, I think the folks at Hacker News would very much like this. I think you'd get a lot of attention if you made a Show HN post.
Seems hard since there's much less citing, and even posts that reference earlier ones don't necessarily link to them (e.g. people often talk about "slack" without linking to the original post).
One feature that might address this, that the LW team might consider building, would be a “link suggestion” feature—i.e., if I am reading a post, perhaps I can highlight a word/phrase and suggestion another post (or whatever) that it should link to. The author of the post, or perhaps a moderator (if the author has consented to allow moderator editing), might then “take the suggestion”, making the suggested hyperlink real.
(One of many such potential enhancements from the “crowdsource everything” category…)
There's a way in which it's still similar, as no one in biology cites Darwin when talking about evolution.
Alright, I've only played with this a bit, but I'm already finding interesting papers from years past that I've missed. I'm just taking old papers I've found notable and throwing them in and finding new reading material.
My only complaint is that it feels like there's actually too little "entropy" in the set of papers that get generated they're almost too similar, I end up having to make several hops through the graph to find something truly eye catching. It might also just be that papers I consider notable are few and far between.
+1 I want at least one parameter slider even if it's just a black box rather than controlling anything directly.
Fantastic work. I'm excited to use this. I'll be showing this off to my undergraduate research group teachers, and perhaps it'll get folded into next year's class. Also, just so you know, the first time I ran it, it took several minutes before it even began processing, and then got stuck on 0%. When I refreshed, it did build the graph for the paper I wanted successfully.
Hey, thanks for the compliment!
Sorry for the malfunction you experienced, it probably happened while we were overloaded. We've since increased the server count and limited the amount of graphs users can build in parallel.
An insider tip: you only have waiting times for graphs that have never been built before. If you return to the graph you've already built, it would be instantaneous.
I build a very similar project - http://thepattern.digital/ ( full source code available https://github.com/applied-knowledge-systems/the-pattern ) and it won the platinum prize on RedisHackathon 2021.
My differentiator from connected papers is that I turn "strings into things" using external UMLC methathesaurus, so my nodes are industry-wide "concepts" and edges in the graph are a list of papers connecting the same concepts.
Shall we collaborate and take both projects further?
I'm impressed. I just tried it on papers in my field (theory of distributed computing) and it works flawlessly. I'll be sure to share the gospel in my research lab!
This is awesome! Thanks for sharing. There are some fields where I want to read related papers, and this is a step up from just going through the citations list. Very cool work, and I like how there is also a list view which is much less cluttered.
I just tried to generate a graph for a friend's paper on Arxiv, but it told me that the back-end was overloaded, so hopefully it's working soon.
I have a few general questions about the site:
- Are either the front-end or the graphs themselves open-source?
- Are the graphs being generated ahead of time or on the fly?
- How did you parse through the citation lists for papers from different journals? Even for Arxiv, it seems like there are at least a few different formats for citations.
- What are some surprising things you've learned from analyzing the graphs you've already generated?
- How do you determine how many nodes to show on the screen?
Hey, glad to see you like the concept! We're actively working on improving the performance.
1. Everything is proprietary for now. After consideration we decided that this project is not well suited for open sourcing at this time.
2. Graphs are generated on the fly, but only for the first time. We keep the results in a cache so when another user asks for the same graph later, they'd get it instantly. Also, asking for graphs which are close in paper-space would also run faster.
3. We rely on external sources (like the Open Corpus by Semantic Scholar) for the citations database. Unfortunately, no database is perfect yet and sometimes citations are badly parsed.
4. First, we found this tool very fun for exploring paper-space in new domains. I sometimes just enter a keyword like "psychology" and start exploring. This gives me a nice overview of the type of titles and branches in new (for me) fields of science.
Second, I was surprised with how easy it was to recognize papers that are bridging multiple disciplines. Take a look at our example graph "deepfruits", for example: there are two obvious clusters. One shows deep learning papers mostly about detection. The other shows papers that describe how these techniques were applied in agriculture.
5. We've experimented early on and arrived to a conclusion that more than ~50 papers on the screen is too much clutter, and it's better to traverse paper-space by building more graphs. Avoiding specifics on purpose :)
Awesome, thanks for the answers!
One other feature I'd really like is the ability to save the papers (and then export) I find through this tool, which would probably require an account for persistence.
Are there plans for something like this in the works?
Yes - these are probably our most requested features and are high in our list of features to add.
I also like the tool and expect to use it at times so thanks for building and sharing.
I have to also share the performance related experience -- yesterday I had several attempts return the system overloaded response.
This morning my test looks to be progressing 45% after about 10 minutes. I suspect that your message there might be a bit optimistic. If generating the results is expected to take more than a few minutes allow some form of notification once the graph has been complete.
Hey, glad you like the concept!
Sorry for the malfunction you experienced, it probably happened while we were overloaded. We've since increased the server count and limited the amount of graphs users can build in parallel.
An insider tip: you only have waiting times for graphs that have never been built before. If you return to the graph you've already built, it would be instantaneous.
This is great!
Is there a way to get the node names to be the name of the paper, instead of the citation?
The problem with doing that is that paper titles are extremely long and clutter the graph too much, and if we only show a few words many nodes get the same title.
As an alternative suggestion: would showing the titles upon instant mouse-over satisfy your need?
That would definitely improve it. Perhaps start concatenated, removing filler words, and emphasizing words that are unique in the graph, then expand to full title on mouseover.. I find myself not using the graph at all because I can't see what the papers are about.
Got it, thanks for the suggestions - we'll definitely brainstorm about this.
In the meantime, mouse-over shows an immediate preview of the title on the right side panel - hopefully that helps you use the graph.
I was literally just imagining something like this yesterday and how cool it would be. And then I saw this link today; you've already built it. And it's more amazing than I imagined! Congrats.
Question: how do I “go to selected node”? That is: how do I go from a graph for paper X, to the graph for paper Y which is part of X’s graph? Clicking a connected node just selects it, double-clicking does nothing, clicking paper title in the detail view takes me to an external site for the paper…
EDIT: Ah, the little “Connected Papers” icon under the “Open in:” inline heading in the detail view. However, that opens the paper in a new window/tab, which is not necessarily what I want…
My suggestion would be to make double-clicking on a node “go to” that node, i.e. load the Connected Papers view for that node in the same window, replacing the current view. (Ideally, this would not involve a full page load, but would replace the content, SPA-style. This would also necessarily be the proper design of this interaction for mobile platforms.)
EDIT 2: Another (additional, ideally) UI approach for this would be for entries in the paper list at the left to have a “go to this node” icon, something like this:
(but of course with more subtle styling, etc.)
Hey, Said. That's some great feedback! I'll share it with the team.
We've been debating for some time about the best way to design this interaction (open a node as a graph). Your suggestions are great and we'll definitely experiment with them. Thank you!
I haven't used this myself, but I'm curious from within the context of the 2020 Review whether anyone ended up making significant use of this.
It's a bit unclear how the Review should relate to "technology projects" vs "pure ideas". But the point of the review is to incentivize intellectual progress, and I think projects that directly help with intellectual labor should count.
This is cool. And I realise this could be tricky to implement, but do you think you'd ever try and sort papers by where they were published or the nationality of the authors? Last night, I was trying to find papers by authors with Indian nationality on AI safety, and found it near impossible. So the aforementioned feature could have helped me save a bunch of time.
Hi Algon, thank you for the feedback.
I'm not sure we have easy access to this metadata about the authors. Even if we did, this feature would probably not be very high on our priority list so I wouldn't expect it soon. Sorry!
Hi, your work is amazing!
We 're working with health data ai and will need such visualisation for another matter then papers. Is it a possibility of partnership or some open-source code possible ?
Hi Jane, feel free to write to us at hello@connectedpapers.com with more details. We're very short on time so not sure we can partner on additional projects right now.
Hi LessWrong. I'm a long time lurker and finally have something that I'm really proud to share with you.
After a long beta, we are releasing Connected Papers to the public!
Connected papers is a unique, visual tool to help researchers and applied scientists find and explore papers relevant to their field of work.
First - let's look at a couple of examples graphs for work that is representative of this community:
Nick Bostrom:
https://www.connectedpapers.com/main/7bba95b3d145564025e26b49ca67f13f884f8560/Superintelligence-Paths-Dangers-Strategies/graph
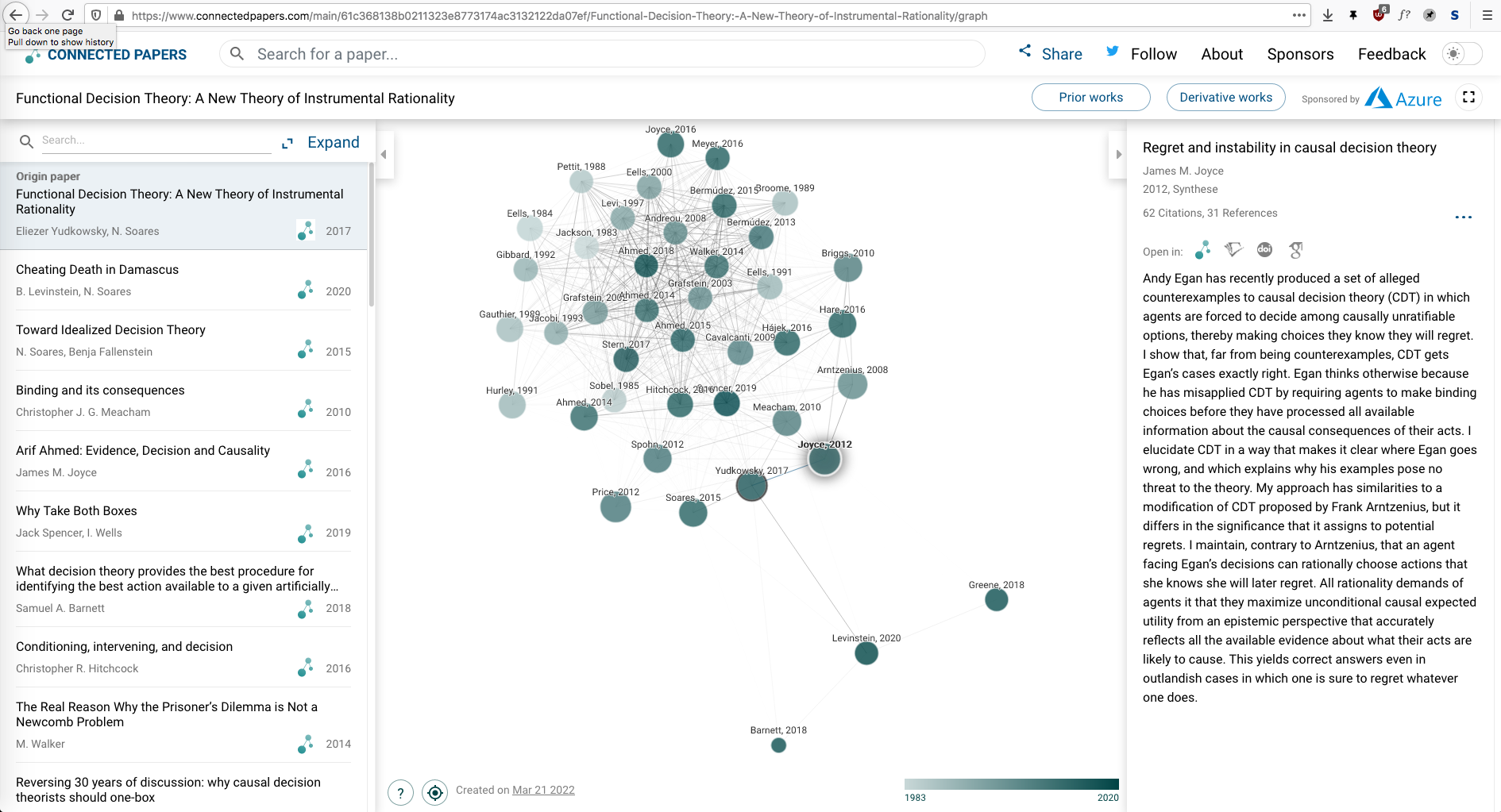
Eliezer Yudkowsky, Nate Soares:
https://www.connectedpapers.com/main/61c368138b0211323e8773174ac3132122da07ef/Functional-Decision-Theory-A-New-Theory-of-Instrumental-Rationality/graph
Did you find new and interesting papers to read? Would this be helpful as an introduction to the literature of a new field of study?
The problem
Almost every research project in academia or industry involves phases of literature review. Many times we find an interesting paper, and we’d like to:
Previously, the best ways to do this were to browse reference lists, or hope to find good keywords in textual search engines and databases.
Enter Connected Papers
It started as a side project between friends. We’ve felt the pains of academic literature review and exploration for years and kept thinking about how to solve it.
For the past year we’ve been meeting on weekends and prototyping a tool that would allow a very different type of search process for academic papers. When we saw how much it improved our own research and development workflows — and got increasingly more requests from friends and colleagues to use it — we committed to release it to the public.
You know… for science.
So how does it work?
Connected Papers is not a citation tree. Those have been done before.
In our graph, papers are arranged according to their similarity. That means that even papers that do not directly cite each other can be strongly connected and positioned close to each other in the graph.
To get a bit technical, our similarity is based primarily on the concepts of co-citation and bibliographic coupling (aka co-reference). According to this measure, two papers that have highly overlapping citations and references are presumed to have a higher chance of treating a related subject matter.
Reading the graph
Our graph is designed to make the important and relevant papers pop out immediately
With our layout algorithm, similar papers cluster together in space and are connected by stronger lines (edges). Popular papers (that are frequently cited) are represented by bigger circles (nodes) and more recent papers are represented by a darker color.
So for example, finding an important new paper in your field is as easy as identifying the dark large node at the center of a big cluster.
List view
In some cases it is convenient to work with just a list of connected papers. For these occasions, we’ve built the List view which you can access by clicking “Expand” at the top of the left panel. Here you can view additional paper details as well as sort and filter them according to various properties.
Prior and derivative works
The Prior works feature lists the top common ancestral papers for the connected papers in the graph. It usually includes seminal works in the field that heavily influenced the next generation.
Meanwhile, the Derivative works feature is the opposite: it shows a list of common descendants of the papers in the graph. It usually includes relevant state of the art papers or systematic reviews and meta-analyses in the field.
We have found these features to be especially useful when we have a paper from one era of research and we would like to be directed to the preceding and succeeding generations of research on the same topic
Help us spread the word
Connected Papers will only grow by word of mouth. Please share Connected Papers in your scientific community!
We are very eager to see how the broader academic community adopts and responds to this tool. We welcome all forms of feedback and would love to brainstorm together about how it can further evolve and improve.