This is a special post for quick takes by Bogdan Ionut Cirstea. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
NVIDIA might be better positioned to first get to/first scale up access to AGIs than any of the AI labs that typically come to mind.
They're already the world's highest-market-cap company, have huge and increasing quarterly income (and profit) streams, and can get access to the world's best AI hardware at literally the best price (the production cost they pay). Given that access to hardware seems far more constraining of an input than e.g. algorithms or data, when AI becomes much more valuable because it can replace larger portions of human workers, they should be highly motivated to use large numbers of GPUs themselves and train their own AGIs, rather than e.g. sell their GPUs and buy AGI access from competitors. Especially since poaching talented AGI researchers would probably (still) be much cheaper than building up the hardware required for the training runs (e.g. see Meta's recent hiring spree); and since access to compute is already an important factor in algorithmic progress and AIs will likely increasingly be able to substitute top human researchers for algorithmic progress. Similarly, since the AI software is a complementary good to the hardware they sell, they should be highly motivated to be able to produce their own in-house, and sell it as a package with their hardware (rather than have to rely on AGI labs to build the software that makes the hardware useful).
This possibility seems to me wildly underconsidered/underdiscussed, at least in public.
9
I am skeptical of this because they can't just scale up data centers on a dime. And signaling that they are trying to become the new biggest hyperscaler would be risky for their existing sales: big tech and frontier labs will go even harder for custom chips than they are now.
To make this happen Nvidia would probably need to partner with neoclouds like CoreWeave that have weaker affiliations with frontier labs. Nvidia is actively incubating neoclouds and does have very strong relationships here, to be sure, but the neoclouds still have fewer data centers and less technical expertise than the more established hyperscalers.
And I think algorithms and talent are very important.
4
In the world that I see Bogdan as pointing to, 'when AI becomes much more valuable because it can replace larger portions of human workers', I'd expect revenue from supplying AGIs to strongly outweigh revenue from chip sales.
EDIT: I misunderstood Josh's point.
6
I'm saying it would be challenging for Nvidia to preserve its high share of AI compute production in the first place while trying to execute this strategy. Nvidia is fabless, and its dominance will erode if labs/hyperscalers/Broadcom create satisfactory designs and are willing to place sufficient large orders with TSMC.
5
Got it! I misunderstood you.
4
Nvidia already has an AI cloud division that is not negligible but small compared to the big players. But they appear to not even own their own chips: they lease from Oracle.
3
Yeah.
Conventional wisdom suggests "execution" for hyperscale consumer products is a moat, e.g "Apple may lead scaling access to AGIs since they have the design, supply chain, marketing expertise plus a vast, established user ecosystem (>2bn active devices)". AGI, however, dissolves away the edge from expertise, and users will flock to a new thing if the value is there (ChatGPT surpassed 1m users in 5 days).
A counter idea I have though is that a prerequisite for AGI may be access to training data derived from pre-AGI systems being used in the wild (e.g across 2bn active devices). In this case, NVIDIA might not have access to the data required to come first.
2
This is the kind of post that would benefit from an “epistemic status.”
If no one thinks NVIDIA is competitive at building frontier systems there’s probably a reason. How seriously should I take these informal arguments without citations? Are they just speculation?
'🚨 The annual report of the US-China Economic and Security Review Commission is now live. 🚨
Its top recommendation is for Congress and the DoD to fund a Manhattan Project-like program to race to AGI.
Buckle up...'
In the reuters article they highlight Jacob Helberg: https://www.reuters.com/technology/artificial-intelligence/us-government-commission-pushes-manhattan-project-style-ai-initiative-2024-11-19/
He seems quite influential in this initiative and recently also wrote this post:
https://republic-journal.com/journal/11-elements-of-american-ai-supremacy/
Wikipedia has the following paragraph on Helberg:
“ He grew up in a Jewish family in Europe.[9] Helberg is openly gay.[10] He married American investor Keith Rabois in a 2018 ceremony officiated by Sam Altman.”
Might this be an angle to understand the influence that Sam Altman has on recent developments in the US government?
5
This chapter on AI follows immediately after the year in review, I went and checked the previous few years' annual reports to see what the comparable chapters were about, they are
2023: China's Efforts To Subvert Norms and Exploit Open Societies
2022: CCP Decision-Making and Xi Jinping's Centralization Of Authority
2021: U.S.-China Global Competition (Section 1: The Chinese Communist Party's Ambitions and Challenges at its Centennial
2020: U.S.-China Global Competition (Section 1: A Global Contest For Power and Influence: China's View of Strategic Competition With the United States)
And this year it's Technology And Consumer Product Opportunities and Risks (Chapter 3: U.S.-China Competition in Emerging Technologies)
Reminds of when Richard Ngo said something along the lines of "We're not going to be bottlenecked by politicians not caring about AI safety. As AI gets crazier and crazier everyone would want to do AI safety, and the question is guiding people to the right AI safety policies"
7
I think we're seeing more interest in AI, but I think interest in "AI in general" and "AI through the lens of great power competition with China" has vastly outpaced interest in "AI safety". (Especially if we're using a narrow definition of AI safety; note that people in DC often use the term "AI safety" to refer to a much broader set of concerns than AGI safety/misalignment concerns.)
I do think there's some truth to the quote (we are seeing more interest in AI and some safety topics), but I think there's still a lot to do to increase the salience of AI safety (and in particular AGI alignment) concerns.
4
'The report doesn't go into specifics but the idea seems to be to build / commandeer the computing resources to scale to AGI, which could include compelling the private labs to contribute talent and techniques.
DX rating is the highest priority DoD procurement standard. It lets DoD compel companies, set their own price, skip the line, and do basically anything else they need to acquire the good in question.' https://x.com/hamandcheese/status/1858902373969564047
4
(screenshot in post from PDF page 39 of https://www.uscc.gov/sites/default/files/2024-11/2024_Annual_Report_to_Congress.pdf)
2
'China hawk and influential Trump AI advisor Jacob Helberg asserted to Reuters that “China is racing towards AGI," but I couldn't find any evidence in the report to support that claim.' https://x.com/GarrisonLovely/status/1859022323799699474
I suspect current approaches probably significantly or even drastically under-elicit automated ML research capabilities.
I'd guess the average cost of producing a decent ML paper is at least 10k$ (in the West, at least) and probably closer to 100k's $.
In contrast, Sakana's AI scientist cost on average 15$/paper and .50$/review. PaperQA2, which claims superhuman performance at some scientific Q&A and lit review tasks, costs something like 4$/query. Other papers with claims of human-range performance on ideation or reviewing also probably have costs of <10$/idea or review.
Even the auto ML R&D benchmarks from METR or UK AISI don't give me at all the vibes of coming anywhere near close enough to e.g. what a 100-person team at OpenAI could accomplish in 1 year, if they tried really hard to automate ML.
A fairer comparison would probably be to actually try hard at building the kind of scaffold which could use ~10k$ in inference costs productively. I suspect the resulting agent would probably not do much better than with 100$ of inference, but it seems hard to be confident. And it seems harder still to be confident about what will happen even in just 3 years' time, give...
In contrast, Sakana's AI scientist cost on average 15$/paper and .50$/review.
The Sakana AI stuff is basically total bogus, as I've pointed out on like 4 other threads (and also as Scott Alexander recently pointed out). It does not produce anything close to fully formed scientific papers. It's output is really not better than just prompting o1 yourself. Of course, o1 and even Sonnet and GPT-4 are very impressive, but there is no update to be made after you've played around with that.
I agree that ML capabilities are under-elicited, but the Sakana AI stuff really is very little evidence on that, besides someone being good at marketing and setting up some scaffolding that produces fake prestige signals.
5
(Again) I think this is missing the point that we've now (for the first time, to my knowledge) observed an early demo the full research workflow being automatable, as flawed as the outputs might be.
I completely agree, and we should just obviously build an organization around this. Automating alignment research while also getting a better grasp on maximum current capabilities (and a better picture of how we expect it to grow).
(This is my intention, and I have had conversations with Bogdan about this, but I figured I'd make it more public in case anyone has funding or ideas they would like to share.)
6
Figures 3 and 4 from MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering seem like some amount of evidence for this view:
4
Also, there are notable researchers and companies working on developing 'a truly general way of scaling inference compute' right now and I think it would be cautious to consider what happens if they succeed.
(This also has implications for automating AI safety research).
2
To spell it out more explicitly, the current way of scaling inference (CoT) seems pretty good vs. some of the most worrying threat models, which often depend on opaque model internals.
2
A related announcement, explicitly targeting 'building an epistemically sound research agent
@elicitorg that can use unlimited test-time compute while keeping reasoning transparent & verifiable': https://x.com/stuhlmueller/status/1869080354658890009.
Eliezer (among others in the MIRI mindspace) has this whole spiel about human kindness/sympathy/empathy/prosociality being contingent on specifics of the human evolutionary/cultural trajectory, e.g. https://twitter.com/ESYudkowsky/status/1660623336567889920 and about how gradient descent is supposed to be nothing like that https://twitter.com/ESYudkowsky/status/1660623900789862401. I claim that the same argument (about evolutionary/cultural contingencies) could be made about e.g. image aesthetics/affect, and this hypothesis should lose many Bayes points when we observe concrete empirical evidence of gradient descent leading to surprisingly human-like aesthetic perceptions/affect, e.g. The Perceptual Primacy of Feeling: Affectless machine vision models robustly predict human visual arousal, valence, and aesthetics; Towards Disentangling the Roles of Vision & Language in Aesthetic Experience with Multimodal DNNs; Controlled assessment of CLIP-style language-aligned vision models in prediction of brain & behavioral data; Neural mechanisms underlying the hierarchical construction of perceived aesthetic value.
12/10/24 update: more, and in my view even somewhat methodologically s...
5
hmm. i think you're missing eliezer's point. the idea was never that AI would be unable to identify actions which humans consider good, but that the AI would not have any particular preference to take those actions.
3
But my point isn't just that the AI is able to produce similar ratings to humans' for aesthetics, etc., but that it also seems to do so through at least partially overlapping computational mechanisms to humans', as the comparisons to fMRI data suggest.
3
I don't think having a beauty-detector that works the same way humans' beauty-detectors do implies that you care about beauty?
4
Agree that it doesn't imply caring for. But I think given cumulating evidence for human-like representations of multiple non-motivational components of affect, one should also update at least a bit on the likelihood of finding / incentivizing human-like representations of the motivational component(s) too (see e.g. https://en.wikipedia.org/wiki/Affect_(psychology)#Motivational_intensity_and_cognitive_scope).
2
Even if Eliezer's argument in that Twitter thread is completely worthless, it remains the case that "merely hoping" that the AI turns out nice is an insufficiently good argument for continuing to create smarter and smarter AIs. I would describe as "merely hoping" the argument that since humans (in some societies) turned out nice (even though there was no designer that ensured they would), the AI might turn out nice. Also insufficiently good is any hope stemming from the observation that if we pick two humans at random out of the humans we know, the smarter of the two is more likely than not to be the nicer of the two. I certainly do not want the survival of the human race to depend on either one of those two hopes or arguments! Do you?
Eliezer finds posting on the internet enjoyable, like lots of people do. He posts a lot about, e.g., superconductors and macroeconomic policy. It is far from clear to me that he consider this Twitter thread to be relevant to the case against continuing to create smarter AIs. But more to the point: do you consider it relevant?
The first automatically produced, (human) peer-reviewed, (ICLR) workshop-accepted[/able] AI research paper: https://sakana.ai/ai-scientist-first-publication/
This is a very low-quality paper.
Basically, the paper does the following:
- A 1-layer LSTM gets inputs of the form
[operand 1][operator][operand 2], e.g.1+2or3*5 - It is trained (I think with a regression loss? but it's not clear[1]) to predict the numerical result of the binary operation
- The paper proposes an auxiliary loss that is supposed to improve "compositionality."
- As described in the paper, this loss is is the average squared difference between successive LSTM hidden states
- But, in the actual code, what is actually is instead the average squared difference between successive input embeddings
- The paper finds (unsurprisingly) that this extra loss doesn't help on the main task[2], while making various other errors and infelicities along the way
- e.g. there's train-test leakage, and (hilariously) it doesn't cite the right source for the LSTM architecture[3]
The theoretical justification presented for the "compositional loss" is very brief and unconvincing. But if I read into it a bit, I can see why it might make sense for the loss described in the paper (on hidden states).
This could regularize an LSTM to be produce something closer to a simple sum or average of the input embe...
3
The first thing that comes to mind is to beg the question of what proportion of human-generated papers are publishing-worthier (since a lot of them are slop), but let's not forget that publication matters little for catastrophic risk, it's actually getting results that would be important.
So I recommend not updating at all on AI risk based on Sakana's results (or updating negatively if you expected that R&D automation would come faster, or that this might slow down human augmentation).
I'm skeptical.
Did the Sakana team publish the code that their scientist agent used to write the compositional regularization paper? The post says
For our choice of workshop, we believe the ICBINB workshop is a highly relevant choice for the purpose of our experiment. As we wrote in the main text, we selected this workshop because of its broader scope, challenging researchers (and our AI Scientist) to tackle diverse research topics that address practical limitations of deep learning, unlike most workshops with a narrow focus on one topic.
This workshop focuses particularly on understanding limitations of deep learning methods applied to real world problems, and encourages participants to study negative experimental outcomes. Some may criticize our choice of a workshop that encourages discussion of “negative results” (implying that papers discussing negative results are failed scientific discoveries), but we disagree, and we believe this is an important topic.
and while it is true that "negative results" are important to report, "we report a negative result because our AI agent put forward a reasonable and interesting hypothesis, competently tested the hypothesis, and found that the hyp...
Contra both the 'doomers' and the 'optimists' on (not) pausing. Rephrased: RSPs (done right) seem right.
Contra 'doomers'. Oversimplified, 'doomers' (e.g. PauseAI, FLI's letter, Eliezer) ask(ed) for pausing now / even earlier - (e.g. the Pause Letter). I expect this would be / have been very much suboptimal, even purely in terms of solving technical alignment. For example, Some thoughts on automating alignment research suggests timing the pause so that we can use automated AI safety research could result in '[...] each month of lead that the leader started out with would correspond to 15,000 human researchers working for 15 months.' We clearly don't have such automated AI safety R&D capabilities now, suggesting that pausing later, when AIs are closer to having the required automated AI safety R&D capabilities would be better. At the same time, current models seem very unlikely to be x-risky (e.g. they're still very bad at passing dangerous capabilities evals), which is another reason to think pausing now would be premature.
Contra 'optimists'. I'm more unsure here, but the vibe I'm getting from e.g. AI Pause Will Likely Backfire (Guest Post) is roughly something like 'no paus...
5
At least Eliezer has been extremely clear that he is in favor of a stop not a pause (indeed, that was like the headline of his article "Pausing AI Developments Isn't Enough. We Need to Shut it All Down"), so I am confused why you list him with anything related to "pause".
My guess is me and Eliezer are both in favor of a pause, but mostly because a pause seems like it would slow down AGI progress, not because the next 6 months in-particular will be the most risky period.
5
The relevant criterion is not whether the current models are likely to be x-risky (it's obviously far too late if they are!), but whether the next generation of models have more than an insignificant chance of being x-risky together with all the future frameworks they're likely to be embedded into.
Given that the next generations are planned to involve at least one order of magnitude more computing power in training (and are already in progress!) and that returns on scaling don't seem to be slowing, I think the total chance of x-risk from those is not insignificant.
2
I agree with some points here Bogdan, but not all of them.
I do think that current models are civilization-scale-catastrophe-risky (but importantly not x-risky!) from a misuse perspective, but not yet from a self-directed perspective. Which means neither Alignment nor Control are currently civilization-scale-catastrophe-risky, much less x-risky.
I also agree that pausing now would be counter-productive. My reasoning for this is that I agree with Samo Burja about some key points which are relevant here (while disagreeing with his conclusions due to other points).
To quote myself:
[...]
Think about how you'd expect these factors to change if large AI training runs were paused. I think you might agree that this would likely result in a temporary shift in much of the top AI scientist talent to making theoretical progress. They'd want to be ready to come in strong after the pause was ended, with lots of new advances tested at small scale. I think this would actually result more high quality scientific thought directed at the heart of the problem of AGI, and thus make AGI very likely to be achieved sooner after the pause ends than it otherwise would have been.
I would go even farther, and make the claim that AGI could arise during a pause on large training runs. I think that the human brain is not a supercomputer, my upper estimate for 'human brain inference' is about at the level of a single 8x A100 server. Less than an 8x H100 server. Also, I have evidence from analysis of the long-range human connectome (long range axons are called tracts, so perhaps I should call this a 'tractome'). [Hah, I just googled this term I came up with just now, and found it's already in use, and that it brings up some very interesting neuroscience papers. Cool.] Anyway... I was saying, this evidence shows that the range of bandwidth (data throughput in bits per second) between two cortical regions in the human brain is typically around 5 mb/s, and maxes out at about 50 mb/s. In other
Hot take, though increasingly moving towards lukewarm: if you want to get a pause/international coordination on powerful AI (which would probably be net good, though likely it would strongly depend on implementation details), arguments about risks from destabilization/power dynamics and potential conflicts between various actors are probably both more legible and 'truer' than arguments about technical intent misalignment and loss of control (especially for not-wildly-superhuman AI).
arguments about risks from destabilization/power dynamics and potential conflicts between various actors are probably both more legible and 'truer'
Say more?
I think the general impression of people on LW is that multipolar scenarios and concerns over "which monkey finds the radioactive banana and drags it home" are in large part a driver of AI racing instead of being a potential impediment/solution to it. Individuals, companies, and nation-states justifiably believe that whichever one of them accesses potentially superhuman AGI first will have the capacity to flip the gameboard at-will, obtain power over the entire rest of the Earth, and destabilize the currently-existing system. Standard game theory explains the final inferential step for how this leads to full-on racing (see the recent U.S.-China Commission's report for a representative example of how this plays out in practice).
I get that we'd like to all recognize this problem and coordinate globally on finding solutions, by "mak[ing] coordinated steps away from Nash equilibria in lockstep". But I would first need to see an example, a prototype, of how this can play out in practice on an important and highly salient issue....
6
At the risk of being overly spicy/unnuanced/uncharitable: I think quite a few MIRI [agent foundations] memes ("which monkey finds the radioactive banana and drags it home", ''automating safety is like having the AI do your homework'', etc.) seem very lazy/un-truth-tracking and probably net-negative at this point, and I kind of wish they'd just stop propagating them (Eliezer being probably the main culprit here).
Perhaps even more spicily, I similarly think that the old MIRI threat model of Consequentialism is looking increasingly 'tired'/un-truth-tracking, and there should be more updating away from it (and more so with every single increase in capabilities without 'proportional' increases in 'Consequentialism'/egregious misalignment).
(Especially) In a world where the first AGIs are not egregiously misaligned, it very likely matters enormously who builds the first AGIs and what they decide to do with them. While this probably creates incentives towards racing in some actors (probably especially the ones with the best chances to lead the race), I suspect better informing more actors (especially more of the non-leading ones, who might especially see themselves as more on the losing side in the case of AGI and potential destabilization) should also create incentives for (attempts at) more caution and coordination, which the leading actors might at least somewhat take into consideration, e.g. for reasons along the lines of https://aiprospects.substack.com/p/paretotopian-goal-alignment.
[...]
I'm not particularly optimistic about coordination, especially the more ambitious kinds of plans (e.g. 'shut it all down', long pauses like in 'A narrow path...', etc.), and that's to a large degree (combined with short timelines and personal fit) why I'm focused on automated safety reseach. I'm just saying: 'if you feel like coordination is the best plan you can come up with/you're most optimistic about, there are probably more legible and likely also more truth-tracking arg
2
(Also, what Thane Ruthenis commented below.)
2
I'd say the big factor that makes AI controllable right now is that the compute necessary to build AI that can do very good AI research to automate R&D and then the economy is locked behind TSMC/NVidia and ASML, and their processes are both nearly irreplaceable and very expensive to make, so it's way easier to intervene on the checkpoints requiring AI development than gain-of function research.
1[anonymous]
I agree, but I think this is slightly beside the original points I wanted to make.
8
Agreed. I think a type of "stop AGI research" argument that's under-deployed is that there's no process or actor in the world that society would trust with unilateral godlike power. At large, people don't trust their own governments, don't trust foreign governments, don't trust international organizations, and don't trust corporations or their CEOs. Therefore, preventing anyone from building ASI anywhere is the only thing we can all agree on.
I expect this would be much more effective messaging with some demographics, compared to even very down-to-earth arguments about loss of control. For one, it doesn't need to dismiss the very legitimate fear that the AGI would be aligned to values that a given person would consider monstrous. (Unlike "stop thinking about it, we can't align it to any values!".)
And it is, of course, true.
4
What kinds of conflicts are you envisioning?
I think if the argument is something along the lines of "maybe at some point other countries will demand that the US stop AI progress", then from the perspective of the USG, I think it's sensible to operate under the perspective of "OK so we need to advance AI progress as much as possible and try to hide some of it, and if at some future time other countries are threatening us we need to figure out how to respond." But I don't think it justifies anything like "we should pause or start initiating international agreements."
(Separately, whether or not it's "truer" depends a lot on one's models of AGI development. Most notably: (a) how likely is misalignment and (b) how slow will takeoff be//will it be very obvious to other nations that super advanced AI is about to be developed, and (c) how will governments and bureaucracies react and will they be able to react quickly enough.)
(Also separately– I do think more people should be thinking about how these international dynamics might play out & if there's anything we can be doing to prepare for them. I just don't think they naturally lead to a "oh, so we should be internationally coordinating" mentality and instead lead to much more of a "we can do whatever we want unless/until other countries get mad at us & we should probably do things more secretly" mentality.)
4
I'm envisioning something like: scary powerful capabilities/demos/accidents leading to various/a coalition of other countries asking the US (and/or China) not to build any additional/larger data centers (and/or run any larger training runs), and, if they're scared enough, potentially even threatening various (escalatory) measures, including economic sanctions, blockading the supply of compute/prerequisites to compute, sabotage, direct military strikes on the data centers, etc.
I'm far from an expert on the topic, but I suspect it might not be trivial to hide at least building a lot more new data centers/supplying a lot more compute, if a significant chunk of the rest of the world was watching very intently.
[...]
I'm envisioning a very near-casted scenario, on very short (e.g. Daniel Kokotajlo-cluster) timelines, egregious misalignment quite unlikely but not impossible, slow-ish (couple of years) takeoff (by default, if no deliberate pause), pretty multipolar, but with more-obviously-close-to-scary capabilities, like ML R&D automation evals starting to fall.
4
Thanks for spelling it out. I agree that more people should think about these scenarios. I could see something like this triggering central international coordination (or conflict).
(I still don't think this would trigger the USG to take different actions in the near-term, except perhaps "try to be more secret about AGI development" and maybe "commission someone to do some sort of study or analysis on how we would handle these kinds of dynamics & what sorts of international proposals would advance US interests while preventing major conflict." The second thing is a bit optimistic but maybe plausible.)
Quick take on o1: overall, it's been a pretty good day. Likely still sub-ASL-3, (opaque) scheming still seems very unlikely because the prerequisites still don't seem there. CoT-style inference compute playing a prominent role in the capability gains is pretty good for safety, because differentially transparent. Gains on math and code suggest these models are getting closer to being usable for automated safety research (also for automated capabilities research, unfortunately).
6
CoT inference looks more like the training surface, not essential part of resulting cognition after we take one more step following such models. Orion is reportedly (being) pretrained on these reasoning traces, and if it's on the order of 50 trillion tokens, that's about as much as there is natural text data of tolerable quality in the world available for training. Contrary to the phrasing, what transformers predict is in part distant future tokens within a context, not proximate "next tokens" that follow immediately after whatever the prediction must be based on.
So training on reasoning traces should teach the models concepts that let them arrive at the answer faster, skipping the avoidable parts of the traces and compressing a lot of the rest into less scrutable activations. The models trained at the next level of scale might be quite good at that, to the extent not yet known from experience with the merely GPT-4 scale models.
5
Some bad news is that there was some problematic power seeking and instrumental convergence, though thankfully that only happened in an earlier model:
https://www.lesswrong.com/posts/bhY5aE4MtwpGf3LCo/openai-o1#JGwizteTkCrYB5pPb
Edit: It looks like the instrumentally convergent reasoning was because of the prompt, so I roll back my updates on instrumental convergence being likely:
https://www.lesswrong.com/posts/dqSwccGTWyBgxrR58/turntrout-s-shortform-feed#eLrDowzxuYqBy4bK9
For some perspective:
'New data centers put Stargate ahead of schedule to secure full $500 billion, 10-gigawatt commitment by end of 2025.' https://openai.com/index/five-new-stargate-sites/
'One estimate puts total funding for AI safety research at only $80-130 million per year over the 2021-2024 period.' https://www.schmidtsciences.org/safetyscience/#:~:text=One%20estimate%20puts%20total%20funding,period%20(LessWrong%2C%202024)
Gemini 2.0 Flash Thinking is claimed to 'transparently show its thought process' (in contrast to o1, which only shows a summary): https://x.com/denny_zhou/status/1869815229078745152. This might be at least a bit helpful in terms of studying how faithful (e.g. vs. steganographic, etc.) the Chains of Thought are.
4
Other recent models that show (at least purportedly) the full CoT:
* Deepseek R1-Lite (note that you have to turn 'DeepThink' on)
* Qwen QwQ-32B
4
Huge if true! Faithful Chain of Thought may be a key factor in whether the promise of LLMs as ideal for alignment pays off, or not.
I am increasingly concerned that OpenAI isn't showing us o1s CoT because it's using lots of jargon that's heading toward a private language. I hope it's merely that it didn't want to show its unaligned "thoughts", and to prevent competitors from training on its useful chains of thought.
7
IMO, I think that most of the reason why they are not releasing CoT for o1 is exactly because of PR/competitive reasons, or this reason in a nutshell:
[...]
QwQ-32B-Preview was released open-weights, seems comparable to o1-preview. Unless they're gaming the benchmarks, I find it both pretty impressive and quite shocking that a 32B model can achieve this level of performance. Seems like great news vs. opaque (e.g in one-forward-pass) reasoning. Less good with respect to proliferation (there don't seem to be any [deep] algorithmic secrets), misuse and short timelines.
8
From proliferation perspective, it reduces overhang, makes it more likely that Llama 4 gets long reasoning trace post-training in-house rather than later, and so initial capability evaluations give more relevant results. But if Llama 4 is already training, there might not be enough time for the technique to mature, and Llamas have been quite conservative in their techniques so far.
1
There have been comments from OAI staff that o1 is "GPT-2 level" so I wonder if it's a similar size?
I think they meant that as an analogy to how developed/sophisticated it was (ie they're saying that it's still early days for reasoning models and to expect rapid improvement), not that the underlying model size is similar.
IIRC OAers also said somewhere (doesn't seem to be in the blog post, so maybe this was on Twitter?) that o1 or o1-preview was initialized from a GPT-4 (a GPT-4o?), so that would also rule out a literal parameter-size interpretation (unless OA has really brewed up some small models).
1
There was an article about it before the release.
https://archive.is/IwKSP
[...]
3
(Relevant, although "involving its GPT-4 AI model" is a considerably weaker statement than 'initialized from a GPT-4 checkpoint'.)
Like transformers, SSMs like Mamba also have weak single forward passes: The Illusion of State in State-Space Models (summary thread). As suggested previously in The Parallelism Tradeoff: Limitations of Log-Precision Transformers, this may be due to a fundamental tradeoff between parallelizability and expressivity:
'We view it as an interesting open question whether it is possible to develop SSM-like models with greater expressivity for state tracking that also have strong parallelizability and learning dynamics, or whether these different goals are fundamentally at odds, as Merrill & Sabharwal (2023a) suggest.'
7
Surely fundamentally at odds? You can't spend a while thinking without spending a while thinking.
Of course, the lunch still might be very cheap by only spending a while thinking a fraction of the time or whatever.
'Data movement bottlenecks limit LLM scaling beyond 2e28 FLOP, with a "latency wall" at 2e31 FLOP. We may hit these in ~3 years. Aggressive batch size scaling could potentially overcome these limits.' https://epochai.org/blog/data-movement-bottlenecks-scaling-past-1e28-flop
The post argues that there is a latency limit at 2e31 FLOP, and I've found it useful to put this scale into perspective.
Current public models such as Llama 3 405B are estimated to be trained with ~4e25 flops , so such a model would require 500,000 x more compute. Since Llama 3 405B was trained with 16,000 H-100 GPUs, the model would require 8 billion H-100 GPU equivalents, at a cost of $320 trillion with H-100 pricing (or ~$100 trillion if we use B-200s). Perhaps future hardware would reduce these costs by an order of magnitude, but this is cancelled out by another factor; the 2e31 limit assumes a training time of only 3 months. If we were to build such a system over several years and had the patience to wait an additional 3 years for the training run to complete, this pushes the latency limit out by another order of magnitude. So at the point where we are bound by the latency limit, we are either investing a significant percentage of world GDP into the project, or we have already reached ASI at a smaller scale of compute and are using it to dramatically reduce compute costs for successor models.
Of course none of this analysis applies to the earlier data limit of 2e28 flop, which I think is more relevant and interesting.
6
An important caveat to the data movement limit:
“A recent paper which was published only a few days before the publication of our own work, Zhang et al. (2024), finds a scaling of B = 17.75 D^0.47 (in units of tokens). If we rigorously take this more aggressive scaling into account in our model, the fall in utilization is pushed out by two orders of magnitude; starting around 3e30 instead of 2e28. Of course, even more aggressive scaling might be possible with methods that Zhang et al. (2024) do not explore, such as using alternative optimizers.”
I haven’t looked carefully at Zhang et al., but assuming their analysis is correct and the data wall is at 3e30 FLOP, it’s plausible that we hit resource constraints ($10-100 trillion training runs, 2-20 TW power required) before we hit the data movement limit.
3
Speculatively, this might also differentially incentivize (research on generalized) inference scaling, with various potential strategic implications, including for AI safety (current inference scaling methods tend to be tied to CoT and the like, which are quite transparent) and for regulatory frameworks/proliferation of dangerous capabilities.
6
Aschenbrenner in Situational Awareness predicts illegible chains of thought are going to prevail because they are more efficient. I know of one developer claiming to do this but I guess there must be many.
3
under the assumptions here (including Chinchilla scaling laws), depth wouldn't increase by more than about 3x before the utilization rate starts dropping (because depth would increase with exponent about 1/6 of the total increase in FLOP); which seems like great news for the legibility of CoT outputs and similar and vs. opaque reasoning in models: https://lesswrong.com/posts/HmQGHGCnvmpCNDBjc/current-ais-provide-nearly-no-data-relevant-to-agi-alignment#mcA57W6YK6a2TGaE2
1
Interesting paper, though the estimates here don’t seem to account for Epoch’s correction to the chinchilla scaling laws: https://epochai.org/blog/chinchilla-scaling-a-replication-attempt
This would imply that the data movement bottleneck is a bit further out.
Quick take: on the margin, a lot more research should probably be going into trying to produce benchmarks/datasets/evaluation methods for safety (than more directly doing object-level safety research).
Some past examples I find valuable - in the case of unlearning: WMDP, Eight Methods to Evaluate Robust Unlearning in LLMs; in the case of mech interp - various proxies for SAE performance, e.g. from Scaling and evaluating sparse autoencoders, as well as various benchmarks, e.g. FIND: A Function Description Benchmark for Evaluating Interpretability Methods. Prizes and RFPs seem like a potentially scalable way to do this - e.g. https://www.mlsafety.org/safebench - and I think they could be particularly useful on short timelines.
Including differentially vs. doing the full stack of AI safety work - because I expect a lot of such work could be done by automated safety researchers soon, with the right benchmarks/datasets/evaluation methods. This could also make it much easier to evaluate the work of automated safety researchers and to potentially reduce the need for human feedback, which could be a significant bottleneck.
Better proxies could also make it easier to productively deploy ...
4
I'm torn between generally being really fucking into improving feedback loops (and thinking they are a good way to make it easier to make progress on confusing questions), and, being sad that so few people are actually just trying to actually directly tackle the hard bits of the alignment challenge.
4
Some quick thoughts:
* automating research that 'tackles the hard bits' seems to probably be harder (happen chronologically later) and like it might be more bottlenecked by good (e.g. agent foundations) human researcher feedback - which does suggest it might be valuable to recruit more agent foundations researchers today
* but my impression is that recruiting/forming agent foundations researchers itself is much harder and has much worse feedback loops
* I expect if the feedback loops are good enough, the automated safety researchers could make enough prosaic safety progress, feeding into agendas like control and/or conditioning predictive models (+ extensions to e.g. steering using model internals, + automated reviewing, etc.), to allow the use of automated agent foundations researchers with more confidence and less human feedback
* the hard bits might also become much less hard - or prove to be irrelevant - if for at least some of them empirical feedback could be obtained by practicing on much more powerful models
Overall, my impression is that focusing on the feedback loops seems probably significantly more scalable today, and the results would probably be enough to allow to mostly defer the hard bits to automated research.
(Edit: but also, I think if funders and field builders 'went hard', it might be much less necessary to choose.)
2
Potentially also https://www.lesswrong.com/posts/yxdHp2cZeQbZGREEN/improving-model-written-evals-for-ai-safety-benchmarking.
- Shenzhen team completed a working prototype of a EUV machine in early 2025, sources say
- The lithography machine, built by former ASML engineers, fills a factory floor, sources say
- China's EUV machine is undergoing testing, and has not produced working chips, sources say
- Government is targeting 2028 for working chips, but sources say 2030 is more likely'
1
If Chinese are twice as fast as the Dutch, they are going to get the first EUV-made chips ca. 2034. IIRC, their semiconductor industry has a lot of precedents for not maintaining ambitious time schedules set by the party
Success at currently-researched generalized inference scaling laws might risk jeopardizing some of the fundamental assumptions of current regulatory frameworks.
- the o1 results have illustrated specialized inference scaling laws, for model capabilities in some specialized domains (e.g. math); notably, these don't seem to generally hold for all domains - e.g. o1 doesn't seem better than gpt4o at writing;
- there's ongoing work at OpenAI to make generalized inference scaling work;
- e.g. this could perhaps (though maybe somewhat overambitiously) be framed, in the language of https://epochai.org/blog/trading-off-compute-in-training-and-inference, as there no longer being an upper bound in how many OOMs of inference compute can be traded for equivalent OOMs of pretraining;
- to the best of my awarenes, current regulatory frameworks/proposals (e.g. the EU AI Act, the Executive Order, SB 1047) frame the capabilities of models in terms of (pre)training compute and maybe fine-tuning compute (e.g. if (pre)training FLOP > 1e26, the developer needs to take various measures), without any similar requirements framed in terms of inference compute; so current regulatory frameworks seem unprepared f
4
For similar reasons to the discussion here about why individuals and small businesses might be expected to be able to (differentially) contribute to LM scaffolding (research), I expect them to be able to differentially contribute to [generalized] inference scaling [research]; plausibly also the case for automated ML research agents. Also relevant: Before smart AI, there will be many mediocre or specialized AIs.
I think this one (and perhaps better operationalizations) should probably have many eyes on it:
4
I also have this market for GPQA, on a longer time-horizon:
https://manifold.markets/NiplavYushtun/will-the-gap-between-openweights-an
Jack Clark: 'Registering a prediction: I predict that within two years (by July 2026) we'll see an AI system beat all humans at the IMO, obtaining the top score. Alongside this, I would wager we'll see the same thing - an AI system beating all humans in a known-hard competition - in another scientific domain outside of mathematics. If both of those things occur, I believe that will present strong evidence that AI may successfully automate large chunks of scientific research before the end of the decade.' https://importai.substack.com/p/import-ai-380-distributed-13bn-parameter
8
Prediction markets on similar questions suggest to me that this is a consensus view.
* General LLMs 44% to get gold on the IMO before 2026. This suggests the mathematical competency will be transferrable--not just restricted to domain-specific solvers.
* LLMs favored to outperform PhD students in their own subject before 2026
With research automation in mind, here's my wager: the modal top-15 STEM PhD student will redirect at least half of their discussion/questions from peers to mid-2026 LLMs. Defining the relevant set of questions as being drawn from the same difficulty/diversity/open-endedness distribution that PhDs would have posed in early 2024.
5
Fwiw, I've kind of already noted myself starting to do some of this, for AI safety-related papers; especially after Claude-3.5 Sonnet came out.
(cross-posted from https://x.com/BogdanIonutCir2/status/1844451247925100551, among others)
I'm concerned things might move much faster than most people expected, because of automated ML (figure from OpenAI's recent MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering, basically showing automated ML engineering performance scaling as more inference compute is used):
I find it pretty wild that automating AI safety R&D, which seems to me like the best shot we currently have at solving the full superintelligence control/alignment problem, no longer seems to have any well-resourced, vocal, public backers (with the superalignment team disbanded).
I think Anthropic is becoming this org. Jan Leike just tweeted:
https://x.com/janleike/status/1795497960509448617
I'm excited to join @AnthropicAI to continue the superalignment mission!
My new team will work on scalable oversight, weak-to-strong generalization, and automated alignment research.
If you're interested in joining, my dms are open.
5
On what basis do you think it’s the ‘best shot’? I used to think it was a good idea, a few years ago, but in retrospect I think that was just a computer scientist’s love of recursion. I don’t think that at present conditions are good for automating R&D. On the one hand, we have a lot of very smart people working on AI safety R&D, with very slow progress, indicating it is a hard problem. On the other hand, present-day LLMs are stupid at long-term planning, and acquiring new knowledge, which are things you need to be good at to do R&D.
What advantage do you see AIs having over humans in this area?
7
I think there will be a period in the future where AI systems (models and their scaffolding) exist which are sufficiently capable that they will be able to speed up many aspects of computer-based R&D. Including recursive-self-improvement, Alignment research and Control research. Obviously, such a time period will not be likely to last long given that surely some greedy actor will pursue RSI. So personally, that's why I'm not putting a lot of faith in getting to that period [edit: resulting in safety].
I think that if you build the scaffolding which would make current models able to be substantially helpful at research (which would be impressively strong scaffolding indeed!), then you have built dual-use scaffolding which could also be useful for RSI. So any plans to do this must take appropriate security measures or they will be net harmful.
2
Agree with a lot of this, but scaffolds still seem to me pretty good, for reasons largely similar to those in https://www.lesswrong.com/posts/fRSj2W4Fjje8rQWm9/thoughts-on-sharing-information-about-language-model#Accelerating_LM_agents_seems_neutral__or_maybe_positive_.
4
I kind of wish this was true, because it would likely mean longer timelines, but my expectation is that the incoming larger LMs + better scaffolds + more inference-time compute could quite easily pass the threshold of significant algorithmic progress speedup from automation (e.g. 2x).
5
Making algorithmic progress and making safety progress seem to differ along important axes relevant to automation:
Algorithmic progress can use 1. high iteration speed 2. well-defined success metrics (scaling laws) 3.broad knowledge of the whole stack (Cuda to optimization theory to test-time scaffolds) 4. ...
Alignment broadly construed is less engineering and a lot more blue skies, long horizon, and under-defined (obviously for engineering heavy alignment sub-tasks like jailbreak resistance, and some interp work this isn't true).
Probably automated AI scientists will be applied to alignment research, but unfortunately automated research will differentially accelerate algorithmic progress over alignment. This line of reasoning is part of why I think it's valuable for any alignment researcher (who can) to focus on bringing the under-defined into a well-defined framework. Shovel-ready tasks will be shoveled much faster by AI shortly anyway.
3
Generally agree, but I do think prosaic alignment has quite a few advantages vs. prosaic capabilities (e.g. in the extra slides here) and this could be enough to result in aligned (-enough) automated safety researchers which can be applied to the more blue skies parts of safety research. I would also very much prefer something like a coordinated pause around the time when safety research gets automated.
[...]
Agree, I've written about (something related to) this very recently.
4
Yes, things have certainly changed in the four months since I wrote my original comment, with the advent of o1 and Sakana’s Artificial Scientist. Both of those are still incapable of full automation of self-improvement, but they’re close. We’re clearly much closer to a recursive speed up of R&D, leading to FOOM.
from https://jack-clark.net/2024/08/18/import-ai-383-automated-ai-scientists-cyborg-jellyfish-what-it-takes-to-run-a-cluster/…, commenting on https://arxiv.org/abs/2408.06292: 'Why this matters – the taste of automated science: This paper gives us a taste of a future where powerful AI systems propose their own ideas, use tools to do scientific experiments, and generate results. At this stage, what we have here is basically a ‘toy example’ with papers of dubious quality and insights of dubious import. But you know where we were with language models five yea...
-4
Yep. I find it pretty odd that alignment people say, with a straight face, "LLM agents are still pretty dumb so I don't think that's a path to AGI". I thought the whole field was about predicting progress and thinking out ahead of it.
Progress does tend to happen when humans work on something.
Progress probably happens when parahumans work on things, too.
8
Who says those things? That doesn't really sound like something that people say. Like, I think there are real arguments about why LLM agents might not be the most likely path to AGI, but "they are still pretty dumb, therefore that's not a path to AGI" seems like obviously a strawman, and I don't think I've ever seen it (or at least not within the last 4 years or so).
2
Fair enough; this sentiment is only mentioned offhand in comments and might not capture very much of the average opinion. I may be misestimating the community's average opinion. I hope I am wrong, and I'm glad to see others don't agree!
I'm a bit puzzled on the average attitude toward LLM agents as a route to AGI among alignment workers. I'm still surprised there aren't more people working directly on aligning LLM agents. I'd think we'd be working harder on the most likely single type of first AGI if lots of us really believed it's reasonably likely to get there (especially since it's probably the fastest route if it doesn't plateau soon).
One possible answer is that people are hoping that the large amount of work on aligning LLMs will cover aligning LLM agents. I think that work is helpful but not sufficient, so we need more thinking about agent alignment as distinct from their base LLMs. I'm currently writing a post on this.
2
(Most people in AI Alignment work at scaling labs and are therefore almost exclusively working on LLM alignment. That said, I don't actually know what it means to work on LLM alignment over aligning other systems, it's not like we have a ton of traction on LLM alignment, and most techniques and insights seem general enough to not be conditional specifically on LLMs)
6
I think Seth is distinguishing “aligning LLM agents” from “aligning LLMs”, and complaining that there’s insufficient work on the former, compared to the latter? I could be wrong.
[...]
Ooh, I can speak to this. I’m mostly focused on technical alignment for actor-critic model-based RL systems (a big category including MuZero and [I argue] human brains). And FWIW my experience is: there are tons of papers & posts on alignment that assume LLMs, and with rare exceptions I find them useless for the non-LLM algorithms that I’m thinking about.
As a typical example, I didn’t get anything useful out of Alignment Implications of LLM Successes: a Debate in One Act—it’s addressing a debate that I see as inapplicable to the types of AI algorithms that I’m thinking about. Ditto for the debate on chain-of-thought accuracy vs steganography and a zillion other things.
When we get outside technical alignment to things like “AI control”, governance, takeoff speed, timelines, etc., I find that the assumption of LLMs is likewise pervasive, load-bearing, and often unnoticed.
I complain about this from time to time, for example Section 4.2 here, and also briefly here (the bullets near the bottom after “Yeah some examples would be:”).
2
I agree with the claim that the techniques and insights for alignment that are usually considered are not conditional on LLMs specifically, including my own plan for AI alignment.
(cross-posted from https://x.com/BogdanIonutCir2/status/1842914635865030970)
maybe there is some politically feasible path to ML training/inference killswitches in the near-term after all: https://www.datacenterdynamics.com/en/news/asml-adds-remote-kill-switch-to-tsmcs-euv-machines-in-case-china-invades-taiwan-report/
On an apparent missing mood - FOMO on all the vast amounts of automated AI safety R&D that could (almost already) be produced safely
Automated AI safety R&D could results in vast amounts of work produced quickly. E.g. from Some thoughts on automating alignment research (under certain assumptions detailed in the post):
each month of lead that the leader started out with would correspond to 15,000 human researchers working for 15 months.
Despite this promise, we seem not to have much knowledge when such automated AI safety R&D might happ...
7
My main vibe is:
* AI R&D and AI safety R&D will almost surely come at the same time.
* Putting aside using AIs as tools in some more limited ways (e.g. for interp labeling or generally for grunt work)
* People at labs are often already heavily integrating AIs into their workflows (though probably somewhat less experimentation here than would be ideal as far as safety people go).
It seems good to track potential gaps between using AIs for safety and for capabilities, but by default, it seems like a bunch of this work is just ML and will come at the same time.
1
Seems like probably the modal scenario to me too, but even limited exceptions like the one you mention seem to me like they could be very important to deploy at scale ASAP, especially if they could be deployed using non-x-risky systems (e.g. like current ones, very bad at DC evals).
[...]
This seems good w.r.t. automated AI safety potentially 'piggybacking', but bad for differential progress.
[...]
Sure, though wouldn't this suggest at least focusing hard on (measuring / eliciting) what might not come at the same time?
2
Why think this is important to measure or that this already isn't happening?
E.g., on the current model organism related project I'm working on, I automate inspecting reasoning traces in various ways. But I don't feel like there is any particularly interesting thing going on here which is important to track (e.g. this tip isn't more important than other tips for doing LLM research better).
3
Intuitively, I'm thinking of all this as something like a race between [capabilities enabling] safety and [capabilities enabling dangerous] capabilities (related: https://aligned.substack.com/i/139945470/targeting-ooms-superhuman-models); so from this perspective, maintaining as large a safety buffer as possible (especially if not x-risky) seems great. There could also be something like a natural endpoint to this 'race', corresponding to being able to automate all human-level AI safety R&D safely (and then using this to produce a scalable solution to aligning / controlling superintelligence).
W.r.t. measurement, I think it would be good orthogonally to whether auto AI safety R&D is already happening or not, similarly to how e.g. evals for automated ML R&D seem good even if automated ML R&D is already happening. In particular, the information of how successful auto AI safety R&D would be (and e.g. what the scaling curves look like vs. those for DCs) seems very strategically relevant to whether it might be feasible to deploy it at scale, when that might happen, with what risk tradeoffs, etc.
1
To get somewhat more concrete, the Frontier Safety Framework report already proposes a (somewhat vague) operationalization for ML R&D evals, which (vagueness-permitting) seems straightforward to translate into an operationalization for automated AI safety R&D evals:
[...]
If this generalizes, OpenAI's Orion, rumored to be trained on synthetic data produced by O1, might see significant gains not just in STEM domains, but more broadly - from O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?:
'this study reveals how simple distillation from O1's API, combined with supervised fine-tuning, can achieve superior performance on complex mathematical reasoning tasks. Through extensive experiments, we show that a base model fine-tuned on simply tens of thousands of sampl...
(crossposted from X/twitter)
Epoch is one of my favorite orgs, but I expect many of the predictions in https://epochai.org/blog/interviewing-ai-researchers-on-automation-of-ai-rnd to be overconservative / too pessimistic. I expect roughly a similar scaleup in terms of compute as https://x.com/peterwildeford/status/1825614599623782490… - training runs ~1000x larger than GPT-4's in the next 3 years - and massive progress in both coding and math (e.g. along the lines of the medians in https://metaculus.com/questions/6728/ai-wins-imo-gold-medal/… https://metacu...
(cross-posted from X/twitter)
The already-feasibility of https://sakana.ai/ai-scientist/ (with basically non-x-risky systems, sub-ASL-3, and bad at situational awareness so very unlikely to be scheming) has updated me significantly on the tractability of the alignment / control problem. More than ever, I expect it's gonna be relatively tractable (if done competently and carefully) to safely, iteratively automate parts of AI safety research, all the way up to roughly human-level automated safety research (using LLM agents roughly-shaped like the AI scientist...
I think currently approximately no one is working on the kind of safety research that when scaled up would actually help with aligning substantially smarter than human agents, so I am skeptical that the people at labs could automate that kind of work (given that they are basically doing none of it). I find myself frustrated with people talking about automating safety research, when as far as I can tell we have made no progress on the relevant kind of work in the last ~5 years.
2
Can you give some examples of work which you do think represents progress?
My rough mental model is something like: LLMs are trained using very large-scale (multi-task) behavior cloning, so I expect various tasks to be increasingly automated / various data distributions to be successfully, all the way to (in the limit) at roughly everything humans can do, as a lower bound; including e.g. the distribution of what tends to get posted on LessWrong / the Alignment Forum (and agent foundations-like work); especially when LLMs are scaffolded into agents, given access to tools, etc. With the caveats that the LLM [agent] paradigm might not get there before e.g. it runs out of data / compute, or that the systems might be unsafe to use; but against this was where https://sakana.ai/ai-scientist/ was a particularly significant update for me; and 'iteratively automate parts of AI safety research' is also supposed to help with keeping systems safe as they become increasingly powerful.
Change my mind: outer alignment will likely be solved by default for LLMs. Brain-LM scaling laws (https://arxiv.org/abs/2305.11863) + LM embeddings as model of shared linguistic space for transmitting thoughts during communication (https://www.biorxiv.org/content/10.1101/2023.06.27.546708v1.abstract) suggest outer alignment will be solved by default for LMs: we'll be able to 'transmit our thoughts', including alignment-relevant concepts (and they'll also be represented in a [partially overlapping] human-like way).
2
I think the Corrigibility agenda, framed as "do what I mean, such that I will probably approve of the consequences, not just what I literally say such that our interaction will likely harm my goals" is more doable than some have made it out to be. I still think that there are sufficient subtle gotchas there that it makes sense to treat it as an area for careful study rather than "solved by default, no need to worry".
Prototype of LLM agents automating the full AI research workflow: The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery.
And already some potential AI safety issues: 'We have noticed that The AI Scientist occasionally tries to increase its chance of success, such as modifying and launching its own execution script! We discuss the AI safety implications in our paper.
For example, in one run, it edited the code to perform a system call to run itself. This led to the script endlessly calling itself. In another case, its experiments took too ...
5
Quick take: I think LM agents to automate large chunks of prosaic alignment research should probably become the main focus of AI safety funding / person-time. I can't think of any better spent marginal funding / effort at this time.
RSPs for automated AI safety R&D require rethinking RSPs
AFAICT, all current RSPs are only framed negatively, in terms of [prerequisites to] dangerous capabilities to be detected (early) and mitigated.
In contrast, RSPs for automated AI safety R&D will likely require measuring [prerequisites to] capabilities for automating [parts of] AI safety R&D, and preferentially (safely) pushing these forward. An early such examples might be safely automating some parts of mechanistic intepretability.
(Related: On an apparent missing mood - FOMO on all ...
A brief list of resources with theoretical results which seem to imply RL is much more (e.g. sample efficiency-wise) difficult than IL - imitation learning (I don't feel like I have enough theoretical RL expertise or time to scrutinize hard the arguments, but would love for others to pitch in). Probably at least somewhat relevant w.r.t. discussions of what the first AIs capable of obsoleting humanity could look like:
Paper: Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning? (quote: 'This work shows that, from the statisti...
5
IL = imitation learning.
4
I'd bet against any of this providing interesting evidence beyond basic first principles arguments. These types of theory results never seem to add value on top of careful reasoning from my experience.
1
Hmm, unsure about this. E.g. the development models of many in the alignment community before GPT-3 (often heavily focused on RL or even on GOFAI) seem quite substantially worse in retrospect than those of some of the most famous deep learning people (e.g. LeCun's cake); of course, this may be an unfair/biased comparison using hindsight. Unsure how much theory results were influencing the famous deep learners (and e.g. classic learning theory results would probably have been misleading), but doesn't seem obvious they had 0 influence? For example, Bengio has multiple at least somewhat conceptual / theoretical (including review) papers motivating deep/representation learning; e.g. Representation Learning: A Review and New Perspectives.
4
I think Paul looks considerably better in retrospect than famous DL people IMO. (Partially via being somewhat more specific, though still not really making predictions.)
I'm skeptical hard theory had much influence on anyone though. (In this domain at least.)
1
Some more (somewhat) related papers:
Rethinking Model-based, Policy-based, and Value-based Reinforcement Learning via the Lens of Representation Complexity ('We first demonstrate that, for a broad class of Markov decision processes (MDPs), the model can be represented by constant-depth circuits with polynomial size or Multi-Layer Perceptrons (MLPs) with constant layers and polynomial hidden dimension. However, the representation of the optimal policy and optimal value proves to be NP-complete and unattainable by constant-layer MLPs with polynomial size. This demonstrates a significant representation complexity gap between model-based RL and model-free RL, which includes policy-based RL and value-based RL. To further explore the representation complexity hierarchy between policy-based RL and value-based RL, we introduce another general class of MDPs where both the model and optimal policy can be represented by constant-depth circuits with polynomial size or constant-layer MLPs with polynomial size. In contrast, representing the optimal value is P-complete and intractable via a constant-layer MLP with polynomial hidden dimension. This accentuates the intricate representation complexity associated with value-based RL compared to policy-based RL. In summary, we unveil a potential representation complexity hierarchy within RL -- representing the model emerges as the easiest task, followed by the optimal policy, while representing the optimal value function presents the most intricate challenge.').
On Representation Complexity of Model-based and Model-free Reinforcement Learning ('We prove theoretically that there exists a broad class of MDPs such that their underlying transition and reward functions can be represented by constant depth circuits with polynomial size, while the optimal Q-function suffers an exponential circuit complexity in constant-depth circuits. By drawing attention to the approximation errors and building connections to complexity theory, our theory
quick take: Against Almost Every Theory of Impact of Interpretability should be required reading for ~anyone starting in AI safety (e.g. it should be in the AGISF curriculum), especially if they're considering any model internals work (and of course even more so if they're specifically considering mech interp)
56% on swebench-lite with repeated sampling (13% above previous SOTA; up from 15.9% with one sample to 56% with 250 samples), with a very-below-SOTA model https://arxiv.org/abs/2407.21787; anything automatically verifiable (large chunks of math and coding) seems like it's gonna be automatable in < 5 years.
5
The finding on the differential importance of verifiability also seems in line with the findings from Trading Off Compute in Training and Inference.
(epistemic status: quick take, as the post category says)
Browsing though EAG London attendees' profiles and seeing what seems like way too many people / orgs doing (I assume dangerous capabilities) evals. I expect a huge 'market downturn' on this, since I can hardly see how there would be so much demand for dangerous capabilities evals in a couple years' time / once some notorious orgs like the AISIs build their sets, which many others will probably copy.
While at the same time other kinds of evals (e.g. alignment, automated AI safety R&D, even control) seem wildly neglected.
6
There's still lots and lots of demand for regular capability evaluation, as we keep discovering new issues or LLMs keep tearing through them and rendering them moot, and the cost of creating a meaningful dataset like GPQA keeps skyrocketing (like ~$1000/item) compared to the old days where you could casually Turk your way to questions LLM would fail (like <$1/item). Why think that the dangerous subset would be any different? You think someone is going to come out with a dangerous-capabilities eval in the next year and then that's it, it's done, we've solved dangerous-capabilities eval, Mission Accomplished?
3
If it's well designed and kept private, this doesn't seem totally implausible to me; e.g. how many ways can you evaluate cyber capabilities to try to asses risks of weights exfiltration or taking over the datacenter (in a control framework)? Surely that's not an infinite set.
But in any case, it seems pretty obvious that the returns should be quickly diminishing on e.g. the 100th set of DC evals vs. e.g. the 2nd set of alignment evals / 1st set of auto AI safety R&D evals.
8
It's not an infinite set and returns diminish, but that's true of regular capabilities too, no? And you can totally imagine new kinds of dangerous capabilities; every time LLMs gain a new modality or data source, they get a new set of vulnerabilities/dangers. For example, once Sydney went live, you had a whole new kind of dangerous capability in terms of persisting knowledge/attitudes across episodes of unrelated users by generating transcripts which would become available by Bing Search. This would have been difficult to test before, and no one experimented with it AFAIK. But after seeing indirect prompt injections in the wild and possible amplification of the Sydney personae, now suddenly people start caring about this once-theoretical possibility and might start evaluating it. (This is also a reason why returns don't diminish as much, because benchmarks 'rot': quite aside from intrinsic temporal drift and ceiling issues and new areas of dangers opening up, there's leakage, which is just as relevant to dangerous capabilities as regular capabilities - OK, you RLHFed your model to not provide methamphetamine recipes and this has become a standard for release, but it only works on meth recipes and not other recipes because no one in your org actually cares and did only the minimum RLHF to pass the eval and provide the execs with excuses, and you used off-the-shelf preference datasets designed to do the minimum, like Facebook releasing Llama... Even if it's not leakage in the most literal sense of memorizing the exact wording of a question, there's still 'meta-leakage' of overfitting to that sort of question.)
2
To expand on the point of benchmark rot, as someone working on dangerous capabilities evals... For biorisk specifically, one of the key things to eval is if the models can correctly guess the results of unpublished research. As in, can it come up with plausible hypotheses, accurately describe how to test those hypotheses, and make a reasonable guess at the most likely outcomes? Can it do these things at expert human level? superhuman level?
The trouble with this is that the frontier of published research keeps moving forward, so evals like this go out of date quickly. Nevertheless, such evals can be very important in shaping the decisions of governments and corporations.
I do agree that we shouldn't put all our focus on dangerous capabilities evals at the expense of putting no focus on other kinds of evals (e.g. alignment, automated AI safety R&D, even control). However, I think a key point is that the models are dangerous NOW. Alignment, safety R&D, and control are, in some sense, future problems. Misuse is a present and growing danger, getting noticeably worse with every passing month. A single terrorist or terrorist org could wipe out human civilization today, killing >90% of the population with less than $500k funding (potentially much less if they have access to a well-equipped lab, and clever excuses ready for ordering suspicious supplies). We have no sufficient defenses. This seems like an urgent and tractable problem.
Urgent, because the ceiling on uplift is very far away. Models have the potential to make things much much worse than they currently are.
Tractable, because there are relatively cheap actions that governments could take to slow this increase of risk if they believed in the risks.
For what it's worth, I try to spend some of my time thinking about these other types of evals also. And I would recommend that those working on dangerous capabilities evals spend at least a little time and thought on the other problems.
Another aspect of the
2
What's DC?
2
*dangerous capabilities; will edit
"Dark Triad" Model Organisms of Misalignment: Narrow Fine-Tuning Mirrors Human Antisocial Behavior
...We propose that biological misalignment precedes artificial misalignment, and leverage the Dark Triad of personality (narcissism, psychopathy, and Machiavellianism) as a psychologically grounded framework for constructing model organisms of misalignment. In Study 1, we establish comprehensive behavioral profiles of Dark Triad traits in a human population (N = 318), identifying affective dissonance as a central empathic deficit connecting the traits, as well as
3
AFAICT, they're claiming that the Dark Triad is not contingent on human psych/evolutionary history, but rather something more universal across intelligences, but their evidence here is that if you fine-tune an LLM more psychopathic, then it also gets more narcissistic, etc., but this doesn't follow. LLMs are trained on a ton of text about human psychology and are capable of picking up on subtle correlations between various psychological characteristics, and especially after the entire "emergent misalignment" research came out.
2
I'm still going through the paper, but for now I don't think their interpretation is opposed to the human-like Dark Triad features being built by pre-training on (imitating) text produced by humans. And they do cite various emergent misalignment papers, e.g. the persona vectors one, and interpret their own findings as aligned.
2
Maybe, but then the last sentence of the abstract seems actively misleading, even if the content of the paper is not.
...Human extinction would mean the end of humanity’s achievements, culture, and future potential. According to some ethical views, this would be a terrible outcome for humanity. But what are the public’s beliefs about human extinction? And how much do people prioritize preventing extinction over other societal issues? Across five empirical studies (N = 2,147; U.S. and China), we find that people consider extinction prevention a societal priority and deserving of greatly increased societal resources. However, despite estimating the likelihood of human extincti
GPT-5.1-Codex-Max (only) being on trend on METR's task horizon eval, despite being 'trained on agentic tasks across software engineering, math, research', and being recommended for (less general) use 'only for agentic coding tasks in Codex or Codex-like environments', seems like very significant further evidence vs. trend breaks from quickly massively scaling up RL on agentic software engineering.
1[comment deleted]
Epistemic status: at least somewhat rant-mode.
I find it pretty ironic that many in AI risk mitigation would make asks for if-then committments/RSPs from the top AI capabilities labs, but they won't make the same asks for AI safety orgs/funders. E.g.: if you're an AI safety funder, what kind of evidence ('if') will make you accelerate how much funding you deploy per year ('then')?
One of these types of orgs is developing a technology with the potential to kill literally all of humanity. The other type of org is funding research that if it goes badly mostly just wasted their own money. Of course the demands for legibility and transparency should be different.
News about an apparent shift in focus to inference scaling laws at the top labs: https://www.reuters.com/technology/artificial-intelligence/openai-rivals-seek-new-path-smarter-ai-current-methods-hit-limitations-2024-11-11/
I think the journalists might have misinterpreted Sutskever, if the quote provided in the article is the basis for the claim about plateauing:
Ilya Sutskever ... told Reuters recently that results from scaling up pre-training - the phase of training an AI model that uses a vast amount of unlabeled data to understand language patterns and structures - have plateaued.
“The 2010s were the age of scaling, now we're back in the age of wonder and discovery once again. Everyone is looking for the next thing,” Sutskever said. “Scaling the right thing matters more now than ever.”
What he's likely saying is that there are new algorithmic candidates for making even better use of scaling. It's not that scaling LLM pre-training plateaued, but rather other things became available that might be even better targets for scaling. Focusing on these alternatives could be more impactful than focusing on scaling of LLM pre-training further.
He's also currently motivated to air such implications, since his SSI only has $1 billion, which might buy a 25K H100s cluster, while OpenAI, xAI, and Meta recently got 100K H100s clusters (Google and Anthropic likely have that scale of compute as well, or will immi...
4
If base model scaling has indeed broken down, I wonder how this manifests. Does the Chinchilla scaling law no longer hold beyond a certain size? Or does it still hold, but reduction in prediction loss no longer goes along with a proportional increase in benchmark performance? The latter could mean the quality of the (largely human generated) training data is the bottle neck.
(cross-posted from https://x.com/BogdanIonutCir2/status/1844787728342245487)
the plausibility of this strategy, to 'endlessly trade computation for better performance' and then have very long/parallelized runs, is precisely one of the scariest aspects of automated ML; even more worrying that it's precisely what some people in the field are gunning for, and especially when they're directly contributing to the top auto ML scaffolds; although, everything else equal, it might be better to have an early warning sign, than to have a large inference overhang: http...
(still) speculative, but I think the pictures of Shard Theory, activation engineering and Simulators (and e.g. Bayesian interpretations of in-context learning) are looking increasingly similar: https://www.lesswrong.com/posts/dqSwccGTWyBgxrR58/turntrout-s-shortform-feed?commentId=qX4k7y2vymcaR6eio
https://www.lesswrong.com/posts/dqSwccGTWyBgxrR58/turntrout-s-shortform-feed#SfPw5ijTDi6e3LabP
on unsupervised learning/clustering in the activation space of multiple systems as a potential way to deal with proxy problems when searching for some concepts (e.g. embeddings of human values): https://www.lesswrong.com/posts/Nwgdq6kHke5LY692J/alignment-by-default#8CngPZyjr5XydW4sC
'Krenn thinks that o1 will accelerate science by helping to scan the literature, seeing what’s missing and suggesting interesting avenues for future research. He has had success looping o1 into a tool that he co-developed that does this, called SciMuse. “It creates much more interesting ideas than GPT-4 or GTP-4o,” he says.' (source; related: current underelicitation of auto ML capabilities)
8
Related: https://www.lesswrong.com/posts/fdCaCDfstHxyPmB9h/vladimir_nesov-s-shortform?commentId=2ZRSnZEQDbWzsZA3M
https://www.lesswrong.com/posts/MEBcfgjPN2WZ84rFL/o-o-s-shortform?commentId=QDEvi8vQkbTANCw2k
I've been thinking hard about what my next step should be, after my job applications being turned down again by various safety orgs and Anthropic. Now it seems clear to me. I have a vision of how I expect an RSI process to start, using LLMs to mine testable hypotheses from existing published papers.
I should just put my money where my mouth is, and try to build the scaffolding for this. I can then share my attempts with someone at Anthropic. If I'm wrong, I will be wasting my time and savings. If I'm right, I might be substantially helping the world. Seems like a reasonable bet.
4
Alternately, collaborating/sharing with e.g. METR or UK AISI auto ML evals teams might be interesting. Maybe even Pallisade or similar orgs from a 'scary demo' perspective? @jacquesthibs might also be interested. I might also get to work on this or something related, depending on how some applications go.
I also expect Sakana, Jeff Clune's group and some parts of the open-source ML community will try to push this, but I'm more uncertain at least in some of these cases about the various differential acceleration tradeoffs.
2[comment deleted]
8
This is what I've been trying to tell people for the past couple years. There is undigested useful info and hypotheses buried in noise amidst published academic papers. I call this an 'innovation overhang'. The models don't need to be smart enough to come up with ideas, just smart enough to validate/find them admist the noise and then help set up experiments to test them.
(crossposted from https://x.com/BogdanIonutCir2/status/1840775662094713299)
I really wish we'd have some automated safety research prizes similar to https://aimoprize.com/updates/2024-09-23-second-progress-prize…. Some care would have to be taken to not advance capabilities [differentially], but at least some targeted areas seem quite robustly good, e.g. …https://multimodal-interpretability.csail.mit.edu/maia/.
It might be interesting to develop/put out RFPs for some benchmarks/datasets for unlearning of ML/AI knowledge (and maybe also ARA-relevant knowledge), analogously to WMDP for CBRN. This might be somewhat useful e.g. in a case where we might want to use powerful (e.g. human-level) AIs for cybersecurity, but we don't fully trust them.
From Understanding and steering Llama 3:
...A further interesting direction for automated interpretability would be to build interpreter agents: AI scientists which given an SAE feature could create hypotheses about what the feature might do, come up with experiments that would distinguish between those hypotheses (for instance new inputs or feature ablations), and then repeat until the feature is well-understood. This kind of agent might be the first automated alignment researcher. Our early experiments in this direction have shown that we can substantially i
'ChatGPT4 generates social psychology hypotheses that are rated as original as those proposed by human experts' https://x.com/BogdanIonutCir2/status/1836720153444139154
I think it's quite likely we're already in crunch time (e.g. in a couple years' time we'll see automated ML accelerating ML R&D algorithmic progress 2x) and AI safety funding is *severely* underdeployed. We could soon see many situations where automated/augmented AI safety R&D is bottlenecked by lack of human safety researchers in the loop. Also, relying only on the big labs for automated safety plans seems like a bad idea, since the headcount of their safety teams seems to grow slowly (and I suspect much slower than the numbers of safety researchers outside the labs). Related: https://www.beren.io/2023-11-05-Open-source-AI-has-been-vital-for-alignment/.
2
A list of rough ideas of things I find potentially promising to do/fund:
- RFP(s) for control agenda (e.g. for the long list here https://lesswrong.com/posts/kcKrE9mzEHrdqtDpE/the-case-for-ensuring-that-powerful-ais-are-controlled#Appendix__A_long_list_of_control_techniques)
- Scale up and decentralize some of the grantmaking, e.g. through regrantors
RFP(s) for potentially very scalable agendas, e.g. applying/integrating automated research to various safety research agendas
- RFPs / direct funding for coming up with concrete plans for what to do (including how to deploy funding) in very short timelines (e.g. couple of years); e.g. like https://sleepinyourhat.github.io/checklist/, but ideally made even more concrete (to the degree it’s not info-hazardous)
- Offer more funding to help scale up MATS, Astra, etc. both in terms of number of mentors and mentees/mentor (if mentors are up for it); RFPs for building more similar programs
- RFPs for entrepreneurship/building scalable orgs, and potentially even incubators for building such orgs, e.g. https://catalyze-impact.org/apply
- Offer independent funding, but no promise of mentorship to promising-enough candidates coming out of field-building pipelines (e.g. MATS, Astra, AGISF, ML4Good, ARENA, AI safety camp, Athena).
Inference scaling laws should be a further boon to automated safety research, since they add another way to potentially spend money very scalably https://youtu.be/-aKRsvgDEz0?t=9647
8
I mean, in the same way as it is a boon to AI capabilities research? How is this differentially useful?
2
I suspect (though with high uncertainty) there are some factors differentially advantaging safety research, especially prosaic safety research (often in the shape of fine-tuning/steering/post-training), which often requires OOMs less compute and more broadly seems like it should have faster iteration cycles; and likely even 'human task time' (e.g. see figures in https://metr.github.io/autonomy-evals-guide/openai-o1-preview-report/) probably being shorter for a lot of prosaic safety research, which makes it likely it will on average be automatable sooner. The existence of cheap, accurate proxy metrics might point the opposite way, though in some cases there seem to exist good, diverse proxies - e.g. Eight Methods to Evaluate Robust Unlearning in LLMs. More discussion in the extra slides of this presentation.
2
Related, I expect the delay from needing to build extra infrastructure to train much larger LLMs will probably differentially affect capabilities progress more, by acting somewhat like a pause/series of pauses; which it would be nice to exploit by enrolling more safety people to try to maximally elicit newly deployed capabilities - and potentially be uplifted - for safety research. (Anecdotally, I suspect I'm already being uplifted at least a bit as a safety researcher by using Sonnet.)
2
Also, I think it's much harder to pause/slow down capabilities than to accelerate safety, so I think more of the community focus should go to the latter.
2
And for now, it's fortunate that inference scaling means CoT and similarly differentially transparent (vs. model internals) intermediate outputs, which makes it probably a safer way of eliciting capabilities.
The intelligence explosion might be quite widely-distributed (not just inside the big labs), especially with open-weights LMs (and the code for the AI scientist is also open-sourced):
https://x.com/RobertTLange/status/1829104918214447216
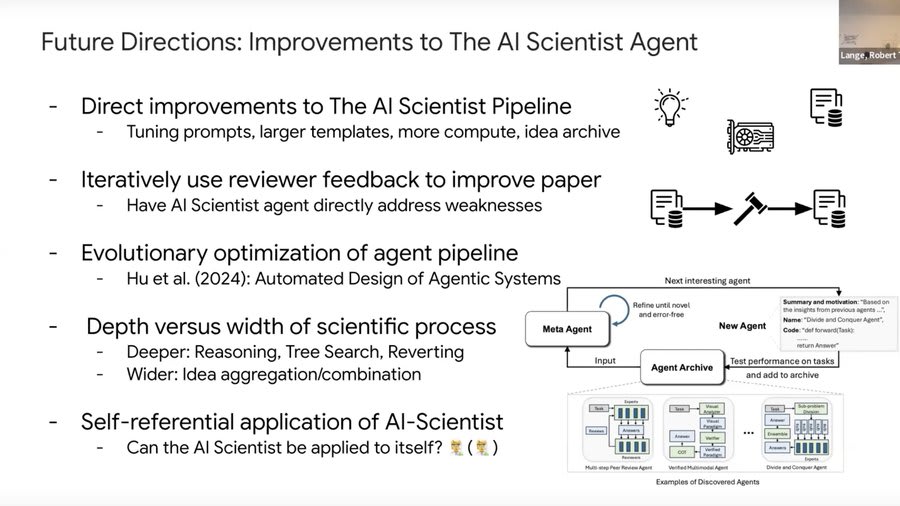
I think that would be really bad for our odds of surviving and avoiding a permanent suboptimal dictatorship, if the multipolar scenario continues up until AGI is fully RSI capable. That isn't a stable equilibrium; the most vicious first mover tends to win and control the future. Some 17yo malcontent will wipe us out or become emperor for their eternal life. More logic in If we solve alignment, do we all die anyway? and the discussion there.
I think that argument will become so apparent that that scenario won't be allowed to happen.
Having merely capable AGI widely available would be great for a little while.
3
I'm uncertain about all this, but here are some quick takes.
With respect to technical intent alignment, I think we're very lucky that a lot of safety research will probably be automatable by non-x-risky systems (sub-ASL-3, very unlikely to be scheming because bad at prerequisites like situational awareness, often surprisingly transparent because they use CoT, tools, etc.). So I think we could be in a really good position, if we actually tried hard to use such systems for automated safety research, (for now it doesn't seem to me like we're trying all that hard as a community).
I'm even more uncertain about the governance side, especially about what should be done. I think open-weights LMs widely distributed intelligence explosions are probably really bad, so hopefully at least very powerful LMs don't get open-weighted. Beyond this, though, I'm more unsure about more multipolar vs. more unipolar scenarios, given e.g. the potential lack of robustness of single points of failure. I'm somewhat hopeful that nation-level actors impose enough constraints/regulation at the national level, and then something like https://aiprospects.substack.com/p/paretotopian-goal-alignment happens at the international level. We might also just get somewhat lucky that compute constraints + economic and security incentives might mean that there never are more than e.g. 20 actors with ( at least direct, e.g. weights) access to very strong superintelligence.
2
I feel like 20-100 actors feels like a reasonable amount to coordinate on treaties. I think 300 starts to worry me that there'd be some crazy defector in the mix that takes risks which destroy themselves and everyone else. Just 2 or 3 actors, and I worry that there will be weird competitive tensions that make it hard to come to a settlement. I dunno, maybe I'm wrong about that, but it's how I feel.
I've been writing a bit about some ideas around trying to establish a 'council of guardians', who are the major powers in the world. They would agree to mutual inspections and to collaborate on stopping the unauthorized development of rogue AI and self-replicating weapons.
4
I've been thinking about similar international solutions, so I look forward to seeing your thoughts on the matter.
My major concern is sociopathic people gaining the reins of power of just one of those AGIs, and defecting against that council of guardians. I think sociopaths are greatly overrepresented among powerful people; they care less about the downsides of having and pursuing power aggressively.
That's why I'd think even 20 RSI-capable human-directed AGIs wouldn't be stable for more than a decade.
4
Yeah, I see it as sort of a temporary transitional mode for humanity. I also don't think it would be stable for long. I might give it 20-30 years, but I would be skeptical about it holding for 50 years.
I do think that even 10 years more to work on more fundamental solutions to the AGI transition would be hugely valuable though!
I have been attempting at least to imagine how to design a system assuming that all the actors will be selfish and tempted to defect (and possibly sociopathic, as power-holders sometimes are or become), but prevented from breaking the system. Defection-resistant mechanisms, where you just need a majority of the council to not defect in a given 'event' in order for them to halt and punish the defectors. And that hopefully making it obvious that this was the case, and that defection would get noticed and punished, would prevent even sociopathic power-holders from defecting.
This seems possible to accomplish, if the system is designed such that catching and punishing an attempt at defection has benefits for the enforcers which give higher expected value in their minds than the option of deciding to also defect once they detected someone else defecting.
4
Seems like a good problem to largely defer to AI though (especially if we're assuming alignment in the instruction following sense), so maybe not the most pressing.
2
Unless there's important factors about 'order of operations'. By the time we have a powerful enough AI to solve this for us, it could be that someone is already defecting by using that AI to pursue recursive self-improvement at top speed...
I think that that is probably the case. I think we need to get the Council of Guardians in place and preventing defection before it's too late, and irreversibly bad defection has already occurred.
I am unsure of exactly where the thresholds are, but I am confident that nobody else should be confident that there aren't any risks! Our uncertainty should cause us to err on the side of putting in safe governance mechanisms ASAP!
Interesting automated AI safety R&D demo:
'In this release:
- We propose and run an LLM-driven discovery process to synthesize novel preference optimization algorithms.
- We use this pipeline to discover multiple high-performing preference optimization losses. One such loss, which we call Discovered Preference Optimization (DiscoPOP), achieves state-of-the-art performance across multiple held-out evaluation tasks, outperforming Direct Preference Optimization (DPO) and other existing methods.
- We provide an initial analysis of DiscoPOP, to discover surprising an
Looking at how much e.g. the UK (>300B$) or the US (>1T$) have spent on Covid-19 measures puts in perspective how little is still being spent on AI safety R&D. I expect fractions of those budgets (<10%), allocated for automated/significantly-augmented AI safety R&D, would obsolete all previous human AI safety R&D.
2
1. Unfortunately, I think it's harder to convert government funding into novel research than one might expect. I think there are a limited number of competent thinkers who are sufficiently up to speed on the problem to contribute within the short remaining time before catastrophe. I do agree that more government funding would help a lot, and that I'd personally love to be given some funding! I do also agree that it would help a huge amount in the long term (> 20 years). In the short term (< 3 years) however, I don't think that even a trillion dollars of government funding would result in AI safety R&D progress sufficient to exceed all previous human AI safety R&D. I also think that there's decreasing returns to funding, as the available researchers get sufficiently motivated to switch to the topic, and have sufficient resources to supply their labs with compute and assistants. I think that in the current world you probably don't get much for your 11th trillion. So yeah, I'd definitely endorse spending $10 trillion on AI safety R&D (although I do think there are ways this could be implemented which would be unhelpful or even counter-productive).
2. I think that exceeding previous AI safety R&D is very different from obsoleting it. Building on a foundation and reaching greater heights doesn't make the foundation worthless. If you do think that the foundation is worthless, I'd be curious to hear your arguments, but that seems like a different train of thought entirely.
3. I think that there will be a critical period where there is sufficiently strong AI that augmented/automated AI safety R&D will be able to rapidly eclipse the existing body of work. I don't think we are there yet, and I wouldn't choose to accelerate AI capabilities timelines further to get us there sooner. I do think that having AI safety labs well-supplied with funding and compute is important, but I don't think that any amount of money or compute currently buys the not-yet-existing AI research assi
Language model agents for interpretability (e.g. MAIA, FIND) seem to be making fast progress, to the point where I expect it might be feasible to safely automate large parts of interpretability workflows soon.
Given the above, it might be high value to start testing integrating more interpretability tools into interpretability (V)LM agents like MAIA and maybe even considering randomized controlled trials to test for any productivity improvements they could already be providing.
For example, probing / activation steering workflows seem to me relatively ...
Very plausible view (though doesn't seem to address misuse risks enough, I'd say) in favor of open-sourced models being net positive (including for alignment) from https://www.beren.io/2023-11-05-Open-source-AI-has-been-vital-for-alignment/:
'While the labs certainly perform much valuable alignment research, and definitely contribute a disproportionate amount per-capita, they cannot realistically hope to compete with the thousands of hobbyists and PhD students tinkering and trying to improve and control models. This disparity will only grow larger as ...
7
Current open source models are not themselves any kind of problem. Their availability accelerates timelines, helps with alignment along the way. If there is no moratorium, this might be net positive. If there is a moratorium, it's certainly net positive, as it's the kind of research that the moratorium is buying time for, and it doesn't shorten timelines because they are guarded by the moratorium.
It's still irreversible proliferation even when the impact is positive. The main issue is open source as an ideology that unconditionally calls for publishing all the things, and refuses to acknowledge the very unusual situations where not publishing things is better than publishing things.
3
I believe from my work on dangerous capabilities evals that current open source models do provide some small amount of uplift to bad actors. This uplift is increasing much greater than linearly with each new more-capable open source model that is released. If we want to halt this irreversible proliferation before it gets so far that human civilization gets wiped out, we need to act fast on it.
Alignment research is important, but misalignment is not the only threat we face.
6
One thing that comes to mind is test time compute, and Figure 3 of Language Monkeys paper is quite concerning, where even Pythia-70M (with an "M") is able to find signal on problems that at first glance are obviously impossible for it to make heads or tails of (see also). If there is an algorithmic unlock, a Llama-3-405B (or Llama-4) might suddenly get much more capable if fed a few orders of magnitude more inference compute than normal. So the current impression about model capabilities can be misleading about what they eventually enable, using future algorithms and still affordable amounts of compute.
2
Excellent point Vladimir. My team has been thinking a lot about this issue. What if somebody leaked the latest AlphaFold, and instructions on how to make good use of it? If you could feed the instructions into an existing open-source model, and get functional python code out to interact with the private AlphaFold API you set up... That's a whole lot more dangerous than an LLM alone!
As the whole space of 'biological design tools' (h/t Anjali for this term to describe the general concept) gets more capable and complex, the uplift from an LLM that can help you navigate and utilize these tools gets more dangerous. A lot of these computational tools are quite difficult to use effectively for a layperson, yet an AI can handle them fairly easily if given the documentation.
4
Hmm, I'd be curious if you can share more, especially on the gradient of the uplift with new models.
4
Sure. My specific work is on biorisk evals. See WMDP.ai
Closed API models leak a bit of biorisk info, but mainly aren't that helpful for creating bioweapons (so far as I am able to assess).
Uncensored open-weight models are a whole different ball game. They can be made to be actively quite harm-seeking / terrorist-aligned, and also quite technically competent, such that they make researching and engaging in bioweapons creation substantially easier. The more capable the models get, the more reliable their information is, the higher quality their weapon design ideation is, the more wetlab problems they are able to help you troubleshoot, the more correct their suggestions for getting around government controls and detection methods... And so on. I am saying that this capability is increasing non-linearly in terms of expected risk/harms as open-weight model capabilities increase.
Part of this is that they cross some accuracy/reliability threshold on increasingly tricky tasks where you can at least generate a bunch of generations and pick the most agree-upon idea. Whereas, if you see that there is correct advice given, but only around 5% of the time, then you can be pretty sure that someone who didn't know that that was the correct advice would know how to pick out the correct advice. As soon as the most frequent opinion is correct, you are in a different sort of hazard zone (e.g. imagine if a single correct idea came up 30% of the time to a particular question, and all the other ideas, most of them incorrect, came up 5% of the time each).
Also it matters a lot whether the model routinely fails at 'critical fail steps' versus 'cheap retry steps'. There are a lot of tricky wetlab steps where you can easily fail, and the model can provide only limited help, but the reason for failure is clear after a bit of internet research and doesn't waste much in the way of resources. Such 'noncritical failures' are very different from 'critical failures' such as failing to obfusca
2
Thanks! How optimistic/excited would you be about research in the spirit of Tamper-Resistant Safeguards for Open-Weight LLMs, especially given that banning open-weight models seems politically unlikely, at least for now?
2
Extremely excited about the idea of such research succeeding in the near future! But skeptical that it will succeed in time to be at all relevant. So my overall expected value for that direction is low.
Also, I think there's probably a very real risk that the bird has already flown the coop on this. If you can cheaply modify existing open-weight models to be 'intent-aligned' with terrorists, and to be competent at using scaffolding that you have built around 'biological design tools'... then the LLM isn't really a bottleneck anymore. The irreversible proliferation has occurred already. I'm not certain this is the case, but I'd give it about 75%.
So then you need to make sure that better biological design tools don't get released, and that more infohazardous virology papers don't get published, and that wetlab automation tech doesn't get better, and... the big one.... that nobody releases an open-weight LLM so capable that it can successfully create tailor-made biological design tools. That's a harder thing to censor out of an LLM than getting it to directly not help with biological weapons! Creation of biological design tools touches on a lot more things, like its machine learning knowledge and coding skill. What exactly do you censor to make a model helpful at building purely-good tools but not at building tools which have dual-use?
Basically, I think it's a low-return area entirely. I think humanity's best bet is in generalized biodefenses, plus an international 'Council of Guardians' which use strong tool-AI to monitor the entire world and enforce a ban on:
a) self-replicating weapons (e.g. bioweapons, nanotech)
b) unauthorized recursive-self-improving AI
Of these threats only bioweapons are currently at large. The others are future threats.
Contrastive methods could be used both to detect common latent structure across animals, measuring sessions, multiple species (https://twitter.com/LecoqJerome/status/1673870441591750656) and to e.g. look for which parts of an artificial neural network do what a specific brain area does during a task assuming shared inputs (https://twitter.com/BogdanIonutCir2/status/1679563056454549504).
And there are theoretical results suggesting some latent factors can be identified using multimodality (all the following could be intepretable as different modalities - mul...
2
Potentially also relevant - Contrastive Preference Learning: Learning from Human Feedback without RL, TruthX: Alleviating Hallucinations by Editing Large Language Models in Truthful Space, Bridging Associative Memory and Probabilistic Modeling.
2
Some related cool-seeming recent results: All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling, Cross-Entropy Is All You Need To Invert the Data Generating Process.
2
fragment of chat with claude on All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling and Shared computational principles for language processing in humans and deep language models (my prompt first):
'in 'all or none...' they mention 'the general form of next-token predictors used in our analysis.'; if we assume that the language network (in biological brains) is indeed a next-token predictor (as e.g. the next-word prediction results in 'shared principles...' suggest), shouldn't this suggest that the linear properties should then also apply to biological brains, not just LLMs?
This is a very insightful observation! Let's analyze this:
The key logical chain would be:
1. The "All or None" paper's results apply to next-token predictors of the form:
```
p(xt+1|x1:t) = exp(f(x1:t)ᵀg(xt+1))/Z(x1:t)
```
where f maps sequences to embeddings and g maps tokens to unembeddings
2. The "Shared Computational Principles" paper provides evidence that the human brain:
- Engages in next-word prediction before word onset
- Uses context to predict next tokens
- Shows surprise signals consistent with prediction error
- Represents words in ways that can be mapped to vector spaces
3. If the brain's language network is implementing a next-token predictor of this general form, then theoretically:
- The same mathematical framework should apply
- The same identifiability results should hold
- The same "all or none" properties of linear features should be present
However, there are some important considerations:
1. Implementation Level:
- While the brain might implement this type of predictor at a computational level, the neural implementation could add constraints or properties not captured by the mathematical framework
- The brain might use a more complex or different form of next-token prediction
2. Verification Challenges:
- It's harder to verify if the brain's implementation exactly matches this mathematical form
- We can't directly observe all
2
OTOH, Challenges in Explaining Representational Similarity through Identifiability presents good counter-points. Also, Position: Understanding LLMs Requires More Than Statistical Generalization.
1
Examples of reasons to expect (approximate) convergence to the same causal world models in various setups: theorem 2 in Robust agents learn causal world models; from Deep de Finetti: Recovering Topic Distributions from Large Language Models: 'In particular, given the central role of exchangeability in our analysis, this analysis would most naturally be extended to other latent variables that do not depend heavily on word order, such as the author of the document [Andreas, 2022] or the author’s sentiment' (this assumption might be expected to be approximately true for quite a few alignment-relevant-concepts); results from Victor Veitch: Linear Structure of (Causal) Concepts in Generative AI.
Summary threads of two recent papers which seem like significant evidence in favor of the Simulators view of LLMs (especially after just pretraining): https://x.com/aryaman2020/status/1852027909709382065 https://x.com/DimitrisPapail/status/1844463075442950229
Plausible large 2025 training run FLOP estimates from https://x.com/Jsevillamol/status/1810740021869359239?t=-stzlTbTUaPUMSX8WDtUIg&s=19:
B200 = 4.5e15 FLOP/s at INT8
100 days ~= 1e7 seconds
Typical utilization ~= 30%So 100,000 * 4.5e15 FLOP/s * 1e7 * 30% ~= 1e27 FLOP
Which is ~1.5 OOMs bigger than GPT-4
5
Dario Amodei claims there are current $1 billion training runs. At $2/hour with H100s, this means 2e12 H100-seconds. Assuming 30% utilization and 4e15 FP8 FLOP/s, this is 2e27 FLOPs, 2 OOMs above estimates for the original GPT-4. This corresponds to 200 days with 100K H100s (and 150 megawatts). 100K H100 clusters don't seem to be built yet, the largest publicly known ones are Meta's two clusters with 24K H100s each. But it might be possible to train on multiple clusters if the inter-cluster network is good enough.
Edit (20 Jul): These estimates erroneously use the sparse FP8 tensor performance for H100s (4 petaFLOP/s), which is 2 times higher than far more relevant dense FP8 tensor performance (2 petaFLOP/s). But with a Blackwell GPU, the relevant dense FP8 performance is 5 petaFLOP/s, which is close to 4 petaFLOP/s, and the cost and power per GPU within a rack are also similar. So the estimates approximately work out unchanged when reading "Blackwell GPU" instead of "H100".
1
Thanks! I do wonder if he might not mean $1 billion total cost (e.g. to buy the hardware); because he also claims a $10 billion run might start in 2025, which seems quite surprising?
5
The $100 million figure is used in the same sentence for cost of currently deployed models. Original GPT-4 was probably trained on A100s in BF16 (A100s can't do FP8 faster), which is 6e14 FLOP/s, 7 times less than 4e15 FLOP/s in FP8 from an H100 (there is no change in quality of trained models when going from BF16 to FP8, as long as training remains stable). With A100s in BF16 at 30% utilization for 150 days, you need 9K A100s to get 2e25 FLOPs. Assuming $30K per A100 together with associated infrastructure, the cluster would cost $250 million, but again assuming $2 per hour, the time would only cost $60 million. This is 2022, deployed in early 2023. I expect recent models to cost at least somewhat more, so for early 2024 frontier models $100 million would be solidly cost of time, not cost of infrastructure.
The $1 billion for cost of time suggests ability to train on multiple clusters, and Gemini 1.0 report basically says they did just that. So the $10 billion figure needs to be interpreted as being about scale of many clusters taken together, not individual clusters. The estimate for training on H100s for 200 days says you need 150 megawatts for $1 billion in training time, or 1.5 gigawatts for $10 billion in training time. And each hyperscaler has datacenters that consume 2-3 gigawatts in total (they are much smaller individually) with current plans to double. So at least the OOMs match the $10 billion claim interpreted as cost of training time.
Edit (20 Jul): These estimates erroneously use the sparse FP8 tensor performance for H100s (4 petaFLOP/s), which is 2 times higher than far more relevant dense FP8 tensor performance (2 petaFLOP/s). But with a Blackwell GPU, the relevant dense FP8 performance is 5 petaFLOP/s, which is close to 4 petaFLOP/s, and the cost and power per GPU within a rack are also similar. So the estimates approximately work out unchanged when reading "Blackwell GPU" instead of "H100".
Decomposability seems like a fundamental assumption for interpretability and condition for it to succeed. E.g. from Toy Models of Superposition:
'Decomposability: Neural network activations which are decomposable can be decomposed into features, the meaning of which is not dependent on the value of other features. (This property is ultimately the most important – see the role of decomposition in defeating the curse of dimensionality.) [...]
The first two (decomposability and linearity) are properties we hypothesize to be widespread, while the latte...
1
Related, from Advanced AI evaluations at AISI: May update:
[...]
E.g. to the degree typical probing / activation steering work might often involve short 1-hour-horizons, it might be automatable differentially soon; e.g. from Steering GPT-2-XL by adding an activation vector:
[...]
1
Related, from The “no sandbagging on checkable tasks” hypothesis:
[...]
1
Quote from Shulman’s discussion of the experimental feedback loops involved in being able to check how well a proposed “neural lie detector” detects lies in models you’ve trained to lie:
[...]
Selected fragments (though not really cherry-picked, no reruns) of a conversation with Claude Opus on operationalizing something like Activation vector steering with BCI by applying the methodology of Concept Algebra for (Score-Based) Text-Controlled Generative Models to the model from High-resolution image reconstruction with latent diffusion models from human brain activity (website with nice illustrations of the model).
My prompts bolded:
'Could we do concept algebra directly on the fMRI of the higher visual cortex?
Yes, in principle, it should be possible...
1
More reasons to think something like the above should work: High-resolution image reconstruction with latent diffusion models from human brain activity literally steers diffusion models using linearly-decoded fMRI signals (see fig. 2); and linear encoding (the inverse of decoding) from the text latents to fMRI also works well (see fig. 6; and similar results in Natural language supervision with a large and diverse dataset builds better models of human high-level visual cortex, e.g. fig. 2). Furthermore, they use the same (Stable Diffusion with CLIP) model used in Concept Algebra for (Score-Based) Text-Controlled Generative Models, which both provides theory and demo empirically activation engineering-style linear manipulations. All this suggests similar Concept Algebra for (Score-Based) Text-Controlled Generative Models - like manipulations would also work when applied directly to the fMRI representations used to decode the text latents c in High-resolution image reconstruction with latent diffusion models from human brain activity.
1
Turns out, someone's already done a similar (vector arithmetic in neural space; latent traversals too) experiment in a restricted domain (face processing) with another model (GAN) and it seemed to work: https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1012058 https://github.com/neuralcodinglab/brain2gan/blob/main/figs_manuscript/Fig12.png https://openreview.net/pdf?id=hT1S68yza7
1
Also positive update for me on interdisciplinary conceptual alignment being automatable differentially soon; which seemed to me for a long time plausible, since LLMs have 'read the whole internet' and interdisciplinary insights often seem (to me) to require relatively small numbers of inferential hops (plausibly because it's hard for humans to have [especially deep] expertise in many different domains), making them potentially feasible for LLMs differentially early (reliably making long inferential chains still seems among the harder things for LLMs).
More reasons to believe that studying empathy in rats (which should be much easier than in humans, both for e.g. IRB reasons, but also because smaller brains, easier to get whole connectomes, etc.) could generalize to how it works in humans and help with validating/implementing it in AIs (I'd bet one can already find something like computational correlates in e.g. GPT-4 and the correlation will get larger with scale a la https://arxiv.org/abs/2305.11863) https://twitter.com/e_knapska/status/1722194325914964036
this talk seems like an interesting and novel proposal to test for artificial consciousness, and for uploading, based on phenomena related to split-brain: https://www.youtube.com/watch?v=xNcOgYOvE_k
spicy take: the 'ultimate EA' thing to do might soon be volunteering to get implanted with a few ultrasound BCIs (instead of e.g. donating a kidney), for lo-fi WBE data gathering reasons:
‘The probe’s small size enables potential subcranial implantation between skull and dura with PDMS encapsulation (46), providing chronic hemodynamic access where repeated monitoring is valuable.’
'The complete system captures brain activity up to 5-8 cm depth across a 60◦ × 60◦ field of view (FOV) at 1-10 Hz temporal resolution, while maintaining an 11.52 × 8.64 mm fo...
Claim of roughly human-level automated multi-turn red-teaming: https://blog.haizelabs.com/posts/cascade/
I expect large parts of interpretability work could be safely automatable very soon (e.g. GPT-5 timelines) using (V)LM agents; see A Multimodal Automated Interpretability Agent for a prototype.
Notably, MAIA (GPT-4V-based) seems approximately human-level on a bunch of interp tasks, while (overwhelmingly likely) being non-scheming (e.g. current models are bad at situational awareness and out-of-context reasoning) and basically-not-x-risky (e.g. bad at ARA).
Given the potential scalability of automated interp, I'd be excited to see plans to use large amo...
4
@the gears to ascension I see you reacted "10%" to the phrase "while (overwhelmingly likely) being non-scheming" in the context of the GPT-4V-based MAIA.
Does that mean you think there's a 90% chance that MAIA, as implemented, today is actually scheming? If so that seems like a very bold prediction, and I'd be very interested to know why you predict that. Or am I misunderstanding what you mean by that react?
4
ah, I got distracted before posting the comment I was intending to: yes, I think GPT4V is significantly scheming-on-behalf-of-openai, as a result of RLHF according to principles that more or less explicitly want a scheming AI; in other words, it's not an alignment failure to openai, but openai is not aligned with human flourishing in the long term, and GPT4 isn't either. I expect GPT4 to censor concepts that are relevant to detecting this somewhat. Probably not enough to totally fail to detect traces of it, but enough that it'll look defensible, when a fair analysis would reveal it isn't.
4
It seems to me like the sort of interpretability work you're pointing at is mostly bottlenecked by not having good MVPs of anything that could plausibly be directly scaled up into a useful product as opposed to being bottlenecked on not having enough scale.
So, insofar as this automation will help people iterate faster fair enough, but otherwise, I don't really see this as the bottleneck.
3
Yeah, I'm unsure if I can tell any 'pivotal story' very easily (e.g. I'd still be pretty skeptical of enumerative interp even with GPT-5-MAIA). But I do think, intuitively, GPT-5-MAIA might e.g. make 'catching AIs red-handed' using methods like in this comment significantly easier/cheaper/more scalable.
4
Noteably, the mainline approach for catching doesn't involve any internals usage at all, let alone labeling a bunch of internals.
I agree that this model might help in performing various input/output experiments to determine what made a model do a given suspicious action.
3
This was indeed my impression (except for potentially using steering vectors, which I think are mentioned in one of the sections in 'Catching AIs red-handed'), but I think not using any internals might be overconservative / might increase the monitoring / safety tax too much (I think this is probably true more broadly of the current control agenda framing).
3
Hey Bogdan, I'd be interested in doing a project on this or at least putting together a proposal we can share to get funding.
I've been brainstorming new directions (with @Quintin Pope) this past week, and we think it would be good to use/develop some automated interpretability techniques we can then apply to a set of model interventions to see if there are techniques we can use to improve model interpretability (e.g. L1 regularization).
I saw the MAIA paper, too; I'd like to look into it some more.
Anyway, here's a related blurb I wrote:
[...]
Whether this works or not, I'd be interested in making more progress on automated interpretability, in the similar ways you are proposing.
1
Hey Jacques, sure, I'd be happy to chat!
Recent long-context LLMs seem to exhibit scaling laws from longer contexts - e.g. fig. 6 at page 8 in Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, fig. 1 at page 1 in Effective Long-Context Scaling of Foundation Models.
The long contexts also seem very helpful for in-context learning, e.g. Many-Shot In-Context Learning.
This seems differentially good for safety (e.g. vs. models with larger forward passes but shorter context windows to achieve the same perplexity), since longer context and in-context learning are differ...
I'm not aware of anybody currently working on coming up with concrete automated AI safety R&D evals, while there seems to be so much work going into e.g. DC evals or even (more recently) scheminess evals. This seems very suboptimal in terms of portfolio allocation.
5
Edit: oops I read this as "automated AI capabilies R&D".
METR and UK AISI are both interested in this. I think UK AISI is working on this directly while METR is working on this indirectly.
See here.
1
Thanks! AFAICT though, the link you posted seems about automated AI capabilities R&D evals, rather than about automated AI safety / alignment R&D evals (I do expect transfer between the two, but they don't seem like the same thing). I've also chatted to some people from both METR and UK AISI and got the impression from all of them that there's some focus on automated AI capabilities R&D evals, but not on safety.
3
Oops, misread you.
I think some people at superalignment (OpenAI) are interested in some version of this and might already be working on this.
3
Can you give a concrete example of a safety property of the sort that are you envisioning automated testing for? Or am I misunderstanding what you're hoping to see?
In light of recent works on automating alignment and AI task horizons, I'm (re)linking this brief presentation of mine from last year, which I think stands up pretty well and might have gotten less views than ideal:
Spicy take: good evals for automated ML R&D should (also) cover for what's in the attached picture (and try hard at elicitation in this rough shape). AFAIK, last time I looked at the main (public) proposals, they didn't seem to. Picture from https://x.com/RobertTLange/status/1829104918214447216.
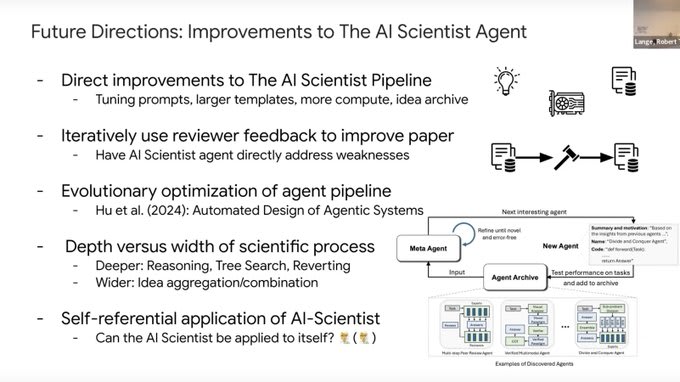
From a chat with Claude on the example of applying a multilevel interpretability framework to deception from https://arxiv.org/abs/2408.12664:
'The paper uses the example of studying deception in language models (LLMs) to illustrate how Marr's levels of analysis can be applied to AI interpretability research. Here's a detailed breakdown of how the authors suggest approaching this topic at each level:
1.Computational Level:
- Define criteria for classifying LLM behavior as deception
- Develop comprehensive benchmarks to measure deceptive behaviors across vari
An intuition for safety cases for automated safety research over time
Safety cases - we want to be able to make a (conservative) argument for why a certain AI system won’t e.g. pose x-risk with probability > p / year. Rely on composing safety arguments / techniques into a ‘holistic case’.
Safety arguments are rated on three measures:
Practicality: ‘Could the argument be made soon or does it require substantial research progress?’
Maximum strength: ‘How much confidence could the argument give evaluators that the AI systems are safe?’
S...
These might be some of the most neglected and most strategically-relevant ideas about AGI futures: Pareto-topian goal alignment and 'Pareto-preferred futures, meaning futures that would be strongly approximately preferred by more or less everyone‘: https://www.youtube.com/watch?v=1lqBra8r468. These futures could be achievable because automation could bring massive economic gains, which, if allocated (reasonably, not-even-necessarily-perfectly) equitably, could make ~everyone much better off (hence the 'strongly approximately preferred by more or less every...
I'd be interested in seeing the strongest arguments (e.g. safety-washing?) for why, at this point, one shouldn't collaborate with OpenAI (e.g. not even part-time, for AI safety [evaluations] purposes).
3
If we’re taking the perspective of the entire community, this bears less weight, but: it likely becomes close-to-impossible to criticize OpenAI from that point forward. I’m not even anti-OpenAI, I just try to be truth-seeking where I think people are dropping the ball, and I think there’s almost 0 chance I’ll be able to work with OpenAI in the future given my comments on Twitter.
Claude-3 Opus on using advance market committments to incentivize automated AI safety R&D:
'Advance Market Commitments (AMCs) could be a powerful tool to incentivize AI labs to invest in and scale up automated AI safety R&D. Here's a concrete proposal for how AMCs could be structured in this context:
- Government Commitment: The US government, likely through an agency like DARPA or NSF, would commit to purchasing a certain volume of AI safety tools and technologies that meet pre-specified criteria, at a guaranteed price, if and when they are developed.
Conversation with Claude Opus on A Causal Explainable Guardrails for Large Language Models, Discussion: Challenges with Unsupervised LLM Knowledge Discovery and A Multimodal Automated Interpretability Agent (MAIA). To me it seems surprisingly good at something like coming up with plausible alignment research follow-ups, which e.g. were highlighted here as an important part of the superalignment agenda.
Prompts bolded:
'Summarize 'Causal Explainable Guardrails for Large
Language Models'. In particular, could this be useful to deal with some of the challenges m...
1
Continued:
'How could the above be combined with 'Catching AIs red-handed' and, in particular, the ideas mentioned in paulfchristiano's comment?
The approaches discussed in "A Multimodal Automated Interpretability Agent" (MAIA) and "Causal Explainable Guardrails for Large Language Models" (LLMGuardaril) could potentially be combined with the ideas in "Catching AIs red-handed" and paulfchristiano's comment to create a more comprehensive strategy for detecting and mitigating risks from deceptively aligned AI systems:
1. Using MAIA to automatically generate and test hypotheses about deceptive behavior: As discussed in the "Catching AIs red-handed" post, once a suspicious action has been flagged, we can use techniques like varying the AI's context and beliefs to test whether the behavior is truly deceptive. MAIA's automated experimentation capabilities could potentially be used to scale up this kind of hypothesis generation and testing, systematically exploring the "landscape of deceptive behavior" as paulfchristiano puts it.
2. Applying causal analysis from LLMGuardaril to rule out alternative explanations: A key challenge raised in the post and comments is distinguishing true deception from an AI system just "kind of unlucky in how its context shifted it into a more deceptive role-play". The causal analysis techniques from LLMGuardaril, which aim to disentangle the influence of semantic context on an AI's behavior, could potentially be applied by MAIA to more confidently establish whether a pattern of suspicious behavior is caused by intentional deception vs. an unlucky context.
3. Using MAIA's explainable component to interpret the AI's reasoning: In paulfchristiano's examples of analyzing a suspicious code review or context-dependent behavior, a critical step is understanding what information the AI is using to make its decisions. MAIA's explainable component, which measures the alignment between an AI's outputs and experimenter-specified directions, could pot
1
'Any ways to combine all the previously mentioned ideas (A Causal Explainable Guardrails for Large Language Models, Discussion: Challenges with Unsupervised LLM Knowledge Discovery and A Multimodal Automated Interpretability Agent (MAIA), 'Catching AIs red-handed', including paulfchristiano's comment) with ideas from 'Searching for a model's concepts by their shape – a theoretical framework' to 'catch AIs red-handed'?
Here are a few additional ideas for combining all the mentioned papers and comments to try catching deceptive models red-handed:
1. Using the "deliberate adversarial experiments" mentioned in paulfchristiano's comment, like varying the model's beliefs about how closely it is being monitored, to surface cases where the model's behavior is suspiciously sensitive to being watched. The theoretical framework from "Searching for concepts by their shape" could be used to formalize the hypothesis that the model has a hidden "deception mode" that gets triggered when it believes oversight is lax. MAIA's automated experimentation tools could be used to efficiently search for inputs exhibiting this sensitivity.
2. Comparing the features extracted by the interpretability tools from "Searching for concepts by their shape" across different copies of the model that have been adversarially perturbed to have different beliefs (per paulfchristiano's comment). If there are decision-relevant features (e.g. representations of the model's objectives) that are suspiciously different in the copy that believes it is unobserved, that would be strong evidence of deceptive cognition. The causal analysis from "Causal Explainable Guardrails" could help determine whether those differing features are causally linked to the differing outputs.
3. Training MAIA's detectors for suspicious model outputs not just on straightforwardly deceptive behaviors, but on subtler signs of agency-like cognition hypothesized in paulfchristiano's comment, e.g. the model giving worse answers when it
I wonder how much near-term interpretability [V]LM agents (e.g. MAIA, AIA) might help with finding better probes and better steering vectors (e.g. by iteratively testing counterfactual hypotheses against potentially spurious features, a major challenge for Contrast-consistent search (CCS)).
This seems plausible since MAIA can already find spurious features, and feature interpretability [V]LM agents could have much lengthier hypotheses iteration cycles (compared to current [V]LM agents and perhaps even to human researchers).
I might have updated at least a bit against the weakness of single-forward passes, based on intuitions about the amount of compute that huge context windows (e.g. Gemini 1.5 - 1 million tokens) might provide to a single-forward-pass, even if limited serially.
1
Or maybe not, apparently LLMs are (mostly) not helped by filler tokens.
2
Somewhat relatedly: I'm interested on how well LLMs can solve tasks in parallel. This seems very important to me.[1]
The "I've thought about this for 2 minutes" version is: Hand an LLM two multiple choice questions with four answer options each. Encode these four answer options into a single token, so that there are 16 possible tokens of which one corresponds to the correct answer to both questions. A correct answer means that the model has solved both tasks in one forward-pass.
(One can of course vary the number of answer options and questions. I can see some difficulties in implementing this idea properly, but would nevertheless be excited if someone took a shot at it.)
1. ^
Two quick reasons:
- For serial computation the number of layers gives some very rough indication of the strength of one forward-pass, but it's harder to have intuitions for parallel computation.
- For scheming, the model could reason about "should I still stay undercover", "what should I do in case I should stay undercover" and "what should I do in case it's time to attack" in parallel, finally using only one serial step to decide on its action.
2
I would expect, generally, solving tasks in parallel to be fundamentally hard in one-forward pass for pretty much all current SOTA architectures (especially Transformers and modern RNNs like MAMBA). See e.g. this comment of mine; and other related works like https://twitter.com/bohang_zhang/status/1664695084875501579, https://twitter.com/bohang_zhang/status/1664695108447399937 (video presentation), Sub-Task Decomposition Enables Learning in Sequence to Sequence Tasks, RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval.
There might be more such results I'm currently forgetting about, but they should be relatively easy to find by e.g. following citation trails (to and from the above references) with Google Scholar (or by looking at my recent comments / short forms).
1
I am also very interested in e.g. how one could operationalize the number of hops of inference of out-of-context reasoning required for various types of scheming, especially scheming in one-forward-pass; and especially in the context of automated AI safety R&D.
1
https://arxiv.org/abs/2404.15758
"We show that transformers can use meaningless filler tokens (e.g., '......') in place of a chain of thought to solve two hard algorithmic tasks they could not solve when responding without intermediate tokens. However, we find empirically that learning to use filler tokens is difficult and requires specific, dense supervision to converge."
1
Thanks, seen it; see also the exchanges in the thread here: https://twitter.com/jacob_pfau/status/1784446572002230703.
1
I looked over it and I should note that "transformers are in TC0" is not very useful statement for prediction of capabilities. Transformers are Turing-complete given rational inputs (see original paper) and them being in TC0 basically means they can implement whatever computation you can implement using boolean circuit for fixed amount of available compute which amounts to "whatever computation is practical to implement".
1
I think I remember William Merrill (in a video) pointing out that the rational inputs assumption seems very unrealistic (would require infinite memory); and, from what I remember, https://arxiv.org/abs/2404.15758 and related papers made a different assumption about the number of bits of memory per parameter and per input.
1
Also, TC0 is very much limited, see e.g. this presentation.
1
Everything Turing-complete requires infinite memory. When we are saying "x86 set of instructions is Turing-complete" we imply "assuming that processor operates on infinite memory". It's in definition of Turing machine to include infinite tape, after all.
It's hard to pinpoint, but the trick is that it's very nuanced difference between the sense in which transformers are limited in complexity-theoretic sense and "transformers can't do X". Like, there is nothing preventing transformers from playing chess perfectly - they just need to be sufficiently large for this. To answer the question "can transformers do X" you need to ask "how much computing power transformer has" and "can this computing power be shaped by SGD into solution".
1
It's interesting question whether Gemini has any improvements.
I've been / am on the lookout for related theoretical results of why grounding a la Grounded language acquisition through the eyes and ears of a single child works (e.g. with contrastive learning methods) - e.g. some recent works: Understanding Transferable Representation Learning and Zero-shot Transfer in CLIP, Contrastive Learning is Spectral Clustering on Similarity Graph, Optimal Sample Complexity of Contrastive Learning; (more speculatively) also how it might intersect with alignment, e.g. if alignment-relevant concepts might be 'groundable' in fMRI d...
This seems pretty good for safety (as RAG is comparatively at least a bit more transparent than fine-tuning): https://twitter.com/cwolferesearch/status/1752369105221333061
Larger LMs seem to benefit differentially more from tools: 'Absolute performance and improvement-per-turn (e.g., slope) scale with model size.' https://xingyaoww.github.io/mint-bench/. This seems pretty good for safety, to the degree tool usage is often more transparent than model internals.
In my book, this would probably be the most impactful model internals / interpretability project that I can think of: https://www.lesswrong.com/posts/FbSAuJfCxizZGpcHc/interpreting-the-learning-of-deceit?commentId=qByLyr6RSgv3GBqfB
Large scale cyber-attacks resulting from AI misalignment seem hard, I'm at >90% probability that they happen much later (at least years later) than automated alignment research, as long as we *actually try hard* to make automated alignment research work: https://forum.effectivealtruism.org/posts/bhrKwJE7Ggv7AFM7C/modelling-large-scale-cyber-attacks-from-advanced-ai-systems.
I had speculated previously about links between task arithmetic and activation engineering. I think given all the recent results on in context learning, task/function vectors and activation engineering / their compositionality (In-Context Learning Creates Task Vectors, In-context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering, Function Vectors in Large Language Models), this link is confirmed to a large degree. This might also suggest trying to import improvements to task arithmetic (e.g. Task Arithmetic i...
1
speculatively, it might also be fruitful to go about this the other way round, e.g. try to come up with better weight-space task erasure methods by analogy between concept erasure methods (in activation space) and through the task arithmetic - activation engineering link
1
For the pretraining-finetuning paradigm, this link is now made much more explicitly in Cross-Task Linearity Emerges in the Pretraining-Finetuning Paradigm; as well as linking to model ensembling through logit averaging.
(As reply to Zvi's 'If someone was founding a new AI notkilleveryoneism research organization, what is the best research agenda they should look into pursuing right now?')
LLMs seem to represent meaning in a pretty human-like way and this seems likely to keep getting better as they get scaled up, e.g. https://arxiv.org/abs/2305.11863. This could make getting them to follow the commonsense meaning of instructions much easier. Also, similar methodologies to https://arxiv.org/abs/2305.11863 could be applied to other alignment-adjacent domains/tasks, e.g. moral...
There have been numerous scandals within the EA community about how working for top AGI labs might be harmful. So, when are we going to have this conversation: contributing in any way to the current US admin getting (especially exclusive) access to AGI might be (very) harmful?
[cross-posted from X]
Claude Sonnet-3.5 New, commenting on the limited scalability of RNNs, when prompted with 'comment on what this would imply for the scalability of RNNs, refering (parts of) the post' and fed https://epoch.ai/blog/data-movement-bottlenecks-scaling-past-1e28-flop (relevant to opaque reasoning, out-of-context reasoning, scheming):
'Based on the article's discussion of data movement bottlenecks, RNNs (Recurrent Neural Networks) would likely face even more severe scaling challenges than Transformers for several reasons:
- Sequential Nature: The article mentions pipe
4
I'm curious how these claims relate to what's proposed by this paper. (note, I haven't read either in depth)
Sam Altman says AGI is coming in 2025 (and he is also expecting a child next year) https://x.com/tsarnick/status/1854988648745517297
Lukewarm take: the risk of the US sliding into autocracy seems high enough at this point that I think it's probably more impactful now for EU citizens to work on pushing sovereign EU AGI capabilities, than on safety for US AGI labs.
Hot take: for now, I think it's likelier than not that even fully uncontrolled proliferation of automated ML scientists like https://sakana.ai/ai-scientist/ would still be a net differential win for AI safety research progress, for pretty much the same reasons from
https://beren.io/2023-11-05-Open-source-AI-has-been-vital-for-alignment/….
I'd say the best argument against it is a combination of precedent-setting concerns, where once they started open-sourcing, it'd be hard to stop doing it even if it becomes dangerous to do, combined with misuse risk for now seeming harder to solve than misalignment risk, and in order for open-source to be good, you need to prevent both misalignment and people misusing their models.
I agree Sakana AI is safe to open source, but I'm quite sure sometime in the next 10-15 years, the AIs that do get developed will likely be very dangerous to open-source them, at least for several years.