I enjoyed this! I performed really poorly!
So after an enjoyable evening of coding up some heuristics and then having very little clue of how to combine and then translate them into probabilities, I realized that my only chance to win was to hope that the data set was in some ways easy, meaning that most participants would get almost everything "right", and the winner might be determined by who was overconfident enough.
Don't get me wrong, my heuristics didn't perform all that well, but I do wonder how much of the "overconfidence" we see is a result of actual miscalibration versus strategic. If you think your discrimination is working really well, you probably want to gamble that it's working better than everyone else's, but if you think it's not working so well, it does seem like the only chance you have of winning is overconfidence plus luck.
For what it's worth, the top three finishers were three of the four most calibrated contestants! With this many strings, I think being intentionally overconfident as a bad strategy. (I agree it would make sense if there were like 10 or 20 strings.)
I think it depends a lot more on the number of strings you get wrong than on the total number of strings, so I think GuySrinivasan has a good point that deliberate overconfidence would be viable if the dataset were easy. I was thinking the same thing at the start, but gave it up when it became clear my heuristics weren't giving enough information.
My own theory though was that most overconfidence wasn't deliberate but simply from people not thinking through how much information they were getting from apparent non-randomness (i.e. the way I compared my results to what would be expected by chance).
Yep, this is indeed a reason proper scoring rules don't remain proper if 1) you only have a small sample size of questions, and 2) utility of winning is not linear in the points you obtain (for example, if you really care about being in the top 3, much more than any particular amount of points).
Some people have debated whether it was happening in the Good Judgement tournaments. If so, that might explain why extremizing algorithms improved performance. (Though I recall not being convinced that it was actually happening there). When Metaculus ran its crypto competition a few years ago they also did some analysis to check if this phenomenon was present, yet they couldn't detect it.
Curated!
And in doing so, I feel proud to assume the role of Patron Saint of LessWrong Challenges, and All Those Who Test Their Art Against the Territory.
Some reasons I'm excited about this post:
1) Challenges help make LessWrong more grounded, and build better feedback loops for actually testing our rationality. I wrote more about this in my curation notice for The Darwin Game challenge, and wrote about it in the various posts of my own Babble Challenge sequence.
2) It was competently executed and analysed. There were nice control groups used; the choice of scoring rule was thought through (as well as including what would've been the results of other scoring rules); the data was analysed in a bunch of different ways which managed to be both comprehensive while at the same time maintaining my curiosity and being very readable.
Furthermore, I can imagine versions of this challenge that would either feel butchered, in such a way that I felt like I didn't learn anything from reading the results, or needlessly long and pedantic, in such a way that getting the insight wouldn't have been worth the trek for most people. Not so with this one. Excellent job, UnexpectedValues.
3) I want to celebrate the efforts of the participants, some of whom devised and implemented some wonderful strategies. The turtle graphic fingerprints, gzip checks, mean-deviation scatter, and many others were really neat. Kudos to all who joined, and especially the winners, Jenny, Reed, Eric, Scy, William, Ben, Simon, Adam and Viktor!
I would love to see more activities like these on LessWrong. If you want to run one and would like help with marketing, funding for prizes, or just general feedback -- do send me a message!
Very cool! One nitpick:
The probability of having as unbalanced a string as #121 in a sample of 62 random strings is 12%... Given that balance between zeros and ones is one of the most basic things to look at, Round 2 participants got unlucky... Contestants justifiably gave probabilities near 0 for both strings.
This feels like a failure to apply Bayes. Let E = "#121 is 3.1 or more stddevs away from evenly split" and H = "#121 is 'real'". Then it is true that real randomness doesn't do 3.1 stddevs very often, so P(E|H) is roughly 1:400 odds. But "given that balance between zeros and ones is one of the most basic things to look at", human participants probably also aren't going to do 3.1 stddevs very often, so P(E|!H) is also very low! How low? Based on the best dataset I have for how humans actually behave on this task (i.e. your dataset, so admittedly this method would not have actually been usable by contest participants), the odds a participant would create a string as unbalanced as #121 (i.e. 56 or fewer of whichever digit was rarer) is 0:62!! But there was 1 participant with each number of rare-digits between 57 and 60, so I'm going to irresponsibly eyeball that curve and say that P(E|!H) is probably somewhere between 1:50 and 1:200 odds. With our 1:400 from earlier, this means an odds ratio of between 2:1 and 8:1 in favor of #121 being human-generated; without more evidence to go on, the correct answer would have thus been between 11% and 33%. "Probabilities near 0" are not justified, unless you're incorporating other evidence as well, or you think both that the correct answer is nearer the 11% end of my range and also that 11% counts as "near 0". (Could one guess P(E|!H) without seeing your dataset? Obviously I'm spoiled on the answers now so I don't know, but I think I might have guessed that "one or two" of 62 participants would do something that extreme, which would correspond to an answer of ~10%.)
Unrelatedly, your post was extra fun for me because I happened to try something along the same lines (but much less well executed) as my middle school science fair project - I had people do Round 1 only (and only ~30 bits, not 150), and then just did some analysis myself to show ways they differed on average from random (primarily just looking at run lengths). Unfortunately I did not put any effort into getting motivated participants - I gathered data in part by getting teachers to force a bunch of uninterested kids to play along, and unsurprisingly ended up with some garbage responses like all 0s or strictly alternating 0s and 1s (and presumably most of the others, while not total garbage, did not represent best effort).
Wow wow wow wow wow.
I only just got around to reading this.
The two most exciting parts for me were listing peoples strategies for coming up with random numbers - I’d never thought of several of these before!
And then the graph of calibration was hilarious! A blue line showing calibration, and then A perfectly orthognoal line showing every single participant being overconfident. I laughed out loud.
This was the best, thank you UnexpectedValues <3
Whoops, missed this post at the time.
In response to:
(4) average XOR-correlation between bits and the previous 4 bits (not sure what this means -Eric)
This is simply XOR-ing each bit (starting with the 5th one) with the previous 4 and adding it all up. This test was to look for a possible tendency (or the opposite) to end streaks at medium range (other tests were either short range or looked at the whole string). I didn't throw in more tests using any other numbers than 4 since using different tests with any significant correlation on random input would lead to overconfidence unless I did something fancy to compensate.
In response to:
“XOR derivative” refers to the 149-bit substring where the k-th bit indicates whether the k-th bit and the (k +1)-th bit of the original string were the same or different. So this is measuring the number of runs ... (3) average value of second XOR derivative and (4) average XOR-correlation between bits and the previous 4 bits...
I’m curious how much, if any, of simon’s success came from (3) and (4).
Values below. Confidence level refers to the probability of randomness assigned to the values that weren't in the tails of any of the tests I used.
Actual result:
Confidence level: 63.6
Score: 21.0
With (4) excluded:
Confidence level: 61.4
Score: 19.4
With (3) excluded:
Confidence level: 62.2
Score: 17.0
With both (3) and (4) excluded:
Confidence level: 60.0
Score: 16.1
Score in each case calculated using the probabilities rounded to the nearest percent (as they were or would have been submitted ultimately). Oddly, in every single case the rounding improved my score (20.95 v. 20.92, 19.36 v. 19.33, 16.96 v. 16.89 and 16.11 v. 16.08.
So, looks I would have only gone down to fifth place if I had only looked at total number of 1's and number of runs. I'd put that down to not messing up calibration too badly, but looks that would have still put me in sixth in terms of post-squeeze scores? (I didn't calculate the squeeze, just comparing my hypothetical raw score with others' post-squeeze scores)
P.S:
With (1) (total number of 1's) excluded, but all of (2), (3), (4) included:
Confidence level: 61.8
Score: 20.2
With (2) (total number of runs) excluded, but all of (1), (3), (4) included:
Confidence level: 59.4
Score: 13.0
With ONLY (1) (total number of 1's) included:
Confidence level: 52.0
Score: -1.8
With ONLY (2) (total number of runs) included:
Confidence level: 57.9
Score: 18.4
So really it was the total number of runs doing the vast majority of the work. All calculations here do include setting the probability for string 106 to zero, both for the confidence level and final score.
There is something I found really interesting about Ben’s submission, which is that his probabilities went as high as 88%. Ben’s was an outlier among the best entries in this sense: most of the entries that did best had a maximum probability in the 60-80 percent range. This confused me: could you really be 88% sure that a string was random, when you know you’re assigning something more like 60-65% to a typical random string? Can a string look really random (rather than merely random)? This sort of seems like an oxymoron: random strings don’t really stand out in any way sort of by definition.
In principle, at least, the explanation would be straightforward: suppose X is a measure of how many tests of randomness (i.e. tests of the presence of some feature which we expect to more commonly occur in real strings than fake ones) a string passes, and we assign our probability monotonically from X.
Your typical fake string fails many tests of randomness, whereas your typical real string fails few. Yet, there is still variation in X within each category. Hence some real strings will pass nearly all the tests, and get an unusually large probability of being real.
I think this is mainly a feature of the relatively short length. Longer random strings would have less variation.
I'll take fifth place in Round 1 (#44), given how little I thought of my execution XD. Debiasing algorithms work. I'm not convinced there's a real detected difference between the top Round 1 participants anyway; we are beating most random strings, and none of the top players thought it was more likely than not any of them were human.
My Round 2 performance was thoroughly middle of the pack, with a disappointing negative score. I didn't spend much effort on it and certainly didn't attempt calibration, so it's not a huge surprise I didn't win, but I still hoped for a positive score. What I am most surprised at is that four of my 0% scores were real (#8, #61, #121, #122). I was expecting one, maybe two (yes, yes, I already said ‘I didn't attempt calibration’) might be wrong, but four seems excessive. I can't really blame calibration for the mediocre performance, since my classification rate (60.5%) was also middle of the road, but I think I underestimated how much bang-for-the-buck I would have gotten from calibration, rather than working on the details.
Perhaps interestingly, someone who bet the mean % for every option (excluding self-guesses), with no weighting, would have scored 19.5 (drawn fourth place), or 19.8 post-squeeze, with a 64.5% classification rate. Even if you exclude everyone who scored 10 or more from that average, the average would have scored 14.5, or 15.8 post-squeeze, with (only) a 59.7% classification rate. So averaging out even a bunch of mediocre opinions seems to get you pretty decent, mostly-well-calibrated results.
Alternatively, someone who bet the weighted average from the column in the sheet, which is of course a strategy impossible to implement without cheating, would have scored 27.7, or 28.0 post-squeeze, with a 74.2% classification rate. So even that form of cheating wouldn't beat the Scy & William duo.
Ah, which Round 1 submission was mine? I think I wrote it down somewhere but I don't know where... I suppose technically I could search my harddrive for each of the strings.
(FYI I was playing to maximize EV rather than skewing my guesses to increase variance.)
My Calibration:
1-10: 0/11 (0%)
11-20: 4/11 (36%) (includes the "tricky" #121 and #122, without which is a more reasonable 18%)
21-30: 2/4 (50%) (-)
31-40: 3/8 (38%)
41-50: 5/7 (71%) (-)
51-60: 14/22 (64%)
61-70: 17/31 (55%) (+)
71-80: 13/23 (57%) (+)
81-90: 4/4 (100%)
91-100: (None)
Points breakdown:
3.0 points for my (3) zero predictions (my own #96 string, the 9-containing #106, and the obviously silly #66).
10.8 points for my (11) 1-10 predictions (all correct).
-4.3 points for my (2) 11% predictions on the "tricky" #121 and #122 strings.
2.9 points for my other (9) 11-20 predictions
0.0 points for my (41) 21-60 predictions
-3.8 points for my (54) 61-80 predictions (most of my overconfidence is here)
3.4 points for my (4) 81-90 predictions (all correct).
(12.0 total)
I'm curious if participants #99, #107 and #124 care to say why they gave my string (#96) the scores they did.
The deceptive strings aren't just skewed in terms of total 1s vs 0s; I was calculating the relative number of each sub-string. string (000, 001, 010, 100, etc.) compared to the naïve expectation given the overall mix of 1's and 0's. 121 and 122 are non-standard, even by that metric (for example, 122 has literally zero instances of "0000" instead of the expected 2.29, and both have very different numbers of "010" and "101" compared to "001" "100" "110" and "011."
I do not recommend this method, as it didn't identify things very well, picking only 30/60 fake strings (other than mine and #106) and inaccurately calling a full 19 real strings fake. But seconding Guy's note: I deliberately skewed my guesses to extremes, figuring that would be the best way to "win," even though the EV was lower than being better calibrated. (ie 10% chance of 1st place + 90% chance of a negative score > 100% chance of a positive score)
I was string #54, and scored -1.7 in round 2, fairly middle of the pack. My probabilities:
- 24 × 0%, 3 were real (13%)
- 4 × 5%, 0 were real (0%)
- 5 × 10%, 3 were real (60%)
- 4 × 15%, 3 were real (75%) (!)
- 2 × 20%, 1 was real (50%)
- 7 × 25%, 1 was real (14%)
- 8 × 30%, 7 were real (88%) (!)
- 14 × 75%, 10 were real (71%)
- 40 × 80%, 24 were real (60%)
- 16 × 85%, 10 were real (63%)
I think the thing I found difficult was I didn't know how to do a bayesian update. I can calculate the probability of a statistic under the "random" hypothesis, but I had no idea what probability to assign it under the "fake" hypothesis, so what next?
In the end I just sorted the strings by a certain statistic and went with my gut, taking into account other info like "number of 1s" and "was this my own string", and starting with a baseline of "given the number of fakes I'm pretty sure I've eliminated, I don't think I can be more than, uh, about 85% confident that any given string is real". I worked from both ends and tried to get my average probability somewhere close to 50%, but that left a lot of space in the middle that I didn't end up using. Clearly this didn't work very well.
(The statistic was something like, probability of the observed "longest run length" combined with "number of changes from 1→0 or 0→1". The two aren't independent, so I got longest run length in closed form and did many simulations to get a rough distribution for number of changes given that.)
Thanks for hosting this contest. The overconfidence thing in particular is a fascinating data point. When I was done with my function that output final probabilities, I deliberately made it way more agnostic, thinking that at least now my estimates are modest -- but it turns out that I should have gone quite a bit farther with that adjustment.
I'm also intrigued by the variety of approaches for analyzing strings. I solely looked at frequency of monotone groups (i.e., how many single 0's, how many 00's, how many 000's, how many 111's, etc.), and as a result, I have widely different estimates (compared to the winning submissions) on some of the strings where other methods were successful.
Reading over this the first thing that sprang to mind is doing an FFT over the sequences and using the spectral flatness as a marker to eliminate simple ones. You could then do PCA on them along with some true pseudorandom sequences and plot, similar to Scy and William's method. I'm not 100% as these sequences are a tad short. Perhaps I'll give this a go however.
Ok so I found time to try this out.
Treating this like an audio signal makes sense, so that we can use analytical tools available in audio signal processing.
The overall challenge is effectively to try and determine whether each sample is white noisey enough.
Why? Think about what white noise is in this context. It's a pure random process. We're trying to determine if there are any particular patterns or skews to each sequence, or if the noise isn't 'white' enough.
If someone put down a completely repeatable sequence, say: [0,1,0,1,0,1,0,1,0,1...] If you were to transform the range to [-1,1,-1,1...] and put it into Audacity, (try it, you can import->raw data) you'd hear a tone, (or an inaudibly short bleep in this case). Very much not random.
In an FFT, we'd see a spike in this particular frequency on our spectrum.
Imagine summing our first sequence with another random repeatable sequence on top: [0,1,0,1,0,1...] + [0,0,0,1,1,1,0,0...] = [0,1,0,2,1,2,0,1...]
Do some tricks to normalize and rescale the data, and we'd hear two different tones. We'd now have two spikes in our FFT.
Imagine just carrying this on for, say, 1000 times - then do our scaling and rounding. The FFT would be so filled out that it would look almost flat
The more tones of random frequency, phase + amplitude you add, the closer and closer it comes to white noise, and therefore a perfectly random process.
White noise, in theory, should be maximally flat. That means that all frequencies over the possible range have equal power.
For a short sequence such as this it won't be perfectly flat, however any large skew in any direction, suggests the presence of patterns which are not random.
We can use two simple spectral features to show this: Spectral Centroid (i.e the centre of mass) Spectral Flatness (i.e a measure of how flat the spectrum is)
Plots
FFT of a pseudorandom number:
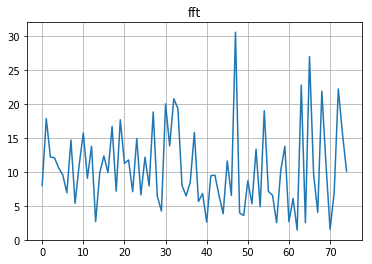
FFT of example 112:
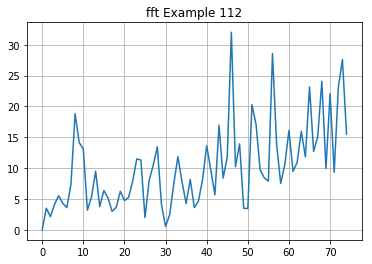
Notice the skew in the example, it's very skewed towards the higher frequencies - this means the flatness will be lower and the centroid will be higher.
So here's a plot of just the centroid vs flatness for all examples + 500 truly pseudorandom examples:
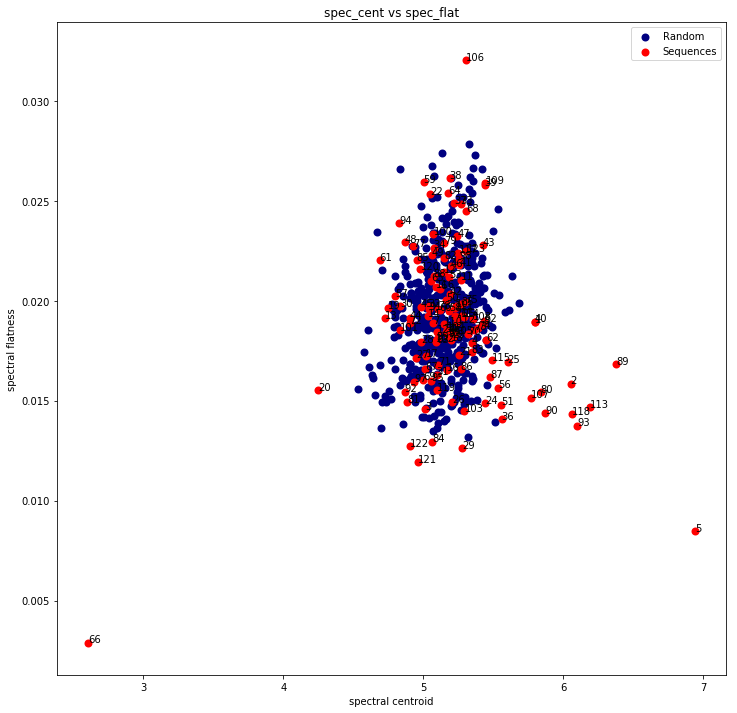
We have some nice separability on a good 12-14 of the examples. Look how far 66 and 5 standout, these would be my 0%ers for sure.
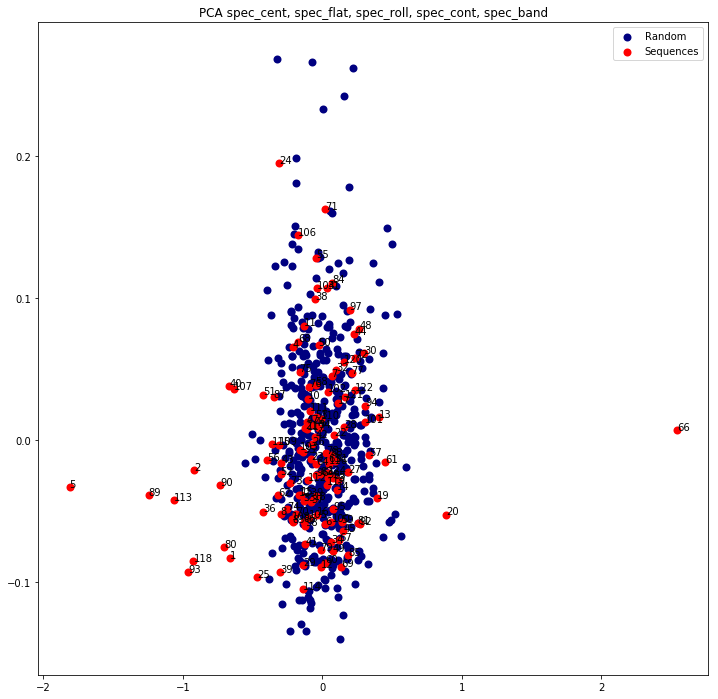
Here's a PCA of several spectral features (rolloff, contrast, bandwidth + 2 above) for good measure:
Wow, really interesting article.
It is really interesting that the median result was negative, although strategic overconfidence as some has pointed out explains some of it.
Found a very interesting paper on the subject of overconfidence: https://www.researchgate.net/publication/227867941_When_90_confidence_intervals_are_50_certain_On_the_credibility_of_credible_intervals
“Estimated confidence intervals for general knowledge items are usually too narrow. We report five experiments showing that people have much less confidence in these intervals than dictated by the assigned level of confidence. For instance, 90% intervals can be associated with an estimated confidence of 50% or less (and still lower hit rates). Moreover, interval width appears to remain stable over a wide range of instructions (high and low numeric and verbal confidence levels).”
From the scientific paper I mentioned in the first comment they used different questions, here is an example:
“The questionnaires asked for interval estimates of birth years for five famous characters from world history (Mohammed, Newton, Mozart, Napoleon, and Einstein), and the years of death for five other famous persons (Nero, Copernicus, Galileo, Shakespeare, and Lincoln).”
I tested to answer these questions myself with 90% confidence intervals, and my result was that I was correct 7/10 questions, so seems like I still am overconfident in my answers even though I just read about it. But to be fair, 10 questions are far from statistical significance.
(Previously in this series: Round 1, Round 2)
In December I ran a pseudorandomness contest. Here’s how it worked:
This post is long because there are lots of fascinating things to talk about. So, feel free to skip around to whichever sections you find most interesting; I’ve done my best to give descriptive labels. But first:
Prizes
Round 1
Thank you to the 62 of you who submitted strings in Round 1! Your strings were scored by the average probability of being real assigned by Round 2 participants, weighted by their Round 2 score. (Entries with negative Round 2 scores received no weight). The top three scores in Round 1 were:
Congratulations to Jenny, Reed, and Eric!
Round 2
A big thanks to the 27 of you (well, 28 — 26 plus a team of two) who submitted Round 2 entries. I estimate that the average participant put in a few hours of work, and that some put in more than 10. Entries were graded using a quadratic scoring rule (see here for details). When describing Round 2, I did a back-of-the-envelope estimate that a score of 15 on this round would be good. I was really impressed by the top two scores:
Three other participants received a score of over 15:
Congratulations to Scy, William, Ben, simon, Adam, and Viktor!
All right, let’s take a look at what people did and how well it worked!
Round 1 analysis
Summary statistics
Recall that the score of a Round 1 entry is a weighted average of the probabilities assigned by Round 2 participants to the entry being real (i.e. truly random). The average score was 39.4% (this is well below 50%, as expected). The median score was 45.7%. Here’s the full distribution:
Interesting: the distribution is bimodal! Some people basically succeeded at fooling Round 2 participants, and most of the rest came up with strings that were pretty detectable as fakes.
Methods
I asked participants to describe the method they used to generate their string. Of the 58 participants who told me what they did with enough clarity that I could categorize their strategy:
Although I didn’t participate, the strategy I thought to use was a mix of memory-based and brain-based. Specifically, I would have taken the digits of Pi as one source of randomness, used my brain to come up with random-ish bits, and then taken the bitwise XOR. (I’m not totally sure I would have been able to come up with 150 digits in 10 minutes with that method, though.)
Common pitfalls
By far the most common mistake made in Round 1 was not having sufficiently long (or sufficiently many) runs, i.e. consecutive zeros or consecutive ones. There is only a 0.5% chance that a random 150-bit string will have no run of length 5 (i.e. 5 zeros or 5 ones in a row); in comparison, 10 of the 62 strings submitted in Round 1 had no length-5 run. Many strings with insufficient runs were generated by either intuition or motor functions, though a few were not. An instructive example:
This generated the following string (Round 2 ID #80):
The fact that this string has no runs of length more than 4 makes a lot of sense! After all, suppose you got four 0’s in a row. That means you had a sequence of five letters, each later than the previous. The last of those letters is likely pretty late in the alphabet, which means that there’s a much greater than 50% chance that the next letter will come earlier in the alphabet (so you’ll write down 1).
The moral here is that there are many ways to mess up besides having a faulty intuitive grasp on randomness: you could also take a pretty good random number generator, but mess up when deciding how to convert it to zeros and ones. One other such pitfall was having a conversion method that resulted in an unbalanced string. One example:
I’m not sure how this contestant divided up the alphabet, but their string ended up with only 57 ones. The probability of a random string being that skewed (in either direction) is just 0.3%.
Some contestants who didn’t get caught for insufficient runs or imbalanced strings got caught with more sophisticated tests (see the discussion of Round 2 below).
Interesting sources of randomness
Here are some Round 1 techniques I found interesting (whether or not they did well):
A nearly perfect source of randomness, if you know enough birthdays! (This person didn’t; they said that they then used song lyrics.)
This seems to me like a great way to extract uniformly random bits from a text (though I’m not sure why they didn’t just put down 0 or 1 based on which of x and y came first).
Round 2 analysis
In Round 2, I gave participants the 62 strings generated by humans in part 1 (“fake” strings) alongside 62 strings random generated by a computer (“real” string), all in a random order, and asked them to assign each string a probability of being real. You can see all 124 strings here.
There’s a lot to say about Round 2. Let’s dive in!
Fake strings were systematically noticed
Figure 1 showed the distribution of Round 1 scores: the average probability assigned by Round 2 participants to each fake string being real (weighted by Round 2 score). What if we similarly assigned scores to real strings?
As you can see, real strings got systematically higher scores than fake strings, by a lot. Only 5 of 62 real strings were judged to be more likely to be fake than real, compared to a majority of fake strings. That’s pretty cool (even if expected).1
What, more concretely, helped people tell real and fake strings apart? Contestants used many methods, but the vast majority of the mileage came from looking at runs (consecutive 0s or 1s): as I mentioned, many fake strings failed to have sufficiently long runs (though in some cases people overcompensated and made their runs too long).
But “looking at runs” alone isn’t enough to get a good score. Let’s say you find a string that has one run of length 5 and no runs of length 6. That’s mildly suspicious, but how do you turn that into a probability? Converting a qualitative amount of “suspicion” into a probability was perhaps the most important part of the contest to get right. To understand why that was so important, let’s take a look at the scoring system used for Round 2.
Scoring system
Slightly paraphrasing/rearranging my Round 2 post:
(For those of you familiar with scoring rules, this just means I was using Brier’s quadratic scoring rule, scaling it so that a totally uninformative forecast would result in 0 points.)
I also didn’t catch that string #106 (which was fake) had a 9 in it; I ended up asking everyone to put down 0% for string #106. This means that everyone had the opportunity to say 0% for #106 and 50% for everything else, for a score of 1.
The other benchmark I set was 15, which was my estimate for what a “good” score would constitute. As I mentioned in the prizes section, five of the 27 Round 2 contestants cleared this bar.
Before going on to the next section, you might want to make a guess about the distribution of scores!
Summary statistics
Here’s the distribution of Round 2 scores.
Scores in the red part were negative: participants with these scores would have been better off saying 50% for everything. Scores in the green were the ones that met my “good score” benchmark.
The average score was -5.5. The median was -1.4. A majority of scores (14 of 27) were negative. This means that most participants would have gotten a better score if they had said 50% for every string!
The reason for this is overconfidence on the part of Round 2 participants. Proper scoring rules punish overconfidence pretty harshly. For example, if a contestant managed to classify 70% of strings correctly (better than almost anyone actually did) but was 90% confident of their classification for each string, their score would have been 0.2 Let’s take a closer look.
Basically everyone was overconfident
One nice thing about proper scoring rules is that you can use people’s answers to infer what score they expected to get. For example, let’s say someone submitted 70% for one of the strings. That means they think there’s a 70% chance of the string being real, in which case they’ll get a score of
and a 30% chance of it being fake, in which case they’ll get a score of
That means their expected score for that string is
You can calculate an expected score for every string and add those up to find the total score that the participant expected.
If the previous paragraph didn’t make sense, here’s a simplification: you can tell what score someone expected to get based on how confident their answers were (how close to 0% or 100%). The more confident someone’s answers, the higher the score they expected to get.
Of course, someone’s true score may differ a lot from their expected score if they aren’t calibrated. If someone is overconfident, their actual score will be below the score they expected to get. If they’re underconfident, their actual score will be above their expected score. So we can figure out whether someone was over- or underconfident by comparing what score they expected to get to their actual score. Here’s a plot of that.
Every single point was below the red line, meaning that every single participant was overconfident (though three were close enough to the line that I’d say they were basically calibrated).
In fact, a nearly perfect predictor of whether someone would get a positive score or a negative score was whether they thought they were going to get a score above 50 or below 50. Everyone who thought they were going to get a score above 50 got a negative score. With one exception, everyone who thought they were going to get a score below 50 got a positive score. This is pretty remarkable!
One concrete way to measure overconfidence is “how much squeezing toward 50% would the participant have benefitted from”. For example, squeezing predictions halfway to 50% would mean that a 20% prediction would be treated as 35% and a 90% prediction as 70%. We can ask: What percent squeezing would optimize a participant’s score?3
For a perfectly calibrated forecaster, the optimal amount of squeezing would be 0%. But everyone was overconfident, so everyone would have benefited from some amount of squeezing. How much squeezing?
The range of optimal squeezing amounts went from 7% (achieved by Ben, who got 2nd place) to 82%, with an average of 47%. So on average, it would have been best for participants to squeeze their probabilities about halfway toward 50% before submitting. (For comparison, the winning team would have benefitted from a 19% squeeze.)
The next chart shows participant scores as a function of how overconfident they were.
This plot shows that being calibrated was crucial to getting a good score. But calibration wasn’t everything: Ben submitted the most calibrated entry (the red point) but got second place, while the winning submission (green), submitted by Scy and William, was only the fourth most calibrated.
So what did the winning team do so well?
Before we answer this, it’s instructive to consider the second most calibrated entry, which is the yellow point in the previous chart. This entry got 10th place out of 27 — better than average, but not by much.
What happened? Out of 124 probabilities, this contestant submitted 50% 114 times, 10% 6 times, and 0% 4 times. (They went 4/4 on the 0% entries and 5/6 on the 10% ones, though the one miss was bad luck — I’ll touch on that later.) This contestant did fine, but didn’t do great because of poor classification, i.e. an inability to systematically sniff out fake strings.
One rudimentary measure of classification is what fraction of strings were “called” correctly. That is, one could look at how well contestants would have done if I had simply awarded each contestant a point for every real string to which they assigned a probability greater than 50% and every fake string to which they assigned a probability less than 50% (and half a point if they said 50%). Here’s a plot of contestant scores vs. the fraction of strings they called correctly.
By this metric, Scy and William were the best at classification by a substantial margin. The 2nd and 3rd best entries by classification got 3rd and 4th place, respectively, in Round 2, behind Scy/William and Ben.
The plot below is meant to illustrate in more detail how exactly Scy and William beat out Ben despite being less calibrated.
Here, every point corresponds to one of the 124 strings. Fake strings are orange; real ones are blue. The x-value is the probability Ben (the most calibrated, 2nd place contestant) assigned to the string being real; the y-value is the probability assigned by Scy and William (1st place, 4th most calibrated).
Here’s the same chart again, this time with emphasis added to two parts of the chart.
The green rectangle contains all the strings that Scy and William said were very likely fake but Ben did not. There are 13 such strings, 11 of which were in fact fake.
The purple rectangle is all the strings that Ben said was very likely fake but Scy and William did not. There are 3 such strings (you only see one dot because they’re on top of each other). One of those was Ben’s string. (The other two had long substrings of the digits of Pi mod 2, which Ben looked for but Scy and William didn’t.)
So basically, even though Scy and William were less calibrated than Ben (three strings they assigned probability 0 to were real), they discerned fake strings better. And ultimately this made them win, earning 28.5 points to Ben’s 25.8.
This is in part why I used the quadratic rule instead of the log rule for scoring: the log rule punishes miscalibration at the extremes really harshly, and I didn’t want someone who was slightly less calibrated but much more discerning to lose. Had I used the log rule (and rounded 0% probabilities of real strings to 1%), Ben would have narrowly won.
Calibration vs. classification
Did more calibrated contestants also classify more strings correctly?
The answer is yes, somewhat. The r^2 of the relationship here is 23%, meaning that contestants’ calibration explained 23% of the variance in in how well they “called” strings. This makes sense: the more effort you put (and the more experience you have with this, etc.), the better you’ll do on both fronts.
(By the way, it’s pretty nice how the top three finishers formed the calibration-classification Pareto frontier!)
If you’re interested in reading more about the calibration-classification dichotomy, I also have a more detailed post about it.
Okay but what strategy did the winners use?
I’ll quote Scy and William’s description of what they did verbatim (modulo small stylistic edits), alongside clarifying comments.
Scy and William kindly shared with me their plot of the mean and standard deviation of run lengths:
(Click here for a larger version of the plot.) In this plot, red points are the 124 strings given to participants (along with their ID numbers), while blue points are computer-generated random strings. The x-axis is the average length of a run; the y-axis is the standard deviation of run lengths.
The idea is pretty simple: blue (truly random) points formed a pretty narrow cloud on this plot. A red point that was far away from this cloud was therefore likely to be fake.
Many people looked at average run lengths, but not many looked at the standard deviation. This helped them catch a few fake strings that the consensus failed to catch, including strings 27 and 124 (whose standard deviation was too small), and 81 and 105 (too large). I haven’t done a deep dive, but it looks to me like this strategy helped set Scy and William’s entry apart.
What other strategies did well?
I’ll again quote the other top contenders’ strategies verbatim. First, Ben (2nd place, most calibrated):
These methods are very solid, but nothing here is particularly special in terms of doing things no one else did. My best guess, then, is that Ben had great execution. That is, his Bayes updates (which many people tried to do with varying degrees of success) were roughly of the correct size. This theory is supported by the fact that Ben was well-calibrated.
There is something I found really interesting about Ben’s submission, which is that his probabilities went as high as 88%. Ben’s was an outlier among the best entries in this sense: most of the entries that did best had a maximum probability in the 60-80 percent range. This confused me: could you really be 88% sure that a string was random, when you know you’re assigning something more like 60-65% to a typical random string? Can a string look really random (rather than merely random)? This sort of seems like an oxymoron: random strings don’t really stand out in any way sort of by definition.
In response, Ben told me:
But the frequency of particular run counts should be at most twice as rare in the 124 Round 2 strings and in a sample of random strings, since half of Round 2 strings are random. So is there overfitting going on? Ben’s submission was well-calibrated, so perhaps not. I remain confused about this.
Next we have simon (3rd place):
I’m curious how much, if any, of simon’s success came from (3) and (4). I’m not sure what (4) refers to, but (3) was not commonly done.
EDIT: See here for simon's explanation of the XOR-correlation, as well as an answer to my curiosity. The answer is: they both helped a decent amount!
Next we have Adam (4th place).
I’m curious about the particular choices of 5 and 6. Would Adam have done better by incorporating evidence from every length?
Finally, Viktor (5th place):
It’s pretty interesting that this did well, given the reliance on gut feeling and the crude 1.4x scaling at the end, but it seems to have worked out! I wonder if a good gut feeling outperforms all but the best automated methods because automated methods are pretty easy to mess up.
Other interesting strategies
Most people did some variation of “I looked at runs”. Relatively few people did anything that surprised me. My favorite of these non-orthodox methods:
Cool! I bet this visualization makes real and fake strings look pretty different.
Another interesting method:
Interesting, I wonder how much you can get out of just looking at linear dependencies like this.
Finally:
Interesting: Measure looked at relative frequencies of all strings of a given length, rather than only looking at runs. I wonder how much that helped.
Final comments
Did participants who did well in Round 2 do well in Round 1?
Interestingly, the was no correlation between Round 1 and Round 2 scores (though as a group, people who participated in Round 2 did quite well in Round 1).
A bit of bad luck for Round 2 participants
Figure 2 showed that two of the random strings looked pretty fake. These were #121 and #122.
#121:101111111010101100110001010111111111111001111111111111100000100011010011011000101110010101111101110111101100000000011011010010101101010111111111110101
#122:101011001110001111010010110111011011000111101001100111111111111011100011111110110111000111011111111111101110010100111110110001100011101110100111000110
What made them look fake is that they had, respectively, 56 and 53 zeros — much less than half of 150 (3.1 and 3.6 standard deviations too few zeros, respectively). The probability of having as unbalanced a string as #121 in a sample of 62 random strings is 12% (not too unusual). The probability of having as unbalanced a string as #122 is just 2%.
Given that balance between zeros and ones is one of the most basic things to look at, Round 2 participants got unlucky in that they were fed a string that looked much faker than the fakest real string should look — in fact, arguably two such strings.
Contestants justifiably gave probabilities near 0 for both strings. This cost participants a few points. This also means that the previously discussed overconfidence is slightly an artifact of this bad luck. If not for this, three participants (the top three by calibration) would have been essentially correctly calibrated; everyone else would have still been overconfident, though.
Raw data
1. This is admittedly a little sketchy, since I’m determining the weights based on ability to discern fake strings. However, I think there are enough total strings that this causes only a small amount of bias.
2. If I had chosen the log scoring rule instead, I would have been punishing overconfidence even more harshly!
3. Interestingly, there is a nice pictorial representation of the optimal amount of squeezing: in Figure 4 (repeated below), it is the distance from the point to the red line, divided by the point’s x-value, and then divided by the square root of 2. Alternatively (using the red point below as an example) it is the ratio of the lengths of the green segments.