So when you're talking about decision theory and your intuitions come into conflict with the math, listen to the math.
I think you're overselling your case a little here. The cool thing about theorems is that their conclusions follow from their premises. If you then try to apply the theorem to the real world and someone dislikes the conclusion, the appropriate response isn't "well it's math, so you can't do that," it's "tell me which of my premises you dislike."
An additional issue here is premises which are not explicitly stated. For example, there's an implicit premise in your post of there being some fixed collection of agents with some fixed collection of preferences that you want to aggregate. Not pointing out this premise explicitly leaves your implied social policy potentially vulnerable to various attacks involving creating agents, destroying agents, or modifying agents, as I've pointed out in other comments.
I suggest the VNM Expected Utility Theorem and this theorem should be used as a test on potential FAI researchers. Is their reaction to these theorems "of course, the FAI has to be designed that way" or "that's a cool piece of math, now let's see if we can't break it somehow"? Maybe you don't need everyone on the research team to instinctively have the latter reaction, but I think you definitely want to make sure at least some do. (I wonder what von Neumann's reaction was to his own theorem...)
Axiom 1: Every person, and the FAI, are VNM-rational agents.
[...]
So why should you accept my axioms?
Axiom 1: The VNM utility axioms are widely agreed to be necessary for any rational agent.
Though of course, humans are not VNM-rational.
There's something a little rediculous about claiming that every member of a group prefers A to B, but that the group in aggregate does not prefer A to B.
But many people don't like this, usually for reasons involving utility monsters. If you are one of these people, then you better learn to like it, because according to Harsanyi's Social Aggregation Theorem, any alternative can result in the supposedly Friendly AI making a choice that is bad for every member of the population. More formally,
That a bad result can happen in a given strategy is not a conclusive argument against preferring that strategy. Will it happen? What's the likelihood that it happens? What's the cost if it does happen?
The two alterna...
Have you looked at some of the more recent papers in this literature (which generally have a lot more negative results than positive ones)? For example Preference aggregation under uncertainty: Savage vs. Pareto? I haven't paid too much attention to this literature myself yet, because the social aggregation results seem pretty sensitive to details of the assumed individual decision theory, which is still pretty unsettled. (Oh, I mentioned another paper here.)
What if we also add a requirement that the FAI doesn't make anyone worse off in expected utility compared to no FAI? That seems reasonable, but conflicts the other axioms. For example, suppose there are two agents: A gets 1 util if 90% of the universe is converted into paperclips, 0 utils otherwise, and B gets 1 util if 90% of the universe is converted into staples, 0 utils otherwise. Without an FAI, they'll probably end up fighting each other for control of the universe, and let's say each has 30% chance of success. An FAI that doesn't make one of them wo...
What if we also add a requirement that the FAI doesn't make anyone worse off in expected utility compared to no FAI?
Sounds obviously unreasonable to me. E.g. a situation where a person derives a large part of their utility from having kidnapped and enslaved somebody else: the kidnapper would be made worse off if their slave was freed, but the slave wouldn't become worse off if their slavery merely continued, so...
I'd be curious to see someone reply to this on behalf of parliamentary models, whether applied to preference aggregation or to moral uncertainty between different consequentialist theories. Do the choices of a parliament reduce to maximizing a weighted sum of utilities? If not, which axiom out of 1-3 do parliamentary models violate, and why are they viable despite violating that axiom?
I don't see how I could agree with this conclusion :
But many people don't like this, usually for reasons involving utility monsters. If you are one of these people, then you better learn to like it, because according to Harsanyi's Social Aggregation Theorem, any alternative can result in the supposedly Friendly AI making a choice that is bad for every member of the population.
If both ways are wrong, then you haven't tried hard enough yet.
Well explained though.
The link to Harsanyi's paper doesn't work for me. Here is a link that does, if anyone is looking for one:
https://hceconomics.uchicago.edu/sites/default/files/pdf/events/Harsanyi_1955_JPE_v63_n4.pdf
Axiom two reminds me of Simpson's paradox. I'm not sure how applicable it is, but I wouldn't be all that surprised so find an explanation that a violation of it this axiom perfectly reasonable. I don't suppose you have a set of more obvious axioms you could work with.
Thanks for posting this! This is a fairly satisfying answer to my question from before.
Can you clarify which people you want to apply this theorem to? I don't think the relevant people should be the set of all humans alive at the time that the FAI decides what to do because this population is not fixed over time and doesn't have fixed utility functions over time. I can think of situations where I would want the FAI to make a decision that all humans alive at a fixed time would disagree with (for example, suppose most humans die and the only ones left happ...
A Friendly AI would have to be able to aggregate each person's preferences into one utility function. The most straightforward and obvious way to do this is to agree on some way to normalize each individual's utility function, and then add them up. But many people don't like this, usually for reasons involving utility monsters.
I should think most of those who don't like it do so because their values would be better represented by other approaches. A lot of those involved in the issue think they deserve more than a on-in-seven-billionth share of the fu...
I wonder how hard it would be to self-modify prior to the imposition of the sort of regime discussed here to be a counter-factual utility monster (along the lines of "I prefer X if Z and prefer not-X if not-Z") who very very much wants to be (and thus becomes?) an actual utility monster iff being a utility monster is rewarded. If this turns out to be easy then it seems like the odds of this already having happened in secret before the imposition of the utility-monster-rewarding-regime would need to be taken into account by those contemplating th...
Does the theorem say anything about the sign of the c_k? Will they always all be positive? Will they always all be non-negative?
Being fair is not, in general, a VNM-rational thing to do.
Suppose you have an indivisible slice of pie, and six people who want to eat it. The fair outcome would be to roll a die to determine who gets the pie. But this is a probabilistic mixture of six deterministic outcomes which are equally bad from a fairness point of view.
Preferring a lottery to any of its outcomes is not VNM-rational (pretty sure it violates independence, but in any case it's not maximizing expected utility).
We can make this stronger by supposing some people like pie more than others...
It is worth mentioning that Rawl's later Veil of Ignorance forces him to satisfy Harsanyi's axioms and Rawl's conclusions are a math error.
Edit: conclusion here. I misinterpreted axiom 2 as weaker than it is; I now agree that the axioms imply the result (though I interpret the result somewhat differently).
I don't think you can make the broad analogy between what you're doing and what Harsanyi did that you're trying to make.
Harsanyi's postulate D is doing most of the work. Let's replace it with postulate D': if at least two individuals prefer situation X to situation Y, and none of the other individuals prefer Y to X, then X is preferred to Y from a social standpoint.
D' is weaker; the weighted...
A Friendly AI would have to be able to aggregate each person's preferences into one utility function. The most straightforward and obvious way to do this is to agree on some way to normalize each individual's utility function, and then add them up. But many people don't like this, usually for reasons involving utility monsters. If you are one of these people, then you better learn to like it, because according to Harsanyi's Social Aggregation Theorem, any alternative can result in the supposedly Friendly AI making a choice that is bad for every member of the population. More formally,
Axiom 1: Every person, and the FAI, are VNM-rational agents.
Axiom 2: Given any two choices A and B such that every person prefers A over B, then the FAI prefers A over B.
Axiom 3: There exist two choices A and B such that every person prefers A over B.
(Edit: Note that I'm assuming a fixed population with fixed preferences. This still seems reasonable, because we wouldn't want the FAI to be dynamically inconsistent, so it would have to draw its values from a fixed population, such as the people alive now. Alternatively, even if you want the FAI to aggregate the preferences of a changing population, the theorem still applies, but this comes with it's own problems, such as giving people (possibly including the FAI) incentives to create, destroy, and modify other people to make the aggregated utility function more favorable to them.)
Give each person a unique integer label from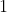 to
to  , where
, where  is the number of people. For each person
is the number of people. For each person 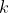 , let
, let 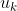 be some function that, interpreted as a utility function, accurately describes
be some function that, interpreted as a utility function, accurately describes 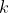 's preferences (there exists such a function by the VNM utility theorem). Note that I want
's preferences (there exists such a function by the VNM utility theorem). Note that I want 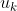 to be some particular function, distinct from, for instance,
to be some particular function, distinct from, for instance, 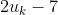 , even though
, even though 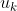 and
and 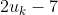 represent the same utility function. This is so it makes sense to add them.
represent the same utility function. This is so it makes sense to add them.
Theorem: The FAI maximizes the expected value of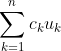 , for some set of scalars
, for some set of scalars 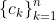 .
.
Actually, I changed the axioms a little bit. Harsanyi originally used “Given any two choices A and B such that every person is indifferent between A and B, the FAI is indifferent between A and B” in place of my axioms 2 and 3 (also he didn't call it an FAI, of course). For the proof (from Harsanyi's axioms), see section III of Harsanyi (1955), or section 2 of Hammond (1992). Hammond claims that his proof is simpler, but he uses jargon that scared me, and I found Harsanyi's proof to be fairly straightforward.
Harsanyi's axioms seem fairly reasonable to me, but I can imagine someone objecting, “But if no one else cares, what's wrong with the FAI having a preference anyway. It's not like that would harm us.” I will concede that there is no harm in allowing the FAI to have a weak preference one way or another, but if the FAI has a strong preference, that being the only thing that is reflected in the utility function, and if axiom 3 is true, then axiom 2 is violated.
proof that my axioms imply Harsanyi's: Let A and B be any two choices such that every person is indifferent between A and B. By axiom 3, there exists choices C and D such that every person prefers C over D. Now consider the lotteries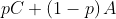 and
and 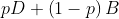 , for
, for 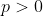 . Notice that every person prefers the first lottery to the second, so by axiom 2, the FAI prefers the first lottery. This remains true for arbitrarily small
. Notice that every person prefers the first lottery to the second, so by axiom 2, the FAI prefers the first lottery. This remains true for arbitrarily small 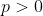 , so by continuity, the FAI must not prefer the second lottery for
, so by continuity, the FAI must not prefer the second lottery for 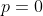 ; that is, the FAI must not prefer B over A. We can “sweeten the pot” in favor of B the same way, so by the same reasoning, the FAI must not prefer A over B.
; that is, the FAI must not prefer B over A. We can “sweeten the pot” in favor of B the same way, so by the same reasoning, the FAI must not prefer A over B.
So why should you accept my axioms?
Axiom 1: The VNM utility axioms are widely agreed to be necessary for any rational agent.
Axiom 2: There's something a little rediculous about claiming that every member of a group prefers A to B, but that the group in aggregate does not prefer A to B.
Axiom 3: This axiom is just to establish that it is even possible to aggregate the utility functions in a way that violates axiom 2. So essentially, the theorem is “If it is possible for anything to go horribly wrong, and the FAI does not maximize a linear combination of the people's utility functions, then something will go horribly wrong.” Also, axiom 3 will almost always be true, because it is true when the utility functions are linearly independent, and almost all finite sets of functions are linearly independent. There are terrorists who hate your freedom, but even they care at least a little bit about something other than the opposite of what you care about.
At this point, you might be protesting, “But what about equality? That's definitely a good thing, right? I want something in the FAI's utility function that accounts for equality.” Equality is a good thing, but only because we are risk averse, and risk aversion is already accounted for in the individual utility functions. People often talk about equality being valuable even after accounting for risk aversion, but as Harsanyi's theorem shows, if you do add an extra term in the FAI's utility function to account for equality, then you risk designing an FAI that makes a choice that humanity unanimously disagrees with. Is this extra equality term so important to you that you would be willing to accept that?
Remember that VNM utility has a precise decision-theoretic meaning. Twice as much utility does not correspond to your intuitions about what “twice as much goodness” means. Your intuitions about the best way to distribute goodness to people will not necessarily be good ways to distribute utility. The axioms I used were extremely rudimentary, whereas the intuition that generated "there should be a term for equality or something" is untrustworthy. If they come into conflict, you can't keep all of them. I don't see any way to justify giving up axioms 1 or 2, and axiom 3 will likely remain true whether you want it to or not, so you should probably give up whatever else you wanted to add to the FAI's utility function.
Citations:
Harsanyi, John C. "Cardinal welfare, individualistic ethics, and interpersonal comparisons of utility." The Journal of Political Economy (1955): 309-321.
Hammond, Peter J. "Harsanyi’s utilitarian theorem: A simpler proof and some ethical connotations." IN R. SELTEN (ED.) RATIONAL INTERACTION: ESSAYS IN HONOR OF JOHN HARSANYI. 1992.