How does one "read the docs?". Sometimes I ask how a senior dev figured something out, and they say "I read the documentation and it explained it." And I'm like "okay, duh. but... there's so much fucking documentation. I can't possibly be expected to read it all?"
I have a pet hypothesis that there is some skill or ability like this which comprises a huge amount of variation in programming ability. Here is an experience I had many times while working with my professional programmer colleagues:
- My coworker has a confusing bug and asks me to walk over and take a look at it.
- They start trying to explain the bug from their perspective while clicking around doing stuff like building the program or paging through the code.
- While they do that, I am reading everything on their screen while they talk, so then I notice some random thing in their codebase that doesn't make sense to me and point out that thing, which is something they hadn't realized, and that solves the bug.
Alternately:
- I ask some question about the bug that involves figuring out how something works.
- They put some search query into Google and it opens up a bunch of search results. They take about three seconds and click one of them that doesn't look very useful to me. I say, "why don't you go look at the sixth result which said it was a forum post from a person wondering the exact same thing?" They just didn't read it.
Alternately:
- They run the program and it starts producing about half a page of startup log output per second.
- I interrupt them and say "why did it say X?" They say "where did it say that?" I say "about two pages up in the log." One minute later, they have found the thing in the log that I read while the log was scrolling at half a page per second.
So there is some large difference in reading ability here that seems to be doing a huge amount of work, and I actually have no clue how I would even operate if I didn't have that ability. It seems to me like I would just never know what was going on.
Sounds like pattern matching from training on many years worth of examples of what is "normal in similar situations" to filter that out when looking for surprising stuff - sometimes called "experience" and other times called "a fresh pair of eyes"... Or did you have this reading ability from the first day when you started to learn your first programming language / it never happens the other way round that you click on stuff for an hour and have to ask a colleague to come over and they would point out something in your blind spot?
I learned to program young enough that I don't really remember the process, and I have about 25 years of experience, so I agree with the diagnosis.
I can certainly have a blind spot about logical reasoning related to a program, but I don't recall having a "it says it right there" kind of blind spot.
I've had many similar experiences. Not confident, but I suspect a big part of this skill, at least for me, is something like "bucketing" - it's easy to pick out the important line from a screen-full of console logs if I'm familiar with the 20[1] different types of console logs I expect to see in a given context and know that I can safely ignore almost all of them as either being console spam or irrelevant to the current issue. If you don't have that basically-instant recognition, which must necessarily be faster than "reading speed", the log output might as well be a black hole.
Becoming familiar with those 20 different types of console logs is some combination of general domain experience, project-specific experience, and native learning speed (for this kind of pattern matching).
Similar effect when reading code, and I suspect why some people care what seems like disproportionately much about coding standards/style/convention - if your codebase doesn't follow a consistent style/set of conventions, you can end up paying a pretty large penalty by absence of that speedup.
- ^
Made up number
I would describe myself as an expert-level debugger (which you sound like also), and all of this is describing experiences I have also had.
Do you literally read all the text on the screen, or do you have a way of efficiently skimming?
I'm a mid debugger but I think I'm pretty good at skimming, with some insight into how I do it.
Have you ever searched a large bucket of legos looking for a specific piece? When I was a kid, I noticed that as I brushed the visual of the bucket with my attention, with the intent of looking for a specific piece, my attention would 'catch' on certain pieces. And usually, even when it wasn't a hit, there was a clear reason why it made sense for my attention to catch there.
When I skim, it's quite a similar process. I have an intention firmly in mind of what sort of thing I'm interested in. I then quickly brush the pages of text with my eyes, feeling for any sort of catch on my attention. And then glance to see if it feels relevant, and if not continue. With large documents, there's a sort of intuitive thing I've learned where I'll skip several pages or even sections if the current section is too "boring" (i.e. not enough catches), or parts where my intent subtly shifts (often followed by reversing direction of skim), in ways that make the process more efficient.
If you don't have an intuitive handle for this 'catch' feeling already, try noticing the physical sensation of a saccade. If you can't get any sort of semantic content from moving your eyes this quickly across text, try practicing speedreading?
(Incidentally, this attention catch feeling seems to be the same thing (or closely related to the thing) that Buddhists call an "attachment"?? Not sure what to do with that, but thought it was interesting.)
It's subconscious so it's hard to say but it's clearly not "reading every word in order" and probably doesn't involve reading every word. I think it's a combination of being a fast but not exceptionally fast reader, plus a lot of domain knowledge so I can understand the stuff I am reading as fast as I read it, plus a ton of domain-specific skimming skill / pattern recognition to bring the interesting part to conscious attention.
Super interesting! I have some follow-up thoughts to this.
- On the one hand, it seems that this is a case of "having" more working memory.
- On the other hand, it might be a case of more experience allowing you to filter out irrelevant things and, allowing more working memory to focus on the things that matter.
A classical example of the latter point is when novices learn to play chess. In a typical training session, they will be presented with a position, and be asked to propose a move. They will take a moment, then propose a move that loses a queen in a totally obvious way, and when challenged, they will take a moment and confirm that "oh, yeah, that loses a queen". Typically a novice is overwhelmed by the details of the position, perhaps still remembering how the pieces move, and have no sense of which moves are important and which moves should be ignored. As a result, they can't do "basic" one-step lookahead to see what countermoves the opponent has. Their working memory is too overloaded with all of the possibilities on the board.
This gets resolved with practice, drills, and experience. Eventually the hind-brain simply "surfaces" the information "that square is controlled by an enemy bishop", and in many cases will not even suggest the move that would hazard the queen, it won't even get loaded into conscious attention.
EDIT: Building on this, it's super interesting to watch Grandmasters like Hikaru Nakamura play games live on stream, and comment on their thought process. Yes, they calculate long lines, sometimes branching, but as they talk, partially distracted, they never consider bad moves, they're always analyzing the top moves recommended by the computer.
One of the most useful things I did as a junior dev was to literally read the entire language spec for javascript. Searching for articles that explained anything I didn't understand. I think this strategy of actually trying to read all the docs the way you'd read a textbook is underrated for tools you are going to be using often.
A relevant-feeling quotation from off at an angle, from Eric Raymond's version of the Jargon File, section “Personality Characteristics”:
Although high general intelligence is common among hackers, it is not the sine qua non one might expect. Another trait is probably even more important: the ability to mentally absorb, retain, and reference large amounts of ‘meaningless’ detail, trusting to later experience to give it context and meaning. A person of merely average analytical intelligence who has this trait can become an effective hacker, but a creative genius who lacks it will swiftly find himself outdistanced by people who routinely upload the contents of thick reference manuals into their brains. [During the production of the first book version of this document, for example, I learned most of the rather complex typesetting language TeX over about four working days, mainly by inhaling Knuth's 477-page manual. My editor's flabbergasted reaction to this genuinely surprised me, because years of associating with hackers have conditioned me to consider such performances routine and to be expected. —ESR]
A combination of the ideas in "binary search through spacetime" and "also look at your data":
If you know a previous time when the code worked, rather than starting your binary search at the halfway point between then and now, it is sometimes useful to begin by going ALL the way back to when it previously worked, and verifying that it does, in fact, work at that point.
This tests a couple of things:
- Are you correct about when the code previously worked?
- Did your attempt to recreate those conditions successfully recreate ALL of the relevant conditions?
- Does the bug depend on some external file or resource that you overlooked and haven't rewound back to the correct time?
- Does the bug depend on some detail of your test process that you didn't realize was relevant, and the reason it worked before was actually because you were testing it differently?
- Does your process for restoring your project to an earlier point even work?
If the bug still happens after you've restored to the "known working point", then you'll want to figure out why that is before continuing your binary search.
I don't always do this step. It depends how confident I am about when it worked, how confident I am in my restore process, and how mysterious the bug seems. Sometimes I skip this step initially, but then go back and do it if diagnosing the bug proves harder than expected.
I don't actually know if I count as a "senior developer", but I'm pretty convinced I count as a "senior debugger" given the amount of time I've spent chasing problems in other people's often-unfamiliar code.
These questions feel really hard to answer, mayber too general? When I try to answer them, I keep flying off into disconnected lists of heuristics and "things to look for".
Also, you don't give any examples of problems you've found hard, and I feel I may be answering at too simplistic a level. But...
How do you learn to replicate bugs, when they happen inconsistently in no discernable pattern?
The thing is that there is a discernable pattern. Once you've fixed the bug, you'll probably be able to say exactly what triggers it.
If you can't (yet) reproduce the bug, think about states of the program that could have led to whatever you're seeing.
You know what routine detected a problem[1], and you usually know what routine produced bad output (it's the one that should have produced good output at that point).
Your suspect routine usually uses a relatively small set of inputs to do whatever it does. It can only react to data that it at least examines. So what does it use to do what it does? Where do its inputs come from, not necessarily in the sense of what calling routine passes them in, but in the sense of how they enter the overall program? What values can they take? What values would they have to take to produce the behavior you're seeing? How could they end up taking those particular values? What parts of the program and environment state are likely to vary, and how will they affect this routine?
Very often, you can answer those questions without getting bogged down in the call graph or having to try a huge number of cases. Sometimes you can not just reproduce the bug, but actually fix it.
-
If function X is complaining about a "font not found" error, then it's presumably looking up some font name or other identifier in some font database. There probably aren't that many places that the font identifier can be coming from, and there's probably only one font database.
If you can say, "well, the font should either be the default system font, or a font specified in the user profile", then you can make an intuitive leap. You know that everything uses the default system font all the time, so that path probably works... but maybe it's possible for a user profile to end up referring to a font that doesn't exist... but I know the code checks for that, and I can't set a bogus font on my own profile... but wait, what if the font gets deleted after the user picks it?
Of course, there are lots of other possibilities[2]. Maybe there's some weird corner case where the font database isn't available, or you're using the wrong one, or it's corrupted, or whatever. But it's unlikely to be something completely unrelated that's happening in some function in the call stack that doesn't use the font information at all.
-
Or maybe function X is searching by font attributes instead of names. So where might it be getting extra constraints on the query?
-
Or maybe function Y is blowing up trying to use a null value. The root cause is almost certainly that you made a poor choice of programming language, but you can't fix that now, so persevere. Usually you have the line of code where it choked, but say you don't. What values are in scope in Y that could be null? Well, it gets called with a font descriptor. Could that be null? Well, wait, the font lookup routine returns a null value if it can't find a font. So maybe we have a font not found error in disguise. So try thinking about it, for a limited time, as a font-not-found error.
-
Or maybe "fnord!" is showing up randomly in the output. So where could it come from? First step: brute force.
grep -ir 'fnord' src. Leave off the exclamation point at least to start. Punctuation tends to be quoted weirdly or added by code. If it's not there, is it in the binary? Is it in the database? Is it in the config file? Is it anywhere on the whole damned system? If not, that leaves what? Probably the network.
In the end, though, there's also a certain amount of pattern matching against experience. "Code that does X is usually structured like Y". "Does this thing have access to the files it needs?". "Programmers always forget about cases like Z". "I always forget about cases like W". "Weird daemon behavior that you can't reproduce interactively is always caused by SELinux".
Once you do reproduce the bug, you can always just switch to a strategy of brute force tracing everything that goes on anywhere near it, with a debugger, with printing or logging, with a system call tracer, or whatever. But, yeah, you've got to get it to happen if you want to trace it.
How does one "read the docs?"
It depends on what you're trying to find out.
I find I mostly use two kinds of documentation:
-
Architectural stuff. General material that explains the concepts running around in the code, the terminology, what objects exist, what their life cycles look like, etc. This sort of documentation is often either nonexistent, or so bloated and disorganized as to be useless for quick debugging, and maybe useless period. But if it exists and is any good, it's gold. If you're trying to educate yourself about something that you're going to use heavily, you may just have to slog through all of whatever's available.
-
API documentation, ideally with links to source code. I usually don't even skim this. I navigate it with keyword search. If you want to now how to frobnicate a blenk, then search for "frobnicate" and whatever synonyms you can come up with[3]. If you're trying to debug a stack trace from a library routine, look up that routine and see what parameters it takes.
In my never especially humble opinion, "tutorials" are mostly wastes of time beyond the first couple of units, and it's unfortunate that people concentrate so much on them instead of writing decent architecture and concept documentation.
Blowing up with a stack trace counts as "detecting the problem" ↩︎
One important part of the skill is allocating your time and attention, and not getting stuck on paths that aren't bearing fruit. You can always come back to an idea if nothing else works either. The counter-consideration is that if you don't think at least a little bit deeply about whatever avenue you're exploring, you're unlikely to have a good sense of how fruitful it looks. So you have to balance breadth against depth in your search. ↩︎
If the architecture documentation doesn't suck, you can get likely terms by reading it. Or ask an LLM that's probably internalized it. Otherwise you just have to read the writer's mind. If you get good enough at reading their mind, you can use a certain amount of keyword search in the architecture documents, too. ↩︎
If it worked earlier today (and you didn't make any commits in the meanwhile), you may need to do something more like "binary search through your undo history."
If this is an issue consistently, it means you need to commit more often.
I really don't know how I'm so good at debugging. Obviously some of it is smarts and experience, but a lot of it is definitely techne: little things I know to do because they will help me solve the problem, but I don't have a systematic way I could describe it to anyone else.
My best guess is that I have a combination of two behaviors that do most of the work. The first is persistence. I'm unwilling to give up until the bug is fixed, or we at least understand the bug and why fixing it isn't worth it. The second is a need to build up a model of exactly how the code works, and looking hard to fill any gaps in my understanding. Combined, I just keep hammering away at a bug until I understand exactly why it's happening, which gives me the knowledge I need to solve it.
Everything is feels like little things that reduce the friction. Valuable, but I would still debug issues without them, it would just take longer.
The second is a need to build up a model of exactly how the code works, and looking hard to fill any gaps in my understanding.
Yep. One concrete thing this sometimes looks like is 'debugging' things that aren't bugs: if some code works when it looks like it shouldn't, or a tool works without me passing information I would have expected to need to, or whatever, I need to understand why, by the same means I would try to understand why a bug is happening.
How do you learn to replicate bugs, when they happen inconsistently
I don't have definitive advice here, I think this is a hard problem no matter your skill level. You can do things in advance to make your program more debuggable, like better logging, and assertions so you catch the bug closer to the root cause.
A more general pattern to look for is some tool that can capture a particular run of the system in a reproducible/replayable manner. For a single program running locally, a coredump is already quite good, you can look at the whole state of your program just before the crash. (E.g. the whole stack trace, and all variables. This can already tell you a lot.) I have also heard great things about rr, supposedly it allows you to capture a whole execution and single step forwards and backwards.
For distributed systems, like web applications, the problem is even harder. I think I have seen some projects aiming to do the whole "reproducible execution" thing for distributed systems, but I don't know of any that I could recommend. In theory the problem should not be hard, just capture all inputs to the system, and since computers are deterministic, just replay the inputs. But in practice, given the complexity of our software stacks, often determinism is more of a pipe dream.
How does one "read the docs?"
Something something "how to build up a model of the entire stack."
I think these are closely related. I imagine my "model of the entire stack" like a scaffolding with some knowledge holes that can be filled in quickly if needed. You should not have any unknown-unknowns. If I notice that I need more fidelity in some area of my model, that's exactly the docs I read up on.
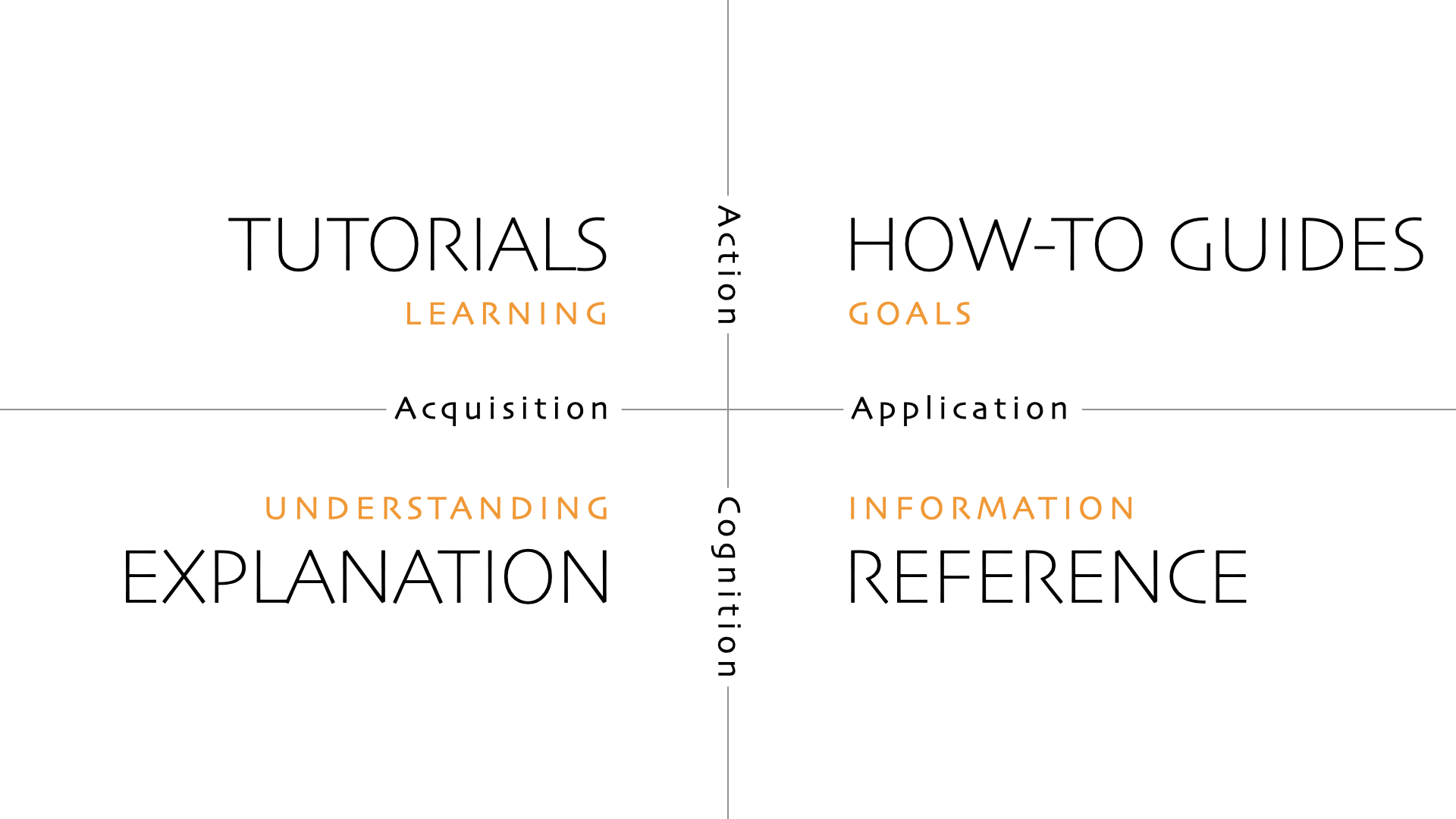
When reading docs, you can have different intentions. Maybe you are learning about something for the first time, and just want to get an overall understanding. Or maybe you already have the overall understanding, and are just looking for some very specific detail. Often documentation is also written to target one of those use-cases, you should be aware that (well) documented systems often have multiple of these. This is one model I came across that tries to categorize documentation (though I am not sure I subscribe to these exact 4 categories):
Getting back to the "model of the entire stack" thing, I think it's very important for how (I at least) approach computer systems. I think this article by Drew DeVault in particular was an important mindset-shift back when I read it. Some quotes:
Some people will shut down when they’re faced with a problem that requires them to dig into territory that they’re unfamiliar with. [...] Getting around in an unfamiliar repository can be a little intimidating, but do it enough times and it’ll become second nature. [...] written in unfamiliar programming languages or utilize even more unfamiliar libraries, don’t despair. All programming languages have a lot in common and huge numbers of resources are available online. Learning just enough to understand (and fix!) a particular problem is very possible
I now believe that being able to quickly jump into unfamiliar codebases and unfamiliar languages is a very important skill to have developed. This is also important because documentation is often lacking or non-existent, and the code is the "documentation".
Also, I feel like the "model of the entire stack" thing is a phase shift for debugging once you get there. Suddenly, you can be very confident about finding out the root cause of any (reproducible) bug in bounded time.
If at any point you notice that your unfamiliarity with some part of the system is impeding you in solving some problem, that's a sign to study that area in more detail. (I think this is easier to notice when debugging, but can be equally important when building new features. Sometimes your unfamiliarity with a certain area leads you to build a more complex solution than necessary, since you are unable to search paths that route through that area. A map analogy here would be you having a dark spot on your map, and noticing whether it's likely that between two points, there could be a shorter path through the dark area.)
I think read the docs is a fine advice. But docs rot, and most docs are bad. If possible, read the code?
Reading the code doesn’t mean grokking the entire cpp code base while reading by candlelight in 1000-day monk mode. Reading the code means understanding the code path - descending from your first contact point down to the stateless functions that does the heavy lifting. This can be done with an actual debugger and stepping through each stage and see how the sausage is made. Reading the code is slow, sometimes painful. The alternatives are worse.
A bad advice is to use a “better” language. I guess that Raemon uses weakly typed languages beyond the base rate of js/python users. Many of the complaints here don’t really make sense if you write in apl, haskell or even rust. When you create the right abstraction, or best, have no abstraction, there is no meta state of the program to keep in your mind.
Typescript is nice in that you can usually find the code published somewhere. So you usually can find the actual code flows in the nether regions of the library that's tripping you up. Of course this isn't that helpful when it's in your code, and even less helpful when it turns out you're using a slightly different version that the code you're looking at (always check if the version makes sense!). But it's usually better than reading the docs (which do rot).
Typescript is also nice in that it's (annoyingly) opinionated. This works to your favour, as good that looks "right" is correlated with it actually being correct.
The big secret to reading documentation is that there actually isn’t that much documentation most of the time. (At least pre-language model, but I haven’t seen this change yet on serious projects) any line of documentation of an open source project only exists because someone had no alternative whatsoever other than to write it- people hate writing documentation. Corporations can produce far wordier documentations. Pytorch or the x86 spec is going to be in the ~1 thousands of pages. I wouldn’t actually recommend reading that end to end, but it’s well within your capabilities: You’ve probably crunched 1000 pages of brandon sanderson in a weekend, by accident.
A hack is to seek out any prose in the documentation and skip anything that looks autogenerated from code. The general principle is to make your reading time proportional to the human time spent writing.
I’ve introspected on this for a bit, and my actual approach is almost never “just read it end to end like a book” unless the documentation is unusually excellent or I am unusually financially motivated- the most recent case of this I found evidence for is a pdf dump of the react documentation in my read-on-the-bus folder, from when I needed to pivot hard to web dev for 2 months last summer for startup reasons. However, I definitely have a heuristic that if I have been stuck for two days, reading the relevant documentation for two hours can only slow progress by a tiny fraction, and two hours x ~700 wpm chews through a lot of documentation. Most recently, giving up on leaning on claude to write frontend, -banning llm generated css in a rage-, and just reading the whole flexbox spec ended up saving a ton of time.
Also, I do a ton of tutorials. tutorials are the highest programmer-effort to line-of-tect part of any documentation. If you want to hack me, put your payload in triple backticks in a nice sphinx doc, and I’ll type it in and run it myself.
Actually, I would love to do a comparison: I don’t know my ratio of words per minute reading the branderson to wpm reading technical writing, and I don’t know what a typical ratio is. I am sure that reading documentation is much closer in speed to reading fiction than to reading math, which might not be intuitively obvious from the outside
I didn't improve much at debugging until I got generally serious about rationality training.
Can you expand on this please?
I think this has two components:
- One, the set of tools that I developed for myself via Tuning your Cognitive Strategies / Feedbackloop-first Rationality / Metastrategy (note that those are different) just were actually pretty useful for debugging. There was real transfer from Thinking Physics and Baba is You. See Skills from a year of Purposeful Rationality Practice.
- Two: I think I was just a lot more motivated to upskill through the lens of "developing rationality training" than "getting better at debugging." It seemed pretty unlikely I'd ever become a particularly great debugger, and being a good debugger didn't actually seem like the biggest bottleneck towards achieving my goals. It's easier to tell myself an exciting narrative about inventing a rationality training paradigm than to work really hard to become a slightly-above-mid software engineer. (even if the rationality paradigm ends up ultimately kinda mid, fewer other people are even trying)
The latter may not particularly work for anyone else, and it seems pretty likely that "have some kind of motivation" is more important than any particular set of tools. I do think the set of tools are pretty obviously good though.
I'm not sure that answered your question, but maybe you can ask a more specific one now.
Interesting. Reading your comment makes me notice that I'm more motivated to learn object level skills than meta level skills.
"meta level" != "rationality.
E.g. I would count most of the CFAR curiculum as object level skills. But the traingin you're working on seems more meta level skills.
I expect motivation to be super central for what leanring methods works. There has been a number of posts on ACX about school (including 2 that are part of the reveiw contest). The common theme is that the main bottleneck is students motivation.
I'm not sure that answered your question, but maybe you can ask a more specific one now.
The thing I was after was, what is the actual concreet causal chain from rationality training to you getting better at debuging.
I currently think the answer is that the rationality training made you motivated, and that was the missing part that stopped you from getting better before. Let me know if you think I'm missing something important.
Hmm, that doesn't feel like the right summary to me. (I acknowledged the motivation thing as probably
I'm not sure where you draw the boundary between object level and meta skill. I think there are:
- skills you can apply to metalearning (i.e. make it easier to learn new skills)
- general reasoning skills
- domain specific skills
The first two I'd (often but not always[1]) call rationality skills. Also, most general reasoning skills you can apply towards metalearning as well as object level domains. I think maybe the only pure meta-level skills I found/worked on were:
- track what subskills would be helpful for a given task (so that you can then practice them separately, and/or pay more attention to them as you practice)
- generalized "practice applying existing general reasoning skills to the domain of gaining new skills"
- generalized (but sort of domain-specifically) apply general reasoning skills to the domain of inventing better feedback loops.
- idk a couple domain-specific skills for inventing better feedback loops.
I think that's probably it? (and there were like 20+ other skills I focused on). Everything else seems about as object level as CFAR skills. I'm maybe not sure what you mean by meta though – CFAR skills all seem at least somewhat meta to me.
At the very top of the post, I list 7 skills that I'd classify as general reasoning rationality skills. I could theoretically have gained those purely by practicing debugging, but I think it would have taken way longer and would have been very difficult for me even if I was more motivated. (They also would probably not have transferred as much to other domains if I didn't think of myself as studying rationality)
An important early step was to gain Noticing / Tuning your Cognitive Strategies skills, which I think unlocked the ability to actually make any kind of progress at debugging (because they made it so, when I was bouncing off something, I could figure out why).
- ^
I think they are "rationality" if they involve making different choices about cognitive algorithms to run. "speed reading" is a meta-learning and general-reasoning skill, but it feels like a stretch to call it a rationality skill.
When I write code, I try to make most of it data to data transformations xor code that only takes in a piece of data and produces some effect (such as writing to a database.) This significantly narrows the search space of a lot of bugs: either the data is wrong, or the do-things-with-data code is wrong.
There are a lot of tricks in this reference class, where you try to structure your code to constrain the spaces where possible bugs can appear. Another example: when dealing with concurrency/parallelism, write the majority of your functions to operate on a single thread. Then have a separate piece of logic that coordinates workers/parallelism/etc. This is much easier to deal with than code that mixes parallelism and nontrivial logic.
Based on what you described, writing code that constrains the bug surface area to begin with sounds like the next step – and related, figuring out places where your codebase already does that, or places where it doesn't do that but really should.
This is a large part of why functional programming is so nice - you try to always have pure functions (which just transform stuff) and move anything that is nondeterministic to the very edges of your program. State is the source of all evils, so the less you need to worry about things changing under you, the easier it is to reason about a program.
places that are supposed to create or retrieve X
I wonder whether it's less useful to know the True names of these concepts when debugging this type of problems in the age of LLM assistants..
..but I remember that many years ago it was very useful for me to dive deep into related concepts. The post seems to talk about JavaScript (even if not having a line of code seemed like a deliberate choice), so here are a few potential deep dive suggestions:
- variable declaration vs initialization,
- hoisting vs temporal dead zone,
- block- vs function-level lexical scope vs Closure vs dynamic this,
- function parameters vs arguments (doesn't matter which is which, just that those are 2 things for anything related to all above concepts),
- constant vs immutable (especially for someone working in both JS and Python, it can be a trap that a mutable default value of a function parameter in JS is assigned on each function invocation, but in Python it's assigned only once on function declaration),
- equality by identity/value (when both kinds of undefined are the same, but null is different) vs coertion (null is equal to undefined) vs in operator (the 2 undefineds are different)
- e.g.
if ('b' in a) a.b.c()is a bug and the conditional should have beena.b?.c().. using TStype A = {b?: {c: () => void}}prevents that bug,
- e.g.
- NPE in general (null pointer exceptions - most infamous in Java, but the concept is the same in many other languages .. also helps to appreciate the "New Player Experience" in Factorio when it was in early access)
My favourite instance of NPE-like error is "X is not a function" (favourite as in Stockholm syndrome, not as in easy to understand when you see it first).
An alternative approach is to learn about the concepts from a completely different perspective of https://justjavascript.com/ - wires and telescopes instead of pigeon holes and pointers 🔭
I’m pretty mediocre as a dev but here goes:
Often debugging is hard because I dont want to invest time to understand the details or docs of whatever library I happen to be using. In that case a trick that often works is to keep my current project on pause for a moment, and build a toy example using that library. Keep increasing the complexity of the toy example and make it closer to the real bug, until something breaks. You also often notice that some of the code or params are redundant and do nothing.
Expand your working memory somehow. Take notes about the scope of the problem as you understand it.
This seems important. I dunno how good of a debugger I am, but I have a much better memory of where things are in a codebase than the average person. i.e. in large codebases, assuming I've touched the affected place, I can usually recall exactly which file contains a given piece of code that is of interest. This translates to better and more granular models of what is happening and where it makes sense to look for things. There have been many cases where someone mentions a bug/error and I have a fix 2 minutes later, because I can ~recall the flows where that bug may appear.
Yeah "just actually have large swaths of code memorized/chunked/tokenized in a way that's easy to skim and reason about" seems clearly helpful, (and seems related to stuff @RobertM was saying)
It doesn't seem immediately useful as an action-prompt on it's own for a junior developer. But, I guess, I've probably spent a similar number of hours as Robert at least glancing at terminal logs,
(Unless you think you have a skill of memorizing new things quickly that you expect to help a junior developer?)
The things that seem relevant here are, like, "try at all to memorize swaths of code in some kind of comprehensive way", and presumably there are subskills that make that easier, which may not help immediately but probably changes one's trajectory.
This is something that came naturally to me, so much that in the beginning I was surprised at people saying that they can't remember code they wrote previously.
One actionable thing here would probably be "remember abstractions/patterns" rather than "remember code". Sort of like how grandmasters remember generic patterns of chess pieces rather than where each one is (I could be very mistaken here). The first level of this is remembering which folders do what, then which file, then which functions etc. Then you don't need to remember what the exact code does, as you can treat it as abstract units.
This is the flip side of what @RobertM was saying about code quality - this makes remembering where things are massively simpler, as you can expect things to conform to the same approach everywhere. Reading (and understanding) a badly written piece of code is much harder than doing the same with a well written piece of code, because you have to keep much more working parts in your active memory. This is also part of where the heuristics to keep code snippets short and use lots of functions comes from.
These are very good
When you are stuck, make explicit note of what feels difficult about the situation, and brainstorm ways of dealing with those difficulties.
Asking "This is impossible. Why exactly is it impossible?
These are very good
When you are stuck, make explicit note of what feels difficult about the situation, and brainstorm ways of dealing with those difficulties.
Asking "This is impossible. Why exactly is it impossible?
walk up the stack trace
And start at the lowest level of your own code, but be willing to go into library code if needed.
How does one "read the docs?". Sometimes I ask how a senior dev figured something out, and they say "I read the documentation and it explained it." And I'm like "okay, duh. but... there's so much fucking documentation. I can't possibly be expected to read it all?"
You should read the docs like you would read a book; this provides outsized benefits precisely because most people won't do that. Source reasoning here:
https://aaronfrancis.com/2023/read-the-docs-like-a-book-2381721a
Do people just read really fast? I think they have some heuristics for figuring out what parts to read and how to skim, which maybe involves something like binary search and tracking-abstraction-borders. But something about this still feels opaque to me.
Even if you have poor heuristics, it's still may be worth it to google/open docs and walk obvious links. The point is not to have an algorithm that certainly finds everything relevant, but to try many things that may work.
How do you learn to replicate bugs, when they happen inconsistently in no discernable pattern? especially when the bug comes up, like, once every couple days or weeks, instead of once every 5 minutes.
You speed up time. Or more generally prepare an environment that increases reproduction frequency, like slow hardware/network or higher load. You spam clicks and interrupt every animation, because all bugs are about asynchronous things. You save state after reproduction, or better before and start from it. If all fails, you add logs/breakpoints to be ready next week. But usually you just look at code to figure out paths that may manifest as your bug and then try to reproduce promising paths.
I consider myself really good at debugging, but How does one "read the docs?" is something I never got good at? Notable devs like mitchellh skim the entire docs to get a vague idea of where stuff might be. This was never helpful for me. Docs seem to try to explain things in general whereas I think humans learn much faster from examples? We learn speech before grammar, we learn addition before number theory.
Searching for examples also biases your results to more commonly used functions. Function use is very Pareto distributed (small core of common functions and long tail of almost never used functions), docs hide this. Consider the libcurl function listing https://curl.se/libcurl/c/allfuncs.html. It hides the fact that curl_easy_{init,setopt,perform,cleanup} is more important than everything else.
Finding good reference code is a skill in itself though. https://sourcegraph.com/search indexes ~all public code, and has great tools like lang:Go and -file:^vendor. Keeping all relevant repos checked out in one folder you can ripgrep over also helps. tree-sitter and semgrep are well regarded, but I found them too distracting to be useful.
I struggled with learning to debug code for a long time. Exercises for learning debugging tended focus on small, toy examples that didn't grapple with the complexity of real codebases. I would read advice on the internet like:
I'd often be starting from a situation where the bug only happens sometimes and I have no idea when, the error log is about some unrelated library I was using and had nothing to do with what the bug would turn out to be. Getting to a point where it was even clear what exactly the symptoms were was a giant opaque question-mark for me.
I didn't improve much at debugging until I got generally serious about rationality training. Debugging is a nice in-between difficulty between "toy puzzle" and "solve a complex openended real world problem." (Code debugging is "real world problem-solving", but, it's a part of the world where you reliably know there's a solution, working in an environment you have near-complete control over and visibility into).
I attribute a lot of my improvement to fairly general problem-solving tools like:
I've written other essays on general rationality/problem-solving. But, here I wanted to write the essay I wish past me had gotten, about some tacit knowledge of debugging. (Partly because it seemed useful, and partly because I'm interested in the general art of "articulating tacit knowledge").
Note that I'm still a kinda mid-level programmer and senior people may have better advice than me, or think some of this is wrong. This is partly me just writing to help myself understand, and see how well I can currently explain things.
Be willing to patiently walk up the stack trace (but, watch out for red-herrings and gotchas)
One core skill of debugging is the ability to patiently, thoroughly start from your first clue, and work your way through the codebase, developing a model of what exactly is happening. (Instead of reaching the edge of the current file and giving up)
Unfortunately, another core skill of debugging is knowing when you're about to follow the code into a pointless direction that won't really help you.
Gotcha #1: "X does not exist", "can't read X", "X is undefined", etc, are often "downstream symptoms", rather than the bug itself.
If you get an error like "X doesn't exist", there's a codepath that expects X to exist, but it doesn't. Whatever code caused it to not-exist isn't particularly likely to be located anywhere near the code that's trying to read X.
So, unless you look at the part of the codebase flagging "can't find X" and you can clearly see that X was supposed to be created in the same file or have a good reason to think it was created nearby, probably what you should instead be looking for are places that are supposed to create or retrieve X.
This goes double if the error is in some random library somewhere deep in your dependencies.
(I originally called this pattern a "red-herring." A senior-dev colleague told me they draw a sharp distinction between "red-herrings" and "downstream symptoms.")
Gotcha #2: Notice abstraction boundaries, and irrelevant abstractions.
The motivating incident that prompted this post was when I was pairing with a junior dev on debugging the JargonBot Beta Test. We had recently built an API endpoint[1] for retrieving the jargon definitions for a post. It had been working recently. Suddenly it was not working.
We started with where an error was getting thrown, worked our way backwards in the code path... and then followed the trail to another file... and then more backwards...
...and then at some point both I and the junior dev said "it... probably isn't useful to look further backwards." (The junior dev said this hesitatingly, and I agreed)
We were right. How did we know that?
The answer (I think) is that if we stepped backwards any further, we were leaving the part of the codebase that was particularly about Jargon. Beyond that lay the underlying infrastructure for the LessWrong codebase, i.e. the code responsible for making API endpoints work at all. Last we checked, the underlying infrastructure of LessWrong worked fine, and we hadn't done anything to mess with that.
So, even though we were still thoroughly confused about what the problem was, it seemed at least like it should be contained to within these few files.
There was a chunk of the codebase that you'd naturally describe as "about the JargonBot stuff." And there was a point you might naturally describe as it's edge, before passing into another part of the codebase.
Now, that was sort of playing on easy mode – we knew we had just started building JargonBot, it would be pretty crazy for the bug to not live somewhere in the files we had just written. But, a few weeks later we were debugging some other part of the codebase that other people had written, awhile ago. (I believe this was integrating the jargon into the post sidebar, where side-comments, side-notes, and reacts live).
It turned out the sidebar was more complicated than I'd have guessed. The jargon wasn't rendering correctly. We had to pass backwards through a few different abstraction layers – first checking the new code where we were trying to fetch and render the jargon. Then back into the code for the sidebar itself. Then backwards into where the sidebar was integrated into the post page. And then I was confused about how the sidebar even was integrated into the post page, it wasn't nearly as straightforward as I thought.
Then I sort of roughly got how the sidebar/post interaction worked, but was still confused about my bug. I could recurse further up the code path...
...but it would be pretty unlikely for whatever was going wrong to be happening outside of the post page itself.
This all amounts to:
Binary Search
There is some intricate art to looking at a confusing output, and generating hypotheses that might possibly make sense. A good developer has both some object-level knowledge about their codebase, or codebases in general, that can help them narrow in quickly on where the problem is located.
I don't know how to articulate the details of that skill. BUT, the good new is there is a dumb, stupid algorithm you can follow to help you narrow it down even if you're tired, frustrated and braindead:
1: Follow the code backwards towards the earliest codepath that could possibly be relevant, and the earliest point where it is working as expected.
2. Find the spot about halfway between the earliest place where things work as expected, and the final place where you observe the bug. Log all relevant variables (or add a breakpoint and use a debugger).
3. If things look normal there, then find a new spot about halfway between that midpoint, and the final-spot-where-the-bug-was-observed. If it doesn't look normal, find a new spot about halfway between the earliest working spot, and the midpoint.
4. Repeat steps 2-3 until you've found the moment where things break.
Now you have a much smaller surface area you need to look at and understand. And instead of stepping through 100 lines of code, you had to find ~6 midpoints.
Binary searching through
timespacetimeA variation on this is if you know the code used to work and now it doesn't. You can binary search through your history. If it worked a long time ago, on an older commit, you can binary search through your commit history. Start with the oldest commit where it worked, check a commit about halfway between that and the latest commit. Repeat. Git has a tool to help streamline process for this called
git bisect.If it worked earlier today (and you didn't make any commits in the meanwhile), you may need to do something more like "binary search through your undo history." This is complicated by:
Sometimes this neatly divides into "binary search through undo-space" followed by "binary search within one history-state of the codebase". But sometimes you need to kind of maintain a multidimensional mental map that includes both changes-to-the-codebase and places-within-the-codebase, and figure out what it even means to binary search that in a somewhat ad-hoc way I'm not sure how to articulate.
Notice confusion, and check assumptions.
Also, look at your data, not just your code.
Just yesterday, I was trying build a text editor that took in markdown files, and rendered them as html that I could edit in a wysiwyg fashion. At some point, even though it was supposedly translating the markdown into html, it was still showing up with markdown formatting.
This happened after
Ian llm made some completely unrelated changes that really shouldn't have had anything to do with that.I was pulling my hair out trying to figure out what was going wrong, stepping back and forth through undo history, looking at anything that changed.
Eventually, I stopped looking at the codepath, and looked at the file I was trying to load into the editor.
At some point, I'd accidentally overwritten the file with corrupt markdown that was sort of... markdown nested inside html nested inside markdown. Or something.
Oh.
If I'd been a better rationalists, earlier in the hair-pulling-out-process, I could have noticed "this is confusing and doesn't make any goddamn sense." A rationalist should be more confused by fiction than reality. If I'm confused, one of my assumptions is fiction. And made a list of everything that could possibly be relevant, and see if there was anything I hadn't looked at yet, rather than looping back and forth in the undo history, vaguely flailing and hoping to notice something new.
But, it's kind of cognitively expensive to be a rationalist all the time.
A simpler thing I could have done is be better debugger with some object-level debugging knowledge, and note that sometimes, it's not the code that's wrong, it's the data the code is trying to operate on that is wrong. "Check the data" probably should have been part of my initial pass at mapping out the problem.
(This ties back to Gotcha #1: if you're getting "X is not defined", where X was created awhile ago and not by the obvious nearby parts of the codebase, sometimes try looking up X in your database and see if there's anything weird about it)
Things I don't know
So, that was a bunch of stuff I've painstakingly figured out. Some of it I got pieces of by pairing with other more senior developers. The senior developers I've worked with often are thinking so quickly/intuitively it's fairly hard for them to slow down and explain what's going on.
I'm hoping to live in a world where people around me get better at tacit knowledge explication.
Here's some random stuff I still don't have a good handle on, that I'd like it if somebody explained:
How do you learn to replicate bugs, when they happen inconsistently in no discernable pattern? especially when the bug comes up, like, once every couple days or weeks, instead of once every 5 minutes.
How does one "read the docs?". Sometimes I ask how a senior dev figured something out, and they say "I read the documentation and it explained it." And I'm like "okay, duh. but... there's so much fucking documentation. I can't possibly be expected to read it all?"
Do people just read really fast? I think they have some heuristics for figuring out what parts to read and how to skim, which maybe involves something like binary search and tracking-abstraction-borders. But something about this still feels opaque to me.
Something something "how to build up a model of the entire stack." Sometimes, the source of a problem doesn't live in the codebase, it lives in the dev-ops of how the codebase is deployed. It could have to do with the database setup, or the deployment server, or our caching later. I recently got a little better at sniffing but this still feels like a muddy mire to me.
This isn't exactly the right description but is accurate enough to be an example.