To understand reality, especially on confusing topics, it's important to understand the mental processes involved in forming concepts and using words to speak about them.

Popular Comments
Recent Discussion
More people should consider dropping out of high school, particularly if they:
- Don't find their classes interesting
- Have self-motivation
- Don't plan on going to university
In most places, once you reach an age younger than the typical age of graduation, you are not legally obligated to attend school. Many continue because it's normal, but some brief analysis could reveal that graduating is not worth the investment for you.
Some common objections I heard:
- It's only more months, why not finish?
Why finish?
- What if 'this whole thing' doesn't pan out?
The mi...
I don't really have a problem with the term "intelligence" myself, but I see how it could carry anthropomorphic baggage for some people. However, I think the important parts are, in fact, analogous between AGI and humans. But I'm not attached to that particular word. One may as well say "competence" or "optimization power" without losing hold of the sense of "intelligence" we mean when we talk about AI.
In the study of human intelligence, it's useful to break down the g factor (what IQ tests purport to measure) into fluid and crystallized intelligence. The ...
(Crossposted from Twitter)
I'm skeptical that Universal Basic Income can get rid of grinding poverty, since somehow humanity's 100-fold productivity increase (since the days of agriculture) didn't eliminate poverty.
Some of my friends reply, "What do you mean, poverty is still around? 'Poor' people today, in Western countries, have a lot to legitimately be miserable about, don't get me wrong; but they also have amounts of clothing and fabric that only rich merchants could afford a thousand years ago; they often own more than one pair of shoes; why, they even have cellphones, as not even an emperor of the olden days could have had at any price. They're relatively poor, sure, and they have a lot of things to be legitimately sad about. But in what sense is...
I wasn't aware of these options, thank you.
UNDERSTANDING COORDINATION PROBLEMS
The following is a post introducing coordination problems, using the examples of poaching, civilisational development, drug addiction and affirmative action. It draws on my experience as a documentary filmmaker. The post is available for free in its original format at nonzerosum.games.

When I was eleven, I disassembled the lock to our back door, and as I opened the housing… it exploded, scattering six tiny brass pellets on to the floor.

I discovered (too late) that a lock of this type contained spring-loaded cylinders of different heights corresponding to the teeth of the key.
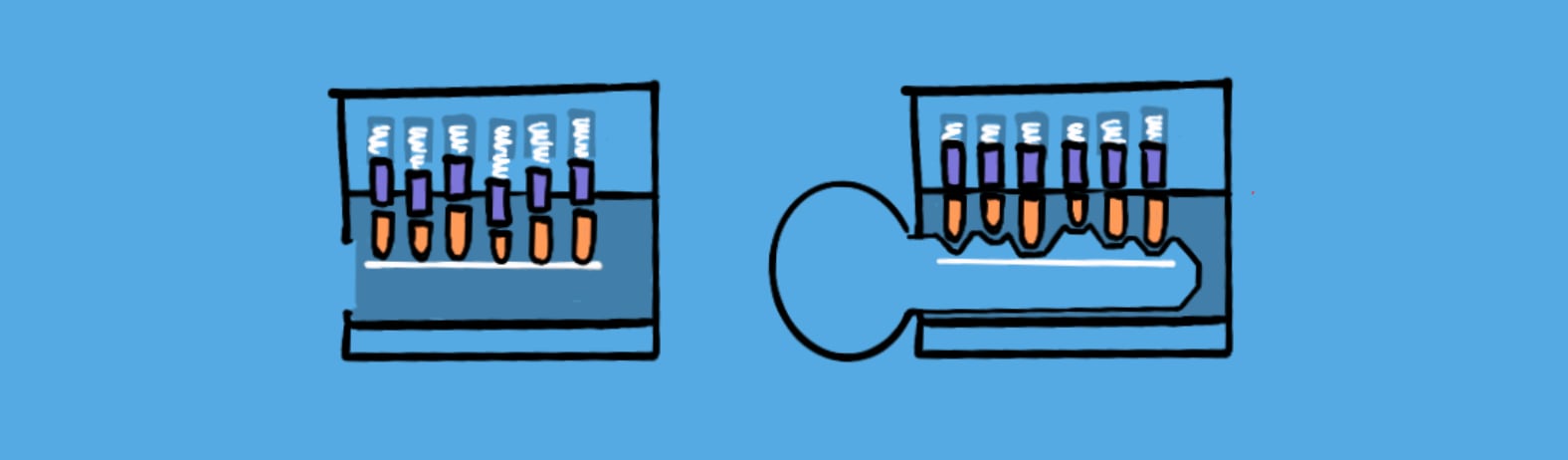
I struggled for hours trying to get the little buggers back in, but it was futile—eventually, my long suffering parents called a locksmith.

The reason fixing the lock was so difficult was not only because it...
I haven't shared this post with other relevant parties – my experience has been that private discussion of this sort of thing is more paralyzing than helpful. I might change my mind in the resulting discussion, but, I prefer that discussion to be public.
I think 80,000 hours should remove OpenAI from its job board, and similar EA job placement services should do the same.
(I personally believe 80k shouldn't advertise Anthropic jobs either, but I think the case for that is somewhat less clear)
I think OpenAI has demonstrated a level of manipulativeness, recklessness, and failure to prioritize meaningful existential safety work, that makes me think EA orgs should not be going out of their way to give them free resources. (It might make sense for some individuals to...
Size.
I asked the Constellation Slack channel how the technical AIS landscape has changed since I last spent substantial time in the Bay Area (September 2023), and I figured it would be useful to post this (with the permission of the contributors to either post with or without attribution). Curious if commenters agree or would propose additional changes!
This conversation has been lightly edited to preserve anonymity.
Me: One reason I wanted to spend a few weeks in Constellation was to sort of absorb-through-osmosis how the technical AI safety landscape has evolved since I last spent substantial time here in September 2023, but it seems more productive to just ask here "how has the technical AIS landscape evolved since September 2023?" and then have conversations armed with that knowledge. The flavor...
My question is why do you consider most work on concentration of power risk net-negative?
TLDR: AI systems are failing in obvious and manageable ways for now. Fixing them will push the failure modes beyond our ability to understand and anticipate, let alone fix. The AI safety community is also doing a huge economic service to developers. Our belief that our minds can "fix" a super-intelligence - especially bit by bit - needs to be re-thought.
I wanted to write this post forever, but now seems like a good time. The case is simple, I hope it takes you 1min to read.
- AI safety research is still solving easy problems. We are patching up the most obvious (to us) problems. As time goes we will no longer be able to play this existential risk game of chess with AI systems. I've argued this a
Appreciating your thoughtful comment.
It's hard to pin down ambiguity around how much alignment "techniques" make models more "usable", and how much that in turn enables more "scaling". This and the safety-washing concern gets us into messy considerations. Though I generally agree that participants of MATS or AISC programs can cause much less harm through either than researchers working directly on aligning eg. OpenAI's models for release.
Our crux though is about the extent of progress that can be made – on engineering fully autonomous mac...
I'm less interested in spreading rationalism per se and more in teaching people about rationality. The other articles are very strongly+closely related to rationality; I chose them since they're articles describing key concepts in rational choice.
