I feel confused about how to engage with this post. I agree that there's a bunch of evidence here that Anthropic has done various shady things, which I do think should be collected in one place. On the other hand, I keep seeing aggressive critiques from Mikhail that I think are low-quality (more context below), and I expect that a bunch of this post is "spun" in uncharitable ways.
That is, I think of the post as primarily trying to do the social move of "lower trust in Anthropic" rather than the epistemic move of "try to figure out what's up with Anthropic". The latter would involve discussion of considerations like: sometimes lab leaders need to change their minds. To what extent are disparities in their statements and actions evidence of deceptiveness versus changing their minds? Etc. More generally, I think of good critiques as trying to identify standards of behavior that should be met, and comparing people or organizations to those standards, rather than just throwing accusations at them.
EDIT: as one salient example, "Anthropic is untrustworthy" is an extremely low-resolution claim. Someone who was trying to help me figure out what's up with Anthropic should e.g. help me calibrate what they mean by "untrustworthy" by comparison to other AI labs, or companies in general, or people in general, or any standard that I can agree or disagree with. Whereas someone who was primarily trying to attack Anthropic is much more likely to use that particular term as an underspecified bludgeon.
My overall sense is that people should think of the post roughly the way they think of a compilation of links, and mostly discard the narrativizing attached to it (i.e. do the kind of "blinding yourself" that Habryka talks about here).
Context: I'm thinking in particular of two critiques. The first was of Oliver Habryka. I feel pretty confident that this was a bad critique, which overstated its claims on the basis of pretty weak evidence. The second was Red Queen Bio. Again, it seemed like a pretty shallow critique: it leaned heavily on putting the phrases "automated virus-producing equipment" and "OpenAI" in close proximity to each other, without bothering to spell out clear threat models or what he actually wanted to happen instead (e.g. no biorisk companies take money from OpenAI? No companies that are capable of printing RNA sequences use frontier AI models?)
In that case I didn't know enough about the mechanics of "virus-producing equipment" to have a strong opinion, but I made a mental note that Mikhail tended to make "spray and pray" critiques that lowered the standard of discourse. (Also, COI note: I'm friends with the founders of Red Queen Bio, and was one of the people encouraging them to get into biorisk in the first place. I'm also friends with Habryka, and have donated recently to Lightcone. EDIT to add: about 2/3 of my net worth is in OpenAI shares, which could become slightly more valuable if Red Queen Bio succeeds.)
Two (even more) meta-level considerations here (though note that I don't consider these to be as relevant as the stuff above, and don't endorse focusing too much on them):
- For reference, the other person I've drawn the most similar conclusion about was Alexey Guzey (e.g. of his critiques here, here, and in some internal OpenAI docs). I notice that he and Mikhail are both Russian. I do have some sympathy for the idea that in Russia it's very appropriate to assume a lot of bad faith from power structures, and I wonder if that's a generator for these critiques.
- I'm curious if this post was also (along with the Habryka critique) one of Mikhail's daily Inkhaven posts. If so it seems worth thinking about whether there are types of posts that should be written much more slowly, and which Inkhaven should therefore discourage from being generated by the "ship something every day" process.
Attacks on the basis of ethic origin are not okay, and I wish you’d have focused on the (pretty important) object-level instead of comparing this to unrelated post.
I also dislike you using, in the original version of your comment (until I DMed you about it), an insensitive form of my name, which is really not okay to use for you or in this context. I also want to note that you only added the words that you don’t endorse the attack based on my ethnicity after I DMed you that these are not okay.
I’d like the comments to focus on the facts and the inferences, not on meta. If I’m getting any details wrong, or presenting anything specific particularly uncharitably, please say that directly. The rest of this comment is only tangentially related to the post and to what I want to talk about here, but it seems good to leave a reply.
___
Sometimes, conclusions don’t need to be particularly nuanced to remain comprehensively truthful. Sometimes, a system is built of many parts, and yet a valid, non-misleading description of that system as a whole is that it is untrustworthy.
___
I want to say that I find it unfortunate that someone is engaging with the post on the basis that I was the person who wrote it, or on the basis of unrelated content or my cultural origin, or speculating about the context behind me having posted it.
I attempted to add a lot on top of the bare facts of this post, because I don’t think it is a natural move for someone at Anthropic who’s very convinced all the individual facts have explanations full of details, to look at a lot of them and consider in which worlds they would be more likely. A lot of the post is aimed at an attempt to make someone who would really want to join or continue to work at Anthropic actually ask themselves the questions and make a serious attempt at answering them, without writing the bottom line first.
Earlier in the process, a very experienced blogger told me, when talking about this post, that maybe I should’ve titled it “Anthropic: A Wolf in Sheep’s Clothing”. I think it would’ve been a better match to the contents than “untrustworthy”, but I decided to go with a weaker and less poetic title that increased the chance of people making the mental move I really want them to make, and if it’s successful, potentially incentivize the leadership of Anthropic to improve and become more trustworthy.
But I relate to this particular post the way I would to journalistic work, with the same integrity and ethics.
If you think that any particular parts of the post unfairly attack Anthropic, please say that; if you’re right, I’ll edit them.
Truth is the only weapon that allows us to win, and I want our side to be known for being incredibly truthful.
___
Separately, I don't think my posts on Lightcone and Red Queen Bio are in a similar category to this post.
Both of those were fairly low-effort. The one on Oliver Habryka basically intentionally so: I did not want to damage Lightcone beyond sharing information with people who’d want to have it. Additionally, for over a month, I did not want or plan to write it at all; but a housemate convinced me right before the start of Inkhaven that I should, and I did not want to use the skills I could gain from Lightcone against them. I don’t think it is a high-quality post. I stand by my accusations, and I think what Oliver did is mean and regretful and there are people who would not want to coordinate with him or donate to Lightcone due to these facts, and I’m happy the information reached them (and a few people reached out to me to explicitly say thanks for that).
The one on Red Queen Bio was written as a tweet once I saw the announcement. I was told about Red Queen Bio a few weeks before the announcement, and thought that what I heard was absolutely insane: an automated lab that works with OpenAI and plans to automate virus production. Once I saw the announcement, I wrote the tweet. The goal of the tweet was to make people pay attention to what I perceived as insanity; I knew nothing about its connection to this community when writing the tweet.
I did triple-check the contents of the tweet with the person who shared information with me, but it still was a single source, and the tweet explicitly said “I learned of a rumor”.
(None of the information about doing anything automatically was public at that point, IIRC.)
The purpose of the tweet was to get answers (surely it is not the case that someone would automate a lab like that with AI!) and if there aren’t any then make people pay attention to it, and potentially cause the government to intervene.
Instead senying the important facts, only a single unimportant one was denied (Hannu said they don’t work on phages but didn’t address any of the questions), and none of the important questions were answered (instead, a somewhat misleading reply was given), so after a while, I made a Substack post, and then posted it as a LW shortform, too (making little investment in the quality; just sharing information). I understand they might not want to give honest answers for PR reasons; I would’ve understood the answer that they cannot give answers for security reasons, but, e.g., are going to have a high BSL and are consulting with top security experts to make sure it’s impossible for a resources attacker to use their equipment to do anything bad; but in fact, no answers were given. (DMing me “Our threat model is focused on state actors and we don’t want it to be publicly known; we’re going to have a BSL-n, we’re consulting with top people in cyber and bio, OpenAI’s model won’t have automated access to virus r&d/production; please don’t share this” would’ve likely caused me to delete the tweet.)
I think it’s still somewhat insane, and I have no reason on priors to expect appropriate levels of security in a lab funded by OpenAI; I really dislike the idea of, e.g., GPT-6 having tool access to print arbitrary RNA sequences. I don’t particularly think it lowered the standard of the discourse.
(As you can see from the reception of the shortform post and the tweet, many people are largely sympathetic to my view on this.)
I understand these people might be your friends; in the case of Hannu, I’d appreciate it if they could simply reply to the six yes/no questions, or state the reasons they don’t want to respond.
(My threat model is mostly around that access to software and a lab for developing viruses seems to help an AI in a loss of control scenario; + all the normal reasons why gain-of-function research is bad, and so pointing out the potential gain-of-function property seems sufficient.)
With my epistemic situation, do you think I was unfair to Red Queen Bio in my posts?
___
I dislike the idea of appeal to Inkhaven as a reason to have a dismissive stance toward a post or having it as a consideration.
I’ve posted many low-effort posts this month; it takes about half an hour to write something, just to post something (sometimes an hour, like here; sometimes ~25 minutes, like here). Many of these were a result of me spending time talking to people about Anthropic (or spending time on other, more important things that had nothing to do with criticism of anyone) and not having time to write anything serious or important. It’s quite disappointing how little of importance I wrote this month, but the reference to this fact at all as a reason to dismiss this post is an error. My friends heard me ask for ideas for low-effort posts to make dozens of times this month. But when I posted low-effort posts, I only posted them on my empty Substack, basically as drafts, to satisfy the technical condition of having written and published a post. There isn’t a single post that I made on LessWrong to satisfy the Inkhaven goal. (Many people can attest to me saying that I might spend a lot of December turning my unpolished posts posted on Substack into posts I’d want to publish on LessWrong.)
And this one is very much not one of my low-effort posts.
I somewhat expected it to be posted after the end of Inkhaven; the reason I posted it on November 28 was that the post was ready.
___
Most things I write about have nothing to do with criticizing others. I understand that these are the posts you happen to see; but I much more enjoy making posts about learning to constantly track cardinal directions or learning absolute pitch as an adult; about people who could’ve destroyed the world, but didn’t (even though some of them are not good people!).
I enjoy even more to make posts that inspire others to make their lives more awesome, like in my post about making a home smarter.
I also posted a short story about automating prisons, just to make a silly joke about
Jalbreaking
(Both pieces of fiction I’ve ever written I wrote at Inkhaven. The other one is published in a draft state and I’ll come back to it at some point, finish it, and post on LessWrong: it’s about alignment-faking.)
Sometimes, I happen to be a person in a position of being able to share information that needs to be shared. I really dislike having to write posts about it, when the information is critical of people. Some at Lighthaven can attest to my very sad reaction to their congratulations on this post: I’m sad that the world is such that the post exists, and don’t feel good about having written it, and don’t like finding myself in a position where no one else is doing something and someone has.
Sometimes, conclusions don’t need to be particularly nuanced. Sometimes, a system is built of many parts, and yet a valid, non-misleading description of that system as a whole is that it is untrustworthy.
The central case where conclusions don't need to be particularly nuanced is when you're engaged in a conflict and you're trying to attack the other side.
In other cases, when you're trying to figure out how the world works and act accordingly, nuance typically matters a lot.
Calling an organization "untrustworthy" is like calling a person "unreliable". Of course some people are more reliable than others, but when you smuggle in implicit binary standards you are making it harder in a bunch of ways to actually model the situation.
I sent Mikhail the following via DM, in response to his request for "any particular parts of the post [that] unfairly attack Anthropic":
I think that the entire post is optimized to attack Anthropic, in a way where it's very hard to distinguish between evidence you have, things you're inferring, standards you're implicitly holding them to, standards you're explicitly holding them to, etc.
My best-guess mental model here is that you were more careful about this post than about the other posts, but that there's a common underlying generator to all of them, which is that you're missing some important norms about how healthy critique should function.
I don't expect to be able to convey those norms or their importance to you in this exchange, but I'll consider writing up a longform post about them.
I think Situational Awareness is a pretty good example of what it looks like for an essay to be optimized for a given outcome at the expense of epistemic quality. In Situational Awareness, it's less that any given statement is egregiously false, and more that there were many choices made to try to create a conceptual frame that promoted racing. I have critiqued this at various points (and am writing up a longer critique) but what I wanted from Leopold was something more like "here are the key considerations in my mind, here's how I weigh them up, here's my nuanced conclusion, here's what would change my mind". And that's similar to what I want from posts like yours too.
This seems focused on intent in a way that’s IMO orthogonal to the post. There’s explicit statements that Anthropic made and then violated. Bringing in intent (or especially nationality) and then pivoting to discourse norms seems on net bad for figuring out “should you assume this lab will hold to commitments in the future when there are incentives for them not to”.
I particularly dislike that this topic has stretched into psychoanalysis (of Anthropic staff, of Mikhail Samin, of Richard Ngo) when I felt that the best part of this article was its groundedness in fact and nonreliance on speculation. Psychoanalysis of this nature is of dubious use and pretty unfriendly.
Any decision to work with people you don't know personally that relies on guessing their inner psychology is doomed to fail.
I sent Mikhail the following via DM, in response to his request for "any particular parts of the post [that] unfairly attack Anthropic":
I think that the entire post is optimized to attack Anthropic, in a way where it's very hard to distinguish between evidence you have, things you're inferring, standards you're implicitly holding them to, standards you're explicitly holding them to, etc.
I asked you for any particular example; you replied that “the entire post is optimized in a way where it’s hard to distinguish…”. Could you, please, give a particular example of where it’s hard to distinguish between evidence that I have and things I’m inferring?
Some examples of statements where it's pretty hard for me to know how much the statements straightforwardly follow from the evidence you have, vs being things that you've inferred because they seem plausible to you:
- Jack Clark would have known this.
- Anthropic's somewhat less problematic behavior is fully explained by having to maintain a good image internally.
- Anthropic is now basically just as focused on commercializing its products.
- Anthropic's talent is a core pitch to investors: they've claimed they can do what OpenAI can for 10x cheaper.
- It seems likely that the policy positions that Anthropic took early on were related to these incentives.
- Anthropic's mission is not really compatible with the idea of pausing, even if evidence suggests it's a good idea to.
If we zoom in on #3, for instance: there's a sense in which it's superficially plausible because both OpenAI and Anthropic have products. But maybe Anthropic and OpenAI differ greatly on, say, the ratio of headcount, or the ratio of executives' time, or the amount of compute, or the internal prestige allocated to commercialization vs other things (like alignment research). If so, then it's not really accurate to say that they're just as focused on commercialization. But I don't know if knowledge of these kinds of considerations informed your claim, or if you're only making the superficially plausible version of the claim.
To be clear, in general I don't expect people to apply this level of care for most LW posts. But when it comes to accusations of untrustworthiness (and similar kinds of accountability mechanisms) I think it's really valuable to be able to create common knowledge of the specific details of misbehavior. Hence I would have much preferred this post to focus on a smaller set of claims that you can solidly substantiate, and then only secondarily try to discuss what inferences we should draw from those. Whereas I think that the kinds of criticism you make here mostly create a miasma of distrust between Anthropic and LessWrong, without adding much common knowledge of the form "Anthropic violated clear and desirable standard X" for the set of good-faith AI safety actors.
I also realize that by holding this standard I'm making criticism more costly, because now you have the stress of trying to justify yourself to me. I would have tried harder to mitigate that cost if I hadn't noticed this pattern of not-very-careful criticism from you. I do sympathize with your frustration that people seem to be naively trusting Anthropic and ignoring various examples of shady behavior. However I also think people outside labs really underestimate how many balls lab leaders have up in the air at once, and how easy it is to screw up a few of them even if you're broadly trustworthy. I don't know how to balance these considerations, especially because the community as a whole has historically erred on the side of the former mistake. I'd appreciate people helping me think through this, e.g. by working through models of how applying pressure to bureaucratic organizations goes successfully, in light of the ways that such organizations become untrustworthy (building on Zvi's moral mazes sequence for instance).
The latter would involve discussion of considerations like: sometimes lab leaders need to change their minds. To what extent are disparities in their statements and actions evidence of deceptiveness versus changing their minds? Etc. More generally, I think of good critiques as trying to identify standards of behavior that should be met, and comparing people or organizations to those standards, rather than just throwing accusations at them.
This sounds to me like a very weak excuse. If you change your mind on something this important (for example, you are now confident alignment is easy despite expecting RSI in a couple of years and doing your best to accelerate it), you had better say so very clearly and very publicly.
This is what a company / leadership / CEO etc. would do if they had a somewhat strong deontology. Just from observing this lack of candor, one should consider Anthropic to be impossible to coordinate with, which is a) not what you want from a frontier AI company and b) clearly justifies calling it "untrustworthy" unless we want to be nitpicky with language, to a degree that IMO is clearly unnecessary.
In this situation, since they lied in the past, we're way past the point where we outsiders (including people who work at Anthropic but can't read the mind of leadership!) can evaluate whether we disagree with Anthropic about critical matters like how difficult alignment is, and try to change their mind (or at least not work for them) if we think they are wrong.
We're in a situation where Anthropic should be considered adversarial. Even if tomorrow they released a statement that they now think alignment is easy, I can't take that statement at face value. Maybe they think alignment is easy; maybe they decided it's impossible to coordinate with anyone and they will lower risk by an epsilon if they are the first to get DSA; maybe they think it's better if everyone dies than to let China win the race; maybe they just think it's fun to build ASI and lied to themselves to justify doing it; who knows.
Against an adversarial opponent, we use POSIWID. We assume there is a hidden goal and try to guess the simplest hidden goal from actions while ignoring statements. What is the simplest hidden goal we can guess? Anthropic doesn't want to be regulated and want to stay in the lead. I can predict that they will keep taking actions that make regulation harder and make them stay in the lead.
The post contains one explicit call-to-action:
If you are considering joining Anthropic in a non-safety role, I ask you to, besides the general questions, carefully consider the evidence and ask yourself in which direction it is pointing, and whether Anthropic and its leadership, in their current form, are what they present themselves as and are worthy of your trust.
If you work at Anthropic, I ask you to try to better understand the decision-making of the company and to seriously consider stopping work on advancing general AI capabilities or pressuring the company for stronger governance.
This targets a very small proportion of people who read this article. Is there another way we could operationalize this work, one that targets people who aren't working/aiming to work at Anthropic?
I expect that a bunch of this post is "spun" in uncharitable ways.
That is, I think of the post as primarily trying to do the social move of "lower trust in Anthropic" rather than the epistemic move of "try to figure out what's up with Anthropic". The latter would involve discussion of considerations like: sometimes lab leaders need to change their minds. To what extent are disparities in their statements and actions evidence of deceptiveness versus changing their minds? Etc. More generally, I think of good critiques as trying to identify standards of behavior that should be met, and comparing people or organizations to those standards, rather than just throwing accusations at them.
“I think a bunch of this comment is fairly uncharitable.”
The first was of Oliver Habryka. I feel pretty confident that this was a bad critique, which overstated its claims on the basis of pretty weak evidence.
I'm curious if this post was also (along with the Habryka critique) one of Mikhail's daily Inkhaven posts. If so it seems worth thinking about whether there are types of posts that should be written much more slowly, and which Inkhaven should therefore discourage from being generated by the "ship something every day" process.
For reference, the other person I've drawn the most similar conclusion about was Alexey Guzey (e.g. of his critiques here, here, and in some internal OpenAI docs). I notice that he and Mikhail are both Russian. I do have some sympathy for the idea that in Russia it's very appropriate to assume a lot of bad faith from power structures, and I wonder if that's a generator for these critiques.
“That is, I think of the comment as primarily trying to do the social move of “lower trust in what Mikhail says” rather than the epistemic move of “figure out what’s up with Mikhail”. The latter would involve considerations like: to what extent disparities between your state of knowledge and Mikhail’s other posts evidence of being uncharitable vs. having different sets of information and trying to share the information? Etc. More generally, I think of good critiques as trying to identify standards of behavior that should be met, and comparing people to those standards, rather than just throwing accusations at them.”
I’d much rather the discussion was about the facts and not about people or conversational norms.
I agree that there are some ways in which my comment did not meet the standard that I was holding your post to. I think this is defensible because I hold things to higher standards when they're more prominent (e.g. posts versus shortforms or comments), and also because I hold things to higher standards when they're making stronger headline claims. In my case, my headline claim was "I feel confused". If I had instead made the headline claim "Mikhail is untrustworthy", then I think it would have been very reasonable for you to be angry at this.
I think that my criticism contains some moves that I wish your criticism had more of. In particular, I set a standard for what I wanted from your criticism:
I think of good critiques as trying to identify standards of behavior that should be met, and comparing people or organizations to those standards, rather than just throwing accusations at them.
and provide a central example of you not meeting this standard:
"Anthropic is untrustworthy" is an extremely low-resolution claim
I also primarily focused on drawing conclusions about the post itself (e.g. "My overall sense is that people should think of the post roughly the way they think of a compilation of links") and relegate the psychologizing to the end. I accept that you would have preferred that I skip it entirely, but it's a part of "figuring out what's up with Mikhail", which is an epistemic move that I endorse people doing after they've laid out a disagreement (but not as a primary approach to that disagreement).
(downvoted because you didn't actually spell out what point you're making with that rephrase. You think nobody should ever call people out for doing social moves? You think Richard didn't do a good job with it?)
This didn't really do what I wanted. For starters, literally quoting Richard is self-defeating – either it's reasonable to make this sort of criticism, or it's not. If you think there is something different between your post and Richard's comment, I don't know what it is and why you're doing the reverse-quote except to be sorta cute.
I don't even know why you think Richard's comment is "primarily doing the social move of lower trust in what Mikhail says". Richard's comment gives examples of why he thinks that about your post, you don't explain what you think is charitable about his.
I think it is necessary sometimes to argue that people are being uncharitable, and looking they are doing a status-lowering move more than earnest truthseeking.
I haven't actually looked at your writing and don't have an opinion I'd stand by, but from my passing glances at it I did think Richard's comment seemed to be pointing at an important thing.
I attempted to demonstrate Richard’s criticism is not reasonable, as some parts of it are not reasonable according to its own criteria.
(E.g., he did not describe how I should’ve approached the Lightcone Infrastructure post better.)
To be crystal clear, I do not endorse this kind of criticism.
Some unstructured thoughts:
I think it's sort of a type error to refer to Anthropic as something that one could trust or not. Anthropic is a company which has a bunch of executives, employees, board members, LTBT members, external contractors, investors, etc, all of whom have influence over different things the company does.
I think the main case where people are tempted to use the word "trust" in connection with Anthropic is when they are trying to decide how good it is to make Anthropic generically more powerful, e.g. by working there on AI capabilities.
I do think that many people (including most Anthropic staff) are well described as trusting Anthropic too much. For example, some people are trustworthy in the sense that things they say make it pretty easy to guess what they're going to do in the future in a wide variety of situations that might come up; I definitely don't think that this is the case for Anthropic. This is partially because it's generally hard to take companies literally when they say things, and partially because Anthropic leadership aren't as into being truthful as, for example, rationalists are. I think that many Anthropic staff take Anthropic leadership at its word to an extent that degrades their understanding of AI-risk-relevant questions.
But is that bad? It's complicated by the fact that it's quite challenging to have enough context on the AI risk situation that you can actually second-guess Anthropic leadership in a way that overall makes the situation better. Most AI-safety-concerned people who work at Anthropic spend most of their time trying to do their job instead of thinking a lot about e.g. what should happen on state legislation; I think it would take a lot of time for them to get confident enough that Anthropic was behaving badly that it would add value for them to try to pressure Anthropic (except by somehow delegating this judgement call to someone who is less COI-ed and who can amortize this work).
I think that in some cases in the past, Anthropic leadership did things that safety-concerned staff wouldn't have liked, and where Anthropic leadership looks like they made the right call in hindsight. For example, I think AI safety people often have sort of arbitrary strong takes about things that would be very bad to do, and it's IMO sometimes been good that Anthropic leadership hasn't been very pressured by their staff.
On the general topic of whether it's good for Anthropic to be powerful, I think that it's also a big problem that Anthropic leadership is way less worried than I am about AIs being egregiously misaligned; I think it's plausible that in the future they'll take actions that I think are very bad for AI risk. (For example, I think that in the face of ambiguous evidence about AI misalignment that I think we're likely to get, they are much more likely than I would be to proceed with building more powerful models.) This has nothing to do with whether they're honest.
I also recommend Holden Karnofsky's notes on trusting AI companies, summarized here.
I think it's sort of a type error to refer to Anthropic as something that one could trust or not.
Note that while the title refers to "Anthropic", the post very clearly discusses Anthropic's leadership, in general and in specific, and discusses Anthropic staff separately.
I kinda agree that it's kinda a type error--but also you have a moral obligation not to be eaten by the sort of process that would eat people, such as "pretend to be appropriately concerned with X-risk in order to get social approval from EA / X-deriskers, including funding and talent, and also act against those interests".
I think that in some cases in the past, Anthropic leadership did things that safety-concerned staff wouldn't have liked, and where Anthropic leadership looks like they made the right call in hindsight. For example, I think AI safety people often have sort of arbitrary strong takes about things that would be very bad to do, and it's IMO sometimes been good that Anthropic leadership hasn't been very pressured by their staff.
Could you give a more specific example, that's among the strongest such examples?
It's complicated by the fact that it's quite challenging to have enough context on the AI risk situation that you can actually second-guess Anthropic leadership in a way that overall makes the situation better.
I don't get this. You said that you yourself think Anthropic leadership is noticeably less honest (than people around here), and less concerned about alignment difficult than you are. Given that, and also given that they clearly have very strong incentives to act against X-derisking interests, and given that their actions seem against X-derisking interests, and (AFAIK?) they haven't credibly defended those actions (e.g. re/ SB 1047) in terms of X-derisking, what else could one be waiting to see before judging Anthropic leadership on the dimension of aiming for X-derisking and/or accurately representing their X-derisking stance?
you have a moral obligation not to be eaten by the sort of process that would eat people
I don't think I have a moral obligation not to do that. I'm a guy who wants to do good in the world and I try to do stuff that I think is good, and I try to follow policies such that I'm easy to work with and so on. I think it's pretty complicated to decide how averse you should be to taking on the risk of being eaten by some kind of process.
When I was 23, I agreed to work at MIRI on a non-public project. That's a really risky thing to do for your epistemics etc. I knew that it was a risk at the time, but decided to take the risk anyway. I think it is sensible for people to sometimes take risks like this. (For what it's worth, MIRI was aware that getting people to work on secret projects is a kind of risky thing to do, and they put some effort into mitigating the risks.)
For example, I think AI safety people often have sort of arbitrary strong takes about things that would be very bad to do, and it's IMO sometimes been good that Anthropic leadership hasn't been very pressured by their staff.
Could you give a more specific example, that's among the strongest such examples?
I think it's probably good that Anthropic has pushed the capabilities frontier, and I think a lot of the arguments that this is unacceptable are kind of wrong. If Anthropic staff had pushed back on this more, I think probably the world would be a worse place. (I do think Anthropic leadership was either dishonest or negligently-bad-at-self-modeling about whether they'd push the capabilities frontier.)
I didn't understand your last paragraph.
I think it is sensible for people to sometimes take risks like this.
I agree. If I say "you have a moral obligation not to cause anyone's death", that doesn't mean "spend all of your energy absolutely minimizing the chances that your decisions minutely increase the risk of someone dying". But it does mean "when you're likely having significant effects on the chances of that happening, you should spend the effort required to mostly eliminate those risks, or avoid the situation, or at least signpost the risks very clearly, etc.". In this case, yeah, I'm saying you do have a strong obligation, which can often require work and some amount of other cost, to not give big amounts of support to processes that are causing a bunch of harm. Like any obligation it's not simplistic or absolute, but it's there. Maybe we still disagree about this.
I think it's pretty complicated to decide how averse you should be to taking on the risk of being eaten by some kind of process.
True, but basically I'm saying "it's really important and also a lot of the responsibility falls on you, and/or on your community / whoever you're deferring to about these questions". Like, it just is really costly to be supporting bad processes like this. In some cases you want to pay the costs, but it's still a big cost. I'm definitely definitely not saying "all Anthropic employees are bad" or something. Some of the research seems neutral or helpful or maybe very helpful (for legibilizing dangers). But I do think there's a big obligation of due diligence about "is the company I'm devoting my working energy to, working towards really bad stuff in the world". For example, yes, Anthropic employees have an obligation to call out if the company leadership is advocating against regulation. (Which maybe they have been doing! In which case the obligation is probably met!)
I think it's probably good that Anthropic has pushed the capabilities frontier, and I think a lot of the arguments that this is unacceptable are kind of wrong.
Oh. Link to an argument for this?
I didn't understand your last paragraph.
If you're curious, basically I'm saying, "yes there's context but people in the space have a voice, and have obligations, and do have a bunch of the relevant context; what else would they need?". I mean, it kind of sounds like you're saying we (someone) should just trust Anthropic leadership because they have more context, even if there's not much indication that they have good intents? That can't be what you mean(?) but it sounds like that.
I agree that treating corporations or governments or countries as single coherent individuals is a type error, since it's important to be able to decompose them into factions and actors to build a good gears-level model that is predictive, and you can easily miss that. I strongly disagree that treating them as actors which can be trusted or distrusted is a type error. You seem to be making the second claim, and I don't understand it; the company makes decisions, and you can either trust it to do what it says, or not - and this post says the latter is the better model for anthropic.
Of course, the fact that you can't trust a given democracy to keep its promises doesn't mean you can't trust any of the individuals in it, and the fact that you can't trust a given corporation doesn't necessarily mean that about the individuals working for the company either. (It doesn't even mean you can't trust each of the individual people in charge - clearly, trust isn't necessarily conserved over most forms of preference or decision aggregation.)
But as stated, the claims made seem reasonable, and in my view, the cited evidence shows it's basically correct, about the company as an entity and its trustworthiness.
I don't really disagree with anything you said here. (Edit to add: except that I don’t agree with the OP’s interpretation of all the evidence listed.)
For example, I think AI safety people often have sort of arbitrary strong takes about things that would be very bad to do, and it's IMO sometimes been good that Anthropic leadership hasn't been very pressured by their staff.
Specific examples would be appreciated.
Do you mean things like opposition to open-source? Opposition to pushing-the-SOTA model releases?
I am so very tired of these threads, but I'll chime in at least for this comment. Here's last time, for reference.
-
I continue to think that working at Anthropic - even in non-safety roles, I'm currently on the Alignment team but have worked on others too - is a great way to contribute to AI safety. Most people I talk to agree that they think the situation would be worse if Anthropic had not been founded or didn't exist, including MIRI employees.
-
I'm not interested in litigating an is-ought gap about whether "we" (human civilization?) "should" be facing such high risks from AI; obviously we're not in such an ideal world, and so discussions from that implicit starting point are imo useless.
-
I have a lot of non-public information too, which points in very different directions to the citations here. Several are from people who I know to have lied about Anthropic in the past; and many more are adversarially construed. For some I agree on an underlying fact and strongly disagree with the framing and implication.
-
I continue to have written redlines which would cause me to quit in protest.
I'm not interested in litigating an is-ought gap about whether "we" (human civilization?) "should" be facing such high risks from AI; obviously we're not in such an ideal world, and so discussions from that implicit starting point are imo useless
My post is about Anthropic being untrustworthy. If that was not the case, if Anthropic clearly and publicly was making the case for doing their work with full understanding of the consequences, if the leadership did not communicate contradictory positions to different people and was instead being honest and high-integrity, I could imagine a case being made for working at Anthropic on capabilities, to have a company that stays at the frontier and is able to get and publish evidence, and use its resources to slow down everyone on the planet.
But we, instead, live in a world where multiple people showed me misleading personal messages from Jack Clark.
One should be careful not to galaxy-brain themselves into thinking that it’s fine for people to be low-integrity.
I don’t think the assumptions that you think I’m making are feeding into most of the post.
Several are from people who I know to have lied about Anthropic in the past
If you think I got any of the facts wrong, please do correct me on them. (You can reach out in private, and share information with me in private, and I will not share it further without permission.)
I continue to have written redlines which would cause me to quit in protest.
I appreciate you having done this.
I haven't followed every comment you've left on these sorts of discussions, but they often don't include information or arguments I can evaluate. Which MIRI employees, and what did they actually say? Why do you think that working at Anthropic even in non-safety roles is a great way to contribute to AI safety? I understand there are limits to what you can share, but without that information these comments don't amount to much more than you asking us to defer to your judgement. Which is a fine thing to do, I just wish it were more clearly stated as such.
Despite working at a competitor, I am happy Anthropic exists. I worry about centralization of control- I want OpenAI to be successful but I don’t want it to be a monopoly. Competition can create incentives to cut corners, but it also enables a variety of ideas and approaches as well as collaboration when it comes to safety. (And there have been some such cross industry collaborations.) In particular I appreciate some of the great research on AI safety that has come from Anthropic.
No company is perfect, we all make mistakes, which we should be criticized for. But I think many of the critiques (of both OpenAI and Anthropic) are based on unrealistic and naive world views.
I suspect the real disagreement between you and Anthropic-blamers like me is downstream of a P(Doom) disagreement (where yours is pretty low and others’ is high), since I’ve seen this is often the case with various cases of smart people disagreeing.
Realistically/pragmatically balanced moves in a lowish-P(Doom) world are unacceptable in a high-P(Doom) world.
I very strongly agree with this and think it should be the top objection people first see when scrolling down. In a low-P(doom) world, Anthropic has done lots of good. (They proved that you can have the best and the most aligned model, and also the leadership is more trustworthy than OpenAI, who would otherwise lead). This is my current view.
In a high-P(doom) world, none of that matters because they've raised the bar for capabilities when we really should be pausing AI. This was my previous view.
I'm grudgingly impressed with Anthropic leadership for getting this right when I did not (not that anyone other than me cares what I believed, having ~zero power).
I’m confused about much of the discussion on this post being about whether Anthropic has done “net good”.
The post is very specifically a deep dive into the fact that Anthropic, like any other company, should not have their leadership’s statements taken at face value. IMO this is a completely unrealistic way to treat companies in any field, and it’s a bit frustrating to see the rationalist presumption of good faith extended over and over by default in contexts where it’s so incredibly exploitable.
Again this is not a specific criticism of Anthropic, if a new lab starts tomorrow promising to build Safe SuperIntelligence for example, we should not assume that we can trust all their leadership’s statements until they’ve mislead people publicly a few times and someone has a deep dive comprehensively documenting it.
I agree that many of the worldviews being promoted are unrealistic - expecting companies in the current competitive race conditions would be a competitive disadvantage.
But I also think that there are worlds where Anthropic or OpenAI as companies cared enough to ensure that they can be trusted to keep their promises. And there are industries (financial auditing, many safety critical industries,) where this is already the case - where companies know that their reputation as careful and honest actors is critical to their success. In those industries, breaking the trust is a quick path to bankruptcy.
Clearly, the need for anything like that type of trustworthiness is not true in the AI industry. Moreover, coordinating a change in the status quo might be infeasible. So again, yes, this is an unrealistic standard.
However, I would argue that high-trust another viable equilibrium, one where key firms were viewed as trustworthy enough that anyone using less-trustworthy competitors would be seen as deeply irresponsible. Instead, we have a world stuck in the low-trust competition in AI, a world where everyone agrees that uploading sensitive material to an LLM is a breach of trust, and uploading patient information is a breach of confidentiality. The only reason to trust the firms is that they likely won't care or check, and certainly not that they can be trusted not to do so. And they are right to say that the firms have not made themselves trustworthy enough for such uses - and that is part of the reason the firms are not trying to rigorously prove themselves trustworthy.
And if AI is going to control the future, as seems increasingly likely, I'm very frustrated that attempts to move towards actually being able to trust AI companies are, as you said, "based on unrealistic and naive world views."
I disagree with the claim that OpenAI and Anthropic are untrustworthy. I agree that there have been may changes in the landscape that caused the leadership of all AI companies to update their views. (For example, IIRC - this was before my time- originally OpenAI thought they’ll never have more than 200 employees.) This makes absolute sense in a field where we keep learning.
Specifically, regarding the question of user data, people at OpenAI (and I’m sure Anthropic too) are very much aware of the weight of the responsibility and level of trust that our users put in us by sharing their data.
However the comments on this blog are not the right place to argue about it so apologies in advance if I don’t respond to more comments.
However the comments on this blog are not the right place to argue about it
Where might be the place to argue about it? (That place might not be as open as LessWrong, which might be ok, but it should really include some people who can represent the perspective from which Anthropic leadership is quite untrustworthy.)
OpenAI has no shortage of critical press, and so there are plenty of public discussions of our (both real and perceived) shortcomings. OpenAI leaders also participate in various public events, panels, podcasts, and Reddit AMAs. But of course we are not entitled to our users’ trust, and need to constantly work to earn it.
Will let Anthropic folks comment on Anthropic.
Are there any examples anywhere of OpenAI leaders, in one of the forums you mentioned, being asked a sequence of questions seriously aimed at testing whether their rationale for opposing AI regulation makes any sense from a safety perspective?
Thanks as always to Zac for continuing to engage on things like this.
Tiny nit for my employer: should probably read “including some* MIRI employees”
like any org, MIRI is made up of people that have significant disagreements with one another on a wide variety of important matters.
More than once I’ve had it repeated to me that ‘MIRI endorses y’, and tracked the root of the claim to a lack of this kind of qualifier. I know you mean the soft version and don’t take you to be over-claiming; unfortunately, experience has shown it’s worth clarifying, even though for most claims in most contexts I’d take your framing to be sufficiently clear.
Regardless of whether you think the company is net positive, or working for it is valuable, are you willing to explicitly disagree with the claim that as an entity, the company cannot be trusted to reliably fulfill all the safety and political claims which it makes, or has made? (Not as in inviolably never doing anything different despite changes, but in the same sense that you trust a person not to break a promise without. e.g., explaining to those it was made to about why it thinks the original promise isn't binding, or why the specific action isn't breaking their trust.)
I think that an explicit answer to this question would be more valuable than the reasonable caveats given.
Your tiredness is understandable and I appreciate you continuing to engage despite that!
Do you have any takes on the specific point of "When a (perhaps naive) rationalist interprets Dario to have made a commitment on behalf of Anthropic regarding safety, should they be surprised when that commitment isn't met?"
A very specific phrasing of this question which would be useful to me: "Should I interpret 'Zac not having quit' to mean that his 'Losing trust in the integrity of leadership' red line has not been crossed and therefore, to his knowledge, Anthropic leadership has never lied about something substantial?"[1]
- ^
tbc, I've worked for many CEOs who occasionally lied, I think it's reasonable for this to not be your red line. But to the extent you can share things (e.g. you endorsing a more heavily caveated version of my question), I would find it helpful.
SB-1047. Anthropic lobbied hard to water down the bill, attempted to kill it, and only performed better than other AI companies due to internal pressure.
Even this single thing alone seems basically unforgiveable.
I'd score these subclaims as complicated, false, and false - complicated because I think Anthropic's proposals were to move from a strong but non-viable bill towards a weaker but viable approach, which was vetoed anyway.
(I appreciate you commenting; and I'm probably not going to try to evaluate your claims, because I'm not trying to be an expert in this stuff; but
- I would suggest linking to an explanation of this;
- I think it would be valuable for someone to evaluate this in more detail.
E.g. I'm pretty skeptical for lay-reasons like "Really? If one of the 3ish major companies strongly supported the bill, that wouldn't much increase its chances of getting passed?" and "Really? But couldn't they have still said the bill was best as-is?" and "Really? How are you / how was Anthropic leadership so confident the bill wasn't viable?" and "Really? We're still doing this 'play it cool' strategy instead of just saying what we think would be good to do?" and "Wow, one of the top companies somehow figured out a way to rationalize not supporting regulating themselves even though they nobly said they would support that and they are such amazing homies, what an incredible surprise". But I could imagine lacking some context that makes the decision seem better.)
Yes, politics at this level is definitely an area where you need both non-layman expertise, and a lot of specific context.
Is there a short summary that you'd be willing to undersign, regarding the intentions / efforts of Anthropic leadership around regulation? E.g.
To my knowledge, Anthropic leadership has so far always done their best efforts to increase the amount of regulation of AI research that would slow down capabilities progress.
Or something like that.
"in December 2024, Jack Clark tried to push Congressman Jay Obernolte (CA-23) for federal preemption of state AI laws" is a very strong claim, and one that I think is impossible for me to evaluate without context we don't have.
I would encourage you to give context on what kinds of advocacy he was purportedly engaged in and what your sources allege to have believed the Congressman's preferences on preemption were already at that time. I would not, for example, be especially surprised if the Congressman was already thinking hard about pushing for preemption at that time and Jack Clark was engaging him in a conversation where he had been made aware of (hypothetically) Congressman Obernolte's plans. For example, I would be very dubious if you were claiming that Jack Clark came up with the idea and pitched it to Congress.
(I personally have no strong public opinion on preemption being good or bad in the abstract; the specific terms of what you're preempting at the state level and what you're doing at the federal level are most of the ballgame here.)
Anthropic wants to stay near the front of the pack at AI capabilities so that their empirical research is relevant, but not at the actual front of the pack to avoid accelerating race-dynamics.
— From an Anthropic employee in a private conversation, early 2023
Note that this is not a quote of an Anthropic employee in a private conversation. Instead, it is a quote of Ray Arnold describing his memory/summary of something an Anthropic told him in a private conversation.
I don't know if Ray was quoting heard from me, but I recall hearing from an employee the intention was to stay 18 or 24 months behind the frontier. Later the employee totally denied having said this though (I don't recall if the objection was the idea of staying behind or the specific numbers).
EDIT: Originally I said that was my best understanding of Mikhail's point. Mikhail has told me it was not his point. I'm keeping this comment as that's a point that I find interesting personally.
Before Mikhail released this post, we talked for multiple house about the goal of the article and how to communicate it better. I don't like the current structure of the post, but I think Mikhail has good arguments and has gathered important data.
Here's the point I would have made instead:
Anthropic presents itself as the champion of AI safety among the AI companies. People join Anthropic because of their trust that the Anthropic leadership will take the best decisions to make the future go well.
There have been a number of incidents, detailed in this post, where it seems clear that Anthropic went against a commitment they were expected to have (pushing the frontier), where their communication was misleading (like misrepresenting the RAISE bill), or where they took actions that seem incongruous with their stated mission (like accepting investment from Gulf states).
All of those incidents most likely have explanations that were communicated internally to the Anthropic employees. Those explanations make sense, and employees believe that the leadership made the right choice.
However, from the outside, a lot of those actions look like Anthropic gradually moving away from being the company that can be trusted to do what's best for humanity. It looks like Anthropic doing whatever it can to win the race even if it increases risks, like all the other AI companies. From the outside, it looks like Anthropic is less special than it seemed at first.
There are two worlds compatible with the observations:
- One where Anthropic is still pursuing the mission, and those incidents were just the best way to pursue the mission. The Anthropic leadership is trustworthy, and their internal explanations are valid and represent their actual view.
- One where the Anthropic leadership is not reliably pursing the mission anymore, where those incidents are in fact evidence of that, but where the leadership is using its capacity of persuasion and the fact that it has access to info employees don't have, to convince them that it was all for the mission, no matter the real reasons
In the second world, working at Anthropic would not reliably improve the world. Anthropic employees would have to evaluate whether to continue working there in the same way as they would if they worked at OpenAI or any other AI company.
All current and potential Anthropic employees should notice that from the outside, it sure does look like Anthropic is not following its mission as much as it used to. There are two hypotheses that explain it. They should make sure to keep tracking both of them. They should have a plan of what they'll do if they're in the least convenient world, so they can face uncomfortable evidence. And, if they do conclude that the Anthropic leadership is not following Anthropic's mission anymore, they should take action.
(I do not endorse any of this, except for the last two sentences, though those are not a comprehensive bottom line. The comment is wrong about my points, my view, what I know, my model of the world, the specific hypotheses I’d want people to consider, etc.
If you think there is an important point to make, I’d appreciate it if you could make it without attributing it to others.)
I feel like the epistemic qualifier at the top was pretty clear about the state of the belief, even if Lucie was wrong! I would not call this "attributing it to others", like nobody is going to quote this in an authoritative tone as something you said, unless the above is really a very egregious summary, but that currently seems unlikely to me.
Edited to say it is not your position. I'm sorry for having published this comment without checking with you.
I endorse the spirit of this distillation a lot more than the original post, though I note that Mikhail doesn't seem to agree.
I don't think those two worlds are the most helpful ones to consider, though. I think it's extremely implausible[1] that Anthropic leadership are acting in some coordinated fashion to deceive employees about their pursuit of the mission while actually profit-maxxing or something.
I think the much more plausible world to watch out for is something like:
- Anthropic leadership is reliably trying to pursue the mission and is broadly acting with good intentions, but some of Anthropic's actions are bad for that mission for reasons like:
- incorrect or biased beliefs by Anthropic leadership about what would be best for that mission
- selective or biased reporting of things in self-serving ways by leadership in ordinary human ways of the sort that don't feel internally like deception but can be easy to slip into under lots of social pressure
- actions on the part of less-mission-aligned employees without sufficient oversight at higher levels of the org
- decisionmakers who just haven't really stopped to think about the consequences of their actions on some aspect of the mission, even though in theory they might realize this was bad
- failures of competence in pursuing a good goal
- random balls getting dropped for complicated big-organization reasons that aren't any one person's fault in a crisp way
Of course this is a spectrum, and this kind of thing will obviously be the case to some nonzero degree; the relevant questions are things like:
- Which actors can I trust that if they're owning some project, that project will be executed competently and with attention paid to the mission-relevant components that I care about?
- What persistent biases do I think are present in this part of the org, and how could I improve that state of affairs?
- Is the degree of failure in this regard large enough that my contributions to Anthropic-as-a-whole are net negative for the world?
- What balls appear to be getting dropped, that I might be able to pick up?
- What internal cultural changes would move decisionmaking in ways that would more reliably pursue the good?
I'd be excited for more external Anthropic criticism to pitch answers to questions like these.
- ^
I won't go into all the reasons I think this, but just to name one, the whole org is peppered with the kinds of people who have quit OpenAI in protest over such actions, that's such a rough environment to maintain this conspiracy in!
I agree that these are not the two worlds which would be helpful to consider, and your list of reasons are closer to my model than Lucie’s representation of my model.
(I do hope that my post somewhat decreases trust in Jack Clark and Dario Amodei and somewhat increases the incentives for the kind of governance that would not be dependent on trustworthy leadership to work.)
Thanks to Mikhail Samin for writing one of the most persuasive and important articles I've read on LessWrong.
I think a lot of the dubious, skeptical, or hostile comments on this post reflect some profound cognitive dissonance.
Rationalists and EAs generally were very supportive of OpenAI at first, and 80,000 Hours encouraged people to work there; then OpenAI betrayed our trust and violated most of the safety commitments that they made. So, we were fooled once.
Then, Rationalists and EAs were generally very supportive of Anthropic, and 80,000 Hours encouraged well-meaning people to work there; then Anthropic betrayed our trust and violated most of the safety commitments they made. So, we were fooled twice. Which is embarrassing, and we find ways to cope with our embarrassment, gullibility, and naivete.
What's the lesson from OpenAI and Anthropic betraying our trust so massively and recklessly?
The lesson is simply about human nature. People are willing to sell their souls. A mid-level hit man is willing to kill someone for about $50,000. A cyber-scammer is willing to defraud thousands of elderly people for a few million dollars. Sam Altman was willing to betray AI Safety to achieve a current net worth of (allegedly) about $2.1 billion. Dario Amodei was willing to betray AI Safety to achieve his current net worth of (allegedly) about $3.7 billion. If the AI bubble doesn't burst soon, they'll each probably be worth over $10 billion within a couple of years.
So, we should have expected that almost anyone, no matter how well-meaning and principled, would eventually succumb to the greed, hubris, and thrills of trying to build Artificial Superintelligence. We like to think that we'd never sell our souls or compromise our principles for $10 billion. But millions of humans compromise their principles, every day, for much, much less than that.
Why exactly did we think Sam Altman or Dario Amodei would be any different? Because they were 'friendlies'? Allies to the Rationalist cause? EA-adjacent? Long-termists who cared about the future?
None of that matters to ordinary humans when they're facing the prospect of winning billions of dollars -- and all they have to do is a bit of rationalization and self-deception, get some social validation from naive worshippers/employees, and tap into that inner streak of sociopathy that is latent in most of us.
In other words, Anthropic's utter betrayal of Rationalists, and EAs, and humanity, should have been one of the least surprising developments in the entire tech industry. Instead, here we are, trading various copes and excuses for this company's rapid descent from 'probably well-intentioned' to 'shamelessly evil'.
we should have expected that almost anyone, no matter how well-meaning and principled, would eventually succumb to the greed, hubris, and thrills of trying to build Artificial Superintelligence.
I don't think this is at all true. I think most people would not do that. I think those company heads are pretty exceptional (but probably not extremely exceptional).
Whether I'm correct or incorrect about that, I think this is a relevant question because if it is exceptional, then it implies a lot of stuff. For example:
- it implies that actually maybe you can mostly convince most people to not do AGI capabilities research;
- it implies that actually maybe you can avoid investing community resources (money, talent, public support, credibility, etc.) into people who would do this--but you would have to be better at detecting them;
- we aren't de facto good enough at detecting such people ("detecting" broadly construed to include creating mutual knowledge of that, common knowledge, etc.).
TsviBT -- I can't actually follow what you're saying here. Could you please rephrase a little more directly and clearly? I'd like to understand your point. Thanks!
I don't think this is at all true. I think most people would not do that. I think those company heads are pretty exceptional (but probably not extremely exceptional).
In this part I'm disagreeing with what I understand to be your proposed explanation for the situation. I think you're trying to explain why "we" (Rationalists and EAs) were fooled by e.g. Sam and Dario (and you're suggesting an update we should make, and other consequences). I think your explanation is that we did not understand that of course leaders of AI companies would pursue AI because almost anybody would in that position. I agree that "we" are under-weighting "people are just fine with risking everyone's lives because of greed, hubris, and thrills", and I personally don't know how to update / what to believe about that, but I don't think the answer is actually "most people would do the same". I don't think most people would e.g. lead a big coordinated PR campaign to get lots of young people to smoke lots of cigarettes, because they wouldn't want to hurt people. (I don't think this is obvious; most people also couldn't do that, so it's hard to tell.)
I'm disagreeing and saying many people would not do that.
Whether I'm correct or incorrect about that, I think this is a relevant question because
Then I'm explaining some of why I care about whether your explanation is correct.
I just want to chime in here as someone who just posted an article, today, that covers interpretability research, primarily by academic researchers, but with Anthropic researchers also playing a key contributor to the story. (I had no idea these posts would come out on the same day.)
I just want to say that I very much appreciate and endorse this kind of post, and I think Anthropic employees should too; and I'm guessing that many of them do. It may be a trite cliche, but it's simply true; with great power comes great responsibility, and there are a lot of reasons to question what the company Anthropic (and other large AI companies) are doing.
As a science journalist, I also have to say that I especially endorse questioning people who would describe themselves as journalists—including myself—on their roles in such matters. The whole point of labelling yourself as a journalist is to try to clarify the principled nature of your work, and it is very unclear to me how anyone can sustain those principles in certain contexts, like working at Anthropic.
That said, generally speaking, I also want to note something of my personal views, which is that I see ethics as being extremely complicated; it's just simply true that we humans live in a space of actions that is often deeply ethically flawed and contradictory. And I believe we need to make space for these contradictions (within reason ... which we should all be trying to figure out, together), and there's really no other way of going through things. But I think fair efforts to hold people and organizations accountable should almost universally tend to be welcomed and encouraged, not discouraged.
But l think the right response to this is simply to see how much we can get without agreeing to these things (which I think are likely still many billions), and then hold firm if they ask.
I think this is specifically talking about investments from gulf states (which imo means it's not "directly contradicted" by the amazon thing). If that's true, I'd suggest making that more clear.
Thanks! I meant to say that the idea that Anthropic would hold firm in the face of pressure from investors is directly contradicted by the amazon thing. Made the edit.
Corrections
[December 6, 2025] Due to concerns with the validity of
Anthropic wants to stay near the front of the pack at AI capabilities so that their empirical research is relevant, but not at the actual front of the pack to avoid accelerating race-dynamics.
— From an Anthropic employee in a private conversation, early 2023
I decided to remove it from the section 0 of the post. (At first, I temporarily added “(approximate recollection)” at the end while checking with Raemon on the details, but decided to delete this entirely once I got the reply.)
I apologize to readers for having had it in the post.
Thanks to @DanielFilan for the flag to it and to Raemon for a quick response on the details and the clarification.
[January 24, 2026] Alex Bores was called a "New York State Senator". His actual title is "New York State Assembly member". I apologize for the oversight and have corrected it in the post.
Slightly OT, but this would be less credible if Anthropic was managing more basic kinds of being trustworthy and transparent, like getting a majority of outages honestly reported on the status page, but that kind of stuff mostly isn't happening either despite being easier and cheaper than avoiding the pressures covered in this post.
E.g. down detector has the service outage I saw yesterday (2025-12-09 ~04:30 UTC) logged, not a peep from Anthropic:
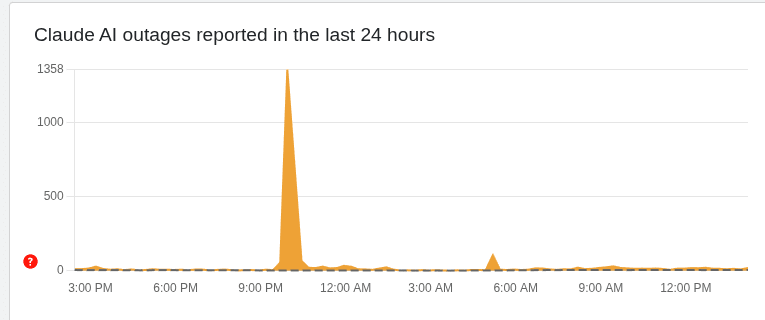
So either they don't know what's happening on their own infrastructure or they're choosing not to disclose it, neither of which is a good look. Compare to Microsoft (hardly a paragon, and yet...) where their daily report to Office 365 admins or Azure admins typically has a dozen or more issues covered and anything non trivial does usually warrant a public technical report on what happened. It's not enough to make admins stop calling it Office 364, but it helps. And the Claude.ai app has far more service interruptions than does O365 [citation needed].
The only public instance of this change being pointed out was a LessWrong comment by someone unaffiliated with Anthropic.
Nitpick: an outside reporter also noticed this on the day of the release and wrote up a story on it. It didn't seem to get much traction though.
Thanks! I meant “pointed out [at the time]”. It has indeed been noticed and pointed out since! Will update the text to clarify.
Anthropic is untrustworthy.
This post provides arguments, asks questions, and documents some examples of Anthropic's leadership being misleading and deceptive, holding contradictory positions that consistently shift in OpenAI's direction, lobbying to kill and water down regulation so helpful that employees of all major AI companies speak out to support it, and violating the fundamental promise the company was founded on. It also shares a few previously unreported details on Anthropic leadership's promises and efforts.[1]
Anthropic has a strong internal culture that has broadly EA views and values, and the company has strong pressures to appear to follow these views and values as it wants to retain talent and the loyalty of staff, but it's very unclear what they would do when it matters most. Their staff should demand answers.
Suggested questions for Anthropic employees to ask themselves, Dario, the policy team, and the board after reading this post, and for Dario and the board to answer publicly
On regulation: Why is Anthropic consistently against the kinds of regulation that would slow everyone down and make everyone more likely to be safer?
To what extent does Jack Clark act as a rogue agent vs. in coordination with the rest of Anthropic's leadership?
On commitments and integrity: Do you think Anthropic leadership would not violate their promises to you, if it had a choice between walking back on its commitments to you and falling behind in the race?
Do you think the leadership would not be able to justify dropping their promises, when they really need to come up with a strong justification?
Do you think the leadership would direct your attention to the promises they drop?
Do you think Anthropic's representatives would not lie to the general public and policymakers in the future?
Do you think Anthropic would base its decisions on the formal mechanisms and commitments, or on what the leadership cares about, working around the promises?
How likely are you to see all of the above in a world where the leadership cares more about competition with China and winning the race than about x-risk, but has to mislead its employees about its nature because the employees care?
How likely are you to see all of the above in a world where Anthropic is truthful to you about its nature and trustworthiness? If you think about all the bits of evidence on this, in which direction are they consistently pointing?
Can you pre-register what kind of evidence would cause you to leave?
On decisions in pessimistic scenarios: Do you think Anthropic would be capable of propagating future evidence on how hard alignment is in worlds where it's hard?
Do you think Anthropic will try to make everyone pause, if it finds more evidence that we live in an alignment-is-hard world?
On your role: In which worlds would you expect to regret working for Anthropic on capabilities? How likely is our world to be one of these? How would you be able to learn, and update, and decide to not work for Anthropic anymore?
I would like to thank everyone who provided feedback on the draft; was willing to share information; and raised awareness of some of the facts discussed here.
If you want to share information, get in touch via Signal: @misha.09.
Table of Contents
0. What was Anthropic's supposed reason for existence?
1. In private, Dario frequently said he won’t push the frontier of AI capabilities; later, Anthropic pushed the frontier.
2. Anthropic said it will act under the assumption we might be in a pessimistic scenario, but it doesn't seem to do this
3. Anthropic doesn't have strong independent value-aligned governance
4. Anthropic had secret non-disparagement agreements
5. Anthropic leadership's lobbying contradicts their image
5.1. Europe
5.2. SB-1047
5.3. Jack Clark publicly lied about the NY RAISE Act
5.4. Jack Clark tried to push for federal preemption
6. Anthropic's leadership quietly walked back the RSP commitments
7. Why does Anthropic really exist?
8. Conclusion
0. What was Anthropic's supposed reason for existence?
— Daniela Amodei, tweet, May 2021
— Anthropic, Core Views on AI Safety: When, Why, What, and How, March 2023
— Dario Amodei, on an FLI podcast, March 2023
Anthropic was supposed to exist to do safety research on frontier models (and develop these models only in order to have access to them; not to participate in the race).
Instead of following that vision, over the years, as discussed in the rest of the post, Anthropic leadership's actions and governance drifted almost toward actively racing, and it's unclear to what extent the entirety of Anthropic's leadership really had that vision to begin with.
Many joined Anthropic thinking that the company would be a force for good. At the moment, it is not.
1. In private, Dario frequently said he won’t push the frontier of AI capabilities; later, Anthropic pushed the frontier
As discussed below, Anthropic leadership gave many, including two early investors, the impression of a commitment to not push the frontier of AI capabilities, only releasing a model publicly after a competitor releases a model of the same capability level, to reduce incentives for others to push the frontier.
In March 2024, Anthropic released Claude 3 Opus, which, according to Anthropic itself, pushed the frontier; now, new Anthropic releases routinely do that.[3]
From @Raemon:
Dustin Moskovitz talked to Dario and came away with this as a commitment, not just a "thing they were trying to do".
Nishad Singh (a former executive of FTX, another early investor) came away with the same impression as Dustin. (As far as I know, this has not been previously publicly reported on.[1])
Anthropic leadership made this promise to many people, including prospective employees and philanthropic investors.
Some of them now consider Dario to have defected.
If Anthropic's policy has changed due to a change in the strategic landscape, they need to at least say so explicitly. And if it has not, they need to explain how their recent actions and current plans are compatible with not pushing the frontier.
2. Anthropic said it will act under the assumption we might be in a pessimistic scenario, but it doesn’t seem to do this
What happens as Anthropic gets evidence that alignment is hard?
Anthropic justified research into dangerous capabilities with this reasoning:
— Anthropic, Model Organisms of Misalignment: The Case for a New Pillar of Alignment Research, August 2023 (emphasis added)
— Anthropic, Core Views on AI Safety: When, Why, What, and How, March 2023 (emphasis added)
In March 2023, Anthropic said that they should act under the assumption that we might be in a pessimistic or near-pessimistic scenario, until we have sufficient evidence that we're not.
In December 2024, with the release of the alignment-faking paper, @evhub (the head of Alignment Stress-Testing at Anthropic) expressed a view that this is evidence that we don't live in an alignment-is-easy world; that alignment is not trivial.
How has Anthropic responded to this evidence that we're unlikely to be in an optimistic scenario?
If they do not currently have the view that we're in an alignment-is-hard world, they should explain why and what would update them, and if they accept that view, they should make explicit claims about how they have tried to "sound the alarm" or "halt AI progress", as they committed to doing, or what specific criteria they have for deciding to do so.
Alternatively, if they believe that their strategy should change in light of other labs' misalignment, or their geopolitical views, or anything else, they need to be honest about having changed their mind.
How much has Anthropic acted in the direction of making it easier for the state and federal governments to hear the alarm, if Anthropic raises it, once it becomes more convinced that we're in a pessimistic or near-pessimistic world?
How does Anthropic build specific guardrails to maintain its commitments? How does it ensure that people who will be in charge of critical decisions are fully informed and have the right motivations and incentives?
From early 2023 to late 2025, Anthropic co-founders and employees keep endorsing this picture:
Yet, in July 2025, Dario Amodei said he sees "absolutely no evidence" for the proposition that they won't have a way to control the technology.
How does Anthropic ensure that the evidence they could realistically get in pessimistic worlds convinces people who make decisions that they're in a pessimistic world, and causes Anthropic to ask labs or state actors to pause scaling?
Has there been any operationalization of how Anthropic could institutionally learn that we live in a pessimistic scenario, and what it would do in response?
We haven't seen answers, which seemingly either means they have not thought about the question, or that they have, but would prefer not to make the conclusions public. Either case seems very worrying.[5]
In a later section, we also discuss lobbying efforts incompatible with the assumption that we might be in a pessimistic scenario.
3. Anthropic doesn't have strong independent value-aligned governance
Anthropic pursued investments from the UAE and Qatar
From WIRED:
Some people might be overindexing on Anthropic's formal documents and structure, whereas, in reality, given their actual institutional structure and the separation of the Long-Term Benefit Trust (even if it were mission aligned) from its operational decisions, it is somewhat straightforward for Anthropic to do things regardless of the formal documents, including giving in to various pressures and incentives in order to stay at the frontier.
If you're a frontier AI company that would have to fundraise in the future, you might find yourself optimizing for investors' interests, because if you don't, raising (now and in the future) would be harder.[6] Because operational and strategic needs influence Anthropic's decisions around where to have datacenters, what to lobby for (including how much to support export controls), which governments to give access to their models to, etc., there's a structural reason for them to circumvent any guardrails intended to prevent governance being wrapped (if any specific and effective guardrails exist at all).
Dario admits this, to some extent (emphasis added):
The idea that Anthropic would hold firm in the face of pressure from investors is directly contradicted by how, as discussed below, Anthropic's investor and partner, Amazon, significantly affected Anthropic's lobbying efforts on SB-1047, which, in my opinion, shows that Dario either didn't realize it and isn't as thoughtful as it tries to appear, or is intentionally misleading about what kind of incentives taking investments would lead to.
Additionally, somewhat speculatively (I was not able to confirm this with multiple independent sources), Anthropic pushed for the diffusion rule because they did not want OpenAI to get investments from Saudi Arabia; Anthropic argued from a concern for safety, while in reality, they sought it because of concerns about their competitiveness.
The Long-Term Benefit Trust might be weak
Depending on the contents of the Investors' Rights Agreement, which is not public, it might be impossible for the directors appointed by the LTBT to fire the CEO. (That, notably, would constitute fewer formal rights than even OpenAI's nonprofit board has over OpenAI's CEO.)
One of the members of Anthropic's board of directors appointed by the LTBT is Reed Hastings. I've not been able to find evidence that he cares about AI x-risk or safety a notable amount.
More general issues
It's unclear, even to some at Anthropic, how much real or formal power, awareness, and expertise the LTBT and the board have.
Some people familiar with the Anthropic leadership's thinking told me that violations of RSP commitments (discussed below) wouldn't matter and there isn't much reason to talk about them, because these commitments and the letter of the policies are irrelevant to the leadership's actual decision-making.
The entire reason to have oversight by a board is to make sure the company follows the rules it says it follows.
If, instead, the rules are ignored when convenient, the company and its board need to implement much stronger governance mechanisms, with explicit guardrails; otherwise, in practice, the board is sidestepped.
Sadly, I've not been able to find many examples of the Anthropic leadership trying to proactively fix issues and improve the state of governance, rather than responding to issues raised by others and trying to save face (such as in the case of non-disparagement agreements, discussed below), or the details on the members of the board and the Long-Term Benefit Trust not being public until after called out.
4. Anthropic had secret non-disparagement agreements
Anthropic has offered (1, 2) severance agreements that include a non-disparagement clause and a non-disclosure clause that covers the non-disparagement clause: you could not say anything bad about Anthropic after leaving the company, and could not disclose the fact that you can't say anything bad about it.
In May 2024, OpenAI's similar agreements[7] were made public, after which OpenAI walked them back.
Despite that, Anthropic did not address the issue of having similar agreements in place until July 2024, when Oliver Habryka publicly shared that he's aware of similar agreements existing at Anthropic as well.
Only when their similar practice became publicly known did Anthropic correct course.
And even then, Anthropic leadership was deceptive about the issue.
Anthropic co-founder @Sam McCandlish replied that Anthropic "recognized that this routine use of non-disparagement agreements, even in these narrow cases, conflicts with [its] mission" and has recently "been going through [its] standard agreements and removing these terms." Moreover: "Anyone who has signed a non-disparagement agreement with Anthropic is free to state that fact (and we regret that some previous agreements were unclear on this point). If someone signed a non-disparagement agreement in the past and wants to raise concerns about safety at Anthropic, we welcome that feedback and will not enforce the non-disparagement agreement."
Oliver Habryka noted that a part of this response is a "straightforward lie":
Neel Nanda confirmed the facts:
Furthermore, at least in one case, an employee tried to push back on the non-disparagement agreement, but their request was rejected. (This has not been previously reported on.[1])
5. Anthropic leadership's lobbying contradicts their image
In a Senate testimony in July 2023, Dario Amodei advocated for legislation that would mandate testing and auditing at regular checkpoints during training, including tests that "could measure the capacity for autonomous systems to escape control", and also require that all models pass according to certain standards before deployment.
In a Time piece, Dario appeared to communicate a similar sentiment:
However, contradictory to that, Anthropic lobbied hard against any mandatory testing, auditing, and RSPs (examples discussed below). To the extent that they feel the specific laws have troubling provisions, they could certainly propose specific new or different rules - but they have not, in general, done so.
From Time:
Europe
European policymakers and representatives of nonprofits reported that Anthropic representatives opposed government-required RSPs in private meetings, with talking points identical to those of people representing OpenAI.[1]
In May 2025, a concern about Anthropic planning to "coordinate with other major AGI companies in an attempt to weaken or kill the code [of practice]" for advanced AI models was shared with members of Anthropic's board and Long-Term Benefit Trust. (The code of practice for advanced AI models[8] narrowly focused on loss of control, cyber, and CBRN risks and was authored by Yoshua Bengio.)[1]
SB-1047
Anthropic lobbied hard to water down the bill, attempted to kill it, and only performed better than other AI companies due to internal pressure.[1]
As a public example, Anthropic attempted to introduce amendments to the bill that would touch on the scope of every committee in the legislature, thereby giving each committee another opportunity to kill the bill, which Max Tegmark called "a cynical procedural move straight out of Big Tech's playbook".
(An Anthropic spokesperson replied to this that the current version of the bill "could blunt America’s competitive edge in AI development" and that the company wanted to "refocus the bill on frontier AI safety and away from approaches that aren’t adaptable enough for a rapidly evolving technology".)
The standard practice of normal laws is to prevent recklessness that could lead to a catastrophe, even if no real harm has occurred yet. Reckless driving, reckless endangerment, and many safety violations are punishable regardless of whether anyone gets hurt; in civil law, injunctions can stop dangerous behaviour before harm occurs.
Anthropic advocated against any form of pre-harm enforcement whatsoever, including simply auditing companies' compliance with their own SSPs[9], recommending that companies be liable for causing a catastrophe only after the fact.
"Instead of deciding what measures companies should take to prevent catastrophes (which are still hypothetical and where the ecosystem is still iterating to determine best practices) focus the bill on holding companies responsible for causing actual catastrophes."
Allowing companies to be arbitrarily irresponsible until something goes horribly wrong is ridiculous in a world where we could be living in a pessimistic or near-pessimistic scenario, but it is what Anthropic pushed for.
It lobbied against liability for reckless behavior. It requested an amendment to make it so that California’s attorney general would only be able to sue companies once critical harm is imminent or has already occurred, rather than for negligent pre-harm safety practices.
Anthropic advocated against a requirement to develop SSPs:
"The current bill requires AI companies to design and implement SSPs that meet certain standards – for example they must include testing sufficient to provide a “reasonable assurance” that the AI system will not cause a catastrophe, and must “consider” yet-to-be-written guidance from state agencies. To enforce these standards, the state can sue AI companies for large penalties, even if no actual harm has occurred."
"While this approach might make sense in a more mature industry where best practices are known, AI safety is a nascent field where best practices are the subject of original scientific research. For example, despite a substantial effort from leaders in our company, including our CEO, to draft and refine Anthropic’s RSP over a number of months, applying it to our first product launch uncovered many ambiguities. Our RSP was also the first such policy in the industry, and it is less than a year old."
A requirement to have policies and do reasonable things to assure that the AI system doesn't cause a catastrophe would be a good thing, actually.
Indeed, in their final letter, Anthropic admitted that mandating the development of SSPs and being honest with the public about them is one of the benefits of the bill.
Anthropic opposed creating an independent state agency with authority to define, audit, and enforce safety requirements. The justification was that the field lacked "established best practices". Thus, an independent agency lacking "firsthand experience developing frontier models" could not be relied on to prevent developers from causing critical harms. Instead, such an agency "might end up harming not just frontier model developers but the startup ecosystem or independent developers, or impeding innovation in general."
The idea that such an agency might end up harming the startup ecosystem or independent developers is ridiculous, as the requirements would only apply to frontier AI companies.
The idea that an independent government agency can't be full of competent people with firsthand experience developing frontier models is falsified by the existence of UK AISI.
And why would the government auditing companies' compliance with their own RSPs be bad?
Their letter had a more positive impact than the null action, including some credit for being one of the two (together with xAI) frontier AI companies who, being okay with the bill, somewhat undermined the "sky is falling" attitude of many opponents; but the letter was very far from what supporting it on net, at the very end, would actually look like.
In Sacramento, letters supporting legislation should include a statement of support in the subject line. If you do not have a clear subject line, then even if you're Anthropic, the California Governor's staffers won't sort it into the category of letters in support, even if there's a mildly positive opinion on a bill inside the letter.
Look up any guidance on legislative advocacy in California. It will be very clear on this: in the subject line, you should clearly state "support"/"request for signature"/etc.; e.g., see 1, 2, 3, 3.5, 4.
Anthropic has not done so. There was no letter in support.
Notably, Anthropic's earlier 'Support If Amended' letter correctly included their position in the subject line, showing they understood proper advocacy format when it suited them.
It's important to note that other AI companies in the race performed much worse than Anthropic and were even more dishonest; but Anthropic's somewhat less problematic behavior is fully explained by having to maintain a good image internally and does not change their clear failure to abide by their own prior intentions to support such efforts and the fact they tried hard to water the bill down and kill it; Anthropic performed much worse than some idealized version of Anthropic that truly cared about AI safety and reasonable legislation.
Dario argued against any regulation except for transparency requirements
In an op-ed against the 10-year moratorium on state regulation of AI, Dario said that state laws, just like federal regulation, should be "narrowly focused on transparency and not overly prescriptive or burdensome", which excludes requiring audits that they explicitly said should be in place in a Senate testimony, excludes mandating that firms even abide by their RSPs, and even excludes a version of SB-1047 with all of Anthropic's amendments that Anthropic claimed it would've supported.
Jack Clark publicly lied about the NY RAISE Act
New York's RAISE Act would apply only to models trained with over $100 million in compute. This is a threshold that excludes virtually all companies except a handful of frontier labs.
Anthropic's Head of Policy, Jack Clark, stated about the NY RAISE Act, among other misleading things:
This is a false statement. The bill's $100M compute threshold means it applies only to frontier labs. No "smaller companies" would be affected. Jack Clark would have known this.
The bill's author, New York State Assembly member Alex Bores, responded directly to Jack Clark:
Jack Clark tried to push for federal preemption
Jack Clark spent efforts in attempts to call for federal preemption of state AI regulations; in particular, in December 2024, Jack Clark tried to push Congressman Jay Obernolte (CA-23) for federal preemption of state AI laws. (This has not previously been reported on.[1])
6. Anthropic's leadership quietly walked back the RSP commitments
— Evan Hubbinger, describing Anthropic's strategy that replaced "think carefully about when to do releases and try to advance capabilities for the purpose of doing safety" in a comment, March 2024
Anthropic's Responsible Scaling Policy (RSP) was presented as binding commitments to safety standards at each capability level.
But Anthropic has quietly weakened these commitments, sometimes without any announcement.
I believe that they use the RSP more as a communication tool than as commitments that Anthropic would follow even when inconvenient.
Unannounced removal of the commitment to plan for a pause in scaling
Anthropic's October 2023 Responsible Scaling Policy had a commitment:
This commitment, without any announcement or mention in the changelog, was removed from the subsequent versions of the RSP.
(Thanks to the Existing Safety Frameworks Imply Unreasonable Confidence post for noticing this.)
Unannounced change in October 2024 on defining ASL-N+1 by the time ASL-N is reached
Anthropic's October 2023 Responsible Scaling Policy stated:
In October 2024, this commitment was removed from RSP version 2.0.
Anthropic did not publicly announce the removal. Blog posts and changelogs did not mention it.
The only public instance of this change being pointed out was a LessWrong comment by someone unaffiliated with Anthropic.
Only in RSP version 2.1, Anthropic acknowledged the change at all, and even then only in the changelog of the RSP PDF file, and misattributed the removal of the commitment to the 2.0->2.1 change:
It has still not been mentioned in the public changelog on the website or in blog posts.
Without announcing or acknowledging this change, Anthropic was preparing to deploy a model it worked with under the ASL-3 standard[11]; as of now, Anthropic's latest model, Claude Sonnet 4.5, is deployed under the ASL-3 standard.
The last-minute change in May 2025 on insider threats
A week before the release of Opus 4, which triggered ASL-3 protections for the first time, Anthropic changed the RSP so that ASL-3 no longer required being robust to employees trying to steal model weights if the employee has any access to "systems that process model weights".
According to Ryan Greenblatt, who has collaborated with Anthropic on research, this might be a significant reduction in the required level of security; there's also skepticism of Anthropic being "highly protected" from organized cybercrime groups if it's not protected from insider threats.
7. Why does Anthropic really exist?
Anthropic is a company started by people who left OpenAI. What did they do there, why did they leave, how was Anthropic supposed to be different, and how is it actually different?
— Anthropic, Company, March 2023
— Anthropic, PBC, Certificate of Incorporation (amended), January 2025
Before starting Anthropic, its founders, while at OpenAI, were the people who ignited the race. From Karen Hao:
According to AI Lab Watch, "When the Anthropic founders left OpenAI, they seem to have signed a non-disparagement agreement with OpenAI in exchange for OpenAI doing likewise. The details have not been published."
It's very unclear to what extent the split was related exclusively to disagreements on AI safety and commercialization vs. research; however, the AI safety branding and promises not to race clearly allowed Anthropic to attract a lot of funding and talent.
And, despite the much-quoted original disagreement over OpenAI's "increasingly commercial focus", Anthropic is now basically just as focused on commercializing its products.
Anthropic's positioning and focus on the culture make people move from other AGI and tech companies to Anthropic and remain at Anthropic. Anthropic's talent is a core pitch to investors: they've claimed they can do what OpenAI can for 10x cheaper.
It seems likely that the policy positions that Anthropic took early on were related to these incentives, the way Sam Altman's congressional testimony, where he's asking legislators to regulate them, might've been caused by the incentives related to an unfriendly board that cares about safety (and now that the OpenAI board's power is gone, he holds positions of a completely different person.)
While the early communications focused on a mission stated similarly to OpenAI's, ensuring that AI benefits all of humanity, and the purpose that was communicated to early employees and philantropic investors was to stay at the frontier to have access to the frontier models to be able to do safety research on them, the actual mission stated in Anthropic's certificate of incorporation has always been to develop advanced AI (to benefit humanity): not ensure that transformative AI is beneficial but to develop advanced AI itself. Anthropic's Certificate of Incorporation also doesn't contain provisions such as OpenAI Charter's merge and assist clause. Anthropic's mission is not really compatible with the idea of pausing, even if evidence suggests it's a good idea to.
8. Conclusion
I wrote this post because I believe Anthropic as a company is untrustworthy, and staff might pressure it more if they understood how misaligned it is.
Sam McCandlish once said:
While other frontier AI companies are even worse, Anthropic is still a lot more of an average frontier AI company that tries to win the race than a company whose whole reason for existing is actually to increase the chance the AI goes well.
There are already unambigous cracks due to incentives, like lobbying against the KYC provision because of Amazon.
Anthropic is not very likely to have governance that, when it matters the most, would be robust to strong pressures.
There are unambiguously bad actions, like lobbying against SB-1047 or against the EU Code of Practice, or for federal preemption, or lying about AI safety legislation.
Anthropic's leadership justifies changing their minds and their actions with right-sounding reasons, but consistently changes their minds towards and acts as a de facto less responsible Anthropic; this is much less likely in a world where they're truly learning more about all sorts of issues and the changes in their views are a random walk, than in a world where they change their minds for pragmatic reasons, and are very different from the image they're presenting internally and externally.
There are many cases of Anthropic's leadership saying very different things to different people. To some, they appear to want to win the race. To others, they say it's "an outrageous lie" that they want to control the industry because they think only they can reach superintelligence safely.
I think it is obvious, from this post, that Anthropic is, in many ways, not what it was intended to be.
The Anthropic leadership also appears to be far less concerned about the threat of extinction than I am and than, in my opinion, the evidence warrants, and in worlds closer to my model of the risk, has a hugely net-negative impact by accelerating the rate of AI capabilities progress.
At various events related to AI safety[12], Anthropic's leadership and employees state that no one should be developing increasingly smart models; that a big global pause/slowdown would be good if possible. However, in reality, Anthropic does not loudly say that, and does not advocate for a global pause or slowdown. Instead of calling for international regulation, Anthropic makes calls about beating China and lobbies against legislation that would make a global pause more likely. Anthropic does not behave as though it thinks the whole industry needs to be slowed down or stopped, even though it tries to appear this way to the AI safety community; it's lobbying is actively fighting the thing that, in a pessimistic scenario, would need to happen.
From Anthropic's RSP:
However, Anthropic does not, in fact, clearly communicate the nature and extent of those risks.
If you really were an AI lab (or an AI lab CEO, or an AI lab policy team) that believed you're doing better than others and you have to do what you're doing even though you'd prefer for everyone not to, you should be loudly, clearly, and honestly saying this: "shut us all down". The fact you're not saying this, and not even really saying "you should regulate all of us" anymore, just like OpenAI has not been saying this since the board losing its fight with Sam Altman, is telling.
It's hard not to agree with @yams, @Joe Rogero, and @Joe Collman:
Or with Dario Amodei:
If you are considering joining Anthropic in a non-safety role, I ask you to, besides the general questions, carefully consider the evidence and ask yourself in which direction it is pointing, and whether Anthropic and its leadership, in their current form, are what they present themselves as and are worthy of your trust.
If you work at Anthropic, I ask you to try to better understand the decision-making of the company and to seriously consider stopping work on advancing general AI capabilities or pressuring the company for stronger governance.
As @So8res puts it:
For most of the previously unreported information that I share in this post, I do not directly cite or disclose sources in order to protect them. In some cases, I've reviewed supporting documents. I'm confident in the sources' familiarity with the information. For some non-public information, I've not been able to add it to this post because it could identify a source that would have access to it, or because I have not been able to verify it with multiple independent sources.
In a contrast with Anthropic's billboards.
Anthropic claimed that Claude 3 Opus has >GPT-4 performance.
It also explicitly said that with the release, they "push the boundaries of AI capabilities".
See related discussion.
New releases that, according to Anthropic, advanced the frontier: Claude 3.5 Sonnet, Claude 3.7 Sonnet and Claude Code, Claude 4, Claude Sonnet 4.5, Claude Opus 4.5.
Other releases, such as of MCP, appear also potentially concerning and contributing to a push of capabilities.
To the best of my understanding, Dustin and Nishad took Dario's words as a promise/commitment, but it is currently unclear to me whether Gwern took it as a commitment as well. I encourage you to look through the original thread (or chat to Gwern) to form an opinion.
There could be reasons to keep the plan non-public, but then they should, at the very least, explicitly say something like, "we've thought about this in detail and have a plan which we have reasons to keep secret".
If Anthropic answered any of these questions somewhere publicly, please point this out, and I'll update the post.
Arguably, investors' power beyond the formal agreements with OpenAI (as well as internal incentives) contributed to OpenAI's board losing when they attempted to fire Sam Altman.
Though in the case of OpenAI there was also a threat of voiding vested equity.
The safety and security chapter of the The General-Purpose AI Code of Practice.
Safety and Security Protocols (SSPs). SB-1047 would've required frontier AI companies to create, implement, annually review, and comply with those: something that Anthropic is supposed to already do with their RSP.
One source shared that they still employ communication tactics in the direction of doing stuff behind the scenes that one wouldn't know about and working in mysterious ways, while not having friends in the current administration.
While not formally triggering the ASL-3 standard as defined at the time, Anthropic had not ruled out that it was an ASL-3 model. The commitment was to have ASL-N+1 defined by the time you're working with ASL-N models; not having done evaluations to determine if you're working with an ASL-N model is not a Get Out of Jail Free card for failing to uphold your prior commitments.
As a specific example, a public discussion with Zac Hatfield-Dodds at LessOnline.
The context is incenting third-party discovery and reporting of issues and vulnerabilities: "Companies making this commitment recognize that AI systems may continue to have weaknesses and vulnerabilities even after robust red-teaming."