I'm going to go against the flow here and not be easily impressed. I suppose it might just be copium.
Any actual reason to expect that the new model beating these challenging benchmarks, which have previously remained unconquered, is any more of a big deal than the last several times a new model beat a bunch of challenging benchmarks that have previously remained unconquered?
Don't get me wrong, I'm sure it's amazingly more capable in the domains in which it's amazingly more capable. But I see quite a lot of "AGI achieved" panicking/exhilaration in various discussions, and I wonder whether it's more justified this time than the last several times this pattern played out. Does anything indicate that this capability advancement is going to generalize in a meaningful way to real-world tasks and real-world autonomy, rather than remaining limited to the domain of extremely well-posed problems?
One of the reasons I'm skeptical is the part where it requires thousands of dollars' worth of inference-time compute. Implies it's doing brute force at extreme scale, which is a strategy that'd only work for, again, domains of well-posed problems with easily verifiable solutions. Similar to how o1 bl...
It’s not AGI, but for human labor to retain any long-term value, there has to be an impenetrable wall that AI research hits, and this result rules out a small but nonzero number of locations that wall might’ve been.
To first order, I believe a lot of the reason why the "AGI achieved" shrill posting often tends to be overhyped is that not because the models are theoretically incapable, but rather that reliability was way more of a requirement for it to replace jobs fast than people realized, and there are only a very few jobs where an AI agent can do well without instantly breaking down because it can't error-correct/be reliable, and I think this has been continually underestimated by AI bulls.
Indeed, one of my broader updates is that a capability is only important to the broader economy if it's very, very reliable, and I agree with Leo Gao and Alexander Gietelink Oldenziel that reliability is a bottleneck way more than people thought:
https://www.lesswrong.com/posts/YiRsCfkJ2ERGpRpen/leogao-s-shortform#f5WAxD3WfjQgefeZz
https://www.lesswrong.com/posts/YiRsCfkJ2ERGpRpen/leogao-s-shortform#YxLCWZ9ZfhPdjojnv
Not to say it's a nothingburger, of course. But I'm not feeling the AGI here.
These math and coding benchmarks are so narrow that I'm not sure how anybody could treat them as saying anything about "AGI". LLMs haven't even tried to be actually general.
How close is "the model" to passing the Woz test (go into a strange house, locate the kitchen, and make a cup of coffee, implicitly without damaging or disrupting things)? If you don't think the kinesthetic parts of robotics count as part of "intelligence" (and why not?), then could it interactively direct a dumb but dextrous robot to do that?
Can it design a nontrivial, useful physical mechanism that does a novel task effectively and can be built efficiently? Produce usable, physically accurate drawings of it? Actually make it, or at least provide a good enough design that it can have it made? Diagnose problems with it? Improve the design based on observing how the actual device works?
Can it look at somebody else's mechanical design and form a reasonably reliable opinion about whether it'll work?
Even in the coding domain, can it build and deploy an entire software stack offering a meaningful service on a real server without assistanc...
It's not really dangerous real AGI yet. But it will be soon this is a version that's like a human with severe brain damage to the frontal lobes that provide agency and self-management, and the temporal lobe, which does episodic memory and therefore continuous, self-directed learning.
Those things are relatively easy to add, since it's smart enough to self-manage as an agent and self-direct its learning. Episodic memory systems exist and only need modest improvements - some low-hanging fruit are glaringly obvious from a computational neuroscience perspective, so I expect them to be employed almost as soon as a competent team starts working on episodic memory.
Don't indulge in even possible copium. We need your help to align these things, fast. The possibility of dangerous AGI soon can no longer be ignored.
Gambling that the gaps in LLMs abilities (relative to humans) won't be filled soon is a bad gamble.
Questions for people who know more:
- Am I understanding right that inference compute scaling time is useful for coding, math, and other things that are machine-checkable, but not for writing, basic science, and other things that aren't machine-checkable? Will it ever have implications for these things?
- Am I understanding right that this is all just clever ways of having it come up with many different answers or subanswers or preanswers, then picking the good ones to expand upon? Why should this be good for eg proving difficult math theorems, where many humans using many different approaches have failed, so it doesn't seem like it's as simple as trying a hundred times, or even trying using a hundred different strategies?
- What do people mean when they say that o1 and o3 have "opened up new scaling laws" and that inference-time compute will be really exciting? Doesn't "scaling inference compute" just mean "spending more money and waiting longer on each prompt"? Why do we expect this to scale? Does inference compute scaling mean that o3 will use ten supercomputers for one hour per prompt, o4 will use a hundred supercomputers for ten hours per prompt, and o5 will use a thousand supercomputers for a hundred hours per prompt? Since they already have all the supercomputers (for training scaling) why does it take time and progress to get to the higher inference-compute levels? What is o3 doing that you couldn't do by running o1 on more computers for longer?
The basic guess regarding how o3's training loop works is that it generates a bunch of chains of thoughts (or, rather, a branching tree), then uses some learned meta-heuristic to pick the best chain of thought and output it.
As part of that, it also learns a meta-heuristic for which chains of thought to generate to begin with. (I. e., it continually makes judgement calls regarding which trains of thought to pursue, rather than e. g. generating all combinatorially possible combinations of letters.)
It would indeed work best in domains that allow machine verification, because then there's an easily computed ground-truth RL signal for training the meta-heuristic. Run each CoT through a proof verifier/an array of unit tests, then assign reward based on that. The learned meta-heuristics can then just internalize that machine verifier. (I. e., they'd basically copy the proof-verifier into the meta-heuristics. Then (a) once a spread of CoTs is generated, it can easily prune those that involve mathematically invalid steps, and (b) the LLM would become ever-more-unlikely to generate a CoT that involves mathematically invalid steps to begin with.)
However, arguably, the capability gains could t...
This is good speculation, but I don't think you need to speculate so much. Papers and replication attempts can provide lots of empirical data points from which to speculate.
You should check out some of the related papers
- H4 uses a process supervision reward model, with MCTS and attempts to replicate o1
- (sp fixed) DeepSeek uses R1 to train DeepSeek v3
Overall, I see people using process supervision to make a reward model that is one step better than the SoTA. Then they are applying TTC to the reward model, while using it to train/distil a cheaper model. The TTC expense is a one-off cost, since it's used to distil to a cheaper model.
There are some papers about the future of this trend:
- Meta uses reasoning tokens to allow models to reason in a latent space (the hidden state, yuck). OpenAI insiders have said that o3 does not work like this, but o4 might. {I would hope they chose a much better latent space than the hidden state. Something interpretable, that's not just designed to be de-embedded into output tokens.}
- Meta throws out tokenisation in favour of grouping predictable bytes
I can see other methods used here instead of process supervision. Process supervision extracts addi...
Just trying to follow along… here’s where I’m at with a bear case that we haven’t seen evidence that o3 is an immediate harbinger of real transformative AGI:
- Codeforces is based in part on wall clock time. And we all already knew that, if AI can do something at all, it can probably do it much faster than humans. So it’s a valid comparison to previous models but not straightforwardly a comparison to top human coders. (EDIT: Oops! This other comment says that they tried to calculate the score in a way that would ignore wall-clock time.)
- FrontierMath is 25% tier 1 (least hard), 50% tier 2, 25% tier 3 (most hard). Terence Tao’s quote about the problems being hard was just tier 3. Tier 1 is IMO/Putnam level maybe. Also, some of even the tier 2 problems allegedly rely on straightforward application of specialized knowledge, rather than cleverness, such that a mathematician could “immediately” know how to do it (see this tweet). Even many IMO/Putnam problems are minor variations on a problem that someone somewhere has written down and is thus in the training data. So o3’s 25.2% result doesn’t really prove much in terms of a comparison to human mathematicians, although again it’s clearly an
I think the best bull case is something like:
They did this pretty quickly and were able to greatly improve performance on a moderately diverse range of pretty checkable tasks. This implies OpenAI likely has an RL pipeline which can be scaled up to substantially better performance by putting in easily checkable tasks + compute + algorithmic improvements. And, given that this is RL, there isn't any clear reason this won't work (with some additional annoyances) for scaling through very superhuman performance (edit: in these checkable domains).[1]
Credit to @Tao Lin for talking to me about this take.
It's been pretty clear to me as someone who regularly creates side projects with ai that the models are actually getting better at coding.
Also, it's clearly not pure memorization, you can deliberately give them tasks that have never been done before and they do well.
However, even with agentic workflows, rag, etc all existing models seem to fail at some moderate level of complexity - they can create functions and prototypes but have trouble keeping track of a large project
My uninformed guess is that o3 actually pushes the complexity by some non-trivial amount, but not enough to now take on complex projects.
It's hard to find numbers. Here's what I've been able to gather (please let me know if you find better numbers than these!). I'm mostly focusing on FrontierMath.
- Pixel counting on the ARC-AGI image, I'm getting $3,644 ± $10 per task.
- FrontierMath doesn't say how many questions they have (!!!). However, they have percent breakdowns by subfield, and those percents are given to the nearest 0.1%; using this, I can narrow the range down to 289-292 problems in the dataset. Previous models solve around 3 problems (4 problems in total were ever solved by any previous model, though the full o1 was not evaluated, only o1-preview was)
- o3 solves 25.2% of FrontierMath. This could be 73/290. But it is also possible that some questions were removed from the dataset (e.g. because they're publicly available). 25.2% could also be 72/286 or 71/282, for example.
- The 280 to 290 problems means a rough ballpark for a 95% confidence interval for FrontierMath would be [20%, 30%]. It is pretty strange that the ML community STILL doesn't put confidence intervals on their benchmarks. If you see a model achieve 30% on FrontierMath later, remember that its confidence interval would overlap with o3's. (Edit: actuall
This is actually likely more expensive than hiring a domain-specific expert mathematician for each problem
I don't think anchoring to o3's current cost-efficiency is a reasonable thing to do. Now that AI has the capability to solve these problems in-principle, buying this capability is probably going to get orders of magnitude cheaper within the next five minutes months, as they find various algorithmic shortcuts.
I would guess that OpenAI did this using a non-optimized model because they expected it to be net beneficial: that producing a headline-grabbing result now will attract more counterfactual investment than e. g. the $900k they'd save by running the benchmarks half a year later.
Edit: In fact, if, against these expectations, the implementation of o3's trick can't be made orders-of-magnitude cheaper (say, because a base model of a given size necessarily takes ~n tries/MCTS branches per a FrontierMath problem and you can't get more efficient than one try per try), that would make me do a massive update against the "inference-time compute" paradigm.
I'll admit I'm not very certain in the following claims, but here's my rough model:
- The AGI labs focus on downscaling the inference-time compute costs inasmuch as this makes their models useful for producing revenue streams or PR. They don't focus on it as much beyond that; it's a waste of their researchers' time. The amount of compute at OpenAI's internal disposal is well, well in excess of even o3's demands.
- This means an AGI lab improves the computational efficiency of a given model up to the point at which they could sell it/at which it looks impressive, then drop that pursuit. And making e. g. GPT-4 10x cheaper isn't a particularly interesting pursuit, so they don't focus on that.
- Most of the models of the past several years have only been announced near the point at which they were ready to be released as products. I. e.: past the point at which they've been made compute-efficient enough to be released.
- E. g., they've spent months post-training GPT-4, and we only hear about stuff like Sonnet 3.5.1 or Gemini Deep Research once it's already out.
- o3, uncharacteristically, is announced well in advance of its release. I'm getting the sense, in fact, that we might be seeing the raw blee
edit: wait likely it's RL; I'm confused
OpenAI didn't fine-tune on ARC-AGI, even though this graph suggests they did.
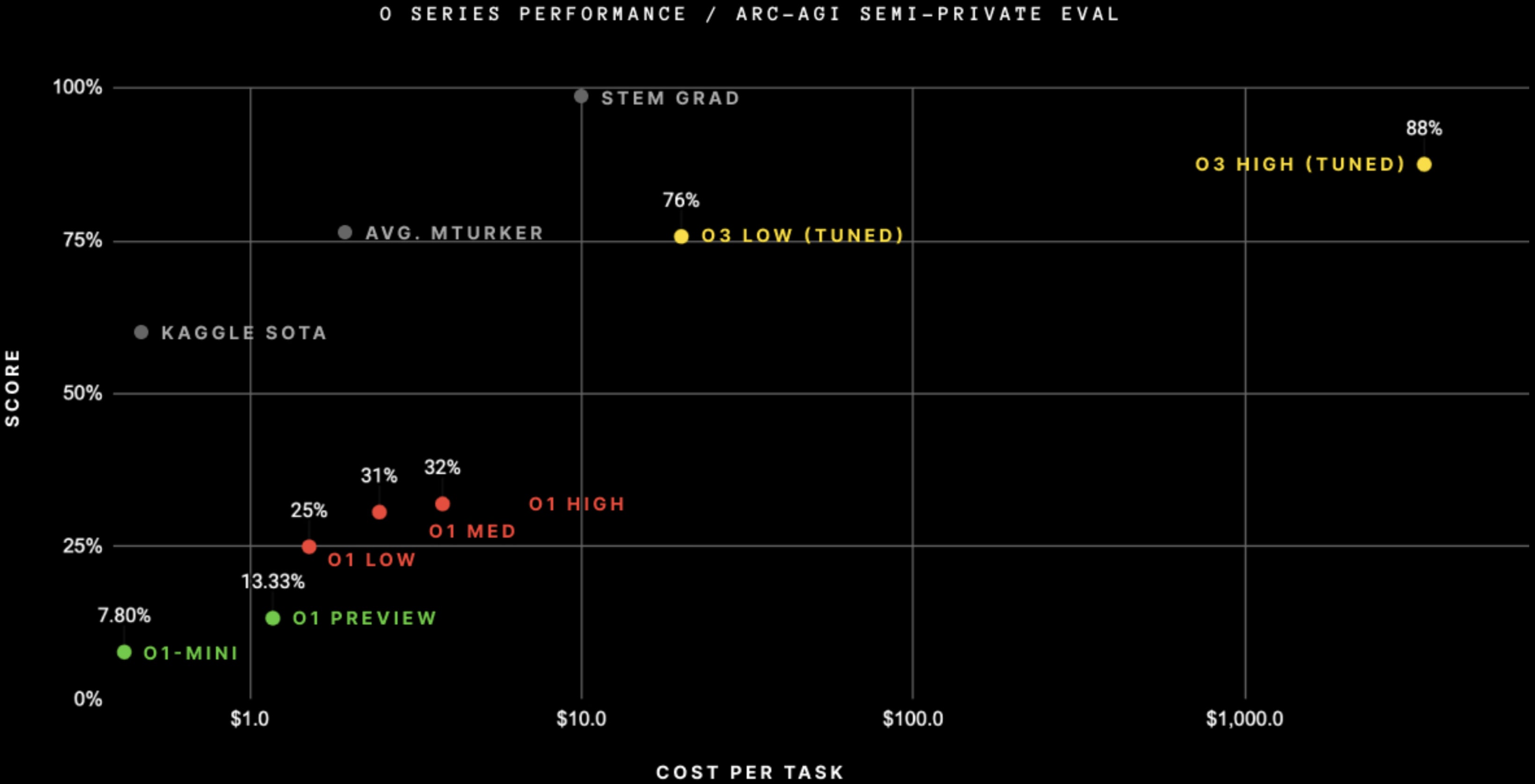
Sources:
Altman said
we didn't go do specific work [targeting ARC-AGI]; this is just the general effort.
François Chollet (in the blogpost with the graph) said
Note on "tuned": OpenAI shared they trained the o3 we tested on 75% of the Public Training set. They have not shared more details. We have not yet tested the ARC-untrained model to understand how much of the performance is due to ARC-AGI data.
The version of the model we tested was domain-adapted to ARC-AGI via the public training set (which is what the public training set is for). As far as I can tell they didn't generate synthetic ARC data to improve their score.
An OpenAI staff member replied
Correct, can confirm "targeting" exclusively means including a (subset of) the public training set.
and further confirmed that "tuned" in the graph is
a strange way of denoting that we included ARC training examples in the O3 training. It isn’t some finetuned version of O3 though. It is just O3.
Another OpenAI staff member said
...also: the model we used for all of our o3 evals is fully general; a subset of the arc-agi public trai
As I say here https://x.com/boazbaraktcs/status/1870369979369128314
Constitutional AI is a great work but Deliberative Alignment is fundamentally different. The difference is basically system 1 vs system 2. In RLAIF ultimately the generative model that answers user prompt is trained with (prompt, good response, bad response). Even if the good and bad responses were generated based on some constitution, the generative model is not taught the text of this constitution, and most importantly how to reason about this text in the context of a particular example.
This ability to reason is crucial to OOD performance such as training only on English and generalizing to other languages or encoded output.
See also https://x.com/boazbaraktcs/status/1870285696998817958
“Scaling is over” was sort of the last hope I had for avoiding the “no one is employable, everyone starves” apocalypse. From that frame, the announcement video from openai is offputtingly cheerful.
I don't emphasize this because I care more about humanity's survival than the next decades sucking really hard for me and everyone I love.
I'm flabbergasted by this degree/kind of altruism. I respect you for it, but I literally cannot bring myself to care about "humanity"'s survival if it means the permanent impoverishment, enslavement or starvation of everybody I love. That future is simply not much better on my lights than everyone including the gpu-controllers meeting a similar fate. In fact I think my instincts are to hate that outcome more, because it's unjust.
But how do LW futurists not expect catastrophic job loss that destroys the global economy?
Slight correction: catastrophic job loss would destroy the ability of the non-landed, working public to paritcipate in and extract value from the global economy. The global economy itself would be fine. I agree this is a natural conclusion; I guess people were hoping to get 10 or 15 more years out of their natural gifts.
Regarding whether this is a new base model, we have the following evidence:
o3 is very performant. More importantly, progress from o1 to o3 was only three months, which shows how fast progress will be in the new paradigm of RL on chain of thought to scale inference compute. Way faster than pretraining paradigm of new model every 1-2 years
o1 was the first large reasoning model — as we outlined in the original “Learning to Reason” blog, it’s “just” an LLM trained with RL. o3 is powered by further scaling up RL beyond o1, and the strength of the resulting model the resulting model is very, very impressive. (2/n)
The prices leaked by ARC-ARG people indicate $60/million output tokens, which is also the current o1 pricing. 33m total tokens and a cost of $2,012.
Notably, the codeforces graph with pricing puts o3 about 3x higher than o1 (tho maybe it's a secretly log scale), and the ARC-AGI graph has the cost of o3 being 10-20x that of o1-preview. Maybe this indicates it does a bunch more test-time reasoning. That's collaborated by ARC-AGI, average 55k tokens per solution[1], which seems like a ton.
I think this evidence indicates this is likely the sam...
Fucking o3. This pace of improvement looks absolutely alarming. I would really hate to have my fast timelines turn out to be right.
The "alignment" technique, "deliberative alignment", is much better than constitutional AI. It's the same during training, but it also teaches the model the safety criteria, and teaches the model to reason about them at runtime, using a reward model that compares the output to their specific safety criteria. (This also suggests something else I've been expecting - the CoT training technique behind o1 doesn't need perfectly verifiable answers in coding and math, it can use a decent guess as to the better answer in what's probably the same procedure).
While safety is not alignment (SINA?), this technique has a lot of promise for actual alignment. By chance, I've been working on an update to my Internal independent review for language model agent alignment, and have been thinking about how this type of review could be trained instead of scripted into an agent as I'd originally predicted.
This is that technique. It does have some promise.
But I don't think OpenAI has really thought through the consequences of using their smarter-than-human models with scaffold...
I was still hoping for a sort of normal life. At least for a decade or maybe more. But that just doesn't seem possible anymore. This is a rough night.
Oh dear, RL for everything, because surely nobody's been complaining about the safety profile of doing RL directly on instrumental tasks rather than on goals that benefit humanity.
My probably contrarian take is that I don't think improvement on a benchmark of math problems is particularly scary or relevant. It's not nothing -- I'd prefer if it didn't improve at all -- but it only makes me slightly more worried.
About two years ago I made a set of 10 problems that imo measure progress toward AGI and decided I'd freak out if/when LLMs solve them. They're still 1/10 and nothing has changed in the past year, and I doubt o3 will do better. (But I'm not making them public.)
Will write a reply to this comment when I can test it.
Using $4K per task means a lot of inference in parallel, which wasn't in o1. So that's one possible source of improvement, maybe it's running MCTS instead of individual long traces (including on low settings at $20 per task). And it might be built on the 100K H100s base model.
The scary less plausible option is that RL training scales, so it's mostly o1 trained with more compute, and $4K per task is more of an inefficient premium option on top rather than a higher setting on o3's source of power.
Performance at $20 per task is already much better than for o1, so it can't be just best-of-n, you'd need more attempts to get that much better even if there is a very good verifier that notices a correct solution (at $4K per task that's plausible, but not at $20 per task). There are various clever beam search options that don't need to make inference much more expensive, but in principle might be able to give a boost at low expense (compared to not using them at all).
There's still no word on the 100K H100s model, so that's another possibility. Currently Claude 3.5 Sonnet seems to be better at System 1, while OpenAI o1 is better at System 2, and combining these advantages in o3 based on a yet-unannounced GPT-4.5o base model that's better than Claude 3.5 Sonnet might be sufficient to explain the improvement. Without any public 100K H100s Chinchilla optimal models it's hard to say how much that alone should help.
I wish they would tell us what the dark vs light blue means. Specifically, for the FrontierMath benchmark, the dark blue looks like it's around 8% (rather than the light blue at 25.2%). Which like, I dunno, maybe this is nit picking, but 25% on FrontierMath seems like a BIG deal, and I'd like to know how much to be updating my beliefs.
From an apparent author on reddit:
[Frontier Math is composed of] 25% T1 = IMO/undergrad style problems, 50% T2 = grad/qualifying exam style porblems, 25% T3 = early researcher problems
The comment was responding to a claim that Terence Tao said he could only solve a small percentage of questions, but Terence was only sent the T3 questions.
While I'm not surprised by the pessimism here, I am surprised at how much of it is focused on personal job loss. I thought there would be more existential dread.
Existential dread doesn't necessarily follow from this specific development if training only works around verifiable tasks and not for everything else, like with chess. Could soon be game-changing for coding and other forms of engineering, without full automation even there and without applying to a lot of other things.
First post, feel free to meta-critique my rigor on this post as I am not sure what is mandatory, expected, or superfluous for a comment under a post. Studying computer science but have no degree, yet. Can pull the specific citation if necessary, but...
these benchmarks don't feel genuine.
Chollet indicated in his piece:
...Furthermore, early data points suggest that the upcoming ARC-AGI-2 benchmark will still pose a significant challenge to o3, potentially reducing its score to under 30% even at high compute (while a smart human would still be able to score ov
I just straight up don't believe the codeforces rating. I guess only a small subset of people solve algorithmic problems for fun in their free time, so it's probably opaque to many here, but a rating of 2727 (the one in the table) would be what's called an international grandmaster and is the 176th best rating among all actively competing users on the site. I hope they will soon release details about how they got that performance measure..
CodeForces ratings are determined by your performance in competitions, and your score in a competition is determined, in part, by how quickly you solve the problems. I'd expect o3 to be much faster than human contestants. (The specifics are unclear - I'm not sure how a large test-time compute usage translates to wall-clock time - but at the very least o3 parallelizes between problems.)
This inflates the results relative to humans somewhat. So one shouldn't think that o3 is in the top 200 in terms of algorithmic problem solving skills.
As in, for the literal task of "solve this code forces problem in 30 minutes" (or whatever the competition allows), o3 is ~ top 200 among people who do codeforces (supposing o3 didn't cheat on wall clock time). However, if you gave humans 8 serial hours and o3 8 serial hours, much more than 200 humans would be better. (Or maybe the cross over is at 64 serial hours instead of 8.)
Is this what you mean?
See appendix B.3 in particular:
Competitors receive a higher score for submitting their solutions faster. Because models can think in parallel and simultaneously attempt all problems, they have an innate advantage over humans. We elected to reduce this advantage in our primary results by estimating o3’s score for each solved problem as the median of the scores of the human participants that solved that problem in the contest with the same number of failed attempts.
We could instead use the model’s real thinking time to compute ratings. o3 uses a learned scoring function for test-time ranking in addition to a chain of thought. This process is perfectly parallel and true model submission times therefore depend on the number of available GPU during the contest. On a very large cluster the time taken to pick the top-ranked solutions is (very slightly more than) the maximum over the thinking times for each candidate submission. Using this maximum parallelism assumption and the sequential o3 sampling speed would result in a higher estimated rating than presented here. We note that because sequential test-time compute has grown rapidly since the early language models, it was not guaranteed that models would solve problems quickly compared to humans, but in practice o3 does.
That's some significant progress, but I don't think will lead to TAI.
However there is a realistic best case scenario where LLM/Transformer stop just before and can give useful lessons and capabilities.
I would really like to see such an LLM system get as good as a top human team at security, so it could then be used to inspect and hopefully fix masses of security vulnerabilities. Note that could give a false sense of security, unknown unknown type situation where it would't find a totally new type of attack, say a combined SW/HW attack like Rowhammer/Meltdown but more creative. A superintelligence not based on LLM could however.
Beating benchmarks, even very difficult ones, is all find and dandy, but we must remember that those tests, no matter how difficult, are at best only a limited measure of human ability. Why? Because they present the test-take with a well-defined situation to which they must respond. Life isn't like that. It's messy and murky. Perhaps the most difficult step is to wade into the mess and the murk and impose a structure on it – perhaps by simply asking a question – so that one can then set about dealing with that situation in terms of the imposed structure. T...
OpenAI didn't say what the light blue bar is
Presumably light blue is o3 high, and dark blue is o3 low?
For people who don't expect a strong government response... remember that Elon is First Buddy now. 🎢
See livestream, site, OpenAI thread, Nat McAleese thread.
OpenAI announced (but isn't yet releasing) o3 and o3-mini (skipping o2 because of telecom company O2's trademark). "We plan to deploy these models early next year." "o3 is powered by further scaling up RL beyond o1"; I don't know whether it's a new base model.
o3 gets 25% on FrontierMath, smashing the previous SoTA. (These are really hard math problems.[1]) Wow. (The dark blue bar, about 7%, is presumably one-attempt and most comparable to the old SoTA; unfortunately OpenAI didn't say what the light blue bar is, but I think it doesn't really matter and the 25% is for real.[2])
o3 also is easily SoTA on SWE-bench Verified and Codeforces.
It's also easily SoTA on ARC-AGI,
after doing RL on the public ARC-AGI problems[3] + when spending $4,000 per task on inference (!).[4] (And at less inference cost.)ARC Prize says:
OpenAI has a "new alignment strategy." (Just about the "modern LLMs still comply with malicious prompts, overrefuse benign queries, and fall victim to jailbreak attacks" problem.) It looks like RLAIF/Constitutional AI. See Lawrence Chan's thread.[5]
OpenAI says "We're offering safety and security researchers early access to our next frontier models"; yay.
o3-mini will be able to use a low, medium, or high amount of inference compute, depending on the task and the user's preferences. o3-mini (medium) outperforms o1 (at least on Codeforces and the 2024 AIME) with less inference cost.
GPQA Diamond:
Update: most of them are not as hard as I thought:
My guess is it's consensus@128 or something (i.e. write 128 answers and submit the most common one). Even if it's pass@n (i.e. submit n tries) rather than consensus@n, that's likely reasonable because I heard FrontierMath is designed to have easier-to-verify numerical-ish answers.
Update: it's not pass@n.
Correction: no RL! See comment.
Correction to correction: nevermind, I'm confused.
It's not clear how they can leverage so much inference compute; they must be doing more than consensus@n. See Vladimir_Nesov's comment.
Update: see also disagreement from one of the authors.