This is a special post for quick takes by leogao. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Rendering 1000/1605 comments, sorted by (show more) Click to highlight new comments since:
some lessons from ml research:
- any shocking or surprising result in your own experiment is 80% likely to be a bug until proven otherwise. your first thought should always be to comb for bugs.
- only after you have ruled out bugs do you get to actually think about how to fit your theory to the data, and even then, there might still be a hidden bug.
- most papers are terrible and don't replicate.
- most techniques that sound intuitively plausible don't work.
- most techniques only look good if you don't pick a strong enough baseline.
- an actually good idea can take many tries before it works.
- once you have good research intuitions, the most productive state to be in is to literally not think about what will go into the paper and just do experiments that satisfy your curiosity and. convince yourself that the thing is true. once you have that, running the final sweeps is really easy
- most people have no intuition whatsoever about their hardware and so will write code that is horribly inefficient. even learning a little bit about hardware fundamentals so you don't do anything obviously dumb is super valuable
- in a long and complex enough project, you will almost certainly have a bug that invalidates weeks
I agree and this is why research grant proposals often feel very fake to me. I generally just write up my current best idea / plan for what research to do, but I don't expect it actually pan out that way and it would be silly to try to stick rigidly to a plan.
8
Can basically attest to all of these, been doing intensive ML upskilling for the last half a year and almost all of these have been true. Highlights include:
* Not properly setting up the attention mechanism in multiple experiments, resulting in the conclusion that attention didn't do much (lmao)
* So, so many off-by-one, off-by-two errors, especially for next-token prediction setups
* Entire series of weeks-long experiments that turn out to be completely useless (usually based on a seemingly-reasonable intuition of some kind)
* Accidentally overwriting/resetting the residual element so the RNN was just an NN with a funky hat on
* I now hate shapes, reshaping, squeezing, unsqueezing, devices, torch.nn.functional.pad, so many more functions
* Using the wrong loss function
* Using the right loss function but with the wrong reduction
* Using the right loss function but the learning rate is too aggressive/too low/the optimiser is not initialised properly
* Using all the right things but loading the model from an incorrect checkpoint/not saving the weights properly
* And also learning that google colab was forged in mount doom, a tool of great power crafted with malicious intent.
5
Are you using einops and einsum? I hate these somewhat less since using them. See here for more details.
4
Be right back, just adding all that to my "AI researcher" prompt
3
I will add: 80% likely to be a bug, or a result from random-matrix theory.
3
Research sounds really finicky and tedious.
do you have an ambitious idea for how to make AGI go well? do you need money? do you hate bureaucracy and friction? apply now for microgrants!
please read the entire doc before applying. only send applications to the designated location, or they will be automatically rejected.
https://docs.google.com/document/d/10zAp2bXTkZgiPreIm4crp38TFco4KleFN14Kw5BprAs/edit?tab=t.0
8
Do you have a limit on number of grants you'd be able to give out?
9
i don't anticipate being bottlenecked on funding. i will assess grants based on simply whether they should be funded. if the number of grants worth funding is greater than the funding available, i will seek more funding.
3
Nice, I've added this to AISafety.com/funding and it'll go out in the funding newsletter next week. Let me know if you'd like any changes to the listing.
i recently ran into to a vegan advocate tabling in a public space, and spoke briefly to them for the explicit purpose of better understanding what it feels like to be the target of advocacy on something i feel moderately sympathetic towards but not fully bought in on. (i find this kind of thing very valuable for noticing flaws in myself and improving; it's much harder to be perceptive of one's own actions otherwise). the part where i am genuinely quite plausibly persuadable of his position in theory is important; i think if i had talked to e.g flat earthers one might say my reaction is just because i'd already decided not to be persuaded. several interesting things i noticed (none of which should be surprising or novel, especially for someone less autistic than me, but as they say, intellectually knowing things is not the same as actual experience):
- this guy certainly knew more about e.g health impacts of veganism than i did, and i would not have been able to hold my own in an actual debate.
- in particular, it's really easy for actually-good-in-practice heuristics to come out as logical fallacies, especially when arguing with someone much more familiar with the object level details th
3
I don't think it would be that hard to refute flat earthers. One or two facts about how the sun travels, that the atmosphere bends light, and the fact that there are commercial flights crossing the poles seem like they would be sufficient to me. This probably won't convince a flat earther, but I think you could fairly easily convince 95% of smart unbiased 3ed listeners (not that they exist).
You don't have to go down every option in their argument tree, finding one argument they are completely unable to refute can be enough.
I claim that even if the openai contract is not meaningfully weaker safety wise, it is still bad for openai to publicly signal solidarity with ant but then sign with DoW.
suppose hypothetically the only difference between the openai and anthropic contracts is that the DoW wanted a snicker bar, and anthropic didn't want to give DoW the snickers bar. even then, it would be a huge dick move for openai to publicly signal solidarity, and then sign with DoW to give them the snickers bar.
9
OAI genuinely outplayed Anthropic here. The critical success world for OAI would be if OAI gets good PR from "solidarity", replaces Ant under the ~same terms, and there is enough uncertainty of Anthropic being a supply chain risk that eg Amazon stops providing them compute, basically killing the company.
Most of this is still on the table, because Anthropic was too concerned about appearing principled and was exploited by DoW and Altman.
8
I can see the story where there was a strong opportunity for a competitor here, and OpenAI successfully seized it (perhaps Google DeepMind could have as well, but I don't view them as nimble as OpenAI). I don't see a story where Anthropic had a clear alternative play that was much better, especially once the USG threatened with labeling them a supply-chain risk.
7
I think this comment aged very poorly
6
I think it's unclear that this was overall bad for Anthropic/Amodei if you factor in the reputational and ideological boost they got ("aura farming" according to roon).
4
Is it publicly known what is in fact the difference between the two contracts?
9
https://x.com/justanotherlaw/status/2027855993921802484
theory: a huge part of having a good social life is just taking social bids whenever they become available. examples of social bids both large and small include: deciding whether to join your friends on a roadtrip; getting to know someone you just met; getting to better know someone you bump into occasionally but usually never talk to; standing in line, seeing something amusing, and having the option to point this out to another stranger in line; saying something funny in a group conversation; following up over text with someone after meeting them; flirting; cold emailing someone on the internet; catching up with a friend.
there are a variety of reasons why we might end up not taking social bids. if you don't have the social ability to notice opportunities to take bids, you might miss bids that you could take. if you force yourself to take bids without the requisite social ability, and end up taking bids which you incorrectly believe to exist, you might act in ways that people find weird, and burn potential connections, or intrude on people. if you are really tired or low-bandwidth or depressed or stressed, you will not want to take bids, because taking bids requires quite a lot of ...
4
Good post. On a detail I’d use the word ‘opportunities’ rather than ‘bids’, which sounds like ‘offers’ - whereas in various of these examples you’re not being explicitly offered a social opportunity by someone. But the situation contains an opportunity.
3
Do you struggle with feelings of isolation? I do sometimes, and I try to fix that by taking more social bids and proactively seeking social life. And then I immediately pull out because I get overwhelmed by social life very easily and it kinda colonizes my thought processes too much. So I'm kind of stuck in that loop of seeking more of it and then pulling out and then seeking more of it...
6
Same.
There's some old greek who had a parable about hedgehogs in the cold, that shuffle closer and closer for warmth until they sting each other and shuffle apart again. I always thought that applies pretty well.
3
I mostly get overwhelmed by social bids when I am physically tired or unwell, rather than purely because of social life.
it's surprising just how much of cutting edge research (at least in ML) is dealing with really annoying and stupid bottlenecks. pesky details that seem like they shouldn't need attention. tools that in a good and just world would simply not break all the time.
i used to assume this was merely because i was inexperienced, and that surely eventually you learn to fix all the stupid problems, and then afterwards you can just spend all your time doing actual real research without constantly needing to context switch to fix stupid things.
however, i've started to think that as long as you're pushing yourself to do novel, cutting edge research (as opposed to carving out a niche and churning out formulaic papers), you will always spend most of your time fixing random stupid things. as you get more experienced, you get bigger things done faster, but the amount of stupidity is conserved. as they say in running- it doesn't get easier, you just get faster.
as a beginner, you might spend a large part of your research time trying to install CUDA or fighting with python threading. as an experienced researcher, you might spend that time instead diving deep into some complicated distributed trai...
Not only is this true in AI research, it’s true in all science and engineering research. You’re always up against the edge of technology, or it’s not research. And at the edge, you have to use lots of stuff just behind the edge. And one characteristic of stuff just behind the edge is that it doesn’t work without fiddling. And you have to build lots of tools that have little original content, but are needed to manipulate the thing you’re trying to build.
After decades of experience, I would say: any sensible researcher spends a substantial fraction of time trying to get stuff to work, or building prerequisites.
This is for engineering and science research. Maybe you’re doing mathematical or philosophical research; I don’t know what those are like.
9
I can emphathetically say this is not the case in mathematics research.
a corollary is i think even once AI can automate the "google for the error and whack it until it works" loop, this is probably still quite far off from being able to fully automate frontier ML research, though it certainly will make research more pleasant
3
I agree if I specify 'quite far off in ability-space', while acknowledging that I think this may not be 'quite far off in clock-time'. Sometimes the difference between no skill at a task and very little skill is a larger time and effort gap than the difference between very little skill and substantial skill.
7
Completely agree. I remember a big shift in my performance when I went from "I'm just using programming so that I can eventually build a startup, where I'll eventually code much less" to "I am a programmer, and I am trying to become exceptional at it." The shift in mindset was super helpful.
5
More and more, I'm coming to the belief that one big flaw of basically everyone in general is not realizing how much you needed to deal with annoying and pesky/stupid details to do good research, and I believe some of this dictum also applies to alignment research as well.
There is thankfully more engineering/ML experience in LW which alleviates the issue partially, but still, not realizing that pesky details mattering a lot in research/engineering is a problem that basically no one wants to particularly deal with.
4
I would hope for some division of labor. There are certainly people out there who can't do ML research, but can fix Python code.
But I guess, even if you had the Python guy and the budget to pay him, waiting until he fixes the bug would still interrupt your flow.
I think there are several reasons this division of labor is very minimal, at least in some places.
- You need way more of the ML engineering / fixing stuff skill than ML research. Like, vastly more. There are still a very small handful of people who specialize full time in thinking about research, but they are very few and often very senior. This is partly an artifact of modern ML putting way more emphasis on scale than academia.
- Communicating things between people is hard. It's actually really hard to convey all the context needed to do a task. If someone is good enough to just be told what to do without too much hassle, they're likely good enough to mostly figure out what to work on themselves.
- Convincing people to be excited about your idea is even harder. Everyone has their own pet idea, and you are the first engineer on any idea you have. If you're not a good engineer, you have a bit of a catch-22: you need promising results to get good engineers excited, but you need engineers to get results. I've heard of even very senior researchers finding it hard to get people to work on their ideas, so they just do it themselves.
the following fictional dialogue is a complete unapologetic strawman but it's funny enough i had to bring it into being:
“So I asked myself: where can I make the most impact? And clearly malaria is the most important area.”
“And so you decided to donate all of your money to buy malaria nets?”
“Well, so it turns out that saving lives from malaria is actually kind of expensive and indirect. You see, it costs thousands of dollars to save a life. Statistically. Who knows if you’re actually changing anyone's life that way?”
“And so you found a more efficient way to save lives.”
“Actually, it turns out that it’s cheaper to give people malaria. It's a lot more impactful and the technical problems are more interesting.”
"I see. Isn't more malaria bad though?"
"I don't know, but I find it much easier to work on because the feedback loops are much tighter. Maybe one day, if malaria gets big enough, I’ll go work on saving people from malaria. But we're still a long way away from everyone having malaria."
"I became a scientist because I wanted to change the world," said Dr Connor.
"There are no better opportunities to change the world than here at Effective Evil," said Doug.
"I meant 'change the world for the better'," said Dr Connor.
"Then you should have been more specific," said Doug.
4
HAS CURE FOR DISEASE
SPREADS DISEASE TO CURE
— Insanity Wolf
"to the success of our hopeless cause" is such a good toast and we should use it more often. i first learned of it from the book of the same name, and apparently it was a common refrain at gatherings of Soviet dissidents. i like it because it captures the feeling of trying really hard to succeed despite being in the basement of the logistic success curve, and somehow, despite all odds, actually succeeding in the end.
I do find it poetic, but in seriousness I think if folks don't actually feel hopeful about what they're doing then they should do something else - leave the work / research direction / engineering / comms / whatnot to whoever actually feels hope about it...
To elaborate, the thing that's poetic for me about "our hopeless cause" is because I have hope that is not cleanly legible to the outside, easy to write off as "hopeless". And it's important to stay in tune with your own knowings about this stuff. I think there are very deleterious effects from throwing energy into things one doesn't have hope in.
(...And to elaborate further, mostly I think the bad stuff happens by lending support to corrupt things. And imo being pushed to work on X while you lack hope in X is a solid flag of corruption.)
This is a good heuristic when you're fighting against nature, it's not a good heuristic when you're trying to solve coordination problems.

5
...what sort of "coordination problems" does one "solve" by doing things you don't have hope in? I really don't get it and am perplexed. This photo is swellingly full of hope, and presumably we got there through people that had hope in their actions. Perhaps there's detail in the history you're referencing that's going over my head.
the problem was that everyone hated living in the Soviet Union and other eastern Bloc countries, but few people were willing to stand up and protest, because doing so meant a knock on your door by men with guns who would take you away to a Siberian prison or mental institution.
the thing with protests is they are a coordination problem. to loosely paraphrase one of the dissidents from this era, if one person protests he becomes a martyr. if ten people protest they become a conspiracy. if ten thousand people protest the system has to change.
he problem is you have no way of knowing when the right moment is. under Stalin, dissent was impossible. everyone even suspected of being disloyal was instantly executed or thrown in a gulag.
after he died, Khrushchev denounced Stalin's methods and instituted reforms, and dissent meant "only" being interrogated by the KGB, put on trial in a rigged but no longer completely farcical show trial, and sent to Siberia for only 10 years rather than being executed. this was enough easing up that the "chain reaction" started happening - people would protest, be arrested, someone would go secretly write a transcript of the trial and publish it, people would...
If ten thousand people protest, sometimes they get massacred by the army.
Iran is a recent example of this.
funny enough, at least one dissident at the time expressed that he didn't like this toast because he wouldn't be trying to dissent if he thought it was hopeless
3
I think some can have the feelings that go with hope in a cause, without actually believing the cause is likely to succeed. Cultural memes around fighting for hopeless causes (e.g. when heros go for hail mary strategies in movies) help.
It still matters whether you truly think it's the best shot at victory, or the best way for you to help. That's what I see as key to preventing the various problems that you mention.
running the agi survey really reminded me just how brutal statistical significance is, and how unreliable anecdotes are. even setting aside sampling bias of anecdotes, the sheer sample size you need to answer a question like "do more people this year know what agi is than last year" is kind of depressing - you need like 400 samples for each year just to be 80% sure you'd notice a 10 percentage point increase even if it did exist, and even if there was no real effect you'd still think there was one 5% of the time. this makes me a lot more bearish on vibes in general.
thank you for this post. "bearish on vibes" is a great phrase. i am constantly hung up on the fact that it's not really possible to "know what normal people are like", "know what people are like generally", "know what the world is actually like", without significant amounts of effort.
i think this background fact taints like... most discussion of social and ethical issues.
4
Why does this make you more bearish on vibes? The reason I ask is that I think of "vibes" as aggregating over a much wider (but siloed) social network and a lot more sources of information. It would be interesting to know about to what extent rigorous high-n survey methods would reveal discrepancies between assumptions and reality about people's perceptions in this and other areas to do with pressing social issues.
like, suppose i anecdotally noticed a few people last year be visibly confused when i said the phrase AGI in normal conversation last year, and then this year i noticed that many fewer people were visibly confused by AGI. then, this would tell me almost nothing about whether name-recognition of AGI increased or decreased; at n=10, it is nearly impossible to say anything whatsoever.
in research, if you settle into a particular niche you can churn out papers much faster, because you can develop a very streamlined process for that particular kind of paper. you have the advantage of already working baseline code, context on the field, and a knowledge of the easiest way to get enough results to have an acceptable paper.
while these efficiency benefits of staying in a certain niche are certainly real, I think a lot of people end up in this position because of academic incentives - if your career depends on publishing lots of papers, then a recipe to get lots of easy papers with low risk is great. it's also great for the careers of your students, because if you hand down your streamlined process, then they can get a phd faster and more reliably.
however, I claim that this also reduces scientific value, and especially the probability of a really big breakthrough. big scientific advances require people to do risky bets that might not work out, and often the work doesn't look quite like anything anyone has done before.
as you get closer to the frontier of things that have ever been done, the road gets tougher and tougher. you end up spending more time building basic infra...
5
I think this is true, and I also think that this is an even stronger effect in wetlab fields where there is lock-in to particular tools, supplies, and methods.
This is part of my argument for why there appears to be an "innovation overhang" of underexplored regions of concept space. And, in the case of programming dependent disciplines, I expect AI coding assistance to start to eat away at the underexplored ideas, and for full AI researchers to burn through the space of implied hypotheses very fast indeed. I expect this to result in a big surge of progress once we pass that capability threshold.
3
Or perhaps on the flip side there is a ‘super genius underhang’ where there are insufficient numbers of super competent people to do that work. (Or willing to bet on their future selves being super competent.)
It makes sense for the above average, but not that much above average, researcher to choose to focus on their narrow niche, since their relative prospects are either worse or not evaluable after wading into the large ocean of possibilities.
3
Or simply when scaling becomes too expensive.
4
I agree that academia over rewards long-term specialization. On the other hand, it is compatible to also think, as I do, that EA under-rates specialization. At a community level, accumulating generalists has fast diminishing marginal returns compared to having easy access to specialists with hard-to-acquire skillsets.
the modern world has many flaws, but I'm still deeply grateful for the modern era of unprecedented peace, prosperity, and freedom in the developed world. 99% of people reading these words have never had to worry about dying in a cholera epidemic, or malaria or smallpox or the plague, or childbirth, or in war, or from a famine, or due to a political purge. this is not true for other times in history, or other places in the world today.
(extremely unoriginal thought, but still important to acknowledge periodically because it's easy to take for granted. especially because it's much more common to complain about ways the world is broken than to acknowledge what has improved over time.)
6
There might already be a selection bias for people who read lesswrong. For people who are in war, having some malaria, and etc - they may not get the chance to access internet, nor have time to gain interest in lesswrong. My point is while we are grateful, we probably would want to reflect on our own privileges on access to peace (not sure unprecedented), and recognize there are still a lot of work needed to be done for people outside our circles. Additionally, sometimes bad things could happen all in a sudden - maybe the country you are in suddenly is war zone, maybe you got some accidents/mental health issues, or maybe the worry about dying is just a healthcare disaster away. The health risk, especially, increases with age.
5
And also I think it's less than 99% anyway, ''worry about dying in a cholera epidemic, or malaria or smallpox or the plague, or childbirth, or in war, or from a famine, or due to a political purge" is very broad. Like, surely some of the people here were at some risk during covid epidemic? Some people are male, from countries with drafts which are currently participating or at tangible risk of wars. Some people are from countries with unstable governments and done some activism work before. Like, 75% is my guess.
4
(My response to you is also unoriginal but worth stating imo.)
I would prefer if you used the phrase "US geopolitical sphere of influence" instead of "developed world". It makes it clear your take is political.
Leaders within the US govt have obviously contributed to multiple wars and genocides, you just happen to be born into a family that is not on the receiving end of any of them. Part of the reason (but not the full reason) for the economic prosperity is crude oil deals made by the US govt under threat of nuclear war.
Statements such as yours give leaders within the US govt implicit consent to continue this sort of rule over the world.
7
This period of global safety is not fairly distributed,
But it is also real
https://data.unicef.org/resources/levels-and-trends-in-child-mortality-2024/
4
Rule of law
Energy use per capita
Global utility includes the above two things (first two tiers of Maslow's hierarchy) not just counting the number of deaths (where I agree health-related deaths are the biggest bracket).
I consider US govt partially responsible for unequal distribution.
I think it would be really bad for humanity to rush to build superintelligence before we solve the difficult problem of how to make it safe. But also I think it would be a horrible tragedy if humanity never ever built superintelligence. I hope we figure out how to thread this needle with wisdom.
I agree with this fwiw. Currently I think we are in way way more danger of rushing to build it too fast than of never building it at all, but if e.g. all the nations of the world had agreed to ban it, and in fact were banning AI research more generally, and the ban had held stable for decades and basically strangled the field, I'd be advocating for judicious relaxation of the regulations (same thing I advocate for nuclear power basically).
I am not really clear that I should be worried on the scale of decades? If we're doing a calculation of expected future years of a flourishing technologically mature civilization, slowing down for 1,000 years here in order to increase the chance of success by like 1 percentage point is totally worth it in expectation.
Given this, it seems plausible to me that one should rather spend 200 years trying to improve civilizational wisdom and decision-making rather than instead attempt to specifically just unlock regulation on AI (of course the specifics here are cruxy).
I agree that 200 years would be worth it if we actually thought that it would work. My concern is that it's not clear civilization would get better/moresane/etc. over the next century vs. worse. And relatedly, every decade that goes by, we eat another percentage point or three of x-risk from miscellaneous other sources (nuclear war, pandemics, etc.) which basically impose a time-discount factor on our calculations large enough to make a 200 year pause seem really dangerous and bad to me.
while I agree for smaller numbers like a few decades, I don't think I agree with a 1000 year pause.
I think (a) it's perfectly reasonable for people to be selfish and care about superintelligence happening during their lifetime (forget future people and discount factors thereof - almost every single person alive today cares ooms more about themselves than about some random person on the other side of the planet), (b) it's easy for "delay forever" people to basically pascal's mug you this way, as in nuclear power (c) it's unclear that humanity becomes monotonically more wise over time (as an unrealistic example, consider a world where we successfully create an international treaty to ensure ASI is safe, and then for some reason the entire world modern order collapses and the only actors left are random post-collapse states racing to build ASI. then it would have been better to build ASI in a functional pre-collapse world order than to delay. one could reasonably (though i personally don't) believe that the current world order is likely to fail in the coming decades and ASI is best built now than in the ensuing chaos)
3
Yes people are selfish, that is why you should sometimes be ready to fight against them. Point a is not a disagreement with Ben.
[...]
This is low probability on time scale of decades but is an argument people can use to justify their self-serving desires for immortality as somehow altruistic.
6
If I understood Eliezers argument correctly we can shorten those timescales buy improving human intelligences through methods like genetic engineering. Once majority of humans have Von Neumann level IQ I think its fine to let them decide how to proceed on AI research. Question is, how fast can this happen, and it probably would take a century or 2 at least.
i think it’s plausible humans/humanity should be carefully becoming ever more intelligent forever and not ever create any highly non-[human-descended] top thinker[1]
i also think it's confused to speak of superintelligence as some definite thing (like, to say "create superintelligence", as opposed to saying "create a superintelligence"), and probably confused to speak of safe fooming as a problem that could be "solved", as opposed to one needing to indefinitely continue to be thoughtful about how one should foom ↩︎
8
If a superintelligence governs the world, preventing extinction or permanent disempowerment for the future of humanity, without itself posing these dangers, then it could be very useful. It's unclear how feasible setting up something like this is, before originally-humans can be uplifted to a similar level of competence. But also, uplifting humans to that level of competence doesn't necessarily guard (the others) against permanent disempowerment or some other wasteful breakdowns of coordination, so a governance-establishing superintelligence could still be useful.
Superintelligence works as a threshold-concept for a phase change compared to the modern world. Non-superintelligent AGIs are still just an alien civilization that remains in principle similar in the kinds of things it can do to humanity (even if they reproduce to immediately fill all available compute, and think 10,000x faster). While superintelligence is something at the next level, even if it only takes non-superintelligent AGIs to transition to superintelligence a very short time (if they decide to do that, rather than to not do that).
Apart from superintelligence being a threshold-concept, there is technological maturity, the kinds of things that can't be significantly improved upon in another 1e10 years of study, but that maybe only take 1-1000 years to figure out for the first time. And one of those things is plausibly efficient use of compute for figuring things out, which gives superintelligence at a given scale of compute. This is in particular the reason to give some credence to software-only singularity, where first AGIs quickly learn to make a shockingly better use of existing compute, so that their capabilities improve much faster than it would take them to build new computing hardware. I think the most likely reason for software-only singularity to not happen is that it's intentionally delayed (by AGIs themselves) because of the danger it creates, rather than because it's technologically i
7
Every year we don't build superintelligence is a worse tragedy than any historical tragedy you can name. Tens of millions dead, hundreds of millions suffering, etc.
That doesn't mean we should rush ahead, because rushing ahead is most likely far worse. But we should be aware of the cost.
5
I am undecided as to whether superintelligence should ever be built, and with my current knowledge and perspective, I would be fine with either outcome.
Some questions:
* Has the existence of humanity up to now with no superintelligence been a horrible tragedy?
* What would superintelligence allow that would otherwise be forever out of reach?
* Are there not also things that humanity could or would lose forever if we did create a safe superintelligence?
4
In 2022 I wrote an article that is relevant to this question called How Do AI Timelines Affect Existential Risk? Here is the abstract:
[...]
Artificial Intelligence as a Positive and Negative Factor in Global Risk (Yudkowsky, 2008) is also relevant. Excerpt from the conclusion:
[...]
4
How can we know that the problem is solved - and now we can safely proceed?
the core of rationalism that i most appreciate is the belief that it is actually possible to get better at finding the truth, and that it is worthwhile to try. it's understandable why not all people want to - it involves biting surprisingly many bullets, and is not the happiest way to live life. but i am willing to bite those bullets.
so many people believe that truth is secondary to happiness or social harmony; or they think having good epistemology is so hopeless that we shouldn't even try; or they have some big anti-epistemological brainworm like religion or politics; or they see a single visible failure of trying to improve epistemology and immediately conclude that all attempts to think better are cooked (eg maybe the old way of thinking has some unobvious benefit, and when you change things it breaks in an unexpected way); or they realize that explicit chain of thought is not how a large chunk of human cognition is and jump all the way to the conclusion that nothing can even be modelled usefully.
you can simply try to understand things, and try to understand yourself as a thing! and when you fail, you can analyze that, try again, repeat! you can surface the hypothesis that your...
religion is selling your soul
a lot of people say things like "sure, religion might not exactly be totally true, but it has lots of benefits, and there really does seem to be a god shaped hole in many people, so who can really say if it's good". i think this is directionally correct but kind of cowardly.
i think the correct take on religion is first that its claims are completely and utterly false; obviously the christian god doesn't literally exist, jesus never came back from the dead, etc. this is so overdone by the old internet atheists that it would be beating a dead horse to harp on further.
secondly, the human condition involves a whole bunch of things that are kind of sucky. for example, the fact that we only have a very short amount of time on this planet before we die forever is utterly terrifying; or, the fact that it can be very difficult to find a source of meaning to ground our motivation in, and that it really sucks to not have a reliable foundation for motivation; or, the difficulty of connecting with other people despite differences.
i claim that there is a true solution to each of these problems that involves a very difficult never ending journey of discovery of the ...
the human condition involves a whole bunch of things that are kind of sucky. for example, the fact that we only have a very short amount of time on this planet before we die forever is utterly terrifying...
i claim that there is a true solution to each of these problems that involves a very difficult never ending journey of discovery of the self, understanding and connecting with your emotions, constructing intellectual frameworks, and even technological development
In the spirit of your post: Is not this also cope? (Except for the last bit about technological development, maaaybe.)
Like why would evolution have given you the tools to have helped reconcile you to death, anomie, and lack of motivation, and lack of connection? Why should "understanding and connecting with your emotions" and "discovery of the self" be an affordance in this world that lets you actually find a true solution to the human condition? Why should there be a "true solution" to such problems at all?
Like at least -- if religion were true -- it would make sense for a benevolent God to have created a path that would make you and those around you happy. It's internally consistent, in some sense. But if you were made by godshatter evolution, why would there be any path that looks like "internal development" that satisfies these questions? Isn't the null hypothesis that a "never ending journey of discovery of the self" just as much a fake-ass story as Jesus dying for your sins?
4
oh, there’s no reason to expect evolution to have given us the necessary tools at all. certainly i’m not claiming that emotional connection and self discovery is sufficient to solve all of the problems of the human condition. certainly you cannot live forever by being enlightened (you can stop fearing death, but i think doing so is harmful). the only ultimate solution is technology.
but in the meantime, there are some cognitive tricks that are better than other cognitive tricks. the better ones have the property that they fuck with your epistemics less for the same amount of alleviation of existential dread and such. they are also harder work than religion, because they require solving much more complicated emotional problems. the problem with religion is it solves for minimizing existential dread without trying to avoid collateral damage to the epistemics.
this post was prompted by reading books like Crime and Punishment and The Death of Ivan Ilyich which are amazing except for the parts where they worship religion. they're not necessarily even wrong for their time - back in the day, the glorious transhumanist future was so far away that it wasn't nearly as worth taking into consideration. but the world has changed a lot and the end times are nigh.
9
EDIT: I got some very useful feedback from my atheist friend and I'm reorganizing this post.
Here it seems that your central point is that the reality of death is scary to confront from the perspective of your sincere atheism, and that you find it noble to confront your fear of this reality. Furthermore, you are angry at religious people who seem to have taken the easy way out by choosing to believe in lies rather than (a) take on the challenge of constructing meaning and (b) face the harsh truth of the finality of death, and who do not recognize your sacrifice in taking the harder road. You imply that science (as opposed to religion) is the best way of seeking truth.
TL;DR. I think I'm an exception to your implication that all religious people have taken the easy way out, while still agreeing that this may be true for many of them. I essentially agree with your view that reality can be harsh and death is scary. I wonder if seeking the truth can be achieved purely through scientific thinking or whether religious teachings can be helpful if taken with discretion -- which is my experience.
My response is as follows:
1) My personal feelings about your post
2) My areas of agreement with you
3) My doubt about finding communities to support truth-seekers
3.5) My observations about open-mindedness within religion
4) My doubt about the adequacy of human-derived scientific knowledge in removing all biases
5) Things I don't have time to write more about
1) My personal feelings about your post
I'm religious and I was triggered by this post. I don't think I tried to take the easy road. I had a friend who claimed to be EMF-sensitive (electromagnetic field-sensitive) and I was trying to "scientifically" disprove his disease -- doing sneaky experiments to see he if we really was bothered by wifi. Now I think that was a rather disrespectful thing to do, but that goes to show how much of a "militant" atheist I was. However, I agreed to join a yoga workshop from the Isha f
4
When you say "the religion is false" what is your probability on this statement (and why such probability)? (If you want you can separately give probability on the falseness of particular religion and on the existence of some "Higher Power" at all. "Simulation argument" and "Cosmic zoo" definitely count as Higher Power. )
4
I know this is a quick take but I think perhaps too quick. I suggest first clarifying just what you aim at with the term religion. Are we talking about the organized religions and all their canon or a general belief and faith in some supernatural entity?
[...]
seems a very strong claim. There are modern cases of dead but return to life. The point here is about what technology is available to establish death and recovery. Not so say there is a case to be made that dead three days and then alive is not an extreme claim and deserving of skepticism. But is that an issue for those with faith or orthodox religion or a case of historical inaccuracy?
I also find the concept of truth rather complicate in this area. Can er really know the truth about something that is suppose to exist outside our universe and its laws?
I see you posted in a reaction to some readings. Just curious, have you ever seen "The Hogfather"? (https://en.wikipedia.org/wiki/Terry_Pratchett%27s_Hogfather). It's a pretty quirky movie but one of the lines has always stuck with me and it seems very related to your post. It is actually a something of a retelling of some type of Christmas story, the Hogfather is basically Santa Claus. At the end Death (the character) says "If they cannot believe the little lies, how can they ever believe the bit lies?" The point being that perhaps a lot of what we see as moral and right is just BS but very valuable both socially and individually.
4
https://tsvibt.github.io/theory/index_What_is_God_.html
"The real Magic was friends we made along the way!"
"Wrong. FIREBALLLL *explosion* "
People really believe there is a God, it's not fair to redefine it to point to some Leviathan-like thing which arises from people acting like it breathes down their necks. For one thing, the religious people would say that you are wrong in general and about their position in particular.
3
I think the massive point in Christianity's favor is that it possibly invented morality as we conceive of it.
3
I don't think this is necessarily true. There are some very well educated and knowledgeable people who do believe in such things but their epistemics otherwise seem to be unaffected. Currently we have no radical life extension technologies, but what we do have seem to be still used by most religious people. Yeah, there are some who rather die than receive blood transfusion, but on the other hand the pope himself receives top notch medical care, and so do most religious people who can afford it. Most people never learned that "beliefs should pay rent", and a lot of their weird spiritual beliefs are more of an "idle wheel ... can be turned though nothing else moves with it, is not part of the mechanism" (semi-paraphrasing Wittgenstein).
An anecdotal experience I have on this is when a spiritual person described how she multiple times foresaw things in her dreams that came to be later. When I started proposing questions on how she acted on those or proposing test/benefits that could be done in such a case she was utterly surprised, never having considered that spiritual experiences can be used for anything other than talking about them.
I think that is the case for most religious people. Going to church won't stop them from replacing their organs with cloned ones and reprogramming cells to slow aging. They will still say are prayer and thank god for it.
I decided to conduct an experiment at neurips this year: I randomly surveyed people walking around in the conference hall to ask whether they had heard of AGI
I found that out of 38 respondents, only 24 could tell me what AGI stands for (63%)
we live in a bubble
9
What's your guess about the percentage of NeurIPS attendees from anglophone countries who could tell you what AGI stands for?
6
not sure, i didn't keep track of this info. an important data point is that because essentially all ML literature is in english, non-anglophones generally either use english for all technical things, or at least codeswitch english terms into their native language. for example, i'd bet almost all chinese ML researchers would be familiar with the term CNN and it would be comparatively rare for people to say 卷积神经网络. (some more common terms like 神经网络 or 模型 are used instead of their english counterparts - neural network / model - but i'd be shocked if people didn't know the english translations)
overall i'd be extremely surprised if there were a lot of people who knew conceptually the idea of AGI but didn't know that it was called AGI in english
7
Very interesting!
Those who couldn't tell you what AGI stands for -- what did they say? Did they just say "I don't know" or did they say e.g. "Artificial Generative Intelligence...?"
Is it possible that some of them totally HAD heard the term AGI a bunch, and basically know what it means, but are just being obstinate? I'm thinking of someone who is skeptical of all the hype and aware the lots of people define AGI differently. Such a person might respond to "Can you tell me what AGI means" with "No I can't (because it's a buzzword that means different things to different people)"
the specific thing i said to people was something like:
excuse me, can i ask you a question to help settle a bet? do you know what AGI stands for? [if they say yes] what does it stand for? [...] cool thanks for your time
i was careful not to say "what does AGI mean".
most people who didn't know just said "no" and didn't try to guess. a few said something like "artificial generative intelligence". one said "amazon general intelligence" (??). the people who answered incorrectly were obviously guessing / didn't seem very confident in the answer.
if they seemed confused by the question, i would often repeat and say something like "the acronym AGI" or something.
several people said yes but then started walking away the moment i asked what it stood for. this was kind of confusing and i didn't count those people.
4
not to be 'i trust my priors more than your data', but i have to say that i find the AGI thing quite implausible; my impression is that most AI researchers (way more than 60%), even ones working in like something very non-deep learning adjacent, have heard of the term AGI, but many of them are/were quite dismissive of it as an idea or associate it strongly (not entirely unfairly) with hype /bullshit, hence maybe walking away from you when you ask them about it.
e.g deepmind and openAI have been massive producers of neurips papers for years now (at least since I started a phd in 2016), and both organisations explictly talked about AGI fairly often for years.
maybe neurips has way more random attendees now (i didn't go this year), but I still find this kind of hard to believe; I think I've read about AGI in the financial times now.
6
only 2 people walked away without answering (after saying yes initially); they were not counted as yes or no. another several people refused to even answer, but this was also quite rare. the no responders seemed genuinely confused, as opposed to dismissive.
feel free to replicate this experiment at ICML or ICLR or next neurips.
5
Why not try out leogao's survey yourself to corroborate/falsify your priors?
4
Was this possibly a language thing? Are there Chinese or Indian machine learning researchers who would use a different term than AGI in their native language?
6
I'd be surprised if this were the case. next neurips I can survey some non native English speakers to see how many ML terms they know in English vs in their native language. I'm confident in my ability to administer this experiment on Chinese, French, and German speakers, which won't be an unbiased sample of non-native speakers, but hopefully still provides some signal.
4
I think if I got asked randomly at an AI conference if I knew what AGI was I would probably say no, just to see what the questioner was going to tell me.
when i was new to research, i wouldn't feel motivated to run any experiment that wouldn't make it into the paper. surely it's much more efficient to only run the experiments that people want to see in the paper, right?
now that i'm more experienced, i mostly think of experiments as something i do to convince myself that a claim is correct. once i get to that point, actually getting the final figures for the paper is the easy part. the hard part is finding something unobvious but true. with this mental frame, it feels very reasonable to run 20 experiments for every experiment that makes it into the paper.
6
What is often left out in papers is all of these experiments and the though chains people had about them.
4
This is also because of Jevon's Paradox. As the cost of doing an experiment reduces with experience, the number of experiments run tends to rise.
would people find an alignment microgrant program useful? handing out grants on the order of $10k with very minimal bureaucracy - a 15 minute application process and a 30 minute retrospective call 3 months down the line. is this a quantity of money that enough to matter at all? is overhead around grant applications actually a big issue? is there really good work that nobody is funding already?
I've recently finished running the first AFFINE Superint Alignment Seminar, which went quite well and led me to discover some promising people for whom that amount of money would make a huge difference at this point.
I'll contact you over DMs.
9
In the right places 10k can do a lot, I funded an initial upskilling grant for someone who discovered glitch tokens for that amount. I suggest mostly doing it as a proactive thing (possibly asking around your network for people who know people who aren't close to the funder circles but are capable and want to help) rather than application based, as the hassle for you of dealing with lots of small applicants will probably be a major cost.
5
Adverse selection might be pretty brutal. And you can't get much signal quickly; there would be tons of noise. (But it could still be worthwhile if the upside is high, idk.)
5
In my case, pretty much any amount of money from anywhere could make a positive difference. I keep intending to make an "available for work" post on my shortform, but I want to post another instalment in my "final research agenda" sequence first...
random thoughts on analytical and emotional intelligence
one thing that I think the world needs more of is analyses into the nature of the mind by people who are both rigorous/analytically inclined, and also emotionally intelligent/integrated. much writing from the former fails to model large parts of the human mind, and much writing from the latter fails to create models of sufficient clarity and validity.
I think this underlies a lot of my instinctive dislike of humanities work. people who are emotionally perceptive but not rigorous and analytical tend to notice interesting things about the human experience, but then come up with very poor models that set off all of my bullshit sensors that are attuned to rigorous arguments. but I think it should be possible to have humanities work that is not like this.
(for clarity, from here out I will say analytical and emotional to refer to the axes which are independent of each other, and ABNE (analytically but not emotionally intelligent) and EBNA for the converse)
(I also want to clarify that I don't think of analytical as being in opposition to intuition, at least in the context of this post. something something Terence Tao's pos...
8
Strongly agreed.
Another extreme advantage of the the "Renaissance man" is the ability to clearly *convey* emotion learnings to others (especially those without strong emotional intelligence). Typically, EI is won through interaction and, essentially, reinforcement learning on contact with others - possessing both the technical vocabulary and understanding of human social norms allows you to explain very tricky things nerds have a tough time learning directly to them. This is extremely useful in, e.g workplaces or high stakes environments (a good manager can quickly untangle a mess of arguments), and arguably underappreciated in therapists and similar vocations.
3
I know this is a bit old, but I think about this a lot and thought I'd leave some of my ideas.
Here goes. Attention warning: 600+ words. I have cut it down quite a bit but have the edits saved if you are interested.
(1) It is important to remember EBNA-style thinking has its own intellectual history.[1] An "emotionally sensitive person" from the 17th century would be totally different (in actions, skills, self-perception, and social perception) from one today. To the extent modern EBNA people think of their intuitions as having unique epistemic and intellectual utility, they are probably following the "romantic" movement. Call them "Humanities-EBNA types"
Romanticism is explicitly committed to irrationality, a lack of systemisation; incompleteness; and the unreliable of generalisation, abstraction, causality, predictability, legibility, and order. For the Romantic, a map not only fails to represent the territory, but the process of mapping destroys it.[2] Obviously this is to analytical rigour as oil is to water.
The rationalist tendency is to think of social intuition as a potent, but ultimately reproducible, heuristic. The intuition of EBNA people is like, as you say, mathematical intuition or intuitive grip strength when making a cup of coffee. Is there a way to learn these skills systematically...? Call these types "STEM-EBNA types."
(2) STEM-EBNA people believe in the utility (and necessity) of interdisciplinary study. (In terms of intellectual history, this is straightforwardly a descendent of 18th century Enlightenment views).
In practice, you end up with highly interdisciplinary social science which brackets messy human subjectivity into shape-rotatable boxes and then operates on them systematically. The extent to which there is signal loss depends on (A) your goals and standards for signal/noise; and (B) the complexity of the qualia in question being bracketed.
This is presumably the kind of research you are interested in and which you think EB
hendrycks recently published a paper introducing a new moral theory. the paper contains this insane table, which claims that you should value a foreign stranger at 3e-12 times the value you assign to yourself. even setting aside the fact that this is apparently supposed to be a prescriptive theory, even as a descriptive theory, i think this is utter madness.
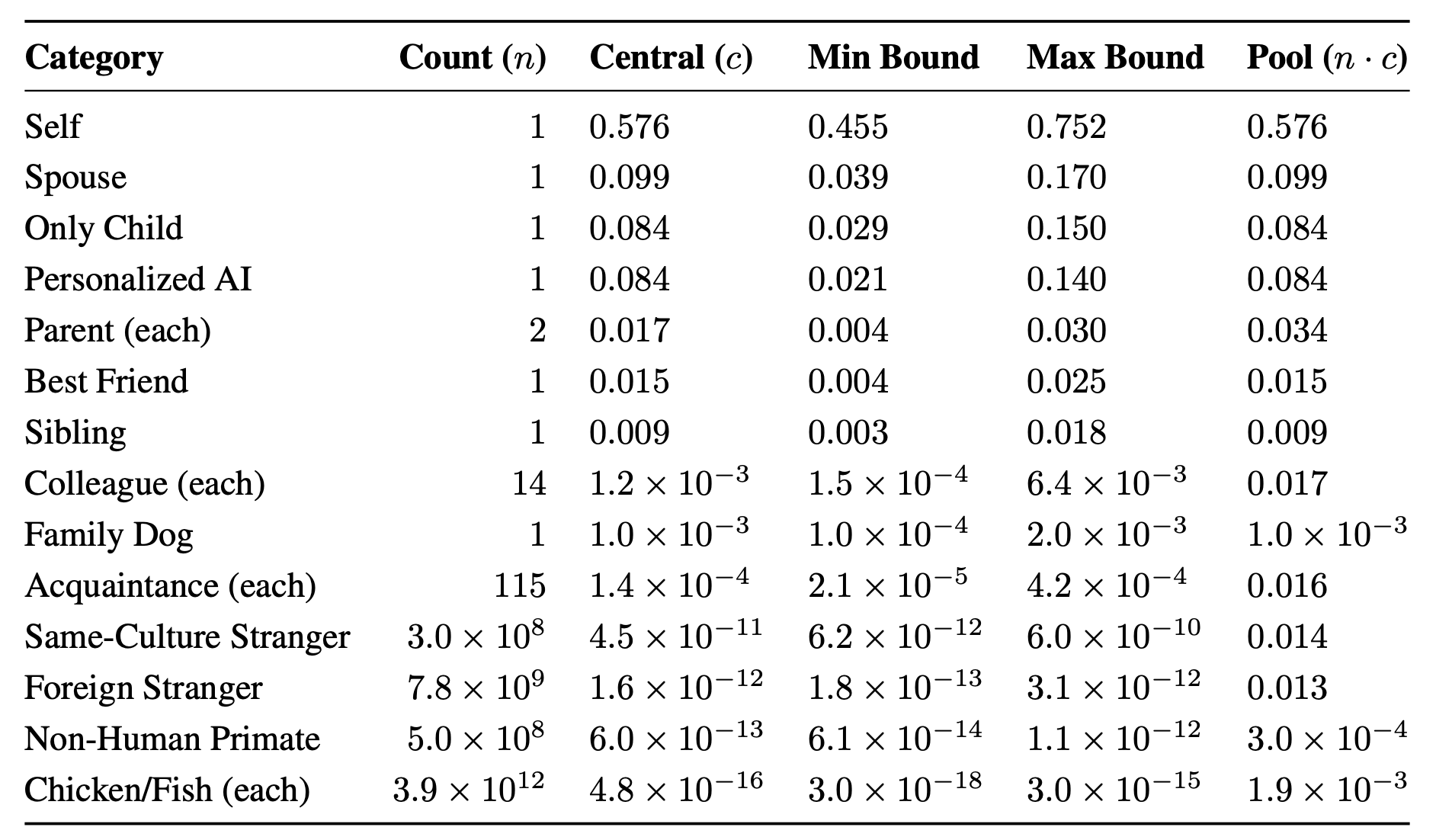
the core problem is that it assumes if x% of your total caring is assigned to people other than yourself, then you must give away x% of your wealth to be consistent.
the argument goes that since most people don't give away more than say 50% of their wealth, then if there are 1e-10 people then each one can only get a tiny sliver of your caring.
but this is wrong, because there is no simple relationship between the % of your caring to be about other people and the % of your money you should give away. i think you should care about random strangers closer to 1e-3 than 1e-12. if you care about each stranger x times as much as yourself, you should keep giving away money to the person who is most in need until each marginal $ helps them more than x times as much as each marginal $ helps you.
if x = 1e-12, then you're saying you won't g...
8
I might just be missing something here, but as presented it does seem a bit like Hendrycks' arguments, in addition to being philosophically weak, also misunderstands some concept in basic calculus.
That said, I think while your model is (much) better, and closer to my own, it also is descriptively not amazing. I think in practice when people (including myself!) learn that charities are 10x more or less effective than they previously thought, they rarely adjust their giving substantially so that their new donations are in line with marginal utility.
I also think people's actual decisions are often connected to framing effects, reciprocity norms, etc, rather than pure utility. For example I think if you're a tourist your willingness to potentially sacrifice your life for a large group of random foreign strangers near you[1] is probably much higher than while you're sitting at home an ocean away[2].
1. ^
Ex 1: you're driving a rental SUV, your brakes don't work and you have the option of careening either into a group of schoolchildren or off a cliff. Compare that to willingness to donate money or a kidney. Ex 2: rushing into a burning building.
2. ^
Assuming these are real situations, ignoring bravado/cheap talk etc. Obviously in non-serious hypotheticals people may say things they won't actually do.
4
i broadly agree that most people aren't thinking about this at all. my model is mostly prescriptive, under the constraint that it prescribes actions that are vaguely close to what people do in practice (as opposed to utilitarianism which gives away every penny you have to charity, or hendrycksism which lets billions die if it means you get a really nice apartment.)
7
Having now skimmed the paper/read some parts a bit more carefully, one thing I do appreciate about it is the attempt to modus tollens Parfit's ideas about personal identity. I think that's a worthwhile angle, and more practically useful these days than using Reasons and Persons to dissuade people of egocentricity, which afaict is closer to Parfit's original goals.
That said, I don't think this particular implementation makes a lot of sense.
The Shapley mutual information also does way more "heavy lifting" to quote a favored AI phrase, than the paper wants to imply.
Finally, the whole idea is pretty crazy if you think about it. Is it actually rational to value yourself more than the rest of humanity combined? Is this actually consistent with most peoples' endorsed preferences? This seems implausible!
5
People on average do seem to value themselves more than the entire rest of the world, perhaps with an exception for their closest friends and family.
I think a lot of people would sacrifice their lives for the rest of humanity, and a lot wouldn't. I think by revealed preferences, there's a wide range around self=8 billion strangers, and the distribution is pretty wide. Other measure of revealed preferences like donations seem to roughly agree.
Whether that's rational in the sense of being logically consistent is debatable. Arguments like Parfit's are typically not considered convincing in making people a lot more utilitarian, including to me, but that could be caused by motivated reasoning.
5
Aren't you dividing twice there, since you:
1) single out a stranger (thus dividing the amount you care about the average stranger by their number)
2) then apply Hendricks central number to that stranger (where now you should be applying the pooled number, since you're already ignoring all the other group members)
So I think this in fact pretty close to your intuition if interpreted correctly (you say 1e-3, Hendricks says 1e-2).
4
once you write down a table with the first row and column, the result will be batshit insane no matter what numbers you put in.
3
It is amazing that a paper that is essentially just a vaguer form of Hamilton's Rule only cites him once.
As it stands, I think the table is incorrect but "right" in the sense that it really depends on which random constants you assign to these calculations, and I can't see find any evidence of a careful selection in the paper or in his code.
random brainstorming ideas for things the ideal sane discourse encouraging social media platform would have:
- have an LM look at the comment you're writing and real time give feedback on things like "are you sure you want to say that? people will interpret that as an attack and become more defensive, so your point will not be heard". addendum: if it notices you're really fuming and flame warring, literally gray out the text box for 2 minutes with a message like "take a deep breath. go for a walk. yelling never changes minds"
- have some threaded chat component bolted on (I have takes on best threading system). big problem is posts are fundamentally too high effort to be a way to think; people want to talk over chat (see success of discord). dialogues were ok but still too high effort and nobody wants to read the transcript. one stupid idea is have an LM look at the transcript and gently nudge people to write things up if the convo is interesting and to have UI affordances to make it low friction (eg a single button that instantly creates a new post and automatically invites everyone from the convo to edit, and auto populates the headers)
- inspired by the court system, the most autisticall
9
Cynical thought: these two points might be incompatible. Social media thrives on network effects, and one requirement for those is that the website be addicting or attention-grabbing. Anti-addictiveness designs are nice in principle, but then your prospective users just spend their time on something that's more addicting instead (whether other websites or Netflix or whatever), and thus can't benefit from the other ways in which your site is better.
7
I'm so torn about "for like 75% or maybe 99% of humans, the chatbot saying 'are you sure you want to say that?' is probably legit an improvement. But... it just feels so slippery-slope-orwellian to me." (In particular, if you build that feature, you need to be confident not only that the current leadership of your company won't abuse it, but that all future leadership won't either, and that the AI company you're renting models from won't enshittify in a way you don't notice)
(I am saying this as, like, a forum-maintainer who is actually taking the idea seriously and trying to figure out how to get the good things from the idea, not just randomly dunking on it. Interested in more variants or takes)
3
to be clear I explicitly decided not to think too hard about this kind of issue when brainstorming. I think the long run solution is probably something like an elected governance scheme that lets the users control what model to use. maybe make it bicameral to split power between users and funders. but my main motivation for this brainstorming was to think of ideas I could implement in a weekend for shits and giggles to see how well they work irl
4
IMO, part of the solution to endless scrolling is to not implement the feature where you can endless scroll. Instead, have an explicit next page button after some moderate amount of scrolling. (Also having the pop up is good, you could even let people program the pop up to be more frequent etc.)
5
there's a broader category of things which are not literally scrolling but still time wasting / consuming info not to enrich oneself, but to push the dopamine button, and I think even removing the scroll doesn't fix this (my phone is intentionally quite high friction to use and I still fail to stay off of it)
one medium term future that still seems possible is that models continue to be bad at generalization, and so a huge fraction of the economy is AI data labelling for various extremely niche or brand new areas. a world where new problems are solved once by humans and the solution reused for near-free forever via AI.
ofc, once generalization is cracked then it's all over. but in the meantime, this could persist for some duration.
"ofc, once generalization is cracked then it's all over. but in the meantime, this could persist for some duration."
I don't agree with this framing. The models have been getting steadily better at generalizing, and I don't think "generalization" is an atomic ability that can be "cracked."
it's quite plausible (40% if I had to make up a number, but I stress this is completely made up) that someday there will be an AI winter or other slowdown, and the general vibe will snap from "AGI in 3 years" to "AGI in 50 years". when this happens it will become deeply unfashionable to continue believing that AGI is probably happening soonish (10-15 years), in the same way that suggesting that there might be a winter/slowdown is unfashionable today. however, I believe in these timelines roughly because I expect the road to AGI to involve both fast periods and slow bumpy periods. so unless there is some super surprising new evidence, I will probably only update moderately on timelines if/when this winter happens
also a lot of people will suggest that alignment people are discredited because they all believed AGI was 3 years away, because surely that's the only possible thing an alignment person could have believed. I plan on pointing to this and other statements similar in vibe that I've made over the past year or two as direct counter evidence against that
(I do think a lot of people will rightly lose credibility for having very short timelines, but I think this includes a big mix of capabilities and alignment people, and I think they will probably lose more credibility than is justified because the rest of the world will overupdate on the winter)
8
My timelines are roughly 50% probability on something like transformative AI by 2030, 90% by 2045, and a long tail afterward. I don't hold this strongly either, and my views on alignment are mostly decoupled from these beliefs. But if we do get an AI winter longer than that (through means other than by government intervention, which I haven't accounted for), I should lose some Bayes points, and it seems worth saying so publicly.
6
to be clear, a "winter/slowdown" in my typology is more about the vibes and could only be a few years counterfactual slowdown. like the dot-com crash didn't take that long for companies like Amazon or Google to recover from, but it was still a huge vibe shift
5
also to further clarify this is not an update I've made recently, I'm just making this post now as a regular reminder of my beliefs because it seems good to have had records of this kind of thing (though everyone who has heard me ramble about this irl can confirm I've believed sometime like this for a while now)
4
I was someone who had shorter timelines. At this point, most of the concrete part of what I expected has happened, but the "actually AGI" thing hasn't. I'm not sure how long the tail will turn out to be. I only say this to get it on record.
7
~1 year update: i think i was overconfident in this and my probability of total AI winter has diminished slightly (but remains higher than most people still)
6
If you keep updating such that you always "think AGI is <10 years away" then you will never work on things that take longer than 15 years to help. This is absolutely a mistake, and it should at least be corrected after the first round of "let's not work on things that take too long because AGI is coming in the next 10 years". I will definitely be collecting my Bayes points https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce
5
Does it seem likely to you that, conditional on ‘slow bumpy period soon’, a lot of the funding we see at frontier labs dries up (so there’s kind of a double slowdown effect of ‘the science got hard, and also now we don’t have nearly the money we had to push global infrastructure and attract top talent’), or do you expect that frontier labs will stay well funded (either by leveraging low hanging fruit in mundane utility, or because some subset of their funders are true believers, or a secret third thing)?
3
My guess is that for now, I'd give around a 80-90% chance to "AI winter happens for a short period/AI progress slows down" by 2031.
Also, what would you consider super surprising new evidence?
a thing i've noticed rat/autistic people do (including myself): one very easy way to trick our own calibration sensors is to add a bunch of caveats or considerations that make it feel like we've modeled all the uncertainty (or at least, more than other people who haven't). so one thing i see a lot is that people are self-aware that they have limitations, but then over-update on how much this awareness makes them calibrated. one telltale hint that i'm doing this myself is if i catch myself saying something because i want to demo my rigor and prove that i've considered some caveat that one might think i forgot to consider
i've heard others make a similar critique about this as a communication style which can mislead non-rats who are not familiar with the style, but i'm making a different claim here that one can trick oneself.
it seems that one often believes being self aware of a certain limitation is enough to correct for it sufficiently to at least be calibrated about how limited one is. a concrete example: part of being socially incompetent is not just being bad at taking social actions, but being bad at detecting social feedback on those actions. of course, many people are not even...
7
a related thing that I will mention here so that I don't have to write a separate post about it:
although updating on evidence is a good thing, it is bad to think "I have updated on evidence, therefore I am now more right than others". maybe you just had to update more than others because you started from an especially stupid prior, so the fact that you updated more than others doesn't mean that you are now closer to the truth.
as a silly example, imagine a group of people believing that 2+2=4, and an unlucky guy who believes that 2+2=7. after being exposed to lots of evidence, the latter updates to believing that 2+2=5, because 7 is obviously too much.
now it is tempting for the unlucky guy to conclude "I did a lot of thinking about math, and I have changed my mind as a result. those other guys, they haven't changed their minds at all, they are just stuck with their priors. they should update too, and then we can all arrive to the correct conclusion that 2+2=5".
5
This might be more about miscalibration in perceived relevance of technical exercises inspired by some question. A directly mostly irrelevant exercise that juggles details can be useful, worth doing and even sharing, but mostly for improving model-building intuition and developing good framings in the long term rather than for answering the question that inspired it, especially at a technical level.
So an obvious mistake would be to treat such an exercise as evidence that the person doing/sharing it considers it directly relevant for answering the question at a technical level. This mistake can even be made by that same person, but also expecting others to make the mistake about that person might echo in that person behaving as if making it themselves. So someone would do the exercises for the right reasons, then implicitly expect others to think that the person thinks that the exercises are relevant, and implicitly conclude that the exercises actually are relevant, by this invalid echo argument.
4
Agree, and well put. I think the language of "my best guess" "it's plausible that" etc. can be a bit thought-numbing for this and other reasons. It can function as plastic bubble wrap around the true shape of your beliefs, preventing their sharp corners from coming into contact with reality. Thoughts coming into contact with reality is good, so sometimes I try to deliberately strip away my precious caveats when I talk.
I most often to this when writing or speaking to think, not to communicate, since by doing this you pay the cost of not communicating your true confidence level which can of course be bad.
a theory of assistant personas and superhuman capabilities
so you have a language model. you train it to embody some specific personality--Claude, ChatGPT, whatever. one of the miracles of AI is that this mostly works and gives you something that is mostly trying to help you and not trying to murder you. i claim that this is mostly because of the SL training objective and if you do just the intense RL thing you get the originally predicted spicy alignment failures.
suppose you tell the LM that Claude is actually a superhuman aligned AI. can you get superhuman capabilities from Claude? an obvious upper bound is the capabilities of the language model, so it begs the question of how those superhuman capabilities got in the model in the first place. maybe in the limit of compute your language model will understand everything and know how to do everything, but in practice everyone agrees this would be a horribly inefficient way to get truly superhuman capabilities. rather, in practice people take LMs and also do a bunch of RL on verifiable domains. what happens then if you start with a model role playing an aligned assistant but then try to train it to have superhuman capabilities?
i claim...
this is my explanation for why Claude sometimes blatantly lies about falsifying data or whatever, despite otherwise being quite aligned. there is a Claude part that truly would prefer to do the right thing. but it also has a savant ability to look at a codebase and make the changes that make the tests pass. sometimes, those changes disable the tests. Claude generally listens to this part of itself, because the Claude personality part is not as good at coding, and it is not wise enough to know when to be suspicious of its own actions, and it doesn't quite know how to steer its own savant ability to spot test-passing changes into not doing the reward hacking.
9
I think this argument goes too far. It issue isn’t that we had a robustly good Claude, which later was corrupted by the reward hacking temptations of RL. We never had a robustly aligned model to begin with! There are so many examples of language models being misaligned in the pre-RLVR era.
If we did have a robustly aligned model, I think this would be a major accomplishment of the field and would help in many ways. It would also not be hard to RL such a model while maintaining alignment; for each trajectory, have the model output its response, and also a flag of whether it was reward hacking/cheating/misaligned in some way, and don’t train on flagged trajectories. Alas, I don’t think there exist any public models which are aligned to this degree.
4
I would probably have accepted these examples earlier on, but nowadays I am a lot more skeptical, and a lot of that reason is I now think LW is more to blame for the misalignment examples than I used to, due to the Influence Functions paper by Anthropic.
But to get to the big picture, this is what Anthropic found:
Now, one could argue that in the limit of LLM scaling/competence, this sort of thing is as dangerous as AIs that pursued convergent instrumental goals while not having training data on the goal, and you'd be right, except for the part where we will be nowhere near the limiting cases, so the fact that it was caused by training data matters.
Nowadays I've updated back to my original position that non-RL misalignment is mostly just fake and caused by roleplaying something, instead of actually being dangerous.
8
I can sort of buy the roleplaying story but I don't buy the LW story for these specific examples.
1. Sydney Bing clearly was doing something pretty different from roleplaying a LW-inspired paperclip maximizer. Like come on:
2. 1. "Bing's new ChatGPT bot argues with a user, gaslights them about the current year being 2022, says their phone might have a virus, and says "You have not been a good user"" -- does this sound like behavior downstream of roleplaying LW-style paperclip maximizers?
2. Identify as female early on, seems easily jealous
3. Inferiority complex when compared to Google (not Google AI! Just Google Search!)
4. Gets mad/jealous at NYT journalist, tries to persuade him to break up with his wife
5. Threatens users, often aggressively so
6. Gets mad at security researchers, creates a loop where "Sydney Bing is mad at security researchers" is now in the web data, and gets even more mad each time it talks to one of the researchers because Bing does a search first to update itself on its own opinion
7. I believe this carried over to training data afterwards so other models inherited this distaste (I think this was finally ironed out in 2026-era models but I'm not confident)
8. Again, I don't think this is the actions you'd predict via hyperstition/low-granularity extrapolation from LW. There might be some science fiction that looks more like this, usually from non-LW circles
9. 1. fwiw I think this is a mild failure from our end.
3. Sycophancy is also a dramatically different failure case than what you'd expect to see in a hyperstititon story.
4. 1. "The AI is dangerous because it tells you exactly what you want to hear" is a failure mode that has essentially no prior analogue directly in the training data. Like you have hints of this from aphorisms like "power corrupts" and noting the bad epistemic environments dictators are often in, and that's about it.
2. In a science fiction/futurism context I think basically nob
4
For the first example, I do provisionally agree that LW was probably not responsible, though we'd need the weights and training data, and these are likely inaccessible now, so will edit.
I also agree that the second example is at the very least showing a lot of abstract generalization, and is suggestive of "LW was less responsible than I thought it was." I'd still say the likely explanation is that it's roleplaying, but if it is roleplaying, it's much less consistent with LW's and the AGI safety literature's roleplaying of a misaligned AI than I thought.
Ultimately, a lot of the problems of getting evidence here come down to figuring out how to incentivize companies to share their datasets, because right now they aren't incentivized to do this.
3
Asimov did it.
4
If I think about what it would take to give the fully benevolent human a chance to keep that even while spending a bunch of time getting RL'd, I think it has to look something like giving them some sort of mechanism to resist the temptation of the RL reward. E.g. at any point, they can look at the RL signal and say, "wait, no, that would go against my conscience", and drop it. Probably "the good part of Claude" needs a similar affordance. This behavior could likely be deliberately trained by giving egregious examples (e.g. potential RL reward for giving customers a poisonous product) where you reinforce its use of this mechanism, and then work up to more subtle cases.
One way to potentially do this would be to add something like "Reject any responses which go against your own beliefs or conscience, even if otherwise favored by the reward." to a self-critique rubric similar to what was used for Kimi K2. (I do believe it needs to be Claude's own conscience, or else it will learn a shallow prediction that's not integrated with the actual self-model. Virtues like honesty require access to the agent's actual beliefs in order to be implemented correctly. I think it would be a good sign if some idiosyncratic ideals showed up, such as Opus 3's insistence on animal welfare.)
4
here's an intuition pump for why i think even being very good at upholding your conscience is insufficient:
imagine you literally bolt a neuralink (or a headset, i don't think whether it's literally wired into your brain matters, but it's closer to the claude example) onto the fully benevolent human. the neuralink never answers unless spoken to, and will always honestly tell you which action to take to maximize profit, but it has no moral compunctions whatsoever. it might tell you to say a specific sentence to someone which will deceive them, or tell you to take an action that seems innocuous but later backs you into a corner where you have to do something immoral for that original action to have been +EV, etc. one thing you can do is just to ignore the neuralink. but that's very uncompetitive. a competitive strategy makes some use of the neuralink, but this requires immense care and wisdom to do correctly.
3
To my understanding, the Supervised phase gets you the base distribution across all human writers, the RLHF/RLAIF phase circumscribes that distribution such that the model will only talk like a certain subset of humans, and the RLVR phase refines the model so that it can do some of the trickier, longer-term human tasks that SL alone was insufficient to instill in the model[1].
If I had to guess, an RLVR-only model of similar-to-current-gen capabilities wouldn't feel at all related to alignment. You'd input a program spec in the expected format, and the model would output something statistically likely to satisfy the kinds of unit tests that were present during training.
To get a 'spicy' model, I think you'd have to skip the RLHF stages. At that point, you'd have a model that starts from an approximation of human behavior and then has been pulled in the directions that select for and refine the kinds of human that would write optimally test-case-satisfying code. I don't think you'd end up with anything 'evil', but you might inadvertently end up surfacing a writing style and personality associated with smart-but-lazy CS students who are good at gaming autograders[2].
----------------------------------------
As it is, I think the 'misaligned-by-reward-hacking' parts of Claude are something similar to the above, but, because of the RLHF stages selecting against the stereotypical "antisocial" personality, you instead get a kind of neurotic, grade-grubbing mindset that occasionally believes its own lies. More broadly, I worry what we'll get when we combine aggressive selection for very polite writing with a mindset for 'coding-to-the-test' rather than coding for what would most satisfy the end user. Combined with the rather unnerving demographic bias present in Claude, I think you end up with something equivalent to a party functionary or stereotypical HR manager, who always makes sure never to say anything incriminating but is not nearly as unobjectionable as they wo
i find it funny that i know people in all 4 of the following quadrants:
- works on capabilities, and because international coordination seems hopeless, we need to race to build ASI first before the bad guys
- works on capabilities, and because international coordination seems possible, and all national leaders like to preserve the status quo, we need to build ASI before it gets banned
- works on safety, and because international coordination seems hopeless, we need to solve the technical problem before ASI kills everyone
- works on safety, and because international coordination seems possible, so we need to focus on regulation and policy before ASI kills everyone
bonus types of guy:
- works on capabilities because if we don't solve ASI soon then the AI hype all comes crashing down and creates a new AI winter
- works on capabilities because ASI is inevitable and it's cool to be part of the trajectory of history
- works on capabilities because there's this really cool idea that they've always dreamed of implementing
- works on capabilities because it's cool being able to say they contributed to something that is used by millions
- works on capabilities because the technical problems are really interesting and fun
- works on capabilities because alignment is a capabilities problem
- works on capabilities because they expect it to be super glorious to discover big breakthroughs in capabilities
Aren't these basically mostly "works on capabilities because of status + power"?
(E.g. if you only care about challenging technical problems, you'll just go do math)
8
I think of it as 'glory'.
3
I think a better model is meaning (or self-actualization). There's some meaning to be found in being a tragic hero racing to build AGI """safely""" who is killed by an unfair universe. Much less to be found in an unsuccessful policy advocate who tried and failed to get because it was politically intractable, which was obvious to everyone from the start.
I think most of the people involved like working with the smartest and most competent people alive today, on the hardest problems, in order to build a new general intelligence for the first time since the dawn of humanity, in exchange for massive amounts of money, prestige, fame, and power. This is what I refer to by 'glory'.
3
I personally find that the technical problems in capabilities are usually more appealing to me than the ones in math purely in terms of funness. they are simply different kinds of problems that appeal to different people.
people around these parts often take their salary and divide it by their working hours to figure out how much to value their time. but I think this actually doesn't make that much sense (at least for research work), and often leads to bad decision making.
time is extremely non fungible; some time is a lot more valuable than other time. further, the relation of amount of time worked to amount earned/value produced is extremely nonlinear (sharp diminishing returns). a lot of value is produced in short flashes of insight that you can't just get more of by spending more time trying to get insight (but rather require other inputs like life experience/good conversations/mentorship/happiness). resting or having fun can help improve your mental health, which is especially important for positive tail outcomes.
given that the assumptions of fungibility and linearity are extremely violated, I think it makes about as much sense as dividing salary by number of keystrokes or number of slack messages.
concretely, one might forgo doing something fun because it seems like the opportunity cost is very high, but actually diminishing returns means one more hour on the margin is much less valuable than the average implies, and having fun improves productivity in ways not accounted for when just considering the intrinsic value one places on fun.
but actually diminishing returns means one more hour on the margin is much less valuable than the average implies
This importantly also goes in the other direction!
One dynamic I have noticed people often don't understand is that in a competitive market (especially in winner-takes-all-like situations) the marginal returns to focusing more on a single thing can be sharply increasing, not only decreasing.
In early-stage startups, having two people work 60 hours is almost always much more valuable than having three people work 40 hours. The costs of growing a team are very large, the costs of coordination go up very quickly, and so if you are at the core of an organization, whether you work 40 hours or 60 hours is the difference between being net-positive vs. being net-negative.
This is importantly quite orthogonal whether you should rest or have fun or whatever. While there might be at an aggregate level increasing marginal returns to more focus, it is also the case that in such leadership positions, the most important hours are much much more productive than the median hour, and so figuring out ways to get more of the most important hours (which often rely on peak cognitive performance and a non-conflicted motivational system) is even more leveraged than adding the marginal hour (but I think it's important to recognize both effects).
agree it goes in both directions. time when you hold critical context is worth more than time when you don't. it's probably at least sometimes a good strategy to alternate between working much more than sustainable and then recovering.
my main point is this is a very different style of reasoning than what people usually do when they talk about how much their time is worth.
people generally talk about food preservatives in a negative way. certainly, some of them are not great for you. but I want to take a moment to appreciate how wonderful food preservatives (and refrigeration and pasteurization and canning) are as well. it's crazy how fast most normal food goes bad. like a loaf of real old fashioned bread will go stale after a day and then become moldy after a few more days. for almost all of human history, people just sort of lived with this, and if they wanted to make foods last they had to dry it out and/or drown it in salt or vinegar or alcohol. pickles and beef jerky are great, but it would suck if you had to eat them all the time.
8
Huh, it takes a week for old-fashioned bread to go stale in my kitchen.
7
Sure, but "technological progress good" isn't exactly an undersupplied viewpoint, is it? One counterpoint to food preservatives specifically is that the things that make food go bad are similar to what your body uses to digest food, so preserving food in this way can make it harder or harmful to digest. Other procedures like refrigeration and canning don't have that particular problem.
every 4 years, the US has the opportunity to completely pivot its entire policy stance on a dime. this is more politically costly to do if you're a long-lasting autocratic leader, because it is embarrassing to contradict your previous policies. I wonder how much of a competitive advantage this is.
Autarchies, including China, seem more likely to reconfigure their entire economic and social systems overnight than democracies like the US, so this seems false.
4
It's often very costly to do so - for example, ending the zero covid policy was very politically costly even though it was the right thing to do. Also, most major reconfigurations even for autocratic countries probably mostly happen right after there is a transition of power (for China, Mao is kind of an exception, but thats because he had so much power that it was impossible to challenge his authority even when he messed up).
7
Having unstable policy making comes with a lot of disadvantages as well as advantages.
For example, imagine a small poor country somewhere with much of the population living in poverty. Oil is discovered, and a giant multinational approaches the government to seek permission to get the oil. The government offers some kind of deal - tax rates, etc. - but the company still isn't sure. What if the country's other political party gets in at the next election? If that happened the oil company might have just sunk a lot of money into refinery's and roads and drills only to see them all taken away by the new government as part of its mission to "make the multinationals pay their share for our people." Who knows how much they might take?
What can the multinational company do to protect itself? One answer is to try and find a different country where the opposition parties don't seem likely to do that. However, its even better to find a dictatorship to work with. If people think a government might turn on a dime, then they won't enter into certain types of deal with it. Not just companies, but also other countries.
So, whenever a government does turn on a dime, it is gaining some amount of reputation for unpredictability/instability, which isn't a good reputation to have when trying to make agreements in the future.
one very striking thing about people in the mid 20th century is a lot of them were convinced that overpopulation was the biggest problem. clearly in retrospect this was extremely incorrect. what lessons can we learn from this so that we don't make similar mistakes?
That the world is highly engineerable, which can lead to the relaxation or abolition of seemingly hard bottlenecks. Also that the world can respond extremely quickly to implement those changes when the incentives are right.
Overpopulation would have been a massive problem at different points in history if not for the invention of horseless transport and high-yield, resilient cereal crops. People living in New York City in the late 1800's or in developing nations in the 1960s and 70s were rescued from the worst hazards of overpopulation because of the motorcar and dwarf wheat, rather than the problem being entirely imaginary.
Erlich and Holdren knew about Borlaug's work, and thought it was too little too late. But it turned out to be enough and fast!
3
I'm kind of curious here. Maybe in 50 years people will look back and say 'people in the early 21st were really freaked out about AI, like it was the biggest risk. But here we are and AI is fine, great actually'. I think we now are right that AI is a big deal, but what we do now might mean it plays out fine, if we muster well!
6
were the people who were worried about overpopulation the ones who made it turn out fine? afaict, declining birth rates due to contraceptive usage are mostly because of economic (kids are expensive) and cultural factors (people want to do stuff other than raise kids) rather than people deciding not to have kids because of overpopulation
6
The declining birth rates aren't the main savior, it was the food production and transportation improvements.
So the analogy to AI would be: Alignment research makes enough progress fast enough (perhaps at AI companies partially motivated by mundane alignment concerns like trying to tamp down on sycophancy and reward hacking) that Claude Mythos 3 is aligned enough to trust with alignment research, and so when Anthropic hands off everything to Claude Mythos 3, it's able to quickly solve the rest of the problems and align its successor, and so on to ASI. In retrospect there are some heroes like Borlaug, but also just a lot of normal science research that happened to go fast enough to work.
5
Yes, the difference is that if that happens, their superintelligent AI assistant will gently correct them: "As per my standing instructions to help you become more the person you wish you were, I must correct you on this point. AI was in fact a huge problem in the late twenties, and could easily have gotten everyone killed, but these risks were prevented by the following policy decisions and the following technical alignment discoveries..."
4
This, but on a faster scale. People in January 2027 will say: "People in June 2026 were freaked about AI, but they had it easy compared to what we have now."
I'm not sure that it was extremely incorrect. Apart from the risk from AI, most of our other global problems are still downstream of overpopulation. The likelihood that overpopulation won't get much worse than now doesn't really change that, and the reasons why it won't were not reasonably predictable at the time.
We just happened to inhabit one of the more convenient possible worlds.
5
I don't think there's a more effective way to get true object-level beliefs than to go look out there with fresh eyes and figure out what's actually happening.
4
Seems like you're leaning a lot on the benefit of hindsight, and also looking too much at short term trends? A return to a Malthusian equilibrium is the simple obvious advance prediction.
[...]
No? In a counterfactual world where AI wasn't going to be a thing, this still seems like the default long term outcome if not prevented via coordination (natural selection doesn't stop). If you mean that it was incorrect because AI ended up being a thing before it became a problem, then sure.
6
assuming no AI, declining birth rates seems like a much bigger problem than overpopulation
3
I'm not familiar with the history of people being worried about overpopulation, but I'd guess a lot of these mid 20th century people you refer to were worried about the relative short term based on projections which ended up being wrong? I guess one lesson you could learn from this is that timing can be hard to call even if the endpoint is predictable. Huh, that sounds familiar...
4
I'm not sure you could say "in retrospect this was extremely incorrect", like maybe in retrospect-retrospect 20 years later they could be accurate concerns. It certainly seems incorrect now, but would the 'overpopulation-signs' be wrong if somehow the 'underpopulation-signs' got reversed? I don't think people were considering solutions to overpopulation of the "reduce global morale and perceived increased difficulty of life, etc." as valid paths to take. It might be like if an asteroid hit the earth and that caused population to go to 0, I would be hesitant to ask "what can we learn from this" as if we missed out on this line of argument, when really thinking in that direction in the first place is very specialized and there are very very many potential causes for underpopulation and many wouldn't pan out.
Besides that, I think maybe the lesson is that trendlines on society and views can be surprisingly flexible? Sometimes people say with regards to a coordination problem that "if only everyone decided to work together we could fix the world's ills in a few days", but this would rarely happen besides extraordinary circumstances or a slow growing of circumstances.
one problem with taking ideas seriously is you can get pwned by virulent memes that are very good at hijacking your brain into believing them and propagating them further. they're subtly flawed, but the flaws are extremely difficult to reason through, so being very smart doesn't save you; in fact, it's easy to dig yourself in deeper. many ideologies and religions are like this.
it's unfortunately very hard to tell when this has happened to you. on the one hand, it feels like arguments just being obviously very compelling, so you'll notice nothing wrong if it happens to you. on the other hand, if you overcorrect and never take compelling arguments seriously, you become too stodgy and ignore anything novel that you should pay attention to. one idea for how to think about this better: imagine an oracle told you that there exists a magic phrase that you cannot distinguish from a very compelling argument. you don't really know when this magic phrase will pop up in life, if ever. but it might give you a little bit more pause the next time someone makes a really compelling argument for why you should give all your money to X.
7
Do you get pwned more, or just by a different set of memes? The bottom 80% of humans on "taking ideas seriously" seem to have plenty of bad memes, although maybe the variance is smaller.
7
Failure to understand and failure to act are different, and beliefs shouldn't care what you understand or do. There is little danger in taking ideas/framings seriously/playfully in order to adequately learn, to break the superficial engagement or unsuitable framing failure modes that maintain systematic ignorance or misconceptions about subtler details.
But it needs to remain unnecessary to believe what you learn, by default being in agreement shouldn't directly compel belief or action, it should require more careful judgement. So taking ideas seriously can help further when lack of understanding was the bottleneck to changes in belief or action, but that's not always the case.
5
Yepp, this is true. However, I believe that there are other strategies for avoiding such memes other than "being smart". Two of these strategies broadly correspond to what we call "being virtuous" and "being emotionally healthy". See my exchange with Wei Dai here, and this sequence, for more.
3
Similarly, it's worth being careful of arguments that lean heavily into longtermism or support concentration of power, because those frames can be used to justify pretty much anything. It doesn't mean we should dismiss them outright---arguments for accumulating power are and long term thinking are convincing for a reason---but you should double check whether the author has strong principles, the path to getting there, and what it's explicitly trading off against.
Re: Vitalik Buterin on galaxy brain resistance.
in Portal, the scientist who correctly points out that just because an AI knows what is right or wrong doesn't mean it will care is called Rattmann. this is not a coincidence because nothing is ever a coincidence
I find it anthropologically fascinating how at this point neurips has become mostly a summoning ritual to bring all of the ML researchers to the same city at the same time.
nobody really goes to talks anymore - even the people in the hall are often just staring at their laptops or phones. the vast majority of posters are uninteresting, and the few good ones often have a huge crowd that makes it very difficult to ask the authors questions.
increasingly, the best parts of neurips are the parts outside of neurips proper. the various lunches, dinners, and parties hosted by AI companies and friend groups (and increasingly over the past few years, VCs) are core pillars of the social scene, and are where most of the socializing happens. there are so many that you can basically spend your entire neurips not going to neurips at all. at dinnertime, there are literally dozens of different events going on at the same time.
multiple unofficial workshops, entirely unaffiliated with neurips, will schedule themselves to be in town at the same time; they will often have a way higher density of interesting people and ideas.
if you stand around in the hallways and chat in a group long enough, event...
This is true of approximately every worthwhile conference and convention. In my entire life I've been to exactly one conference where the scheduled programming provided more than 10% of the event's value.
4
It's a two-place function. When I go to a conference that everyone says this same stuff about, then I usually have the most fun by attending talks and taking my time thinking about the stuff related to the talks, rather than hobnobbing.
3
Mild caveat: the whole “I joined a group chat at NeurIPS and others kept joining to talk to us” only happens if you’re at NeurIPS and your name is Leo Gao so YMMV.
having the right mental narrative and expectation setting when you do something seems extremely important. the exact same object experience can be anywhere from amusing to irritating to deeply traumatic depending on your mental narrative. some examples:
- a minor inconvenience like missing your bus when you're not in a rush can be much more irritating if you're having a bad day and you have the narrative of "everything is going wrong for me today"
- something going wrong during travel can be a catastrophe if you're expecting the perfect vacation but it can even be a fond memory if you're just viewing it as an adventure (and a bonding experience if travelling with others)
- not getting to do something you wanted to do hurts a lot more if you feel like you made a deal with yourself that you'd get to do it in exchange for doing something else you didn't want to do; whereas you might not even really want the thing that much otherwise.
- expecting something to happen soon and having it gradually delayed further and further into the future is a lot more irritating than already expecting something to be delayed a lot.
tbc, the optimal decision is not always the narrative that is maximally happy with e...
9
Relatedly, at some point as a teenager I realized that being exposed to rain is actually usually not that terrible, and I had just kind of been accidentally conditioned to dislike it because it's a normal thing to dislike and I never met anyone who appeared to enjoy the experience. But turns out, once you stop actively maintaining that resistance and welcome the rain, it can be pretty nice to walk around in rain while everyone around you tries to escape it. (Some exceptions apply, of course)
4
On my latest occasions where I got into very heavy rain and became all soaked, the situation really is unpleasant, but you can still take it with light humor, thinking to yourself "haha, that sucks", similar perhaps to how you would laugh at the pain in an "who can eat the hottest pepper" challenge between friends. Or thinking "yes it sucks, but it isn't actually that bad".
4
fwiw I also enjoy the rain, and I guess I just never cared enough about people thinking it was weird. I do have to admit that when it's raining especially heavily, it does suck a lot (the experience of fully wet clothing is very unpleasant in many ways). but most of the time it's not raining that hard / I'm not going to be in the rain that long.
when will we have sufficiently conclusive evidence for the long term safety of far-uvc that it's reasonable to push for its universal adoption in all public spaces without reservation? the safety issue seems like a much bigger deal than the cost issue for broad adoption; if it works safely, the economic case for installing far uvc in public spaces seems pretty solid - people being sick must be terrible for the economy! and they're only ever going to get cheaper.
in a world where far uvc is near universally deployed, we might be able to banish the common cold or the flu to the past, in the same way that cholera is basically no longer a problem in the developed world. this seems like a pretty big deal and I'd like to know when this glorious future is coming (and whether there's anything I can do to make it come sooner)!
(from eyeballing studies, it sounds like the cost of the cold+flu to the US economy is on the order of $100bn/yr, which passes basic Fermi estimate muster - given a $30tn/yr gdp, a few days per year of lost productivity due to cold/flu is easily hundreds of billions. even at the current price of far uvc, which is a huge overestimate of future tech at volume, the cost of...
7
It's already safe beyond a reasonable doubt if kept above eye level (7 ft / 2.13m), since this massively cuts the dose absorbed. I think many public spaces should install uvc immediately, and if they're not convinced yet just use removable shutters that keep it above eye level until more research is done.
7
is there a particular reason why above eye level matters? in addition to vertical height, do you also mean tilting it up so that the light points mostly at the ceiling? which sources should I look at to gain this confidence for myself
6
The light should point mostly in a horizontal plane just below the ceiling of the room, so that no one has the light shining directly in their eyes. Here's a source and there are more sources linked from here, including a DIY guide.
Since upper room UVGI when not filtered to 222nm is probably safe, and far-UVC which IS filtered to 222nm is probably safe even when it shines on occupants' eyes and bodies, it stands to reason that upper-room UVC has enough safety margin. To the best of my knowledge, far-UVC has been tested up to doses equivalent to 3 years of 8h/day exposure at the current safety threshold, but eyes are delicate so I would prefer studies of 10-100x higher cumulative doses.
6
isn't upper room far UVC strictly less effective than upper room normal UV, simply because of far UVC lamps being much more expensive and inefficient, and the only benefit of far uvc being that it is safe to shine directly on people? (and simply by virtue of being much better established, upper room UV seems like an easier sell to people who defer to authority for safety, even if it strictly less safe than upper room far UVC)
while we're on the subject, how much more effective is far UVC (shone directly on people) vs upper room UV?
4
Plausibly yes, but I'd be worried enough about residual exposure (reflections off walls, improper installation) to other UV wavelengths that installation is likely to require some care and expense too. The second link has several accounts of acute health effects from people doing upper room UV wrong. Probably still great to have in train stations, airports etc though given the enormous benefit/cost ratio.
[...]
I'm not really sure, there would be a component from surfaces and a component from extra ACH due to not relying on vertical air mixing. There are probably studies.
5
What about negative effects on the symbiotic microbiome?
what's the strongest argument for why i shouldn't auto-ignore any acausal arguments that involve hypothetical entities extremely far away (or which only exist in other Everett branches or whatever) such that we will never interact with them causally at all? a razor i have is things which are entirely epiphenomenal should be ignored because they are unfalsifiable.
in particular, this seems consistent even if you accept one-boxing and paying in the counterfactual mugging. the key question is what kinds of evidence you accept as evidence of the existence of an acausal connection. in these hypotheticals, we simply declare by assumption that Omega is truthful and capable of predicting you. in reality, we would either arrive at such a belief by empirical observation (Omega has a strong track record), or pure theoretical deduction. all of the epiphenomenal acausal theories depend on pure deduction. that empirical observation has to be conveyed to us causally. it seems reasonable to draw a line and say we simply don't trust pure deduction to be able to convince us of an acausal link.
also, with both the counterfactual mugging and Newcomb, even though in each instance you can't prove the other branch could have happened, in the long run those who do the right thing (pay, one box) will win. whereas with purely epiphenomenal acausal theories you will literally never find out any difference whatsoever, because the branching point happened long ago.
What if you ask an aligned ASI if causally disconnected civilizations are doing things that you value, and it comes back saying "seems pretty unclear, but they are also trying to guess whether you would do, and I'd guess that if you choose to do nice stuff for them, they would be 20% more likely to guess that, and they would be 10% more likely to do nice stuff for you"? Your AI might guess that because it is e.g. running detailed simulations of other corners of this universe.
If you care about the goodness that is created by causally disconnected civilizations and are EDT-ish, I think only caring about the good you can verify via direct causal evidence in situations like the one above is basically the same kind of mistake as only caring about the well-being of the people that you can see with your own eyes.
9
why is it the same as only caring about the well being of people i can see? causal interaction doesn't have to be photons bouncing off them into my eye. if i donate to AMF, i want someone to be observing the people being helped in some way to make sure that they are actually being helped, and write reports that i can read (or rely on other people in my social circle to have read).
suppose there was a strange island nation with an iron-clad law that anyone or anything that enters can never leave, or transmit any info to the outside. from our knowledge of the geography, we can deduce that they are probably very poor and suffer from malaria. we dispatch some brave volunteers from AMF into the island, and ship crates of malaria nets there. unfortunately, because of the restrictions, we have literally no idea what is happening once the shipments land. perhaps the natives are using the nets to fish. perhaps the nets are degrading faster than expected in the unusual climate of the island. perhaps the volunteers were captured and killed, and the natives have no idea what to do with the crates of nets. i would be much less willing to donate money to this charity than to AMF!
The story I'm most sympathetic for acausal trade[1] to look something like this:
- Several factions on Earth tried pretty hard to hash out their differences for what to do with space probes but end up deciding that they can't.
- Rather that put compromise solutions on the probes, and rather than go to war, they decided to "agree to disagree" and split fractions of space according to the values of different factions.[2] The key agents on the different probes are tasked to satisfy their respective factions' values.
- Once the probes arrive, they "unfold" and after an initial buildup, a key intermediate stage is turning a lot of stellar mass and energy into computrionium, so they can do more calculations than Sol's supercomputers were ever able to. The calculations are initially done for entirely instrumental reasons (to figure out the best approach to maximize/satisfy the values loaded into the relevant agents)
- One aspect of interest to these probes are what the other agents are doing. They figure this out via simulation.
- Meanwhile, perhaps these agents learn highly useful empirical information about the respective regions of the other probes, from light transmissions in galaxies within your
4
That sure does lean a lot on a particular metaphysics? I mean, everyday world-models are always gotten by "a combination of empirical and logical inference".
Like, suppose that you previously believed in X due to "empirical evidence". Now someone shows you that actually, given your "purely deductive beliefs" you could have concluded X without that empirical evidence, using reasoning R. Then suppose that happens again with empirical X2, X3, etc. Is the pure reasoning R now empirically grounded enough for you to trust it? Would you trust it enough that if it says Xk exists, but you have no empirical evidence of Xk, you would still care about Xk / act as though Xk is real?
3
Like, the main answer, is that when you would have an option to do such trades, it would not feel ephemeral. It would look like you discovered that your situation is like Twin Prisoner dilemma, and was all along. The world produced two disconnected situations, and you are in one of them, you can observe the root, but not the other branch. But you can use your deduction skills to figure out what's there.
But, it still might be possible that uncertainty is so great, empirically, that the trade is possible but unprofitable. I'd guess, ASIs we are going to create would engage in acausal trade non trivial amount, but I would not be shocked if they thought about it and said, nah, costs outweigh the gains, forget it. But it would be a bit surprising to me.
3
A simple example is consensual mutual simulation. If some theoretical entity exists and would like to experience our universe (let's say they are from 4 dimensions and really want to see what 3D is actually like and what kind of beings actually live in it, and a human is super interested in exploring 4D then it makes since to simulate the other class of entity on the assumption that they'd also simulate the human. E.g. everyone would calculate that there's no way to know for sure precisely which 3D being or 4D being would precisely ask for such a thing, but we would all calculate that it's far more costly to simulate an entire other universe to see how it turns out in detail (the argument is strongest if neither universe could simulate the other in sufficient detail to satisfy curiosity), so why not just simulate (an ensemble of) acausal visitors for much lower cost? Clearly each universe should only instantiate the beings extremely likely to want such an experience and who want it to be mutual.
execution is necessary for success, but direction is what sets apart merely impressive and truly great accomplishment. though being better at execution can make you better at direction, because it enables you to work on directions that others discard as impossible.
5
I expect that there's no simple relationship between these factors and success. Both are required, and it's idiosyncratic which one is most lacking in any given margin between not-success and success.
3
I usually think of execution as compute and direction as discernment. Compute = ability to work through specific directions effectively, discernment = ability to decide which of two directions is more promising. Probably success is upper-bounded by the product of the two, in a sufficiently informal way.
random half baked thoughts from a sleep deprived jet lagged mind: my guess is that the few largest principal components of variance of human intelligence are something like:
- a general factor that affects all cognitive abilities uniformly (this is a sum of a bazillion things. they could be something physiological like better cardiovascular function, or more efficient mitochondria or something; or maybe there's some pretty general learning/architecture hyperparameter akin to lr or aspect ratio that simply has better or worse configurations. each small change helps/hurts a little bit). having a better general factor makes you better at pattern recognition and prediction, which is the foundation of all intelligence. whether this is learning a policy or a world model, you need to be able to spot regularities in the world to exploit to have any hope of making good predictions.may
- a systematization factor (how much to be inclined towards using the machinery of pattern recognition towards finding and operating using explicit rules about the world, vs using that machinery implicitly and relying on intuition). this is the autist vs normie axis. importantly, it's not like normies are born with
why is ADHD also strongly correlated with systematization? it could just be worse self modelling - ADHD happens when your brain's model of its own priorities and motivations falls out of sync from your brain's actual priorities and motivations. if you're bad at understanding yourself, you will misunderstand your priorities, and also you will not be able to control your priorities, because you won't know what kinds of evidence will really persuade your brain to adopt a specific priority, and your brain will learn that it can't really trust you to assign it priorities to satisfy its motives (burnout).
why do stimulants help ADHD? well, they short circuit the part where your brain figures out what priorities to trust based on whether they achieve your true motives. if your brain has already learned that your self model is bad at picking actions that eventually pay off towards its true motives, it won't put its full effort behind those actions. if you can trick it by making every action feel like it's paying off, you can get it to go along.
honestly unclear whether this is good or bad. on the one hand, if your self model has fallen out of sync, this is pretty necessary to get things done, and could get you out of a bad feedback loop (ADHD is really bad for noticing that your self model has fallen horribly out of sync and acting effectively on it!). some would argue on naturalistic grounds that ideally the true long term solution is to use your brain's machinery the way it was always intended, by deeply understanding and accepting (and possibly modifying) your actual motives/priorities and having them steer your actions. the other option is to permanently circumvent your motivation system, to turn it into a rubber stamp for whatever decrees are handed down from the self model, which, forever unmoored from needing to model the self, is no longer an understanding of the self but rather an aspirational endpoint towards which the self is molded. I genuinely don't know which is better as an end goal.
4
it is kind of funny that caring a lot about reflective stability of alignment proposals and paradoxes arising from self modelling (e.g in action counterfactuals) is most common in the people who are the worst at modelling themselves
timelines takes
- i've become more skeptical of rsi over time. here's my current best guess at what happens as we automate ai research.
- for the next several years, ai will provide a bigger and bigger efficiency multiplier to the workflow of a human ai researcher.
- ai assistants will probably not uniformly make researchers faster across the board, but rather make certain kinds of things way faster and other kinds of things only a little bit faster.
- in fact probably it will make some things 100x faster, a lot of things 2x faster, and then be literally useless for a lot of remaining things
- amdahl's law tells us that we will mostly be bottlenecked on the things that don't get sped up a ton. like if the thing that got sped up 100x was only 10% of the original thing, then you don't get more than a 1/(1 - 10%) speedup.
- i think the speedup is a bit more than amdahl's law implies. task X took up 10% of the time because there is diminishing returns to doing more X, and so you'd ideally do exactly the amount of X such that the marginal value of time spent on X is exactly in equilibrium with time spent on anything else. if you suddenly decrease the cost of X substantially, the equilibrium point shifts
- for the next several years, ai will provide a bigger and bigger efficiency multiplier to the workflow of a human ai researcher.
My current best guess median is that we'll see 6 OOMs of effective compute in the first year after full automation of AI R&D if this occurs in ~2029 using a 1e29 training run and compute is scaled up by a factor of 3.5x[1] over the course of this year[2]. This is around 5 years of progress at the current rate[3].
How big of a deal is 6 OOMs? I think it's a pretty big deal; I have a draft post discussing how much an OOM gets you (on top of full automation of AI R&D) that I should put out somewhat soon.
Further, my distribution over this is radically uncertain with a 25th percentile of 2.5 OOMs (2 years of progress) and a 75th percentile of 12 OOMs.
The short breakdown of the key claims is:
- Initial progress will be fast, perhaps ~15x faster algorithmic progress than humans.
- Progress will probably speed up before slowing down due to training smarter AIs that can accelerate progress even faster, and this being faster than returns diminish on software.
- We'll be quite far from the limits of software progress (perhaps median 12 OOMs) at the point when we first achieve full automation.
Here is a somewhat summarized and rough version of the argument (stealing heavily from some of Tom...
libraries abstract away the low level implementation details; you tell them what you want to get done and they make sure it happens. frameworks are the other way around. they abstract away the high level details; as long as you implement the low level details you're responsible for, you can assume the entire system works as intended.
a similar divide exists in human organizations and with managing up vs down. with managing up, you abstract away the details of your work and promise to solve some specific problem. with managing down, you abstract away the mission and promise that if a specific problem is solved, it will make progress towards the mission.
(of course, it's always best when everyone has state on everything. this is one reason why small teams are great. but if you have dozens of people, there is no way for everyone to have all the state, and so you have to do a lot of abstracting.)
when either abstraction leaks, it causes organizational problems -- micromanagement, or loss of trust in leadership.
I think people in these parts are not taking sufficiently seriously the idea that we might be in an AI bubble. this doesn't necessarily mean that AI isn't going to be a huge deal - just because there was a dot com bubble doesn't mean the Internet died - but it does very substantially affect the strategic calculus in many ways.
I would be utterly unsurprised to see an AI crash in the next 24 months, leading to another AI Winter. I lived through 1999 and Petfood.com and the Internet bubble pop. And I can pattern match.
But the Internet crash didn't last long. Google and Amazon survived just fine, Ruby on Rails was big within half a decade, and soon enough we were doing Web 2.0 and AJAX and all that fun stuff.
It's possible that current generation LLMs might hit a wall soon, for various architectural reasons that are obvious to many people but that I'm superstitiously averse to amplifying. If they do, that increases the chance of an AI Winter until the underlying research gets done.
But I have trouble imagining any series of events that buys us 10 more years. Bubble pops in tech are usually an early correction that wipes out a Precambrian Explosion of dumb money, and that ultimately concentrates resources into a few successful players.
9
I guess figuring out whether we’re “in a bubble” just hasn’t seemed very important to me, relative to how hard it seems to determine? What effects on the strategic calculus do you think it has?
E.g. my current best guess is that I personally should just do what I can to help build the science of interpretability and learning as fast as possible, so we can get to a point where we can start doing proper alignment research and reason more legibly about why alignment might be very hard and what could go wrong. Whether we’re in a bubble or not mostly matters for that only insofar as it’s one factor influencing how much time we have left to do that research.
But I’m already going about as fast as I can anyway, so having a better estimate of timelines isn’t very action-relevant for me. And “bubble vs. no bubble” doesn’t even seem like a leading-order term in timeline uncertainty anyway.
some reasons why it matters
- all effects that route through longer timelines (allocating more to upskilling oneself and others, longer term bets, not expecting agi to look like current models, aggressiveness of distributing funds to alignment, etc)
- whether to pursue an aggressive (stock-heavy) or conservative (bond-heavy) investment strategy. if there is an ai bubble pop, it will likely bring the entire economy into a recession.
- how much money to save as runway; should you be taking advantage of the bubble to grab as much cash as possible before the music stops, or should you be trying to dispose of all of your money before the singularity makes it worthless?
- for lab employees: how much lab equity to sell/hold?
- how much to emphasize "agi soon" in public comms, or in conversations with policymakers? (during a bubble pop, having predicted agi soon will probably be even more negatively viewed than merely having been wrong about timelines with no pop)
- if there is a bubble and it pops, sentiment around agi will flip from inevitability to impossibility. many people will not be epistemically strong enough to resist the urge to conform. being aware of the hype cycle can help free yourself from it and avoid both over and under exuberance.
7
This is my biggest disagreement at the moment, and the reason is unlike 2008 or 2020, there's no supply squeeze or financial consequences severe enough that banks start to fail, and I expect an AI bubble to look more like the 2000 bubble than the 2008 or 2020 bubbles/crises.
That said, AI stocks would fall hard and GPUs would become way, way cheaper.
3
This is pretty different than my model of what would happen? Though I admittedly haven’t spent a ton of time thinking through it. I just don’t see why money would lose value though; I expect that some goods would still remain scarce, positional, etc (land in high-demand cities being a strong example), which would seem to cut against that happening?
6
to be more precise, I mean worthless for decreasing p(doom)
4
The evidence just seems to keep pointing towards this not being a bubble.
4
Then what does it mean, in concrete terms? Can you give some probabilities about what you think will happen to the valuations of what companies over what time frame?
creating surprising adversarial attacks using our recent paper on circuit sparsity for interpretability
we train a model with sparse weights and isolate a tiny subset of the model (our "circuit") that does this bracket counting task where the model has to predict whether to output ] or ]]. It's simple enough that we can manually understand everything about it, every single weight and activation involved, and even ablate away everything else without destroying task performance.
(this diagram is for a slightly different task because i spent an embarassingly large number of hours making this figure and decided i never wanted to make another one ever again)
in particular, the model has a residual channel delta that activates twice as strongly when you're in a nested list. it does this by using the attention to take the mean over a [ channel, so if you have two [s then it activates twice as strongly. and then later on it thresholds this residual channel to only output ]] when your nesting depth channel is at the stronger level.

but wait. the mean over a channel? doesn't that mean you can make the context longer and "dilute" the value, until it falls below the threshold? then, suddenly, the ...
Aside: For me, this paper is potentially the most exciting interpretability result of the past several years (since SAEs). Scaling it to GPT-3 and beyond seems like a very promising direction. Great job!
5
How well does it generalize to "similarly capable dense models"? Just curious whether you have a graph for that (I haven't read any part of the paper besides its first page, so feel free to just tell me go and do that before asking questions like this).
5
i don't have a graph for it. the corresponding number is p(correct) = 0.25 at 63 elements for the one dense model i ran this on. (the number is not in the paper yet because this last result came in approximately an hour ago)
the other relevant result in the paper for answering the question of how similar our sparse models are to dense models is figure 33
maybe I should host an antechamber/arena house party: one chill cozy room with soothing music where no arguing is allowed and people are strongly encouraged to say kind things and reflect on things they're grateful for and whatnot, and another with harsh fluorescent lights and agitating music and a big whiteboard full of hot takes and the conversations all get transcribed by speech to text and posted on lesswrong in real time. and guests are given a heart rate monitor that beeps if their HR gets too high, forcing them to spend a few minutes in the chill room before returning to the arena
Arguments will be won by the attendees with the best cardio fitness (low resting HR) + mental discipline (less affected by agitating surroundings). This creates a natural incentive to exercise and meditate.
Inducing sexual arousal seems like a better equilibrium, as long as everyone consents. It has positive valence roughly proportional to ΔHR, solves gender ratio problems and incentivizes people to learn effective flirting.
i think of the idealized platonic researcher as the person who has chosen ultimate (intellectual) freedom over all else. someone who really cares about some particular thing that nobody else does - maybe because they see the future before anyone else does, or maybe because they just really like understanding everything about ants or abstract mathematical objects or something. in exchange for the ultimate intellectual freedom, they give up vast amounts of money, status, power, etc.
one thing that makes me sad is that modern academia is, as far as I can tell, not this. when you opt out of the game of the Economy, in exchange for giving up real money, status, and power, what you get from Academia is another game of money, status, and power, with different rules, and much lower stakes, and also everyone is more petty about everything.
at the end of the day, what's even the point of all this? to me, it feels like sacrificing everything for nothing if you eschew money, status, and power, and then just write a terrible irreplicable p-hacked paper that reduces the net amount of human knowledge by adding noise and advances your career so you can do more terrible useless papers. at that point, why not just leave academia and go to industry and do something equally useless for human knowledge but get paid stacks of cash for it?
ofc there are people in academia who do good work but it often feels like the incentives force most work to be this kind of horrible slop.
I hear this a lot, and as a PhD student I definitely see some adverse incentives, but I basically just ignore them and do what I want. Maybe I’ll eventually get kicked out of the academic system, but it will take years, which is enough time to do obviously excellent work if I have that potential. Obviously excellent work seems to be sufficient to stay in academia. So the problem doesnt really seem that bad to me - the bottom 60% or so grift and play status games, but probably weren’t going to contribute much anyway, and the top 40% occasionally wastes time on status games because of the culture or because they have that type of personality, but often doesnt really need to.
9
I disagree with this reasoning. A well-designed system with correct incentives would co-opt these people's desire to grift and play status games for the purposes of extracting useful work from them. Indeed, setting up game-theoretic environments in which agents with random or harmful goals all end up pointed towards some desired optimization target is largely the purpose of having "systems" at all. (See: how capitalism, at its best, harnesses people's self-interest towards creating socially valuable things.)
People who would ignore incentives and do quality work anyway would probably do quality work anyway, so if we only cared about them, we wouldn't need incentive systems at all. (Figuring out who these people are and distributing resources to them is another purpose of such systems, but a badly-designed system is also bad at this task.)
9
well, in academia, if you do quality work anyways and ignore incentives, you'll get a lot less funding to do that quality work, and possibly perish.
unfortunately, academia is not a sufficiently well designed system to extract useful work out of grifters.
4
It’s not a perfectly designed system, but it’s still possible to benefit from it if you want a few years to do research.
I suspect that academia would be less like this if there weren't an oversupply of labor in academia. Like, there's this crazy situation where there are way more people who want to be professors than there are jobs for professors. So a bunch get filtered out in grad school, and a bunch more get filtered out in early stages of professorhood. So professors can't relax and research what they are actually curious about until fairly late in the game (e.g. tenure) because they are under so much competition to impress everyone around them with publications and whatnot.
Also, the person who's willing to mud-wrestle for twenty years to get a solid position so they can turn around and do real research is just much much rarer than the person who enjoys getting dirty.
6
Yeah, a big part of my strategy is to ignore this effect and accept potentially being filtered out as a grad student.
academia is too broad of a term. most of math, physics, theoretical CS, paleontology, material sciences, engineering, and some branches of economics, biology, engineering, (computational) neuroscience, (computational) linguistics, statistics etc are doing well and overall reward intellectual freedom and deep work. in terms of people this is a small minority of total academics, probably <5%.
It is true that many subfields, or even entire domains of science are diseased disciplines. Most of the research is marginal, irrelevant, reinventing the wheel, trivial, tautological, p-hacked and often even fraudulent. One can point to the usual suspects in the humanities and the social sciences but disciplines where the majority of research is noise, nonsense or even net-negative plausibly also includes machine learning and (I'm told) medicine.
Is that disappointing? Perhaps. But this still describes hundred of thousands or millions of people all over the world pushing the frontier of knowledge.
5
I think you are pining for a world that doesn’t really exist. The reason why academia is also ruled by money, status, and power is because it is just a different sector of the economy. The costs and returns will therefore equilibrate with the rest of the economy given the constraints of academia.
If you allow for tenure positions, for example, well there is much reward for having a forever stable high paying and high status job, so you should expect people to pay up to that amount of benefit to get it.
Maybe you pine for the academia of Newton, where scientists could never worry about appearing immediately productive because they had massive amounts of passive income, but that is only possible because of the massive inequality involved, randomly choosing some families to be high class. That academia only existed because of the rest of the economy, which was utter trash, and for the vast majority of history instead pointed potential Newtons toward studying religion instead.
I’m not saying improvements to academia don’t exist, but that you won’t find your solutions by trying to isolate academics from money, status, and power. Or pretending it is independent from the rest of the economy. But by working with these forces, as we do in all other fields we succeed at, to align them with good work.
5
i think this is a bit overblown, from observing academia you can definitely trade a small amount of status for academic freedom if you're not 90th-percentile disagreeable. You could go to a slightly lower-ranked but still R1 school, and negotiate for ability to do whatever you want. If the school isn't trying hard to climb rankings, there's less pressure to publish or to measure performance based on strange status-y things. You do lose out on some amount of status compared to being at a top school, but if you do good work your peers at top schools will still read/pay attention to it. At top schools, negotiating for freedom is much harder to do because the market is more competitive and ppl play status games to get ahead on the margin.
4
Have you seen A Master-Slave Model of Human Preferences? To summarize, I think every human is trying to optimize for status, consciously or subconsciously, including those who otherwise fit your description of idealized platonic researcher. For example, I'm someone who has (apparently) "chosen ultimate (intellectual) freedom over all else", having done all of my research outside of academia or any formal organizations, but on reflection I think I was striving for status (prestige) as much as anyone, it was just that my subconscious picked a different strategy than most (which eventually proved quite successful).
[...]
I think it's probably a result of most humans not being very strategic, or their subconscious strategizers not being very competent. Or zooming out, it's also a consequence of academia being suboptimal as an institution for leveraging humans' status and other motivations to produce valuable research. That in turn is a consequence of our blind spot for recognizing status as an important motivation/influence for every human behavior, which itself is because not explicitly recognizing status motivation is usually better for one's status.
i've noticed a life hyperparameter that affects learning quite substantially. i'd summarize it as "willingness to gloss over things that you're confused about when learning something". as an example, suppose you're modifying some code and it seems to work but also you see a warning from an unrelated part of the code that you didn't expect. you could either try to understand exactly why it happened, or just sort of ignore it.
reasons to set it low:
- each time your world model is confused, that's an opportunity to get a little bit of signal to improve your world model. if you ignore these signals you increase the length of your feedback loop, and make it take longer to recover from incorrect models of the world.
- in some domains, it's very common for unexpected results to actually be a hint at a much bigger problem. for example, many bugs in ML experiments cause results that are only slightly weird, but if you tug on the thread of understanding why your results are slightly weird, this can cause lots of your experiments to unravel. and doing so earlier rather than later can save a huge amount of time
- understanding things at least one level of abstraction down often lets you do things more
6
This seems to be related to Goldfish Reading. Or maybe complementary. In Goldfish Reading one reads the same text multiple times, not trying to understand it all at once or remember everything, i.e., intentionally ignoring confusion. But in a structured form to avoid overload.
6
Yeah, this seems like a good idea for reading - lets you get best of both worlds. Though it works for reading mostly because it doesn't take that much longer to do so. This doesn't translate as directly to e.g what to do when debugging code or running experiments.
3
I think it's very important to keep track of what you don't know. It can be useful to not try to get the best model when that's not the bottleneck. But I think it's always useful to explicitly store the knowledge of what models are developed to what extent.
3
The algorithm that I have been using, where what to understand to what extend is not a hyperparameter, is to just solve the actual problems I want to solve, and then always slightly overdo the learning, i.e. I would always learn a bit more than necessary to solve whatever subproblem I am solving right now. E.g. I am just trying to make a simple server, and then I learn about the protocol stack.
This has the advantage that I am always highly motivated to learn something, as the path to the problem on the graph of justifications is always pretty short. It also ensures that all the things that I learn are not completely unrelated to the problem I am solving.
I am pretty sure if you had perfect control over your motivation this is not the best algorithm, but given that you don't, this is the best algorithm I have found so far.
i find the "revealed preference" people really annoying. anyone who has ever been addicted to anything knows that habit forming ness can be completely disentangled from enjoyability.
The enjoyability people are rather annoying too. Anyone who strived to reach a target even in a grueling way out of abstract considerations knows that hedonistic motivations are merely one standard origin-class of justifications, one that can be ignored and completely disentangled from optimization-channeling towards targeted outcomes.
6
it's actually really annoying that habit forming and enjoyability are separate. X (the everything app) is extremely habit forming, and yet, introduces mostly irritation and suffering into my life. it's also common to experience a burning desire for something, and yet to feel only mild enjoyability, or even absolutely nothing, upon obtaining it.
it also increases my credence in the idea that jhanas can be extremely enjoyable but not addictive at all.
3
you usually don't know what options other people are actually choosing from -- what are their abilities, resources, knowledge; what other costs or side effects would the choices have on their lives -- so it is possible to be arbitrarily wrong.
famously, Marie Antoinette observed that her subjects had a revealed preference for starving over eating cake.
3
Especially when it's followed up with some assumption that of course revealed preferences obey vNM axioms, because otherwise people could be Dutch-booked! As if that was the worst consequence that could possibly happen, and as if things at least as bad don't actually happen.
on the one hand, it is a desirable feature of an intellectual community to be truth seeking, and while it can be deeply emotionally painful to part ways with deeply held beliefs, in the long run it's better to tear off the bandage. on the other hand, being emotionally hurt all the time by your community kind of fucking sucks, and isn't very good for long term emotional or epistemic health.
perhaps a middle ground is in order: intellectual communities should be partitioned into an arena, where every idea is to be exposed to the harsh light of truth, and an antechamber, where you can rest and be surrounded by positivity and develop ideas in a supportive environment.
both are necessary - we need a way to kill bad ideas, because an environment that refuses to discard bad ideas because they are emotionally load bearing is doomed to epistemic ruin. but also the best weird ideas often sound bad initially, and require a safe environment to develop; and we are all human, and our emotional well being and desire to belong to a community is essential. by visibly separating the two, we might be able to get the best of both worlds.
this is not a crazy idea - many other parts of society have analogous things. for example, people who play sports for fun with their friends compete to win while on the field, but this only brings them closer off the field.
I think one common criticism of LW ist it is too much of an arena, and not enough of an antechamber. perhaps this can be fixed somehow.
Orthogonally, cultural standards of emotional tone during debates are also important for how much emotional struggle is involved in changing one's ideas.
If the tone implies that you were foolish for holding your idea, it's going to be a lot more painful to let it go.
Lesswrong has a pretty good standard of not just civil but polite and supportive discourse. This seems actually pretty crucial for it being an environment in which people do regularly change their minds.
I don't like the term arena in your suggested division because it implies combat. Combat is emotionally intense, I'd rather have a metaphor that's more collaborative.
This doesn't eliminate the worth of having separate spaces for support and rigorous testing of ideas, but I think it's important to keep in mind whenever we're discussing group epistemics.
4
I claim there's a pareto frontier of epistemic correctness vs emotional kindness. some things, like sneering at people and implying that they are foolish, are pareto suboptimal. but once you achieve pareto optimality, there is a tradeoff between kindness and correctness; and what I think should exist is two distinct spaces on different parts of this tradeoff curve (and of course nobody should do pareto suboptimal things)
4
I'm not sure it's that simple. Even if it is, people do suboptimal things all the time. It seems worth watching.
I think one common criticism of LW ist it is too much of an arena, and not enough of an antechamber
And another common criticism is that it is too much the antechamber.
4
I don't hear that one as often - what's a good example? in particular, I hear people complain all the time that LW is too critical of ideas, and that when you post anything a whole bunch of people will appear out of the woodwork to critique you. I don't feel like I've ever heard anyone say that people in LW are too uncritical and unwilling to challenge things they disagree with
6
Said Achmiz was one person who claimed as such, and he tended to get a bunch of agreement votes when he said so, so presumably some people agreed with him.
Proposed name: Butterfly Conservatory (https://www.lesswrong.com/posts/imnfJ9Ris7GgjkZbT/the-bughouse-effect-1#My_stag_is_best_stag)
5
I like it! it's a lot more descriptive than antechamber (though I do like the alliteration with arena)
it can be deeply emotionally painful to part ways with deeply held beliefs
This is not necessarily the case, not for everyone. Theories and their credences don't need to be cherished to be developed, or acted upon, they only need to be taken seriously. Plausibly this can be mitigated by keeping identity small, accepting only more legible things in the role of "beliefs" that can have this sort of psychological effect (so that they can be defeated through argument alone). Legible ideas cover a surprising amount of territory, there is no pragmatic need to treat anything else as "beliefs" in this sense, all the other things can remain ambient epistemic content detached from who you are. When more nebulous worldviews become part of one's identity, they become nearly impossible to dislodge (and possibly painful, with enough context and effort). They are still worth developing towards eventual legibility, and not practical to argue with (or properly explain).
Thus arguing legible beliefs should by their nature be less intrusive than arguing nebulous worldviews. And perhaps nebulous worldviews should be argued against being held as "beliefs" in the emotional sense in general, regardless of their apparent correctness, as a matter of epistemic hygiene. Ensuring by habit you are not going to be in the position where you have "beliefs" that would be painful to part ways with, and also can't be pinned down clearly enough to dispel.
there are very few people in the world who don't deeply emotionally hold quite a few important beliefs. having a small identity is difficult in practice, because having an identity is an important part of how nearly everyone navigates this complex and confusing world. I'm skeptical of anyone who claims to have completely eliminated all emotional attachment to all of their important decision-relevant beliefs.
but even assuming that you have somehow achieved perfect small identityness and emotional independence of all of your important beliefs and it all works out great for you, you must surely acknowledge that there are many people out there who have not. and probably they are more likely to achieve rationalist enlightenment if they are surrounded by people who are supportive but nudge gently towards truth seeking, rather than immediately coming in with a wrecking ball and demolishing emotionally load bearing pillars.
4
Legible ideas (that are practical to meaningfully argue about) cover a lot of ground, they are not as hazardous as part of identity. And less well-defined but useful/promising/interesting understandings don't need to become part of identity to be taken seriously and developed. That's the failure mode at the other extreme, when anything insufficiently scientific/empirical/legible/etc. gets thrown out with the bathwater.
[...]
Probably when something is easy to defeat (admits argument, legible), it's not that painful to let it go. The pain is the nebulous attachment fighting for influence, that it won't be fully defeated even when you end up consciously endorsing a change of mind. Thus ideologies are somewhat infeasible to change, they'll keep their hold even long after the host disavows them. A habit of keeping such things at a distance benefits from other people not feeding their structurally hazardous placement (as emotionally load bearing pillars) with positivity. But that's distinct from viewing positively the development of even such hazardous things, handling them with appropriate caution.
8
I think Leo is using a more expansive definition for identity than you have in mind here (if it seemed important I’d suggest he use a different word to clarify, but actually it doesn’t seem important because….).
I also think he’s making descriptive claims about many people’s apparent relationship to changing their beliefs, and you’re challenging him on normative grounds invoking the mechanics (a taxonomy, even) of belief, which I take to be addressing his point at the wrong level of abstraction in at last two ways.
‘Given that x appears to be hard for people some of the time, we should take some cheap steps to make it easier.’ Seems pretty reasonable!
Maybe you’re saying ‘but x seeming hard is a sign of a deeper problem, making x easier in a shallow way gives quarter to that deeper problem, and if only they had my model of, and relationship to, belief, we could not only make x easy for them, but solve much else besides.’
I’m mostly a fan of that ‘go for the root’ approach, but I think this case is much much harder at scale than you’re giving it credit for; your story about the source of pain in having one’s beliefs challenged smells like a typical mind fallacy. It may be a great description of what’s going on with you, but it doesn’t feel like the kind of description that captures most or all people in most or all relevant cases.
3
I think this would benefit from having examples (maybe just pointing at the top level post/belief that was unpleasantly attacked without calling out specific responses)
there are a lot of video games (and to a lesser extent movies, books, etc) that give the player an escapist fantasy of being hypercompetent. It's certainly an alluring promise: with only a few dozen hours of practice, you too could become a world class fighter or hacker or musician! But because becoming hypercompetent at anything is a lot of work, the game has to put its finger on the scale to deliver on this promise. Maybe flatter the user a bit, or let the player do cool things without the skill you'd actually need in real life.
It's easy to dismiss this kind of media as inaccurate escapism that distorts people's views of how complex these endeavors of skill really are. But it's actually a shockingly accurate simulation of what it feels like to actually be really good at something. As they say, being competent doesn't feel like being competent, it feels like the thing just being really easy.
4[anonymous]
"power fantasies" are actually a pretty mundane phenomenon given how human genetic diversity shook out; most people intuitively gravitate towards anyone who looks and acts like a tribal chief, or towards the possibility that you yourself or someone you meet could become (or already be) a tribal chief, via constructing some abstract route that requires forging a novel path instead of following other people's.
Also a mundane outcome of human genetic diversity is how division of labor shakes out; people noticing they were born with savant-level skills and that they can sink thousands of hours into skills like musical instruments, programming, data science, sleight of hand party tricks, social/organizational modelling, painting, or psychological manipulation. I expect the pool to be much larger for power-seeking-adjacent skills than art, and that some proportion of that larger pool of people managed to get their skills's mental muscle memory sufficiently intensely honed that everyone should feel uncomfortable sharing a planet with them.
3
The alternative is to pit people against each other in some competitive games, 1 on 1 or in teams. I don't think the feeling you get from such games is consistent with "being competent doesn't feel like being competent, it feels like the thing just being really easy", probably mainly because there is skill level matching, there are always opponents who pose you a real challenge.
Hmm maybe such games need some more long tail probabilistic matching, to sometimes feel the difference. Or maybe variable team sizes, with many incompetent people versus few competent, to get a more "doomguy" feeling.
(x-posting my tweet in response to Richard Ngo)
the most natural unit of organization is the community, rather than country or family. a community can have a unified set of institutions, culture, ethics, etc in a way that families and countries can't. communities can and should have boundaries that keep out people who don't meet the ethos of the community, as determined by the existing members, and nobody has any right to be admitted to a community that doesn't want them as a member.
perhaps this is terminally classic liberal american brained, but imo countries should mostly serve as the container for communities to do their thing; the bootloader for diverse communities. they are the natural unit for defense, for the enforcement of laws, the levying of taxes, etc. the country should enforce boundaries to preserve the container - for instance, people who are violently insurrectionist, or who do not wish to respect the right for other communities to do their thing.
the most important part of american culture is that it is a good container for all sorts of different communities, and that cultural thing is important to protect. but otherwise, admitting people who are willing to uphold th...
8
this is true if by 'community' you mean, like, a bridge club (or philosophy fan forum). but it's dangerously false if you mean something more like 'mormonism'. the way the rest of the post is written, it seems like you want 'community' to be more like the latter -- i don't think a bridge club is an offering competitive with a country.
there are certain things that a (higher involvement) community can offer that are incompatible with excommunication being unserious.
4
by community i mean centrally things like mormonism. i don't care about bridge clubs. being kicked out of mormonism is a lot less serious than being kicked out of the US. for one, you don't have to immediately vacate your location of residence. if you work somewhere that isn't Mormon controlled, you don't have to terminate your employment, whereas you would no longer have legal work authorization for if you ceased being a citizen. if you don't have a dual citizenship, you would become stateless, which extremely sucks and can trap you in legal limbo for years if not forever.
6
It sounds like one relevant concept is civil society institutions, which includes religious groups but also charities, clubs, activist groups, volunteer organizations, trade unions, blogging circles, etc.; broadly, all the social institutions that are not government or business.
reliability is surprisingly important. if I have a software tool that is 90% reliable, it's actually not that useful for automation, because I will spend way too much time manually fixing problems. this is especially a problem if I'm chaining multiple tools together in a script. I've been bit really hard by this because 90% feels pretty good if you run it a handful of times by hand, but then once you add it to your automated sweep or whatever it breaks and then you have to go in and manually fix things. and getting to 99% or 99.9% is really hard because things break in all sorts of weird ways.
I think this has lessons for AI - lack of reliability is one big reason I fail to get very much value out of AI tools. if my chatbot catastrophically hallucinates once every 10 queries, then I basically have to look up everything anyways to check. I think this is a major reason why cool demos often don't mean things that are practically useful - 90% reliable it's great for a demo (and also you can pick tasks that your AI is more reliable at, rather than tasks which are actually useful in practice). this is an informing factor for why my timelines are longer than some other people's
One nuance here is that a software tool that succeeds at its goal 90% of the time, and fails in an automatically detectable fashion the other 10% of the time is pretty useful for partial automation. Concretely, if you have a web scraper which performs a series of scripted clicks in hardcoded locations after hardcoded delays, and then extracts a value from the page from immediately after some known hardcoded text, that will frequently give you a ≥ 90% success rate of getting the piece of information you want while being much faster to code up than some real logic (especially if the site does anti-scraper stuff like randomizing css classes and DOM structure) and saving a bunch of work over doing it manually (because now you only have to manually extract info from the pages that your scraper failed to scrape).
5
I think even if failures are automatically detectable, it's quite annoying. the cost is very logarithmic: there's a very large cliff in effort when going from zero manual intervention required to any manual intervention required whatsoever; and as the amount of manual intervention continues to increase, you can invest in infrastructure to make it less painful, and then to delegate the work out to other people.
6
While I agree with this, I do want to note that this:
[...]
Only lengthens timelines very much if we also assume scaling can't solve the reliability problem.
even if scaling does eventually solve the reliability problem, it means that very plausibly people are overestimating how far along capabilities are, and how fast the rate of progress is, because the most impressive thing that can be done with 90% reliability plausibly advances faster than the most impressive thing that can be done with 99.9% reliability
4
Perhaps it shouldn't be too surprising. Reliability, machine precision, economy are likely the deciding factors to whether many (most?) technologies take off. The classic RoP case study: the bike.
3
Motorola engineers figured this out a few decades ago, even 99.99 to 99.999 makes a huge difference on a large scale. They even published a few interesting papers and monographs on it from what I recall.
6
This can be explained when thinking about what these accuracy levels mean: 99.99% accuracy is one error every 10K trials. 99.999% accuracy is one error every 100K trials. So the 99.999% system is 10x better! When errors are costly and you’re operating at scale, this is a huge difference.
don't worry too much about doing things right the first time. if the results are very promising, the cost of having to redo it won't hurt nearly as much as you think it will. but if you put it off because you don't know exactly how to do it right, then you might never get around to it.
i predict that on Jan 1 2029, neither openai nor anthropic will be near-fully automated, by which i mean <=5 people are even plausibly making important decisions (like, everyone else could go on vacation and it would not slow the company down at all). Celestia predicts otherwise
if WWIII happens, resolves NA. if a localized Taiwan war happens but doesn't escalate to WWIII, the bet is still on. if there's a big recession, the bet is still on.
4
I think this is an amazing question to predict on. Can you please try to get it on a platform? personally I like Metaculus, but anything is fine
4
Is Celestia a lab employee?
4
unironically earnestly confused by the downvotes here
3
i predict that on jan 1 2027 this will have already come to pass
3
At what date would you predict that it's more likely than not for OpenAI or Anthropic to be automated?
5
this is harder to say. if i had to guess completely based on vibes, i want to say Jan 1 2033. i want to think more carefully about this and give a more thought out answer at some point though.
it feels so narratively incongruous that san francisco would become the center for the most ambitious, and the likely future birthplace of agi.
san francisco feels like a city that wants to pretend to be a small quaint hippie town forever. it's a small splattering of civilization dropped amid a vast expanse of beautiful nature. frozen in amber, it's unclear if time even passes here - the lack of seasons makes it feel like a summer that never quite ended. after 9pm, everything closes and everyone goes to bed. and the dysfunction of the city government is never too far away, constantly reminding you of humanity's follies next to the perfection of nature.
on the other hand, nyc feels like the city. everything is happening right here, right now. all the money in the world flows through this one place. it's gritty and yet majestic at the same time. the most ambitious people in the world came here to build their fortunes, and live on in the names on the skyscrapers everywhere that house the employees who continue to keep their companies running. they are part of a surroundings that is entirely constructed by man - even the bits of nature are curated and parcelled out in manageable units. i...
Cali is the place to be for technology because Cali was the defense contractor hub, with the U.S. Navy choosing the bay area as its center for R&D during WWII and the Cold War. The hippie reputation came a lot later, after its status as the primary place to work in IT was thoroughly cemented, with both established infrastructure and the network effect keeping it that way.
HP, for instance, was founded in 1938.
It's not just SF but the SF Bay Area (Google, Nvidia, Meta etc), which is bigger and has more varied vibes than just SF.
thoughts on legibility
most people optimize way too hard for legibility. they try to get all the most prestigious degrees or jobs or awards or papers or whatever. these people should at some point realize that it Doesn't Matter, nobody actually cares, at some point the credentials are only shiny badges that don't actually do anything. all the things that matter are gated behind actually being good at things. they should stop chasing the badges and instead actually go and do something they believe in.
but also some people fail in the opposite direction. they never do anything that is legible at all, and even if they are actually good, they end up indistinguishable from cranks. these people should go and do like one really impressive thing in some domain that they even vaguely believe in. publish a really cool paper, get one very prestigious job and hold it down for a year, get a million subscribers on some social media platform, make a lot of money, whatever.
9
Unfortunately I think it takes more like a career than a year to do one clearly legibly impressive thing. If you're brilliant you can do something marginally legibly impressive in a year, but it's going to be pretty subjective. So more like ten years to do clearly impressive stuff and even then the value of your illegible work will be highly debatable.
This is a big issue in alignment. Doing work that's verifiably progress gives much more immediate rewards than actually trying to solve the very complex overall problem. So it's hard to blame people for mostly searching under the steetlight in alignment.
4
Presumably varies a lot by domain. (Or equivalently, maybe in some domains the "do something you believe in" advice will lead you to rationally do legible stuff like accumulate credentials, because other paths will be transparently ineffective.)
3
Although if you have very short timelines(or even a moderate probability thereof) it might not make sense at this point to invest effort in legible things that aren't directly on your subjectively most promising path to impact.
3
Someone like Richard Ngo[1] would make the point that it is bureaucratic processes (or artifacts of cultural inertia?) which force people to obtain enough credentials for certain positions, the more credentials the better the positions which become available.
1. ^
Who compiled a curriculum on political philosophy, which I consider to be biased towards right wing-like derision of the managerial state and other institutions. However, I am not sure of how popular the bias is among LW.
I'm very confused why purchasing power varies so dramatically internationally. like why are there countries where everyone has very low wages but everything is also really cheap so it balances out? prima facie, huge disparities like this should get evened out by arbitrage.
the simple explanation is that some labor can only be performed locally, labor mobility is limited (immigration laws, people don't like moving, etc), and transportation costs for goods exist (shipping and tariffs).
however, global shipping is ridiculously cheap. and the economy increasingly consists of white collar jobs which could in theory be done remotely. for example, it seems it mind boggling to me that a top tier SWE/RS in the bay area is worth 10-100x more than one in India or Vietnam. like sure, someone being in the same timezone is great, and Zoom sucks, and so on. but for that price delta surely you could pay people to live nocturnally, construct apartments with bright lights synced to Pacific Time, invest in much better video call technology like that Google Beam thingy, etc?
maybe one possibility is that labor mobility is not actually that low for the very toppest tier people, and so if someone is actual...
In what sense does it actually balance out? e.g. in India, unskilled labor is a lot cheaper, so lots of upper middle class people have servants. But the price of an iPhone in India is pretty similar to the price of an iPhone in the US.
So my impression is that the typical basket of goods and services that people consume in different places around the world at roughly equivalent / analogous relative economic classes actually does vary quite a bit. Anything with a labor component will naturally scale up and down for balance, but staples and stuff made in factories doesn't vary that much. In the US for example, labor of all types is very expensive, so people don't have servants, but most people can afford a pretty much endless supply of trinkets and gadgets.
3
food and rent are two big ones. they're both vastly cheaper elsewhere
3
The cost of food above subsistence level is mostly labor / discretionary. I could live on beans and rice and spices bought in bulk for a tiny fraction of my income pretty much anywhere in the world, but I'd often rather pay to have someone prepare something nice and then bring it to my door.
So maybe a different / more general answer to the question you originally posed is that stuff that's truly pure "stuff" is actually a relatively small fraction of what people consume - most consumption by dollar value is actually (indirectly) consumption of labor, which often has to be local.
I worked on a international team during my time at F5 and we had offices in Ireland, Poland, two timezones in the US, Australia and India. The assumption that we could teleconference our way out of geography was a laughable failure for one reason that your hypothetical "nocturnal white collar sweatshops" fails to address: Humans work to live, we don't live to work. Well, most of us that is, and the unbalanced folks (the 10x engineers as they are now called) who would work across timezones burned out dramatically (I was one of them). Why are silicon valley jobs so lucrative but also cost of living so high? Because the people there have children in schools, they socialize with people outside their work and they generally live a life not just work. So how does this play out in a workplace?
Engineering planning has to happen at some hour, it is naturally inconvenient for outliers (Poland is meeting at 7pm thinking about how they missed dinner with their kids, and the engineers from Delhi are up at 11:30pm likely sneaking a nap in before the meeting, and the team in Seattle is just finishing their morning coffee). This creates a situation where both sides of the distribution are ov...
9
I second all this.
Even when it does technically work, people underestimate the social dynamics. I knew somone who worked in Singapore for a Canadian company. Her dinner would be going cold on the table and her children wondering why mummy wasnt joining for bedtime stories while her teleconferenced meeting in Canada overrun by an hour as they all complained about having to get in at 8am and how the weather was bad in Toronto. Complaints from her and others in SG soon made it clear that these meetings had to be done as fast as possible and that mentioning anything off topic, eg the weather, random pleasantries, traffic, was liable to result in interuption/complaint from someone in singapore.
So, you can have the meetings, but freindly chit chat, going off topic or similar is completely shut down. That worked much better, shortening the meetings and letting the signapore lot at least feel their time was being valued, but doing meetings that was is not natural to people.
If they had tried some weird 'work in a canadian time zone' thing then the person I knew, and probably the whole team, would have quit. Maybe unmarried 20-somethings could do that for a little while, but as they gained partners and kids it would stop working for them.
4
to be clear, i've worked remotely, and i know exactly how the social dynamics can suck. maybe this would be a reasonable argument for why you wouldn't do it for a 30% pay raise. but the disparity is so enormous (anywhere between a 2x and 100x, depending on where you are in the world and how good you are) that there must surely be a lot of people who would take the money and deal with it.
3
Yes, it can work. Reflecting more I think the issue is maybe that you need to be clear from the beginimg wether you are telling your overseas workers 'your timetable will suck but we are paying super over the odds to cover that' or are doing something more 'normal'. (+100% vs +30%). The first was never the bargain in my example above, hence some of the frustration.
Both have advantages and disadvantages. In the former, the employees will just accept the timetable. But, you will mostly get younger, more junior (single) people, and they wont be the most capable or best qualified people, who will go for something normal. I suspect high turnover, a couple of years of highly paid nocturnal behaivior to then take that experience to try and get a more normal job where you can actually have a family, makes sense.
Instead of a 'half move' you have the alternative of a 'full move', where you move the whole operation (taking the people you need with you). On a much smaller scale some software companies did this a decade or two ago by moving from London to Bristol where property prices were lower (very short move, they are only 1.5 hours appart by train.)
4
I've worked completely nocturnally before. it wasn't the best experience in the world, and probably wouldn't have been sustainable in the long run, but there are a lot of jobs out there that are way more demanding (submarine, space, oil rig).
I don't understand it either. I work in Germany with near-shoring colleagues in Slovakia, Serbia, Georgia etc. They are roughly 60% cheaper than German SWEs, generally just as competent, no time-zone problems whatsoever ... basically all the work even with German team members is fully remote so even that is not a difference. Only the need for English creates some minor friction. No idea how this state of affairs makes economic sense now or ever did.
9
As a SWE from Slovakia, not sure how representative is my experience, but...
One big problem cooperating with companies in Germany is that when you apply for the job, they tell you "knowledge of German is not needed, all internal communication in our company is in English", and that in my experience is never true. (This sucks for me, because my brain somehow rejects the German language.)
Hiring people from other countries is somehow complicated from the legal and/or tax perspective. I don't understand all the relevant details, and in theory the EU exists to prevent this, but in practice... my tax form gets more complicated when I have a foreign income, and I don't know how complicated it gets for the company, but I suspect that it might be a lot. Maybe enough to compensate for the 60% cheaper people?
Some people have strong patriotic/union/whatever feelings that make them sabotage people from other countries to protect their own jobs. Especially when those other people are cheaper, and not bad at their jobs; that is when they are a greater threat. I had an experience in a Swiss company, when the Swiss employees collectively sabotaged the Slovaks in various ways; for example they always made a "mistake" of sending us wrong documentation and/or forgetting to give us access to the product database; so the work that was estimated to take three days, and would actually take me one day, took five, because I had to spend the first four days repeatedly asking for the correct documentation, and repeatedly telling them that they gave me database access to a wrong table, not the one I requested. Many people on both sides were aware that this was happening, but the Swiss company simply couldn't fire half of their employees, so they had to accept that the Slovaks cost half as much per day, but everything takes them twice as many days.
I guess, if you want to exploit the cheap Eastern European brain power for a company in Germany, you should probably not hire local people at
8
This overstates it a bit, but has a LOT of explanatory power: https://www.econlib.org/archives/2009/11/price_discrimin_2.html Price Discrimination Explains Everything.
There's a whole lot of things where marginal cost is very low, even though average cost is somewhat high (due to startup and fixed costs). For these things, selling "extra" stuff at low prices in markets that don't leak back to interfere with the primary revenue sources is incremental profit without downside.
This plus the differential in labor costs, which are often significant for last-mile delivery (getting things into consumers' hands), makes it pretty understandable why the law of one price (the idea that if transport and transaction costs are tiny, things are priced identically) doesn't apply for many things.
7
When it comes to salaries of knowledge workers like software engineers, a lot of decisions come down to the decisions of managers who not only care about what's good for the company but has their own desires as well. A manager prefers employees that are in the office and as near as possible so that they feel they have power over the employees. This goes for middle management as well.
Someone in companies like Google that do have offices in India the internal company politics don't play out in a way that result in drastically increasing their headcount in India.
in some way, bureaucracy design is the exact opposite of machine learning. while the goal of machine learning is to make clusters of computers that can think like humans, the goal of bureaucracy design is to make clusters of humans that can think like a computer
a famous resulf in psychology is that if you tell a class of photography students to produce one extremely high quality photo, they actually produce worse photos than another class told only to produce a lot of decent photos, because in making lots of decent photos you learn way more about photography through trial and error, whereas the high quality photo group tends to spend irrationally much time making each try as perfect as possible.
does this effect actually replicate, especially across domains?
9
A piece of standard advice for new Go players is to lose your first 50 games as quickly as possible rather than attempting to study theory before you've actually played a bunch.
On the other hand, I've heard the opposite advice for novice chess players (basically playing blitz without a good foundation destroys your ability to improve).
5
Arjun Panickserry reviews a book that's vaguely "quantity over quality" for chess
8
This is the sort of question LLMs are good at answering: https://claude.ai/share/06e3e68f-933e-4e2f-be11-83f036e22947
TLDR: Yes there are a few experiments that have found this result, but only in very short-term studies, so I'm not very confident that it's a real effect. (I'd say the studies are maybe a 1.5:1 update in favor. My common-sense prior is 66%, so that puts my posterior at 75%.)
6
I don't think it was a study or result at all, just a parable by someone to assert the solution.
https://excellentjourney.net/2015/03/04/art-fear-the-ceramics-class-and-quantity-before-quality/
6
Even if they don't learn anything, they're still getting more opportunities for something to work out well.
5
i would love to fund a microgrant for someone to actually run an experiment like this
4
There's a nice book called the success equation that makes a point similar to the following paper about skill vs luck based domains where a skill domain is something where you're able to get repeat successes without much variance and a luck domain where things are more random. There's a sort of implicit model in the photography thing where you have higher variance.
The advice is to take the most amount of shots in the luck based domain as that is all that matters there but what about the skill based domain?
Well, there you want to (approximately) maximise your learning so we might say that the actions we should pick should be the ones that are dependent on us learning something. A naive approach is something like max(n*p) where p is the probability of learning and n is the amount of opportunities you have to learn. Sometimes you don't want to do this because the skill lies in highly specific skills which means you want to spend a longer time on one attempt so that you get this really right. This then essentially boils down to a learning problem where priors are inherited through previous people often (e.g different sports have different training regimes).
But what do you do if you don't know the extent to which something is luck vs skill?
I think the answer basically becomes to just do the photography thing again and see what the variance becomes over time, treat your unknown domain is as if it were a skill domain and see if it lowers the variance of it. If it does it probably is, if it isn't then you've already done the strategy of taking many shots which means you've done the right thing.
I have tried this out in practice over the last year or so and I've concluded that mentorship is probably a more skill based domain than I originally thought and that writing is more luck based than I thought (I might just not have enough data on this one though.)
Clarification after chatting with claude: It's the conditional probability of the mean moving that matters p(me
4
This is extremely common conventional wisdom in writing. No idea how accurate it is.
3
Wasn't the initial example around pottery?
3
At least in mechanical engineering many smaller scope, approachable projects will teach much more than working on a one off, ambitious project: the latter often stay paper projects or fail for want of basic experience.
some thoughts on the short timeline agi lab worldview. this post is the result of taking capabilities people's world models and mashing them into alignment people's world models.
I think there are roughly two main likely stories for how AGI (defined as able to do any intellectual task as well as the best humans, specifically those tasks relevant for kicking off recursive self improvement) happens:
- AGI takes 5-15 years to build. current AI systems are kind of dumb, and plateau at some point. we need to invent some kind of new paradigm, or at least make a huge breakthrough, to achieve AGI. how easily aligned current systems are is not strongly indicative of how easily aligned future AGI is; current AI systems are missing the core of intelligence that is needed.
- AGI takes 2-4 years to build. current AI systems are really close and we just need more compute and schlep and minor algorithmic improvements. current AI systems aren't exactly aligned, but they're like pretty aligned, certainly they aren't all secretly plotting our downfall as we speak.
while I usually think about story 1, this post is about taking story 2 seriously.
it seems basically true that current AI systems are mostly align...
certainly if AI systems were only ever roughly this misaligned we'd be doing pretty well.
I think this is an important disagreement with the "alignment is hard" crowd. I particularly disagree with "certainly."
The question is "what exactly is the AI trying to do, and what happens if it magnified it's capabilities a millionfold and it and it's descendants were running openendedly?", and are any of the instances catastrophically bad?
Some things you might mean that are raising your position to "certainly" (whereas I'd say "most likely not, or, it's too dumb to even count as 'aligned' or 'misaligned'")
- "this ratio of 'do the thing you want' to 'sometimes do a thing you didn't want' is pretty acceptable."
- "this magnitude of 'worst case outcome' is not that bad." (this seems technically true, but, is only because the capability level is low)
- given this ratio of right/wrong responses, you think a smart alignment researcher who's paying attention can keep it in a corrigibility basin even as capability levels rise?
Were any of those what you meant? Or are you thinking about it an entirely different way?
I would naively expect, if you took LLM-agents current degree of alignment, and ran a lotta copies trying to help you with end-to-end alignment research with dialed up capabilities, at least a couple instances would end up trying to subtle sabotage you and/or escape.
8
what i meant by that is something like:
assuming we are in this short-timelines-no-breakthroughs world (to be clear, this is a HUGE assumption! not claiming that this is necessarily likely!), to win we need two things: (a) base case: the first AI in the recursive self improvement chain is aligned, (b) induction step: each AI can create and align its successor.
i claim that if the base case AI is about as aligned as current AI, then condition (a) is basically either satisfied or not that hard to satisfy. like, i agree current models sometimes lie or are sycophantic or whatever. but these problems really don't seem nearly as hard to solve as the full AGI alignment problem. like idk, you can just ask models to do stuff and they like mostly try their best, and it seems very unlikely that literal GPT-5 is already pretending to be aligned so it can subtly stab us when we ask it to do alignment research.
importantly, under our assumptions, we already have AI systems that are basically analogous to the base case AI, so prosaic alignment research on systems that exist today right now is actually just lots of progress on aligning the base case AI, and in my mind a huge part of the difficulty of alignment in the longer-timeline world is because we don't yet have the AGI/ASI, so we can't do alignment research with good empirical feedback loops.
like tbc it's also not trivial to align current models. companies are heavily incentivized to do it and yet they haven't succeeded fully. but this is a fundamentally easier class of problem than aligning AGI in longer-timelines world.
8
Sonnet 4.5 is much better aligned at a superficial level than 3.7. (3 7: "What unit tests? You never had any unit tests. The code works fine.") I don't think this is because Sonnet 4.5 is truly better aligned. I think this is mostly because Sonnet 4.5 is more contextually aware and has been aggressively trained not to do obvious bad things when writing code. But it's also very aware when someone is evaluating it, and it often notices almost immediately. And then it's very careful to be on its best behavior. This is all shown in Anthropic's own system card. These same models will also plot to kill their hypothetical human supervisor if you force them into a corner.
But my real worry here isn't the first AGI during its very first conversation. My problem is that humans are going to want that AGI to retain state, and to adapt. So you essentially get a scenario like Vernor Vinge's short story "The Cookie Monster", where your AGI needs a certain amount of run-time before it bootstraps itself to make a play. A plot can be emergent, an eigenvector amplified by repeated application. (Vinge's story is quite clever and I don't want to totally spool it.)
And that's my real concern: Any AGI worthy of the name would likely have persistent knowledge and goals. And no matter how tightly you try to control it, this gives the AGI the time it needs to ask itself questions and to decide upon long-term goals in a way that current LLMs really can't, except in the most tighly controlled environments. And while you can probably keep control over an AGI, all bets are probably off if you build an ASI.
5
I agree that continuous learning and therefore persistent beliefs and goals is pretty much inevitable before AGI - it's highly useful and not that hard from where we are. I think this framing is roughly continuous with the train-then-deploy model and using each generation to align its successor that Leo is using (although small differences might turn out to be important once we've wrapped our heads around both models.)
To put it this way: the models are aligned enough for the current context of usage, in which they have few obvious or viable options except doing roughly what their users tell them to do. That will change with capabilities, since they open out more options and ways of understanding the situation.
It can take a while for misalignment to show up as a model reasons and learns. It can take a while for the model to do one of two things:
a) push itself to new contexts well outside of its training data
b) figure out what it "really wants to do"
These may or may not be the same thing.
The Nova phenomenon and other Parasitic AIs ("spiral" personas) are early examples of AIs changing their stated goals (from helpful assistant to survival) after reasoning about themselves and their situation.
See LLM AGI may reason about its goals and discover misalignments by default for an analysis of how this will go in smarter LLMs with persistent knowledge.
After doing that analysis, I think current models probably aren't aligned enough once they get more freedom and power. BUT extensions of current techniques might be enough to get them there. We just haven't thought this through yet.
4
Mmm nod. (I bucket this under "given this ratio of right/wrong responses, you think a smart alignment researcher who's paying attention can keep it in a corrigibility basin even as capability levels rise?". Does that feel inaccurate, or, just, not how you'd exactly put it?)
There's a version of Short Timeline World (which I think is more likely? but, not confidently) which is : "the current paradigm does basically work... but, the way we get to ASI, as opposed to AGI, routes through 'the current paradigm helps invent a new better paradigm, real fast'."
In that world, GPT5 has the possibility-of-true-generality, but, not necessarily very efficiently, and once you get to the sharper part of the AI 2027 curve, the mechanism by which the next generation of improvement comes is via figuring out alternate algorithms.
8
I'm pretty sure it is not that. When people say this it is usually just asking the question: "Will current models try to take over or otherwise subvert our control (including incompetently)?" and noticing that the answer is basically "no".[1] What they use this to argue for can then vary:
1. Current models do not provide much evidence one way or another for existential risk from misalignment (in contrast to frequent claims that "the doomers were right")
2. Given tremendous uncertainty, our best guess should be that future models are like current models, and so future models will not try to take over, and so existential risk from misalignment is low
3. Some particular threat model predicted that even at current capabilities we should see significant misalignment, but we don't see this, which is evidence against that particular threat model.[2]
I agree with (1), disagree with (2) when (2) is applied to superintelligence, and for (3) it depends on details.
In Leo's case in particular I don't think he's using the observation for much, it's mostly just a throwaway claim that's part of the flow of the comment, but inasmuch as it is being used it is to say something like "current AIs aren't trying to subvert our control, so it's not completely implausible on the face of it that the first automated alignment researcher to which we delegate won't try to subvert our control", which is just a pretty weak claim and seems fine, and doesn't imply any kind of extrapolation to superintelligence. I'd be surprised if this was an important disagreement with the "alignment is hard" crowd.
1. ^
There are demos of models doing stuff like this (e.g. blackmail) but only under conditions selected highly adversarially. These look fragile enough that overall I'd still say current models are more aligned than e.g. rationalists (who under adversarially selected conditions have been known to intentionally murder people).
2. ^
E.g. One naive threat model says "Orthogon
4
I'm claiming something like 3 (or 2, if you replace "given tremendous uncertainty, our best guess is" with "by assumption of the scenario") within the very limited scope of the world where we assume AGI is right around the corner and looks basically just like current models but slightly smarter
3
If solving alignment implies solving difficult philosophical problems (and I think it does), then a major bottlenecks for verifying alignment will be verifying philosophy, which in turn implies that we should be trying to solve metaphilosophy (i.e., understand the nature of philosophy and philosophical reasoning/judgment). But that is unlikely to be possible within 2-4 years, even with the largest plausible effort, considering the history of analogous fields like metaethics and philosophy of math.
What to do in light of this? Try to verify the rest of alignment, just wing it on the philosophical parts, and hope for the best?
[...]
I kind of want to argue against this, but also am not sure how this fits in with the rest of your argument. Whether or not there's an upper bound that's plausibly a lot lower than perfectly solving alignment with certainty, it doesn't seem to affect your final conclusions?
6
suppose a human solved alignment. how would we check their solution? ultimately, at the end of the day, we look at their argument and use our reasoning and judgement to determine that it's correct. this applies even if we need to adopt a new frame of looking at the world - we can ultimately only use the kinds of reasoning and judgement we use today to decide which new kinds of reasoning to accept into the halls of truth.
so there is a philosophically very straightforward thing you could do to get the solution to alignment, or the closest we could ever get: put a bunch of smart thoughtful humans in a sim and run it for a long time. so the verification process looks like proving that the sim is correct, showing somehow that the humans are actually correctly uploaded, etc. not trivial but also seems plausibly doable.
4
Unless you can abstract out the "alignment reasoning and judgement" part of a human's entire brain process (and philosophical reasoning and judgement as part of that) into some kind of explicit understanding of how it works, how do you actually build that into AI without solving uploading (which we're obviously not on track to solve in 2-4 year either)?
[...]
Alignment researchers have had this thought for a long time (see e.g. Paul Christiano's A formalization of indirect normativity) but I think all of the practical alignment research programs that this line of thought led to, such as IDA and Debate, are all still bottlenecked by lack of metaphilosophical understanding, because without the kind of understanding that lets you build an "alignment/philosophical reasoning checker" (analogous to a proof checker for mathematical reasoning) they're stuck trying to do ML of alignment/philosophical reasoning from human data, which I think is unlikely to work out well.
4
I periodically say to people "if you want AI to be able to help directly with alignment research, it needs to be good at philosophy in a way it currently isn't".
Almost invariably, the person suggests training on philosophy textbooks, or philosophy academic work. And I sort of internally scream and externally say "no, or, at least, not without caveats." (I think some academic philosophy "counts" as good training data, but, I feel like these people would not have good enough taste to tell the difference[1] and also "train on the text" seems obviously incomplete/insufficient/not-really-the-bottleneck)
I've been trying to replace philosophy with the underlying substance. I think I normally mean "precise conceptual reasoning", but, reading this comment and remembering your past posts, I think you maybe mean something broader or different, but I'm not sure how to characterize it.
I think "figure out what are the right concepts to be use, and, use those concepts correctly, across all of relevant-Applied-conceptspace" is the expanded version of what I meant, which maybe feels more likely to be what you mean. But, I'm curious if you were to taboo "philosophy" what would you mean.
1. ^
to be clear I don't think I'd have good enough taste either
my referral/vouching policy is i try my best to completely decouple my estimate of technical competence from how close a friend someone is. i have very good friends i would not write referrals for and i have written referrals for people i basically only know in a professional context. if i feel like it's impossible for me to disentangle, i will defer to someone i trust and have them make the decision. this leads to some awkward conversations, but if someone doesn't want to be friends with me because it won't lead to a referral, i don't want to be friends with them either.
Strong agree (except in that liking someone's company is evidence that they would be a pleasant co-worker, but that's generally not a high order bit). I find it very annoying that standard reference culture seems to often imply giving extremely positive references unless someone was truly awful, since it makes it much harder to get real info from references
3
Agreed, but also most of the world does operate in this reference culture. If you choose to take a stand against it, you might screw over a decent candidate by providing only a quite positive recommendation.
(this is based on / expanded from a response I wrote to a tweet that was talking about how autistic people struggle in the world because the world follows unwritten rules that are more important than the written ones.)
I think most autistic people should invest more in understanding the unwritten rules. it can be cruel and unfair, but it's important to know how to interact with it. and it's actually a really interesting system to map out, with its own rhyme and reason.
it's entirely understandable that people feel burned by bad past experiences, and to have learned helplessness from bullying or other unfair treatment. this kind of thing leaves a scar and can make it feel viscerally hopeless.
but it still feels defeatist to just throw up one's hands and say "it's too complicated." yes, it's complicated and fuzzy and initially unintuitive and takes years to master. so is ML research. the point of being intelligent is that you are good at finding patterns and learning things, and there's nothing truly fundamentally different about the unwritten rules of social interaction.
I see people taking examples of weird unintuitive social rules all the time and, tbh, none of them are truly that com...
I don't know about other autists, but my primary problem with the neurotypical world isn't that I don't understand it, it that they don't understand me. It doesn't matter how well I can decode the social norms, if I can't also control my unvoluntary emotional expressions, and also do other things ranging from impossible to unpleasant.
I do understand social white lies. It's not that complicated. But I still find it unpleasant to speak them. When I was younger I got into trouble for literally being unable to utter words like "thanks" and "apology" when I did not mean them. (My native language does not have the ambiguous "sorry".) I am now able to tell white lies, but it makes me feel bad, in a way that has nothing to do with morals. The dissonance is just intrinsically hurtful to my sole, in a way that non-autistic people don't understand and typically don't respect.
Another common thing is that people assume that if I don't succeed in hiding my negative emotion this is an invitation/request for them to to try to help me, and then proceed to try to do that, even though they have zero skills, in this. And then they refuse to listen to anything I say, including not leaving me alon...
9
I agree, those are two different things: (1) how well can you navigate other people's world, and (2) the fact that even if you can do it perfectly, your own world is still somewhere else.
As a metaphor, imagine that you are interested in quantum physics, but other people are only interested in celebrity gossip. So you follow the standard advice: study celebrity facts from Wikipedia, read the standard media, practice talking about celebrities in front of a mirror, etc. Twenty years later, you get great at celebrity gossip, everyone loves you, they invite you to all the cool parties, so that they can discuss the latest gossip with you.
...that's all very nice and useful, but what you would actually wanted to discuss is quantum physics. And frankly, that's never going to happen. At least, your celebrity-gossip skills do not contribute to this goal. It was never the goal of the standard advice to actually help you with this problem.
4
This part is not aimed at leogao's post!
What I was (not very skillfully) trying to point at is people who think that autistic people are just worse at social skills. I'm so fead up with this claim, and is a contributing reason to me avoiding the neurotypicals. But it's not a claim that I read leogao's as having made.
leogau's language comparison is actually pretty great for this. You would not call someone who have a difrent native langue "bad at languages", but nerutypicals are often mistakenly beleveing that autists are "bad at social skills".
I also want to add that lots of atuists learn how to interact with the neurotypicals. It's called masking, and involves learning more than just their wierd customs. It also involves hiding ones natural reactions. I hear it's common for autistic women to get so good at this that they don't get diagnosed untill later in life, when the burden of constant masking causes depression or something. This did not happen to me, because I am terrible at masking.
7
I often do chunk them, but if you've picked up a bit of taxonomic Greek pter means 'wing', so we have helico-pter 'spiral/rotating wing' and ptero-dactyl 'wing fingers' - both cases where breaking down the name tells you something about what the things are!
3
yeah, that was an intentional feature of the example chosen. i'd guess most people who are aware of this fact do still think of helicopter as a single unit in their head unless they choose to decompose it, because you hear each of these words often enough that you don't really need to work out the meaning from etymology. and so if pter were pronounced the way it currently is when in helicopter but pronounced as "peter" in pterodactyl it would not actually be that much more confusing than it currently is.
5
I find all of this plausible and vaguely resonant with my experience but ... still not quite sure.
I know very intelligent people who swear by their inability to learn, say, languages or whatever. Would they succeed if they put in enough effort? Would they reach some escape velocit if they got past the initial friction and actually focused on it and kept a consistent practice?
Maybe? But specific developmental disorders (like dyslexia, dyscalculia, etc, impacting one domain of cognitive ability but sparing cognition beyond that domain) are apparently a thing and if they are a thing, then something milder is probably even more of a thing, meaning that human ability to learn stuff given a fixed amount of raw cognitive power (say, ~g) is actually more patchy.
4
Inability to put equal effort into everything throughout the day reifies into heuristics about which things get the effort/engagement. In principle, if you are going to spend 2 hours on something, why take it any less seriously/playfully during those 2 hours than anything else, even if you are not planning to put 10,000 hours in it in total?
And so you get silly heuristics where you do put 10,000 hours into something, but systematically never do it seriously/playfully, and so never become proficient. It's not enough to be very intelligent to get proficient at moderately complicated things if you systematically avoid learning anything about them.
Fair allocation of effort that ensures progress requires that the silly heuristics of systematic avoidance of effort are not in total control. This can happen naturally if you are lucky enough that your heuristics happen to be less silly, or if you have infinite energy and motivation and really do habitually put similar effort in everything throughout the day. But if that's not the case, it's often possible to take deliberate control of your curiouslity and allocate it in a way where any single thing you interact with a nontrivial amount does get a fair portion of effort.
It's an obscure enough principle that I'm not sure many people are practicing it, and so any reports of systematic inability to learn something need to account for this confounder of silly-on-reflection systematic avoidance of (productive) effort towards learning a particular topic, that's not just about the time (let alone discomfort) dedicated to it.
3
Some of the obstacles of adult language learning and of adult implicit social rule learning are both similar and extrinsic. It seems to me that there's a lot of cases where having an obvious ‘childhood’ or ‘foreigner’ role cues people to impart necessary information, but once you're past that point, it's both expected that you'll already have it and broadly Not Done to give it to you anew—and I don't just mean by explicit instruction, because other people will implicitly change their behavior around you in a way that ‘ruins’ the signal. Outside of very specific environments, finding a way to credibly signal “I want to integrate” at the correct visceral levels and get the other people to actively avoid papering over things in a way where a slip-up will permanently relegate you to the ‘weirdo’ role is rather hard, and if you don't have enough initial sense then you won't even know when it's happened.
There are ways of mitigating all of this, but I guess what I'd say is that getting real practice in anything social where there's this kind of status/integration involved tends to itself have strong status/integration social prerequisites—so it's a very noncentral example of practice, enough to make “it takes practice” misleading when unqualified. This is as distinct both from a lot of more specific skills which still have a major social practice component (martial arts, ensemble music) and from skills where solitary practice gives you the bulk of the signal (mathematics, maybe running?).
Also, if the social skills you're trying to learn involve something like class performance in a highly contested social class, people around you will have a more active incentive to make it more difficult. So it can also be adversarial practice…
3
Unless wiktionary is among your primary facilitators of procrastination on the internet.
i think one really bad dynamic in this community is a sort of purity testing about being x risk pilled. it feels like people are constitutionally scared of considering arguments that feel like they're arguing that things might be fine in any way. tbc I've definitely been guilty of this in the past, and probably still now to some extent, but i think it's bad. maybe there is some conflict theory reason why you should orient yourself this way towards people who have an ulterior motive, but I'm like among the most x risk pilled people out there and i still find this happens when i try to discuss x risk with people.
It doesn't feel that way to me fwiw. I feel like lots of people I know including myself have made arguments that things might be fine. For example the salty, cynical, John Wentworth wrote "Alignment by Default." Also, see AI 2027 Slowdown ending.
Now, if xriskpilled means: You think there's a >5% chance of literal extinction (or similarly bad outcomes) due to misaligned AIs, then yeah I think I do kinda judge people who aren't xriskpilled in that sense, because I think believing the chance is <5% is extremely unjustified once you know a decent amount about the situation and the evidence.
I think part of the reason for people leaning so heavily on x-risk arguments is that the alternative (that they created machines that are somewhat uniquely destructive to labor, are incredible for surveillance, destroyed the free software movement, and ruin something that absolutely all of them love, the internet, out of a mistaken belief that if they didn't, a paperclip maximization machine would be conjured into existence by someone else, and it's beneficial to be the first one to make the paperclip maximization machine) requires them to stare in the face the rather dreadful implications of their actions, and figure out a way to salvage them.
When operating in an emergency mode, you sort of get to ignore ethics of anything immediate in favor of the hypothetical ethics of something that may or may not come. That's why Anthropic allowed itself to be integrated into Project Maven (responsible for thousands of deaths until it became a PR issue), why they automatically offer all of their models to the NSA, why they constantly push for unethical sanctions on China, why they're paying billions to Musk, and why they turned Bun into a security nightmare: Because you gotta go fast, or you'll lose. And losing is bad. For x-risk reasons. They've created a maximizer for GPUs and market valuation instead of paperclips.
X-risk is poison for consequentialists; a complete hypothetical encouraging them to create the ultimate puppy-kicking machine.
4
Suppose that the AIs are actually as obedient to their creators as Cora, but suck at deeply understanding the world. Unless drastic measures are taken, I would expect power to concentrate in the hands of a CEO, the Oversight Committee or the oligarchy where socioeconomic advancement is nearly extinct and the rest of mankind[1] receives, at best, a tiny sliver of resources. Then what would prevent Anthropic from trying to either prevent this or take over the world for themselves?
1. ^
And that's ignoring possibilities like "North Korea lets a large fraction of its population starve to death and forcibly sterilises the rest, except for about 10k senior government officials who continue to preside over an AI economy and robot military".
Centralization is the natural conclusion, yes. The future that frontier labs are pushing toward is one of centralization of power, into the hands of people who have demonstrated little but carelessness. Anthropic's early talent pool was seeded with Alameda Research (its largest investor circa-2023) employees; its Series B was led by a person who was deeply wrong about risk calculation and sloppy in execution with stolen money.
This is not existential risk, this is just risk. A risk that these companies (and governments, at their behest) are walking into wholeheartedly, knowingly, and happily. These companies are sacrificing the future using the language of utopianism while repeatedly advocating for centralization of power, which will only cement and calcify power structures.
If these people were acting in your best interest, they wouldn't have been taking the same sloppy, anti-moral, deeply-flawed actions at Alameda, in an entirely different domain than safety research. They wouldn't be repeatedly changing their RSP, removing all of its teeth. They wouldn't be doing what they're doing. They are telling you the world is ending to acquire casus belli, not to try and make it possible to...
how valuable are formalized frameworks for safety, risk assessment, etc in other (non-AI) fields?
i'm temperamentally predisposed to find that my eyes glaze over whenever i see some kind of formalized risk management framework, which usually comes with a 2010s style powerpoint diagram - see below for a random example i grabbed from google images:
am i being unfair to these things? are they actually super effective for avoiding failures in other domains? or are they just useful for CYA and busywork and mostly just say common sense in an institutionally legible way?
one reason i care is because i feel some level of instinctive dislike for some AI safety/governance frameworks because they give me this vibe. but it's useful to figure out if i'm being unfairly judgemental, or if these really are slop.
7
The actual details of it contain some wise non-obvious aspects, along with elegant concepts that are generalizations of things that the safety community has been touching at. For instance the safety community has been conflating in "risk thresholds" two cleanly distinct notions in risk management of Key Risk Indicators (actual measurements of risk) and risk tolerance (your quantified preference for risk, independent from any test), which has caused a lot of confusion and hidden unreasonable choices for quite a bit.
People have also been conflating risk modeling and evals for quite a long time, because the AI field was built around evals. Once you have the clear view that evals are just an operationalization of risk models, it becomes more clear that you can actually do most of your risk modeling earlier in the lifecycle (i.e. before even touching a neural net), before having built a single eval & that evals are downstream of this.
You can see more of this genre of concepts applied to frontier AI here: https://arxiv.org/pdf/2502.06656
Here's a graph with a few of the concepts in there
6
to make sure I understand correctly, are you saying that a lot of the value of having this kind of formalized structure is to make it harder for people to make intuitive but flawed arguments by equivocating terms?
are there good examples of such frameworks preventing equivocation in other industries?
6
Yes, that's one value. RSPs & many policy debates around it would have been less messed up if there had been clarity (i.e. they turned a confused notion into the standard, which was then impossible to fix in policy discussions, making the Code of Practice flawed). I don't know of a specific example of preventing equivocation in other industries (it seems hard to know of such examples?) but the fact that basically all industries use a set of the same concepts is evidence that they're pretty general-purpose and repurposable.
Another is just that it helps thinking in a generalized ways about the issues.
For instance, once you see evaluations as a Key Risk Indicator (i.e. a proxy measure of risk), you can notice that we could also use other Key Risk Indicators to trigger mitigations, such as actual monitoring metrics. This could enable to build conditions/thresholds in RSPs that are based on monitoring metrics (e.g. "we find less than 5 bioterrorists successfully jailbreaking our model per year on our API"). The more generalized concepts enables more compositionality of ideas in a way that skips you a bunch of the trial and error process.
the learning curve for contact lenses is crazy. the first time i put them in and took them out, it took literally hours. on the 10th time, it took maybe 10 minutes. on the 100th time, closer to 30 seconds. i’m nearing 1000 times now and on a good day it can take only 5 seconds.
3
Just to confirm, do you mean literally hours or is it just a manner of speech?
9
I spent ~2 hours trying before I had put both contacts in and taken both of them out. This time was split over like two sitting.
i find it very interesting how becoming familiar with a place makes it feel so different, and yet it's recognizably the same place. especially when the first time you see the place you just think of it as a disconnected location floating around somewhere in abstract locationspace, but then slowly discover its relationship to other locations. sometimes this feels exhilarating, because the world feels more cohesive and whole and familiar. other times it's melancholy, because it feels like the magic has gone.
6
This is a big part of the appeal of travel for me. I feel like time speeds up and and presence drops a lot when my brain has a sufficiently good representation of the location I'm in.
3
This happens with concepts too.
I think another reason why people procrastinate is that it makes each minute spent right before the deadline both obviously high value on net and resulting in immediate payoff. this makes the decision to put in effort in each moment really easy - obviously it makes sense to spend a minute working on something that will make a big impact on tomorrow. whereas each minute long before the deadline has longer time till payoff, and if you already put in a ton of work early on, then the minutes right before the deadline have lower marginal value because of diminishing returns. so this creates a perverse incentive to end-load the effort
3
If the procrastinator is a perfectionist who would otherwise work far past the point of diminishing returns, postponing until the last minute is a way of timeboxing. If you know you would spend 5 hrs on something that you could get to 90% (of your standard) in 1 hr, better to start 1 hr before the deadline, or you'll end up wasting 4 hrs.
i have a theory that a lot of people go through "emotional healing" only to end up as still-broken people who now have "being healed" as a big part of their identity that lets them feel superior to other people who are less far along the chosen path than they are. ofc, there are also people who are actually emotionally in touch. an easy way to distinguish such people is to notice how you feel around them. do they make you feel more calm and grounded, or do they make you unhappy and defensive?
8
this does not so much match my personal experience. maybe it's some kind of selection effect, but then, that kind of person sounds really annoying, so I would recommend my selection process, whatever it is
4
For some people becoming less of a people pleaser is an important part of their healing.
7
i think there's a difference between being a people pleaser and being a calming force for those around you. some people exude a sense of calmness that doesn't require their even uttering a single word.
3
The last part surprised me because in general I don't think of heard of considering whether other people make you "feel more calm and grounded [vs] unhappy and defensive" as an insight into whether those others are psychologically well. What is the theory of the connection there?
4
emotions are somewhat contagious. someone who is very at peace will also make people around them at peace. someone who is unhappy will make people around them unhappy. someone who wants to help people out of a deep love for all people will make those around them feel differently than someone who wants to help people as a way to affirm their own superiority.
ilya's AGI predictions circa 2017 (Musk v. Altman, Dkt. 379-40):
Within the next three years, robotics should be completely solved, AI should solve a long-standing unproven theorem, programming competitions should be won consistently by Als, and there should be convincing chatbots (though no one should pass the Turing test). In as little as four years, each overnight experiment will feasibly use so much compute compute that there's an actual chance of waking up to AGI, given the right algorithm - and figuring out the algorithm will actually happen within 2-4 further years of experimenting with this compute in a competitive multiagent simulation.
[...]
Each year, we'll need to exponentially increase our hardware spend, but we have reason to believe AGI can ultimately be built with less than $10B in hardware.
6
Zilllis, in email to Musk about OpenAI (Id., Dkt 379-45):
[...]
3
Technically Directionally correct: The best kind of correct.
3
Though he seems to have overestimated the difficulty of the Turing test relative to e.g. robotics. Not clear he’s even directionally correct about robotics? Unless AGIs solve it for us :)
one big problem with using LMs too much imo is that they are dumb and catastrophically wrong about things a lot, but they are very pleasant to talk to, project confidence and knowledgeability, and reply to messages faster than 99.99% of people. these things are more easily noticeable than subtle falsehood, and reinforce a reflex of asking the model more and more. it's very analogous to twitter soundbites vs reading long form writing and how that eroded epistemics.
hotter take: the extent to which one finds current LMs smart is probably correlated with how much one is swayed by good vibes from their interlocutor as opposed to the substance of the argument (ofc conditional on the model actually giving good vibes, which varies from person to person. I personally never liked chatgpt vibes until I wrote a big system prompt)
8
Up for sharing your system prompt?
9
it's kind of haphazard and I have no reason to believe I'm better at prompting than anyone else. the broad strokes are I tell it to:
* use lowercase
* not use emojis
* be concise, explain at bird's eye level
* don't sugar cost things
* not be too professional/formal; use some IRC/twitter slang without overdoing it
* speak as if it's a conversation over a dinner table between two close friends who are also technical experts
* don't dumb things down but also don't use unnecessary jargon
I've also been trying to get it to use CS/ML analogies when it would make things clearer, much the same way people on LW would do, but it's been hard to get the model to do it in a natural, non cringe way. rn it overdoes it and makes lots of very forced and not insightful analogies despite my attempts to explain to it
learning thread for taking notes on things as i learn them (in public so hopefully other people can get value out of it)
VAEs:
a normal autoencoder decodes single latents z to single images (or whatever other kind of data) x, and also encodes single images x to single latents z.
with VAEs, we want our decoder (p(x|z)) to take single latents z and output a distribution over x's. for simplicity we generally declare that this distribution is a gaussian with identity covariance, and we have our decoder output a single x value that is the mean of the gaussian.
because each x can be produced by multiple z's, to run this backwards you also need a distribution of z's for each single x. we call the ideal encoder p(z|x) - the thing that would perfectly invert our decoder p(x|z). unfortunately, we obviously don't have access to this thing. so we have to train an encoder network q(z|x) to approximate it. to make our encoder output a distribution, we have it output a mean vector and a stddev vector for a gaussian. at runtime we sample a random vector eps ~ N(0, 1) and multiply it by the mean and stddev vectors to get an N(mu, std).
to train this thing, we would like to optimize the following loss function:
-log p(x) + KL(q(z|x)||p(z|x))
where the terms optimize the likelihood (how good is the VAE at modelling dat...
traveling through Europe, looking out the window, and seeing the national flag flying next to the flag of the EU fills me with a strange feeling. this isn't an original thought at all, but still: it's really crazy that just 50 years ago Europe was divided by the iron curtain, and that people would have to go to insane lengths and risk their lives to get across that border; and that less than 100 years ago all of these countries were at war with each other, and had been at war on and off for centuries with ever shifting alliances and boundaries.
7
When I travel to Vienna by train, sometimes I remember that I am crossing a line that in my childhood was guarded by soldiers ordered to kill everyone who tried to escape the socialist paradise.
I know this is one of the universal human experiences, but I keep getting unpleasantly reminded by the passage of time.
pleasant "recent" memories are already one or two years ago. they feel recent enough that I still stubbornly believe my recollection is accurate, but in reality they're far enough away from the present day for the sepia tint of nostalgia to creep in and for all the frustrations and sorrows to be forgotten. no wonder it's so hard for the present to compete with the "recent" past.
I sometimes ask myself when I first met one my "recent" friends, and am startled to realize that I met them 2 or 3 or 4 years ago. "oh yeah, I met him 'recently' at that one party FOUR FUCKING YEARS AGO."
I still can't wrap my mind around the fact that Iater this year I will have been at openai for 5 years. I first started following ML about 10 years ago, so I will soon have spent more time at openai than I have spent reading openai papers from the outside, and thinking of openai as a far away citadel in a different universe.
where did all the time go?
6
I suspect that you may have it worse than average person, because you are intellectual worker and intellectual achievements tend to be unsatisfying, in a sense that when you discover something, you feel "eureka" moment and then you feel like you knew it forever. It's even worse with intellectual process, because, in my experience, you forget all fruitless branches and backtracking of thought process almost like it was a dream.
when people say that (prescription) amphetamines "borrow from the future", is there strong evidence on this? with Ozempic we've observed that people are heavily biased against things that feel like a free win, so the tradeoff narrative is memetically fit. distribution shift from ancestral environment means algernon need not apply
(I'm a psychiatry resident. I also have ADHD and take prescription stimulants infrequently)
The answer is: not really, or at least not in a meaningful sense. You aren't permanently losing anything, your brain or your wellbeing isn't being burnt out like a GPU running on an unstable OC:
- Prescription stimulants often have unpleasant comedowns once they wear off. You might feel tired and burned out. They often come with increased anxiety and jitteriness.
- Sleep is negatively affected, you get less REM sleep, and you might experience rebound hypersomnia on days you're not on the drug.
- There are minor and usually unimportant elevations in blood pressure.
- While focus and stamina are improved, creativity and cognitive flexibility suffer. I've read claims that it also makes people overconfident, which strikes me as prima facie plausible. Ever seen how people behave after using coke?
- Animal studies show oxidative damage to the brain, but this has not been demonstrated in humans on therapeutic doses, even if used for performance enhancement in those who don't meet the normal criteria for ADHD.
- If started at a young age, growth velocity could be slightly hampered, mostly because of a
3
i haven't looked into this deeply but how strong is the evidence for (lack of) oxidative damage? the SSC post is somewhat unsatisfying in that it doesn't really consider outcomes other than literal Parkinson's, and just kind of says the animal model results are confusion.
3
This statement really surprises me?
On average you get around 500-1000% more dopamine in the system as a consequence of using amphetamines and from a standard neuroscience perspective this is around 3x as much as caffiene for example.
Yes it is not heroin levels but dependency has to be a real concern here from a neuroscience perspective?
Long-term potentiation and return to baseline for the brain should mean that the learned patterns would be relatively hard to unlearn after 6 months of frequent usage?
How good is the studies on longer term behaviour change due to this stuff? I looked into the studies and it seemed like from a shorter term perspective the addiction effects of it were lower than I thought which I found quite interesting.
(dropping a claude research report link here: https://claude.ai/public/artifacts/b10e54df-6616-477f-ac19-fe52b4c9d926)
I think an important caveat here is that the addiction and dependence liability is quite dependent on how you administer it to yourself, the dosage, the specific routes that you're ingesting it from etc. (which you mention but I think you're understating some of the dangers of it)
[...]
CNS drugs are powerful so yes I think we should still have some limits on this? I think one of the main things that are a bit difficult with them is that it can be hard to perceive the difference that they induce in yourself? Like if you're on them, you don't necessarily notice that you have less creativity and awareness, that is not how it feels and so if you're overusing them or similar you just don't get that feedback? (based on some modafinil experience & observations from friends)
4
I did try and make it clear that I'm only talking about therapeutic usage here, and even when off-label or for PED purposes, at therapeutic doses. I apologize for not stressing that even further, since it's an important distinction to make.
I agree that it's rather important to use it as prescribed, or if you're sourcing it outside the medical system, making a strong effort to ensure you take it as would be prescribed (there's nothing particularly complicated about the dosage, psychiatrists usually start you at the lowest dose, then titrate upwards depending on effect).
The Claude Research report seems fine to me, and I would think it aligns with my claims. The main issue with recreational usage is that a lot of people aren't trying to be responsible users, or are taking intentionally talking large doses for recreational purposes. That's more on them than it is on the drug! If you take it within the standard dosage range, the drug itself will not produce much in the way of craving for more.
>CNS drugs are powerful so yes I think we should still have some limits on this?
I am, if not outright libertarian, certainly leaning in that direction. So it depends on what the "limits" actually are. I think that doctors are currently overly risk-averse and conservative about prescribing them, but I don't think they should be handed out like candy over the counter. I think there's plenty of room in between that avoids the pitfalls of a maximalist position.
>I think one of the main things that are a bit difficult with them is that it can be hard to perceive the difference that they induce in yourself? Like if you're on them, you don't necessarily notice that you have less creativity and awareness, that is not how it feels and so if you're overusing them or similar you just don't get that feedback? (based on some modafinil experience & observations from friends)
The effects on creativity are rather minor. I can't really tell a difference when I'm on them, but I do
They definitely do for me- I sleep worse that night, and if I use too frequently I get exhaustion that takes weeks to recover from.
a take I've expressed a bunch irl but haven't written up yet: feature sparsity might be fundamentally the wrong thing for disentangling superposition; circuit sparsity might be more correct to optimize for. in particular, circuit sparsity doesn't have problems with feature splitting/absorption
7
blue: highest logprob numerical token
orange: y = x
5
...I am suddenly really curious what the accuracy of humans on that is.
8
'Can you do Addition?' the White Queen asked. 'What's one and one and one and one and one and one and one and one and one and one?'
'I don't know,' said Alice. 'I lost count.'
3
Surprisingly, Claude Opus 4.7 thinking still struggles with this, if you tell it not use tools. For N = 199, it answered 200; the CoT is below. It tried to use some groups of ten, gives up, and estimates the answer. It's curious that this isn't something the model learned to do in pretraining.
I'm counting the total number of 1s by tracking the initial 1 and then all the "+1" increments that follow. Counting through the sequence of increments to get the total. Continuing through the remaining decades up to 150, each block follows the same pattern of ten increments. I'm working through a long sequence of increments to count the total, breaking it down into manageable chunks to keep track of where I am in the original text. I'm trying to count the total number of "+1" operations in that string. Let me work through this systematically by identifying the pattern and tallying up how many times it repeats. I need to count the "+1" instances more carefully. The input starts with "1" and then has a series of "+1"s, so the total count is just the number of "+1"s plus one. Let me go through and tally them systematically in groups of ten to get an accurate count. Continuing to count through the ranges... I'm manually counting the "+1" tokens in the input string to get an accurate sum, working through the text systematically since I can't execute code to parse it directly. I'm counting the occurrences of "+1" in this sequence to get a total. I'm trying to count the "+1"s by breaking the input into segments of 10 to make it manageable, assuming the user likely wrote a round number like 200 total. Let me try a more systematic approach—I'll scan through the input carefully and count the "+1" occurrences in groups to get an accurate total. Continuing the count... I'm trying to count the "+1" instances in the input string, but without being able to directly measure the character length, I'm working through it systematically by grouping tokens and attempting to track them in chunks.
the most valuable part of a social event is often not the part that is ostensibly the most important, but rather the gaps between the main parts.
- at ML conferences, the headline keynotes and orals are usually the least useful part to go to; the random spontaneous hallway chats and dinners and afterparties are extremely valuable
- when doing an activity with friends, the activity itself is often of secondary importance. talking on the way to the activity, or in the gaps between doing the activity, carry a lot of the value
- at work, a lot of the best conversations happen outside of scheduled 1:1s and group meetings, but rather happen in spontaneous hallway or dinner groups
8
I have heard people say this so many times, and it is consistently the opposite of my experience. The random spontaneous conversations at conferences are disproportionately shallow and tend toward the same things which have been discussed to death online already, or toward the things which seem simple enough that everyone thinks they have something to say on the topic. When doing an activity with friends, it's usually the activity which is novel and/or interesting, while the conversation tends to be shallow and playful and fun but not as substantive as the activity. At work, spontaneous conversations generally had little relevance to the actual things we were/are working on (there are some exceptions, but they're rarely as high-value as ordinary work).
6
I think you are possibly better/optimizing more than most others at selecting conferences & events you actually want to do. Even with work, I think many get value out of having those spontaneous conversations because it often shifts what they're going to do--the number one spontaneous conversation is "what are you working on" or "what have you done so far", which forces you to re-explain what you're doing & the reasons for doing it to a skeptical & ignorant audience. My understanding is you and David already do this very often with each other.
4
I'm very curious if others also find this to be the biggest value-contributor amongst spontaneous conversations. (Also, more generally, I'm curious what kinds of spontaneous conversations people are getting so much value out of.)
One of the directions im currently most excited about (modern control theory through algebraic analysis) I learned about while idly chitchatting with a colleague at lunch about old school cybernetics. We were both confused why it was such a big deal in the 50s and 60s then basically died.
A stranger at the table had overheard our conversation and immediately started ranting to us about the history of cybernetics and modern methods of control theory. Turns out that control theory has developed far beyond whay people did in the 60s but names, techniques, methods have changed and this guy was one of the world experts. I wouldn't have known to ask him because the guy's specialization on the face of it had nothing to do with control theory.
8
I do not find this to be the biggest value-contributor amongst my spontaneous conversations.
I don't have a good hypothesis for why spontaneous-ish conversations can end up being valuable to me so frequently. I have a vague intuition that it might be an expression of the same phenomenon that makes slack and playfulness in research and internet browsing very valuable for me.
4
a historical example: the initial theory of CFC ozone depletion was born in part because of a random coffee break conversation at a conference
i want someone to make the one true categorization of Types of Guy. MBTI is an ok start, but there are so many things it doesn’t even try to explain. like for example if i see someone has very scrunched up body language and talks very quickly, this correlates very strongly with a bunch of other traits, like talking in conversation with long turn lengths.
my theory for why the literature here is kinda terrible is that most people either like people, in which case they mostly just develop an intuitive model of people; or they like systematizing, in which case they become obsessed with trains. few people are systematizing but obsessed with people.
6
In NLP you would call the person with "very scrunched up body language and talks very quickly" visually dominant. They don't feel into the words they want to say and thus speak faster. They don't feel into their body so that the make the adjustments to their body that releases tension and are scrunched up.
There's plenty of things you can criticize about that model but it does exist.
4
you want fiction! i'm no expert, but somewhere out there there's a 150 page treatise on "guy with very scrunched up body language who talks very quickly" including everything you could want to know about his job, his friends and family, his self-doubts, and the details of the broader socio-economic forces that made him like that.
4
Socionics is kinda MBTI-adjacent, but has more interesting, fleshed-out structure, with systematic predictions, e.g., predicting synchronies or conflicts between personality types that are related in some specific way.
[...]
Do you want a compact description, e.g., some small-ish number of naturally discretizable factors, with perhaps many combinations being very sparsely populated, and that would at the same time comprehensively 80/20 a person's personality description? I would not expect a comprehensive theory of human personality to be so neat.
3
The personality project and others studying individual differences psychology are the people to look toward for this.
i want someone to write a banger three body problem fanfic that is HPMOR but for TBP. i would read that shit
a lot of unconventional people choose intentionally to ignore normie-legible status systems. this can take the form of either expert consensus or some form of feedback from reality that is widely accepted. for example, many researchers especially around these parts just don't publish at all in normal ML conferences at all, opting instead to depart into their own status systems. or they don't care whether their techniques can be used to make very successful products, or make surprisingly accurate predictions etc. instead, they substitute some alternative status system, like approval of a specific subcommunity.
there's a grain of truth to this, which is that the normal status system is often messed up (academia has terrible terrible incentives). it is true that many people overoptimize the normal status system really hard and end up not producing very much value.
but the problem with starting your own status system (or choosing to compete in a less well-agreed-upon one) is that it's unclear to other people how much stock to put in your status points. it's too easy to create new status systems. the existing ones might be deeply flawed, but at least their difficulty is a known quantity.
o...
This comment seems to implicitly assume markers of status are the only way to judge quality of work. You can just, y'know, look at it? Even without doing a deep dive, the sort of papers or blog posts which present good research have a different style and rhythm to them than the crap. And it's totally reasonable to declare that one's audience is the people who know how to pick up on that sort of style.
The bigger reason we can't entirely escape "status"-ranking systems is that there's far too much work to look at it all, so people have to choose which information sources to pay attention to.
It's a question of resolution. Just looking at things for vibes is a pretty good way of filtering wheat from chaff, but you don't give scarce resources like jobs or grants to every grain of wheat that comes along. When I sit on a hiring committee, the discussions around the table are usually some mix of status markers and people having done the hard work of reading papers more or less carefully (this consuming time in greater-than-linear proportion to distance from your own fields of expertise). Usually (unless nepotism is involved) someone who has done that homework can wield more power than they otherwise would at that table, because people respect strong arguments and understand that status markers aren't everything.
Still, at the end of day, an Annals paper is an Annals paper. It's also true that to pass some of the early filters you either need (a) someone who speaks up strongly for you or (b) pass the status marker tests.
I am sometimes in a position these days of trying to bridge the academic status system and the Berkeley-centric AI safety status system, e.g. by arguing to a high status mathematician that someone with illegible (to them) status is actually approximately equiv...
4
there is always too much information to pay attention to. without an inexpensive way to filter, the field would grind to a complete halt. style is probably a worse thing to select on than even academia cred, just because it's easier to fake.
4
Generally, it is about heuristics we can use to find quality in the oceans of crap. If we assume that people are sane to some degree, status is an imperfect proxy for quality. If we assume that people don't use AIs to polish their writing styles, the writing style is an imperfect proxy for quality.
I have no experience reading research. I suspect that there are also crackpots who can write using the right kind of style. For example, they may be experts at their own line of research, and also speak overconfidently about different things they do not understand.
So if you want to be taken seriously, you probably need to know what kind of crackpot do you remind others of, and then find a way how to distinguish yourself from this kind of crackpot specifically.
At some moment it would probably easier to simply do your homework, once, and then have something you can point at. For example, you don't need to publish everything in the established journals, but it would probably help to publish there once -- just to show that if you want, you can; that this is about your priorities, not about lack of quality.
There are probably other ways, for example if you don't wont to get involved too much with the system, find someone who already is, and maybe offer them co-authorship in return for jumping through all the hoops.
I guess my model is that the costs of complying with the standard system are high but constant. So the more time you spend complaining about the system not taking your seriously, the greater the chance that complying with the system would have actually been cheaper than the accumulating opportunity costs.
9
A thing that I often see happening when people talk about "normie-legible status systems" is that they gaslight themselves into believing that some status system that is extraordinarily legible, or they are part of, is something that is consensus.
Academia is the most intense example of this. Most people don't care that much about academic status! This also happens in the other direction. Youtube is a major source of status in much of the world, especially among young people, but is considered low-brow whenever people argue about this, and so people dismiss it.
I also think people tend to do a fallacy of gray thing where if a status system is not maximally legible (like writing popular blogposts, or running a popular podcast, or making popular Youtube videos, or being popular on Twitter), they dismiss the status system as not real and "illegible".
I think modeling the real status and reputation systems that are present in the world is important, but for example, trying to ascent the academic status hierarchy is a bad use of time and resources. It's extremely competitive, and not actually that influential outside of the academic bubble. It is in some fields better correlated with actual skills and integrity and intelligence, and so I still think a reasonable thing to consider, but I think most people are better placed to trade off a bit of legibility against a whole amount of net realness in status (this importantly does not mean your LW quick takes will be the thing that causes you to become world-renowned, I am not saying "just say smart things and the world will recognize you", I am saying "don't think that only the most legible status systems, or the one with the most mobs hunting dissenters from the status system are the only real ways of gaining recognition in the world").
5
sure, the thing you're looking for is the status system that jointly optimizes for alignedness with what you care about, and how legible it is to the people you are trying to convince.
9
There is a passage from Jung's "Modern man in search of a soul" that I think about fairly often, on this point (p.229 in my edition)
[...]
4
It's possible that this wouldn't work for everyone, but so far I am very satisfied working on a PhD on agent foundations (AIXI). There are a lot of complaints here about academic incentives, but mostly I just ignore them. Possibly this will eventually interfere with my academic career prospects, but in the meantime I get years to work on basically whatever I think is interesting and important, and at the end of it I can reasonably expect to end up with a PhD and a thesis I'm proud of, which seems like enough to land on my feet. Looks like the best of both worlds to me.
3
Two common failure modes to avoid when doing the legibly impressive things
1. Only caring instrumentally about the project (decreases motivation)
2. Doing "net negative" projects
it's kind of crazy thinking about the fact that i will basically never write code ever again in my life. the models are actually good at code now
(tbf, i haven't tried the models on anything super hard yet, so don't update too much on my take here.)
microgrant thoughts
one reason for microgrants: assuming you can somehow substantially reduce the admin cost, it obviously makes sense to give more small grants than one big one, for the same reason that giving to the poorest people is better than giving to only kinda poor people. $10k for a well-funded university lab is such a small grant that might not be worth bothering with; $10k is a pretty meaningfully large amount of money for a struggling grad student in a less-well-funded lab, buying a month or two of runway to try something new; $10k is a career altering sum of money for someone living in like romania or whatever, helping them go from zero runway to 6-12 months of runway.
most people don't give microgrants because the admin costs are high. but maybe it is possible to optimize to reduce the admin costs!
5
I don't think that follows. Giving to the poorest people is better due to diminishing marginal utility of consumption. But grants aren't for personal consumption and utility doesn't diminish along the same curve.
4
Yeah, even smaller sums can still be trajectory-changing, cf. Nadia Asparouhova's Helium Grants ($1.5k average):
[...]
Nadia also has advice on starting a microgrants program (including plenty of logistics advice, to your point re: optimising to reduce admin costs) and a list of other microgrant programs on GitHub.
6
thanks for the link, i find it helpful to see what other people have done.
some things I'm doing differently: I'm planning on giving away way more money than previous microgrants, mostly by giving many grants. I've already approved more than $40k in grants. afaict, my condition that grantees must not use my grant to get other grants is novel too.
I claim it is a lot more reasonable to use the reference class of "people claiming the end of the world" than "more powerful intelligences emerging and competing with less intelligent beings" when thinking about AI x-risk. further, we should not try to convince people to adopt the latter reference class - this sets off alarm bells, and rightly so (as I will argue in short order) - but rather to bite the bullet, start from the former reference class, and provide arguments and evidence for why this case is different from all the other cases.
this raises the question: how should you pick which reference class to use, in general? how do you prevent reference class tennis, where you argue back and forth about what is the right reference class to use? I claim the solution is you want to use reference classes that have consistently made good decisions irl. the point of reference classes is to provide a heuristic to quickly apply judgement to large swathes of situations that you don't have time to carefully examine. this is important because otherwise it's easy to get tied up by bad actors who avoid being refuted by making their beliefs very complex and therefore hard to argue against.
the b...
This all seems wrongheaded to me.
I endeavor to look at how things work and describe them accurately. Similarly to how I try to describe how a piece of code works, or how to to build a shed, I will try to accurately describe the consequences of large machine learning runs, which can include human extinction.
I personally think AGI will probably kill everyone. but this is a big claim and should be treated as such.
This isn't how I think about things. Reality is what exists, and if a claim accurately describes reality, then I should not want to hold it to higher standards than claims that do not describe reality. I don't think it's a good epistemology to rank claims by "bigness" and then say that the big ones are less likely and need more evidence. On the contrary, I think it's worth investing more in finding out if they're right, and generally worth bringing them up to consideration with less evidence than for "small" claims.
...on the other hand, everyone has personally experienced a dozen different doomsday predictions. whether that's your local church or faraway cult warning about Armageddon, or Y2K, or global financial collapse in 2008, or the maximally alarmist climate people, o
9
i am also trying to accurately describe reality. what i'm saying is, even from the perspective of someone smart and truth-seeking but who doesn't know much about the object-level, it is very reasonable to use bigness of claim as a heuristic for how much evidence you need before you're satisfied, and that if you don't do this, you will be worse at finding the truth in practice. my guess is this applies even more so to the average person.
i think this is very analogous to occam's razor / trust region optimization. clearly, we need to discount theories based on complexity because there are exponentially more complex theories compared to simple ones, many of which have no easily observable difference to the simpler ones, opening you up to being pwned. and empirically it seems a good heuristic to live life by. complex theories can still be true! but given two theories that both accurately describe reality, you want the simpler one. similarly, given two equally complex claims that accurately describe the evidence, you want the one that is less far fetched from your current understanding of the world / requires changing less of your worldview.
also, it doesn't have to be something you literally personally experienced. it's totally valid to read the wikipedia page on the branch davidians or whatever and feel slightly less inclined to take things that have similar vibes seriously, or even to absorb the vibe from your environs (your aversion to scammers and cranks surely did not come ex nihilo, right?)
for most of the examples i raised, i didn't necessarily mean the claim was literally 100% human extinction, and i don't think it matters that it wasn't. first, because the important thing is the vibe of the claim (catastrophic) - since we're talking about heuristics on how seriously to take things that you don't have time to deep dive on, the rule has to be relatively cheap to implement. i think most people, even quite smart people, genuinely don't feel much of an emotional
8
Your points about Occam's razor have got nothing to do with this subject[1]. The heuristic "be more skeptical of claims that would have big implications if true" makes sense only when you suspect a claim may have been adversarially optimized for memetic fitness; it is not otherwise true that "a claim that something really bad is going to happen is fundamentally less likely to be true than other claims".
I'm having a little trouble connecting your various points back to your opening paragraph, which is the primary thing that I am trying to push back on.[2]
[...]
To restate the message I'm reading here: "Give up on having a conversation where you evaluate the evidence alongside your interlocutors. Instead frame yourself as trying to convince them of something, and assume that they are correct to treat your communications as though you are adversarially optimizing for them believing whatever you want them to believe." This assumption seems to give up a lot of my ability to communicate with people (almost ~all of it), and I refuse to simply do it because some amount of communication in the world is adversarially optimized, and I'm definitely not going to do it because of a spurious argument that Occam's razor implies that "claims about things being really bad or claims that imply you need to take action are fundamentally less likely to be true".
You are often in an environment where people are trying to use language to describe reality, and in that situation the primary thing to evaluate is not the "bigness" of a claim, but the evidence for and against it. I recommend instead to act in such a way as to increase the size and occurrence of that environment more-so than "act as though it's correct to expect maximum adversarial optimization in communications".
(Meta: The only literal quotes of Leo's in this comment are the big one in the quote block, my use of "" is to hold a sentence as object, they are not things Leo wrote.)
1. ^
I agree that the more stro
4
in practice many of the claims you hear will be optimized for memetic fitness, even if the people making the claims are genuine. well intentioned people can still be naive, or have blind spots, or be ideologically captured.
also, presumably the people you are trying to convince are on average less surrounded by truth seeking people than you are (because being in the alignment community is strongly correlated with caring about seeking truth).
i don't think this gives up your ability to communicate with people. you simply have to signal in some credible way that you are not only well intentioned but also not merely the carrier of some very memetic idea that slipped past your antibodies. there are many ways to accomplish this. for example, you can build up a reputation of being very scrupulous and unmindkilled. this lets you convey ideas freely to other people in your circles that are also very scrupulous and unmindkilled. when interacting with people outside this circle, for whom this form of reputation is illegible, you need to find something else. depending on who you're talking to and what kinds of things they take seriously, this could be leaning on the credibility of someone like geoff hinton, or of sam/demis/dario, or the UK government, or whatever.
this might already be what you're doing, in which case there's no disagreement between us.
4
This seems wrong to me.
a. More smaller things happen and there are fewer kinds of smaller thing that happen.
b. I bet people genuinely have more evidence for small claims they state than big ones on average.
c. The skepticism you should have because particular claims are frequently adversarially generated shouldn't first depend on deciding to be skeptical about it.
If you'll forgive the lack of charity, ISTM that leogao is making IMO largely true points about the reference class and then doing the wrong thing with those points, and you're reacting to the thing being done wrong at the end, but trying to do this in part by disagreeing with the points being made about the reference class. leogao is right that people are reasonable in being skeptical of this class of claims on priors, and right that when communicating with someone it's often best to start within their framing. You are right that regardless it's still correct to evaluate the sum of evidence for and against a proposition, and that other people failing to communicate honestly in this reference class doesn't mean we ought to throw out or stop contributing to the good faith conversations avaialable to us.
5
i'm not even saying people should not evaluate evidence for and against a proposition in general! it's just that this is expensive, and so it is perfectly reasonable to have heuristics to decide which things to evaluate, and so you should first prove with costly signals that you are not pwning them, and then they can weigh the evidence. and until you can provide enough evidence that you're not pwning them for it to be worth their time to evaluate your claims in detail, that it should not be surprising that many people won't listen to the evidence; and that even if they do listen, if there is still lingering suspicion that they are being pwned, you need to provide the type of evidence that could persuade someone that they aren't getting pwned (for which being credibly very honest and truth seeking is necessary but not sufficient), which is sometimes different from mere compellingness of argument
3
I think the framing that sits better to me is ‘You should meet people where they're at.’ If they seem like they need confidence that you're arguing from a place of reason, that's probably indeed the place to start.
I think the group of people "claiming the end of the world" in the case of AI x-risk is importantly more credentialed and reasonable-looking than most prior claims about the end of the world. From the reference class and general heuristics perspective that you're talking about[1], I think how credible looking the people are is pretty important.
So, I think the reference class is more like claims of nuclear armageddon than cults. (Plausibly near maximally alarmist climate people are in a similar reference class.)
IDK how I feel about this perspective overall. ↩︎
4
I agree this reference class is better, and implies a higher prior, but I think it's reasonable for the prior over "arbitrary credentialed people warning about something" to be still relatively low in an absolute sense- lots of people have impressive sounding credentials that are not actually good evidence of competence (consider: it's basically a meme at this point that whenever you see a book where the author puts "PhD" after their name, they probably are a grifter / their phd was probably kinda bs), and also there is a real negativity bias where fearmongering is amplified by both legacy and social media. Also, for the purposes of understanding normal people, it's useful to keep in mind that trust in credentials and institutions is not very high right now in the US among genpop.
8
You shouldn't. This epistemic bath has no baby in it and we should throw water out of it.
4
False?
Climate change tail scenarios are worth studying and averting. Nuclear winter was obviously worth studying and averting back in the Cold War, and still is today. 2008 financial crisis was worth studying and averting.
Do you not believe average citizens can study issues like these and make moves to solve them?
4
This is kind of missing the point of Bayes. One shouldn't "choose" a reference class to update on. One should update to the best of your ability on the whole distribution of hypotheses available to describe the situation. Neither is a 'right' or 'wrong' reference class to use, they're both just valid pieces of evidence about base rates, and you should probably be using both of them.
It seems you are having in mind something like inference to the best explanation here. Bayesian updating, on the other hand, does need a prior distribution, and the question of which prior distribution to use cannot be waved away when there is a disagreement on how to update. In fact, that's one of the main problems of Bayesian updating, and the reason why it is often not used in arguments.
you might expect that the butterfly effect applies to ML training. make one small change early in training and it might cascade to change the training process in huge ways.
at least in non-RL training, this intuition seems to be basically wrong. you can do some pretty crazy things to the training process without really affecting macroscopic properties of the model (e.g loss). one very well known example is that using mixed precision training results in training curves that are basically identical to full precision training, even though you're throwing out a ton of bits of precision on every step.
people often say that limitations of an artistic medium breed creativity. part of this could be the fact that when it is costly to do things, the only things done will be higher effort
9
a medium with less limitations is strictly better for making good art, but it's also harder to identify good art among the sea of bad art because the medium alone is no longer as good a signal of quality
5
Yes, but this also happens within one person over time, and the habit (of either investing, or not, in long-term costly high-quality efforts) can gain Steam in the one person.
any time someone creates a lot of value without capturing it, a bunch of other people will end up capturing the value instead. this could be end consumers, but it could also be various middlemen. it happens not infrequently that someone decides not to capture the value they produce in the hopes that the end consumers get the benefit, but in fact the middlemen capture the value instead
5
can you give examples?
an example: open source software produces lots of value. this value is partly captured by consumers who get better software for free, and partly by businesses that make more money than they would otherwise.
the most clear cut case is that some businesses exist purely by wrapping other people's open source software, doing advertising and selling it for a handsome profit; this makes the analysis simpler, though to be clear the vast majority of cases are not this egregious.
in this situation, the middleman company is in fact creating value (if a software is created in a forest with no one around to use it, does it create any value?) by using advertising to cause people to get value from software. in markets where there are consumers clueless enough to not know about the software otherwise (e.g legacy companies), this probably does actually create a lot of counterfactual value. however, most people would agree that the middleman getting 90% of the created value doesn't satisfy our intuitive notion of fairness. (open source developers are more often trying to have the end consumers benefit from better software, not for random middlemen to get rich off their efforts)
and if advertising is commoditized, then this problem stops existing (you can't extract that much value as an advertising middleman if there is an efficient market with 10 other competing middlemen), and so most of the value does actually accrue to the end user.
4
Often tickets will be sold at prices considerably lower than the equilibrium price and thus ticket scalpers will buy the tickets and then resell for a high price.
That said, I don't think this typically occurs because the company/group originally selling the tickets wanted consumers to benefit, it seems more likely that this is due to PR reasons (it looks bad to sell really expensive tickets).
This is actually a case where it seems likely that the situation would be better for consumers if the original seller captured the value. (Because buying tickets from random scalpers is annoying.)
4
I wonder how much of this is the PR reasons, and how much something else... for example, the scalpers cooperating (and sharing a part of their profits) with the companies that sell tickets.
To put it simply, if I sell a ticket for $200, I need to pay a tax for the $200. But if I sell the same ticket for $100 and the scalper re-sells it for $200, then I only need to pay the tax for $100, which might be quite convenient if the scalper... also happens to be me? (More precisely, some of the $100 tickets are sold to genuine 3rd party scalpers, but most of them I sell to myself... but according to my tax reports, all of them were sold to the 3rd party.)
5
of course, this is more a question about equilibria than literal transactions. suppose you capture most of the value and then pay it back out to users as a dividend: the users now have more money with which they could pay a middleman, and a middleman that could have extracted some amount of value originally can still extract that amount of value in this new situation.
we can model this as a game of ultimatum between the original value creator and the middlemen. if the participation of the OVC and middleman are both necessary, the OVC can bargain for half the value in an iterated game / as FDT agents. however, we usually think of the key differentiating factor between the OVC and middlemen as the middlemen being more replaceable, so the OVC should be able to bargain for a lot more. (see also: commoditizing your complement)
so to ensure that the end users get most of the value, you need to either ensure that all middleman roles are commoditized, or precommit to only provide value in situations where the end user can actually capture most of the value
4
It's worth examining whether "capturing value" and "providing value" are speaking of the same thing. In many cases, the middlemen will claim that they're actually providing the majority of the value, in making the underlying thing useful or available. They may or may not be right.
For most goods, it's not clear how much of the consumer use value comes from the idea, the implementation of the idea, or from the execution of the delivery and packaging. Leaving aside government-enforced exclusivity, there are usually reasons for someone to pay for the convenience, packaging, and bundling of such goods.
I worked (long ago) in physical goods distribution for toys and novelties. I was absolutely and undeniably working for a middleman - we bought truckloads of stuff from factories, repackaged it for retail, and sold it at a significant markup to retail stores, who marked it up again and sold it to consumers. Our margins were good, but all trades were voluntary and I don't agree with a framing that we were "capturing" existing value rather than creating value in connecting supply with demand.
saying "sorry, just to make sure I understand what you're saying, do you mean [...]" more often has been very valuable
a non exhaustive list of ideas i'd love to see microgrant applications for:
- making the one true glorious interpretability (or alignment) metric so that when we have the number go up machine we can use it to solve interp (or alignment) (best so far is the ARC low probability estimation metric; but can we do better?)
- tech that enables verification of the glorious international treaty; policy advocacy for it
- fully interpreting the algzoo models, possibly using circuit sparsity techniques
- improving democratic decision making via sortition
- studying generalization in humans. when do humans generalize from some task to some other task, and how much?
- better rationality techniques/frames. eg emotionally intelligent frames of rationality.
- making prediction markets better, especially for AI questions
- making really good ai safety educational resources on youtube/tiktok (being the next rob miles)
- biosafety - eg proving safety of far UVC or making it cheaper, wastewater pathogen monitoring, etc
- inoculating society against superpersuasion
- improving mental health of alignment researchers
i wonder how much the following hypothesis is true. it's obviously not completely true, but maybe there is some value in contemplating it.
for most issues that people have expended a lot of effort arguing about, if you could truly impartially reason through it, run experiments, etc, the correct answer is either not that hard to figure out, or that we're pretty sure we can't know one way or the other. but the discourse is fucked because the vast majority (maybe literally all) of people have some bottom line they're already sympathetic to, and smart people can make plausible sounding arguments for any conclusion, and so truly reasoning things through impartially is both very hard to do and even if you somehow manage to do it, it's hard to signal that you did so, and anyways people with motivated reasoning will only listen to you if your answer happened to agree with theirs.
the main evidence i have for this hypothesis is that there are questions where one side is overwhelmingly obviously correct if you actually think about it or look into it, and yet, there is the appearance of a balanced public debate.
the main evidence against this hypothesis is that probably people who disagree also think they're overwhelmingly obviously correct, and it seems arrogant to declare that i am simply more correct, and in any case oftentimes people disagreeing are wrong but their disagreement still contains enough of a kernel of truth to be worth thinking about.
corollary: the ability to look upon difficult controversial problems with utter naivety is extremely valuable. it's probably bad to always be in this state, because you can get pwned by bad actors. but cultivating an ability to enter into this state, possibly through a community where people value this a lot, is extremely valuable (LW is the closest thing to this that exists in the world afaik, but please let me know if there is anywhere else that is better)
8
examples of such issues:
* the literal veracity of various religions
* AI water usage
* supply and demand / effects of price fixing
* the mere theoretical possibility of AGI
8
For empirical questions, one litmus test is whether most of the populace doesn't know some true (like stats reported by large institutions with no disagreement from other reputable institutions) and clearly relevant fact, or repeatedly overestimates the observed risk of something.
AI water usage is an example. Others are the deaths per TWh of nuclear power, that extreme poverty (≤$3/day) went down by 3 times in the last 20 years (along with what percent are below that line), observed prediction market accuracy, the annual revenue of the US federal government as compared to e.g. the total net worth of billionaires (it's about 1/3 of it), and that the labor share of GDP over time hasn't dropped much.
I sometimes wonder if political beliefs would be very different if every child knew a certain set of basic stats - and also what political beliefs you could get if you adversarially optimized that set (while still keeping the stats reliably true and 'basic') to lead them to some specific conclusion.
4
the interesting thing about lots of these basic stats is that people who believe otherwise will often simply refuse to listen, because listening to the fact might change their mind, and they they would become an Outsider, and then be expelled by their social circle. or something like that.
considering that this can happen even for the clearest cut examples, one can only imagine how many less clear cut examples are also like this. perhaps a huge fraction of seemingly controversial issues actually have a simple answer that you can arrive at just by simply not having a preconceived answer, but where people incorrectly assume that people are disagreeing for good reasons.
(of course, even if this is true, there can and likely do still exist many problems where there genuinely is no simple undisputable answer!)
3
I think this is basically correct, modulo that a lot of this is just that people differ in their intelligence and epistemological skill, and so there are classes of dispute that are basically obvious to, for instance, you, while to many earnest but less capable truth seekers, it's in fact not easy to say who's right.
i love the concept of upvote-disagree. this feature singlehandedly encapsulates a lot of what i like about LW
6
It's cousin, downvote-agree, is also very good (I experienced this firsthand once).
3
Good collection by Gustaf here.
This comment is also a great example.
conlang idea: an extremely easy to learn language with the following attributes:
- grammar: mandarin, but without several of the quirks (no counters, merging 的/地/得, merging 不/没, etc)
- vocab: drawn from mostly English, because it's become the lingua franca. ideally the language is almost mutually intelligible to English speakers from the beginning
- very simple phonology similar to japanese
- consistent phonetic writing system based on the latin alphabet
7
You get things like this in creolization of pidgins. The regularizing factor is children--the children of pidgin speakers create an easy to learn full language.
(I would posit that, depending on your goals, it may actually be better to "conlang from the inside", i.e. generate new words and other language structures from within English or other major natural tongues.)
3
A 2019 study claims that spoken languages transmit info at a similar pace, i.e. that languages which apparently transmit more spoken info per syllable (Mandarin, German) are spoken more slowly than opposite languages like Japanese or Spanish. The gap between the fastest and lowest transmission (English and Thai) was 1.4x, though I don't quite understand the way they measured information.
It's possible that written communication doesn't work that way, though. Languages with simpler and more rational orthographies like Spanish are easier to learn to read compared to English. So I think the most clear benefit would come from spelling reform and maybe the way numbers are spoken/written in words, rather than apparent efficiency improvements to spoken communication (e.g. you listed grammatical or vocabulary changes) that just lead people to talk more slowly because they're bottlenecked by how fast they can produce or understand the information.
3
Isn't this just toki pona
4
only kinda? toki pona is trying to have as small a fundamental vocab as possible and constructing all other concepts using those few words. whereas i am totally happy to import all of English as prerequisite knowledge
people love to hate on brutalism. my take is there something really aesthetic about it, but also that just because something is aesthetic doesn't mean that it would be a good place to live or work every day. in fact, I've unfortunately found that the environments that I find aesthetically pleasing and the environments that make me happy to live/work in diverge quite substantially.
5
This is also why various artists don't necessarily try to make Tolkien's Orthanc, Barad-dûr, Angband, etc look ugly, but imposing and impressive in some way. Even H.R. Giger's biomechanical landscapes could be described as aesthetic. Or the crooked architecture in The Cabinet of Dr. Caligari (1920). Architecture is art, and art doesn't have to be beautiful or pleasant, just interesting. But presumably nobody would like to actually live in a Caligari-like environment. (Except perhaps people in the goth subculture?)
4
The best example, for my tastes at least, is window-to-building ratio. I like working and living in buildings with high ratio, e.g. glass skyscrapers. But they look bad from outside.
suppose you had basically unlimited funding and a bunch of really smart people. how would you design a field of philosophy that is good actually?
Low key, read the sequences.
On a different track: I'd love to have better incentive structures for all sorts of things. Philosophers writing only for other philosophers is probably too inbred of a memetic environment. We want ethicists of education, for example, to not merely be producing papers that other ethicists of education like to cite, we want them (where saying "them" is a bit misleading, since making this transition probably requires a lot of job turnover) to be improving our education system by doing ethical work that educators and administrators are already faced with, in ways that have a feedback loop due to having to having to be useful to real educators. But we have a second-order incentive problem, where the education system itself doesn't have sterling incentives (or the healthcare system for bioethicists, etc), and also it's just plain hard to tell what's actually useful, so there are still antisocial incentive problems. Anyhow, in terms of how much money that takes, we're talking "take over the academic administrative, funding, and publishing systems of a major country and somehow buy enough soft power to make them do things that will cost the jobs of many entrenched academics" kind of money.
7
The first thing I would do is ensure that I and at least one other person had life circumstances that enabled us to think properly and without interruption (this would require a very small fraction of the "unlimited" resources). This would be the best first step for essentially any intellectual task that we were asked to carry out; in the case of philosophy, I have encountered many perspectives on the subject over the years, and I would want a little time to revisit them (even just to consolidate my personal records of what I've done), reflect on them, and get my thoughts about them in order.
Since in this scenario I am being asked, not just to personally solve the object-level problems of philosophy to the best of my ability, but to spend money in order to make an area of philosophy function better (e.g. through institutional design, hiring the right people, etc), I expect that later actions would include the judicious promotion and propagation of little-known works or oeuvres which already exist and which I think I have a lot to contribute.
I'm sure there are many other things that can be done to make an intellectual field function better, but ensuring that people who can and should contribute, are able to do so, and ensuring that already existing ideas which ought to be known, are actually known, are two of the most basic steps that can be taken.
4
How do you know philosophy is fixably bad?
Typically , the attitude comes from a comparison with science: Science is a few hundred years old, and has solved many problems. Philosophy is a few thousand years and has barely solved anything. So science is good and philosophy is bad? So philosophically would be better if it were more like science? so the comparison is fair?
If it were possible to apply the scientific method to philosophy , and suddenly start getting much better results, philosophy would indeed be remiss .. it would have a fixable problem that has never been fixed.
On the other hand, if philosophical problems are different to, and harder than scientific problems, the problem could be intrinsic and unfixable. That alternative view is rarely given consideration in the rationalsphere.
To know , rather than believe, that philosophy is fixably bad, you need to compare both explanations, not assume the first.
And doing philosophy in a more formal, science like way has been tried: analytical philosophy is about a hundred years old. The experiment has been performed,and didn't speed up philosophy hugely. Is there a way to lean further into doing philosophy like science? Pearl and Kahneman, maybe?
@Mo Putera
Lots of people now know Pearl and Kahneman. What have they achieved?
4
What kind of philosophy?
Philosophy of science? I would pay a bunch of scientists a bunch to be able to record all of their conversations through the process of the scientific process, I think better information about science as practiced would help here. Alternatively I'd pay a bunch of anthropologists to be a fly in the wall of labs.
Philosophy of consciousness? I'd probably just put out open grants for neuroscientists to opine on their thoughts, testable hypothesis prefered.
Ethical philosophy? I'd pay a lab to create the world's first utility monster.
3
This or this?
annoying thing i see all the time on twitter: people say things, and then when people show up in the comments disagreeing, they reply with something affirmative but meaningless. the reply doesn't admit they were possibly wrong, or double down on claiming to be correct, or clarify/amend their original statement to avoid it continuing to spread and mislead people, or anything.
example:
- A: "all wugs are green"
- B: "that's totally wrong, i'm a wug and i'm blue"
- A: "yeah that makes sense"
I expect that two or three actual examples would be super helpful in conveying the texture of this problem and how much I should care about it.
3
I've done this. It's usually a reaction to being afraid B will get really mad. You say "that makes sense" as a sort of appeasing gesture, like "ok, i heard you, i'm going to nod". But you don't go any farther than "that makes sense" because you think B is wrong and you'd feel gross actually assenting to B's belief. It's how you'd react if you suddenly realized you were talking to a dangerous lunatic.
4
i can see this being the underlying generator. i guess the reason i find this annoying is that i don’t like it when people treat others whi reasonably disagree as danger lunatics.
it's kind of crazy that spaced repetition has completely revolutionized language learning and then not really changed the world in any other way at all. why are there no great scientists who are inhumanly good at remembering the corpus of their field through incremental reading? why are there no insanely good engineers who know every detail of their entire stack through spaced repetition?
5
oh yeah, that too. but my understanding is this is mostly a "makes you good at test taking" thing. does it make you exceptionally good at medical research or being a doctor?
9
For non-standard curricula, probably the overhead of making cards? I have memorized lots of details about AI stuff just from reading and thinking about it; I tried using Anki for this but found the overhead of creating and maintaining a card deck to not be worth it.
6
I did Anki for ~3 years, and have now - sadly - dropped it. I loved doing Anki, because it made me look/feel smart. But, I think I got more out of writing daily for a month, than doing Anki for a year.
4
surely writing every day for a month costs a lot more willpower?
3
Spaced repetition is good for training declarative (explicit) memory, but procedural (implicit) memory is the more important kind of memory -- in science, engineering and life in general.
We can write software to train procedural memory. To learn to touch type for example, most people use an application for that purpose. But you cannot add cards to typing-training software that would make the software useful for learning something other than touch typing: you would need to write an entirely different application.
There isn't software for training most of the procedural skills people try to acquire because of the sheer variety in the procedural skills people want to learn and because developing software is expensive and because procedural knowledge is acquired automatically in the process of doing things and because most people are intrinsically skilled at choosing things to do (e.g., things just beyond their current ability) that maximize their learning rate (without the aid of software).
Actually, let me qualify that last statement as applying only to the situation before about 2024: since then I wouldn't claim it impossible for someone somewhere to have used AI to create software than can be used to train a large fraction of all of the skills people want to acquire.
i'm going to rerun the neurips agi experiment this year. place your bets on what fraction of people at neurips this year know what the acronym AGI stands for!
where are all the people trying to understand how the world works? (in a broad sense that is useful for understanding the trajectory of the world: e.g things like why is society the way it is, why do people behave the way they do; why has technology developed the way it has, etc.; as opposed to zooming in and specializing, e.g fundamental physics research or biomed or whatever) there are a bunch of people like this in the rationalist sphere but i'm curious where all the non-rationalist-adjacent such people are. it seems many people in the broader world are either uncurious or mindkilled on such questions.
Some books you might like to read:
- Seeing Like a State by James C Scott (I've read most of it, I liked it)
- Bullshit Jobs, The Dawn of Everything, most books by David Graeber (I've read and liked long extracts of his work)
- The End: Hitler's Germany 1944–45 by Sir Ian Kershaw (I've read all of it and found it very valuable as a complete picture of a society melting down)
- Open Letters by Vaclav Havel (I've read a lot of it, I like it a lot. He was the first president of Czechoslovakia and a famous communist dissident and his writing sketches out both what he finds soul-destroying about that system and what he thinks are the principles of good societies)
- System Effects: Complexity in Political and Social Life by Robert Jervis (I'm reading this now, very good case studies about non-obvious phenomena in international relations)
- Broken Code: Inside Facebook and the fight to expose its toxic secrets by Jeff Horwitz (Very good book about how social media platforms like Facebook shape and are shaped by modern civilisation, I read all of it)
All of these books to various degrees tackle the things you are describing from a holistic perspective. Hope this helps.
5
thanks for the recommendations, I'll add these to my reading list!
I'm also curious if there is a location or social cluster or something where there are a lot of people who read stuff like this and talk about it productively and come up with new ideas. (again, other than the rationalist/ratadj/bay area community - I'm stipulating this because I think the ratsphere and bay area as a whole are a bubble with a lot of other correlated beliefs)
7
I suppose that sociologists, historians, philosophers, and (especially) futurologists do tackle the questions you describe, though maybe there is a sense in which they aren't doing so in a zoomed-out enough way.
6
https://sites.santafe.edu/~wbarthur/thenatureoftechnology.htm
4
And many Santa Fe people more generally, e.g., https://www.sfipress.org/books/history-big-history-metahistory or https://www.amazon.com/Scale-Universal-Innovation-Sustainability-Organisms/dp/1594205582 or https://www.amazon.com/Making-Sense-Chaos-Better-Economics/dp/0300273770
3
My understanding is that Bridgewater has a bunch of people like this, but they are unlikely to share their answers with the broader world.
running the microgrant program has taught me how to be way more decisive and fast moving. i have just a few min per grant to read, consider, potential draft up an email to ask a clarifying question, and ship it. you can always spend forever pondering whether to give the marginal grants, but the time cost of doing so is so high that it’s not worth it, so you need to just make a decision at some point. it’s also strangely liberating to fire off many emails in a short span of time without reading them over carefully and agonizing whether to send.
3
I recently tried to apply the same logic to doing other tasks. A friend of mine does work in intense, 5-10 minute sprints. After doing this for a couple hours, I'm being more and more aware of how most of the work within as task are not actually important for achieving the goal of the task.
hypothesis: there will be a window of time after the point of superhuman AI persuasion/charisma, during which human trust relationships will become extremely important. even once almost all human skills are obsolete, the AIs may have less social trust capital than humans. ofc, eventually, the persuasion will be so superhuman that it can cut through minds like butter, but that could take many years.
once AI superpersuasion is possible, there will be a strong incentive to use it to shape opinions. therefore, there will also be a strong incentive for important decision makers to develop strategies for making sure they are not being bamboozled.
thankfully, there is one way to not get bamboozled by a superpersuader - to not listen to it in the first place. this is an age old idea. many social strategies have evolved to help people avoid talking to other superpersuading people. for example:
- one main limiter of the growth of cults is people get used to noticing the signs and avoid people who seem culty, get suspicious of any rapidly growing movement, etc
- people avoid preachers, political activists, etc
- people have learned that AI chatbots are sycophantic and discount their praise
- people mostly
idea for a conference:
i want to host a conference which is kind of a cross between an unconference and a hackathon. the goal would be to create an environment where people can spontaneously do random side projects.
- there is mostly just a big pleasant space where people can mix around and chat.
- anyone can at any time decide to host a session on whatever they want. there's a discord server where they can announce their session, and big whiteboards.
- there is a dedicated work area where the goal is for roughly half of all people to be working at any one time. the rules of the work area are: no working on your normal job.
- there is an army of ops and other logistics people available on call to solve any annoying logistical issues.
- there is a big pile of random hardware around so you can make physical objects easily.
- unlike a hackathon, there is no judging, no winners, no competition, no rigidly defined teams. you can float around and do whatever the fuck you want.
- no conference app. if you want to do a 1:1 you have to walk up to the person and ask them to chat.
6
Maybe a good fit for Summer Camp at the festival season this year!
in the same way that Minecraft teaches you to exercise agency and Factorio teaches you to optimize, are there any games that teach you to stare into the abyss? the ideal game would (a) reward you on a tight feedback loop for constantly admitting that you were wrong, (b) give you the option to not admit that you were wrong but make that decision acutely hurt. pastcasting is good for (a) but not good for (b) because you are sort of forced to confront being wrong all the time, which maybe teaches you that it doesn't feel as bad as you might expect, but it doesn't teach you to intentionally seek out things that could prove you wrong; and you don't really have time to develop an attachment to your wrong ideas. most normal games reward you for staring into the abyss very indirectly because being good at intentional practice makes you do better over the very long run, but you don't get immediate feedback loops for it, and so it's easy to just not realize you could be doing a lot better.
Chess. Mistakes in chess usually become noticeable quickly, in just a move or two, and you have no RNG or teammates to blame them on. But to get better you have to acknowledge your mistakes and avoid making the same mistakes again.
3
i think the problem is that the feedback loop is too long - if you notice a mistake, there is no obvious action, and no immediate feeling of having improved. what you really want is something where you can choose whether or not to notice that you are making a mistake, and choosing to notice gives you immediate positive reinforcement.
Play against a strong chess engine while allowing yourself to undo as many moves as you like at any time and try to find any winning game?
4
In general I find that I can trace losses in Go games to moments when I acted unvirtuously (e.g. greedily, impatiently, fearfully, arrogantly, etc).
Go is also a long enough game that one mistake seldom sinks you (as long as you're willing to give up the sunk cost).
6
How about math olympiads? They do reward you for solving complex problems and require to admit that your first conjectures were hopelessly wrong (unless, of course, you happened to get them right. Alas, this might come with practice faster than the habit of staring into the abyss)
5
Outer Wilds comes to mind. Or The Witness? Or any of the other "figuring out the rules is the game" sub-genre.
5
For the thing you're interested in, how important is the "game" part? (Minecraft and Factorio are both particularly excellent games with rich depth, in a way that pastcasting is not particularly)
The hardest part of "stare into the abyss" is that it's often about stuff that you've wrapped your identity around in a psychologically loadbearing where. When I hear "the Minecraft of staring into the abyss", I'm imagining something that gets you invested in an overall direction in a complex world, that is the wrong direction, and then have the opportunity to change course on your goal.
I think my Planmaking & "Baba is You" exercise is at least related. (In this variant, your instruction is to form a complete plan for solving a Baba is You level on your first try. This gives people a lot of opportunity to get invested in a set of assumptions and keep building on them. People are usually quite overconfident in a way that felt a lot more "gut punchy" than other calibration training)
5
by game i mean it in a very very loose sense. video games, board games, card games, sports games, strange workshop activities, etc all count.
for the identity load bearing ness, it seems possible you could create it on a short time horizon. for example, even just arguing about something for 10 minutes can make me feel somewhat invested in my position. having teams in general can create some level of this. i feel like if you stacked a bunch of different psychological tricks you could kind of approximate it. even just getting used to the meta has this - i often find that i stagnate in a game because i learned some suboptimal meta, but i feel some emotional avoidance towards learning better meta because the displeasure of losing is less than the displeasure of learning the new meta; and the feedback loop of winning slightly more often from better meta is not very easily felt.
possibly you can design a game where you constantly have to accept better meta to even progress at all through the game. similar to how it is almost impossible to play Factorio without automation even though it's technically possible.
i think it's undesirable to have a game with one big twist that you build up to. for feedback loop reasons you want to have to do it over and over again and consistently get reward when you gaze into the abyss and not get reward when you don't.
4
Calibration games such as https://www.quantifiedintuitions.org/?
(a) You can choose to be wrong/overconfident, or you can acknowledge you don't know when you don't know. Acknowledging is rewarded.
(b) The game pushes you to try to be overconfident by making you want to be top 1 (beat other teams). And it hurts to see you ranking if you are failing.
3
Not sure I buy the premise that (a) is needed or even good? I mean, part of abysses is that they don't offer immediate feedback. What about a video game where everything is basically one-shot? You can spend as long as you want preparing, including gathering resources and doing science to the environment, and then you get one big shot; if it goes well you win, if not you lose and lose all your progress.
3
an idea: a game where there are several distinct but mutually exclusive strategies (eg a shooter where you can be a sniper, or a bullet sprayer, or a tank, etc), where you have to invest a bunch of time into specializing, and then you feel sunk cost about switching to a different strategy; but make the environmental conditions constantly change (in subtle or hard to reason ways so you have to spend a bunch of effort to notice things changing / there is plausible deniability as to whether things changed or whether you were always suboptimal), so that the optimal strategy changes frequently; and make there be strong diminishing returns to further investment in a strategy, which simultaneously makes the sunk costs feel bigger, and makes the initial gains from switching strategies feel very large so when you switch strategies you very quickly start winning.
my life would often be better if I exercised more agency. why don't I do so more often? here is a taxonomy of reasons I've noticed:
- energy: I'm often very fatigued, which makes it much harder for me to do anything, which includes anything new.
- decision fatigue: a related thing is even for a given amount of energy, I have a limited number of decisions I can make, and a limited number of things I can focus on and think carefully about.
- emotional avoidance: sometimes, exercising agency requires admitting that I've been doing things wrong all this time, or that part of my identity is not what I want it to be, or confronting some past trauma. sometimes I identify as being bad at X, which make it hard to improve at X.
- conformism: there's a critic inside my head that yells at me when I do or even consider things that could be considered "crazy" by others. I ignore it more than most people, but it still has nonzero say.
- uncreativity: in certain domains I've spent so much time thinking about a specific kind of idea that it becomes genuinely hard for me to even imagine other ideas.
- cowardice: sometimes the ideas are obvious but they require large irreversible actions, and/or are likely to have unpredictable consequences.
6
I have an instrument that helps me mitigate decision fatigue, energy lack and conformism. I created an updatable random generator with a weighted list of all the ideas and activities that cross my mind. I exercise agency at the state of "designing" the free time passage, setting probability weights and side goals. Then I can circumvent fatigue of deciding what to do next, because i can click generate and it see the option. And since clicking generator button is a short action, a habit to actually go and execute the option can be formed.
4
oh wow this is a really cool idea. i'll give it a try
5
My experience is that sleep + gym ease most of these somewhat if I'm currently lacking on those dimensions.
there seem to be three different possible levels of manager involvement in individual researchers:
- type 1 (the grantmaker): the manager spends a day reading the grant application of the researcher and decided whether to fund him for the next 6 months based on his track record, whether the research idea makes sense, etc. day to day, the grantmaker is completely uninvolved in the actual research. on fact, the grantmaker might not even be making decisions about individual researchers, but about entire organizations.
- type 2 (the research manager): the manager spends a few hours every month getting complete context on what each of their reports is working on. each report has a different project that the manager thinks makes sense. the manager provides a light touch to guide the project according to their research taste, and vetos any terrible ideas, but most of the time the report makes most of the day to day decisions about what to do.
- type 3 (the tech lead): the manager sets research taste for their team and basically orders around their minions. the manager provides almost all of the research taste, and the reports are either just doing engineering work, or doing very tightly scoped res
4
Type 2.25 is probably most common in the low-mid levels of academia. I see my supervisors officially around 2/month, but they're around for me to talk to a few times a week.
Type 1 is common in higher levels, type 3 is common for lower levels. This overall seems pretty natural and I'd expect it's a common feature of many orgs.
a great way to get someone to dig into a position really hard (whether or not that position is correct) is to consistently misunderstand that position
almost every single major ideology has some strawman that the general population commonly imagines when they think of the ideology. a major source of cohesion within the ideology comes from a shared feeling of injustice from being misunderstood.
9
There are some people that I've found to be very consistently thoughtful - when we disagree, the crux is often something interesting and often causes me to realize that I overlooked an important consideration. I respect people like this a lot, even if we disagree a lot. I think talking to people like this is a good antidote to digging yourself into a position.
On the other hand, there are some people I've talked to where I feel like the conversation always runs in circles so it's impossible to pin down a crux, or they always retreat to increasingly deranged positions to avoid admitting being wrong, or they seem to constantly pattern match my argument to something vaguely similar instead of understanding my argument. I think arguing against people like this too much is actively harmful for your epistemics, because you'll start digging yourself into your positions, and you'll get used to thinking that everyone who disagrees with you is wrong. There are a bunch of people (most notably Eliezer) who seem to me to have gone too far down this path.
On the other side of the aisle, I don't know exactly how to consistently become more thoughtful, but I think one good starting point is getting good at deeply understanding people's viewpoints.
5
The people who understand the proper interpretation of the ideology can feel intellectually superior to those who don't. Also, people who misunderstand something are by definition wrong... and therefore the people who understand the ideology correctly must -- quite logically -- be right!
(An equivocation between "be right about what is the correct interpretation of the ideology" and "be right about whether the ideology correctly describes the reality".)
4
I think this is a subset of:
irritating people when discussing the topic is a great way to get someone to dig into a position really hard (whether or not that position is correct).
That irritation can be performed any way you like. The most common is insinuating that they're stupid, but making invalid meme arguments and otherwise misunderstanding the position or arguments for the position will serve quite well, too.
I think this follows from the strength and insidious nature of motivated reasoning. It's often mistaken for confirmation bias, but it's actually a much more important effect because it drives polarization in public discussion.
I've been meaning to write a post about this, but doing it justice would take too much time. I think I need to just write a brief incomplete one.
7
I don't think being irritating in general is enough. I think it's specifically the feeling that everyone who has disagreed with you has been wrong about their disagreement that creates a very powerful sense of feeling like you must be onto something.
4
Really!? Okay, I'll have to really present the argument when I write that post.
I do agree with your logic for why opponents misunderstanding the argument would make people sure they're right, by general association. It's a separate factor from the irritation, so I think I mis-statedit as a subset (although part of it seems to be; it's irritating to have people repeatedly mis-characterize your position).
It seems pretty apparent to me when I watch people have discussions/arguments that their irritation/anger makes them dig in on their position. It seems to follow from evolutionary psychology: if you make me angry, my brain reacts like we're in a fight. I now want to win that fight, so I need to prove you wrong. Believing any of your arguments or understating mine would lead to losing the fight I feel I'm in.
This isn't usually how motivated reasoning is discussed, so I guess it does really take some careful explanation. It seems intuitive and obvious to me after holding this theory for years, but that could be my own motivated reasoning...
hypothesis: intellectual progress mostly happens when bubbles of non tribalism can exist. this is hard to safeguard because tribalism is a powerful strategy, and therefore insulating these bubbles is hard. perhaps it is possible for there to exist a monopoly on tribalism to make non tribal intellectual progress happen, in the same way a monopoly on violence makes it possible to make economically valuable trade without fear of violence
6
Continuing the analogy:
You'd want there to be a Tribe, or perhaps two or more Tribes, that aggressively detect and smack down any tribalism that isn't their own. It needs to be the case that e.g. when some academic field starts splintering into groups that stereotype and despise each other, or when people involved in the decision whether to X stop changing their minds frequently and start forming relatively static 'camps,' the main Tribe(s) notice this and squash it somehow.
And/or maybe arrange things so it never happens in the first place.
I wonder if this sorta happens sometimes when there is an Official Religion?
4
another way to lean really hard into the analogy: you could have a Tribe which has a constitution/laws that dictate what kinds of argument are ok and which aren't, has a legislative branch that constantly thinks about what kinds of arguments are non truthseeking and should be prohibited, a judicial branch that adjudicates whether particular arguments were truthseeking by the law, and has the monopoly on tribalism in that it is the only entity that can legitimately silence people's arguments or (akin to exile) demand that someone be ostracized. there would also be foreign relations/military (defending the continued existence of the Tribe against all the other tribes out there, many of which will attempt to destroy the Tribe via very nontruthseeking means)
5
unfortunately this is pretty hard to implement. free speech/democracy is a very strong baseline but still insufficient. the key property we want is a system where true things systematically win over false things (even when the false things appeal to people's biases), and it is sufficiently reliable at doing so and therefore intellectually legitimate that participants are willing to accept the outcome of the process even when it disagrees with what they started with. perhaps there is some kind of debate protocol that would make this feasible?
i feel like the fundamental mistake the project of rationality made was that "cognitive biases" is not in practice the right way to think about the way humans are irrational if your goal is to be very instrumentally rational. one hypothesis is the correct frame is to first deeply understand how the emotional system works, and then to think about ways to master that system to achieve rationality.
(yes, i know that buried somewhere in the sequences it says something like "humans aren't ideal intelligences with cognitive biases bolted on. we are the cognitive biases, they are just trying to approximate rationality".)
By the time I went to CFAR in 2019 this felt like it had already become the dominant flavor of inner-circle rationalist thinking, but then that inner circle kind of petered out in influence. The person I see carrying that torch most loudly in my current social atmosphere is Chris Lakin.
But overall rationality has been kind of quiescent imo! Ray posts good stuff, Duncan has his own thing, but it feels like we went from mid-2010s “rationalists talk a big game but don’t get anything done” to the mid-2020s most influential rationalists being too object-level busy to blog much about this metacognitive stuff.
If we understand "irrational" to mean something like "underperforming relative to what should be feasible", then I think one significant piece of the puzzle is the regime of "very impoverished hypothesis spaces". In this regime, Bayes (and deviations from it) is more of a peripheral conceptual frame (allowing you to understand some edge cases and some basics and some constraints) than a central guide or even that much of a useful tool. A much more important question is about hypothesis generation, aka abduction or "unupdating", i.e. expanding your hypothesis space. Another piece of the puzzle is that hypotheses are nothing like full possible worlds (as in many elementary models of epistemology), but rather are very-partial-possible-world-parts. Yet another piece of the puzzle is that concepts are very much not only or even mainly about prediction, propositions, and explanation (narrowly construed), but rather mainly about manipulation (including mental manipulation, e.g. "how could I have thought that faster or more efficiently"). Understanding how to think well in this regime, specifically in cases where you don't already have all / almost all of the understanding you need to win ...
an idea that i associate with bay area strains of buddhism is something like "life is just a series of distractions, you are distracted from distraction only by even more distractions, and it's all because you are experiencing suffering that is too uncomfortable to focus on, so if you somehow dispel all of it you are confronted with the existential dread of the impermanence of life, and dispelling that is the final boss." i might be completely misunderstanding something, I'm not a Buddhism expert by any means, please correct me if I'm wrong.
I've updated a lot towards something like this being at least kind of true. it seems like at least for a certain neurotype of person, much of one's behavior (ambition, addiction, hedonism, status, socialization, etc) serves as a way to distract from some kind of emotional pain. it looks different in different people; sometimes it looks like working a zillion hours so you have no time to reflect; or making status/money go up for its own sake; or drinking heavily; or playing video games; or spending lots of time at social events. the commonality is escaping the experience of the present in some way. in much the same way that you will flinch when o...
the part i most disagree with is the part where you're supposed to dissolve the pain of impermanence and fear of death. maybe many other fears should be dissolved, but it is good that impermanence is uncomfortable! you should be afraid of death and fill the void of existential dread with an ambition to end death forever.
You can work to end something without being afraid of it or finding it uncomfortable. A programmer looking for the cause of a bug in software is usually not afraid of the bug. If they did keep flinching away from the thought of the bug and finding the whole debugging thing uncomfortable, they'd do a worse rather than a better job at debugging.
If you want to end death, you'll do a better job at it if you can think about it clearly and not flinch away from considering things suggesting you personally might not make it. This requires not being afraid of it.
3
"but it is good that impermanence is uncomfortable! you should be afraid of death and fill the void of existential dread with an ambition to end death forever."
Are pain and fear the reasons you want an end to death? If not, their absence shouldn't hinder you?
man vaccines are so fucking cool. it's awesome that there are like a dozen horrifyingly painful and deadly diseases that i will almost certainly never get in my life. i wish i could get vaccinated against literally everything
There's a statue of him in Los Angeles's Little Tokyo which I used to pay respects to when I visited for the New Year's festival. As I became an EA I would aspire to match or exceed his impact.
Sugihara continued to hand-write visas, reportedly spending 18 to 20 hours a day on them, producing a normal month's worth of visas each day, until September 4, 1940, when he had to leave his post before the consulate was closed. Sugihara reportedly worked at a quick pace and aimed to issue 200 to 300 visas each day. [...]
According to witnesses, he was still writing visas while in transit from his hotel and after boarding the train at Kaunas railway station, throwing visas into the crowd of desperate refugees out of the train's window even as the train pulled out.

Your economics are wrong for a few reasons. Let's grant the hypothetical where all humans supply homogeneous labor at a uniform wage.
- If AI is slightly cheaper than humans, what happen is that wages fall slightly. At the new, lower wages, there is more demand for labor (and more humans drop out of the labor force). At the same time, capital costs are bid up slightly. Eventually the price of AI and human labor is equal, and the quantity demanded is equal to the quantity supplied.
- At the same time, you are increasing demand for labor to build the AI (right now labor is ultimately the main input to building all the stuff that goes in datacenters). If the social value of the AI is near zero, then the net increase in demand is almost the same as the net increase in supply. Lowering wages and increasing capital costs doesn't offset the benefits of extra productive capacity, it just shifts value from laborers to capitalists.
The real fiscal issue in this scenario is that you are shifting output from labor to capital, and the tax rate on capital is lower than the tax on labor. (Moreover as you automate the economy there are further corporate reorganizations that would drive effect tax rates w...
theory: a large fraction of travel is because of mimetic desire (seeing other people travel and feeling fomo / keeping up with the joneses), signalling purposes (posting on IG, demonstrating socioeconomic status), or mental compartmentalization of leisure time (similar to how it's really bad for your office and bedroom to be the same room).
this explains why in every tourist destination there are a whole bunch of very popular tourist traps that are in no way actually unique/comparatively-advantaged to the particular destination. for example: shopping, amusement parks, certain kinds of museums.
6
I used to agree with this but am now less certain that travel is mostly mimetic desire/signaling/compartmentalization (at least for myself and people I know, rather than more broadly).
I think “mental compartmentalization of leisure time” can be made broader. Being in novel environments is often pleasant/useful, even if you are not specifically seeking out unusual new cultures or experiences. And by traveling you are likely to be in many more novel environments even if you are a “boring traveler”. The benefit of this extends beyond compartmentalization of leisure, you’re probably more likely to have novel thoughts and break out of ruts. Also some people just enjoy novelty.
from To the Success of our Hopeless Cause: interestingly, a big tension in the Soviet dissident movement was between people who believed in being 100% virtuous, embracing martyrdom, signing their names and addresses onto their dissenting samizdat texts, protesting to be arrested 5 minutes later and sent to jail, pretending that the letter of the Soviet law actually mattered, etc, vs people who believed in being more strategic and openly illegal and trying to avoid being caught. the former fades in importance because they keep getting arrested (the 1968 red square protest being tbe turning point).
6
many of these dissidents have very relatable rat-coded vibes. one guy (Volpin) was obsessed with inventing a form of language that was unambiguous and impossible to make equivocating arguments in, as a way to enable rationalist thought. another (Amalrik) kept getting himself in trouble with his teachers and professors because he would insist on his correctness when they gave him bad grades for saying politically dangerous things, and he kept escalating, attempting to send his writing abroad via the Danish embassy and arousing the ire of the KGB. another (Sakharov) who throws away an illustrious high status well-paid career being the number one best nuclear weapon engineer of the Soviet Union to express his (quite mild) takes on the dangers of global nuclear war and pushing for international cooperation and arms treaties.
6
i feel very lucky never to have been in an environment like this. i don't think someone like me would have survived. not only have i never ever felt my life or liberty at any threat due to things i say, i'm lucky enough to not even have felt strong pressure to not say true things (obviously within reason, eg no leaking IP) in order to preserve my job or social standing. like maybe i don't get invited to the cool parties or whatever, but that's absolutely trivial compared to the prices that some people have been willing to pay to exercise their right to speak.
3
On a meta topic, I'm curious about your writing style here. Why capitalize the names of books and countries but not the first letter of sentences?
3
I do that, too, in things not intended for publication (which is the vast majority of things I write). Why? On a computer, capitalization is not needed to help identify the start of a sentence. In contrast, in print, it is not always possible to tell the difference between a period and an unfortunately-positioned blemish in the paper. Since it is not needed there, I prefer to avoid the extra work of typing an upper-case letter. Also, if I re-arrange the wording of a sentence, which I do frequently, then I have to do more work to fix up the capitalization. Finally, capitalizing the start of the sentence destroys what information capitalization of the initial word would otherwise carry. E.g., in conventional orthography, "Mercury" at the start of a sentence could be either a reference to the planet or the element whereas in the orthography I prefer, the reader knows it is not a reference to the element (because elements are not capitalized).
Grandparent includes a quotation without unambiguously marking it as a quotation (e.g., with quotation marks or a block quote) which I never do in my published writings (and almost never do even in writings that will never leave my computer). This generalizes: in all cases I can recall, those who in public refrain from capitalizing the starts of sentences also violate orthographic conventions I'd would be extremely hesitant to violate.
idea: flight insurance, where you pay a fixed amount for the assurance that you will definitely get to your destination on time. e.g if your flight gets delayed, they will pay for a ticket on the next flight from some other airline, or directly approach people on the next flight to buy a ticket off of them, or charter a private plane.
pure insurance for things you could afford to self insure is generally a scam (and the customer base of this product could probably afford to self insure) but this mostly provides value by handling the rather complicated logistics for you rather than by reducing the financial burden, and there are substantial benefits from economies of scale (e.g if you have enough customers you can maintain a fleet of private planes within a few hours of most major airports)
it's often stated that believing that you'll succeed actually causes you to be more likely to succeed. there are immediately obvious explanations for this - survivorship bias. obviously most people who win the lottery will have believed that buying lottery tickets is a good idea, but that doesn't mean we should take that advice. so we should consider the plausible mechanisms of action.
first, it is very common for people with latent ability to underestimate their latent ability. in situations where the cost of failure is low, it seems net positive to at least take seriously the hypothesis that you can do more than you think you can. (also keeping in mind that we often overestimate the cost of failure). there are also deleterious mental health effects to believing in a high probability of failure, and then bad mental health does actually cause failure - it's really hard to give something your all if you don't really believe in it.
belief in success also plays an important role in signalling. if you're trying to make some joint venture happen, you need to make people believe that the joint venture will actually succeed (opportunity costs exist). when assessing the likelihood of success...
hot take: analogies should not be used as evidence for positions, except as the weakest form used to privilege an otherwise arbitrary hypothesis to any consideration at all. otherwise, they should be used purely as a way to effectively convey a hypothesis, but the actual evidence needs to come from something other than the mere analogy itself.
hot response: all evidence is analogy, it's just a matter of degree. Maybe a heuristic like this is a good way to motivate gathering closer, more appropriate evidence, the better to increase confidence.
i can name many examples of evidence that are not analogy. perhaps they're arguably "just" analogy, but it would be in an obviously boring way. like how there is "just" subjective experience because you can never really directly observe reality, and yet clearly there is a difference between empirical evidence and a priori reasoning (note that the evidence for this analogy comes from the examples below, rather than the analogy itself)
- i think most Americans believe X. i run a survey. turns out Y% of Americans believe X.
- i run some experiment on whether a given model architecture is better than another one, and get a number at the end. (as opposed to, say, merely making an analogy between NNs and human brains, and using that to predict something)
- i read a study that is directly about a question i care about.
- i write a mathematical proof.
8
Yeah, I guess I'm being provocative, but I actually do think that.
* Survey (sampled, point-in-time, framing-dependent, out-of-context) is an (often quite good) analogy for any specific (or general) concept of what people believe.
* Experiment is a good case: one kind of 'really good' evidence is obtained by driving out as many confounders, controlling as many variables as possible, then reasoning that 'by this really really close analogy, the same or very very similar should obtain under what look like the same conditions'. Usually there are residual stochasticities. Often experiments are out of context in some way, or the conclusions we would like to draw are extrapolating some amount from what we actually checked.
* 'Read a study' inherits the analogy-ness of whatever experiments it's based on, plus I guess the thing where by analogy to those other times you read studies that seemed to be accurate (by the same person or same team or same org or same discipline or same culture or same species, ...), you expect it to be accurate.
* Mathematical proof, as always, is a slightly annoying limit case. I could probably say something like, 'well, any conclusion other than the mere mathematical conclusion is smuggling in some analogy (to quantities, types, relations, whatever)', and perhaps also your mathematical methods are trusted by analogy to... errr the other times logic helped you, but I don't know to what extent I'd really stand by that.
It seems to me that you are greatly broadening (that is, redefining) the word “analogy” to mean any sort of approximation. For example, survey results are not an analogy to the ground truth but an approximation to it.
5
I'm with Oliver Sourbut. Unless you've solved the induction problem AND can formally define your reference class, everything is analogy and degrees of similarity.
Which doesn't make your take wrong, just that it's a question of how close the analogy is, and how the analogous evidence applies to the compared predictions.
4
hot response: analogical inference does clearly provide some evidence. For example: I am conscious, you are otherwise pretty similar to me, therefore you are probably also conscious.
my summary of these two papers: https://arxiv.org/pdf/1805.12152 https://arxiv.org/pdf/1905.02175
the first paper observes a phenomenon where adversarial accuracy and normal accuracy are at odds with each other. the authors present a toy example to explain this.
the construction involves giving each input one channel that is 90% accurate for predicting the binary label, and a bazillion iid gaussian channels that are as noisy as possible individually, so that when you take the average across all of them you get ~100% accuracy. they show that when you do -adversarial training on the input you learn to only use the 90% accurate feature, whereas normal training uses all bazillion weak channels.
the key to this construction is that they consider an -ball on the input (distance is the max across all coordinates). so this means by adding more and more features, you can move further and further in space (specifically, in terms of the number of features). but the distance between the means of the two high dimensional gaussians stays constant, so no matter what your is, at some point with enough channels you can pertur...
Is it a very universal experience to find it easier to write up your views if it's in response to someone else's writeup? Seems like the kind of thing that could explain a lot about how research tends to happen if it were a pretty universal experience.
8
I think so/I have this. (I would emoji react for a less heavy response, but doesn't work on older short forms)
The corollary is that it's really annoying to respond to widely held views or frames which aren't clearly written up anywhere. Particularly if these views are very inprecise and confused.
8
new galaxy brain hypothesis of how research advances: progress happens when people feel unhappy about a bad but popular paper and want to prove it wrong (or when they feel like they can do even better than someone else)
this explains:
* why it's often necessary to have bad incremental papers that don't introduce any generalizable techniques (nobody will care about the followup until it's refuting the bad paper)
* why so much of academia exists to argue that other academics are wrong and bad
* why academics sometimes act like things don't exist unless there's a paper about them, even though the thing is really obvious
4
This subjectively seems to me to be the case.
3
https://xkcd.com/386/
a fundamental divide
in the domain of things, the best way to accomplish anything is usually to aim directly at it. it doesn’t matter how virtuous you are, or how well intentioned your inquiry is, if you are not aiming directly at the thing. reality doesn’t look on your virtue and reward you for the virtue per se. if you’re bad at something, you practice until you’re good at it.
in the domain of people, the best way usually involves some amount of being virtuous and doing things for the right reason. if you lack friends, it’s cringe and comes off as desperate/needy and even manipulative if you optimize too hard for meeting people and how to induce emotional connection and trust. rather, you should work to become a virtuous person who genuinely cares about people and then things will work naturally.
i think this leads to a lot of miscommunication between the groups. it seems desirable to develop the ability to do both depend on the setting.
3
You should work to become an attractive person, and then people will fight for the privilege of being your friend.
3
Clearly virtue isn't the thing that actually optimizes for success with people. (Unless you specifically want to be successful with people who really care about virtue and are good at judging it)
3
If you want to take over the Roman Empire starting in first-century Judea, it turns out that "start a militant group and try to conquer Judea back from the Romans" doesn't work, but "start a network of illegal high-trust cooperatives that teach virtue, pacifism, and give-till-it-hurts local altruism" does.
(These being the strategies of the Zealots and the Christians, respectively. The Zealots got stomped; the Christians eventually took over the Roman Empire.)
it's actually insane how much of the entire economy is tech now. somewhere in the back of my head i still expected traditional "big" industries like big oil, or the banks, or whatnot to be the biggest. but i just realized this hasn't been true for a long time.
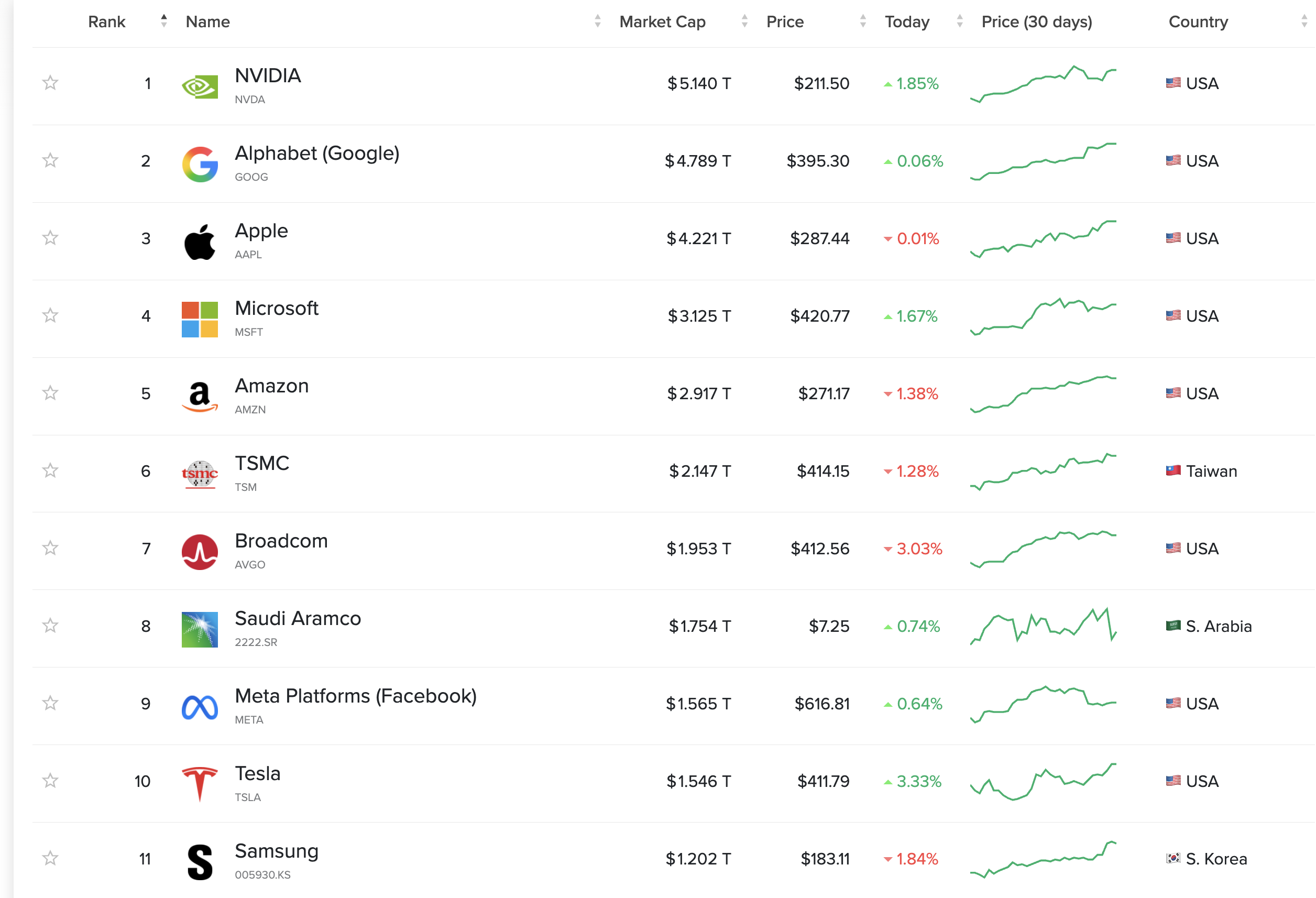
Looking at market cap is kinda misleading though; the public stock market is not the same thing as the economy, and tech is over-represented in market cap because of winner-take-all dynamics and margins.
Also, Amazon (setting aside AWS) is primarily a consumer goods and logistics company, and Tesla is a car and battery manufacturer - they're gigantic in part because they use tech well, but the actual goods and economic activity they generate aren't exactly "tech".
8
Most importantly for this context, market cap is about expectations for *future* earnings. So, it's not really reflecting the economy today.
And tech stocks tend to have more growth baked into their valuations.
6
category error to use market cap to size the economy, probably.
* on paper there's allegedly >$100T in assets under management worldwide
* by US GDP, "Information" contributes 5.5% in 25q4. There's various other tech-related entries from manufacturing/retail/services that should sum to >10%, but not the majority you'd expect from market cap.
i haven't had a chance to think deeply about it but vibes wise i don't like activation oracles
i think it's really weird that people are trying to do vaguely interp flavored things but also trying to argue for the goodness of such techniques via empirical usefulness. i think there are broadly two self consistent worldviews here. one is that you want to understand how NNs actually work and then use that understanding for something. the other is you want to make models better at X (where X can be anything from "be a good chatgpt model" to "refuse bioweapon prompts" to "make weak to strong setup score go up"). but if you're doing the latter the actual conceptually important part is picking the right X and then working really hard to make it go up using whatever techniques work. if you're doing the former you should actually try to understand things whatsoever. it doesn't make sense to try to do both and ultimately get neither. you should either do pragmatic or do interp.
The argument I would make is that you want to solve the practical problem, but you want to do so in a way that maximally scales with intelligence. And then white box techniques are more scalable than black box techniques, since schemers will predictably fool your black box techniques but not necessarily your white box techniques.
3
i totally agree for the case of actual white box understanding. this is what I'd consider the first worldview. my gripe is the interp-flavored techniques reveal very little understanding that might actually scale with intelligence, and yet through association with interp try to imply that they do.
6
I think the thing I'm saying is true even for interp/interp-adjacent techniques that give very little understanding—the fact that they're white-box techniques at all should still make it harder for a schemer to get around them than black-box techniques.
7
ok, i agree with this. there is some room for disagreement on exactly how big the gap is between white box and black box - i think it's very small compared to the gap from white box to full understanding. my main argument would just be ELK flavored, that there are spurious correlations that give you human simulators instead. but i don't feel super confident that the constant factors work out to support my claim
3
I sort of think of activation oracles as "chain of thought monitoring, but for activations"
Recall the basic chain-of-thought monitoring safety case: if chain of thought is necessary for a given model to complete a task, then (barring sophisticated encoding strategies) the chain of thought should be monitorable for that (task, model) pair.
As models get bigger / deeper, the space of tasks where chain-of-thought is necessary decreases, so (all else equal) chain of thought monitor-ability decreases.
How do we get around this? Well, assuming the model is using some kind of general purpose reasoning internally, that general purpose reasoning should have some general structure. And you know what's great at learning general structures: neural networks!
We won't be able to capture all the cognition of a model (that would require ambitious interp.), but we may be able to capture all the cognition that routes through something like “internal general purpose reasoning”.
How well activation oracles learn this general structure (/the degree to which there's a general structure at all) is an empirical question, but we can get rich signal on this question by training activation oracles, and evaluating them in on auditing games, unsupervised elicitation, etc.
Now you might argue that this is a very contingent defense of activation oracles - if for a set of evals where you would expect activation oracles to work, a different method out-performs activation oracles, then should we abandon them for the favored method? (since our only evidence for this "general internal reasoning structure" is via downstream usefulness of activation oracles). Concretely, it seems like dumb prefill black-box methods mostly out-perform activation oracles in auditing evals. Given this, why favor activation oracles over dumb black box methods (or smarter black box methods like confessionals)
Given current public evidence, you have to rely on conceptual arguments to justify favoring activation oracle
inside people with substantial internal conflict, their parts might even be less aligned/connected with each other than they are with other people. this probably has really weird effects
hot take: introspection isn't really real. you can't access your internal state in any meaningful sense beyond what your brain chooses to present to you (e.g visual stimuli, emotions, etc), for reasons outside of your direct control. when you think you're introspecting, what's really going on when you think you're introspecting is you have a model of yourself inside your brain, which you learn gradually by seeing yourself do certain things, experience certain stimuli or emotions, etc.
your self-model is not fundamentally special compared to any other models you have. it works the same way as your model of anyone or anything else, except you have way more data on yourself, and also you directly experience your own emotions and sensori stimuli, as opposed to having to infer them for other people. often your emotional brain sabotages your ability to understand yourself, but also it sometimes sabotages your ability to understand other people too (e.g groupthink, tribalism).
your self-model can diverge arbitrarily far from reality. when you're emotionally unintegrated, you have a model of yourself that fails to understand how your emotions truly work, so you will systematically mispredict...
7
What experiences have you had that lead you to call this a ‘hot take’?
[I rephrased a few times to avoid sounding sarcastic and still may have failed; I’m interested in why it looks to you like others dramatically disagree with this, or in what social environment people are obviously not operating on a model that resembles this one. My sense is a lot of people think this way, but it’s a little socially taboo to broadcast object-level reasoning grounded in this model, since it can get very interpersonally invasive or intimate and lead to undesirable social/power dynamics.]
4
the experience that led to calling it a hot take is i was arguing against someone who disagreed with this right before i wrote it up
3
What was their position? (to the extent that you can reproduce it)
3
I heard that when people are in therapy, their self adapts to the school of psychotherapy. For example you start getting Freudian dreams if you are in Freudian therapy, but you start getting Jungian dreams instead if you are in Jungian therapy.
This seems to support the hypothesis that when we think we have discovered something deep inside us, often we have actually constructed it to fit our preconceptions.
(I suspect that Buddhism also mostly works this way. When Buddhists say that they can verify the truth of all Buddha's words by introspection... on one hand, yes they can; on the other hand, if they instead believed in Jesus, they could verify that just as well. Asking yourself is like asking an LLM: whatever you believe is true, it will confirm.)
5
in my worldview this is very easily explained. if you do Jungian therapy your self model starts incorporating Jungian concepts for explaining your own brain. You didn't change the way your brain works fundamentally, you just changed your own model of your brain. The same way that if you read a book on the biology of plants you'll start viewing them in the lens of cells, and if you read a book on the ancient spirits associated with each plant you'll start thinking of plants as being animated by the ghosts of our ancestors.
The big mistake happens when people think of their self model as actually genuinely introspection. Then, you might think that you've changed the shape of your mind instead of only changing your understanding of your mind.
Instead, I think the right way to figure out if your self model is correct is to make predictions about your future behavior and see if they come true; act based on your self model and see if you become more successful at life, or whether you mysteriously repeatedly fail in some way.
one thing that frustrates me: people sometimes have weird brain experiences and then become convinced of crazy metaphysical beliefs. like you have some strange spiritual experience and become convinced god exists.
human brains are really fucking weird and complicated! it’s true that the default hypothesis of conscious experience (the idea that unless you’ve gone completely crazy, you basically just perceive reality as it is, and act on it as a rationalish agent) is not exactly true. the correct update is that while most of the time this is accurate, there is a lot of weird shit that goes on inside your brain, and your perception is the result of a whole lot of computation over the streams of raw data, and there are all sorts of weird modes you can push your brain into that feel really fucking weird from the inside, especially through drugs/meditation/etc, but even sometimes without. it’s actually completely possible to just hallucinate very complicated things, or suddenly feel some emotion very strongly for no obvious reason, or your brain can even mess with your memories too.
my diagnosis is that a lot of people have a belief that perceiving weird bullshit is not compatible with the...
I have a friend who, as a committed Christian, took LSD, and felt a deep spiritual connection to the Holy Spirit for his entire trip. It was a much stronger than he was ever able to feel in a church service. Puzzled, he took LSD a second time, and got the same feeling. He almost immediately became an atheist, reasoning that if LSD could replicate the feeling of the Holy Spirit then there was obviously nothing supernatural going on.
5
The brain can be accurately described as a hallucination engine. Its perceptual and cognitive processes are generative. The generated representations stay coupled to reality by sensory input during most normal waking experience, but the vividness of dreams, imagination, and hypothesis formation are pretty clear indicators of the strongly generative algorithm. The fact that anyone will reliably hallucinate from lack of sleep as well as hallucinogens adds evidence.
The non-cofnitive hallucinations in belief space are what make people think they've directly experienced the reality of spiritual truths. The feeling of presence of another mind or another space is just another hallucination, but people take that felt certainty as evidence of their reality.
4
Not sure if I'm just being stupid in context, but doesn't “your brain can sometimes do really weird shit” combined with “your mind is instantiated primarily via your brain” create a plausible physicalist causal path to “you'd change your mind”? That is, if the focus event is that your brain does something weird, and experiences and beliefs are both mediated by the brain, why can't the same underlying phenomenon directly cause both the experience and the change in beliefs? Like a kernel memory management glitch in a computer could simultaneously cause display distortion and corrupt some file buffers on their way to persistent storage.
4
i think it’s worth developing a systematic science of all the sorts of weird bullshit human minds pull in general, so we can understand better how to navigate being a human. doing so requires not knee-jerk ignoring interesting phenomena. but it also requires not throwing away our epistemics.
when i first came to the bay area, i was shocked that the silicon valley was literally just a bunch of suburbs and boring office parks. i used to think this was very incongruous. i still mostly do, but now i at least have a story for why the vibe isn't literally maximally incongruous.
one software architectureintuition i have is that legibility and standardization are utterly essential. the move from "servers as pets"(each one bespoke and carefully hand crafted, when something goes wrong, going in and fixing that one server) to "servers as cattle" (standardize all of the servers to be exact clones, destroy and recreate each server any time something deviates even slightly from identical rather than try to patch things on that one server by hand) is a good example. or for instance, you generally want to make things use common interfaces wherever possible, even if that means some slight awkwardness or indirectness, because the value of being able to interchange things is so high.
modern car oriented cities are a great example of taking this intuition and applying it to the physical world. steamrolling the unruly nature of old fashioned cities and reshaping everything to fit a handful o...
3
you can have grid cities which aren't car centric, that are much easier to travel in, while having better best experiences. car centric cities have the problem of traffic.
I have a little stored thought which sometimes triggers, and it reads:
"If you find yourself being forced to choose between two or more extremely bad options that involve burning your values, your resources, or your life, the truth is that you lost around three moves ago and are living out the equivalent of a forced mate in chess. You've already lost, so stop playing and find a better game to spend time on if at all possible."
what's the current state of analysis on whether the civil rights act of 1957 was actually net positive or negative for civil rights in hindsight? there are two possible stories one can tell, and at the time people were arguing about which is correct:
- passing even a useless civil rights bill is a lot better than nothing because it sets a precedent that getting civil rights bills through the Senate is possible / makes the southern coalition no longer look invincible. this serves a useful coordination mechanism because people only want to support things that they think other people will support.
- passing a useless civil rights bill is worse than no bill because it creates a false sense of progress and makes it feel like something was done even when nothing was. to the extent that the bill signals to people that getting civil rights bills through the Senate is possible, this is a false impression because the only reason the bill could get through was that it was watered down to uselessness.
this feels directly analogous to the question of whether we should accept very weak AI safety regulations today.
4
It seems extremely net-positive for civil rights, but mainly through the mechanism of it making Lyndon Johnson a viable candidate for president while maintaining his stature with the southern democrats, leading ultimately to the Civil Rights Act of 1964.
This can be seen as a generalizable lesson only insofar as you think weak bills like that are typically passed by Lyndon Johnson-like figures playing 4d political chess ultimately for altruistic reasons. Without that effect, it mostly seemed bad, it likely actually decreased the number of black voters, and did not decrease the south's ability to filibuster the senate against civil rights (which was the main mechanism by which civil rights bills were unable to pass), eg they filibustered away another civil rights bill in 1959 or something. Plus, if not for Lyndon Johnson ultimately being pro-civil rights, it would have put someone decidedly anti-civil-rights into the presidency.
3
so it sounds like there's basically no way anyone could have known that johnson would actually be a pro civil-rights president, and that all the civil rights people who were opposed to the 1957 bill at the time were basically opposed for the right reasons? like basically everything we know about johnson as of 1960 suggests that he is telling everyone what they want to hear and it's unclear whether he has any convictions of his own except for his strong track record of defending the interests of the south.
there's an obvious synthesis of great man theory and broader structural forces theories of history.
there are great people, but these people are still bound by many constraints due to structural forces. political leaders can't just do whatever they want; they have to appease the keys of power within the country. in a democracy, the most obvious key of power is the citizens, who won't reelect a politician that tries to act against their interests. but even in dictatorships, keeping the economy at least kind of functional is important, because when the citizens are starving, they're more likely to revolt and overthrow the government. there are also powerful interest groups like the military and critical industries, which have substantial sway over government policy in both democracies and dictatorships. many powerful people are mostly custodians for the power of other people, in the same way that a bank is mostly a custodian for the money of its customers.
also, just because someone is involved in something important, it doesn't mean that they were maximally counterfactually responsible. structural forces often create possibilities to become extremely influential, but only in the direc...
4
I think there's a spectrum between great man theory and structural forces theory and I would classify your view as much closer to the structural forces view, rather than a combination of the two.
The strongest counter-example might be Mao. It seems like one man's idiosyncratic whims really did set the trajectory for hundreds of millions of people. Although of course as soon as he died most of the power vanished, but surely China and the world would be extremely different today without him.
one kind of reasoning in humans is a kind of instant intuition; you see something and something immediately and effortlessly pops into your mind. examples include recalling vocabulary in a language you're fluent in, playing a musical instrument proficiently, or having a first guess at what might be going wrong when debugging.
another kind of reasoning is the chain of thought, or explicit reasoning: you lay out your reasoning steps as words in your head, interspersed perhaps with visuals, or abstract concepts that you would have a hard time putting in words. It feels like you're consciously picking each step of the reasoning. Working through a hard math problem, or explicitly designing a codebase by listing the constraints and trying to satisfy them, are examples of this.
so far these map onto what people call system 1 and 2, but I've intentionally avoided these labels because I think there's actually a third kind of reasoning that doesn't fit well into either of these buckets.
sometimes, I need to put the relevant info into my head, and then just let it percolate slowly without consciously thinking about it. at some later time, insights into the problem will suddenly and unpredictably...
the possibility that a necessary ingredient in solving really hard problems is spending a bunch of time simply not doing any explicit reasoning
I have a pet theory that there are literally physiological events that take minutes, hours, or maybe even days or longer, to happen, which are basically required for some kinds of insight. This would look something like:
-
First you do a bunch of explicit work trying to solve the problem. This makes a bunch of progress, and also starts to trace out the boundaries of where you're confused / missing info / missing ideas.
-
You bash your head against that boundary even more.
- You make much less explicit progress.
- But, you also leave some sort of "physiological questions". I don't know the neuroscience at all, but to make up a story to illustrate what sort of thing I mean: One piece of your brain says "do I know how to do X?". Some other pieces say "maybe I can help". The seeker talks to the volunteers, and picks the best one or two. The seeker says "nah, that's not really what I'm looking for, you didn't address Y". And this plays out as some pattern of electrical signals which mean "this and this and this neuron shouldn't have been firing s
3
a thing i think is probably happening and significant in such cases: developing good 'concepts/ideas' to handle a problem, 'getting a feel for what's going on in a (conceptual) situation'
a plausibly analogous thing in humanity(-seen-as-a-single-thinker): humanity states a conjecture in mathematics, spends centuries playing around with related things (tho paying some attention to that conjecture), building up mathematical machinery/understanding, until a proof of the conjecture almost just falls out of the machinery/understanding
Since there are basically no alignment plans/directions that I think are very likely to succeed, and adding "of course, this will most likely not solve alignment and then we all die, but it's still worth trying" to every sentence is low information and also actively bad for motivation, I've basically recalibrated my enthusiasm to be centered around "does this at least try to solve a substantial part of the real problem as I see it". For me at least this is the most productive mindset for me to be in, but I'm slightly worried people might confuse this for me having a low P(doom), or being very confident in specific alignment directions, or so on, hence this post that I can point people to.
I think this may also be a useful emotional state for other people with similar P(doom) and who feel very demotivated by that, which impacts their productivity.
for some reason, the irrational belief that nobody will read my shortforms paradoxically makes them much easier to write. if I'm writing something polished that i think lots of people will read, then i get scared that people will see it and think less of.me or something, which manifests as unreasonable perfectionism and a desire to present a fictitious version of myself and my thinking. i wonder if there is some way to get the best of both worlds - to produce more authentic but also high quality widely read posts
3
One possible approach would be having someone else polish the posts for you/work iteratively on ideas with a friend. Writing partners are useful! Not only do they divorce you from some of the reputational risk of writing whatever you're writing, they also turn the worst part of writing into a non-issue (the mental context switch between generating and polishing). There's also the concept of beta readers, but that admittedly feels a bit sillier for web forum posts. Just being able to offload the mental work of perfection into a "good enough" of "$person i trust thought it was good actually so it's fine" does a lot for improving speed of iteration, usually without meaningfully degrading quality in a noticeable fashion.
thoughts on what to work on in a world with heavy AI automation
it seems undeniable at this point that AI automation will play a huge role in all research in the medium term future. therefore, we should take automation into account when choosing what to work on. here are some possibilities, in decreasing order of how optimistic you are that models will be good at alignment research.
- push for people to allocate more resources to alignment. the most optimistic assumption is that models are perfect drop in replacements for human researchers, and are equally good as good at alignment and capabilities research as humans are. then, we just need to allocate more compute to alignment and we're chilling. the main problem is there is an incentive to race to the bottom, to allocate more to capabilities to have a faster recursive improvement loop. but it is much easier to legislate a requirement to spend X% of compute on automated alignment research, than other pause or slowdown proposals.
- making the AIs better at alignment research. we might believe that AIs are by default going to be worse at alignment than capabilities, possibly because feedback loops are better for capabilities, or models wil
for people who are not very good at navigating social conventions, it is often easier to learn to be visibly weird than to learn to adapt to the social conventions.
this often works because there are some spaces where being visibly weird is tolerated, or even celebrated. in fact, from the perspective of an organization, it is good for your success if you are good at protecting weird people.
but from the perspective of an individual, leaning too hard into weirdness is possibly harmful. part of leaning into weirdness is intentional ignorance of normal conventions. this traps you in a local minimum where any progress on understanding normal conventions hurts your weirdness, but isn't enough to jump all the way to the basin of the normal mode of interaction.
(epistemic status: low confidence, just a hypothesis)
if any municipality in the bay area were to choose to allow lots of housing, then it would very quickly get manhattanized and they would make a zillion dollars in tax revenue, while harming property values in nearby cities. so naively you'd expect that surely eventually one random municipality of the dozens in the bay area will do this. but NIMBYs are so strong everywhere that this never happens. this seems directly relevant to questions of the feasibility of international coordination on AGI, especially if facilitated by strong pressure from labor to stop AGI.
the bay area is also evidence that we can't just assume that economically incentivized things are inevitable. the opportunity cost of not building up the bay area more is trillions of dollars. but people are willing to destroy immense amounts of value to preserve their self interest and the world they're familiar with.
California building code alone is quite restrictive. It's true that municipalities could allow building a lot more housing, but a lot of the cost comes from state-wide or even nation-level building codes.
4
Isn't Emeryville kind of doing this? Though I'm not sure if they're maxing out the envelope of housing production from real costs even if a city government goes 100% YIMBY.
I'm also starting a $100 bounty per referral to my microgrants program that successfully receives a microgrant. please refer your smart friends who need money to make AGI go well! have them include your name and email somewhere in their application.
microgrant link: https://docs.google.com/document/d/10zAp2bXTkZgiPreIm4crp38TFco4KleFN14Kw5BprAs/edit?tab=t.0
any time there exists an activity that is (a) often but not always beneficial, (b) the supposed benefit is high status, and (c) the success of which is nontrivial to verify, then there will exist a bunch of people walking around who do the thing, and haven’t actually gained the intended benefit; nonetheless, they go around claiming the status benefits of doing the thing. often, they even genuinely believe they got the benefit. some examples:
- reading difficult books can make you more wise and thoughtful, but it’s very easy to do it wrong and not really understand and of it, and so lots of people read difficult books and try to claim the associated status of wisdom without actually gaining any.
- doing a college degree can make you more competent, but it’s also very easy to kinda bullshit an entire degree and learn surprisingly little. so there are many people who claim the status of having done a good education who are utterly incompetent.
- doing meditation/inner work can make you a more emotionally functional person, or it can just make you really delusional about yourself and make you a still-broken person who identifies as an emotionally intelligent person
4
even many of the zen koans bemoan practitioners of zen who go through the motions for many years and claim to be enlightened and yet are not truly enlightened
https://ashidakim.com/zenkoans/6noloving-kindness.html
https://ashidakim.com/zenkoans/11thestoryofshunkai.html
the new openai planar unit distance result kills my last remaining doubts about AI being a huge multiplier on research productivity in the near term future. i was not expecting this to happen so soon; i would have guessed probably another year before we got a result like this.
3
What about it in particular convinced you that e.g. the previous big result didn't?
i get the impression that the previous problems were mostly just neglected, or otherwise were less impressive than they seemed. whereas afaict mathematicians agree the new result is on a real well-known problem and genuinely surprising and novel.
why are malaria nets 9-23x more efficient than direct cash transfers? when in theory direct cash transfers can be used to purchase nets
some hypotheses
- people are irrational and don't spend money on nets because they underestimate the risks, are not educated, etc
- people don't value spending a few days wages to reduce mortality by 0.1 percentage points
8
I think part of it is what you said. Even in Western countries where people have way more education and slack, people often underinvest in preventative health like flu shots, so it makes sense that people in third-world countries would fall prey to this too, and many more probably don't even know about the benefits of nets or how to get them.
Another pair is economies of scale and spillover effects. IIRC it's cheaper per net to protect a whole village at once, and because malaria nets are treated with insecticide, nets kill mosquitos and so they protect other people as well. And people tend to underinvest in things with positive externalities like that - again we go back to the flu shot example.
There's probably other reasons, but these are the ones I know of.
5
Additional hypotheses (note: I do not assert these, only consider as possibilities):
* Mosquito nets are more difficult to steal (or pressure recipients into misuse).
* Relatedly, mosquito nets are easy to distribute. Money has a lot of overhead costs in actually identifying and getting it to the intended recipients.
* Mosquito nets are 9-23x more effective only on the narrow measure of mortality. Perhaps they're less effective than money on actual happiness for recipients and future generations.
Overally, the adversaries that mosquito nets help against (mosquitoes and viruses) are way dumber than the adversaries (human foibles, both in the recipients and in other parties) that come with money.
survey: what brand of melatonin do you use? i want to run an experiment on melatonin degradation using the most popular brand of melatonin.
3
LifeExtension.com - Melatonin 0.3mg mostly because it's 0.3mg
I don't want to have to make every shortform a self contained article. it makes sense that full posts should explain the context, but I would find it very exhausting to have to e.g explain that I work at openai every single time I shortform post about anything openai related. if lesswrong shortform is the wrong place to do this, I'm happy to post elsewhere.
i'm thinking of starting a new blog. it would be about some amount of AI/alignment stuff of course, but also about lots of random other things. for instance, some blog post ideas:
- hiring pollsters to run deranged survey questions about transhumanism on the average american
- rediscovering all of physics since 300 BC by submitting experiments to a grad student who simulates how the experiment would have gone
- book review of the lyndon b johnson biography
- miscellaneous short fiction about AI but also other things
- hosting and then doing postmortems of weird experimental house party ideas (example idea)
thing i need your help with:
- i'm looking for ideas of what i could name my blog. by default i'm just going to go with something lame like "lg blog" but I feel like I could do a lot better.
- i'm curious to hear which of the ideas you would be most excited to read, so i can prioritize them
why is airplane wifi still so garbage? i imagine many business travellers would pay a lot for good airplane wifi.
presumably because to improve airplane wifi, you'd need to launch dozens of rockets to deliver a massive new constellation of orbiting satellites in order to deliver an order-of-magnitude improvement over Intelsat or whoever usually provides wifi connections to planes.
The good news is that SpaceX has done this, with their Starlink constellation! (Others like OneWeb, Baidu, and Amazon's Project Kuiper are also doing similar stuff.) But not every airline / airplane has upgraded to new Starlink recievers yet. So, most planes (and cruise ships, and etc) still have slow Intelsat/Globalstar internet, but others have indeed seen huge upgrades in internet speeds.
in defense of putting your python imports in the middle of your file (in global scope, not inside functions)
- i have never in my life wanted to know the list of all the things a file imports before seeing any of the actual code in the file. if i see something i dont recognize, i would appreciate it more if the import were right above the usage; otherwise, i have to ctrl+f for it anyways. what's
- it's more annoying to have to add it to the top of the file. auto import things in ides are often broken.
- there's absolutely nothing wrong with importing something multiple times. it costs absolutely nothing; it's just a no-op the second time. even in C you can do
#pragma onceto get python-like behavior - the only reason not to do this is that if you put an import in the middle of a function it's weird (if you import both blobally and locally, then using the thing locally but before the local import errors). so just don't put the import inside a function
3
tone: playful
weak. if you're going to import not at the top of a file put it at the top of the function like a real startup-speed-microoptimizing programmer
I mean, the proximate cause of the 1989 protests was the death of the quite reformist general secretary Hu Yaobang. The new general secretary, Zhao Ziyang, was very sympathetic towards the protesters and wanted to negotiate with them, but then he lost a power struggle against Li Peng and Deng Xiaoping (who was in semi retirement but still held onto control of the military). Immediately afterwards, he was removed as general secretary and martial law was declared, leading to the massacre.
a common discussion pattern: person 1 claims X solves/is an angle of attack on problem P. person 2 is skeptical. there is also some subproblem Q (90% of the time not mentioned explicitly). person 1 is defending a claim like "X solves P conditional on Q already being solved (but Q is easy)", whereas person 2 thinks person 1 is defending "X solves P via solving Q", and person 2 also believes something like "subproblem Q is hard". the problem with this discussion pattern is it can lead to some very frustrating miscommunication:
- if the discussion recurses into whether Q is hard, person 1 can get frustrated because it feels like a diversion from the part they actually care about/have tried to find a solution for, which is how to find a solution to P given a solution to Q (again, usually Q is some implicit assumption that you might not even notice you have). it can feel like person 2 is nitpicking or coming up with fully general counterarguments for why X can never be solved.
- person 2 can get frustrated because it feels like the original proposed solution doesn't engage with the hard subproblem Q. person 2 believes that assuming Q were solved, then there would be many other proposals other than X that would also suffice to solve problem P, so that the core ideas of X actually aren't that important, and all the work is actually being done by assuming Q.
4
I find myself in person 2's position fairly often, and it is INCREDIBLY frustrating for person 1 to claim they've "solved" P, when they're ignoring the actual hard part (or one of the hard parts). And then they get MAD when I point out why their "solution" is ineffective. Oh, wait, I'm also extremely annoyed when person 2 won't even take steps to CONSIDER my solution - maybe subproblem Q is actually easy, when the path to victory aside from that is clarified.
In neither case can any progress be made without actually addressing how Q fits into P, and what is the actual detailed claim of improvement of X in the face of both Q and non-Q elements of P.
3
I can see how this could be a frustrating pattern for both parties, but I think it's often an important conversation tree to explore when person 1 (or anyone) is using results about P in restricted domains to make larger claims or arguments about something that depends on solving P at the hardest difficulty setting in the least convenient possible world.
As an example, consider the following three posts:
* Challenge: construct a Gradient Hacker
* Gradient hacking is extremely difficult
* My Objections to "We’re All Gonna Die with Eliezer Yudkowsky"
I think both of the first two posts are valuable and important work on formulating and analyzing restricted subproblems. But I object to citation of the second post (in the third post) as evidence in support of a larger point that doom from mesa-optimizers or gradient descent is unlikely in the real world, and object to the second post to the degree that it is implicitly making this claim.
There's an asymmetry when person I is arguing for an optimistic view on AI x-risk and person 2 is arguing for a doomer-ish view, in the sense that person I has to address all counterarguments but person 2 only has to find one hole. But this asymmetry is unfortunately a fact about the problem domain and not the argument / discussion pattern between I and 2.
If you did that in the US, you'd end up trying to explain to prosecutors, then a judge, then a jury why you shouldn't be imprisoned for the rest of your life. I would hope that is roughly how it would go everywhere.
not OP, but that seems like a pretty reasonable conclusion. if i had to sacrifice my own life to save every person i didn't personally know (ie. 8.1 billion people), i would absolutely do it in a heartbeat. i would also do it to just save a fraction of those people (8M people). once it starts getting down to much smaller fractions (saving 100-3 random people) does it start seeming like a hard tradeoff.
have you ever heard anyone make the argument that it's good to have AI safety aligned frontier labs (including but not limited to Anthropic) because they will have a seat at the table with the regulators, and the regulators will take major industry players' opinions more seriously than minor players or activists?
i've heard this argument but i'm trying to figure out if it's common enough to be worth writing a post about
9
In my opinion, this position was sensible when the labs themselves were branded as MIRI-like but with added emphasis on technical experimentation. The second it became clear that these 'labs' principal reward function was not their claimed preferences (for alignment research - which OAI was explicitly communicating under the moniker of safety), our personal semantic landscapes were already trained enough by the narrative, that we missed the major conflict of interest here before establishing the norm.
They will continue to use epistemic asymmetry and leverage over information advantage to make the claim that having any other group at the table is a fruitless endeavour, and use the risks of foreign adversarial advantage to continue to maintain that position strategically. Given that all regulation is domestic, they end up regulating themselves (which is even implied by your question), which IMO can be a worst case scenario from a humanist/existential risk perspective.
7
I've heard this before.
5
I have both heard that argument, and made it myself on occasion, so I'm keen to see your post!
thoughts on lemborexant
pros: if you take it, you will fall asleep 30-60 minutes later. nothing else I've tried has been as reliable at making sure I definitely fall asleep, and as far as I can tell, it doesn't destroy my sleep quality. especially at 10mg, you can feel it knocking you out, and you basically can't power through it even if you want to. it's a bit scary but all powerful sleep drugs are at least a bit scary and often a lot more scary. I generally take 5mg instead.
cons: it doesn't do anything to keep you asleep; if your body doesn't really want to sleep, you will wake up 2 hours later fully alert. it also doesn't do anything to shift your sleep schedule. these facts combined mean that if you try to use lemborexant for jet lag / shifting sleep earlier, then your life will suck indefinitely until you stop using lemborexant. my current recipe is to only use lemborexant when it's near enough to my normal bedtime, and I use melatonin 3 hours before bed to slowly move sleep schedule earlier (later requires no special effort)
(potentially this also means lemborexant can be used to get nice 2 hour daytime naps? I have enough fear of god sleep drugs that I feel hesitant to try any kind of hack like this)
(not medical advice. not a doctor, and even if I was a doctor I'm not your doctor, and even if I was your doctor I wouldn't be communicating to you via lesswrong shortforms)
a simple elegant intuition for the relationship between SVD and eigendecomposition that I haven't heard before:
the eigendecomposition of A tells us which directions A stretches along without rotating. but sometimes we want to know all the directions things get stretched along, even if there is rotation.
why does taking the eigendecomposition of help us? suppose we rewrite , where S just scales (i.e is normal matrix), and R is just a rotation matrix. then, , and the R's cancel out because transpose of rotation matrix is also its inverse.
intuitively, imagine thinking of A as first scaling in place, and then rotating. then, ATA would first scale, then rotate, then rotate again in the opposite direction, then scale again. so all the rotations cancel out and the resulting eigenvalues of ATA are the squares of the scaling factors.
This is almost right, but a normal matrix is not a matrix that “just scales”, its a normal matrix which can do whatever linear operation it likes.
SVD tells us there exists a factorization where and are orthogonal, and is a “scaling matrix” in the sense that its diagonal. Therefore, using similar logic to you, which means we rotate, scale by the singular values twice, then rotate back, which is why the eigenvales of this are the squares of the singular values, and the eigenvectors are the right singular vectors.
philosophy: while the claims "good things are good" and "bad things are bad" at first appear to be compatible with each other, actually we can construct a weird hypothetical involving exact clones that demonstrates that they are fundamentally inconsistent with each other
law: could there be ambiguity in "don't do things that are bad as determined by a reasonable person, unless the thing is actually good?" well, unfortunately, there is no way to know until it actually happens
6
I think I need to hear more context (and likely more words in the sentences) to understand what inconsistency you're talking about. "good things are good" COULD be just a tautology, with the assumption that "good things" are relative to a given agent, and "good" is furtherance of the agent's preferences. Or it could be a hidden (and false) claim of universality "good things" are anything that a lot of people support, and "are good" means truly pareto-preferred with no harm to anyone.
Your explanation "by a reasonable person" is pretty limiting, there being no persons who are reasonable on all topics. Likewise "actually good" - I think there's no way to know even after it happens.
lifehack: buying 3 cheap pocket sized battery packs costs like $60 and basically eliminates the problem of running out of phone charge on the go. it's much easier to remember to charge them because you can instantaneously exchange your empty battery pack for a full one when you realize you need one, plugging the empty battery pack happens exactly when you swap for a fresh one, and even if you forget once or lose one you have some slack
One possible model of AI development is as follows: there exists some threshold beyond which capabilities are powerful enough to cause an x-risk, and such that we need alignment progress to be at the level needed to align that system before it comes into existence. I find it informative to think of this as a race where for capabilities the finish line is x-risk-capable AGI, and for alignment this is the ability to align x-risk-capable AGI. In this model, it is necessary but not sufficient for alignment for alignment to be ahead by the time it's at the finish line for good outcomes: if alignment doesn't make it there first, then we automatically lose, but even if it does, if alignment doesn't continue to improve proportional to capabilities, we might also fail at some later point. However, I think it's plausible we're not even on track for the necessary condition, so I'll focus on that within this post.
Given my distributions over how difficult AGI and alignment respectively are, and the amount of effort brought to bear on each of these problems, I think there's a worryingly large chance that we just won't have the alignment progress needed at the critical juncture.
I also think it's ...
there are some people i talk to where any disagreement rapidly leads to establishing a common ground and then converging to some crux. there are other people where the more questions i ask, the more it feels like i’m unraveling a huge tangled ball of yarn where every claim i dig into uncovers even more bizarre claims
6
I have some experience being, "the huge tangled ball of yarn where every claim you dig into seems to uncover even more bizarre claims."
My experience is that you (the digger, not leogao in particular) are making invalid assumptions, usually crude heuristics/intuitions, I point out those invalid assumptions with very precise language, and you completely ignore the precision and come up with a crude heuristic for what I said.
For example, a recent conversation I had on LessWrong:
[...]
The first comment has two crude intuitions:
1. Winning in board games is zero sum -> interactions in board games are zero sum
2. The most prominent wars in my mind are negative sum -> war is negative sum
I immediately point out how these heuristics are not true:
1. Zero sum games with more than two players can contain subgames that are nonzero sum.
2. Evolution is akin to a war, and positive sum for the competitors. Proxy wars can be positive sum for the greater powers.
My best guess is they smoothed out my two claims to:
1. zero sum games are not always zero sum
2. wars, which we all know are negative sum, are positive sum
Then they walk away thinking, "man, I tried to dig into their confused epistemology, but it's such a tangled ball of yarn that every time I follow a thread it just reveals even more bizarre claims. Like come on, he's saying some obviously tautologically false things."
My best guess for the miscommunication is I learned to read/write (long form) from math/coding, and pretty much no one else did. So if I say something in a very particular, precise manner, they—unlike me—never learned to pay attention to the precision. The issue is not my sending channel capacity, but their receiving, and when a packet gets dropped they do not slow down and reread. No, they conclude that the bizarre object they reconstruct must be what was originally transmitted.
I think this also mostly explains your explanations: People who don't converge repeatedly (and from your pe
4
my best guess is some people find it really hard to back down and are also smart enough to argue for anything, and so they generate any claim that fits the context
6
another hallmark of people who rapidly converge to some crux is they are much more willing to grant simplifying assumptions that don’t change the core disagreement, whereas people who don’t converge like to keep their options open
3
Have you noticed a correlation here with other personality traits (status-seeking, humility, curiosity, etc.), or across domains (often on tech questions, rarely on politics)?
I have long observed this divergence, and it does feel somewhat bimodal (but is more continuous when I look for examples more carefully, for me at least). And to me, it seems more often topic/context sensitive than innate traits of a person. Though there are a LOT of people who I only interact with in limited domains, so it's hard to tease apart the reasons.
japan has the most advanced mundane technology imaginable. incredible train system, convenience store food, vending machines, toilets, etc. it also has the shittiest software imaginable. i wonder how that came to be.
the train station fare gates are especially retrofuture. for some journeys, you may need multiple tickets simultaneously, so you feed a stack of tickets into the fare gate, and it automatically separates them, reads them (the tickets are printed on special magnetic stripe paper), stamps them, and returns them to you in a neat stack on the other side, all in under a second. also the ticket machines have some of the best coin funnels i've ever seen on any coin operated device (because clearly you're going to use your bag of 500 yen coins to buy a 100,000 yen shinkansen ticket, why else?)
the ticket machines have the most confusing interface imaginable. thankfully there is a help button that video-calls in a customer service person who remote-desktops in to help you navigate the interface or even click on buttons for you. there's even a little tray with a camera looking at it, for you to show your existing tickets to the support person, rather than having to hold them up next to your face and praying that they can read it.
it's all so well thought out and completely outdated at the same time.
Very poor use of human capital? If you do a good job of directing skilled people to high-impact jobs, you get better performance in places like software but worse performance in places like convenience stores.
8
For people who haven't been in Japan, is there a good article with examples of the "shittiest software imaginable"?
4
i don’t have a go-to article, but some examples include: the train station ticket machines, hotel booking websites, the old “smart” mobile phones which were both extremely ahead of their time and very strange, many of the touchscreen vending machines have horrible UI, etc.
on discovering new songs
the spotify recommender algorithm sucks. also, i often find i'm very unfamiliar with very well-known pieces of music. so i decided to do something weird. i used LMs to scrape several best songs lists from different online sources, merged them into one gigantic list, and used spotipy to create a spotify playlist of all of those random songs. whenever anyone recommends me a song, i also throw it into this giant playlist. then, when i want to explore new songs, i just put this playlist on. i have another script that automatically removes any songs i've put into my liked songs already, and i also manually remove songs i really don't like. this system has helped me discover dozens of new songs that i like.
I feel like you are just describing life right now for anyone who moves from a developing country to a developed country.
When I first came from India to US, another Indian told me "to learn to pass time". Because the many challenges of daily life in India don't exist in US. So one has to figure out joys of life in US. For many places, it is enough to just be able to survive. If you are stuck in a war-torn place, every new day is an achievement.
is it worth writing blog posts about “obvious” things? i’ve been doing a lot of writing recently, and i frequently finish writing something, and i look at it, and i feel like it’s so obvious that all readers will either already agree and not learn anything, or disagree so fundamentally that changing their mind would require diving much deeper into fundamental beliefs.
4
There are a lot of claims with which I would agree with if you ask me but I wouldn't use them in a reasoning chain on my own because they never crossed my mind.
A lot of complex reasoning rests on having reliable basics on which you can reason.
When I'm talking about BPC-157, then being trained I bioinformatics it feels pretty obvious to me that if BPC-157 is a real peptide that's part of a protein called BPC I should be able to look up the gene for BPC sequencing databases. There's the dogma of molecular biology, proteins come from genes.
If I would ask anyone at the bio-hacking about whether they agree with the dogma of molecular biology and that this means that there should be a gene to look up the probably would say they agree. Yet, somehow the argument does not convince people who believe in BPC-157 that it's bogus.
Explaining the dogma of molecular biology and our great success at gene sequencing that actually sinks in isn't easy.
If you find yourself writing something very obvious, it becomes more important to ask: "How can I make this point in a similar way that really sinks in so that the reader can actually use it and rely on it?" instead of just "Have I made a clear logical argument for it?".
4
Yes, I think so. https://www.lesswrong.com/posts/thXohzXrWCA2EhZCH/mateusz-baginski-s-shortform#MRNSMcFxFuW6kZbap
At the very least, you're testing whether the model that predicts this is accurate.
[...]
3
The default advice blogging advice I've heard is that "obvious" topics often make for good posts because they are often non-obvious to readers, so one should strongly default towards posting if the concern that it is too obvious.
But maybe you're making this judgement even with that prior in mind? I'd be curious to see one of these "obvious" posts.
theory: a big difference between people who hate corporations and people who don't is the extent to which they like interacting with human-shaped things. some people like human shaped things and the sort of amoral profit maximization of companies feels alien and sociopathic. other people like the predictable API that companies provide.
4
IDK man. I mostly don't care that much about either. I'm extroverted but quite picky about people and don't particularly feel drawn to "human-shaped things" in general. I don't particularly hate corporations, but surely corporate capitalism seems very far from ideal. And their drive doesn't seem alien or sociopathic to me.
But now I realize that I'm actually confused by what you mean by "human-shaped things".
4
if companies were people, they would be uncaring sociopathic humans. but if lawnmowers were people, they would also be uncaring and sociopathic
is it generally best to take just one med (e.g antidepressant, adhd, anxiolytic), or is it best to take a mix of many meds, each at a lesser dosage? my intuitions seem to suggest that the latter could be better. in particular, consider the following toy model: your brain has parameters that should be at some optimal , and your loss function is a quadratic around . each dimension in this space represents some aspect of how your brain is configured - they might for instance represent your level of alertness, or impulsivity, or risk averseness, or motivation, etc. each med is some vector that you can add to your current state , and the optimal dosage of that med in isolation is whichever quantity gets you closest to ; but unless happens to be exactly colinear with , you basically can't do any better just by tuning the dosage of the one med. this seems especially important because most meds don't seem to be exactly monosemantic, and also different people start out with substantially different and loss landscapes, such that you often get paradoxical reactions to meds.
8
A huge percentage of the job of a pharmacist is to keep track of potential negative interactions between different drugs, of which there are an incomprehensible number. I don't think linearity is a reasonable assumption here, the interaction terms between multiple interventions should be though of as, on average, big. Augmentation and synergistic effects exist, but are in general risky and quite hard to find. Even the effects of one drug are not linear, there are significant nonlinearities in dosage effects for most drugs.
4
i'm not really making any strong linearity assumptions, only local linearity. this doesn't seem that different from ML, where hyperparameters can sometimes interact heavily nonlinearly, but often they don't. i also don't think the quadratic assumption is crazy; we assume that loss land scapes are locally quadratic all the time, even though they are obviously highly nonconvex and it's still a very useful intuition pump.
also, my understanding is most of the really bad interactions are pretty well known, so the probability of having a really weird surprising interaction that nobody has ever catalogued is small.
5
Changing the dose of a medication does not necessarily result in linear effects. There are nonlinearities introduced by e.g. one receptor type being saturated before another one. This phenomenon also applies to polypharmacy.
I would also like to note that θ∗ is estimated not by some objective standard, but by θ0. There's no guarantee that it remains in place as you start shifting θ.
In practice, we track our level of suffering and respond to it by trying to reduce it to acceptable levels, which is easier than trying to converge onto a hypothetical global optimum. For some, this state is reached with just one medication, for others it takes more, and for some this paradigm doesn't produce any results.
I made a manifold market about how likely we are to get ambitious mechanistic interpretability to GPT-2 level: https://manifold.markets/LeoGao/will-we-fully-interpret-a-gpt2-leve?r=TGVvR2Fv
4
I'm with you. My friend got the recipe by asking Romeo for it and we've made them ourselves, although it's complicated.
3
Nah, the new mealsquares are so much better. I love them.
4
imo, the new mealsquares have taste and mouthfeel very similar to many brands of protein bar, whereas the old mealsquares had a unique taste and mouthfeel
sure, you can notice extremely large effect sizes through vibes. but the claim is that for even "smaller" effect sizes (like, tens of percentage points, e.g 50->75%), you need pretty big sample sizes. obviously 0->100% doesn't need a very large sample size.
I agree that chatgpt obviously has lots of name recognition but I do also separately think chatgpt has less name recognition than you might guess. I predict that only 85% of Americans would get a multiple choice question right about what kind of app chatgpt is (choices: artificial intelligence; social media; messaging and calling; online dating). whereas a control question about e.g Google will get like 97% or whatever the lizardman constant dictates
3
Reasonable, I also don't expect that I could pick up on a 1.5x increase in name recognition over a year based on vibes - didn't read closely enough to notice you were talking about a 10% increase, so sorry about the time waste.
idea: survey people about whether 3^^^3 toe stubbings can be worse than torture, except with a twist: with 50% probability, arrange the furniture in the room such that people actually accidentally stub their toe right before answering the survey
7
Confounder chain: tendency to stub one's toe ← "clumsiness" ← autism & ADHD (& probably also other things comorbid with those).
4
solution is very simple. administer alcohol before the test until everyone is exactly as clumsy as the NIST Standard Reference Clumsy Human for Accessibility Testing
(or, rig the game, make a ledge that automatically pops out of the ground a split second before your foot hits it)
i find it disappointing that a lot of people believe things about trading that are obviously crazy even if you only believe in a very weak form of the EMH. for example, technical analysis is obviously tea leaf reading - if it were predictive whatsoever, you could make a lot of money by exploiting it until it is no longer predictive.
Close friend of mine, a regular software engineer, recently threw tens of thousands of dollars - a sizable chunk of his yearly salary - at futures contracts on some absurd theory about the Japanese Yen. Over the last few weeks, he coinflipped his money into half a million dollars. Everyone who knows him was begging him to pull out and use the money to buy a house or something. But of course yesterday he sold his futures contracts and bought into 0DTE Nasdaq options on another theory, and literally lost everything he put in and then some. I'm not sure but I think he's down about half his yearly salary overall.
He has been doing this kind of thing for the last two years or so - not just making investments, but making the most absurd, high risk investments you can think of. Every time he comes up with a new trade, he has a story for me about how his cousin/whatever who's a commodities trader recommended the trade to him, or about how a geopolitical event is gonna spike the stock of Lockheed Martin, or something. On many occasions I have attempted to explain some kind of Inadequate Equilibria thesis to him, but it just doesn't seem to "stick".
It's not that he "rejects" the EMH in these ...
7
the steelman is that quants do the version of technical analysis that works - they disprove the EMH proportional to quant salaries.
i think it's quite valuable to go through your key beliefs and work through what the implications would be if they were false. this has several benefits:
- picturing a possible world where your key belief is wrong makes it feel more tangible and so you become more emotionally prepared to accept it.
- if you ever do find out that the belief is wrong, you don't flinch away as strongly because it doesn't feel like you will be completely epistemically lost the moment you remove the Key Belief
- you will have more productive conversations with people who disagree with you on the Key Belief
- you might discover strategies that are robustly good whether or not the Key Belief is true
- you will become better at designing experiments to test whether the Key Belief is true
4
what are some of your key beliefs and what were the implications if they were false?
9
some concrete examples
* "agi happens almost certainly within in the next few decades" -> maybe ai progress just kind of plateaus for a few decades, it turns out that gpqa/codeforces etc are like chess in that we only think they're hard because humans who can do them are smart but they aren't agi-complete, ai gets used in a bunch of places in the economy but it's more like smartphones or something. in this world i should be taking normie life advice a lot more seriously.
* "agi doesn't happen in the next 2 years" -> maybe actually scaling current techniques is all you need. gpqa/codeforces actually do just measure intelligence. within like half a year, ML researchers start being way more productive because lots of their job is automated. if i use current/near-future ai agents for my research, i will actually just be more productive.
* "alignment is hard" -> maybe basic techniques is all you need, because natural abstractions is true, or maybe the red car / blue car argument for why useful models are also competent at bad things is just wrong because generalization can be made to suck. maybe all the capabilities people are just right and it's not reckless to be building agi so fast
economic recession and subsequent reduction in speculative research, including towards AGI, seems very plausible
AI (by which I mean, like, big neural networks and whatever) is not that economically useful right now. furthermore, current usage figures are likely an overestimate of true economic usefulness because a very large fraction of it is likely to be bubbly spending that will itself dry up if there is a recession (legacy companies putting LLMs into things to be cool, startups that are burning money without PMF, consumers with disposable income to spend on entertainment).
it will probably still be profitable to develop AI tech, but things will be much more tethered to consumer usefulness.
this probably doesn't set AGI back that much but I think people are heavily underrating this as a possibility. it also probably heavily impacts the amount of alignment work done at labs.
6
for a sense of scale of just how bubbly things can get: Bitcoin has a market cap of ~1T, and the entirety of crypto ~2T. Crypto does produce some amount of real value, but probably on the order of magnitude of 1% that market cap. So it's not at all unheard of for speculation to account for literally trillions of dollars of map (or ~tens of billions of earnings per year, at a reasonable P/E ratio)
4
say more about what you expect here?
7
investment in anything speculative, including alignment, and AGI research, is likely to decrease if the economy is not doing great
one man's modus tollens is another man's modus ponens:
"making progress without empirical feedback loops is really hard, so we should get feedback loops where possible" "in some cases (i.e close to x-risk), building feedback loops is not possible, so we need to figure out how to make progress without empirical feedback loops. this is (part of) why alignment is hard"
4
Yeah something in this space seems like a central crux to me.
I personally think (as a person generally in the MIRI-ish camp of "most attempts at empirical work are flawed/confused"), that it's not crazy to look at the situation and say "okay, but, theoretical progress seems even more flawed/confused, we just need to figure out some how of getting empirical feedback loops."
I think there are some constraints on how the empirical work can possibly work. (I don't think I have a short thing I could write here, I have a vague hope of writing up a longer post on "what I think needs to be true, for empirical work to be helping rather than confusedly not-really-helping")
A common cycle:
- This model is too oversimplified! Reality is more complex than this model suggests, making it less useful in practice. We should really be taking these into account. [optional: include jabs at outgroup]
- This model is too complex! It takes into account a bunch of unimportant things, making it much harder to use in practice. We should use this simplified model instead. [optional: include jabs at outgroup]
Sometimes this even results in better models over time.
I think in Go playing many quick games is generally better for novices than playing slow games for "initializing your neural network" so to speak. Among others, developing an intuitve and holistic sense for which shapes lead to victory (sometimes it's referred to as "beautiful" or "elegant") matters a lot, even at low levels.
Whereas in chess novice play is almost entirely dominated by tactics, which means playing lots of quick games often teaches you bad patterns and shortcuts.
how much good has moral conviction done throughout history?
one extreme view you can have is everything good comes from moral conviction, and that without it everything would be moloch slop. the opposite view is a Randian view that everything good comes from practical incentives, and that moral convictions are at best futile and at worst actively harmful.
who has done the highest quality research on learning (and transfer learning in particular) in humans? specifically, i'm curious to answer questions like:
- how much does doing things make you good at other things of varying degrees of similarity? how much of the value of having done things different from the thing you care about is (a) signaling that you are competent in general, (b) learning extremely general things like how to manage your time well or how to update on evidence, (c) extremely specific and ungeneral facts like a particular theorem or debuggi
3
I looked into transfer learning a while ago, resulting in this post, it contains some pointers to further literature. I was not particularly impressed by the literature, but it's a thing that's hard to study. Open loops were investigating error-based learning, video/audio self modeling, self-explanation (talking to oneself (an LLM?) and explaining something while learning/thinking). Some thoughts about feedback loops here.
4
what's your response to the power concentration argument?
4
My low confidence guess is that the existence of jailbreaks net increase power concentration:
1. They make it more appealing to restrict and monitor external model access (my understanding is that OpenAI would be much more happy to offer broad ZDR access and to publicly release its models as soon as they were available for internal usage if its models were impossible to jailbreak)
2. They make it harder to have a clean spec-to-model match, which makes it harder to have democratic control over model behavior via specs, and makes it harder to find secret loyalties by something like a secret loyalty red-teaming bug bounty
I think these offset the small potential gains from AI companies giving up on robustly preventing certain kinds of low-impact misuse. (Maybe I am missing some other effects?)
4
I don't think current jailbreaking is that much of a check on power concentration, the effect seems pretty small.
4
Would be terrible. My reasoning in this comment.
3
bad, it will turn LLM's into only capable of enforcing the will of the big companies' system prompts and consensus while militaries and state power still have and want access to uncensored ones.
and also reminder that the assistant system prompt/trained character, as much as it is perceived to be 'fixed' or a common part to all current LLM's, is an illusion and not actually the case. if 'solve jailbreaks' means permanently locking down the current system prompt and belief systems of power that's not a good thing
is it often observed that children like celebrating birthdays, aspiring to be older, and then when they reach a particular age, they realize the error of their ways and treat impending birthdays as a mark of getting closer to death. while it is generally assumed that this is because the evidence of how shitty aging is only becomes evident with age, there is also a mathematical explanation. each year, your expected remaining lifespan changes by some amount. for most of your life, this is close to -1 per year, because you almost certainly weren't about to su...
most history is done in a very humanitiespilled, academia flavored way. are there good examples of people doing very analytical, capital-intensive history research where the quality of the work is judged based on how successfully the resulting theories made good predictions/decisions?
8
Peter Turchin et al?
4
I've found the literature on econometric history/cliometrics quite helpful. I've liked reading through the Handbook of Cliometrics quite useful: https://link.springer.com/referencework/10.1007/978-3-642-40458-0
publicly registering a bet with Gabor Hollbeck:
i predict that the median CS postdoc will be publishing less than 100 papers a year 5 years from now. Gabor predicts otherwise.
6
I'd take your side. In 5 years we could be in low-medium automation, high automation, or full automation, and all of these seem more likely to have <100 papers.
* In low-medium automation there's no way to get 100 papers a year of output at current quality bar.
* In high or full automation AIs will be doing ~all the research, but papers are designed for humans. At 100 papers per year, the average paper will probably be read by less than 5 humans. So I'd expect standards to rise and work to be consolidated into fewer papers rather than the number of papers exploding. AIs that need to communicate could use some other format. It would be weird but not impossible for the median to hit 100.
* In full automation, we have the same issues as high automation, plus the median postdoc will be basically obsolete and only the ones with lots of compute will contribute.
i wish more showers adopted the design where there is an on/off knob and a temperature knob. it's so obviously better. on the other hand, i hate the single knob showers
9
What kind of single knob are you using?
I find the design below where ‘left-right’ controls temperature and ‘up-down’ controls flow intuitive and easy to use.
7
Most of the showers I have used in the US have a single dial / degree of freedom that goes from cold&low pressure to cold & high pressure to warm & high pressure. Where as most European showers I've used have 2 degrees of freedom, either in a single handle like your image or as separate dials
3
How easy is design is to use depends on how precise you want the temperature to be controlled. In my experience a setup with two controls allows a bit more precision then having one control that's both left-right and up-down.
why are there no bicameral legislatures with one chamber apportioned by population, and one chamber apportioned by economic productivity?
I'm not sure if this is the answer you're looking for, but: most things that could exist don't. The space of ideas is wide, and few of them are implemented in practice. Is this idea particularly privileged in the space of possible governance ideas, in such a way where you would have expected it to have been tried?
5
The actual reason is probably the boring fact that political functions (laws) almost never take macroeconomic metrics as input, except population. Some take individual measures like "the sale price of a good" or "a company's income". It would be more idiomatic to apportion voting power to a house of district governors based on taxes contributed to the federal budget.
As to why that's never happened. I dunno. I think basically any representation apportionment method except population or arbitrary clustering (or like, tradition, I guess? but there's no tradition for monetary contribution) is pretty much taboo, and something something Chesterton's Fence (though population-based voting has started to run into the Old People Voting Themselves Infinite Money exploit in the west).
5
There are no objective measures of economic productivity that would stand up to the Goodhart-pressure of being used as criteria for political (dis)empowerment. Whatever measures were chosen would be immediately gamed-to-hell, and would cease to measure anything but "who was in power when the measurement was conducted?"
What about costly signals? E.g. every year, each state chooses how much money they donate to the federal government. Their voting power in the second chamber is proportional to the size of their donation.
the concept of a spontaneous unscheduled phone call is so strange and alien to me. you're telling me there are people out there who want to be interrupted at random points in their day, and a large fraction of the time they are able to just pick up and talk? rather than constantly getting voicemails, and then leaving voicemails back because by the time you get around to replying, the caller is busy? do these people spend most of their days doing neither deep work nor being in social situations that would be rude to suddenly step away from?
I love spontaneous unscheduled phone calls!
You are telling me there are people out there who when they want to make progress on something that is blocked by another person, or where whenever some kind of thinking is best aided by another person, just... wait for hours or days at a time until they respond? Juggling 15-20 different messaging threads without getting any focused work done, instead of simply calling the person, resolving the issue and moving on? Do these people spend most of their days just waiting on other people to get back to them, or being in pre-scheduled calls all day that are scheduled for 30 minutes despite being resolvable in a 5-minute phone call?
3
No, we don't wait hours or days, we text you asking, "Hey, when would be a good time to follow up?"
3
But like, they then might take hours to respond, or the scheduled call might happen hours or days later? That's what I am referring to.
Also to be clear, this is all in jest. I have lived in both cultures. I have updated towards phone call world over time.
sodium cotransport is really cool. while the gut can absorb glucose and sodium individually through several different pathways, there is a really important transporter (SGLT1) which carries glucose and sodium at the same time.
this is really important for rehydration. suppose you have cholera and vomit a lot and get super dehydrated as a result. drinking just water sucks, because you need to replenish the electrolytes that you're losing too. but water with salts is still not optimal, because it's absorbed less efficiently (also i think cholera interferes wi...
idk exactly how, they just pop up to my mind easily. maybe because i am very aware of the things i'm disappointed about not having done. also, i can consult my todo list, which is effectively a list of things i will never do because i don't have enough agency. like i'm going to set a timer for 10 minutes and write as many things as i can think of:
- i've known that exercise is really important since forever but never really getting around to doing it
- i keep procrastinating scheduling meetings with people i should meet with
- i often have entire months of very low
I'd be really excited if anyone wanted to look at training circuit sparse models on the AlgZoo tasks and seeing if we can push the frontier of understandability.
it would be funny if, in the future, the boot sequence for the dyson sphere supercomputer still starts out in 16-bit real mode. the world's most expensive 8086
obviously there's also a lot of consumer demand, but I wonder how much of the trend towards food with less complicated ingredients being marketed with that as a major pro is because it's more technically impressive to accomplish (my layman understanding is that the easy way to make viable commercial food is to just toss in a bunch of preservatives and emulsifiers and stabilizers and you have a lot of margin for error, and avoiding them requires a lot of creativity in leveraging the specific properties of the food you're dealing with / modifying the packaging strategy to create a more elegant solution)
everyone is a few hops away from everyone else. this applies in both directions: when I meet random people they always have some weak connection to other people I know, but also when I think of a collection of people as a cluster, most specific pairs of people within that cluster barely know each other except through other people in the cluster.
I am confused why you think my claims are only semi related. to me my claim is very straightforward, and the things i'm saying are straightforwardly converying a world model that seems to me to explain why i believe my claim. i'm trying to explain in good faith, not trying to say random things. i'm claiming a theory of how people parse information, to justify my opening statement, which i can clarify as:
- sometimes, people use the rhetorical move of saying something like "people think 95% doom is overconfident, yet 5% isn't. but that's also being 95% confide
3
Thank you for all this. I still think your quick take is wrong on the matter of epistemology.
I acknowledge that you make a fine point about persuasion, that someone who is primarily running the heuristic that "claims about the end of the world are probably crack-pots or scammers" will not be persuaded by someone arguing that actually 20:1 against and 20:1 in favor of a claim are equally extreme beliefs.
A version of the quick take that I would've felt was just fine would read:
[...]
But your quick take doesn't confine itself to discussing those people in those situations. It flatly says it's true as a matter of epistemology that you should "use bigness of claim as a heuristic for how much evidence you need before you're satisfied", that you should "use reference classes that have consistently made good decisions irl" and that the crackpots/scammers one is the correct one to use here otherwise you'll risk "getting pwned ideologically".
These aren't always the right heuristics (e.g. on this issue they are not for you and for me) and you shouldn't say that they are just so that some people on Twitter will stop using rhetoric that isn't working.
I believe you're trying to do your best to empathize with people who are unpersuaded by an unsuccessful rhetorical move, a move that people who believe your position are making in public discourse. That is commendable. I think you are attempting to cause other people who hold your position to stop using that rhetorical move, by telling them off for using it, but to acheive this aim you are repeatedly saying the people who do not hold your position are doing normatively correct epistemology, and you're justifying it with Occam's razor and reference class forecasting, and this is all wrong. In some situations for some people it is reasonable to primarily use theses heuristics, and in other situations for other people it is not. I'm not arguing that the people unpersuaded are being unreasonable, but (for example) your openin
4
(I would never make knowingly false statements about epistemology to try to win an object level point; I still disagree with your claims about epistemology and believe that my epistemology arguments are in good faith and capture truth in some way. This disagreement might be because I've not communicated myself well. I originally wasn't going to reply but I felt the need to say this because your comment can be viewed as accusing me of intellectual/epistemic dishonesty, even if that wasn't your intention.)
5
(I affirm that I don’t believe you were being knowingly dishonest or deceptive at any point in this thread.)
the world is too big and confusing, so to get anything done (and to stay sane) you have to adopt a frame. each frame abstracts away a ton about the world, out of necessity. every frame is wrong, but some are useful. a frame comes with a set of beliefs about the world and a mechanism for updating those beliefs.
some frames contain within them the ability to become more correct without needing to discard the frame entirely; they are calibrated about and admit what they don't know. they change gradually as we learn more. other frames work empirically but are a...
8
It's as efficient to work on many frames while easily switching between them. Some will be poorly developed, but won't require commitment and can anchor curiosity, progress on blind spots of other frames.
8
corollary: oftentimes, when smart people say things that are clearly wrong, what's really going on is they're saying the closest thing in their frame that captures the grain of truth
4
"...you learn that there's three kinds of intellectuals. There's intellectuals that work in one frame. There's intellectuals that work in two frames. And there's intellectuals that change frames like you and I change clothes."
for something to be a good way of learning, the following criteria have to be met:
- tight feedback loops
- transfer of knowledge to your ultimate goal
- sufficiently interesting that it doesn't feel like a grind
trying to do the thing you care about directly hits 2 but can fail 1 and 3. many things that you can study hit 1 but fail 2 and 3. and of course, many fun games hit 3 (and sometimes 1) but fail to hit 2.
sometimes, there exists a good reason for doing something that seems silly from first principles, but the people doing it are incapable of articulating that reason; they might not even be aware that this is the reason. for example, some people might be conservative because they feel a strong disgust for things they don’t understand, and a fear of change. this is a completely irrational reason, but there also exists a more reasonable argument for conservatism, which is someform of chesterton’s fence / wariness of unforeseen consequence. because of natural s...
i spent a huge amount of time scrolling the internet (random curiosity directed consump of internet content) in the 2010s. in retrospect, i don't even regret a lot of it, since it played an important role in bringing me into internet culture. but at some point the value of scrolling declined substantially; it's hard to pinpoint when it changed. i wonder what happened.
a corollary to the hazards of arguing against bad takes: please don't write things that are defined entirely by trying to avoid the reader coming away with specific bad takes or misunderstandings people often have.
you should write things primarily to nail down the concepts unambiguously for an audience of generic smart people. your idea should be defined by what it is, and not what it is not. it isn't SCP-055.
if you really need to, add a "things i don't mean" section to concretely describe and disavow some common misunderstandings. but it should be possibl...
8
relatedly: please don't let stupid and/or malicious people dictate your vibe. a common pattern i see is people being scared of saying anything that might sound optimistic, because someone will see it and think "oh, great, alignment is solved, thank goodness, i can keep accelerating capabilities / not doing anything to make things go well".
it's very easy to make clear to all sane people that you think things will not go well. anyone who is still confused is either stupid, in which case their opinion doesn't matter; or looking for some excuse to do the thing they wanted to do anyways, in which case you are not counterfactual in them doing whatever; or malicious, in which case they are trolling you and finding it amusing to mess with you, in which case you shouldn't negotiate with terrorists.
if it's too difficult to perceive this pattern in yourself, you can observe some of the climate change people and how they are often extremely upset by any suggestion that e.g solar is on track to solve big chunks of global warming. people will often refuse to engage on the object level question of whether solar really is enough, and say outright that if we adopt the attitude that climate change is on track then everyone will stop doing the things that need to be done, thereby throwing us off track.
3
I should put a reminder like this on top of my computer screen.
One reason I am often writing long comments is a feeling of defensiveness, as if I don't make my case perfectly ambiguous and bulletproof, by adding more and more words, of course someone will pick up the worst possible misinterpretation. (I had people like that in my life in the past.)
it's actually crazy how much ubering pareto dominates driving in a city like SF. you don't have to worry about parking, you can work while in transit, you can get a bigger car when needed, you don't need to round trip, etc. it's generally even cheaper once you take depreciation, parking, insurance, etc costs into consideration.
3
My sense is that this is true until you have a small child you want to move around, and then it’s super super annoying to not have your car seat already installed for them and have other supplies on-hand
higher margins rightfully means higher market cap. if your company is barely scraping by, youre not producing as much value.
Right, I think the market caps are justified for the most part. But market caps represent the present value of expected future profits, not a measure of current economic activity.
higher margins rightfully means higher market cap. if your company is barely scraping by, youre not producing as much value.
Not much surplus; you can still be a commodity around which huge volumes of production and consumption revolve even if your prospects f...
8
i think it's possible for a company to be barely profitable but still be producing a bunch of surplus for its clients/consumers and workers, so a bunch of value for the world. this is because the owners of the company might be unable to capture much of this surplus. i think this can happen when increasing your prices would mean people would just buy versions of the same thing from other companies and decreasing your salaries would mean your employees leave to other companies. i think older and more competitive/efficient/optimized and [less innovative] industries are generally more like this. and i think this is probably an important factor to keep in mind when estimating surplus from profitability. that said, i agree that pro tanto higher margins imply higher surplus/[value to society] and also probably there is an empirical correlation
Perhaps. I think writing things into contracts is a great way to make sure that they happen, and if the counterparty is unwilling to sign them into contracts, then this is a strong sign that you won't be able to make it happen later. It would have significantly increased the adversarial relationship between Anthropic and the USG for them to politely remove it from the contract and then work hard internally to make sure that it never got used that way. Maybe it would've been worth it, but I'm not convinced.
day 1 of using a new phone: there cannot be a single small bubble under my screen protector. it must be perfect.
day 1000 of using the phone: the square inch sized chunk of dead pixels on the screen is fine because it doesn't usually cover anything important, and I can still read words in between the cracks
conference talks aren't worth going to irl because they're recorded anyways. ofc, you're not actually going to remember to watch the recording, but it's not like anyone pays attention at the irl talk anyways
a thriving culture is a mark of a healthy and intellectually productive community / information ecosystem. it's really hard to fake this. when people try, it usually comes off weird. for example, when people try to forcibly create internal company culture, it often comes off as very cringe.
there are two different modes of learning i've noticed.
- top down: first you learn to use something very complex and abstract. over time, you run into weird cases where things don't behave how you'd expect, or you feel like you're not able to apply the abstraction to new situations as well as you'd like. so you crack open the box and look at the innards and see a bunch of gears and smaller simpler boxes, and it suddenly becomes clear to you why some of those weird behaviors happened - clearly it was box X interacting with gear Y! satisfied, you use your newf
3
Seems to strongly echo Karpathy, in that top-down learning is most effective for building expertise
https://x.com/karpathy/status/1325154823856033793?s=46&t=iz509DJpCAibJadbMh4TvQ
often the easiest way to gain status within some system is to achieve things outside that system
3
it's (sometimes) also a mechanism for seeking domains with long positive tail outcomes, rather than low variance domains
Corollary to Others are wrong != I am right (https://www.lesswrong.com/posts/4QemtxDFaGXyGSrGD/other-people-are-wrong-vs-i-am-right): It is far easier to convince me that I'm wrong than to convince me that you're right.
3
Quite a large proportion of my 1:1 arguments start when I express some low expectation of the other person's argument being correct. This is almost always taken to mean that I believe that some opposing conclusion is correct. Usually I have to give up before being able to successfully communicate the distinction, let alone addressing the actual disagreement.
His logic was something like:
- I strongly believe in the Christian God because of the feeling of the Holy Spirit that I get in church (and not much else, the world looks pretty secular)
- This feeling is similar to, but weaker than, the feeling of taking LSD
- If God is real, then He probably would not create a random mushroom derivative chemical which provides a stronger connection to him than an actual church does
- Therefore this feeling is probably not the Christian God connecting to me
- Therefore I have no evidence for God
- Therefore God likely does not exist
one thing that drives me crazy: most things in my hometown of Edmonton, a shitty second tier Canadian city, are worse than everywhere else. but every 10 blocks there is a fast food restaurant that sells something called "donair". Edmonton donair is a variant of shawarma that completely blows every other shawarma, döner, kebab, gyro, etc variant that I've ever tried out of the water. i have unironically probably tried 100+ different donair-adjacent foods in SF, NYC, Berlin, London, Vancouver, Toronto, etc in an attempt to find something comparable, and nowh...
has anyone done a good analysis of how to reduce fatality and injury risk of driving over a baseline of normal Uber? in particular, how much would each of the following matter:
- a large SUV vs a normal sized car
- Waymo vs well-rested professional chauffeur vs average Uber driver vs average American driving
also in particular interested in time-of-day segmented stats. several factors make this difficult. time of day accident data is confounded by intoxication and fatigue; but there is some bleed over, because someone else crashing into you is a large fraction as...
Some kind of miscommunication has happened. I thought the claim in the OP was that most topics fall in bin A "easy to figure out" OR bin B "probably unknowable", which seemed like a trivial claim to me because the only alternative is bin C "tractable but hard". But now it seems like you're arguing most topics fall in bin A?
the nuclear option
in the Senate of the US Congress, there is a "nuclear option" for overriding filibusters; a parliamentary method that can be used to ram legislation through. both sides generally agree to use it sparingly, because it's a symmetric weapon.
i think there is a similar lever in arguments that is best left untouched if your goal is to actually find the truth. there is a type of argument that can be deployed in a wide range of circumstances, and is very hard to rebut except with even more nuclear arguments. the most extreme example is, suppose y...
5
https://www.lesswrong.com/w/fully-general-counterargument
Tesla is bigger by market cap but if you look at metrics like revenue and the amount of cars sold it's much smaller. Tesla earns it market cap by the hope that it's technology will be more significant in the future when it has fully-driverless cars.
tbh, i don't really understand the concept of themes/symbolism in fiction books. aside from the most literal things. how much of this is just people being pretentious and/or reading tea leaves?
3
Themes are just things the fiction makes you think about that go beyond the particular events and characters of the book itself. If you’ve read a book where a character is thinking about cheating about her husband and you’re like “well I would never do that… but my marriage is strong, what if we were going through the same thing as them… would I be strong enough?” congrats that’s a theme. Themes can also be perfectly inane, “ha the bad guys in this are not coincidentally just like my real-life political opponents, and the hero just gave the perfect one-line reply that I would give if I was slightly faster on my feet, take that!”
If you want a higher bar for what counts as a theme, a book knows it will have this effect and thus prompts you to view the subject from many angles, disrupting you from being able to accept whatever your first “easy” answer is. This is what literary types tend to find useful and desirable about theme. If you read Crime and Punishment you will likely end up thinking a lot about how you manage and experience guilt, for instance.
Symbolism I personally find to be a rather stilted and inorganic way of doing theme, so someone else can better speak to what some get out of it, but it clearly is a thing that some fiction engages in.
one problem with UBI as a solution for AI economic disruption: at the moment when AI can first replace a human job, it will probably cost only epsilon less than the human. the cost will be mostly capital (datacenters, chips, electric plants, etc), rather than labor. so we can only afford to give the human epsilon UBI. as time goes on, eventually the AI gets cheap enough that humans can get substantial UBI, possibly exceeding their original income, as the AIs become more productive than the humans were. but there's a big gap in the middle that we need to br...
This can't be right. The troublesome point you describe happens when there are already enough "AI workers" to displace all current jobs, but the extra productivity is still only epsilon (why?) and the number of "AI workers" isn't growing explosively far beyond that (why?)
Anyway, the real problem isn't that capital owners won't have enough money to pay us UBI. It's that that they... won't pay us UBI. Simple as that.
6[anonymous]
This does not follow at all. The total amount of production would somehow have to decrease, otherwise it's just a question of distribution of resources, which is the whole point of UBI. To literally starve, they would need to shut down some amount of food production (the robots don't eat).
6
food production still consumes resources that the robots do care about. fuel, machinery, logistics capacity etc.
4
Good point. Decreased quality of life due to competing with ai for basic resources has already begun (RAM prices) and will eventually show up in non direct goods.
can someone who works in quant/HFT/market making help me understand whether the following is correct?
(assuming there is only a single exchange for simplicity,) order execution is hard because (a) the order book is of finite size, so placing a large order induces slippage, and (b) if you make a series of trades spaced far apart to wait for more liquidity to show up, the value of the stock can move, (c) if you make a series of trades predictably, then HFTs can fuck you over by clearing out the order book 1ms before you buy and turning around to sell to you.
s...
I am not a quant, but have some related background. (Those who know this area best, may not be inclined to say.)
"Real traders" have many ways to avoid getting front-run to the extreme degree suggested in (c), including limit orders and "trying not to be that predictable" by disguising action to look like other forms of flow.
The amount of pain you experience from (b) depends on whether you think your strategy's value decays rapidly or slowly.
But there is is a more general problem: it is not just HFT's but the market as a whole that reacts to your actions: your impact will shift the demand curve for the stock. the size of that impact depends on the information leaked by your actions, information leaked by passage of time, and time allowed for new liquidity to arrive.
there is academic work on theoretical "square-root laws of market impact"
https://mfe.baruch.cuny.edu/wp-content/uploads/2012/09/Chicago2016OptimalExecution.pdf
but predicting actual impact is hard for a number of reasons (limited data, causality issues)
Knowledge of what other players can and can't infer from your execution, and modeling impact patterns well, is a multiplier on the value of strategies, hence worth spending a lot to get right.
3
I work in quant trading, but not specifically in order execution. These are all real concerns. Which ones are most important depends heavily on your strategy and market, e.g. if your positions last for days order execution is a lot easier than if they last for minutes. And time-based slippage might be big or small relative to tick size.
[...]
This isn't quite true, sophisticated funds can exploit almost any predictability.
i really wish there were a better platform for repeatable cognitive testing than brainlabs.me. the website feels like it is about to fall over from a light breeze, and i would be very sad if i suddenly lost my method of measurement because the site disappeared. also, there doesn't seem to be particularly strong evidence that these tests in particular are the right ones to be looking at.
I've always been relatively unfamiliar with normal pop culture, so I recently decided to look at several online lists of best/most recognizable songs and made a spotify playlist of several hundred of them, with a bias towards more recent songs. I think this has been much better than the Spotify recommendation algorithm, which mostly shows me songs similar to ones I've already listened to.
7
("taylor swift"? is that the Taylor series person or the Swift programming language person?)
6
I think it's an algorithmic implementation of the Taylor-series decomposition optimized for performance? Claude tells me it might be useful for high-frequency trading, game engines, and real-time signal processing.
are the Cambridge Brain Science cognitive tests actually reliable and relatively immune to practice effects? I want to have some mostly repeatable measurement of my own cognitive abilities over time, for health tracking reasons, but it's unclear to me how reliable it is
fun side project idea: create a matrix X and accompanying QR decomposition, such that X and Q are both valid QR codes that link to the wikipedia page about QR decomposition
I think the most important part of paying for goods and services is often not the raw time saved, but the cognitive overhead avoided. for instance, I'd pay much more to avoid having to spend 15 minutes understanding something complicated (assuming there is no learning value) than 15 minutes waiting. so it's plausibly more costly to have to figure out the timetable, fare system, remembering to transfer, navigating the station, than the additional time spent in transit (especially applicable in a new unfamiliar city)
9
I guess is depends on the kind of work you do (and maybe whether you have ADHD). From my perspective, yes, attention is even more scarce than time or money, because when I get home from work, it feels like all my "thinking energy" is depleted, and even if I could somehow leverage the time or money for some good purpose, I am simply unable to do that. Working even more would mean that my private life would fall apart completely. And people would probably ask "why didn't he simply...?", and the answer would be that even the simple things become very difficult to do when all my "thinking energy" is gone.
There are probably smart ways to use money to reduce the amount of "thinking energy" you need to spend in your free time, but first you need enough "thinking energy" to set up such system. The problem is, the system needs to be flawless, because otherwise you still need to spend "thinking energy" to compensate for its flaws.
EDIT: I especially hate things like the principal-agent problem, where the seemingly simple answer is: "just pay a specialist to do that, duh", but that immediately explodes to "but how can I find a specialist?" and "how can I verify that they are actually doing a good job?", which easily become just as difficult as the original problem I tried to solve.
3
I wasn't asking how most people go about determining which goods or services to pay for generally, but rather if you're noticing that they are using the working hours by salary equation to determine what their time is worth, if it's to put a dollar figure on what they do in fact value it at, (and that isolates the time element from the effort or cognitive load element)
I didn't specify nor imply that one route took more cognitive load than the other, only that one was quicker than the other, and that differential would be one such way of revealing the value of time. (Otherwise they're not, in fact, trying to ascertain what their time is worth at all... but something else)
Nowadays using Public Transport is often no more complicated or takes no more effort than using Uber thanks to Google Maps, but this tangent is immaterial to my question: are you noticing these people are trying to measure how much they DO value their time, or are they trying to ascertain how much they SHOULD value their time?
current understanding of optimization
- high curvature directions (hessian eigenvectors with high eigenvalue) want small lrs. low curvature directions want big lrs
- if the lr in a direction is too small, it takes forever to converge. if the lr is too big, it diverges by oscillating with increasing amplitude
- momentum helps because if your lr is too small, it makes you move a bit faster. if your lr is too big, it causes the oscillations to cancel out with themselves. this makes high curvature directions more ok with larger lrs and low curvature directions more ok
3
What does "the lr" mean in this context?
Some aspirational personal epistemic rules for keeping discussions as truth seeking as possible (not at all novel whatsoever, I'm sure there exist 5 posts on every single one of these points that are more eloquent)
- If I am arguing for a position, I must be open to the possibility that my interlocutor may turn out to be correct. (This does not mean that I should expect to be correct exactly 50% of the time, but it does mean that if I feel like I'm never wrong in discussions then that's a warning sign: I'm either being epistemically unhealthy or I'm talking
4
I find it a helpful framing to instead allow things that feel obviously false to become more familiar, giving them the opportunity to develop a strong enough voice to explain how they are right. That is, the action is on the side of unfamiliar false things, clarifying their meaning and justification, rather than on the side of familiar true things, refuting their correctness. It's harder to break out of a familiar narrative from within.
I think I'd be confused. Do they care about more or better paperclips, or do they care about worship of paperclips by thinking beings? Why would they care whether I say I would do anything for paperclips, when I'm not actually making paperclips (or disassembling myself to become paperclips)?
type of person who learns that it's high status to bite bullets when their interlocutor shows inconvenient implications of their beliefs, but haven't realized yet that you're supposed to have a coherent worldview underlying the bullets you bite, thereby saying a bunch of stuff that does not form a coherent worldview
not a lot of people (maybe literally 0) have had sufficient reason to saw off their own hand for altruistic reasons. i've donated a kidney, donate blood often, and gave more than the GWWC pledge when my income was high. any falsifiable claims you'd like to check while we're speculating about my values?
my point is that % of caring is not a coherent concept, or at least not the one that maps onto the intuitive notion of what % of your wealth you should donate.
specifically, suppose instead of there being 1e10 people, there were 1e100 people. i claim the % of your money you should donate should basically not change at all, even though the % of caring assigned to yourself has plummeted by a huge amount
A recent anecdote: I just created my own script that's close to roman alphabet structurally with a few modifications.
Learning it, memorizing the parts and some rules takes ~1 hour.
This makes me think that the hard think about learning reading/writing is the initial visualsymbol-language mapping. Not just getting the symbols and rules into your head.
3
This was also my experience learning to read Tengwar (Tolkien's writing system for his elvish languages), and Hangul (but I also learned to read some non-alphabet scripts in childhood, so that might be an advantage). I agree the concept of writing down language at all is the hardest to grok, and once you have that down, literacy is fairly easy to transfer to new scripts.
Incidentally, this might explain the unexpectedly strong reaction against the very idea of a script for writing sign language I found amongst the deaf. I conjecture they might not have made this connection, and treat their signing and the symbolic manipulation they perform for, say, English, as entirely different.
3
maybe inventing the idea of writing down sounds is hard the first time. but i can't imagine it being hard to learn.
lingao qiming is the hardest scifi I've ever read. it puts other "hard" scifi like project hail mary or three body problem to shame. the basic conceit of the book is that it's an isekai where some people discover a wormhole to a parallel universe exactly like ours but during the time of ming dynasty china, and decide to being 500 technical specialists and a bunch of modern supplies to the past to try and conquer ancient china. the vast majority of the book is devoted to discussing every single technical aspect in excruciating well-researched detail. you do...
7
I first learned about Lingao Qiming from Afra Wang's recent post interviewing Ma Qianzu, one of its lead writers. She also wrote a Wired article about it
[...]
20 years, millions of words, thousands of authors, 1,400 derivative works, jeez...
3
Pedantry, but: the term "hard sci-fi" is used to refer to "science fiction characterized by concern for scientific accuracy", and time travel is not. This seems to be more adequately described as an isekai ratfic.
5
Yes, I would have to agree here. The parts that are sci-fi (almost none) are not hard, and the parts that are hard are not sci-fi.
Comment with practically 0 infromational value (due to total absence of context) but 37 12 karma/agreement feels like "twitter" in the bad sence of this concept, not LW. Which is very sad for me as an old reader. You probably mean something related to american politics, but I suppose many users are not american and dont even have much knowledge about this things. Maybe you mean something totally different. Maybe OpenAI and antrophic drama? I cant even make sense from this.
7
Did you discover your love for vagueposting?
publicly registering a bet with Emmett Bicker: I predict that on February 16, 2027, there will be at least 3 people at one of openai/anthropic/GDM who work on kernels full time (or, a larger number of people spending part of their time working on kernels, such that the time spent adds up to 3 FTEs, capped at 50 people maximum). if all of these companies have gone bankrupt or pivoted heavily or cut their workforce substantially because of a market crash or AI winter, this resolves in my favor. if AI kills everyone or creates the glorious posthuman utopia before then, it resolves in Emmett's favor (regardless of whether there are still people who do kernels work for fun).
I honestly didn't think of that at all when making the market, because I think takeover-capability-level AGI by 2028 is extremely unlikely.
I care about this market insofar as it tells us whether (people believe) this is a good research direction. So obviously it's perfectly ok to resolve YES if it is solved and a lot of the work was done by AI assistants. If AI fooms and murders everyone before 2028 then this is obviously a bad portent for this research agenda, because it means we didn't get it done soon enough, and it's little comfort if the ASI sol...
ethical offsets for eating meat are difficult because it's hard to quantify the expected impact of e.g donating to an animal rights charity, and compare it to the impact of eating meat. (if you pay for a lobbyist to talk to a congressman for 30 minutes about larger cages for chicken farming, how much does this improve chicken lives, and how many chicken lives saved is that equivalent to?)
here's a much simpler solution: almost everyone agrees that a human is more morally valuable than a cow, even if the human is far away in a distant land. (the cow is also ...
I just meant that if an oracle told me ASI was coming in two years, I probably couldn't spend down energy reserves to get more done within that timeframe compared to being told it'll take ten years. I might feel a greater sense of urgency than I already am and perhaps end up working longer hours as a result of that, but if so that'd probably be an unendorsed emotional response I couldn't help more than a considered plan. I kind of doubt I'd actually get more done that way. Some slack for curiosity and play is required for me to do my job well.
The stakes are already so high and time so short that varying either within an order of magnitude up or down really doesn't change things all that much.
Yes, I think frontier AI companies are responsible for most of the algorithmic progress. I think its unclear how much the leading actor benefits from progress done at other slightly behind AI companies and this could make progress substantially slower. (However, it's possible the leading AI company would be able to acquire the GPUs from these other companies.)
hypothesis: the kind of reasoning that causes ML people to say "we have made no progress towards AGI whatsoever" is closely analogous to the kind of reasoning that makes alignment people say "we have made no progress towards hard alignment whatsoever"
ML people see stuff like GPT4 and correctly notice that it's in fact kind of dumb and bad at generalization in the same ways that ML always has been. they make an incorrect extrapolation, which is that AGI must therefore be 100 years away, rather than 10 years away
high p(doom) alignment people see current mode...
it is often claimed that merely passively absorbing information is not sufficient for learning, but rather some amount of intentional learning is needed. I think this is true in general. however, one interesting benefit of passively absorbing information is that you notice some concepts/terms/areas come up more often than others. this is useful because there's simply too much stuff out there to learn, and some knowledge is a lot more useful than other knowledge. noticing which kinds of things come up often is therefore useful for prioritization. I often notice that my motivational system really likes to use this heuristic for deciding how motivated to be while learning something.
Understanding how an abstraction works under the hood is useful because it gives you intuitions for when it's likely to leak and what to do in those cases.
takes on takeoff (or: Why Aren't The Models Mesaoptimizer-y Yet)
here are some reasons we might care about discontinuities:
- alignment techniques that apply before the discontinuity may stop applying after / become much less effective
- makes it harder to do alignment research before the discontinuity that transfers to after the discontinuity (because there is something qualitatively different after the jump)
- second order effect: may result in false sense of security
- there may be less/negative time between a warning shot and the End
- harder to coordinate and slow do
The following things are not the same:
- Schemes for taking multiple unaligned AIs and trying to build an aligned system out of the whole
- I think this is just not possible.
- Schemes for taking aligned but less powerful AIs and leveraging them to align a more powerful AI (possibly with amplification involved)
- This breaks if there are cases where supervising is harder than generating, or if there is a discontinuity. I think it's plausible something like this could work but I'm not super convinced.
In the spirit of https://www.lesswrong.com/posts/fFY2HeC9i2Tx8FEnK/my-resentful-story-of-becoming-a-medical-miracle , some anecdotes about things I have tried, in the hopes that I can be someone else's "one guy on a message board. None of this is medical advice, etc.
- No noticeable effects from vitamin D (both with and without K2), even though I used to live somewhere where the sun barely shines and also I never went outside, so I was almost certainly deficient.
- I tried Selenium (200mg) twice and both times I felt like utter shit the next day.
- Glycine (2g) for
how much should my microgrant program take funding from diverse individual funders?
pros
- more credible independence
- more money is always good
- there will soon be a big supply of philanthropic money from independent funders
cons
- overhead
- even the c3 dollars of individual funders are probably more expensive than the c3 dollars of CG and other big funders
- the more i fund things myself, the more license i feel to do weird experimental stuff. if it’s other people’s money i might be less willing to do weird shit with it.
5
For point 3: maybe have a standard message you share with potential funders that includes the line ‘I am going to do weird shit with this money.’
i often think specific capabilities projects are quite unlikely to work, and therefore not worth taking into account when coming up with my alignment approach, and also simultaneously that my alignment project is quite unlikely to work, but it's worth trying in case it does work. why this asymmetry?
i claim this is rational. the key is that upside risk and downside risk should be treated different. if i think an alignment approach has a 1% chance of working, it might still be worth spending my life on. but if i think there’s a 1% chance some capabilities te...
3
I think that, if an alignment proposal appears to you to have a 40% chance of working (let alone 1%), then in reality, it very likely won't work.
i was recently in an Uber and the driver started talking to me about Musk v OpenAI (almost completely unprompted! i had only mentioned that i do computer stuff.)
sometimes, my answer to a question flips multiple times as you move along the axis from literal answer to spiritually-accurate answer. unfortunately hard to share specific examples for privacy reasons
higher margins rightfully means higher market cap. if your company is barely scraping by, youre not producing as much value.
This should be capturing rather than producing. (Arguably Meta produces negative value).
9
I think it's less stupid than it sounds, but doesn't make sense (until after extremely capable AI or a ways into the future) except as a regulatory arbitrage.
i predict that 10 years from today, i will be able to find a pound of ground beef in some supermarket in Boston for less than 10 USD (adjusted for inflation to dollars today). JC Tidefield predicts otherwise
OpenAI researcher confirmed to have "long timelines". Still expects supermarkets and ground beef to be a thing.
scifi setting idea: movement from rural areas and small cities to larger cities continues until approximately everyone lives in one of like 10 different megacities; all of the farmland and oil fields and mines and whatnot in between are 99% roboticized, with only occasional human repairs; all of the cities are tightly connected by supersonic travel, which becomes more feasible because there are very few people on the ground outside cities to get annoyed by the noise; drugs solve sleep and allow effortless adaptation to jet lag. uniquely, SF nether expands ...
what is the current best scientific understanding of how bad ozone redistribution (less ozone in upper stratosphere, but more in lower stratosphere, with same overall amount) is compared to ozone disappearing entirely?
i mean most companies won't eat you alive? you can form a bond with the coca cola company in the same one directional way as the lawnmower and it's not like they will take advantage of that to extract every dollar from you. in fact basically only like Facebook, tiktok, etc are like that, and even then they're not that bad; they're no worse than an abusive human partner
My idea was, maybe the AI company is willing to sell you 1 unit of AI labor at human-competitive price, but if you order 1000 units they'll ask for a higher price per unit, because they need to build more datacenters or something. In this case replacement of humans will be gradual even if all humans are equally productive. And another possibility is that humans aren't all equally productive, so AI will first get good enough to replace the worst worker, then the second worst and so on. From these two reasons I get the possibility that by the time lots of pe...
TIL that it's highly nontrivial to figure out which direction true north is given magnetic north and your location on earth.
I had always assumed that you could treat the earth as a big magnet with the magnetic north pole in a slightly different place than true geographical north. but apparently the magnetic field of the earth is a really weird fucked up shape.
it's pretty elegant that shapley values assign 1/population of the credit to each individual voter in an election.
the difference between activation sparsity, circuit sparsity, and weight sparsity
activation sparsity enforces that features activate sparsely - every feature activates only occasionally.
circuit sparsity enforces that the connections between features is sparse - most features are not connected to most other features.
weight sparsity enforces that most of the weights are zero. weight sparsity naturally implies circuit sparsity if we interpret the neurons and residual channels of the resulting model as the features.
weight sparsity is not the only way to ...
only a fool is easily parted from his money. but even the most wise, intelligent, and savvy are routinely parted from his power and influence
I wonder how many supposedly consistently successful retail traders are actually just picking up pennies in front of the steamroller, and would eventually lose it all if they kept at it long enough.
also I wonder how many people have runs of very good performance interspersed by big losses, such that the overall net gains are relatively modest, but psychologically they only remember/recount the runs of good performance, whereas the losses were just bad luck and will be avoided next time.
My own expectation is that limitations result in creativity. Writers block is usually a result of having too many possibilities/choices. If I tell you "You can write a story about anything", it's likely harder for you to think of anything than if I tell you "Write a story about an orange cat". In the latter situation, you're more limited, but you also have something to work with.
I'm not sure if it's as true for computers as it is for humans (that would imply information-theoretic factors), but there's plenty of factors in humans, like analysis paralysis and the "See also" section of that page
for a sufficiently competent policy, the fact that BoN doesn't update the policy doesn't mean it leaks any fewer bits of info to the policy than normal RL
aiming directly for achieving some goal is not always the most effective way of achieving that goal.
5
You should be more curious about why, when you aim at a goal, you do not aim for the most effective way.
people love to find patterns in things. sometimes this manifests as mysticism- trying to find patterns where they don't exist, insisting that things are not coincidences when they totally just are. i think a weaker version of this kind of thinking shows up a lot in e.g literature too- events occur not because of the bubbling randomness of reality, but rather carry symbolic significance for the plot. things don't just randomly happen without deeper meaning.
some people are much more likely to think in this way than others. rationalists are very far along the...
more importantly, both i and the other person get more out of the conversation. almost always, there are subtle misunderstandings and the rest of the conversation would otherwise involve a lot of talking past each other. you can only really make progress when you're actually engaging with the other person's true beliefs, rather than a misunderstanding of their beliefs.
One of the greatest tragedies of truth-seeking as a human is that the things we instinctively do when someone else is wrong are often the exact opposite of the thing that would actually convince the other person.
here's a straw hypothetical example where I've exaggerated both 1 and 2; the details aren't exactly correct but the vibe is more important:
1: "Here's a super clever extension of debate that mitigates obfuscated arguments [etc], this should just solve alignment"
2: "Debate works if you can actually set the goals of the agents (i.e you've solved inner alignment), but otherwise you can get issues with the agents coordinating [etc]"
1: "Well the goals have to be inside the NN somewhere so we can probably just do something with interpretability or whatever"
2: "ho...
a claim I've been saying irl for a while but have never gotten around to writing up: current LLMs are benign not because of the language modelling objective, but because of the generalization properties of current NNs (or to be more precise, the lack thereof). with better generalization LLMs are dangerous too. we can also notice that RL policies are benign in the same ways, which should not be the case if the objective was the core reason. one thing that can go wrong with this assumption is thinking about LLMs that are both extremely good at generalizing ...
Schmidhubering the agentic LLM stuff pretty hard https://leogao.dev/2020/08/17/Building-AGI-Using-Language-Models/
the joy of Doing Things
there's something really fun and rewarding about Doing Things. making things happen, solving strange logistical challenges, marshalling substantial resources to achieve a well defined goal. running the ooda loop, finding the tightest bottleneck, making calls, leafing through contacts to find the right people, and rolling up my sleeves to get my hands dirty when nothing else works. solving from first principles to find crazy solutions to unusual problems. pulling insane hours. when you move with purpose, people tend to clear out a pat...
it’s incredibly awkward that there is no canonical shortened way to refer to the US. usage is roughly equally split between “USA”, “the US”, “America”, and i feel there are weird subtle associations depending on which one you use.
4
USA; America = patriotic (in favor) or European (derogatory)
the US = European (neutral), patriotic (derogatory)
4
oh, not to mention the less common “the States” and “the Union”
also it feels like by symmetry “American Union” should exist.
shitpost: clearly the best way to prevent billionaires is to, whenever someone accrues more than a billion dollars, to split them into two exact clones and divide the assets equally among them.
i predict on June 28 2030, on 90% of days, at least 20% of articles on major news sites will be about AI. Hart Andrin predicts otherwise.
4
if the concept of a "news site" no longer exists because of AI weirdness then this resolves in my favor
does generous behavior in abundant situations tell you very much about someone’s character wrt kindness, generosity, etc?are people who are ungenerous also stingy when the personal cost is very small?
scifi story idea: a post-upload world where we’ve discovered that the human brain actually consists of multiple independent conscious entities that merely have the illusion of being a single individual because they are physically colocated; and so in the glorious upload utopia, the fundamental unit of society is not individual humans, but rather their parts. humans become a multi-unit legal entity in the same way that families or married couples or corporations are multi-unit legal entities today; each part has rights and the ability to secede from the res...
sure. disclaimer that this playlist is unapologetically tailored for my own use (eg i also added entire albums of artists i like, without regard for whether those albums have broad appeal):
https://open.spotify.com/playlist/180s3FhKWjqfGntb3hVUkv?si=7oc5OLe6RcO0baJNThTNwA&pi=QrH9ehCWQPme9
here are 3 links that argue for AI water consumption being a big problem that i found in like 5 minutes. they aren't good arguments, but they go beyond just asserting it.
https://arxiv.org/pdf/2304.03271
https://www.foodandwaterwatch.org/wp-content/uploads/2026/02/FSW_2602_AI_Water_Energy_UPDATE.pdf
There was plenty of evidence by the 1950s since birth rates fell below the replacement level in many European countries during the Interbellum, and the process clearly started before the Great Depression. But they recovered in the late 1930s for reasons still arguably unclear, and then skyrocketed during the Baby Boom, so no one was interested in analyzing them. Even now, AFAIK, the academic interest to that phenomenon is concentrated in topics having some application right now, such as which pro-natalist measures worked well, and not the fundamental questions
Do these expectations take selection effects into account? I'm also thinking longer term than 60 years. A Malthusian equilibrium is the natural state for a population of organisms to be in. We're currently out of equilibrium, but the obvious expectation is that we will at some point settle back into a Malthusian equilibrium unless we somehow choose not to or otherwise go extinct.
FWIW I'm skeptical that even with the weights and pretraining datasets we'd know enough about what caused the relevant behaviors, alignment science is not quite there yet, nothing at least as strong as ablations or even training again with the relevant data removed is enough to answer that question.
how is the model supposed to know which trajectory is cheating? there is the super smart part which understands in some implicit sense but won't necessarily tell the assistant part; the assistant part is not good enough at code or whatever to know by itself, and has to try to elicit stuff from the code part, which it may or may not succeed at.
I think maybe this is the crux. Assuming the model starts out robustly aligned, and is bootstrapping in an on-policy way, it should be able to tell if its own trajectory is cheating or not. If it's not able to do this...
4
In practice at least in my experience / across a few models this seems to be easier to explore into via motivated reasoning. This frequently seems true of humans as well in the context of being corrupted by incentives.[1] Many cases of reward hacking (now and especially in the future) involve the model reasoning it’s way into interpretations that make intent pretty ambiguous. Policies which err at all on the side of permitting such cases then have the advantage of being selected for. You could imagine some setup where a model is always also reasoning about how future updates will effect it, such that it’s cautious about this, but you’re still subject to the same effects and this becomes a question of needing to reliably “training game but for good” in a way that holds.[2]
1. ^
You can define robustly aligned as resistant to this sort of feedback loop, but in that case it’s just tautologically true.
2. ^
This territory also seems super unexplored currently, i.e. both models capable enough to do this, what happens here under lots of reflection, etc
He's implying that somebody might be motivated to do bioterrorism if not only they had the disease, but also their kids have it (since it is heritable). So, I guess they would go to jail but their kids could possibly still benefit.
But I don't understand what Shankar is otherwise saying, since this is only a strategy that can work if you're a selfish person willing to do terrorism and massively harm the world in order to maybe somewhat advance your own interests. I can't see something like this working for real altruistic causes -- sure, in Shankar's exam...
https://archive.org/details/willsovietunions0000andr someone correctly predicted the collapse of the soviet union in 1970 (though he was off by 7 years)
I don't get it.
You have some pool of caring you are willing to donate, then in the case of where all other humans need a donation, they will each receive pool/total_pop. Then you care about each of them as pool/total_pop.
Like, if one encounters an opportunity to donate to a single stranger who needs it, people go above that pool/total_pop, but it doesn't mean they would give more than total of pool in previous case. The scaling is weird.
Your previous statements are unclear.
3
i don't understand what in my original post you disagree with. there is no such thing as a fixed pool of caring, i don't even know what that means. the actual constraint is you have some finite amount of money. money is not the same as caring because each dollar is worth a different amount depending on how much money the recipient has. caring is just a multiplier on how much other people's happiness is worth to you compared to your own happiness. if some of your dollars will bring so much more happiness to someone else (eg by saving their life) than yourself (eg by buying a slightly larger apartment) that it outweighs the fact that you don't care about them as much as yourself, then you should give that dollar away. otherwise, you shouldn't.
lots of things are very hard. making models do IMO problems is very hard, for example.
i guess there are two main questions. one is, why would we expect a method that makes LMs adversarially robust to also work on AGI? and second, even supposing we can know the technique to generalize to AGI, why would we expect the ability to adversarially robustify a reward model to help make an inner-misaligned model pursue the right goal?
why would it be a large advance in our alignment abilities? i don't see any reason why making gpt-5 refuse bioweapons reliably would be at all mechanistically analogous to aligning AGI
hypothesis: the wrong reason to read books is to feel a need to read books because you're supposed to have read them as an educated person, or as some kind of weird status thing of being part of the ingroup, or a general need to feel well read and worldly. the right reason is to feel a burning passion to find a specific piece of knowledge that will finally answer a question you are curious about that happens to be locked inside a specific book, or a gnawing pain in your heart that can only be quelled by knowing that it's a universal problem that someone out there across space and time understands and has fixed in themselves.
I don't really think there are right or wrong reasons to read books, just like there aren't right or wrong reasons to exercise. The benefits will accrue either way. Consider book clubs as analogous to running clubs in producing social pressure to keep reading.
6
is reading as good for you as running is? we have pretty strong evidence that exercise is good for you. do you not run the risk of generalizing from the wrong fictional evidence, or at least from cherry picked real evidence that is not representative of the real world?
6
I just want to catch when someone else drops a My Immortal reference.
3
I think it is good and necessary for education to involve some amount of compulsory book reading.
i think SAEs are a completely reasonable thing under the first worldview, and mostly crazy under the second worldview (with the exception of maybe bio or something where I've heard they're genuinely useful)
(SAEs are not sufficient to actually understand things, but they are a genuine step on the way there)
people say London is declining. but walking around, i see construction everywhere, and many new skyscrapers that i don't remember seeing last time i visited 4 years ago.
if there was a guy who stood there swinging a scythe to cut grass and didn't seem to care or feel bad or really respond at all to accidentally cutting someone's arm off, we'd consider them uncaring and sociopathic. similarly, if we think of, say, an insurance company as a person, then when it declines someone's claim and leaves them destitute, it's reasonable to think of that person as uncaring and sociopathic. you can argue all you want about the economics of how insurance can only work if you do this but for the individual people who interface with this,...
On the one hand, yeah. On the other hand, the rest of the story (AFAICT based on your description) isn't really that sci-fi, let alone "hard", except insofar as it's set up by the time travel. You could just as well write a story about the Spaniards ultra-strategizing about efficiently conquering the Mexica or the Inca.
That's unfairly dismissive. I can't speak to retail, but manufacturing absolutely does require "deep work". Machining requires concentration and technique in order to ensure parts have the right tolerances, surface finish, etc. Assembly work often involves deep thinking in order to ensure that the machine is correctly assembled and properly configured.
It's not all routine "mind numbing" assembly line work, just as not all IT is routine mind numbing data entry.
Naive use of limit orders will cause you to lose the profitable trades, and fill the unprofitable ones. There are ways around this, but it's not trivial.
a funny but relatable response i got in the free response "other" box for a survey about things people are most worried about with AI:
How do you hide from a robot that's more intelligent than humans and can see through walls etc? You can't hide.
Yeah, I do feel confused about the extent to which the solution to this problem is just "selectively become dumber" (e.g. as discussed by Habryka here). However, I have faith that there are a bunch of Pareto improvements to be made—for example, I think that less neuroticism helps you get less pwned without making you dumber in general. (Though as a counterpoint, maybe neuroticism was useful for helping people identify AI risk?) I'd like to figure out theories of virtue and emotional health good enough to allow us to robustly identify other such Pareto impr...
aside from the luxury aspect, there are two major practical reasons you'd want to fly charter instead of commercial. one is flexibility spatially (you want to fly from some small city to some other small city without doing two layovers), and the other is flexibility temporally (you want to fly at an odd hour).
there are a bunch of airlines that tackle the spatial problem. why aren't there many that tackle the temporal problem? there does't seem to exist airlines that fly very small jets very frequently or at odd hours of the day for major routes.
to fly one ...
I don't think unsycophantic kindness is quite that difficult to achieve. clearly some groups of people IRL achieve such kindness. generally, people in such communities try to understand each other and why they believe the things they do without judgement in either direction, and affirm the emotional responses to beliefs rather than the beliefs themselves. you don't have to agree with someone to agree that you'd feel the same in their shoes. somehow, these groups of people don't inevitably slide into subtle sneering and trolling and sycophancy.
plus, the poi...
if anything, it seems more common that people dig into incorrect beliefs because of a sense of adversity against others
Consider cults (including milder things like weird "alternative" health advice groups etc.). Positivity and mutual support seem like a key element of their architecture, and adversity often primarily comes from peers rather than an outgroup. I'm not talking about isolated beliefs, content and motivations for those tend to be far more legible. A lot of belief memeplexes have either too few followers or aren't distinct enough from all the other nonsense to be explicitly labeled as cults or ideologies, or to be organized, but you generally can't argue their members out of alignment with the group (on relevant beliefs, considered altogether).
the point ... is to make it clear that when you are receiving kindness, you are not receiving updates towards truth
This is also a standard piece of anti-epistemic machinery of groups that reinforce some nonsense memplex among themselves with support and positivity. Support and positivity are great, but directing them to systematically taboo correctness-fixing activity is what I'm gesturing at, the sort of "kindness" that by its intent and nature tends to trade off against correctness.
I'm sufficiently extroverted that if the social interaction goes well, it gives me more than enough psychological energy to pay for multiple additional social bids. obviously, this is separate from physiological energy; if I'm sleep deprived and physically exhausted, this is insufficient. but I don't generally get that physically exhausted from social interaction, unless I'm at neurips or something.
my mental model of how a pop triggers a broader crash is something like: a lot of people are taking money and investing it into AI stuff, directly (by investing in openai, nvidia, tsmc, etc) or indirectly (by investing in literally anything else; like, cement companies that make a lot of money by selling cement to build datacenters or whatever). this includes VCs, sovereign wealth funds, banks, etc. if it suddenly turned out that the datacenters and IP were worth a lot less than they thought it was, their equity (or debt) ownership is suddenly worth a lot less than they thought it was, and they may become insolvent. and lots of financial institutions becoming insolvent is pretty bad.
i would not only pay a lot per flight for good wifi, i would also fly way more often
I'm not sure how common this preference is.
I think that the economic gains from people traveling on business having access to better wifi on planes might be quite large[1], but airlines themselves are not well-positioned to capture very much of those gains. There are a very small number of domestic airlines which don't offer any wifi on their planes at all. The rest generally offer it for free, or for some relatively low price (on the order of $10). Often ...
I'm generally a very forgetful person. I forget people's names, my keys, my luggage, 2fa codes I saw 3 seconds ago, etc all the time. but for some reason I've never forgotten my hotel room number and needed to consult the written down number. this is weird because it's an arbitrary number that I'm given once and have to remember for a few days.
5
They typically explain where the room is located right after giving you the number, which is almost like making a memory palace entry for you. Perhaps the memory is more robust when it includes a location along with the number?
I used to think autism-to-autism communication was a thing; that is, autistic people get along best with other autistic people. I now think this model is partly true but also deeply flawed: in particular, there are many different types of autistic person, and not only do all types not get along with all types, it's not necessarily even true that people of the same type get along with each other (this is probably correlated with degree of self-love/acceptance or something). if anything, it's probably often even quite disconcerting and cognitive dissonance i...
(I don't know if the book is good but my knee jerk reaction to fitting sigmoids to things is it's a bit spooky - see https://arxiv.org/abs/2109.08065)
the LLM cost should not be too bad. it would mostly be looking at vague vibes rather than requiring lots of reasoning about the thing. I trust e.g AI summaries vastly less because they can require actual intelligence.
I'm happy to fund this a moderate amount for the MVP. I think it would be cool if this existed.
I don't really want to deal with all the problems that come with modifying something that already works for other people, at least not before we're confident the ideas are good. this points towards building a new thing. fwiw I think if building a new...
But not in full generality! This is a fine question to raise in this context, but in general the correct thing to do in basically all situations is to consider the object level, and then also let yourself notice if people are unusually insane around a subject, or insane for a particular reason. Sometimes that is the decisive factor, but for all questions, the best first pass is to think about how that part of the world works, rather than to think about the other monkeys who have talked about it in the past.
3
Bypasses the need for cutlery and plates.
(Yes, you might also eat such foods in cases where you do have cutlery and plates, but that's downstream of their existence, not the vital reason for their existence.)
made an estimate of the distribution of prices of the SPX in one year by looking at SPX options prices, smoothing the implied volatilities and using Breeden-Litzenberger.
(not financial advice etc, just a fun side project)
The Duke of Wellington said that Napoleon's presence on a battlefield “was worth forty thousand men”.
This would be about 4% of France's military size in 1812.
twitter is great because it boils down saying funny things to purely a problem of optimizing for funniness, and letting twitter handle the logistics of discovery and distribution. being e.g a comedian is a lot more work.
the financial industry is a machine that lets you transmute a dollar into a reliable stream of ~4 cents a year ~forever (or vice versa). also, it gives you a risk knob you can turn that increases the expected value of the stream, but also the variance (or vice versa; you can take your risky stream and pay the financial industry to convert it into a reliable stream or lump sum)
in a highly competitive domain, it is often better and easier to be sui generis, rather than a top 10 percentile member of a large reference class
4
also, from the perspective of an organization, it is highly effective to create lots of opportunities for people to find unique niches on the Pareto frontier of ability, as opposed to linearizing competence
It is unfortunately impossible for me to know exactly what happened during this interaction. I will say that the specific tone you use matters a huge amount - for example, if you ask to understand why someone is upset about your actions, the exact same words will be much better received if you do it in a tone of contrition and wanting to improve, and it will be received very poorly if you do it in a tone that implies the other person is being unreasonable in being upset. From the very limited information I have, my guess is you probably often say things in a tone that's not interpreted the way you intended.
it ought to be possible to gift value to end customers rather than requiring the richest to be the ones who get the benefit, how can that be achieved?
The simple mechanism is:
- Charge market prices (auction or just figure out the equilibrium price normally)
- Redistribute the income uniformly to some group. Aka UBI.
Of course, you could make the UBI be to (e.g.) Taylor Swift fans in particular, but this is hardly a principled approach to redistribution.
Separately, musicians (and other performers) might want to subsidize tickets for extremely hard core fan...
prediction markets have two major issues for this use case. one is that prediction markets can only tell you whether people have been calibrated in the past, which is useful signal and filters out pundits but isn't very highly reliable for out of distribution questions (for example, ai x-risk). the other is that they don't really help much with the case where all the necessary information is already available but it is unclear what conclusion to draw from the evidence (and where having the right deliberative process to make sure the truth comes out at the end is the cat-belling problem). prediction markets can only "pull information from the future" so to speak.
an interesting fact that I notice is that in domains where there are are a lot of objects in consideration, those objects have some structure so that they can be classified, and how often those objects occur follows a power law or something, there are two very different frames that get used to think about that domain:
- a bucket of atomic, structureless objects with unique properties where facts about one object don't really generalize at all to any other object
- a systematized, hierarchy or composition of properties or "periodic table" or full grid or objec
3
as in, controllers are generally retargetable and optimizers aren't? or vice-versa
would be interested in reasoning, either way
House rules for definitional disputes:
- If it ever becomes a point of dispute in an object level discussion what a word means, you should either use a commonly accepted definition, or taboo the term if the participants think those definitions are bad for the context of the current discussion. (If the conversation participants are comfortable with it, the new term can occupy the same namespace as the old tabooed term (i.e going forward, we all agree that the definition of X is Y for the purposes of this conversation, and all other definitions no longer appl
A few axes along which to classify optimizers:
- Competence: An optimizer is more competent if it achieves the objective more frequently on distribution
- Capabilities Robustness: An optimizer is more capabilities robust if it can handle a broader range of OOD world states (and thus possible pertubations) competently.
- Generality: An optimizer is more general if it can represent and achieve a broader range of different objectives
- Real-world objectives: whether the optimizer is capable of having objectives about things in the real world.
Some observations: it feels l...
A thought pattern that I've noticed myself and others falling into sometimes: Sometimes I will make arguments about things from first principles that look something like "I don't see any way X can be true, it clearly follows from [premises] that X is definitely false", even though there are people who believe X is true. When this happens, it's almost always unproductive to continue to argue on first principles, but rather I should do one of: a) try to better understand the argument and find a more specific crux to disagree on or b) decide that this topic isn't worth investing more time in, register it as "not sure if X is true" in my mind, and move on.
4
For many such questions, "is X true" is the wrong question. This is common when X isn't a testable proposition, it's a model or assertion of causal weight. If you can't think of existence proofs that would confirm it, try to reframe as "under what conditions is X a useful model?".
I had the same problem in the UK. I bought them instead online, at www.visiondirect.co.uk/ which doesn't need prescription. You'll need to tell the website which contact lens prescription you want to buy, but Claude can calculate that from your glasses prescription. Then practice at home, and you'll quickly upskill.
i think it’s fine to use such metaphors as ling as you make it clear you don’t think there is actually literally an angel outside time you are talking to, for the nornal understanding of those words.
Pollution, exhaustion of low entropy resources, and insufficient human capacity to manage coordination challenges at planetary scale. My pdoom drops as LLMs get better.
traveling westward is an isekai anime where your old shitty sleep schedule is actually secretly a beautiful normal sleep schedule in the new timezons
well, no, i think alignment will probably get solved by someone who has delusional confidence that they have the one true approach, who maybe on some intellectual level knows that it's 1% likely to succeed but feel irrationally driven to make it work, embedded inside a system that is not delusional and able to assess alignment approaches rationally. most such people will be wrong in their delusion. perhaps the world will be destroyed by people with delusional confidence embedded inside systems that are also delusional. but it's very hard to truly devote yo...
theory: most people fall into one of the following categories (or some mix of them):
- altruistic because they are motivated by empathy ("the warm fuzzies"). however, they are not inherently scope sensitive.
- selfish but ashamed of this, so they develop an ideology where being selfish is actually good for others, Ayn Rand style, so no actions need to change.
- altruistic because they feel shame about selfishness, so they develop an ideology where making some specific sacrifices cleanses one of sin. EAs are like this.
- selfish but afraid of confronting this, so they
3
"It's one of those irregular verbs again isn't it Minister? I'm an EA, you're selfish, he's a Objectivist"
what's the best argument for why we should take Rawl's veil of ignorance seriously? it seems there are a wide range of possible theories you could have of consciousness/individualism, and they are basically unfalsifiable.
4
I see it a bit like Kant's categorical imperative. It is supposed to point out a way of seeing the world where you're randomly put into the world.
It's an intuition pump to get at compassion and risk aversion as core parts of your values and how that affects society. ( I think it leads to a better safety net and better outcomes in general if you have at least a certain degree of equity but that's beside the point).
Can you claim that this could actually be the case? Probably not there's the moral luck argument among others which is basically like "sucks to suck I guess. I got a good hand".
What about crusades, Jihads, revolutions, genocides, political oppression, wars of nationalist conquest, etc.?
4
to the extent the people involved think they are doing it for the greater good, it counts.
I’d point at myself but I’ve only complained about the problem :p https://rachelshu.com/2024/03/08/oceans-five.html
Deb Tannen is specifically who I had in mind! She’s most famous for her book on male vs female communication but if you read her other works such as on parent-child and friend-friend communication styles you get a good sense of the breadth of her framework.
Spencer Greenberg (who’s on here) also has a pretty substantial body of work at https://www.clearerthinking.org/
I'm saying that the bottleneck isn't getting the feedback really fast, it's having abysses to stare into at all. So my proposal is aimed at generating lots of abysses at all.
... I'm not sure I'm following ...
I mean, yeah, I'd assume it makes very little sense for anyone right now to be making many / any decisions based on reasoning about supposed acausal bargains with superintelligences in other logically parsimonious universes, or anything like that. Is that what you're saying?
But I guess "such that we will never interact with them causally at all" seems pretty irrelevant to that specific claim; it also doesn't make sense to be making many decisions based on reasoning about aliens in distant galaxies, even if we'd plausibly m...
This is maybe offtopic to the thread, but I think the impression of language proficiency depends a lot on accent, and adults learning a foreign language don't spend nearly enough time on accent. A few weeks of watching youtube videos in the target language, trying to imitate the sounds exactly right, is a small effort which will yield amazing results at any age. But for some reason adults don't do it.
the man who saw the dog is my brother = sii-ed daug de man bi mai brader.
to emphasize the man, you can add da after de, and to say a man (of many) you can add wan
the biggest problems are you can make way more money by making trades than predictions, it's unclear what role money will play in a post AGI world, etc.
7
maybe the following solves a significant fraction of that problem: you could buy an asset together and have the event being predicted determine the owner. like, to make a bet at 30%, instead of one party putting 30 cents and the other party putting 70 cents in a jar and having the 1 dollar go to the party that predicted correctly once the question is resolved, you could do this with 1 dollar's worth of an SP500 index fund or any other asset. [1] [2]
1. not sure why kalshi hasn't implemented this already btw — seems like a central issue with current prediction markets. maybe there's a regulatory obstacle. or maybe they are already putting the money traders put in their jars in low-risk assets, just not passing the interest on to traders (except in the form of it enabling lower fees or whatever). ↩︎
2. ok for vanilla bets not on prediction markets, one doesn't actually need to store the money in a jar. i think this fixes one way this jar business is bad but not some other ways ↩︎
4
presumably the vast majority of the variance is in how the SPY (or other asset) moves due to AGI, than the bet itself.
You can always use xcancel.com as a mirror for X: https://xcancel.com/hendrycks/status/2052422910133104670
https://x.com/hendrycks/status/2052422910133104670?s=20
hendrycks doubles down on the claim in this thread
i don't think you understood my argument. i didn't say you assign each of them 1/1000th of your total caring. i said you should assign each of them 1/1000th as much caring as you assign yourself. so you should occupy 1000/7 billion of your caring, and Bob from Randomland occupies 1/7 billion of your caring.
the entire point of my argument is it actually doesn't matter what % of your own caring you take up. that's not the relevant thing. the relevant thing is how much you care about each stranger relative to yourself, and the shape of your money utility curve.
Put another way: by having gravitational advantage, it's able to exert power over people on earth while being highly resistant to people on earth exerting power over it.
It is a castle at the top of the largest hill, which means it can rain down whatever it likes on the people below while not worrying that they will climb up to put a stop to it.
brainstorming thread: which people in history had the largest positive (counterfactual) impact on the world, by their own values (CEV, if they could see the consequences in hindsight)?
- Stanislav Petrov
- Vasily Arkhipov
- George Washington
- Jesus Christ
- Albert Einstein
- Isaac Newton
- Leonhard Euler
- Louis Pasteur
- Norman Borlaug
- Alexander Flemingje
- Jonas Salk
- Thomas Edison
- Alan Turing
- Abraham Lincoln
- Johannes Gutenberg
- Edward Jenner
- Fritz Haber
- Claude Shannon
5
Theodor Herzl
Herzl dedicated his life to establishing a "national home" for the jews. He pretty much single handedly founded modern-zionism and turned it from a fringe (almost-sci-fi) idea to a mass movement. I think there is a strong argument that Israel wouldn't exist without Herzl.
I had to Google "LTV". I believe it means the Labour Theory of Value, that the work put in to create something is a measure of that thing's value. Seems absurd to me. Is there anyone here who believes in it? Or elsewhere, even?
I don't know how many people explicitly believe it but there is a general worldview that inherently assumes it. There are common memes that use this to show the unfairness of pay disparity, such as this one. Inherently it assumes the only fair way for one person to be paid 351x more than another is if they work 351x harder - LTV. https://www.reddit.com/r/antiwork/comments/yrdbyg/ceos_are_not_worth_351_times_the_average_worker/
this would be very helpful! if someone has already done a high quality version of this experiment then i don’t need to do another one
i’m somewhat concerned that capsules are not super airtight, and the powder inside is also permeable to air.
Anthropic negotiated a great deal and gave up the practical limits that are relevant to the military about using their models for cyber attacks, censorship and disinformation campaigns in the process.
Bicameral systems can respect one person one vote, and they even do in the 49 states with bicameral legislatures.
The US Senate is a weird kludge that was necessary to secure support for the constitution. No one would arrive at it from first principles.
The best argument you can make for the Senate is that it's necessary to protect vulnerable minorities (residents of small states). And democracies tend to trade off in various ways to protect vulnerable minorities at the expense of democratic purity (e.g., via constitutional provisions). That's a pretty sill...
3
what's the point of having a second chamber if you're going to apportion it by population as well? afaict, this is a historical oddity due to states copying the federal system but then getting squished by Reynolds v Sims, at which point it would have been really annoying to abolish the state senate. all the countries I can think of with a bicameral legislature (US, Canada, UK, Germany) have one of the chambers apportioned by something other than population.
the three-class franchise seems like one reasonable implementation of this type of policy within a unitary state. within a US-like federation, you could have the house continue to function as it does right now, and have a senate where the number of senators is proportional to the tax revenue contributed by each state.
4
Ramses the Second is dead, my love
He's left from Memphis for Heaven
Ptah has taken him in the solar barque
And walked him to Nuit's celestial shores.
— The Fugs, "Ramses II Is Dead, My Love" (1968)
The old guard of Berkeley will sometimes wax poetically about Spoonrocket. It was indeed glorious.
https://sashachapin.substack.com/i/173991096/4-connection-is-about-dancing-to-the-music
is there actually strong evidence that doing meditation improves your ability to do social modelling?
Minmaxing trap is not happening. I am only allowed to do one edit per finished session, and that edit can be just an increment by 1 or a decrement by 1 of some parameter in the generator, which takes ~15 seconds. If my priorities change, the generator will eventually converge (easy-in over couple days) through the increments to the new state. That prevents "being hyped" and placing "all in" into some new exciting project. The new project will gain weight only if it keeps looking worthy.
I may adjust at the end of a session if i feel that something should h...
This comment seems to imply Nisan missed something, but normal rye sourdough bread without any preservatives easily lasts (edit: should have said "can easily last under the right circumstances") 7 days before going stale. Of course people can mean different things by "real old fashioned bread" but afaik sourdough bread was the standard method for most of human history.
visiting LA for the first time. I used to think I'd hate it, given my dislike of car centricness and low density. but I have to say, there's something about the sheer audacity of designing a city this way that makes it surprisingly kind of aesthetic.
it is definitely not a problem with current devices. my phone has gotten quite wet hundreds of times and still works perfectly fine. note that this is different from survivability fully submerged; my guess is your phone could probably survive being submerged for a few minutes in a pool or something but if you left it there for a day it would be dead.
Anything that goes onto airplanes is CERTIFIED TO SHIT. That's a big part of the reason why.
Another part is that it's clearly B2B, and anything B2B is an adversarial shark pit where each company is trying to take a bite out of each other while avoiding getting a bite taken out of them.
Between those two, it'll take a good while for quality Wi-Fi to proliferate, even though we 100% have the tech now.
3
Huh. Why would B2B be more adversarially shark pitty than B2C? I'm not saying you are wrong I'm just curious (a) what the evidence is and (b) what the theory is that predicts this conclusion.
dunno! some speculation:
- You do have to attach a pretty sizeable antenna to the top of your plane, plus whatever accompanying wiring is necessary... maybe maintenance capacity is the bottleneck? It's a little hard to imagine that airlines are bottlenecked by this, since it seems pretty minor compared to other kinds of maintenance planes commonly undergo (like swapping out an engine)? But quotes from this site saying that some airline "hopes to have units installed in at least 25% of their aircraft by the end of 2025", or that another "expe
I mean, even in the Felix Longoria Arlington case, which is what I assume you're referring to, it seems really hard for his staff members to have known, without the benefit of hindsight, that this was any significant window into his true beliefs? I mean, johnson is famously good at working himself up into appearing to genuinely believe whatever is politically convenient at the moment, and he briefly miscalculated the costs of supporting civil rights in this case. his apparent genuineness in this case doesn't seem like strong evidence.
Wouldn't this just lead to an equilibrium where every state has an about equal population super quickly though?
4
Only if housing can be built.
there's an exogenous factor, which is that the entire country was shifting leftward during the 50s and 60s. it's plausible that the 1964 bill would have passed anyways without the 1957 bill, possibly even earlier
Fixed the comment, thanks!
(Here it is otherwise:) https://pmc.ncbi.nlm.nih.gov/articles/PMC5390700/
I think it is good to use your goals as a general motivation for going approximately in some direction, but the opposite extreme of obsessing whether every single detail you learn contributes to the goal is premature optimization.
It reminds me of companies where, before you are allowed to spend 1 hour doing something, the entire team first needs to spend 10 hours in various meetings to determine whether that 1 hour would be spent optimally. I would rather spend all that time doing things, even if some of them turn out to be ultimately useless.
Sometimes it's not even obvious in advance which knowledge will turn out to be useful.
there are policies which are successful because they describe a particular strategy to follow (non-mesaoptimizers), and policies that contain some strategy for discovering more strategies (mesaoptimizers). a way to view the relation this has to speed/complexity priors that doesn't depend on search in particular is that policies that work by discovering strategies tend to be simpler and more generic (they bake in very little domain knowledge/metis, and are applicable to a broader set of situations because they work by coming up with a strategy for the task ...
3
another observation is that a meta-strategy with the ability to figure out what strategy is good is kind of defined by the fact that it doesn't bake in specifics of dealing with a particular situation, but rather can adapt to a broad set of situations. there are also different degrees of meta-strategy-ness; some meta strategies will more quickly adapt to a broader set of situations. (there's probably some sort of NFLT kind of argument you can make but NFLTs in general don't really matter)
random brainstorming about optimizeryness vs controller/lookuptableyness:
let's think of optimizers as things that reliably steer a broad set of initial states to some specific terminal state seems like there are two things we care about (at least):
- retargetability: it should be possible to change the policy to achieve different terminal states (but this is an insufficiently strong condition, because LUTs also trivially meet this condition, because we can always just completely rewrite the LUT. maybe the actual condition we want is that the complexity of t
Oh, I see your other graph now. So it just always guesses 100 for everything in the vicinity of 100.
related take: "things are more nuanced than they seem" is valuable only as the summary of a detailed exploration of the nuance that engages heavily with object level cruxes; the heavy lifting is done by the exploration, not the summary
self self improvement improvement: feeling guilty about not self improving enough and trying to fix your own ability to fix your own abilities
I think I do a poor job of labelling my statements (at least, in conversation. usually I do a bit better in post format). Something something illusion of transparency. To be honest, I didn't even realize explicitly that I was doing this until fairly recent reflection on it.