Popular Comments
Recent Discussion
On June 22nd, there was a “Munk Debate”, facilitated by the Canadian Aurea Foundation, on the question whether “AI research and development poses an existential threat” (you can watch it here, which I highly recommend). On stage were Yoshua Bengio and Max Tegmark as proponents and Yann LeCun and Melanie Mitchell as opponents of the central thesis. This seems like an excellent opportunity to compare their arguments and the effects they had on the audience, in particular because in the Munk Debate format, the audience gets to vote on the issue before and after the debate.
The vote at the beginning revealed 67% of the audience being pro the existential threat hypothesis and 33% against it. Interestingly, it was also asked if the listeners were prepared to change...
I wasn't able to find the full video on the site you linked, but I found it here, if anyone else has the same issue:
Most people avoid saying literally false things, especially if those could be audited, like making up facts or credentials. The reasons for this are both moral and pragmatic — being caught out looks really bad, and sustaining lies is quite hard, especially over time. Let’s call the habit of not saying things you know to be false ‘shallow honesty’[1].
Often when people are shallowly honest, they still choose what true things they say in a kind of locally act-consequentialist way, to try to bring about some outcome. Maybe something they want for themselves (e.g. convincing their friends to see a particular movie), or something they truly believe is good (e.g. causing their friend to vote for the candidate they think will be better for the country).
Either way, if you...
being able to credibly commit to doing this at appropriate times seems useful. I wouldn't want to commit to doing it at all times; becoming cooperatebot makes it rational for cooperative-but-preference-misaligned actors to exploit you. Shallow honesty seems like a good starting point for being able to say when you are attempting to be deep honest, perhaps. But for example, I would sure appreciate it if people could be less deeply honest about the path to ai capabilities. I do think the "deeply honest at the meta level" thing has some promise.
A few days ago I came upstairs to:

Me: how did you get in there?Nora: all by myself!
Either we needed to be done with the crib, which had a good chance of much less sleeping at naptime, or we needed a taller crib. This is also something we went through when Lily was little, and that time what worked was removing the bottom of the crib.
It's a basic crib, a lot like this one. The mattress sits on a metal frame, which attaches to a set of holes along the side of the crib. On it's lowest setting, the mattress is still ~6" above the floor. Which means if we remove the frame and sit the mattress on the floor, we gain ~6".

Without the mattress weighing it down, though, the crib...
at that point you should just move to something optimized for being easy to get in and out of, like a bed
yes, yes. Exactly. Isn't it much more practical to put her in a bet/mattress on the floor? That's what we do. Just using the mattress from the crib, for example.
A couple years ago, I had a great conversation at a research retreat about the cool things we could do if only we had safe, reliable amnestic drugs - i.e. drugs which would allow us to act more-or-less normally for some time, but not remember it at all later on. And then nothing came of that conversation, because as far as any of us knew such drugs were science fiction.
… so yesterday when I read Eric Neyman’s fun post My hour of memoryless lucidity, I was pretty surprised to learn that what sounded like a pretty ideal amnestic drug was used in routine surgery. A little googling suggested that the drug was probably a benzodiazepine (think valium). Which means it’s not only a great amnestic, it’s also apparently one...
it's extremely high immediate value -- it solves IP rights entirely.
It's the barbed wire for IP rights
With this article, I intend to initiate a discussion with the community on a remarkable (thought) experiment and its implications. The experiment is to conceptualize Stuart Kauffman's NK Boolean networks as a digital social communication network, which introduces a thus far unrealized method for strategic information transmission. From this premise, I deduce that such a technology would enable people to 'swarm', i.e.: engage in self-organized collective behavior without central control. Its realization could result in a powerful tool for bringing about large-scale behavior change. The concept provides a tangible connection between network topology, common knowledge and cooperation, which can improve our understanding of the logic behind prosocial behavior and morality. It also presents us with the question of how the development of such a technology should be...
Nice! I actually had this as a loose idea in the back of my mind for a while, to have a network of people connected like this and have them signal to each other their track of the day, which could be actual fun. It is a feasible use case as well. The underlying reasoning is also that (at least for me) I would be more open to adopt an idea from a person with whom you feel a shared sense of collectivity, instead of an algorithm that thinks it knows me. Intrinsically, I want such an algorithm to be wrong, for the sake of my own autonomy :)
The way I see it, th...
Do we expect future model architectures to be biased toward out-of-context reasoning (reasoning internally rather than in a chain-of-thought)? As in, what kinds of capabilities would lead companies to build models that reason less and less in token-space?
I mean, the first obvious thing would be that you are training the model to internalize some of the reasoning rather than having to pay for the additional tokens each time you want to do complex reasoning.
The thing is, I expect we'll eventually move away from just relying on transformers with scale. And so...
This posts assumes basic familiarity with Sparse Autoencoders. For those unfamiliar with this technique, we highly recommend the introductory sections of these papers.
TL;DR
Neuronpedia is a platform for mechanistic interpretability research. It was previously focused on crowdsourcing explanations of neurons, but we’ve pivoted to accelerating researchers for Sparse Autoencoders (SAEs) by hosting models, feature dashboards, data visualizations, tooling, and more.
Important Links
- Explore: The SAE research focused Neuronpedia. Current SAEs for GPT2-Small:
- Upload: Get your SAEs hosted by Neuronpedia: fill out this <5 minute application
- Participate: Join #neuronpedia on the Open Source Mech Interp Slack
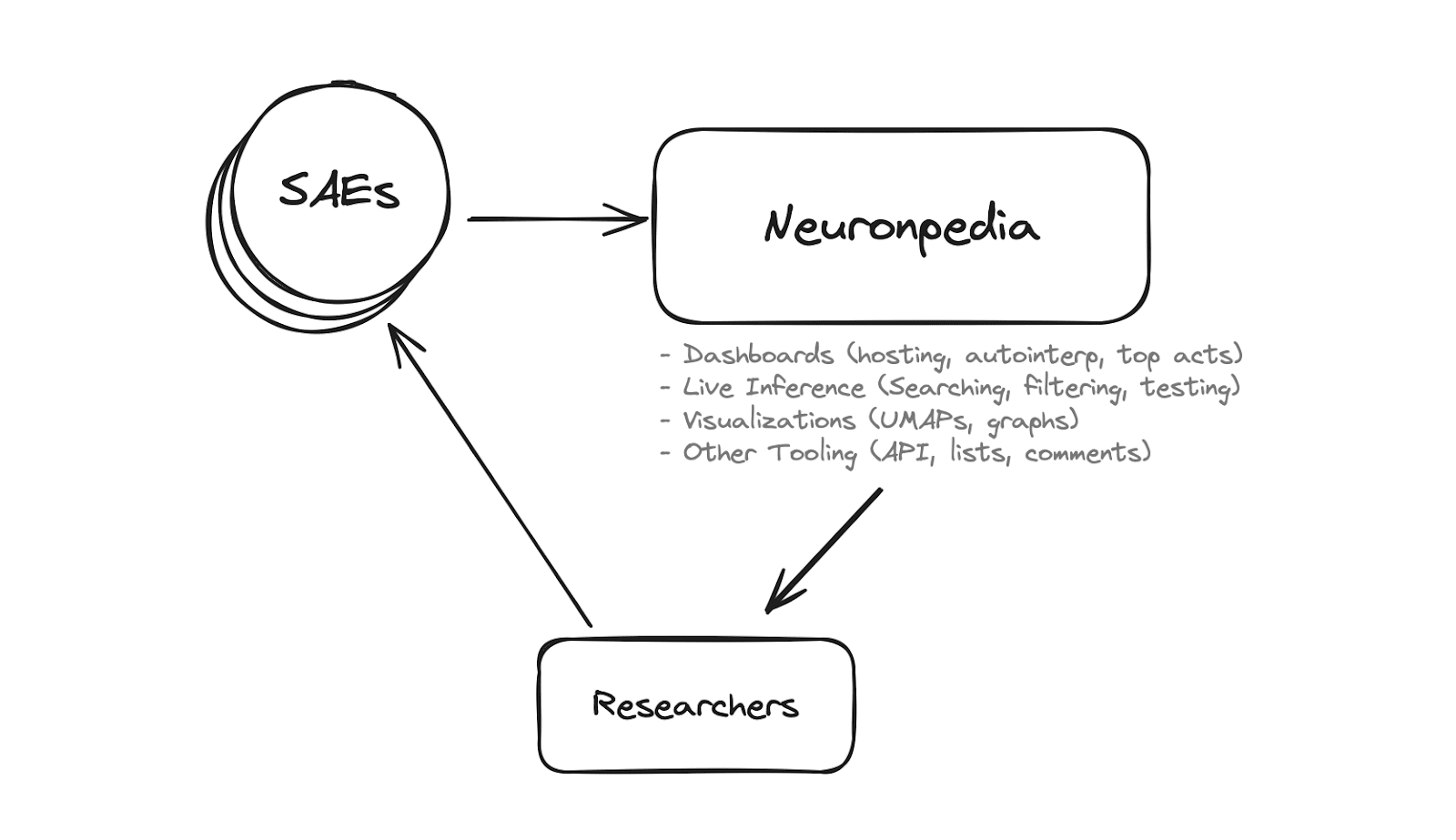
Neuronpedia has received 1 year of funding from LTFF. Johnny Lin is full-time on engineering, design, and product, while Joseph Bloom is supporting with...
Neuronpedia has an API (copying from a recent message Johnny wrote to someone else recently.):
"Docs are coming soon but it's really simple to get JSON output of any feature. just add "/api/feature/" right after "neuronpedia.org".for example, for this feature: https://neuronpedia.org/gpt2-small/0-res-jb/0
the JSON output of it is here: https://www.neuronpedia.org/api/feature/gpt2-small/0-res-jb/0
(both are GET requests so you can do it in your browser)note the additional "/api/feature/"i would prefer you not do this 100,000 times in a loop though - if you'd l...
Every few years, someone asks me what I would do to solve a Trolley Problem. Sometimes, they think I’ve never heard of it before—that I’ve never read anything about moral philosophy (e.g. Plato, Foot, Thomson, Graham)—and oh do they have a zinger for me. But for readers who are well familiar with these problems, I have some thoughts that may be new. For those that haven't done the reading, I'll provide links and some minor notes and avoid recapping in great detail.
Ask a dozen people to explain what the trolley problem is and you are likely to get a dozen variations. In this case my contact presented the scenario as a modified Bystander variation format—though far evolved away from Philippa Foot's original version in “The Problem of...
Although I somewhat agree with the comment about style, I feel that the point you're making could be received with some more enthusiasm. How well-recognized is this trolley problem fallacy? The way I see it, the energy spent on thinking about the trolley problem in isolation illustrates innate human short-sightedness and perhaps a clear limit of human intelligence as well. 'Correctly' solving one trolley problem does not prevent that you or someone else will be confronted with the next. My line of arguing is that the question of ethical decision making req...
