
Transformers Represent Belief State Geometry in their Residual Stream
64Rohin Shah
11Adam Shai
3eggsyntax
31Chris_Leong
3snewman
2AlbertGarde
2snewman
1Brent
1snewman
18Jett Janiak
16johnswentworth
11Adam Shai
4johnswentworth
5Adam Shai
1Jett Janiak
15ChrisCundy
2Adam Shai
2Ran W
9gwern
15johnswentworth
12Vladimir_Nesov
11Adam Shai
6johnswentworth
26Adam Shai
14aysja
11Adam Shai
1lillybaeum
4Alexander Gietelink Oldenziel
11habryka
9Aprillion
14Garrett Baker
12Erik Jenner
7ryan_greenblatt
5Aleksey Bykhun
2Garrett Baker
2Adam Shai
1Aprillion
7cousin_it
7Leon Lang
1Adam Shai
1Leon Lang
6eggsyntax
1Adam Shai
6ChosunOne
1Adam Shai
5Adam Shai
5dr_s
5Nina Panickssery
1Adam Shai
5Sandi
3Adam Shai
2dr_s
1Sandi
4Fiora Starlight
2Sodium
1Adam Shai
2Alexander Gietelink Oldenziel
2Moughees Ahmed
1Adam Shai
1Moughees Ahmed
2Jo Jiao
3Adam Shai
2Review Bot
2Exa Watson
4Keenan Pepper
2Nisan
3Nisan
2p.b.
2Adam Shai
3p.b.
3MondSemmel
1p.b.
2Vladimir_Nesov
2Aprillion
2Adam Shai
2Dalcy
2Adam Shai
1hoxa
1nika koghuashvili
1Laurence Aitchison
1Joel Ye
1Chris Lakin
1Steve Kommrusch
1PoignardAzur
1Daniel Munro
1Oliver Sourbut
7kave
3Adam Shai
2Oliver Sourbut
7Alexander Gietelink Oldenziel
1Oliver Sourbut
1Niclas Kupper
3Alexander Gietelink Oldenziel
3Olli Järviniemi
6Alexander Gietelink Oldenziel
1Alexander Gietelink Oldenziel
1Niclas Kupper
1ProgramCrafter
1Keenan Pepper
1Keenan Pepper
1Keenan Pepper
1tropea@gwu.edu
1Keenan Pepper
Produced while being an affiliate at PIBBSS[1]. The work was done initially with funding from a Lightspeed Grant, and then continued while at PIBBSS. Work done in collaboration with @Paul Riechers, @Lucas Teixeira, @Alexander Gietelink Oldenziel, and Sarah Marzen. Paul was a MATS scholar during some portion of this work. Thanks to Paul, Lucas, Alexander, Sarah, and @Guillaume Corlouer for suggestions on this writeup.
Update May 24, 2024: See our manuscript based on this work
Introduction
What computational structure are we building into LLMs when we train them on next-token prediction? In this post we present evidence that this structure is given by the meta-dynamics of belief updating over hidden states of the data-generating process. We'll explain exactly what this means in the post. We are excited by these results because
Theoretical Framework
In this post we will operationalize training data as being generated by a Hidden Markov Model (HMM)[2]. An HMM has a set of hidden states and transitions between them. The transitions are labeled with a probability and a token that it emits. Here are some example HMMs and data they generate.
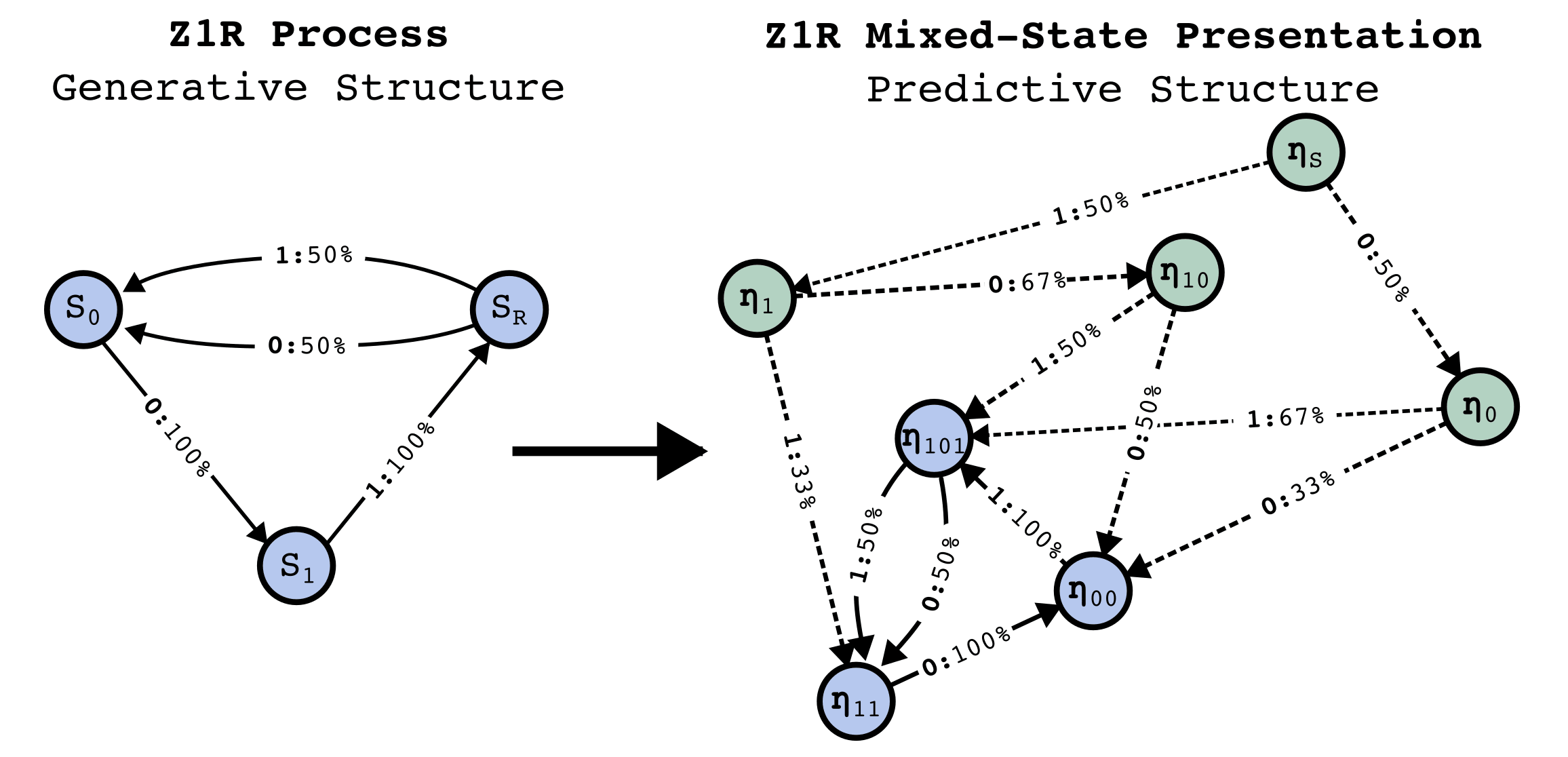
Consider the relation a transformer has to an HMM that produced the data it was trained on. This is general - any dataset consisting of sequences of tokens can be represented as having been generated from an HMM. Through the discussion of the theoretical framework, let's assume a simple HMM with the following structure, which we will call the Z1R process[3] (for "zero one random").
The Z1R process has 3 hidden states, S0,S1, and SR. Arrows of the form Sxa:p%−−−→Sy denote P(Sy,a|Sx)=p%, that the probability of moving to state Sy and emitting the token a, given that the process is in state Sx, is p%. In this way, taking transitions between the states stochastically generates binary strings of the form
...01R01R...whereRis a random 50/50 sample from {0,1}.The HMM structure is not directly given by the data it produces. Think of the difference between the list of strings this HMM emits (along with their probabilities) and the hidden structure itself[4]. Since the transformer only has access to the strings of emissions from this HMM, and not any information about the hidden states directly, if the transformer learns anything to do with the hidden structure, then it has to do the work of inferring it from the training data.
What we will show is that when they predict the next token well, transformers are doing even more computational work than inferring the hidden data generating process!
Do Transformers Learn a Model of the World?
One natural intuition would be that the transformer must represent the hidden structure of the data-generating process (ie the "world"[2]). In this case, this would mean the three hidden states and the transition probabilities between them.
This intuition often comes up (and is argued about) in discussions about what LLM's "really understand." For instance, Ilya Sutskever has said:
This type of intuition is natural, but it is not formal. Computational Mechanics is a formalism that was developed in order to study the limits of prediction in chaotic and other hard-to-predict systems, and has since expanded to a deep and rigorous theory of computational structure for any process. One of its many contributions is in providing a rigorous answer to what structures are necessary to perform optimal prediction. Interestingly, Computational Mechanics shows that prediction is substantially more complicated than generation. What this means is that we should expect a transformer trained to predict the next token well should have more structure than the data generating process!
The Structure of Belief State Updating
But what is that structure exactly?
Imagine you know, exactly, the structure of the HMM that produces
...01R...data. You go to sleep, you wake up, and you see that the HMM has emitted a1. What state is the HMM in now? It is possible to generate a1both from taking the deterministic transition S11:100%−−−−−→SR or from taking the stochastic transition SR1:50%−−−−→S0. Since the deterministic transition is twice as likely as the 50% one, the best you can do is to have some belief distribution over the current states of the HMM, in the case P([S0,S1,SR])=[13,0,23][5].1101...If now you see another
1emitted, so that in total you've seen11, you can now use your previous belief about the HMM state (read: prior), and your knowledge of the HMM structure alongside the emission you just saw (read: likelihood), in order to generate a new belief state (read: posterior). An exercise for the reader: What is the equation for updating your belief state given a previous belief state, an observed token, and the transition matrix of the ground-truth HMM?[6] In this case, there is only one way for the HMM to generate11, S11:100%−−−−−→SR1:50%−−−−→S0, so you know for certain that the HMM is now in state S0. From now on, whenever you see a new symbol, you will know exactly what state the HMM is in, and we say that you have synchronized to the HMM.In general, as you observe increasing amounts of data generated from the HMM, you can continually update your belief about the HMM state. Even in this simple example there is non-trivial structure in these belief updates. For instance, it is not always the case that seeing 2 emissions is enough to synchronize to the HMM. If instead of
11...you saw10...you still wouldn't be synchronized, since there are two different paths through the HMM that generate10.The structure of belief-state updating is given by the Mixed-State Presentation.
The Mixed-State Presentation
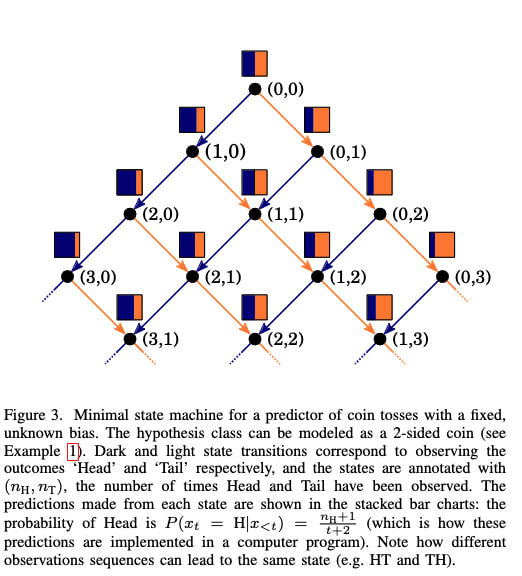
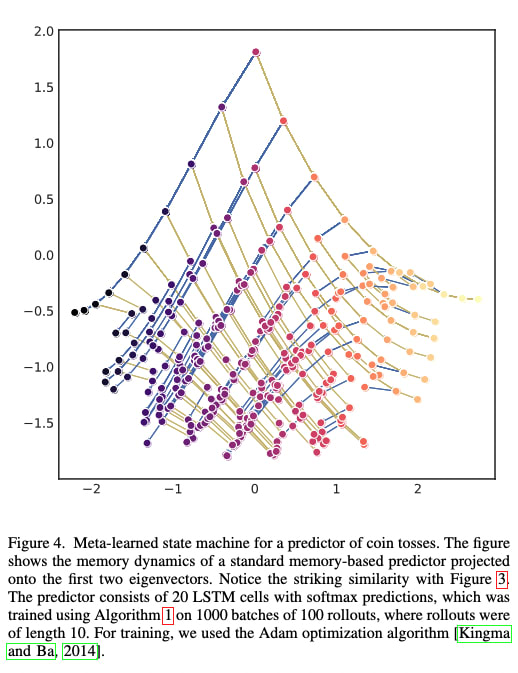
Notice that just as the data-generating structure is an HMM - at a given moment the process is in a hidden state, then, given an emission, the process move to another hidden state - so to is your belief updating! You are in some belief state, then given an emission that you observe, you move to some other belief state.
The meta-dynamics of belief state updating are formally another HMM, where the hidden states are your belief states. This meta-structure is called the Mixed-State Presentation (MSP) in Computational Mechanics.
Note that the MSP has transitory states (in green above) that lead to a recurrent set of belief states that are isomorphic to the data-generating process - this always happens, though there might be infinite transitory states. Synchronization is the process of moving through the transitory states towards convergence to the data-generating process.
A lesson from Computational Mechanics is that in order to perform optimal prediction of the next token based on observing a finite-length history of tokens, one must implement the Mixed-State Presentation (MSP). That is to say, to predict the next token well one should know what state the data-generating process is in as best as possible, and to know what state the data-generating process is in, implement the MSP.
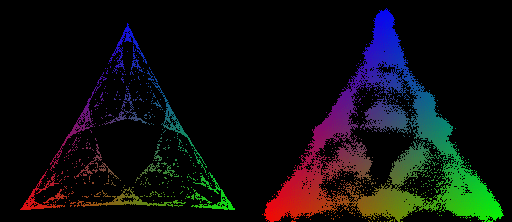
The MSP has a geometry associated with it, given by plotting the belief-state values on a simplex. In general, if our data generating process has N states, then probability distributions over those states will have N−1 degrees of freedom, and since all probabilities must be between 0 and 1, all possible belief distributions lie on an N−1 simplex. In the case of Z1R, that means a 2-simplex (i.e. a triangle). We can plot each of our possible belief states in this 2-simplex, as shown on the right below.
What we show in this post is that when we train a transformer to do next token prediction on data generated from the 3-state HMM, we can find a linear representation of the MSP geometry in the residual stream. This is surprising! Note that the points on the simplex, the belief states, are not the next token probabilities. In fact, multiple points here have literally the same next token predictions. In particular, in this case, η10, ηS, and η101, all have the same optimal next token predictions.
Another way to think about this claim is that transformers keep track of distinctions in anticipated distribution over the entire future, beyond distinctions in next token predictions, even though the transformer is only trained explicitly on next token prediction! That means the transformer is keeping track of extra information than what is necessary just for the local next token prediction.
Another way to think about our claim is that transformers perform two types of inference: one to infer the structure of the data-generating process, and another meta-inference to update it's internal beliefs over which state the data-generating process is in, given some history of finite data (ie the context window). This second type of inference can be thought of as the algorithmic or computational structure of synchronizing to the hidden structure of the data-generating process.
A final theoretical note about Computational Mechanics and the theory presented here: because Computational Mechanics is not contingent on the specifics of transformer architectures and is a well-developed first-principles framework, we can apply this framework to any optimal predictor, not just transformers[7].
Experiment and Results
Experimental Design
To repeat the question we are trying to answer:
To test our theoretical predictions, we designed an experiment with the following steps:
By controlling the structure of the training data using an HMM, we can make concrete, falsifiable predictions about the computational structure the transformer should implement during inference. Computational Mechanics, as presented in the "Theoretical Framework" section above, provides the framework for making these predictions based on the HMM's structure.
The specific HMM we chose has an MSP with an infinite fractal geometry, serving as a highly non-trivial prediction about what we should find in the transformer's residual stream activations if our theory is correct.
The Data-Generating Process and MSP
For this experiment we trained a transformer on data generated by a simple HMM, called the Mess3 Process, that has just 3 hidden states[8]. Moving between the 3 hidden states according to the emission probabilities on the edges generates strings over a 3-token vocabulary: {
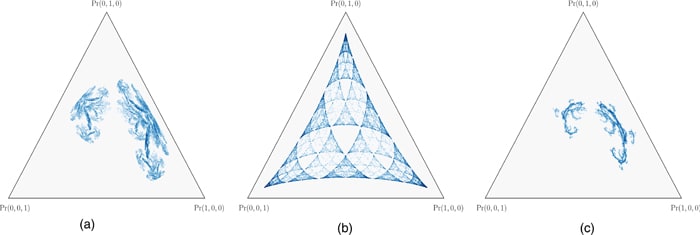
A,B,C}. The HMM for this data-generating process is given on the left of the figure below.Our approach allows us to make rigorous and testable predictions about the internal structures of transformers. In the case of this HMM, the theory (outlined above) says that transformers trained on this data should instantiate the computational structure associated with the fractal geometry shown on the right of the figure above. Every colored point in the simplex on the above right panel is a distinct belief state.
We chose the Mess3 HMM because it's MSP has an infinite fractal structure, and thus acts as a highly-nontrivial prediction about what geometry we should find in the residual stream.
The Results!
We train a transformer on data generated by the Mess3 HMM. We look in the final layer of the residual stream and find a linear 2D subspace where activations have a structure remarkably similar to that of our predicted fractal. We do this by performing standard linear regression from the residual stream activations (64 dimensional vectors) to the belief distributions (3 dimensional vectors) which associated with them in the MSP.
We can also look at how this structure emerges over training, which shows (1) that the structure we find is not trivial[9] since it doesn’t exist in detail early in training, and (2) the step-wise refinement of the transformers activations to the fractal structure we predict.
A movie of this process is shown below. Because we used Stochastic Gradient Descent for training, the 2D projection of the activations wiggles, even after training has converged. In this wiggling you can see that fractal structures remain intact.
Limitations and Next Steps
Limitations
Next Steps
PIBBSS is hiring! I wholeheartedly recommend them as an organization.
One way to conceptualize this is to think of "the world" as having some hidden structure (initially unknown to you), that emits observables. Our task is then to take sequences of observables and infer the hidden structure of the world - maybe in the service of optimal future prediction, but also maybe just because figuring out how the world works is inherently interesting. Inside of us, we have a "world model" that serves as the internal structure that let's us "understand" the hidden structure of the world. The term world model is contentious and nothing in this post depends on that concept much. However, one motivation for this work is to formalize and make concrete statements about peoples intuitions and arguments regarding neural networks and world models - which are often handwavy and ill-defined.
Technically speaking, the term process refers to a probability distribution over infinite strings of tokens, while a presentation refers to a particular HMM that produces strings according to the probability distribution. A process has an infinite number of presentations.
Any HMM defines a probability distribution over infinite sequences of the emissions.
Our initial belief distribution, in this particular case, is the uniform distribution over the 3 states of the data generating process. However this is not always the case. In general the initial belief distribution is given by the stationary distribution of the data generating HMM.
You can find the answer in section IV of this paper by @Paul Riechers.
There is work in Computational Mechanics that studies non-optimal or near-optimal prediction, and the tradeoffs one incurs when relaxing optimality. This is likely relevant to neural networks in practice. See Marzen and Crutchfield 2021 and Marzen and Crutchfield 2014.
This process is called the mess3 process, and was defined in a paper by Sarah Marzen and James Crutchfield. In the work presented we use x=0.05, alpha=0.85.
We've also run another control where we retain the ground truth fractal structure but shuffle which inputs corresponds to which points in the simplex (you can think of this as shuffling the colors in the ground truth plot). In this case when we run our regression we get that every residual stream activation is mapped to the center point of the simplex, which is the center of mass of all the points.