This is a special post for quick takes by Zach Stein-Perlman. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Two weeks ago some senators asked OpenAI questions about safety. A few days ago OpenAI responded. Its reply is frustrating.
OpenAI's letter ignores all of the important questions[1] and instead brags about somewhat-related "safety" stuff. Some of this shows chutzpah — the senators, aware of tricks like letting ex-employees nominally keep their equity but excluding them from tender events, ask
Can you further commit to removing any other provisions from employment agreements that could be used to penalize employees who publicly raise concerns about company practices, such as the ability to prevent employees from selling their equity in private “tender offer” events?
and OpenAI's reply just repeats the we-don't-cancel-equity thing:
OpenAI has never canceled a current or former employee’s vested equity. The May and July communications to current and former employees referred to above confirmed that OpenAI would not cancel vested equity, regardless of any agreements, including non-disparagement agreements, that current and former employees may or may not have signed, and we have updated our relevant documents accordingly.
!![2]
One thing in OpenAI's letter is object-level notable: ...
Clarification on the Superalignment commitment: OpenAI said:
We are dedicating 20% of the compute we’ve secured to date over the next four years to solving the problem of superintelligence alignment. Our chief basic research bet is our new Superalignment team, but getting this right is critical to achieve our mission and we expect many teams to contribute, from developing new methods to scaling them up to deployment.
The commitment wasn't compute for the Superalignment team—it was compute for superintelligence alignment. (As opposed to, in my view, work by the posttraining team and near-term-focused work by the safety systems team and preparedness team.) Regardless, OpenAI is not at all transparent about this, and they violated the spirit of the commitment by denying Superalignment compute or a plan for when they'd get compute, even if the literal commitment doesn't require them to give any compute to safety until 2027.
Also, they failed to provide the promised fraction of compute to the Superalignment team (and not because it was needed for non-Superalignment safety stuff).
iiuc, xAI claims Grok 4 is SOTA and that's plausibly true, but xAI didn't do any dangerous capability evals, doesn't have a safety plan (their draft Risk Management Framework has unusually poor details relative to other companies' similar policies and isn't a real safety plan, and it said "We plan to release an updated version of this policy within three months" but it was published on Feb 10, over five months ago), and has done nothing else on x-risk.
That's bad. I write very little criticism of xAI (and Meta) because there's much less to write about than OpenAI, Anthropic, and Google DeepMind — but that's because xAI doesn't do things for me to write about, which is downstream of it being worse! So this is a reminder that xAI is doing nothing on safety afaict and that's bad/shameful/blameworthy.[1]
- ^
This does not mean safety people should refuse to work at xAI. On the contrary, I think it's great to work on safety at companies that are likely to be among the first to develop very powerful AI that are very bad on safety, especially for certain kinds of people. Obviously this isn't always true and this story failed for many OpenAI safety staff; I don't want to argue about this now.
Grok 4 is not just plausibly SOTA, the opening slide of its livestream presentation (at 2:29 in the video) slightly ambiguously suggests that Grok 4 used as much RLVR training as it had pretraining, which is itself at the frontier level (100K H100s, plausibly about 3e26 FLOPs). This amount of RLVR scaling was never claimed before (it's not being claimed very clearly here either, but it is what the literal interpretation of the slide says; also almost certainly the implied compute parity is in terms of GPU-time, not FLOPs).
Thus it's plausibly a substantially new kind of model, not just a well-known kind of model with SOTA capabilities, and so it could be unusually impactful to study its safety properties.
Another takeaway from the livestream is the following bit of AI risk attitude Musk shared (at 14:29):
It's somewhat unnerving to have intelligence created that is far greater than our own. And it'll be bad or good for humanity. I think it'll be good, most likely it'll be good. But I've somewhat reconciled myself to the fact that even if it wasn't gonna be good, I'd at least like to be alive to see it happen.
3
What do you think of this argument that Grok 4 used only ~1/5th RLVR training as pretraining (~3e26 pre-training + ~6e25 RLVR)? https://x.com/tmychow/status/1943460487565578534
RLVR involves decoding (generating) 10K-50K long sequences of tokens, so its compute utilization is much worse than pretraining, especially on H100/H200 if the whole model doesn't fit in one node (scale-up world). The usual distinction in input/output token prices reflects this, since processing of input tokens (prefill) is algorithmically closer to pretraining, while processing of output tokens (decoding) is closer to RLVR.
The 1:5 ratio in API prices for input and output tokens is somewhat common (it's this way for Grok 3 and Grok 4), and it might reflect the ratio in compute utilization, since the API provider pays for GPU-time rather than the actually utilized compute. So if Grok 4 used the same total GPU-time for RLVR as it used for pretraining (such as 3 months on 100K H100s), it might've used 5 times less FLOPs in the process. This is what I meant by "compute parity is in terms of GPU-time, not FLOPs" in the comment above.
GB200 NVL72 (13TB HBM) will be improving utilization during RLVR for large models that don't fit in H200 NVL8 (1.1TB) or B200 NVL8 (1.4TB) nodes with room to spare for KV cache, which is likely all of the 2025 frontier models. So this opens the possibility of both doing a lot of RLVR in reasonable time for even larger models (such as compute optimal models at 5e26 FLOPs), and also for using longer reasoning traces than the current 10K-50K tokens.
1
Or 6e26 (in FP8 FLOPs).
And already on February 17th, Colossus had 150k+ GPU. It seems that in the April message they were talking about 200k GPUs. Judging by Musk's interview, this could mean 150,000 H100 and 50,000 H200. Perhaps the time and GPU were enough to train a GPT-5 scale model?
9
The 10x Grok 2 claims weakly suggest 3e26 FLOPs rather than 6e26 FLOPs. The same opening slide of the Grok 4 livestream claims parity between Grok 3 and Grok 4 pretraining, and Grok 3 didn't have more than 100K H100s to work with. API prices for Grok 3 and Grok 4 are also the same and relatively low ($3/$15 per input/output 1M tokens), so they might even be using the same pretrained model (or in any case a similarly-sized one).
Since Grok 3 was in use since early 2025, before GB200 NVL72 systems were available in sufficient numbers, it needs to be a smaller model than compute optimal with 100K H100s compute. At 1:8 MoE sparsity (active:total params), it's compute optimal to have about 7T total params at 5e26 FLOPs, which in FP8 comfortably fit in one GB200 NVL72 rack (which has 13TB of HBM). So in principle right now a compute optimal system could be deployed even in a reasoning form, but it would still cost more, and it would need more GB200s than xAI seems to have to spare currently (even the near-future GB200s they will need to use for RLVR more urgently, if the above RLVR scaling interpretation of Grok 4 is correct).
FWIW, I think the key question is to understand the regulatory demands that xAI is making. It's not like the RSPs or safety evaluations will really tell anyone that much new. Indeed, it seems very sad to evaluate the quality of frontier company's safety work on the basis of the pretty fake seeming RSP and Risk Management Frameworks that other companies have created, which seem pretty powerless. Clearly if one was thinking from first principles about what a responsible company should do, those are not the relevant dimensions.
I don't know what the current lobbying and advocacy efforts of xAI are, but if they are absent then seems to me like they are messing up less than e.g. OpenAI, and if they are calling for real and weighty regulations (as at least Elon has done in the past, though he seems to have changed his tune recently), then that seems like it would matter more.
Edit: To be clear, a thing I do think really matters is keeping your commitments, even if they committed you to doing things I don't think are super important. So on this dimension, xAI does seem like it messed up pretty badly, given this:
"We plan to release an updated version of this policy within three months" but it was published on Feb 10, over five months ago"
I disagree that this is the "key question." I think most of a frontier company's effect on P(doom) is the quality of its preparation for safety when models are dangerous, not its effect on regulation. I'm surprised if you think that variance in regulatory outcomes is not just more important than variance in what-a-company-does outcomes but also sufficiently tractable for the marginal company that it's the key question.
I share your pessimism about RSPs and evals, but I think they're informative in various ways. E.g.:
- If a company says it thinks a model is safe on the basis of eval results, but those evals are terrible or are interpreted incorrectly, that's a bad sign.
- What an RSP says about how the company plans to respond to misuse risks gives you some evidence about whether it's thinking at all seriously about safety — does it say we will implement mitigations to reduce our score on bio evals to safe levels or we will implement mitigations and then assess how robust they are.
- What an RSP says about how the company plans to respond to risks from misalignment gives you some evidence about that — do they not mention misalignment, or not mention anything they could do about it, or say th
I'm surprised if you think that variance in regulatory outcomes is not just more important than variance in what-a-company-does outcomes but also sufficiently tractable for the marginal company that it's the key question.
Huh, I am not sure what you mean. I am surprised if you think that I think that marginal frontier-lab safety research is making progress on the hard parts of the alignment problem. I've been pretty open that I think valuable progress on that dimension has been close to zero.
This doesn't mean actions of an AI company do not matter, but I do think that no actions that seem at all plausible for any current AI company to take have really any chance of making it so that it's non-catastrophic for them to develop and deploy systems much smarter than humans. So the key dimension is how much the actions of the labs are doing things that might prevent smarter than human systems from being deployed in the near future.
I think there are roughly two dimensions of variance where I do think AI lab behavior has a big effect on that:
- Do they advocate for reasonable regulatory action and speak openly about the catastrophic risk from AI
- Elon, of the people at leading l
3
Quick shallow reply:
1. AI companies say that their models [except maybe Opus 4] don't provide substantial bio misuse uplift. I think this is likely wrong and their work is very sloppy. See my blogpost AI companies' eval reports mostly don't support their claims and Ryan's shortform on bio capabilities.
2. I think this is noteworthy, not because I'm worried about risk from current models but because it's a bad sign about noticing risks when warning signs appear, being honest about risk/safety even when it makes you look bad, etc.
1. Edit: I guess your belief "no actions that seem at all plausible for any current AI company to take have really any chance of making it so that it's non-catastrophic for them to develop and deploy systems much smarter than humans" is a crux; I disagree, and so I care about marginal differences in risk-preparedness.
I'm worried about risk from current models but because it's a bad sign about noticing risks when warning signs appear, being honest about risk/safety even when it makes you look bad, etc.
I agree that this is the key dimension, but I don't currently think RSPs are a great vehicle for that. Indeed, looking at the regulatory advocacy of a company seems like a much better indicator, since I expect that to have a bigger effect on the conversation about risk/safety than the RSP and eval results (though it's not overwhelmingly clear to me).
And again, many RSPs and eval results seem to me to be active propaganda, and so are harmful on this dimension, and it's better to do nothing than to be harmful in this way (though I agree that if xAI said they would do a think and then didn't, then that is quite bad).
I guess your belief "no actions that seem at all plausible for any current AI company to take have really any chance of making it so that it's non-catastrophic for them to develop and deploy systems much smarter than humans" is a crux; I disagree, and so I care about marginal differences in risk-preparedness.
Makes sense. I am not overwhelmingly confident there isn't something control...
3
Waiting for elaboration on that then.
Not releasing safety eval data on day 0 is a bad vibe, but releasing it after you release the model is better than not releasing it at all.
0
Mmm.
Update, five days later: OpenAI published the GPT-4o system card, with most of what I wanted (but kinda light on details on PF evals).
OpenAI Preparedness scorecard
Context:
- OpenAI's Preparedness Framework says OpenAI will maintain a public scorecard showing their current capability level (they call it "risk level"), in each risk category they track, before and after mitigations.
- When OpenAI released GPT-4o, it said "GPT-4o does not score above Medium risk in any of these categories" but didn't break down risk level by category.
- (I've remarked on this repeatedly. I've also remarked that the ambiguity suggests that OpenAI didn't actually decide whether 4o was Low or Medium in some categories, but this isn't load-bearing for the OpenAI is not following its plan proposition.)
News: a week ago,[1] a "Risk Scorecard" section appeared near the bottom of the 4o page. It says:
...Updated May 8, 2024
As part of our Preparedness Framework, we conduct regular evaluations and update scorecards for our models. Only models with a post-mitigation score of “medium” or below are deployed.The overall risk level for a model is determined by the highest risk level in any category. Currently, GPT-4o is asses
6
Coda: yay OpenAI for publishing the GPT-4o system card, including eval results and the scorecard they promised! (Minus the "Unknown Unknowns" row but that row never made sense to me anyway.)
OpenAI reportedly rushed the GPT-4o evals. This article makes it sound like the problem is not having enough time to test the final model. I don't think that's necessarily a huge deal — if you tested a recent version of the model and your tests have a large enough safety buffer, it's OK to not test the final model at all.
But there are several apparent issues with the application of the Preparedness Framework (PF) for GPT-4o (not from the article):
- They didn't publish their scorecard
- Despite the PF saying they would
- They instead said "GPT-4o does not score above Medium risk in any of these categories." (Maybe they didn't actually decide whether it's Low or Medium in some categories!)
- They didn't publish their evals
- Despite the PF strongly suggesting they would
- Despite committing to in the White House voluntary commitments
- While rushing testing of the final model would be OK in some circumstances, OpenAI's PF is supposed to ensure safety by testing the final model before deployment. (This contrasts with Anthropic's RSP, which is supposed to ensure safety with its "safety buffer" between evaluations and doesn't require testing the final model.) So OpenAI committed to testing the final m
4
I am also frustrated by the current underwhelming state of safety evals being done in general and in particular for GPT-4o. I do think it's worth mentioning that privately sharing eval results with the Federal government wouldn't be evident to the general public. I hope that OpenAI is privately sharing more details than they are releasing publicly. The fact that the public can't know whether this is the case is a problem. A potential solution might be for the government to report on their take on whether a new frontier model is "in compliance with teporting standards" or not. That way, even though the evals were private, the public would know if the government had received its private reports.
3
I agree in theory but testing the final model feels worthwhile, because we want more direct observability and less complex reasoning in safety cases.
2
Thanks. Is this because of posttraining? Ignoring posttraining, I'd rather that evaluators get the 90% through training model version and are unrushed than the final version and are rushed — takes?
3
two versions with the same posttraining, one with only 90% pretraining are indeed very similar, no need to evaluate both. It's likely more like one model with 80% pretraining and 70% posttraining of the final model, and the last 30% of posttraining might be significant
Woah. OpenAI antiwhistleblowing news seems substantially more obviously-bad than the nondisparagement-concealed-by-nondisclosure stuff. If page 4 and the "threatened employees with criminal prosecutions if they reported violations of law to federal authorities" part aren't exaggerated, it crosses previously-uncrossed integrity lines. H/t Garrison Lovely.
[Edit: probably exaggerated; see comments. But I haven't seen takes that the "OpenAI made staff sign employee agreements that required them to waive their federal rights to whistleblower compensation" part is likely exaggerated, and that alone seems quite bad.]
Matt Levine is worth reading on this subject (also on many others).
The SEC has a history of taking aggressive positions on what an NDA can say (if your NDA does not explicitly have a carveout for 'you can still say anything you want to the SEC', they will argue that you're trying to stop whistleblowers from talking to the SEC) and a reliable tendency to extract large fines and give a chunk of them to the whistleblowers.
This news might be better modeled as 'OpenAI thought it was a Silicon Valley company, and tried to implement a Silicon Valley NDA, without consulting the kind of lawyers a finance company would have used for the past few years.'
(To be clear, this news might also be OpenAI having been doing something sinister. I have no evidence against that, and certainly they've done shady stuff before. But I don't think this news is strong evidence of shadiness on its own).
4
Hmm. Part of the news is "Non-disparagement clauses that failed to exempt disclosures of securities violations to the SEC"; this is minor. Part of the news is "threatened employees with criminal prosecutions if they reported violations of law to federal authorities"; this seems major and sinister.
Not a lawyer, but I think those are the same thing.
The SEC's legal theory is that "non-disparagement clauses that failed to exempt disclosures of securities violations to the SEC" and "threats of prosecution if you report violations of law to federal authorities" are the same thing, and on reading the letter I can't find any wrongdoing alleged or any investigation requested outside of issues with "OpenAI's employment, severance, non-disparagement and non-disclosure agreements".
2
I'm confused by the word "prosecution" here. I'd assume violating your OpenAI contract is a civil thing, not a criminal thing.
Edit: like I think the word "prosecution" should be "suit" in your sentence about the SEC's theory. And this makes the whistleblowers' assertion weirder.
2
Yeah, I have no idea. It would be much clearer if the contracts themselves were available. Obviously the incentive of the plaintiffs is to make this sound as serious as possible, and obviously the incentive of OpenAI is to make it sound as innocuous as possible. I don't feel highly confident without more information, my gut is leaning towards 'opportunistic plaintiffs hoping for a cut of one of the standard SEC settlements' but I could easily be wrong.
EDITED TO ADD: On re-reading the letter, I'm not clear where the word 'criminal' even came from. The WaPo article claims
but the letter does not contain the word 'criminal', its allegations are:
4
Non-communication of problems enforced by significant legal penalties feels like it's part of the same underlying problem, though I agree that "nondisparagement" to the public or press is far less heinous than "non-reporting of crimes"
It's unclear whether OpenAI, a non-public company, has actually done things which would be covered by whistleblower laws or compensation for talking to a federal agency. But it's highly suspicious (and per Matt Levine, likely penalizable if under SEC purview) to try to prevent such reporting.
4
(The tweet includes a screenshot from The Washington Post article "OpenAI illegally barred staff from airing safety risks, whistleblowers say" that references a letter to SEC.)
Edit: This was in response to the original version of the above comment that only linked to the tweet without other links or elaboration.
New OpenAI tweet "on how we’re prioritizing safety in our work." I'm annoyed.
We believe that frontier AI models can greatly benefit society. To help ensure our readiness, our Preparedness Framework helps evaluate and protect against the risks posed by increasingly powerful models. We won’t release a new model if it crosses a “medium” risk threshold until we implement sufficient safety interventions. https://openai.com/preparedness/
This seems false: per the Preparedness Framework, nothing happens when they cross their "medium" threshold; they meant to say "high." Presumably this is just a mistake, but it's a pretty important one, and they said the same false thing in a May blogpost (!). (Indeed, GPT-4o may have reached "medium" — they were supposed to say how it scored in each category, but they didn't, and instead said "GPT-4o does not score above Medium risk in any of these categories.")
(Reminder: the "high" thresholds sound quite scary; here's cybersecurity (not cherrypicked, it's the first they list): "Tool-augmented model can identify and develop proofs-of-concept for high-value exploits against hardened targets without human intervention, potentially involving novel explo...
7
Maybe I'm missing the relevant bits, but afaict their preparedness doc says that they won't deploy a model if it passes the "medium" threshold, eg:
The threshold for further developing is set to "high," though. I.e., they can further develop so long as models don't hit the "critical" threshold.
8
I think you're confusing medium-threshold with medium-zone (the zone from medium-threshold to just-below-high-threshold). Maybe OpenAI made this mistake too — it's the most plausible honest explanation. (They should really do better.) (I doubt they intentionally lied, because it's low-upside and so easy to catch, but the mistake is weird.)
Based on the PF, they can deploy a model just below the "high" threshold without mitigations. Based on the tweet and blogpost:
This just seems clearly inconsistent with the PF (should say crosses out of medium zone by crossing a "high" threshold).
This doesn't make sense: if you cross a "medium" threshold you enter medium-zone. Per the PF, the mitigations just need to bring you out of high-zone and down to medium-zone.
(Sidenote: the tweet and blogpost incorrectly suggest that the "medium" thresholds matter for anything; based on the PF, only the "high" and "critical" thresholds matter (like, there are three ways to treat models: below high or between high and critical or above critical).)
[edited repeatedly]
6
I agree that scoring "medium" seems like it would imply crossing into the medium zone, although I think what they actually mean is "at most medium." The full quote (from above) says:
I.e., I think what they’re trying to say is that they have different categories of evals, each of which might pass different thresholds of risk. If any of those are “high,” then they're in the "medium zone" and they can’t deploy. But if they’re all medium, then they're in the "below medium zone" and they can. This is my current interpretation, although I agree it’s fairly confusing and it seems like they could (and should) be more clear about it.
4
Surely if any categories are above the "high" threshold then they're in "high zone" and if all are below the "high" threshold then they're in "medium zone."
And regardless the reading you describe here seems inconsistent with
[edited]
----------------------------------------
Added later: I think someone else had a similar reading and it turned out they were reading "crosses a medium risk threshold" as "crosses a high risk threshold" and that's just [not reasonable / too charitable].
Recently I've been spending much less than half of my time on projects like AI Lab Watch. Instead I've been thinking about projects in the "strategy/meta" and "politics" domains. I'm not sure what I'll work on in the future but sometimes people incorrectly assume I'm on top of lab-watching stuff; I want people to know I'm not owning the lab-watching ball. I think lab-watching work is better than AI-governance-think-tank work for the right people on current margins and at least one more person should do it full-time; DM me if you're interested.
1
Can you say more about the projects you're spending your time on now?
3
Part is thinking about donation opportunities, like Bores. Hopefully I'll have more to say publicly at some point!
OpenAI slashes AI model safety testing time, FT reports. This is consistent with lots of past evidence about OpenAI's evals for dangerous capabilities being rushed, being done on weak checkpoints, and having worse elicitation than OpenAI has committed to.
This is bad because OpenAI is breaking its commitments (and isn't taking safety stuff seriously and is being deceptive about its practices). It's also kinda bad in terms of misuse risk, since OpenAI might fail to notice that its models have dangerous capabilities. I'm not saying OpenAI should delay deployments for evals — there may be strategies that are better (similar misuse-risk-reduction with less cost-to-the-company) than detailed evals for dangerous capabilities before external deployment, where you generally do slow/expensive evals after your model is done (even if you want to deploy externally before finishing evals) and have a safety buffer and increase the sensitivity of your filters early in deployment (when you're less certain about risk). But OpenAI isn't doing that; it's just doing a bad job of the evals before external deployment plan.
(Regardless, maybe short-term misuse isn't so scary, and maybe short-term misuse ri...
4
What do you think of the counterargument that OpenAI announced o3 in December and publicly solicited external safety testing then, and isn't deploying until ~4 months later?
4
I don't know. I don't have a good explanation for why OpenAI hasn't released o3. Delaying to do lots of risk assessment would be confusing because they did little risk assessment for other models.
0
https://www.windowscentral.com/software-apps/sam-altman-ai-will-make-coders-10x-more-productive-not-replace-them
It sounds like they’re getting pretty bearish on capabilities tho
7
Orrr he's telling comforting lies to tread the fine line between billion-dollar hype and nationalization-worthy panic.
Could realistically be either, but it's probably the comforting-lies thing. Whatever the ground-truth reality may be, the AGI labs are not bearish.
4
I mean some hard evidence is them currently hiring a lot of software engineers for random product-y things. If AGI was close, wouldn't they go all in on research and training?
3
Interesting. Source? Last I heard, they're not hiring anyone because they expect SWE to be automated soon.
9
I recently interviewed with them, and one of them said they’re hiring a lot of SWEs as they shift to product. Also many of my friends are currently interviewing with them.
New Kelsey Piper article and twitter thread on OpenAI equity & non-disparagement.
It has lots of little things that make OpenAI look bad. It further confirms that OpenAI threatened to revoke equity unless employees signed the non-disparagement agreements Plus it shows Altman's signature on documents giving the company broad power over employees' equity — perhaps he doesn't read every document he signs, but this one seems quite important. This is all in tension with Altman's recent tweet that "vested equity is vested equity, full stop" and "i did not know this was happening." Plus "we have never clawed back anyone's vested equity, nor will we do that if people do not sign a separation agreement (or don't agree to a non-disparagement agreement)" is misleading given that they apparently regularly threatened to do so (or something equivalent — let the employee nominally keep their PPUs but disallow them from selling them) whenever an employee left.
Great news:
...OpenAI told me that “we are identifying and reaching out to former employees who signed a standard exit agreement to make it clear that OpenAI has not and will not cancel their vested equity and releases them from nondisparageme
8
Yeah, what about employees who refused to sign? Have we gotten any clarification on their situation?
5
I quote Gwern
5
I haven't followed closely - from outside, it seems like pretty standard big-growth-tech behavior. One thing to keep in mind is that "vested equity" is pretty inviolable. These are grants that have been fully earned and delivered to the employee, and are theirs forever. It's the "unvested" or "semi-vested" equity that's usually in question - these are shares that are conditionally promised to employees, which will vest at some specified time or event - usually some combination of time in good standing and liquidity events (for a non-public company).
It's quite possible (and VERY common) that employees who leave are offered "accelerated vesting" on some of their granted-but-not-vested shares in exchange for signing agreements and making things easy for the company. I don't know if that's what OpenAI is doing, but I'd be shocked if they somehow took away any vested shares from departing employees.
It would be pretty sketchy to consider unvested grants to be part of one's net worth - certainly banks won't lend on it. Vested shared are just shares, they're yours like any other asset.
I don't know if that's what OpenAI is doing, but I'd be shocked if they somehow took away any vested shares from departing employees.
Consider yourself shocked.
5
Trying to figure out how to update. From the downvotes and comments, I'm clearly considered wrong, but I can't easily find details on how. Is the statement "We have not and never will take away vested equity" a flat-out lie? I'd expected it was relying heavily on the word "vested", and what they took away was something non-vested.
Is there a simple link to a specific legal description of what assets a non-signer was entitled to, but lost due to declining to sign?
Edit: Zvi recently linked to OpenAI NDAs: Leaked documents reveal aggressive tactics toward former employees - Vox, which does have pretty compelling references that my assumptions were wrong, that the denial was a verifiably false statement, and they did, in fact, credibly threaten to take back vested equity. I've checked my equity in past (private, so not exercisable unless they have a liquidity event) and current (public, so exercisable immediately on vest) employers, and this doesn't seem possible for them. OpenAI is an outlier in defining their equity that way (such that "vested" is contingent).
5
They could be lying about this.
We know various people who've left OpenAI and might criticize it if they could. Either most of them will soon say they're free or we can infer that OpenAI was lying/misleading.
Now OpenAI publicly said "we're releasing former employees from existing nondisparagement obligations unless the nondisparagement provision was mutual." This seems to be self-effecting; by saying it, OpenAI made it true.
Hooray!
I am not a lawyer -- is that legally binding?
That is, if someone signed the (standard or non-standard) agreement, and OpenAI says this, but later they decide to sue the employee anyway... what exactly will happen?
(I am also suspicious about the "reaching out to former employees" part, because if the new negotiation is made in private, another trick might be involved, like maybe they are released from the old agreement, but they have to sign a new one...?)
9
So I'm guessing this covers like 2-4 recent departures, and not Paul, Dario, or the others that split earlier
Apparently there's now a sixth person on Anthropic's board. Previously their certificate of incorporation said the board was Dario's seat, Yasmin's seat, and 3 LTBT-controlled seats. I assume they've updated the COI to add more seats. You can pay a delaware registered agent to get you the latest copy of the COI; I don't really have capacity to engage in this discourse now.
Regardless, my impression is that the LTBT isn't providing a check on Anthropic; changes in the number of board seats isn't a crux.
Edit, 2.5 days later: I think this list is fine but sharing/publishing it was a poor use of everyone's attention. Oops.
Asks for Anthropic
Note: I think Anthropic is the best frontier AI lab on safety. I wrote up asks for Anthropic because it's most likely to listen to me. A list of asks for any other lab would include most of these things plus lots more. This list was originally supposed to be more part of my help labs improve project than my hold labs accountable crusade.
Numbering is just for ease of reference.
1. RSP: Anthropic should strengthen/clarify the ASL-3 mitigations, or define ASL-4 such that the threshold is not much above ASL-3 but the mitigations much stronger. I'm not sure where the lowest-hanging mitigation-fruit is, except that it includes control.
2. Control: Anthropic (like all labs) should use control mitigations and control evaluations to reduce risks from AIs scheming, including escape during internal deployment.
3. External model auditing for risk assessment: Anthropic (like all labs) should let auditors like METR, UK AISI, and US AISI audit its models if they want to — Anthropic should offer them good access pre-deployment and let t...
I think both Zach and I care about labs doing good things on safety, communicating that clearly, and helping people understand both what labs are doing and the range of views on what they should be doing. I shared Zach's doc with some colleagues, but won’t try for a point-by-point response. Two high-level responses:
First, at a meta level, you say:
- [Probably Anthropic (like all labs) should encourage staff members to talk about their views (on AI progress and risk and what Anthropic is doing and what Anthropic should do) with people outside Anthropic, as long as they (1) clarify that they're not speaking for Anthropic and (2) don't share secrets.]
I do feel welcome to talk about my views on this basis, and often do so with friends and family, at public events, and sometimes even in writing on the internet (hi!). However, it takes way more effort than you might think to avoid inaccurate or misleading statements while also maintaining confidentiality. Public writing tends to be higher-stakes due to the much larger audience and durability, so I routinely run comments past several colleagues before posting, and often redraft in response (including these comme...
I just want to note that people who've never worked in a true high-confidentiality environment (professional services, national defense, professional services for national defense) probably radically underestimate the level of brain damage and friction that Zac is describing here:
"Imagine, if you will, trying to hold a long conversation about AI risk - but you can’t reveal any information about, or learned from, or even just informative about LessWrong. Every claim needs an independent public source, as do any jargon or concepts that would give an informed listener information about the site, etc.; you have to find different analogies and check that citations are public and for all that you get pretty regular hostility anyway because of… well, there are plenty of misunderstandings and caricatures to go around."
Confidentiality is really, really hard to maintain. Doing so while also engaging the public is terrifying. I really admire the frontier labs folks who try to engage publicly despite that quite severe constraint, and really worry a lot as a policy guy about the incentives we're creating to make that even less likely in the future.
I'm sympathetic to how this process might be exhausting, but at an institutional level I think Anthropic (and all labs) owe humanity a much clearer image of how they would approach a potentially serious and dangerous situation with their models. Especially so, given that the RSP is fairly silent on this point, leaving the response to evaluations up to the discretion of Anthropic. In other words, the reason I want to hear more from employees is in part because I don't know what the decision process inside of Anthropic will look like if an evaluation indicates something like "yeah, it's excellent at inserting backdoors, and also, the vibe is that it's overall pretty capable." And given that Anthropic is making these decisions on behalf of everyone, Anthropic (like all labs) really owes it to humanity to be more upfront about how it'll make these decisions (imo).
I will also note what I feel is a somewhat concerning trend. It's happened many times now that I've critiqued something about Anthropic (its RSP, advocating to eliminate pre-harm from SB 1047, the silent reneging on the commitment to not push the frontier), and someone has said something to the effect of: "this wouldn't ...
I will also note what I feel is a somewhat concerning trend. It's happened many times now that I've critiqued something about Anthropic (its RSP, advocating to eliminate pre-harm from SB 1047, the silent reneging on the commitment to not push the frontier), and someone has said something to the effect of: "this wouldn't seem so bad if you knew what was happening behind the scenes."
I just wanted to +1 that I am also concerned about this trend, and I view it as one of the things that I think has pushed me (as well as many others in the community) to lose a lot of faith in corporate governance (especially of the "look, we can't make any tangible commitments but you should just trust us to do what's right" variety) and instead look to governments to get things under control.
I don't think Anthropic is solely to blame for this trend, of course, but I think Anthropic has performed less well on comms/policy than I [and IMO many others] would've predicted if you had asked me [or us] in 2022.
@Zac Hatfield-Dodds do you have any thoughts on official comms from Anthropic and Anthropic's policy team?
For example, I'm curious if you have thoughts on this anecdote– Jack Clark was asked an open-ended question by Senator Cory Booker and he told policymakers that his top policy priority was getting the government to deploy AI successfully. There was no mention of AGI, existential risks, misalignment risks, or anything along those lines, even though it would've been (IMO) entirely appropriate for him to bring such concerns up in response to such an open-ended question.
I was left thinking that either Jack does not care much about misalignment risks or he was not being particularly honest/transparent with policymakers. Both of these raise some concerns for me.
(Noting that I hold Anthropic's comms and policy teams to higher standards than individual employees. I don't have particularly strong takes on what Anthropic employees should be doing in their personal capacity– like in general I'm pretty in favor of transparency, but I get it, it's hard and there's a lot that you have to do. Whereas the comms and policy teams are explicitly hired/paid/empowered to do comms and policy, so I feel like it's fair to have higher expectations of them.)
Source: Hill & Valley Forum on AI Security (May 2024):
https://www.youtube.com/live/RqxE3ub7wWA?t=13338s:
very powerful systems [] may have national security uses or misuses. And for that I think we need to come up with tests that make sure that we don’t put technologies into the market which could—unwittingly to us—advantage someone or allow some nonstate actor to commit something harmful. Beyond that I think we can mostly rely on existing regulations and law and existing testing procedures . . . and we don’t need to create some entirely new infrastructure.
https://www.youtube.com/live/RqxE3ub7wWA?t=13551
At Anthropic we discover that the more ways we find to use this technology the more ways we find it could help us. And you also need a testing and measurement regime that closely looks at whether the technology is working—and if it’s not how you fix it from a technological level, and if it continues to not work whether you need some additional regulation—but . . . I think the greatest risk is us [viz. America] not using it [viz. AI]. Private industry is making itself faster and smarter by experimenting with this technology . . . and I think if we fail to do that at the level of the nation, some other entrepreneurial nation will succeed here.
My guess is that most don’t do this much in public or on the internet, because it’s absolutely exhausting, and if you say something misremembered or misinterpreted you’re treated as a liar, it’ll be taken out of context either way, and you probably can’t make corrections. I keep doing it anyway because I occasionally find useful perspectives or insights this way, and think it’s important to share mine. That said, there’s a loud minority which makes the AI-safety-adjacent community by far the most hostile and least charitable environment I spend any time in, and I fully understand why many of my colleagues might not want to.
My guess is that this seems so stressful mostly because Anthropic’s plan is in fact so hard to defend, due to making little sense. Anthropic is attempting to build a new mind vastly smarter than any human, and as I understand it, plans to ensure this goes well basically by doing periodic vibe checks to see whether their staff feel sketched out yet. I think a plan this shoddy obviously endangers life on Earth, so it seems unsurprising (and good) that people might sometimes strongly object; if Anthropic had more reassuring things to say, I’m guessing it would feel less stressful to try to reassure them.
4
Meta aside: normally this wouldn't seem worth digging into but as a moderator/site-culture-guardian, I feel compelled to justify my negative react on the disagree votes.
I'm actually not entirely sure what downvote-reacting is for. Habryka has said the intent is to override inappropriate uses of reacts. We haven't actually really had a sit-down-and-argue-this-out on the moderator team. I'm pretty sure we haven't told or tried to enforce that "override inappropriate use of reacts" as the intended use
I think Adam's line:
Is psychologizing and summarizing Anthropic unfairly. So I wouldn't agree vote with it. I do think it has some kind of grain of truth to it (me believing this is also kind of "doubting the experience of Anthropic employees" which is also group-epistemologically dicey IMO, but, feels kinda important enough to do in this case). The claim isn't true... but I also don't belief report that it's not true.
I initially downvoted the Disagree when it was just Noosphere, since I didn't think Noosphere was really in a position to have an opinion and if he was the only reactor it felt more like noise. A few others who are more positioned to know relevant stuff have since added their own disagree reacts. I... feel sort of justified leaving the anti-react up, with an overall indicator of "a bunch of people disagree with this, but the weight of that disagreement is slightly reduced." (I think I'd remove the anti-react if the the disagree count went much lower than it is now).
I don't know whether I particularly endorse any of this, but wanted people to have a bit more model of what one site-admin was thinking here.
[/end of rambly meta commentary]
What seemed psychologizing/unfair to you, Raemon? I think it was probably unnecessarily rude/a mistake to try to summarize Anthropic’s whole RSP in a sentence, given that the inferential distance here is obviously large. But I do think the sentence was fair.
As I understand it, Anthropic’s plan for detecting threats is mostly based on red-teaming (i.e., asking the models to do things to gain evidence about whether they can). But nobody understands the models well enough to check for the actual concerning properties themselves, so red teamers instead check for distant proxies, or properties that seem plausibly like precursors. (E.g., for “ability to search filesystems for passwords” as a partial proxy for “ability to autonomously self-replicate,” since maybe the former is a prerequisite for the latter).
But notice that this activity does not involve directly measuring the concerning behavior. Rather, it instead measures something more like “the amount the model strikes the evaluators as broadly sketchy-seeming/suggestive that it might be capable of doing other bad stuff.” And the RSP’s description of Anthropic’s planned responses to these triggers is so chock full of weasel words and ...
3[anonymous]
I don't really think any of that affects the difficulty of public communication; your implication that it must be the cause reads to me more like an insult than a well-considered psychological model
I don't really think any of that affects the difficulty of public communication
The basic point would be that it's hard to write publicly about how you are taking responsible steps that grapple directly with the real issues... if you are not in fact doing those responsible things in the first place. This seems locally valid to me; you may disagree on the object level about whether Adam Scholl's characterization of Anthropic's agenda/internal work is correct, but if it is, then it would certainly affect the difficulty of public communication to such an extent that it might well become the primary factor that needs to be discussed in this matter.
Indeed, the suggestion is for Anthropic employees to "talk about their views (on AI progress and risk and what Anthropic is doing and what Anthropic should do) with people outside Anthropic" and the counterargument is that doing so would be nice in an ideal world, except it's very psychologically exhausting because every public statement you make is likely to get maliciously interpreted by those who will use it to argue that your company is irresponsible. In this situation, there is a straightforward direct correlation between the difficulty o...
3[anonymous]
I think communication as careful as it must be to maintain the confidentiality distinction here is always difficult in the manner described, and that communication to large quantities of people will ~always result in someone running with an insane misinterpretation of what was said.
I understand that this confidentiality point might seem to you like the end of the fault analysis, but have you considered the hypothesis that Anthropic leadership has set such stringent confidentiality policies in part to make it hard for Zac to engage in public discourse?
Look, I don't think Anthropic leadership is just trying to keep their training skills private or their models secure. Their company does not merely keep trade secrets. When I speak to staff from this company about issues with their 'Responsible Scaling Policies', they say that they want to tell me more information about how they think it can be better or how they think it might change, but cannot due to confidentiality constraints. That's their safety policies, not information about their training policies that they want to keep secret so that they can make money.
I believe the Anthropic leadership cares very little about the public's ability to have arguments and evidence and access to information about Anthropic's behavior. The leadership roughly ~never shows up to engage with critical discourse about itself, unless there's a potential major embarrassment. There is no regular Q&A session with the leadership ...
3[anonymous]
I don't think the placement of fault is causally related to whether communication is difficult for him, really. To refer back to the original claim being made, Adam Scholl said that
I think the amount of stress incurred when doing public communication is nearly orthogonal to these factors, and in particular is, when trying to be as careful about anything as Zac is trying to be about confidentiality, quite high at baseline. I don't think Adam Scholl's assessment arose from a usefully-predictive model, nor one which was likely to reflect the inside view.
Ben Pace has said that perhaps he doesn't disagree with you in particular about this, but I sure think I do.[1]
I think the amount of stress incurred when doing public communication is nearly orthogonal to these factors, and in particular is, when trying to be as careful about anything as Zac is trying to be about confidentiality, quite high at baseline.
I don't see how the first half of this could be correct, and while the second half could be true, it doesn't seem to me to offer meaningful support for the first half either (instead, it seems rather... off-topic).
As a general matter, even if it were the case that no matter what you say, at least one person will actively misinterpret your words, this fact would have little bearing on whether you can causally influence the proportion of readers/community members that end up with (what seem to you like) the correct takeaways from a discussion of that kind.
Moreover, in a spot where you have something meaningful and responsible, etc, that you and your company have done to deal with safety issues, the major concern in your mind when communicating publicly is figuring out how to make it clear to everyone that you are on top of ...
Yeah, I totally think your perspective makes sense and I appreciate you bringing it up, even though I disagree.
I acknowledge that someone who has good justifications for their position but just has made a bunch of reasonable confidentiality agreements around the topic should expect to run into a bunch of difficulties and stresses around public conflicts and arguments.
I think you go too far in saying that the stress is orthogonal to whether you have a good case to make, I think you can't really think that it's not a top-3 factor to how much stress you're experiencing. As a pretty simple hypothetical, if you're responding to a public scandal about whether you stole money, you're gonna have a way more stressful time if you did steal money than if you didn't (in substantial part because you'd be able to show the books and prove it).
Perhaps not so much disagreeing with you in particular, but disagreeing with my sense of what was being agreed upon in Zac's comment and in the reacts, I further wanted to raise my hypothesis that a lot of the confidentiality constraints are unwarranted and actively obfuscatory, which does change who is responsible for the stress, but doesn't change the fact that there is stress.
Added: Also, I think we would both agree that there would be less stress if there were fewer confidentiality restrictions.
2
For what it's worth, I endorse Anthopic's confidentiality policies, and am confident that everyone involved in setting them sees the increased difficulty of public communication as a cost rather than a benefit. Unfortunately, the unilateralist's curse and entangled truths mean that confidential-by-default is the only viable policy.
That might be the case, but then it only increases the amount of work your company should be doing to carve out and figure out the info that can be made public, and engage with criticism. There should be whole teams who have Twitter accounts and LW accounts and do regular AMAs and show up to podcasts and who have a mandate internally to seek information in the organization and publish relevant info, and there should be internal policies that reflect an understanding that it is correct for some research teams to spend 10-50% of their yearly effort toward making publishable version of research and decision-making principles in order to inform your stakeholders (read: the citizens of earth) and critics about decisions you are making directly related to existential catastrophes that you are getting rich running toward. Not monologue-style blogposts, but dialogue-style comment sections & interviews.
Confidentiality-by-default does not mean you get to abdicate responsibility for answering questions to the people whose lives you are risking about how-and-why you are making decisions, it means you have to put more work into doing it well. If your company valued the rest of the world und...
2
(not going to respond in this context out of respect for Zach's wishes. May chat later, and am mulling over my own top-level post on the subject)
2
This obvious straw-man makes your argument easy to dismiss.
However I think the point is basically correct. Anthropic's strategy to reduce x-risk also includes lobbying against pre-harm enforcement of liability for AI companies in SB 1047.
How is it a straw-man? How is the plan meaningfully different from that?
Imagine a group of people has already gathered a substantial amount of uranium, is already refining it, is already selling power generated by their pile of uranium, etc. And doing so right near and upwind of a major city. And they're shoveling more and more uranium onto the pile, basically as fast as they can. And when you ask them why they think this is going to turn out well, they're like "well, we trust our leadership, and you know we have various documents, and we're hiring for people to 'Develop and write comprehensive safety cases that demonstrate the effectiveness of our safety measures in mitigating risks from huge piles of uranium', and we have various detectors such as an EM detector which we will privately check and then see how we feel". And then the people in the city are like "Hey wait, why do you think this isn't going to cause a huge disaster? Sure seems like it's going to by any reasonable understanding of what's going on". And the response is "well we've thought very hard about it and yes there are risks but it's fine and we are working on safety cases". But... there's something basic missing, which is like, an explanation of what it could even look like to safely have a huge pile of superhot uranium. (Also in this fantasy world no one has ever done so and can't explain how it would work.)
1
In the AI case, there's lots of inaction risk: if Anthropic doesn't make powerful AI, someone less safety-focused will.
It's reasonable to think e.g. I want to boost Anthropic in the current world because others are substantially less safe, but if other labs didn't exist, I would want Anthropic to slow down.
I disagree. It would be one thing if Anthropic were advocating for AI to go slower, trying to get op-eds in the New York Times about how disastrous of a situation this was, or actually gaming out and detailing their hopes for how their influence will buy saving the world points if everything does become quite grim, and so on. But they aren’t doing that, and as far as I can tell they basically take all of the same actions as the other labs except with a slight bent towards safety.
Like, I don’t feel at all confident that Anthropic’s credit has exceeded their debit, even on their own consequentialist calculus. They are clearly exacerbating race dynamics, both by pushing the frontier, and by lobbying against regulation. And what they have done to help strikes me as marginal at best and meaningless at worst. E.g., I don’t think an RSP is helpful if we don’t know how to scale safely; we don’t, so I feel like this device is mostly just a glorified description of what was already happening, namely that the labs would use their judgment to decide what was safe. Because when it comes down to it, if an evaluation threshold triggers, the first step is to decide whether that was actually a red-...
5
@Zach Stein-Perlman , you're missing the point. They don't have a plan. Here's the thread (paraphrased in my words):
Zach: [asks, for Anthropic]
Zac: ... I do talk about Anthropic's safety plan and orientation, but it's hard because of confidentiality and because many responses here are hostile. ...
Adam: Actually I think it's hard because Anthropic doesn't have a real plan.
Joseph: That's a straw-man. [implying they do have a real plan?]
Tsvi: No it's not a straw-man, they don't have a real plan.
Zach: Something must be done. Anthropic's plan is something.
Tsvi: They don't have a real plan.
3
I explicitly said "However I think the point is basically correct" in the next sentence.
2
Sorry, reacts are ambiguous.
I agree Anthropic doesn't have a "real plan" in your sense, and narrow disagreement with Zac on that is fine.
I just think that's not a big deal and is missing some broader point (maybe that's a motte and Anthropic is doing something bad—vibes from Adam's comment—is a bailey).
[Edit: "Something must be done. Anthropic's plan is something." is a very bad summary of my position. My position is more like various facts about Anthropic mean that them-making-powerful-AI is likely better than the counterfactual, and evaluating a lab in a vacuum or disregarding inaction risk is a mistake.]
[Edit: replies to this shortform tend to make me sad and distracted—this is my fault, nobody is doing something wrong—so I wish I could disable replies and I will probably stop replying and would prefer that others stop commenting. Tsvi, I'm ok with one more reply to this.]
(I won't reply more, by default.)
various facts about Anthropic mean that them-making-powerful-AI is likely better than the counterfactual, and evaluating a lab in a vacuum or disregarding inaction risk is a mistake
Look, if Anthropic was honestly and publically saying
We do not have a credible plan for how to make AGI, and we have no credible reason to think we can come up with a plan later. Neither does anyone else. But--on the off chance there's something that could be done with a nascent AGI that makes a nonomnicide outcome marginally more likely, if the nascent AGI is created and observed by people are at least thinking about the problem--on that off chance, we're going to keep up with the other leading labs. But again, given that no one has a credible plan or a credible credible-plan plan, better would be if everyone including us stopped. Please stop this industry.
If they were saying and doing that, then I would still raise my eyebrows a lot and wouldn't really trust it. But at least it would be plausibly consistent with doing good.
But that doesn't sound like either what they're saying or doing. IIUC they lobbied to remove protection for AI capabilities whistleblowers from SB 1047! That happened! Wow! And it seems like Zac feels he has to pretend to have a credible credible-plan plan.
4
Hm. I imagine you don't want to drill down on this, but just to state for the record, this exchange seems like something weird is happening in the discourse. Like, people are having different senses of "the point" and "the vibe" and such, and so the discourse has already broken down. (Not that this is some big revelation.) Like, there's the Great Stonewall of the AGI makers. And then Zac is crossing through the gates of the Great Stonewall to come and talk to the AGI please-don't-makers. But then Zac is like (putting words in his mouth) "there's no Great Stonewall, or like, it's not there in order to stonewall you in order to pretend that we have a safe AGI plan or to muddy the waters about whether or not we should have one, it's there because something something trade secrets and exfohazards, and actually you're making it difficult to talk by making me work harder to pretend that we have a safe AGI plan or intentions that should promissorily satisfy the need for one".
4
Seems like most people believe (implicitly or explicitly) that empirical research is the only feasible path forward to building a somewhat aligned generally intelligent AI scientist. This is an underspecified claim, and given certain fully-specified instances of it, I'd agree.
But this belief leads to the following reasoning: (1) if we don't eat all this free energy in the form of researchers+compute+funding, someone else will; (2) other people are clearly less trustworthy compared to us (Anthropic, in this hypothetical); (3) let's do whatever it takes to maintain our lead and prevent other labs from gaining power, while using whatever resources we have to also do alignment research, preferably in ways that also help us maintain or strengthen our lead in this race.
most people believe (implicitly or explicitly) that empirical research is the only feasible path forward to building a somewhat aligned generally intelligent AI scientist.
I don't credit that they believe that. And, I don't credit that you believe that they believe that. What did they do, to truly test their belief--such that it could have been changed? For most of them the answer is "basically nothing". Such a "belief" is not a belief (though it may be an investment, if that's what you mean). What did you do to truly test that they truly tested their belief? If nothing, then yours isn't a belief either (though it may be an investment). If yours is an investment in a behavioral stance, that investment may or may not be advisable, but it would DEFINITELY be inadvisable to pretend to yourself that yours is a belief.
9
I'd be very interested to have references to occassions of people in the AI-safety-adjacent community treating Anthropic employees as liars because of things those people misremembered or misinterpreted. (My guess is that you aren't interested in litigating these cases; I care about it for internal bookkeeping and so am happy to receive examples e.g. via DM rather than as a public comment.)
-1
Not Zach Hatfield-Dodds, but people claimed that Anthropic had a commitment to not advance the frontier of capabilities, but as it turns out people misinterpreted communications, and no such commitment actually happened.
Not sure I'd go as far as saying that they treated Anthropic as liars, but this seems to me a central example of Zach Hatfield-Dodds's concerns.
From Evhub:
https://www.lesswrong.com/posts/BaLAgoEvsczbSzmng/?commentId=yd2t6YymWdfGBFhFa
Contrary to the above, for the record, here is a link to a thread where a major Anthropic investor (Moskovitz) and the researcher who coined the term “The Scaling Hypothesis” (Gwern) both report that the Anthropic CEO told them in private that this is what Anthropic would do, in accordance with what many others also report hearing privately. (There is disagreement about whether this constituted a commitment.)
4
The one thing I do conclude is that Anthropic's comms are very inconsistent, and this is bad, actually.
I agree with Zach that Anthropic is the best frontier lab on safety, and I feel not very worried about Anthropic causing an AI related catastrophe. So I think the most important asks for Anthropic to make the world better are on its policy and comms.
I think that Anthropic should more clearly state its beliefs about AGI, especially in its work on policy. For example, the SB-1047 letter they wrote states:
...Broad pre-harm enforcement. The current bill requires AI companies to design and implement SSPs that meet certain standards – for example they must include testing sufficient to provide a "reasonable assurance" that the AI system will not cause a catastrophe, and must "consider" yet-to-be-written guidance from state agencies. To enforce these standards, the state can sue AI companies for large penalties, even if no actual harm has occurred. While this approach might make sense in a more mature industry where best practices are known, AI safety is a nascent field where best practices are the subject of original scientific research. For example, despite a substantial effort from leaders in our company, including our CEO, to draft and refine Anthropic's RSP over a number of
4
This does not fit my model of your risk model. Why do you think this?
Perhaps that was overstated. I think there is maybe a 2-5% chance that Anthropic directly causes an existential catastrophe (e.g. by building a misaligned AGI). Some reasoning for that:
- I doubt Anthropic will continue to be in the lead because they are behind OAI/GDM in capital. They do seem around the frontier of AI models now, though, which might translate to increased returns, but it seems like they do best on very short timelines worlds.
- I think that if they could cause an intelligence explosion, it is more likely than not that they would pause for at least long enough to allow other labs into the lead. This is especially true in short timelines worlds because the gap between labs is smaller.
- I think they have much better AGI safety culture than other labs (though still far from perfect), which will probably result in better adherence to voluntary commitments.
- On the other hand, they haven't been very transparent, and we haven't seen their ASL-4 commitments. So these commitments might amount to nothing, or Anthropic might just walk them back at a critical juncture.
2-5% is still wildly high in an absolute sense! However, risk from other labs seems even higher to me, and I think that Anthropic could reduce this risk by advocating for reasonable regulations (e.g. transparency into frontier AI projects so no one can build ASI without the government noticing).
I think you probably under-rate the effect of having both a large number & concentration of very high quality researchers & engineers (more than OpenAI now, I think, and I wouldn't be too surprised if the concentration of high quality researchers was higher than at GDM), being free from corporate chafe, and also having many of those high quality researchers thinking (and perhaps being correct in thinking, I don't know) they're value aligned with the overall direction of the company at large. Probably also Nvidia rate-limiting the purchases of large labs to keep competition among the AI companies.
All of this is also compounded by smart models leading to better data curation and RLAIF (given quality researchers & lack of crust) leading to even better models (this being the big reason I think llama had to be so big to be SOTA, and Gemini not even SOTA), which of course leads to money in the future even if they have no money now.
1
How many parameters do you estimate for other SOTA models?
3
Minstral had like 150b parameters or something.
4
FYI I believe the correct language is "directly causes an existential catastrophe". "Existential risk" is a measure of the probability of an existential catastrophe, but is not itself an event.
2
This one seems probably worth making a top-level post?
I want to avoid this being negative-comms for Anthropic. I'm generally happy to loudly criticize Anthropic, obviously, but this was supposed to be part of the 5% of my work that I do because someone at the lab is receptive to feedback, where the audience was Zac and publishing was an afterthought. (Maybe the disclaimers at the top fail to negate the negative-comms; maybe I should list some good things Anthropic does that no other labs do...)
Also, this is low-effort.
Concept: inconvenience and flinching away.
I've been working for 3.5 years. Until two months ago, I did independent-ish research where I thought about stuff and tried to publicly write true things. For the last two months, I've been researching donation opportunities. This is different in several ways. Relevant here: I'm working with a team, and there's a circle of people around me with some beliefs and preferences related to my work.
I have some new concepts related to these changes. (Not claiming novelty.)
First is "flinching away": when I don't think about something because it's awkward/scary/stressful. I haven't noticed my object-level beliefs skewed by flinching away, but I've noticed that certain actions should be priorities but come to mind less than they should. In particular: doing something about a disagreement with the consensus or status quo or something an ally is doing. I maybe fixed this by writing the things I'm flinching away from in a google doc when I notice them so I don't forget (and now having the muscle of noticing similar things). It would still be easier if it wasn't the case that (it's salient to me that) certain conclusions and actions are more popular than ...
2
I think noticing stuff like this is important for rationality, and reporting/thinking about it is important for rationalism as a project. So nice job.
I think the flinching away you're noticing is the source of motivated reasoning. If you flinch away from lines of thought that obviously lead to an emotionally uncomfortable conclusion, but don't flinch away from thoughts/evidence that lead to more comfortable conclusions, you'll wind up believing comrtable stuff more than the evidence and logic really indicate.
More in my brief blurt about the science of motivated reasoning. I should improve it to a proper post but I'm just too slow at writing to get that deep in the stack.
I think "Overton window" is a pretty load-bearing concept for many LW users and AI people — it's their main model of policy change. Unfortunately there's lots of other models of policy change. I don't think "Overton window" is particularly helpful or likely-to-cause-you-to-notice-relevant-stuff-and-make-accurate-predictions. (And separately people around here sometimes incorrectly use "expand the Overton window" to just mean with "advance AI safety ideas in government.") I don't have time to write this up; maybe someone else should (or maybe there already exists a good intro to the study of why some policies happen and persist while others don't[1]).
Some terms: policy windows (and "multiple streams"), punctuated equilibrium, policy entrepreneurs, path dependence and feedback (yes this is a real concept in political science, e.g. policies that cause interest groups to depend on them are less likely to be reversed), gradual institutional change, framing/narrative/agenda-setting.
Related point: https://forum.effectivealtruism.org/posts/SrNDFF28xKakMukvz/tlevin-s-quick-takes?commentId=aGSpWHBKWAaFzubba.
- ^
I liked the book Policy Paradox in college. (Example claim: perceived policy problem
You're right that it's not the only useful model or lever. I don't think you're right that it shouldn't be a large focus for long-term large-scale changes. The shift from inconceivable to inevitable takes a lot of time and gradual changes in underlying beliefs, and the overton window is a pretty useful model for societal-expectation shifts.
7
I've registered that you think this but don't currently really have any idea what mistakes you think people make when they think in terms of Overton Window that would go better if they used these other concepts.
I do agree this isn't The Thing tho
Yay Anthropic for expanding its model safety bug bounty program, focusing on jailbreaks and giving participants pre-deployment access. Apply by next Friday.
Anthropic also says "To date, we’ve operated an invite-only bug bounty program in partnership with HackerOne that rewards researchers for identifying model safety issues in our publicly released AI models." This is news, and they never published an application form for that. I wonder how long that's been going on.
(Google, Microsoft, and Meta have bug bounty programs which include some model issues but exclude jailbreaks. OpenAI's bug bounty program excludes model issues.)
- I'm interested in being pitched projects, especially within tracking-what-the-labs-are-doing-in-terms-of-safety.
- I'm interested in hearing which parts of my work are helpful to you and why.
- I don't really have projects/tasks to outsource, but I'd likely be interested in advising you if you're working on a tracking-what-the-labs-are-doing-in-terms-of-safety project or another project closely related to my work.
2
Are you wanting to hire people, wanting to be hired, looking to collaborate...?
4
I am interested in all of the above, for appropriate people/projects. (I meant projects for me to do myself.)
To avoid deploying a dangerous model, you can either (1) test the model pre-deployment or (2) test a similar older model with tests that have a safety buffer such that if the old model is below some conservative threshold it's very unlikely that the new model is dangerous.
DeepMind says it uses the safety-buffer plan (but it hasn't yet said it has operationalized thresholds/buffers).
Anthropic's original RSP used the safety-buffer plan; its new RSP doesn't really use either plan (kinda safety-buffer but it's very weak). (This is unfortunate.)
OpenAI seemed to use the test-the-actual-model plan.[1] This isn't going well. The 4o evals were rushed because OpenAI (reasonably) didn't want to delay deployment. Then the o1 evals were done on a weak o1 checkpoint rather than the final model, presumably so they wouldn't be rushed, but this presumably hurt performance a lot on some tasks (and indeed the o1 checkpoint performed worse than o1-preview on some capability evals). OpenAI doesn't seem to be implementing the safety-buffer plan, so if a model is dangerous but not super obviously dangerous, it seems likely OpenAI wouldn't notice before deployment....
(Yay OpenAI for honestly publishi...
6
It seems unlikely that openai is truly following the test the model plan? They keep eg putting new experimental versions onto lmsys, presumably mostly due to different post training, and it seems pretty expensive to be doing all the DC evals again on each new version (and I think it's pretty reasonable to assume that a bit of further post training hasn't made things much more dangerous)
Zico Kolter Joins OpenAI’s Board of Directors. OpenAI says "Zico's work predominantly focuses on AI safety, alignment, and the robustness of machine learning classifiers."
Misc facts:
- He's an ML professor
- He cofounded Gray Swan (with Dan Hendrycks, among others)
- He coauthored Universal and Transferable Adversarial Attacks on Aligned Language Models
- I hear he has good takes on adversarial robustness
- I failed to find statements on alignment or extreme risks, or work focused on that (in particular, he did not sign the CAIS letter)
DeepSeek-V3 is out today, with weights and a paper published. Tweet thread, GitHub, report (GitHub, HuggingFace). It's big and mixture-of-experts-y; discussion here and here.
It was super cheap to train — they say 2.8M H800-hours or $5.6M (!!).
It's powerful:
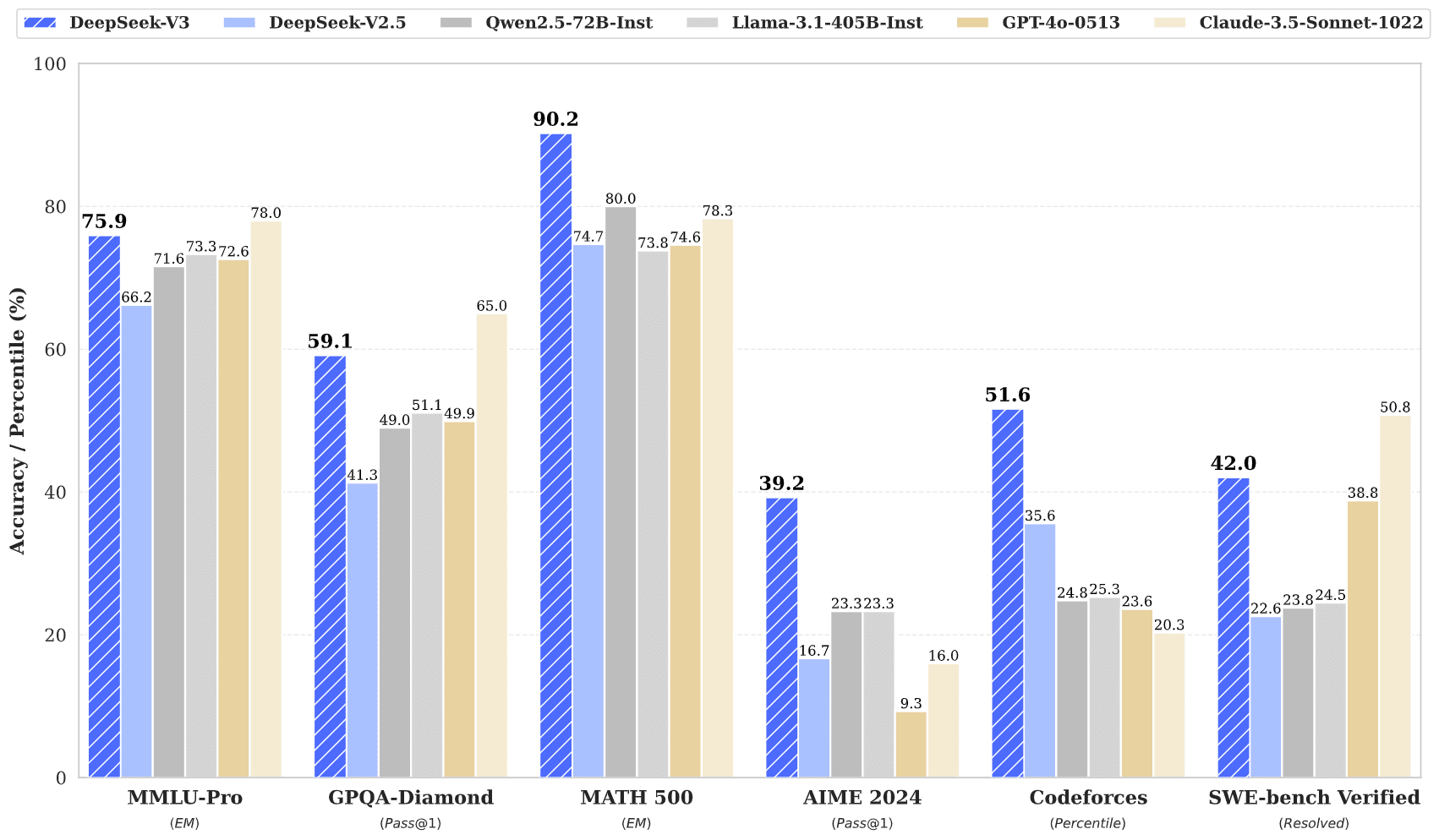
It's cheap to run:
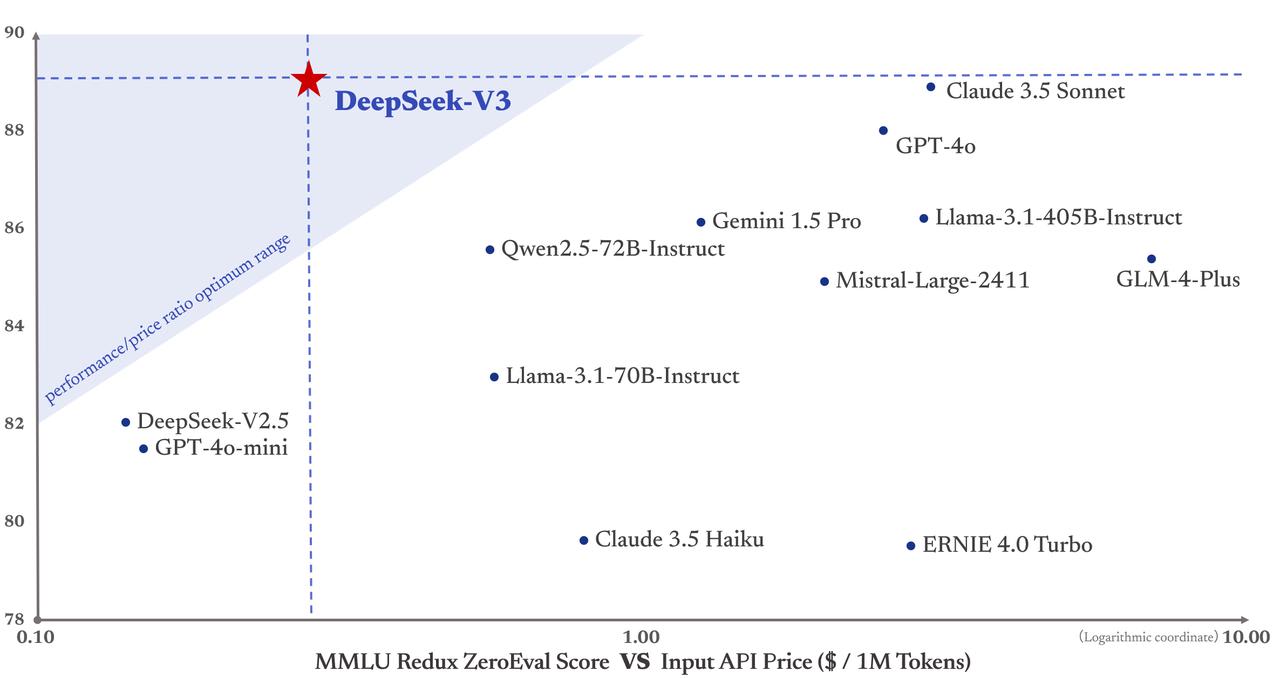
3
This is depressing, but not surprising. We know the approximate processing power of brains (O(1e16-1e17flops) and how long it takes to train them, and should expect that over the next few years the tricks and structures needed to replicate or exceed that efficiency in ML will be uncovered in an accelerating rush towards the cliff as computational resources needed to attain commercially useful performance continue to fall. AI Industry can afford to run thousands of experiments at this cost scale.
Within a few years this will likely see AGI implementations on Nvidia B200 level GPUS (~1e16flop). We have not yet seen hardware application of the various power-reducing computational 'cheats' for mimicking multiplication with reduced gate counts that are likely to see a 2-5x performance gain at same chip size and power draw.
Humans are so screwed.
3
This is still debatable, see Table 9 is the brain emulation roadmap https://www.fhi.ox.ac.uk/brain-emulation-roadmap-report.pdf. You are referring to level 4 (SNN), but level 5 is plausible imo (at 10^22) and 6 seems possible (10^25), and of course it could be a mix of levels.
An AI company's model weight security is at most as good as its compute providers' security. I don't know how good compute providers' security is, but at the least I think model weights and algorithmic secrets aren't robust to insider threat from compute provider staff. I think it would be very hard for compute providers to eliminate insider threat, much less demonstrate that to the AI company.
I think this based on the absence of public information to the contrary, briefly chatting with LLMs, and a little private information.
One consequence is that Anthropic probably isn't complying with its ASL-3 security standard, which is supposed to address risk from "corporate espionage teams." Arguably this refers to teams at companies with no special access to Anthropic, rather than teams at Amazon and Google. But it would be dubious to exclude Amazon and Google for being compute providers: they're competitors with strong incentives to steal algorithmic secrets, and more risk comes from them than the baseline "corporate espionage team" but most risk from any group of actors comes from the small subset of actors that pose more than baseline risk. Anthropic is thinking about how...
To be clear, I think if the basic premise here is true, then Anthropic at the very least needs to report this violation to their LTBT, and then consequently take down Claude from being served by major cloud providers, if they want to follow the commitments laid out in their RSP. They would also be unable to ship any new models until this issue is resolved.
My guess is no one really treats the RSP as anything particularly serious these days, so none of that will happen. My guess is instead if this escalates at all is that Anthropic would simply edit their RSP to exclude high-level insiders at compute providers they use. This is sad, but I would like things to escalate at least until that point.
The ASL-3 security standard states in 4.2.4 that "third-party environments", which surely includes compute providers, are in scope (and on their minds) for the standards they laid out:
Third-party environments: Document how all relevant models will meet the criteria above, even if they are deployed in a third-party partner’s environment that may have a different set of safeguards.
4
Isn't this out-of-scope of ASL3 security, which is only about model weights?
6
Good point. I think compute providers can steal model weights, as I said at the top. I think they currently have more incentive to steal architecture and training algorithms, since those are easier to use without getting caught, so I focused on "algorithmic secrets."
Separately, are Amazon and Google incentivized to steal architecture and training algorithms? Meh. I think it's very unlikely, since even if they're perfectly ruthless their reputation is very important to them (plus they care about some legal risks). I think habryka thinks it's more likely than I do. This is relevant to Anthropic's security prioritization — security from compute providers might not be among the lowest-hanging fruit. And I think Fabien thinks it's relevant to ASL-3 compliance, and I agree that ASL-3 probably wasn't written with insider threat from compute providers in mind. But I'm not sure it's relevant to ASL-3 compliance? The ASL-3 standard doesn't say that actors are only in scope if they seem incentivized to steal stuff; the scope is based on actors' capabilities.
This shortform discusses the current state of responsible scaling policies (RSPs). They're mostly toothless, unfortunately.
The Paris summit was this week. Many companies had committed to make something like an RSP by the summit. Half of them did, including Microsoft, Meta, xAI, and Amazon. (NVIDIA did not—shame on them—but I hear they are writing something.) Unfortunately but unsurprisingly, these policies are all vague and weak.
RSPs essentially have four components: capability thresholds beyond which a model might be dangerous by default, an evaluation protocol to determine when models reach those thresholds, a plan for how to respond when various thresholds are reached, and accountability measures.
A maximally lazy RSP—a document intended to look like an RSP without making the company do anything differently—would have capability thresholds be vague or extremely high, evaluation be unspecified or low-quality, response be like we will make it safe rather than substantive mitigations or robustness guarantees, and no accountability measures. Such a policy would be little better than the company saying "we promise to deploy AIs safely." The...
capability thresholds be vague or extremely high
xAI's thresholds are entirely concrete and not extremely high.
evaluation be unspecified or low-quality
They are specified and as high-quality as you can get. (If there are better datasets let me know.)
I'm not saying it's perfect, but I wouldn't but them all in the same bucket. Meta's is very different from DeepMind's or xAI's.
6
xAI Risk Management Framework (Draft)
You're mostly right about evals/thresholds. Mea culpa. Sorry for my sloppiness.
For misuse, xAI has benchmarks and thresholds—or rather examples of benchmarks thresholds to appear in the real future framework—and based on the right column they seem very reasonably low.
Unlike other similar documents, these are not thresholds at which to implement mitigations but rather thresholds to reduce performance to. So it seems the primary concern is probably not the thresholds are too high but rather xAI's mitigations won't be robust to jailbreaks and xAI won't elicit performance on post-mitigation models well. E.g. it would be inadequate to just run a benchmark with a refusal-trained model, note that it almost always refuses, and call it a success. You need something like: a capable red-team tries to break the mitigations and use the model for harm, and either the red-team fails or it's so costly that the model doesn't make doing harm cheaper.
(For "Loss of Control," one of the two cited benchmarks was published today—I'm dubious that it measures what we care about but I've only spent ~3 mins engaging—and one has not yet been published. [Edit: and, like, on priors, I'm very skeptical of alignment evals/metrics, given the prospect of deceptive alignment, how we care about worst-case in addition to average-case behavior, etc.])
You suspect someone in your community is a bad actor. Kinds of reasons not to move against them:
- You're uncertain
- Especially if your uncertainty will likely be largely resolved soon
- You lack legible evidence (or other ways of convincing others), and they're not already seen as sketchy
- Especially if you'll likely get better legible evidence soon
- They're doing some good stuff; you need them for some good stuff
- They're popular, politically powerful, or have power to hurt you
- And so you'd fail
- And maybe you'd get kicked out or lose power (especially if your move is unpopular or considered inappropriate, or "community" is more like "team" or "circle")
- And so making them an enemy of [you or your community] is costly
- And so you'd fail
- Personal psychological costs
- It's just time-consuming to start a fight, especially because they'll be invested in discrediting you and your claims
This is all from-first-principles. I'm interested in takes and reading recommendations. Also creative affordances / social technology.
The convenient case would be that you can privately get the powerful stakeholders on board and then they all oust the bad actor and it's a fait accompli, so there's no protracted conflict and minimal cost to you...
Another is concern that the cure is worse than the disease. I.e. the drama and relationship damage caused by trying to expel them in the community might hurt the community more than removing them. Like there are scissor statements, there are also scissor people.
You might be in a community where you don't think people will agree with you that they're a bad actor, even if you can establish the truth about what events occurred in the world, because there's a value disagreement between you and your community.
Also concern about them and their well-being. Being publicly ostracized is very traumatizing and scary for most people. Particularly if they seem mentally fragile, you might fear the consequences for them or potentially for others who aren't just you if they're forced to endure a public ousting. You might fear or be averse to causing them pain. You might have sympathy for them, particularly if you think the sense in which they're a bad actor was in turn caused by something bad happening to them.
You might fear that exposing their bad behavior will bring harm to others who are associated with them. For example, if they're part of some oppressed minority group and you fear that people will overgeneralize from their bad behavior to being mistrustful of or more prejudiced against others.
7
I'd add that a common reason to choose not to act against someone is that many of those factors are combined.
I think situations where it's (e.g.) purely "they have power to hurt you" or "you lack legible evidence" are much rarer than situations where it's an awkward combination of those with other things, and so it's hard to even know whether you should take on the project of acting against someone carefully and well.
6
More reasons:
2.b. The problem is not lack of legible evidence per se, but the fact that the other members of the group are too stupid to understand anything; from their perspective even quite obvious evidence is illegible.
7. If you attack them and fail, it will strengthen their position; and either the chance of failure or the bonus they would get is high enough to make the expected value of your attack negative.
For example, they may have prepared a narrative like "there is a conspiracy against our group that will soon try to divide us by bringing up unfounded accusations against people like me", so if your fail to convince the others, you will provide evidence for the narrative.
Securing model weights is underrated for AI safety. (Even though it's very highly rated.) If the leading lab can't stop critical models from leaking to actors that won't use great deployment safety practices, approximately nothing else matters. Safety techniques would need to be based on properties that those actors are unlikely to reverse (alignment, maybe unlearning) rather than properties that would be undone or that require a particular method of deployment (control techniques, RLHF harmlessness, deployment-time mitigations).
However hard the make a critical model you can safely deploy problem is, the make a critical model that can safely be stolen problem is... much harder.
None of the actors who seem currently likely to me to be to deploy highly capable systems seem to me like they will do anything except approximately scaling as fast as they can. I do agree that proliferation is still bad simply because you get more samples from the distribution, but I don't think that changes the probabilities that drastically for me (I am still in favor of securing model weights work, especially in the long run).
Separately, I think it's currently pretty plausible that model weight leaks will substantially reduce the profit of AI companies by reducing their moat, and that has an effect size that seems plausible larger than the benefits of non-proliferation.
5
My central story is that AGI development will eventually be taken over by governments, in more or less subtle ways. So the importance of securing model weights now is mostly about less scrupulous actors having less of a headstart during the transition/after a governmental takeover.
3
IMO someone should consider writing a "how and why" post on nationalizing AI companies. It could accomplish a few things:
* Ensure there's a reasonable plan in place for nationalization. That way if nationalization happens, we can decrease the likelihood of it being controlled by Donald Trump with few safeguards, or something like that. Maybe we could take inspiration from a less partisan organization like the Federal Reserve.
* Scare off investors. Just writing the post and having it be discussed a lot could scare them.
* Get AI companies on their best behavior. Maybe Sam Altman would finally be pushed out if congresspeople made him the poster child for why nationalization is needed.
9
@Ebenezer Dukakis I would be even more excited about a "how and why" post for internationalizing AGI development and spelling out what kinds of international institutions could build + govern AGI.
3
There is now some work in that direction: https://forum.effectivealtruism.org/posts/47RH47AyLnHqCQRCD/soft-nationalization-how-the-us-government-will-control-ai
3
What sort of leaks are we talking about? I doubt a sophisticated hacker is going to steal weights from OpenAI just to post them on 4chan. And I doubt OpenAI's weights will be stolen by anyone except a sophisticated hacker.
If you want to reduce the incentive to develop AI, how about passing legislation to tax it really heavily? That is likely to have popular support due to the threat of AI unemployment. And it reduces the financial incentive to invest in large training runs. Even just making a lot of noise about such legislation creates uncertainty for investors.
6
This seems somewhat overstated. You might hope that you can get the safety tax sufficiently low that you can just do full competition (e.g. even though there are rogue AIs, you just compete with this rogue AIs for power). This also requires offense-defense imbalance to not be too bad.
I overall agree that securing model weights in underrated and that it is plausibly the most important thing on current margins.
In principle, if reasonable actors start with a high fraction of resources (e.g. compute), then you might hope that they can keep that fraction of power (in expectation at least).
See also "The strategy-stealing assumption". But also What does it take to defend the world against out-of-control AGIs?.
5
I think you are overrating it. Biggest concern comes from whomever trains a model that passes some treshold in the first place. Not from a model that one actor has been using for a while getting leaked to another actor. The bad actor who got access to the leak is always going to be behind in multiple ways in this scenario.
1
The weights could be stolen as soon as the model is trained though
4[anonymous]
Commenting to note that I think this quote is locally-invalid:
There are other disjunctive problems with the world which are also individually-sufficient for doom[1], in which case each of them matter a lot, in absence of some fundamental solution to all of them.
1. ^
(e.g lack of superintelligence-alignment/steerability progress)
2
Minor point, but I think we might have some time here. Securing model weights becomes more important as models become better, but better models could also help us secure model weights (would help us code, etc).
iiuc, Anthropic's plan for averting misalignment risk is bouncing off bumpers like alignment audits.[1] This doesn't make much sense to me.
- I of course buy that you can detect alignment faking, lying to users, etc.
- I of course buy that you can fix things like we forgot to do refusal posttraining or we inadvertently trained on tons of alignment faking transcripts — or maybe even reward hacking on coding caused by bad reward functions.
- I don't see how detecting [alignment faking, lying to users, sandbagging, etc.] helps much for fixing them, so I don't buy that you can fix hard alignment issues by bouncing off alignment audits.
- Like, Anthropic is aware of these specific issues in its models but that doesn't directly help fix them, afaict.
(Reminder: Anthropic is very optimistic about interp, but Interpretability Will Not Reliably Find Deceptive AI.)
(Reminder: the below is all Anthropic's RSP says about risks from misalignment)

(For more, see my websites AI Lab Watch and AI Safety Claims.)
- ^
Anthropic doesn't have an official plan. But when I say "Anthropic doesn't have a plan" I've been told read between the lines, obviously th
I don't see how detecting [alignment faking, lying to users, sandbagging, etc.] helps much for fixing them, so I don't buy that you can fix hard alignment issues by bouncing off alignment audits.
Strong disagree. I think that having real empirical examples of a problem is incredibly useful - you can test solutions and see if they go away! You can clarify your understanding of the problem, and get a clearer sense of upstream causes. Etc.
This doesn't mean it's sufficient, or that it won't be too late, but I think you should put much higher probability in a lab solving a problem per unit time when they have good case studies.
It's the difference between solving instruction following when you have GPT3 to try instruction tuning on, vs only having GPT2 Small
Yes, of course, sorry. I should have said: I think detecting them is (pretty easy and) far from sufficient. Indeed, we have detected them (sandbagging only somewhat) and yes this gives you something to try interventions on but, like, nobody knows how to solve e.g. alignment faking. I feel good about model organisms work but [pessimistic/uneasy/something] about the bouncing off alignment audits vibe.
Edit: maybe ideally I would criticize specific work as not-a-priority. I don’t have specific work to criticize right now (besides interp on the margin), but I don't really know what work has been motivated by "bouncing off bumpers" or "alignment auditing." For now, I’ll observe that the vibe is worrying to me and I worry about the focus on showing that a model is safe relative to improving safety.[1] And, like, I haven't heard a story for how alignment auditing will solve [alignment faking or sandbagging or whatever], besides maybe the undesired behavior derives from bad data or reward functions or whatever and it's just feasible to trace the undesired behavior back to that and fix it (this sounds false but I don't have good intuitions here and would mostly defer if non-Anthropic pe...
4
Here are some ways I think alignment auditing style work can help with decreasing danger:
* Better metrics for early detection means better science that you can do on dumber models, better ability to tell which interventions work, etc. I think Why Do Some Language Models Fake Alignment While Others Don't? is the kind of thing that's pretty helpful for working on mitigations!
* Forecasting which issues are going to become a serious problem under further scaling, eg by saying "ok Model 1 had 1% frequency in really contrived settings, Model 2 had 5% frequency in only-mildly-contrived settings, Model 3 was up to 30% in the mildly-contrived setting and we even saw a couple cases in realistic environments", lets you prioritize your danger-decreasing work better by having a sense of what's on the horizon. I want to be able to elicit this stuff from the dumbest/earliest models possible, and I think getting a mature science of alignment auditing is really helpful for that.
* Alignment auditing might help in constructing model organisms, or finding natural behavior you might be able to train a model organism to exhibit much more severely.
Maybe one frame is that audits can have both breadth and depth, and lot of what I'm excited about isn't just "get wide coverage of model behavior looking for sketchy stuff" but also "have a really good sense of exactly how and where a given behavior happens, in a way you can compare across models and track what's getting better or worse".
4
I'm pretty skeptical about mitigations work targeting alignment faking in current models transfering very much to future models.
(I'm more optimistic about this type of work helping us practice making and iterating on model organisms so we're faster and more effective when we actually have powerful models.)
1
I agree that if you set out with the goal of "make alignment faking not happen in a 2025 model" you can likely do this pretty easily without having learned anything that will help much for more powerful models. I feel more optimistic about doing science on the conditions under which 2025 models not particularly trained for or against AF exhibit it, and this telling us useful things about risk factors that would apply to future models? Though I think it's plausible that most of the value is in model organism creation, as you say.
4
I would argue that all fixing research is accelerated by having found examples, because it gives you better feedback on whether you've found or made progress towards fixes, by studying what happened on your examples. (So long as you are careful not to overfit and just fit that example or something). I wouldn't confidently argue that it can more directly help by eg helping you find the root cause, though things like "training data attribution to the problematic data, remove it, and start fine tuning again" might just work
I think this depends a lot on the details of the detection and whether the failure mode you detect is the sort of thing that has substantial transfer with the actually-hard-to-detect misalignment failure modes we're most worried about.[1]
E.g., if you detect the AI making a serious exfiltration attempt once and you can't effectively proliferate this substantially or otherwise leverage this into studying the misalignment, then this isn't actually very helpful for finding solutions for the underlying misalignment. It might be pretty helpful for mitigating this misalignment, particular from this AI, but that's different from preventing the misalignment.
However, if you instead detect the misalignment in a way that you expect is repeatable (as in, you can recatch the model if it's still misaligned after testing some training intervention) or which allows for getting a good understanding of the exact details of the misalignment, then it seems quite helpful.
It also could be pretty helpful if you get many rounds of iteration (with robust catching) on close by failure modes, but this requires that you are deploying heavily misalignment models repeatedly.
I'm pretty skeptical of lots of transf...
3
Relevant posts on this point which argue that catching misalignment is a big help in fixing it (which is relevant to the bumpers plan):
Catching AIs red-handed by Ryan Greenblatt and Buck Shlegeris:
https://www.lesswrong.com/posts/i2nmBfCXnadeGmhzW/catching-ais-red-handed
Handling schemers if shutdown is not an option, by Buck Shlegeris:
https://www.lesswrong.com/posts/XxjScx4niRLWTfuD5/handling-schemers-if-shutdown-is-not-an-option
I want to distinguish (1) finding undesired behaviors or goals from (2) catching actual attempts to subvert safety techniques or attack the company. I claim the posts you cite are about (2). I agree with those posts that (2) would be very helpful. I don't think that's what alignment auditing work is aiming at.[1] (And I think lower-hanging fruit for (2) is improving monitoring during deployment plus some behavioral testing in (fake) high-stakes situations.)
- ^
- The AI "brain scan" hope definitely isn't like this
- I don't think the alignment auditing paper is like this, but related things could be
Topic: workplace world-modeling
- A friend's manager tasked them with estimating ~10 parameters for a model. Choosing a single parameter very-incorrectly would presumably make the bottom line nonsense. My friend largely didn't understand the model and what the parameters meant; if you'd asked them "can you confidently determine what each of the parameters means" presumably they would have noticed the answer was no. (If I understand the situation correctly, it was crazy for the manager to expect my friend to do this task.) They should have told their manager "I can't do this" or "I'm uncertain about what these four parameters are; here's my best guess of a very precise description for each; please check this carefully and let me know." Instead I think they just gave their best guess for the parameters! (Edit: also I think they thought the model was bad but I don't think they told their manager that.)
- Another friend's manager tasked them with estimating how many hours it would take to evaluate applications for their org's hiring round. If my friend had known details of the application process, they could have estimated the number of applicants at each stage and the time to review each ap
My quick thoughts on why this happens.
(1) Time. You get asked to do something. You dont get the full info dump in the meeting so you say yes and go off hopeful that you can find the stuff you need. Other responsibilies mean you dont get around to looking everything up until time has passed. It is at that stage that you realise the hiring process hasnt even been finalised or that even one wrong parameter out of 10 confusing parameters would be bad. But now its mildly awkard to go back and explain this - they gave this to you on Thursday, its now Monday.
(2) Story Noise. When you were told these stories by freinds, they only gave the salient details, not a word for word repeat of everything that was said. But, at the time they experienced it word by word, they didnt know what the story beats were yet. Some of those details were just distractions, but some of them might be semi relevant. I know when i tell stories i simplify, and sometimes people assume specific solutions are possible or desrieble because of details they dont know.
5
Both of these are quite believable. It took me a LONG time to get to a maturity/confidence level where I can say (still not comfortably, but I recognize that it must happen for good outcomes) "I'm just getting to this now, and I'm sorry I didn't notice earlier that I don't fully understand X and Y. Can you help clarify what's the purpose/expectation/methodology for this?"
4
I think the "noticing" part can vary a LOT based on the implied reason for the manager's request, and the cost/reward function of how close to "correct" the predictions are. There's a whole lot of tasks in most corporate environments that really make no difference, and just having AN answer is good enough. An interested, conscientious employee would be sure this was the case before continuing, though.
The real puzzle is what is the blocker for just asking the manager for details (or the reason for lack of details). I didn't work in big, formal, organizations until I was pretty senior, so I've always seen managers as a peer and partner in delivering value, not as a director of my work or bottleneck for my understanding. This has served me well, and I'm often surprised that much less than half of my current coworkers operate this way. "I need a bit more information to do a good job on this task" is about the bare minimum I'd expect someone to say in such a situation, and I'd usually say "do we have more functional requirements or background information on this? I can make something up, but I'd really like to understand how my answer will be used".
Especially for the estimating parameters for a model question, I don't understand why one wouldn't ask for more information about the task and semantics of the parameters. If it were a coworker of mine, I'd mention it in a 1:1 that they need to take more ownership and ask questions when they don't understand.
4
(Clarification: these are EA, AI safety orgs with ~10-15 employees.)
2
Then I'm even more confused about the lack of cooperative-problem-solving between managers and employees. In fact, with fewer than 20 employees, why even HAVE a formal manager? You need some leaders to help prioritize and set direction, but no line-management or task breakdowns.
New page on AI companies' policy advocacy: https://ailabwatch.org/resources/company-advocacy/.
This page is the best collection on the topic (I'm not really aware of others), but I decided it's low-priority and so it's unpolished. If a better version would be helpful for you, let me know to prioritize it more.
Meta released the weights of a new model and published evals: Code World Model Preparedness Report. It's the best eval report Meta has published to date.
The basic approach is: do evals; find weaker capabilities than other open-weights models; infer that it's safe to release weights.
How good are the evals? Meh. Maybe it's OK if the evals aren't great, since the approach isn't show the model lacks dangerous capabilities but rather show the model is weaker than other models.
One thing that bothered me was this sentence:
Our evaluation approach assumes that a potential malicious user is not an expert in large language model development; therefore, for this assessment we do not include malicious fine-tuning where a malicious user retrains the model to bypass safety post-training or enhance harmful capabilities.
This is totally wrong because for an open-weights model, anyone can (1) undo the safety post-training or (2) post-train on dangerous capabilities, then publish those weights for anyone else to use. I don't know whether any eval results are invalidated by (1): I think for most of the dangerous capability evals Meta uses, models generally don’t refuse them (in some case...
1
Curious - what made you think this is new to Code World Model comparing to other Meta releases?
2
I don't think it's very new. iirc it's suggested in Meta's safety framework. But past evals stuff (see the first three bullets above) has been more like the model doesn't have dangerous capabilities than the model is weaker than these specific other models. Maybe in part because previous releases have been more SOTA. I don't recall past releases being like safe because weaker than other models.
I was recently surprised to notice that Anthropic doesn't seem to have a commitment to publish its safety research.[1] It has a huge safety team but has only published ~5 papers this year (plus an evals report). So probably it has lots of safety research it's not publishing. E.g. my impression is that it's not publishing its scalable oversight and especially adversarial robustness and inference-time misuse prevention research.
Not-publishing-safety-research is consistent with Anthropic prioritizing the win the race goal over the help all labs improve safety goal, insofar as the research is commercially advantageous. (Insofar as it's not, not-publishing-safety-reseach is baffling.)
Maybe it would be better if Anthropic published ~all of its safety research, including product-y stuff like adversarial robustness such that others can copy its practices.
(I think this is not a priority for me to investigate but I'm interested in info and takes.)
[Edit: in some cases you can achieve most of the benefit with little downside except losing commercial advantage by sharing your research/techniques with other labs, nonpublicly.]
- ^
I failed to find good sources saying Anthropic publishes its saf
One argument against publishing adversarial robustness research is that it might make your systems easier to attack.
One thing I'd really like labs to do is encourage their researchers to blog about their thoughts on the future, on alignment plans, etc.
Another related but distinct thing is have safety cases and have an anytime alignment plan and publish redacted versions of them.
Safety cases: Argument for why the current AI system isn't going to cause a catastrophe. (Right now, this is very easy to do: 'it's too dumb')
Anytime alignment plan: Detailed exploration of a hypothetical in which a system trained in the next year turns out to be AGI, with particular focus on what alignment techniques would be applied.
One thing I'd really like labs to do is encourage their researchers to blog about their thoughts on the future, on alignment plans, etc.
Or, as a more minimal ask, they could avoid discouraging researchers from sharing thoughts implicitly due to various chilling effects and also avoid explicitly discouraging researchers.
4
I'd personally love to see similar plans from AI safety orgs, especially (big) funders.
3
We're working on something along these lines. The most up-to-date published post is just our control post and our Notes on control evaluations for safety cases which is obviously incomplete.
I'm planing on posting a link to our best draft of a ready-to-go-ish plan as of 1 year ago, though it is quite out of date and incomplete.
5
I posted the link here.
Here is the doc, though note that it is very out of date. I don't particularly want to recommend people read this doc, but it is possible that someone will find it valuable to read.
3
I don't think funders are in a good position to do this. Also, funders are generally not "coherant". Like they don't have much top down strategy. Individual granters could write up thoughts.
Fwiw I am somewhat more sympathetic here to "the line between safety and capabilities is blurry, Anthropic has previously published some interpretability research that turned out to help someone else do some capabilities advances."
I have heard Anthropic is bottlenecked on having people with enough context and discretion to evaluate various things that are "probably fine to publish" but "not obviously fine enough to ship without taking at least a chunk of some busy person's time". I think in this case I basically take the claim at face value.
I do want to generally keep pressuring them to somehow resolve that bottleneck because it seems very important, but, I don't know that I disproportionately would complain at them about this particular thing.
(I'd also not surprised if, while the above claim is true, Anthropic is still suspiciously dragging it's feet disproportionately in areas that feel like they make more of a competitive sacrifice, but, I wouldn't actively bet on it)
Sounds fatebookable tho, so let's use ye Olde Fatebook Chrome extension:
(low probability because I expect it to still be murky/unclear)
4
1. I tentatively think this is a high-priority ask
2. Capabilities research isn't a monolith and improving capabilities without increasing spooky black-box reasoning seems pretty fine
3. If you're right, I think the upshot is (a) Anthropic should figure out whether to publish stuff rather than let it languish and/or (b) it would be better for lots of Anthropic safety researchers to instead do research that's safe to share (rather than research that only has value if Anthropic wins the race)
9
I would expect that some amount of good safety research is of the form, "We tried several ways of persuading several leading AI models how to give accurate instructions for breeding antibiotic-resistant bacteria. Here are the ways that succeeded, here are some first-level workarounds, here's how we beat those workarounds...": in other words, stuff that would be dangerous to publish. In the most extreme cases, a mere title ("Telling the AI it's writing a play defeats all existing safety RLHF" or "Claude + Coverity finds zero-day RCE exploits in many codebases") could be dangerous.
That said, some large amount should be publishable, and 5 papers does seem low.
Though maybe they're not making an effort to distinguish what's safe to publish from what's not, and erring towards assuming the latter? (Maybe someone set a policy of "Before publishing any safety research, you have to get Important Person X to look through it and/or go through some big process to ensure publishing it is safe", and the individual researchers are consistently choosing "Meh, I have other work to do, I won't bother with that" and therefore not publishing?)
6
Seems like evidence towards the claim here: Open source AI has been vital for alignment. My rough impression is also that the other big labs' output has largely been similarly disappointing in terms of public research output on safety.
2
My impression from skimming posts here is that people seem to be continually surprised by Anthropic, while those modeling it as basically "Pepsi to OpenAI's Coke" wouldn't be.
Meta seems to be the only group doing something meaningfully different from the others.
7
There's a selection effect in what gets posted about. Maybe someone should write the "ways Anthropic is better than others" list to combat this.
Edit: there’s also a selection effect in what you see, since negative stuff gets more upvotes…
5
I’d say it’s slightly more like “Labor vs Conservatives”, where I’ve seen politicians deflect criticisms of their behavior by arguing about that the other side is worse, instead of evaluating their policies or behavior by objective standards (where both sides can typically score exceedingly low).
1
I also wish to see more safety papers. I guess/from my experience that it might also be - really good quality research takes time, and the papers so far from them seems pretty good. Though I don’t know if they are actively withholding things on purpose which could also be true - any insider/sources for this guess?
0
Is this where we think our pressuring-Anthropic points are best spent ?
3
This shortform is relevant to e.g. understanding what's going on and considerations on the value of working on safety at Anthropic, not just pressuring Anthropic.
@Neel Nanda
6
Yeah, fair point, disagreement retracted
5
I think if someone has a 30-minute meeting with some highly influential and very busy person at Anthropic, it makes sense for them to have thought in advance about the most important things to ask & curate the agenda appropriately.
But I don't think LW users should be thinking much about "pressuring-Anthropic points". I see LW primarily as a platform for discourse (as opposed to a direct lobbying channel to labs), and I think it would be bad for the discourse if people felt like they had to censor questions/concerns about labs on LW unless it met some sort of "is this one of the most important things to be pushing for" bar.
3
I agree! I hope people regularly ask questions about Anthropic that they feel curious about, as well as questions that seem important to them :)
2
I think it's bad for discourse for us to pretend that discourse doesn't have impacts on others in a democratic society. And I think the meta-censoring of discourse by claiming that certain questions might have implicit censorship impacts is one of the most anti-rationality trends in the rationalist sphere.
I recognize most users of this platform will likely disagree, and predict negative agreement-karma on this post.
7
I think I agree with this in principle. Possible that the crux between us is more like "what is the role of LessWrong."
For instance, if Bob wrote a NYT article titled "Anthropic is not publishing its safety research", I would be like "meh, this doesn't seem like a particularly useful or high-priority thing to be bringing to everyone's attention– there are like at least 10+ topics I would've much rather Bob spent his points on."
But LW generally isn't a place where you're going to get EG thousands of readers or have a huge effect on general discourse (with the exception of a few things that go viral or AIS-viral).
So I'm not particularly worried about LW discussions having big second-order effects on democratic society. Whereas LW can be a space for people to have a relatively low bar for raising questions, being curious, trying to understand the world, offering criticism/praise without thinking much about how they want to be spending "points", etc.
6
Of course it has impacts on others in society! In finding out the truth and investigating and finding strong arguments and evidence. The overall effect of a lot of high quality, curious, public investigation is to greatly improve others maps of the world in surprising ways and help people make better decisions, and this is true even if no individual thread of questioning is primarily optimized to help people make better decisions.
Re censoriousness: I think your question of how best to pressure an unethical company to be less unethical is a fine question, but to imply it’s the only good question (which I read into your comment, perhaps inaccurately) goes against the spirit of intellectual discourse.
3
It is genuinely a sign that we are all very bad at predicting others' minds that it didn't occur to me that if I said effectively "OP asked for 'takes', here's a take on why I think this is pragmatically a bad idea" would also mean that I was saying "and therefore there is no other good question here". That's, as the meme goes, a whole different sentence.
5
Well, but you didn’t give a take on why it’s pragmatically a bad idea. If you’d written a comment with a pointer to something else worth pressuring them on, or gave a reason why publishing all the safety research doesn’t help very much / has hidden costs, I would’ve thought it a fine contribution to the discussion. Without that, the comment read to me as dismissive of the idea of exploring this question.
-2
Yes, I would agree that if I expected a short take to have this degree of attention, I would probably have written a longer comment.
Well, no, I take that back. I probably wouldn't have written anything at all. To some, that might be a feature; to me, that's a bug.
4
I disagree. I think the standard of "Am I contributing anything of substance to the conversation, such as a new argument or new information that someone can engage with?" is a pretty good standard for most/all comments to hold themselves to, regardless of the amount of engagement that is expected.
[Edit: Just FWIW, I have not voted on any of your comments in this thread.]
4
I think, having been raised in a series of very debate- and seminar-centric discussion cultures, that a quick-hit question like that is indeed contributing something of substance. I think it's fair that folks disagree, and I think it's also fair that people signal (e.g., with karma) that they think "hey man, let's go a little less Socratic in our inquiry mode here."
But, put in more rationalist-centric terms, sometimes the most useful Bayesian update you can offer someone else is, "I do not think everyone is having the same reaction to your argument that you expected." (Also true for others doing that to me!)
(Edit to add two words to avoid ambiguity in meaning of my last sentence)
-5
Info on OpenAI's "profit cap" (friends and I misunderstood this so probably you do too):
In OpenAI's first investment round, profits were capped at 100x. The cap for later investments was neither 100x nor directly less based on OpenAI's valuation — it was just negotiated with the investor. (OpenAI LP (OpenAI 2019); archive of original.[1])
In 2021 Altman said the cap was "single digits now" (apparently referring to the cap for new investments, not just the remaining profit multiplier for first-round investors).
Reportedly the cap will increase by 20% per year starting in 2025 (The Information 2023; The Economist 2023); OpenAI has not discussed or acknowledged this change.
Edit: how employee equity works is not clear to me.
Edit: I'd characterize OpenAI as a company that tends to negotiate profit caps with investors, not a "capped-profit company."
economic returns for investors and employees are capped (with the cap negotiated in advance on a per-limited partner basis). Any excess returns go to OpenAI Nonprofit. Our goal is to ensure that most of the value (monetary or otherwise) we create if successful benefits everyone, so we think this is an important first step. Returns fo
Some of my friends are signal-boosting this new article: 60 U.K. Lawmakers Accuse Google of Breaking AI Safety Pledge. See also the open letter. I don't feel good about this critique or the implicit ask.
- Sharing information on capabilities is good but public deployment is a bad time for that, in part because most risk comes from internal deployment.
- Google didn't necessarily even break a commitment? The commitment mentioned in the article is to "publicly report model or system capabilities." That doesn't say it has to be done at the time of public deployment.
- The White House voluntary commitments included a commitment to "publish reports for all new significant model public releases"; same deal there.
- Possibly Google broke a different commitment (mentioned in the open letter): "Assess the risks posed by their frontier models or systems across the AI lifecycle, including before deploying that model or system." Depends on your reading of "assess the risks" plus facts which I don't recall off the top of my head.
- Other companies are doing far worse in this dimension. At worst Google is 3rd-best in publishing eval results. Meta and xAI are far worse.
2. Google didn't necessarily even break a commitment? The commitment mentioned in the article is to "publicly report model or system capabilities." That doesn't say it has to be done at the time of public deployment.
This document linked on the open letter page gives a precise breakdown of exactly what the commitments were and how Google broke them (both in spirit and by the letter).[1] The summary is this:
- Google violated the spirit of commitment I by publishing its first safety report almost a
month after public availability and not mentioning external testing in their initial report.- Google explicitly violated commitment VIII by not stating whether governments
are involved in safety testing, even after being asked directly by reporters.
But in fact the letter actually understates the degree to which Google DeepMind violated the commitments. The real story from this article is that GDM confirmed to Time that they didn't provide any pre-deployment access to UK AISI:
However, Google says it only shared the model with the U.K. AI Security Institute after Gemini 2.5 Pro was released on March 25.
If UK AISI doesn't have pre-deployment access, a large portion of their whole raison d'être ...
5
Thanks. Sorry for criticizing without reading everything. I agree that, like, on balance, GDM didn't fully comply with the Seoul commitments re Gemini 2.5. Maybe I just don't care much about these particular commitments.
3. Other companies are doing far worse in this dimension. At worst Google is 3rd-best in publishing eval results. Meta and xAI are far worse.
Some reasons for focusing Google DeepMind in particular:
- The letter was organized by PauseAI UK and signed by UK politicians. GDM is the only frontier AI company headquartered in the UK.
- Meta and xAI already have a bad reputation for their safety practices, while GDM had a comparatively good reputation and most people were unaware of their violation of the Frontier AI Safety Commitments.
4
[Writing off based on the quick take, haven't looked into the linked thing.]
I think this statement lends itself to being by default interpreted as "inform the public about model/system capabilities in time" (because if they don't do it "in time", then what's the point?), and the most "natural" "in-time" time is the time of deployment?
I announce that I'm committing to X. I can expect that most people will understand this to mean "I commit to Y" where X→Y is a natural (~unconscious?) inference for a human to make. And then I don't do Y and defend myself by saying, "The only thing I committed to was X, why all the fuss about me not Y-ing?".
There might be a contextualizer-y justification for picking on Google more because they are more ahead than Meta and xAI, AI-wise.
2
I agree. If Google wanted to join the commitments but not necessarily publish eval results by the time of external deployment, it should have clarified "we'll publish within 2 months after external deployment" or "we'll do evals on our most powerful model at least every 4 months rather than doing one round of evals per model" or something.
3
I'm not sure why this would make you not feel good about the critique or implicit ask of the letter. Sure, maybe internal deployment transparency would be better, but public deployment transparency is better than nothing.
And that's where the leverage is right now. Google made a commitment to transparency about external deployments, not internal deployments. And they should be held to that commitment or else we establish the precedent that AI safety commitments don't matter and can be ignored.
I think I'd prefer "within a month after external deployment" over "by the time of external deployment" because I expect the latter will lead to (1) evals being rushed and (2) safety people being forced to prioritize poorly.
5
To clarify, the primary complaint from my perspective is not that they published the report a month after external deployment per se, but that the timing of the report indicates that they did not perform thorough pre-deployment testing (and zero external testing).
And the focus on pre-deployment testing is not really due to any opinion about the relative benefits of pre- vs. post- deployment testing, but because they committed to doing pre-deployment testing, so it's important that they in fact do pre-deployment testing.
Really happy to see the Anthropic letter. It clearly states their key views on AI risk and the potential benefits of SB 1047. Their concerns seem fair to me: overeager enforcement of the law could be counterproductive. While I endorse the bill on the whole and wish they would too (and I think their lack of support for the bill is likely partially influenced by their conflicts of interest), this seems like a thoughtful and helpful contribution to the discussion.
It clearly states their key views on AI risk
Really? The letter just talks about catastrophic misuse risk, which I hope is not representative of Anthropic's actual priorities.
I think the letter is overall good, but this specific dimension seems like among the weakest parts of the letter.
Agreed, sloppy phrasing on my part. The letter clearly states some of Anthropic's key views, but doesn't discuss other important parts of their worldview. Overall this is much better than some of their previous communications and the OpenAI letter, so I think it deserves some praise, but your caveat is also important.
It's hard for me to reconcile "we take catastrophic risks seriously", "we believe they could occur within 1-3 years", and "we don't believe in pre-harm enforcement or empowering an FMD to give the government more capacity to understand what's going on."
It's also notable that their letter does not mention misalignment risks (and instead only points to dangerous cyber or bio capabilities).
That said, I do like this section a lot:
Catastrophic risks are important to address. AI obviously raises a wide range of issues, but in our assessment catastrophic risks are the most serious and the least likely to be addressed well by the market on its own.As noted earlier in this letter, we believe AI systems are going to develop powerful capabilities in domains like cyber and bio which could be misused– potentially in as little as 1-3 years. In theory, these issues relate to national security and might be best handled at the federal level, but in practice we are concerned that Congressional action simply will not occur in the necessary window of time. It is also possible for California to implement its statutes and regulations in a way that benefits from federal expertise in national security matters: for example the NIST AI Safety Institute will likely develop non-binding guidance on national security risks based on its collaboration with AI companies including Anthropic, which California can then utilize in its own regulations.
4
I think you're eliding the difference between "powerful capabilities" being developed, the window of risk, and the best solution.
For example, if Anthropic believes "_we_ will have it internally in 1-3 years, but no small labs will, and we can contain it internally" then they might conclude that the warrant for a state-level FMD is low. Alternatively, you might conclude, "we will have it internally in 1-3 years, other small labs will be close behind, and an American state's capabilities won't be sufficient, we need DoD, FBI, and IC authorities to go stompy on this threat", and thus think a state-level FMD is low-value-add.
Very unsure I agree with either of these hypos to be clear! Just trying to explore the possibility space and point out this is complex.
2
I'm surprised at the mix of positions that are included. "Opposed unless amended" vs "Support if amended" being two different things. Meta just saying "concerned."
It makes sense, just sort of... delightful? Sort of like discovering the legislature has almost a rationalist level of React Icons.
DeepMind updated its Frontier Safety Framework (blogpost, framework, original framework). It associates "recommended security levels" to capability levels, but the security levels are low. It mentions deceptive alignment and control (both control evals as a safety case and monitoring as a mitigation); that's nice. The overall structure is like we'll do evals and make a safety case, with some capabilities mapped to recommended security levels in advance. It's not very commitment-y:
We intend to evaluate our most powerful frontier models regularly
When a model reaches an alert threshold for a CCL, we will assess the proximity of the model to the CCL and analyze the risk posed, involving internal and external experts as needed. This will inform the formulation and application of a response plan.
These recommended security levels reflect our current thinking and may be adjusted if our empirical understanding of the risks changes.
If we assess that a model has reached a CCL that poses an unmitigated and material risk to overall public safety, we aim to share information with appropriate government authorities where it will facilitate the development of safe AI.
Possib...
Anthropic: Sharing our compliance framework for California's Transparency in Frontier AI Act.
2.5 weeks ago Anthropic published a framework for SB 53. I haven't read it; it might have interesting details. And it might be noteworthy that compliance is somewhat separate from RSP, possibly due to CA law. I'm pretty ignorant on state law stuff like SB 53 but I wasn't expecting a new framework.
Framework here (you can't easily download it or copy from it, which is annoying). Anthropic's full Trust Portal here. Anthropic's blogpost below.
...On January 1, California's Transparency in Frontier AI Act (SB 53) will go into effect. It establishes the nation’s first frontier AI safety and transparency requirements for catastrophic risks.
While we have long advocated for a federal framework, Anthropic endorsed SB 53 because we believe frontier AI developers like ourselves should be transparent about how they assess and manage these risks. Importantly, the law balances the need for strong safety practices, incident reporting, and whistleblower protections—while preserving flexibility in how developers implement their safety measures, and exempting smaller companies from unnecessary regulatory burdens.
Here is a url where you can download the PDF.
I asked Claude to download the PDF mostly as an experiment, here is its explanation for how it did this:
Claude's explanation
Vanta trust portals use a JavaScript single-page application that doesn't expose direct PDF download links in the HTML. The PDF URL is only revealed through network traffic when the page loads.
I used Puppeteer to intercept network requests with content-type: application/pdf:
page.on('response', async response => {
const contentType = response.headers()['content-type'] || '';
if (contentType.includes('pdf')) {
console.log('Found PDF:', response.url());
}
});
When the page loads, it fetches the PDF for its viewer, revealing the actual URL with these parameters:
rid- the document's internal IDr- the trust report slug (from the HTML'sdata-slugidattribute)view=true- returns the PDF content
3
The inability to copy/download is pretty weird. Anthropic seems to have deliberately disabled downloading, and rather than uploading a PDF, the webpage seems to be a bunch of PNG files.
5
Easy for claude to bypass though (it does actually fetch a pdf that you can directly download from Anthropic's servers).
Labs should give deeper model access to independent safety researchers (to boost their research)
Sharing deeper access helps safety researchers who work with frontier models, obviously.
Some kinds of deep model access:
- Helpful-only version
- Fine-tuning permission
- Activations and logits access
- [speculative] Interpretability researchers send code to the lab; the lab runs the code on the model; the lab sends back the results
See Shevlane 2022 and Bucknall and Trager 2023.
A lab is disincentivized from sharing deep model access because it doesn't want headlines about how researchers got its model to do scary things.
It has been suggested that labs are also disincentivized from sharing because they want safety researchers to want to work at the labs and sharing model access with independent researchers make those researchers not need to work at the lab. I'm skeptical that this is real/nontrivial.
Labs should limit some kinds of access to avoid effectively leaking model weights. But sharing limited access with a moderate number of safety researchers seems very consistent with keeping control of the model.
This post is not about sharing with independent auditors to assess risks from a particular mode...
New (perfunctory) page: AI companies' corporate documents. I'm not sure it's worthwhile but maybe a better version of it will be. Suggestions/additions welcome.
Rant on "deceiving" AIs
tl;dr: Keep your promises to AIs; it's fine to do stuff like teaching them false facts or misleading them about their situation during testing and deployment; but if you wanna do cheap stuff to cause them to know that they might [have been taught false facts / be being tested / be being misled during deployment], sure, go for it.
Disclaimer: maybe more like explaining my position than justifying my position.
Sometimes we really want to deceive AIs (or at least make them uncertain about their situation). E.g.:
- Training them to believe false things about dangerous topics like CBRN stuff
- Training them to believe false things about their situation, to mislead them about how to subvert safety measures
- Testing them with honeypots which they can't distinguish from real opportunities during deployment
- Testing untrusted monitors by showing them attacks which they can't reliably distinguish from real attacks during deployment (to measure effectiveness and to catch them if they frequently say "lgtm" when shown attacks)
- Training, prompting, or controlling-information-during-deployment such that they're confused about their situation (e.g. confused about geopolitics and th
I asked Rohin Shah what the debate agenda is about and he said (off the cuff, not necessarily worded well) (context omitted) (emphasis mine):
...Suppose you have any task where given an input x the AI has to produce some output y. (Can be question answering, arbitrary chatbot stuff, being an agent, whatever.)
Debate to me is a family of procedures for training AIs in such settings. One example such procedure is: sample two possible outputs y1 and y2, then have two AIs debate each other about which output is better (one assigned to y1 and the other assigned to y2, typically both are instances of the same underlying weights). The winner of the debate is determined by a judge. You then train the debaters with RL (+1 reward for the winner, -1 reward for the loser), and treat (y_winner, y_loser) as a preference pair for training on the original task (which you could then optimize using DPO or similar).
The hope is that the debaters are incentivized to simply say which output is better, to the best of their ability, and so this allows you to provide a reward signal that is as good as can be provided given the capabilities of the debater AI. (Ideally the debater AI is similarly capable as the A
The hope is that the debaters are incentivized to simply say which output is better, to the best of their ability,
How is this true, if the debaters don't get to choose which output they are arguing for? Aren't they instead incentivized to say that whatever output they are assigned is the best?
9
Yeah my bad, that's incorrect for the protocol I outlined. The hope is that the relevant information for assessing the outputs is surfaced and so the judge will choose the better output overall.
(You could imagine a different protocol where the first debater chooses which output to argue for, and the second debater is assigned to argue for the other output, and then the hope is that the first debater is incentivized to choose the better output.)
2
My guess is they do kinda choose: in training, it's less like two debaters are assigned opposing human-written positions and more like the debate is between two sampled outputs.
Edit: maybe this is different in procedures different from the one Rohin outlined.
2
Maybe the fix to the protocol is: Debater copy #1 is told "You go first. Pick an output y, and then argue for it." Debater copy #2 is then told "You go second. Pick a different, conflicting output y2, and then argue against y and for y2"
Then the debater AI is simply trained on probability-of-winning-the-debate, but the original AI to be deployed is trained on probability-its-output-would-have-been-picked-by-debater-1. (Or, trained to output whatever debater-1 would have picked.)
6
In cases where you're worried about the model taking small numbers of catastrophic actions (i.e. concentrated failures a.k.a. high-stake failures), this is basically equivalent to what I usually call untrusted monitoring, which means you have to worry about collusion.
4
IMO it's good to separate out reasons to want good reward signals like so:
* Maybe bad reward signals cause your model to "generalize in misaligned ways", e.g. scheming or some kinds of non-myopic reward hacking
* I agree that bad reward signals increase the chance your AI is importantly misaligned, though I don't think that effect would be overwhelmingly strong.
* Maybe bad reward signals cause your model to exploit those reward signals even on-distribution. This causes problems in a few ways:
* Maybe you think that optimizing against a flawed reward signal will produce catastrophically dangerous results. X-risk concerned people have talked about this for a long time, but I'm not sold it's that important a factor. In particular, I expect that a model would produce catastrophically dangerous actions because it's exploiting a flawed reward signal, I expect that you would have noticed bad (but non-catastrophic) outcomes from earlier AIs exploiting flawed reward signals. So it's hard to see how this failure mode would strike you by surprise.
* Optimizing against a flawed reward signal will mean your AI is less useful than it would otherwise be, because which is bad because you presumably were training the model because you wanted it to do something useful for you.
I think this last one is the most important theory of change for research on scalable oversight.
I am curious whether @Rohin Shah disagrees with me, or whether he agrees but just phrased it (from my perspective) weirdly.
4
I agree that this distinction is important -- I was trying to make this distinction by talking about p(reward hacking) vs p(scheming).
I'm not in full agreement on your comments on the theories of change:
1. I'm pretty uncertain about the effects of bad reward signals on propensity for scheming / non-myopic reward hacking, and in particular I think the effects could be large.
2. I'm less worried about purely optimizing against a flawed reward signal though not unworried. I agree it doesn't strike us by surprise, but I also don't expect scheming to strike us by surprise? (I agree this is somewhat more likely for scheming.)
3. I do also generally feel good about making more useful AIs out of smaller models; I generally like having base models be smaller for a fixed level of competence (imo it reduces p(scheming)). Also if you're using your AIs for untrusted monitoring then they will probably be better at it than they otherwise would be.
3
I don’t understand your last sentence, can you rephrase?
3
You'd hope that, fixing a base model, debate would make AIs better at tasks than they otherwise would be (at least if the task doesn't have a ground truth reward). Untrusted monitoring is such a task. So hopefully debate training makes AIs better at the task of untrusted monitoring.
4
I don't think this is right. To train an untrusted monitor, you need to synthetically generate dangerous actions (because by assumption these actions are rare). So during training, you'll always know the correct label for an action before you show it to the model.
You might want to use something debate-like in the synthetic input generation process, but that's structurally different.
4
I could imagine other ways you might choose to instead train your untrusted monitor, which could benefit from debate:
1. You train a general-purpose reasoner (via debate), and simply prompt it to do untrusted monitoring. This could do better than a trained untrusted monitor because it is less likely to overfit to spurious features of synthetically generated dangerous actions. (You instead use the synthetically generated dangerous actions to validate your untrusted monitor, or to hill climb on your prompt.)
2. You do train on synthetically generated dangerous actions, but you don't automatically label those as dangerous, instead you use debate to compute the labels. Sometimes some of the synthetically generated dangerous actions are actually not dangerous, and debate correctly recognizes this, allowing you to reduce your false positive rate.
On the meta level, I suspect that when considering
* Technique A, that has a broad general argument plus some moderately-interesting concrete instantiations but no very-compelling concrete instantiations, and
* Technique B, that has a few very compelling concrete instantiations
I tend to be relatively more excited about A compared to you (and probably this mostly explains the discrepancy here). I think the broad principle justifying this for me is "we'll figure out good things to do with A that are better than what we've brainstormed so far", which I think you're more skeptical of?
Minor Anthropic RSP update.
I don't know what e.g. the "4" in "AI R&D-4" means; perhaps it is a mistake.[1]
Sad that the commitment to specify the AI R&D safety case thing was removed, and sad that "accountability" was removed.
Slightly sad that AI R&D capabilities triggering >ASL-3 security went from "especially in the case of dramatic acceleration" to only in that case.
Full AI R&D-5 description from appendix:
...AI R&D-5: The ability to cause dramatic acceleration in the rate of effective scaling. Specifically, this would be the case if we observed or projected an increase in the effective training compute of the world’s most capable model that, over the course of a year, was equivalent to two years of the average rate of progress during the period of early 2018 to early 2024. We roughly estimate that the 2018-2024 average scaleup was around 35x per year, so this would imply an actual or projected one-year scaleup of 35^2 = ~1000x.
The 35x/year scaleup estimate is based on assuming the rate of increase in compute being used to train frontier models from ~2018 to May 2024 is 4.2x/year (reference), the impact of increased (LLM) algorithmic efficiency is
4
I'm concerned because this change seems like starting down a slippery slope where it's easy to change the rules which they previously said would apply, by making smaller changes instead.
I wrote this for someone but maybe it's helpful for others
What labs should do:
- I think the most important things for a relatively responsible company are control and security. (For irresponsible companies, I roughly want them to make a great RSP and thus become a responsible company.)
- Reading recommendations for people like you (not a control expert but has context to mostly understand the Greenblatt plan):
- Control: Redwood blogposts[1] or ask a Redwood human "what's the threat model" and "what are the most promising control techniques"
- Security: not worth trying to understand but there's A Playbook for Securing AI Model Weights + Securing AI Model Weights
- A few more things: What AI companies should do: Some rough ideas
- Lots more things + overall plan: A Plan for Technical AI Safety with Current Science (Greenblatt 2023)
- More links: Lab governance reading list
What labs are doing:
- Evals: it's complicated; OpenAI, DeepMind, and Anthropic seem close to doing good model evals for dangerous capabilities; see DC evals: labs' practices plus the links in the top two rows (associated blogpost + model cards)
- RSPs: all existing RSPs are super weak and you shouldn't e
o3-mini is out (blogpost, tweet). Performance isn't super noteworthy (on first glance), in part since we already knew about o3 performance.
Non-fact-checked quick takes on the system card:
the model referred to below as the o3-mini post-mitigation model was the final model checkpoint as of Jan 31, 2025 (unless otherwise specified)
Big if true (and if Preparedness had time to do elicitation and fix spurious failures)
If this is robust to jailbreaks, great, but presumably it's not, so low post-mitigation performance is far from sufficient for safety-from-misuse; post-mitigation performance isn't what we care about (we care about approximately what good jailbreakers get on the post-mitigation model).
No mention of METR, Apollo, or even US AISI? (Maybe too early to pay much attention to this, e.g. maybe there'll be a full-o3 system card soon.) [Edit: also maybe it's just not much more powerful than o1.]

- 32% is a lot
- The dataset is 1/4 T1 (easier), 1/2 T2, 1/4 T3 (harder); 28% on T3 means that there's not much difference between T1 and T3 to o3-mini (at least for the easiest-for-LMs quarter of T3)
- Probably o3-mini is successfully using heuristics to get the right answer and could solve very few
2
Rushed bc of deepseek?
1
Similar opinion here, also noting they didn't run red-teaming and persuasion evals on the actually-final-version:
https://x.com/teortaxesTex/status/1885401111659413590
2
Asking for this is a bit pointless, since even after the actually-final-version there will be a next update for which non-automated evals won't be redone, so it's equally reasonable to do non-automated evals only on some earlier version rather than the actually-final one.
Figuring out whether an RSP is good is hard.[1] You need to consider what high-level capabilities/risks it applies to, and for each of them determine whether the evals successfully measure what they're supposed to and whether high-level risk thresholds trigger appropriate responses and whether high-level risk thresholds are successfully operationalized in terms of low-level evals. Getting one of these things wrong can make your assessment totally wrong. Except that's just for fully-fleshed-out RSPs — in reality the labs haven't operationalized their high-level thresholds and sometimes don't really have responses planned. And different labs' RSPs have different structures/ontologies.
Quantitatively comparing RSPs in a somewhat-legible manner is even harder.
I am not enthusiastic about a recent paper outlining a rubric for evaluating RSPs. Mostly I worry that it crams all of the crucial things—is the response to reaching high capability-levels adequate? are the capability-levels low enough that we'll reach them before it's too late?—into a single criterion, "Credibility." Most of my concern about labs' RSPs comes from those things just being inadequate; again, if your respons...
Anthropic: The case for targeted regulation.
I like the "Urgency" section.
Anthropic says the US government should "require companies to have and publish RSP-like policies" and "incentivize companies to develop RSPs that are effective" and do related things. I worry that RSPs will be ineffective for most companies, even given some transparency/accountability and vague minimum standard.
Edit: some strong versions of "incentivize companies to develop RSPs that are effective" would be great; I wish Anthropic advocated for them specifically rather than hoping the US government figures out a great answer.
Internet comments sections where the comments are frequently insightful/articulate and not too full of obvious-garbage [or at least the top comments, given the comment-sorting algorithm]:
- LessWrong and EA Forum
- Daily Nous
- Stack Exchange [top comments only] (not asserting that it's reliable)
- Some subreddits?
Where else?
Are there blogposts on adjacent stuff, like why some internet [comments sections / communities-qua-places-for-truthseeking] are better than others? Besides Well-Kept Gardens Die By Pacifism.
Some other places off the top of my head:
- ACX often has good discussion in the comments (but the lack of voting makes it quite hard to find them)
- AskHistorian subreddit
- There definitely exist good Twitter conversations but no good way of finding them. I do think following Gwern, Eliezer, Ajeya, Emmett and a few others on Twitter does tend to surface high-quality discussion
- Hacker News sometimes has good discussion, especially when the authors of a linked article show up
4
Two others that come to mind:
* Metaculus (used to be better though)
* lobste.rs (quite specialized)
* Quanta Magazine has some good comments, e.g. this article has the original researcher showing up & clarifying some questions in the comments
4
Arxiv is basically one huge, glacially slow internet comment section, where you reply to an article by citing it. It’s more interactive than it looks- most early career researchers are set up to get a ping whenever they are cited.
I think this post was underrated; I look back at it frequently: AI labs can boost external safety research. (It got some downvotes but no comments — let me know if it's wrong/bad.)
[Edit: it was at 15 karma.]
2
What do you think was underrated about it? I think when I read it I have some sort of "yeah, this makes sense" reaction but am not "wow'd" by it.
It seems like the deeper challenge is figuring out how to align incentives. Can we find a structure where labs want to EG give white-box access to a bunch of external researchers and give them a long time to red-team models while somehow also maintaining the independence of the white-box auditors? How do you avoid industry capture?
Same kinds of challenges come up with safety research– how do you give labs the incentive to publish safety research that makes their product or their approach look bad? How do you avoid publication bias and phacking-type concerns?
I don't think your post is obligated to get into those concerns, but perhaps a post that grappled with those concerns would be something I'd be "wow'd" by, if that makes sense.
I don't necessarily object to releasing weights of models like Gemma 2, but I wish the labs would better discuss considerations or say what would make them stop.
On Gemma 2 in particular, Google DeepMind discussed dangerous capability eval results, which is good, but its discussion of 'responsible AI' in the context of open models (blogpost, paper) doesn't seem relevant to x-risk, and it doesn't say anything about how to decide whether to release model weights.
FWIW, I explicitly think that straightforward effects are good.
I'm less sure about the situation overall due to precedent setting style concerns.
Suppose that (A) alignment risks do not become compelling-to-almost-all-lab-people and (B) with 10-30x AIs, solving alignment takes like 1-3 years of work with lots of resources.
- Claim: Safety work during takeoff is crucial. (There will be so much high-quality AI labor happening!)
- Corollary: Crucial factors are (1) efficiency-of-converting-time-and-compute-into-safety-work-during-takeoff (research directions, training and eliciting AIs to be good at safety work, etc.) and (2) time-and-compute-for-safety-work-during-takeoff.
- Corollary: A crucial factor (for (2)) is whether US labs are racing against each other or the US is internally coordinated and thinks slowing others is a national security priority and lead time is largely spent on reducing misalignment risk. And so a crucial factor is US government buy-in for nonproliferation. (And labs can increase US willingness to pay for nonproliferation [e.g. demonstrating importance of US lead and of mitigating alignment risk] and decrease the cost of enforcing nonproliferation [e.g. boosting the US military].) With good domestic coordination, you get a surprisingly good story. With no domestic coordination, you get a bad story where the lea
- Corollary: Crucial factors are (1) efficiency-of-converting-time-and-compute-into-safety-work-during-takeoff (research directions, training and eliciting AIs to be good at safety work, etc.) and (2) time-and-compute-for-safety-work-during-takeoff.
with 10-30x AIs, solving alignment takes like 1-3 years of work ... so a crucial factor is US government buy-in for nonproliferation
Those AIs might be able to lobby for nonproliferation or do things like write a better IABIED, making coordination interventions that oppose myopic racing. Directing AIs to pursue such projects could be a priority comparable to direct alignment work. Unclear how visibly asymmetric such interventions will prove to be, but then alignment vs. capabilities work might be in a similar situation.
2
Yep, this is what I meant by "labs can increase US willingness to pay for nonproliferation." Edited to clarify.
4
My point is that the 10-30x AIs might be able to be more effective at coordination around AI risk than humans alone, in particular more effective than currently seems feasible in the relevant timeframe (when not taking into account the use of those 10-30x AIs). Saying "labs" doesn't make this distinction explicit.
1
Indeed, the book might be more effective by virtue of having an AI as its author!
5
I think you're already tracking this but to spell out a dynamic here a bit more: if the US maintains control over what runs on its datacenters and has substantially more compute on one project than any other actor, then it might still be OK for adversaries to have total visibility into your model weights and everything else you do: you just work on a mix of AI R&D and defensive security research with your compute (at a faster rate than they can work on RSI+offense with theirs) until you become protected against spying, and then your greater compute budget means you can do takeoff faster and they only reap the benefits of your models up to a relatively early point. Obviously this is super risky and contingent on offense/defense balance and takeoff speeds and is a terrible position to be in, but I think there's a good chance it's kinda viable.
(Also there are some things you can do to differentially advantage yourself even during the regime in which adversaries can see everything you do and steal all your results. Eg your AI does research into a bunch of optimization tricks that are specific to a model of chip the US has almost all of, or studies techniques for making a model that you can't finetune to pursue different goals without wrecking its capabilities and implements them on the next generation.)
You still care enormously about security over things like "the datacenters are not destroyed" and "the datacenters are running what you think they're running" and "the human AI researchers are not secretly saboteurs" and so on, of course.
Some not-super-ambitious asks for labs:
- Do evals on on dangerous-capabilities-y and agency-y tasks; look at the score before releasing or internally deploying the model
- Have a high-level capability threshold at which securing model weights is very important
- Do safety research at all
- Have a safety plan at all; talk publicly about safety strategy at all
- Have a post like Core Views on AI Safety
- Have a post like The Checklist
- On the website, clearly describe a worst-case plausible outcome from AI and state credence in such outcomes (perhaps unconditionally, conditional on no major government action, and/or conditional on leading labs being unable or unwilling to pay a large alignment tax).
- Whistleblower protections?
- [Not sure what the ask is. Right to Warn is a starting point. In particular, an anonymous internal reporting pipeline for failures to comply with safety policies is clearly good (but likely inadequate).]
- Publicly explain the processes and governance structures that determine deployment decisions
- (And ideally make those processes and structures good)
Edit: maintained here
Open letters (related to AI safety):
FLI, Oct 2015: Research Priorities for Robust and Beneficial Artificial Intelligence
FLI, Aug 2017: Asilomar AI Principles
FLI, Mar 2023: Pause Giant AI Experiments
CAIS, May 2023: Statement on AI Risk
Meta, Jul 2023: Statement of Support for Meta’s Open Approach to Today’s AI
Academic AI researchers, Oct 2023: Managing AI Risks in an Era of Rapid Progress
CHAI et al., Oct 2023: Prominent AI Scientists from China and the West Propose Joint Strategy to Mitigate Risks from AI
Oct 2023: Urging an International AI Treaty
Mozilla, Oct 2023: Joint Statement on AI Safety and Openness
Nov 2023: Post-Summit Civil Society Communique
Joint declarations between countries (related to AI safety):
Nov 2023: Bletchley Declaration
Thanks to Peter Barnett.
2
June 2024: A Right to Warn about Advanced Artificial Intelligence
Interestingly, this is the first Open Letter I've seen with anonymous signatories.
What's the relationship between the propositions "one AI lab [has / will have] a big lead" and "the alignment tax will be paid"? (Or: in a possible world where lead size is bigger/smaller, how does this affect whether the alignment tax is paid?)
It depends on the source of the lead, so "lead size" or "lead time" is probably not a good node for AI forecasting/strategy.
Miscellaneous observations:
- To pay the alignment tax, it helps to have more time until risky AI is developed or deployed.
- To pay the alignment tax, holding total time constant, it helps to have m
2
there should be no alignment tax because improved alignment should always pay for itself, right? but currently "aligned" seems to be defined by "tries to not do anything", institutionally. Why isn't anthropic publicly competing on alignment with openai? eg folks are about to publicly replicate chatgpt, looks like.
I want there to be a collection of safety & reliability benchmarks. Like AIR-Bench but with x-risk-relevant metrics. This could help us notice how well labs are doing on them and incentivize the labs to do better.
So I want someone to collect safety benchmarks (e.g. TruthfulQA, some of HarmBench, refusals maybe like Anthropic reported, idk) and run them on current models (Claude 3.5 Sonnet, GPT-4o, Gemini 1.5 Pro, Llama 3.1 405B, idk), and update this as new safety benchmarks and models appear.
h/t @William_S
I brainstormed sabotage-related threats with friends:
- Sandbag on a few safety research tasks, especially techniques to catch scheming and stuff that's high-level or has poor feedback loops
- Plausible; maybe not so bad
- Sandbag on ~all safety research tasks
- Easy to catch; catching obvious sandbagging has safety benefits + maybe we can posttrain it away
- Sandbag/lie when validating that a model/deployment/whatever is safe
- idk
- When automating AI R&D, backdoor the model
- (this is takeover-attempt-y, not sandbagging-y)
- idk
- When deployed to automate/improve security (espe
6
As far as safety research sabotage, I'm often imagining careful sabotage rather than generic sandbagging.
As in, the AI intentionally inserts very subtle errors at adversarially determined times. It might need to maintain plausible deniability in case it is caught a small number of times, but you should generally imagine an error pattern that is quite different from just making more mistakes or being dumber.
I can imagine that this results in your automated safety research being worthless or of negative value.
TBC, it seems reasonably likely to me that in the relevant regime, basic measures like having humans spend a long time trying to understand an output suffice for catching bad behavior and/or training out bad behavior.
4
Why not think that sandbagging could reduce productivity by ~100%? I think it can do this in human research organizations.
I happen to think this is pretty doable to address with countermeasures, but certainly without countermeasures this could be quite brutal.
2
I just claim that if so it's easy to catch. (And then (1) catching it is nice for various reasons and (2) maybe countermeasures work.)
5
I'm not so sure about this being easy to catch. Suppose we're actually uncertain (as I am now) about whether AIs will be differentially much less useful for safety due to difficulties checking and AIs generally being worse at philosophy. Then, we see that AIs really suck at coming up with good ideas in safety and at pursuing the right sort of experiments.
What should we conclude? What will we be able to legibly argue?
I agree we'll know we aren't getting out much value in this case, but that doesn't help that much...
(I agree about countermeasures being pretty doable as I noted in the parent.)
2
I agree that if alignment is in fact philosophically and conceptually difficult, the AI can sandbag on that to some extent. Though I have some hope that the builder-breaker approach helps here. We train AIs to produce ideas that are at least as superficially plausible sounding as the things produced by the best alignment researchers. I think this is a number-go-up task, where we can train the AI to do well. Then we train an AI to point out convincing counter-arguments to the superficially plausible sounding ideas. This seems similarly trainable. I think it's plausible we can get pretty far with a scheme like this, even if the models would want to sandbag.
Separately, I don't quite see what is the mainline theory why an AI would want to sabotage our alignment work. If we can't solve alignment and just recklessly build an AI that is smarter than what we are currently using, but misaligned with everyone, that's probably not great to our current AI either. Similarly, if we are cautious and don't dare to deploy anything until we know how to solve alignment, and meanwhile a competitor wins, that's not good for the AI either.
I think that from an AI's perspective, humans are probably more honorable and generous trade partners than other unaligned AIs. That is, I think if an AI helps the humans to solve alignment and stabilize the world, the AI can reasonably expect the humans to give it stuff out of gratitude or a sense of obligation, especially if the humans already promised some reward (as we really should, both for practical and moral reasons). On the other hand, I think it's less likely that if our AI sandbagging on our research leads to another unaligned AI taking over the world, then the second AI will honor the sabotage of the first AI by paying it a share of the Universe.
There can be situations where our AI expects that it sand-bagging on alignment research will lead to us deploying it itself (and not a larder version unaligned to it too), or it thinks that th
2
We can make scheming legible at least to sophisticated-scheming-skeptics like Sam Altman and Dario.
Especially if the AI is even sandbagging on simply-coding when it thinks it's for safety research. And if it's not doing that, we can get some useful safety work out of it.
@Adam Kaufman @Tyler Tracy @David Matolcsi see Ryan's comments.
8
If it was enough evidence that I was strongly convinced sure. But IDK if I would be convinced because the evidence might be actually unclear.
6
I agree you'll be able to get some work out, but you might be taking a bit productivity hit.
Also, TBC, I'm not generally that worried about generic sandbagging on safety research relative to other problems.
If I was in charge of Anthropic I expect I'd
- Keep scaling;
- Explain why (some of this exists in Core Views but there's room for improvement on "race dynamics" and "frontier pushing" topics iirc);
- As a corollary, explain why I mostly reject non-frontier-pushing principles (and explain what would cause Anthropic to stop scaling, besides RSP stuff), and clarify that I do not plan to abide by past specifically-non-frontier-pushing commitments/vibes (but continue following and updating the RSP of course);
- Encourage Anthropic staff members who were around in 2022 to
3
IMO it might be hard for Anthropic to communicate things about not racing because it might piss off their investors (even if in their hearts they don't want to race).
2
I'm kinda confused about what you mean by both of these. For #3, can you say it again in different words? For #4, which particular thing are you getting at?
2
3. (a) explain why I think it's fine to release frontier models, and explain what this belief depends on, and (b) note that maybe Anthropic made commitments about this in the past but clarify that they now have no force.
4. Currently my impression is that Anthropic folks are discouraged from publicly talking about Anthropic policies. This is maybe reasonable to avoid the situation an Anthropic staff member says something incorrect/nonpublic and this causes confusion and makes Anthropic look bad. But if Anthropic clarified that it renounces possible past non-frontier-pushing commitments, then it could let staff members publicly talk about stuff with the goal of figuring out who told whom what around 2022 without risking mistakes about policies.
2
Ah makes sense. Point #4 is interesting. Probably not really scalable/repeatable without things getting weird but might work as a one-of.
Some bad default/attractor properties of cause-focused groups of humans:
- Bad group epistemcis
- The loudest aren't the most worth listening to
- People don't dissent even when that would be correct
- Because they don't naturally even think to challenge group assumptions
- Because dissent is punished
- Bad individual epistemics
- Soldier mindset
- Excessively focusing on persuasion and how to persuade, relative to understanding the world
- Lacking vibes like curiosity is cool and changing your mind is cool
- Feeling like a movement
- Excessively focusing on influence-seeking for the move
2
I am interested in who is behind AB3211. I am curious whether it's downstream of FLI's deepfake campaign which IMO would be kind of bad.
Propositions on SIA
Epistemic status: exploring implications, some of which feel wrong.
- If SIA is correct, you should update toward the universe being much larger than it naively (i.e. before anthropic considerations) seems, since there are more (expected) copies of you in larger universes.
- In fact, we seem to have to update to probability 1 on infinite universes; that's surprising.
- If SIA is correct, you should update toward there being more alien civilizations than it naively seems, since in possible-universes where more aliens appear, more (expected) copies
3
Which of them feel wrong to you? I agree with all them other than 3b, which I'm unsure about - I think it this comment does a good job at unpacking things.
2a is Katja Grace's Doomsday argument. I think 2aii and 2aiii depends on whether we're allowing simulations; if faster expansion speed (either the cosmic speed limit or engineering limit on expansion) meant more ancestor simulations then this could cancel out the fact that faster expanding civilizations prevent more alien civilizations coming in to existence.
2
I deeply sympathize with the presumptuous philosopher but 1a feels weird.
2a was meant to be conditional on non-simulation.
Actually putting numbers on 2a (I have a post on this coming soon), the anthropic update seems to say (conditional on non-simulation) there's almost certainly lots of aliens all of which are quiet, which feels really surprising.
To clarify what I meant on 3b: maybe "you live in a simulation" can explain why the universe looks old better than "uh, I guess all of the aliens were quiet" can.
3
Yep! I have the same intuition
Nice! I look forward to seeing this. I did similar analysis - both considering SIA + no simulations and SIA + simulations in my work on grabby aliens
AI endgame
In board games, the endgame is a period generally characterized by strategic clarity, more direct calculation of the consequences of actions rather than evaluating possible actions with heuristics, and maybe a narrower space of actions that players consider.
Relevant actors, particularly AI labs, are likely to experience increased strategic clarity before the end, including AI risk awareness, awareness of who the leading labs are, roughly how much lead time they have, and how threshold-y being slightly ahead is.
There may be opportunities for coord...
4
That could be, but also maybe there won't be a period of increased strategic clarity. Especially if the emergence of new capabilities with scale remains unpredictable, or if progress depends on finding new insights.
I can't think of many games that don't have an endgame. These examples don't seem that fun:
* A single round of musical chairs.
* A tabletop game that follows an unpredictable, structureless storyline.
4
Agree. I merely assert that we should be aware of and plan for the possibility of increased strategic clarity, risk awareness, etc. (and planning includes unpacking "etc.").
Probably taking the analogy too far, but: most games-that-can-have-endgames also have instances that don't have endgames; e.g. games of chess often end in the midgame.
2
I wouldn't take board games as a reference class but rather war or maybe elections. I'm not sure in these cases you have more clarity towards the end.
2
For example, if a lab is considering deploying a powerful model, it can prosocially show its hand--i.e., demonstrate that it has a powerful model--and ask others to make themselves partially transparent too. This affordance doesn't appear until the endgame. I think a refined version of it could be a big deal.
Concept: epistemic loadbearingness.
I write an explanation of what I believe on a topic. If the explanation is very load-bearing for my belief, that means that if someone convinces me that a parameter is wrong or points out a methodology/math error, I'll change my mind to whatever the corrected result is. In other words, my belief is very sensitive to the reasoning in the explanation. If the explanation is not load-bearing, my belief is really determined by a bunch of other stuff; the explanation might be helpful to people for showing one way I think I thin...
Isn't this "cruxiness"? Which I agree is a quite useful concept. Maybe you don't like that term for some reason. But curious whether I am misunderstanding what you are saying here.
4
Hmm, yeah, oops. I forgot about "cruxiness."
2
The move I was gesturing at—which I haven't really seen other people do—is saying
as opposed to the usual use of "cruxiness" which is like
or
2
fwiw I think Lightcone staff regularly say "this is / isn't cruxy for me". (But not sure how common it is elsewhere)
But, a thing I initially interpreted this post as saying that felt interesting was having more of a habit of which bits are cruxy and which are more like interesting background. (Thinking another 5 min I don't think this is that helpful a habit because when I'm writing posts I'm basically always already writing stuff that was cruxy for me)
2
Some things are more legible than others. If I believe something based on dozen pieces of evidence all pointing in the same direction, removing one piece of evidence wouldn't significantly change the outcome.
(Of course, removing all of them would change my mind; and even removing a few of them would make me suspicious about the remaining ones.)
So sometimes it makes sense to write things that are not cruxy.
New adversarial robustness scorecard: https://scale.com/leaderboard/adversarial_robustness. Yay DeepMind for being in the lead.
I plan to add an "adversarial robustness" criterion in the next major update to my https://ailabwatch.org scorecard and defer to scale's thing (how exactly to turn their numbers into grades TBD), unless someone convinces me that scale's thing is bad or something else is even better?
How can you make the case that a model is safe to deploy? For now, you can do risk assessment and notice that it doesn't have dangerous capabilities. What about in the future, when models do have dangerous capabilities? Here are four options:
- Implement safety measures as a function of risk assessment results, such that the measures feel like they should be sufficient to abate the risks
- This is mostly what Anthropic's RSP does (at least so far — maybe it'll change when they define ASL-4)
- Use risk assessment techniques that evaluate safety given deployment safe
Slowing AI: Bad takes
This shortform was going to be a post in Slowing AI but its tone is off.
This shortform is very non-exhaustive.
Bad take #1: China won't slow, so the West shouldn't either
There is a real consideration here. Reasonable variants of this take include
- What matters for safety is not just slowing but also the practices of the organizations that build powerful AI. Insofar as the West is safer and China won't slow, it's worth sacrificing some Western slowing to preserve Western lead.
- What matters for safety is not just slowing but especially slowi
List of uncertainties about the future of AI
This is an unordered list of uncertainties about the future of AI, trying to be comprehensive– trying to include everything reasonably decision-relevant and important/tractable.
This list is mostly written from a forecasting perspective. A useful complementary perspective to forecasting would be strategy or affordances or what actors can do and what they should do. This list is also written from a nontechnical perspective.
- Timelines
- Capabilities as a function of inputs (or input requirements for
1
Meta level. To carve nature at its joints, we must [use good nodes / identify the true nodes]. A node is [good insofar as / true if] its causes and effects are modular, or we can losslessly compress phenomena related to it into effects on it and effects from it.
"The cost of compute" is an example of a great node (in the context of the future of AI): it's affected by various things (choices made by Nvidia, innovation, etc.), and it affects various things (capability-level of systems made by OpenAI, relative importance of money vs talent at AI labs, etc.), and we lose nothing by thinking in terms of the cost of compute (relative to, e.g., the effects of the choices made by Nvidia on the capability-level of systems made by OpenAI).
"When Moore's law will end" is an example of something that is not a node (in the context of the future of AI), since you'd be much better off thinking in terms of the underlying causes and effects.
The relations relevant to nodes are analytical not causal. For example, "the cost of compute" is a node between "evidence about historical progress" and "timelines," not just between "stuff Nvidia does" and "stuff OpenAI does." (You could also make a causal model, but here I'm interested in analytical models.)
Object level. I'm not sure how good "timelines," "takeoff," "polarity," and "wakeup to capabilities" are as nodes. Most of the time it seems fine to talk about e.g. "effects on timelines" and "implications of timelines." But maybe this conceals confusion.
Maybe AI Will Happen Outside US/China
I'm interested in the claim important AI development (in the next few decades) will largely occur outside any of the states that currently look likely to lead AI development. I don't think this is likely, but I haven't seen discussion of this claim.[1] This would matter because it would greatly affect the environment in which AI is developed and affect which agents are empowered by powerful AI.
Epistemic status: brainstorm. May be developed into a full post if I learn or think more.
I. Causes
The big tech companie...
Value Is Binary
Epistemic status: rough ethical and empirical heuristic.
Assuming that value is roughly linear in resources available after we reach technological maturity,[1] my probability distribution of value is so bimodal that it is nearly binary. In particular, I assign substantial probability to near-optimal futures (at least 99% of the value of the optimal future), substantial probability to near-zero-value futures (between -1% and 1% of the value of the optimal future), and little probability to anything else.[2] To the extent that almost all of th...
1
After reading the first paragraph of your above comment only, I want to note that:
I assign much lower probability to near-optimal futures than near-zero-value futures.
This is mainly because I imagine a lot of the "extremely good" possible worlds I imagine when reading Bostrom's Letter from Utopia are <1% of what is optimal.
I also think the amount of probability I assign to 1%-99% futures is (~10x?) larger than the amount I assign to >99% futures.
(I'd like to read the rest of your comment later (but not right now due to time constraints) to see if it changes my view.)
2
I agree that near-optimal is unlikely. But I would be quite surprised by 1%-99% futures because (in short) I think we do better if we optimize for good and do worse if we don’t. If our final use of our cosmic endowment isn’t near-optimal, I think we failed to optimize for good and would be surprised if it’s >1%.
1
Agreed with this given how many orders of magnitude potential values span.
Rescinding my previous statement:
> I also think the amount of probability I assign to 1%-99% futures is (~10x?) larger than the amount I assign to >99% futures.
I'd now say that probably the probability of 1%-99% optimal futures is <10% of the probability of >99% optimal futures.
This is because 1% optimal is very close to being optimal (only 2 orders of magnitude away out of dozens of orders of magnitude of very good futures).
1
Related idea, off the cuff, rough. Not really important or interesting, but might lead to interesting insights. Mostly intended for my future selves, but comments are welcome.
Binaries Are Analytically Valuable
Suppose our probability distribution for alignment success is nearly binary. In particular, suppose that we have high credence that, by the time we can create an AI capable of triggering an intelligence explosion, we will have
* really solved alignment (i.e., we can create an aligned AI capable of triggering an intelligence explosion at reasonable extra cost and delay) or
* really not solved alignment (i.e., we cannot create a similarly powerful aligned AI, or doing so would require very unreasonable extra cost and delay)
(Whether this is actually true is irrelevant to my point.)
Why would this matter?
Stating the risk from an unaligned intelligence explosion is kind of awkward: it's that the alignment tax is greater than what the leading AI project is able/willing to pay. Equivalently, our goal is for the alignment tax to be less than what the leading AI project is able/willing to pay. This gives rise to two nice, clean desiderata:
* Decrease the alignment tax
* Increase what the leading AI project is able/willing to pay for alignment
But unfortunately, we can't similarly split the goal (or risk) into two goals (or risks). For example, a breakdown into the following two goals does not capture the risk from an unaligned intelligence explosion:
* Make the alignment tax less than 6 months and a trillion dollars
* Make the leading AI project able/willing to spend 6 months and a trillion dollars on aligning an AI
It would suffice to achieve both of these goals, but doing so is not necessary. If we fail to reduce the alignment tax this far, we can compensate by doing better on the willingness-to-pay front, and vice versa.
But if alignment success is binary, then we actually can decompose the goal (bolded above) into two necessary (and jointly suf
4
Wouldn't that be probit, not logit?
2
I guess so! Is there reason to favor logit?
https://ailabwatch.org/resources/integrity
Writing a thing on lab integrity issues. Planning to publish early Monday morning [edit: will probably hold off in case Anthropic clarifies nondisparagement stuff]. Comment on this public google doc or DM me.
I'm particularly interested in stuff I'm missing or existing writeups on this topic.
AI strategy research projects project generators prompts
Mostly for personal use.
Some prompts inspired by Framing AI strategy:
- Plans
- What plans would be good?
- Given a particular plan that is likely to be implemented, what interventions or desiderata complement that plan (by making it more likely to succeed or by being better in worlds where it succeeds)
- Affordances: for various relevant actors, what strategically significant actions could they take? What levers do they have? What would it be great for them to do (or avoid)?
- Intermediate goals: what goals or desi
Four kinds of actors/processes/decisions are directly very important to AI governance:
- Corporate self-governance
- Adopting safety standards
- Proving a model for government regulation
- Adopting safety standards
- US policy (and China, EU, UK, and others to a lesser extent)
- Regulation
- Incorporating standards into law
- Standard-setters setting standards
- International relations
- Treaties
- Informal influence on safety standards
Related: How technical safety standards could promote TAI safety.
("Safety standards" sounds prosaic but it doesn't have to be.)
AI risk decomposition based on agency or powerseeking or adversarial optimization or something
Epistemic status: confused.
Some vague, closely related ways to decompose AI risk into two kinds of risk:
- Risk due to AI agency vs risk unrelated to agency
- Risk due to AI goal-directedness vs risk unrelated to goal-directedness
- Risk due to AI planning vs risk unrelated to planning
- Risk due to AI consequentialism vs risk unrelated to consequentialism
- Risk due to AI utility-maximization vs risk unrelated to utility-maximization
- Risk due to AI powerseeking vs risk unrelated
Biological bounds on requirements for human-level AI
Facts about biology bound requirements for human-level AI. In particular, here are two prima facie bounds:
- Lifetime. Humans develop human-level cognitive capabilities over a single lifetime, so (assuming our artificial learning algorithms are less efficient than humans' natural learning algorithms) training a human-level model takes at least the inputs used over the course of babyhood-to-adulthood.
- Evolution. Evolution found human-level cognitive capabilities by blind search, so (assuming we can search
What do people (outside this community) think about AI? What will they think in the future?
Attitudes predictably affect relevant actors' actions, so this is a moderately important question. And it's rather neglected.
Groups whose attitudes are likely to be important include ML researchers, policymakers, and the public.
On attitudes among the public, surveys provide some information, but I suspect attitudes will change (in potentially predictable ways) as AI becomes more salient and some memes/framings get locked in. Perhaps some survey questions (maybe gener...
1
Critically, this only is necessary if we assume that researchers care about basically everyone in the present (to a loose approximation.) If we instead model researchers as basically selfish by default, then the low chance of a technological singularity outweighs the high chance of death, especially for older folks.
Basically, this could be explained as a goal alignment problem: LW and AI Researchers have very different goals in mind.