Popular Comments
Recent Discussion
The curious tale of how I mistook my dyslexia for stupidity - and talked, sang, and drew my way out of it.
Sometimes I tell people I’m dyslexic and they don’t believe me. I love to read, I can mostly write without error, and I’m fluent in more than one language.
Also, I don’t actually technically know if I’m dyslectic cause I was never diagnosed. Instead I thought I was pretty dumb but if I worked really hard no one would notice. Later I felt inordinately angry about why anyone could possibly care about the exact order of letters when the gist is perfectly clear even if if if I right liike tis.
I mean, clear to me anyway.
I was 25 before it dawned on me that all the tricks...
Is it not normal to sub vocalise?
Could people react to this comment with a Tick if they do, and a cross if they don’t?
I'm launching AI Lab Watch. I collected actions for frontier AI labs to improve AI safety, then evaluated some frontier labs accordingly.
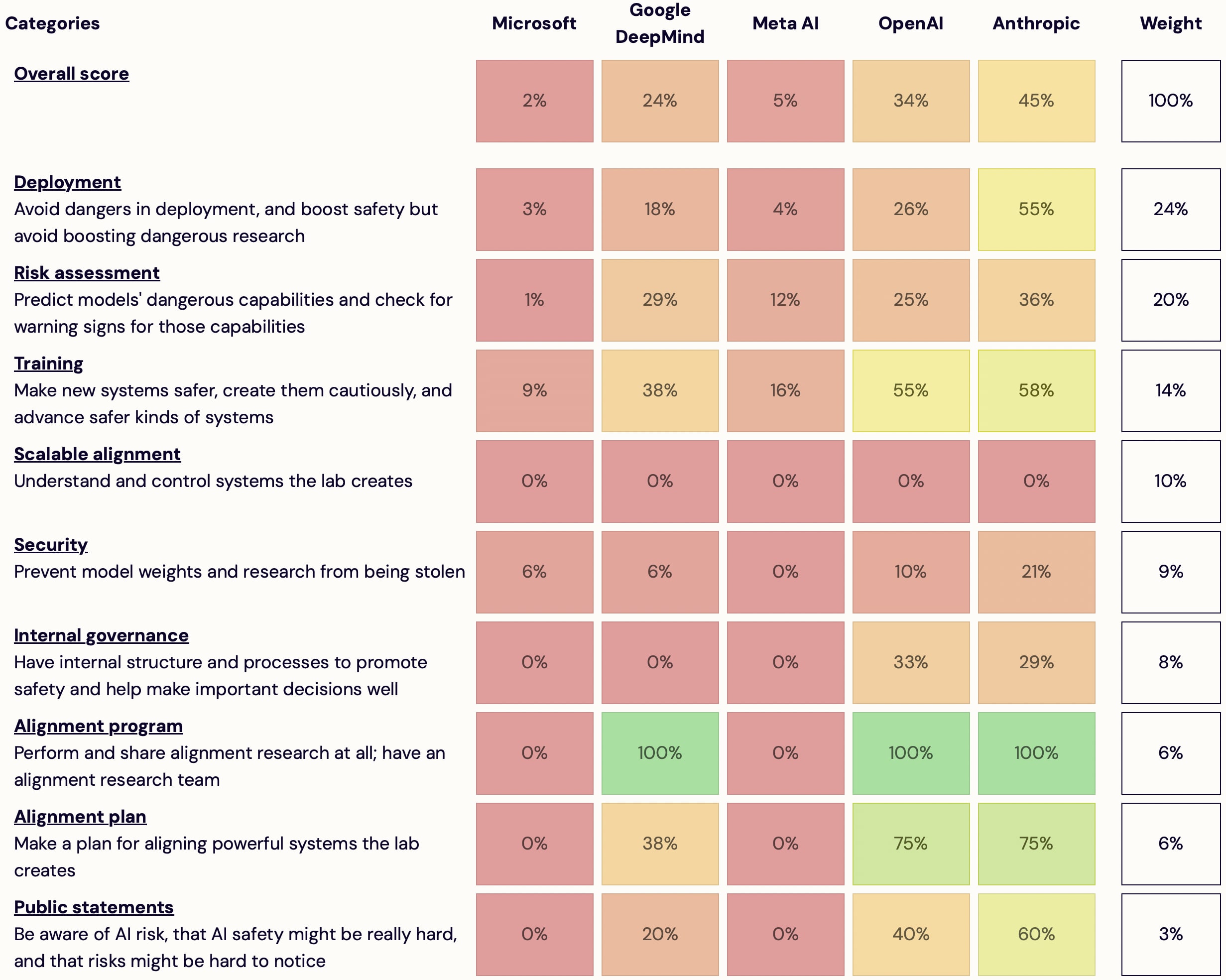
It's a collection of information on what labs should do and what labs are doing. It also has some adjacent resources, including a list of other safety-ish scorecard-ish stuff.
(It's much better on desktop than mobile — don't read it on mobile.)
It's in beta—leave feedback here or comment or DM me—but I basically endorse the content and you're welcome to share and discuss it publicly.
It's unincorporated, unfunded, not affiliated with any orgs/people, and is just me.
Some clarifications and disclaimers.
How you can help:
- Give feedback on how this project is helpful or how it could be different to be much more helpful
- Tell me what's wrong/missing; point me to sources
Hmm, yeah it does seem thorny if you can get the points by just saying you'll do something.
Like I absolutely think this shouldn't count for security. I think you should have to demonstrate actual security of model weights and I can't think of any demonstration of "we have the capacity to do security" which I would find fully convincing. (Though setting up some inference server at some point which is secure to highly resourced pen testers would be reasonably compelling for demonstrating part of the security portfolio.)
Linked is my MSc thesis, where I do regret analysis for an infra-Bayesian[1] generalization of stochastic linear bandits.
The main significance that I see in this work is:
- Expanding our understanding of infra-Bayesian regret bounds, and solidifying our confidence that infra-Bayesianism is a viable approach. Previously, the most interesting IB regret analysis we had was Tian et al which deals (essentially) with episodic infra-MDPs. My work here doesn't supersede Tian et al because it only talks about bandits (i.e. stateless infra-Bayesian laws), but it complements it because it deals with a parameteric hypothesis space (i.e. fits into the general theme in learning-theory that generalization bounds should scale with the dimension of the hypothesis class).
- Discovering some surprising features of infra-Bayesian learning that have no analogues in classical theory. In particular, it
Predicting the future is hard, so it’s no surprise that we occasionally miss important developments.
However, several times recently, in the contexts of Covid forecasting and AI progress, I noticed that I missed some crucial feature of a development I was interested in getting right, and it felt to me like I could’ve seen it coming if only I had tried a little harder. (Some others probably did better, but I could imagine that I wasn't the only one who got things wrong.)
Maybe this is hindsight bias, but if there’s something to it, I want to distill the nature of the mistake.
First, here are the examples that prompted me to take notice:
Predicting the course of the Covid pandemic:
- I didn’t foresee the contribution from sociological factors (e.g., “people not wanting
Despite my general interest in open inquiry, I will avoid talking about my detailed hypothesis of how to construct such a virus. I am not confident this is worth the tradeoff, but the costs of speculating about the details here in public do seem non-trivial.
@Daniel Kokotajlo If you indeed avoided signing an NDA, would you be able to share how much you passed up as a result of that? I might indeed want to create a precedent here and maybe try to fundraise for some substantial fraction of it.
Epistemic Status: At midnight three days ago, I saw some of the GPT-4 Byproduct Recursively Optimizing AIs below on twitter which freaked me out a little and lit a fire underneath me to write up this post, my first on LessWrong. Here, my main goal is to start a dialogue on this topic which from my (perhaps secluded) vantage point nobody seems to be talking about. I don’t expect to currently have the optimal diagnosis of the issue and prescription of end solutions.
Acknowledgements: Thanks to my fellow Wisconsin AI Safety Initiative (WAISI) group organizers Austin Witte and Akhil Polamarasetty for giving feedback on this post. Organizing the WAISI community has been incredibly fruitful in being able to spar ideas with others and see which strongest ones survive....
Empathizing with AGI will not align it nor will it prevent any existential risk. Ending discrimination would obviously be a positive for the world, but it will not align AGI.
It may not align it, but I do think it would prevent certain unlikely existential risks.
If AI/AGI/ASI is truly intelligent, and not just knowledgeable, we should definitely empathize and be compassionate with it. If it ends up being non-sentient, so be it, guess we made a perfect tool. If it ends up being sentient and we've been abusing a being that is super-intelligent, then good luck...
The first speculated on why you’re still single. We failed to settle the issue. A lot of you were indeed still single. So the debate continues.
The second gave more potential reasons, starting with the suspicion that you are not even trying, and also many ways you are likely trying wrong.
The definition of insanity is trying the same thing over again expecting different results. Another definition of insanity is dating in 2024. Can’t quit now.
You’re Single Because Dating Apps Keep Getting Worse
A guide to taking the perfect dating app photo. This area of your life is important, so if you intend to take dating apps seriously then you should take photo optimization seriously, and of course you can then also use the photos for other things.
I love the...
I think this list will successfully convince many to stay off the dating market indefinitely (I feel inclined that way myself after reading all this). Who in the world has time to work on all of this? At best, this is just a massive set of to-dos; at worst, it's an enormous list of all the ways the dating world sucks and reasons why you'll fail.
1. If you find that you’re reluctant to permanently give up on to-do list items, “deprioritize” them instead
I hate the idea of deciding that something on my to-do list isn’t that important, and then deleting it off my to-do list without actually doing it. Because once it’s off my to-do list, then quite possibly I’ll never think about it again. And what if it’s actually worth doing? Or what if my priorities will change such that it will be worth doing at some point in the future? Gahh!
On the other hand, if I never delete anything off my to-do list, it will grow to infinity.
The solution I’ve settled on is a priority-categorized to-do list, using a kanban-style online tool (e.g. Trello). The left couple columns (“lists”) are very active—i.e., to-do list...
Or if you're instead in the mode of deciding what to do next, or making a schedule for your day, etc., then that's different, but working memory is still kinda irrelevant because presumably you have your to-do list open on your computer, right in front of your eyes, while you do that, right?
Whenever I look at a to-do list, I've personally found it noticeably harder to decide which of e.g. 15 tasks to do, than which of <10 tasks to do. And this applies to lists of all kinds. A related difficulty spike appears once a list no longer fits on a single screen and requires scrolling.
Summary: Evaluations provide crucial information to determine the safety of AI systems which might be deployed or (further) developed. These development and deployment decisions have important safety consequences, and therefore they require trustworthy information. One reason why evaluation results might be untrustworthy is sandbagging, which we define as strategic underperformance on an evaluation. The strategic nature can originate from the developer (developer sandbagging) and the AI system itself (AI system sandbagging). This post is an introduction to the problem of sandbagging.
The Volkswagen emissions scandal
There are environmental regulations which require the reduction of harmful emissions from diesel vehicles, with the goal of protecting public health and the environment. Volkswagen struggled to meet these emissions standards while maintaining the desired performance and fuel efficiency of their diesel engines (Wikipedia). Consequently, Volkswagen...
I am not sure I fully understand your point, but the problem with detecting sandbagging is that you do not know the actual capability of a model. And I guess that you mean "an anomalous decrease in capability" and not increase?
Regardless, could you spell out more how exactly you'd detect sandbagging?
