Bounty offered for Analysis of the Results
I'm offering a pool of $100+ of my personal money for the best analyses of the results, as judged by me. I'm looking for things that are meaningful insights drawn from the data, e.g. modeling the interaction between the karma score of a post and its vote outcomes.
There are a number of aggregate stats for each post included in the linked spreadsheet, but I'm also open to making available further stats or data to people upon request so long as they keep the voters anonymous.
EDIT: Be creative in what analyses you might run and don't limit yourself to just what's the in spreadsheet. As above, I'll share more data if it seems appropriate. This might be data about posts, comments, and anything else to do with the site.
One thing I'd be interested to learn is whether alignment forum participants' votes would have produced the same top 15 AI posts, but I don't want to run that analysis myself.
Here are the AF-user results (including both AF and non-AF posts)
One of the more noteworthy-bits here, I think, is that "Are Minimal Circuits Daemon Free?" not only moves up relative to other AF posts, but is in the top-10 overall.
I'd love to see a cluster analysis. I suspect there will be some obvious groups like "AI alignment vs. rationality", but also could give some interesting data on things like if "rationality vs. postrationality" is a real split or "Combat vs. Nurture" etc.
In that same vein, I'd also be really interested to see the vote results if pairwise-bounded quadratic voting was used. Intuitively to me this feels like an interesting attempt to look at "debiasing" the votes away from factions, and looking more at what the non-factional consensus is.
So one user spent 465 of their 500 available votes to downvote "Realism about Rationality".
I wonder whether that reflects exceptionally strong dislike of that post, or whether it means that they voted "No" on that and nothing on anything else, and then the -30 is just what the quadratic-vote-allocator turned that into.
I suspect the latter, and further suspect that whoever it was might not have wanted their vote interpreted quite that way. (Not with much confidence in either case.)
If a similar system is used on future occasions, it might be a good idea to limit how strong votes are made for users who don't cast many votes. Of course you should be able to spend your whole budget on downvoting one thing you really hate, but you should have to do it deliberately and consciously.
If a similar system is used on future occasions, it might be a good idea to limit how strong votes are made for users who don't cast many votes.
The quadratic-vote-allocator's multiplier of non-quadratic votes was capped at a multiplier of 6x. A "No" vote starts out with a cost -4, so even if you only voted "No" on one item, it wouldn't become more than a cost of 24 which translates into a vote with weight -6.
I'd say the -30 was intentional.
Easy to make it possible with explicit quadratic voting but not interpret people who use non-quadratic voting to cast only 1-3 votes in this way.
I'm quite curious how this ordering correlated with the original LessWrong Karma of each post, if that analysis hasn't been done yet. Perhaps I'd be more curious to better understand what a great ordering would be. I feel like there are multiple factors taken into account when voting, and it's also quite possible that the userbase represents multiple clusters that would have distinct preferences.
The "Click Here If You Would Like A More Comprehensive Vote Data Spreadsheet" link includes both vote totals and karma, making it easy to calculate the correlation using Google Sheet's CORRELATE function. Pearson correlation between karma and vote count is 0.355, or if we throw away the outlier of Affordance Widths that was heavily downvoted due to its author, 0.425.
Scatterplots with "Affordance Widths" removed:
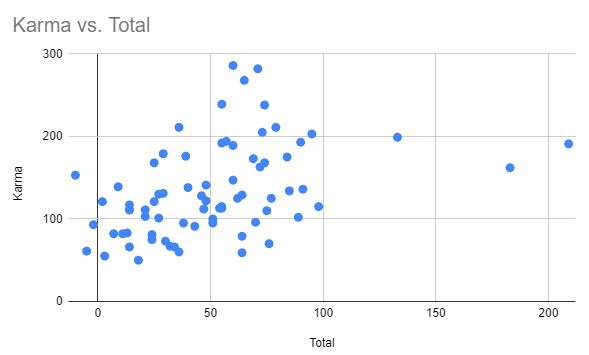

Pearson correlation between karma and vote count is 0.355
And it's even larger (r = -0.46) between amount of karma and ranking in the vote.
That's an interesting measure, let's plot that too. (Ranks reversed so that rank 1 is represented as 74, rank 2 as 73, and so on.)
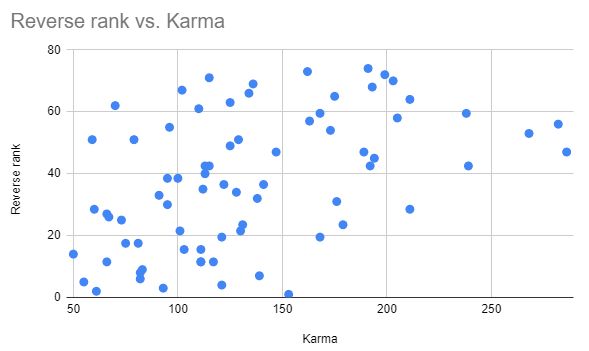
Interesting. From the data, it looks like there's a decent linear correlation up to around 150 Karma or so, and then after that the correlation looks more nebulous.
That seems like weak evidence of karma info-cascades: posts with more karma get more upvotes *simply because* they have more karma, in a way which ultimately doesn't correlate with their "true value" (as measured by the review process).
Potential mediating causes include users being anchored by karma, or more karma causing a larger share of the attention of the userbase (due to various sorting algorithms).
It was 1st June 2018 that we built strong/weak upvotes - before then you had to always vote your max strength. I could imagine that being responsible for the apparent info-cascades in very popular post.
If voters are at all consistent, you'd expect at lease some positive correlation because the same factors that made them upvote for karma also made upvote for the Review.
Beyond that, I'm guessing people voted for the posts they'd read, and people would have read higher karma posts more often since they get more exposure, e.g. sticking around the Latest Posts list for longer.
Correlation looks good all the way except for the three massive outliers at the top of the rankings.
I just realised my own voting (and I suspect that of most people) was inefficient.
Once I decided on all of my votes I should have decreased all of the votes by 1, including putting a -1 vote on any that I had previously been neutral on (ignoring the off-by-one error thing for the moment).
This wouldn't have changed the net effect of my vote but would have given me extra points to spend (the small cost of paying for negative results would have been more than offset by the large benefit from decreasing the positive votes).
I think most other people made the same mistake (well, it's a mistake if voting effect size was a high priority rather than, say, speed) due to the large number of neutral votes (~71%) and the ratio between positive vs negative votes (4.8 : 1) although both of these might have been effected somewhat by the off-by-one correction.
It's far worse than that.
Even without the off-by-one bug, if you were able to vote on all the nominees, then the most efficient use of points would have been to make your average vote as close to 0 as possible. For instance, imagine there were 50 nominees, and one voter rated 5 of them at 10 to use their 500 points. If instead, they rated each of those 5 at 9, and the other 45 at -1, that would be 405+45=450 points, with exactly the same overall impact on relative standings. (In algebraic terms, this is a simple quadratic decomposition, akin to the fact that mean squared error equals bias squared plus variance).
It's clear from the vote results that the average voter did not ensure mean-0 and thus probably left some voting power on the table. The average of all votes is substantially positive.
This is even more "irrational" for those voters who were also authors of one or more of the works. Such voters were not allowed to vote on their own works, but could have helped their works win by voting all other works down. In other words, the incentive would be to have their average vote be negative, not just zer0.
I myself subtracted 2 from all my default-calculated votes for the above two reasons. Frankly, this 2-point difference (reduced to 1 in many cases by the off-by-one bug correction) was less than I considered selfishly rational, but I didn't want to take too much advantage of such "underhanded" strategy. Looking at the voting results, I don't think it's likely that anybody else but me did this.
I wonder whether there is a way to take someone's vote and infer a more optimal allocation of the votes, and then scale that up to use the full available points, so that we could potentially estimate the size of the impact of this.
There were also something like 10 who didn't spend their full vote-ballot, so my guess is that optimality concerns aren't a super big deal for many users, though I generally think that we should align the natural interaction with the system with the one that also spends your points most effectively, since anything else just weirdly biases the results towards people who either just vote differently naturally, or are thinking more about meta-level voting strategies, neither of which seems like a particularly good bias.
Note that I considered this, but saw that the final decision of what would be included was subjective anyway, and it would be a stronger signal to the judges to spend a lot of my points on a few posts I thought really deserved it and would otherwise be underrated.
Thanks, I was trying to work out a simple way to calculate how many times it would be worthwhile subtracting extra 1s - making the average close to 0 is a helpful simple rule.
Do you have suggestions for what to do instead, that'd roughly preserve the advantages of the current system, while being more intuitive?
Note that one of the desiderata I'd prefer out of this is "positive votes actually mean 'I liked this post' and negative votes actually mean 'I disliked this post' as opposed to 'I strategically voted this number to have a cumulative effect across my overall votes'".
(This isn't crucial but it does make the swarmplots more intuitive to read)
There's frequently a tradeoff between "less strategic incentives" and "more-intelligible under honesty". I don't think that you should pick the former every time, but it is certainly better to err a little bit on the side of the former and get good-but-slightly-more-confusing results, than to err on the side of the latter and get results that are neither good nor intelligible (because strategic voting has ruined that, too).
I agree, just looking for Pareto improvements if they exist (since we didn’t try much at all this year for them, it seemed plausible such things existed)
Put a cap on the variance (standard deviation squared) of votes, rather than the sum-squared of votes? That would be equivalent to subtracting the mean from each vote ...
(Maybe you have to count the zero votes in the calculation)
Will that be obvious while the person is voting? (I guess this may be more of a UI question than a voting-theory question)
I can imagine, similar to how we have a button for 're-order the posts', we could have a button for 'normalise my votes'.
Yeah, I actually found this to be a pretty annoying artifact of the voting system once I realized it.
Yeah! I also noticed this when looking over the results; there was a paragraph on it in the OP that I cut.
The team will be conducting a Review of the Review where we take stock of what happened, discuss the value and costs of the Review process, and think about how to make the review process more effective and efficient in future years.
I just want to speak up for myself, as I mentioned in a different comment, that at least in my mind, we need to properly review this year's Review before we're definitely committing to run this every year. I think the OP implies a greater level of confidence that the project was a "success" and will be repeated in subsequent than I feel.
Just so far, I've seen a lot of good come from this year's review that I'm very pleased with, but it's a costly project (for the team and the community), so that calculation needs to be done carefully.
This comment shouldn't be interpreted as a sign that I'm negative on the Review. This is my attitude to every project that takes up significant resources. I won't have a firm opinion until I've thought about the Review a lot more and discussed at length with the team. We had to get the results out there quick though, ;)
On a self-interested note: you listed the top 15, but it appears my post, A Voting Theory Primer for Rationalists, was tied for 15th place, and yet was left off of the list. If that reflects some implicit tie-breaker, I'd like to know what it is. And — speaking purely as the author, not as a voting theorist — I'd suggest maybe you should just include my post in the list.
I'll make a separate post with some analysis ideas later.
- It seems like very few people voted overall if the average is "10-20" voters per post. I hope they are buying 50+ books each otherwise I don't see how the book part is remotely worth it.
- The voting was broken in multiple ways - you could spend as many points as possible, but instead of a cut-off, your vote was just cast out due to the organizers' mistake to allow it.
- The voting was broken in the way described in the post, too.
- People didn't understand how the voting worked (Look at the few comments here) so they didn't really even manage to vote in the way that satisfies their preferences best. The system and the explanation seem at fault.
- I note that a lot of promotion went into this - including emails to non-active users, a lot of posts about it, long extended reviews.
So, my question is - do the organizers think it was worth it? And if yes, do you think it is worth it enough for publishing in a book? And if yes to both - what would failure have looked like?
It seems like very few people voted overall if the average is "10-20" voters per post. I hope they are buying 50+ books each otherwise I don't see how the book part is remotely worth it.
I'm confused by this. Why would only voters be interested in the books? Also, this statement assumes that you have to sell 500-1000 books for it to be worth it– what's the calculation for the value of a book sold vs the cost of making the books?
The voting was broken in multiple ways - you could spend as many points as possible, but instead of a cut-off, your vote was just cast out due to the organizers' mistake to allow it.
I was surprised by this design decision too, though I'll note that the number of points spent was displayed and went red once you exceeded the budget. (Which has the advantage of if you're going over, you can place a vote and then decide whether to remove it or another.) Everyone except for the single person who spent 10,000 points kept to 500 or less.
I’m confused by this. Why would only voters be interested in the books?
Because I doubt there are all that much more people interested in these than the number of voters. Even at 1000 it doesn't seem like a book makes all that much sense. In fact, I still don't get why turning them into a book is even considered.
Print-on-demand books aren't necessarily very expensive: I've made board books for my friend's son in print runs of one or two for like thirty bucks per copy. If the team has some spare cash and someone wants to do the typesetting, a tiny print run of 100 copies could make sense as "cool in-group souvenir", even if it wouldn't make sense as commercial publishing.
Printing costs are hardly the only or even main issue, and I hadn't even mentioned them. You are right though, those costs make the insistence on publishing a book make even less sense.
What, in your view, is the main issue? Other than printing/distribution costs, the only other problem that springs to mind is the opportunity cost of the labor of whoever does the design/typesetting, but I don't think either of us is in a good position to assess that. What bad thing happens if the people who run a website also want to print a few paper books?
Why are so many resources being sunk into this specifically? I just don't understand how it makes sense, what the motivation is and how they arrived at the idea. Maybe there is a great explanation and thought process which I am missing.
From my point of view, there is little demand for it and the main motivation might plausibly have been "we want to say we've published a book" rather than something that people want or need.
Having said that, I'd rather get an answer to my initial comment - why it makes sense to you/them - rather than me having to give reasons why I don't see how it makes sense.
We have written some things about our motivation on this, though I don't think we've been fully comprehensive by any means (since that itself would have increased the cost of the vote a good amount). Here are the posts that we've written on the review and the motivation behind it:
- The LessWrong 2018 Review
- Voting Phase of 2018 LW Review
- (Feedback Request) Quadratic voting for the 2018 Review
- The Review Phase
The first post includes more of our big-picture motivation for this. Here are some of the key quotes:
Quotes
In his LW 2.0 Strategic Overview, habryka noted:
We need to build on each other’s intellectual contributions, archive important content, and avoid primarily being news-driven.
We need to improve the signal-to-noise ratio for the average reader, and only broadcast the most important writing
[...]
Modern science is plagued by severe problems, but of humanity’s institutions it has perhaps the strongest record of being able to build successfully on its previous ideas.
The physics community has this system where the new ideas get put into journals, and then eventually if they’re important, and true, they get turned into textbooks, which are then read by the upcoming generation of physicists, who then write new papers based on the findings in the textbooks. All good scientific fields have good textbooks, and your undergrad years are largely spent reading them.
Over the past couple years, much of my focus has been on the early-stages of LessWrong's idea pipeline – creating affordance for off-the-cuff conversation, brainstorming, and exploration of paradigms that are still under development (with features like shortform and moderation tools).
But, the beginning of the idea-pipeline is, well, not the end.
I've written a couple times about what the later stages of the idea-pipeline might look like. My best guess is still something like this:
I want LessWrong to encourage extremely high quality intellectual labor. I think the best way to go about this is through escalating positive rewards, rather than strong initial filters.
Right now our highest reward is getting into the curated section, which... just isn't actually that high a bar. We only curate posts if we think they are making a good point. But if we set the curated bar at "extremely well written and extremely epistemically rigorous and extremely useful", we would basically never be able to curate anything.
My current guess is that there should be a "higher than curated" level, and that the general expectation should be that posts should only be put in that section after getting reviewed, scrutinized, and most likely rewritten at least once.
I still have a lot of uncertainty about the right way to go about a review process, and various members of the LW team have somewhat different takes on it.
I've heard lots of complaints about mainstream science peer review: that reviewing is often a thankless task; the quality of review varies dramatically, and is often entangled with weird political games.
------
Before delving into the process, I wanted to go over the high level goals for the project:
1. Improve our longterm incentives, feedback, and rewards for authors
2. Create a highly curated "Best of 2018" sequence / physical book
3. Create common knowledge about the LW community's collective epistemic state regarding controversial posts
-------
Longterm incentives, feedback and rewards
Right now, authors on LessWrong are rewarded essentially by comments, voting, and other people citing their work. This is fine, as things go, but has a few issues:
- Some kinds of posts are quite valuable, but don't get many comments (and these disproportionately tend to be posts that are more proactively rigorous, because there's less to critique, or critiquing requires more effort, or building off the ideas requires more domain expertise)
- By contrast, comments and voting both nudge people towards posts that are clickbaity and controversial.
- Once posts have slipped off the frontpage, they often fade from consciousness. I'm excited for a LessWrong that rewards Long Content, that stand the tests of time, as is updated as new information comes to light. (In some cases this may involve editing the original post. But if you prefer old posts to serve as a time-capsule of your post beliefs, adding a link to a newer post would also work)
- Many good posts begin with an "epistemic status: thinking out loud", because, at the time, they were just thinking out loud. Nonetheless, they turn out to be quite good. Early-stage brainstorming is good, but if 2 years later the early-stage-brainstorming has become the best reference on a subject, authors should be encouraged to change that epistemic status and clean up the post for the benefit of future readers.
The aim of the Review is to address those concerns by:
- Promoting old, vetted content directly on the site.
- Awarding prizes not only to authors, but to reviewers. It seems important to directly reward high-effort reviews that thoughtfully explore both how the post could be improved, and how it fits into the broader intellectual ecosystem. (At the same time, not having this be the final stage in the process, since building an intellectual edifice requires four layers of ongoing conversation)
- Compiling the results into a physical book. I find there's something... literally weighty about having your work in printed form. And because it's much harder to edit books than blogposts, the printing gives authors an extra incentive to clean up their past work or improve the pedagogy.
------
Common knowledge about the LW community's collective epistemic state regarding controversial posts
Some posts are highly upvoted because everyone agrees they're true and important. Other posts are upvoted because they're more like exciting hypotheses. There's a lot of disagreement about which claims are actually true, but that disagreement is crudely measured in comments from a vocal minority.
The end of the review process includes a straightforward vote on which posts seem (in retrospect), useful, and which seem "epistemically sound". This is not the end of the conversation about which posts are making true claims that carve reality at it's joints, but my hope is for it to ground that discussion in a clearer group-epistemic state.
Further Comments
I expect we will write some more in the future about some of the broader goals behind the review, but the above I think summarizes a bunch of the high-level considerations reasonably well.
I think one way one could describe at least my motivation for the review is that one of the big holes that I've always perceived in LessWrong, and the internet at large, is the focus on things that are popular in the moment, and that it's hard for people to really build on other people's ideas and make long-term intellectual progres. The review is an experiment in creating an incentive and attention allocation mechanism that tries to counteract those forces. I am not yet sure how much it succeeded at that, though I am broadly pleased with how it went.
I'd rather get an answer to my initial comment - why it makes sense to you/them
Sure. I explained my personal enthusiasm for the Review in a November comment.
I hope they are buying 50+ books each otherwise I don’t see how the book part is remotely worth it.
As a data point, I did not vote, but if there is a book, I will almost certainly be buying a copy of it if it is reasonably priced, i.e. similar price to the first two volumes of R:A-Z ($ 6-8).
So, my question is - do the organizers think it was worth it? And if yes, do you think it is worth it enough for publishing in a book? And if yes to both - what would failure have looked like?
These are really excellent questions. The OP mentions the intention to "review the review" in coming weeks; there will be posts about this, so hang tight. Obviously the whole project had very high costs, so we have to think carefully through whether the benefits justify them and whether we should continue the Review process in future years. Speaking for myself, it's not obvious that it was worth it, but still quite possible. It's a hard question because I expect the many of the benefits to accrue over time and be not straightforward to measure.
I think we should do a thorough review now with what we know now, and would need to do another review in ~year's time before pressing go on the next iteration.
I've generally been pushing for all major projects at LW to be properly reviewed with an eye to: Where they worth it? What did we learn? And what remains to be done?
Thanks for the reply. That seems like a sensible position.
It sounds like maybe you were less involved in this than some of the 7(is that right?) other employees/admins so I'm very curious to hear their take, too.
There are five people on the team. I wasn't the most involved, but I was still very involved. But you'll hear from all of soon, don't you worry.
Promoted to curated: This is a bit of an odd curation, but my guess is that the vote results are of interest to many people, and many will be happy to have read them, so it seems like a good curation target. Less curated for the statistics or the writing, and more curated to establish common-knowledge of the vote results.
Truth/Usefulness vs Prestige/Reputation
A worry I have with our voting system this year is that it felt more like "ranking posts by prestige" than "ranking them by truth/usefulness." It so happens that "prestige in LW community" does prioritize truth/usefulness and I think the outcome mostly tracked that, but I think we can do better.
The reason I'm worried is a) I'd expected, by default, for these things to be jumbled together, and b) whatever you thought of Affordance Widths, it seems pretty unlikely for it's "-140" score to be based on the merits of the post, rather than people not wanting the author represented in a Best of LW book.
I think reputational effects matter and it's fine to give people an outlet for that, but I think it's better if we ask those questions separately from questions of truth, and usefulness. (And, I think the vote and overall Review process is more interesting if truth/usefulness is the primary thing getting looked into)
It so happens I don't think Affordance Widths was in the top 35 posts, and not something I'd have included in the book on its merits (not because it was wrong – it seems like a basically true model to me – just because there was other stuff that was better). I think it's plausible for the post to have ended up with a negative score on it's own merits, but I doubt that an author-blind review would have given it -140.
So right now, I'd assume that we'd get similar results from any post by a similarly unpopular author, even if the ideas in the post were quite important.
I think it's pretty important for the community to be able to engage with that sort of thing, and maybe collectively decide "okay, we're not putting this in our public facing book for reputational reasons, but we should at least be able to evaluate it clearly in our inward facing review process."
And meanwhile, the fact that that post's score was clearly determined reputationally reinforces some of my prior-worries about the vote getting truth and prestige jumbled together, in less controversial post examples.
I had been worried about this earlier in the design-process for the review. A major reason I didn't object to the system we ended up with is...
...well, if you tell people "evaluate these posts for truth/usefulness", but clearly the results of the vote are going to translate into prestige, it seems like it makes the situation worse rather than better if you try to pretend otherwise.
But I think I might be interested in experimenting in another direction next year, where the vote isn't focused on relative ranking of posts at all, instead it's more like a survey where people answer qualitative questions, like:
- Have you thought about the ideas in this post in the past year?
- Do the ideas in this post seem important?
- How do you feel about this post's epistemics
- Should this post appear in a public-facing Best of LW book?
- Should this post appear in an inward-facing, high-context LW Journal?
Just looking at the distributions on the individual articles is a bit interesting. Wonder if there are common characteristics about the articles with similar distribution patters of the votes.
The votes are in!
59 of the 430 eligible voters participated, evaluating 75 posts. Meanwhile, 39 users submitted a total of 120 reviews, with most posts getting at least one review.
Thanks a ton to everyone who put in time to think about the posts - nominators, reviewers and voters alike. Several reviews substantially changed my mind about many topics and ideas, and I was quite grateful for the authors participating in the process. I'll mention Zack_M_Davis, Vanessa Kosoy, and Daniel Filan as great people who wrote the most upvoted reviews.
In the coming months, the LessWrong team will write further analyses of the vote data, and use the information to form a sequence and a book of the best writing on LessWrong from 2018.
Below are the results of the vote, followed by a discussion of how reliable the result is and plans for the future.
Top 15 posts
Top 15 posts not about AI
Top 10 posts about AI
(The vote included 20 posts about AI.)
The Complete Results
Click Here If You Would Like A More Comprehensive Vote Data Spreadsheet
To help users see the spread of the vote data, we've included swarmplot visualizations.
Probably False
When Do They Work?
examples in AI
Looking, insight meditation,
and enlightenment in
non-mysterious terms
moral weight
How reliable is the output of this vote?
For most posts, between 10-20 people voted on them (median of 17). A change by 10-15 in a post's score is enough to move a post up or down around 10 positions within the rankings. This is equal to a few moderate strength votes from two or three people, or an exceedingly strong vote from a single strongly-feeling voter. This means that the system is somewhat noisy, though it seems to me very unlikely that posts at the very top could end up placed much differently.
The vote was also affected by two technical mistakes the team made:
The effect size of these errors is not certain since it's hard to know how people would have voted counterfactually. My sense is that the effect is pretty small, and that the majority of noise in the system comes from elsewhere.
Finally, we discarded exactly one ballot, which spent 10,000 points on voting instead of the allotted 500. Had a user gone over by a small amount e.g. 1-50 points, we had planned to scale their votes down to fit the budget. However when someone's allocation was so extreme, we were honestly unsure what adjustment to their votes they would have wanted, as if their points had been normalised down to 500, the majority of their votes would have been adjusted to zero. (This decision was made without knowing the user who cast the ballot or which posts were affected.)
Overall, I think the vote is a good indicator to about 10 places within the rankings, but, for example, I wouldn't agonise over whether a post is at position #42 vs #43.
The Future
This has been the first LessWrong Annual Review. This project was started with the vision of creating a piece of infrastructure that would:
The vote reveals much disagreement between LessWrongers. Every post has at least five positive votes and every post had at least one negative vote – except for An Untrollable Mathematician Illustrated by Abram Demski, which was evidently just too likeable – and many people had strongly different feelings about many posts. Many of these seem more interesting to me than the specific ranking of the given post.
In total, users wrote 207 nominations and 120 reviews, and many authors updated their posts with new thinking, or clearer explanations, showing that both readers and authors reflected a lot (and I think changed their mind a lot) during the review period. I think all of this is great, and like the idea of us having a Schelling time in the year for this sort of thinking.
Speaking for myself, this has been a fascinating and successful experiment - I've learned a lot. My thanks to Ray for pushing me and the rest of the team to actually do it this year, in a move-fast-and-break-things kind of way. The team will be conducting a Review of the Review where we take stock of what happened, discuss the value and costs of the Review process, and think about how to make the review process more effective and efficient in future years.
In the coming months, the LessWrong team will write further analyses of the vote data, award prizes to authors and reviewers, and use the vote to help design a sequence and a book of the best writing on LW from 2018.
I think it's awesome that we can do things like this, and I was honestly surprised by the level of community participation. Thanks to everyone who helped out in the LessWrong 2018 Review - everyone who nominated, reviewed, voted and wrote the posts.