This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
This is a linkpost for On Duct Tape and Fence Posts.
Eliezer writes about fence post security. When people think to themselves "in the current system, what's the weakest point?", and then dedicate their resources to shoring up the defenses at that point, not realizing that after the first small improvement in that area, there's likely now a new weakest point somewhere else.
Fence post security happens preemptively, when the designers of the system fixate on the most salient aspect(s) and don't consider the rest of the system. But this sort of fixation can also happen in retrospect, in which case it manifest a little differently but has similarly deleterious effects.
Consider a car that starts shaking whenever it's driven. It's uncomfortable, so the owner gets a pillow to put...
In the general case I agree it's not necessarily trivial; e.g. if your program uses the whole range of decimal places to a meaningful degree, or performs calculations that can compound floating point errors up to higher decimal places. (Though I'd argue that in both of those cases pure floating point is probably not the best system to use.) In my case I knew that the intended precision of the input would never be precise enough to overlap with floating point errors, so I could just round anything past the 15th decimal place down to 0.
We've been told by VCs and founders in the AI space that Human-level Artificial Intelligence (formerly AGI), followed by Superintelligence, will bring about a techno-utopia, if it doesn't kill us all first.
In order to fulfill that dream, AI must be sentient, and that requires it have consciousness. Today, AI is neither of those things so how do we get there from here?
Questions about AI consciousness and sentience have been discussed and debated by serious researchers, philosophers, and scientists for years; going back as far as the early sixties at RAND Corporation when MIT Professor Hubert Dreyfus turned in his report on the work of AI pioneers Herbert Simon and Allan Newell entitled "Alchemy and Artificial Intelligence."
Dreyfus believed that they spent too much time pursuing AGI and not...
I just finished reading The Mom Test for the second time. I took "raw" notes here. In this post I'll first write up a bullet-point summary and then ramble off some thoughts that I have.
Summary
Introduction:
- Trying to learn from customer conversations is like trying to excavate a delicate archeological site. The truth is down there somewhere, but it's fragile. When you dig you get closer to the truth, but you also risk damaging or smashing it.
- Bad customer conversations are worse than useless because they mislead you, convincing you that you're on the right path when instead you're on the wrong path.
- People talk to customers all the time, but they still end up building the wrong things. How is this possible? Almost no one talks to customers correctly.
- Why another
Hm, maybe.
Sometimes it can be a win-win situation. For example, if the call leads to you identifying a problem they're having and solving it in a mutually beneficial way.
But often times that isn't the case. From their perspective, the chances are low enough where, yeah, maybe the cold call just feels spammy and annoying.
I think that cold calls can be worthwhile from behind a veil of ignorance though. That's the barometer I like to use. If I were behind a veil of ignorance, would I endorse the cold call? Some cold calls are well targeted and genuine, in which case I would endorse them from behind a veil of ignorance. Others are spammy and thoughtless, in which case I wouldn't endorse them.
Concerns over AI safety and calls for government control over the technology are highly correlated but they should not be.
There are two major forms of AI risk: misuse and misalignment. Misuse risks come from humans using AIs as tools in dangerous ways. Misalignment risks arise if AIs take their own actions at the expense of human interests.
Governments are poor stewards for both types of risk. Misuse regulation is like the regulation of any other technology. There are reasonable rules that the government might set, but omission bias and incentives to protect small but well organized groups at the expense of everyone else will lead to lots of costly ones too. Misalignment regulation is not in the Overton window for any government. Governments do not have strong incentives...
(Surely cryonics doesn't matter given a realistic action space? Usage of cryonics is extremely rare and I don't think there are plausible (cheap) mechanisms to increase uptake to >1% of population. I agree that simulation arguments and similar considerations maybe imply that "helping current humans" is either incoherant or unimportant.)
(Half-baked work-in-progress. There might be a “version 2” of this post at some point, with fewer mistakes, and more neuroscience details, and nice illustrations and pedagogy etc. But it’s fun to chat and see if anyone has thoughts.)
1. Background
There’s a neuroscience problem that’s had me stumped since almost the very beginning of when I became interested in neuroscience at all (as a lens into AGI safety) back in 2019. But I think I might finally have “a foot in the door” towards a solution!
What is this problem? As described in my post Symbol Grounding and Human Social Instincts, I believe the following:
- (1) We can divide the brain into a “Learning Subsystem” (cortex, striatum, amygdala, cerebellum and a few other areas) on the one hand, and a “Steering Subsystem”
If step 5 is indeed grounded in the spatial attention being on other people, this should be testable! For example, people who pay less spatial attention to other people should feel less intense social emotions - because the steering system circuit gets activated less often and weaker. And I think that is the case. At least ChatGPT has some confirming evidence, though it's not super clear and I haven't yet looked deeper into it.
With my electronic harp mandolin project I've been enjoying working with analog and embedded audio hardware. And a few weeks ago, after reading about Ugo Conti's whistle-controlled synth I wrote to him, he gave me a call, and we had a really interesting conversation. And my existing combination of hardware for my whistle synth [1] is bulky and expensive. Which has me excited about a new project: I'd like to make an embedded version.
Yesterday I got started on the first component: getting audio into the microcontroller. I want to start with a standard dynamic mic, so I can keep using the same mic for talkbox and whistle synth, so it should take standard balanced audio on XLR as input. In a full version this would need an XLR port, but for now I...
Whoops! You're right! Will do.
I like the rough thoughts way though. I'm not here to like read a textbook.
Epistemic Status: Musing and speculation, but I think there's a real thing here.
I.
When I was a kid, a friend of mine had a tree fort. If you've never seen such a fort, imagine a series of wooden boards secured to a tree, creating a platform about fifteen feet off the ground where you can sit or stand and walk around the tree. This one had a rope ladder we used to get up and down, a length of knotted rope that was tied to the tree at the top and dangled over the edge so that it reached the ground.
Once you were up in the fort, you could pull the ladder up behind you. It was much, much harder to get into the fort without the ladder....
Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
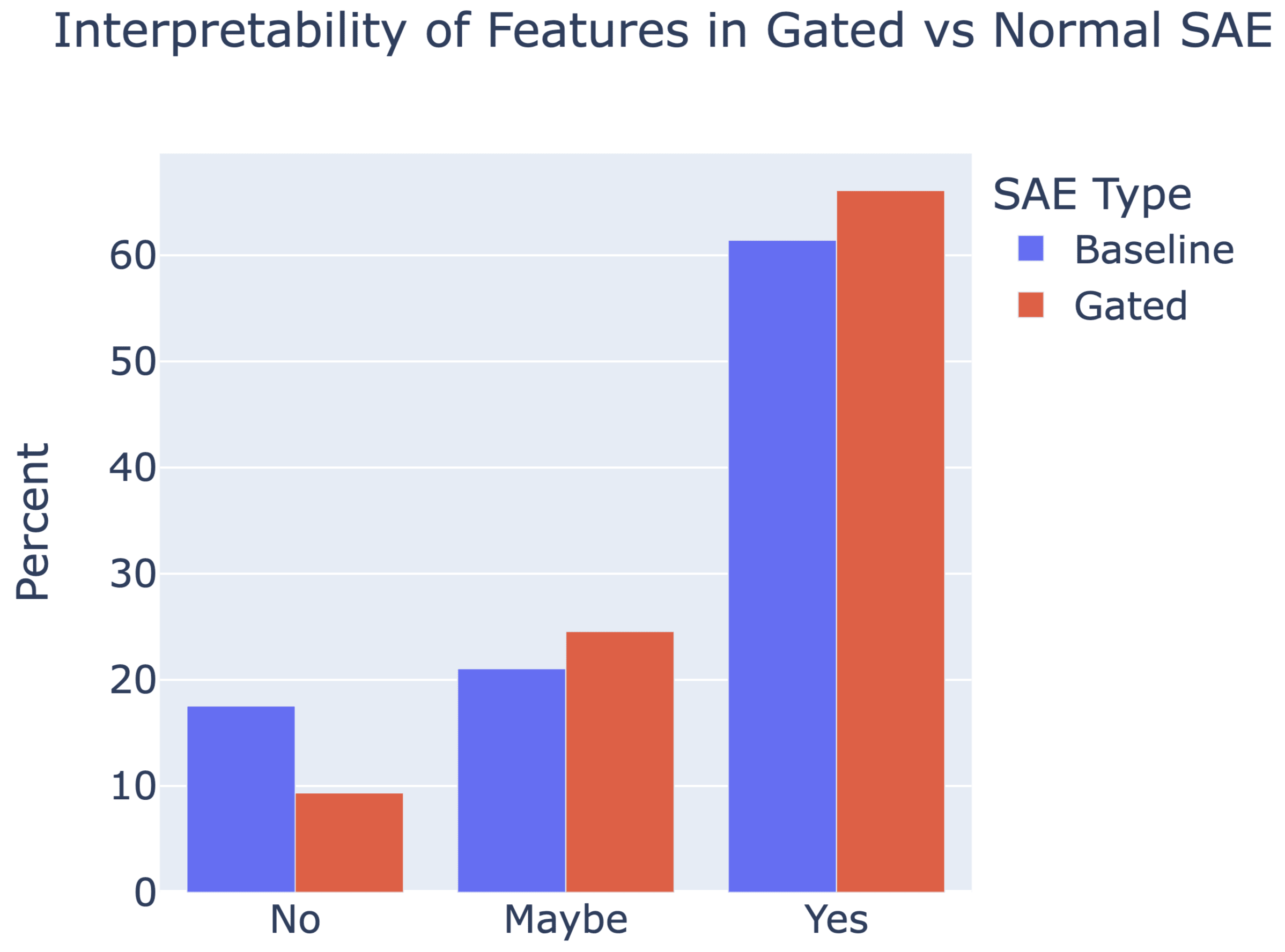
See Sen's Twitter summary, my Twitter summary, and the paper!
We use learning rate 0.0003 for all Gated SAE experiments, and also the GELU-1L baseline experiment. We swept for optimal baseline learning rates on GELU-1L for the baseline SAE to generate this value.
For the Pythia-2.8B and Gemma-7B baseline SAE experiments, we divided the L2 loss by , motivated by wanting better hyperparameter transfer, and so changed learning rate to 0.001 or 0.00075 for all the runs (currently in Figure 1, only attention output pre-linear uses 0.00075. In the rerelease we'll state all the values used). We didn't see n...
