This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
My current main cruxes:
- Will AI get takeover capability? When?
- Single ASI or many AGIs?
- Will we solve technical alignment?
- Value alignment, intent alignment, or CEV?
- Defense>offense or offense>defense?
- Is a long-term pause achievable?
If there is reasonable consensus on any one of those, I'd much appreciate to know about it. Else, I think these should be research priorities.
In short: Training runs of large Machine Learning systems are likely to last less than 14-15 months. This is because longer runs will be outcompeted by runs that start later and therefore use better hardware and better algorithms. [Edited 2022/09/22 to fix an error in the hardware improvements + rising investments calculation]
| Scenario | Longest training run |
| Hardware improvements | 3.55 years |
| Hardware improvements + Software improvements | 1.22 years |
| Hardware improvements + Rising investments | 9.12 months |
| Hardware improvements + Rising investments + Software improvements | 2.52 months |
Larger compute budgets and a better understanding of how to effectively use compute (through, for example, using scaling laws) are two major driving forces of progress in recent Machine Learning.
There are many ways to increase your effective compute budget: better hardware, rising investments in AI R&D and improvements in algorithmic efficiency. In this article...
This is actually corrected on the Epoch website but not here (https://epochai.org/blog/the-longest-training-run)
Post for a somewhat more general audience than the modal LessWrong reader, but gets at my actual thoughts on the topic.
In 2018 OpenAI defeated the world champions of Dota 2, a major esports game. This was hot on the heels of DeepMind’s AlphaGo performance against Lee Sedol in 2016, achieving superhuman Go performance way before anyone thought that might happen. AI benchmarks were being cleared at a pace which felt breathtaking at the time, papers were proudly published, and ML tools like Tensorflow (released in 2015) were coming online. To people already interested in AI, it was an exciting era. To everyone else, the world was unchanged.
Now Saturday Night Live sketches use sober discussions of AI risk as the backdrop for their actual jokes, there are hundreds...
The reason why EY&co were relatively optimistic (p(doom) ~ 50%) before AlphaGo was their assumption "to build intelligence, you need some kind of insight in theory of intelligence". They didn't expect that you can just take sufficiently large approximator, pour data inside, get intelligent behavior and have no idea about why you get intelligent behavior.
Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
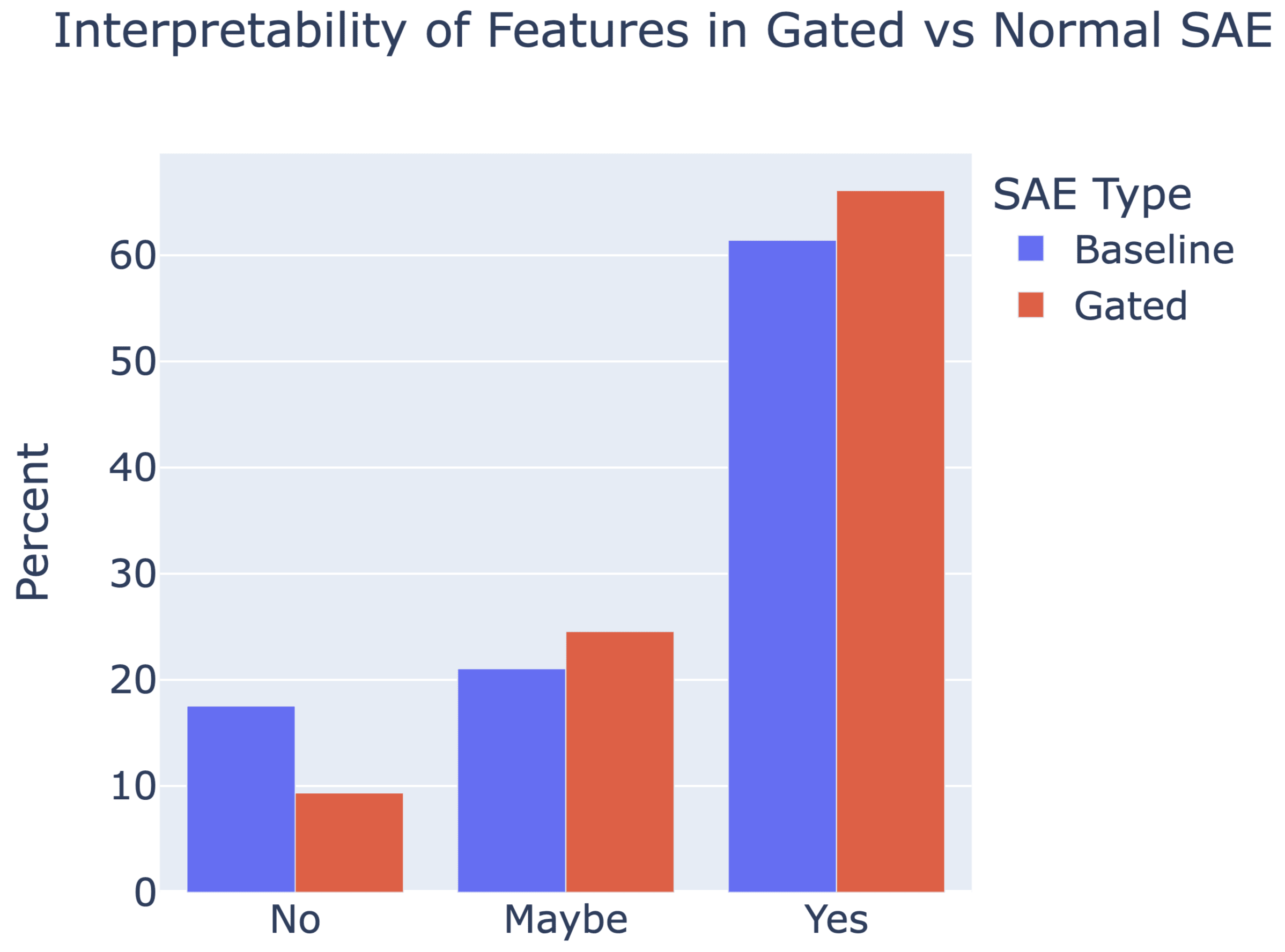
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
See Sen's Twitter summary, my Twitter summary, and the paper!
UPDATE: we've corrected equations 9 and 10 in the paper (screenshot of the draft below) and also added a footnote that hopefully helps clarify the derivation. I've also attached a revised figure 6, showing that this doesn't change the overall story (for the mathematical reasons I mentioned in my previous comment). These will go up on arXiv, along with some other minor changes (like remembering to mention SAEs' widths), likely some point next week. Thanks again Sam for pointing this out!
Updated equations (draft):

Updated figure 6 (shrinkage comparison for GE...
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
In some of his books on evolution, Dawkins also said very similar things when commenting on Darwin vs Wallace, basically saying that there's no comparison, Darwin had a better grasp of things, justified it better and more extensively, didn't have muddled thinking about mechanisms, etc.
List sorting does not play well with few-shot mostly doesn't replicate with davinci-002.
When using length-10 lists (it crushes length-5 no matter the prompt), I get:
- 32-shot, no fancy prompt: ~25%
- 0-shot, fancy python prompt: ~60%
- 0-shot, no fancy prompt: ~60%
So few-shot hurts, but the fancy prompt does not seem to help. Code here.
I'm interested if anyone knows another case where a fancy prompt increases performance more than few-shot prompting, where a fancy prompt is a prompt that does not contain information that a human would use to solve the task. ...
I'm against intuitive terminology [epistemic status: 60%] because it creates the illusion of transparency; opaque terms make it clear you're missing something, but if you already have an intuitive definition that differs from the author's it's easy to substitute yours in without realizing you've misunderstood.
TL;DR: This post discusses our recent empirical work on detecting measurement tampering and explains how we see this work fitting into the overall space of alignment research.
When training powerful AI systems to perform complex tasks, it may be challenging to provide training signals that are robust under optimization. One concern is measurement tampering, which is where the AI system manipulates multiple measurements to create the illusion of good results instead of achieving the desired outcome. (This is a type of reward hacking.)
Over the past few months, we’ve worked on detecting measurement tampering by building analogous datasets and evaluating simple techniques. We detail our datasets and experimental results in this paper.
Detecting measurement tampering can be thought of as a specific case of Eliciting Latent Knowledge (ELK): When AIs successfully tamper with...
That's right. We initially thought it might be important so that the LLM "understood" the task better, but it didn't matter much in the end. The main hyperparameters for our experiments are in train_ray.py, where you can see that we use a "token_loss_weight" of 0.
(Feel free to ask more questions!)
Crosspost from my blog.
If you spend a lot of time in the blogosphere, you’ll find a great deal of people expressing contrarian views. If you hang out in the circles that I do, you’ll probably have heard of Yudkowsky say that dieting doesn’t really work, Guzey say that sleep is overrated, Hanson argue that medicine doesn’t improve health, various people argue for the lab leak, others argue for hereditarianism, Caplan argue that mental illness is mostly just aberrant preferences and education doesn’t work, and various other people expressing contrarian views. Often, very smart people—like Robin Hanson—will write long posts defending these views, other people will have criticisms, and it will all be such a tangled mess that you don’t really know what to think about them.
For...
What makes you believe that Substack is to blame and not him unpublishing it?
